TAC KBP 2016 Cold Start Slot Filling and Slot Filler ......o 6= R q. We define the task to classify...
9
HAL Id: hal-01571795 https://hal.archives-ouvertes.fr/hal-01571795 Submitted on 10 Sep 2019 HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci- entific research documents, whether they are pub- lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers. L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés. TAC KBP 2016 Cold Start Slot Filling and Slot Filler Validation Systems by IRT SystemX Rashedur Rahman, Brigitte Grau, Sophie Rosset, Yoann Dupont, Jérémy Guillemot, Christian Lautier, Wilson Fred To cite this version: Rashedur Rahman, Brigitte Grau, Sophie Rosset, Yoann Dupont, Jérémy Guillemot, et al.. TAC KBP 2016 Cold Start Slot Filling and Slot Filler Validation Systems by IRT SystemX. Text Analysis Conference, National Institute of Standards and Technology, Nov 2016, Gaithersburg, Maryland, United States. hal-01571795
Transcript of TAC KBP 2016 Cold Start Slot Filling and Slot Filler ......o 6= R q. We define the task to classify...

HAL Id: hal-01571795https://hal.archives-ouvertes.fr/hal-01571795
Submitted on 10 Sep 2019
HAL is a multi-disciplinary open accessarchive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come fromteaching and research institutions in France orabroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, estdestinée au dépôt et à la diffusion de documentsscientifiques de niveau recherche, publiés ou non,émanant des établissements d’enseignement et derecherche français ou étrangers, des laboratoirespublics ou privés.
TAC KBP 2016 Cold Start Slot Filling and Slot FillerValidation Systems by IRT SystemX
Rashedur Rahman, Brigitte Grau, Sophie Rosset, Yoann Dupont, JérémyGuillemot, Christian Lautier, Wilson Fred
To cite this version:Rashedur Rahman, Brigitte Grau, Sophie Rosset, Yoann Dupont, Jérémy Guillemot, et al.. TACKBP 2016 Cold Start Slot Filling and Slot Filler Validation Systems by IRT SystemX. Text AnalysisConference, National Institute of Standards and Technology, Nov 2016, Gaithersburg, Maryland,United States. �hal-01571795�

TAC KBP 2016 Cold Start Slot Filling and Slot Filler Validation Systems byIRT SystemX
Rashedur Rahman (1,2,3), Brigitte Grau (2,3,4), Sophie Rosset (2,3),Yoann Dupont (5), Jeremy Guillemot (1), Olivier Mesnard (1),
Christian Lautier (5), Wilson Fred (5)
(1) IRT SystemX (2) LIMSI, CNRS (3) University Paris Saclay (4) ENSIIE (5) Expert System [email protected], [email protected], [email protected]
Abstract
This paper describes the participation of IRTSystemX at TAC KBP 2016, for the twotracks, CSSF and SFV (filtering and ensem-ble). We have submitted 4 runs for each trackof SFV which are our first submission and thissubmissions are applicable for only cold startmonolingual English SF/KB runs (for both fil-tering and ensemble). The classifier modelswe use for SFV track are the same for bothfiltering and ensemble task.
1 Introduction
This year IRT SystemX participates at TAC KBPevaluation task for two tracks: cold start monolin-gual English slot filling (English CSSF) and SFV(monolingual English). We submit three runs forCSSF and four runs for SFV filtering and ensemble.Our SF system first processes the collection in orderto build a knowledge graph based on NER, sentencesplitting, relation extraction and entity linking. Wethen perform SF query in this graph for collectingthe candidate fillers that are submitted to a binaryclassifier to decide if they are correct or wrong byextracting features from the knowledge graph.
Our SFV system is also developed based on a bi-nary classifier that uses some voting, linguistic andglobal knowledge features to validate a slot fillerby analyzing the information provided in the SF re-sponse and the knowledge graph.
