
The Chronology of the Texts in the Holy Quran According … Arabic word of a verse, which is the...
88
The candidate confirms that the work submitted is their own and the appropriate credit has been given where reference has been made to the work of others. I understand that failure to attribute material which is obtained from another source may be considered as plagiarism. (Signature of student)____________________________________ The Chronology of the Texts in the Holy Quran According to NLP Techniques Sameer Mabrouk A Alrehaili MSc Advanced Computer Science 2011/2012
Transcript of The Chronology of the Texts in the Holy Quran According … Arabic word of a verse, which is the...

The candidate confirms that the work submitted is their own and the appropriate credit has been
given where reference has been made to the work of others.
I understand that failure to attribute material which is obtained from another source may be
considered as plagiarism.
(Signature of student)____________________________________
The Chronology of the Texts in the
Holy Quran According to NLP
Techniques
Sameer Mabrouk A Alrehaili
MSc Advanced Computer Science
2011/2012

i
Summary
Text analysis has helped in a number of computational linguistics matters and
has been improved recently by providing a number of methods for analyzing the
texts. The parts of a text that have been arranged in a chronological order might
help in understanding the text much better, especially if the content includes
important topics. Moreover, the interpretation of that text with consideration of
the underlying circumstances as well as related events might be more sensible
than just looking to the literal interpretation.
The aim of this project is to investigate a number of chronological arrangements
of the Holy Quran as depicted in previous researches, focusing on the
arrangements that divide into 7 phases that were proposed by [1] and trying to
find other markers of styles supporting it.
In this project, I find that most features supporting this 7-phases chronology are
depending on the feature’s word count. Other features such as conceptual
occurrence of “Allah” and related verses give a slightly similar number to the
independent markers.The most significant results were when I obtained a
reverse order with relative markers such as the 11th most-frequent Part-of-
speech tags and the 28th most-frequent morphemes.
I also found a way to evaluate these orders using the agreements’ criterion with
the well-known studied chronology called Mecca-Medina. This project provides a
solution to some of these problems by building a database that contains a
number of arrangements of texts, with features of each time period or phase. In
Addition, a web user interface developed on http://www.salrehaili.com/quran, in
order to make the expirements done during this project, are avialble for
researches who are interested in the chronological order of the Quran.

ii
Acknowledgements
First and foremost, I would like to express my gratitude to Allah (God) for
blessing me and providing the opportunity to complete this project. I pray that
this project be successful and useful.
Secondly, I would like to thank my parents for their endless support during this
work in my entire MSc course and my academic life. I would also like to thank
my family brothers, sisters and those who have helped me, especially my wife
and my daughter “Mayar”, to be patient during my work on this project.
I would also like to thank my project supervisor, Dr Muller. He has given positive
comments during the hard times of this project. He has provided eternal
encouragement during long meeting and provided useful advices to avoid
difficulties in the project. I have now realised every advice that he suggested
me.
I would also like to thank my project assessor, Eric Atweel, for his feedback on
both the interim report and at progress meeting. Without his expertise and
advice, this project would have not been where it is today. It has been a great
experience working with him.
Thank you also to Benham for providing me a copy of the corpus used in his
research as well as his feedback on my work.

iii
Contents
Summary .................................................................................................................................................. i
Acknowledgements ................................................................................................................................. ii
Contents ................................................................................................................................................. iii
List of Figures ......................................................................................................................................... v
List of Tables ......................................................................................................................................... vi
Glossary ................................................................................................................................................ vii
1. Introduction ..................................................................................................................................... 1
1.1 Understanding the problem ............................................................................................................... 1
1.2 The overall aim ................................................................................................................................. 2
1.3 Objectives ......................................................................................................................................... 2
1.4 Minimum Requirements ................................................................................................................... 3
1.5 Degree Relevance ............................................................................................................................. 3
1.6 Deliverables ...................................................................................................................................... 4
1.7 Research methodology ...................................................................................................................... 4
1.8 Report Layout ................................................................................................................................... 5
2. Background ..................................................................................................................................... 6
2.1 Computational linguistics ................................................................................................................. 6
2.2 What is the Holy Quran .................................................................................................................. 10
2.3 Traditional order of the Holy Quran ............................................................................................... 11
2.4 Quran Divisions .............................................................................................................................. 12
2.5 Previous works ................................................................................................................................ 13
2.6 Two phases...................................................................................................................................... 14
2.7 Four phases ..................................................................................................................................... 15
2.8 Evaluation techniques ..................................................................................................................... 16
2.9 Historical information ..................................................................................................................... 16
2.10 Similar Researches ........................................................................................................................ 18
2.11 Feedback from interested scholars ................................................................................................ 18
2.12 Evaluation data .............................................................................................................................. 18
2.13 Tools used in this project: ............................................................................................................. 19
3. Project Management ..................................................................................................................... 20
3.1 Project management approach .................................................................................................... 20
3.2 Development tasks ...................................................................................................................... 22

iv
3.3 Initial Schedule ........................................................................................................................... 23
3.4 Revised schedule ......................................................................................................................... 26
3.5 Minimum requirements changing ............................................................................................... 27
4. Implementations ............................................................................................................................ 28
4.1 Design ......................................................................................................................................... 28
4.2 Collecting the corpus .................................................................................................................. 29
4.3 Pre-processing ............................................................................................................................. 30
4.4 Design and create a database ...................................................................................................... 33
4.5 Basic Markers ............................................................................................................................. 37
4.6 Occurences of Allah names......................................................................................................... 39
4.7 Conceptual markers .................................................................................................................... 39
4.8 Related verse ............................................................................................................................... 40
4.9 Relative frequencies of Part-of-Speech tagset in the Quran ....................................................... 41
4.10 28th most frequent morphemes in the Quran ............................................................................ 44
4.11 Relative frequencies of vowels ................................................................................................. 45
5. Results and Evaluation .................................................................................................................. 46
5.1 Results ....................................................................................................................................... 46
5.2 Experiment One: arrangements of 194 blocks ............................................................................ 46
5.3 Experiment number two: Groups ................................................................................................ 50
5.4 Experiment number three: Passages, or 7 phases........................................................................ 54
5.1 Relative frequencies of 11 most frequent tags ...................................................................... 57
6. Conclusions ................................................................................................................................... 59
6.1 Future works ......................................................................................................................... 60
Bibliography ............................................................................................................................................ i
Appendix A: Personal Reflection .......................................................................................................... iv
Appendix B: Interim Report ................................................................................................................... v
Appendix C: Feedback ........................................................................................................................... vi
Appendix D: Figures ............................................................................................................................. vii
Appendix E: Text arrangements used in the project ............................................................................ viii
Chronological Order of Suras from Tanzil project ........................................................ xiii
Appendix F: Initial minimum requirements ........................................................................................ xviii
Appendix G: Web user interface ........................................................................................................... xix

v
List of Figures
Figure 1: shows the traditional order of the Holy Quran order, Suras arrangement not according to
Mecca-Medina. ..................................................................................................................................... 11
Figure 2 shows the previous Quranic chronologies (1) ........................................................................ 13
Figure 3, shows the iterative approach life cycle .................................................................................. 21
Figure 4, the project in detailed tasks ................................................................................................... 22
Figure 5, shows the Gantt chart of this project ..................................................................................... 24
Figure 6, shows the revised Gantt chart ................................................................................................ 26
Figure 7, ERD diagram for the database ............................................................................................... 34
Figure 8, shows several different order and markers for each verse. .................................................... 34
Figure 9, taken from (http://www.textminingthequran.com/apps/referents.php?con=1 ) shows a list of
the concept of Allah from , there are 3061 word related to Allah in the Quran according to Tafsir Ibn
Khathir. ................................................................................................................................................. 39
Figure 10, shows the Mean Verse Length for 194 blocks according to scheme of blocks described in
Sadeghi paper ........................................................................................................................................ 46
Figure 11, represents blocks from 108 to 137 using MVL with three vowel symbols as well as the
number of morphemes in the block. ...................................................................................................... 47
Figure 12, represents blocks from 176 to last block using five markers. .............................................. 47
Figure 13, the frequencies of most frequent word in the Holy Quran “ Allah “. .................................. 48
Figure 14, shows the frequencies of words that related to the concept of Allah over 194 blocks
division. ................................................................................................................................................. 49
Figure 15, the frequencies related verses over 194 blocks. ................................................................... 49
Figure 16, the number of Meccan verses in each block ........................................................................ 50
Figure 17, shows different markers according to groups level, similar pattern can be seen for first four
markers. ................................................................................................................................................. 50
Figure 18, the occurance of Allah in each group of text ....................................................................... 51
Figure 19, occurance of word related to the concept of allah according to 22 groups division. ........... 51
Figure 20, the number of verses that directly related to the verses in the group. .................................. 52
Figure 21, the percntage of Meccan verses that each group has. .......................................................... 53
Figure 22, Meccan and Medinan verses occurrence in each passage ................................................... 54
Figure 23, the percentage of Meccan verses in each passage it is clearly that the percentage of Meccan
verses are higher from passage 1 to 6. .................................................................................................. 55
Figure 24, shows three most frequent vowel symbols in Arabic language, x passages ordering
according to the timeline and y is the frequencies of these symbols. ................................................... 56

vi
List of Tables
Table 1, shows the time table of the project tasks................................................................................. 24
Table 2, revised timetable divided in 6 main tasks ............................................................................... 26
Table 3, shows most frequent words in the text in descending order. .................................................. 31
Table 4 .................................................................................................................................................. 31
Table 5, 30th most frequent words in the Quran ................................................................................... 31
Table 6, ................................................................................................................................................. 44
Table 7, shows 8 passage of texts increase dramatically according to the 8 different features ............ 50
Table 8, ................................................................................................................................................. 52
Table 9, ................................................................................................................................................. 52
Table 10, 11 most frequent morphemes in the Quran aacording to the order proposed by Bazrgan .... 53

vii
Glossary
Marker
One of the characteristics used to distinguish one phase from another.
Phase
A group of verses that belong to same period.
Sura
Is the Arabic word of a division that composed of several verses called chapter. The plural form of Sura is Suras.
Aya
The Arabic word of a verse, which is the shortest division in the Quran and is group of words that complete in itself. The plural form of Aya is Ayat.
Arrangements
Quran text divided in different order to traditional order such as blocks, groups and passages.
Blocks
An arrangement of the Quran verses in 194 phases.
Groups
An arrangement of the Quran verses in 22 phases, which is derived by merging several blocks.
Passages
An arrangement of Quran verses in 7 phases, which is derived by merging several groups.
Mecca-Medina
An arrangement of the Quran Suras based on the places of the revelation.

1
Chapter 1
1. Introduction
In this chapter, I clarify the problem that has been tackled with the discussion of
the general area of this project. Additionally, this chapter outlines the goal and
objectives as well as describes the research methodology that has been used to
reach to my solution. Finally, its layout provides guidance to the reader about
the rest of the report.
1.1 Understanding the problem
The Holy Quran is the scriptures of the 2.1 billion Muslims around the world [2].
The earliest Muslims who were around the Prophet Muhammad and lived in the
period of the revelation understand the Holy Quran more than people today
because they were remembering some of the contextual situations of the verses.
Islamic scholars review the situation of the verse, such as the location of
revelation, the occasion on which a verse was revealed, and preceding verses
that address similar topic. This information helps in interpretation due to
dependency between the verses. However, there is a consensus that the Holy
Quran order is not according to the chronology of the revelation. Consequently,
it is easily misunderstood.
An example of misunderstanding of the Quran is when someone says that
Alcohol is not forbidden except during praying times, the verse (4:43) in the
Quran which says “Believers, do not pray when you are drunk” represents only a
gradient stage in the legislation of prohibition; alcohol was forbidden on the
stages to make it easier for people to follow this legislation. In modern times,
people do not understand why there is a verse that says alcohol has more
disadvantages than its advantages while another verse prohibits drinking alcohol

2
entirely (5:90) and another mentions drinking without any mention of
prohibition (16:67).
Reading these verses without knowing their context for them and their
chronological order as it was sent down could cause misunderstanding of the
Islamic rules and may produce incorrect interoperation of the Holy Quran.
Therefore, producing a computational method or technique to show the suitable
order of those verses would help in the interpretation.
1.2 The overall aim
With the increase in text-analysis technology that detects the relationship
between the parts of texts in order to attribute authorship to disputed
documents, detect plagiarism, and determine the chronology of document parts,
there is pressure to create a suitable way to determine which text come before
the other. As was said above, the Holy Quran is not in the chronological order
according to the date of the verses or Sura [3]. The verses were revealed
responding to various events and incidents as well as the cultural-social
circumstances of the revelation period. This overall aim of this project is to
identify features that are related to the temporal ordering of the Holy Quran.
1.3 Objectives
The objectives of the project are to
• Understand the issue by investigate existing research into
computational linguistics, with a particular focus on the Quran corpus
and theme;
• Collecting the corpus of the Holy Quran and tokenizing the text down
to word level;

3
• Design a DB that facilitates testing of different orders against markers
of style and to record verses in both numbering systems (Sura &
verse) and verses;
• Creating different arrangements of the Quran text.
• Compute different markers of style related to time, such as Mean
Verse Length;
• Represent different styles of the proposed chronology.
1.4 Minimum Requirements
• Collecting the corpus of the Holy Quran according to the arrangement
as described in this paper [1].
• Compute different markers of style for the corpus.
• Create a database of verses and consider different orders and markers.
• Identify some markers of style that indicate whether divided texts are
in accurate order.
Possible Enhancements:
• Develop an API which allows interested researchers to easily compute
features with arrangements of the text.
• Use additional markers and rearrangements.
• To create a user interface that applies different markers for a
generated order.
1.5 Degree Relevance
This project was created based on the knowledge and skills acquired from
several modules of my Advanced Computer Science MSc course in the School of
Computing at the University of Leeds. COMP5410M (Language) was useful as it
introduced a strong background for computational linguistics areas such as text
analytics, corpus linguistics, corpus Arabic, and corpus annotation techniques, in
particular, Arabic and Quran Corpus.

