
The “Checklist” - 3b. Estimation blending and assessing - Bayesian estimation
14
The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimation Bayesian estimation • When the data are invariants εt (1b.3), hence i.i.d. variables, the joint distribution is the product of the distribution of the invariants f (i|θ)= f (1|θ) ··· f (¯ t |θ) (2b.36) • We want to estimate θ and get the predictive distribution (24.7) for the invariants εt at time t> ¯ t. • The invariants are independent only conditionally on the parameters. However unconditionally they are dependent. Example: conditional independency ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update
-
Upload
arpm-advanced-risk-and-portfolio-management -
Category
Economy & Finance
-
view
37 -
download
0
Transcript of The “Checklist” - 3b. Estimation blending and assessing - Bayesian estimation

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimation
Bayesian estimation
• When the data are invariants εt (1b.3), hence i.i.d. variables, the jointdistribution is the product of the distribution of the invariants
f(i|θ) = f(ε1|θ) · · · f(εt|θ) (2b.36)
• We want to estimate θ and get the predictive distribution (24.7) forthe invariants εt at time t > t.
• The invariants are independent only conditionally on the parameters.However unconditionally they are dependent.
Example: conditional independency
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationExponential family invariants
Exponential family invariants
Consider a sample of invariants (i.i.d.) {εt}tt=1 in the exponential family(23.16). Then, the conditional likelihood (23.3)
f(ε1, . . . , εt|θ)i.i.d.= f(ε1|θ) · · · f(εt|θ) = et(θ
′η−ψ(θ)+ln h) (2b.40)
where ln h ≡ 1t
∑tt=1 lnh(εt) and
η ≡ 1
t
t∑t=1
φ(εt) (2b.41)
is still an exponential family with log partition function tψ(·) and featurestη.
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationExponential family invariants
Prior and posterior distributions• The conjugate prior distribution (24.18) reads
Θ|tηpri ,νprit∼ Conj (tψ (·) , tηpri ,
νprit
) = Conj (ψ (·) ,ηpri , νpri)
(2b.42)where ηpri and νpri are pre-specified parameters
• The posterior for θ (24.6) reads
Θ|tηpos ,νpost∼ Conj (tψ (·) , tηpos ,
νpost
) = Conj (ψ (·) ,ηpos , νpos)
(2b.43)with new parameters
ηpos ≡νpri
νpri + tηpri +
t
νpri + tη, νpos ≡ νpri + t (2b.44)
• The MAP estimator (24.9) reads
θMAP = (∇θψ)−1(ηpos) (2b.45)
• The shrinkage relationship holds
E{φ(X)} = ηlow confidence ν
pri←− ηpos
high confidence νpri−→ ηpri (2b.46)
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationExponential family invariants
Predictive distribution
The predictive distribution (24.7) is given by
f(εt|ε1, . . . , εt) ≡∫f(εt|θ)fψ(θ|ηpos , νpos)dθ
=g(ηpos , νpos)h(εt)
g( 11+νpos
φ(εt) +νpos
1+νposηpos , 1 + νpos)
, t > t (2b.47)
where fψ(θ|ηpos , νpos) is the density function of Conj (ψ (·) ,ηpos , νpos) and gis defined as in (23.18).
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationExponential family invariants
Bayesian estimation
Model (likelihood) Normal εt|µ,σ2 ∼ N (µ,σ2)
Prior NIW
{M |σ2 ∼ N (µpri ,
1tpriσ2)
(Σ2)−1 ∼Wishart(νpri ,1νpri
(σ2pri)−1)
Posterior NIW
{M |σ2 ∼ N (µpos ,
1tposσ2)
(Σ2)−1 ∼Wishart(νpos ,1νpos
(σ2pos)−1)
Predictive t εt|(ε1, . . . , εt) ∼ t(νpos ,µpos ,tpos+1
tposσ2
pos), t > t
Table 2b.4. NIW model for Bayesian estimation of location and dispersion
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationConditional likelihood
Conditional likelihood
Suppose that the i.i.d. invariants εt (1b.3) are (conditionally) multivariatenormal
εt|µ,σ2 ∼ N (µ,σ2) (2b.37)
Then the conditional likelihood (2b.36) reads
f(i|µ,σ2) = (2π)−ıt2 |σ2|
−t2 e−
t2
[tr(σ2(σ2)−1)+(µ−µ)′(σ2)−1(µ−µ)] (2b.40)
