
String Matching with Alphabet Sampling
20
String Matching con Campionamento dell’Alfabeto Dall’articolo “String matching with alphabet sampling” di Claude, Navarro, Peltola, Salmela, Tarhio.
-
Upload
tiziana-spata -
Category
Education
-
view
72 -
download
1
Transcript of String Matching with Alphabet Sampling

String Matching con
Campionamento dell’Alfabeto
Dall’articolo “String matching with alphabet sampling”
di Claude, Navarro, Peltola, Salmela, Tarhio.
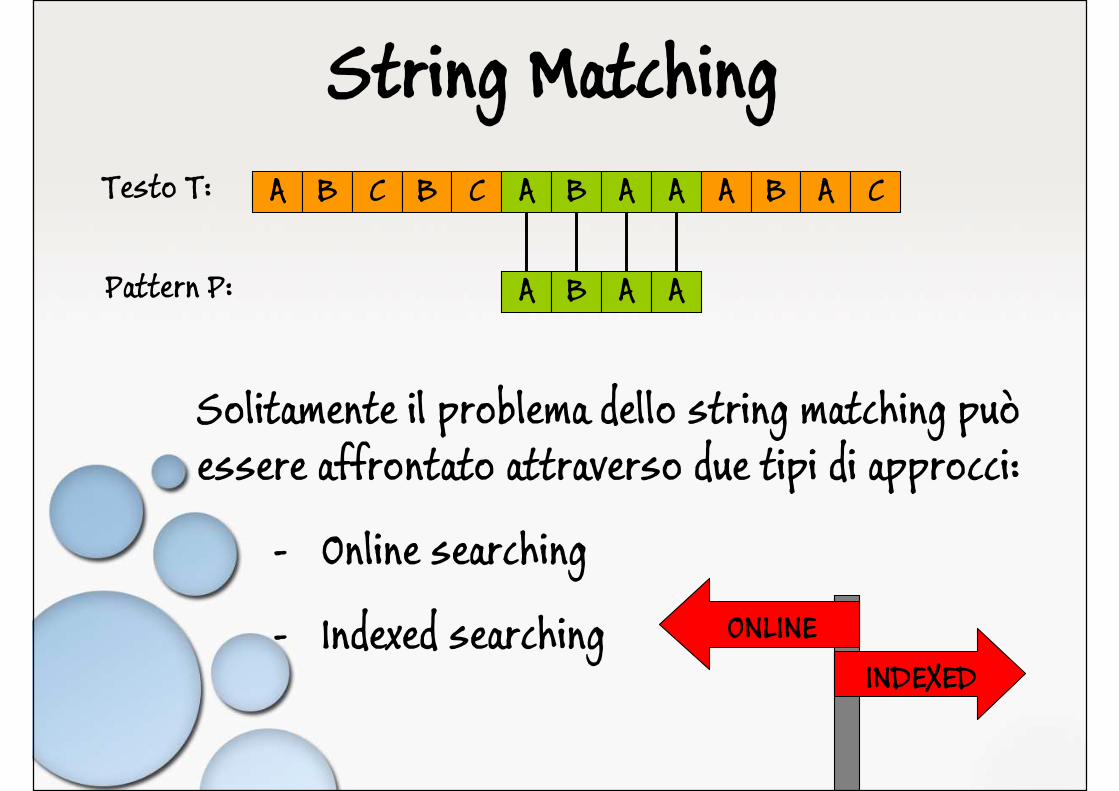
String Matching
Solitamente il problema dello string matching può essere affrontato attraverso due tipi di approcci:
- Online searching
- Indexed searching ONLINEINDEXED
A B C B C A B A A A B A C
A B A A
Testo T:
Pattern P:

Approccio Semi-indexed
Tale approccio si compone di più passi fondamentali:1. campionamento dell’alfabeto e del testo;
2. indicizzazione del testo;3. campionamento del pattern;
4. scansione del testo;5. verifica.

