

Supported by EU projects
18
Supported by EU projects 12/12/2013 Athens, Greece Open Data in Agriculture Hands-on with data infrastructures that can power your agricultural data products
description
Open Data in Agriculture. Hands-on with data infrastructures that can power your agricultural data products. 12/12/2013 Athens, Greece. Supported by EU projects. Tutorial on defining users’ clusters in agricultural sciences, using the VIVO tool. Alberto Nogales Alcal á University (UAH). - PowerPoint PPT Presentation
Transcript of Supported by EU projects

Supported by EU projects
12/12/2013Athens, Greece
Open Data in AgricultureHands-on with data infrastructures that
can power your agricultural data products

Alberto NogalesAlcalá University (UAH)
Tutorial on defining users’ clusters in
agricultural sciences, using the VIVO tool
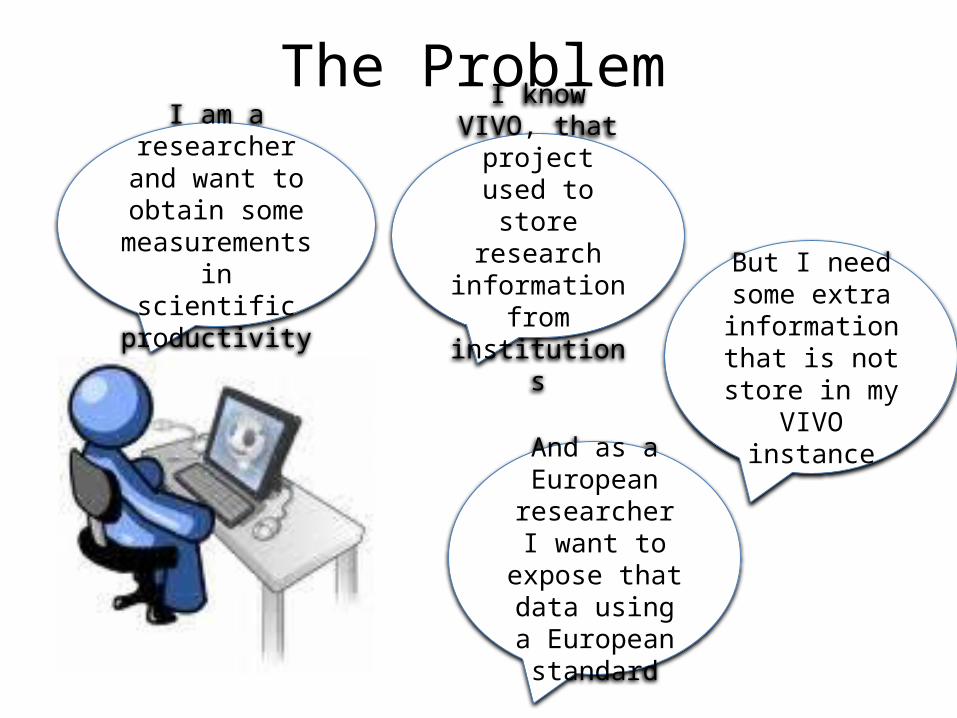
The ProblemI am a researcher
and want to obtain some
measurements in scientific
productivity
I know VIVO, that project used to store research information from
institutions But I need some extra
information that is not store in my
VIVO instanceAnd as a
European researcher I
want to expose that data using a
European standard

The Standards
1) An open source web application.
2) Enables the discovery of researchers across institutions.
3) Based on local instances that can interconnect between them.
1) A standard for managing and exchanging research data.
2) Enables integrated research information environment.
3) Allows standardised exchange of information.

Our development in steps1) What information does not share VIVO and
Google Scholar Detect which fields are useful.
2) Obtain new information with GS scraper using titles from OpenAGRIS and aggregate it to the VIVO instance. VIVO export/import New information added
3) Use the VIVO-CERIF translator. Convert the CERIF instance into CERIF-LD. VIVO-CERIF translator Obtain VIVO instance in a European standard.

Step 1Title*
Description (authors, journal…)URL
References*Cites
Google Scholar VIVOFileFormatVersionBibtex cite*Number of citesRanking in GS
AuthorsEventIssueDate (year)VolumeStart and end pageDOIPMCIDNIHMSID

Step2Objective: Combine titles from OpenAGRIS obtained with the scrapper with titles stored in VIVO instances.
Solution:
1) Combine information from scrapper database with VIVO information. Using titles.
2) Annotate information in VIVO instances. VIVO component – Export.

Step 3Objective: Obtain a CERIF instance with the new information after combining GS and VIVO.
Solution: XSLT transformation.1) It extracts RDF from a VIVO instance converting it to CERIF model in XML. VIVO-Cerif translator.
2) The translation from one language to another is made using XSLT sheets.
3) The equivalences between RDF and XML has been set by euroCRIS CERIF and VIVO members in a mapping document (v 0.2).

Workflow
VIVO.rdf Google Scholar GS scraper
New Information
VIVOimport/export
VIVO++.rdf
CERIF CERIF-LD
VIVO-CERIFTranslator
1
2
3
4
5

Use case
1) We have a paper from OpenAGRIS which have some information stored in Google Scholar.