4
1.6 Deliverables
An API with a database that contains several markers and arrangements can be
used to record new markers or arrangements or represent the relationship
between them. A web user interface, to represent my expirments and make it
available for interested researchers.
1.7 Research methodology
My methodology in this project begins by dividing the Quran text into groups,
then extracting some features from each group related to the time period. In
other words, this distinguishes a group from others. Determining whether these
features are related to a certain time or not is very simple, as previous studies
pointed out that a verse length increases monotonically over time. The style of
extracted feature or its representation should be a unique. If there are some
features that have a similar style—especially if they are independent of each
other—that means they could help us detect the chronological order. Therefore,
I will start with the feature of verse length because many researchers observed
its style. Then I will look for other features have a similar style of verse length; if
there is similar pattern over a selected group, then this feature will be accepted
and it will identify the periodic ordering. Otherwise, the feature will not support
the selected group of text. At this point, I shall try other features or other
dividings of text.

5
1.8 Report Layout
The remainder of the report is to split into sections explaining different stages of
the project.
Chapter 2 presents an overview of the previous research of the project, giving
more explanation on the problem to be tackled, the methodologies considered,
as well as the techniques which will be used to evaluate the software.
Chapter 3 discusses the project management, laying out the aims and
requirements that were decided upon, as well as the decisions made relating to
the program structure, usability and experiment design.
Chapter 4 explains the implementations in three sections; design, preparation,
and markers of style computing.
Chapter 5 discusses results and evaluate the success of the project and whether
it has met its aims. In addition, it addresses the limitations have encountered
during the project.
Section 6 is conclusion with possible future works.

6
Chapter 2
2. Background
This chapter provides an introduction to the nature of the problem tackled in this
project, information relates to the problem, research on possible divisions and
features for use in the solution as presented in this project and research
methodologies, as well as the evaluation techniques will be used to evaluate the
success of the project.
2.1 Computational linguistics
Computational linguistics, or Natural Processing Language (NLP), is an
interdisciplinary sub-field of computer science that is concerned with the
processing of natural languages in terms of the computational perspective [4],
[22] . This field has become an important field of industrial development as well
as has shifted from studying theoretical models and small prototype to producing
a practical system that can work on large corpora [5]. The nature of projects in
this field is often expected to manage by multidisciplinary teams such as
computer scientists and language experts (those persons who have command on
the languages used in the project). For example, an English-language knows the
rules of how humans recognise verbs from the nouns in sentences in English
sentences; this is a task not easily accomplished for a computer. However, some
skills are tough to be accomplished by computer.

7
Tokenization:
In text processing, the first step is often a tokenization, which is a process of
dividing the given text into small units called tokens [6] [7]. This process seems
easy in a language such as English that separates words by whitespace
character; however, whitespace is not enough to break the text into words.
Consider the following sentences:
1- What’re you looking for?
2- I went to New York.
If we use white spaces as a word boundary, the number of words in the first
sentences would be four, “are” not counting because it is part of a contraction.
Other examples like contractions, such as abbreviations (i.e.. Ph.D., W.C,
K.S.A), may result in an error in the process of tokenization because it does not
distinguish between the dot which means a sentence boundary and the dot of an
abbreviation. This problem can be solved by removing punctuation marks from
words, but in some cases it is important to keep them so that we can make a
distinction between “Wash.,” an abbreviation for Washington, from the verb
“wash” [6]. In the second example from the list above, New York would be
considered as two words even though it is a city in the United States. To avoid
this problem a technique named Entity Detection is used [7]. Fortunately in
Arabic, abbreviation does not exist. The tokenization is a crucial one for the
tagging process [8].
Part-of-speech tagging/Morphological analysis:
Part-of-speech tagging is the process of assigning the tag set class to each word
in the corpus [7] or classifying the morpheme into classes. The Quranic Corpus
labels the words into 44 tags or classes. Morphology Analysis in Arabic language
is complex and challenging for computer due to different scripts and vowels not
always included in the written text [9]. Arabic words may be composed of
several types of morphemes (i.e stem, prefix, suffix and clitic). The latter three
components may be attached to the stem without orthographic marks like
apostrophes used in English [10]. A complex example of Arabic morphology can
be seen in the following figure form [11].

8
Figure 1: A word with colour-coded part-of-speech tags that composed of five morphemes fromhttp://corpus.quran.com
Difficulties:
One of oldest difficulties in computational linguistics and NLP is dealing with
ambiguous aspects of texts including lexical and syntactic ambiguity
[12]. Lexical ambiguity occurs when a word or phrase has more than one
meaning; in these situations, the software may have difficulty determining which
meaning is intended. In English, an example would be the word “bear,” which
can be a noun representing an animal or a verb meaning “to carry.” One of
methods used to solve this problem is called Word Sense Disambiguation [7].
By contrast, syntactic ambiguity is the result of relationships between words,
rather than word meanings in and of themselves. An example of syntactic
ambiguity would be “The car was found by a tree.” A reader knows that this
sentence describes the location where the car was found – not who found the
car. Although a human would be able to understand that a tree cannot have the
agency to “find” anything, computer software would not necessarily be able to
do so.

9
In recent years, a subfield of computational linguistics has emerged:
computational stylistics. The goal of this field is to address some of the issues
associated with syntactic ambiguity. Among the applications for computational
linguistics are determining authorship, detecting plagiarism, extracting
information, clarifying word meaning, and, most recently, aiding in generating
the chronological order of texts.
In this study, we will focus on the latter application: the chronological ordering
of texts. In other words, we are interested in detecting how the text evolves
stylistically over time as opposed to the meaning of the text.
While most traditional research in the field of Natural Language Processing has
focused on the analysis of the subject of the text (i.e., the meaning), relatively
new vein of research focuses on linguistic style (i.e., how a text conveys its
meaning). Computational Stylistics is a trend in Natural Language Processing
that looks for patterns in a text to determine authorship of disputed documents
(Is Shakespeare really who we think he is?) or the chronology of texts [13].
Stylometry is the application of the study of linguistic style (stylistics). Although
this is usually done in the context of written language, it has been applied
successfully to music and fine art as well. In addition to its clear importance in
the academic realm, it has also proven useful in legal settings. In recent years,
it has been explored as a tool for chronological study of texts (as opposed to
stylistic analysis primarily to determine meaning).
Few scholars have studied the chronology of the Quran. The studies of those
who have can be divided into four categories: Phases 1 and 2 (Mecca and

10
2.2 What is the Holy Quran
The Holy Quran is the last sacred book among books that were sent down to
God’s prophets. The Holy Quran is undoubtedly an important book; Muslims take
the rules and guidance from the Quran such as rules of marriage, divorce,
inheritance, finance, etc. The Holy Quran is composed of verses, also known as
“Ayat”; there are 6236 verses in the Quran, categorised in 114 Chapters or
(Sura). A verse is the shortest division in the Quran and is a group of words that
is complete in itself. Chapters are varying in length; one chapter has 286 verses
while another has only 3 verses. This division to Sura and Aya helps in referring
to a specific verse, the notation (113:1) meanings we refer to a chapter (Sura)
number 113 and verse (Aya) number 1.
The Holy Quran was sent down through the Holy Spirit (angel Gabriel) to the
prophet Muhammad during a period of approximately 23 years from 610 to 633
CE [14]. The Holy Quran was not sent down as a single book as it is known
today; neither was it revealed in a single session. The revelation came in
response to specific events. Therefore, in order to understand the Quran it is
important to know about the prophet Muhammad’s history. The first part of the
revelation was in Mecca, the city in which the prophet Muhammad was born.
Prophet Muhammad was born in Mecca; and the first revelation was done when
he was 40 years old. He continued to teach people Islam in Mecca for 13 years.
The verses revealed in this period are called “Meccan.”. Then, he migrated to
Medina, which is about 400 km from Mecca. The verses revealed after his
migration to Medina are called “Medinan.”.

11
2.3 Traditional order of the Holy Quran
There is a consensus among Muslims that the Holy Quran is not arranged
according to the date in which the verses or chapters were revealed or even the
place where they were revealed [3], [15]. There is an agreement among
scholars that the order of verses in every chapter was done by the Prophet
Muhammad following Allah’s command. He was instructed to put these verses in
a specified location (Ahmad [399], Abu Dawood [768], Tormithi [3086] and
Nessae [8007]. Also the chapter order is believed to be according to the order
when the angel Gabriel revealed the Quran to the prophet Muhammad every
Ramadan. For instance, we find the Sura AL-Alaq (The Clot), one of Meccan
Sura, as the 96th Sura, but there are claims that this Sura was the first Sura
revealed. Similarly, the 2nd Sura, called AL-Baqarah (The Cow), is one of the
Sura that was revealed in Medina or after the migration of the prophet
Muhammad. Although the chapters have been arranged in an order that is
different from the sequence of revelation, we do not say that it has been
arranged in the wrong way because it was revealed to respond to various events
and incidents.
The following figure shows the current order of the Suras in the Holy Quran in
terms of classification to Mecca and Medina periods.
Figure 2: Traditional Order of the Holy Quran.
1
2
1 6
11
16
21
26
31
36
41
46
51
56
61
66
71
76
81
86
91
96
10
1
10
6
11
1
Traditional order of Sura's in the Holy
Quran
Sura no

12
Figure 2 shows the tradisional order of the Holy Quran. The X-coordinate
represents the order of 1 to 114 of Suras. Y shows where these Suras were
revealed. If we assume that the given order is follows the same sequence of the
revelation, it means that the Suras on the left side of the figure should be
located on the point 1 in the Y-coordinate while the right side located on point 2
of Y. It is clearly seen that the Suras are not ordered based on time because
there are some Suras, like Suras number 2 and 3, which were sent down in
Medina. Also the last four Suras appear to have been revealed in Mecca.
2.4 Quran Divisions
The Holy Quran consists of 30 parts and all of these parts are divided into a
number of sections called Hizb; each Hizb is divided into a number of
subsections named Ruba, and each Ruba has verses. The signs and this division
came after the death of the Prophet, peace be upon him, and his successors.
The purpose of these divisions is not to sort the text according to revelation time
but to facilitate the search and access to the content of the Quran.
A verse is the smallest part that can be read in the Holy Quran. For example,
verse No. 1 Sura No. 108 AL-Kawther (A river in paradise); “Indeed, we have
given you AL-Kawther”. There are some verses that consist of only 2 or 3
letters; these are special verses that comes in the beginning of a Sura and are
also called as mystery letters. Twenty-nine Suras are begin with these letters 2,
3, 7, 10, 11, 12, 13, 14, 15, 19, 20, 26, 27, ,28 , 29, 30, 31, 32, 36, 38, 40, 41,
42, 43, 44, 45, 46, 50, and 68 [16] .
Numbering of the verses is not part of the Quran, but a way to facilitate access
to particular parts of the Quranic text. According to Coofian numbering system,
there are 6236 verses in the Holy Quran distributed in 114 Suras.
These Suras are not the same length; shortest chapter, for example, Sura no
108 (Al-Kawthar), has only three verses, while the longest one Sura, no 2, (Al-

13
Baqarah), has 286 verses [3] .These suras are identified as Meccan or Medinan.
The first is Mecca and the second is Medina. Mecca and Medina are two cities in
The Arab peninsula, most of which is called now Kingdom Of Saudi Arabia. Some
scholars identified them as before or after the migration of Muhammad from
Mecca to Medina. There are 89 Meccan Suras and 25 Medinan Suras. Some are
mixed and have verses from the two periods. These Suras were revealed in
Mecca then completed later after migration to Medina.
2.5 Previous works
Traditional 1 2
Weil, et
al.
1 2 3 4
Bazargan 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 21 22
Modified
Bazargan
1 2 3 4 5 6 7
Figure 3: The Previous Quranic Chronologies [1]
Early studies in the Holy Quran chronologies show there are only two phases
(Mecca-Medina) according to the location of revelation. The Meccan period lasted
for 13 years, and the remaining 10 years belong to Medina. The Weil, et al.
chronology has more detail for the Mecca period: early, mid, late. Bazargan has
proposed a 22-phase chronology, with 12 for Mecca and 11 for Medina. The
modified Bazargan merges the Bazargan chronology into 7 phases.