We incorporate a common technique for bothtasks (SF and SFV) which is community graphbased relation validation (?). Let, a graph G =(V,E), query relation (slot) Rq, query entity vqεV ,
candidate filler-entities Vc = {vc1, vc2, . . . , vcn}εVwhere Rq = e(vq, vc)εE. The candidate list is gen-erated based on the extracted relations. Supposeother semantic relations RoεE where Ro 6= Rq. Wedefine the task to classify whether a filler-entity c ofCv is correct or wrong for a query relation (Rq) byanalyzing the communities of query entity and can-didate fillers where a community is built with a setof entities which are mostly inter-related.
Barack Obama
DX
C
Figure 1: Community graph
alan gross judy gross
Doc-1
Alan Gross Judy
name.first name.firstname.last
per:parents 0.5
per:spouse 0.7
IN_SAME_SENTENCE
per:parents 0.5
Sentence-1
per:spouse 0.7
Figure 2: Knowledge graph

Fig. 1 shows an example of community basedrelation validation task where the query entity,type and slot name are Barack Obama, personand spouse accordingly. The slot filler candidatesare Michelle Robinson and Hilary Clinton that arelinked to Barack Obama by spouse relation hypoth-esis. The communities of Barack Obama (greenrectangle), Michelle Robinson (purple circle) andHilary Clinton (orange ellipse) are constructed byin same sentence relation which means the pair ofentities are mentioned in the same sentences in thetexts. We want to classify Michelle Robinson as thecorrect slot filler based on community analysis.
2 Corpus processing
This section describes some preprocessing on theKBP evaluation corpus that we use in our SF andSFV systems.
2.1 Named Entity Recognition andClassification
We used Expert System France’s proprietary frame-work Luxid1 to extract named entities in text. Be-fore extracting NEs, Luxid first uses the XeLDAframework (?) to process input text up to thePOS tagging, which provides a rich morphosyn-tactic analysis. NER is then done by rules usingXeLDA as the most basic information and outputsstructured NEs. For example, the system will findthe person President B. Obama with the follow-ing components: title=president, firstName=B., last-Name=Obama. The biggest problem in KBP tasksbeing silence, improving the recall of the NER wasthe first step. To this effect, we extracted variouslexica: a location lexicon from Geonames (?) anda first name lexicon using Yago3 (?) and removedentries that were too ambiguous or too noisy. We re-moved entries that were present in wiktionary’s fre-quency lists2 stripped of already known entities, thisallows to filter the most ambiguous words. Then,we checked if they were ambiguous with commonnouns. This process also allowed us to generate alist of terms that are ambiguous between differenttypes of entities (for example Paris can be both a first
1http://www.expertsystem.com/fr/2en.wiktionary.org/wiki/Wiktionary:
Frequency_lists
name and a location) that would be disambiguatedwith specific rules.
Luxid also has an annotation propagation systemat document level that allows it to retrieve more en-tities. It would include examples such as the personBarack Obama being propagated to B. Obama.
We also had a scope problem and could not yieldsome relations. For example, in Luxid, the title ofa person is one of its components, not an entity ofits own (meaning that president is not extracted un-less there is a more reliable entity next to it such asB. Obama). Since we modeled relations betweenentities and not components, we could not extractthe relation ”per:title”, despite having the informa-tion. Some entities were not extracted at all, suchas facilities and religion or political affiliation. Weare working on those issues, but could not integratethem for KBP.
In addition we used a fusion of Luxid and Stan-ford NERs specially for SFV task that increased therecall. When an entity is detected by both Luxidand Stanford we accept only the Luxid detected en-tity because luxid gives additional information aboutthe entity (such as, first name and last name compo-nents). However, we used only Luxid for detectingnamed entities in the CSSF system.
2.2 Relation Detection
The great variability of ways to state a fact or a rela-tion in natural language leads us to prefer a systembased on learning than a ruled based system to ex-tract relation. On the other hand, supervised learningsystems need large corpus of text with annotationsof relation. The cost of such resource exceed thebudget of our project and in the perspective of sub-mission to multilingual track, we predict that distantsupervision is the most rational choice.
