
Tecnologia di un Database Server (parte 2)
124
1 Tecnologia di un Database Server (parte 2) S. Costantini Dispensa per il Corso di Basi di dati
-
Upload
leo-dorsey -
Category
Documents
-
view
25 -
download
0
description
Tecnologia di un Database Server (parte 2). S. Costantini Dispensa per il Corso di Basi di dati. Premessa. Questa dispensa integra i contenuti del Libro di Testo del Corso di Basi di dati. - PowerPoint PPT Presentation
Transcript of Tecnologia di un Database Server (parte 2)

1
Tecnologia di un Database Server (parte 2)
S. CostantiniDispensa per il Corso di Basi di dati

2
Premessa
• Questa dispensa integra i contenuti del Libro di Testo del Corso di Basi di dati
Il materiale per queste slides è stato tratto in parte da (we acknowledge that this material is partly taken from):
Phil Bernstein, Lecture Notes for a graduate course on Transaction Processing at the University of Washington,
URL http://research.microsoft.com/~philbe/

3
Sommario
1. Locking e Lock Manager2. Implementazione del Locking3. Il Deadlock4. Locking Gerarchico5. Modello Matenatico del Locking6. Ottimizzazioni7. Gestore degli Accessi8. Gestore dell’affidabilità9. TP-Monitors10. Basi di Dati e Web

4
Locking e Lock Manager
S. Costantini

5
Modello di un SistemaTransazione 1 Transazione N
DatabaseServer
Bot,SQL QueriesCommit, Abort
Ottimizzatore QueryEsecutore Query
SchedulerBuffer Manager
Recovery manager
Database

6
Locking
• Obiettivo: assicurare schedule serializzabili delle transazioni
• Implementazione: ritardare le operazioni che possono alterare la serializzabilita’ ponendo blocchi (locks) sui dati condivisi

7
Assunzione: operazioni atomiche
• La Teoria del Controllo di Concorrenza considera le operazioni di Read e Write.
• Quindi assume assume che esse siano atomiche– altrimenti, dovrebbe considerare le operazioni di piu’ basso
livello che implementano Read e Write
• Read(x) - restituisce il valore corrente di x nel DB• Write(x, val) sovrascrive x (l’intera pagina che lo
contiene!)• Questa assunzione permette di astrarre l’esecuzione delle
transazioni a sequenze di Read e Write

8
Locking• Ciascuna transazione pone un lock su ogni dato al
quale intende accedere– il lock è una prenotazione– va effettuato prima di leggere/scrivere una dato– la transazione può ottenere il lock richiesto, oppure deve
restare in attesa di ottenerlo– la transazione rilascia il dato dopo l’uso (unlock)
• Ipotesi di lavoro: tutte le transazioni fanno commit, ossia nessuna fallisce (ipotesi di commit-proiezione)

9
Locking di base
• indichiamo con:– rl(x) un read lock sul dato x – r(x) la lettura del dato x– wl(x) il lock in scrittura del dato x– w(x) la scrittura del dato x– ru(x) e wu(x) sono i relativi unlock
• Con opi(x) indichiamo che l’operazione (una delle precedenti) è stata effettuata dalla transazione Ti

10
Locking di base
• Stato possibile del dato x:
– libero
– read-locked (x è soggetto a lock condiviso)
– write-locked (x è soggetto a lock esclusivo)

11
Gestione richieste di lock
• rli(x) sempre concessa se x è libero o read-locked (più transazioni possono porre un lock condiviso) ma negata se x è write-locked.
• wli(x) concessa solo se x è libero, ossia solo una transazione può scrivere un dato, escludendo tutte le altre.

12
Locking: sommario• Ciascuna transazione pone un lock su ogni dato al quale intende
accedere– il lock e’ una prenotazione– ci sono read locks e write locks– se una transazione ha un write lock su x, allora nessun’altra transazione
può avere alcun lock su x
• Esempio– rli[x], rui[x], wli[x], wui[x] sono operazioni lock/unlock wl1[x] w1[x]
rl2[x] r2[x] e’ impossibile
– wl1[x] w1[x] wu1[x] rl2[x] r2[x] e’ OK

13
Gestione Richieste di Lock
• Formato effettivo delle le operazioni di lock– Lock(trans-id, data-item-id, mode=r/w)– Unlock(trans-id, data-item-id)– Unlock(trans-id)
• trans-id: identificatore della transazione
• data-item-id: identificatore del dato x
• mode = r/w indica se si tratta di un read o write lock

14
Gestione richieste di lock
• Le transazioni che non ottengono un lock vengono poste in attesa.
• Lo scheduler (o lock manager, o data manager) gestisce una tabella di lock
• Tabella di lock: contiene le richieste accettate e rifiutate

15
Gestione richieste di lock
• ogni riga della tabella di lock contiene:– il nome x del dato– l’elenco delle transazioni che hanno ottenuto un
lock (indicando di che tipo)– l’elenco delle transazioni che sono state poste
in attesa perchè non hanno ottenuto un lock (indicando di che tipo)

16
Lock manager• Il lock manager gestisce le operazioni
– Lock(trans-id, data-item-id, mode=r/w)– Unlock(trans-id, data-item-id)– Unlock(trans-id)
• Memorizza i lock nella lock table.
Data Item Lista Locks Lista d’attesa
x [T1,r] [T2,r] [T3,w]
y [T4,w] [T5,w] [T6, r]

