Structured Storage System Cassandra - A Decentralized
37
Cassandra - A Decentralized Structured Storage System Nguyen Tuan Quang Saltlux – Vietnam Development Center 2016.03.21
Transcript of Structured Storage System Cassandra - A Decentralized

Cassandra - A Decentralized Structured Storage System
Nguyen Tuan Quang
Saltlux – Vietnam Development Center
2016.03.21

Agenda
•••••
Database System Outlines
Cassandra Overview
Data Model & Architecture
Key features
Comparison

Database Market

Relational DBMS
•••
Since 1970
Use SQL to manipulate data
Excellent for applications such as management (accounting, reservations, staff management, etc)

Relational DBMS
••
Schemas aren't designed for sparse data
Databases are simply not designed to be distributed

New Trends and Requirements

New Trends and Requirements

CAP Theory
all nodes see the same data at the same time
the system continues to operate despite arbitrary message loss
every request receives a response about whether it was successful or failed

Consistency Level
• Strong (Sequential): After the update completes any subsequent access will return the updated value
• Weak (weaker than Sequential): The system does not guarantee that subsequent accesses will return the updated value
• Eventual: All updates will propagate throughout all of the replicas in a distributed system, but that this may take some time. Eventually, all replicas will be consistent.

Cassandra
•
• Apache Cassandra was initially developed at Facebook to power their Inbox Search
Originally designed at Facebook, Cassandra came from Amazon’s highly available Dynamo and Google’s BigTable data model

Use-case: Facebook Inbox Search
••
•
Cassandra developed to address this problem.
50+TB of user messages data in 150 node cluster on which Cassandra is tested.
Search user index of all messages in 2 ways.– Term search : search by a key word
– Interactions search : search by a user id

Use-cases: Apple• Cassandra is Apple's dominant NoSQL database
– MongoDB - 35 job listings (iTunes, Customer Systems Platform, and others)
– Couchbase - 4 job listings (iTunes Social)
– Hbase - 33 job listings (Maps, Siri, iAd, iCloud, and more)
– Cassandra - 70 job listings (Maps, iAd, iCloud, iTunes, and more) Replication and Multi Data Center Replication

Use-cases: NetFlix

Use-cases - Apple

Data Model
•••
Keyspace is the outermost container for data in
Cassandra Columns are grouped into Column Families.
Each Column has– Name
– Value–Timestamp

Keyspace: metasearch
Data Model for Tornado
Metasearch
TOPIC_URL
URL1
TOPIC_CONTENT
CONTENT 1
TOPIC_TITLE
TOPIC_TITLE1
TOPIC_URL
URL2
TOPIC_CONTENT
CONTENT 2
TOPIC_TITLE
TOPIC_TITLE2
Column Families: Metasearch_korean
Row 1 Key
Row 2 Key

• PartitioningHow data is partitioned across nodes
• ReplicationHow data is duplicated across nodes
• Cluster MembershipHow nodes are added, deleted to the cluster
System Architecture

••
•
Nodes are logically structured in Ring Topology.
Hashed value of key associated with data partition is used to assign it to a node in the ring.
Hashing rounds off after certain value to support ring
structure.
• Lightly loaded nodes moves position to alleviate highly loaded nodes.
Partitioning

Partitioning
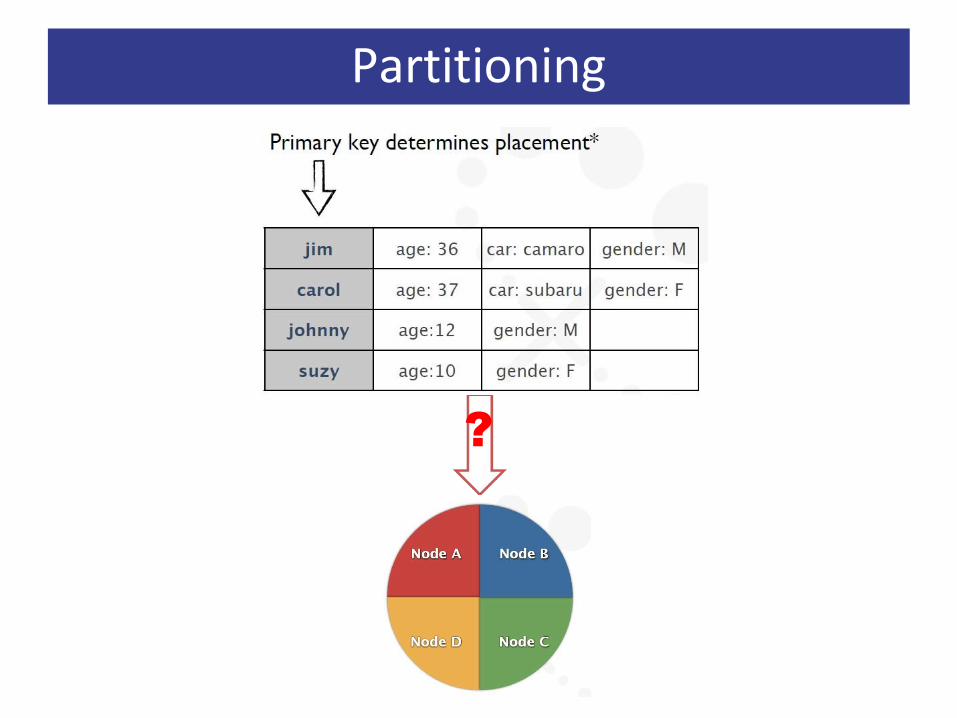
Partitioning
?