Use Case2) We have also the paper stored in VIVO but there is only a few information about it. For example the references are not stored.
3) Looking at the VIVO ontology we know we can use a property to reference papers called “cites”

Use Case
5) Using the VIVO import/export we can add new information from Google Scholar.
6) Using the VIVO-CERIF translator we can obtain the information in another format.
4) Looking at the VIVO ontology we know we can use a property to reference papers called “cites”.
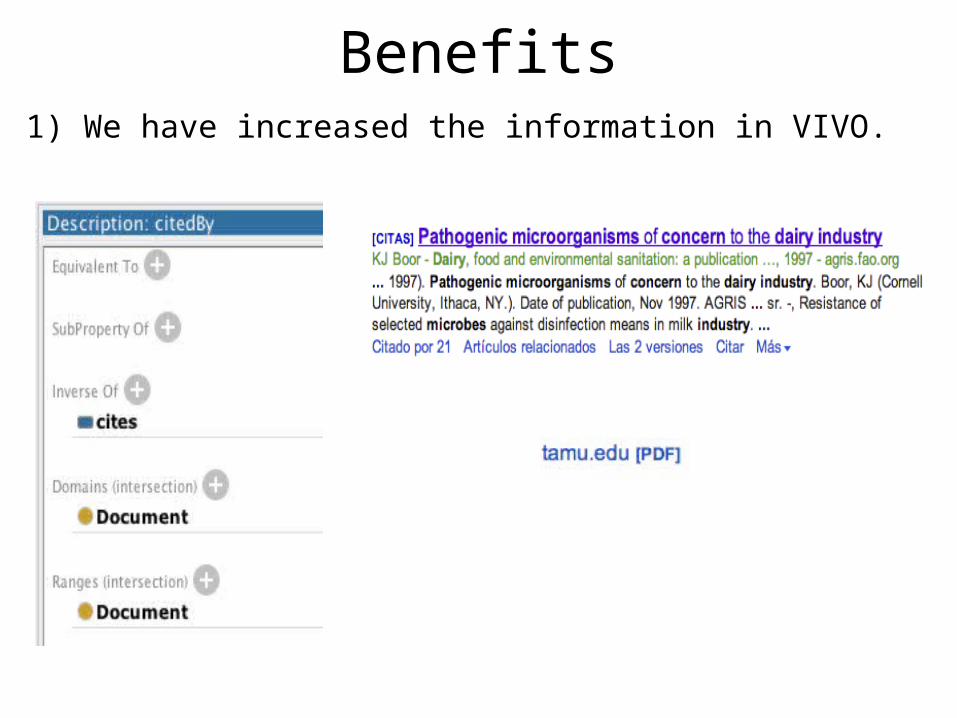
Benefits1) We have increased the information in VIVO.

Benefits
2) We have transformed VIVO to an open standard from the EU
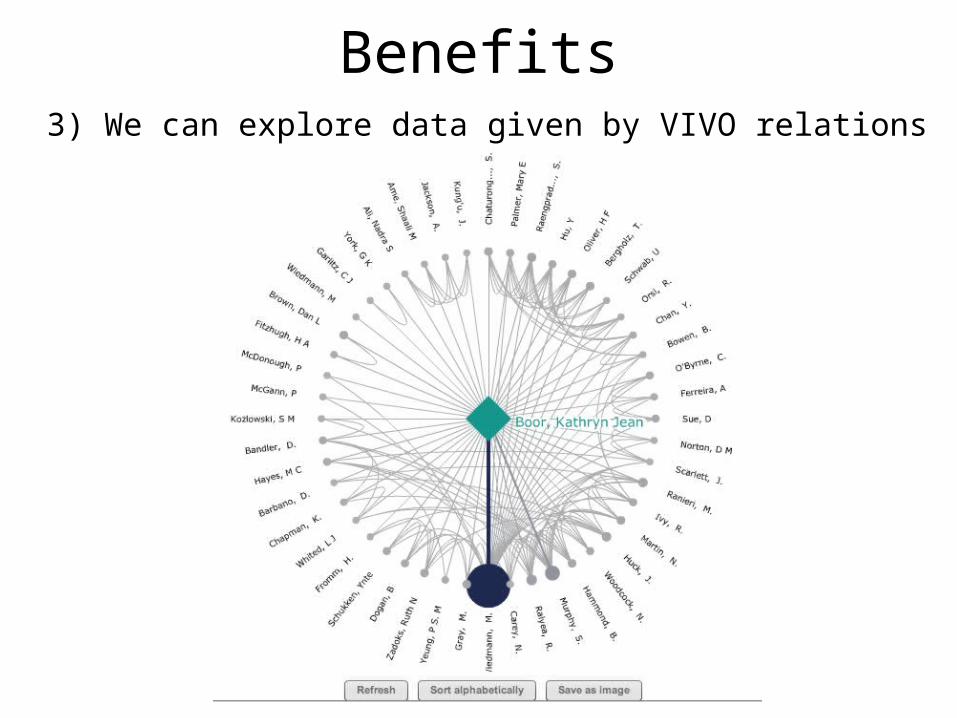
Benefits3) We can explore data given by VIVO relations

Obtain sources for hacking
1) Use a public VIVO instance.http://datahub.io/es/dataset/vivo-cornell-university
2) Obtain a VIVO instance from SPARQL endpoint. Using the command CONSTRUCT.http://sparql.vivo.ufl.edu/
3) Use a CERIF instance and translate it with the VIVOCerif translator.http://www.eurocris.org/Uploads/Web%20pages/CERIF-1.5/ (cfRMAS xml file)

Useful links1) VIVO project. http://www.vivoweb.org/
2) VIVO ontology. http://vivoweb.org/files/vivo-core-public-1.5.owl
3) VIVO import/export. https://github.com/ieru/vivo-io
4) VIVOCerif translator. https://github.com/ieru/cerif2vivo
5) CERIF .xml to .sqlhttp://sourceforge.net/projects/ceriftgtoolbox/
6) CERIF to CERIF-LD. https://code.google.com/p/cerif-linked-data/


















