
Formal verification Marco A. Peña Universitat Politècnica de Catalunya.
Upload
jack-dennisCategory
view
217download
0
Synthesis of Embedded Software for Reactive Systems
Jordi CortadellaUniversitat Politècnica de Catalunya, Barcelona
Joint work with:
Robert Clarisó, Alex Kondratyev, Luciano Lavagno, Claudio Passerone and Yosinori Watanabe (UPC, Cadence Berkeley Labs, Politecnico di Torino)
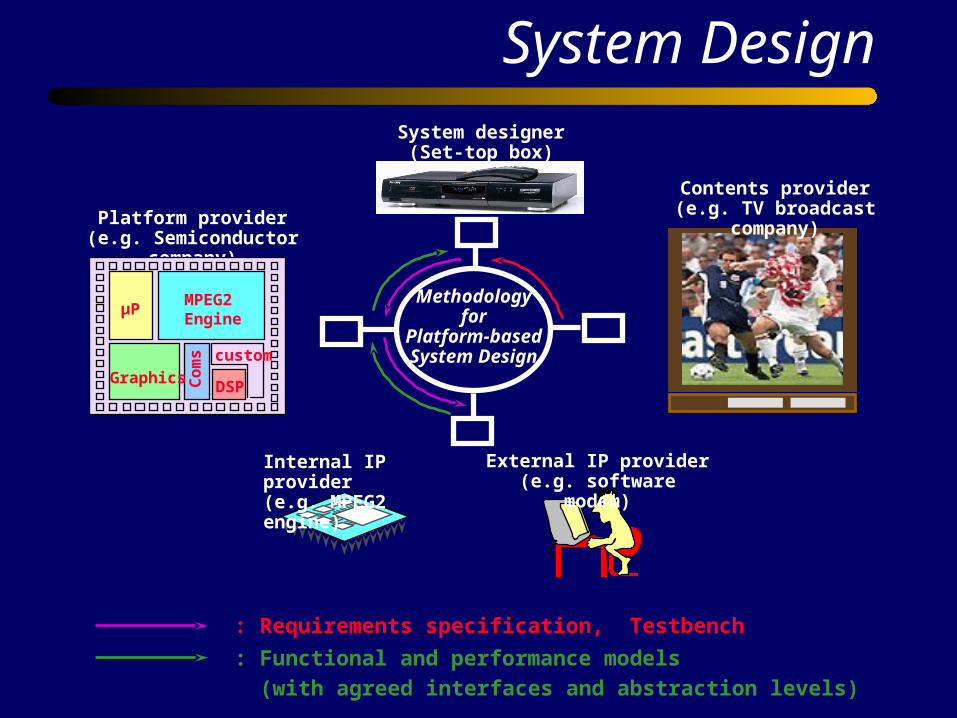
System Design
External IP provider(e.g. software modem)
Internal IP provider(e.g. MPEG2 engine)
System designer(Set-top box)
Contents provider(e.g. TV broadcast company)
Methodologyfor
Platform-basedSystem Design
Platform provider(e.g. Semiconductor company)
µP
DSPCom
s
MPEG2Engine
customGraphics
: Requirements specification, Testbench
: Functional and performance models
(with agreed interfaces and abstraction levels)

etropolisMetropolis Project
• Goal: develop a formal design environment– Design methodologies: abstraction levels, design problem formulations
– EDA: formal methods for automatic synthesis and verification,
a modeling mechanism: heterogeneous semantics, concurrency
• Participants:– UC Berkeley (USA): methodologies, modeling, formal methods
– CMU (USA): formal methods
– Politecnico di Torino (Italy): modeling, formal methods
– Universitat Politècnica de Catalunya (Spain): modeling, formal methods
– Cadence Berkeley Labs (USA): methodologies, modeling, formal methods
– Philips (Netherlands): methodologies (multi-media)
– Nokia (USA, Finland): methodologies (wireless communication)
– BWRC (USA): methodologies (wireless communication)
– BMW (USA): methodologies (fault-tolerant automotive controls)
– Intel (USA): methodologies (microprocessors)
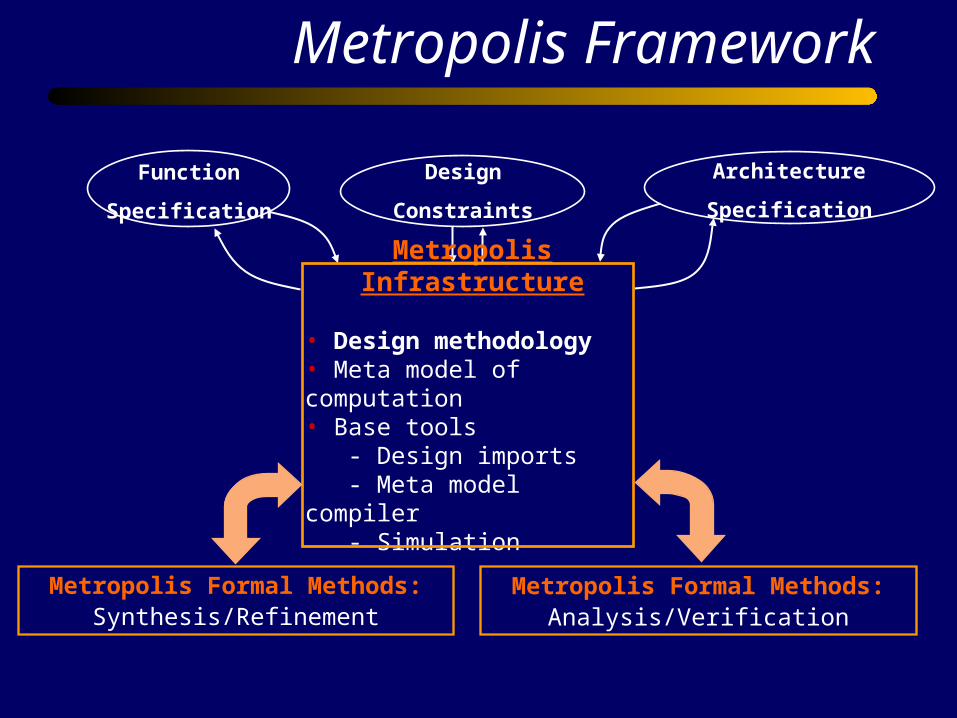
Metropolis Framework
Design
Constraints
Function
Specification
Architecture
Specification
Metropolis Infrastructure
• Design methodology• Meta model of computation• Base tools - Design imports - Meta model compiler - Simulation
Metropolis Formal Methods:Synthesis/Refinement
Metropolis Formal Methods:Analysis/Verification

Outline
• The problem– Synthesis of concurrent specifications
for sequential processors
– Compiler optimizations across processes
• Previous work: Dataflow networks– Static scheduling of SDF networks
– Code and data size optimization
• Quasi-Static Scheduling of process networks– Petri net representation of process networks
– Scheduling and code generation
• Open problems
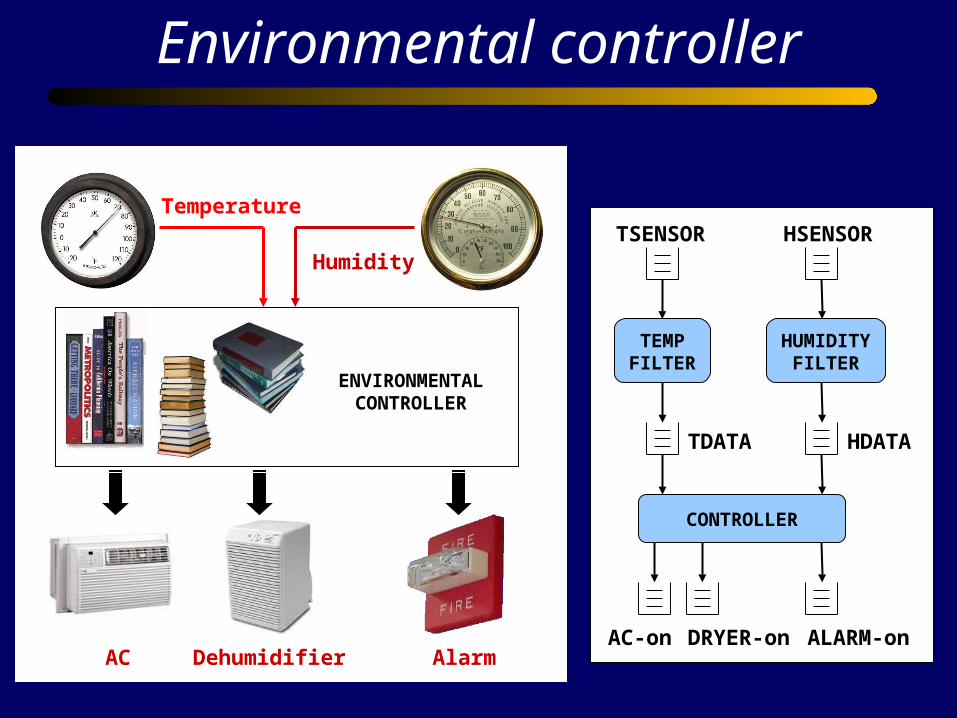
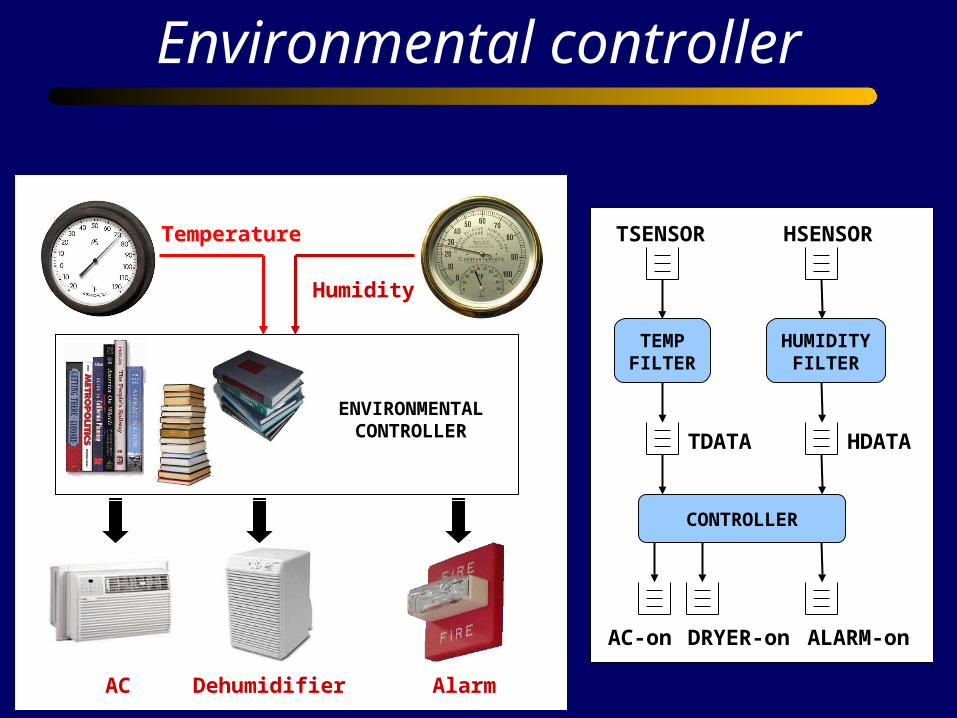
Environmental controller
AC Dehumidifier Alarm
Temperature
Humidity
ENVIRONMENTALCONTROLLER
TEMPFILTER
HUMIDITYFILTER
CONTROLLER
TSENSOR HSENSOR
HDATATDATA
AC-on DRYER-on ALARM-on
Environmental controller
TEMPFILTER
HUMIDITYFILTER
CONTROLLER
TSENSOR HSENSOR
HDATATDATA
AC-on DRYER-on ALARM-on
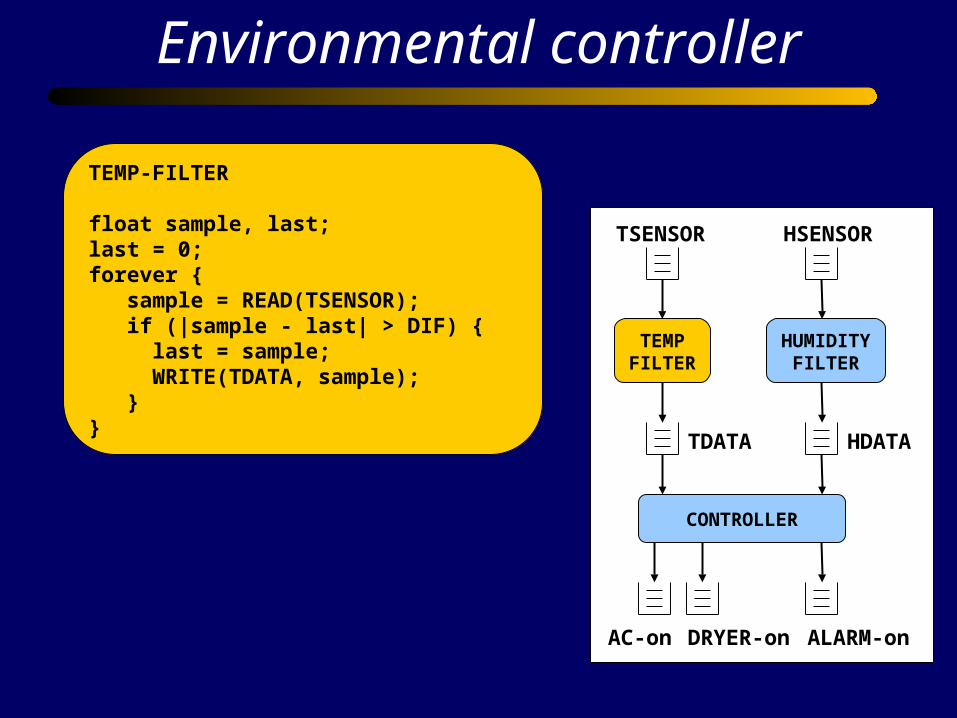
TEMP-FILTER
float sample, last;last = 0;forever { sample = READ(TSENSOR); if (|sample - last| > DIF) { last = sample; WRITE(TDATA, sample); }}
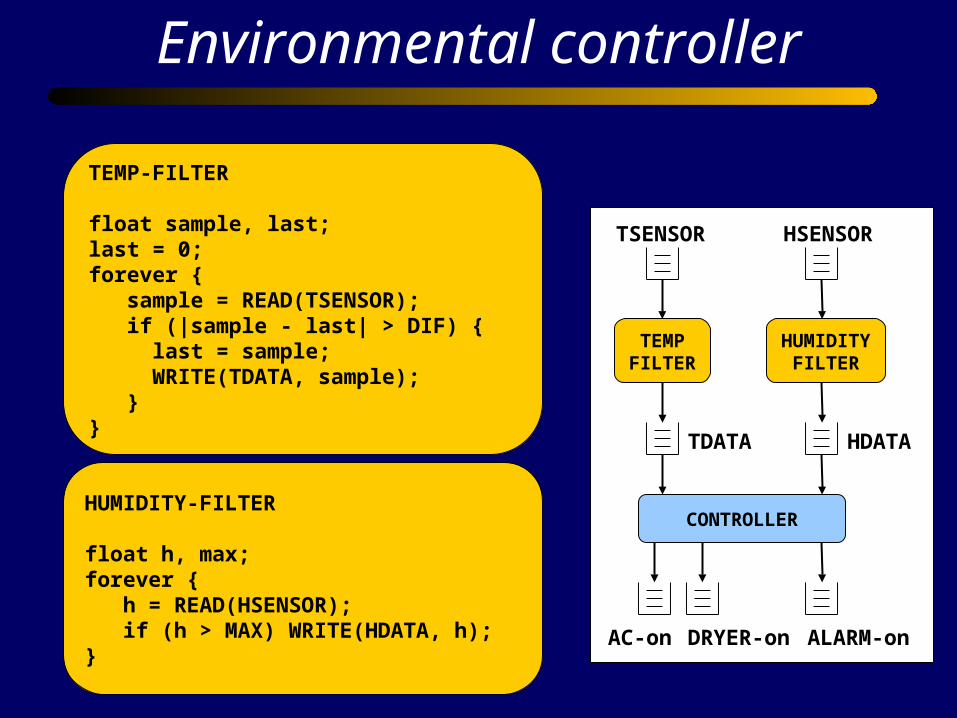
Environmental controller
TEMPFILTER
HUMIDITYFILTER
CONTROLLER
TSENSOR HSENSOR
HDATATDATA
AC-on DRYER-on ALARM-on
TEMP-FILTER
float sample, last;last = 0;forever { sample = READ(TSENSOR); if (|sample - last| > DIF) { last = sample; WRITE(TDATA, sample); }}
HUMIDITY-FILTER
float h, max;forever { h = READ(HSENSOR); if (h > MAX) WRITE(HDATA, h);}
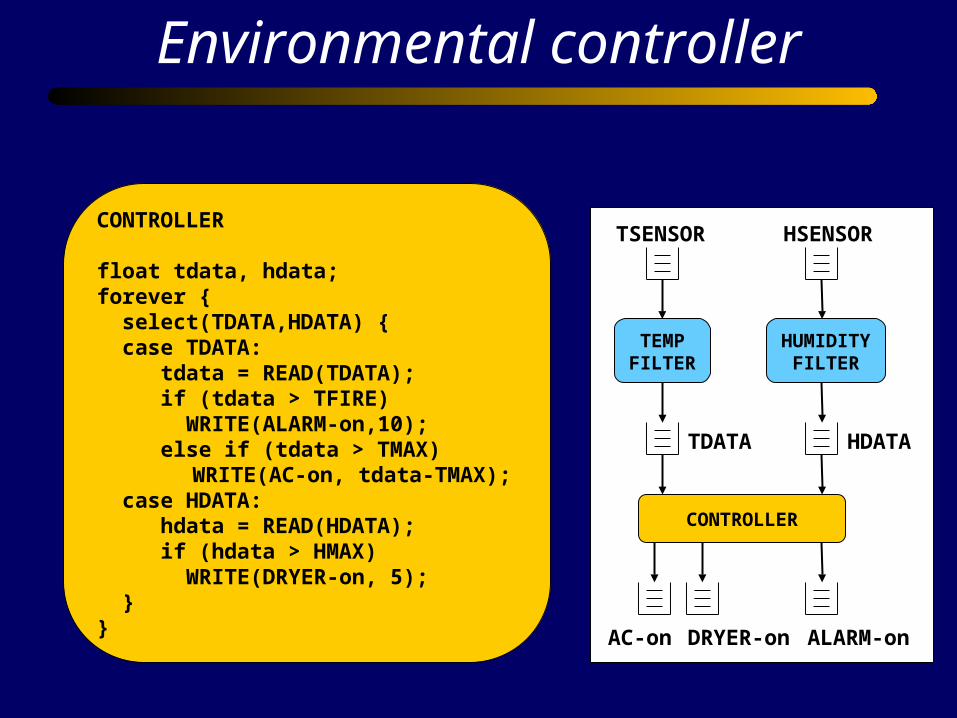
Environmental controller
TEMPFILTER
HUMIDITYFILTER
CONTROLLER
TSENSOR HSENSOR
HDATATDATA
AC-on DRYER-on ALARM-on
CONTROLLER
float tdata, hdata;forever { select(TDATA,HDATA) { case TDATA: tdata = READ(TDATA); if (tdata > TFIRE) WRITE(ALARM-on,10); else if (tdata > TMAX)
WRITE(AC-on, tdata-TMAX); case HDATA: hdata = READ(HDATA); if (hdata > HMAX) WRITE(DRYER-on, 5); }}
TEMPFILTER
HUMIDITYFILTER
CONTROLLER
TSENSOR HSENSOR
HDATATDATA
AC-on DRYER-on ALARM-on
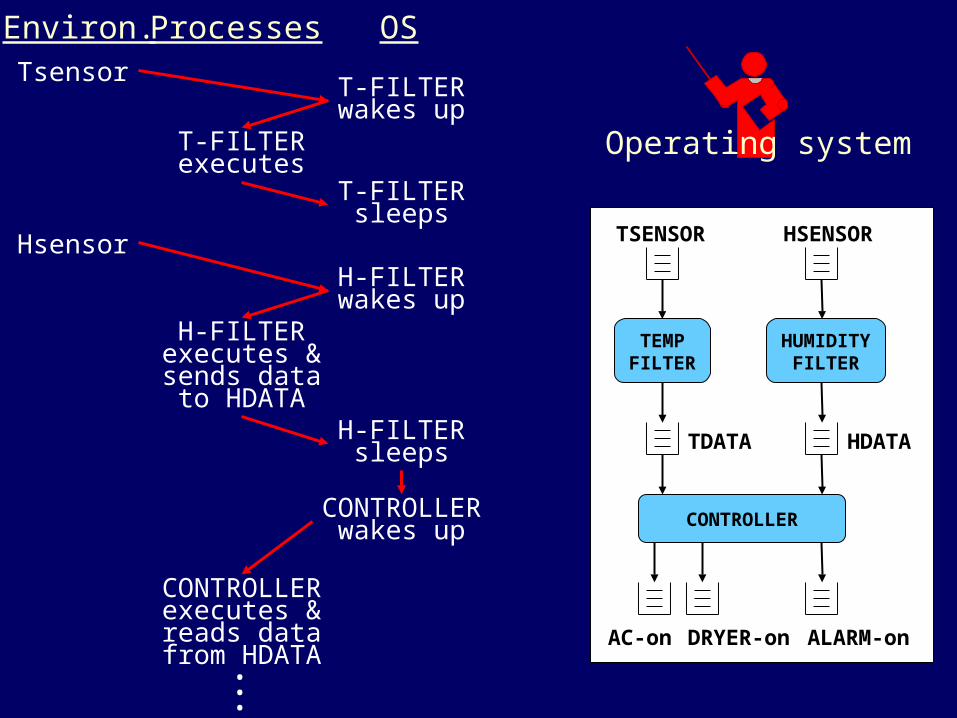
TsensorT-FILTERwakes up
T-FILTERexecutes
T-FILTERsleeps
HsensorH-FILTERwakes up
H-FILTERexecutes &sends datato HDATA
H-FILTERsleeps
CONTROLLERwakes up
CONTROLLERexecutes &reads data
from HDATA...
Environ. Processes OS
Operating system

