
Take a read: mRNA abundance - University Of...
10
mRNA abundance estimation with RNAseq Hector Corrada Bravo CMSC858B Spring 2012 Many slides courtesy of Ben Langmead @ JHSPH Mapping CTCAAACTCCTGACCTTTGGTGATCCACCCGCCTNGGCCTTC Take a read: And a reference sequence: >MT dna:chromosome chromosome:GRCh37:MT:1:16569:1 GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTT CGTCTGGGGGGTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTC GCAGTATCTGTCTTTGATTCCTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATT ACAGGCGAACATACTTACTAAAGTGTGTTAATTAATTAATGCTTGTAGGACATAATAATA ACAATTGAATGTCTGCACAGCCACTTTCCACACAGACATCATAACAAAAAATTTCCACCA AACCCCCCCTCCCCCGCTTCTGGCCACAGCACTTAAACACATCTCTGCCAAACCCCAAAA ACAAAGAACCCTAACACCAGCCTAACCAGATTTCAAATTTTATCTTTTGGCGGTATGCAC TTTTAACAGTCACCCCCCAACTAACACATTATTTTCCCCTCCCACTCCCATACTACTAAT CTCATCAATACAACCCCCGCCCATCCTACCCAGCACACACACACCGCTGCTAACCCCATA CCCCGAACCAACCAAACCCCAAAGACACCCCCCACAGTTTATGTAGCTTACCTCCTCAAA GCAATACACTGACCCGCTCAAACTCCTGGATTTTGGATCCACCCAGCGCCTTGGCCTAAA CTAGCCTTTCTATTAGCTCTTAGTAAGATTACACATGCAAGCATCCCCGTTCCAGTGAGT TCACCCTCTAAATCACCACGATCAAAAGGAACAAGCATCAAGCACGCAGCAATGCAGCTC AAAACGCTTAGCCTAGCCACACCCCCACGGGAAACAGCAGTGATTAACCTTTAGCAATAA ACGAAAGTTTAACTAAGCTATACTAACCCCAGGGTTGGTCAATTTCGTGCCAGCCACCGC GGTCACACGATTAACCCAAGTCAATAGAAGCCGGCGTAAAGAGTGTTTTAGATCACCCCC TCCCCAATAAAGCTAAAACTCACCTGAGTTGTAAAAAACTCCAGTTGACACAAAATAGAC TACGAAAGTGGCTTTAACATATCTGAACACACAATAGCTAAGACCCAAACTGGGATTAGA TACCCCACTATGCTTAGCCCTAAACCTCAACAGTTAAATCAACAAAACTGCTCGCCAGAA CACTACGAGCCACAGCTTAAAACTCAAAGGACCTGGCGGTGCTTCATATCCCTCTAGAGG AGCCTGTTCTGTAATCGATAAACCCCGATCAACCTCACCACCTCTTGCTCAGCCTATATA CCGCCATCTTCAGCAAACCCTGATGAAGGCTACAAAGTAAGCGCAAGTACCCACGTAAAG ACGTTAGGTCAAGGTGTAGCCCATGAGGTGGCAAGAAATGGGCTACATTTTCTACCCCAG AAAACTACGATAGCCCTTATGAAACTTAAGGGTCGAAGGTGGATTTAGCAGTAAACTAAG AGTAGAGTGCTTAGTTGAACAGGGCCCTGAAGCGCGTACACACCGCCCGTCACCCTCCTC AAGTATACTTCAAAGGACATTTAACTAAAACCCCTACGCATTTATATAGAGGAGACAAGT CGTAACCTCAAACTCCTGCCTTTGGTGATCCACCCGCCTTGGCCTACCTGCATAATGAAG AAGCACCCAACTTACACTTAGGAGATTTCAACTTAACTTGACCGCTCTGAGCTAAACCTA GCCCCAAACCCACTCCACCTTACTACCAGACAACCTTAGCCAAACCATTTACCCAAATAA AGTATAGGCGATAGAAATTGAAACCTGGCGCAATAGATATAGTACCGCAAGGGAAAGATG AAAAATTATAACCAAGCATAATATAGCAAGGACTAACCCCTATACCTTCTGCATAATGAA TTAACTAGAAATAACTTTGCAAGGAGAGCCAAAGCTAAGACCCCCGAAACCAGACGAGCT ACCTAAGAACAGCTAAAAGAGCACACCCGTCTATGTAGCAAAATAGTGGGAAGATTTATA How do we determine the read’s point of origin with respect to the reference? CTCAAAGACCTGACCTTTGGTGATCCACCC-----GCCTNGGCCTTC |||||| |||| |||| ||||||||| |||| ||||| CTCAAACTCCTGGATTTTG--GATCCACCCAGCTGGCCTTGGCCTAA Hypothesis 1: Hypothesis 2: CTCAAACTCCTGACCTTTGGTGATCCACCCGCCTNGGCCTTC |||||||||||| ||||||||||||||||||||| ||||| | CTCAAACTCCTG-CCTTTGGTGATCCACCCGCCTTGGCCTAC Answer: sequence similarity Read Reference Read Reference Say hypothesis 2 is correct. Why are there still mismatches and gaps? Which hypothesis is better? Mapping CTCAAACTCCTGACCTTTGGTGATCCACCCGCCTNGGCCTTC >MT dna:chromosome chromosome:GRCh37:MT:1:16569:1 GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTT CGTCTGGGGGGTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTC GCAGTATCTGTCTTTGATTCCTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATT ACAGGCGAACATACTTACTAAAGTGTGTTAATTAATTAATGCTTGTAGGACATAATAATA ACAATTGAATGTCTGCACAGCCACTTTCCACACAGACATCATAACAAAAAATTTCCACCA AACCCCCCCTCCCCCGCTTCTGGCCACAGCACTTAAACACATCTCTGCCAAACCCCAAAA ACAAAGAACCCTAACACCAGCCTAACCAGATTTCAAATTTTATCTTTTGGCGGTATGCAC TTTTAACAGTCACCCCCCAACTAACACATTATTTTCCCCTCCCACTCCCATACTACTAAT CTCATCAATACAACCCCCGCCCATCCTACCCAGCACACACACACCGCTGCTAACCCCATA CCCCGAACCAACCAAACCCCAAAGACACCCCCCACAGTTTATGTAGCTTACCTCCTCAAA GCAATACACTGACCCGCTCAAACTCCTGGATTTTGTGATCCACCCAGCGCCTTGGCCTAA CTAGCCTTTCTATTAGCTCTTAGTAAGATTACACATGCAAGCATCCCCGTTCCAGTGAGT TCACCCTCTAAATCACCACGATCAAAAGGAACAAGCATCAAGCACGCAGCAATGCAGCTC AAAACGCTTAGCCTAGCCACACCCCCACGGGAAACAGCAGTGATTAACCTTTAGCAATAA ACGAAAGTTTAACTAAGCTATACTAACCCCAGGGTTGGTCAATTTCGTGCCAGCCACCGC GGTCACACGATTAACCCAAGTCAATAGAAGCCGGCGTAAAGAGTGTTTTAGATCACCCCC TCCCCAATAAAGCTAAAACTCACCTGAGTTGTAAAAAACTCCAGTTGACACAAAATAGAC TACGAAAGTGGCTTTAACATATCTGAACACACAATAGCTAAGACCCAAACTGGGATTAGA TACCCCACTATGCTTAGCCCTAAACCTCAACAGTTAAATCAACAAAACTGCTCGCCAGAA CACTACGAGCCACAGCTTAAAACTCAAAGGACCTGGCGGTGCTTCATATCCCTCTAGAGG AGCCTGTTCTGTAATCGATAAACCCCGATCAACCTCACCACCTCTTGCTCAGCCTATATA CCGCCATCTTCAGCAAACCCTGATGAAGGCTACAAAGTAAGCGCAAGTACCCACGTAAAG ACGTTAGGTCAAGGTGTAGCCCATGAGGTGGCAAGAAATGGGCTACATTTTCTACCCCAG AAAACTACGATAGCCCTTATGAAACTTAAGGGTCGAAGGTGGATTTAGCAGTAAACTAAG AGTAGAGTGCTTAGTTGAACAGGGCCCTGAAGCGCGTACACACCGCCCGTCACCCTCCTC AAGTATACTTCAAAGGACATTTAACTAAAACCCCTACGCATTTATATAGAGGAGACAAGT CGTAACCTCAAACTCCTGGCCTTTGGTGATCCACCCGCCTTGGCCTACCTGCATAATGAA AAGCACCCAACTTACACTTAGGAGATTTCAACTTAACTTGACCGCTCTGAGCTAAACCTA GCCCCAAACCCACTCCACCTTACTACCAGACAACCTTAGCCAAACCATTTACCCAAATAA AGTATAGGCGATAGAAATTGAAACCTGGCGCAATAGATATAGTACCGCAAGGGAAAGATG AAAAATTATAACCAAGCATAATATAGCAAGGACTAACCCCTATACCTTCTGCATAATGAA TTAACTAGAAATAACTTTGCAAGGAGAGCCAAAGCTAAGACCCCCGAAACCAGACGAGCT ACCTAAGAACAGCTAAAAGAGCACACCCGTCTATGTAGCAAAATAGTGGGAAGATTTATA GGTAGAGGCGACAAACCTACCGAGCCTGGTGATAGCTGGTTGTCCAAGATAGAATCTTAG TTCAACTTTAAATTTGCCCACAGAACCCTCTAAATCCCCTTGTAAATTTAACTGTTAGTC This is an alignment: Software programs that compare reads to references and find alignments are aligners. Read Reference Read Reference Alignment is computationally difficult because references (e.g. human) are very long (more than 1M times longer than what’s shown to the left) and sequencers produce data very rapidly, e.g. up to 25 billion bases per day in 2010. Sequencing throughput increases by ~5x per year, whereas computers get faster at a rate closer to ~2x every 2 years. CTCAAAGACCTGACCTTTGGTGATCCACCC-----GCCTNGGCCTTC |||||| |||| |||| ||||||||| |||| ||||| CTCAAACTCCTGGATTTTG--GATCCACCCAGCTGGCCTTGGCCTAA Mapping CTCAAACTCCTGACCTTTGGTGATCCA Take a read: And a reference sequence: >MT dna:chromosome chromosome:GRCh37:MT:1:16569:1 GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTT CGTCTGGGGGGTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTC GCAGTATCTGTCTTTGATTCCTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATT ACAGGCGAACATACTTACTAAAGTGTGTTAATTAATTAATGCTTGTAGGACATAATAATA ACAATTGAATGTCTGCACAGCCACTTTCCACACAGACATCATAACAAAAAATTTCCACCA AACCCCCCCTCCCCCGCTTCTGGCCACAGCACTTAAACACATCTCTGCCAAACCCCAAAA ACAAAGAACCCTAACACCAGCCTAACCAGATTTCAAATTTTATCTTTTGGCGGTATGCAC TTTTAACAGTCACCCCCCAACTAACACATTATTTTCCCCTCCCACTCCCATACTACTAAT CTCATCAATACAACCCCCGCCCATCCTACCCAGCACACACACACCGCTGCTAACCCCATA CCCCGAACCAACCAAACCCCAAAGACACCCCCCACAGTTTATGTAGCTTACCTCCTCAAA GCAATACACTGACCCGCTCAAACTCCTGGATTTTGTGATCCACCCAGCGCCTTGGCCTAA CTAGCCTTTCTATTAGCTCTTAGTAAGATTACACATGCAAGCATCCCCGTTCCAGTGAGT TCACCCTCTAAATCACCACGATCAAAAGGAACAAGCATCAAGCACGCAGCAATGCAGCTC AAAACGCTTAGCCTAGCCACACCCCCACGGGAAACAGCAGTGATTAACCTTTAGCAATAA ACGAAAGTTTAACTAAGCTATACTAACCCCAGGGTTGGTCAATTTCGTGCCAGCCACCGC GGTCACACGATTAACCCAAGTCAATAGAAGCCGGCGTAAAGAGTGTTTTAGATCACCCCC TCCCCAATAAAGCTAAAACTCACCTGAGTTGTAAAAAACTCCAGTTGACACAAAATAGAC TACGAAAGTGGCTTTAACATATCTGAACACACAATAGCTAAGACCCAAACTGGGATTAGA TACCCCACTATGCTTAGCCCTAAACCTCAACAGTTAAATCAACAAAACTGCTCGCCAGAA CACTACGAGCCACAGCTTAAAACTCAAAGGACCTGGCGGTGCTTCATATCCCTCTAGAGG AGCCTGTTCTGTAATCGATAAACCCCGATCAACCTCACCACCTCTTGCTCAGCCTATATA CCGCCATCTTCAGCAAACCCTGATGAAGGCTACAAAGTAAGCGCAAGTACCCACGTAAAG ACGTTAGGTCAAGGTGTAGCCCATGAGGTGGCAAGAAATGGGCTACATTTTCTACCCCAG AAAACTACGATAGCCCTTATGAAACTTAAGGGTCGAAGGTGGATTTAGCAGTAAACTAAG AGTAGAGTGCTTAGTTGAACAGGGCCCTGAAGCGCGTACACACCGCCCGTCACCCTCCTC AAGTATACTTCAAAGGACATTTAACTAAAACCCCTACGCATTTATATAGAGGAGACAAGT CGTAACCTCAAACTCCTGGCCTTTGGTGATCCACCCGCCTTGGCCTACCTGCATAATGAA AAGCACCCAACTTACACTTAGGAGATTTCAACTTAACTTGACCGCTCTGAGCTAAACCTA GCCCCAAACCCACTCCACCTTACTACCAGACAACCTTAGCCAAACCATTTACCCAAATAA AGTATAGGCGATAGAAATTGAAACCTGGCGCAATAGATATAGTACCGCAAGGGAAAGATG AAAAATTATAACCAAGCATAATATAGCAAGGACTAACCCCTATACCTTCTGCATAATGAA TTAACTAGAAATAACTTTGCAAGGAGAGCCAAAGCTAAGACCCCCGAAACCAGACGAGCT ACCTAAGAACAGCTAAAAGAGCACACCCGTCTATGTAGCAAAATAGTGGGAAGATTTATA CTCAAACTCCTGACCTTTGGTGATCCA |||||||||||| |||||||||||||| CTCAAACTCCTGCCCTTTGGTGATCCA Hypothesis 1: Hypothesis 2: Read Reference Read Reference Is there any way to break the tie? Which hypothesis is better? CTCAAACTCCTGACCTTTGGTGATCCA |||||||||||||||||| |||||||| CTCAAACTCCTGACCTTTCGTGATCCA
-
Upload
truongdang -
Category
Documents
-
view
215 -
download
0
Transcript of Take a read: mRNA abundance - University Of...

mRNA abundance estimation with RNAseq
Hector Corrada BravoCMSC858B Spring 2012
Many slides courtesy of Ben Langmead @ JHSPH
Mapping
CTCAAACTCCTGACCTTTGGTGATCCACCCGCCTNGGCCTTC
Take a read:
And a reference sequence:>MT dna:chromosome chromosome:GRCh37:MT:1:16569:1GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTTCGTCTGGGGGGTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTCGCAGTATCTGTCTTTGATTCCTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATTACAGGCGAACATACTTACTAAAGTGTGTTAATTAATTAATGCTTGTAGGACATAATAATAACAATTGAATGTCTGCACAGCCACTTTCCACACAGACATCATAACAAAAAATTTCCACCAAACCCCCCCTCCCCCGCTTCTGGCCACAGCACTTAAACACATCTCTGCCAAACCCCAAAAACAAAGAACCCTAACACCAGCCTAACCAGATTTCAAATTTTATCTTTTGGCGGTATGCACTTTTAACAGTCACCCCCCAACTAACACATTATTTTCCCCTCCCACTCCCATACTACTAATCTCATCAATACAACCCCCGCCCATCCTACCCAGCACACACACACCGCTGCTAACCCCATACCCCGAACCAACCAAACCCCAAAGACACCCCCCACAGTTTATGTAGCTTACCTCCTCAAAGCAATACACTGACCCGCTCAAACTCCTGGATTTTGGATCCACCCAGCGCCTTGGCCTAAACTAGCCTTTCTATTAGCTCTTAGTAAGATTACACATGCAAGCATCCCCGTTCCAGTGAGTTCACCCTCTAAATCACCACGATCAAAAGGAACAAGCATCAAGCACGCAGCAATGCAGCTCAAAACGCTTAGCCTAGCCACACCCCCACGGGAAACAGCAGTGATTAACCTTTAGCAATAAACGAAAGTTTAACTAAGCTATACTAACCCCAGGGTTGGTCAATTTCGTGCCAGCCACCGCGGTCACACGATTAACCCAAGTCAATAGAAGCCGGCGTAAAGAGTGTTTTAGATCACCCCCTCCCCAATAAAGCTAAAACTCACCTGAGTTGTAAAAAACTCCAGTTGACACAAAATAGACTACGAAAGTGGCTTTAACATATCTGAACACACAATAGCTAAGACCCAAACTGGGATTAGATACCCCACTATGCTTAGCCCTAAACCTCAACAGTTAAATCAACAAAACTGCTCGCCAGAACACTACGAGCCACAGCTTAAAACTCAAAGGACCTGGCGGTGCTTCATATCCCTCTAGAGGAGCCTGTTCTGTAATCGATAAACCCCGATCAACCTCACCACCTCTTGCTCAGCCTATATACCGCCATCTTCAGCAAACCCTGATGAAGGCTACAAAGTAAGCGCAAGTACCCACGTAAAGACGTTAGGTCAAGGTGTAGCCCATGAGGTGGCAAGAAATGGGCTACATTTTCTACCCCAGAAAACTACGATAGCCCTTATGAAACTTAAGGGTCGAAGGTGGATTTAGCAGTAAACTAAGAGTAGAGTGCTTAGTTGAACAGGGCCCTGAAGCGCGTACACACCGCCCGTCACCCTCCTCAAGTATACTTCAAAGGACATTTAACTAAAACCCCTACGCATTTATATAGAGGAGACAAGTCGTAACCTCAAACTCCTGCCTTTGGTGATCCACCCGCCTTGGCCTACCTGCATAATGAAGAAGCACCCAACTTACACTTAGGAGATTTCAACTTAACTTGACCGCTCTGAGCTAAACCTAGCCCCAAACCCACTCCACCTTACTACCAGACAACCTTAGCCAAACCATTTACCCAAATAAAGTATAGGCGATAGAAATTGAAACCTGGCGCAATAGATATAGTACCGCAAGGGAAAGATGAAAAATTATAACCAAGCATAATATAGCAAGGACTAACCCCTATACCTTCTGCATAATGAATTAACTAGAAATAACTTTGCAAGGAGAGCCAAAGCTAAGACCCCCGAAACCAGACGAGCTACCTAAGAACAGCTAAAAGAGCACACCCGTCTATGTAGCAAAATAGTGGGAAGATTTATAGGTAGAGGCGACAAACCTACCGAGCCTGGTGATAGCTGGTTGTCCAAGATAGAATCTTAGTTCAACTTTAAATTTGCCCACAGAACCCTCTAAATCCCCTTGTAAATTTAACTGTTAGTCCAAAGAGGAACAGCTCTTTGGACACTAGGAAAAAACCTTGTAGAGAGAGTAAAAAATTTAACACCCATAGTAGGCCTAAAAGCAGCCACCAATTAAGAAAGCGTTCAAGCTCAACACCCACTACCTAAAAAATCCCAAACATATAACTGAACTCCTCACACCCAATTGGACCAATCTATCACCCTATAGAAGAACTAATGTTAGTATAAGTAACATGAAAACATTCTCCTCCGCATAAGCCTGCGTCAGATTAAAACACTGAACTGACAATTAACAGCCCAATATCTACAATCAACCAACAAGTCATTATTACCCTCACTGTCAACCCAACACAGGCATGCTCATAAGGAAAGGTTAAAAAAAGTAAAAGGAACTCGGCAAATCTTACCCCGCCTGTTTACCAAAAACATCACCTCTAGCATCACCAGTATTAGAGGCACCGCCTGCCCAGTGACACATGTTTAACGGCCGCGGTACCCTAACCGTGCAAAGGTAGCATAATCACTTGTTCCTTAAATAGGGACCTGTATGAATGGCTCCACGAGGGTTCAGCTGTCTCTTACTTTTAACCAGTGAAATTGACCTGCCCGTGAAGAGGCGGGCATAACACAGCAAGACGAGAAGACCCTATGGAGCTTTAATTTATTAATGCAAACAGTACCTAACAAACCCACAGGTCCTAAACTACCAAACCTGCATTAAAAATTTCGGTTGGGGCGACCTCGGAGCAGAACCCAACCTCCGAGCAGTACATGCTAAGACTTCACCAGTCAAAGCGAACTACTATACTCAATTGATCCAATAACTTGACCAACGGAACAAGTTACCCTAGGGATAACAGCGCAATCCTATTCTAGAGTCCATATCAACAATAGGGTTTACGACCTCGATGTTGGATCAGGACATCCCGATGGTGCAGCCGCTATTAAAGGTTCGTTTGTTCAACGATTAAAGTCCTACGTGATCTGAGTTCAGACCGGAGTAATCCAGGTCGGTTTCTATCTACNTTCAAATTCCTCCCTGTACGAAAGGACAAGAGAAATAAGGCCTACTTCACAAAGCGCCTTCCCCCGTAAATGATATCATCTCAACTTAGTATTATACCCACACCCACCCAAGAACAGGGTTTGTTAAGATGGC
How do we determine the read’s point of origin with respect to the reference?