In this section, we describe our system for extrac-tion of relation between mentions, which uses mul-tiR (?) with distant supervision (?).
2.2.1 Training DataAs a first step we have built a repository of facts
that conforms to KBP model. Our first attempt tobuild such a repository relied on FreeBase (?) how-ever too many types of relation were missing. Thefacts are now extracted from Wikidata (?) : we havequeried Wikidata to get the most complete set of

Wikidata types (and subtypes) which maps to KBPtypes and relation types. We then parsed a dumpof Wikidata and checked every relation between twoentities to test if it is conform to a KBP model. Ifthis is the case, we insert the entities (if they do notalready exist) and the relation in the KBP reposi-tory. As a second step we build a corpus of sen-tences which express KBP relations. We used thesource texts of TAC-KBP 2014 (news, blog, forum)corpus (?) to automatically produce a corpus anno-tated with relations. We used our NER system to de-tect entities mentions and sentences boundaries. Assoon as two entities mentioned in the same sentenceare in relation in the repository of facts, we select thesentence and add it to the corpus with an annotationwhich reflects the fact(s) in the repository.
In run#1, we use facts from FreeBase to producea first model for 8 relations. In run#2, we use factsfrom Wikidata to produce a second model for 25 re-lations.
We notice that about nine tenth of sentences didnot express the relation. In spite of this high level ofnoise, we decided no to filter or enhanced the repos-itory of facts as done in ?).
2.2.2 Machine Learning ModelWe use MultiR with distant supervision to score
relation hypotheses between entity mentions. ?)emits the hypothesis that different sentences mayexpress different relations for the same couple ofentities, such as founder of(Jobs,Apple Inc.) andceo of(Jobs,Apple Inc.). His proposition combinesthe following:
• the extraction of relation(s) at corpus level,that is the types of relation between a givenpair of entities. For the previous example,it would be founder of(Jobs,Apple Inc.) andceo of(Jobs,Apple Inc.).
• the extraction of a relation at sentence level,that is identifying the relation that is expressedbetween two entities in a given snippet (ornone).
The model is both a joint probability over two ran-dom variables:
• Y, the variable modeling the set of relationtypes between two entities at corpus level and,
• Z, the variable modeling the set of relations in-stances between two entities at sentence level
and a conditional probability as is defined by theequation 1.
p(Y = y, Z = z|x; θ) =1
Zx
∏r
φjoin(yr, z)∏i
φextract(zi, xi)
(1)Where Zx is a normalization factor, φjoin is an in-
dicator function as defined in equation 2 and φextract
take the form of the equation 3.
φjoin(yr, z) =
{1 if yr = true ∧ ∃ i : zi = r0 otherwise
(2)
φextract(zi, xi) = exp(Σjθjφj(zi, xi) (3)
The idea is that the training is going to be con-strained by facts (in this case, y), but allows moreflexibility for latent variables Zi that can take mul-tiple values for a given couple of entities dependingon the sentence.
The dependencies between x and y are shown infigure 3.
Figure 3: dependencies between variables Y and Z
2.2.3 TrainingTraining is done inline, with iteration on each tu-
ple i.
• for the set of all sentences that mentions the tu-ple, zi’ is computed as the most likely z (with-out taking into account the fact yi). Then a mostlikely value yi’ is computed taking into accountdependencies.

• If yi’ and yi differs, we must slightly changethe model: zi* is computed taking into accountyi as a constraint. We alter the model of delta,as the difference between features for zi* andfeature for zi’.
2.2.4 FeaturesWe used most features mentioned by ?) with
some some differences. We used lemmatization, as?) did not use it. For each kind of feature, we usedthree variants: one using the word themselves, thesecond one using their POS tags and the last onetheir lemmas.
We did not use the combination features in oursystem as ?) did. We think that is the main reasonwhy we cannot manage to discriminate relations.
We also added different filters for words betweentwo entities, such as nouns or verbs.
We were in the process of adding dependencybased features (dependency path, words, lemmas,filtered words, etc.), but did not manage to integratethem in time for the runs.
