
Task assignment using a problem-space genetic algorithm
18
CONCURRENCY: PRACTICE AND EXPERIENCE, VOL. 7(5), 41 1-428 (AUGUST 1995) Task assignment using a problem-space genetic algorithm IMTIAZ AHMAD AND MUHAMMAD K. DHODHI Department of Electrical and Computer Engineering Kuwait Unrversit): POBox5969Safat 13060. Kuwait SUMMARY The task assignment problem is one of assigning tasks of a parallel program among the pro- cessors of a distributed computing system in order to reduce the job turnaround time and to increase the throughput of the system. Since the task assignment problem is known to be NP-complete except in a few special situations, satisfactory suboptimal solutions obtainable in a reasonable amount of computation time are generally sought. In the paper we introduce a technique based on the problem-space genetic algorithm (PSGA) for the static task assignment problem in both homogeneous and heterogeneous distributed computing systems to reduce the task turnaround time and to increase the throughput of the system by properly balancing the load and reducing the interprocessor communication time among processors.The PSGA based approach combines the power of genetic algorithms, a global search method, with a simple and fast problem-specific heuristic to search a large solution space efficiently and effectively to find the best possible solution in an acceptable CPU time. Experimental results on test examples from the literature show considerable improvements in both the assignment cost and the CPU times over the previous work. The proposed scheme is also applied to a digital signal processing (DSP) systemconsisting of 119 tasks to illustrate its balancing properties and computational ad- vantage on a large system. The proposed scheme offers 12-30% improvement in the assignment cost as compared to the previous best known results for the DSP example. 1. INTRODUCTION The rapid progress of VLSILJLSI and computer networking technologies has made dis- tributed computing systems economically attractive for many computer applications. Dis- tributed computing provides a facility for remote computing resources and data access. Besides their flexibility, reliability and modularity, distributed systems can be used for par- allel processing[9]. However, several problems have slowed down the widespread use of distributed systems. One of the major problems is the throughput degradation caused by the imbalance of the processor’s load and the large amount of interprocessor communication (IPC) overhead due to inadequate task assignment[7-91. The task assignment problem is one of assigning tasks of a parallel program among the processors of a parallel computer in order to reduce the job turnaround time and to increase the throughput of the system[2,3]. This can be done by maximizing and balancing the utilization of resources while minimiz- ing the communication between processors. But there exists a conflict between these two criteria, as the load balancing calls for distributingthe tasks over different processors, while minimization of interprocessor communication drives the task assignment to assign all the tasks onto a single processor. The task assignment problem is known to be NP-complete ex- cept under a few special situations[ 1.21. Hence satisfactory suboptimal solutions obtainable in a reasonable amount of computation time are generally sought[2-171. CCC 1040-3108/95/050411-18 01995 by John Wiley & Sons, Ltd Received 5 September 1994 Revised 21 April 1995
-
Upload
imtiaz-ahmad -
Category
Documents
-
view
220 -
download
5
Transcript of Task assignment using a problem-space genetic algorithm

CONCURRENCY: PRACTICE AND EXPERIENCE, VOL. 7(5), 41 1-428 (AUGUST 1995)
Task assignment using a problem-space genetic algorithm IMTIAZ AHMAD AND MUHAMMAD K. DHODHI Department of Electrical and Computer Engineering Kuwait Unrversit): POBox5969Safat 13060. Kuwait
SUMMARY The task assignment problem is one of assigning tasks of a parallel program among the pro- cessors of a distributed computing system in order to reduce the job turnaround time and to increase the throughput of the system. Since the task assignment problem is known to be NP-complete except in a few special situations, satisfactory suboptimal solutions obtainable in a reasonable amount of computation time are generally sought. In the paper we introduce a technique based on the problem-space genetic algorithm (PSGA) for the static task assignment problem in both homogeneous and heterogeneous distributed computing systems to reduce the task turnaround time and to increase the throughput of the system by properly balancing the load and reducing the interprocessor communication time among processors.The PSGA based approach combines the power of genetic algorithms, a global search method, with a simple and fast problem-specific heuristic to search a large solution space efficiently and effectively to find the best possible solution in an acceptable CPU time. Experimental results on test examples from the literature show considerable improvements in both the assignment cost and the CPU times over the previous work. The proposed scheme is also applied to a digital signal processing (DSP) systemconsisting of 119 tasks to illustrate its balancing properties and computational ad- vantage on a large system. The proposed scheme offers 12-30% improvement in the assignment cost as compared to the previous best known results for the DSP example.
1. INTRODUCTION
The rapid progress of VLSILJLSI and computer networking technologies has made dis- tributed computing systems economically attractive for many computer applications. Dis- tributed computing provides a facility for remote computing resources and data access. Besides their flexibility, reliability and modularity, distributed systems can be used for par- allel processing[9]. However, several problems have slowed down the widespread use of distributed systems. One of the major problems is the throughput degradation caused by the imbalance of the processor’s load and the large amount of interprocessor communication (IPC) overhead due to inadequate task assignment[7-91. The task assignment problem is one of assigning tasks of a parallel program among the processors of a parallel computer in order to reduce the job turnaround time and to increase the throughput of the system[2,3]. This can be done by maximizing and balancing the utilization of resources while minimiz- ing the communication between processors. But there exists a conflict between these two criteria, as the load balancing calls for distributingthe tasks over different processors, while minimization of interprocessor communication drives the task assignment to assign all the tasks onto a single processor. The task assignment problem is known to be NP-complete ex- cept under a few special situations[ 1.21. Hence satisfactory suboptimal solutions obtainable in a reasonable amount of computation time are generally sought[2-171.
CCC 1040-3108/95/050411-18 01995 by John Wiley & Sons, Ltd
Received 5 September 1994 Revised 2 1 April 1995