CTCAAAGACCTGACCTTTGGTGATCCACCC-----GCCTNGGCCTTC|||||| |||| |||| ||||||||| |||| |||||CTCAAACTCCTGGATTTTG--GATCCACCCAGCTGGCCTTGGCCTAA
Hypothesis 1:
Hypothesis 2:
CTCAAACTCCTGACCTTTGGTGATCCACCCGCCTNGGCCTTC|||||||||||| ||||||||||||||||||||| ||||| |CTCAAACTCCTG-CCTTTGGTGATCCACCCGCCTTGGCCTAC
Answer: sequence similarity
Read
Reference
Read
Reference
Say hypothesis 2 is correct. Why are there still mismatches and gaps?
Which hypothesis is better?
Mapping
CTCAAACTCCTGACCTTTGGTGATCCACCCGCCTNGGCCTTC
>MT dna:chromosome chromosome:GRCh37:MT:1:16569:1GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTTCGTCTGGGGGGTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTCGCAGTATCTGTCTTTGATTCCTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATTACAGGCGAACATACTTACTAAAGTGTGTTAATTAATTAATGCTTGTAGGACATAATAATAACAATTGAATGTCTGCACAGCCACTTTCCACACAGACATCATAACAAAAAATTTCCACCAAACCCCCCCTCCCCCGCTTCTGGCCACAGCACTTAAACACATCTCTGCCAAACCCCAAAAACAAAGAACCCTAACACCAGCCTAACCAGATTTCAAATTTTATCTTTTGGCGGTATGCACTTTTAACAGTCACCCCCCAACTAACACATTATTTTCCCCTCCCACTCCCATACTACTAATCTCATCAATACAACCCCCGCCCATCCTACCCAGCACACACACACCGCTGCTAACCCCATACCCCGAACCAACCAAACCCCAAAGACACCCCCCACAGTTTATGTAGCTTACCTCCTCAAAGCAATACACTGACCCGCTCAAACTCCTGGATTTTGTGATCCACCCAGCGCCTTGGCCTAACTAGCCTTTCTATTAGCTCTTAGTAAGATTACACATGCAAGCATCCCCGTTCCAGTGAGTTCACCCTCTAAATCACCACGATCAAAAGGAACAAGCATCAAGCACGCAGCAATGCAGCTCAAAACGCTTAGCCTAGCCACACCCCCACGGGAAACAGCAGTGATTAACCTTTAGCAATAAACGAAAGTTTAACTAAGCTATACTAACCCCAGGGTTGGTCAATTTCGTGCCAGCCACCGCGGTCACACGATTAACCCAAGTCAATAGAAGCCGGCGTAAAGAGTGTTTTAGATCACCCCCTCCCCAATAAAGCTAAAACTCACCTGAGTTGTAAAAAACTCCAGTTGACACAAAATAGACTACGAAAGTGGCTTTAACATATCTGAACACACAATAGCTAAGACCCAAACTGGGATTAGATACCCCACTATGCTTAGCCCTAAACCTCAACAGTTAAATCAACAAAACTGCTCGCCAGAACACTACGAGCCACAGCTTAAAACTCAAAGGACCTGGCGGTGCTTCATATCCCTCTAGAGGAGCCTGTTCTGTAATCGATAAACCCCGATCAACCTCACCACCTCTTGCTCAGCCTATATACCGCCATCTTCAGCAAACCCTGATGAAGGCTACAAAGTAAGCGCAAGTACCCACGTAAAGACGTTAGGTCAAGGTGTAGCCCATGAGGTGGCAAGAAATGGGCTACATTTTCTACCCCAGAAAACTACGATAGCCCTTATGAAACTTAAGGGTCGAAGGTGGATTTAGCAGTAAACTAAGAGTAGAGTGCTTAGTTGAACAGGGCCCTGAAGCGCGTACACACCGCCCGTCACCCTCCTCAAGTATACTTCAAAGGACATTTAACTAAAACCCCTACGCATTTATATAGAGGAGACAAGTCGTAACCTCAAACTCCTGGCCTTTGGTGATCCACCCGCCTTGGCCTACCTGCATAATGAA AAGCACCCAACTTACACTTAGGAGATTTCAACTTAACTTGACCGCTCTGAGCTAAACCTAGCCCCAAACCCACTCCACCTTACTACCAGACAACCTTAGCCAAACCATTTACCCAAATAAAGTATAGGCGATAGAAATTGAAACCTGGCGCAATAGATATAGTACCGCAAGGGAAAGATGAAAAATTATAACCAAGCATAATATAGCAAGGACTAACCCCTATACCTTCTGCATAATGAATTAACTAGAAATAACTTTGCAAGGAGAGCCAAAGCTAAGACCCCCGAAACCAGACGAGCTACCTAAGAACAGCTAAAAGAGCACACCCGTCTATGTAGCAAAATAGTGGGAAGATTTATAGGTAGAGGCGACAAACCTACCGAGCCTGGTGATAGCTGGTTGTCCAAGATAGAATCTTAGTTCAACTTTAAATTTGCCCACAGAACCCTCTAAATCCCCTTGTAAATTTAACTGTTAGTCCAAAGAGGAACAGCTCTTTGGACACTAGGAAAAAACCTTGTAGAGAGAGTAAAAAATTTAACACCCATAGTAGGCCTAAAAGCAGCCACCAATTAAGAAAGCGTTCAAGCTCAACACCCACTACCTAAAAAATCCCAAACATATAACTGAACTCCTCACACCCAATTGGACCAATCTATCACCCTATAGAAGAACTAATGTTAGTATAAGTAACATGAAAACATTCTCCTCCGCATAAGCCTGCGTCAGATTAAAACACTGAACTGACAATTAACAGCCCAATATCTACAATCAACCAACAAGTCATTATTACCCTCACTGTCAACCCAACACAGGCATGCTCATAAGGAAAGGTTAAAAAAAGTAAAAGGAACTCGGCAAATCTTACCCCGCCTGTTTACCAAAAACATCACCTCTAGCATCACCAGTATTAGAGGCACCGCCTGCCCAGTGACACATGTTTAACGGCCGCGGTACCCTAACCGTGCAAAGGTAGCATAATCACTTGTTCCTTAAATAGGGACCTGTATGAATGGCTCCACGAGGGTTCAGCTGTCTCTTACTTTTAACCAGTGAAATTGACCTGCCCGTGAAGAGGCGGGCATAACACAGCAAGACGAGAAGACCCTATGGAGCTTTAATTTATTAATGCAAACAGTACCTAACAAACCCACAGGTCCTAAACTACCAAACCTGCATTAAAAATTTCGGTTGGGGCGACCTCGGAGCAGAACCCAACCTCCGAGCAGTACATGCTAAGACTTCACCAGTCAAAGCGAACTACTATACTCAATTGATCCAATAACTTGACCAACGGAACAAGTTACCCTAGGGATAACAGCGCAATCCTATTCTAGAGTCCATATCAACAATAGGGTTTACGACCTCGATGTTGGATCAGGACATCCCGATGGTGCAGCCGCTATTAAAGGTTCGTTTGTTCAACGATTAAAGTCCTACGTGATCTGAGTTCAGACCGGAGTAATCCAGGTCGGTTTCTATCTACNTTCAAATTCCTCCCTGTACGAAAGGACAAGAGAAATAAGGCCTACTTCACAAAGCGCCTTCCCCCGTAAATGATATCATCTCAACTTAGTATTATACCCACACCCACCCAAGAACAGGGTTTGTTAAGATGGC
This is an alignment:
Software programs that compare reads to references and find alignments are aligners.
Read
Reference
Read
Reference
Alignment is computationally difficult because references (e.g. human) are very long (more than 1M times longer than what’s shown to the left) and sequencers produce data very rapidly, e.g. up to 25 billion bases per day in 2010.
Sequencing throughput increases by ~5x per year, whereas computers get faster at a rate closer to ~2x every 2 years.