Approccio Semi-indexedUn approccio di tipo semi-indexed è composto dai seguenti elementi:
• il testo campionato Tx, di lunghezza nx;• la mappatura delle posizione M, una tabelladi dimensione floor(nx/q) tale che:
M[ i ] = j � T[ j ] = Tx[q · i]

Approccio Semi-indexedFunzionamento del pre-processing:
Si trova un’occorrenza alla posizione Tx[2].
Tale posizione è mappata quindi è sufficiente verificare un’occorrenza a partire dalla posizione T[4], così si trova un match.
A B A A C A B D A A
0 5 8
B C B D
A C A B
C B
Testo T:
Tx:
Mappatura M
Pattern P:
Px:si omettono le a

Verifica
se l’ occorrenza include una posizione
mappata, è sufficiente controllare solo
una posizione di T e cioè l’ esatta
posizione di uno dei caratteri di P nella
possibile occorrenza reale;
se l’ occorrenza include una posizione
mappata, è sufficiente controllare solo
una posizione di T e cioè l’ esatta
posizione di uno dei caratteri di P nella
possibile occorrenza reale;
se Px è stato trovato nella generica posizione ir
in Tx, per trovare la posizione di inizio dell’occorrenza reale, viene controllata l’area:T[ M[i
r/q] + (i
rmo d q)- j
1+1 ; M[i
r/q+1 ] - (q-(i
rmo d q)) – j
1+1 ]
se Px è stato trovato nella generica posizione ir
in Tx, per trovare la posizione di inizio dell’occorrenza reale, viene controllata l’area:T[ M[i
r/q] + (i
rmo d q)- j
1+1 ; M[i
r/q+1 ] - (q-(i
rmo d q)) – j
1+1 ]

Ricerca: BMH algorithmfor i � 1 to σ do
d[i] � mx
for i � 1 to mx– 1 do
d[ Px[i] ] � m
x– 1
pos � 1while pos ≤ n
x– m
x+1 do
j � mx
while j≥1 and Tx[pos+j-1] = P
x[j] do
j � j – 1if j = 0 then
if l’occorrenza in Txcontiene una posizione mappata then
verifica la posizione corrispondente in T per trovare l’occorrenzaelse
verifica l’occorrenza che inizia da M[pos/q]+(pos mod q)-j1 +1 a
M[pos/q+1]-(q-(pos mod q))-j1 +1 in T
pos � pos + d[ Tx [pos + m
x-1] ]
O(mx +σ)Complessità totale: O(m
x· n
x)
N.B. d[i] è la distanza dall’ultima occorrenza di i alla fine
O(mx) · O(nx-mx+1)
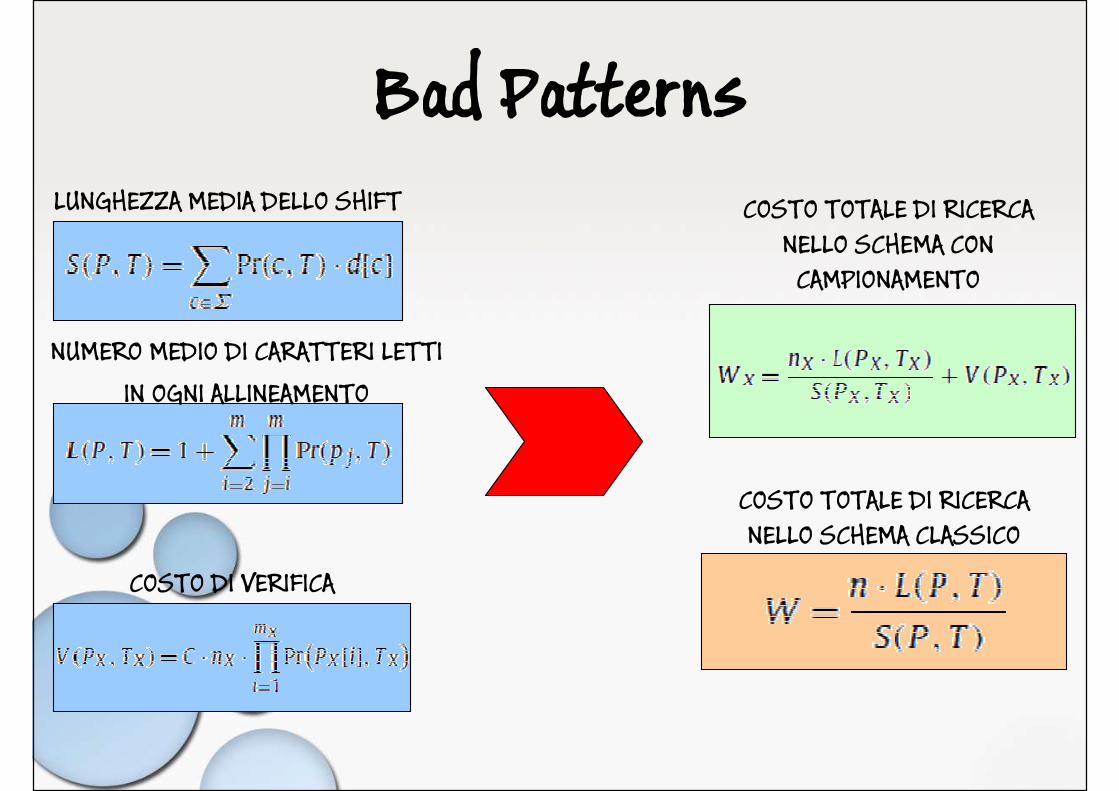
Bad PatternsLUNGHEZZA MEDIA DELLO SHIFT
NUMERO MEDIO DI CARATTERI LETTIIN OGNI ALLINEAMENTO
COSTO DI VERIFICA
COSTO TOTALE DI RICERCA NELLO SCHEMA CON CAMPIONAMENTO
COSTO TOTALE DI RICERCA NELLO SCHEMA CLASSICO

