
Creating Speaking Web Pages: The Text-to-Speech Integrated Development Environment (TTS-IDE)

1
TEXT-TO-SPEECH SYNTHESIS USING TACOTRON 2 AND WAVEGLOW WITH TENSOR CORES
Rafael Valle, Ryan Prenger and Yang Zhang

2
OUTLINE
1.Text to Speech Synthesis
2.Tacotron 2
3.WaveGlow
4.TTS and TensorCores

3
TEXT TO SPEECH SYNTHESIS (TTS)
0
0.5
1
1.5
2
2.5
3
3.5
USD Billions
Global TTS Market Value 1
2016 2022Apple
SiriMicrosoft
CortanaAmazon
Alexa / Polly
Nuance
VocalizerGoogle
TTS
1 https://www.marketsandmarkets.com/PressReleases/text-to-speech.asp
Human to ? Interaction

4
APPLICATIONS OF TTS
Smart Home Devices Audio Books
Video GamesSelf-Driving CarsVocaloids
Health Care

5
TEXT TO SPEECH SYNTHESIS
for - ty per - c-
of aent
Text Input
Forty percent of a
Speech Output

6
SPEECH SYNTHESIS: THE VODER 1939

7
PARAMETRIC SPEECH SYNTHESIS
Pneumatic speech synthesizer developed
by von Kempelen in 1791.
Voder speech synthesizer developed
by Homer Dudley in 1939.

8
CONCATENATIVE TTS SYNTHESIS
First practical application in 1936: British Phone company’s Talking Clock
for - ty per - c - of aent
Database

9
CONCATENATIVE TTS SYNTHESIS
https://wezs.com/~danguy/monguy/TTS.html
• Requires collecting speech units
• Requires designing cost heuristics• Requires acoustic processing

10
PARAMETRIC (DEEP LEARNING) TTS SYNTHESIS
for - ty per - c-
of aent
Text Input
Forty percent of a
Audio Output
Deep Learning

11
DEEP LEARNING TTS SYNTHESIS
Linguistic or Acoustic features
for - ty per - c-
of aent
Text Input
Forty percent of a
Audio OutputX
1º 2º

12
OUTLINE
1.Text to Speech Synthesis
2.Tacotron 2
3.WaveGlow
4.TTS and TensorCores

13
TEXT TO (MEL) SPECTROGRAM WITH TACOTRON
Tacotron
CBHG:Convolution Bank (k=[1, 2, 4, 8…])
Convolution stack (ngram like)Highway
bi-directional GRU
Tacotron 2
Location sensitive attention, i.e. attend to:
Memory (encoder output)
Query (decoder output)Location (attention weights)
Cumulative attention weights (+= )

14
Implementationshttps://github.com/NVIDIA/tacotron2/https://github.com/NVIDIA/OpenSeq2Seq/
Deep Learning Framework and Libraries– PyTorch– TensorFlow– NVIDIA’s Automatic Mixed Precision
Training Setup– NVIDIA’s Tesla V100– Good results in less than a day starting fresh– Good results in a few hours warm-starting

15
TTS DATASET
LJS (Linda Johnson: single native speakers, ~24 hours)
● 7 non-fiction books
● “All of my recordings were done from the sofa in my family room!”
● “All of my recordings were done on a MacBook Pro.”
● https://keithito.com/LJ-Speech-Dataset/
● https://librivox.org/reader/11049
Sometimes raw text, other times ARPAbet

16
MEL TO AUDIO WITH WAVENET
Sampling Rates44100 Hz
22050 Hz16000 Hz
https://deepmind.com/blog/wavenet-generative-model-raw-audio/

17
WAVENET IMPLEMENTATION DETAILS
Naïve PyTorch -> 20 samples per second
Inference PyTorch on Volta -> 200 samples per second
nv-wavenet -> 20000 samples per second

18
MEAN OPINION SCORES: TACOTRON AND WAVENET
https://arxiv.org/abs/1712.05884

19
OUTLINE
1.Text to Speech Synthesis
2.Tacotron 2
3.WaveGlow
4.TTS and TensorCores

20
WAVENET IS THE BOTTLENECK
Ping, W. Deep Voice 3: Scaling Text-to-Speech with Convolutional
Sequence Learning. https://arxiv.org/abs/1710.07654
Shen, J. Et al. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions. https://arxiv.org/abs/1712.05884
TacoTron2 DeepVoice 3