2.2.5 InferenceWe did not use MultiR to infer relations at corpus
level (i.e. Y), rather only to learn how to infer valuesat sentence level (i.e. Z). The objective of our exper-iment was to consider a great set of different featuresat mention level and to study how to combine themto produce the best hypothesis at entity level in SFV.
2.3 Knowledge Graph and Community GraphGeneration
We generate a knowledge graph as illustrated inFig.2 after applying named entity recognition, sen-tence splitting and relation extraction on the eval-uation corpus. The knowledge graph representsthe documents, sentences, mentions and entities asnodes and relations among these are denoted byedges. The edge between two entities also holds theMultiR relation hypothesis (found at mention level)and the confidence score.
We also create a community graph (Fig. 1) basedon the entity level information in the knowledgegraph. Since the community graph is constructedbased on the knowledge graph, the semantics aremaintained in the community graph. We includeperson, location and organization typed entities as
the community members in our community-graph-based analysis.
In the knowledge graph multiple mentions of thesame entity (found in the same document) are linkedto a common entity node. In many cases an en-tity is mentioned in different documents in vari-ous forms (for example, Barack Obama, PresidentBarack Obama, President Obama etc) that create re-dundant entity nodes in the knowledge graph. Wedetect such kind of entity nodes based on commu-nity analysis and consolidate them into a single en-tity node by keeping references of the mentions, sen-tences and documents.
3 Global Knowledge Graph Features
We assume that a correct filler-entity of a SF queryshould be a strong member in the community ofthe query entity and such community can be ex-tracted from the texts by extracting semantic rela-tions and/or based on their existences in the samesentences. We hypothesize that the network density(eq. 4) of a community of a correct filler-entity withthe query entity should be higher than a commu-nity of an incorrect filler-entity with the query entity.In Fig. 1 the community of Michelle Robinson withBarack Obama is more dense than the community ofHilary Clinton.
ρnetwork =number of existing edges
number of possible edges(4)
cosine similarity =|X ∩ Y |√|X||Y |
(5)
where, X and Y are the set of community-members of query and filler entity accordingly
MI(X,Y ) = H(X) +H(Y )−H(X, Y ) (6)
where,H(X) = −n∑
i=1
p(xi) log2(p(xi)),
X and Y are the communities of query and filler entity accordingly
and p(x) refers to the probability of centrality degree of a community-member
Eigenvector centrality (?) measures the influenceof a neighbor node to measure the centrality of anode in a community. We quantify the influence ofthe candidate fillers in the community of a query en-tity by calculating the absolute difference betweenthe eigenvector centrality scores of the query entityand a filler entity. We hypothesize that the differ-ence should be smaller for a correct filler than an

incorrect filler. We also hypothesize that the mutualinformation (eq. 6) and similarity (eq. 5) betweenthe community of a correct filler and the communityof the query entity should be higher than an incor-rect filler. The community of an entity (query entityor a candidate filler-entity) is expanded up to level 3for measuring the eigenvector centrality and mutualinformation.
4 CSSF System Overview
The system we used for CSSF works in two steps.The first step extracts relation hypotheses related
to the query entity mentions at sentence level basedon their respective types, following the KBP model.In other words, for one given couple of entity men-tions, we only generate as hypotheses the subset ofthe KBP relations that takes the respective mentiontypes as argument.
The second step consolidates relation hypothesesat mention level to find a relation candidate at entitylevel, using graph based features to decide whichis the best one between a given couple of entities.We first create entities as clusters of entity mentions,some being merged and others discarded in the pro-cess. We then use a trained classifier to rank theset of relations hypotheses and select the most likelyone. A set of features was used in the classifier:MultiR score of hypothesis, frequency of hypothe-sis, centrality of nodes in the graph.
4.1 Runs
Three runs were submitted. Both run#1 and #2 arebased on a 25-relations detection module. Run#1makes use of a light version of the consolidation stepwhile Run#2 make use of the complete one exceptfor the centrality computation that was made at rank1 only. Run#3 is based on a very simple 8-relationsdetection module.
