
TechDay - Toronto 2016 - Hyperconvergence and OpenNebula
25
Hyperconvergence and Opennebula Varadarajan Narayanan Wayz Infratek , Canada Opennebula Tech Day , Toronto 19 April 2016
-
Upload
opennebula-project -
Category
Technology
-
view
459 -
download
0
Transcript of TechDay - Toronto 2016 - Hyperconvergence and OpenNebula

Hyperconvergence and
Opennebula
Varadarajan Narayanan Wayz Infratek , Canada
Opennebula Tech Day , Toronto 19 April 2016

“Hyperconvergence is a type of infrastructure system with a software defined architecture which integrates compute, storage, networking and virtualization and other resources from scratch in a commodity hardware box supported by a single vendor”
Hyperconvergence - Definition

● Use of commodity X86 hardware● Scalability ● Enhanced performance● Centralised management● Reliability● Software focused● VM focused● Shared resources ● Data protection
HC - What does it offer ?

Nutanix, Cloudweavers ,VMware EVO:Rail, Simplivity, Scale computing , Stratoscale ,Cloudistics , Gridstore , Cohesity , Starwind….
The players

It is a regular server with CPU, RAM, network interfaces, Disk controllers and drives.As far as drives are concerned there are only three manufacturers in the world.There is really nothing special about the hardware. It is all about software….
There is nothing special about storage servers

● Scale out - Add compute + storage nodes ● Asymmetric scaling -Add only compute nodes● Asymmetric scaling - Add only storage nodes● Fault tolerance and High availability● Add / remove drives on the fly● Take out drives and insert in any other server.● Drive agnostic -any mix of drives SS, spinny● Add servers on the fly and servers need not be identical● Performance increases with capacity increase● Handle IO blender effect - Any application on any server● No special skills are required to manage
Mission impossible ?

Opennebula

A robust Hyperconvergent infrastructure can be created by using Opennebula as a virtualization platform and combining with high availability solutions like DRBD and / or a fault tolerant distributed storage system.
Hyperconvergence

Distributed Block storage:Ceph, Gluster, LVM, ZFS, Sheepdog, Amazon EBS
Distributed File systems:MooseFS, LizardFS, Xtreme FS, HDFS
StorPool, OpenVStorage
and other systems.
Storage backend technologies
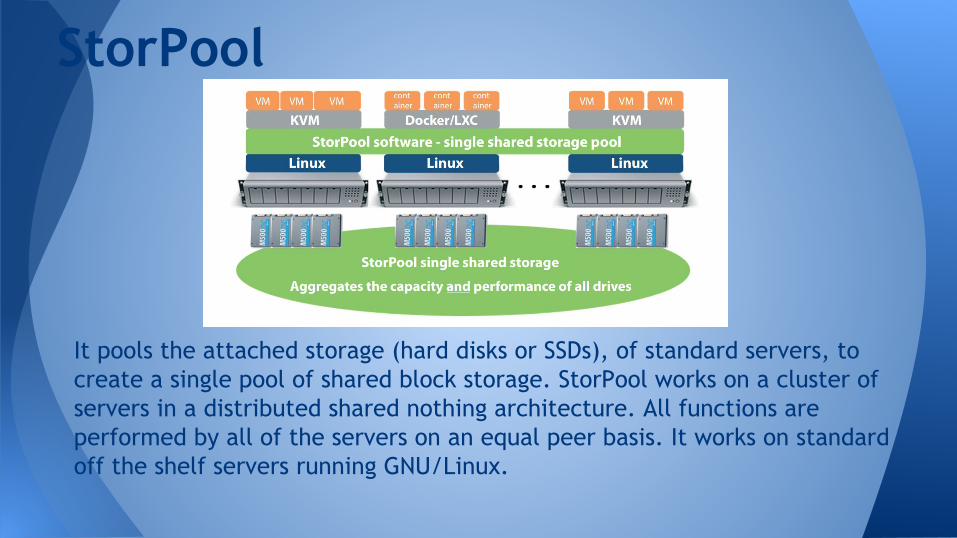
StorPool
It pools the attached storage (hard disks or SSDs), of standard servers, to create a single pool of shared block storage. StorPool works on a cluster of servers in a distributed shared nothing architecture. All functions are performed by all of the servers on an equal peer basis. It works on standard off the shelf servers running GNU/Linux.

The software consists of two parts – a storage server, (target) and a storage client, (driver, initiator), that are installed on each physical server, (host, node). Each host can be a storage server, a storage client, or both (i.e. a converged set up, converged infrastructure). To storage clients, StorPool volumes appear as local block devices under /dev/storpool/*. Data on volumes can be read and written by all clients simultaneously and consistency is guaranteed through a synchronous replication protocol. The StorPool client communicates in parallel with all of the StorPool servers.
Storpool
Storpool

● StorPool is a storage software installed on every server and controls the drives (both hard disks and SSDs) in the server.
● Servers communicate with each other to aggregate the capacity and performance of all the drives.
● StorPool provides standard block devices.● Users can create one or more volumes through its volume manager. ● Data is replicated and striped across all drives in all servers to provide
redundancy and performance.● Replication level can be chosen by the user.● There are no central management or metadata servers.● The cluster uses a shared-nothing architecture. Performance scales with
every added server or or drive.● System is managed through a CLI and JSON API.
StorPool overview