21
WAVENET IS THE BOTTLENECK
Ping, W. Deep Voice 3: Scaling Text-to-Speech with Convolutional
Sequence Learning. https://arxiv.org/abs/1710.07654
Shen, J. Et al. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions. https://arxiv.org/abs/1712.05884
TacoTron2 DeepVoice 3

22
AUTO-REGRESSION IS INHERENTLY SERIAL
van den Oord, A. WaveNet: A Generative Model for Raw Audio.https://arxiv.org/pdf/1609.03499.pdf
𝑃 𝑥0, 𝑥1, 𝑥2, … = 𝑃 𝑥0 𝑃 𝑥1 𝑥0)𝑃 𝑥2 𝑥1, 𝑥0 …
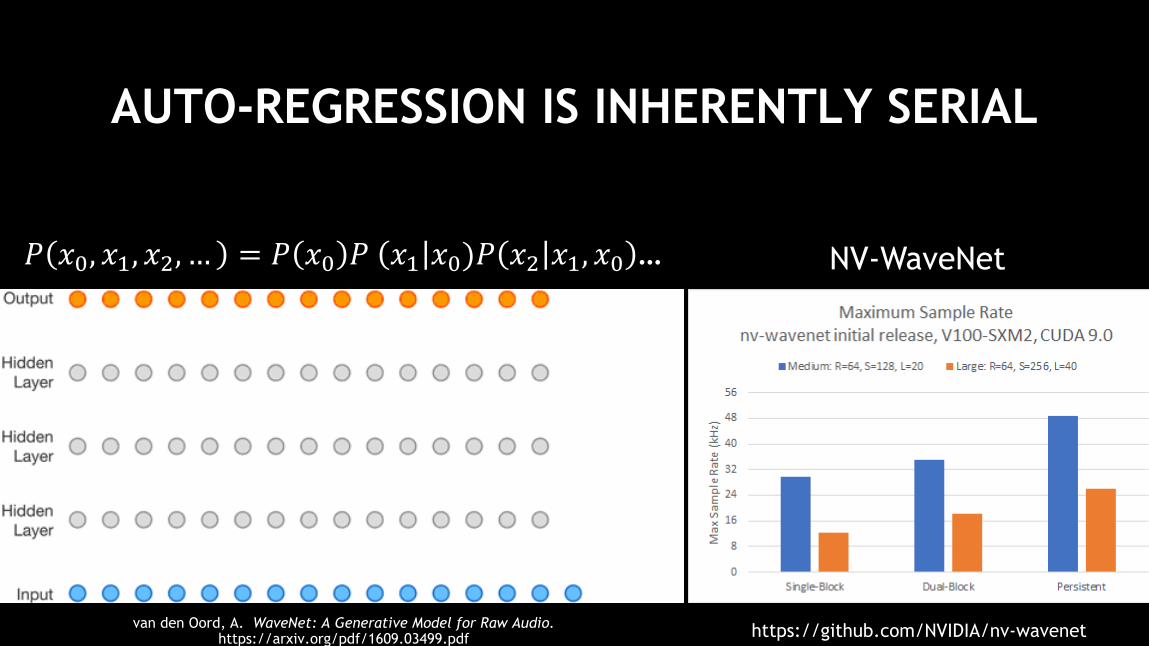
23
AUTO-REGRESSION IS INHERENTLY SERIAL
NV-WaveNet
https://github.com/NVIDIA/nv-wavenetvan den Oord, A. WaveNet: A Generative Model for Raw Audio.
https://arxiv.org/pdf/1609.03499.pdf
𝑃 𝑥0, 𝑥1, 𝑥2, … = 𝑃 𝑥0 𝑃 𝑥1 𝑥0)𝑃 𝑥2 𝑥1, 𝑥0 …

