
Spark on Kubernetes - Advanced Spark and Tensorflow Meetup - Jan 19 2017 - Anirudh Ramanthan from...
31
Spark on Kubernetes Advanced Spark and TensorFlow Meetup (19 Jan 2017) Anirudh Ramanathan (Google) GitHub: foxish
-
Upload
chris-fregly -
Category
Software
-
view
933 -
download
0
Transcript of Spark on Kubernetes - Advanced Spark and Tensorflow Meetup - Jan 19 2017 - Anirudh Ramanthan from...

Spark on KubernetesAdvanced Spark and TensorFlow Meetup (19 Jan 2017)
Anirudh Ramanathan (Google)GitHub: foxish

What is Kubernetes
● Open source cluster manager originally developed by Google
● Based on a decade and a half of experience in running containers at scale
● Has over 1000 contributors and 30,000+ commits on Github
● Container centric infrastructure
● Deploy and manage applications declaratively

High level overview
users
master
nodes
CLI
API
UI
apiserver
kubelet
kubelet
kubelet
scheduler

Concepts
0. Container: A sealed application package (Docker)
1. Pod: A small group of tightly coupled Containersexample: content syncer & web server
2. Controller: A loop that drives current state towards desired stateexample: replication controller
3. Service: A set of running pods that work togetherexample: load-balanced backends

Concept: Pod
Pod
Volume
Containers
Pod
Containers
8080 8080 8080
Volume
Node● Pods are the atom of
scheduling and scaling
● Pods may contain one or more containers and attached volumes
● Each pod has its own IP address

Why Spark?
● Spark is used for processing many kinds of workloads○ Batch
○ Interactive
○ Streaming
● Lots of organizations already run their serving workloads in Kubernetes
● Better resource sharing and management when all workloads run on a
single cluster manager

Spark Standalone on Kubernetes
Setup one master controller and a worker pods in a standalone cluster on top of Kubernetes: https://github.com/kubernetes/kubernetes/tree/master/examples/spark
● Resource negotiation tied to Spark standalone and Kubernetes configuration
● No easy way to dynamically scale number of workers when there are idle resources
● Lacks robust authentication and authorization mechanism
● FIFO scheduling only

Spark External Cluster Backends
● Standalone Mode
● YARN client/cluster mode
● Mesos client/cluster mode

Spark External Cluster Backends
● Standalone Mode
● YARN client/cluster mode
● Mesos client/cluster mode
● Kubernetes client/cluster mode

Kubernetes as a Cluster Scheduler Backend
● Cluster mode support
● The driver shall run within the
cluster
● Coarse grained mode
● Spark talks to kubernetes
clusters directly
spark-submit
--master=k8s://<IP>
Kubernetes
driv
er &
ex
ecut
ors

Spark Cluster Mode
http://spark.apache.org/docs/latest/cluster-overview.html
● Each application gets its own
executor processes
● Tasks from different
applications run in different
JVMs
● Executors talk back to the Driver
and run tasks in multiple
threads

Roadmap
● Phase 1 design complete; implementation in progress
● Phase 2 & 3 design in progress
● https://github.com/apache-spark-on-k8s/spark
● https://issues.apache.org/jira/browse/SPARK-18278

Communication
● Kubernetes provides a REST API
● Fabric8's Kubernetes Java client
to make REST calls
● Allows us to create, watch,
delete Pods and higher level
controllers from Scala/Java
code
REST API c
alls
apiserver
scheduler

Spark Configuration
● Spark configuration options provided to spark-submit at the time of invocation
● https://github.com/apache-spark-on-k8s/spark/blob/k8s-support-alternate-incremental/docs/running-on-kubernetes.md

Dynamic Executor Scaling
Hypothesis 1
● The set of executors can be adequately represented by a ReplicaSet
ReplicaSet
create
run 3 executor pods

Dynamic Executor Scaling
Hypothesis 1
● The set of executors can be adequately represented by a ReplicaSet
● Which one do we kill?● Spark knows to intelligently
scale down but the ReplicaSet does not
ReplicaSet
kill one?
scale down to 2

Solution: Driver pod as controller
● Let the Spark driver pod launch
executor pods
● Scale up/down can be such that
we lose the least amount of
cached data spark
-subm
it
kubernetes cluster
apiserver
scheduler

Solution: Driver pod as controller
● Let the Spark driver pod launch
executor pods
● Scale up/down can be such that
we lose the least amount of
cached data
kubernetes cluster
apiserver
schedulerspark driver pod
schedule driver pod

Solution: Driver pod as controller
● Let the Spark driver pod launch
executor pods
● Scale up/down can be such that
we lose the least amount of
cached data
kubernetes cluster
apiserver
schedulerspark driver pod
create executor pods