17
Il Locking di base non basta• Non garantisce la serializzabilita’
– rl1[x] r1[x] ru1[x] wl1[x] w1[x] wu1[x] c1
rl2[y] r2[y] wl2[x] w2[x] ru2[y] wu2[x] c2
• Eliminando i lock operations, abbiamor1[x] r2[y] w2[x] c2 w1[x] c1 che non e’ serializzabile
• Possibile soluzione: ogni transazione acquisisce tutti i lock all’inizio e li rilasci tutti alla fine
• Problema: si limita troppo la concorrenza

18
Two-Phase Locking (2PL)Two-Phase locking: stesso effetto di tutti i lock
all’inizio, ma meno vincoli sulla concorrenza
• La transazione acquisisce man mano i lock necessari– richiede un lock solo quando deve operare su quel
dato, e non all’inizio;
• Nel frattempo effettua le operazioni sui dati;
• Rilascia gradualmente i lock, con la condizione che dopo il primo unlock non può più fare lock

19
Two-Phase Locking (2PL)• Una transazione è two-phase locked (2PL) se:
– prima di leggere x, pone un read lock on x– prima di scrivere x, pone un write lock on x– mantiene ciascun lock fino a dopo l’esecuzione
dell’operazione sul dato – dopo il primo unlock, non può porre nuovi lock

20
Two-Phase Locking (2PL)
• Una transazione acquisisce i lock durante la fase crescente e li rilascia nella fase calante
• Esempio precedente: T2 e’ 2PL, ma non T1 perche’ ru1[x] precede wl1[x]

21
Rilasciare la Commit-proiezione
• il 2PL si basa sulla commit-proiezione, ossia sull’ipotesi che tutte le transazioni facciano commit (e non abort)
• Occorre ora rilasciare questa ipotesi• Se le transazioni possono fare abort, i
problemi si complicano ed occorre porre condizioni addizionali al 2PL per evitare malfunzionamenti

22
Problemi• Se Tk legge da Ti e Ti fa abort, Tk deve fare abort
– Esempio - w1[x] r2[x] a1 vuol dire che T2 deve fare abort
• Ma se Tk ha gia’ fatto commit?
– Esempio - w1[x] r2[x] c2 a1
– T2 non può fare abort dopo il commit

23
Recoverability• L’esecuzione deve essere recoverable:
Il commit di una transazione T deve essere successivo al commit delle transazioni da cui legge.
– Recoverable - w1[x] r2[x] c1 c2
– Non recoverable - w1[x] r2[x] c2 a1
• Si devono sincronizzare le operazioni

24
2PL e Recoverability
• 2PL non garantisce la recoverability
• Esempio: La seguente esecuzione è non-recoverable, ma è 2PL wl1[x] w1[x] wu1[x] rl2[x] r2[x] c2 … c1

25
Recoverability: Problemi
• La recoverability garantisce la coerenza d’uso dei dati, ma genera aborti a catena
• Gli aborti a caten cascading aborts (cosiddetto effetto domino) causano inefficienza perchè molte transazioni vengono uccise, perdendo il lavoro fatto.

26
Evitare Abort a cascata(cascading aborts)
• Per evitare aborti a cascata, lo scheduler deve assicurare che le transazioni leggano solo da transazioni che hanno fatto commit
• Esempio– evita cascading aborts: w1[x] c1 r2[x]
– permette cascading aborts: w1[x] r2[x] a1
• Un sistema che evita cascading aborts garantisce la recoverability e si chiama sistema stretto (sistema che garantisce la strictness = no effetto domino)

27
Strictness
• Un sistema stretto consente di eseguire ri[x] o wi[x] solo se tutte le transazioni precedenti che hanno scritto x hanno gia’ fatto commit o abort.
• Esempi – stretto: w1[x] c1 w2[x] a2
– non stretto: w1[x] w2[x] … a1 a2
– stretto: w1[x] w1[y] c1 w2[y] r2[x] a2
– non stretto: w1[x] w1[y] … w2[y] a1 r2[x] a2
• “Stricness” evita “cascading aborts” (effetto domino)

28
Nota: Gestione dell’abort
• Occorre annullare (undo) ogni write, w[x], ripristinando la before image (=il valore di x prima dell’esecuzione di w[x])
• Esempio - w1[x,2] scrive il valore “2” in x.
– w1[x,2] w1[y,3] c1 w2[y,1] r2[x] a2
– abort T2 : si ripristina la before image of w2[y,2] = 3

29
Osservazione: Brain Concurrency Control
• Se l’utente vuole usare l’output della transazione T1 come input per la transazione T2, deve aspettare che T1 faccia commit prima di lanciare T2.
• Solo così e’ garantito che T1 venga effettivamente serializzata prima di T2.
• Infatti, i sistemi serializzano secondo i criteri visti e non secondo le intenzioni dell’utente: se l’utente lancia prima T1 e poi T2 (ma prima che T1 termini) l’ordine fra esse non è garantito.