CTCAAAGACCTGACCTTTGGTGATCCACCC-----GCCTNGGCCTTC|||||| |||| |||| ||||||||| |||| |||||CTCAAACTCCTGGATTTTG--GATCCACCCAGCTGGCCTTGGCCTAA
Mapping
CTCAAACTCCTGACCTTTGGTGATCCA
Take a read:
And a reference sequence:>MT dna:chromosome chromosome:GRCh37:MT:1:16569:1GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTTCGTCTGGGGGGTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTCGCAGTATCTGTCTTTGATTCCTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATTACAGGCGAACATACTTACTAAAGTGTGTTAATTAATTAATGCTTGTAGGACATAATAATAACAATTGAATGTCTGCACAGCCACTTTCCACACAGACATCATAACAAAAAATTTCCACCAAACCCCCCCTCCCCCGCTTCTGGCCACAGCACTTAAACACATCTCTGCCAAACCCCAAAAACAAAGAACCCTAACACCAGCCTAACCAGATTTCAAATTTTATCTTTTGGCGGTATGCACTTTTAACAGTCACCCCCCAACTAACACATTATTTTCCCCTCCCACTCCCATACTACTAATCTCATCAATACAACCCCCGCCCATCCTACCCAGCACACACACACCGCTGCTAACCCCATACCCCGAACCAACCAAACCCCAAAGACACCCCCCACAGTTTATGTAGCTTACCTCCTCAAAGCAATACACTGACCCGCTCAAACTCCTGGATTTTGTGATCCACCCAGCGCCTTGGCCTAACTAGCCTTTCTATTAGCTCTTAGTAAGATTACACATGCAAGCATCCCCGTTCCAGTGAGTTCACCCTCTAAATCACCACGATCAAAAGGAACAAGCATCAAGCACGCAGCAATGCAGCTCAAAACGCTTAGCCTAGCCACACCCCCACGGGAAACAGCAGTGATTAACCTTTAGCAATAAACGAAAGTTTAACTAAGCTATACTAACCCCAGGGTTGGTCAATTTCGTGCCAGCCACCGCGGTCACACGATTAACCCAAGTCAATAGAAGCCGGCGTAAAGAGTGTTTTAGATCACCCCCTCCCCAATAAAGCTAAAACTCACCTGAGTTGTAAAAAACTCCAGTTGACACAAAATAGACTACGAAAGTGGCTTTAACATATCTGAACACACAATAGCTAAGACCCAAACTGGGATTAGATACCCCACTATGCTTAGCCCTAAACCTCAACAGTTAAATCAACAAAACTGCTCGCCAGAACACTACGAGCCACAGCTTAAAACTCAAAGGACCTGGCGGTGCTTCATATCCCTCTAGAGGAGCCTGTTCTGTAATCGATAAACCCCGATCAACCTCACCACCTCTTGCTCAGCCTATATACCGCCATCTTCAGCAAACCCTGATGAAGGCTACAAAGTAAGCGCAAGTACCCACGTAAAGACGTTAGGTCAAGGTGTAGCCCATGAGGTGGCAAGAAATGGGCTACATTTTCTACCCCAGAAAACTACGATAGCCCTTATGAAACTTAAGGGTCGAAGGTGGATTTAGCAGTAAACTAAGAGTAGAGTGCTTAGTTGAACAGGGCCCTGAAGCGCGTACACACCGCCCGTCACCCTCCTCAAGTATACTTCAAAGGACATTTAACTAAAACCCCTACGCATTTATATAGAGGAGACAAGTCGTAACCTCAAACTCCTGGCCTTTGGTGATCCACCCGCCTTGGCCTACCTGCATAATGAA AAGCACCCAACTTACACTTAGGAGATTTCAACTTAACTTGACCGCTCTGAGCTAAACCTAGCCCCAAACCCACTCCACCTTACTACCAGACAACCTTAGCCAAACCATTTACCCAAATAAAGTATAGGCGATAGAAATTGAAACCTGGCGCAATAGATATAGTACCGCAAGGGAAAGATGAAAAATTATAACCAAGCATAATATAGCAAGGACTAACCCCTATACCTTCTGCATAATGAATTAACTAGAAATAACTTTGCAAGGAGAGCCAAAGCTAAGACCCCCGAAACCAGACGAGCTACCTAAGAACAGCTAAAAGAGCACACCCGTCTATGTAGCAAAATAGTGGGAAGATTTATAGGTAGAGGCGACAAACCTACCGAGCCTGGTGATAGCTGGTTGTCCAAGATAGAATCTTAGTTCAACTTTAAATTTGCCCACAGAACCCTCTAAATCCCCTTGTAAATTTAACTGTTAGTCCAAAGAGGAACAGCTCTTTGGACACTAGGAAAAAACCTTGTAGAGAGAGTAAAAAATTTAACACCCATAGTAGGCCTAAAAGCAGCCACCAATTAAGAAAGCGTTCAAGCTCAACACCCACTACCTAAAAAATCCCAAACATATAACTGAACTCCTCACACCCAATTGGACCAATCTATCACCCTATAGAAGAACTAATGTTAGTATAAGTAACATGAAAACATTCTCCTCCGCATAAGCCTGCGTCAGATTAAAACACTGAACTGACAATTAACAGCCCAATATCTACAATCAACCAACAAGTCATTATTACCCTCACTGTCAACCCAACACAGGCATGCTCATAAGGAAAGGTTAAAAAAAGTAAAAGGAACTCGGCAAATCTTACCCCGCCTGTTTACCAAAAACATCACCTCTAGCATCACCAGTATTAGAGGCACCGCCTGCCCAGTGACACATGTTTAACGGCCGCGGTACCCTAACCGTGCAAAGGTAGCATAATCACTTGTTCCTTAAATAGGGACCTGTATGAATGGCTCCACGAGGGTTCAGCTGTCTCTTACTTTTAACCAGTGAAATTGACCTGCCCGTGAAGAGGCGGGCATAACACAGCAAGACGAGAAGACCCTATGGAGCTTTAATTTATTAATGCAAACAGTACCTAACAAACCCACAGGTCCTAAACTACCAAACCTGCATTAAAAATTTCGGTTGGGGCGACCTCGGAGCAGAACCCAACCTCCGAGCAGTACATGCTAAGACTTCACCAGTCAAAGCGAACTACTATACTCAATTGATCCAATAACTTGACCAACGGAACAAGTTACCCTAGGGATAACAGCGCAATCCTATTCTAGAGTCCATATCAACAATAGGGTTTACGACCTCGATGTTGGATCAGGACATCCCGATGGTGCAGCCGCTATTAAAGGTTCGTTTGTTCAACGATTAAAGTCCTACGTGATCTGAGTTCAGACCGGAGTAATCCAGGTCGGTTTCTATCTACNTTCAAATTCCTCCCTGTACGAAAGGACAAGAGAAATAAGGCCTACTTCACAAAGCGCCTTCCCCCGTAAATGATATCATCTCAACTTAGTATTATACCCACACCCACCCAAGAACAGGGTTTGTTAAGATGGC
CTCAAACTCCTGACCTTTGGTGATCCA|||||||||||| ||||||||||||||CTCAAACTCCTGCCCTTTGGTGATCCA
Hypothesis 1:
Hypothesis 2:
Read
Reference
Read
Reference
Is there any way to break the tie?
Which hypothesis is better?
CTCAAACTCCTGACCTTTGGTGATCCA|||||||||||||||||| ||||||||CTCAAACTCCTGACCTTTCGTGATCCA

Mapping
Recall that reads come with per-cycle quality values (in red)
In FASTQ format (left), qualities are encoded as ASCII characters like B, = or %, but really they’re integers [0, 40]
A quality value Q is a function of the probability P that the sequencing machine called the wrong base:
Q = 10: 1 in 10 chance that base was miscalledQ = 20: 1 in 100 chanceQ = 30: 1 in 1000 chance
Higher is “better.”
