
TEXAS ADVANCED COMPUTING CENTER User experiences on Heterogeneous TACC IBM Power4 System Avi...
24
TEXAS ADVANCED COMPUTING CENTER User experiences on Heterogeneous TACC IBM Power System Avi Purkayastha Kent Milfeld, Chona Guiang Texas Advanced Computing Center University of Texas, Austin ScicomP 8 Minneapolis, MN August 4-8, 2003
-
Upload
philip-patrick -
Category
Documents
-
view
220 -
download
4
Transcript of TEXAS ADVANCED COMPUTING CENTER User experiences on Heterogeneous TACC IBM Power4 System Avi...

TEXAS ADVANCED COMPUTING CENTER
User experiences on Heterogeneous TACC IBM Power4 System
Avi PurkayasthaKent Milfeld, Chona Guiang
Texas Advanced Computing CenterUniversity of Texas, Austin
ScicomP 8Minneapolis, MNAugust 4-8, 2003

TEXAS ADVANCED COMPUTING CENTER
Outline• Architectural Overview
– TACC Heterogeneous Power4 System– Fundamental differences/similarities of TACC
Power4 nodes• Resource Allocation Policies• Scheduling
– Simple and advanced job scripts– Pre-processing LL with Job filter
• Performance Analysis– STREAM, NPB benchmarks– Finite Difference and Molecular Dynamics
Applications– MPI Bandwidth Performance
• Conclusions

TEXAS ADVANCED COMPUTING CENTER
TACC Cache/Micro-architecture Features
• L1 32KB/data 2-way assoc. (write through) 64KB/instruction direct mapped
• L2 1.44MB (unified) 8-way assoc.• L3 32MB 8-way assoc.• memory 32 GB/Node (p690H)
128 GB/Node (p690T) 8 GB/Node (p655H)
128/128/4x128 Byte Lines for L1/L2/L3

TEXAS ADVANCED COMPUTING CENTER
Comparison of TACC Power4 Nodes
• All nodes have same processing speed but different memory configurations; p690H, p655H have 2G/proc; p690T has 4G/proc.
• Only p690T has dual-core processors hence share L2 cache while others have dedicated L2 cache.
• p655 nodes have PCI-X adapters while the other nodes have PCI adapters, hence former has faster throughputs on message-passing.
• Global address snooping is absent on the p655s; this provides about 10% improvement in performance over the p690s.

TEXAS ADVANCED COMPUTING CENTER
TACC Power4 Systemlonghorn.tacc.utexas.edu
LoginGPFS
P690 HPC
P690Turbo
P690sHPC
P655sHPC
32 nodes4-way SMP8GB/node
3 nodes16-way SMP32GB/node
1 node32-way128GB
login node13-way16GBGPFS nodes3 1-way6 GB
16 procs. 32 procs. 48 procs. 128 procs.22GB 128GB 96 GB 256GB
Totals

TEXAS ADVANCED COMPUTING CENTER
TACC Power4 Systemlonghorn.tacc.utexas.edu
LoginGPFSP690 HPC
P690Turbo
P690sHPC
P655sHPC
32ports
32ports
IBM HPC Dual-Plane SP Switch2

TEXAS ADVANCED COMPUTING CENTER
TACC Power4 Systemlonghorn.tacc.utexas.edu
x16
SP Switch 2
LoginP690
TurboP690
HPCP690
/srcatch36GB
/srcatch /srcatch /srcatch36GB 36GB 36GB
/archive
/home 1/4TB
/work4.5 TB
HPCP690
HPCP690
HPCP655
/srcatch18GB
/srcatch18GB
local
archiva
l
x16
work
HPCP655

TEXAS ADVANCED COMPUTING CENTER
LoadLeveler Batch Facility
• Used to execute a batch parallel job• POE options: Use Environment Variables
for LoadLeveler Scheduling– Adapter Specification– MPI parameters– Number of Nodes– Class (Priority)– Consumable Resources
• Also have simple job scripts (PBS like) to address users migrating from clusters

TEXAS ADVANCED COMPUTING CENTER
Job Filter• TACC Power4 system is heterogeneous
– some nodes have large memories– some have faster communication throughput– some have dual cores, with different processor counts– need to address cluster users
• Part of the scheduling is just categorizing the job requests into classes • Problem with LoadLeveler is that a job cannot be changed from one class
to another -- hence a filter has evolved.• Filter also optimizes resource allocation and scheduling policies with
emphasis on application performance.
job submission
job filter
one of following queues{ LH13, LH16, LH32, LH4 }
scheduler determines priority and releases jobs for execution