30
Implementazione del Locking

31
Locking Automatizzato
• Nei sistemi stretti il 2PL puo’ essere reso trasparente per l’ applicazione
• quando un data manager riceve una Read o Write da una transazione, emette un lock di read o write.
• Come fa il data manager a sapere quando e’ ok rilasciare i locks (per essere two-phase)?

32
Locking Automatizzato
• Come fa il data manager a sapere quando e’ ok rilasciare i locks (per essere two-phase)?
• Di solito, il data manager mantiene i lock di ogni transazione finche’ essa fa commit o abort. In particolare: – rilascia i read locks appene riceve il commit– rilascia i write locks solo quando accetta il commit,
per garantire la strictness

33
Implementazione del 2PL
• Il data manager implementa il locking cosi’:– includendo un lock manager– generando un lock per ogni Read o Write– prevedendo la gestione dei deadlocks (vedi più avanti)

34
Lock manager• Il lock manager gestisce le operazioni
– Lock(trans-id, data-item-id, mode=r/w)– Unlock(trans-id, data-item-id)– Unlock(trans-id)
• Memorizza i lock nella lock table.
Data Item Lista Locks Lista d’attesa
x [T1,r] [T2,r] [T3,w]
y [T4,w] [T5,w] [T6, r]

35
Come è rappresentato il dato x?
• Dalla memoria secondaria non si trasferiscono mai singole tuple, ma “pezzi” più ampi, in genere pagine
• Quindi, x si rappresenta:– indicando la pagina in cui si trova x– identificando x nella pagina (ad es. tramite la
chiave)

36
Come è memorizzata la tabella?
• Certo non sequenzialmente: troppo lento cercare i lock su x per accesso sequenziale.
• Occorre una opportuna struttura dati– in generale: tabella hash– funzione di hash f applicata su x– f(x) identifica la riga di x nella tabella di
locking ed è detto data-item-id

37
Lock manager
• Il chiamante genera il data-item-id, applicando una funzione di hashing sul nome del dato
• Infatti, la lock table e’ hashed sul data-item-id
• Lock e Unlock devono essere atomici, quindi l’accesso alla lock table deve essere “locked”
• Lock e Unlock vengono chiamati frequentemente. Devono essere molto veloci: < 100 istruzioni.

38
Lock manager (cont.)
• In SQL Server 7.0– I locks nella tabella occupano circa 32 bytes – Ogni lock contiene il Database-ID, Object-Id, e altre
informazioni specifiche quali il record id (RID) o la chiave della tupla.

39
Il Deadlock

40
Deadlock• Un insieme di transazioni e’ in deadlock se ogni
transazione e’ bloccata, e lo rimarra’ tutti’infinito se il sistema non interviene. – Esempio rl1[x] concesso
rl2[y] concesso wl2[x] bloccata
wl1[y] bloccata e deadlocked

41
Deadlock• Con il deadlock, 2PL evita le esecuzioni non
serializzabili: – Ad es. rl1[x] r1[x] rl2[y] r2[y] … w2[x] w1[y]
– oppure (caso della perdita di update) rl1[x] r1[x] rl2[x] r2[x] … w2[x] w1[x]
– Per eliminare il deadlock: abort di una transazione– rilascio del lock senza abortire: si viola il 2PL

42
Prevenzione del Deadlock
• Mai concedere un lock che puo’ portare al deadlock
• Tecnica spesso usata nei sistemi operativi
• Inutilizzabile nel 2PL, perche’ richiederebbe l’esecuzione seriale delle transazioni.
– Esempio per prevenire il deadlock,rl1[x] rl2[y] wl2[x] wl1[y], il sistema nega rl2[y]

43
Prevenzione del Deadlock
• Prevenire i deadlock non e’ praticabile in generale, perche’ pone eccessivi constraints alle applicazioni.
• Porre tutti i lock in scrittura tutti all’inizio delle transazioni – Previene il deadlock perche’ la transazione “parte” solo
se ha tutti i dati a sua esclusiva disposizione– riduce troppo la concorrenza.

44
Rilevazione del Deadlock
• Si cerca di rilevare i deadlock automaticamente, e si abortisce una delle transazioni (la vittima).
• E’ l’approccio piu’ usato, perche’– consente una piu’ intensiva utilizzazione delle risorse

45
Rilevazione del Deadlock
• timeout-based deadlock detection - Se una transazione resta bloccata per troppo tempo, allora abortiscila.– Semplice ed efficiente da implementare– Ma determina aborti non necessari e – Alcuni deadlocks persistono troppo a lungo

46
Rilevazione Tramite Waits-for Graph
• Rilevazione esplicita dei deadlock tramite un grafo chiamato Waits-for Graph– Nodi = {transazioni}– Archi = {Ti Tk | Ti attende che Tk rilasci un
lock}– Esempio precedente: T1 T2
• Teorema: Se c’e un deadlock, allora il Waits-for Graph ha un ciclo.

47
Rilevazione tramite Waits-for Graph (cont.)
• Per rilevare i deadlocks– quando una transazione si blocca, aggiungi un arco– periodicamente cerca i cicli nel Waits-for Graph
• Non occorre verificare troppo spesso. (Un ciclo non scompare finche’ non lo si “rompe”)
• quando si trova un deadlock, si seleziona una vittima dal ciclo e la si abortisce.
• Si seleziona una vittima che ha fatto poco lavoro (ad es., ha acquisito il numero minimo di lock).