14
As some Suras contains verses from Mecca and Medina, it may not be possible
to rearrange the Suras. Block scheme has used from Bazrgan’s chronology to
rearrange the text [1]. A block is a set of verses that are believed to belong to
the same period. A Sura can be divided into one block or more, but a block
cannot have verses from different Suras. See Appendix E, a notation “(1) 96: 1-
5” means that Block 1 is defined as verses from 1 to 5 in Sura. 96.
2.6 Two phases
Most previous studies in the chronology of the Holy Qur’an are divided into
two phases (Mecca and Medina) and also explained the difference between those
two periods due to of the occurrence of certain words or phrases in the text. A
large number of scholars were interested in this chronological order of the Holy
Qur’an, therefore, a much work has been done to distinguish between these
periods by the style of words composing the verses or the style of the verse.
The style of verses: Meccan verses deal with matters of faith and uniformity
and give arguments and evidence that there is only one God [18], because the
Arabs before Islam were taking a number of idols and Khbl Lat and Uzza
worship. While the Medinan verses deal with the civil legislation and provisions
such as prayer, fasting, war, and the Hajj and Umrah and family affairs and so
on [18].
The form of the verses: Meccan verses tend to be short, compared to
Medinan [18], [19]. For example, verse 282, one of the Medinan verses, of Sura
No. 1 is the longest verse in the Holy Quran and has 128 words, while the first
verse of Sura No. 96 contains only 5 words and was revealed in Mecca.
According to [18] and [19], Meccan Suras also tend to be short, whereas the
Medinan tend to be long. However, there are some exceptions. For example,
Sura No. 103 (Time) that was revealed in Medina is shorter than Sura No. 96
(The Clot), which was revealed in Mecca.

15
Another marker used to distinguish between Meccan and Medinan verses is the
style of speech: in Meccan verses the phrases “O people” and “O son of Adam”
were used while “O believers” was used in Medinan verses [18].
[16] said that the most prominent feature is the rhyme, as 90% of the verses of
the Quran contain a pattern close to the prose. Most rhymes used in the Holy
Quran end with “im,” “un,” “in,” or “um.” This feature is valuable for this project
and can be taken as a marker of style to test the proposed order by [1].
However this feature cannot be easily captured because they sometimes have a
similar pronunciation but different spelling of the word at the end of verse.
The most common Diacritics used in Arabic script [16] are the vowel a, the
vowel i, the vowel u, the lack of vowel, and the double consonant.
[20] chose only long chapters in the Holy Quran in order to be classified into
Meccan-Medinan using a multivariate technique called hierarchical clustering.
She has done a comparison between the words that appear more than 1000
times in both periods.
[21], also using the categorization of classical binary Mecca and Medina, used a
machine learning algorithm such as Support Vector Machine (SVM) and Navie
Bayesian classifiers. Using fuzzy-single linkage, Meccan suras have been
clustered into 7 clusters and Medinan suras into 3 clusters.
2.7 Four phases
According to [16], the most commonly accepted chronology is four phases:
dividing Meccan suras into three periods (Early Meccan, Middle Meccan, and Late
Meccan) and Medinan into one. This may be reasonable because the Mecca
period was longer than the period of Medina.
[1] used univariate markers of styles such as mean verse length, the 28 most
frequent morphemes in the Quran, 114 other common morphemes, and 3693

16
uncommon morphemes to verify his chronology. He also used multivariate
techniques such as PCA and MDS in order to verify the chronology of the Holy
Quran in seven passages. This is based on a different assumption of Bazargan
and Noldeke, which says that “the style of the Qur’an changes in one direction
without reversal,” but it is not necessarily true that the style is changing in one
direction without reversal. He corroborates the phases using the principle of
“Criterion of Concurrent Smoothness,” which means using independent markers
of style with particular sequences of text and seeing whether these markers vary
in smooth fashion or not. If yes, it means this chronology is true.. He used the
blocks scheme described in section 2.5 by Bazargan, and the chronology
proposed by Noldeke, described in section no 2.5. After that he merged them
into 22 groups. His work differs from previous research in that previous research
adopted the method of generating chronological order depending on the style
change in one direction and no reversal.
2.8 Evaluation techniques
The criteria will be used to decide whether the sequences generated using
markers of style are in the right order or not. Two different criteria have been
set out: historical information such as Meccan-Medinan, similar researches,
comparing the proposed order with a list of well-known date of verse and
feedback of interested scholars.
2.9 Historical information
A number of researchers have studied the classification of the Holy Quran into
two phases known as Mecca and Medina. This is helpful in this evaluation if I
calculate how many Meccan and Medinan verses are in the proposed order. If
the number of Meccan verses decreased and Medina increased, this means this
order is consistent with these previous studies. The rate will not be 100%, as
there will be some errors due to blocks, groups, and passages having mixed
verses from the two periods.

17
It is well known that the prophet Muhammad was not able to read or write,
although he is the most influential person in the history [30]. Everything in his
life was recorded by his companions, such as sayings and conduct and even his
personal life was told by his wives, and this information was gathered later in
books called “Hadith”. While the Holy Quran is considered to be the first source
of the Islamic law, the Hadith is considered to be the second source and is
important in understanding the Holy Quran.
The confidence of this criterion depends on the authenticity of the Hadith. Hadith
has been evaluated by scholars by dividing it into four categories according to
the degree of authenticity and reliability.
1. Sahih: the genuine traditions and has high degree of authenticity
2. Moothaq: almost like the Sahih but the person who narrated it is not as
reliable as the person who narrated the Sahih
3. Hasan: has low degree of authenticity
4. Dha’eef: not reliable, weak traditions
So, this criterion will be useful for evaluating my project as there are many
Hadiths about the revelation order of the Holy Quran. If my computation marker
of style is monotonically increasing, this mean there is a relation but does not
mean this is the right chronology. Therefore, this criterion will decide if the
proposed order is consistent with this information.
[29] provides a chronological order for the Holy Quran according to the
information coming from Hadith. This chronology is not only based on the whole
Sura, but it also mentions if some verses in a particular Sura were not revealed
in the same period. For instance, Sura number 68 in the traditional order has the
order number 2, except verses 17-33 and 48-50, which were revealed later in
Medina. Further detail can be shown in appendix E .

18
2.10 Similar Researches
A similar study is found in the paper “The Chronology of The Quran: A
stylometric Research Program” described here [1], and I compare my results
with Sadeghi’s to judge my work’s success. The similarity between my work and
Sadeghi’s is that we used the same scheme in dividing the Sura. The 114 Suras
were divided into 194 blocks, then merged into to 22 groups, then merged into 7
passages. My project differed from Sadeghi’s in three ways: First, I used a
different version of the Holy Quran. Second, different markers of style were
produced here. Third, I did not exclude any verse of the Holy Quran, while he
excluded 188 verses, due to repetitions and refining the style, more details in
[1].
2.11 Feedback from interested scholars
Client feedback – from the scholars who are interested in the study of the
chronology of the Holy Quran to see how appropriate the delivered solution was
and what changes could be implemented to improve it further.
2.12 Evaluation data
I will use the same data for evaluation; because of the uniqueness of the text of
the Holy Quran, there is no choice but to evaluate my solution using other texts.
The Quran is written in Uthmanic script, which is different from modern Arabic
spelling and uses didactics or vowel symbols that are not used in modern Arabic
books. It also has different punctuation marks that are not used in other texts,
like pause markers which determine when the reader should pause. The
following table presents pause markers.

19
Compulsory, you have to stop here. Unless the meaning of م
the verse will be destroyed.
� Means do not stop but it is not forbidden
.It is recommended to stop here ط
.Continuing is preferred صلي
.Necessary to stop قلي
.It is permissible to pause here ج
Table 1: special markers used in the Quran text
2.13 Tools used in this project:
Although there are several toolkits available to manipulate the natural language,
such as NLTK to build python programs, I preferred to use Java for this project.
The main reason for that is it has a strong library to manipulate the text.
Another reason is because I have enough experience with Java programming
language. Moreover, the Quranic Arabic Corpus offers an API that allows us to
access and analyse the Holy Quran.
JQuranTree is a Java API that allows access to the Holy Quran text using
different formats of text with a particular location (i.e., by access to Buckwalter
transliteration format within Sura number, verse number, or token number)
[11]. It provides classes for searching for chapters, verses, tokens or characters.
Conceptual features have been based on the Textmining website [23].
Data supplied for this project consists of 6236 verses in an XML file with Java
library (JQuranTree) to gain access to these verses according to their location in
the Holy Quran, library and XML file have been downloaded from the site [11].

20
Chapter 3
3. Project Management
In this chapter, I address the choice of project management approach that I
adopted to manage this project as well as the initial and revised schedule. A
number of project management tools were used to help accomplish the
objectives of this project.
3.1 Project management approach
In order to progress through the project steadily and effectively as well as to
meet the minimum requirements and complete the objective in section 1.3, an
iterative approach [24] as shown in figure 4 was used to manage this project.
This approach starts with developing a prototype according to the initial
requirements, then testing and modification. This process of making a prototype
is continued to produce many versions of the product until we fulfil the final
requirements taken during the process. Repeating the process helps the
manager to receiving feedback before, throughout the project and corrects the
errors which leads to a reduction in risk [25]. It also is one of the fast project
management approachthat allow you to see the results quickly [26]. In this
approach, the work development can start with incomplete requirements.
Therefore, it would be suitable if we want to change the requirements later.

21
Figure 4: The Life Cycle of the Iterative Approach
As I said the iterative development has the advantage of getting feedback and
changing the requirements during the development process because you can see
the results fast. It also allows you to reduce the risks and get high quality
results. The requirements can be changed any time during the development
time.
It also fits the nature of the project because it is repeatable and able to be
modified many times during the process until getting improved version. Each
time we need to compare the style of the new marker over the selected periodic
groups of text with the style of the marker verse length. The extracted features
should be independent, so the way of computing them is not the same but the
testing and evaluating for all features are same.
Requirements
Analysis
DesignImplementation
Testing

22
3.2 Development tasks
I categorised the project objective into sub-objectives and list them with the
tasks that must be achieved in order to complete these sub-objectives
effectively and be manageable tasks. The following figure shows the
necessary sub-tasks under each main task in the project.
Figure 5: detailed list of tasks to be performed for the project
1. Preparation
a. Collect data: download a copy of the Holy Quran, including different
types of transliterations
b. Design: design a template to save different dividings of texts
2. Pre-processing: do some experiments to investigate the most important
words mentioned in the text
3. Divide the text: three types of divisions has been used one in previous
research (see Appendix E and section 2.1)
4. Features extracting:
project
Preparation
collecting data
Databae design
preprocessing
divide data
blocks
groups
passages
features extracting
calculate frequiencies
record in DB
represent features
evaluation