Qs are estimated by the sequencer’s software and aren’t necessarily accurate
Q = !10 · log10(P )
Mapping
CTCAAACTCCTGACCTTTGGTGATCCA
Take a read:
And a reference sequence:>MT dna:chromosome chromosome:GRCh37:MT:1:16569:1GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTTCGTCTGGGGGGTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTCGCAGTATCTGTCTTTGATTCCTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATTACAGGCGAACATACTTACTAAAGTGTGTTAATTAATTAATGCTTGTAGGACATAATAATAACAATTGAATGTCTGCACAGCCACTTTCCACACAGACATCATAACAAAAAATTTCCACCAAACCCCCCCTCCCCCGCTTCTGGCCACAGCACTTAAACACATCTCTGCCAAACCCCAAAAACAAAGAACCCTAACACCAGCCTAACCAGATTTCAAATTTTATCTTTTGGCGGTATGCACTTTTAACAGTCACCCCCCAACTAACACATTATTTTCCCCTCCCACTCCCATACTACTAATCTCATCAATACAACCCCCGCCCATCCTACCCAGCACACACACACCGCTGCTAACCCCATACCCCGAACCAACCAAACCCCAAAGACACCCCCCACAGTTTATGTAGCTTACCTCCTCAAAGCAATACACTGACCCGCTCAAACTCCTGGATTTTGTGATCCACCCAGCGCCTTGGCCTAACTAGCCTTTCTATTAGCTCTTAGTAAGATTACACATGCAAGCATCCCCGTTCCAGTGAGTTCACCCTCTAAATCACCACGATCAAAAGGAACAAGCATCAAGCACGCAGCAATGCAGCTCAAAACGCTTAGCCTAGCCACACCCCCACGGGAAACAGCAGTGATTAACCTTTAGCAATAAACGAAAGTTTAACTAAGCTATACTAACCCCAGGGTTGGTCAATTTCGTGCCAGCCACCGCGGTCACACGATTAACCCAAGTCAATAGAAGCCGGCGTAAAGAGTGTTTTAGATCACCCCCTCCCCAATAAAGCTAAAACTCACCTGAGTTGTAAAAAACTCCAGTTGACACAAAATAGACTACGAAAGTGGCTTTAACATATCTGAACACACAATAGCTAAGACCCAAACTGGGATTAGATACCCCACTATGCTTAGCCCTAAACCTCAACAGTTAAATCAACAAAACTGCTCGCCAGAACACTACGAGCCACAGCTTAAAACTCAAAGGACCTGGCGGTGCTTCATATCCCTCTAGAGGAGCCTGTTCTGTAATCGATAAACCCCGATCAACCTCACCACCTCTTGCTCAGCCTATATACCGCCATCTTCAGCAAACCCTGATGAAGGCTACAAAGTAAGCGCAAGTACCCACGTAAAGACGTTAGGTCAAGGTGTAGCCCATGAGGTGGCAAGAAATGGGCTACATTTTCTACCCCAGAAAACTACGATAGCCCTTATGAAACTTAAGGGTCGAAGGTGGATTTAGCAGTAAACTAAGAGTAGAGTGCTTAGTTGAACAGGGCCCTGAAGCGCGTACACACCGCCCGTCACCCTCCTCAAGTATACTTCAAAGGACATTTAACTAAAACCCCTACGCATTTATATAGAGGAGACAAGTCGTAACCTCAAACTCCTGGCCTTTGGTGATCCACCCGCCTTGGCCTACCTGCATAATGAA AAGCACCCAACTTACACTTAGGAGATTTCAACTTAACTTGACCGCTCTGAGCTAAACCTAGCCCCAAACCCACTCCACCTTACTACCAGACAACCTTAGCCAAACCATTTACCCAAATAAAGTATAGGCGATAGAAATTGAAACCTGGCGCAATAGATATAGTACCGCAAGGGAAAGATGAAAAATTATAACCAAGCATAATATAGCAAGGACTAACCCCTATACCTTCTGCATAATGAATTAACTAGAAATAACTTTGCAAGGAGAGCCAAAGCTAAGACCCCCGAAACCAGACGAGCTACCTAAGAACAGCTAAAAGAGCACACCCGTCTATGTAGCAAAATAGTGGGAAGATTTATAGGTAGAGGCGACAAACCTACCGAGCCTGGTGATAGCTGGTTGTCCAAGATAGAATCTTAGTTCAACTTTAAATTTGCCCACAGAACCCTCTAAATCCCCTTGTAAATTTAACTGTTAGTCCAAAGAGGAACAGCTCTTTGGACACTAGGAAAAAACCTTGTAGAGAGAGTAAAAAATTTAACACCCATAGTAGGCCTAAAAGCAGCCACCAATTAAGAAAGCGTTCAAGCTCAACACCCACTACCTAAAAAATCCCAAACATATAACTGAACTCCTCACACCCAATTGGACCAATCTATCACCCTATAGAAGAACTAATGTTAGTATAAGTAACATGAAAACATTCTCCTCCGCATAAGCCTGCGTCAGATTAAAACACTGAACTGACAATTAACAGCCCAATATCTACAATCAACCAACAAGTCATTATTACCCTCACTGTCAACCCAACACAGGCATGCTCATAAGGAAAGGTTAAAAAAAGTAAAAGGAACTCGGCAAATCTTACCCCGCCTGTTTACCAAAAACATCACCTCTAGCATCACCAGTATTAGAGGCACCGCCTGCCCAGTGACACATGTTTAACGGCCGCGGTACCCTAACCGTGCAAAGGTAGCATAATCACTTGTTCCTTAAATAGGGACCTGTATGAATGGCTCCACGAGGGTTCAGCTGTCTCTTACTTTTAACCAGTGAAATTGACCTGCCCGTGAAGAGGCGGGCATAACACAGCAAGACGAGAAGACCCTATGGAGCTTTAATTTATTAATGCAAACAGTACCTAACAAACCCACAGGTCCTAAACTACCAAACCTGCATTAAAAATTTCGGTTGGGGCGACCTCGGAGCAGAACCCAACCTCCGAGCAGTACATGCTAAGACTTCACCAGTCAAAGCGAACTACTATACTCAATTGATCCAATAACTTGACCAACGGAACAAGTTACCCTAGGGATAACAGCGCAATCCTATTCTAGAGTCCATATCAACAATAGGGTTTACGACCTCGATGTTGGATCAGGACATCCCGATGGTGCAGCCGCTATTAAAGGTTCGTTTGTTCAACGATTAAAGTCCTACGTGATCTGAGTTCAGACCGGAGTAATCCAGGTCGGTTTCTATCTACNTTCAAATTCCTCCCTGTACGAAAGGACAAGAGAAATAAGGCCTACTTCACAAAGCGCCTTCCCCCGTAAATGATATCATCTCAACTTAGTATTATACCCACACCCACCCAAGAACAGGGTTTGTTAAGATGGC
CTCAAACTCCTGACCTTTGGTGATCCA|||||||||||| ||||||||||||||CTCAAACTCCTGCCCTTTGGTGATCCA
Hypothesis 1:
Hypothesis 2:
Read
Reference
Read
Reference
Which hypothesis is better?
CTCAAACTCCTGACCTTTGGTGATCCA|||||||||||||||||| ||||||||CTCAAACTCCTGACCTTTCGTGATCCA
Q=30
Q=10
Mapping
CTCAAACTCCTGACCTTTGGTGATCCA
Take a read:
And a reference sequence:>MT dna:chromosome chromosome:GRCh37:MT:1:16569:1GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTTCGTCTGGGGGGTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTCGCAGTATCTGTCTTTGATTCCTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATTACAGGCGAACATACTTACTAAAGTGTGTTAATTAATTAATGCTTGTAGGACATAATAATAACAATTGAATGTCTGCACAGCCACTTTCCACACAGACATCATAACAAAAAATTTCCACCAAACCCCCCCTCCCCCGCTTCTGGCCACAGCACTTAAACACATCTCTGCCAAACCCCAAAAACAAAGAACCCTAACACCAGCCTAACCAGATTTCAAATTTTATCTTTTGGCGGTATGCACTTTTAACAGTCACCCCCCAACTAACACATTATTTTCCCCTCCCACTCCCATACTACTAATCTCATCAATACAACCCCCGCCCATCCTACCCAGCACACACACACCGCTGCTAACCCCATACCCCGAACCAACCAAACCCCAAAGACACCCCCCACAGTTTATGTAGCTTACCTCCTCAAAGCAATACACTGACCCGCTCAAACTCCTGGATTTTGTGATCCACCCAGCGCCTTGGCCTAACTAGCCTTTCTATTAGCTCTTAGTAAGATTACACATGCAAGCATCCCCGTTCCAGTGAGTTCACCCTCTAAATCACCACGATCAAAAGGAACAAGCATCAAGCACGCAGCAATGCAGCTCAAAACGCTTAGCCTAGCCACACCCCCACGGGAAACAGCAGTGATTAACCTTTAGCAATAAACGAAAGTTTAACTAAGCTATACTAACCCCAGGGTTGGTCAATTTCGTGCCAGCCACCGCGGTCACACGATTAACCCAAGTCAATAGAAGCCGGCGTAAAGAGTGTTTTAGATCACCCCCTCCCCAATAAAGCTAAAACTCACCTGAGTTGTAAAAAACTCCAGTTGACACAAAATAGACTACGAAAGTGGCTTTAACATATCTGAACACACAATAGCTAAGACCCAAACTGGGATTAGATACCCCACTATGCTTAGCCCTAAACCTCAACAGTTAAATCAACAAAACTGCTCGCCAGAACACTACGAGCCACAGCTTAAAACTCAAAGGACCTGGCGGTGCTTCATATCCCTCTAGAGGAGCCTGTTCTGTAATCGATAAACCCCGATCAACCTCACCACCTCTTGCTCAGCCTATATACCGCCATCTTCAGCAAACCCTGATGAAGGCTACAAAGTAAGCGCAAGTACCCACGTAAAGACGTTAGGTCAAGGTGTAGCCCATGAGGTGGCAAGAAATGGGCTACATTTTCTACCCCAGAAAACTACGATAGCCCTTATGAAACTTAAGGGTCGAAGGTGGATTTAGCAGTAAACTAAGAGTAGAGTGCTTAGTTGAACAGGGCCCTGAAGCGCGTACACACCGCCCGTCACCCTCCTCAAGTATACTTCAAAGGACATTTAACTAAAACCCCTACGCATTTATATAGAGGAGACAAGTCGTAACCTCAAACTCCTGGCCTTTGGTGATCCACCCGCCTTGGCCTACCTGCATAATGAA AAGCACCCAACTTACACTTAGGAGATTTCAACTTAACTTGACCGCTCTGAGCTAAACCTAGCCCCAAACCCACTCCACCTTACTACCAGACAACCTTAGCCAAACCATTTACCCAAATAAAGTATAGGCGATAGAAATTGAAACCTGGCGCAATAGATATAGTACCGCAAGGGAAAGATGAAAAATTATAACCAAGCATAATATAGCAAGGACTAACCCCTATACCTTCTGCATAATGAATTAACTAGAAATAACTTTGCAAGGAGAGCCAAAGCTAAGACCCCCGAAACCAGACGAGCTACCTAAGAACAGCTAAAAGAGCACACCCGTCTATGTAGCAAAATAGTGGGAAGATTTATAGGTAGAGGCGACAAACCTACCGAGCCTGGTGATAGCTGGTTGTCCAAGATAGAATCTTAGTTCAACTTTAAATTTGCCCACAGAACCCTCTAAATCCCCTTGTAAATTTAACTGTTAGTCCAAAGAGGAACAGCTCTTTGGACACTAGGAAAAAACCTTGTAGAGAGAGTAAAAAATTTAACACCCATAGTAGGCCTAAAAGCAGCCACCAATTAAGAAAGCGTTCAAGCTCAACACCCACTACCTAAAAAATCCCAAACATATAACTGAACTCCTCACACCCAATTGGACCAATCTATCACCCTATAGAAGAACTAATGTTAGTATAAGTAACATGAAAACATTCTCCTCCGCATAAGCCTGCGTCAGATTAAAACACTGAACTGACAATTAACAGCCCAATATCTACAATCAACCAACAAGTCATTATTACCCTCACTGTCAACCCAACACAGGCATGCTCATAAGGAAAGGTTAAAAAAAGTAAAAGGAACTCGGCAAATCTTACCCCGCCTGTTTACCAAAAACATCACCTCTAGCATCACCAGTATTAGAGGCACCGCCTGCCCAGTGACACATGTTTAACGGCCGCGGTACCCTAACCGTGCAAAGGTAGCATAATCACTTGTTCCTTAAATAGGGACCTGTATGAATGGCTCCACGAGGGTTCAGCTGTCTCTTACTTTTAACCAGTGAAATTGACCTGCCCGTGAAGAGGCGGGCATAACACAGCAAGACGAGAAGACCCTATGGAGCTTTAATTTATTAATGCAAACAGTACCTAACAAACCCACAGGTCCTAAACTACCAAACCTGCATTAAAAATTTCGGTTGGGGCGACCTCGGAGCAGAACCCAACCTCCGAGCAGTACATGCTAAGACTTCACCAGTCAAAGCGAACTACTATACTCAATTGATCCAATAACTTGACCAACGGAACAAGTTACCCTAGGGATAACAGCGCAATCCTATTCTAGAGTCCATATCAACAATAGGGTTTACGACCTCGATGTTGGATCAGGACATCCCGATGGTGCAGCCGCTATTAAAGGTTCGTTTGTTCAACGATTAAAGTCCTACGTGATCTGAGTTCAGACCGGAGTAATCCAGGTCGGTTTCTATCTACNTTCAAATTCCTCCCTGTACGAAAGGACAAGAGAAATAAGGCCTACTTCACAAAGCGCCTTCCCCCGTAAATGATATCATCTCAACTTAGTATTATACCCACACCCACCCAAGAACAGGGTTTGTTAAGATGGC
CTCAAACTCCTGACCTTTGGTGATCCA|||||||||||| ||||||||||||||CTCAAACTCCTG-CCTTTGGTGATCCA
Hypothesis 1:
Hypothesis 2:
Read
Reference
Read
Reference
Is there any way to break the tie?
