
The 2017 DAVIS Challenge on Video Object Segmentation · Abstract We present the 2017 DAVIS...
6
1 The 2017 DAVIS Challenge on Video Object Segmentation Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbel´ aez, Alexander Sorkine-Hornung, and Luc Van Gool Abstract—We present the 2017 DAVIS Challenge on Video Object Segmentation, a public dataset, benchmark, and competition specifically designed for the task of video object segmentation. Following the footsteps of other successful initiatives, such as ILSVRC [1] and PASCAL VOC [2], which established the avenue of research in the fields of scene classification and semantic segmentation, the DAVIS Challenge comprises a dataset, an evaluation methodology, and a public competition with a dedicated workshop co-located with CVPR 2017. The DAVIS Challenge follows up on the recent publication of DAVIS (Densely-Annotated VIdeo Segmentation [3]), which has fostered the development of several novel state-of-the-art video object segmentation techniques. In this paper we describe the scope of the benchmark, highlight the main characteristics of the dataset, define the evaluation metrics of the competition, and present a detailed analysis of the results of the participants to the challenge. Index Terms—Video Object Segmentation, DAVIS, Open Challenge, Video Processing ✦ 1 I NTRODUCTION Public benchmarks and challenges have been an important driving force in the computer vision field, with examples such as Imagenet [1] for scene classification and object detection, PASCAL [2] for semantic and object instance seg- mentation, or MS-COCO [4] for image captioning and object instance segmentation. From the perspective of the avail- ability of annotated data, all these initiatives were a boon for machine learning researchers, enabling the development of new algorithms that had not been possible before. Their challenge and competition side motivated more researchers to participate and push towards the new different goals, by setting up a fair environment where test data are not publicly available. The Densely-Annotated VIdeo Segmentation (DAVIS) initiative [3] provided a new dataset with 50 high-definition sequences with all their frames annotated with object masks at pixel-level accuracy, which has allowed the appearance of a new breed of video object segmentation algorithms [5], [6], [7], [8] that pushed the quality of the results significantly, almost getting to the point of saturation of the original dataset (around 80% performance by [5] and [6]). We will refer to this version of the dataset as DAVIS 2016. To further push the performance in video object seg- mentation, we present the 2017 DAVIS Challenge on Video Object Segmentation, which consists of a new, larger, more challenging dataset (which we refer to as DAVIS 2017) and • J. Pont-Tuset, S. Caelles, and L. Van Gool are with the Computer Vision Laboratory, ETH Z¨ urich, Switzerland. • F. Perazzi and A. Sorkine-Hornung are with Disney Research, Z¨ urich, Switzerland. • P. Arbel´ aez is with the Department of Biomedical Engineering, Universi- dad de los Andes, Colombia. Contacts and updated information can be found in the challenge website: http://davischallenge.org Fig. 1. Example annotations of the DAVIS 2017 dataset: The four first images come from new videos, the last two from videos originally in the DAVIS dataset re-annotated with multiple objects. a public challenge competition and workshop. As the main new challenge, the new sequences have more than one annotated object in the scene, and we have re-annotated the original ones that have more than one visible object. The complexity of the videos has also increased with more distractors, smaller objects and fine structures, more occlu- sions and fast motion, etc. Overall, the new dataset consists of 150 sequences, totaling 10459 annotated frames and 376 objects. Figure 1 shows a set of example frames with the corresponding overlaid object annotations, and Section 2 gives detailed facts and figures about the new annotations. We hosted a public competition challenge based on the task of segmenting the objects in the video given the arXiv:1704.00675v3 [cs.CV] 1 Mar 2018
Transcript of The 2017 DAVIS Challenge on Video Object Segmentation · Abstract We present the 2017 DAVIS...

1
The 2017 DAVIS Challenge onVideo Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles,Pablo Arbelaez, Alexander Sorkine-Hornung, and Luc Van Gool
Abstract—We present the 2017 DAVIS Challenge on Video Object Segmentation, a public dataset, benchmark, and competitionspecifically designed for the task of video object segmentation. Following the footsteps of other successful initiatives, such asILSVRC [1] and PASCAL VOC [2], which established the avenue of research in the fields of scene classification and semanticsegmentation, the DAVIS Challenge comprises a dataset, an evaluation methodology, and a public competition with a dedicatedworkshop co-located with CVPR 2017. The DAVIS Challenge follows up on the recent publication of DAVIS (Densely-Annotated VIdeoSegmentation [3]), which has fostered the development of several novel state-of-the-art video object segmentation techniques. In thispaper we describe the scope of the benchmark, highlight the main characteristics of the dataset, define the evaluation metrics of thecompetition, and present a detailed analysis of the results of the participants to the challenge.
