
Static Translation of Stream Programming to a Parallel System S. M. Farhad PhD Student Supervisor:...
24
Static Translation of Stream Programming to a Parallel System S. M. Farhad PhD Student Supervisor: Dr. Bernhard Scholz Programming Language Group School of Information Technology University of Sydney
-
date post
21-Dec-2015 -
Category
Documents
-
view
221 -
download
1
Transcript of Static Translation of Stream Programming to a Parallel System S. M. Farhad PhD Student Supervisor:...

Static Translation of Stream Programming to a Parallel
SystemS. M. FarhadPhD Student
Supervisor: Dr. Bernhard ScholzProgramming Language Group
School of Information TechnologyUniversity of Sydney
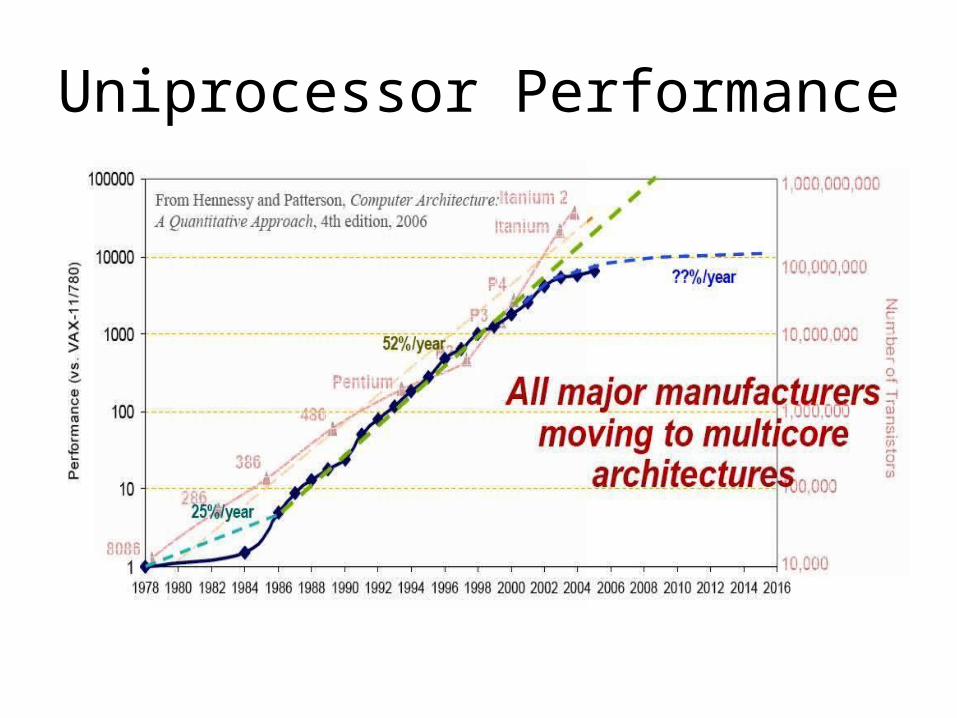
Uniprocessor Performance

Motivation
1985 199019801970 1975 1995 2000
4004
8008
80868080 286 386 486 Pentium P2 P3P4Itanium
Itanium 2
2005 20??
# ofcores
1
2
4
8
16
32
64
128
256
512
Athlon
Raw
Power4Opteron
Power6
Niagara
YonahPExtreme
Tanglewood
Cell
IntelTflops
Xbox360
CaviumOcteon
RazaXLR
PA-8800
CiscoCSR-1
PicochipPC102
Broadcom 1480 Opteron 4P
Xeon MP
AmbricAM2045

Motivation
For uniprocessors,C was:•Portable•High Performance•Composable•Malleable•Maintainable
Uniprocessors:C is the commonmachine language
1985 199019801970 1975 1995 2000
4004
8008
80868080 286 386 486 Pentium P2 P3P4Itanium
Itanium 2
2005
Raw
Power4Opteron
Power6
Niagara
YonahPExtreme
Tanglewood
Cell
IntelTflops
Xbox360
CaviumOcteon
RazaXLR
PA-8800
CiscoCSR-1
PicochipPC102
Broadcom 1480
20??
# ofcores
1
2
4
8
16
32
64
128
256
512
Opteron 4P
Xeon MP
Athlon
AmbricAM2045

