
“Spikey Workloads” Emergency Management in the Cloud
25
AWS Government, Education, & Nonprofits Symposium Canberra, Australia | May 6, 2015 “Spikey Workloads”: Emergency Management in the Cloud Cameron Maxwell Professional Services Amazon Web Services Michael Jenkins Chief Architect Emergency Management Victoria
-
Upload
amazon-web-services -
Category
Technology
-
view
224 -
download
1
Transcript of “Spikey Workloads” Emergency Management in the Cloud

AWS Government, Education, & Nonprofits Symposium
Canberra, Australia | May 6, 2015
“Spikey Workloads”: Emergency Management in the CloudCameron MaxwellProfessional Services Amazon Web Services
Michael JenkinsChief Architect Emergency Management Victoria

Emergency Management Victoria

Use of AWS for Emergency Management• We have adopted AWS for new Emergency Management
Workloads • AWS has been used for public/community publishing to
Mobile and Web sites, notably the FireReady mobile app and the http://emergency.vic.gov.au website.
• AWS is a fundamental enabler for our latest systems, particularly ‘EM-COP’, a geospatial collaboration platform for all responders across all related agencies, departments, and private organisations in Victoria.

Emergency Management Tech 101• From a tools and technology perspective, the
biggest challenge is being ready for sudden spikes in workload
• Preparation, forecasts, and testing are essential to be ready for massive demand at short/no notice
• System performance matters most during an emergency, which is the period of maximum use

System Failures Affect Us All
London's emergency services experience
telecoms failure
Telstra dials D for divert as
emergency call fail safe
Victorian emergency dispatch systems fail six times in eight months
Flood warning failed to reach many in Jambin
Brisbane Floods – Council Web Site stays down during crisis

Prepare for Massive Demand

Prepare for Bursts of Demand

Think Through the Failure Scenarios• Everything will fail eventually – how you respond
to failure is all important • Have a plan B, C, and D where possible • Research past failures – your own, your service
providers, other organisations in the sector. • Don’t repeat past mistakes

Emergency Management in the Cloud• Elastic, on demand • Web scale • Low cost • Full range of services • Many options for
reliability, availability
Figure 1. The Cloud
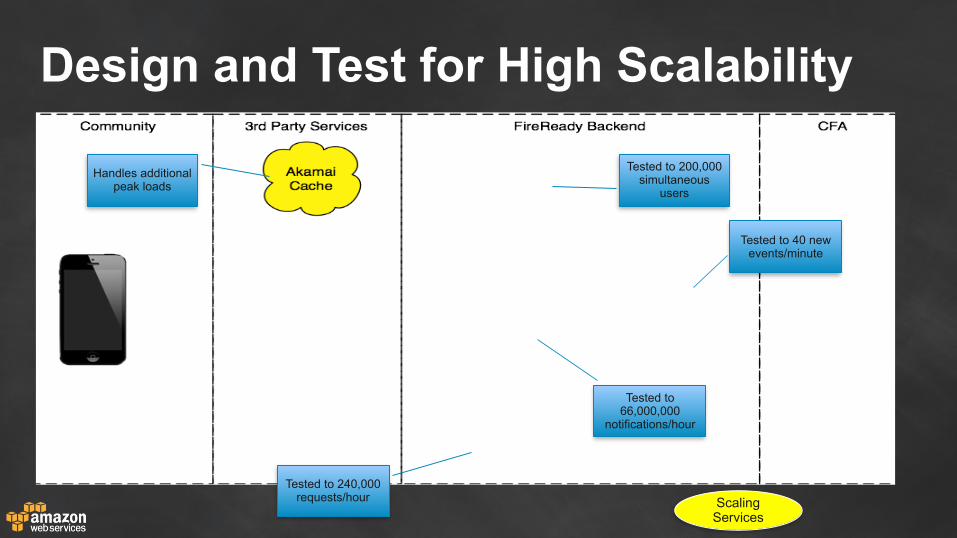
Design and Test for High Scalability
Scaling Services
Tested to 200,000 simultaneous
users
Tested to 40 new events/minute
Tested to 66,000,000
notifications/hour
Tested to 240,000 requests/hour
Handles additional peak loads

Engineer for Reliability Under Load• Design for Resilience
– Reduce Single Points of Failure – Use CloudFront or another CDN instead of your own web server
cluster to reduce the compute dependency during high demand – Design for multiple availability zones and regions from day one
• Design for Rapid Response and Recovery – Integrate Route53 health checks and CloudWatch alarms for
automatic failover – Invest the time in tuning ASG triggers and test them extensively

Launch When Proven, Certain• An unreliable system can be worse than nothing
at all • Maintain multiple channels for communication
and control • Always consider business continuity and manual
work-arounds for worst case scenarios • Even a few minutes outage could cost peoples’
lives

Scale Down to Save Costs• Engineering for massive scale can be
prohibitively expensive, unless elastic services are used
• AWS allows us to provide assured performance for massive demand at short notice, and just as quickly scale back to minimal cost
• With AWS we can deliver systems we could not otherwise afford to operate

Conclusion• We use AWS to rapidly scale up and down to
service unpredictable, spikey workloads • We’ve engineered highly available and resilient
systems within AWS • Hosting in AWS allows us to deliver and operate
systems that are reliable in emergencies without investing in “worst case” infrastructure