Index Terms—Video Object Segmentation, DAVIS, Open Challenge, Video Processing
✦
1 INTRODUCTION
Public benchmarks and challenges have been an importantdriving force in the computer vision field, with examplessuch as Imagenet [1] for scene classification and objectdetection, PASCAL [2] for semantic and object instance seg-mentation, or MS-COCO [4] for image captioning and objectinstance segmentation. From the perspective of the avail-ability of annotated data, all these initiatives were a boonfor machine learning researchers, enabling the developmentof new algorithms that had not been possible before. Theirchallenge and competition side motivated more researchersto participate and push towards the new different goals,by setting up a fair environment where test data are notpublicly available.
The Densely-Annotated VIdeo Segmentation (DAVIS)initiative [3] provided a new dataset with 50 high-definitionsequences with all their frames annotated with object masksat pixel-level accuracy, which has allowed the appearance ofa new breed of video object segmentation algorithms [5], [6],[7], [8] that pushed the quality of the results significantly,almost getting to the point of saturation of the originaldataset (around 80% performance by [5] and [6]). We willrefer to this version of the dataset as DAVIS 2016.
To further push the performance in video object seg-mentation, we present the 2017 DAVIS Challenge on VideoObject Segmentation, which consists of a new, larger, morechallenging dataset (which we refer to as DAVIS 2017) and
• J. Pont-Tuset, S. Caelles, and L. Van Gool are with the Computer VisionLaboratory, ETH Zurich, Switzerland.
• F. Perazzi and A. Sorkine-Hornung are with Disney Research, Zurich,Switzerland.
• P. Arbelaez is with the Department of Biomedical Engineering, Universi-dad de los Andes, Colombia.
Contacts and updated information can be found in the challenge website:http://davischallenge.org
Fig. 1. Example annotations of the DAVIS 2017 dataset: The four firstimages come from new videos, the last two from videos originally in theDAVIS dataset re-annotated with multiple objects.
a public challenge competition and workshop. As the mainnew challenge, the new sequences have more than oneannotated object in the scene, and we have re-annotatedthe original ones that have more than one visible object.The complexity of the videos has also increased with moredistractors, smaller objects and fine structures, more occlu-sions and fast motion, etc. Overall, the new dataset consistsof 150 sequences, totaling 10459 annotated frames and 376objects. Figure 1 shows a set of example frames with thecorresponding overlaid object annotations, and Section 2gives detailed facts and figures about the new annotations.
We hosted a public competition challenge based onthe task of segmenting the objects in the video given the
arX
iv:1
704.
0067
5v3
[cs
.CV
] 1
Mar
201
8

2
DAVIS 2016 DAVIS 2017train val Total train val test-dev test-challenge Total
Number of sequences 30 20 50 60 30 30 30 150Number of frames 2079 1376 3455 4219 2023 2037 2180 10459Mean number of frames per sequence 69.3 68.8 69.1 70.3 67.4 67.9 72.7 69.7Number of objects 30 20 50 138 59 89 90 376Mean number of objects per sequence 1 1 1 2.30 1.97 2.97 3.00 2.51
TABLE 1Size of the DAVIS 2016 and 2017 dataset splits: number of sequences, frames, and annotated objects.
detailed segmentation of each object in the first frame (theso-called semi-supervised scenario in DAVIS 2016). Section 3describes the task in detail and the metrics used to evaluatethe results. The results of the competition were presented ina workshop in the Computer Vision and Pattern Recognition(CVPR) conference 2017, in Honolulu, Hawaii. The chal-lenge received entries from 22 different teams and broughtan improvement of 20% to the state of the art. Section 4gives a detailed analysis of the results of the top-performingteams.
