
The ATLAS Production System. The Architecture ATLAS Production Database Eowyn Lexor Lexor-CondorG...
16
The ATLAS Production System
-
Upload
andrew-maxwell -
Category
Documents
-
view
224 -
download
1
Transcript of The ATLAS Production System. The Architecture ATLAS Production Database Eowyn Lexor Lexor-CondorG...

The ATLASProduction System
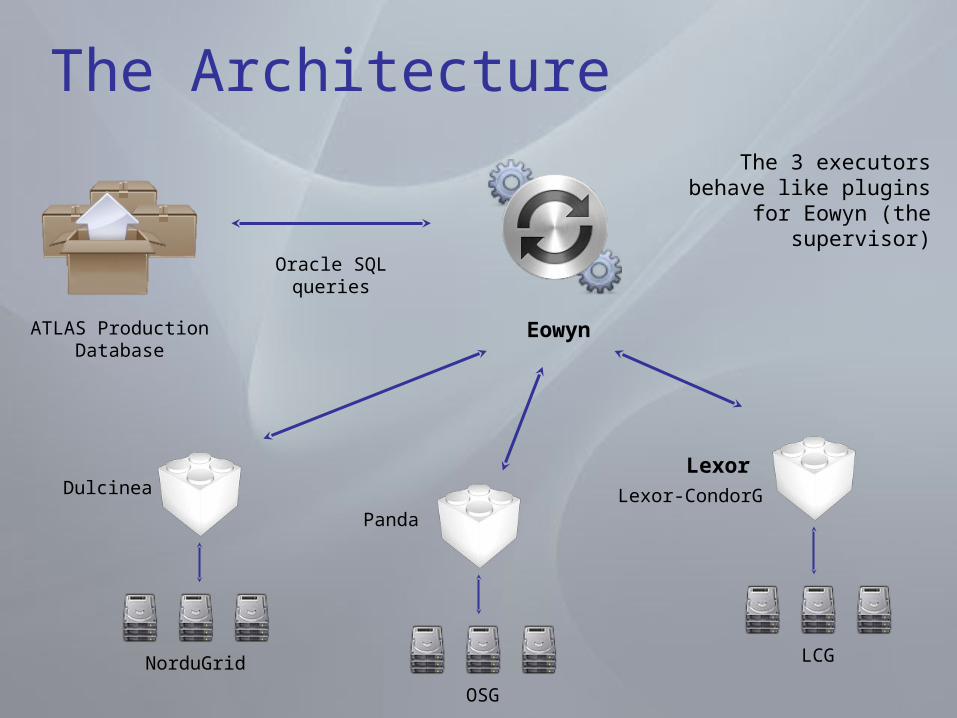
The Architecture
ATLAS Production Database
Eowyn
LexorLexor-CondorG
Oracle SQL queries
Dulcinea
NorduGrid
Panda
OSG
LCG
The 3 executors behave like plugins for Eowyn
(the supervisor)