Hint: In Illumina sequencing, sequencing errors almost never manifest as gaps
Which hypothesis is better?
CTCAAACTCCTGACCTTTGGTGATCCA|||||||||||||||||| ||||||||CTCAAACTCCTGACCTTTCGTGATCCA
Mapping
CTCAAACTCCTGACCTTTGGTGATCCA|||||||||||| ||||||||||||||CTCAAACTCCTG-CCTTTGGTGATCCA
Read
Reference
Aligners can employ penalties to account for the relative probability of seeing different dissimilarities
Estimates vary, but small gaps (“indels”) occur in humans at 1 in ~10-100K positions.
SNPs occur in humans at 1 in ~1K positions, but depending on Q, sequencing error may be more likely
Penalty = 45
CTCAAACTCCTGACCTTTGGTGATCCA||||| |||||||||||||| ||||||CTCAA-CTCCTGACCTTTGGCGATCCA
Read
Reference
Penalty = 55
Q=10
CTCAAACTCCTGACCTTTGGTGATCCA|||||||||||||||||||||| ||||CTCAAACTCCTGACCTTTGGTGCTCCA
Read
Reference
Penalty = 30
Q=40
Pengap ! "10 log10(Pgap)
= "10 log10(0.00005)
# 45
Penmm ! argmin("10 log10(Pmiscall),"10 log10(PSNP))
= argmin(Q,"10 log10(0.001))
= argmin(Q, 30)

Fast Alignment• Bowtie: ultra-fast mapping of short reads to
reference genome
• http://bowtie-bio.sourceforge.net
0 0 0 15 15 0 0 15 15 0 0 0 0 0 0 0 0 0 0 0 0 15 15 0 0 0 0 15 15
15 15 15 0 0 30 15 0 0 0 15 0 15 0 0 15 15 15 0 15 15 0 0 30 0 0 0 0 0
0 0 0 30 15 0 0 30 15 0 0 0 0 0 0 0 0 0 0 0 0 30 15 0 0 0 0 15 15
0 0 0 15 45 5 0 15 45 5 0 0 0 0 0 0 0 0 0 0 0 15 45 5 0 0 0 15 30
0 0 0 0 5 15 0 0 5 60 20 0 0 0 15 0 0 0 15 0 0 0 5 15 0 15 15 0 0
15 15 15 0 0 20 30 0 0 20 75 35 15 0 0 30 15 15 0 30 15 0 0 20 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 35 90 50 30 0 0 0 0 0 0 0 0 0 0 35 0 0 0 0
0 0 0 0 0 0 0 0 0 15 0 50 60 20 45 5 0 0 15 0 0 0 0 0 0 50 15 0 0
15 15 15 0 0 15 15 0 0 0 30 10 65 30 5 60 20 15 0 30 15 0 0 15 0 10 20 0 0
c c c t t c c t t a c g c g a c c c a c c t t c g a a t ttcttacgac
Reference (n)
Read
(m)
Dynamic programming alignment
n >> m
Fill
Smith-Waterman
d = 6 billion (2 x 109) reads m = 100 ntn = 3 billion (3 x 109) nt
!
! 1 week-long run of
Illumina HiSeq 2000
100 processors, each capable of 100 billion cell updates per second, would take 6 years
! human
Dynamic programming alignment
Total of d x m x n = 2 x 1021 cell updates
Indexing
Seeding schemes:
Map data structures:
When to extend:
Contiguous seeds, spaced seeds, various weights, spans, intervals, ...
Hash table, lookup table, sorted arrays, trie, "nite state machine, ...
Every seed hit, every N hits, q-gram "lter, ...
Maq, SOAP, ZOOM!, GSNAP, BFAST, BLAT, ELAND, MOSAIK, Novoalign, RazerS, PerM, SHRiMP, ...
Inverted index
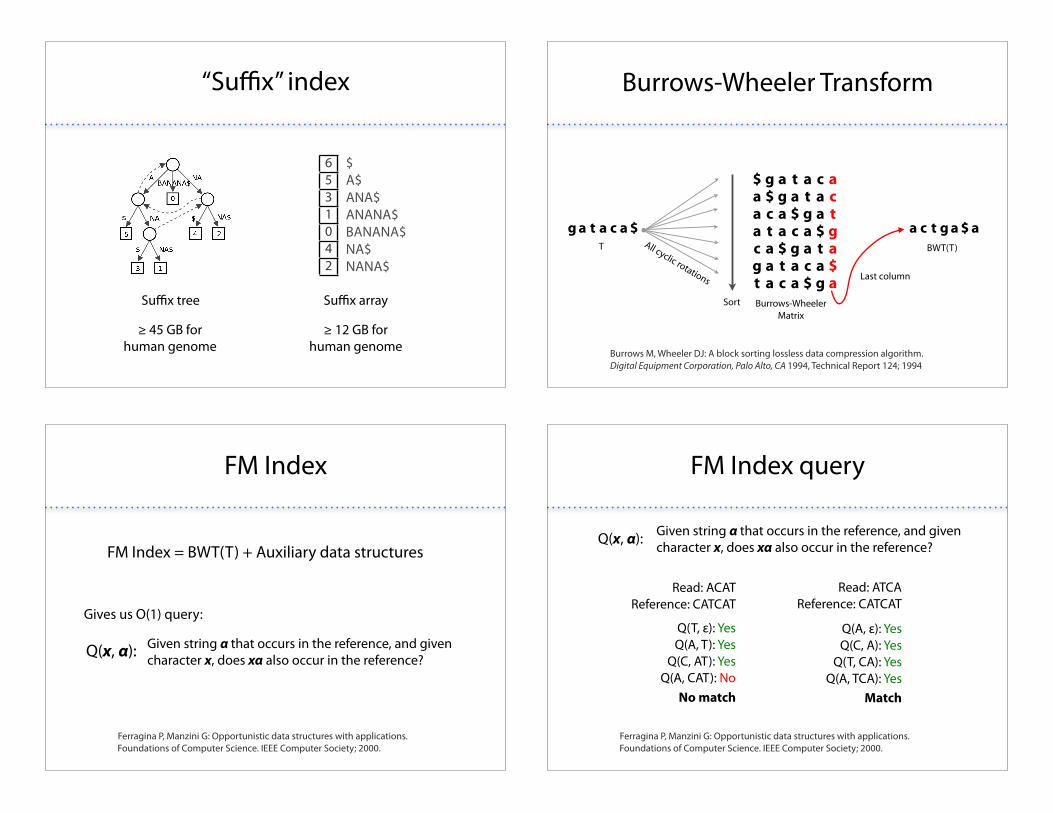
“Su#x” index
6531042
$A$ANA$ANANA$BANANA$NA$NANA$
Su#x tree Su#x array
$ 45 GB forhuman genome
$ 12 GB forhuman genome
Burrows-Wheeler Transform
Burrows M, Wheeler DJ: A block sorting lossless data compression algorithm. Digital Equipment Corporation, Palo Alto, CA 1994, Technical Report 124; 1994
g a t a c a $ a c t g a $ aT
Burrows-Wheeler Matrix
BWT(T)All cyclic rotations
Sort
Last column
$ g a t a c aa $ g a t a ca c a $ g a ta t a c a $ gc a $ g a t ag a t a c a $t a c a $ g a
FM Index
Ferragina P, Manzini G: Opportunistic data structures with applications. Foundations of Computer Science. IEEE Computer Society; 2000.
FM Index = BWT(T) + Auxiliary data structures
Given string ! that occurs in the reference, and given character x, does x! also occur in the reference?Q(x, !):
Gives us O(1) query:
FM Index query
Read: ACATReference: CATCAT
Q(T, %): YesQ(A, T): Yes
Q(C, AT): YesQ(A, CAT): No
Read: ATCAReference: CATCAT
Q(A, %): YesQ(C, A): Yes
Q(T, CA): YesQ(A, TCA): Yes
Given string ! that occurs in the reference, and given character x, does x! also occur in the reference?Q(x, !):
No match Match
Ferragina P, Manzini G: Opportunistic data structures with applications. Foundations of Computer Science. IEEE Computer Society; 2000.
