
The Bursty Structure of On-Line Information · PDF file · 2003-07-09The Bursty...
29
The Bursty Structure of On-Line Information Streams Jon Kleinberg Cornell University Includes joint work w/ Jon Aizen, Dan Huttenlocher, Tony Novak Internet Archive and Cornell University
Transcript of The Bursty Structure of On-Line Information · PDF file · 2003-07-09The Bursty...

The Bursty Structure of On-LineInformation Streams
Jon KleinbergCornell University
Includes joint work w/ Jon Aizen, Dan Huttenlocher, Tony NovakInternet Archive and Cornell University

Temporal Dynamics of Information
Many on-line information sources have a stream-like structure.
• E-mail: personal message stream with rapid topic changes.
• News coverage, emerging media like weblogs.
Web as current awareness medium, not just information repository.
• The scientific literature (on a slower time scale).
• Collective user behavior on large Web sites.
How do we organize and search for this type of content?
Need a model that can recognize its “bursty” nature.
• Breaking news, saturation coverage.
• The sudden popularity of a book on Amazon.
• The footprint of a deadline in your e-mail.
Burstiness as an intrinsic property of streams ...

Bursty Streams of InformationAll e-mail messages containing “ITR”, 1997-2001
0
20
40
60
80
100
120
140
1.4e+06 1.5e+06 1.6e+06 1.7e+06 1.8e+06 1.9e+06 2e+06 2.1e+06 2.2e+06 2.3e+06 2.4e+06 2.5e+06
mes
sag
e #
Minutes since 1/1/97
“I know a burst when I see one.” −→ ??
• Inspection not likely to give the full structure in the sequence.
• Want to perform burst detection efficiently for all terms in corpus.
• Build time-lines from burstiest items.

The role of time in narratives. . . there seems something else in life besides time, something which
may conveniently be called “value,” something which is measured not
by minutes or hours but by intensity, so that
when we look at our past it does not stretch
back evenly but piles up into a few notable
pinnacles, and when we look at the future it
seems sometimes a wall, sometimes a cloud,
sometimes a sun, but never a chronological
chart.
- E.M. Forster, Aspects of the Novel (1928)
• Anisochronies in narratives [Genette 1980, Chatman 1978]:
non-uniform relation between time span of a story’s events
and the time it takes to relate them.

Overview
1. A method for identifying bursts in a single stream.
2. Enumerating the most significant bursts:
time-line construction.
3. Applying burst detection to usage data from a high-traffic Web site:
detecting discrete variations in user interest over time.