Compiler optimizations
• Instruction level
• Basic blocks
• Intra-procedural(across basic blocks)
• Inter-procedural
• Inter-process ?
• a = b*16 a = b >> 4
• common subexpr.,copy propagation
• loop invariants,induction variables
• inline expansion,parameter propagation
• channel optimizations,OS overhead reduction
Each optimization enables further optimizations at lower levels

Partial evaluation (example)
Specification:
subsets (n,k) = n! / (k! * (n-k)!)
________________________________________________
int subsets (int n, int k)
{ return fact(n) / (fact(k) * fact(n-k)); }
int pairs (int n)
{ return subsets (n,2);}
... print (pairs(x+1)) ...... print (pairs(x+1)) ...
... print (pairs(5)) ...
Partial evaluation (compiler optimizations)

Partial evaluation (example)
Specification:
subsets (n,k) = n! / (k! * (n-k)!)
________________________________________________
int subsets (int n, int k)
{ return fact(n) / (fact(k) * fact(n-k)); }
int pairs (int n)
{ return subsets (n,2);}
... print ((x+1)*x / 2) ...... print ((x+1)*x / 2) ...
... print (pairs(5)) ...Partial evaluation (compiler optimizations)

Partial evaluation (example)
Specification:
subsets (n,k) = n! / (k! * (n-k)!)
________________________________________________
int subsets (int n, int k)
{ return fact(n) / (fact(k) * fact(n-k)); }
int pairs (int n)
{ return subsets (n,2);}
... print ((x+1)*x / 2) ...... print ((x+1)*x / 2) ...
... print (10) ...

Inter-process partial evaluation
forever {
n = read (A);
write (B,n);
write (C, n-2);
write (D, 2);}
forever {
x = read (E);
y = read (F);
z = read (G);
write (H, x/(y*z));}
x!
A
H
x!
x!
n
pairs (n)

Inter-process partial evaluation
forever {
n = read (A);
write (B,n);
write (C, n-2);
write (D, 2);}
forever {
x = read (E);
y = read (F);
z = read (G);
write (H, x/(y*z));}
x!
A
H
x!
x!
No chances for optimization

Inter-process partial evaluation
forever {
n = read (A);
write (B,n);
write (C, n-2);
write (D, 2);}
forever {
x = read (E);
y = read (F);
z = read (G);
write (H, x/(y*z));}
x!
A
H
x!
x!2...2 2...2

Inter-process partial evaluation
forever {
n = read (A);
write (B,n);
write (C, n-2);
write (G, 2);}
forever {
x = read (E);
y = read (F);
z = read (G);
write (H, x/(y*z));}
x!
A
H
x!
2...2 2...2

Inter-process partial evaluation
forever {
n = read (A);
write (B,n);
write (C, n-2);
write (G, 2);}
forever {
x = read (E);
y = read (F);
z = read (G);
write (H, x/(y*z));}
x!
A
H
x!
2...2 2...2

Inter-process partial evaluation
forever {
n = read (A);
write (B,n);
write (C, n-2);
write (G, *);}
forever {
x = read (E);
y = read (F);
read (G);
write (H, x/(y*2));}
x!
A
H
x!
• Copy propagation across processes• Channel G only synchronizes (token available)

Inter-process partial evaluation
forever {
n = read (A);
write (B,n);
write (C, n-2);
write (G, *);}
forever {
x = read (E);
y = read (F);
read (G);
write (H, x/(y*2));}
x!
A
H
x!
By scheduling operations properly, FIFOs may become variables(one element per FIFO, at most)

Inter-process partial evaluation
forever {
n = read (A);
v1 = n;
v3 = n-2;
x = v2;
y = v4;
write (H, x/(y*2));}
x!
A
H
x!
v1 v2
v3 v4
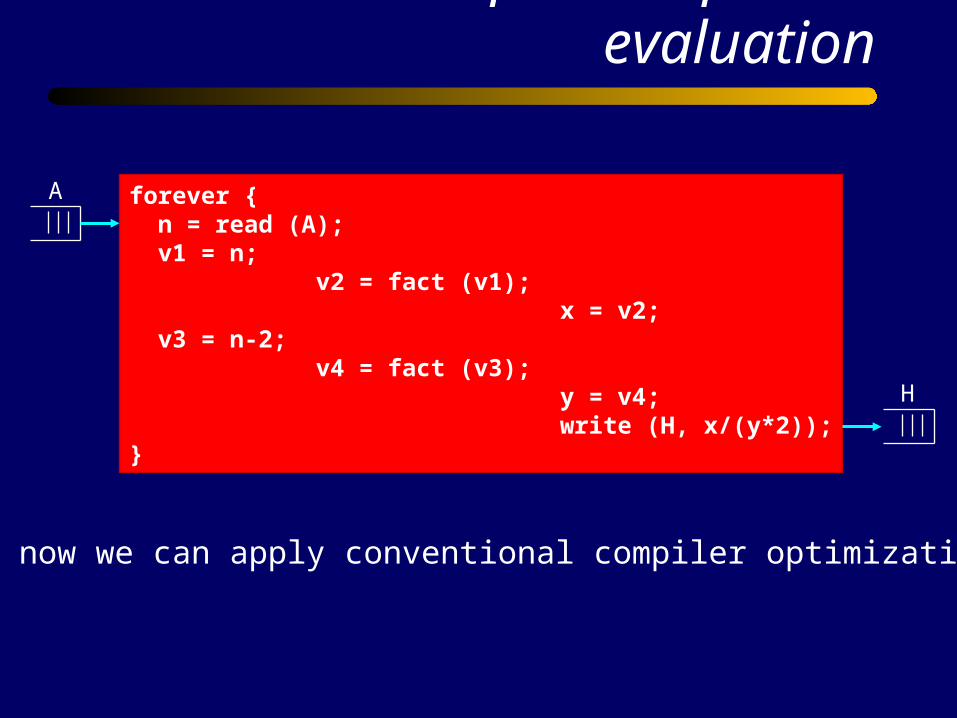
Inter-process partial evaluation
forever { n = read (A); v1 = n; v2 = fact (v1); x = v2; v3 = n-2; v4 = fact (v3); y = v4; write (H, x/(y*2));}
A
H
And now we can apply conventional compiler optimizations
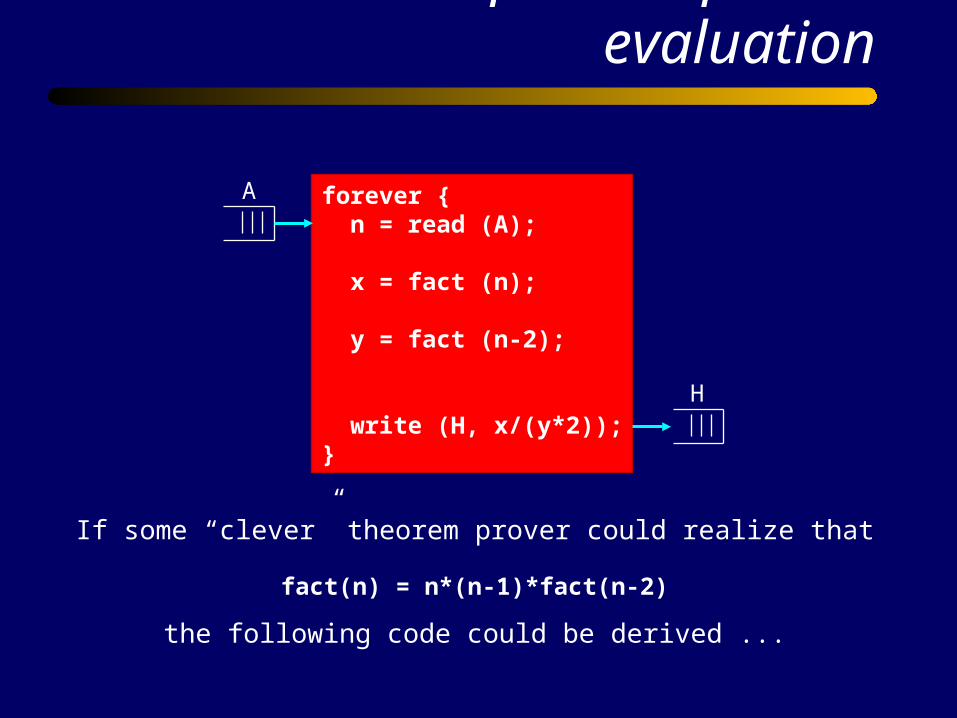
Inter-process partial evaluation
forever { n = read (A); x = fact (n); y = fact (n-2);
write (H, x/(y*2));}
A
H
If some “clever” theorem prover could realize that
fact(n) = n*(n-1)*fact(n-2)
the following code could be derived ...

Inter-process partial evaluation
forever {
n = read (A);
write (H,n*(n-1)/*2);
}
A
H

Inter-process partial evaluation
forever {
n = read (A);
write (B,n);
write (C, n-2);
write (D, 2);}
forever {
x = read (E);
y = read (F);
z = read (G);
write (H, x/(y*z));}
x!
A
H
x!
x!
This was the original specification of the system !

Inter-process partial evaluation
This is the final implementation after inter-process optimization:
• Only one process (no context switching overhead)
• Channels substituted by variables (no communication overhead)
forever {
n = read (A);
write (H,n*(n-1)/*2);
}
A
H
TEMPFILTER
HUMIDITYFILTER
CONTROLLER
TSENSOR HSENSOR
HDATATDATA
AC-on DRYER-on ALARM-on
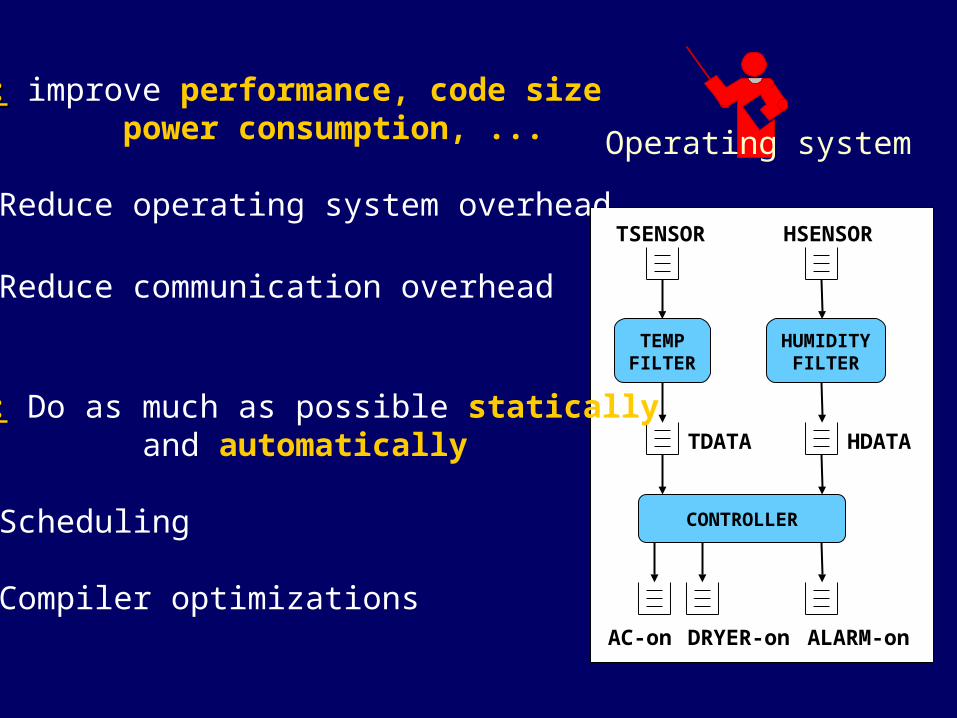
Operating system
Goal:Goal: improve performance, code size power consumption, ...
• Reduce operating system overhead
• Reduce communication overhead
How?: Do as much as possible statically and automatically
• Scheduling
• Compiler optimizations

Outline
• The problem– Synthesis of concurrent specifications
– Compiler optimizations across processes
• Previous work: Dataflow networks– Static scheduling of SDF networks
– Code and data size optimization
• Quasi-Static Scheduling of process networks– Petri net representation of process networks
– Scheduling and code generation
• Open problems