24
TRANSFORMING WHITENOISE TO AUDIO IS PARALLEL
Mel-Spectrogram
Gaussian Noise
25
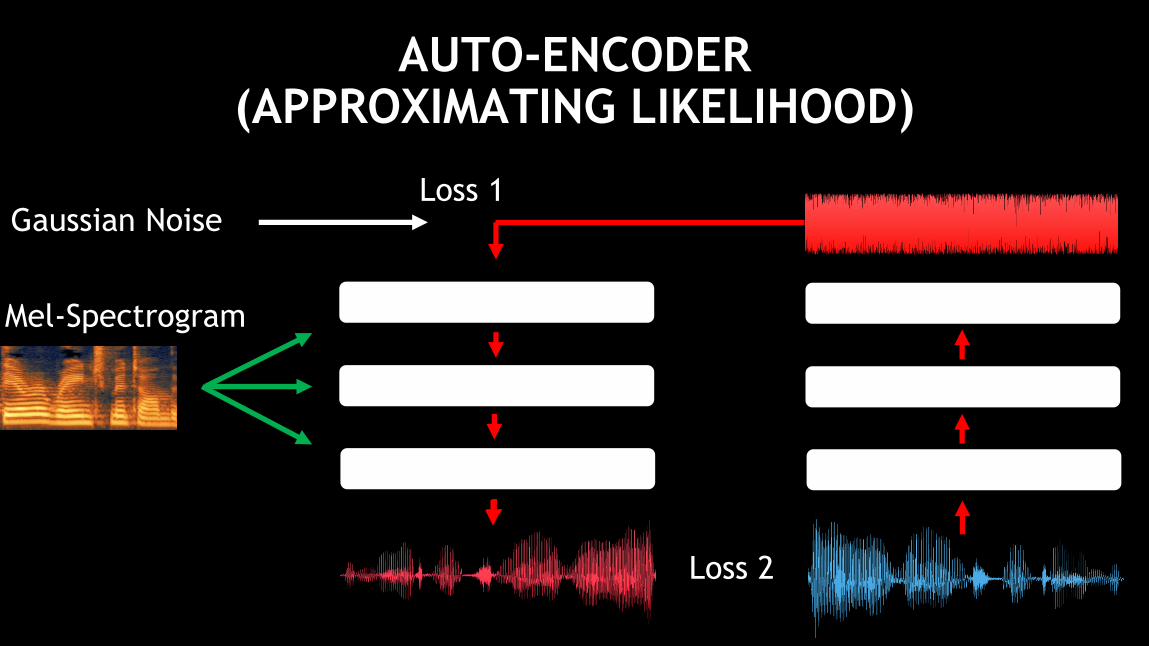
AUTO-ENCODER(APPROXIMATING LIKELIHOOD)
Loss 1
Loss 2
Gaussian Noise
Mel-Spectrogram

26
INVERTIBLE NETWORK(EXACT LIKELIHOOD)
Mel-Spectrogram
Gaussian Noise
Loss 1

27
HOW TO MAKE A NETWORK INVERTIBLE
audio samples

28
HOW TO MAKE A NETWORK INVERTIBLE
audio samples

29
HOW TO MAKE A NETWORK INVERTIBLE

30
HOW TO MAKE A NETWORK INVERTIBLE
Coupling network
(s, b)
(s, b)
(s, b)
(s, b)
(s, b)
(s, b)

31
HOW TO MAKE A NETWORK INVERTIBLE
Coupling network
(s, b)
(s, b)
(s, b)
(s, b)
(s, b)
(s, b)
+ bs ●
+ bs ●
+ bs ●
+ bs ●
+ bs ●
+ bs ●

32
HOW TO MAKE A NETWORK INVERTIBLE
Coupling network
(s, b)
(s, b)
(s, b)
(s, b)
(s, b)
(s, b)
- b) / s(
- b) / s
- b) / s
- b) / s
- b) / s
- b) / s(
(
(
(
(