Threshold-Based Methods
0
1
2
3
4
5
6
7
8
900 1000 1100 1200 1300 1400 1500 1600 1700 1800
?
?# m
essa
ges
rcv
d
Days since 1/1/97
Swan, Allan, Jensen [2000] proposed threshold-based methods.
• Bin relevant messages by day.
• Contiguous set of days above threshold constitutes an episode.
• Unfortunately, data is often very noisy:
No 7 non-zero days in a row, but episodes may last months.
Multiple time scales? Bursts within bursts?
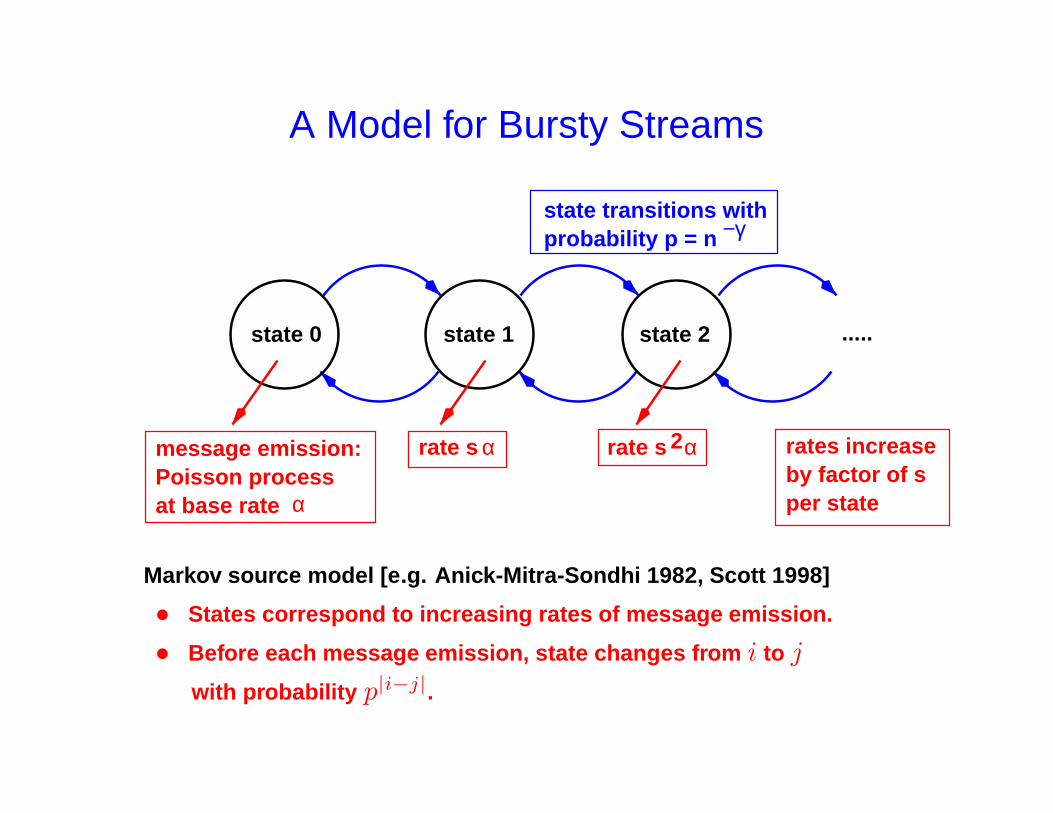
A Model for Bursty Streams
state 0 state 1 state 2 .....
message emission:Poisson process at base rate α
by factor of sper state
rates increase2rate s α rate s α
state transitions withprobability p = n −γ
Markov source model [e.g. Anick-Mitra-Sondhi 1982, Scott 1998]
• States correspond to increasing rates of message emission.
• Before each message emission, state changes from i to j
with probability p|i−j|.

A Model for Bursty Streams
state 0 state 1 state 2 .....
message emission:Poisson process at base rate α
by factor of sper state
rates increase2rate s α rate s α
state transitions withprobability p = n −γ
Theorem: Let events take place in [0, T ], and let δ(x) = minni=1
xi.
The maximum likelihood state sequence involves only states
0, 1, . . . , k, where k ≤ d1 + logs T + logs δ(x)e.
Using Thm, reduce to finite-state case and use dynamic programming.

Hierarchical StructureDefine a burst of intensity j to be a maximal interval in which optimal
state sequence is in state j or higher.
Bursts are naturally nested: each burst of intensity j is contained in a
unique burst of intensity j − 1 −→ hierarchical tree structure.
0 1 32 0 1 32
20 1 3
time
optimal state sequence bursts
tree representation

0 1 2 3 4 50 1 2 3 4 5intensities
10/28/9910/28
10/28 11/2 11/9
11/1511/1611/161/2/00 1/2
1/5
2/42/14
2/21
7/10
7/10
7/14
10/31
0 1 2 3 4 5intensities
10/28/9910/28
10/28 11/2 11/9
11/1511/1611/161/2/00 1/2
1/5
2/42/14
2/21
7/10
7/10
7/14
10/31
10/28/99-2/21/00
10/28-2/14
10/28-11/16
11/2-11/16
11/9-11/15
1/2-2/4
1/2-1/5
7/10/00-10/31/00
7/10-7/14
intensities
10/28/9910/28
10/28 11/2 11/9
11/1511/1611/161/2/00 1/2
1/5
2/42/14
2/21
7/10
7/10
7/14
10/31

0 1 2 3 4 5
11/15: letter of intent deadline
1/5: pre-proposal deadline
2/14: full proposal deadline
4/17: full proposal deadline
7/11: unofficial notification
9/13: official announcement
intensities
10/28/9910/28
10/28 11/2 11/9
11/1511/1611/161/2/00 1/2
1/5
2/42/14
2/21
7/10
7/10
7/14
10/31
(large proposals)
(large proposals)
(small proposals)
(large proposals)
(small proposal)
of awards

Enumerating Bursts for Time-LineConstruction
Can enumerate bursts for every word in the corpus.
• Essentially one pass over an inverted index.
• Weight of burst B of intensity j is
log(Pr [state j | B] /Pr [state j − 1 | B]).
Over history of a conference or journal, topics rise/fall in significance.
Using words as stand-ins for topic labels:
What are the most prominent topics at different points in time?
• Take words in paper titles over history of conference.
• Compute bursts for each word; find those of greatest weight.
(Use a source model for “batched” arrivals.)
• All words are considered. (Even stop-words.)