Dataflow networks
• Powerful mechanism for data-dominated systems
• (Often stateless) actors perform computation
• Unbounded FIFOs perform communication via sequences of tokens carrying values– (matrix of) integer, float, fixed point– image of pixels, …..
• Determinacy: – unique output sequences given unique input sequences
– Sufficient condition: blocking read(process cannot test input queues for emptiness)
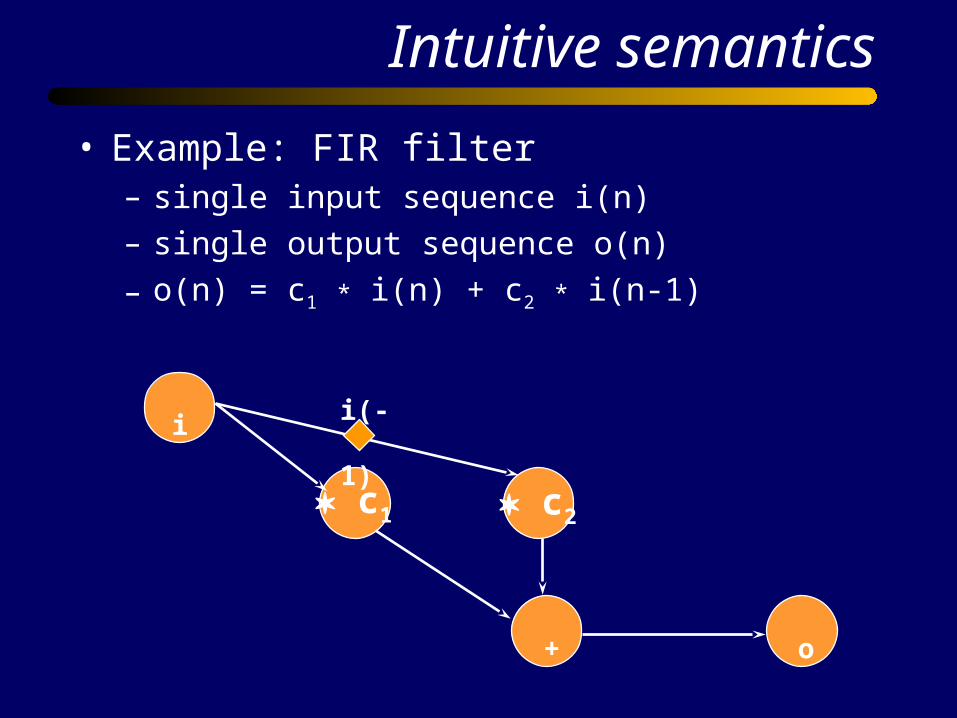
Intuitive semantics
• Example: FIR filter– single input sequence i(n)
– single output sequence o(n)
– o(n) = c1 * i(n) + c2 * i(n-1)
c1
+ o
i i(-1)
c2
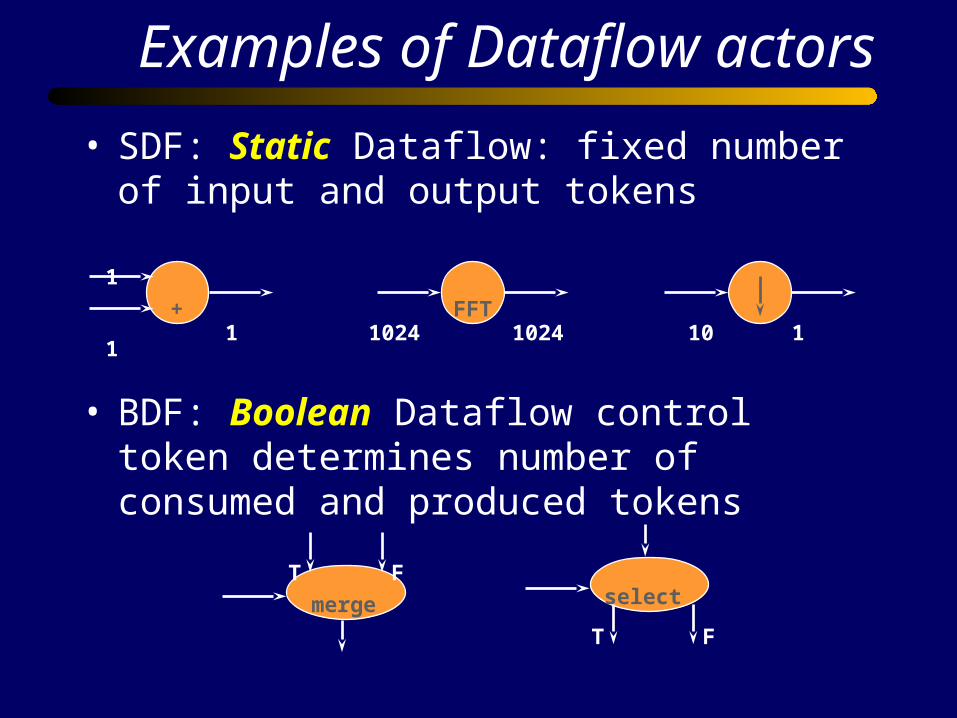
Examples of Dataflow actors
• SDF: Static Dataflow: fixed number of input and output tokens
• BDF: Boolean Dataflow control token determines number of consumed and produced tokens
+
1
11
FFT1024 1024 10 1
merge selectT F
FT

Static scheduling of DF• Key property of DF networks: output sequences do not depend on
firing sequence of actors (marked graphs)
• SDF networks can be statically scheduled at compile-time – execute an actor when it is known to be fireable– no overhead due to sequencing of concurrency– static buffer sizing
• Different schedules yield different – code size– buffer size– pipeline utilization

Balance equations
• Number of produced tokens must equal number of consumed tokens on every edge (channel)
• Repetitions (or firing) vector v of schedule S: number of firings of each actor in S
• v(A) ·np = v(B) ·nc
must be satisfied for each edge
np nc
A B A Bnp nc

Balance equations
B C
A3
1
1
1
2
2
11
• Balance for each edge:– 3 v(A) - v(B) = 0
– v(B) - v(C) = 0
– 2 v(A) - v(C) = 0
– 2 v(A) - v(C) = 0

Balance equations
• M ·v = 0iff S is periodic
• Full rank (as in this case) • no non-zero solution • no periodic schedule
(too many tokens accumulate on AB or BC)
3 -1 00 1 -12 0 -12 0 -1
M =
B C
A3
1
1
1
22
11

Balance equations
• Non-full rank• infinite solutions exist (linear space of dimension 1)
• Any multiple of v = |1 2 2|T satisfies the balance equations• ABCBC and ABBCC are minimal valid schedules• ABABBCBCCC is non-minimal valid schedule
2 -1 00 1 -12 0 -12 0 -1
M =
B C
A2
1
1
1
22
11

Static SDF scheduling
• Main SDF scheduling theorem (Lee ‘86):
– A connected SDF graph with n actors has a periodic schedule iff its topology matrix M has rank n-1
– If M has rank n-1 then there exists a unique smallest integer solution v to
M v = 0
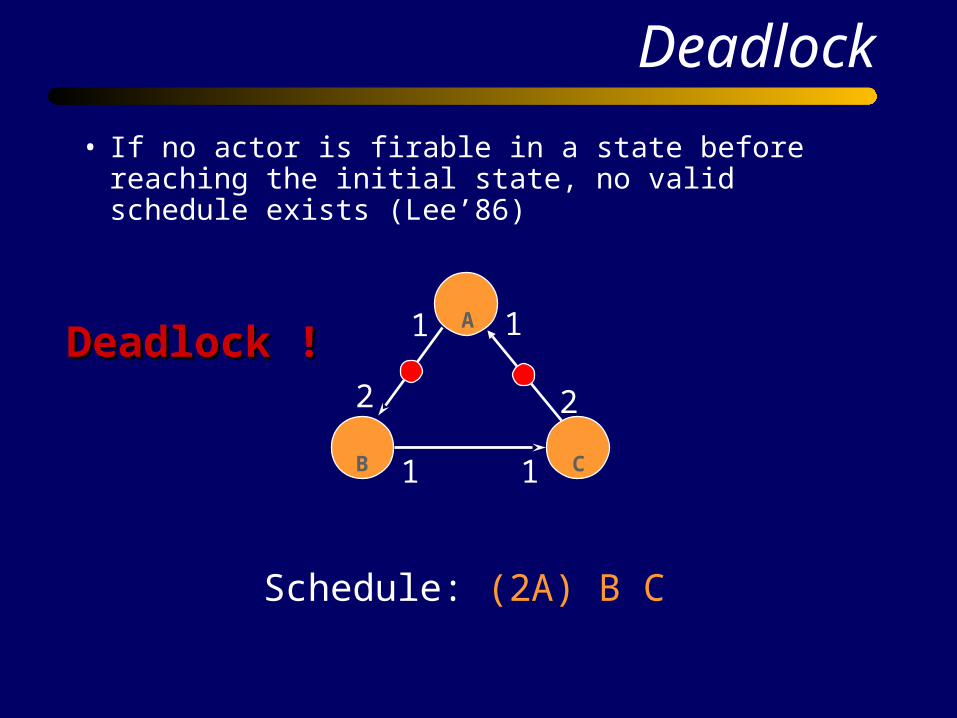
Deadlock
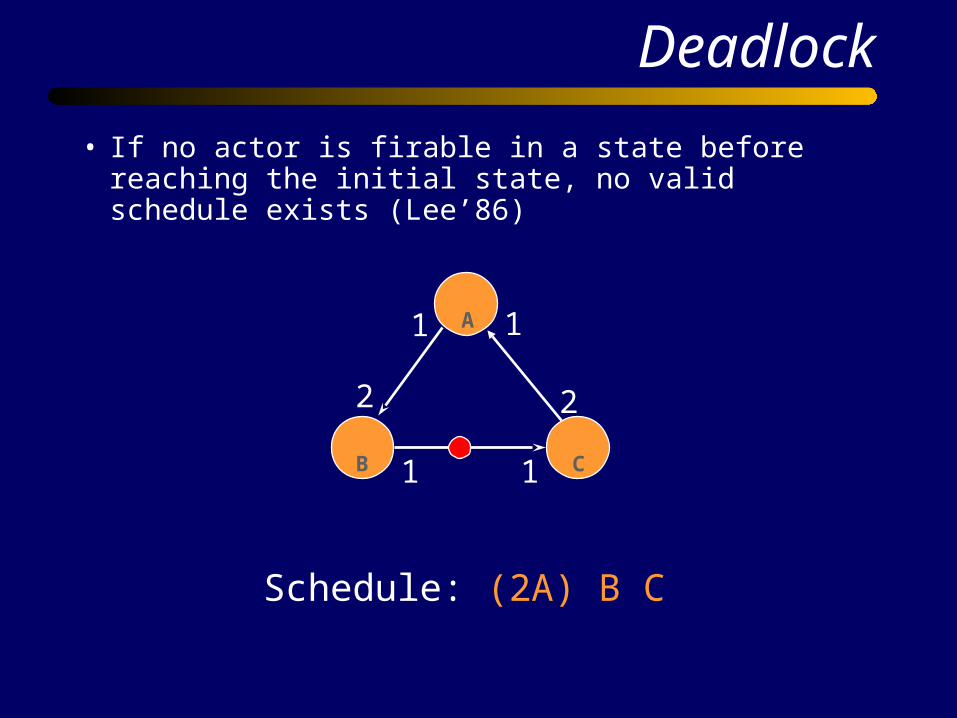
• If no actor is firable in a state before reaching the initial state, no valid schedule exists (Lee’86)
B C
A
2
1
1
1
2
1
Schedule: (2A) B C
Deadlock !Deadlock !
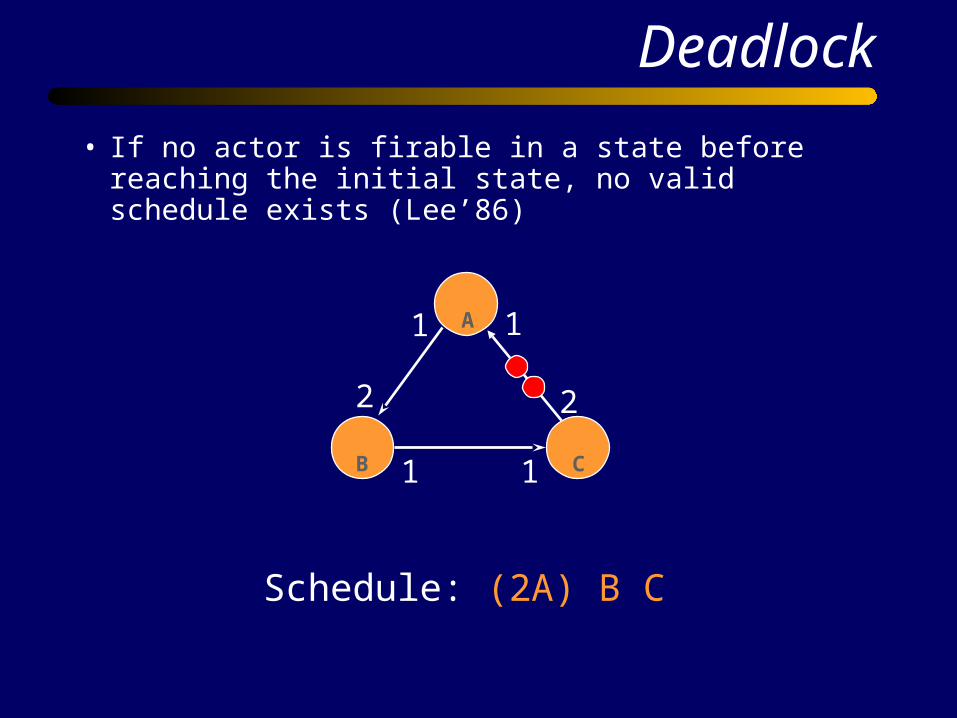
Deadlock
• If no actor is firable in a state before reaching the initial state, no valid schedule exists (Lee’86)
B C
A
2
1
1
1
2
1
Schedule: (2A) B C
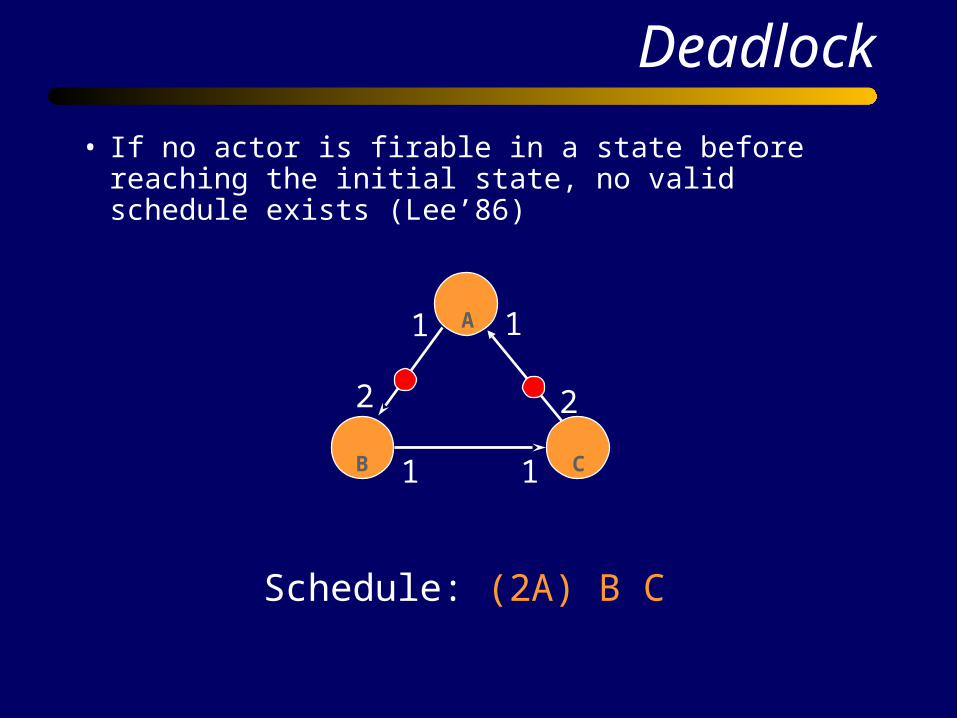
Deadlock
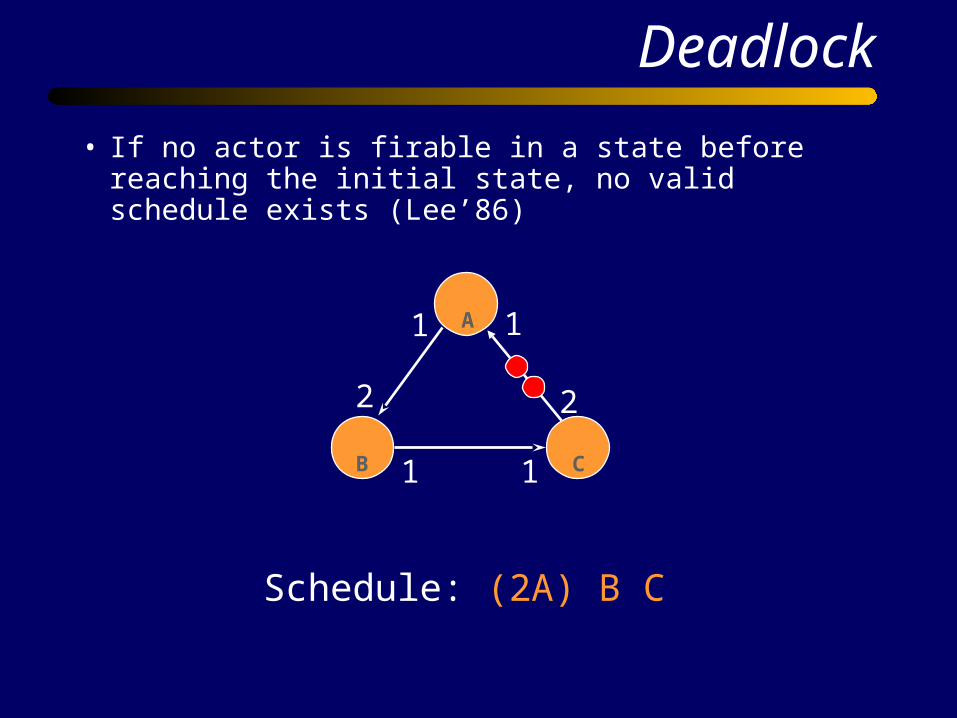
• If no actor is firable in a state before reaching the initial state, no valid schedule exists (Lee’86)
B C
A
2
1
1
1
2
1
Schedule: (2A) B C
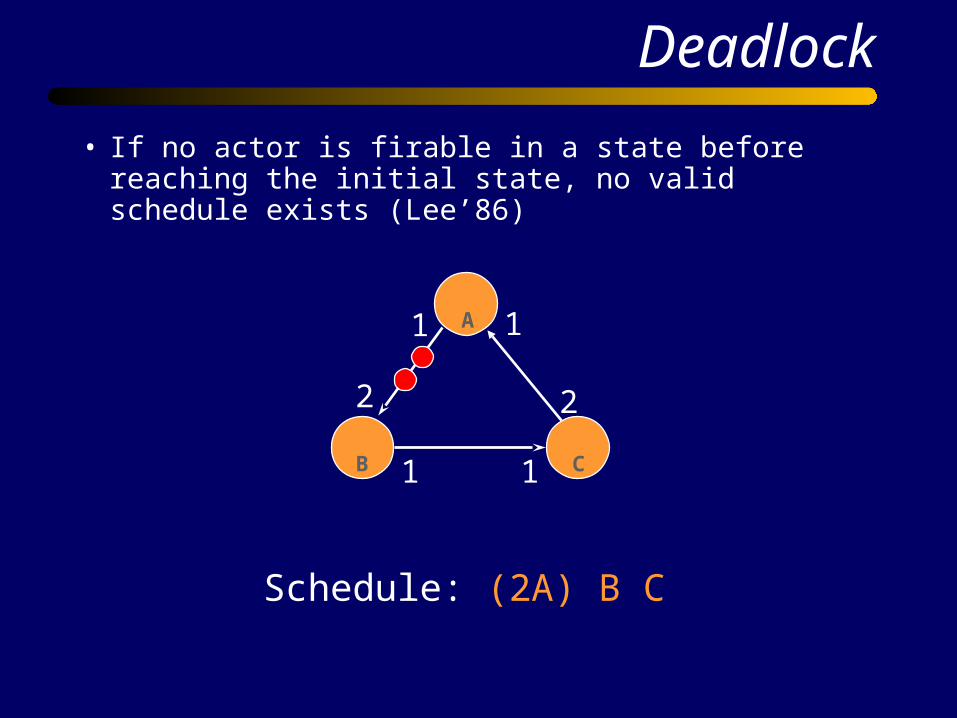
Deadlock
• If no actor is firable in a state before reaching the initial state, no valid schedule exists (Lee’86)
B C
A
2
1
1
1
2
1
Schedule: (2A) B C
Deadlock
• If no actor is firable in a state before reaching the initial state, no valid schedule exists (Lee’86)
B C
A
2
1
1
1
2
1
Schedule: (2A) B C
Deadlock
• If no actor is firable in a state before reaching the initial state, no valid schedule exists (Lee’86)
B C
A
2
1
1
1
2
1
Schedule: (2A) B C