412 IMTIAZ AHMAD A N D MUHAMMAD K . DHODHI
Many approaches have been reported for solving the task assignment problem in dis- tributed computing systems and can roughly be classified into four categories: graph- theoretical[2-6], mathematical programming[7,8], heuristic techniques[9-18] and proba- bilistic approaches such as simulated annealing based techniques[ 19-22], mean filed an- nealing[23] and genetic algorithms[24]. A good overview of the task assignment problem can be found in [ 121. Because of the intractable nature of the task assignment problem and its importance in ever-increasing demand for distributed computing, an efficient algorithm for the task assignment problem is desirable to obtain the best possible solution within acceptable CPU times. In this paper we introduce an approach based on the problem-space genetic algorithm (PSGA) for the static task assignment problem in distributed computing systems to reduce the job turnaround time and to increase the throughput of the system by proper load balancing and minimizing the interprocessor communication time. Static assignment is a priori assignment of tasks to the processors, where allocation does not change during the lifetime of tasks. The proposed PSGA based approach combines the power of the genetic algorithm with a problem-specific heuristic to search a large solution space efficiently and effectively to obtain the best possible solution within acceptable CPU times.
Genetic algorithms are probabilistic techniques that start from an initial population of randomly generated potential solutions to a problem, and gradually evolve towards better solutions through a repetitive application of genetic operators, crossover and mutation[25]. Crossover is a reproduction technique that takes two parent chromosomes and mates them to produce two child chromosomes. Mutation is used for finding new points in the search space so that population diversity can be maintained. A standard genetic algorithm consists of the following[26]:
1 . coding of the problem to make a chromosome; each position of a chromosome is
2. a method to create an initial population of chromosomes 3. a decoding scheme to compute the fitness of each chromosome based on a cost
4. a method to select mates from the population based on selection criteria and apply
5. repeat this process for many generations.
The recent literature reports a number of successful applications of genetic algorithms to a wide range of problems in diverse fields, such as the task assignment problem[24], standard cell placement[27], searching, machine learning and machine identification[26,:!8,29]. GA can be parallelized efficiently without modifying the algorithm because they process several solutions simultaneously, as compared to simulated annealing, which improves one solution iteratively.
GAS are blind search techniques and they require problem-specific genetic operators (crossover, mutation) to obtain good solutions. Storer et al.[30] have proposed a new search method which integrates a fast, problem-specific heuristic with the local search. The key concept in this method is to base the definition of the search neighborhood on a heuristic/problem pair (h, p), where h is a known fast heuristic and p represents the problem data. Since a heuristic h is a mapping from a problem to a solution, the pair (h , p ) is an encoding of a specific solution. By perturbing the problem p, a neighborhood of solutions
called a gene and values assigned to genes are called ‘alleles’
function
genetic operators to create offspring and form a new population

TASK ASSIGNMENT USING A PROBLEM-SPACE GENETIC ALGORITHM 413
F a t Heuristic
0 ,+
Chromosome - -
Solution 7 Problem Space Solution Space
Figure 1. Problem-space genetic algorithms
is generated. This neighborhood forms the basis for a local search. The problem space is generated by perturbing the problem data. Let P be a set of rn problems obtained by perturbing the original problem data. That is, P = p, = po t 6, j = 1, ...., m, where po is the value for the original problem and 6 is the randomly generated perturbation vector. The perturbation range depends on the specific problem. To keep the generated ‘dummy’ problem values in the proximity of the original problem values, upper and lower limits on the perturbation can be introduced. The solution subset S corresponding to the problem set P can be created by the application of an heuristic, h, S = h(p,), j=l ,..., m.
PSGA is different from the hybrid GAs[28] for the graph coloring problem. The hybrid GA uses an ordered-based encoding technique to represent a chromosome and then uses a greedy algorithm as a decoder to map from a chromosome to a solution. The hybrid GA requires a uniform order-based crossover operator and special mutation operator, while PSGA can use any crossover and mutation operator. In PSGA[30,31], as shown in Figure 1, the chromosome is based on the problem data and all the genetic operators are applied in the problem space, so there is no need to modify genetic operators for each application. The solution is obtained by applying a simple and fast known heuristic to map from the problem space to the solution space, where each chromosome guides the heuristic to generate a different solution.
The key insight to understanding the problem space approach is that we utilize a different search space. That is, we are more concerned with the search space than the search method. We use GAS to search this space because they have been shown previously to work well in the problem space[30]. Traditional local search approaches to combinatorial optimization problems are conducted in neighborhoods defined by swapping elements in incumbent sequences[ 19-22]. Similarly, traditional GA approaches utilize a sequence-based encoding of the solution. The problem-space approach is based on an entirely different neighborhood structure. It presumes that the base heuristic h has been designed to give reasonably good solutions to the problem at hand. If this heuristic is applied to a new set of problem data differing only slightly from the original problem, the resultant solution should also be a reasonably good solution to the original problem. Thus, if one applies the base heuristic to problem data in the neighborhood of the original, one expects to generate a set of good solutions. This last point is important because it implies that good solutions are clustered

414 1MTlAZ AHMAD AND MUHAMMAD K. DHODHI
Figure 2. An example of TIC from Efe[9/
together in this search space. Since good solutions tend to be clustered near the original problem, the search can be conducted much more efficiently.
Problem-space genetic algorithm based technique offers several advantages over the simulated annealing based approach as well as traditional genetic algorithms. By operating in the problem space, standard crossover operators are trivially constructed and applied on the perturbed problem data. PSGA uses a fast heuristic to map from the problem space to the solution space, and therefore it avoids the disadvantages of probabilistic approaches such as local fine tuning in the last stage of traditional GAS, and, moreover, PSGA has a fast convergence rate as compared to the standard GA. The PSGA based technique is objective independent, and thus it can be applied to combinatorial optimization problems with any objective functions.
The remainder of the paper is organized as follows. The task assignment problem is defined in Section 2 and the strategy for task assignment for homogeneous systems is discussed in Section 3. Extensions of the proposed scheme for heterogeneous processors is briefly described in Section 4. Experimental results are reported in Section 5 and, finally, Section 6 concludes this paper.
2. THE TASK ASSIGNMENT PROBLEM
The assignment problem can bedescribed by two undirected graphs, aprocessors interaction graph (PIG), and a task interaction graph (TIG). The PIG, G(e Ep), represents a distributed computing system, whose nodes, P = I, 2, ..., n, represent homogeneous processors, and edges, E p , represent the communication links between processors[20]. Each processor is an independent computer with its own memory, control, input/output and arithmetic capability. The cost of communication is directly proportional to the size of the message and the distance between the sender and receiver processor. We define the distance, &, between any two processors k and 1 as the length of the shortest path between them. The TIG, G(V ET), characterize a parallel program, whose nodes, V = 1, 2, ..., m, represent the tasks of a program, and edges, ET, correspond to the data communication between those tasks. The edge weight eij between node i and node j represents the relative amount of communication between the two tasks. The node weight wi denotes the work to be performed by task i on a processor. An example of TIG adopted from [9] is shown i n Figure 2.