Word Interval of burst
grammars 1969 STOC — 1973 FOCS
automata 1969 STOC — 1974 STOC
languages 1969 STOC — 1977 STOC
machines 1969 STOC — 1978 STOC
recursive 1969 STOC — 1979 FOCS
classes 1969 STOC — 1981 FOCS
some 1969 STOC — 1980 FOCS
sequential 1969 FOCS — 1972 FOCS
equivalence 1969 FOCS — 1981 FOCS
programs 1969 FOCS — 1986 FOCS
program 1970 FOCS — 1978 STOC
on 1973 FOCS — 1976 STOC
complexity 1974 STOC — 1975 FOCS
problems 1975 FOCS — 1976 FOCS
relational 1975 FOCS — 1982 FOCS
logic 1976 FOCS — 1984 STOC
vlsi 1980 FOCS — 1986 STOC
probabilistic 1981 FOCS — 1986 FOCS
how 1982 STOC — 1988 STOC
parallel 1984 STOC — 1987 FOCS
algorithm 1984 FOCS — 1987 FOCS
graphs 1987 STOC — 1989 STOC
learning 1987 FOCS — 1997 FOCS
competitive 1990 FOCS — 1994 FOCS
randomized 1992 STOC — 1995 STOC
approximation 1993 STOC —
improved 1994 STOC — 2000 STOC
codes 1994 FOCS —
approximating 1995 FOCS —
quantum 1996 FOCS —
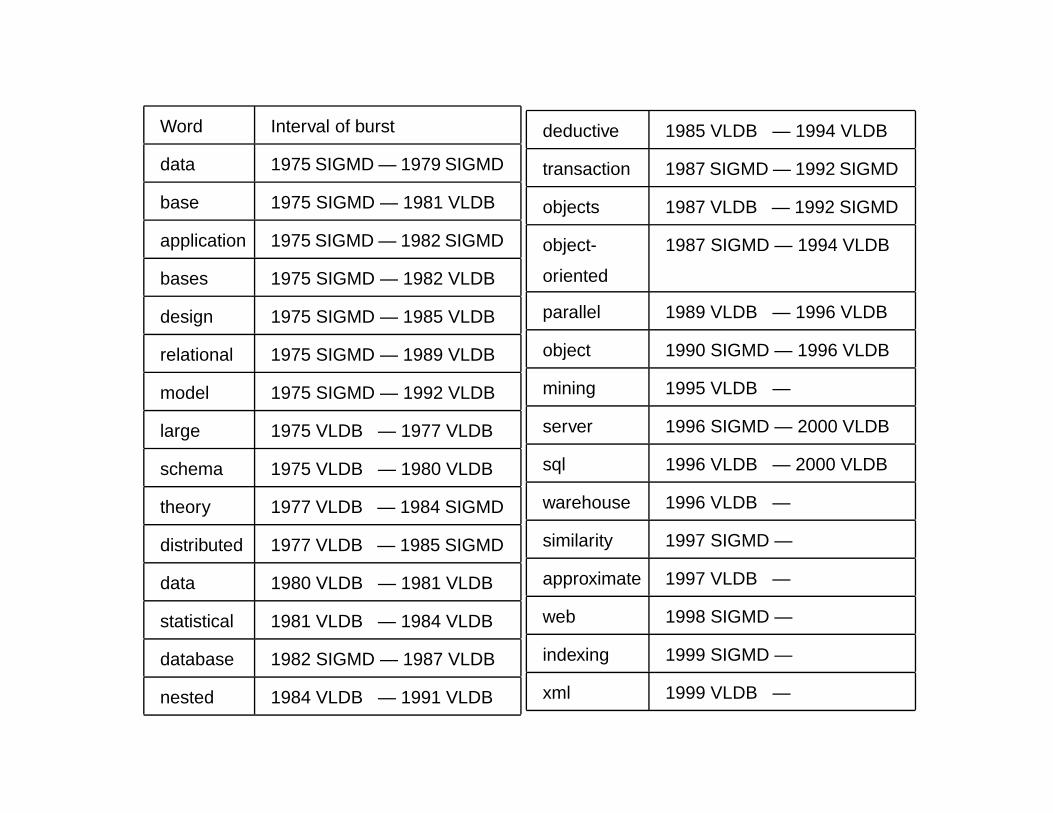
Word Interval of burst
data 1975 SIGMD — 1979 SIGMD
base 1975 SIGMD — 1981 VLDB
application 1975 SIGMD — 1982 SIGMD
bases 1975 SIGMD — 1982 VLDB
design 1975 SIGMD — 1985 VLDB
relational 1975 SIGMD — 1989 VLDB
model 1975 SIGMD — 1992 VLDB
large 1975 VLDB — 1977 VLDB
schema 1975 VLDB — 1980 VLDB
theory 1977 VLDB — 1984 SIGMD
distributed 1977 VLDB — 1985 SIGMD
data 1980 VLDB — 1981 VLDB
statistical 1981 VLDB — 1984 VLDB
database 1982 SIGMD — 1987 VLDB
nested 1984 VLDB — 1991 VLDB
deductive 1985 VLDB — 1994 VLDB
transaction 1987 SIGMD — 1992 SIGMD
objects 1987 VLDB — 1992 SIGMD
object-
oriented
1987 SIGMD — 1994 VLDB
parallel 1989 VLDB — 1996 VLDB
object 1990 SIGMD — 1996 VLDB
mining 1995 VLDB —
server 1996 SIGMD — 2000 VLDB
sql 1996 VLDB — 2000 VLDB
warehouse 1996 VLDB —
similarity 1997 SIGMD —
approximate 1997 VLDB —
web 1998 SIGMD —
indexing 1999 SIGMD —
xml 1999 VLDB —