Code size minimization
• Assumptions (based on DSP architecture):– subroutine calls expensive– fixed iteration loops are cheap
(“zero-overhead loops”)
• Global optimum: single appearance schedulee.g. ABCBC A (2BC), ABBCC A (2B) (2C)
• may or may not exist for an SDF graph…
• buffer minimization relative to single appearance schedules
(Bhattacharyya ‘94, Lauwereins ‘96, Murthy ‘97)

• Assumption: no buffer sharing• Example:
v = | 100 100 10 1|T
• Valid SAS: (100 A) (100 B) (10 C) D• requires 210 units of buffer area
• Better (factored) SAS: (10 (10 A) (10 B) C) D• requires 30 units of buffer area, but…• requires 21 loop initiations per period (instead of 3)
Buffer size minimization
C D1 10
A
B10
10
1
1

Scheduling more powerful DF• SDF is limited in modeling power • More general DF is too powerful
– non-Static DF is Turing-complete (Buck ‘93) – bounded-memory scheduling is not always possible
• Boolean Data Flow: Quasi-Static Scheduling of special “patterns”– if-then-else, repeat-until, do-while
• Dynamic Data Flow: run-time scheduling– may run out of memory or deadlock at run time
• Kahn Process Networks: quasi-static scheduling using Petri nets – conservative: schedulable network may be declared unschedulable

Outline
• The problem– Synthesis of concurrent specifications
– Compiler optimizations across processes
• Previous work: Dataflow networks– Static scheduling of SDF networks
– Code and data size optimization
• Quasi-Static Scheduling of process networks– Petri net representation of process networks
– Scheduling and code generation
• Open problems