48
Ripartenza Ciclica• Le transazioni possono ripartire e abortire all’infinito:
mai uccidere la più vecchia– T1 inizia. Poi T2 inizia.
– vanno in deadlock, e T1 (la piu’ vecchia) e’ abortita.
– T1 riparte, T2 continua, e vanno ancora in deadlock
– T2 (la piu’ vecchia) e’ abortita ...
• Scegliere come vittima la transazione piu’ giovane evita la ripartenza ciclica, perche’ la piu’ vecchia non viene mai abortita, e può infine terminare.
• Le due diverse euristiche si possono combinare

49
SQL Server 7.0• Abortisce la transazione piu’ “economica” per il
roll back. – La “piu’ economica” viene determinata in termini del
numero di operazioni fatte (registrate nel file di log).– Permette il completamento delle transazioni che hanno
fatto molto lavoro.
• SET DEADLOCK_PRIORITY LOW (vs. NORMAL) permette ad un processo di designarsi da solo come vittima.

50
Locking distribuito
• Supponiamo che una transazione possa accedere dati presso molti data managers
• Ogni data manager tratta i lock nel modo usuale
• Ogni transazione esegue commit o abort, nei confronti di tutti i data managers
• Problema: deadlock distribuito

51
Deadlock distribuito• Il deadlock interessa due nodi.
Il nodo singolo non puo’ rilevarlo
• La rilevazione tramite timeout e’ la piu’ usata
rl1[x]wl2[x] (bloccata)
Nodo 1
rl2[y]wl1[y] (bloccata)
Nodo 2

52
Locking Gerarchico

53
Granularita’ dei Lock• Granularita’ - dimensione dei dati su cui fare lock
– ad es., files, pagine, record, campi
• Granularita’ grossolana implica:– pochi lock, basso locking overhead– lock su grosse porzioni di dati, alta probabilita’ di conflitti, quindi
concorrenza effettiva bassa
• Granularita’ sottile implica:– molti lock, alto locking overhead– conflitti solo quando due transazioni tentano di accedere
concorrentemente proprio lo stesso dato

54
Multigranularity Locking (MGL)• Lock di differente granularita’
– grosse query fanno lock su grosse porzioni di dati (ad es. tabelle), transazioni brevi fanno lock su pochi dati (ad es. righe)
• Il Lock manager non puo’ rilevare i conflitti!– ogni data item (ad es. tabella o riga) ha un differente id

55
Multigranularity Locking (MGL)
• Multigranularity locking e’ un “trucco”– sfrutta la naturale struttura gerarchica dei dati– prima del lock su dati di basso livello, si fa un intention
lock sulla struttura di piu’ alto livello che li contiene (cioè segnala l’intenzione di effettuare operazioni)
– ad es., prima di un read-lock su una, si fa un intention-read-lock sulla tabella che contiene la riga

56
MGL Grafi di Schema e istanzaDatabase
area
File
Record
DB1
A1 A2
F1 F2 F3
R1.1 R1.2 R2.1 R2.2 R2.3 R2.1 R2.2
Lock di Schema
Lock di istanza
• Prima di un read lock su R2.3, si fa un intention-read lock su DB1, e poi A2, e poi F2 (i lock si rilasciano all’inverso)

57
MGL Matrice di Compatibilita’r w ir iw riw
r y n y n n
w n n n n n
ir y n y y y
iw n n y y n
riw n n y n n
riw = read conintenzione di write,per scansione cheaggiorna alcunidei record che legge
• Ad es., ir e’ in conflitto con w, perche’ ir segnala un r-lock su un dato piu’ interno, che e’ in conflitto con un w-lock sulla struttura che lo contiene.

58
SQL Server 7.0
• SQL Server 7.0 accetta lock su tabelle, pagine, e righe.
• Usa lock di intention read (“share”) e intention write (“exclusive”) a livello di pagina di tabella.