TEXAS ADVANCED COMPUTING CENTER
POE: Simple Job Script I
#!/bin/csh…# @ job type = parallel# @ tasks = 16# @ memory = 1000# @ walltime = 00:30:00# @ class = normal# @ queuepoe a.out
MPI example

TEXAS ADVANCED COMPUTING CENTER
POE: Simple Job Script II
#!/bin/csh…# @ job type = parallel# @ threads = 16# @ memory = 1000# @ walltime = 00:30:00# @ class = normal# @ queuesetenv OMP_NUM_THREADS 16poe a.out
OpenMP example

TEXAS ADVANCED COMPUTING CENTER
POE: Advanced Job Script MPI example across Nodes
#!/bin/csh…# @ resources = ConsumableCpus(1) ConsumableMemory(1500mb)# @ network.MPI=csss,not_shared,us# @ node = 4 # @tasks_per_node=16# @ class = normal# @ queuesetenv MP_SHARED_MEMORY true poe a.out
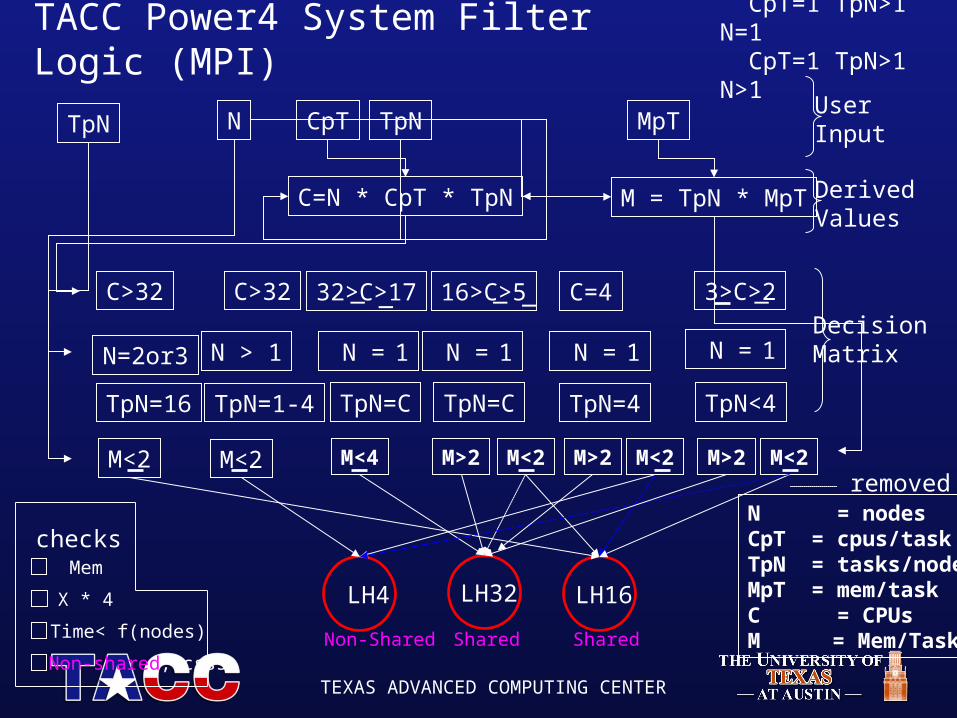
TEXAS ADVANCED COMPUTING CENTER
N CpT MpTTpNUser Input
N > 1 N = 1
Mem
checks
X * 4
Time< f(nodes)
Non-shared, csss
C=N * CpT * TpN M = TpN * MpT
C>32 32>C>17 16>C>5 3>C>2
LH32 LH4 LH16
N = 1 N = 1
_ _
DecisionMatrix
DerivedValues
TACC Power4 System Filter Logic (MPI)
Non-Shared Shared
C=4
N = 1
M<2
TpN=1-4 TpN=4 TpN<4TpN=16
N=2or3
M<2
TpN
_ _ _
M<2M>2M<2M>2M<2M>2M<4
Shared
TpN=CTpN=C
CpT=1 TpN>1 N=1 CpT=1 TpN>1 N>1
N = nodesCpT = cpus/taskTpN = tasks/nodeMpT = mem/taskC = CPUsM = Mem/Task
C>32
removed

TEXAS ADVANCED COMPUTING CENTER
CpT MpTUser Input
Mem
checks
X * 4
Time< f(nodes)
Non-shared, csss
C= CpT M = (MpT)/C
N = nodesCpT = cpus/taskTpN = tasks/nodeMpT = mem/taskC = CPUsM = Mem/Cpu
32>C>17 16>C>5 4>C>1
LH32 LH4 LH16
M<4 M<2 M<2
_ _DecisionMatrix
DerivedValues
Non-Shared
TACC Power4 System Filter Logic (OMP)
16>C>5 _
2<M<4
CpT>1 TpN=1 N=1