2 DATASET FACTS AND FIGURES
The main new challenge added to the DAVIS sequences inits edition of 2017 is the presence of multiple objects inthe scene. As it is well known, the definition of an objectis granular, as one can consider a person as including thetrousers and shirt, or consider them as different objects. InDAVIS 2016 the segmented object was defined as the mainobject in the scene with a distinctive motion. In DAVIS 2017,we also segment the main moving objects in the scene, butwe also divide them by semantics, even though they mighthave the same motion. Specifically, we generally segmentedpeople and animals as a single instance, together with theirclothes, (including helmet, cap, etc.), and separated anyobject that is carried and easily separated (such as bags, skis,skateboards, poles, etc.). As an example, Figure 2 showsdifferent pairs of DAVIS 2016 segmentation (left) togetherwith their DAVIS 2017 multiple-object segmentations.
As is a common practice in the computer vision chal-lenges, we divide our dataset into different splits. Firstof all, we extend the train and val sets of the originalDAVIS 2016, with annotations that are made public forthe whole sequence. We then define two other test sets(test-dev and test-challenge), for which only themasks on the first frames are made public. We set up anevaluation server in Codalab where researchers are able tosubmit their results, download an evaluation file, and pub-lish their performance on the public leaderboard. Duringthe challenge, submissions for test-dev were unlimitedand for a longer period of time, whereas test-challenge,which determined the winners, was only open for a shortperiod of time and for a limited number of submissions.After the challenge, test-dev submissions remain open aswe expect future methods to publish their results on this set.
Table 1 shows the number of sequences, frames, andobjects on each of the dataset splits. Please note that trainand val in DAVIS 2017 include the sequences of the re-spective sets in DAVIS 2016 with multiple objects annotatedwhen applies. This is the reason why the mean number of
Fig. 2. Example annotations of the DAVIS 2017 vs the single-objectcounterpart in DAVIS 2016: Semantics play a role even if the objectshave the same motion.
objects per sequence is smaller in these two sets, despite allnew sequences have around 3 objects per sequence in mean.The length of the sequences is kept similar to DAVIS 2016:around 70 frames.
In terms of resolution, the majority of new sequencesare at 4k resolution (3840×2160 pixels), but there are alsosome 1440p, 1080p, and 720p images at its raw resolution.Despite this, the challenge will be on the downsampled 480pimages, as it was the de facto standard for DAVIS 2016, and tofacilitate their processing given the large amount of frames.We plan to increase the resolution used in future editions ofthe challenge.
3 TASK DEFINITION AND EVALUATION METRICS
The challenge will be focused on the so-called semi-supervised video object segmentation task, that is, the algo-rithm is given a video sequence and the mask of the objectsin the first frame, and the output should be the masks ofthose objects in the rest of the frames. This excludes moresupervised approaches that include a human in the loop(interactive segmentation) and unsupervised techniques (noinitial mask is given). Please note that all objects in a framehave its unique identifier and so the expected output is a setof indexed masks by identifier.
3
Measure 1st [9] 2nd [10] 3rd [11] 4th [12] 5th [13] 6th [14] 7th [15] 8th [16] 9th [17] OSVOS [5]
J&F Mean M ↑ 69.9 67.8 63.8 61.5 57.7 56.9 53.9 50.9 49.7 49.0Mean M ↑ 67.9 65.1 61.5 59.8 54.8 53.6 50.7 49.0 46.0 45.6
J Recall O ↑ 74.6 72.5 68.6 71.0 60.8 59.5 54.9 55.1 49.3 46.7Decay D ↓ 22.5 27.7 17.1 21.9 31.0 25.3 32.5 21.3 33.1 34.2Mean M ↑ 71.9 70.6 66.2 63.2 60.5 60.2 57.1 52.8 53.3 52.5
F Recall O ↑ 79.1 79.8 79.0 74.6 67.2 67.9 63.2 58.3 58.4 56.0Decay D ↓ 24.1 30.2 17.6 23.7 34.7 27.6 33.7 23.7 36.4 35.9
T Mean M ↓ 26.0 37.1 41.6 54.3 51.3 67.1 61.3 75.6 65.9 67.1
TABLE 2Final results of the 2017 DAVIS Challenge on the Test-Challenge set: As a baseline, we add the naive generalization of OSVOS to multiple
objects by tracking each of them independently.