23
a. Calculate frequencies: calculating an aspect in the text: for
example, calculate the number of morphemes in a given word
b. Record in DB: try to find a method to record every extracted
feature to DB instead of repeating the process every time
5. Represent features: find any relation between those divisions of text and
extracted features by plotting them against each other
3.3 Initial Schedule
Before starting the project work, an initial plan was constructed for this project
with implementation of some of the tasks described in the proposed table.
However, while the project was in progress, I needed to change the design a
number of times, resulting in a change in the plan and schedule as well. The
main reason for this change is that during the development I received feedback
that gave me more understanding about the project.
The Gantt chart is a useful technique used in project scheduling that was
invented by Henry Gantt in 1917. The Gantt chart below, which is illustrated in
[27], is widely used among project managers to organize their project tasks
[28]. The Gantt chart for this project, shown below, is split into 20 tasks during
28 weeks starting from 13 February 2012 until the end of August 2012. Each
horizontal bar represents the duration of an activity or task in the project.
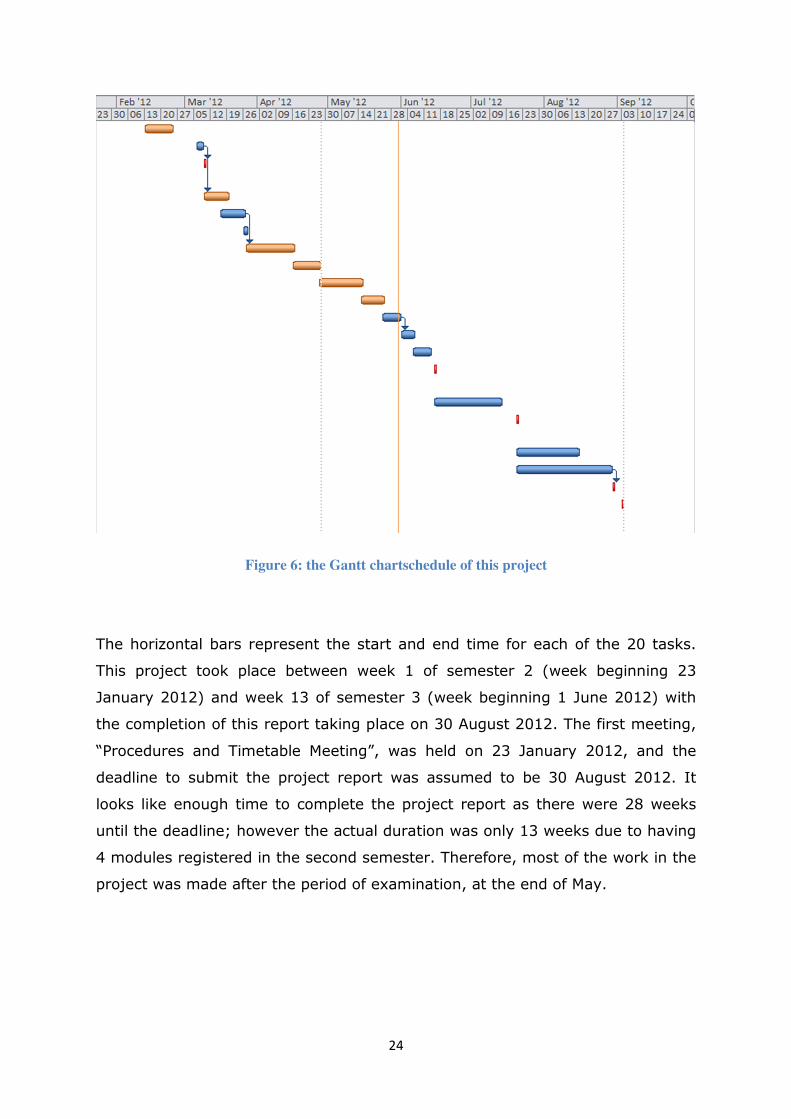
24
Figure 6: the Gantt chartschedule of this project
The horizontal bars represent the start and end time for each of the 20 tasks.
This project took place between week 1 of semester 2 (week beginning 23
January 2012) and week 13 of semester 3 (week beginning 1 June 2012) with
the completion of this report taking place on 30 August 2012. The first meeting,
“Procedures and Timetable Meeting”, was held on 23 January 2012, and the
deadline to submit the project report was assumed to be 30 August 2012. It
looks like enough time to complete the project report as there were 28 weeks
until the deadline; however the actual duration was only 13 weeks due to having
4 modules registered in the second semester. Therefore, most of the work in the
project was made after the period of examination, at the end of May.

25
Table 2: shows the time table of the project tasks
The timetable lists tasks (without any details) per specified periods. It also has
important dates in order, such as the deadline for submitting reports.
Background reading and reviewing for methods and Quran corpus were between
16/03 and 26/03. To use a suitable method to collect the text of the Quran, I
have put 2 days because I have come across a website allowing downloading of
a copy of the Quran. After that I stopped working on the project due to having
two course works followed by exams for four modules. I was required to submit
the interim report in the middle of June, therefore after the exam period I read
more about the problem and how it can be solved for 6 days as well as trying to
do some experiments to understand it better. There were 10 days alloted for
writing up what was done so far, then starting real experiments until mid-July.
Then my work time was parallel on improving and waiting up until the end of
August.

26
3.4 Revised schedule
Figure 7 and table 3 show the modified planning and timetable. The initial
schedule was revised by adding more time for the implementation phase,
totalling 36 days instead of 21 days. This was done to find more features like
conceptual features. The revised version of the schedule has 6 main tasks. The
data preparation phase began mid-June and lasted for 6 days. In this phase I
learned the tools for dealing with the corpus, designed the database to store
different formats and orders of texts, as well as did more pre-processing for it.
The next stage required dividing the texts into particular groups so that each
Sura was divided into one or more blocks; this work occurred between 21 June
and 27 June. Next, I tried to find several markers until the middle of July.
Representing these markers and plot, the most important was attached in the
report after mid-July for 5 days. Then, I put 16 days for the evaluation followed
by writing up. The revised Gantt Chart is shown in figure 7.
Figure 7: shows the revised Gantt chart
The revised schedule can be seen in table 3. This schedule allowed less time for
writing and testing.
15-0622-0629-0606-0713-0720-0727-0703-0810-0817-0824-0831-0807-09
Data preparation
dividing texts
features computing
plotting features with orders
evaluation
Writing up

27
No Tasks Start Date Duration End Date
1 Data preparation 15-Jun 6 20-Jun
2 dividing texts 21-Jun 7 27-Jun
3 features computing 28-Jun 18 15-Jul
4 plotting features with orders 16-Jul 5 20-Jul
5 Evaluation 21-Jul 16 05-Aug
6 Writing up 06-Aug 25 30-Aug Table 3: revised timetable divided in 6 main tasks from mid of June until the deadline
3.5 Minimum requirements changing
During the development process of this project I changed the minimum
requirements in order to be more precise. The initial requirements shown in the
appendix F were submitted on 9 March 2012. On 27 July I modified these
requirements as can be seen in the section1.4 I removed the first one “Through
review of the sequence in the Quran” because it was too general. The second
requirement was modified to be more precise too. I did not change the third
one. In addition, one more was added, which is “Create a database of verses
and consider different orders and markers”.

28
Chapter 4
4. Implementations
This chapter contains a description of my implementations. The description is
broken into three sections; design, preparation and markers computing.
This project contains a number of development tasks required to complete the
main objectives listed in section 1.3 . The next section shows some of issues in
the design to be considered in approaching each task, and some information that
is required for understanding the requirements in the implementation.
4.1 Design
Depending on the purpose and objectives described in section1.3, the following
tasks have been done to achieve the goal of this project:
To verify the chronology proposed [1], there are a number of steps which have
been working out as follows:
1. Collecting the Corpus: An electronic version of the Holy Quran.
2. Create a database that will be used to record the verses and extracted
markers of them, Structure Query language (SQL) would be useful if I
record extracted features with different arrangements of texts.
3. Extracting markers of style from the text: features related to time, such
as verse length, increases against time gradually.
4. Represent markers of style in specific order.

29
4.2 Collecting the corpus
A corpus is a big set of data for the purpose of analysis using computational
linguistics techniques.
Deciding which corpus to work with is another issue because there are
several electronic versions that are available online. And those versions are
different in terms of the numbering systems they used in numbering the
verses. For example, whether “Bismillahi-rraHmani-rraHeem” may be
included in a Sura or not. In Medina Mushaf, it is only included in the
beginning of Sura number no 1.
The famous project that provided a verified copy of the Holy Quran is the
Tanzil Project, which is connected to Edina Mushaf [29]. Tanzil offers several
types of Quran text, such as simple, Uthmanic, with diacritics or not, and
pause marks, as well as in different file format like XML, SQL dump file, or
text file. Tanzil numbers verses in each Sura according to Medina Mushaf by
including the verse number and Sura number. This way makes the searching
in the Quran easy because we do not need to look to all 6236 verses to find a
verse; instead we just enter the Sura number and verse number. For
example if we want to refer to verse number 3 in Sura number 2 we type
(2:3).
Figure 8: the xml file downloaded from Tanzil web site, it has 114 Sura and each Sura has several verses(aya)

30
I used a version of Tanzil with Jquran Tree library from [11]. This API provides a
set of functions to access the Quran text with several formats like text with
diacritics, removed diacritics text and Bukwalter transliteration. It also offers an
orthographic model that provides not just a verse by its location but a specific
word; you just need to provide the word location. For example, to get the third
word in the Sura number 113 and verse number 3, you just need to write the
following lines.
Figure 9 show an example of how to obtaina specific token using JquranTree in different format.
Output:
Format Output
RemoveDiacritics غاسق
Unicode ٍَغاِسق
Buckwalter gaAsiqK
4.3 Pre-processing
Before conducting any experiments, a pre-processing work was done for the
Quran text to investigate the most frequent words. I wrote a code to extract the
frequencies list of each word in the Holy Quran in order to see the most
significant words. First, all verses were written to a text file to get the
frequencies of every single word for mining the data.

31
Figure 10:this function recieves an array of verses and filename, then it write these verses to the a given filename.
This process is required for the following function. WordLists is the function
responsible for calculating the number of occurrences for all tokens provided in
the text file.
Figure 11: A procedure that obtain the word occurrences in a given file
This function tokenizes the word and computes its frequencies in the provided
file.

32
For example, assume I provide a file that has the following text:
The key of my car is here. I lost the key of my house.
WordList would return something like the following:
Word Occurrences The 2 Key 2 Of 2 My 2 Car 1 Is 1 Here 1 I 1 Lost 1 House 1
Table 4: shows most frequent words in the text in descending order.
Applying pre-processing for Quran text:
1-10 11-20 21-30
من 2589
هللا 2153
ان 1603
فى 1185
ما 1010
812 �
الذين 811
ا� 763
و� 658
وما 646
علٮا 428
قال 416
لھم 373
ثم 340
لكم 337
ومن 337
كان 333
وان 322
بۦه 298
بما 296
قل 294
ا�رض 287
او 280
ذالك 280
الذى 268
الٮا 265
ھو 265
ءامنوا۟ 263
ھم 261
على 258
Table 5: 30th
most frequent words in the Quran
After we know the way to access the Quran texts in several formats we can get
some features. An easy example of one feature is the Mean Verse Length. This
can be obtained using a loop starting from 1 to 114 (due to there being only 114
Suras), then taking an inner loop depending on the verses that a Sura has.
However this will give the features with the traditional order of the Holy Quran.

33
The scheme we need to work with is described in section 2.3 and is different
from this scheme. Some Suras have been divided into several blocks and others
taken intact. Therefore I encoded the specific order in a text file and read the
verse number from that file.
Figure 12: the text file used to read the verses order
The left-most number is the block number; notice line number 8 and 9 has the
same block. Line number 8 means take the verses from 1 to 5 from Sura
number 88 and assign it in block number 8. Line number 9 means take the verse
from 8 to 16 from the same Sura and assign it in block 8.
This way of computing features was used in the early stage of this project when
we needed many files for computing features according to the order encoded in
the text file. After that we created a database to record the verses and features
in order to exploit the Structure Query Language (SQL) and its built-in functions
in searching and ordering.
4.4 Design and create a database
In order to represent the style of several markers within different temporal
groups of text, I constructed database with the following design.

34
Figure 13: ERD diagram for the database
There are only two tables. The first is Chapters, which represents the Suras. It
has Sura name and its number. The second table is the important one called
Verses (Aya). Here we recorded 6236 verses along with several markers and
orders. An example can be seen in Figure 7; Marker1, Marker2, and Marker4 are
word counts, and the symbol of Fatha and Kasrah have been computed for each
verse. Order5 is the revelation order adapted from [29]. Order33 field is the
order proposed by Bazargan and order44 the 7-phases order or Bazargan
modified order.
Figure 14: shows several different order and markers for each verse.
After computing some markers with orders, I can use SQL to produce these
combinations of ordered markers. For example, assume I want the style of
Marker1 with the order44; I only need to write the following SQL statement.