Word Interval of burst
depression 1930 – 1937
recovery 1930 – 1937
banks 1931 – 1934
democracy 1937 – 1941
wartime 1941 – 1947
production 1942 – 1943
fighting 1942 – 1945
japanese 1942 – 1945
war 1942 – 1945
peacetime 1945 – 1947
program 1946 – 1948
veterans 1946 – 1948
wage 1946 – 1949
housing 1946 – 1950
atomic 1947 – 1959
collective 1947 – 1961
aggression 1949 – 1955
defense 1951 – 1952
free 1951 – 1953
soviet 1951 – 1953
korea 1951 – 1954
communist 1951 – 1958
program 1954 – 1956
alliance 1961 – 1966
communist 1961 – 1967
poverty 1963 – 1969
propose 1965 – 1968
tonight 1965 – 1969
billion 1966 – 1969
vietnam 1966 – 1973

A Permutation Test
Is it the content that’s bursty, or just the time series?
Permutation test (see [Swan-Jensen 2000])
• Start with full e-mail corpus, arrival times t1, . . . , tN .
• Shuffle messages via random permutation π:
message π(i) arrives at time ti (instead of message i).
• Total weight of all bursts in shuffled corpus more than order of
magnitude smaller than in true corpus (25K vs. 370K)
• Almost no hierarchy in shuffled version: average of 16 words with
depth ≥ 2, versus 3865 in true corpus.

Further Related WorkMarkov source models for time-series analysis
• Fraud detection, Web page requests [Scott 98, Scott-Smyth 02].
Change detection and piece-wise function approximation
• Long history in statistics [Hudson 1966, Hawkins 1976].
• Recent applications in data mining for trend and event detection
[Keogh-Smyth 1997, Han et al. 1998, Mannila-Salmenkivi 2001]
• Fast algorithms for change detection over windows
[Charikar et al. 2002, Zhu-Shasha 2003], Google Zeitgeist.
Hierarchical representations of time series
• Hierarchical HMMs [Fine-Singer-Tishby 1998, Murphy-Paskin 2001]
Topic detection and tracking of news streams
• [Allan et al. 1998, Yang et al. 1998]
Visualization of news streams
• Wavelet Analysis [Miller et al. 98], ThemeRiver [Havre et al. 2000].

