
Structure Clipper an interactive tool for extracting ...bulletin.acscinf.org/PDFs/247nm51.pdf ·...
23
1 Structure Clipper – an interactive tool for extracting chemical structures from patents Christopher Kibbey and Jacquelyn Klug-McLeod Pfizer Worldwide Research and Development, Worldwide Medicinal Chemistry, Computational Sciences Center of Emphasis Groton, CT
Transcript of Structure Clipper an interactive tool for extracting ...bulletin.acscinf.org/PDFs/247nm51.pdf ·...

1
Structure Clipper – an interactive tool for
extracting chemical structures from patents
Christopher Kibbey and Jacquelyn Klug-McLeod
Pfizer Worldwide Research and Development,
Worldwide Medicinal Chemistry,
Computational Sciences Center of Emphasis
Groton, CT

2 Introduction
Medicinal chemists rely on patent intelligence at three distinct junctures of a
research program:
1. Inception of an idea
2. Ongoing competitive intelligence over the course of the project
3. Preparation of a patent application
Comprehensive patent databases enable broad searches around a proposed
chemical series. However, a thorough assessment of the chemical space
disclosed in relevant patents is critical to understanding the competitive
landscape. Medicinal chemists spend considerable effort identifying “key”
compounds in competitor’s patents. Software tools that facilitate structure retrieval
and annotation are highly desired. Lastly, software capable of converting chemical
text and images to electronic structures can aid preparation of a patent
application.

3 Motivation for Structure Clipper
Access to electronic structures from patents combined with chemoinformatic tools
and in-silico models is crucial to understanding the competitive landscape around a
new chemical series.
• Assess the relative strengths and weaknesses of our chemical matter relative
to our competitors
• Facilitate identification of unexplored areas of chemical space in a competitor’s
IP
• Influence the prioritization of multiple series for early projects
• Drive patent strategies to strike a balance between cost and maintaining our
competitive advantage
• Protect Pfizer’s chemical equity
The lack of automated tools for obtaining electronic structures from patents at low
cost and in a format compatible with Pfizer’s internal tools prompted the
development of Structure Clipper.

4 Project Goals and Technical Challenges
An earlier version of Structure Clipper was developed in 2010, however, the tool
required users to manually select structure images and chemical text for processing.
While the tool was considered useful, the semi-automated extraction of structures
from large documents was tedious. Medicinal chemists desired a more automated
approach.
Desired features for an updated version of Structure Clipper included:
• Automated extraction of chemical structures from a native PDF document
• Compatible with US, EP, WO patents and journal articles in English
• Requires sophisticated image processing, and OCR for success
• Extracted structures are traceable to the document page and source location
• Requires user interface for displaying PDF page contents and
highlighting source location for extracted structures
• Manual correction of extracted structures
• Correct errors in chemical names
• Correct errors in structures generated from images
• Integration with existing Pfizer molecular design tools

5 Structure Clipper - Overview
Structure Clipper is integrated into the Pfizer Compound Analysis Tool (PCAT)
Access to in-silico models and
other chemoinformatic tools
Extracted chemical
structures
PDF page viewer
highlights location of
extracted chemical
structures
Images are converted to electronic structures using OSRA 2.0.
Chemical names are converted using ACD Labs and OpenEye name-to-structure tools.