59
Modello Matematico del Locking
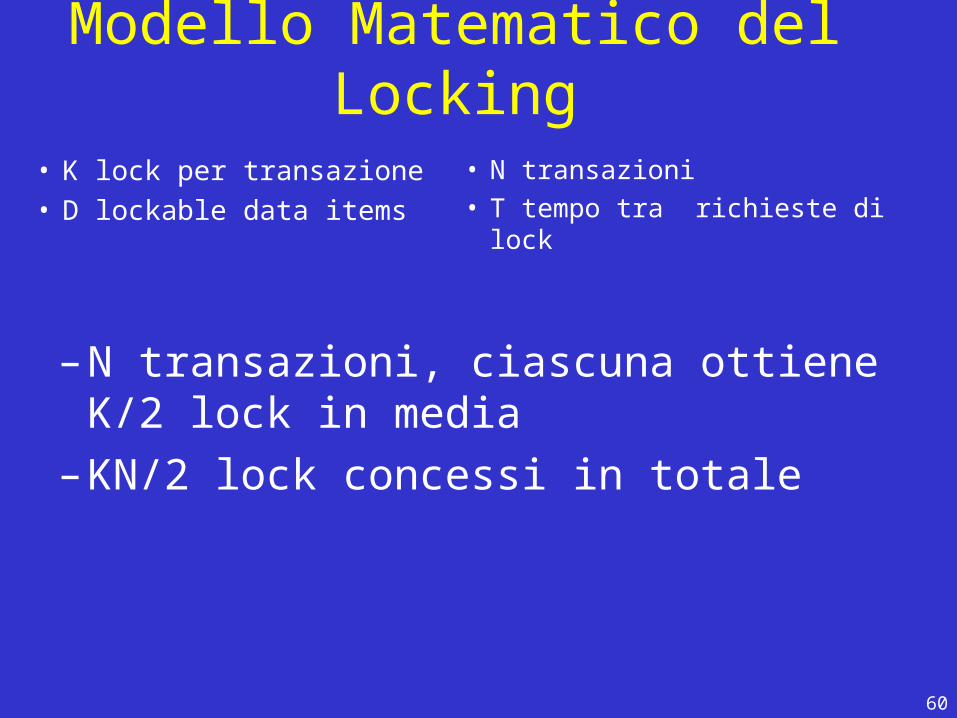
60
Modello Matematico del Locking
– N transazioni, ciascuna ottiene K/2 lock in media
– KN/2 lock concessi in totale
• K lock per transazione• D lockable data items
• N transazioni• T tempo tra richieste di lock

61
Modello Matematico del Locking
– Ciascuna richiesta ha probabilita' KN/2D di conflitto con un lock esistente.
– Ciascuna transazione richiede K locks, quindi la sua probabilita' di entrare in conflitto e' K2N/2D.

62
Modello Matematico del Locking
– La probabilita' di deadlock e' proporzionale a K4N/D2
– Prob(deadlock) / Prob(conflitto) = K2/D
– Se K=10 e D = 106, allora K2/D = .0001

63
Ottimizzazioni

64
Hot Spot Techniques
• Hot spot - un data item che e’ piu' usato di altri, per cui molte transazioni ne fanno uso.– cataloghi ed elenchi– end-di-file marker – contatori usati per assegnare numeri seriali
• Gli hot spots spesso creano un collo di bottiglia che serializza le transazioni.

65
Hot Spot Techniques (cont.)
• Sono necessarie tecniche per ridurre il tempo t di durata di un lock sugli hot data, ad esempio:– mantenere gli hot data in memoria centrale– eseguire in batch le operazioni su hot data– partizionare gli hot data

66
Partizionamento
• Suddividere cataloghi e inventari in parti
• Ciascuna transazione puo’ accedere solo una partizione.
• Esempio– ciascuna biglietteria ha una parte dei biglietti– se li vende tutti, deve richiedere altri biglietti
dalle altre biglietterie

67
Tecniche di Query-Update
• Alcune query durano molto tempo e fanno lock su molti dati — degradano la performance se competono con brevi transazioni di update
• Esistono diverse soluzioni– Usare un data warehouse– Accettare vincoli di consistenza piu’ deboli– Usare multiversioni dei dati

68
Data Warehouse• Un data warehouse e’ una copia del DB, che e'
periodicamente aggiornata
• Tutte le query girano sul data warehouse
• Tutte le transazioni di update girano su DB
• Separazione fra transazioni e query
• Quanto spesso aggiornare il data warehouse?– Stop alle transazioni per copiare il DB nel data
warehouse. E’ possibile invece effettuare query– Le query non hanno sempre l’ultima versione dei dati

69
Multiversioni dei Dati• La granularità del locking deve arrivare al record
• ciascuna write crea una nuova versione, invece di sovrascrivere il valore esistente.
• Ciascun record ha una sequenza di versioni.
• Ogni versione e’ annotata con l’id della transazione che ha scritto quella versione
Tid TidPrec. Matr Nome Stipendio123 null 1 Bill 100175 123 1 Bill 125134 null 2 Sue 120199 134 2 Sue 140227 null 27 Steve 80

70
Multiversioni dei Dati (cont.)• Si eseguono le transazioni usando 2PL
• Si eseguono le query in snapshot mode
– quando una query legge x, legge l’ultima versione di x scritta da una transazione che ha fatto commit.
– cosi', ogni query fa riferimento allo stato del database relativo a quando ha iniziato l'esecuzione
– occorre una gestione particolare del commit, visto che al commit il valore attuale di ogni dato va aggiornato tenendo conto delle multiversioni.

71
Gestore degli Accessi(Buffer Manager)

72
Gestore degli accessi
• E’ il modulo di piu’ basso livello del data manager
• Nei DBMS relazionali viene chiamato RSS (Relational Storage System)
• Effettua in pratica gli accessi alla BD
• Conosce l’organizzazione fisica delle pagine
• Conosce la disposizione delle tuple nelle pagine
• Usa un buffer manager per la gestione del trasferimento effettivo delle pagine

73
Indici
• Come si implementano Read e Write?
• Bisogna reperire i dati in Memoria di Massa
• A partire dal valore della chiave di una tupla, occorre trovare il record id– Record id = [pagina-id, offset-nella-pagina]
• Un indice collega i valori delle chiavi ai record id.– Le strutture indice piu’ comuni: tabelle hash e B-alberi