Partitioning

Partitions, Partition Key

Replication
• Each data item is replicated at N (replication factor) nodes.
• Different Replication Policies– Rack Unaware – replicate data at N-1 successive nodes after its
coordinator
– Rack Aware – uses ‘Zookeeper’ to choose a leader which tells nodes the range they are replicas for
– Datacenter Aware – similar to Rack Aware but leader is chosen at Datacenter level instead of Rack level.

10
F
E
D
C
B
A N=3
h(key2)
h(key1)
24
Partitioning and Replication
1/2* Figure taken from Avinash Lakshman and Prashant Malik (authors of the paper) slides.
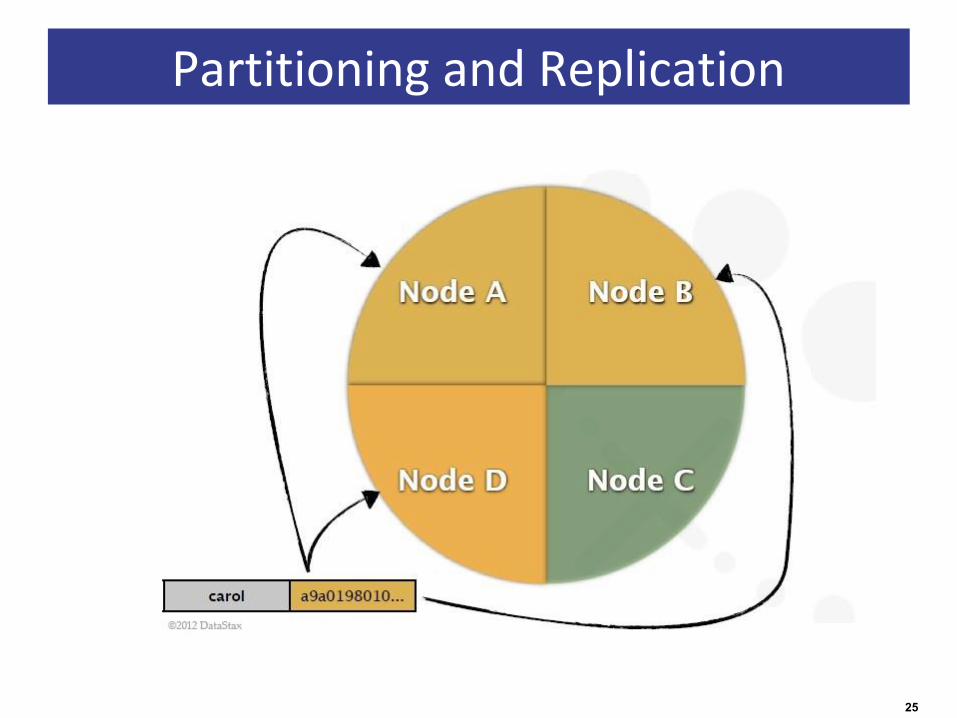
25
Partitioning and Replication

Cassandra Key features
• Big Data Scalability– Scalable to petabytes
– New nodes = linear performance increase
– Add new nodes online