where i ≡ {ε1, . . . , εt},
µ ≡ 1t
t∑t=1
εt (2b.38)
is the sample mean, and
σ2 ≡ 1t
t∑t=1
(εt − µ)(εt − µ)′ (2b.39)
is the sample covariance.
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationPrior distribution
Prior distribution
In the Bayesian framework, the parameters θ ⇔ (µ,σ2) are realizations ofthe random variables Θ⇔ (M ,Σ2).The prior distribution (24.4) for (M ,Σ2) is the normal-inverse-Wishart(NIW) distribution, i.e.
(Σ2)−1 ∼Wishart(νpri ,1
νpri(σ2
pri)−1) (2b.41)
where σ2pri is an ı× ı symmetric and positive matrix and νpri is a positive
scalar; and
M |σ2 ∼ N (µpri ,1
tpriσ2) (2b.42)
where µpri is an ı× 1 vector and tpri is a positive scalar.The marginal distribution of M is Student t
M ∼ t(νpri ,µpri ,1
tpriσ2
pri) (2b.43)
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationPrior distribution
Location and dispersion of the prior distribution
• The expectation of ME{M} = µpri (2b.44)
• The covariance of M
Cv{M} =νpri
νpri − 2
1
tpriσ2
pri (2b.45)
• The expectation of (Σ2)−1
E{(Σ2)−1} = (σ2pri)−1 (2b.46)
• The covariance of (Σ2)−1
Cv{(Σ2)−1} =1
νpri(Iı2 + Kı,ı)((σ2
pri)−1 ⊗ (σ2
pri)−1) (2b.47)
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update
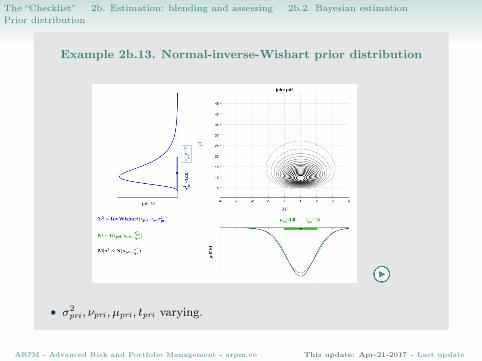
The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationPrior distribution
Example 2b.13. Normal-inverse-Wishart prior distribution
• σ2pri , νpri , µpri , tpri varying.
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationPosterior distribution
Posterior distribution
The posterior (24.6) is also normal-inverse-Wishart
(Σ2)−1 ∼Wishart(νpos ,1
νpos(σ2
pos)−1) (2b.48)
andM |σ2 ∼ N (µpos ,
1
tposσ2). (2b.49)
The unconditional posterior of M is also Student t
M ∼ t(νpos ,µpos ,1
tposσ2
pos). (2b.50)
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationPosterior distribution
Posterior distribution
The posterior expectation µpos reads
µpos =tpri
tpri + tµpri +
t
tpri + tµ (2b.51)
The posterior dispersion parameter σ2pos reads
σ2pos =
νpriνpri + t
σ2pri +
t
νpri + tσ2
+1
(νpri + t)( 1t
+ 1tpri
)(µpri − µ)(µpri − µ)′ (2b.52)
The parameter tpos istpos = tpri + t (2b.53)
The parameter νpos isνpos = νpri + t (2b.54)
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update
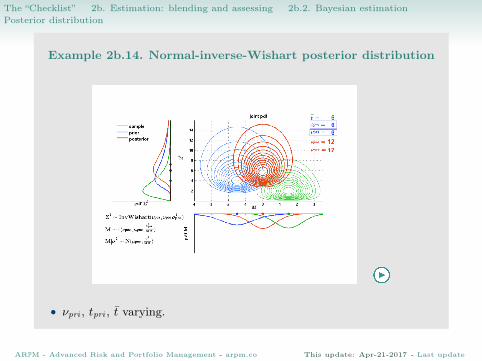
The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationPosterior distribution
Example 2b.14. Normal-inverse-Wishart posterior distribution
• νpri , tpri , t varying.
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationClassical equivalent
Classical equivalent
The classical equivalents (24.8) of the location parameter M and thedispersion parameter Σ2 satisfy the shrinkage effect (24.13)
µlarge dataset t←− µcl_eq = µpos
high confidence tpri−→ µpri (2b.67)
andσ2 large dataset t←− σ2
cl_eq = σ2pos
high confidence νpri−→ σ2pri (2b.68)
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update

The “Checklist” > 2b. Estimation: blending and assessing > 2b.2. Bayesian estimationUncertainty
Uncertainty
• The uncertainty of the expectation estimate (24.10) reads
s2µ =
νpostpos(νpos − 2)
σ2pos (2b.66)
• The uncertainty of the covariance estimate (24.10) reads
s2σ2 = 1
νpos(Iı2 + Kı,ı)((σ2
pos)−1 ⊗ (σ2
pos)−1) (2b.67)
where Kı,ı is the ı2 × ı2 commutation matrix (E.27.212).
ARPM - Advanced Risk and Portfolio Management - arpm.co This update: Apr-21-2017 - Last update






![Projector Station for Blending - pro.sony · [Sony Corporation] > [Projector Station for Blending] > [PS for Blending]. For Windows 8, start the software using the [PS for Blending]](https://static.fdocuments.in/doc/165x107/5f6f6b9611addf735154fc46/projector-station-for-blending-prosony-sony-corporation-projector-station.jpg)