74
Indirizzi di Memoria di Massa
• Per un dato x, il suo indirizzo in memoria di massa è costituito da:– numero N della pagina/blocco in cui si trova– offset F che indica che X è nella F-esima
posizione del blocco N– quindi, x (che al livello fisico viene detto
“record”) ha indirizzo fisico (N,F) che viene detto Record-id

75
Indici
• Per ottenere il Record-id R di un dato X partendo dalla sua chiave K, si utilizza una struttura dati detta indice
• Mediante un indice si ottiene in modo efficiente R partendo da K
• Strutture più usate per gli indici: tabelle hash e alberi (B-alberi)

76
Indice come Tabella Hash
• La chiave K di una tupla viene usata tramite una funzione hash per decidere la pagina in cui memorizzare la tupla.
• Ossia: Num_pagina = f(K)• Ricerca di x: data la sua chiave K,
calcolando f(K) si ottiene la pagina dove si trova la tupla X, che viene poi cercata sequenzialmente nella pagina.

77
Creazione Tabella Hash• L’hashing usa una funzione H:VB, dalle chiavi al
numero del blocco (pagina) dove si trova il dato– V = matricola B = {1 .. 1000}
H(v) = v mod 1000– se una pagina va in overflow, allora si deve aggiungere
una lista di pagine extra– Al 90% di carico delle pagine, 1.2 accessi per richiesta!– ma, va male per accessi su intervalli (10 < v < 75)

78
Indici come alberi
• per reperire i record-id relativi ai dati contenuti in una certa tabella, si costruisce un albero a partire dalle chiavi.
• La chiave K del dato cercato va reperita mediante una visita nell’albero, fino ai nodi foglia.
• Esiste sempre una foglia che riporta K, e in essa è riportato il Record-id R

79
B-albero
Ki Pi Ki+1K1 P1 Kn-1 Pn. . . . . .
K´i P´i K´i+1K´1 P´1 K´n-1 P´n. . . . . .
• Ogni nodo e' un sequence di coppie [puntatore, chiave]
• K1 < K2 < … < Kn-2 < Kn-1
• P1 punta a un nodo contenente chiavi < K1
• Pi punta a un nodo contenente chiavi in intervallo [Ki-1, Ki)
• Pn punta a un nodo contenente chiavi > Kn-1
• Dunque, K ´1 < K ´2 < … < K ´n-2 < K ´n-1

80
Esempio n=3127 496
14 83 221 352
127 145 189 221 245 320
521 690
352 353 487
• Notare che le foglie sono ordinate per chiave, da sinistra a destra
• Importante: per ogni chiave, la foglia contiene il Record-id della tupla, o la tupla stessa

81
Inserzione• Per inserire la chiave v, si cerca la foglia dove v dovrebbe
trovarsi: se c’e’ spazio, si inserisce• Se no, si spezza la foglia in due, e si modifica il padre per
prevedere i puntatori alle due foglie
19 --
12 14 17X
15 19
12 14
X
15 17
Per inserire la chiave 15• si spezza la foglia• nel padre, [0, 19)diventa [0, 15) e [15, 19)• se il padre e’ pieno, bisogna spezzarlo (in modo simile)• l’albero resta automaticamentebilanciato

82
B-albero: Osservazioni• L’algoritmo di cancellazione riunisce nodi adiacenti
con riempimento < 50%
• La radice ed i nodi di livello uno sono mantenuti in una cache, per ridurre il tempo di accesso
• Indice secondario: le foglie contengono in realta’ coppie [chiave, Record-id]
• Indice primario: le foglie contengono i record

83
B+Alberi• Ogni nodo foglia ha un puntatore al successivo• facilita la ricerca su intervalli: trovata la prima chiave
dell’intervallo, basta scorrere le foglie adiacenti mediante i puntatori
19 --
12 14 17
P
CX
15 19
12 14
X
15 17
P
C´C

84
B+Albero: ottimizzazione• B+albero - ciascuna foglia ha un puntatore alla prossima, nell’ordine
dato dalle chiavi
• Obiettivo: ottimizzare interrogazioni il cui predicato di selezione definisce un intervallo di valori ammissibili
• Trovato il primo valore della chiave, si scandiscono sequenzialmente i nodi foglia

85
Controllore dell’Affidabilità
S. Costantini

86
Introduzione
• Un database puo’ divenire inconsistente a causa di:– fallimento di una transazione(abort)– errore di sistema (a volte causato da un OS crash)– media crash (disco corrotto)
• Il sistema di recovery assicura che il database contenga esattamente gli aggiornamenti prodotti dalle transazioni committed (cioe’ assicura atomicita’ e persistenza, nonostante i guasti )

87
Terminologia• Affidabilita’ - il grado di certezza con il quale un
sistema fornisce i risultati attesi su prove ripetute
• L’affidabilita’ si misura come mean-time-between-failures (MTBF)
• Disponibilita’ - frazione di tempo nel quale il sistema fornisce i risultati attesi.
• La disponibilita’ e’ ridotta anche dai tempi di riparazione e manutenzione preventiva
• Disponibilita’ = MTBF/(MTBF+MTTR), where MTTR is mean-time-to-repair