Cassandra Key features
• No Single Point of Failture– All nodes are the same
– Read/write from any nodes
– Can replicate from different data centers
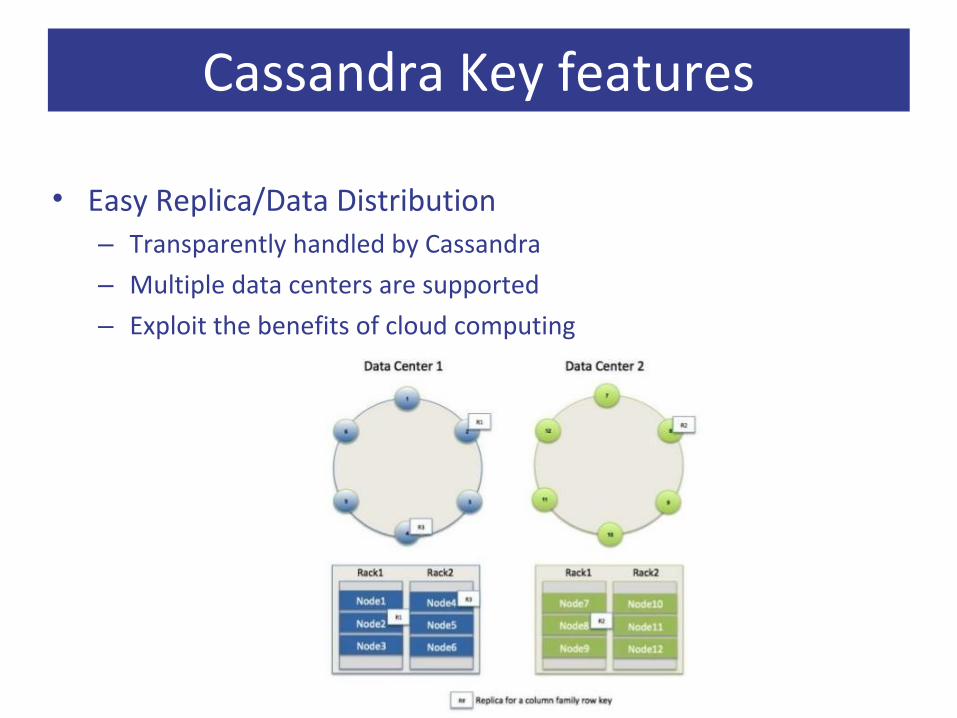
Cassandra Key features
• Easy Replica/Data Distribution– Transparently handled by Cassandra
– Multiple data centers are supported
– Exploit the benefits of cloud computing
Cassandra Key features
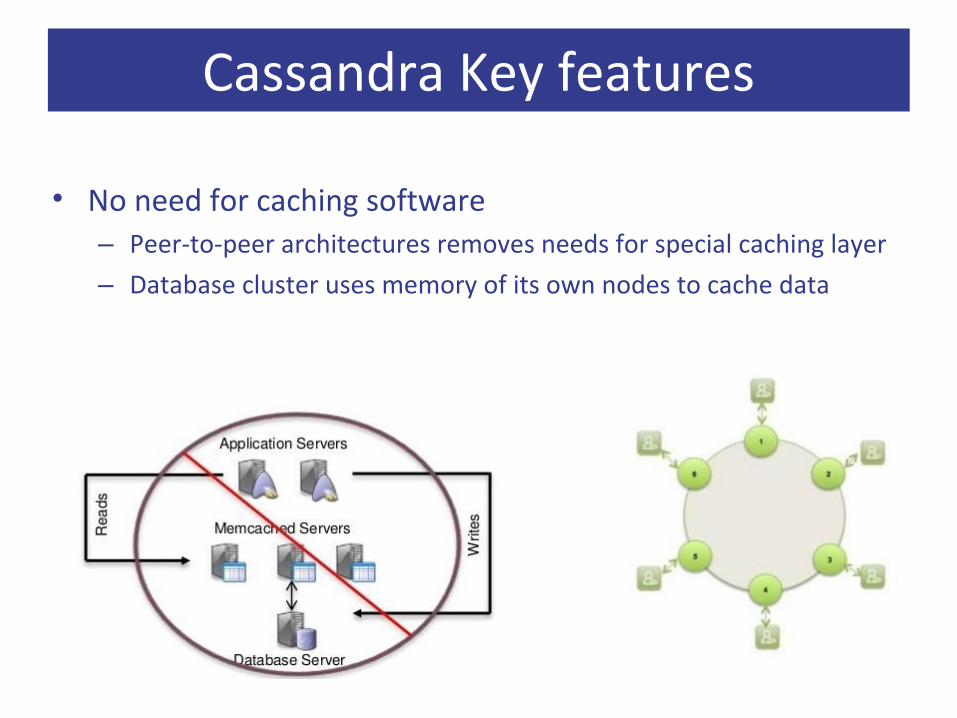
• No need for caching software– Peer-to-peer architectures removes needs for special caching layer
– Database cluster uses memory of its own nodes to cache data