Our system got few correct answers. This can beexplained by many factors: the low performance ofour first processing stage (entity recognition, clas-sification of relation between mentions) and the nocompletions of some work (our model take into ac-count only 25 relations among 43 from the KBPmodel). The main benefit of this work was to setupa global architecture for a KBP system and we planto focus on enhancing every parts in the future.
4.2 Perspectives
We plan to improve our system by first analyzingthe errors using a finer and finer grain: starting fromNER up to the relation hypothesis at entity level.We also plan to include more features in our re-lation extraction system, starting with dependency-based features. Improving the distant learning pro-cedure is planned as well: first, by using the pseudo-relevance relation feedback described by ?) andstudying deeper the role of negative examples. Weplan to reduce the silence also, by extracting enti-ties such as religion and political parties, as well asincluding coreference resolution in our system.
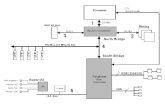
5 SFV System Overview
We develop our SFV system based on validating re-lation between the query entity and filler value byanalyzing the SF system responses (relation prove-nance text, filler, system and confidence scores) andknowledge at the corpus level. We use voting, lin-guistic and global knowledge based features for SFVtask. The voting features include filler, source-document, system credibility and confidence score.Basically we build classifier models for validatingrelations between a query and filler entity. We usethe same classifier models for both SFV filtering andensemble tasks.
Our SFV system basically contains three levels:1. input file processing 2. feature extraction and 3.binary classification. Figure 4 illustrates the differ-ent levels of the SFV system.
Input file processing: all the system responses(input for SFV task) are merged into a single fileand the responses are grouped into individual filesregarding the query ids.
Feature extraction: at this level, we generatea feature vector for each response of a query byanalyzing the relation provenance text, system-ids,document-ids and filler values.
Binary classification: finally each response isclassified as correct or wrong by using a pre-trainedclassifier.
Our system decides the best filler for a single-valued slot based on the confidence score resulted bythe classifier model. Moreover, the redundant fillersare resolved by simple string matching technique.

System-1 Responses
System-2 Responses
System-MResponses
…
Merged System Responses
Query-1 Responses
Query-2 Responses
Query-NResponses
…
Single Response
Filler and DocumentCredibility
Linguistic and Graph Features
System Credibility
Feature Vector(single response)
Binary Classification
1,2,3…L
ConfidenceScore
Figure 4: Slot Filler Validation System
5.1 SFV Features
In our SFV system we use three groups of featuresfor training the relation validation classifier modelsand validating responded slot fillers. The featuregroups are linguistic, graph and voting (includingconfidence score) that are briefly discussed below.
5.1.1 Linguistic FeaturesUsually the relation between a pair of entities is
expressed by texts at the sentence level. We ex-tract the corresponding sentence(s) of a slot filler re-sponse and perform some linguistic analysis to de-cide if the relation holds or not. Our linguistic anal-ysis includes semantic and syntactic feature extrac-tion. We analyze the seed words for characterizingthe semantic of a relation. On the other hand, weuse some dependency pattern based features for SFVtask that includes dependency pattern length, clausedetection and dependency pattern edit distance.
5.1.2 Graph FeaturesWe analyze the community of a query entity and
the candidate filler entities to decide if they supportthe claimed relation or not. We measure some cen-trality based on the community analysis as discussedin Section 3. Additionally the similarity and densityof the communities are calculated as the SFV fea-tures.
5.1.3 Voting and Confidence ScoresOur SFV system takes into account some voting
features by calculating the credibility of the fillervalues, reference documents and systems based onall the responses of a query. Moreover, we use theconfidence score as a feature given by the system fora slot filling response.
5.2 Training Data and Machine LearningModels
We prepared the training data by processing the as-sessments of cold start slot filling responses of 2014and 2015. Basically our system learns the triggerwords and dependency patterns by analyzing the re-lation provenance texts of 2014 SF responses. Weuse the assessment data of 2015 slot filling responsesfor training four classifier models. These modelsvalidate a relation that is claimed by a SF response(query entity, filler value and the relation provenancetext) as correct or wrong.
