Sparse Normalized Local Alignment Nadav Efraty Gad M. Landau.
42
Sparse Normalized Local Alignment Nadav Efraty Gad M. Landau
-
date post
20-Dec-2015 -
Category
Documents
-
view
224 -
download
1
Transcript of Sparse Normalized Local Alignment Nadav Efraty Gad M. Landau.

Sparse Normalized Local Alignment
Nadav EfratyGad M. Landau

Goal
To find the substrings, X’ and Y’, whose normalized alignment value
LCS(X’,Y’)/(|X’|+|Y’|) is the highest,
Or higher than a predefined similarity level.

• Introduction
• The O(rLloglogn) normalized local LCS algorithm
• The O(rMloglogn) normalized local LCS algorithm
• Conclusions and open problems

Introduction

LCS-.
computing a dynamic programming
table of size (n+1)x(m+1) :
T(i,0)=T(0,j)=0
for all i,j (1 ≤ i ≤ m ; 1 ≤ j ≤ n)
if Xj=Yi then T(i,j)=T(i-1,j-1)+1,
else, T(i,j)=max{T(i-1,j) , T(i,j-1)}
Background - Global similarity

BEDABAC
00000000
C00000001
B01111111
A01112222
D01122222
A01123333
C01123334
B01123444
D01123444
Xj=Yi
T(i,j)=T(i-1,j-1)+1
Xj≠YiT(i,j)=max{T(i,j-1),T(i-1,j)}
The naive LCS algorithmBackground - Global similarity

BEDABAC
00000000
C00000001
B01111111
A01112222
D01122222
A01123333
C01123334
B01123444
D01123444
Background - Global similarity
The typical staircase shape of the layers in the matrix

Edit distance measures the minimal number of operations that are required to transform one string into another one.
operations:
• substitution
• Deletion
• insertion.
Background - Global similarity

The Smith Waterman algorithm (1981)
T(i,0)=T(0,j)=0 ,
for all i,j (1 ≤ i ≤ m ; 1 ≤ j ≤ n)
T(i,j)=max{T(i-1,j-1)+ S(Yi,Xj) , T(i-1,j)+ D(Yi) ,
T(i,j-1)+ I(Xj) , 0}
Background - Local similarity

Background - Local similarity
• Mosaic effect - Lack of ability to discard poorly conserved intermediate segments.
• Shadow effect – Short, but more biologically important alignments may not be detected because they are overlapped by longer (and less important) alignments.
70/10000
40/100
• The sparsity of the essential data is not exploited.
BEDABAC
00000000
C00000001
B01111111
A01112222
D01122222
A01123333
C01123334
B01123444
D01123444
40 32-30
40 10 42
The weaknesses of the Smith Waterman algorithm:

The solution: NormalizationThe statistical significance of the local alignment depends on both its score and length. Instead of searching for an alignment that maximizes the score S(X,Y), search for the alignment that maximizes S(X,Y)/(|X|+|Y|).

Arslan, Egecioglu, Pevzner (2001) uses a mathematical technique that allows convergence to the optimal alignment value through iterations of the Smith Waterman algorithm.
SCORE(X’,Y’)/(|X’|+|Y’|+L), where L is a constant that controls the amount of normalization.
O(n2logn).

• The degree of similarity is defined as LCS(X’,Y’)/(|X’|+|Y’|).
• M - a minimal length constraint.
• Similarity level.
Our approach

The O(rLloglogn) normalized local LCS algorithm

Definitions
• A chain is a sequence of matches that is strictly increasing in both components.
• The length of a chain from match (i,j) to match (i’,j’) is i’-i+j’-j, that is, the length of the substrings which create the chain.
00
n
m
Y
X
00
J’ n
i
i’
m
J
Y
X
)i,j(
)i’,j(’
• A k-chain(i,j) is the shortest chain of k matches starting from (i,j).
• The normalized value of k-chain(i,j) is k divided by its length.