COME CAMPIONARE L’ALFABETO
BISOGNA MINIMIZZARE IL COSTO PER CARATTERE DI TESTO:
dove:
N.B.
il costo di verifica viene sempre incrementato quando viene rimosso un carattere dall’alfabeto mentre il costo di ricerca può e decrementare il costo totale in base ad alcuni parametri.
COSTO DIRICERCA
COSTO DIRICERCA
COSTO DIVERIFICA
COSTO DIVERIFICA

DECREMENTARE IL COSTO DI RICERCA
COSTO DI RICERCA NEL CASO DI UN CARATTERE, CON PROBABILIA’ p, RIMOSSO:
Calcolando la derivata prima di tale funzione, si può osservare che ha un andamento di questo tipo:
hR(p)
ppZ pR
hR(0)
Pr(c)>>PR

CAMPIONAMENTO DELL’ALFABETO
Ropt� {}sort ∑ in ordine decrescente in base alle probabilità di
occorrenzafindOpt (1, {})return Ropt
findOpt (c, R)If c = σ+1 then
if E(∑ \ R) < E(∑ \ Ropt) thenRopt = R
elsepR = (a∑ – aR) / (1 – bR)if Pr(c) > pR thenfindOpt (c+1, R U {c})findOpt (c+1, R)
elsefindOpt (σ+1, R)

RISULTATI SPERIMENTALISono state implementate tre versioni dell’approccio semi-index:
- Basic: cerca all’interno del testo campionato tranne se il patterncampionato ha lunghezza 0;
- Estimated Best Text: si stima il costo di ricerca usando iltesto campionato e il testo originale e si sceglie il testo con costo minore;
- Optimal Text: ogni pattern viene cercato sia nel testo originale che in quello campionato e si scegliela ricerca con runtime minore (serve solo a dare un lower bound).