35
This will produce a vector of words count for the order4. Then, it can be plotted
to observe the pattern of the style. I can use others built in functions that SQL
offer like avg. It is not necessary to add the command “order by” if we use
“group by” due to this function’s ability to sort the rows according to the field
used in “group by”.
Output:
1 1253 We divided 6236 verses into 7 groups according to the
description in section 2.5, these results will be analysed
later in chapter 5.
2 3910
3 3199
4 3615
5 23841
6 28910
7 11745
This process requires a previous process to record the markers and
arrangements to the Verses table.
To do so, the following code is used for building Insert SQL statement for each
verse and sending it to the function ExcuteQuery that will record the verses into
the the Database.
Figure 15: Buliding Insertion SQL statement
I made the process of extracting features and recording them automatic. Let me
explain that by an example. Assume we want to find the frequencies of God’s

36
names such as “Al-rahman” and “Al-raheem”. To do so, the following code is
responsible for it
Figure 16: computing the occurrences for a word considering multiple synonyms
It is divided into two parts, the first being responsible for computing the
frequencies for a given list of words in a provided file and regular expression.
The results of this part create an array of frequencies for each verse. In this
example we use a list of 99 names for Allah in the provided file. pFix and sFix
were used to consider the boundaries of these words.
The second part is responsible for building an SQL statement and performing it
in order to record this marker into the database.
The Markers function receives the text format used in the search; in this case I
type 1, which refers to Arabic removed diacritics text. This function invokes the
function of Key_Words, which retrieves a list of keywords that are recorded in a
given file. Then these keywords are passed to the function CountOccurences,
which returns the number of occurrences for them in the given format text using
regular expression provided.

37
Figure 17:Markers function which return an array of frequencies for a given keywords and regular expression
Figure 18: calculate the number of occurrences of provided array (needle) in a given text ( haystack)
4.5 Basic Markers
Word count is the easiest one among all the features that can be extracted using
String functions with any programming language. Java provides many functions
to manipulate with the strings variables such as split function that divides the
text into tokens depending on the regular expression provided to the function.
For example, to calculate the number of words in verse number 3 in the Sura
number 1, the following code will illustrate this. MVL calculated using the
following formula:

38
MVL =����������� ������������
����������������������
One method to calculate the tokens number in a verse is listed below.
String arr[] = Document.getChapter(1).getVerse(3).toBuckwalter().split(" ");
System,output.println(arr.length);
Figure 19: compute the words number in a verse
An Alternative and easy way to us JquranTree as follow:
System.out.println(Document.getChapter(1)..getVerse(3).getTokenCount());
Figure 20: using JquranTree tokenizer
select avg(Marker1) from verses group by order22;
select avg(Marker1) from verses group by order33;
select avg(Marker1) from verses group by order44;
Figure 21: retrive the Marker1 according to three different divided text
Vowels markers Fathah, Dammah, Kasrah also using similar procedures as
explained above.
Fatha frequencies =�����������������������
���������������������
Other way to calculate this marker by creating a file that only has a white space
and run the following function:

39
4.6 Occurences of Allah names
Assume we have a vector V of words that refer to Allah.
To compute the frequencies of these names is as shown in the below:
Allah names frequenciesin phase a =∑ ������ ���������
�����������������������
4.7 Conceptual markers
The concept of Allah includes that every verb related to him such as in (112:4)
“Nor is there to Him any equivalent”. The name of Allah is not specifically in this
verse but ”Him” refers to Allah, therefore this verse has a concept of Allah.
I used HTTPWebRequest class that is supported by Java to read contents from a
web application that provides a list of the Allah concept in the Quran and its
locations. Then I transferred contents to the database. [23] Offfers a list of
verses that have a concept of this entry word.
Figure 22: taken from (http://www.textminingthequran.com/apps/referents.php?con=1 ) shows a list of the concept of
Allah from , there are 3061 word related to Allah in the Quran according to TafsirIbnKhathir.

40
The following code was used to transfer the frequencies to the verses table in
the database.
Figure 23: the function that is the responsibe to return the concept frequencies of a given word.
4.8 Related verse
Related verses based on the information from Tafser Ibn Kathir. We just collect
directed related verses from [23] using same technique in conceptual markers.

41
Figure 24: extraxting the feature of related verses
4.9 Relative frequencies of Part-of-Speech tagset in the Quran
We employ the Quranc Arabic corpus Part-of-Speech tags shown in the following
table in the project. I also used here the same techniques as used in 4.3, 4.4
number to extract the morphemes frequencies for a token.

42
No Tag Frequency Description
1 N 25137 Noun
2 PRON 24691 Personal pronoun
3 V 19356 Verb
4 P 13007 Preposition
5 CONJ 9450 Coordinating conjunction
6 PN 3911 Proper noun
7 REL 3575 Relative pronoun
8 REM 2925 Resumption particle
9 NEG 2688 Negative particle
10 ACC 2283 Accusative particle
11 ADJ 1961 Adjective
12 EMPH 1244 Emphatic lam prefix
13 T 1166 Time adverb
14 DEM 1059 Demonstrative pronoun
15 COND 1049 Conditional particle
16 INTG 946 Interogative particle
17 SUB 684 Subordinating conjunction
18 LOC 669 Location adverb
19 RES 558 Restriction particle
20 CERT 414 Particle of certainty
21 VOC 376 Vocative particle
22 RSLT 350 Result particle
23 PRO 332 Prohibition particle
24 PRP 319 Purpose lam prefix
25 CIRC 293 Circumstantial particle
26 SUP 235 Supplemental particle
27 PREV 162 Preventive particle
28 FUT 161 Future particle
29 RET 122 Retraction particle
30 EXP 104 Exceptive particle
31 INC 90 Inceptive particle
32 CAUS 88 Particle of cause
33 IMPV 78 Imperative lam prefix
34 EXL 66 Explanation particle
35 AMD 65 Amendment particle
36 INT 47 Particle of interpretation
37 ANS 40 Answer particle
38 EXH 40 Exhortation particle
39 SUR 35 Surprise particle
40 AVR 33 Aversion particle
41 INL 30 Quranic initials
42 EQ 6 Equalization particle
43 COM 3 Comitative particle
44 IMPN 2 Imperative verbal noun
Table 6: Part-of-Speech tags used in the Quranic Arabic Corpus http://corpus.quran.com/

43
Relative frequency of a tag is the number of occurences for this tag in the text
divided by total number of tags.
An example of computing relative frequency of Noun in the phase 7 is shown
below:
Relative frequency of Noun in phase 7 =������������������������
���������������������������
Figure 25: a function receives location and returned an array of Part-of-Speech tags.
I type the location (6:113:8) this means the 8th token in verse number 113 of
sura number 6. This word has 5 morphemes as the following output shows:
The following figure shows the output for first verse in the Quran. The (bisomi
{ll¬ahilr¬aHoma’nlr¬aHiymi) it is clear that it has 4 words and 5 morphemes
and 3 types of part-of-speech tagsets.

44
Figure 26: Part-of-Speech information tags
Another example for extracting feature from the text:
I prepared a file that contains a list of questions in Arabic and provide that file to
the function as can be seen below.
Figure 27: shows how to extract the question feature in each verse as well as record it to the database.
The difficulties I confronted here are that Arabic text has different spelling in
several question words; for instance, the word أأسلمتم would be written as ءاسلمتم
and the word ارأيت would be ارءيت.
4.10 28th most frequent morphemes in the Quran
Most frequent morphemes in the Quran are shown in the following table:
No Morpheme Meaning Description
1 Wa And prefixed conjunction 2 I /e/ or /i/ Kasrah, Sound like e or i 3 L For Preposition 4 U /u/ or /o/ Dammah, Sound like o or u 5 A /a/ Fathah, Sound equivalent a 6 An About Double Fatha 7 Min From Preposition 8 Una 3rd person plural personal
pronoun 9 Fa then, and so prefixed resumption particle

45
10 Hum they 3rd person masculine plural personal pronoun
11 Llah God’s name Allah 12 Ma 13 In 14 Bi prefixed preposition 15 Un nominative feminine indefinite
noun 16 La 17 Kum Masculine plural Enclitic pronoun 18 Hu Him 3rd person masculine singular
possessive pronoun 19 La 20 Fi In prefixed preposition 21 Ina 22 Ka prefixed preposition 23 Hi him 3rd person masculine singular
object pronoun 24 Li to indirect
object prefixed preposition
25 Ha Her 3rd person feminine singular object pronoun
26 Inna accusative particle 27 Na Our Enclitic pronouns 28 alladina who masculine plural relative
pronoun Table 7:28 most frequent morphemes based on [1]
Relative frequency of a morpheme is the total of occurences these morphemes normalise by the all
28 morphemes.
4.11 Relative frequencies of vowels
No Vowel Frequency Description
1 a 122948 Fatha,Sound equivalent to a 2 i 45970 Kasrah, Sound like I or e 3 u 37320 Dmmah, Sound like u or o 4 aa 15955 Sound aa 5 ii 4194 Sound ii 6 final an 3741 Double Fatha 7 final in 2633 Double Kasrah 8 final un 2519 Double Dammah 9 uu 2034 Sound uu
Table 8: 9th
vowels used in relative frequencies of vowels
Similar to the releative frequencies of morphemes and tags, we normlise by total
number of all vowels that appeare.
Notice: there are further implementations in appendix G.

46
Chapter 5
5. Results and Evaluation
In this chapter I present and evaluate the results of the project. I chose a set of
criteria to judge the success of this project. In addition, I am going to address
any limitations I have encountered during the project.
5.1 Results
I divided this section into three parts; the first part shows the results according
to blocks division. The second presents the results for 22 groups of consecutive
texts. Finally, the last part is according tothe 7 phases chronology proposed by
[1].
5.2 Experiment One: arrangements of 194 blocks
Figure 28: The Mean Verse Length for 194 blocks according to scheme of blocks described in [1]
It is clear that the verse length increases in coherence with the Bazargn’s blocks
except for the three blocks (110, 132 and 179). This confirms the claim that
says the length of a verse tends to increase with time.
0
20
40
60
80
1
10
19
28
37
46
55
64
73
82
91
10
0
10
9
11
8
12
7
13
6
14
5
15
4
16
3
17
2
18
1
19
0
Mean Verse Length

47
Figure 29: representsblocks from 108 to 137 using MVL with three vowel symbols as well as the count of morphemes in
the block.
The results for the other four markers show a similar pattern. There are two
peaks at 110 and 132 and one valley at 179. However, the overall trend is a
gradual increasing over 194 blocks or time. However, this similarity may due to
the dependency between markers and the word count. The first peaks occurs at
block number 110 which has only one verse the 31st verse of Sura 74. This verse
is different to these verses that were revealed at Mecca due to its long length.
The second peak occurs at 132, which belongs to the period of Mecca but has a
long length as well.
Figure 30: represents blocks from 176 to last block using five markers.
In this figure, the increase in length is even clearer than in the previous one.The
decline at 179 may be because this block has only three verses, belonging to
Sura number 110. Despite that Sura was revealed in Medina according to the
revelation order in the appendix E its verses are not as long as typical Medina
verses.
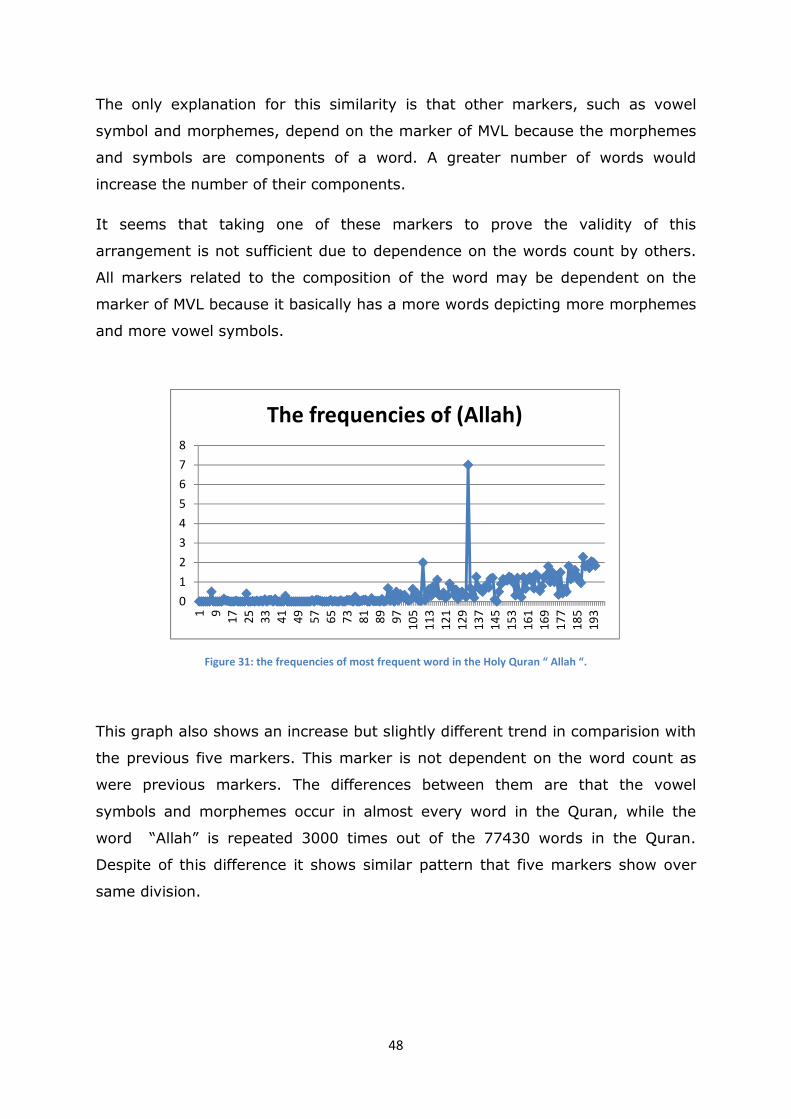
48
The only explanation for this similarity is that other markers, such as vowel
symbol and morphemes, depend on the marker of MVL because the morphemes
and symbols are components of a word. A greater number of words would
increase the number of their components.
It seems that taking one of these markers to prove the validity of this
arrangement is not sufficient due to dependence on the words count by others.
All markers related to the composition of the word may be dependent on the
marker of MVL because it basically has a more words depicting more morphemes
and more vowel symbols.
Figure 31: the frequencies of most frequent word in the Holy Quran “ Allah “.
This graph also shows an increase but slightly different trend in comparision with
the previous five markers. This marker is not dependent on the word count as
were previous markers. The differences between them are that the vowel
symbols and morphemes occur in almost every word in the Quran, while the
word “Allah” is repeated 3000 times out of the 77430 words in the Quran.
Despite of this difference it shows similar pattern that five markers show over
same division.
0
1
2
3
4
5
6
7
8
1 9
17
25
33
41
49
57
65
73
81
89
97
10
5
11
3
12
1
12
9
13
7
14
5
15
3
16
1
16
9
17
7
18
5
19
3
The frequencies of (Allah)