88
Terminologia (cont.)
• Failure (fallimento) - un evento dove il sistema dia risultati inattesi (sbagliati o mancanti)
• Fault (guasto) - causa identificata o ipotizzata di fallimento – Es. Un guasto nella scheda di memoria che causa un
malfunzionamento del software
• Transient fault - e’ occasionale, e non avviene nuovamente se si ritenta l’operazione
• Permanent fault - non-transient fault

89
Quali sono le cause di guasto?
• Il maggior problema e’ il software• Environment - incendi, terremoti, vandalismi, mancanza di
elettricita’, guasto al condizionatore• system management - manutenzione, configurazione
Tandem ‘89 Tandem ‘85 AT&T/ESS ‘85Environment 7% 14%Hardware 8% 18% Subtotal 15% 32% 20%system Mgmt 21% 42% 30%Software 64% 25% 50%

90
Assunzioni• Two-phase locking, che mantiene i write locks fino a
dopo il commit. Questo assicura– recoverability– no aborti a catena– strictness (non si utilizzano mai dati non committed)
• Gestione a livello di pagine– locks su pagine– il database e’ un insieme di pagine– le read e write operano su pagine

91
Modello della Memoria
• Memoria Stabile - resiste ai fallimenti di sistema
• Buffer (volatile) - contiene copie di alcune pagine, che vanno perse in caso di fallimenti
DatabaseLog
Read, Write
Fix, FlushUse, Unfix
Buffer Manager
Buffer
Read, Write

92
Buffer Manager
• Fornisce primitive per accedere al buffer
• Fix carica una pagina nel buffer (la pagina diventa valida)
• Politica no-steal = mai deallocare pagine attive
• Use accede ad una pagina valida

93
Buffer Manager
• Unfix rende una pagina non piu’ valida
• Politica no-force = non riscrivere nel DB tutte le pagine attive al commit
• Flush periodicamente riscrive nel DB le pagine non piu’ valide
• Force trasferisce in modo sincrono una pagina dal buffer al DB (transazione sospesa fino a fine trasferimento)

94
Il LOG
• LOG: file sequenziale del gestore dell’affidabilità
scritto in memoria stabile e’ una registrazione delle attivita’ del
sistema

95
Checkpoint
• operazione periodica coordinata con buffer-manager flush di tutte le pagine di transazioni terminate registrazione identificatori transazioni in corso non si accettano commit durante il checkpoint si scrive in modo sincrono (force) l’elenco
transazioni attive nel LOG formato del record CKPT(T1,...,Tn)

96
DUMP
• copia completa del DB, fatta quando il sistema non è operativo (non ci sono transazioni attive)
copia memorizzata su memoria stabile (backup )
record di dump nel LOG formato record DUMP(C) dove C è il
dispositivo di backup

97
Organizzazione del LOG
• Record del LOG di transazione di sistema (checkpoint, DUMP)
• Record di TRANSAZIONE: le transazioni registrano nel LOG le operazioni,
nell’ordine in cui le effettuano begin: record B(T) commit/abort C(T), A(T) T e’ l’identificatore della transazione

98
Organizzazione del LOG
Record di UPDATE identificatore transazione T identificatore oggetto O valore di O prima della modifica, before state valore di O dopo la modifica, after state U(T,O,BS,AS)

99
Organizzazione del LOG
Record di DELETE identificatore transazione T identificatore oggetto O valore di O prima della cancellazione, before state D(T,O,BS)

100
Organizzazione del LOG
Record di INSERT identificatore transazione T identificatore oggetto O valore di O dopo l’inserzione, after state I(T,O,AS)

101
UNDO e REDO
UNDO : si ricopia BS su O, – INSERT: si cancella O
REDO : si ricopia AS su O– DELETE: si cancella O
UNDO e REDO sono idempotenti UNDO(UNDO(A)) = UNDO(A) REDO(REDO(A)) = REDO(A)
• Utile se errori durante il ripristino

102
Gestione delle Transazioni
Regola WAL: Write Ahed Log
• BS scritta nel LOG prima di operare nella BD
>>> permette UNDO operazioni se no commit
Regola Commit-Precedenza
• AS nel LOG prima del COMMIT
>>> permette REDO operazioni se problema dopo commit (in no force)

103
Gestione delle Transazioni
Versione semplificata WAL + Commit-Precedenza: – record delle operazioni inseriti nel LOG prima
di operare sulla BD, e prima del commit
GUASTO prima del commit: UNDO di tutte le operazioni di ogni transazione attiva mediante LOG
COMMIT/ABORT: la transazione scrive RECORD DI COMMIT/ABORT
GUASTO dopo il commit: REDO di tutte le operazioni della transazione mediante LOG

104
Gestione dei Guasti
Guasto transitorio:
perso il contenuto del buffer resta il LOG
– RIPRESA A CALDO (warm restart)
Guasto permanente ad un disco: resta il LOG (assunzione memoria stabile)
– RIPRESA A FREDDO (cold restart)

105
Ripresa a caldo
Si cerca ultimo checkpoint nel LOG Si decidono transazioni da rifare (insieme di REDO)
e disfare (insieme di UNDO) UNDO: transazioni attive al checkpoint REDO: inizialmente vuoto Si scorre il LOG:
B(T) => T in UNDO C(T) => T in REDO
Si applicano UNDO e REDO