The problem• Given: a network of Kahn processes
– Kahn process: sequential function + ports– communication: port-based, point-to-point, uni-
directional, multi-rate
• Find: a single sequential task– functionally equivalent to the original
network (modulo concurrency)– threads driven by input stimuli
(no OS intervention)
TEMPFILTER
HUMIDITYFILTER
CONTROLLER
TSENSOR HSENSOR
HDATATDATA
AC-on DRYER-on ALARM-on
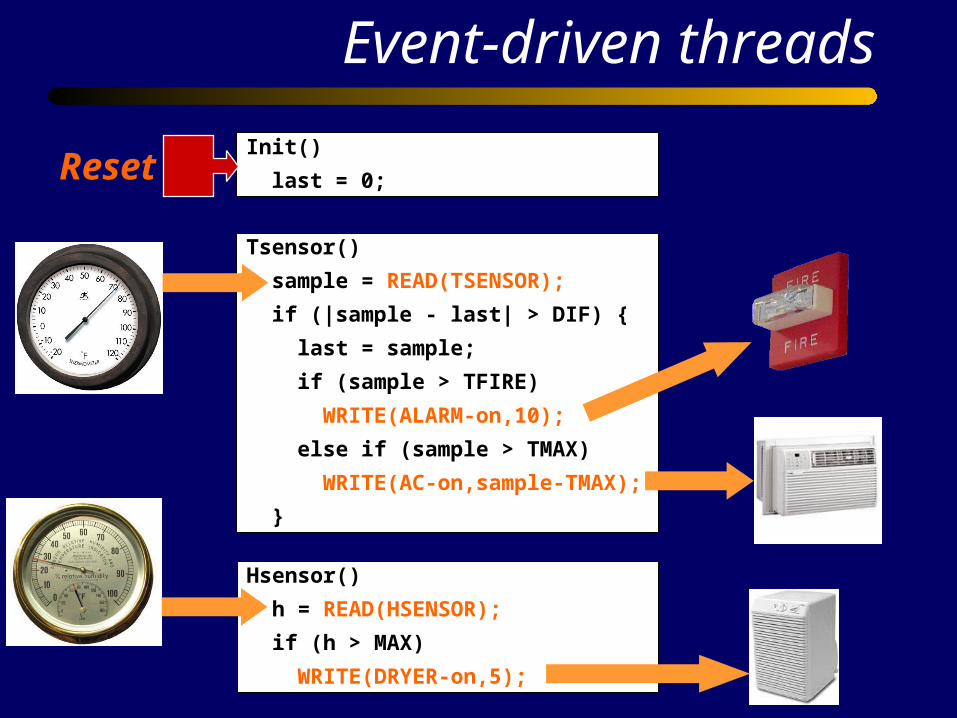
Init()
last = 0;
Tsensor()
sample = READ(TSENSOR);
if (|sample - last| > DIF) {
last = sample;
if (sample > TFIRE)
WRITE(ALARM-on,10);
else if (sample > TMAX)
WRITE(AC-on,sample-TMAX);
}
Hsensor()
h = READ(HSENSOR);
if (h > MAX)
WRITE(DRYER-on,5);
Event-driven threads
Reset
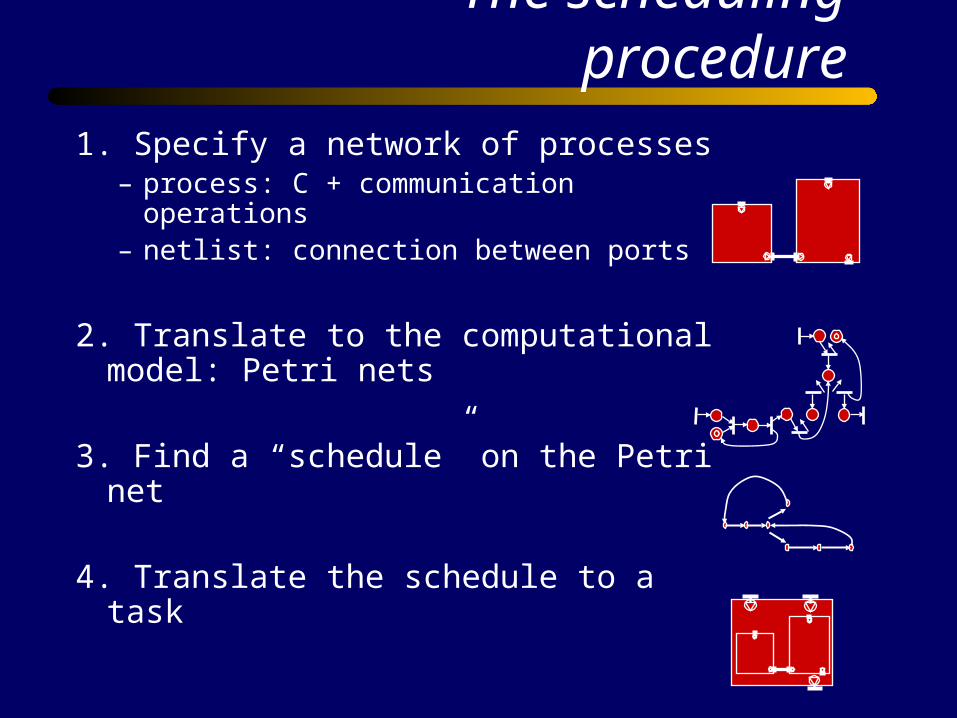
The scheduling procedure
1. Specify a network of processes– process: C + communication operations– netlist: connection between ports
2. Translate to the computational model: Petri nets
3. Find a “schedule” on the Petri net
4. Translate the schedule to a task
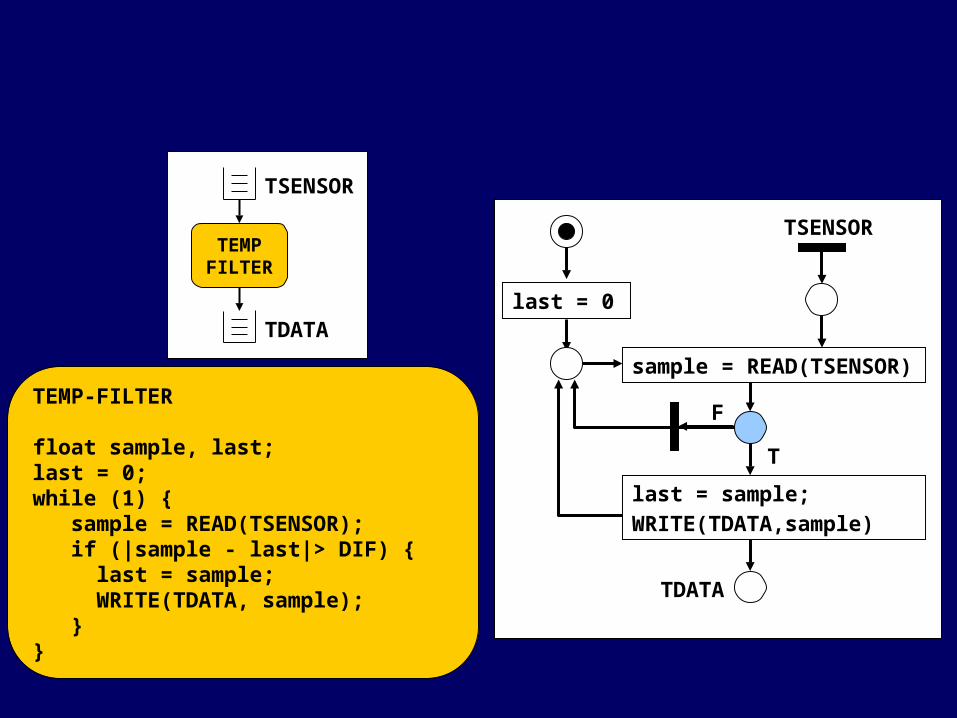
TEMP-FILTER
float sample, last;last = 0;while (1) { sample = READ(TSENSOR); if (|sample - last|> DIF) { last = sample; WRITE(TDATA, sample); }}
TSENSOR
sample = READ(TSENSOR)
last = sample;WRITE(TDATA,sample)
TDATA
last = 0
TEMPFILTER
TSENSOR
TDATA
T
F
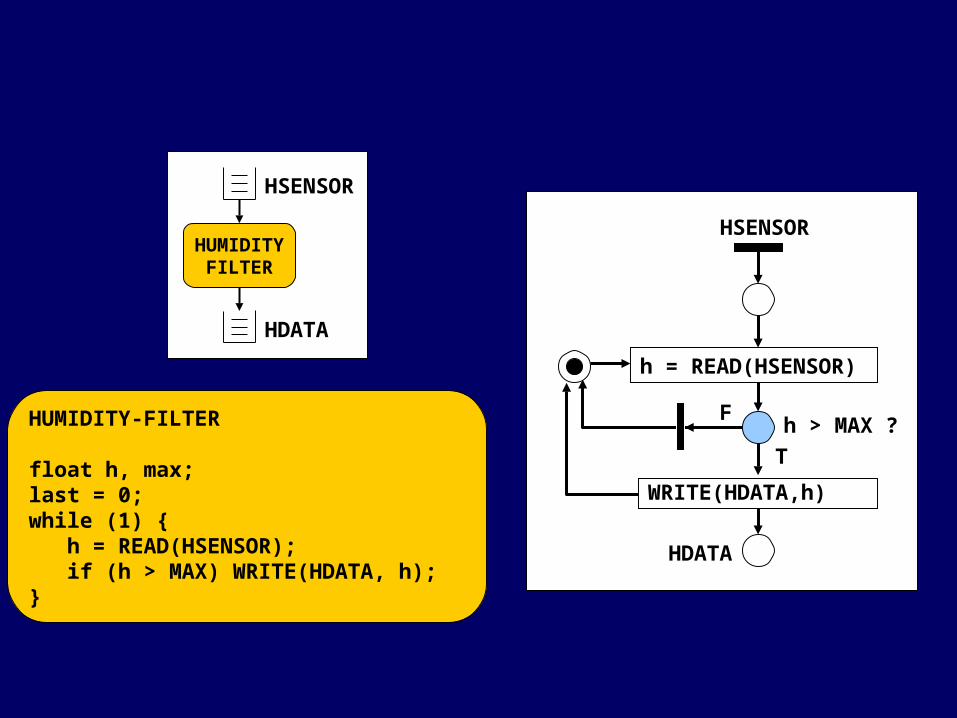
HUMIDITY-FILTER
float h, max;last = 0;while (1) { h = READ(HSENSOR); if (h > MAX) WRITE(HDATA, h);}
HUMIDITYFILTER
HSENSOR
HDATA
HSENSOR
h = READ(HSENSOR)
WRITE(HDATA,h)
HDATA
T
Fh > MAX ?
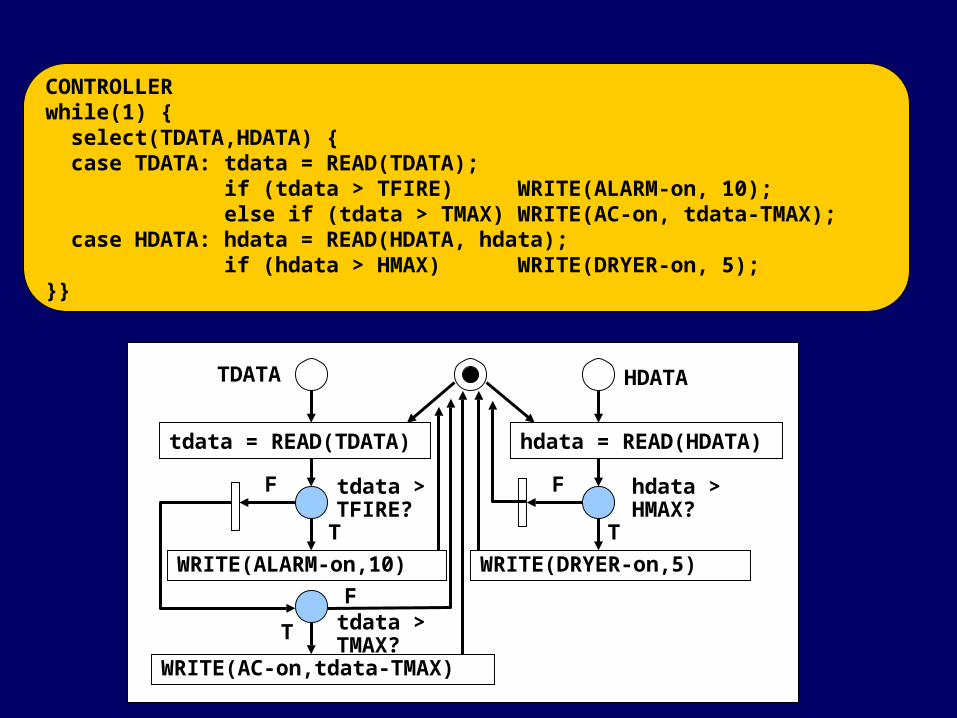
HDATA
WRITE(ALARM-on,10)
T
F
h > MAX ?
TDATA
hdata = READ(HDATA)tdata = READ(TDATA)
WRITE(AC-on,tdata-TMAX)
T
WRITE(DRYER-on,5)
Ftdata > TFIRE?
tdata > TMAX?
T
F
hdata > HMAX?
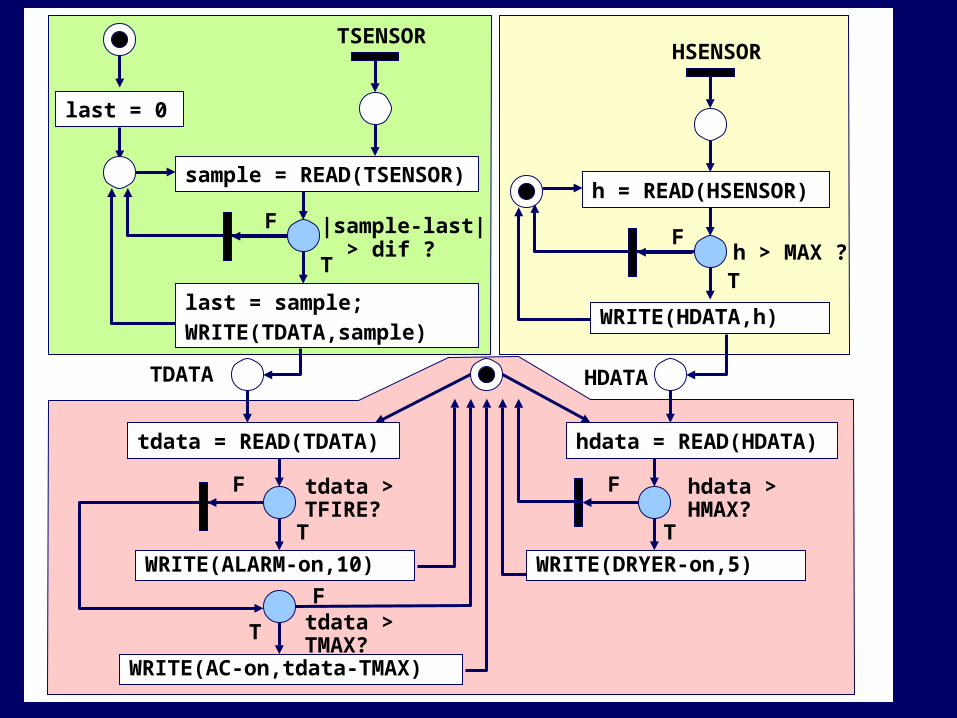
CONTROLLERwhile(1) { select(TDATA,HDATA) { case TDATA: tdata = READ(TDATA); if (tdata > TFIRE) WRITE(ALARM-on, 10); else if (tdata > TMAX) WRITE(AC-on, tdata-TMAX); case HDATA: hdata = READ(HDATA, hdata); if (hdata > HMAX) WRITE(DRYER-on, 5);}}
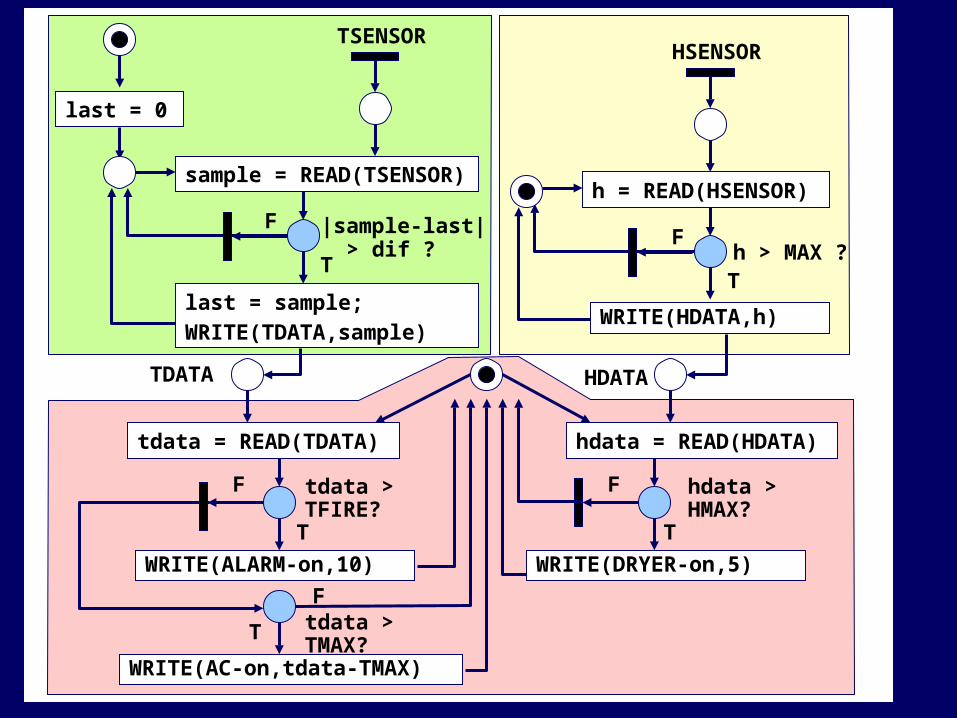
WRITE(ALARM-on,10)
T
F
h > MAX ?
TDATA
hdata = READ(HDATA)tdata = READ(TDATA)
WRITE(AC-on,tdata-TMAX)
T
WRITE(DRYER-on,5)
Ftdata > TFIRE?
tdata > TMAX?
T
F
hdata > HMAX?
HSENSOR
h = READ(HSENSOR)
WRITE(HDATA,h)
T
F
TSENSOR
sample = READ(TSENSOR)
last = sample;WRITE(TDATA,sample)
last = 0
|sample-last| > dif ?T
F
HDATA
h > MAX ?
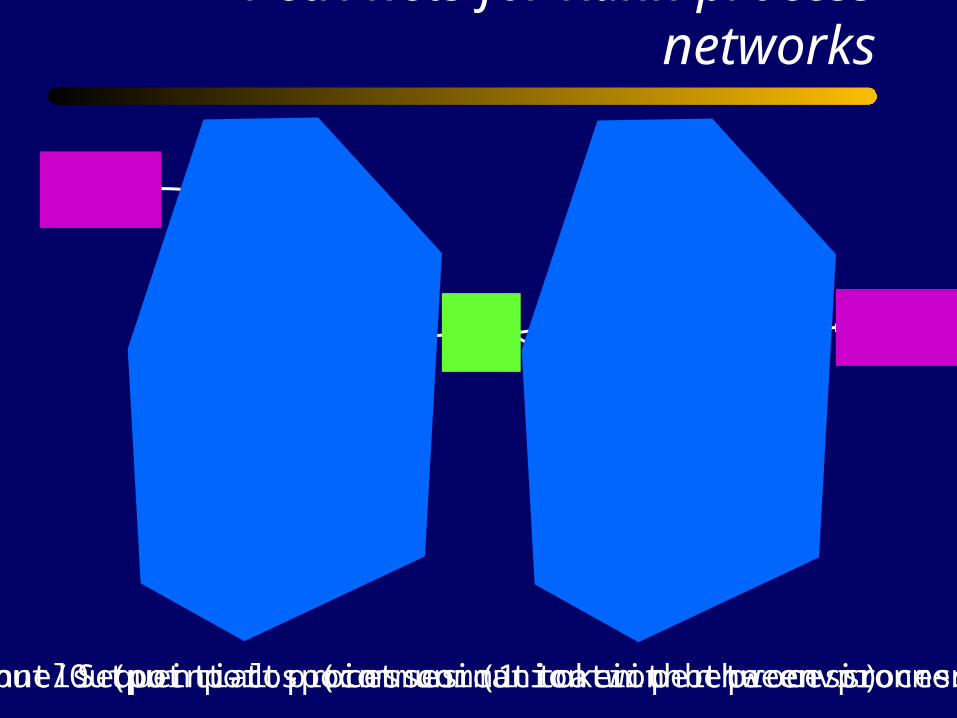
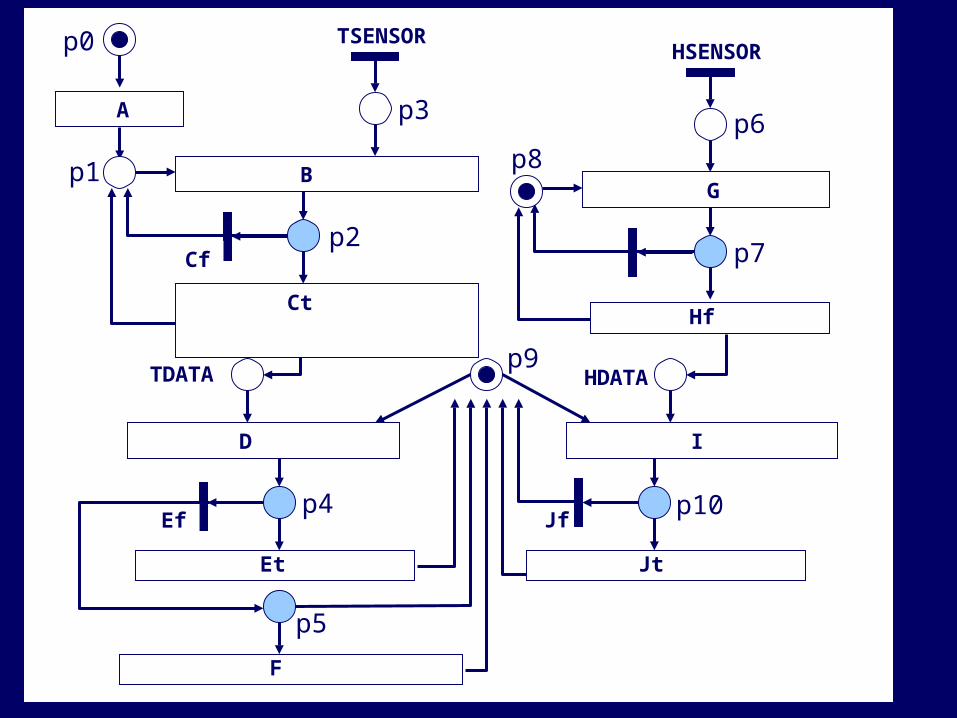
Petri nets for Kahn process networks
Sequential processes (1 token per process)Input/Output ports (communication with the environment)Channels (point-to-point communication between processes)
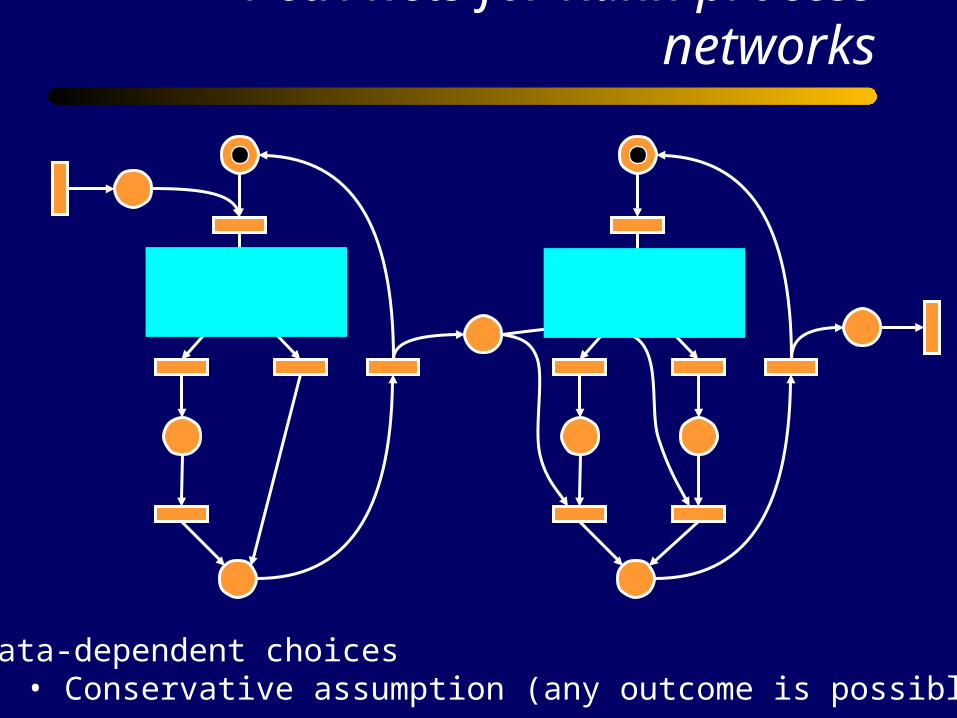
Petri nets for Kahn process networks
True False True False
Data-dependent choices• Conservative assumption (any outcome is possible)
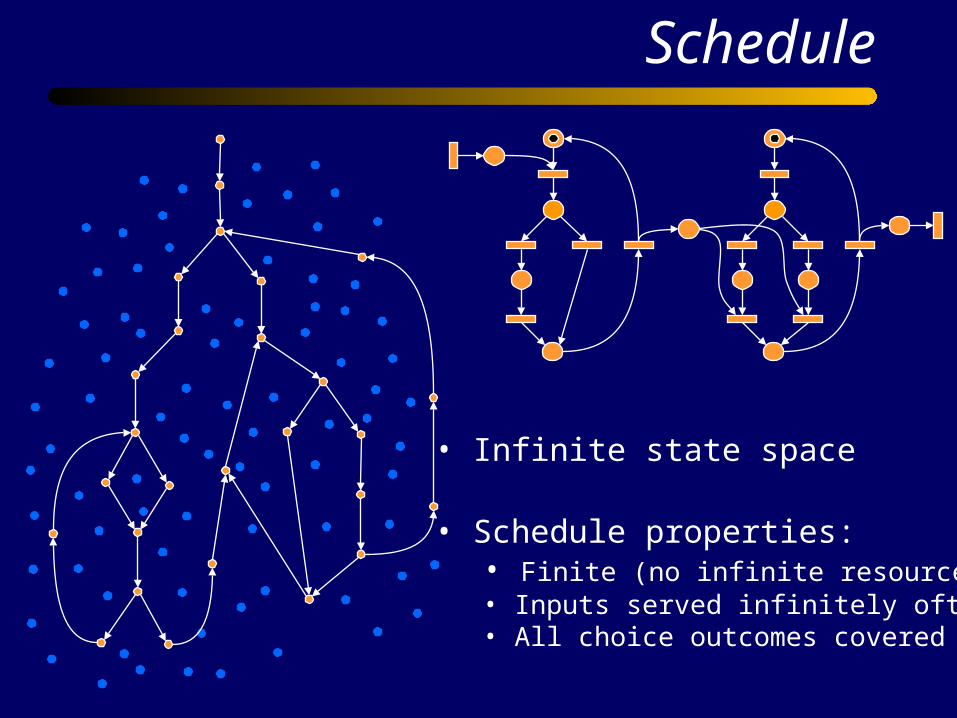
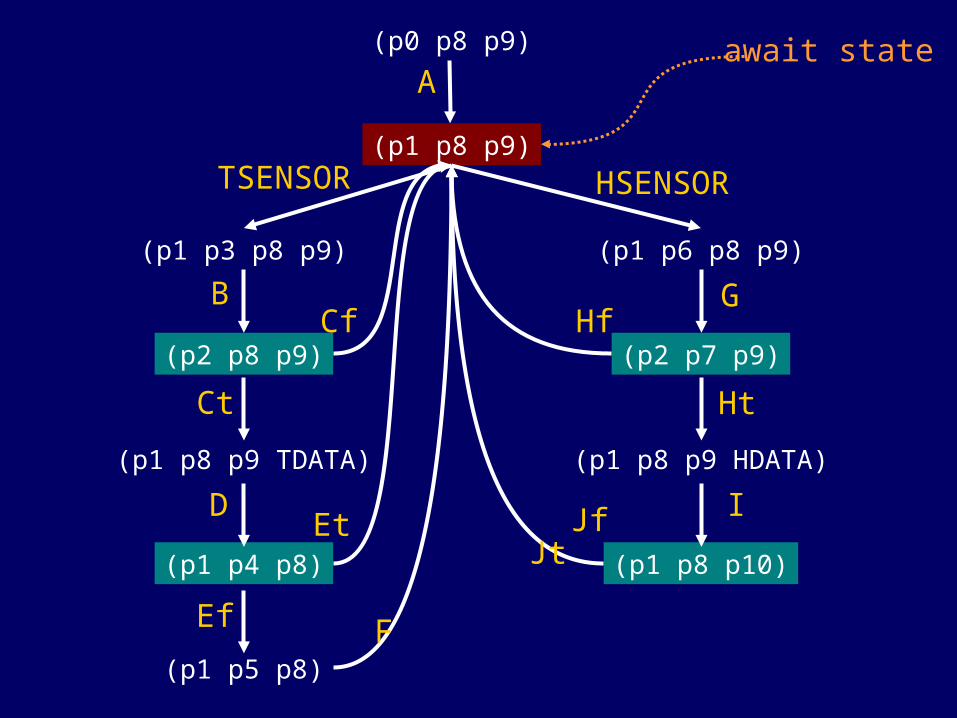
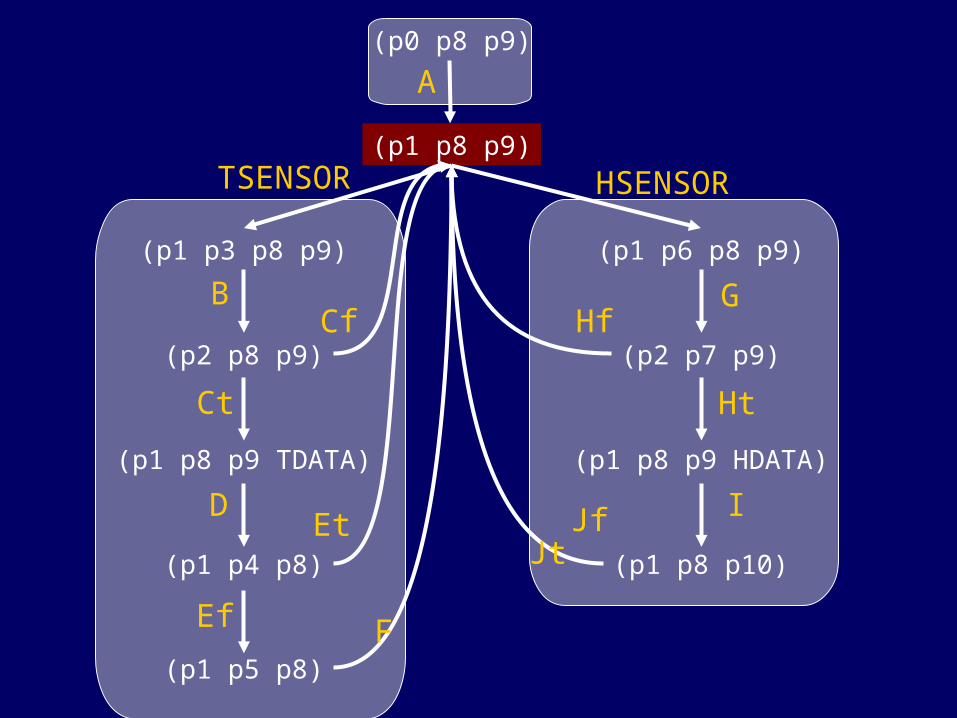
Schedule
• Infinite state space
• Schedule properties:• Finite (no infinite resources)• Inputs served infinitely often• All choice outcomes covered
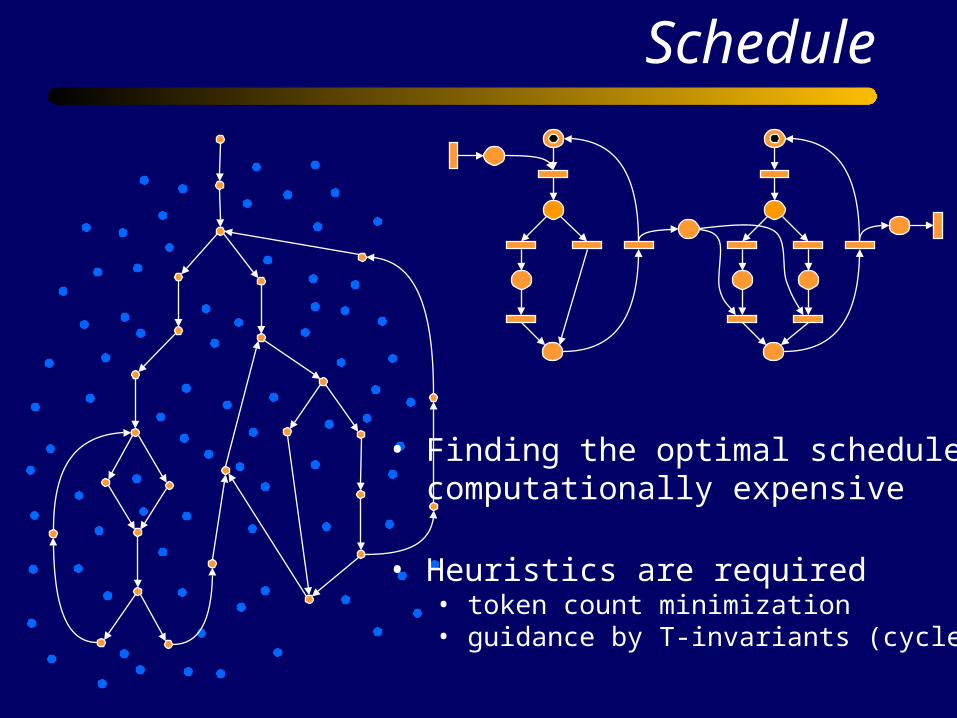
Schedule
• Finding the optimal schedule is computationally expensive
• Heuristics are required• token count minimization• guidance by T-invariants (cycles)
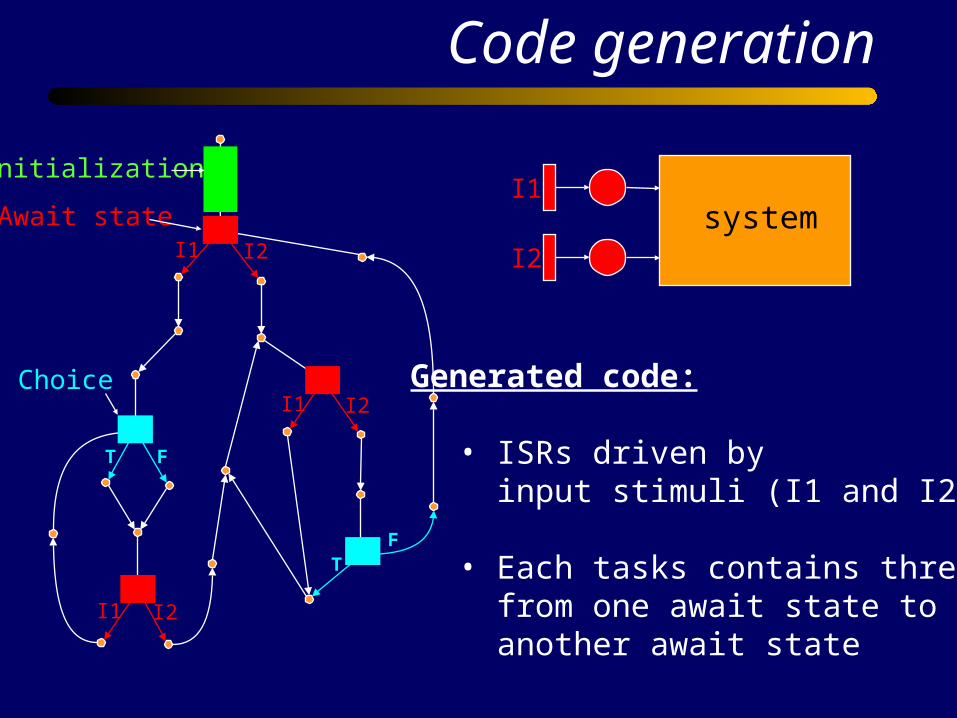
Code generation
I1
I2
system
T F
TF
I1 I2
I1 I2
I1 I2
Initialization
Await state
Choice Generated code:
• ISRs driven by input stimuli (I1 and I2)
• Each tasks contains threads from one await state to another await state
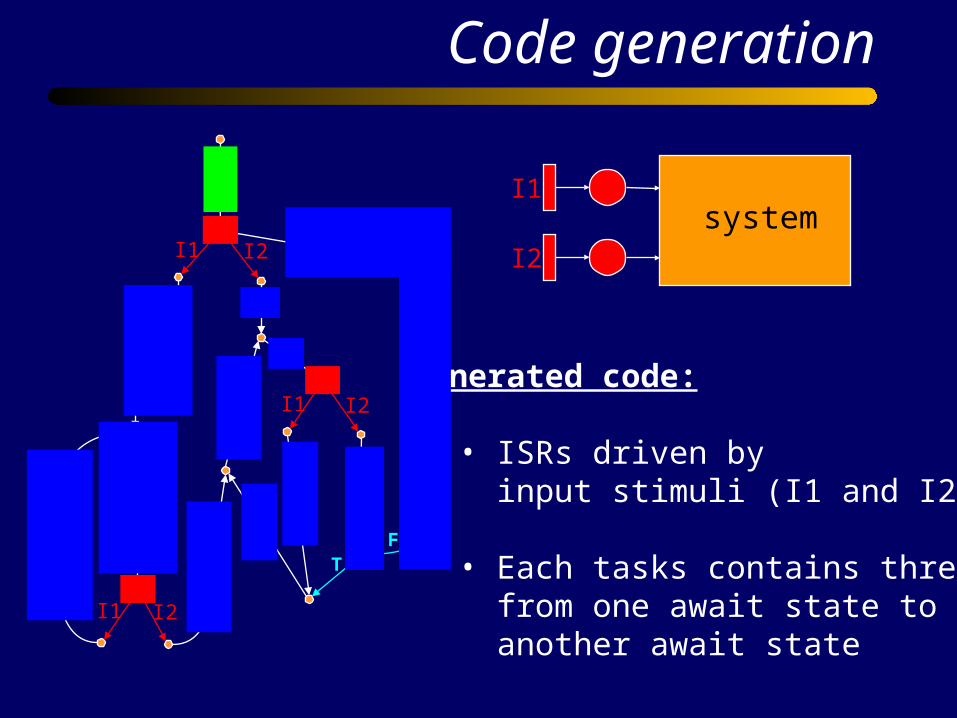
Code generation
I1
I2
system
T F
TF
I1 I2
I1 I2
I1 I2
Generated code:
• ISRs driven by input stimuli (I1 and I2)
• Each tasks contains threads from one await state to another await state
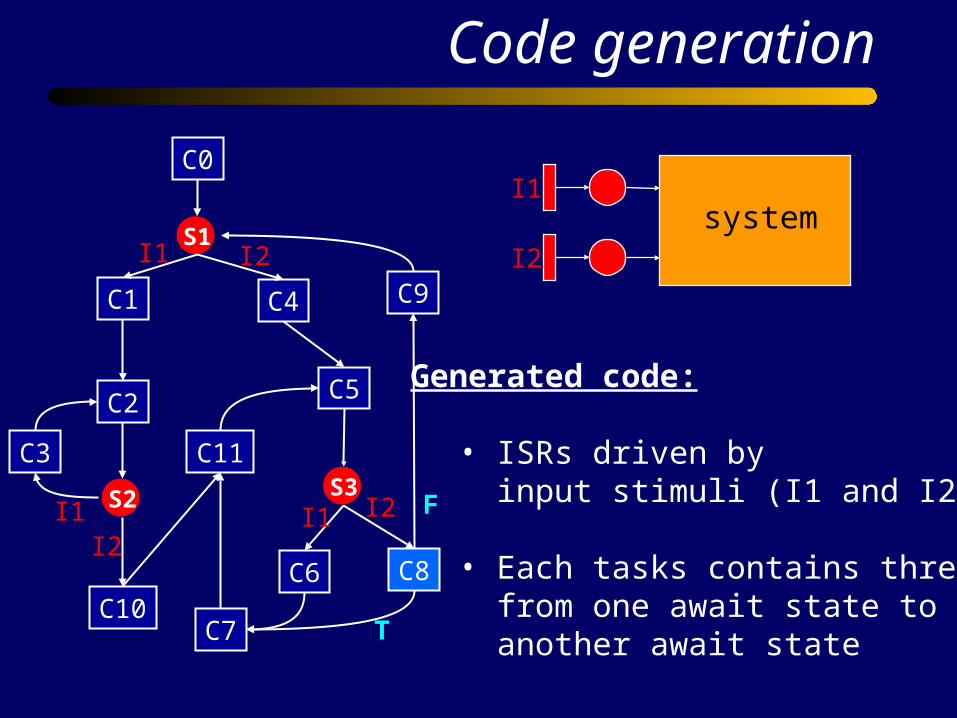
Code generation
I1
I2
system
Generated code:
• ISRs driven by input stimuli (I1 and I2)
• Each tasks contains threads from one await state to another await state
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
S1
S2 S3C11
I1I2
I1 I2
I1 I2
T
F
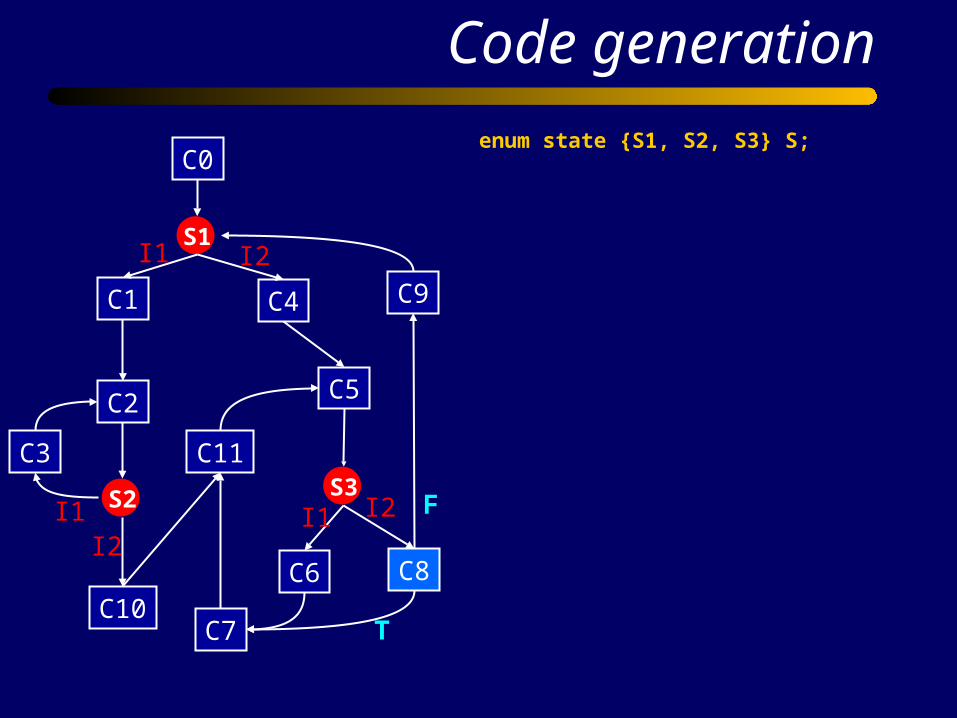
Code generation
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
S1
S2 S3C11
I1I2
I1 I2
I1 I2
T
F
enum state {S1, S2, S3} S;