The Production Database
Jobs are grouped in “datasets” and “tasks”: basically, they both represent the complete collection of jobs of the same kind.Tasks have been introduces only to distinguish logically datasets into the prodDB and the Production System.
It’s an Oracle database, located at CERN, in which jobs for ATLAS are defined
Tasks
Thus, from the supervisor point of view, only the task distinction is relevant
Oracle DB
(ProdDB for friends)
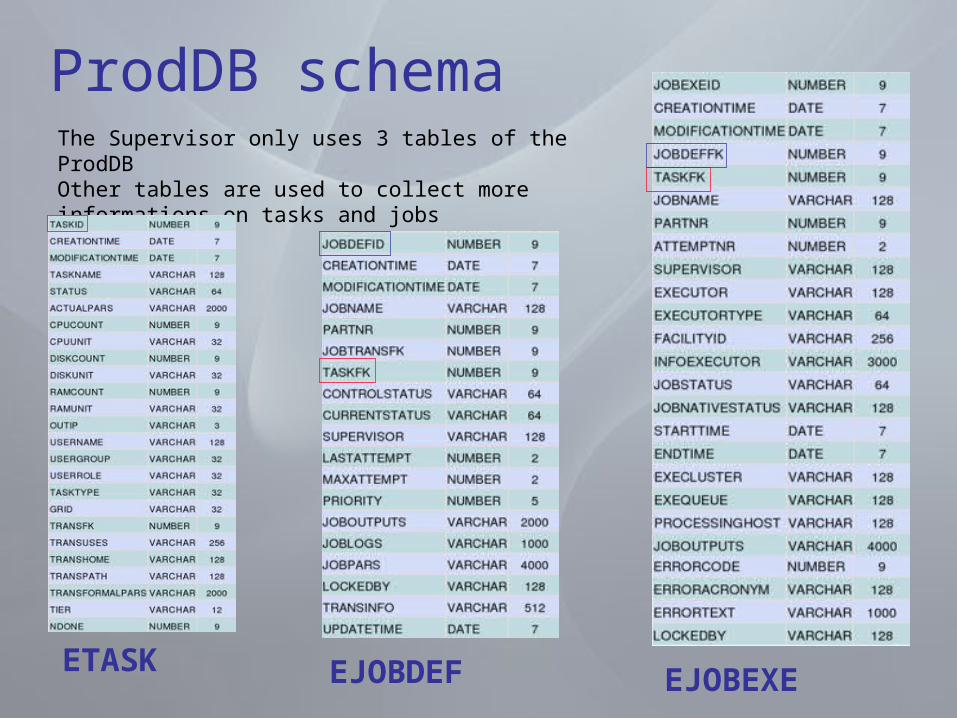
ProdDB schemaThe Supervisor only uses 3 tables of the ProdDBOther tables are used to collect more informations on tasks and jobs
ETASKEJOBEXEEJOBDEF
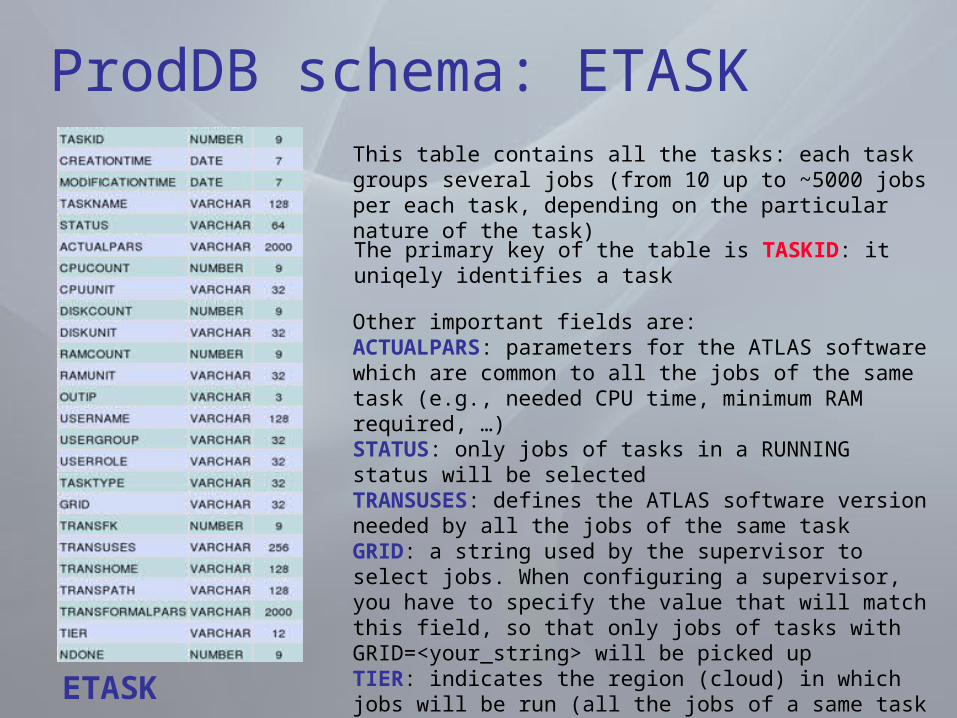
ProdDB schema: ETASKThis table contains all the tasks: each task groups several jobs (from 10 up to ~5000 jobs per each task, depending on the particular nature of the task)
ETASK
The primary key of the table is TASKID: it uniqely identifies a task
Other important fields are:ACTUALPARS: parameters for the ATLAS software which are common to all the jobs of the same task (e.g., needed CPU time, minimum RAM required, …)STATUS: only jobs of tasks in a RUNNING status will be selectedTRANSUSES: defines the ATLAS software version needed by all the jobs of the same taskGRID: a string used by the supervisor to select jobs. When configuring a supervisor, you have to specify the value that will match this field, so that only jobs of tasks with GRID=<your_string> will be picked upTIER: indicates the region (cloud) in which jobs will be run (all the jobs of a same task will run in the same cloud)