6 Structure Clipper – Interactive Selection Synchronization
Compound selection is synchronized between the PCAT table and PDF page view
Selecting a compound in the
PCAT table will display the source
location in the PDF page viewer
Selecting a compound in the
PCAT table will display the source
location in the PDF page viewer.
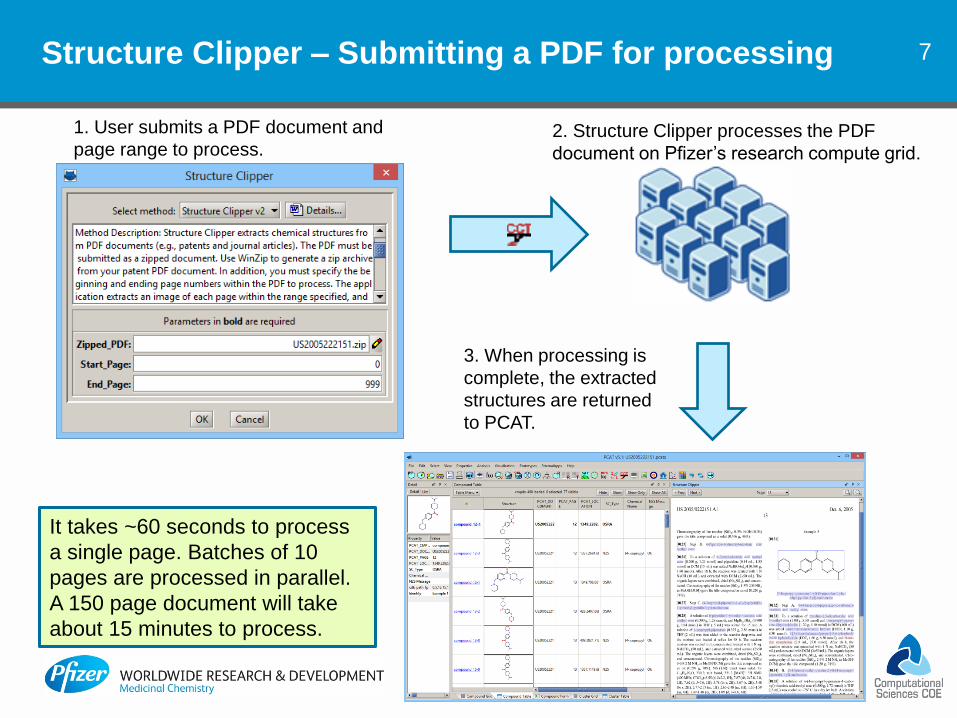
7 Structure Clipper – Submitting a PDF for processing
1. User submits a PDF document and
page range to process. 2. Structure Clipper processes the PDF
document on Pfizer’s research compute grid.
3. When processing is
complete, the extracted
structures are returned
to PCAT.
It takes ~60 seconds to process
a single page. Batches of 10
pages are processed in parallel.
A 150 page document will take
about 15 minutes to process.

8 Segregating example compounds from reagents, intermediates,
and Markush fragments found in the document
Structure clipper tags
extracted structures with an
identifier (e.g., example,
compound, intermediate, step)
found in the surrounding text.
These identifiers may be used
to isolate example compounds
from reagents and
intermediates extracted from
the document.
Alternatively, Ward’s
clustering may be applied to
the collection of extracted
compounds to segregate
compounds by structural
similarity.

9 Image Preparation – key to accurate conversion of text
and images to electronic structures
Structure Clipper processes PDF pages as images to ensure compatibility with documents that
lack electronic text. Tesseract v3.02 is used to perform OCR on a page image. OSRA v2.0
converts structure images to electronic form.
Both OCR and OSRA algorithms rely on inflection points computed from outlines traced along the
perimeter of content in the page image. Pixelated and low-resolution images result in spurious, or
insufficient inflection points, which contribute to errors in the OCR and OSRA output.
Structure Clipper applies an RGB image filter and smoothing algorithm to generate high-quality,
300 dpi images of PDF pages for input to OSRA and OCR.
Image
Processing

10
A particle
detection
algorithm is
applied to
the black &
white page
image
in order to
locate the
rectangular
boundaries
of discrete
elements
found on the
page.
Structure Clipper – Preliminary Image Analysis
Image
Analysis

11 Shape descriptors are used to identify text characters
and bonds within structure images
• Circularity 1.0 is a perfect circle, 0.0 is a line
• Aspect ratio AR increases as particle becomes elongated
• Roundness differs from circularity in that it considers
density
• Solidity measures how much the particle fills the
rectangular region
4π × ([Area])
([Perimeter]2)
([Major Axis])
([Minor Axis])
4 × ([Area])
(π × [Major axis]2)
([Area])
([Convex area])
Letters generally have circularity > 0.2 and solidity < 0.7
Bond segments in chemical structures are characterized by large aspect ratios
Shape descriptors also are computed for discrete elements found in the page image.

12 Isolation of structure images for OSRA
Structure Clipper analyzes a PDF page image for intersecting regions that comprise a single
structure image. The union of these intersecting regions defines a rectangular boundary for
the sub-image submitted to OSRA for conversion to an electronic structure.

13 Isolation of structure sub-images improves OSRA
performance
Consider the following example taken from page 72 of WO2009158571. OSRA combines
structures lying in close proximity within this image into a single molecule.
Structure Clipper isolates sub-image
regions containing discrete structures to
improve OSRA performance.