● Fully integrated with Opennebula● Runs on commodity hardware● Clean code built ground up and not a fork of something● End to end data integrity with 64 bit checksum for each sector.● No metadata servers to slow down operations● Own network protocol designed for efficiency and performance● Suitable for hyperconvergence as it uses ~10% of the server
resources of a typical server● Shared nothing architecture for maximum scalability and
performance ● SSD support● In service rolling upgrades● Snapshots, clones, rolling upgrades, QoS, synchronous replication
StorPool - Features

● StorPool uses a patented 64 bit end to end data integrity checksum to protect the customer's data. From the moment an application sends data to StorPool, a checksum is calculated, which is then stored with the data itself. This covers not only the storage system, but also network transfers, protects against software stack bugs, and misplaced/phantom/partial writes performed by the hard disks or SSDs, etc.
● StorPool keeps 2 or 3 copies of the data in different servers or racks, in order to provide data redundancy. StorPool uses replication algorithm, since it does not have a huge performance impact on the system ,unlike erasure coded (RAID 5, 6) systems, heavily tax the CPU and use a lot of RAM. unavailable.
Data redundancy

Fault tolerance

StorPool has built in thin provisioning, StorPool also makes copies of the data and stripes them across the cluster of servers for redundancy and performance. However any stripe which does not hold data, takes zero space on the drives. When data appears, it is only then that space is allocated.Thin provisioning is basically allows you to provision more storage visible to users than is physically available on the system.
Thin provisioning

The StorPool solution is fundamentally about scaling out (i.e. scale by adding more drives or nodes), rather than scaling up (i.e. adding capacity by buying a larger storage box and then migrating all of the data to it). This means StorPool can scale out storage independently by IOPS, storage space and bandwidth. There is no bottleneck or single point of failure. StorPool can grow seamlessly without interruption and in small steps – be it one disk drive, one server and one network interface at a time. Not only is the scale-out approach simpler and less risky, it is also a far more economical method.
Scale out vs Scale up

The QoS (Quality of Service), ensures that the required level of storage performance and SLAs are met. StorPool has built in QoS between volumes and the user configurable limit of IOPS and MB/s, per volume. In this way no single user can take over the resources of the entire storage system. Also by using this feature, a particular user can be guaranteed a certain level of service parameters.
QOS

StorPool offers a data tiering functionality. It is implemented by allowing users to make groups, (pools), of drives on which to place data. For example the user can make a pool of SSDs and place important data with high performance requirements on this set of drives, and then they can make another pool for HDD drives and place data which has lower performance requirements, on these drives. The user can then live migrate data between the pools.The data tiering functionality also allows the building of hybrid pools, where a copy of the data is stored on SSDs and redundant copies are stored on HDDs. This hybrid system delivers near all SSD performance, but at a much lower cost. This functionality also allows customers to deliver “data locality”, by placing data on a particular compute node, which is going to access the data locally.
Flexible Data tiering

StorPool offers a data tiering functionality. It is implemented by allowing users to make groups, (pools), of drives on which to place data. For example the user can make a pool of SSDs and place important data with high performance requirements on this set of drives, and then they can make another pool for HDD drives and place data which has lower performance requirements, on these drives. The user can then live migrate data between the pools.
The data tiering functionality also allows the building of hybrid pools, where a copy of the data is stored on SSDs and redundant copies are stored on HDDs. This hybrid system delivers near all SSD performance, but at a much lower cost. This functionality also allows customers to deliver “data locality”, by placing data on a particular compute node, which is going to access the data locally.
Flexible Data tiering

Write back cache (WBC), is a technology that significantly increases the speed at which storage write operations are performed. In StorPool’s case it is used to cache writes on hard disks, since they are the slowest type of drives.
StorPool has proprietary Write Back Cache technology which enables sub millisecond write latencies on hard disks. It allows write operations to be stashed in memory and immediately acknowledged by the storage system, and then flushed to the hard disk at a later stage. The benefits of this feature are a solid increase in performance and a sizable cost reduction, as customers no longer need a RAID controller.
Write back cache (WBC)

Datastore – all common image operations including: define the datastore; create, import images from Marketplace, clone images
Virtual Machines – instantiate a VM with raw disk images on an attached StorPool block device, stop, suspend, start, migrate, migrate-live, snapshot-hot of VM disk.
The add-on is implemented by writing StorPool drivers for datastore_mad and tm_mad and a patch to Sunstone's datastores-tab.js for UI.
Opennebula - StorPool

Catalog: http://opennebula.org/addons/catalog/
Docs :https://github.com/OpenNebula/addon-storpool/blob/master/README.md
Github :https://github.com/OpenNebula/addon-storpool
Opennebula Integration

Colocation or on-premise ?Hyperconverged infrastructure can be on premise or colocated. A "Micro data center" is a stand alone housing which replicates all the cooling , security and power capability of a traditional data center. Thus it is possible to seamlessly integrate and manage on-premise and colocated infrastructure

Thank you !


