Motivation
What is the commonmachine languagefor multicores?
1985 199019801970 1975 1995 2000
4004
8008
80868080 286 386 486 Pentium P2 P3P4Itanium
Itanium 2
2005
Raw
Power4Opteron
Power6
Niagara
YonahPExtreme
Tanglewood
Cell
IntelTflops
Xbox360
CaviumOcteon
RazaXLR
PA-8800
CiscoCSR-1
PicochipPC102
Broadcom 1480
20??
# ofcores
1
2
4
8
16
32
64
128
256
512
Opteron 4P
Xeon MP
Athlon
AmbricAM2045

Common Machine Languages
Common Properties
Single flow of control
Single memory image
Uniprocessors:
Differences:
Register File
ISA
Functional Units
Register AllocationInstruction Selection
Instruction Scheduling
Common Properties
Multiple flows of control
Multiple local memories
Multicores:
Differences:
Number and capabilities of cores
Communication Model
Synchronization Model
von-Neumann languages represent the common properties and abstract away the differences
Stream Programming Language is acommon machine language for multicores

Properties of Stream Programs [W. Thies ‘02]
• A large (possibly infinite) amount of data• Limited lifespan of each data item• Little processing of each data item
• A regular, static computation pattern• Stream program structure is relatively
constant• A lot of opportunities for compiler
optimizations

Application of Streaming Programming

Model of Computation
• Synchronous Dataflow [Lee ‘92]– Graph of autonomous filters– Communicate via FIFO channels
• Static I/O rates [Edward ‘87]– Compiler decides on an order
of execution (schedule)– Static estimation of
computationAdder
Speaker
AtoD
FMDemod
Scatter
Gather
LPF2 LPF3
HPF2 HPF3
LPF1
HPF1

parallel computation
StreamIt Language Overview [Thies ‘04]
• StreamIt is a novel language for streaming– Exposes parallelism and
communication– Architecture independent– Modular and composable
• Simple structures composed to creates complex graphs
– Malleable• Change program behavior
with small modifications
may be any StreamIt language construct
joinersplitter
pipeline
feedback loop
joiner splitter
splitjoin
filter

11
Mapping of Filters to Multicores
• Task Parallelism [Edward ‘87]• Fine-Grained Data Parallelism [Michael ‘06]• 3-phase solution [Michael ’06]• Orchestrating the Execution of Stream Programs
[Kudlur ‘08]

12
Baseline 1: Task Parallelism
Adder
Splitter
Joiner
Compress
BandPass
Expand
Process
BandStop
Compress
BandPass
Expand
Process
BandStop
• Inherent task parallelism between two processing pipelines
• Task Parallel Model:– Only parallelize explicit
task parallelism – Fork/join parallelism
• Execute this on a 2 core machine ~2x speedup over single core

13
Baseline 2: Fine-Grained Data Parallelism
Adder
Splitter
Joiner
• Each of the filters in the example are stateless
• Fine-grained Data Parallel Model:– Fiss each stateless filter N
ways (N is number of cores)– Remove scatter/gather if
possible
• We can introduce data parallelism– Example: 4 cores
• Each fission group occupies entire machineBandStopBandStopBandStopAdder
Splitter
Joiner
ExpandExpandExpand
ProcessProcessProcess
Joiner
BandPassBandPassBandPass
CompressCompressCompress
BandStopBandStopBandStop
Expand
BandStop
Splitter
Joiner
Splitter
Process
BandPass
Compress
Splitter
Joiner
Splitter
Joiner
Splitter
Joiner
ExpandExpandExpand
ProcessProcessProcess
Joiner
BandPassBandPassBandPass
CompressCompressCompress
BandStopBandStopBandStop
Expand
BandStop
Splitter
Joiner
Splitter
Process
BandPass
Compress
Splitter
Joiner
Splitter
Joiner
Splitter
Joiner

14
3-Phase Solution [Michael ‘06]
RectPolar
Splitter
Joiner
AdaptDFT AdaptDFT
Splitter
Splitter
Amplify
Diff
UnWrap
Accum
Amplify
Diff
Unwrap
Accum
Joiner
Joiner
PolarRect
66
20
2
1
1
1
2
1
1
1
20 Data Parallel
Data Parallel
Target a 4 core machine
Data Parallel, but too little work!