RISULTATI SPERIMENTALI
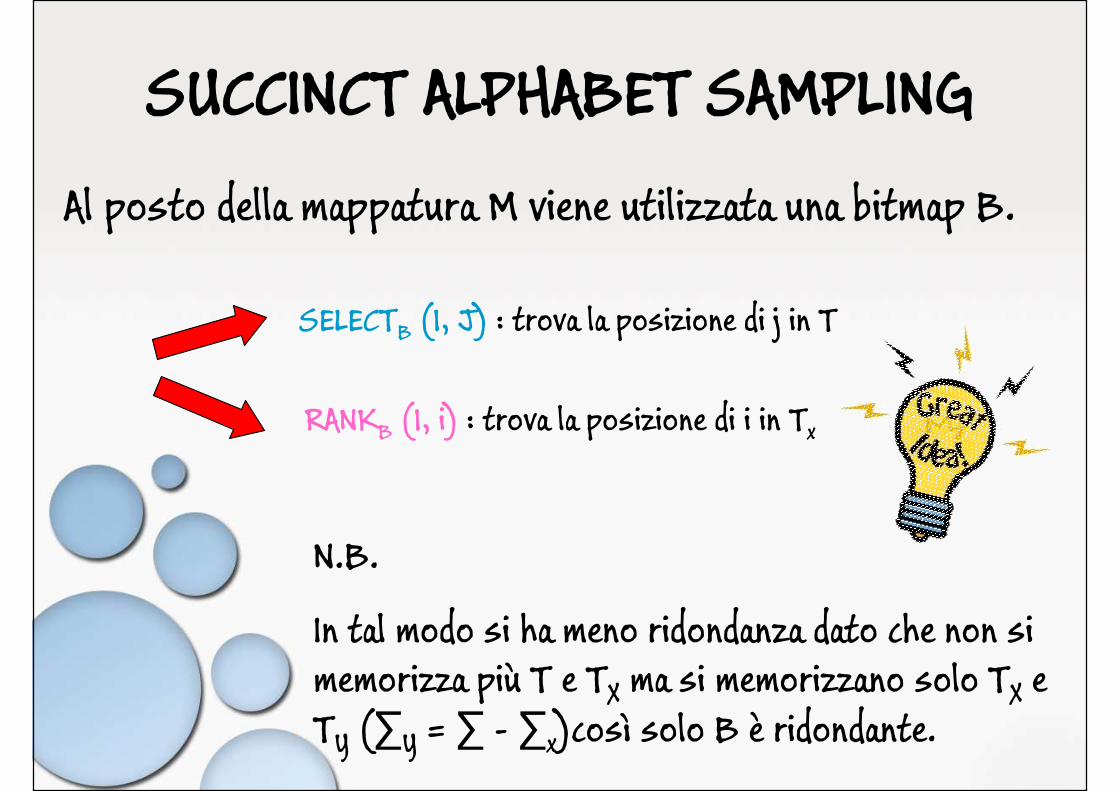
SUCCINCT ALPHABET SAMPLING
Al posto della mappatura M viene utilizzata una bitmap B.
SELECTB (1, J) : trova la posizione di j in T
RANKB (1, i) : trova la posizione di i in Tx
N.B.
In tal modo si ha meno ridondanza dato che non si memorizza più T e TX ma si memorizzano solo TX e TY (∑Y = ∑ - ∑x)così solo B è ridondante.

SUCCINCT ALPHABET SAMPLING
T = { a b b a b a c b a a c c }
P = { a c b } PX = { c b }
PY = { a }
TX = { b b b c b c c }
TY = { a a a a a a}
BP =
Candidato: TX[4] � nel testo originale corrisponde ad i = SELECTB (1, 4) = 7. Il match potenziale inizia, allora, dalla posizione i-j+1 (dove j è la posizione del primo carattere di PX in P) = 7-2+1 = 6. Infine si verifica se B[6...8] corrisponde a BP[1, 3].
0 1 1
1 1 0 10 0 1 1 0 0 1 1B =