The Bursty Nature of Weblogs
Word burst analysis incorporated by Daypop (www.daypop.com),
a leading blog search engine.
• Daily ranked lists of bursts for mainstream news and for weblogs
separately.
• Highlights differences in focus.
Evolution of the link structure among weblogs over time
[Kumar-Novak-Raghavan-Tomkins 2003]
• Run burst detection on edges; find small sets of nodes that induce
multiple bursty edges overlapping in time.
• More general problem of identifying “subgraph bursts.”

Tracking User Interest at Web Sites
Item 1 descriptor
Acquireitem 1
Search:
Directory:
New:
Featured:
descriptor descriptor descriptorItem 2 Item 3 Item 4
Acquire Acquire Acquire acquisition
navigation
description
item 2 item 3 item 4
Current work with Jon Aizen, Dan Huttenlocher, Tony Novak
Temporal analysis of usage to enhance experience of site visitors
Many high-volume sites fit navigation-description-acquisition pattern
E-commerce: books at amazon.com, products at bestbuy.com
Research: papers at arXiv, CiteSeer.

Tracking User Interest at Web Sites
Our experiments focus on the Internet Archive (www.archive.org)
• Founded by Brewster Kahle in 1996.
• A library of digital media: movies, audio material, books,
(wide public use since Sept. 2002).
Snapshots of the Web from its early history (via Wayback Machine).
• Exhibits N-D-A structure:
Each digital item has a descriptor containing the option
to download (acquire).
• Aizen and Kahle provide extensive domain expertise about the
site’s user population.
• Also provide opportunity to perform experiments by modifying site.

Measuring Interest in Items
Which items are of greatest interest to the site’s visitors?
• Most Popular: rank items by total number of acquisitions.
• Batting Average: the fraction of visits to an item’s description that
were followed by an acquisition.
(Corrected for small sample size.)
• Track burstiness of these measures.
What do sudden changes signify?

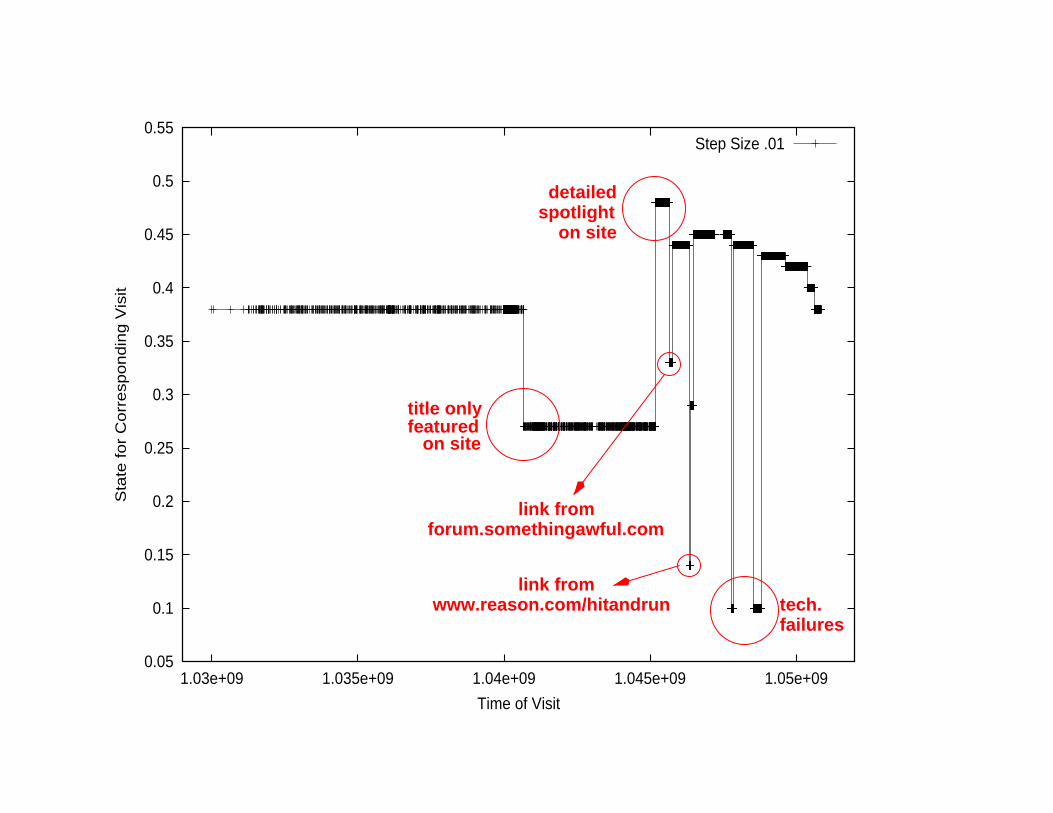
Bursts in the Batting Average
.......... state 0 state 1state -1
downloadwith prob. q
prob. q prob. q + ε− εper stateprob. + ε
state transitions withprobability p = n −γ
Hidden Markov model where states correspond to increasing coin bias.
• If state set too small: miss brief bursts and produce spurious ones.
• We use large state set w/ fast algorithm for optimal state sequence.
[Felzenszwalb-Huttenlocher-Kleinberg 2003].