15
Data Parallelize
RectPolarRectPolarRectPolar
Splitter
Joiner
AdaptDFT AdaptDFT
Splitter
Splitter
Amplify
Diff
UnWrap
Accum
Amplify
Diff
Unwrap
Accum
Joiner
RectPolar
Splitter
Joiner
RectPolarRectPolarRectPolarPolarRect
Splitter
Joiner
Joiner
66
20
2
1
1
1
2
1
1
1
20
5
5
Target a 4 core machine

16
Data + Task Parallel Execution
Time
Cores
21
Target 4 core machine
Splitter
Joiner
Splitter
Splitter
Joiner
Splitter
Joiner
RectPolarSplitter
Joiner
Joiner
66
2
1
1
1
2
1
1
1
5
5
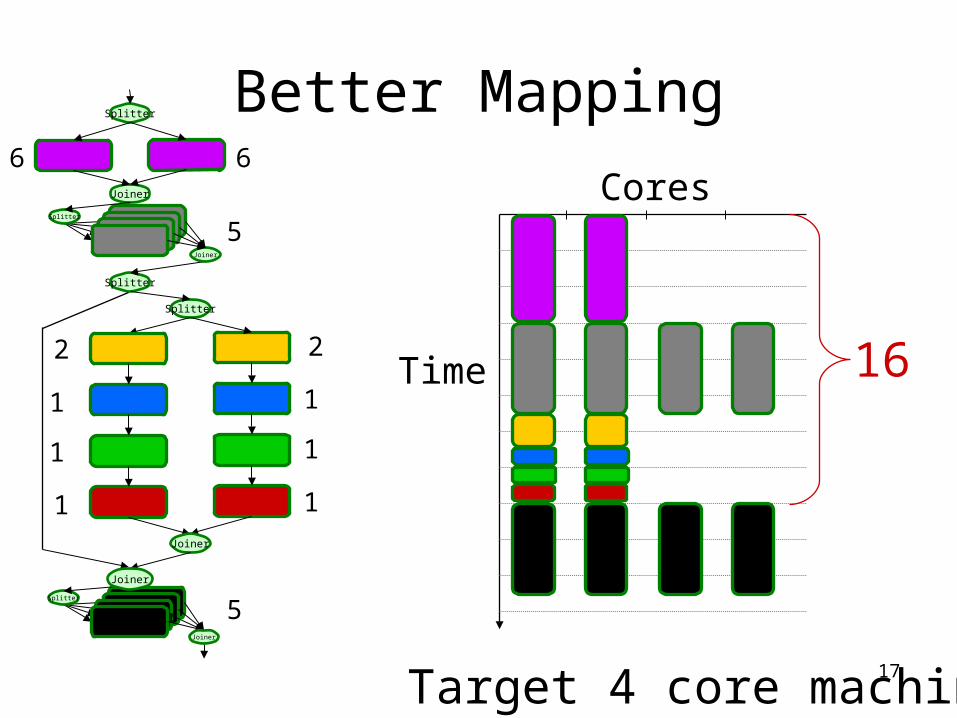
17
Better Mapping
Time
Cores
Target 4 core machine
Splitter
Joiner
Splitter
Splitter
Joiner
Splitter
Joiner
RectPolarSplitter
Joiner
Joiner
66
2
1
1
1
2
1
1
1
5
5
16