RunningBoxing
Turtle LionsMonkeys
Demolition
Ocean-BirdsSelfie
Inflatable
Speed-Skating
Varanus-TreeBurnout
Kart-Turn
Mbike-Santa
ChoreographyPole-Vault
E-Bike
Kids-Turning
Grass-ChopperBike-Trial
Dive-InDolphins
Hurdles
Wings-Turn
Dog-ControlSkydive
TackleJuggle
VietnamSwing-Boy
0
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
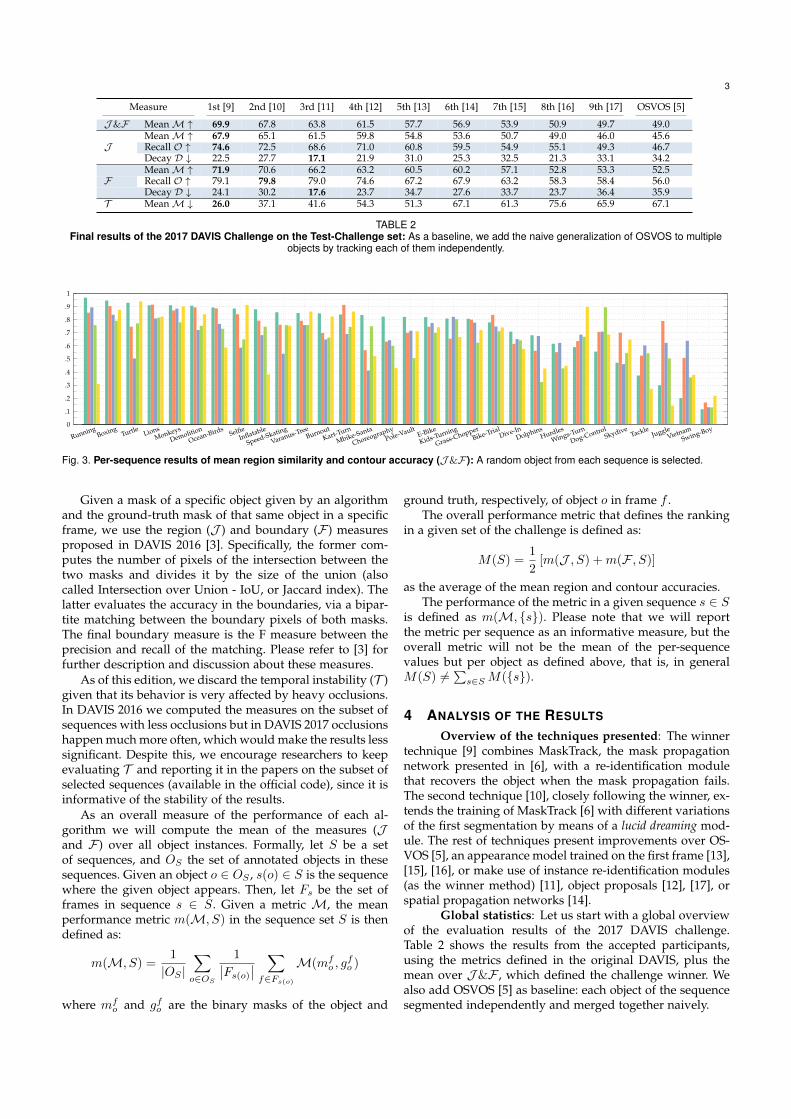
Fig. 3. Per-sequence results of mean region similarity and contour accuracy (J&F ): A random object from each sequence is selected.
Given a mask of a specific object given by an algorithmand the ground-truth mask of that same object in a specificframe, we use the region (J ) and boundary (F ) measuresproposed in DAVIS 2016 [3]. Specifically, the former com-putes the number of pixels of the intersection between thetwo masks and divides it by the size of the union (alsocalled Intersection over Union - IoU, or Jaccard index). Thelatter evaluates the accuracy in the boundaries, via a bipar-tite matching between the boundary pixels of both masks.The final boundary measure is the F measure between theprecision and recall of the matching. Please refer to [3] forfurther description and discussion about these measures.
As of this edition, we discard the temporal instability (T )given that its behavior is very affected by heavy occlusions.In DAVIS 2016 we computed the measures on the subset ofsequences with less occlusions but in DAVIS 2017 occlusionshappen much more often, which would make the results lesssignificant. Despite this, we encourage researchers to keepevaluating T and reporting it in the papers on the subset ofselected sequences (available in the official code), since it isinformative of the stability of the results.