49
Figure 32, shows the frequencies of words that related to the concept of Allah over 194 blocks division.
This marker does not support this method of division in comparing with others
markers. The pattern is not showing increasing of this feature over the blocks
division.
Figure 33: the frequencies related verses over 194 blocks.
Related verse marker has less fluctuation than marker related to the concept of
Allah. It increases in different way of previous features.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1 8
15
22
29
36
43
50
57
64
71
78
85
92
99
10
6
11
3
12
0
12
7
13
4
14
1
14
8
15
5
16
2
16
9
17
6
18
3
19
0
19
7
concept of allah
0
2
4
6
8
10
12
14
1
11
21
31
41
51
61
71
81
91
10
1
11
1
12
1
13
1
14
1
15
1
16
1
17
1
18
1
19
1
related verse
related verse

50
In order to evaluate these results using the Meccan-Medinan criterion, I
calculated the number of verses revealed in Mecca and in Medina for each block.
Then, if I assumed that the Meccan verses were sent down before the Medinan
verses, the number of Meccan verses will be larger in the first half of the blocks,
and Medianan verses will be larger in the other half.
Figure 34: the number of Meccanverses in each block
The percentage of verses that were revealed in Mecca in blocks 1 to 140 is much
larger than the percentage in the later blocks. This means that there is a clear
agreement with the Meccan-Medinan arrangement of texts.
5.3 Experiment number two: Groups
Figure 35: shows different markers according to groups level, similar pattern can be seen for first four markers.
0
10
20
30
40
50
60
70
80
90
100
0 20 40 60 80 100 120 140 160 180
Meccan Verses
0
10
20
30
40
50
60
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
MVL
fatha
Damma
Kasrah
morphemes

51
Five dependant’s markers show increasing over 22 consecutive texts.
Figure 36: the occurance of Allah in each group of text
The occurrence of “Allah” is increasing over the 22 phases. Although there are
some fluctuations between phases 11 and 16, the overall trend shows an
agreement with the dependant markers fatha, Damma, Kasrah and morphemes
number that influenced by the words count.
Figure 37: occurance of word related to the concept of allah according to 22 groups division.
This confirms that this marker does not support this chronology
0
0.5
1
1.5
2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
Allah
0
0.05
0.1
0.15
0.2
0.25
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
concept of allah

52
Figure 38: the number of verses that directly related to the verses in the group.
Related verses marker does not support the 22 groups.
The relative frequency of Part-of-speech-tag set
No N PRON V P CONJ PN REL REM NEG ACC ADJ
22 16.90 16.07 12.87 9.25 6.06 3.58 2.81 2.26 1.76 1.11 1.23
17 17.34 19.53 13.98 9.86 7.14 3.70 2.99 2.49 1.78 1.47 1.57
11 17.62 19.97 15.55 10.19 6.78 2.46 2.19 1.82 2.18 1.87 1.38
10 17.64 20.98 16.08 9.99 7.16 2.98 2.61 2.35 1.92 1.76 0.97
21 17.81 17.27 13.41 9.49 5.70 3.65 2.63 3.19 1.82 1.48 1.22
16 18.35 20.22 15.39 10.53 6.94 2.93 3.11 1.79 2.25 1.55 1.23
13 18.54 18.89 15.06 9.60 6.85 3.82 3.12 2.42 1.96 2.14 1.37
20 18.63 18.41 14.60 9.58 6.77 3.52 2.48 2.71 1.74 1.12 1.86
18 18.73 18.04 14.83 9.95 7.60 4.00 2.93 2.39 2.13 1.19 1.53
19 18.80 17.08 14.61 10.00 7.76 4.16 3.34 1.58 1.99 1.55 1.87
15 19.09 17.67 15.19 10.51 6.18 4.74 3.15 3.19 1.97 1.87 1.27
9 19.11 19.83 14.67 10.19 7.24 2.69 2.86 1.98 2.15 1.79 1.23
14 19.19 18.85 14.39 11.13 7.09 3.49 3.47 2.05 2.23 1.94 1.79
7 19.34 19.37 16.49 9.68 7.44 1.81 3.04 2.07 2.43 1.45 1.48
8 20.29 18.93 15.70 9.63 7.95 2.73 2.94 1.87 2.27 1.95 1.51
12 20.55 17.80 14.49 11.76 8.11 3.43 3.67 1.64 2.28 1.84 1.74
6 20.91 21.05 14.89 9.95 8.71 2.19 2.29 1.69 2.05 2.07 1.19
5 21.23 21.31 14.45 10.18 7.65 1.53 2.10 2.05 2.34 2.03 1.71
4 22.57 21.70 15.54 10.15 7.43 1.75 1.81 2.85 1.71 2.66 1.58
3 23.81 19.50 14.56 9.79 8.05 1.47 1.89 2.60 2.27 2.74 2.20
2 24.53 15.15 17.22 8.87 10.32 1.24 2.13 1.87 2.75 1.76 2.54
1 27.47 12.40 15.75 6.87 13.57 1.51 2.85 1.51 2.35 2.35 4.19 Table 9: most 11th frequent tags in the Quran aacording to the order proposed by Bazrgan
0
0.5
1
1.5
2
2.5
3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
related verse

53
Relative frequent markers show different results from basic markers that may
depend on the word counts. With this marker, I saw an increase in almost
reverse order of the 22 groups. It can be seen that there are three markers—N,
CONJ, and ADJ—that support this arrangement.
Figure 39: Three relative frequency of Part-of-speech tags
Figure 40: the percntage of Meccan verses that each group has.
Bazrgan’s chronology divides the text into 22 groups, from 1 to11 belonging to
Mecca, and 12 to 22 referring to Medina. In this figure, it is clear that the
percentage of Meccan verses is above 80% in groups 1-12, and this percentage
declines in the later groups, most of which belong to the Medina period.
0.00
5.00
10.00
15.00
20.00
25.00
30.00
22 17 11 10 21 16 13 20 18 19 15 9 14 7 8 12 6 5 4 3 2 1
N
CONJ
ADJ
0
20
40
60
80
100
120
140
0 5 10 15 20 25
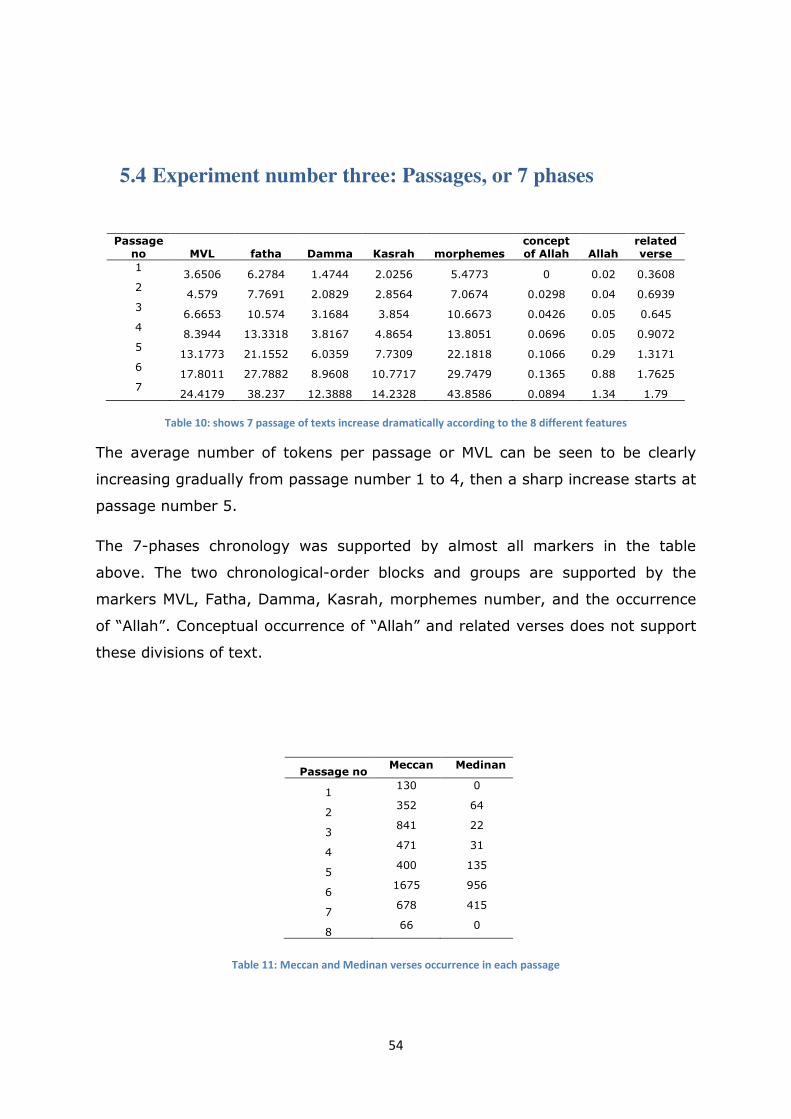
54
5.4 Experiment number three: Passages, or 7 phases
Passage no MVL fatha Damma Kasrah morphemes
concept of Allah Allah
related verse
1 3.6506 6.2784 1.4744 2.0256 5.4773 0 0.02 0.3608
2 4.579 7.7691 2.0829 2.8564 7.0674 0.0298 0.04 0.6939
3 6.6653 10.574 3.1684 3.854 10.6673 0.0426 0.05 0.645
4 8.3944 13.3318 3.8167 4.8654 13.8051 0.0696 0.05 0.9072
5 13.1773 21.1552 6.0359 7.7309 22.1818 0.1066 0.29 1.3171
6 17.8011 27.7882 8.9608 10.7717 29.7479 0.1365 0.88 1.7625
7 24.4179 38.237 12.3888 14.2328 43.8586 0.0894 1.34 1.79
Table 10: shows 7 passage of texts increase dramatically according to the 8 different features
The average number of tokens per passage or MVL can be seen to be clearly
increasing gradually from passage number 1 to 4, then a sharp increase starts at
passage number 5.
The 7-phases chronology was supported by almost all markers in the table
above. The two chronological-order blocks and groups are supported by the
markers MVL, Fatha, Damma, Kasrah, morphemes number, and the occurrence
of “Allah”. Conceptual occurrence of “Allah” and related verses does not support
these divisions of text.
Table 11: Meccan and Medinan verses occurrence in each passage
Passage no Meccan Medinan
1 130 0
2 352 64
3 841 22
4 471 31
5 400 135
6 1675 956
7 678 415
8 66 0