Code generation
enum state {S1, S2, S3} S;
Init () { C0(); S = S1; return;}
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
S1
S2 S3C11
I1I2
I1 I2
I1 I2
T
F
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
S1
S2 S3C11
I1I2
I1 I2
I1 I2
T
F
Code generation
C1
C2
C3
C5
C6
C7
S1
S2 S3C11
I1
I1
I1
enum state {S1, S2, S3} S;
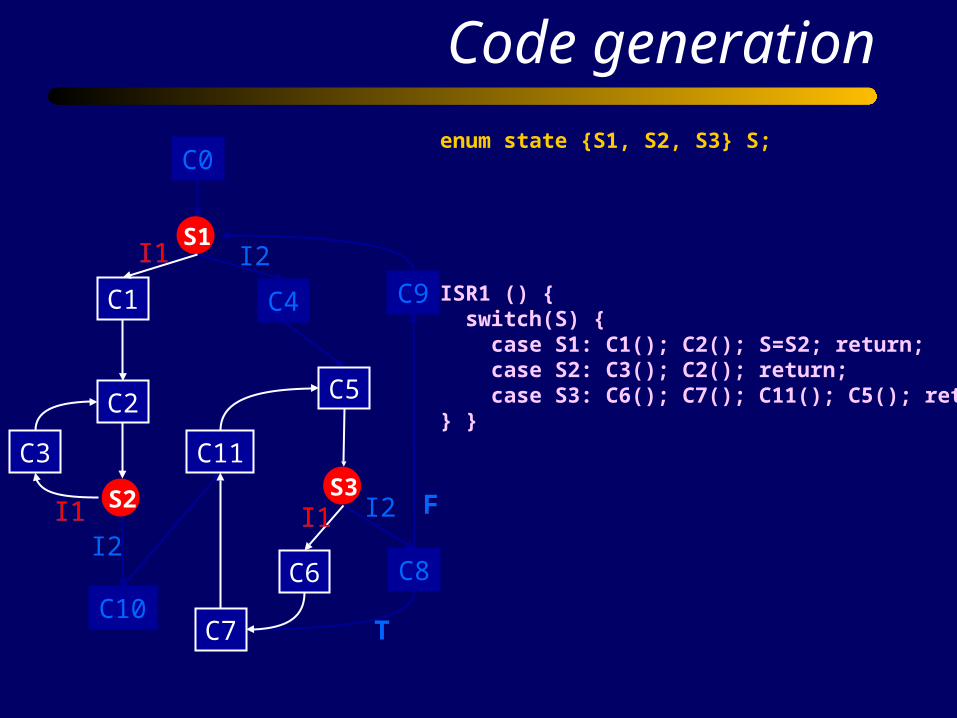
ISR1 () { switch(S) { case S1: C1(); C2(); S=S2; return; case S2: C3(); C2(); return; case S3: C6(); C7(); C11(); C5(); return;} }
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
S1
S2 S3C11
I1I2
I1
I1 I2
T
F
Code generation
enum state {S1, S2, S3} S;
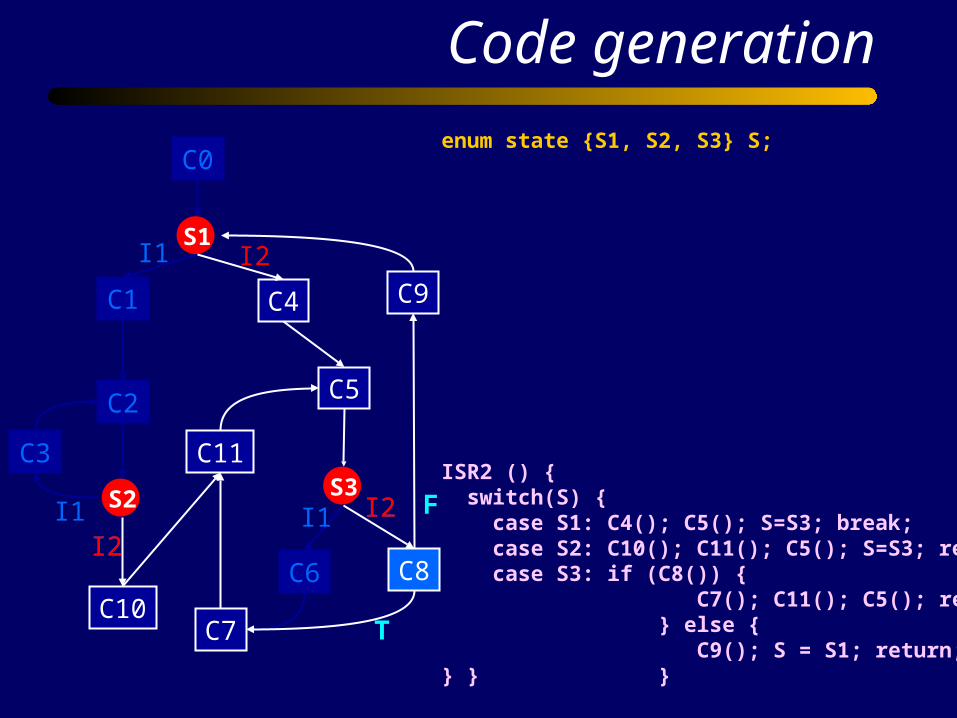
ISR2 () { switch(S) { case S1: C4(); C5(); S=S3; break; case S2: C10(); C11(); C5(); S=S3; return; case S3: if (C8()) { C7(); C11(); C5(); return; } else { C9(); S = S1; return;} } }
C4
C5
C7
C8
C9
C10
S1
S2 S3C11
I2
I2
I2
Code generation
enum state {S1, S2, S3} S;
Init () { C0(); S = S1; return;}
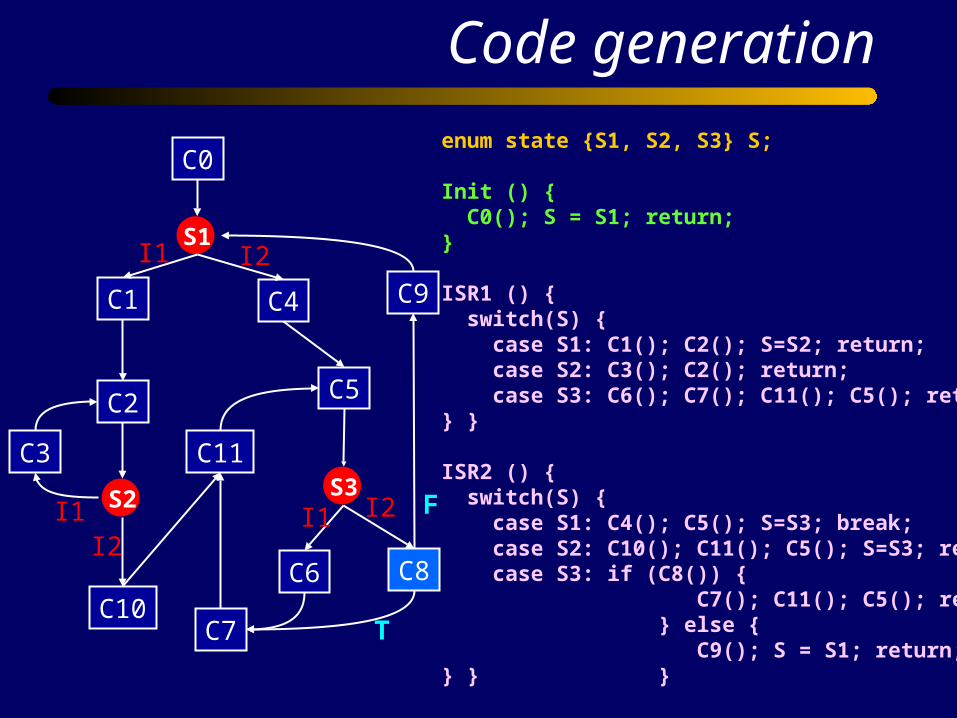
ISR1 () { switch(S) { case S1: C1(); C2(); S=S2; return; case S2: C3(); C2(); return; case S3: C6(); C7(); C11(); C5(); return;} } ISR2 () { switch(S) { case S1: C4(); C5(); S=S3; break; case S2: C10(); C11(); C5(); S=S3; return; case S3: if (C8()) { C7(); C11(); C5(); return; } else { C9(); S = S1; return;} } }
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
S1
S2 S3C11
I1I2
I1 I2
I1 I2
T
F