18
Phase 3: Coarse-Grained Software Pipelining
RectPolar
RectPolar
RectPolar
RectPolar
Prologue
New Steady
State
• New steady-state is free of dependencies
• Schedule new steady-state using a greedy partitioning

19
Greedy Partitioning [Michael ‘06]
Target 4 core machine
Time 16
CoresTo Schedule:

Static Translation of Stream Programs [Proposal]
• We study – A mathematical model and algorithms to resolve
bottlenecks in stream programs– Map actors of stream programs to processors in a
parallel systems– Compute a schedule for each processor
• Goal is to statically optimize the throughput of a stream program
• Assuming constant input bandwidth
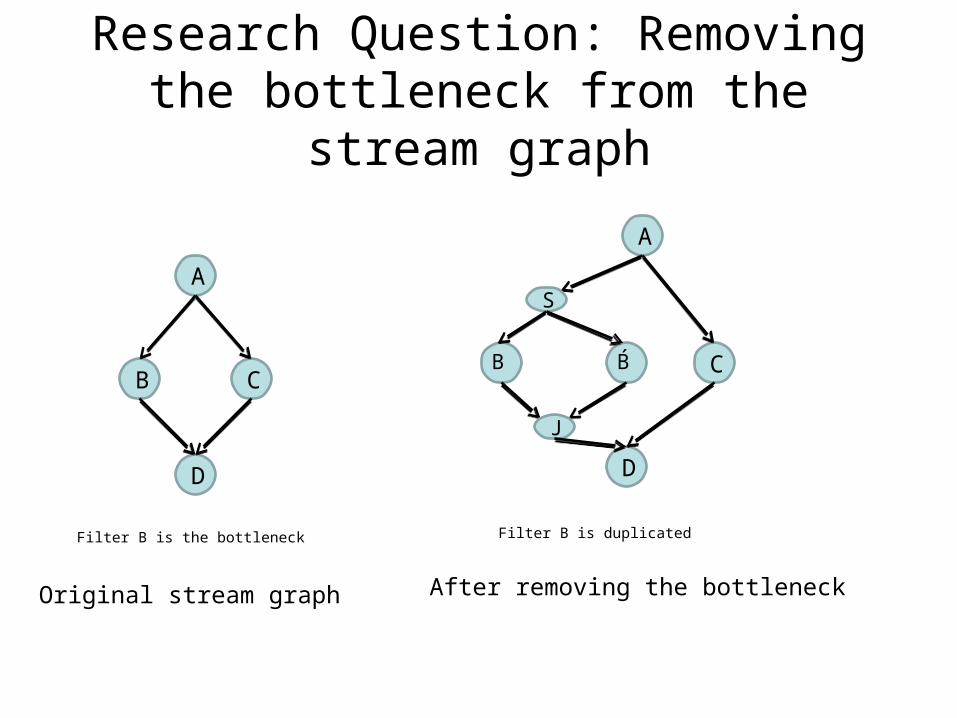
Research Question: Removing the bottleneck from the stream graph
A
B C
D
Original stream graph
Filter B is the bottleneck
A
C
D
B BM
S
J
After removing the bottleneck
Filter B is duplicated

Research Method
• Perform a quantitative analysis that detects bottlenecks in the stream graph
• The bottleneck resolver duplicates actors that impose a bottleneck.
• The process continues until the program is bottleneck free
• Then mapping the actors to processors is performed via Integer Linear Programming

Plan
• Background study
• Research question
• Proposal
• Implementation
• Results
• Publication

Question?



![DSE_5210-5220_US_WEB[1] FARHAD](https://static.fdocuments.in/doc/165x107/577d37551a28ab3a6b956e56/dse5210-5220usweb1-farhad.jpg)












![Mapping Stream Programs onto Heterogeneous Multiprocessor Systems [by Barcelona Supercomputing Centre, Spain, Oct 09] S. M. Farhad Programming Language.](https://static.fdocuments.in/doc/165x107/56649e115503460f94afcb3e/mapping-stream-programs-onto-heterogeneous-multiprocessor-systems-by-barcelona.jpg)