TASK ASSIGNMENT USING A PROBLEM-SPACE GENETIC ALGORITHM 415
Given a TIG and a PIG, an assignment of tasks to processors can be described formally as a function A that maps the set of tasks V to the set of processors P :
A:V-> P
where A(i) = j if task i is assigned to processorj, 1 5 i 5 m, 1 5 j 5 n (1)
The objective function (cost function) is the key issue as it reflects the goal of optimiza- tion. Cost functions that have been used with the task allocation problem may be broadly categorized as belonging to one of two models: a minimax cost mode1[5,22] or a summed cost model[ 19-21,23,24]. With the minimax cost model, the total time required (the exe- cution time + communication time) by each processor under a given mapping is estimated and the maximum cost among all processors is to be minimized. We will use the minimax cost model, because conceptually it is the more accurate one.
The execution cost of a processor k, defined as Cexe(A)k for an assignment A, is
i m
Cexe(A)k = w, V A(i) = k i= 1
The total communication cost for an assignment A for a processor k denoted as
i=m j=m
Ccom(A)t = d,q,lAu) * e i j VA(i) = k andA(j)#k (3) i=l j=i+l
The total cost of a processor k is the sum of the execution cost and the communication cost for a given assignment A,
Ctotul(A)k = Cexe(A)k + Ccom(A)k (4)
Then the bottleneck processor in the system is the critical processor which has the maximum cost. That is,
Cosr(A) = mar(Crotal(A)k for 1 I k I n ) (5 )
The total cost of an assignment in the system is equal to the maximum workload of the critical processor. The goal of task assignment is to find an assignment A which has the minimum cost in all possible assignments, i.e.
Minimize( Cost(A) VA) (6)
3. THE ASSIGNMENT STRATEGY
In this Section, first we give a summary of the proposed assignment strategy followed by its detailed discussion.
3.0.1. Algorithmsummary
Some of the main steps of the algorithm are given below:

416 IMTIAZ AHMAD AND MUHAMMAD K. DHODHI
Step 1.
Step 2. Step 3.
Step 4.
Read the TIG, PIG and build a database which includes the adjacency list for each node. Obtain the population size (N,) and the number of generations ( N 8 ) . Build the first chromosome based on problem data and perturb the first chro- mosome to generate an initial population of size N p . For i := 1 to N , Do
Apply the mapping heuristic to generate a solution for each chromosome in the population. Calculate the cost and fitness for each chromosome. Save the current fittest solution in a database. Select chromosomes based on their fitness from the current population. Apply crossover and mutation to generate offspring to form a new population. Replace the old population with a new population.
Step 5. Select the best final solution.
The detailed implementation of each step of the proposed algorithm is described next.
3.1. Initial population
An initial population of size 4 for the TIC of Figure 2 is given in Figure 3. A chromosome consists of an array of real numbers representing the priority for each node of a TIC. The priority ( fr( , ) ' of each node i for the first chromosome of the initial population is computed as below:
( f r o ) ' = w; * m * Random(0,l) (7)
where m is number of nodes, wi is weight of a node in TIG. The objective is to keep some knowledge about the problem data in determining the
priority of the nodes. The rest of the chromosomes in the initial population are generated with a random perturbation in the priority as shown below:
where ( f r o ) ' is the priority of node i in the first chromosome based on the original problem data, and Uniform (-Q, p ) is a random number generated uniformly between -77 and p. We are taking the value of ~ = p = Max {(Pr(,)i'd i}/4, but 77 and p do not need to have the same values. (Pr)'is the priorityfor node i of the chromosome calculated by perturbing the original problem data. The lower bound (77) and upper bound ( p ) on the perturbation keep the dummy values in proximity to the original problem. As one can see from Figure 3, each chromosome has a different priority value for each node in different chromosomes, so each chromosome guides the heuristic to generate a different solution. We have used a small population size for demonstration purposes only. Once the initial population (Po) is constructed, the PSGA based technique generates subsequent populations f ' , f ? . , ..., f ' - ' , Pi by applying the genetic operators (Selection, Crossover and Mutation).
3.2. Mapping heuristic
The PSGA based method uses the concept of a heuristic/problem pair (h, p) to map each chromosome to generate a solution. The mapping heuristic is applied to generate a solution from a given chromosome with the objective of balancing the load among processors. In

TASK ASSIGNMENT USING A PROBLEM-SPACE GENETIC ALGORITHM 417
#2 6 I 57 I 92 169 I178 1127 I 71 I I27 I I65 110
1 . 2 3 4 5 6 7 8 9 10
#3 I 64 I 119 I 95 I 70 1234 I 68 I 22 I 81 I 167 1 14 1 Perturbed fromchromosome~l priorities 1 2 3 4 5 6 7 8 9 1 0 /
#4 I l l I117 I 10 1128 1232 156 I 5 I 76 1192 I 10 Ir( I 2 3 4 5 6 7 8 9 I0
Figure 3. Initial population of four chromosomes
Mappingheuristic (chromosome): Build prioritylist of nodes based on their priority value in the chromosome. while (prioritylist <> null) do begin
Select the node i from priorityht with the highest priority. Assign node i to processor k with the least load. Update Cexe(A)k by adding to it w;. Delete node i from prioritylist.
end while end Mappingheuristic.
Figure 4. Pseudocode for mapping heuristic
this heuristic the nodes in each chromosome of a population are sorted into descending order according to their priority. Then the mapping heuristic selects a node with the highest priority and allocates it to the processor which has the lowest load currently among the given processors for load balancing consideration. The load of a processor is the sum of the execution cost of all the tasks mapped to the processor. This heuristic blindly assigns the tasks to the processor without taking into consideration the communication cost. Its sole objective is to generate a feasible mapping of the tasks to processors. Pseudocode for the mapping heuristic is given in Figure 4.
The mapping heuristic just gives the execution cost on each processor, the total cost of each processor (load + intermodule communication cost) is computed by a separate procedure using equations (2)-(5). The cost of assignment is the maximum cost among all the processors. The task assignment and cost of mapping for each chromosome in the initial population are given in Table 1.
3.3. Cost and fitness function
The cost function is the key issue as it reflects the goal of the optimization. We are taking equation (5) as the cost function to be minimized. The fitness function measures the usefulness of arbitrary points in a search space. The following cost-to-fitness mapping function was used to calculate the fitness of each chromosome[30]:

418 IMTIAZ AHMAD AND MUHAMMAD K. DHODHI
Table 1. Cost and fitness calculation for population
Solution # P; Task assignment Cost (p,) Cost(A) Fitness -
PI 3 ,4 ,5 165
P3 6,7,8, 10 180 1 Pz 1 , 2 , 9 200 200 0.228469
PI 2 ,5 ,8 I90
P3 3 ,4 ,6 I75 2 Pz 1,7,9, 10 190 190 0.325301
PI 3.4, 5 165
P3 1,2,8, 10 280 PI I , 2 ,3 ,5 180
P3 4 , 7 , 8 145
3 Pz 6 7 , 9 260 280 O.oooc)OO
4 Pz 6,9, 10 160 180 0.446229
wheref(i) is the fitness of chromosome i, MaxCost is the maximum cost of a chromosome in the population, Cost(i) is the cost of chromosome i, N,, is the population size, and 7 is a parameter which is used for fitness scaling to balance convergence and diversity. Generally T is i n the range of 1 to 5 . The fitness of each chromosome in the initial population is given in Table 1 with the value of 7 as 3. This fitness function gives more preference to chromosomes with less cost.
3.4. Selection, crossover and mutation
Chromosomes for reproduction are selected based on their fitness. Chromosomes with higher fitness will have a higher probability of contributing one or more offspring in the next generation. This method is an artificial version of natural selection, the Darwinian idea of survival of the fittest[25,26]. The selection method was implemented using a biased roulette wheel where each chromosome in the population has a slot sized in proportion to its fitness. Each time we require an offspring, a simple spin of the weighted roulette wheel gives a parent chromosome. The chromosomes selected for reproduction from the initial population depending upon their fitness are given in Figure 5 .
Crossover is a reproduction technique that takes two parent chromosomes and mates them to produce two child chromosomes. Mutation is used for finding new points in the search space so that population diversity can be maintained. By operating in the problem space, a simple one-point crossover operator was applied to the priority of the chromosome. In a one-point crossover operator, a cross site is selected randomly and the value of the priority to the right of the crosssite is swapped among the two mating chromosomes. Mutation was implemented by selecting a gene at random and perturbing its value. The crossover is applied with a certain crossover rate (P,o,,,> which is the ratio of the number of offspring produced by crossover in each generation to the population size. It controls the amount of crossover being applied. Mutation was implemented by selecting a gene at random with a mutation rate P, and replacing its value. The mutation rate ( P , ) is the percentage of the

TASK ASSIGNMENT USING A PROBLEM-SPACE GENETIC ALGORITHM 419
1 2 3 4
#2 6 1 5 7 1 9 2 1 6 9 1 2 3 4
Parent chromosomes (before crossover)
5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10
#2 6 ( 5 7 1 9 2 1 6 9 ( 2 3 2 1 5 6 ( 5 1 7 6 1 1 9 2 l l O
5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10
1 7 8 ~ 1 2 7 ~ 7 1 ~ 1 2 7 ~ 1 6 5 ~ 1 0 (mom)
Offspring chromosomes (after crossover)
Figure 5. Crossover to generate a new population
total number of genes in the population which are mutated in each generation. P, is usually low. In Figure 5, showing chromosomes selected for crossover, the crossover site (xsite) for the priority is shown to form a new population. For the sake of simplicity, we do not show the mutation operator.
3.5. Parameter tuning
Finding suitable values of control parameters such as crossover rate P,,,,,, mutation rate P,,,, population size N p and number of generations NR is itself a hard problem. We have performed experiments on a set of problems with crossover rates of 1 .O, 0.95,0.9,0.85,0.7, 0.6 and 0.55, and mutation rates of 0.001, 0.002, 0.009, 0.01 and 0.015. The population size varied between 100 and 250 and the number of generation between 50 and 250. It was determined experimentally that for the task assignment problem population sizes between 150 and 200 and the number of generations between 80 and 100 is sufficient to arrive at good solutions. It may appear that the number of generations is too low as compared to the traditional GAS. One of the reasons for arriving at good solutions earlier is the application of a problem-specific heuristic (that is, a heuristic guided search instead of a blind search). The P,,,,, = 0.6 and P , = 0.001 performed quite well.
3.6. Time and space complexity
The time complexity of the probabilistic techniques such as genetic algorithms cannot be determined. However, the main time-consuming steps in the proposed algorithm include mapping from the problem space to a solution for each chromosome in the current popula- tion, and evaluation of each solution by calculating the cost and the fitness values. The main computational step is the sorting of nodes according to the priority in each chromosome, which is of the order of U(NlogzN) , where N is the number of nodes. The run time for the PSGA depends on the population size N p and the number of generations NR. The tasks of mapping from a chromosome to a solution and the cost calculation can be performed in parallel. The values of Ng and population size are much smaller for the proposed technique as compared to the standard GAS, as explained in the previous subsection. The PSGA based technique, like the standard GAS, is memory intensive. PSGA maintains a population of chromosomes with the population size 100-200, which is the price that we have to pay. But the memory overhead of maintaining a population is paid for by rapid convergence.
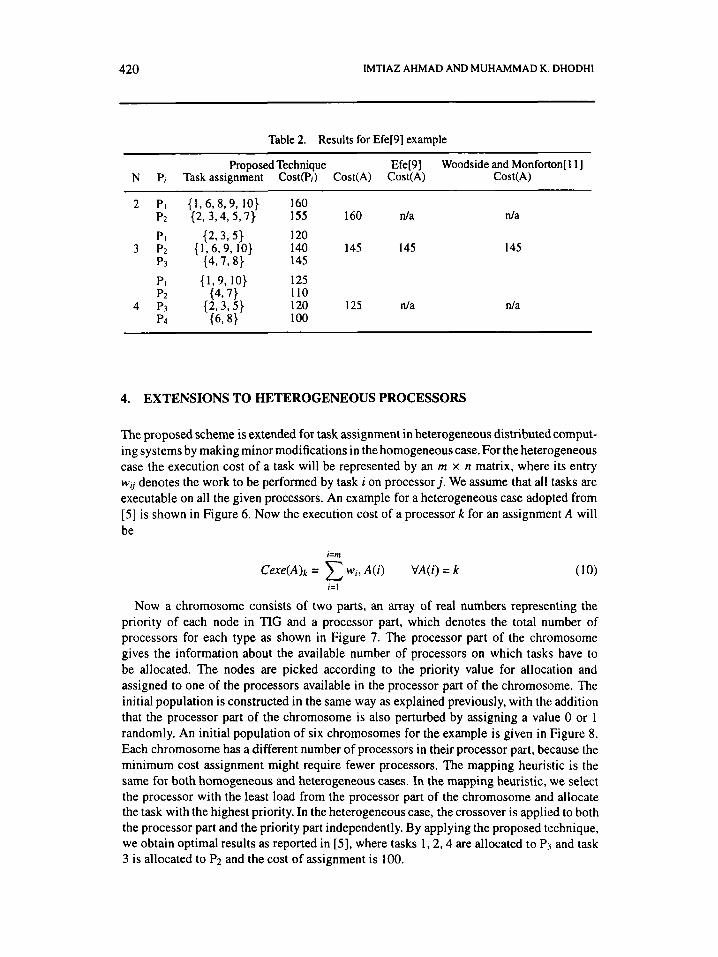
By applying the proposed technique, the results for the Efe[9] example are shown in Table 2 for different numbers of processors. For three processors the results are the same as the best possible results reported in [9, 111.
420 IMTIAZ AHMAD AND MUHAMMAD K. DHODHI
Table 2. Results for Efe[9] example
Proposed Technique Efe[9] Woodside and Monforton[ 1 I ] N P, Task assignment Cost(Pi) Cost(A) Cost(A) Cost(A)
2 PI P2
PI 3 P2
P3 PI P2
4 P3 P4
{1,6,8,9, 10) 160 (2, 3,4, 5 ,7 } 155 160 d a
{ 2,3,5) 120 { 1,6,9, 10) 140 145 145
{4,7,8} 145
{ 1,9,10) 125 110 120 125 n/a
(43 7) { 2,3,5)
(638) 100
n/a
145
d a
4. EXTENSIONS TO HETEROGENEOUS PROCESSORS
The proposed scheme is extended for task assignment in heterogeneous distributed comput- ing systems by making minor modifications in the homogeneous case. For the heterogeneous case the execution cost of a task will be represented by an m x n matrix, where its entry wij denotes the work to be performed by task i on processorj. We assume that all tasks are executable on all the given processors. An example for a heterogeneous case adopted from [ 5 ] is shown in Figure 6. Now the execution cost of a processor k for an assignment A will be
r=m
Cexe(A)k = wi, A ( i ) VA(i ) = k i = l
Now a chromosome consists of two parts, an array of real numbers representing the priority of each node in TIC and a processor part, which denotes the total number of processors for each type as shown in Figure 7. The processor part of the chromosome gives the information about the available number of processors on which tasks have to be allocated. The nodes are picked according to the priority value for allocation and assigned to one of the processors available in the processor part of the chromosome. The initial population is constructed in the same way as explained previously, with the addition that the processor part of the chromosome is also perturbed by assigning a value 0 or 1 randomly. An initial population of six chromosomes for the example is given in Figure 8. Each chromosome has a different number of processors in their processor part, because the minimum cost assignment might require fewer processors. The mapping heuristic is the same for both homogeneous and heterogeneous cases. In the mapping heuristic, we select the processor with the least load from the processor part of the chromosome and allocate the task with the highest priority. In the heterogeneous case, the crossover is applied to both the processor part and the priority part independently. By applying the proposed technique, we obtain optimal results as reported in [ 5 ] , where tasks 1,2,4 are allocated to P:, and task 3 is allocated to P2 and the cost of assignment is 100.