Code generation
enum state {S1, S2, S3} S;
Init () { C0(); S = S1; return;}
ISR1 () { switch(S) { case S1: C1(); C2(); S=S2; return; case S2: C3(); C2(); return; case S3: C6(); C7(); C11(); C5(); return;} } ISR2 () { switch(S) { case S1: C4(); C5(); S=S3; break; case S2: C10(); C11(); C5(); S=S3; return; case S3: if (C8()) { C7(); C11(); C5(); return; } else { C9(); S = S1; return;} } }
Init ()
ISR1 ()
ISR2 ()
Reset
I1
I2
S
Environmental controller
AC Dehumidifier Alarm
Temperature
Humidity
ENVIRONMENTALCONTROLLER
TEMPFILTER
HUMIDITYFILTER
CONTROLLER
TSENSOR HSENSOR
HDATATDATA
AC-on DRYER-on ALARM-on
WRITE(ALARM-on,10)
T
F
h > MAX ?
TDATA
hdata = READ(HDATA)tdata = READ(TDATA)
WRITE(AC-on,tdata-TMAX)
T
WRITE(DRYER-on,5)
Ftdata > TFIRE?
tdata > TMAX?
T
F
hdata > HMAX?
HSENSOR
h = READ(HSENSOR)
WRITE(HDATA,h)
T
F
TSENSOR
sample = READ(TSENSOR)
last = sample;WRITE(TDATA,sample)
last = 0
|sample-last| > dif ?T
F
HDATA
h > MAX ?
Et h > MAX ?
TDATA
I D
F
Jt
HSENSOR
G
Hf
TSENSOR
B
Ct
A
HDATA
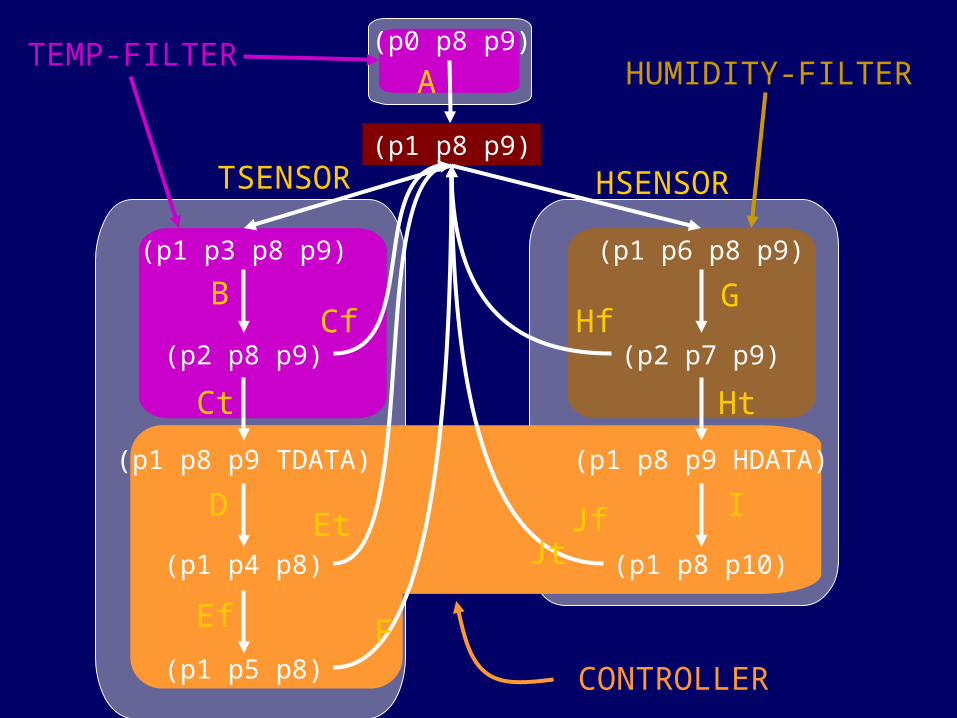
p1
p2
p3
p4
p5
p6
p7
p8
Ef
p0
p9
p10
Cf
Jf
(p0 p8 p9)
(p1 p8 p9)
(p1 p3 p8 p9)
(p2 p8 p9)
(p1 p8 p9 TDATA)
(p1 p4 p8)
(p1 p5 p8)
(p1 p6 p8 p9)
(p2 p7 p9)
(p1 p8 p9 HDATA)
(p1 p8 p10)
A
B
Ct
Cf
D
Ef
Et
F
G
Ht
I
Hf
JfJt
TSENSOR HSENSOR
await state
(p0 p8 p9)
(p1 p8 p9)
(p1 p3 p8 p9)
(p2 p8 p9)
(p1 p8 p9 TDATA)
(p1 p4 p8)
(p1 p5 p8)
(p1 p6 p8 p9)
(p2 p7 p9)
(p1 p8 p9 HDATA)
(p1 p8 p10)
A
B
Ct
Cf
D
Ef
Et
F
G
Ht
I
Hf
JfJt
TSENSOR HSENSOR
(p0 p8 p9)
(p1 p8 p9)
(p1 p3 p8 p9)
(p2 p8 p9)
(p1 p8 p9 TDATA)
(p1 p4 p8)
(p1 p5 p8)
(p1 p6 p8 p9)
(p2 p7 p9)
(p1 p8 p9 HDATA)
(p1 p8 p10)
A
B
Ct
Cf
D
Ef
Et
F
G
Ht
I
Hf
JfJt
TSENSOR HSENSOR
TEMP-FILTERHUMIDITY-FILTER
CONTROLLER

Tsensor()
{
sample = READ(TSENSOR);
if (|sample - last| > DIF) {
last = sample;
WRITE (TDATA,sample);
tdata = READ (TDATA);
if (tdata > TFIRE)
WRITE(ALARM-on,10);
else if (tdata > TMAX)
WRITE(AC-on,tdata-TMAX);
}
}
Channel elimination
Code generation and optimization

Tsensor()
{
READ(TSENSOR,sample,1);
if (|sample - last| > DIF) {
last = sample;
WRITE (TDATA,sample,1);
READ (TDATA,tdata,1);
if (tdata > TFIRE)
WRITE(ALARM-on,10);
else if (tdata > TMAX)
WRITE(AC-on,tdata-TMAX);
}
}
Copy propagationtdata = sample
Code generation and optimization