As an overall measure of the performance of each al-gorithm we will compute the mean of the measures (Jand F ) over all object instances. Formally, let S be a setof sequences, and OS the set of annotated objects in thesesequences. Given an object o ∈ OS , s(o) ∈ S is the sequencewhere the given object appears. Then, let Fs be the set offrames in sequence s ∈ S. Given a metric M, the meanperformance metric m(M, S) in the sequence set S is thendefined as:
m(M, S) =1
|OS |∑
o∈OS
1∣∣Fs(o)
∣∣∑
f∈Fs(o)
M(mfo , g
fo )
where mfo and gfo are the binary masks of the object and
ground truth, respectively, of object o in frame f .The overall performance metric that defines the ranking
in a given set of the challenge is defined as:
M(S) =1
2[m(J , S) +m(F , S)]
as the average of the mean region and contour accuracies.The performance of the metric in a given sequence s ∈ S
is defined as m(M, {s}). Please note that we will reportthe metric per sequence as an informative measure, but theoverall metric will not be the mean of the per-sequencevalues but per object as defined above, that is, in generalM(S) 6= ∑
s∈S M({s}).
4 ANALYSIS OF THE RESULTS
Overview of the techniques presented: The winnertechnique [9] combines MaskTrack, the mask propagationnetwork presented in [6], with a re-identification modulethat recovers the object when the mask propagation fails.The second technique [10], closely following the winner, ex-tends the training of MaskTrack [6] with different variationsof the first segmentation by means of a lucid dreaming mod-ule. The rest of techniques present improvements over OS-VOS [5], an appearance model trained on the first frame [13],[15], [16], or make use of instance re-identification modules(as the winner method) [11], object proposals [12], [17], orspatial propagation networks [14].
Global statistics: Let us start with a global overviewof the evaluation results of the 2017 DAVIS challenge.Table 2 shows the results from the accepted participants,using the metrics defined in the original DAVIS, plus themean over J&F , which defined the challenge winner. Wealso add OSVOS [5] as baseline: each object of the sequencesegmented independently and merged together naively.

4
0 .1 .2 .3 .4 .5 .6 .7 .8 .9 10
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
J&F 1st [9]
J&F
2nd
[10]
0 .1 .2 .3 .4 .5 .6 .7 .8 .9 10
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
J&F 1st [9]
J&F
3rd
[11]
0 .1 .2 .3 .4 .5 .6 .7 .8 .9 10
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
J&F 1st [9]
J&F
4th
[12]
0 .1 .2 .3 .4 .5 .6 .7 .8 .9 10
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
J&F 1st [9]
J&F
5th
[13]
Fig. 4. Performance comparison: (Mean J&F ) between the first methods, for the whole set of objects of DAVIS-2017 Test-Challenge.
Measure 1st [9] 2nd [10] 3rd [11] 4th [12] 5th [13] 6th [14] 7th [15] 8th [16] 9th [17] OSVOS [5]
J&F Mean M ↑ 82.4 81.9 75.8 74.3 76.8 78.0 77.3 63.8 64.8 67.2
TABLE 3Results evaluated as a single foreground-background classification: all segmented objects as foreground, rest background.
We can observe that the nine methods cover the wholespectrum between barely improving over the OSVOS base-line (49.7%) and being 20 points above it (69.9%). The winneris 2.1% over the runner up, and wins not only in terms ofJ&F but also in four other metrics.
Figure 3 breaks down the performance into sequences,by showing the result in one random object from each ofthem. The sequences are sorted by the performance of thewinner method on each of them. We can observe some easyobjects where all techniques perform well (Boxing), otherschallenging for everyone (Swing-Boy), and others with alarge variance between techniques (Juggle).
To further explore whether there are some trends in theperformance in each sequence, Figure 4 shows the comparedperformance on all 92 objects between the first techniqueand the following ones. Although some correlation can beseen, there are still a significant amount of objects that arewell segmented by one of the techniques and not by theother, proof of the variety of techniques presented, and thatthere is still room for improvement. To further make thispoint, the oracle result obtained from choosing the bestresult for each object from a set of techniques is 75.3%,76.7%, 77.4%, and, 77.9%; when combining up to the second,third, fourth, and fifth best techniques, respectively. In otherwords, combining the first two gets a +5.4% boost over thefirst technique.
Failure analysis: To further analyze where the cur-rent methods fail, and to isolate how much having multipleobjects adds to the challenge, Table 3 shows the evaluationof the same results but transforming all object masks (andground truth) to a single foreground-background segmen-tation. We can observe that the results increase dramatically(e.g. up to 82.4% from 69.9% in the case of the winner).