Basically we extract the text-snippets based onthe relation provenance offset of the slot filling re-sponses. Then the snippets are separated into twocategories: positive and negative according to theirrelation provenance assessment. If the assessment ofrelation provenance offset is correct (C) (when thefiller is correct or inexact) for a slot filling responsethe relation provenance snippet is considered as apositive snippet. Otherwise, the snippet is countedas negative. Then we generate the feature vectorsof the slot filling responses and build classifier mod-els. We notice that around 2, 000 round-1 SF queriesof 2015 KBP CSSF were assessed by NIST wherearound 50% of the queries were responded by bothcorrect and wrong fillers. We compile our experi-mental data set from the responses of these queries.We also notice that there are a lot of responses thathave the same feature vector. Therefore, the dupli-cate vectors have been removed from the dataset.Moreover, our system is not able to extract linguis-tic features for some of the slot filling responses.We classify these responses by using only the fea-tures based on voting and confidence score. Oneof the classifier models we build by using voting,linguistic and graph features together though graphfeatures are extracted from very few CSSF/KB re-sponses. The classifier assigns mean values for themissing attributes in the feature vectors for whichgraph features are not available.
We train the Random Forest (?) classifier in Weka(?) to build 4 models regarding different feature sets.Model-1 includes voting, linguistic and communityanalysis. Model-2 excludes the community basedfeatures of Model-1. On the other hand, Model-3and Model-4 use only the linguistic and voting fea-

tures accordingly.
5.3 Experiment and ResultsWe have submitted 4 SFV (filtering) and 4 SFV (en-semble) runs according to the classifier models de-scribed in Section 5.2. This submissions are foronly Cold Start monolingual English SF/KB runs.
We evaluate our classifier models by measuringthe performances of relation validation on a test cor-pus, which is a part of 2015 data. Table 1 shows thestatistics of training and test instances for relationvalidation task and Table 2 depicts the precision, re-call and F-score regarding the classification task. Weobserve that linguistic features improves the F-scoresignificantly over the voting features. The graphfeatures does not improve the classification perfor-mance significantly over linguistic features becauseour system is not able to extract graph features forall the SF responses. Graph features are extractedfor a limited number of responses that counts around5, 000 responses from 260 queries.
Model Training Testvoting 25,390 6,348linguistic 26,280 6,552voting + linguistic 26,280 6,552voting + linguistic + graph 26,280 6,552
Table 1: Statistics of training and test data set for differentmodels
Feature Set P R Fvoting 93.1 93.1 93.1linguistic 83.3 83.8 83.4voting + linguistic 94.4 94.4 94.4voting + linguistic + graph 94.5 94.5 94.5
Table 2: Classification performances of different models(in %)
We have submitted 4 runs for SFV (ensem-ble) task that use different feature sets for validat-ing relations: Run#1(voting + linguistic + graph),Run#2(voting + linguistic), Run#3 (linguistic) andRun#4(voting). Figure 5 depicts the official score ofSFV (ensemble) task. Run#2 achieves the highest F-score (24.79) among 4 runs. We compare this scoreto the CS KB/SF runs by different systems as shown
27
,89
29
,73
23
,12 2
6,7
1
14
,63
14
,04
10
,83
7,3
9
23
,9
24
,79
19
,46
19
,49
32
,05
33
,97
27
,47
38
,4
14
,37
14
,66
10
,85
12
,61
26
,13
27
,5
21
,91
29
,76
24
,69
26
,44
19
,96
20
,47
14
,89
13
,48
10
,82
5,2
3
22
,02
22
,56
17
,5
14
,48
0
5
10
15
20
25
30
35
40
Run-1 Run-2 Run-3 Run-4 Run-1 Run-2 Run-3 Run-4 Run-1 Run-2 Run-3 Run-4
Precision Recall F-Score
hop-0 hop-1 all
Figure 5: SFV (ensemble) official score
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
1,1
0 10 20 30 40 50 60 70
F-sc
ore
rat
io
CS KB/SF systems
Figure 6: Ratio of CS KB/SF F-scores to IRT SystemXSFV (ensemble) submission (Run#2)
in Figure 6. We calculate the ratio of F-score of CSKB/SF runs to our best SFV ensemble run. Onlyfour CS KB/SF runs obtain higher F-score than ourSFV ensemble run.