The algorithm
• For each match (a,b), construct k-chain(a,b) for 1≤k≤L (L=LCS(X,Y)).
• Examine all the k-chains with k≥M, starting from each match, and report either:– The k-chains with the highest normalized
value.– k-chains whose normalized value exceed
a predefined threshold.
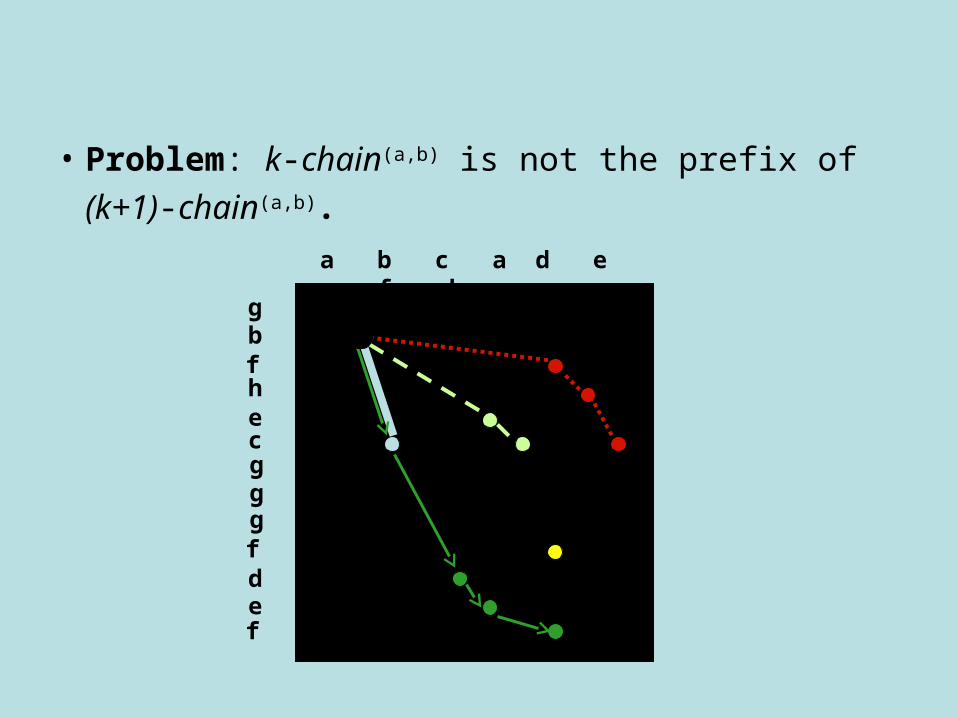
• Problem: k-chain(a,b) is not the prefix of
(k+1)-chain(a,b).a b c a d e c f h c
gbfhecgggfdef
12345678910111213
1 2 3 4 5 6 7 8 9 10

a b c a d e c f h c
gbfhecg
1234567
1 2 3 4 5 6 7 8 9 10
Solution: (k+1)-chain(a,b) : (a,b) is concatenated to a k-chain(i’,j’) below and to the right of (a,b).

Question: How can we find the proper match (i’,j’) which is the head of the k-chain that should be concatenated to (a,b) in order to construct (k+1)-chain(a,b).

Definitions:Range- The range of a match (i,j) is (0…i-
1,0…j-1).Mutual range- An area of the table which is
overlapped by at least two ranges of distinct matches.
Owner- (i’,j’) is the owner of the range where k-chain(i’,j’) is the suffix of (k+1)-chain(a,b) for any match (a,b) in the range.
L separated lists of ranges and their owners are maintained by the algorithm.

If (a,b) is in the range of a single match (i’,j’) (it is not in a mutual range), k-chain(i’,j’) would be the suffix of (k+1)-chain(a,b).
If (x,y) is in the mutual range of two matches, how can we determined which of them should be concatenated to (a,b)?
Lemma: A mutual range of two matches is owned completely by one of them.
)i,j(
)i’,j(
00
j’ n
i
i’
m
j
)i’,j(’
)i,j(’
Y
X
Case 1
)i,j(
)i’,j(’
00
n
i
i’
m
Y
Xj’ j
Case 2

Lemma: A mutual range of two matches, p ((i,j)) and q ((i’,j’)), is owned completely by one of them.
Proof: There are two distinct cases:
Case 1: i≤i’ and j≤j‘;
)i,j(
)i’,j(
00
J’ n
i
i’
m
J
)i’,j(’
)i,j(’
Y
X

)i,j(
00
n
i
i’
m
Y
XJ’ J
)i’,j(’
LLpp
LLqq
Case 2: i<i‘ and j>j‘; The mutual range of p and q is (0...i-1,0...j'-1) .
Entry (i-1,j'-1) is the mutual point (MP) of p and q .
p will be the owner of the mutual range if Lp+(j-j') ≤ Lq+(i'-i)