TEXAS ADVANCED COMPUTING CENTER
Batch Resource Limits• serial (front end)
– 8 hours, up to 2 jobs, • development (front end)
– 12 GB, 2 hours, upto 8 CPUs• normal/high (some default examples)
– <= 8 GBs, < 4 CPUs (LH16)– <= 8 GBs, 4 CPUs (LH4)– > 32 GBs, 5<= CPUs <=16 (LH32)– For various other combination possibilities, see
the User Guide• dedicated (by special request only)

TEXAS ADVANCED COMPUTING CENTER
Application Performance
• Effects of compute intensive and memory intensive scientific applications on the different nodes. Examples are STREAM, NPB etc.
• Effects of different kinds of MPI functionality on the different nodes. Examples include MPI ping-pong and MPI All-to-All Send_Recv’s

TEXAS ADVANCED COMPUTING CENTER
Scientific Applications
• SM: Stommel model of ocean “circulation” ; solves 2-D partial differential equation.
– Uses Finite Difference approx for derivatives on discretized domain, (timed for a constant number of Jacobi iterations).
– Parallel version uses Domain Decomposition for grid 1Kx1K
• Memory Intensive Application• Nearest Neighbor communication
• MD: Molecular Dynamics of a Solid Argon Lattice.
– Uses Verlet algorithm for propagation (displacement & velocities).
– Calculation done for 1 pico second for size 4.153
• Compute Intensive Application• Global communications

TEXAS ADVANCED COMPUTING CENTER
Scientific Applications II
Stommel MD
lh4 63.6 889
lh16 51.86 883
lh32 71.75 882
• lh16 architecture best suited for memory intensive application combined with nearest neighbor communication.• L2 cache sharing is most ill suited for memory intensive application.
Time(secs)

TEXAS ADVANCED COMPUTING CENTER
NAS Parallel Benchmarks
22811.20.78.590.511.1lh32
1.829.120.428.667.516lh161.3825.211.91.18.649.714lh4
mgluftisepbtcg
Class B results
23.517150.83.134.242137.1lh32
1910787.38.534.130437.6lh16
14.1102534.734.222432.1lh4
mgluftisepbtcg
Class C results
Time (secs)
Time (secs)

TEXAS ADVANCED COMPUTING CENTER
STREAM Benchmarks*
Copy Scale Add Triads
p655 8.1 8.18 11 11.17
p690_H 20.27 20.26 24.71 25.06
p690_T 28.6 29 32.22 32.25
Results courtesy of John McCalpin STREAM web-sitehttp://www.cs.virginia.edu/stream/

TEXAS ADVANCED COMPUTING CENTER
STREAM Benchmarks*
• Results for p655 used large pages and threads• Results for p690s used small pages and threads• p655 tested system has 64G memory, TACC
system has 8 G of memory• p690 tested system has 128G memory, TACC
system has 32 G of memory• Systems with larger memory and CPUS can
prefetch data streaming, hence applications with STREAM like kernels should perform better on p690s than p655s

TEXAS ADVANCED COMPUTING CENTER
MPI On-node Performance
IBM P690 Turbo 1.93 GB/s @ 256K 1.39 GB/s @ 2MIBM P690 HPC 1.89 GB/s @ 256K 1.32 GB/s @ 2MIBM P655 HPC 2.47 GB/s @ 256K 1.62 GB/s @ 2M
Ping Pong
IBM P690 Turbo 1.10 GB/s @ 32K 549 MB/s @ 2MIBM P690 HPC 1.76 GB/s @ 128K 862 MB/s @ 2MIBM P655 HPC 2.71 GB/s @ 256K 1.67 GB/s @ 2M
Bisection Bandwidth

TEXAS ADVANCED COMPUTING CENTER
MPI Off-node Performance
IBM P690 320-330 MB/s @ 2M-4M IBM P655 400-410 MB/s @ 2M-4M
Sustained off-node range measurements
Cruiser adapter on p655s vs Corsair on p690s

TEXAS ADVANCED COMPUTING CENTER
Thoughts and Comments• p690T are most suited for large memory, threaded
(OMP) type applications.• Applications such as FD, which typically contain
nearest-neighbor communication with large memory requirements, are best suited for p690H type nodes.
• Large MPI distributed jobs are best suited for p655 nodes as they are most balanced nodes.
• Latency sensitive, but small MPI jobs are better suited for p690H node than using the slower interconnect with p655s.
• In general, p690s are more limited by slower interconnect than helped by shared memory -- exceptions include FD, Linpack.


