0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
1.03e+09 1.035e+09 1.04e+09 1.045e+09 1.05e+09
Sta
te fo
r C
orre
spon
ding
Vis
it
Time of Visit
Step Size .01
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
1.03e+09 1.035e+09 1.04e+09 1.045e+09 1.05e+09
Sta
te for
Corr
esp
ondin
g V
isit
Time of Visit
Step Size .01
link fromwww.reason.com/hitandrun
detailed
title only
on site
on site
forum.somethingawful.comlink from
featured
spotlight
tech.failures

Why Does the Batting Average Change?
In the absence of external events, the BA tends to stabilize.
(Like learning the bias of a coin.)
Many sources of abrupt, discrete change.
Large-weight bursts provide a chronology of events impinging
on the item:
• On-site spotlight increases visibility.
(Can assess effectiveness of highlighting.)
• Off-site referrer can drive in sub-population with different interests.
(“Back-links” to active discussions in the Web at large.)
• Technical failures.
• Strong positive or negative reviews.

Enhancements to the Internet Archive site
• Featured rankings of items based on batting average.
. A ranking scheme with high “turbulence”
(new items can score highly).
• Annotating items with referrers responsible for significant bursts.
. What is the outside world saying about the item?
. A natural way to “surf backward” from the item
(see also [Chakrabarti-Gibson-McCurley 1999]).

Feedback effectsRanking by raw popularity:
• Ordering of top items becomes ultra-stable.
(Top 5 has essentially has not changed since Archive went public.)
• Self-reinforcing measure: people look at items simply because
they’re on the “Most Popular” list. (The rich get richer.)
Ranking by Batting Average:
• Non-self-reinforcing, with interesting dynamics:
. An item can have niche appeal, achieve high BA with few visits.
. It enters “Top BA” list, receives surge of visits.
. Its BA may collapse, or may remain stable.
More general issue: dynamics of popularity and reputation
e.g. [Huberman-Wu 2002], [Krapivsky-Redner 2002]

Further DirectionsEfficient streaming computation of bursty items
• In a data stream model, find bursts of large weight for all items
(e.g. all possible words) simultaneously.
• One pass, limited storage.
On-line burst prediction
• Given a stream of e-mail messages / paper titles / Web downloads,
how early can a large-weight burst be identified (on-line)?
• 2003 KDD Cup competition, using e-Print arXiv (www.arxiv.org)
[Gehrke-Ginsparg-Kleinberg]
Correlations and causality among multiple streams
• E.g. referrers, reviews, and downloads at the Internet Archive.
• Reliably determining the impact of a review?

ReflectionsThe fact that we need tools to pre-screen our email for us just shows
how information-overloaded our society has become.
– Slashdot posting
24 April 2002, 2:10 PM
Who the @#$! gets so much email they need to mine for text ??!!
dont change your email filtering, change your pathetic life !!
– Slashdot posting
24 April 2002, 6:02 PM
If only it were so simple ...
• Increasingly able to measure personal activity at unprecedented
levels of detail.
• Coping with a world in which your on-line tools know more about
you than you realize.


