RISULTATI SPERIMENTALI

SAMPLED SUFFIX ARRAYSuffix Array:
Il testo T è stato campionato eliminando le a
in ordine alfabetico...
Creazione del suffix array: O(n)Complessità spaziale: O(nx)
T = A B A A C A B D A A1 2 3 4 5 6 7 8 9 10 2
758
ABAACABDAABDAACABDAADAA
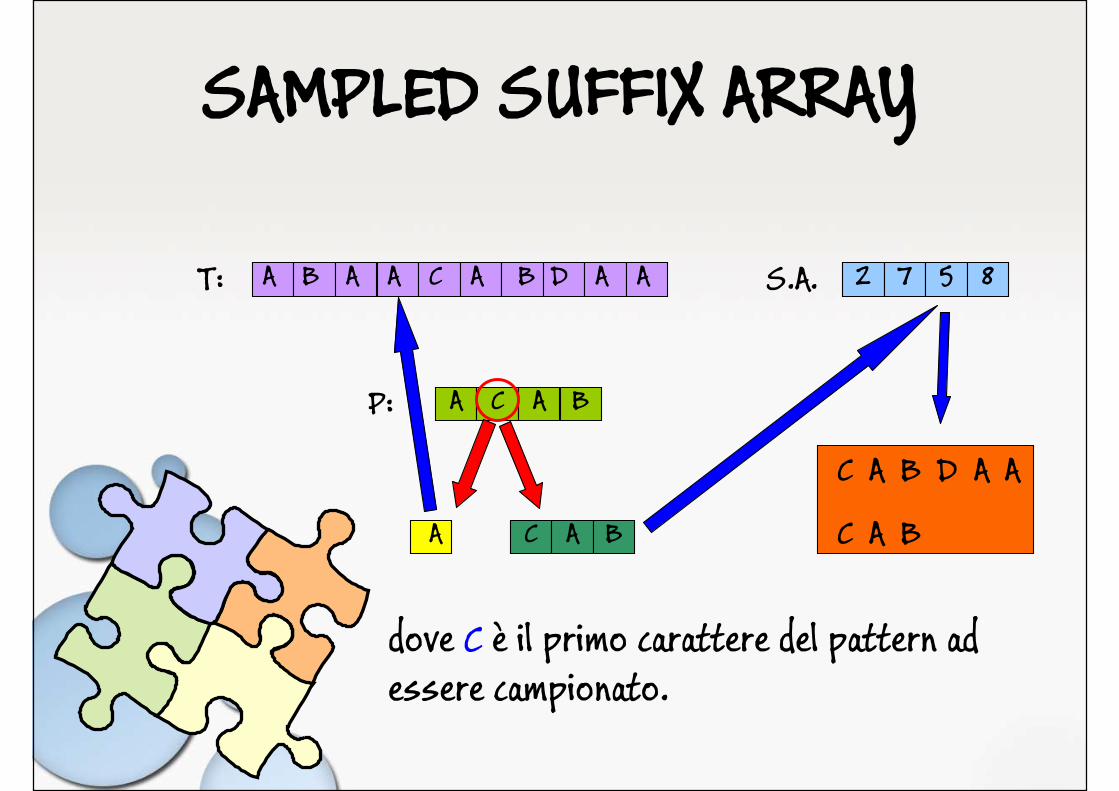
SAMPLED SUFFIX ARRAY
T: A B A A C A B D A A S.A. 2 7 5 8
P: A C A B
A C A B
C A B D A A
C A B
dove C è il primo carattere del pattern ad essere campionato.

OTTIMIZZARE IL CAMPIONAMENTO
E’ possibile dimostrare che il costo totale relativo a tale approccio può essere minimizzato scegliendo un alfabetocampionato contenente un set di carattere con frequenza minima. Infatti questa scelta minimizzerebbe sia il costo di ricerca che il costo di verifica.

CONCLUSIONIApproccio semi-index, su distribuzioni di caratteri non uniformi:- 5 volte più veloce rispetto alla ricerca online al prezzo di solo il
14% di spazio extra- sul testo è possibile applicare qualsiasi trasformazione o
compressione.Approccio sampled suffix array:- anche su distribuzioni di caratteri uniformi- vanta le stesse performance del suffix array classico
ma con un consumo di spazio pari ad 1/8
Tuttavia tali approcci non possono essere applicati in casi in cui l’alfabeto o il pattern sono troppo corti.


