One of the thesis to justify this behavior is that currentmethods are good at foreground-background segmentationbut struggle to separate between foreground objects. Weinvestigate into it by separating the set of misclassifiedpixels into global false positives, global false negatives, andidentity switches (pixel label swapped between objects).Linking to the previous experiment, the first two type of
0 1 2 3 4 5
1st [9]
2nd [10]
3rd [11]
4th [12]
5th [13]
6th [14]
7th [15]
8th [16]
9th [17]
Percentage of misclassified pixels (%)
FP-Close FP-Far FN ID Switches
Fig. 5. Classification of the error pixels into false positives, falsenegatives, and swapped object: Errors are given in percentage oferroneous pixels in the image, averaged per object.
errors are the ones that are also done in the single-objectcase, whereas the latter is considered correct. False positivesare further divided into FP-close and FP-far, to separatebetween boundary inaccuracies and spurious detections (asdone in [5]). Figure 5 depicts the percentage of pixels in theimage that fall into each of these categories. Surprisingly,false negatives dominate the types of errors, not only infront of the false positives (as also observed in [5]), but alsowith respect to identity switches. We believe a possible ex-planation of this imbalance is that spurious detections (FP-Far) might be more noticeable to humans, so in the processof manually adjusting the parameters of an algorithm, thesolutions leading to higher false negatives are unconsciouslychosen.
Note that the percentage of misclassified pixels is notdirectly comparable to J and F (5th has less wronglyclassified pixels than 4th), because the latter depend alsoon the size of each object. Let us therefore analyze theperformance of the methods with respect to the size of theobjects: a foreground object that is completely missed but it

5
0.1 1 100
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
Object area (%)
J&F
1st[
9]
0.1 1 100
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
Object area (%)
J&F
2nd
[10]
0.1 1 100
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
Object area (%)
J&F
3rd
[11]
0.1 1 100
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
Object area (%)
J&F
4th
[12]
Fig. 6. Performance on all 92 objects ( ) with respect to their area, for the first four techniques: The line ( ) shows the mean quality whenwe remove the objects smaller than a certain size.
is very small would not affect the foreground-backgroundresult significantly despite affecting the multi-object casesignificantly. To analyze this, Figure 6 shows the perfor-mance of the first four methods in all objects with respectto their area (red crosses ).
We can observe that there is indeed a certain tendencyfor small objects to be more difficult than the large ones. Theblue lines ( ) depict the evolution of the mean qualitywhen removing the smaller objects than a certain threshold.This way, the curve starts at the mean over all objects(challenge result), and each step removes the smallest objectfrom the mean. We can observe that in some methods suchas the winner, the quality goes up to 85% (+15%) if weremove all objects whose area is below 5% of the image area.The fourth method, in contrast, is more robust to object sizeand gets only up to +8%.
To sum up, multiple objects add a new challenge ofidentity preserving, and although it is significant, the errorsare still dominated by false negatives, as in the single-object case. The presence of small objects also poses a newchallenge that was not observed in the single-object casesimply because the sample of objects did not include smallones.
Qualitative results: Figure 7 shows a set of selectedqualitative results comparing the performance of the firstfour method (right-most four columns) and the groundtruth (left-most column), covering a wide range of chal-lenges and behaviors. Please refer also to Figure 3 to matcheach sequence to its mean quantitative performance. On thefirst row, an easy sequence in which performance is good onall methods. The three following rows (turtle, mbike-santa,and choreography) show cases where the winner indeedobtains the best results, despite the identity switch in one ofthe choreographers. Rows 5 (Vietnam) and 6 (juggle) showthe opposite: the runner up showing better performancethan the winner. In the first case there is again an identityswitch, whereas in the second the ball is completely lost.The final row (swing-boy) shows a sequence where none ofthe techniques correctly segment the chain of the swing.
5 CONCLUSIONS
This paper presented the 2017 DAVIS Challenge on VideoObject Segmentation, which extends the DAVIS (Densely-Annotated VIdeo Segmentation [3]) dataset with more
videos and more challenging scenarios (especially morethan one object per sequence). We also defined the metricsand competitions of the public challenge that we hostedin conjunction with CVPR 2017, and provided a detailedanalysis of the results obtained by the participating teams.