ProdDB schema: EJOBDEFThis table contains all the jobs
EJOBDEF
The primary key of the table is JOBDEFID: it uniqely identifies a job
Other important fields are:TASKFK: jobs with the same TASKFK are part of the same task (identified by TASKID=TASKFK in the ETASK table, see the preceding slide)CURRENTSTATUS: only jobs in a TOBEDONE currentstatus will be selected. Jobs can be considered successful only once the supervisor has put them in DONE currentstatusMAXATTEMPT: jobs that fail are resubmitted by the supervisor as many times as its MAXATTEMPTLASTATTEMPT: tells the number of attempt of the last (re)submission. It increases of 1 at each submission of the job. Only jobs with LASTATTEMPT<MAXATTEMPT will be picked upJOBPARS: lists specific parameters of a job (e.g., input files, random numbers, …) that, together with ETASK.PARS, will be used by the ATLAS software

ProdDB schema: EJOBEXE(1)
This table contains all the attempts in running a job
EJOBEXE
The primary key of the table is JOBEXEID: it uniqely identifies an attempt
Other important fields are:JOBDEFFK: entries with the same JOBDEFFK represent resubmissions of the same job, identified by JOBDEFID=JOBDEFFK in the EJOBDEF tableTASKFK: entries with the same TASKFK are resubmissions of jobs of the same task, identified by TASKID=TASKFK in the ETASK tableJOBSTATUS: shows the status of the job in the executor (submitted, shceduled, running,…). Successful jobs are marked as ‘finished’ATTEMPTNR: tells the number of the attempt of resubmission the entry refers to (a job that has been submitted 3 times will have 3 correspondig records in EJOBEXE with 3 different JOBEXEID and 3 different ATTEMPTNR: 1, 2, 3)

FACILITYID: this string represent the ID of the collection of jobs on the gLite Resource BrokerINFOEXECUTOR: this string represent the ID of the job on the remote grid (on LCG, it’s just the JobID).The groups different jobs, that are run separately, each with its JobID, but may be queried all in one using the CollectionIDEXECLUSTER: this string tells the name of the CE on which the job runsERRORACRONYM: if an attempt to run a job fails, this acronym is filled with a tag giving the nature of the occurred problemERRORTEXT: if an attempt to run a job fails, this field is filled with an error message giving more informations on the errorJOBOUTPUTS: this lists the produced output files and their LFC logical file names
ProdDB schema: EJOBEXE(2)
EJOBEXE

ProdDB schemaAn example: task identified by taskid 1000 in the ETASK table consists of 2 jobs, identified by jobdefid 10000 and 10001 in the EJOBDEF table. Job 10001 runs successfully at the very first attempt (one only entry in the EJOBEXE table), while job 10000 fails twice, then it’s resubmitted a third time and it succeeds (three entries in the EJOBEXE table)
ETASK
TASKID=1000
EJOBDEF
JOBDEFID=10000TASKFK=1000
JOBDEFID=10001TASKFK=1000
EJOBEXE
JOBEXEID=200JOBDEFFK=10000TASKFK=1000status=finished
JOBEXEID=201JOBDEFFK=10001TASKFK=1000status=failed
JOBEXEID=202JOBDEFFK=10001TASKFK=1000status=failed
JOBEXEID=203JOBDEFFK=10001TASKFK=1000status=finished

The supervisor: Eowyn
Eowyn is the brain of the production system. It is the main running process and the only one which directly interacts with the ProdDB (executors do not perform queries to the DB).Eowyn activity can be sketched out as:
• select free jobs from the ProdDB;• pass the jobs to an executor: the executor will take care of the
submission of the jobs;• ask the executor about the status of the jobs;• validate finished jobs: if the produced output files are ok, jobs will be
considered successful, otherwise they’ll be released and made ready
for further resubmission;• update the entries of such jobs in the database.