14 Manual correction of OSRA generated structures
Structure Clipper provides a convenient means for correcting errors in OSRA
generated structures. Right-click on a structure image, then select “Edit OSRA
Structure” from the pop-up menu. The selected molecule is loaded into a
Marvin Sketch editor.

15 Image preparation for optical character recognition (OCR)
Structure images are deleted from the page image prior to OCR processing. This
ensures structure images are not misinterpreted as text.
Tesseract OCR can interpret underlined text, provided the text characters do not
overlap with the underline. Characters that overlap an underline are misinterpreted
by OCR. Structure Clipper automatically corrects underlined text to ensure
accurate conversion to electronic text.

16 Chemical Name Annotation
Structure Clipper is designed to identify IUPAC chemical names in electronic text.
Structure Clipper cannot interpret chemical formulas, common names,
abbreviations, or Smiles.
Structure Clipper aggregates words generated by Tesseract OCR into chemical
names using a set of internal rules. An aggregated chemical name is validated by
the presence of token characters (e.g., {}[]()-,.) and recognized sub-terms.
Structure Clipper’s chemical dictionary (46,000 entries) was created by parsing
sub-terms found in 25 million IUPAC chemical names. In addition, a dictionary of
stop-words is used to reject common words found in the document text.

17 Correcting misspelled terms in IUPAC names
Structure Clipper uses the Java open source spell checker, Jazzy, and an internal
chemical dictionary to validate sub-terms found in aggregated chemical names. Jazzy
usually can correct spelling errors in chemical sub-terms involving a difference of a single
character. A triples dictionary, consisting of the most frequently observed three-letter
sequences found in the chemical dictionary, is used to perform more rigorous correction of
spelling errors that cannot be automatically corrected by Jazzy.
Example: pipcridinc is not in the chemical dictionary and Jazzy suggests no alternates
• pip is in the triples dictionary
• cri is not in the triples dictionary, eri is suggested as an alternate
• piperidinc is not in the chemical dictionary
• piperidine, piperidinic suggested as alternates
• piperidine has 2 character differences from pipcridinc
• piperidinic has 3 character differences from pipcridinc
• piperidine returned as corrected spelling
In addition, a set of common OCR character errors is evaluated to correct spelling errors
that may be present in chemical sub-terms.
• rn -> m, xn -> m, lt -> h, lx -> h, rl -> n, ri -> n, il -> rt, vv -> w, ix -> in

18 Manual correction of IUPAC chemical names
Chemical names that fail name-to-structure conversion
are highlighted in red, and the corresponding structure
cell in the PCAT table is left empty. Failed chemical
names may be corrected by right-clicking on the name
and selecting “Edit Chemical Name” from the pop-up
menu.
Structure Clipper displays an image
of the selected chemical name,
along with the recognized text in an
editable text field.