ACKNOWLEDGMENTS
Research partially funded by the workshop sponsors:Google, Disney Research, NVIDIA, Prof. Luc Van Gool’sComputer Vision Lab at ETHZ, and Prof. Fuxin Li’s groupat the Oregon State University. The authors gratefully ac-knowledge support by armasuisse, and thank NVIDIA Cor-poration for donating the GPUs used in this project.
REFERENCES
[1] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma,Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, andL. Fei-Fei, “ImageNet Large Scale Visual Recognition Challenge,”IJCV, 2015.
[2] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn,and A. Zisserman, “The PASCAL Visual Object ClassesChallenge 2012 (VOC2012) Results,” http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html.
[3] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross,and A. Sorkine-Hornung, “A benchmark dataset and evaluationmethodology for video object segmentation,” in CVPR, 2016.
[4] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan,P. Dollr, and C. Zitnick, “Microsoft COCO: Common Objects inContext,” in ECCV, 2014.
[5] S. Caelles, K.-K. Maninis, J. Pont-Tuset, L. Leal-Taixe, D. Cremers,and L. Van Gool, “One-shot video object segmentation,” in CVPR,2017.
[6] F. Perazzi, A. Khoreva, R. Benenson, B. Schiele, and A.Sorkine-Hornung, “Learning video object segmentation from static im-ages,” in CVPR, 2017.
[7] N. Nicolas Marki, F. Perazzi, O. Wang, and A. Sorkine-Hornung,“Bilateral space video segmentation,” in CVPR, 2016.
[8] F. Perazzi, O. Wang, M. Gross, and A. Sorkine-Hornung, “Fullyconnected object proposals for video segmentation,” in ICCV,2015.
[9] X. Li, Y. Qi, Z. Wang, K. Chen, Z. Liu, J. Shi, P. Luo, C. C. Loy,and X. Tang, “Video object segmentation with re-identification,”The 2017 DAVIS Challenge on Video Object Segmentation - CVPRWorkshops, 2017.
[10] A. Khoreva, R. Benenson, E. Ilg, T. Brox, and B. Schiele, “Luciddata dreaming for object tracking,” The 2017 DAVIS Challenge onVideo Object Segmentation - CVPR Workshops, 2017.
[11] T.-N. Le, K.-T. Nguyen, M.-H. Nguyen-Phan, T.-V. Ton, T.-A. N. (2),X.-S. Trinh, Q.-H. Dinh, V.-T. Nguyen, A.-D. Duong, A. Sugimoto,T. V. Nguyen, and M.-T. Tran, “Instance re-identification flow forvideo object segmentation,” The 2017 DAVIS Challenge on VideoObject Segmentation - CVPR Workshops, 2017.

6
Ground Truth 1st [9] 2nd [10] 3rd [11] 4th [12]
Fig. 7. Qualitative results: Comparison between top-performing methods in different sequences.
[12] A. Shaban, A. Firl, A. Humayun, J. Yuan, X. Wang, P. Lei,N. Dhanda, B. Boots, J. M. Rehg, and F. Li, “Multiple-instancevideo segmentation with sequence-specific object proposals,” The2017 DAVIS Challenge on Video Object Segmentation - CVPR Work-shops, 2017.
[13] P. Voigtlaender and B. Leibe, “Online adaptation of convolutionalneural networks for the 2017 davis challenge on video object seg-mentation,” The 2017 DAVIS Challenge on Video Object Segmentation- CVPR Workshops, 2017.
[14] J. Cheng, S. Liu, Y.-H. Tsai, W.-C. Hung, S. Gupta, J. Gu, J. Kautz,S. Wang, and M.-H. Yang, “Learning to segment instances in
videos with spatial propagation network,” The 2017 DAVIS Chal-lenge on Video Object Segmentation - CVPR Workshops, 2017.
[15] H. Zhao, “Some promising ideas about multi-instance video seg-mentation,” The 2017 DAVIS Challenge on Video Object Segmentation- CVPR Workshops, 2017.
[16] A. Newswanger and C. Xu, “One-shot video object segmentationwith iterative online fine-tuning,” The 2017 DAVIS Challenge onVideo Object Segmentation - CVPR Workshops, 2017.
[17] G. Sharir, E. Smolyansky, and I. Friedman, “Video object segmen-tation using tracked object proposals,” The 2017 DAVIS Challenge
on Video Object Segmentation - CVPR Workshops, 2017.

