The executors
Executors are Python modules that behave just like plugins for Eowyn. When configuring Eowyn, you choose which executor it has to use. Eowyn loads the corresponding module and, from now on, it becomes insensible to the grid flavour you’re using.The executors submit the job on the grids, they ask for their status to the underlying middleware and they retrieve the output log files.The main activities of the executors may be outlined as:
• tell Eowyn how many jobs can be submitted on the corresponding grid
(the number is estimated on a count of free CPUs published by the
sites);• receive the jobs from Eowyn and prepare them (parsing of the job
parameters and construction of the corresponding JDL);• submit of the jobs on the corresponding grid;• ask for the status of the jobs (to be reported to Eowyn);• retrieve the output logs of finished jobs.

Job workflow
Job worflow consists of three main steps:
Definition - jobs entries are created in the ProdDB
Selection - Eowyn picks up jobs from the ProdDB
Submission - Eowyn passes the jobs to an executor and it submits them to the grid

Job workflow: definition
Jobs are definied by:• creating a task in the ETASK table on the ProdDB;• creating an entry for each job in the EJOBDEF table.
Note that no entries are needed in the EJOBEXE table: this table is entirely managed by Eowyn and no user should modify it.The definition steps are done through simple Python scripts interfacing to the ProdDB or using a Java graphical interface named AtCom.You may perform this actions from any machine: you only need the user and password to access the database.
AtCom can be downloaded from the web,see the wiki pagehttps://uimon.cern.ch/twiki/bin/view/Atlas/AtCom

Job workflow: selection
Eowyn picks up jobs from the ProdDB with simple SQL queries. The SELECT statement asks for:
For the curious ones (and a bit pervert!), the select statement is constructed by the Python function getFreeJobs in <Production>/Eowyn/ProdDBProxyOracle.py
ETASK.STATUS = ‘RUNNING’
ETASK.GRID = <string> (configured at installation)
ETASK.TASKID = EJOBDEF.TASKFK
EJOBDEF.CURRENTSTATUS = ’TOBEDONE’
EJOBDEF.LOCKEDBY = NULL
EJOBDEF.LASTATTEMPT < EJOBDEF.MAXATTEMPT
ETASK.TASKID = <task_#> (if configured at installation)
ETASK.TIER = <cloud> (if configured at installation)

Job workflow: submission
Eowyn passes the selected jobs to the executor, which parses the job parameters (they’re in XML format) and submits them to the underlying grid.
Lexor (the LCG executor) stores a copy of the scripts of the jobs in a local
directory (by default, under /tmp/<user_name>/JOBDIR).
From now on, the job is in the hands of the executor. From time to time
(configurable at installation) Eowyn asks the executor for the status of the
jobs. The executor asks for it to the grid middleware (the L&B on LCG) and
returns the answer to Eowyn, who in turn updates the corresponding entry in
the ProdDB.
Note that the grid JobID of a job is also passed from the executor to Eowyn
and it’s stored in the job entry in the EJOBEXE table (and it’s logged in the
log file of Eowyn in your run directory).
All submission parameters (how many jobs per “bunch of submission”, time interval between two subsequent submission, grid to be used, RB to be used, …) are set in the two config files Mystart.py and Executor.conf in the run directory
Want to know more…
Documentation on the ProdSys can be found in the Wiki page
https://uimon.cern.ch/twiki/bin/view/Atlas/ProdSys
If you have any problem with your ProdSys instance, you can ask
for help to
or submit bugs on GGUS
www.ggus.org


