6531042
$A$ANA$ANANA$BANANA$NA$NANA$
Su#x tree Su#x array$ 45 GB $ 12 GB
FM Index
$ B A N A N AA $ B A N A NA N A $ B A NA N A N A $ BB A N A N A $N A $ B A N AN A N A $ B A
2-4 GB
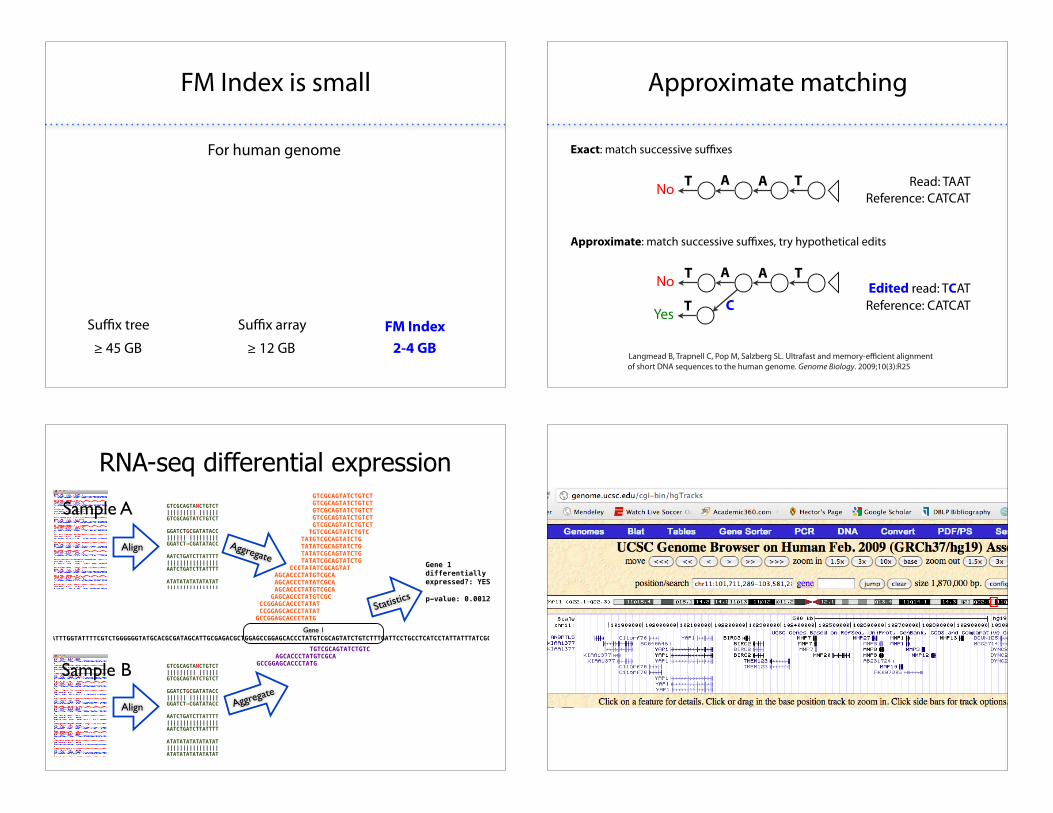
FM Index is small
For human genome
Approximate matching
Approximate: match successive su#xes, try hypothetical edits
Exact: match successive su#xes
TA A Read: TAATReference: CATCAT
TNo
TA ATNo Edited read: TCATReference: CATCATTYes C
Langmead B, Trapnell C, Pop M, Salzberg SL. Ultrafast and memory-e#cient alignment of short DNA sequences to the human genome. Genome Biology. 2009;10(3):R25
RNA-seq differential expression
GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTTCGTCTGGGGGGTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTCGCAGTATCTGTCTTTGATTCCTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATT
GTCGCAGTATCTGTCT GTCGCAGTATCTGTCT GTCGCAGTATCTGTCT GTCGCAGTATCTGTCT GTCGCAGTATCTGTCT TGTCGCAGTATCTGTC TATGTCGCAGTATCTG TATATCGCAGTATCTG TATATCGCAGTATCTG TATATCGCAGTATCTG CCCTATATCGCAGTAT AGCACCCTATGTCGCA AGCACCCTATATCGCA AGCACCCTATGTCGCA GAGCACCCTATGTCGC CCGGAGCACCCTATAT CCGGAGCACCCTATATGCCGGAGCACCCTATG
GTCGCAGTANCTGTCT||||||||| ||||||GTCGCAGTATCTGTCT
GGATCTGCGATATACC|||||| |||||||||GGATCT-CGATATACC
AATCTGATCTTATTTT||||||||||||||||AATCTGATCTTATTTT
ATATATATATATATAT||||||||||||||||ATATATATATATATAT
TCTCTCCCANNAGAGC||||||||| |||||TCTCTCCCAGGAGAGC
Align Aggregate
Statistics
Gene 1differentially expressed?: YES
p-value: 0.0012
TGTCGCAGTATCTGTC AGCACCCTATGTCGCAGCCGGAGCACCCTATGGTCGCAGTANCTGTCT
||||||||| ||||||GTCGCAGTATCTGTCT
GGATCTGCGATATACC|||||| |||||||||GGATCT-CGATATACC
AATCTGATCTTATTTT||||||||||||||||AATCTGATCTTATTTT
ATATATATATATATAT||||||||||||||||ATATATATATATATAT
TCTCTCCCANNAGAGC||||||||| |||||TCTCTCCCAGGAGAGC
Align Aggregate
Gene 1
Sample A
Sample B
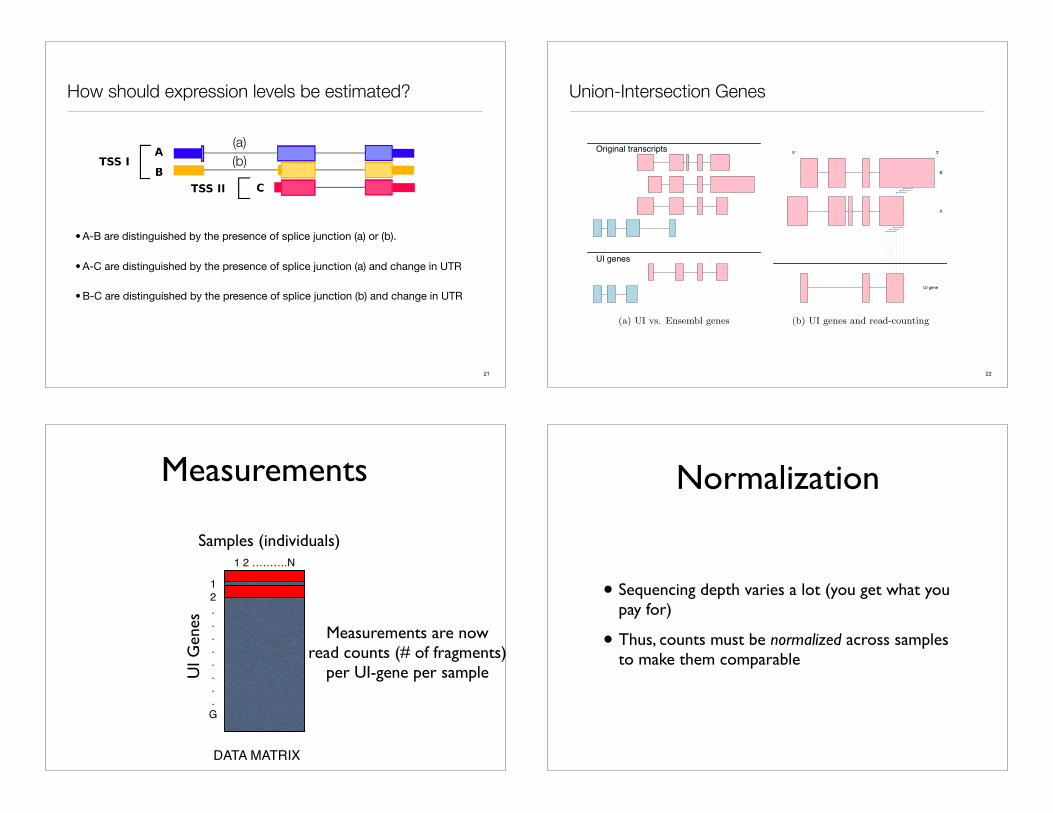
How should expression levels be estimated?
21
• A-B are distinguished by the presence of splice junction (a) or (b).
• A-C are distinguished by the presence of splice junction (a) and change in UTR
• B-C are distinguished by the presence of splice junction (b) and change in UTR
(a)(b)
UI genes
Original transcripts
(a) UI vs. Ensembl genes
A
B
UI gene
!
!
!
!
!
!
5' 3'
(b) UI genes and read-counting
Figure SS1: Union-intersection and Ensembl gene models. Panel (a): Illustration of union-intersection(UI) and Ensembl gene definitions for two genes (pink and blue) with multiple isoforms (see Section S2).The original transcripts, as would be reported by Ensembl, are displayed in the top panel. Below are thecorresponding UI and Ensembl gene models. Note that because the genes overlap, the entire exon region isremoved, not just the overlap. Panel (b): Illustration of read-counting for a gene with two isoforms. IsoformA has a shorter 3’-most exon as compared to Isoform B. The UI gene model includes the entire 3’-most exonfor Isoform A. In addition to reads originating from the constitutive portion of the UI gene, reads emanatingexclusively from Isoform B may also be counted.
46
Union-Intersection Genes
22
Measurements
12........G
1 2 ……….N
DATA MATRIX
Samples (individuals)
UI G
enes Measurements are now
read counts (# of fragments)per UI-gene per sample
Normalization
• Sequencing depth varies a lot (you get what you pay for)
• Thus, counts must be normalized across samples to make them comparable

Normalization
• Proposals:
• total count normalization: not great, genes with very high counts can skew results
• upper-quartile normalization: about 75% of the data behaves similarly, only upper counts mess things up
Normalization
Modeling
• Three main proposals:
• Counts follow a Poisson distr.