Tsensor()
{
READ(TSENSOR,sample,1);
if (|sample - last| > DIF) {
last = sample;
WRITE (TDATA,sample);
tdata = READ (TDATA);
if (sample > TFIRE)
WRITE(ALARM-on,10);
else if (sample > TMAX)
WRITE(AC-on,sample-TMAX);
}
}
Code generation and optimization
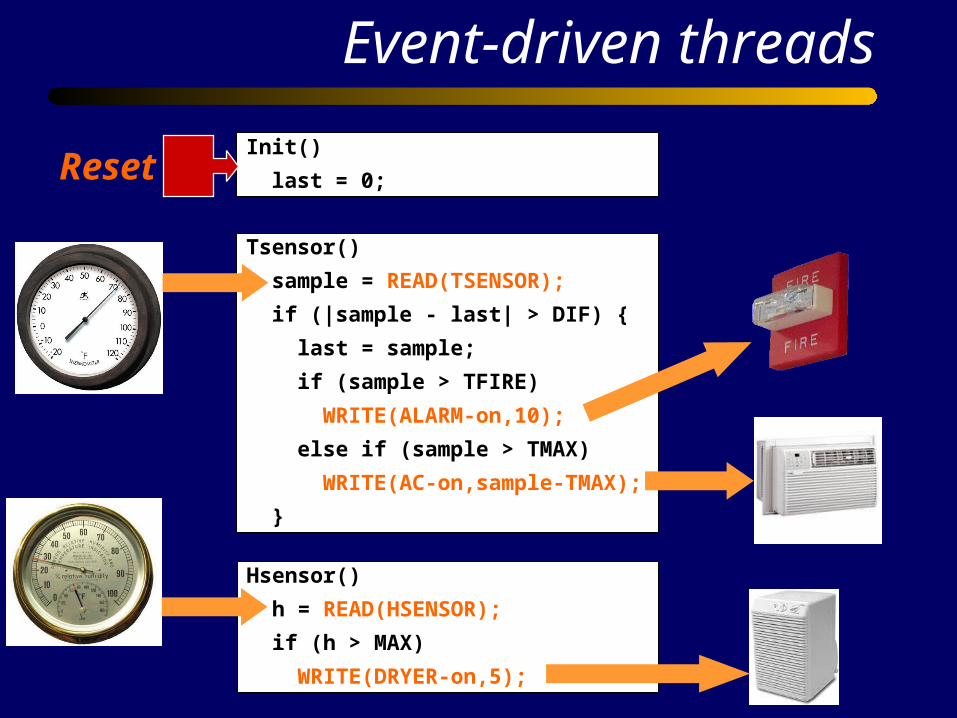
Init()
last = 0;
Tsensor()
sample = READ(TSENSOR);
if (|sample - last| > DIF) {
last = sample;
if (sample > TFIRE)
WRITE(ALARM-on,10);
else if (sample > TMAX)
WRITE(AC-on,sample-TMAX);
}
Hsensor()
h = READ(HSENSOR);
if (h > MAX)
WRITE(DRYER-on,5);
Event-driven threads
Reset
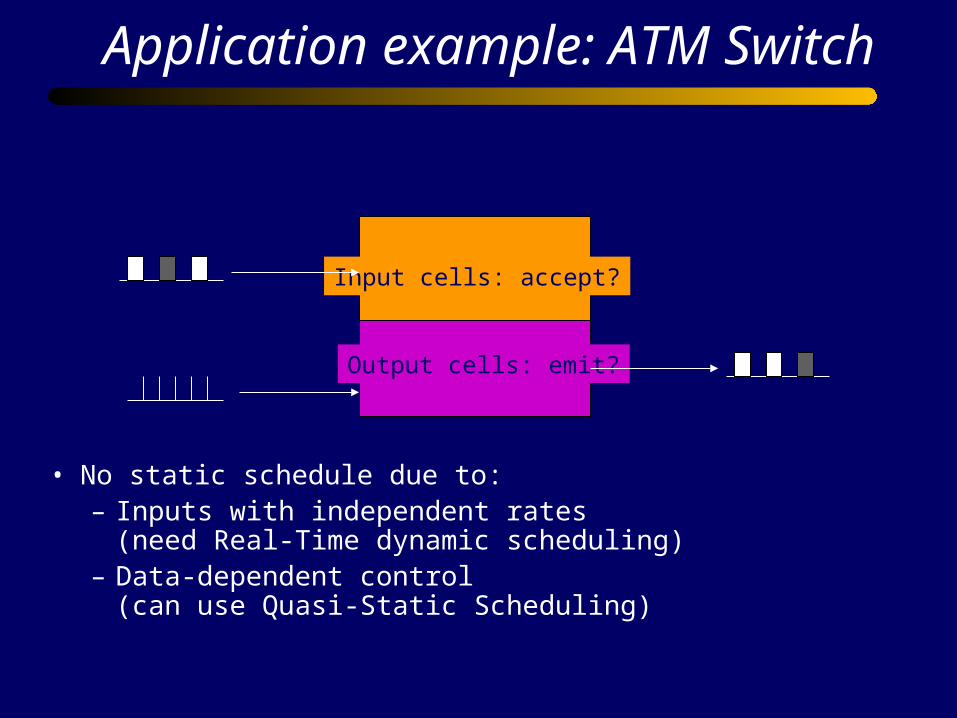
Application example: ATM Switch
Input cells: accept?
Output cells: emit?
• No static schedule due to:– Inputs with independent rates
(need Real-Time dynamic scheduling) – Data-dependent control
(can use Quasi-Static Scheduling)
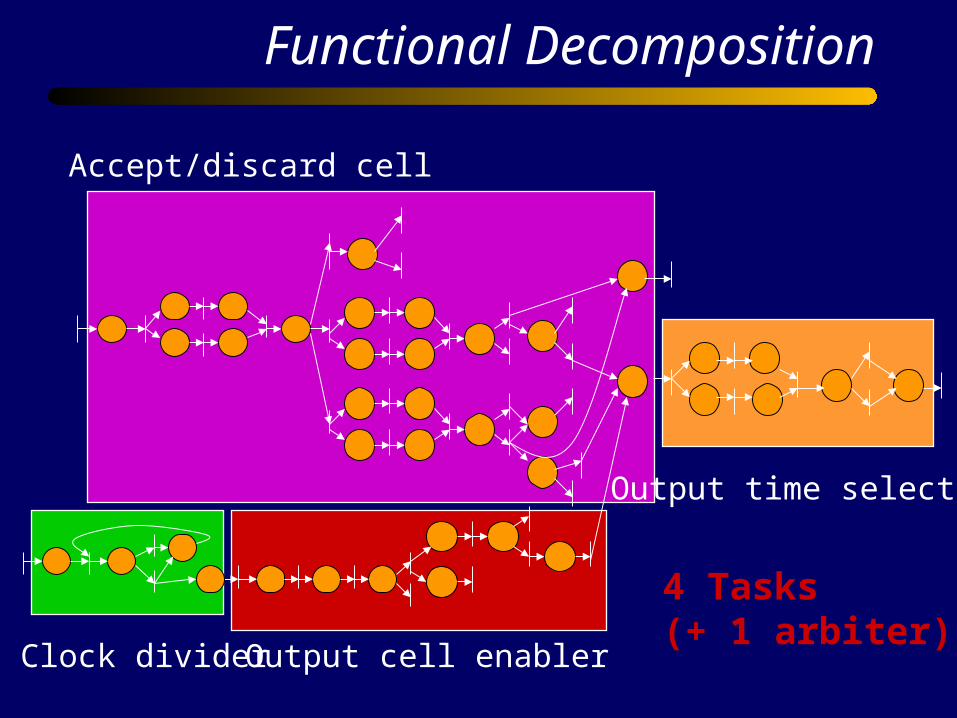
Functional Decomposition
4 Tasks(+ 1 arbiter)
Accept/discard cell
Clock divider
Output time selector
Output cell enabler
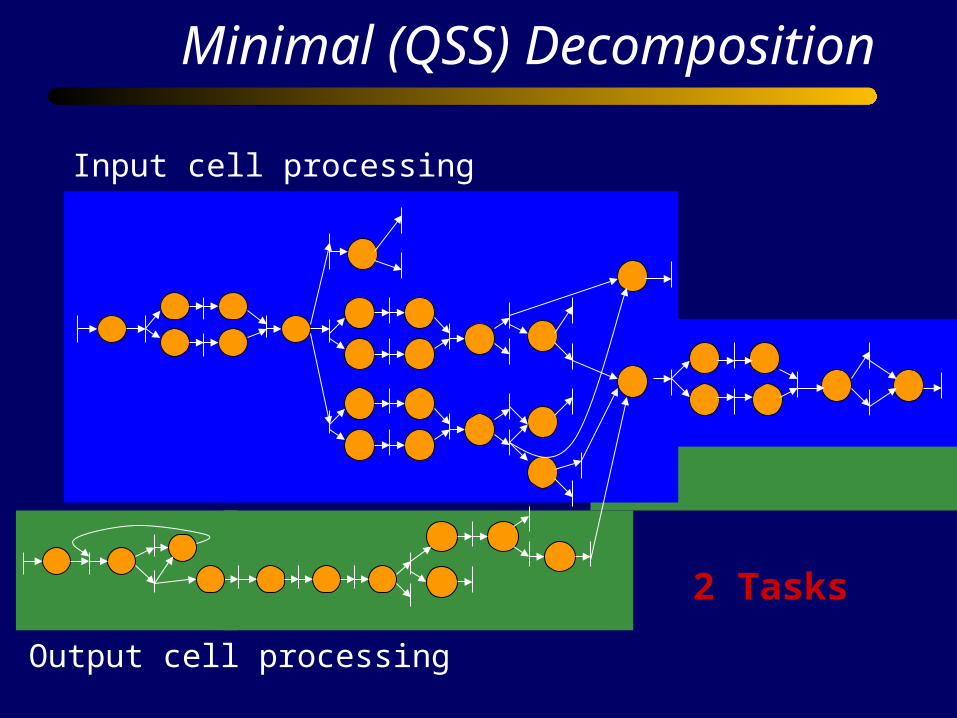
Minimal (QSS) Decomposition
2 Tasks
Input cell processing
Output cell processing

ATM: experimental results
Sw Implementation QSS Functional partitioning
Number of tasks 2 5
Lines of C code 1664 2187
Clock cycles 197,526 249,726
4+1 Tasks 2 Tasks
Functional partitioning QSS
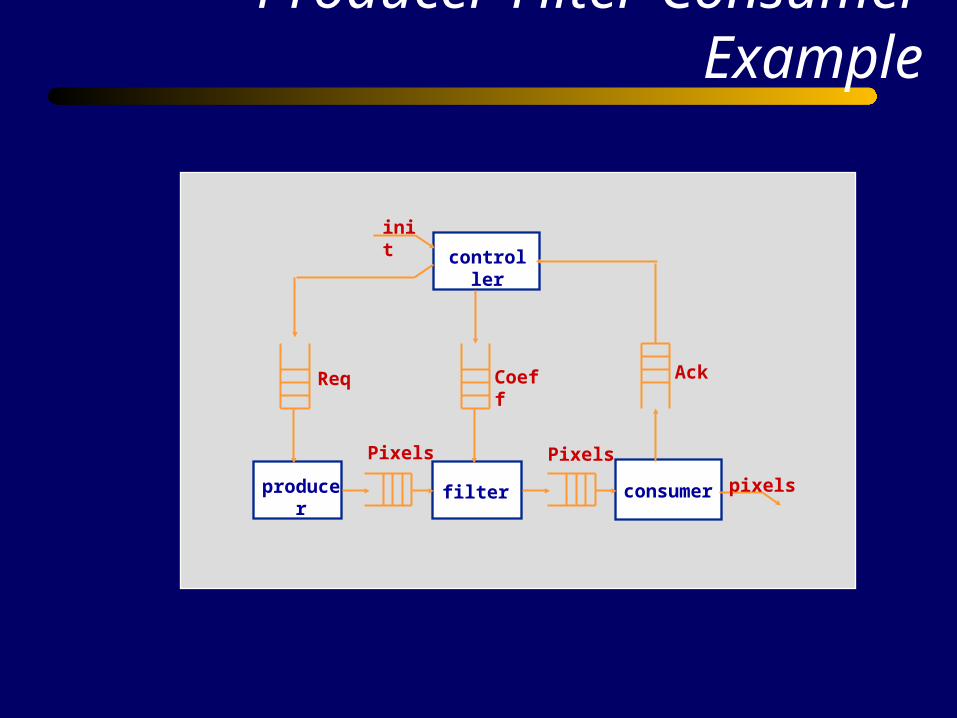
Producer-Filter-Consumer Example
controller
filterproducer consumer
init
Req AckCoeff
Pixels Pixels
pixels
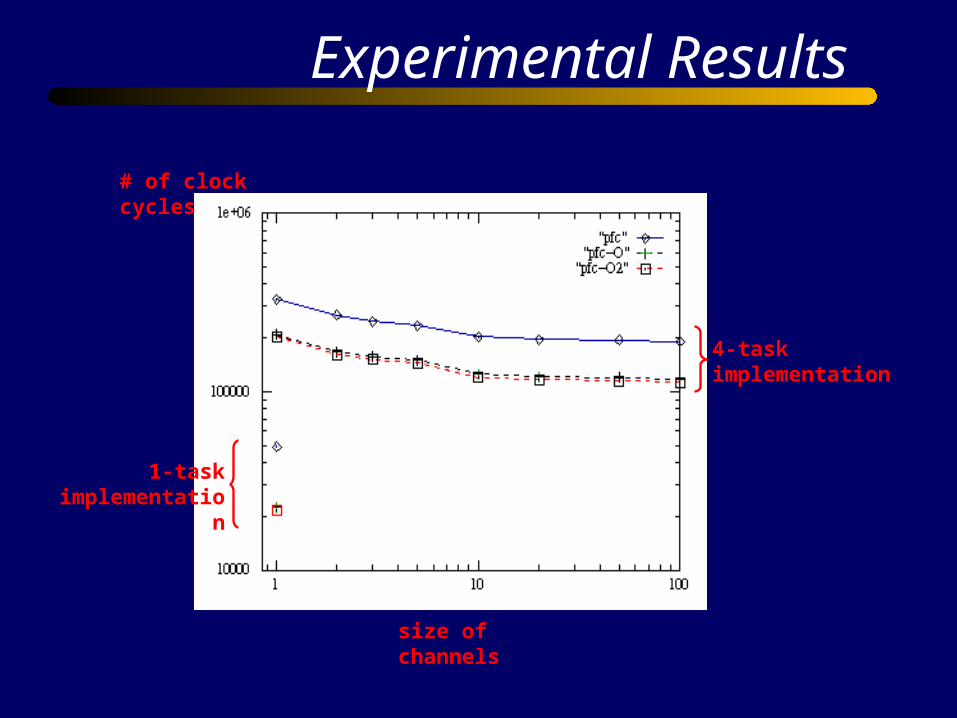
Experimental Results
# of clock cycles
size of channels
4-task implementation
1-task implementation

Open problems
• Is a system schedulable ? (decidability)
• False paths in concurrent systems(data dependencies)
• Synthesis for multi-processors
• Abstraction / partitioning
• and many others ...

(Quasi) Static Scheduling approaches
• Lee et al. ‘86: Static Data Flow: cannot specify data-dependent control
• Buck et al. ‘94: Boolean Data Flow: undecidable schedulability check, heuristic pattern-based algorithm
• Thoen et al. ‘99: Event graph: no schedulability check, no task minimization
• Lin ‘97: Safe Petri Net: no schedulability check, single-rate, reachability-based algorithm
• Thiele et al. ‘99: Bounded Petri Net: partial schedulability check, reachability-based algorithm
• Cortadella et al. ‘00: General Petri Net: maybe undecidable schedulability check, balance equation-based algorithm
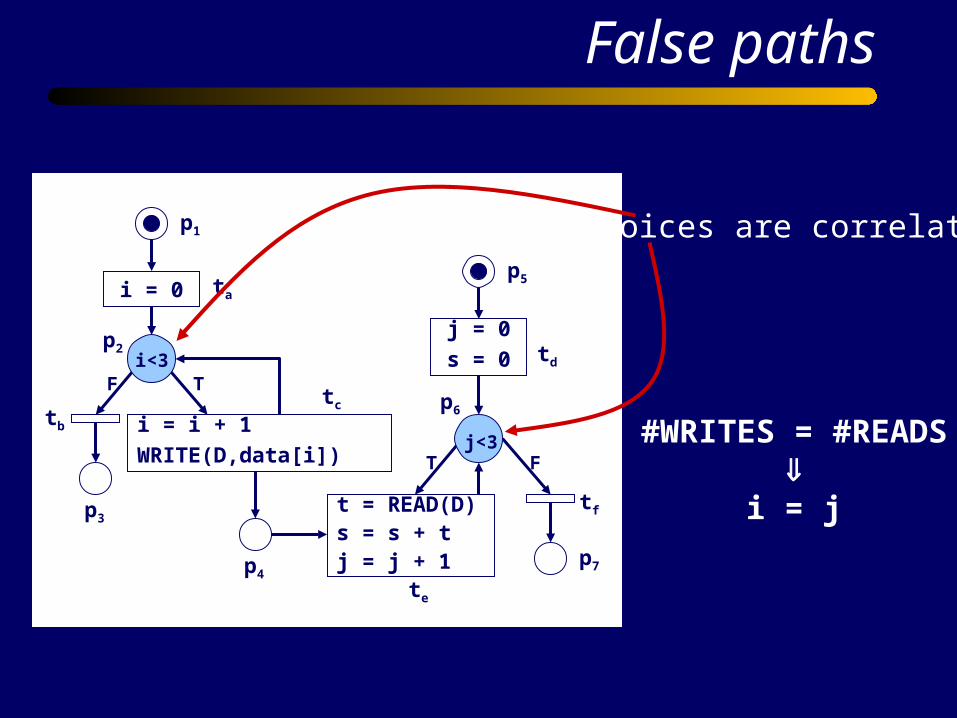
t = READ(D)s = s + tj = j + 1
j = 0
s = 0
i = 0
i = i + 1
WRITE(D,data[i])
td
tf
te
tb
ta
tc
TF
T F
p1
p5
p6
p7p4
p3
p2i<3
j<3
False paths
Choices are correlated
#WRITES = #READS
i = j
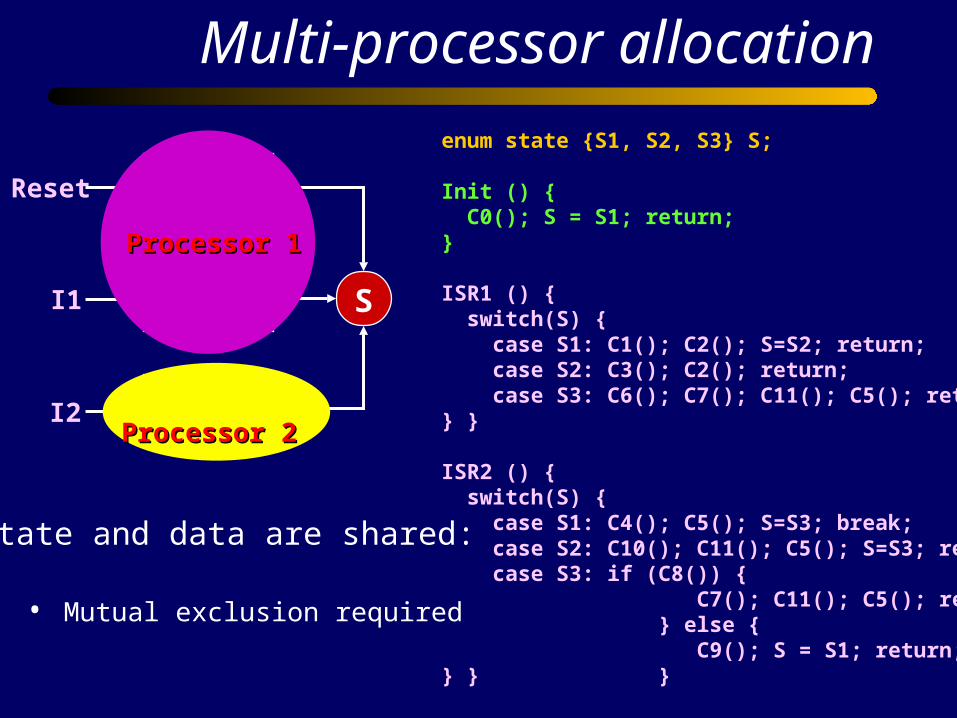
Multi-processor allocation
enum state {S1, S2, S3} S;
Init () { C0(); S = S1; return;}
ISR1 () { switch(S) { case S1: C1(); C2(); S=S2; return; case S2: C3(); C2(); return; case S3: C6(); C7(); C11(); C5(); return;} } ISR2 () { switch(S) { case S1: C4(); C5(); S=S3; break; case S2: C10(); C11(); C5(); S=S3; return; case S3: if (C8()) { C7(); C11(); C5(); return; } else { C9(); S = S1; return;} } }
Init ()
ISR1 ()
ISR2 ()
Reset
I1
I2
S
Processor 1Processor 1
Processor 2Processor 2
State and data are shared:
• Mutual exclusion required

Conclusions• Reactive systems
– OS required to control concurrency– Processes are often reused in different environments
• Static and Quasi-Static Scheduling minimize run-time overhead by automatic partitioning the system functions into input-driven threads– No context switch required (OS overhead is reduced)– Compiler optimizations across processes
• Much more research is needed:– strategies to find schedules (decidability ?)– false paths in concurrent systems– what about multiple processors?– ...


