55
The order of these passages seems to support the claims of many scholars that
a word’s use increases over time in the Holy Quran. This table also show that
Meccan verses are decreasing and the Medinan ones are increasing in this order,
and this is another support because the Meccan verses were sent down before
the Medinan verses, according to the historical information. On the other hand, it
seems that the passages have mixed verses from different periods.
Figure 41: the percentage of Meccan verses in each passage it is clearly that the percentage of Meccan verses are higher
from passage 1 to 6.
In this section, we show the relative frequencies of 11 most frequent of the 44
morphemes.
N PRON V P CONJ
4 9021.429 9057.143 6142.857 4328.571 3250
1 11825 7300 8300 4275 4975
3 16957.14 16300 11671.43 7628.571 5585.714
7 19736.84 19142.11 15121.05 10484.21 6852.632
6 20765.91 20418.18 16318.18 11465.91 7950
2 30460 24940 18620 12520 10300
5 764000 804800 626900 399200 300900 Table 12: Relative frequencies of 11 most frequent tags List 1
0
20
40
60
80
100
120
140
0 2 4 6 8 10

56
PN REL REM NEG ACC ADJ
4 650 892.8571 871.4286 992.8571 864.2857 728.5714
1 600 1025 900 1325 850 1225
3 1314.286 1357.143 2142.857 1285.714 2000 1185.714
7 3978.947 2931.579 3021.053 1968.421 1373.684 1589.474
6 4211.364 3540.909 2443.182 2281.818 1850 1686.364
2 1880 2420 3320 2900 3500 2820
5 99200 106100 79300 86900 72400 51700 Table 13: Relative frequencies of 11 most frequent tags list2
Table 12 and 13 shows the results of the relative frequency of the 11 most
frequent Tagsets in the Quran. For example, the relative frequencies of Nouns
for verse number 1 in Sura number 1 in the Quran (bisomi {ll~ahi
{lr~aHoma`ni {lr~aHiymi) can be seen below.:
Relative frequency of Noun =����� ����!���
��������������������������× 100 in this case it equal to
%
& ×
100 = 20 Notice that “somi” is a Noun while “ll~ahi” is Proper Noun.
The most significant finding in this part is that different relative frequencies of
morphemes increase in different orders proposed in [1].
Figure 42: shows three most frequent vowel symbols in Arabic language, x passages ordering according to the timeline
and y is the frequencies of these symbols.
This figure also shows an increasing pattern, which means that these markers
are in support of the hypothesis word length tends to increase over time.
However, these markers may have been influenced by the marker of word
0
5
10
15
20
25
30
35
40
1 2 3 4 5 6 7
fatha
damma
kasrah

57
length because the more the number of words that formed the verse, the more
the number of vowels that would be there. Therefore, the dependency between
word length and vowel symbols is very clear here.
This marker also has a similar pattern to previous ones. It may be because of
the dependency due to a word containings one morpheme or more.
5.1 Relative frequencies of 11 most frequent tags
Figure 43: relative frequencies of Noun, Verb, Conjective
and Adjective over reversal 7 phases order
Figure 44: Three part-of-speech tagset within level of
Passages
Figure 43 and 44 show the most significant results, which depict that the 7
phases are increasing monotonically in a reverse order.
Limitation
The results have been affected by the method used in carrying out this study.
There is no project which is perfect with its results showing 100% success and
this project is no exception. There are some limitations which have been noticed.
The first limitation in our methods is the use of tokenise the corpus which gives
different results [1]. I have noticed slightly different results that were obtained
by JQuran Tree from the kenization process in the library JQuran Tree.
0
5
10
15
20
25
30
7 6 5 4 3 2 1
N
V
CONJ
ADJ
0
5
10
15
20
25
30
7 6 5 4 3 2 1
N
CONJ
ADJ

58
Sura Number Number of word obtained using JQuran
Tree
Number of Words from[1]
37 861 865
36 725 729
21 1169 1174
25 893 896
27 1151 1158
11 1917 1945
29 976 977
Table 14: The variation of the number of words from experiment done in [1]
The only matched results are for Sura number 57 and 13.
Second limitation, is in the method of computing five dpendants marker. We
normalise by number of verses in the phase instead of the total number of
marker in all phases. Verses number decrease in latest phases, which means
dividing by small number. Thus the marker increases dpepending on the number
of verses.

59
Chapter 6
6. Conclusions
In this chapter, I summarise the findings in respect to the initial aims and the
objectives of this project. In addition, I suggest further works based on this
project.
The aim of this project was to identify features related to the temporal ordering
of the Holy Quran. I collected a verified copy of the Holy Quran and divided it
into three different arrangements. The first one arranges the text into 194
blocks, which is explained in detail in the background chapter. The second
division is 22 phases, which is the chronology proposed by Bazargan, while third
is the modified Bazargan. I also applied some markers of style to identify
whether these markers support the arrangements or not.
The basic markers that are dependent on the words count including Mean verse
length, the three most common vowel symbols in Arabic, the number of
morphemes, and the occurrence of “Allah”, support these texual arrangements.
In contrast, blocks and groups arrangements do not appear to be supported by
other markers like the conceptual occurrence of “Allah” and related verses.
In addition, the relative frequencies for 11th most frequent tags support the
reversal order for the 7-phases’ chronology. And the relative frequencies for 28
most common morphemes show a different order.
It seems the modified Bazargan’s chronology is supported by only dependant
markers, except for conceptual frequencies of “Allah”, which is not dependant on
word count.
As a result of these findings, an API has been produced to test several markers
computed during the implementation of the project, as well as a web user
interface to make the expirements available for interested researchers.

60
6.1 Future works
If I had more time, I would compute the markers of tajweed and pause markers
that could be an alternative to verse numbering systems, which our project is
based on. The pause markers or the system of stop and start, do not have big
variation as verses have, therefore it is worthable to be considered.
We use the criteria of agreement to evaluate the results. The suggestion for
future works could be improved by the agreement between the proposed order
and historical information.

i
Bibliography
[1] B. Sadeghi, “The Chronology of the Qurān: A Stylometric Research Program,” Arabica, pp. 210-
299, 2011.
[2] “Muslim Population in the world,” [Online]. Available: http://muslimpopulation.com/.
[Accessed 25 07 2012].
[3] M. M. Ali, "Holy Quran: English Translation and Commentary", U.S.A: Ahmadiyya Anjuman
Isha'at Islam Lahore Inc, 2002.
[4] R. Grishman, "Computational Linguistics: An Introduction", Newcastle: Cambridge University
Press, 1986.
[5] C. F. a. S. L. Alexander Clark, "The Handbook of Computational Linguistics and Natural Language
Processing", Chichester: Blackwell Publishing Ltd, 2010.
[6] C. D. M. a. H. Schütze, “Foundations of Statistical Natural Language Processing,” The MIT Press,
1999.
[7] D. J. a. J. H. Martin, "Speech and Language processing: an introduction to natural language
processing, comutational linguistics, and speech recognition", London: Prentice-Hall
International(UK), 2000.
[8] M. A. Attia, “Arabic Tokenization System,” The University of Manchester, Manchester.
[9] M. S. a. E. Atwell, “Fine-Grain Morphological Analyzer and Part-of-Speech Tagger for Arabic
Text,” in Proceedings of the Language Resource and Evaluation Conference LREC 2010, Malta,
2010.
[10] C. i. A. L. A. S. Study, “Clitics in Arabic Language: A Statistical Study,” in PACLIC 24 Proceedings,
Riyadh.
[11] K. Dukes, “Java API - Quran Java API,” 2011. [Online]. Available: http://corpus.quran.com/.
[Accessed 01 05 2012].
[12] P. G. E. Eneko Agirre, "Word Sense Disambiguation: Algorithms and Applications", Oxford:
Springer, 2007.
[13] D. L. HOOVER, “Stylometry, Chronology and the Styles of Henry James,” 2006.

ii
[14] Z. Sardar, "What Do Muslims Believe? ".
[15] m.m.akbar, "Authenticity of Quran", 2002.
[16] J. Kaltner, "Introducing to the Qur'an", U.S.A: Fortress Press, 2011.
[17] K. D. a. N. Habash, “Morphological Annotation of Quranic Arabic,” 2010.
[18] A. J. a. M. Jaffer, "Quranic Sciences", London: ICAS Press, 2009.
[19] M. Ahmad, “Statistical profile of Holy Quran and Symmetry of Makki and Madni Suras,” Pakistan
Journal of Commerce and Social Sciences, pp. 1-16, 2008.
[20] N. Thabet, “Understanding the thematic structure of the Qur’an: an exploratory multivariate
approach,” University of Newcastle, Newcastle, 2005.
[21] M. Nassourou, “A Knowledge-based Hybrid Statistical Classifier for Reconstructing the
Chronology of the Quran”.
[22] R. Mitkov, "The Oxford Handbook Of Computational Linguistics", New York: Oxford University
Press, 2003.
[23] A.-B. Sharaf, “TextMiningTheQuran.com,” 2011. [Online]. Available:
http://www.textminingthequran.com/apps/referents.php?con=1. [Accessed 01 06 2012].
[24] M. C. Bob Hughes, "Software Project Management", Fifth Edition, Berkshire: McGraw-Hill
Companies, 2009.
[25] C. Larman, "Agile and Iterative Development: A Manager's Guide", Boston: Pearson Education,
Inc., 2004.
[26] I. S. Kurt Bittner, "Managing Iterative Software Development Projects", Boston: Pearson
Education, Inc., 2007.
[27] W. N. P. F. W. T. Wallace Clark, "The Gantt chart: a working tool of management", London: The
Ronald Press Company, 1922.
[28] H. Maylor, “The Gantt Chairt: A Working Tool of,” European Management Journal, pp. 92-100,
2001.
[29] “Tanzil Quran Navigator,” 2007. [Online]. Available: http://tanzil.info/. [Accessed 01 06 2012].
[30] M. H. Hart, "The 100: a ranking of the most influential persons in history", Carol Pub. Group,
1978.
[31] K. D. ·. E. A. ·. N. Habash, “Supervised Collaboration for Syntactic Annotation of Quranic Arabic,”
2011.

iii
[32] K. D. A.-B. S. Eric Atwell, “Understanding the Quran”.
[33] J. Gilchrist, “Muhammad and the Religion of Islam,” 1986.
[34] “http://tanzil.info/,” [Online]. [Accessed 01 05 2012].
[35] M. H. M. G. Francisco Macias, “A Formal Experiment Comparing Extreme Programming with
Traditional Software Construction,” in Proceedings of the Fourth Mexican International
Conference on, Mexican, 2003.
[36] N. Y. Habash, "Introduction to Arabic Natural Language Processing", Morgan & Calypool, 2010.
[37] K. Dukes, “Java API,” 2009. [Online]. Available: http://corpus.quran.com/java/. [Accessed 01 06
2012].
[38] C. D. M. a. H. Schütze, Foundation of Statistical language processing, Manchester, 1999.

iv
Appendix A
Appendix A: Personal Reflection
There were certainly challenging moments encountered during my work on this
project. These challenges have changed my mind and improved my experiences.
One of the challenging parts of the project was the management of time; I
needed to change my planning twice as the implementation stage was increased.
I think it is important to divide the main tasks into small units and it is crucial to
know when to start and stop working on these subtasks. As some tasks are not
clear during the early stage of the project, as to the number of hours required,
the first timetable will be modified while the project progresses. In order to
avoid excess modifications, it is important to start early and allow some gaps
between the subtasks so that such a modification does not affect other tasks. It
is also a good practice if you construct an alternative plan in case the initial plan
fails.
An example of what have changed my mind that, I thought, If work continuously
without having some rest would finish early, and keeping me connected with the
tasks of the project. But what happened with me in this project is the reverse. I
did not enjoy weekends from 15 of june until 16 of august. Therefore, any
students reading this should not miss weekends or at least one day a week in
order to increase your activity.
Despite that my background is in web developing, I enjoyed this project. This
project allows me to see web as I have never seen before. My previous works
dealing with issues like designing a form or a service that allows user to post or
retrive contents. But this project gave me enthusiasm to explore more about the
textual content of web. I am looking to finish this project to looking for another
idea that has just corssed my mind. Overall, I think this project was a start
toward the researching life.

v
Appendix B:
Appendix B: Interim Report
The interim report is submitted with the hard copy only.