19 Manual correction of IUPAC chemical names
After the user corrects errors in the
recognized chemical name,
Structure Clipper resubmits the
edited name for name-to-structure
conversion. Blue highlighting
signifies successful conversion of an
edited chemical name to a structure.
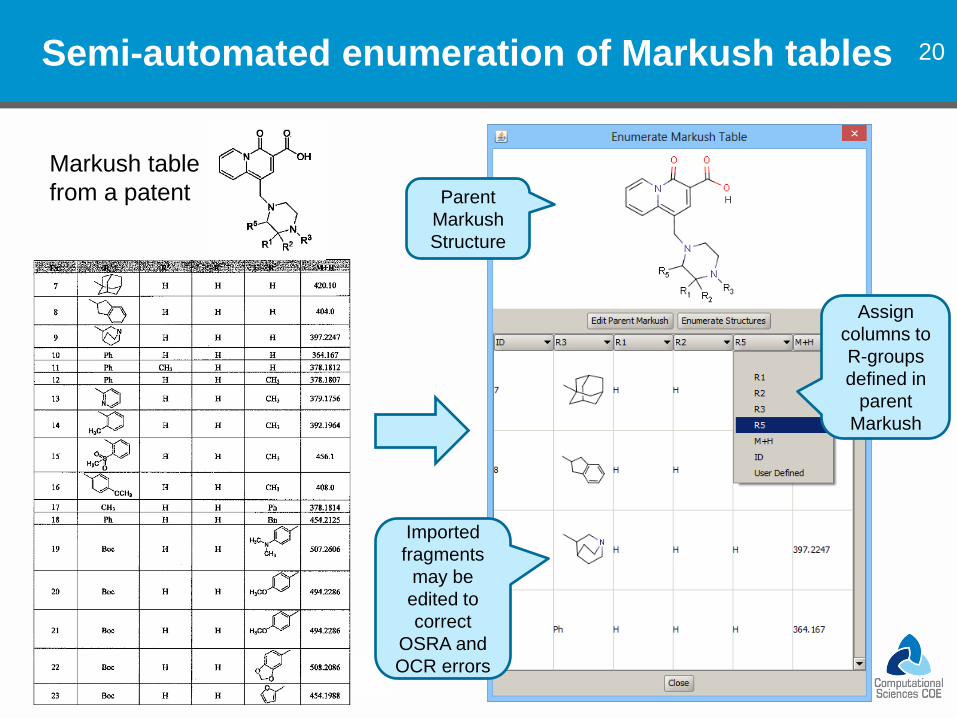
20 Semi-automated enumeration of Markush tables
Imported
fragments
may be
edited to
correct
OSRA and
OCR errors
Markush table
from a patent Parent
Markush
Structure
Assign
columns to
R-groups
defined in
parent
Markush
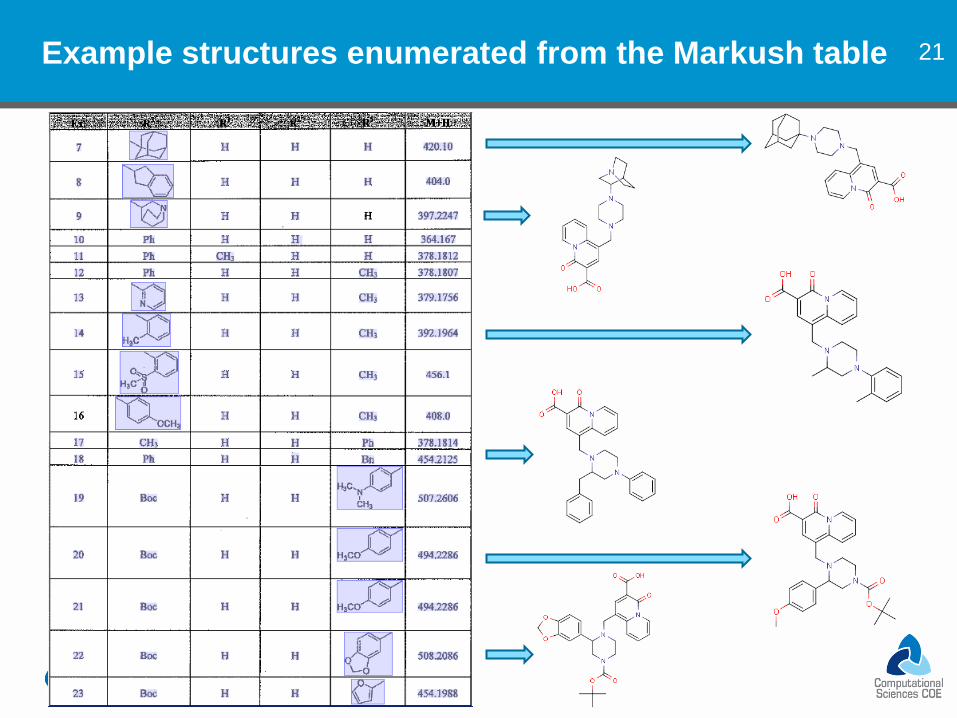
21 Example structures enumerated from the Markush table

22 Future Directions
Planned enhancements to Structure Clipper include:
1. Semi-automated extraction of bio-assay data from tables
2. Improved recognition of abbreviated groups, chemical formulas and Smiles
3. Extraction of reaction schemes, description of synthesis, and yield
4. Extraction of gene symbols, biological targets, and disease information

23 Acknowledgements
We wish to acknowledge the following individuals for their efforts in beta-
testing and providing useful suggestions during the development of Structure
Clipper.
• Brian Gerstenberger
• Robert Owen
• Martin Pettersson
• Vineet Sardar
• Keith Schreiber
• Christoph Zapf


