33
https://github.com/NVIDIA/waveglow

34
DECREASING TEMPERATURE CAN HELP
Mel-Spectrogram
Gaussian Noise 𝜎 ~ 0.8

35
PARALLEL SOLUTION WORKS
Loss
NV-WaveNet: 24-48khz (1.2x – 2.4x realtime)
WaveGlow (published): 520 khz (24.5x realtime)
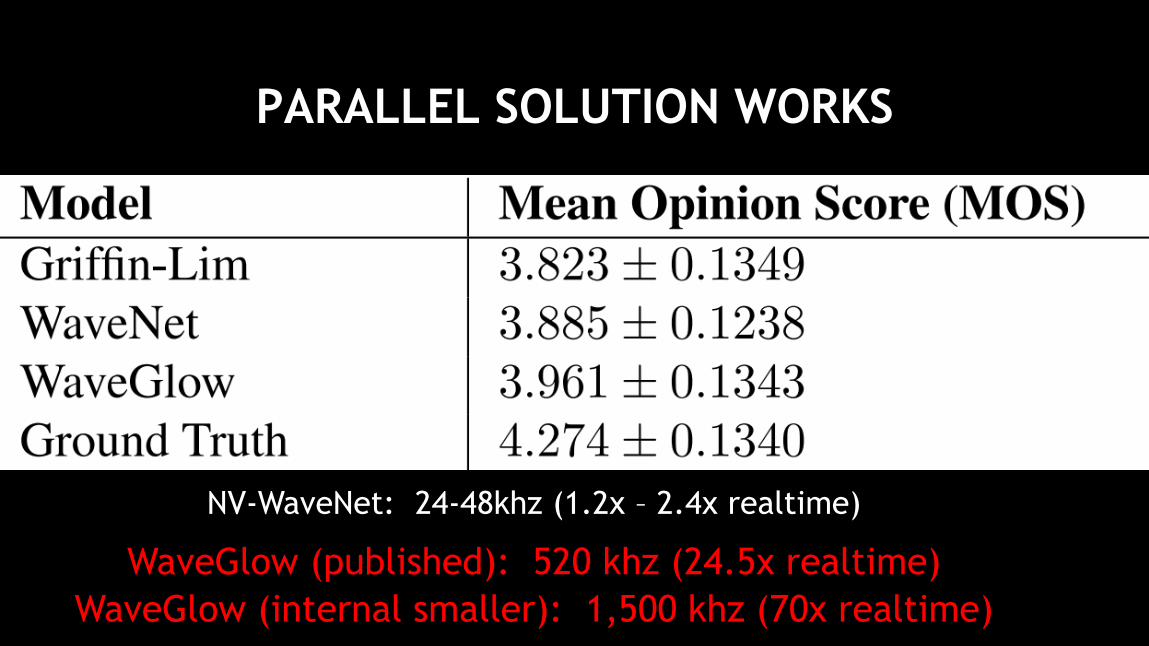
36
PARALLEL SOLUTION WORKS
Loss
NV-WaveNet: 24-48khz (1.2x – 2.4x realtime)
WaveGlow (published): 520 khz (24.5x realtime)
WaveGlow (internal smaller): 1,500 khz (70x realtime)

37
RELATED WORK
Parallel WaveNet/ClariNet
Very similar network/inference
Very different training procedure
WaveRNN
More like optimized auto-regressive
Can get some parallelism with subscale trick

38
OUTLINE
1.Text to Speech Synthesis
2.Tacotron 2
3.WaveGlow
4.TTS and Tensor Cores

39
INFERENCE SPEED UP
0
1
2
3
w/o Tensor Cores w/ Tensor Cores
sam
ple
s/s
in M
Hz
On DGX-1 1 Tesla V100 GPU
Batch size: 1
with Tensor Cores – Automatic Mixed Precision
1.8x

40
INFERENCE SPEED UP
0
1
2
3
real-time w/o TensorCores
w/ TensorCores
1x
sam
ple
s/s
in M
Hz
On DGX-1 1 Tesla V100 GPU
Batch size: 1
with Tensor Cores – Automatic Mixed Precision
70x
125x

41
TENSOR CORES SPEED UP MATRIX MULTIPLICATIONS
FP16 x FP16 + FP32
x

42
w/o Tensor Cores w/ Tensor Cores
Inference time 29ms 15ms
2X FASTER INFERENCE WITH TENSOR CORES

43
TRAINING SPEED UP
0
200
400
600
800
1000
FP32 Tensor Cores
train
ing t
ime in h
ours
On DGX-1 1 Tesla V100 GPUover 1000 Epochs
with Tensor Cores – Automatic Mixed Precision
1.9xfaster

44
TRAINING WITH TENSOR CORES
-8
-7
-6
-5
-4
-3
-2
-1
0
1
0k 10k 20k 30k 40k 50k 60k 70k 80k 90k 100k
FP32 Tensor Cores
Loss
Iterations
Tensor Coresachieve similar
training loss

45
USING TENSOR CORES WITH AMP
Automatic Mixed Precision library that enables Tensor Cores transparently
manages type conversions and master weights
automatic loss scaling to prevents gradient underflow
Different levels of optimization
white/black list allow user to enforce precision
Easy code adjustment

46
INFERENCE WITH AMP IS EASYCode Example
FP32

47
INFERENCE WITH AMP IS EASYCode Example
FP32 Tensor Cores with AMP
1.8x1x

48
TRAINING WITH AMP IS EASYCode Example
FP32

49
TRAINING WITH AMP IS EASYCode Example
Tensor Coreswith AMP
1.9xspeed up

50
CONCLUSION
Tensor Cores achieve close to 2x faster inference and training on Waveglow
AMP enables Tensor Cores transparently for training and inference
Code available on NGC and github
https://ngc.nvidia.com/catalog/model-scripts/
https://github.com/NVIDIA/tacotron2
https://github.com/NVIDIA/waveglow
https://github.com/NVIDIA/apex/tree/master/apex/amp



