• Works well capturing technical replicates, but, too limited to capture biological variability?
• log(Counts) follow a Normal distribution (Myrna)
• Seems to capture biological variability better, for large sample sizes
• Counts follow a negative binomial distribution (DEseq)
Poisson Distribution
f(k;λ) =e−λλk
k!Mean & Variance: λ
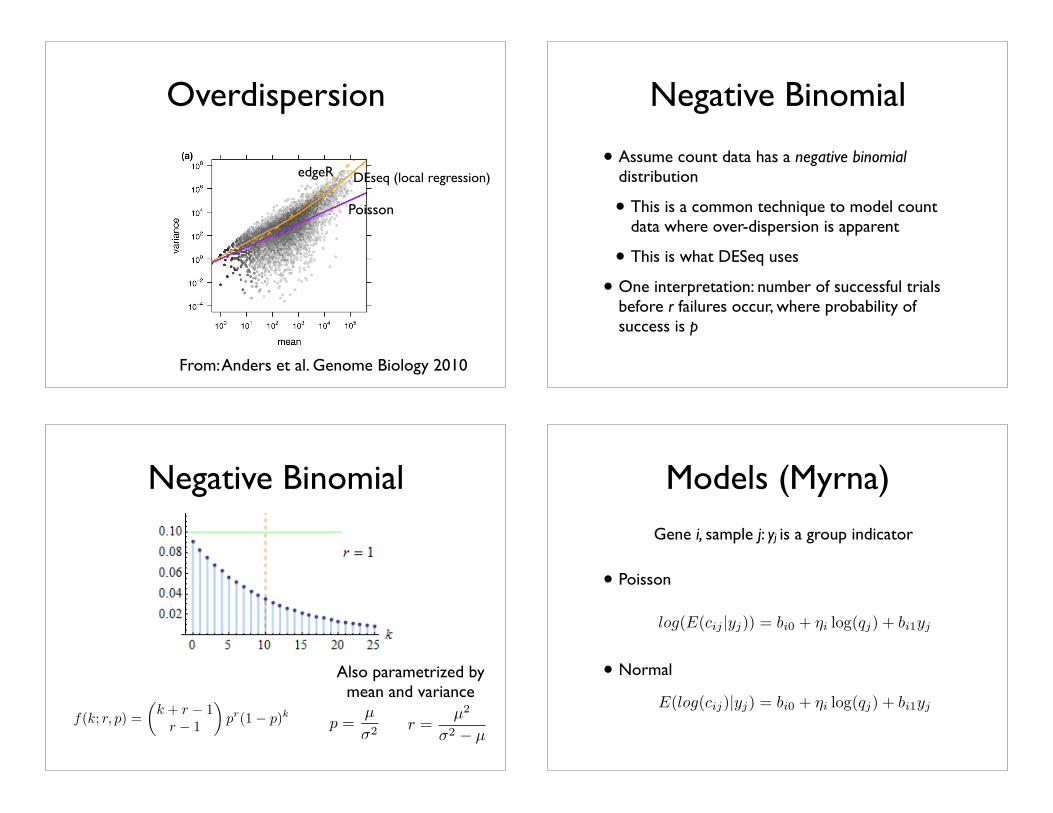
Overdispersion
From: Anders et al. Genome Biology 2010
Poisson
DEseq (local regression)edgeR
Negative Binomial
• Assume count data has a negative binomial distribution
• This is a common technique to model count data where over-dispersion is apparent
• This is what DESeq uses
• One interpretation: number of successful trials before r failures occur, where probability of success is p
Negative Binomial
f(k; r, p) =�
k + r − 1r − 1
�pr(1− p)k
Also parametrized by mean and variance
p =µ
σ2 r =µ2
σ2 − µ
Models (Myrna)
• Poisson
• Normal
log(E(cij |yj)) = bi0 + ηi log(qj) + bi1yj
Gene i, sample j: yj is a group indicator
E(log(cij)|yj) = bi0 + ηi log(qj) + bi1yj

Test
• Differential expression tests that the means for each group are different
• Idea: compare model where means are allowed to be different vs. model where means are constrained to be equal
• Statistic: log of likelihood ratio
• This statistic follows an asymptotic chi-square distribution
• But getting p-values by permutation is preferred
!"#$%&'(")
*+
,"'((")-#"./0-12-"3(/4-50/67-%).-)"&#%0'8%9")-4/&#-5&':;47
<=>-;?#%)-(%#$0/(@-A0%((-0%B/0(-%$$0'/.-&%)."#0C
,DE%0?/(-(;"?0.-B/-?)'F"�C-.'(4&'B?4/.
!"#$%&'(")
*G
H"&#%0-#"./0-12-"3(/4-50/67-%).-)"&#%0'8%9")-4/&#-5&':;47
RNAseq
• Fairly new assay, kinks are still being worked out
• The statistics for moderate sample sizes are still under-developed
• Computational requirements are going to get worse
• Cloud architectures might be the way to go for many analysts
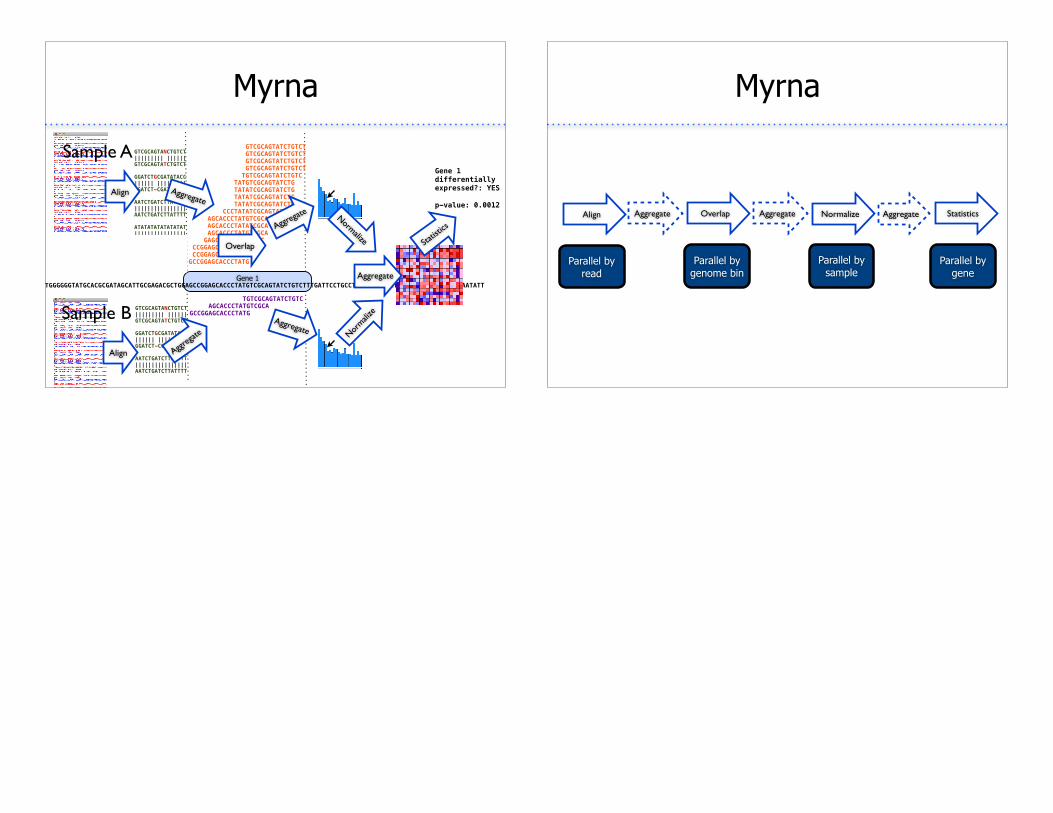
Myrna
Gene 1GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTTCGTCTGGGGGGTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTCGCAGTATCTGTCTTTGATTCCTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATT
GTCGCAGTATCTGTCT GTCGCAGTATCTGTCT GTCGCAGTATCTGTCT GTCGCAGTATCTGTCT TGTCGCAGTATCTGTC TATGTCGCAGTATCTG TATATCGCAGTATCTG TATATCGCAGTATCTG TATATCGCAGTATCTG CCCTATATCGCAGTAT AGCACCCTATGTCGCA AGCACCCTATATCGCA AGCACCCTATGTCGCA GAGCACCCTATGTCGC CCGGAGCACCCTATAT CCGGAGCACCCTATATGCCGGAGCACCCTATG
GTCGCAGTANCTGTCT||||||||| ||||||GTCGCAGTATCTGTCT
GGATCTGCGATATACC|||||| |||||||||GGATCT-CGATATACC
AATCTGATCTTATTTT||||||||||||||||AATCTGATCTTATTTT
ATATATATATATATAT||||||||||||||||ATATATATATATATAT
TCTCTCCCANNAGAGC||||||||| |||||TCTCTCCCAGGAGAGC
Gene 1differentially expressed?: YES
p-value: 0.0012
TGTCGCAGTATCTGTC AGCACCCTATGTCGCAGCCGGAGCACCCTATG
GTCGCAGTANCTGTCT||||||||| ||||||GTCGCAGTATCTGTCT
GGATCTGCGATATACC|||||| |||||||||GGATCT-CGATATACC
AATCTGATCTTATTTT||||||||||||||||AATCTGATCTTATTTT
ATATATATATATATAT||||||||||||||||ATATATATATATATAT
TCTCTCCCANNAGAGC||||||||| |||||TCTCTCCCAGGAGAGC
Sample A
Sample B
Align Aggrega
te
Aggregate
Overlap
Aggregate Normalize
Aggregate Normali
ze
Aggregate
Statist
ics
Align
Myrna
Parallel by read
Parallel by genome bin
Parallel by sample
Parallel by gene
Aggregate Overlap Aggregate Normalize AggregateAlign Statistics


