106
Ripresa a Freddo
Si usa l’ultimo DUMP per ripristinare uno stato stabile della BD
si ripercorre il LOG rifacendo tutte le azioni successive al DUMP
si fa ripresa a caldo dall’ultimo checkpoint

107
Ottimizzazioni User-Level
• Se la frequenza dei checkpoint si puo’ variare, regolarla mediante esperimenti
• Partitionare il DB su piu’ dischi per ridurre il tempo di restart

108
Media Failures• Un media failure e’ la perdita di parte della memoria
stabile• La maggior parte dei dischi ha MTBF a piu’ di 10 anni, ma
su 10 dischi...• E’ importante avere dischi “shadow”, ossia un disco
duplicato che faccia da copia “ombra’ della memoria stabile– Le Write vanno su entrambe le copie.
– Le Read vanno su una sola copia (in alternanza, per efficienza)

109
RAID• RAID - redundant array of inexpensive disks
– Array ridondante di dischi di basso costo– Si basa su un array di N dischi in parallelo– Soluzione ancora piu’ sicura rispetto al disco ombra
... ...
M blocchi dati N-M blocchi di correzione errore

110
Dove Usare Dischi Ridondanti?
• Preferibilmente sia per il DB che per il LOG• Ma almeno per il LOG
– in un algoritmo di UNDO, e’ l’unico modo di avere before images sicure
– in un algoritmo di REDO, e’ l’unico modo di avere after images sicure
• Se non si ha almeno un disco ombra per il LOG, il sistema ha un grosso punto debole

111
TP Monitors(Transaction Processing Monitors)
Stefania Costantini

112
Architettura Client-Server
Presentation Manager
Workflow Control(gestisce le richieste)
Database Server
Front-End(Client)
Back-End(Server)
Utente finale
Transaction Program
richieste

113
Cosa fa un TP Monitor
• TP Monitor = Transaction Processing Monitor = Controllore dell’elaborazione delle Transazioni
• Una richiesta e’ un messaggio che descrive una unita’ di lavoro che il sistema deve eseguire.
• Un TP monitor coordina il flusso di richieste di esecuzione di transazioni provenienti da varie fonti (terminali e programmi applicativi)

114
Cosa fa un TP Monitor
• Struttura fondamentale:
– Traduce l’input (proveniente da form/menu, o da un’istruzione in qualche linguaggio) in forma standard
– Determina il tipo di transazione
– Fa partire la transazione
– Restituisce in forma opportuna l’output della transazione

115
Presentation Server
Controllore di Workflow
Transaction Server Transaction Server
Rete
Richieste
Messaggiodi richiesta
Architettura 3-Tierdi un TP Monitor
• Gli elementi dello schema possono essere distribuiti in rete
Code

116
Architettura 3-Tier
• La struttura dell’applicazione ricalca la struttura del sistema
• Elementi del TP Monitor in un’architettura 3-Tier:– Presentation server : forms/menus, validazione degli
input (password, connessione sicura)– Workflow controller : data una richiesta, produce la
chiamata al programma corretto – Transaction server : esegue le richieste

117
Presentation Server
• Presentation independence - l’applicazione e’ indipendente dal tipo di dispositivo di i/o– terminale, ma anche telefono cellulare o lettore di codici
a barre, o di carte di credito
• Il Presentation server ha due livelli: – Raccogliere gli input – Costruire le richieste

118
Autenticazione• Autenticazione : determinare l’identita’ dell’utente
e/o del dispositivo– Il sistema client può effettuare l’autenticazione, che
comunque il server effettua nuovamente (non si fida dei client)
– Encryption della comunicazione client/server opportuno
• Occorrono funzioni di sistema per creare accounts, initializzare passwords, assegnare ore di accesso
• E’ una parte importante dello sviluppo di applicazioni TP

119
Workflow Controller• Routing - Mappa il tipo di richiesta nel network id
del server che potra’ elaborarla, e invia la risposta al client
• Gestisce errori ed eccezioni

120
Transaction Server• Transaction server - programma applicativo che
effettua il “real work” dell’elaborazione delle richieste
• Per portabilita’, e’ opportuno che sia scritto in un linguaggio di programmazione standard (C, C++, Java, COBOL) interfacciato con un Data Manipulation Language standard (SQL)

121
Basi di Dati e Web
Stefania Costantini

122
Transazioni su Internet• Web browser = presentation manager• Messaggio dal web browser al server = richiesta di transazione su sistema (Transaction server) di cui si da’ l’URL• http = protocollo di comunicazione client/server • Web server = include il workflow controller• 3-Tier su Web:
– Presentation manager su client– Workflow controller su server– Transaction server molteplici, distribuiti su Internet

123
TP Monitor per Internet• Il web server deve operare da workflow controller. I
transaction server sono in generale remoti.
Webbrowser
Trad. URLWorkflowController
TP system
Web Server
TransactionServer
DB Server
• TP monitors and DB servers attualmente sono sempre piu’ spesso integrati nei
• Web server

124
Architettura tradizionale
• Sistema/Programma dove si vuole eseguire la transazione : gateway
• CGI (Common gateway Interface): programma chiamato dal server
• CGI fornisce richiesta e parametri al gateway (nel nostro caso al TP system)


