• Preprocessing.
• Process the matches row by row, from bottom up. For the matches of row i:– Stage 1: Construct k-chains 1≤k≤L for all the
matches in the row i, using the L lists of ranges and owners.
– Stage 2: Update the lists of ranges and owners with the matches of row i and their k-chains.
• Examine the k-chains of all matches and report the ones with the highest normalized value.
The algorithm
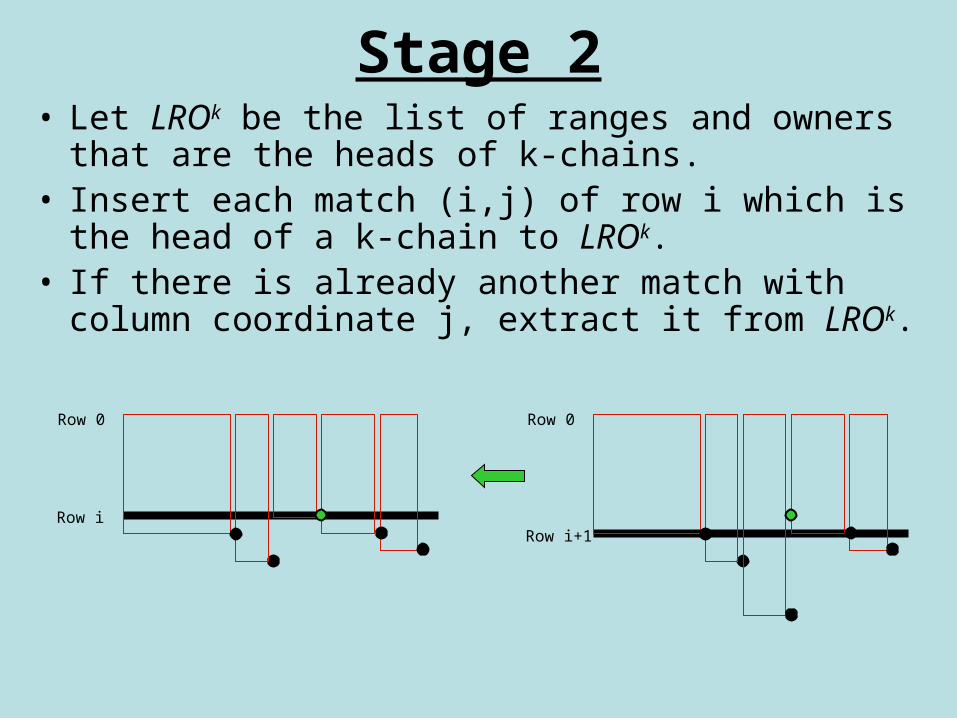
Stage 2• Let LROk be the list of ranges and owners that are
the heads of k-chains.• Insert each match (i,j) of row i which is the head of
a k-chain to LROk.• If there is already another match with column
coordinate j, extract it from LROk.
Row i+1
Row 0
Row i
Row 0
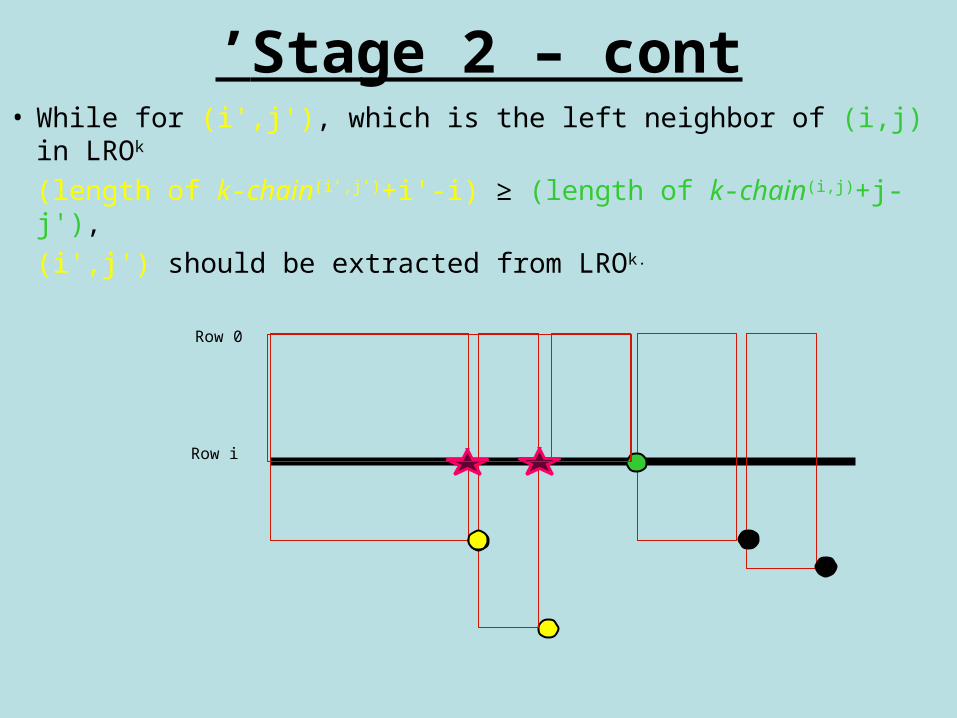
Stage 2 – cont’• While for (i',j'), which is the left neighbor of (i,j) in LROk
(length of k-chain(i’,j’)+i'-i) ≥ (length of k-chain(i,j)+j-j'),
(i',j') should be extracted from LROk.
Row i
Row 0

Stage 1• Constructing (k+1)-chain(i,j): concatenating (i,j)
to the match in LROk which is the owner of the range of (i,j).
• Record the value of (k+1)-chain(i,j) with the match (i,j).
Row i
Row 0

Reporting the best alignments• The best alignment is either the alignment with
the highest normalized value or the alignments whose similarity exceed a predefined value.
• Check all the k-chains, k≥M, starting from each match and report the best alignments.