TASK ASSIGNMENT USING A PROBLEM-SPACE GENETIC ALGORITHM 42 1
Execution cost
Figure 6. A n example adoptedfrom IS]: ( a ) PIG: ( b ) TIC with execution cost matrix
p P 2 P 3 f-- Type of processor #of processors of each type
+ Priority of each node in TIG I 2 3 4 4- NodenumberinTIG
Figure 7. Chromosome encoding for heterogeneous processors
P I p2 p3 PI p 2 p3 PI p2 p3 m, m, 1 2 3 4 1 2 3 4 1 2 3 4
Chromosome # I Chromosome #2 Chromosome #3
Chromosome #6 Chromosome #4 Chromosome #5
Figure 8. An initial population of six chromosomes
5. EXPERIMENTAL RESULTS
The described problem-space genetic algorithm for task assignment in distributed comput- ing systems was implemented in C on a SUN SPARCstation 10 and has been tested on many test examples reported in the literature. The results are very encouraging and the proposed scheme offers a considerable improvement in both the assignment cost and in the CPU times over the previous work. We present results from three test examples for which the best possible results have been reported. For all the test examples the population size is 160, the number of generations is 100 and the CPU time reported is on a SUN SPARCstation 10.
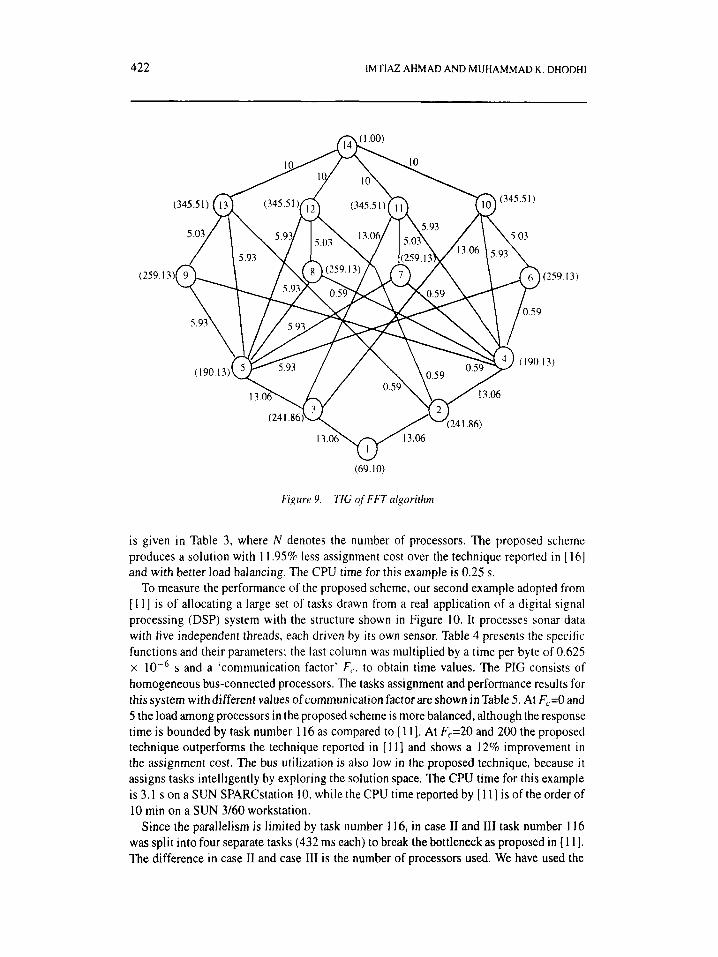
Our first test example is an FFT task interaction graph taken from [ 161 as shown in Figure 9. The numbers inside the parentheses denote the task execution times, and the weight on the edge denotes the intermodule communication cost. The FlT task interaction graph is assigned to homogeneous fully connected processors. The comparison of results with [ 161
422 IMTlAZ AHMAD AND MUHAMMAD K . DHODHI
(259
W (69.10)
Figure 9. TIG of FFT algorithm
is given i n Table 3, where N denotes the number of processors. The proposed scheme produces a solution with 1 1.95% less assignment cost over the technique reported i n [ 161 and with better load balancing. The CPU time for this example is 0.25 s.
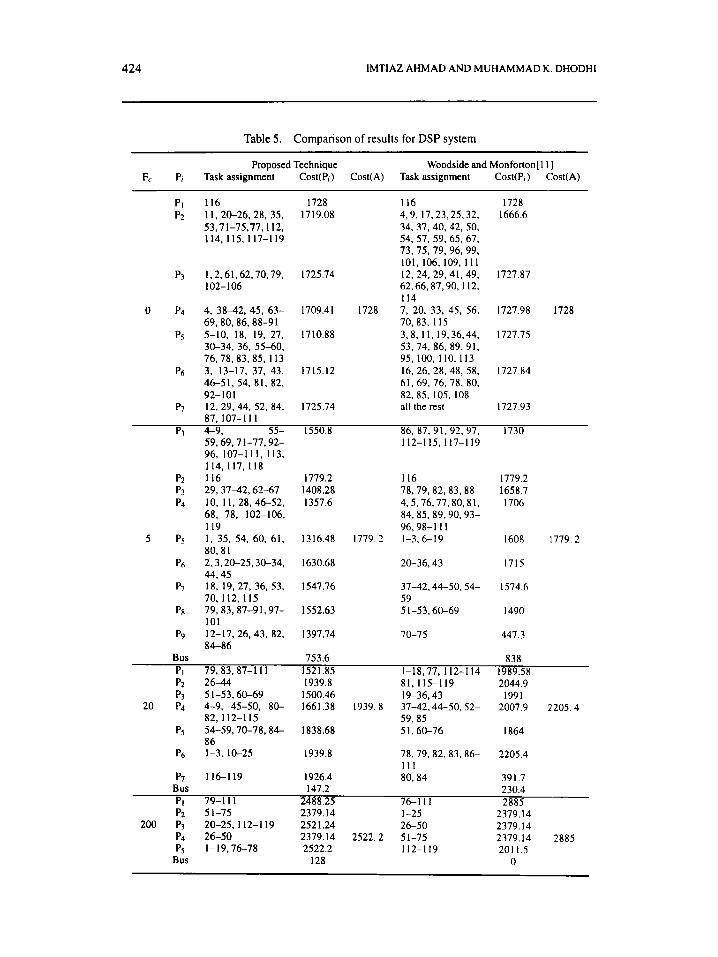
To measure the performance of the proposed scheme, our second example adopted from [ 1 11 is of allocating a large set of tasks drawn from a real application of a digital signal processing (DSP) system with the structure shown in Figure 10. It processes sonar data with five independent threads, each driven by its own sensor. Table 4 presents the specific functions and their parameters; the last column was multiplied by a time per byte of 0.625 x s and a ‘communication factor’ F L l to obtain time values. The PIG consists of homogeneous bus-connected processors. The tasks assignment and performance results for this system with different values ofcommunication factor are shown in Table 5. At F,=O and 5 the load among processors in the proposed scheme is more balanced, although the response time is bounded by task number I16 as compared to [ 1 I ] . At Fc=20 and 200 the proposed technique outperforms the technique reported in [ 1 1 1 and shows a 12% improvement i n the assignment cost. The bus utilization is also low in the proposed technique, because i t assigns tasks intelligently by exploring the solution space. The CPU time for this example is 3.1 s on a SUN SPARCstation 10, while the CPU time reported by [ 111 is of the order of 10 rnin on a SUN 3/60 workstation.
Since the parallelism is limited by task number 116, in case I1 and 111 task number 116 was split into four separate tasks (432 ms each) to break the bottleneck as proposed i n [ 11 I . The difference in case I1 and case 111 is the number of processors used. We have used the