Scalable Messaging Architecture
Push Notif Broker
APNSiOS
GCM Android
Autoscaling Action
• +100% instances • 5m grace & cooldown
Total Fire Ban SQS queue
Incidents / Warnings SQS queue
Master Node Slave Nodes
Sender nodesNotif Batches SQS queue
Autoscaling Action
• +50% instances • 5m grace & cooldown
CloudWatch Alarm
• > 500 messages
CloudWatch Alarm
• > 1000 messages
Autoscaling Action
• +200% instances • 5m grace & cooldown
CloudWatch Alarm
• > 2000 messages
End User
OSOM Feed
Incident
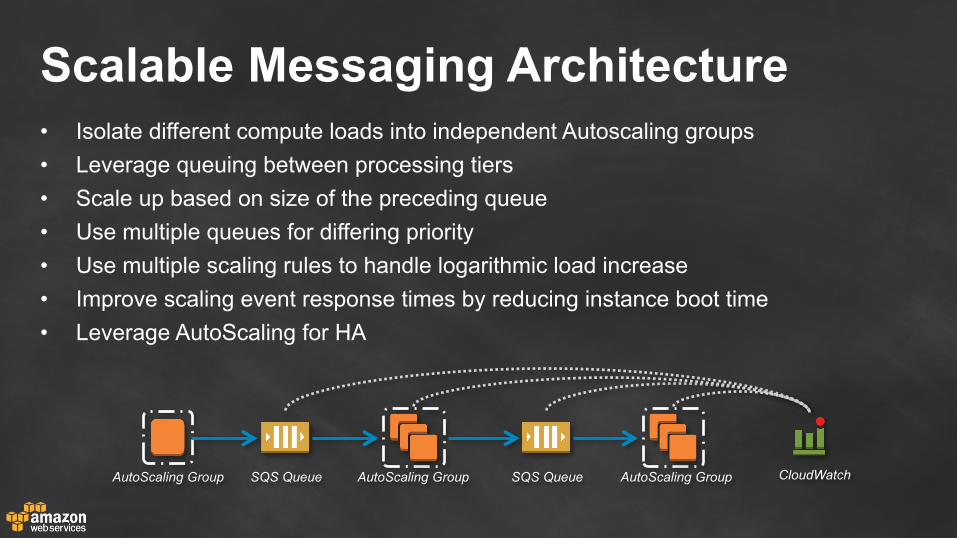
Scalable Messaging Architecture• Isolate different compute loads into independent Autoscaling groups • Leverage queuing between processing tiers • Scale up based on size of the preceding queue • Use multiple queues for differing priority • Use multiple scaling rules to handle logarithmic load increase • Improve scaling event response times by reducing instance boot time • Leverage AutoScaling for HA
AutoScaling GroupSQS QueueAutoScaling GroupSQS QueueAutoScaling Group CloudWatch

Testing• What works well at the small scale does not always translate to
large scale
• Playback of real events to simulate known situations
• Test each component / tier independently in addition to the whole
• Use mockups / stubs to simulate external entities
• Know your user base and their platforms
• Test your scaling capability and response time
• Test your availability!

Unit Testing• Replay data from previous known event • Test processing tiers independently • Input and output should be a known correlation • Reuse input data from failed tests
Sender NodesMockup Notification
DestinationNotif Batches SQS Queue
Incidents / WarningsSQS Queue
Message FeedLoad Generator Master Node
Notif Batches SQS QueueSlave Nodes
Incidents / WarningsSQS Queue

End to end load testing• Replay data from previous known event, BUT add a load multiplier i.e. 10x users then 100x
users • Identify weak points in the architecture & fix moving forward • Identify Autoscaling parameters • Mockup destinations must be as simple as possible
– 4 lines of PHP that dump the HTTP POST beats 1000s of lines of java that add unnecessary complexity
Sender NodesMockup Notification
DestinationNotif Batches SQS QueueSlave Nodes
Incidents / WarningsSQS Queue
Message FeedLoad Generator Master Node

Auditability and Accounting
SNS Topic SQS Queue DynamoDB TableEvent Processor
Sender Nodes Mockup NotificationDestination
Notif Batches SQS Queue
Slave NodesIncidents / WarningsSQS Queue
Message FeedLoad Generator
Master Node
Auditor

Auditability and Accounting• Correlation, summaries, accuracy • Testing
– 100% aim – Reproducibility – Rapid iterations
• Operations – Throughput – Analysis of 3rd parties performance
• Asynchronous is a must

Uptake and successUser base tripled in 2 weeks
As of midnight on 17th Jan
• Over 330k devices registered • 5.7M Total push notifications
• 1.4M Warnings • 3.8M Incidents
• #1 App on iTunes store

Continuous Improvement• Infrastructure and application evolve in tandem • Accuracy
– Started at 66% accuracy @ 1% peak simulated load – Finished at 100% accuracy @ 10% peak simulate load – 3 days elapsed time
• Test frequency – Started with > 4 hour turnaround – Finished with < 1 hour turnaround

“…had been outside just 20 minutes earlier checking…”
“… just 30-40m away from the house.”
“Without the app we wouldn’t have known.”

Thank you


