Cassandra Key features
• Tunable Data Consistency– Choose between strong and eventually consistency
– Can be done on per-operation basis, and for both reads and writes

Cassandra Key features
• Tunable Data Consistency– Choose between strong and eventually consistency
– Can be done on per-operation basis, and for both reads and writes

Mongodb vs. Cassandra
Comparison with MySQL
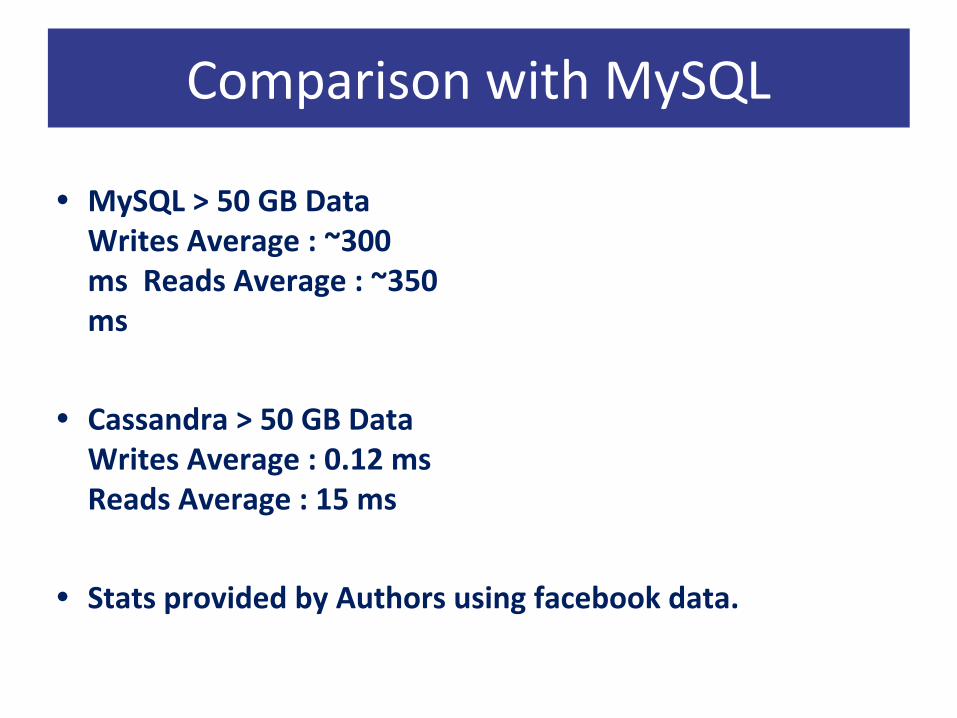
• MySQL > 50 GB Data Writes Average : ~300 ms Reads Average : ~350 ms
• Cassandra > 50 GB Data Writes Average : 0.12 ms Reads Average : 15 ms
• Stats provided by Authors using facebook data.

Key features Recaps
•
•
•
Distributed and Decentralized– Some nodes need to be set up as masters in order to organize other
nodes, which are set up as slaves
– That there is no single point of failure
High Availability & Fault Tolerance– You can replace failed nodes in the cluster with no downtime, and
you can replicate data to multiple data centers to offer improved local performance and prevent downtime if one data center experiences a catastrophe such as fire or flood.
Tunable Consistency– It allows you to easily decide the level of consistency you require, in
balance with the level of availability

Key features Recaps
• Elastic Scalability–
Elastic scalability refers to a special property of horizontal
scalability. It means that your cluster can seamlessly scale up and scale back down.

References
•
•
•••
https://jaxenter.com/evaluating-nosql-performance-which-database-is- right-for-your-data-107481.html
http://www.slideshare.net/amcsquarelearning/learn-mongo-db-at- amc-square-learning?next_slideshow=1https://en.wikipedia.org/wiki/Apache_Cassandra
http://www.datastax.com/
http://www.slideshare.net/asismohanty/cassandra-basics-20

Thank You