TASK ASSIGNMENT USING A PROBLEM-SPACE GENETIC ALGORITHM 423
Table 3. Comparison of assignment results for FFT TIG
Proposed technique Saje and Sagar[ 161 N P, Task assignment Cost(P,) Cost(A) Task assignment Cost(P;) Cost(A)
PI 1.2, 3,4,6, 10, 1 1 1740.07 2 P2 S,7 ,8 ,9 , 12, 13, 14 1706.51 1740.07 n/a n/a n/a
3 PZ I , 3.5, 6, 10 1178.02 1193.21 5 ,6 ,7 ,8 1015.23 1355.27 PI 2.4, 12, 13, 14 1193.21 I , 2,3,4, 10 1139.08
P3 7, 8,9, 1 1 1181.51 9, 11, 12, 13, 14 1355.27 PI 7,9, 13 898.36 P2 6,8, 12 898.36
P4 3,5,11,14 868.69 4 P3 1, 2,4, 10 897.22 898.36 n/a n/a n/a
Table 4. Software parameters of DSP system
Task number p(i) (ms) bytes to next task
Function
1, 26.51.76, 80.84 2, 10, 18.27, 35,43, 52,60,68,77,81, 85 3, 1 I , 19, 28, 36,44, S3,61,69,78, 82,86 4, 12,20,29,37,45, 54,62,70,79,83,87 5, 13,21, 30,38,46, 55,63,71,92,97, 102, 107 6, 14.22,31,39,47, 56,64,72,93,98, 103, 108 7, 15,23,32,40,48,57,65,13,94,99, 104, 109 8, 16.24, 33,41,49,58,66,74,95, 100, 105, 110 9, 17,25,34,42, SO, 59,67,75,96, 101, 106, 1 1 1 88 89 90 91 112 113 114 I15 I16 I I7 118 1 I9
Remove DC Bandshift FIR Filter FFT Hanning Window Power Integrate Normalize Quantize Cross-multiply Integrate2 Bearing Beam form Form Cell Power2 Normalize2 Concatenate m 2 Power3 Normalize3 Quantize2
170.24 62.72
227.84 409.6 21.28
11.2 3.07 0.3 1 0.28
22.24 6.14 1.23
99.68 75
25.5 12 75
1728 52.5 22.5
21
2048 2048 512 32K 32K 16K
1024 1024
0 16K 16K
0 16K
4096 1 0
8K 8K 8K 8K
0
same number of processors as reported in [ 1 1 1 for comparison purposes. The results in Table 6 show the effectiveness of the proposed technique. Note that Fc=20 for case 11, the assignment cost in [ 1 I] is the load on the bus, because the bus is the bottleneck resource. In case I11 the proposed scheme offers a 30.29% improvement in the response time for seven processors, which shows the strength of the proposed scheme for a large set of tasks.
To compare the performance for heterogeneous processors, our final example is adopted from [22], whose TIC consists of 12 tasks and PIG consists of six processors as given in Figure 1 1. The execution cost matrix and the intermodule communication costs matrix are given in Tables 7 and 8, respectively. The technique reported in [22] uses a simulated annealing based approach to solve the problem and takes into consideration the memory
424 IMTlAZ AHMAD AND MUHAMMAD K . DHODHI
Table 5. Comparison of results for DSP system ~~ ~
Proposed Technique Woodside and Monforton[ 1 I ] F, P, Task assignment Cost(P,) Cost(A) Task assignment Cost(P,) Cost(A)
PI 116 1728 1 I6 1728 P2 11 , 20-26, 28, 35, 1719.08 4,9,17,23,25,32, 1666.6
53.71-75.77.112, 34, 37, 40.42, 50, 1 14, I 1 5,117-1 19 54, 57, 59, 65, 67,
73. 75, 79, 96, 99. 101, 106,109, I 1 1
102- I06 62.66,87,90, I 12, P3 1,2,61,62,70.79. 1725.74 12. 24, 29,41, 49. 1727.87
114 0 P4 4, 3842 , 45, 63- 1709.41 1728 7, 20, 33, 45, 56, 1727.98 1728
69.80.86.88-9 1 70,83, 115
30-34, 36. 55-60, 76,78,83,85, 113 95,100, 110. 113
46-51, 54, 81, 82, 92-101 82.85, 105. 108
87, 107-11 1
59.69.7 1-77.92- 112-115.117-119 96. 107-111, 113, 114, 117,118
Ps 5-10, 18. 19, 27, 1710.88 3,8, 11, 19.36,44. 1727.75 53, 74, 86, 89, 91,
Pg 3, 13-17, 37, 43, 1715.12 16, 26, 28, 48, 5 8 , 1727.84 61, 69. 76, 78, 80.
Pi 12, 29, 44, 52, 84, 1725.74 all the rest 1727.93
PI 4-9, 55- 1550.8 86, 87, 91, 92, 97, 1730
P2 116 1779.2 I16 1779.2 P3 29.3742.62-67 1408.28 78,79.82, 83.88 1658.7 P4 10, 1 1, 28, 46-52, 1357.6 4,5,76,77.80,81, 1706
68, 78, 102-106, 84,85,89,90,93- I19 96.98-1 1 I
5 P5 1 , 35, 54, 60. 61, 1316.48 1779.2 1-3.6-19 1608 1779.2 80,81
44.45
70, 112. 115 59
101
84-86
Pb 2,3,20-25.30-34, 1630.68 20-36,43 1715
P i 18, 19, 27, 36, 53, 1547.76 37-42,44-50,54- 1574.6
PR 79.83.87-91.97- 1552.63 51-53,60-69 I490
Py 12-17, 26. 43, 82, 1397.74 70-75 447.3
Bus 753.6 838
P2 26-44 1939.8 81. 115-1 19 2044.9 P3 51-53.6049 1500.46 19-36.43 1991
1521.85 1-18.77.112-114 1989.58 PI 79.83.87-1 11
20 P4 4-9, 45-50, 80- 1661.38 1939.8 3742.44-50.52- 2007.9 2205.4 82, 112-1 15 59.85
86 P5 54-59.70-78.84- 1838.68 51.60-76 I864
78,79.82,83,86- 2205.4 Pb 1-3, 10-25 1939.8 I l l
P7 116-119 1926.4 80.84 39 I .7 Bus 147.2 230.4 PI 79-111 2488.25 76-1 I 1 2885 P2 51-75 2379.14 1-25 2379.14
200 P3 20-25.112-1 19 2521.24 26-50 2379.14 2379.14 2522.2 51-75 2379.14 2885 P4 26-50
Bus I28 0 P5 1-19.76-78 2522.2 112-1 19 2011.5