Complexity analysis• Preprocessing- O(nlogΣY)
• Stage 1- – For each of the r matches we construct at most L
k-chains. – Using a Johnson Tree stage 1 is computed in
O(rLloglogn) time.
• Stage 2- Each of the r matches is inserted and extracted at most once to each of the LROks. Total, O(rLloglogn) time.

Complexity analysis• Reporting the best alignments is done in O(rL)
time.
• Total time complexity of this algorithm is O(nlogΣY + rLloglogn).
• Space complexity is O(rL+nL).

The O(rMloglogn) normalized local LCS algorithm

The O(rMloglogn) normalized local LCS algorithm
Reoprts:
The normalized alignment value of the best
possible local alignment. (value and
substrings).

Computing the highest normalized value
Definition: A sub-chain of a k-Chain is a path that contains a sequence of x ≤ k consecutive matches of the k-Chain.
Claim: When a k-chain is split into a number of non overlapping consecutive sub-chains, the normalized value of a k-chain is smaller or equal than that of its best sub-chain.
Result: The normalized value of any k-chain (k≥M) is smaller or equal than the value of its best sub-chain with M to 2M-1 matches.

Computing the highest normalized value• A sub-chains of less than M matches may not be
reported.
• Sub-chains of 2M matches or more, can be split into shorter sub-chains of M to 2M-1 matches.
• Is it sufficient to construct all the sub-chains of exactly M matches?
• No - Sub-chains of M+1 to 2M-1 matches can not be split to sub-chains of M matches.

Computing the highest normalized value
The algorithm: For each match construct all the k-chains, for k≤2M-1.
• The algorithm constructs all these chains, that are, in fact, the sub-chains of all the longer k-chains.
• A longer chain can not be better than its best sub-chain.
• This algorithm is able to report the highest normalized value of a sub-chain (of at least M matches) which is equal to the highest normalized value of a chain of at least M matches.

Constructing the longest optimal alignment
Definition: A perfect alignment is an alignment of two identical strings. Its
normalized value is½
Unless the optimal alignment is perfect, the longest optimal alignment has no more than 2M-1 matches.

Constructing the longest optimal alignment
Assume there is a chain with more than 2M-1matches whose normalized value is the optimal, denoted by LB.
• LB may be split to a number of sub-chains of M matches, followed by a single sub-chain of between M and 2M-1 matches.
• The normalized value of each such sub-chain must be equal to that of LB, otherwise, LB is not optimal.
• Each such sub-chain must start and end at a match, otherwise, the normalized value of the chain comprised of the same matches will be higher than that of LB.
10/30 0/20/3 = 10/35 < 10/30

• when the head of the second is not next to the tail of the first, the concatenated chain is not optimal.
Constructing the longest optimal alignment
10/30 10/300/2 20/62
• Note that if we concatenate two optimal sub-chains where the head of the second is next to the tail of the first the concatenated chain is optimal.
10/30 10/30 20/60
• The tails and heads of the sub-chains from which LB is comprised must be next to each other.

• But, what happens if we examine the following sub-chain:
Constructing the longest optimal alignment• If the tails and heads of the optimal sub-chains from which LB
is comprised are next to each other then their concatenation (i.e. LB) is optimal. Lets examine the first two sub-chains:
M/L M/L 2M/2L
M/L M/L
It’s number of matches is M+1 and its length is L+2.• Since M/L<½, (M+1)/(L+2)>M/L. Thus, we found a chain of M+1 matches whose
normalized value is higher than that of LB, in contradiction to the optimality of LB.

Closing remarks

The advantages of the new algorithm
• The first algorithm to combine the “normalized local” and the “sparse”.
• Ideal for textual local comparison (where the sparsity is typically dramatic) as well as for screening bio sequences.
• As a normalized alignment algorithm, it does not suffer form the weaknesses from which non normalized algorithms suffer.
• A straight forward approach to the minimal constraint which is easy to control and understand, and in the same time, does not require reformulation of the original problem.
• the minimal constraint is problem related rather than input related.