vi
Appendix C:
Appendix C: Feedback

vii
Appendix D
Appendix D: Figures

viii
Appendix E:
Appendix E: Text arrangements used in the project
Groups:
Group 1: blocks{2-16}, Group 2: blocks{17-34}, Group 3: blocks{1,35-65},
Group 4: blocks{66-82}, Group 5: blocks{83-91}, Group 6: blocks{92-101},
Group 7: blocks{102-110}, Group 8: blocks{111-116}, Group 9: blocks{117-
121}, Group 10: blocks{122-126}, Group 11: blocks{127-131}, Group 12:
blocks{132-138}, Group 13: blocks{139-143}, Group 14: blocks{144-150},
Group 15: blocks{151-154}, Group 16: blocks{155-160}, Group 17:
blocks{161-164}, Group 18: blocks{165-167}, Group 19: blocks{168-174},
Group 20: blocks{175-178}, Group 21: blocks{179-183}, Group 22:
blocks{184-194}
Passages:
Passage 1: group{2}, Passage 2: group{3}, Passage 3: group{4}, Passage 4:
group{5}, Passage 5: group{6-11}, Passage 6: group{12-19}, Passage 7:
group{20-22}
Blocks:
Block number Sura From To
1 96 1 5
2 74 1 7
3 103 1 2
4 51 1 6
5 102 1 2
6 52 1 8
7 112 1 4
8 88 1 16
ix
9 86 11 17
10 82 1 5
11 91 1 10
12 108 1 3
13 87 1 7
14 85 1 22
15 81 1 29
16 94 1 8
17 93 1 11
18 114 1 6
19 79 1 26
20 74 8 10
21 92 1 21
22 107 1 7
23 70 5 18
24 91 11 15
25 77 1 50
26 78 1 36
27 74 11 56
28 106 1 4
29 53 1 25
30 89 1 30
31 84 1 25
32 80 1 42
33 104 1 9
34 109 1 6
35 96 6 19
36 88 6 26
37 75 7 40
38 95 1 8
39 75 1 19
40 56 1 96
41 55 1 76
42 87 8 19
43 1 1 7
44 100 1 11
45 69 38 52
46 79 27 46
47 111 1 5
48 113 1 5
49 90 1 20
50 102 3 8
51 105 1 5
52 68 1 16
53 89 15 26
54 99 1 8

x
55 86 1 10
56 53 33 62
57 101 1 11
58 37 1 182
59 82 6 19
60 69 1 37
61 70 19 35
62 83 1 36
63 44 43 59
64 23 1 11
65 26 52 227
66 38 67 88
67 15 1 99
68 69 4 12
69 97 1 5
70 51 7 60
71 54 1 55
72 68 17 52
73 44 1 42
74 70 1 44
75 52 9 28
76 43 66 80
77 71 1 28
78 55 8 78
79 73 1 19
80 20 1 52
81 19 75 98
82 52 21 49
83 15 6 48
84 26 1 51
85 76 1 31
86 38 1 66
87 50 1 45
88 36 1 83
89 103 3 3
90 23 12 118
91 41 1 8
92 43 1 89
93 33 1 68
94 21 1 112
95 72 1 28
96 78 37 40
97 85 8 11
98 19 1 74
99 98 1 8
100 31 1 11
xi
101 30 1 27
102 25 1 77
103 20 53 135
104 67 1 30
105 14 42 52
106 19 34 40
107 16 1 128
108 18 1 110
109 32 1 30
110 74 31 31
111 17 9 111
112 40 1 60
113 2 1 245
114 27 1 93
115 39 29 66
116 45 1 37
117 64 1 18
118 11 1 123
119 41 9 36
120 30 28 60
121 17 1 100
122 7 59 206
123 24 46 57
124 22 18 69
125 6 1 117
126 29 1 69
127 34 10 54
128 10 71 109
129 38 26 29
130 12 1 111
131 28 1 88
132 73 20 20
133 40 7 85
134 53 23 32
135 18 29 59
136 31 12 34
137 14 1 41
138 42 1 53
139 2 30 195
140 35 4 45
141 39 1 52
142 47 1 38
143 8 1 75
144 61 1 14
145 41 37 54
146 17 53 70

xii
147 46 1 28
148 16 33 119
149 5 7 40
150 62 1 11
151 3 32 180
152 63 1 11
153 22 1 78
154 3 1 200
155 7 1 176
156 59 1 24
157 39 67 75
158 34 1 9
159 9 38 70
160 10 1 70
161 57 1 29
162 16 90 97
163 24 1 34
164 2 40 152
165 33 4 73
166 4 44 175
167 6 31 165
168 13 1 43
169 9 71 129
170 48 1 29
171 65 8 12
172 5 51 86
173 49 1 18
174 28 76 84
175 4 1 126
176 18 9 28
177 9 1 37
178 46 15 35
179 110 1 3
180 14 6 31
181 58 1 22
182 5 27 120
183 2 21 283
184 60 1 13
185 35 1 18
186 66 1 12
187 6 135 153
188 65 1 7
189 4 127 176
190 24 35 64
191 5 12 50
192 2 164 286

xiii
193 33 53 55
194 5 1 6
Chronological Order of Suras from Tanzil project
Order Sura Name Number Type Note
1 Al-Alaq 96 Meccan
2 Al-Qalam 68 Meccan Except 17-33 and 48-50, from Medina
3 Al-Muzzammil 73 Meccan Except 10, 11 and 20, from Medina
4 Al-Muddaththir 74 Meccan
5 Al-Faatiha 1 Meccan
6 Al-Masad 111 Meccan
7 At-Takwir 81 Meccan
8 Al-A'laa 87 Meccan
9 Al-Lail 92 Meccan
10 Al-Fajr 89 Meccan
11 Ad-Dhuhaa 93 Meccan
12 Ash-Sharh 94 Meccan
13 Al-Asr 103 Meccan
14 Al-Aadiyaat 100 Meccan
15 Al-Kawthar 108 Meccan
16 At-Takaathur 102 Meccan
17 Al-Maa'un 107 Meccan Only 1-3 from Mecca; rest from Medina
18 Al-Kaafiroon 109 Meccan
19 Al-Fil 105 Meccan
20 Al-Falaq 113 Meccan
21 An-Naas 114 Meccan
22 Al-Ikhlaas 112 Meccan

xiv
23 An-Najm 53 Meccan Except 32, from Medina
24 Abasa 80 Meccan
25 Al-Qadr 97 Meccan
26 Ash-Shams 91 Meccan
27 Al-Burooj 85 Meccan
28 At-Tin 95 Meccan
29 Quraish 106 Meccan
30 Al-Qaari'a 101 Meccan
31 Al-Qiyaama 75 Meccan
32 Al-Humaza 104 Meccan
33 Al-Mursalaat 77 Meccan Except 48, from Medina
34 Qaaf 50 Meccan Except 38, from Medina
35 Al-Balad 90 Meccan
36 At-Taariq 86 Meccan
37 Al-Qamar 54 Meccan Except 44-46, from Medina
38 Saad 38 Meccan
39 Al-A'raaf 7 Meccan Except 163-170, from Medina
40 Al-Jinn 72 Meccan
41 Yaseen 36 Meccan Except 45, from Medina
42 Al-Furqaan 25 Meccan Except 68-70, from Medina
43 Faatir 35 Meccan
44 Maryam 19 Meccan Except 58 and 71, from Medina
45 Taa-Haa 20 Meccan Except 130 and 131, from Medina
46 Al-Waaqia 56 Meccan Except 81 and 82, from Medina
47 Ash-Shu'araa 26 Meccan Except 197 and 224-227, from Medina
48 An-Naml 27 Meccan
49 Al-Qasas 28 Meccan Except 52-55 from Medina and 85 from Juhfa at the time of the
Hijra

xv
50 Al-Israa 17 Meccan Except 26, 32, 33, 57, 73-80, from Medina
51 Yunus 10 Meccan Except 40, 94, 95, 96, from Medina
52 Hud 11 Meccan Except 12, 17, 114, from Medina
53 Yusuf 12 Meccan Except 1, 2, 3, 7, from Medina
54 Al-Hijr 15 Meccan Except 87, from Medina
55 Al-An'aam 6 Meccan Except 20, 23, 91, 93, 114, 151, 152, 153, from Medina
56 As-Saaffaat 37 Meccan
57 Luqman 31 Meccan Except 27-29, from Medina
58 Saba 34 Meccan
59 Az-Zumar 39 Meccan
60 Al-Ghaafir 40 Meccan Except 56, 57, from Medina
61 Fussilat 41 Meccan
62 Ash-Shura 42 Meccan Except 23, 24, 25, 27, from Medina
63 Az-Zukhruf 43 Meccan Except 54, from Medina
64 Ad-Dukhaan 44 Meccan
65 Al-Jaathiya 45 Meccan Except 14, from Medina
66 Al-Ahqaf 46 Meccan Except 10, 15, 35, from Medina
67 Adh-Dhaariyat 51 Meccan
68 Al-Ghaashiya 88 Meccan
69 Al-Kahf 18 Meccan Except 28, 83-101, from Medina
70 An-Nahl 16 Meccan Except last three verses 127-129, from Medina
71 Nooh 71 Meccan
72 Ibrahim 14 Meccan Except 28, 29, from Medina
73 Al-Anbiyaa 21 Meccan
74 Al-Muminoon 23 Meccan
75 As-Sajda 32 Meccan Except 16-20, from Medina
76 At-Tur 52 Meccan

xvi
77 Al-Mulk 67 Meccan
78 Al-Haaqqa 69 Meccan
79 Al-Ma'aarij 70 Meccan
80 An-Naba 78 Meccan
81 An-Naazi'aat 79 Meccan
82 Al-Infitaar 82 Meccan
83 Al-Inshiqaaq 84 Meccan
84 Ar-Room 30 Meccan Except 17, from Medina
85 Al-Ankaboot 29 Meccan Except 1-11, from Medina
86 Al-Mutaffifin 83 Meccan Last from Mecca
87 Al-Baqara 2 Medinan Except 281 from Mina at the time of the Last Hajj
88 Al-Anfaal 8 Medinan Except 30-36 from Mecca
89 Aal-i-Imraan 3 Medinan
90 Al-Ahzaab 33 Medinan
91 Al-Mumtahana 60 Medinan
92 An-Nisaa 4 Medinan
93 Az-Zalzala 99 Medinan
94 Al-Hadid 57 Medinan
95 Muhammad 47 Medinan Except 13, from during the Hijrah
96 Ar-Ra'd 13 Medinan
97 Ar-Rahmaan 55 Medinan
98 Al-Insaan 76 Medinan
99 At-Talaaq 65 Medinan
100 Al-Bayyina 98 Medinan
101 Al-Hashr 59 Medinan
102 An-Noor 24 Medinan
103 Al-Hajj 22 Medinan Except 52-55, from between Mecca and Medina

xvii
104 Al-Munaafiqoon 63 Medinan
105 Al-Mujaadila 58 Medinan
106 Al-Hujuraat 49 Medinan
107 At-Tahrim 66 Medinan
108 At-Taghaabun 64 Medinan
109 As-Saff 61 Medinan
110 Al-Jumu'a 62 Medinan
111 Al-Fath 48 Medinan While returning from Hudaybiyya
112 Al-Maaida 5 Medinan Except 3, from Arafat on Last Hajj
113 At-Tawba 9 Medinan Except last two verses from Mecca
114 An-Nasr 110 Medinan Last one, from Mina on Last Hajj
Noldeke arrangements:
Early Meccan
Nöldeke are: 96, 74, 111, 106, 108, 104, 107, 102, 105, 92, 90, 94, 93, 97,
86, 91, 80, 68, 87, 95, 103, 85, 73, 101, 99, 82, 81, 53, 84, 100, 79, 77, 78,
88, 89, 75, 83, 69, 51, 52, 56, 70, 55, 112, 109, 113, 114, 1.
Middle Mecca
The suras of the period are: 54, 37, 71, 76, 44, 50, 20, 26, 15, 19, 38, 36,
43, 72, 67, 23, 21, 25, 17, 27, 18.
Late meccan
The suras of this period are: 32, 41, 45, 16, 30, 11, 14, 12, 40, 28, 39, 29,
31, 42, 10, 34, 35, 7, 46, 6, 13.
Medina
The suras of the period are: 2, 98, 64, 62, 8, 47, 3, 61, 57, 4, 65, 59, 33, 63,
24, 58, 22, 48, 66, 60, 110, 49, 9, 5. 2

xviii
Appendix F:
Appendix F: Initial minimum requirements
• Re-implement the experiment described in (Sadeghi, 2011).
• Generate different permutations of text.
• Do same whether reversing the order provide monotonically increasing
or not. (is not an English sentence).
• Compute the markers used in (Sadeghi, 2011) essay.
• Represent the Quran in statistical

xix
Appendix G:
Appendix G: Web user interface
A web user interface has been developed in order to make the analysis have
been done during this project available for interested scholars. The form
developed using php programming language and supporting Ajax technologies.
It allows user to do epirements by coosing one of marker against a selected
order as well as, it offers four different normalisation variables that can be
applied.
This is a screenshot of the form published.

xx
This screenshot represent the three section that this interface provide; a form to
recive the marker, division, and the function of normalisation. The seconde
section, show the results in a table. Third section, plot the given table in 2
dimition.


