TASK ASSIGNMENT USJNG A PROBLEM-SPACE GENETIC ALGORJTHM 425
Figure 10. Structure of DSP system
Figure 11. Topology of system
capacity limits and real-time deadline for tasks. Although we did not take into consideration such constraints, the best possible assignment found by our technique satisfies all those constraints. The comparison of results with [22] is given in Table 9, where TIC #1 consists oftasks 14,TIG#2consistsof tasks 1-8,TIG#3 consistsof tasks 1-10andTIG#4 consists of tasks 1-12. The proposed technique produces less or at least the same assignment cost as compared to their approach [22]. The CPU time was 0.5 s, while the CPU time is not reported in (221.
6. CONCLUSIONS
In distributed computing systems proper assignment of modules among processors is an important factor for efficient utilization of resources. In this paper we have proposed a scheme based on the problem-space genetic algorithm (PSGA) for the static task assignment problem in both homogeneous and heterogeneous distributed computing systems to reduce the task turnaround time and to increase the throughput of the system by properly balancing the load and reducing the intermodule communication cost among processors. The proposed problem-space genetic algorithms (PSGA) based scheme is a blend of a genetic algorithm

426 IMTIAZ AHMAD AND MUHAMMAD K DHODHI
Table 6. Summary of results for DSP example
Proposed technique Woodside and Monforton[ 1 I ] Improvements Case F, N Cost(A) Bus Bus Cost(A) Bus Bus ir i Cost(A)
utilization utilization
0 I S
20 200 20
II 200 20
I l l 200
~
I 9 7 5
19 5 I I
~~ ~
1728 1779.2 1939.8 2522.2
1521.85 2522.2 1939.8 201 1.5
0 753.6 147.2
128 480 I28
140.8 384
0 1728 42.3% 1779 2 7.6% 2205.4
5.07% 2885.5 3 1.54% 1304.3 5.07% 2885.5 7.25% 2399.45
19.09% 2885.5
0 838
230.4 0
1670.4 0
I056 0
0 474'
10.5% 0
loo% 0
44% 0
~~
0 0
12 04% 12 6% 8 89% 12 6%
19 15% 30 29%
Table 7. Execution cost matrix
TasWroc. PI PZ P3 Pj PS P6
1 12 23 38 76 20 34 2 45 15 30 25 16 21 3 60 52 70 42 45 32 4 45 55 60 80 61 51 5 14 15 17 21 24 28 6 32 18 26 29 37 24 7 27 34 19 42 21 34 8 41 23 53 29 42 24 9 8 10 1 1 9 10 3 10 14 20 32 16 15 18 1 1 33 48 42 26 36 40 12 56 43 37 34 32 41
Table 8. Intermodule communication costs
Tasks 1 2 3 4 5 6 7 8 9 10 1 1 12
1 0 25 0 35 13 3 10 0 26 19 12 0 2 2 5 0 1 8 0 0 2 1 0 1 4 0 3 5 0 3 3 0 1 8 0 3 5 2 5 0 2 1 2 0 0 2 5 0 4 35 0 35 0 12 34 0 0 0 19 0 0 5 13 0 25 12 0 6 21 30 27 0 0 4 6 3 2 1 0 3 4 6 0 1 5 0 0 0 1 1 0 7 10 0 2 0 2 1 15 0 1 5 0 1 7 0 0 8 0 14 12 0 30 0 15 0 0 24 15 0 9 2 6 0 0 0 2 7 0 0 0 0 2 8 3 2 5
10 19 35 0 19 0 0 17 24 28 0 0 0 1 1 12 0 25 0 0 1 1 0 15 5 0 0 14 12 0 3 0 0 4 0 0 0 5 0 14 0