6 Conclusion
In this paper we present the TAC KBP2016 CSSFand SFV system by IRT SystemX. We apply a graphbased relation validation method for selecting thecorrect slot filler(s) among several candidates. TheSF system uses distant supervision for extracting re-lations by using MultiR. Our current SF system islimited to extracting 25 KBP relations and has tobe improved to extracting all the KBP relations de-fined by TAC. On the other hand, the SFV systembuilds some binary classification models based onseveral features that include global knowledge, lin-guistic and voting features. We submit SFV runs for

the first time ever. Our current SFV system is notefficient enough to filter out redundant fillers whichhas to be improved in the future.
ReferencesKurt Bollacker, Colin Evans, Praveen Paritosh, Tim
Sturge, and Jamie Taylor. 2008. Freebase: a col-laboratively created graph database for structuring hu-man knowledge. In Proceedings of the 2008 ACMSIGMOD international conference on Management ofdata, pages 1247–1250. ACM.
Phillip Bonacich and Paulette Lloyd. 2001. Eigenvector-like measures of centrality for asymmetric relations.Social networks, 23(3):191–201.
Mark Hall, Eibe Frank, Geoffrey Holmes, BernhardPfahringer, Peter Reutemann, and Ian H Witten. 2013.The weka data mining software: An update; sigkdd ex-plorations, volume 11, issue 1, 2009. Reproduced withpermission of the copyright owner. Further reproduc-tion prohibited without permission.
Raphael Hoffmann, Congle Zhang, Xiao Ling, LukeZettlemoyer, and Daniel S. Weld. 2011. Knowledge-based weak supervision for information extraction ofoverlapping relations. In Proceedings of the 49th An-nual Meeting of the Association for ComputationalLinguistics: Human Language Technologies - Volume1, HLT ’11, pages 541–550, Stroudsburg, PA, USA.Association for Computational Linguistics.
Andy Liaw and Matthew Wiener. 2002. Classificationand regression by randomforest. R News, 2(3):18–22.
Farzaneh Mahdisoltani, Joanna Biega, and FabianSuchanek. 2014. Yago3: A knowledge base frommultilingual wikipedias. In 7th Biennial Conferenceon Innovative Data Systems Research. CIDR Confer-ence.
Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky.2009. Distant supervision for relation extraction with-out labeled data. In Proceedings of the Joint Confer-ence of the 47th Annual Meeting of the ACL and the4th International Joint Conference on Natural Lan-guage Processing of the AFNLP: Volume 2-Volume 2,pages 1003–1011. Association for Computational Lin-guistics.
Herve Poirier. 1999. The xelda framework. In Baslowworkshop on Distributing and Accessing LinguisticResources, pages 33–38. Sheffield.
Rashedur Rahman, Brigitte Grau, and Sophie Rosset.2016. Graph based relation validation method. InInternational Conference on Knowledge Engineeringand Knowledge Management, EKAW.
Mihai Surdeanu and Heng Ji. 2014. Overview of the en-glish slot filling track at the tac2014 knowledge base
population evaluation. In Proc. Text Analysis Confer-ence (TAC2014).
Bernard Vatant and Marc Wick. 2012. Geonames ontol-ogy.
Denny Vrandecic and Markus Krotzsch. 2014. Wiki-data: a free collaborative knowledgebase. Communi-cations of the ACM, 57(10):78–85.
Wei Xu, Raphael Hoffmann, Le Zhao, and Ralph Grish-man. 2013. Filling knowledge base gaps for distantsupervision of relation extraction. In ACL (2), pages665–670.