TASK ASSIGNMENT USING A PROBLEM-SPACE GENETIC ALGORITHM 427
Table 9. Comparison of assignment results for heterogeneous processors
Proposed technique Lin and Hsu[22] Improvement in TlG # P; Task assignment Cost(A) Task assignment Cost(A) Cost(A)
{ I A 10)
(5,7,8) 301 (4,6, 12) 306 1.6%
(3.9, 1 1 )
and a heuristic, which uses a different neighborhood structure to search a large solution space in an intelligent way in order to find the best possible solution within acceptable CPU times. Experimental results on test examples showed that considerable improvements in the assignment cost can be obtained by using the proposed technique as compared to the previous best known results for the test examples. We are extending our work to include more factors such as memory requirements, deadlines and precedence constraints into the model. Moreover, the synergy of evolution and heuristic offers a rich area for further exploration.
REFERENCES 1 . M. R. Garey and D. S . Johnson, Computers and Intractability: A Guide to the Theory of NP
Completeness, San Francisco, CA, W. H. Freeman, 1979. 2 . H. S. Stone, ‘Multiprocessor scheduling with the aid of network flow algorithms’, IEEE Trans.,
3. S. H. Bokhari, Assignment Problems in Parallel and Distributed Computing, Kluwer Academic, Boston, M A , 1987.
4. C. H. Lee, D. Lee and M. Kim, ‘Optimal task assignmentin linear array networks’, IEEE Trans.,
5 . C . C . Shen and W. H. Tsai, ‘A graph matching approach to optimal task assignment in distributed computing using a minimax criterion’, IEEE Trans., C-34, (3). 197-203 (1985).
6. K. G . Shin and M. S. Chen, ‘On the number of acceptable task assignments in distributed computing systems’, IEEE Trans., C-39, (1). 99-1 10 (1990).
7. W. W. Chu, L. J . Holloway, M.-T. L. Lan and K. Efe, ‘Task allocation in distributed data processing’, Comput., 13, (1 I), 57-69 (1980).
8. P. Y. R. Ma, E. Y. S . Lee and J . Tsuchiya, ‘A task allocation model for distributed computing
SE-3, ( l ) , 85-93 (1977).
C-41, (7). 877-880 (1992).

42 8 IMTIAZ AHMAD AND MUHAMMAD K . DHODHI
9.
10.
1 1 .
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25. 26.
27.
28. 29.
30.
31.
K. Efe, ‘Heuristic models of task assignment scheduling in distributed systems’, Comput. 15. (6). 50-56 ( I 982). S . Y. Lee and J. K. Aggarwal, ‘A mapping strategy for parallel processing’, IEEE Trans., C-36, (5). 433-442 (1 987). C.’M. Woodside and G. G. Monforton, ‘Fast allocation of processes in distributed and parallel systems’, IEEE Trans. Parallel Distrib. Syst., 4, (2). 164174 (1993). V. Chaudhry and J . K. Aggarwal, ‘A generalized scheme for mapping parallel algorithms’, IEEE Trans. Parallel Distrib. Syst., 4, (3), 328-346 (1 993). V. M. Lo, ‘Heuristic algorithms for task assignment in distributed systems’, IEEE Trans., C-37, ( I I ) , 1384-1397(1988). C. E. Houstis, ‘Module allocation of real-time applications to distributed systems’, IEEE Trans.,
J . B. Sinclair, ‘Efficient computation of optimal assignments for distributed tasks’, J. Parallel Distrib. Comput., 4,342-362 (1987). A. K. Sarje and G. Sagar, ‘Heuristic model for task allocation in distributed computer systems’, IEEProc. E, 138, ( S ) , 313-318(1991). A. N. Tantawi and D. Towsley, ‘Optimal static load balancing in distributed computer systems’, J. ACM, 32,445-465 (1985). N. S. Bowen, C. N. Nikolaou and A. Ghafoor, ‘On the assignment problem of arbitrary process systems to heterogeneous distributed computer systems’, IEEE Trans., C-41, (3’1, 257-273 ( 1 992). J . Shield, ‘Partitioning concurrent VLSI simulation programs on to a multiprocessor by simulated annealing’, IEE P roc. E, 134, ( I ) , 24-30 ( I 987). F. Ercal, J. Ramanujam and P. Sadayappan, ‘Task allocation onto a hypercube by recursive mincut bipartitioning’, J. Parallel Distrib. Cotnpirt.. 10, 35-44 (1990). S. Selvakumar and C. S. R. Murthy, ‘An efficient heuristic algorithm for mapping parallel programs onto multicomputers’, Microprocess. and Microprogram., 36,83-92 ( 1 992/1993). F. T. Lin and C. C. Hsu, ‘Task assignment scheduling by simulated annealing’, IEEE Region
SE-16, (7). 699-709 (1 990).
10 Conference on Computer and Communication Systems, Hong Kong, September 19901 pp. 279-283. T. Bultan and C. Aykanat, ‘A new mapping heuristic based on mean field annealing’, J. Parallel Distrib. Comput., 16, (4), 292-305 (1992). T. Chockalingam and S. Arankumar, ‘A randomized heuristic for the mapping problem: The genetic approach’, Parallel Comput., 18, 1157-1 165 (1992). J . H. Holland, Adaption in Natural and ArtiJicial Systems, MIT Press, Cambridge, MA, 1975. D. E. Goldberg, Genetic Algorithms in Search, Optimization and Machitie Learning, Addison- Wesley, 1989. K . Shahookar and P. Mazumder, ‘A genetic approach to standard cell placement \using meta- genetic parameter optimization’, IEEE Trans., CAD-9, 500-5 l l (1990). L. Davis, Handbook of Genetic Algorithms, Van Nostrand Reinhold, New York, 19!)1. 2. Michalewicz, Genetic Algorithms + Data Structures = Evolution Programs, Springer-Verlag, New York, 1992. R. H. Storer, D. S. Wu and R. Vaccari, ‘New search space for sequencing problems with application to job shop scheduling’, Manage. Sci., 38, (10). 1495-1509 (1992). Muhammad K. Dhodhi, Data Path Synthesis Using ConcurrentScheduling and Allocation Based on Problem-Space Genetic Algorithms, PhD dissertation, Department of Electrical Engineering and Computer Science, Lehigh University, Bethlehem, PA, August 1992.


