Solution: Driver pod as controller
● Let the Spark driver pod launch
executor pods
● Scale up/down can be such that
we lose the least amount of
cached data
spark driver pod
kubernetes cluster
apiserver
schedulerschedule
executor pods

Solution: Driver pod as controller
● Let the Spark driver pod launch
executor pods
● Scale up/down can be such that
we lose the least amount of
cached data
spark driver pod
kubernetes cluster
apiserver
scheduler

Solution: Driver pod as controller
● Let the Spark driver pod launch
executor pods
● Scale up/down can be such that
we lose the least amount of
cached data
Spark job completed
kubernetes cluster
apiserver
schedulerget
output/l
ogs

Demo

Shuffle Service
● The shuffle service is a component that persists files written by
executors beyond the lifetime of the executors
● Important (and required) for dynamic allocation of executors
● Typically one per node or instance and shared by different executors
● Can kill executors without fear of losing data and triggering
recomputation
● Considering two possible designs of the Shuffle Service
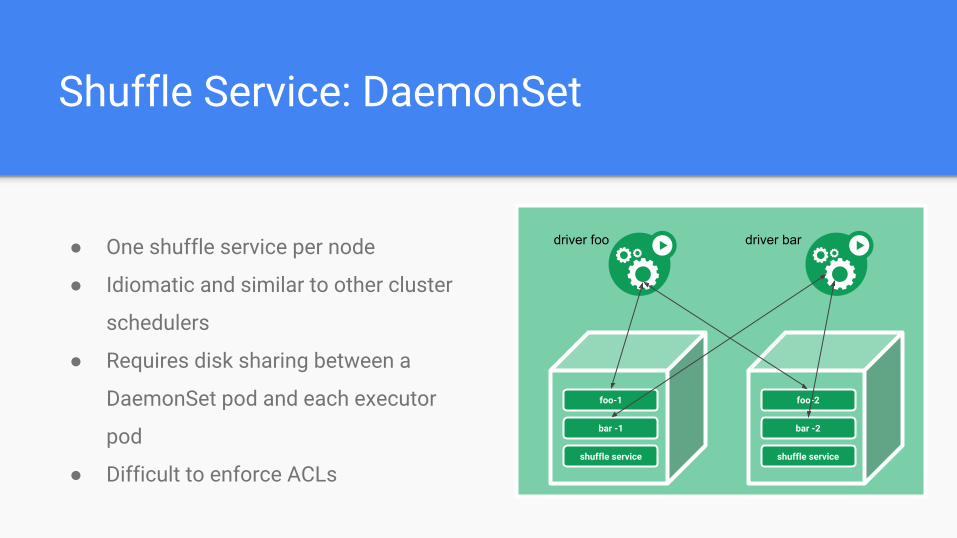
Shuffle Service: DaemonSet
● One shuffle service per node
● Idiomatic and similar to other cluster
schedulers
● Requires disk sharing between a
DaemonSet pod and each executor
pod
● Difficult to enforce ACLs
foo-1
bar -1
shuffle service
foo-2
bar -2
shuffle service
driver foo driver bar

Shuffle Service: Per Executor
● Strong isolation possible between
shuffle files
● Resource wastage in having multiple
shuffle services per node
● Disk sharing between containers in a
Pod is trivial
● Can expose shuffle service on Pod IP
driver foo driver bar
foo-1
shuffle service
bar-1
shuffle service
foo-2
shuffle service
bar-2
shuffle service

Resource Allocation
● Kubernetes lets us specify soft and hard limits on resources (CPU,
Memory, etc)
● Pods may be in one of 3 QoS levels○ Guaranteed
○ Burstable
○ Best Effort
● Scheduling, Pre-emption based on QoS

Resource Allocation
● Today, we launch Drivers and Executors with guaranteed resources.
● In the near future:○ QoS level of executors should be decided based on a notion of priority
○ Must be able to overcommit cluster resources for Spark batch jobs and pre-empt/scale
down when higher priority jobs come in
● Schedule and execute Spark Jobs launched by the same and different
tenants fairly

Extending the Kubernetes API
● Use ThirdPartyResources to extend
the API dynamically
● SparkJob can be added to the API
● SparkJob object can be written to by
the Spark Driver to allow recording
parameters
● Can perform better cluster-level
aggregation/decisions

Contributions Welcome
● JIRA:
https://issues.apache.org/jira/browse/SPA
RK-18278
● Our fork:
https://github.com/apache-spark-on-k8s/sp
ark/
● Progress:
https://github.com/apache-spark-on-k8s/sp
ark/issues/4
Contributors:
● Matt Cheah
● Andrew Ash
● Anirudh Ramanathan
● Tim Chen
● Erik Erlandson
● Iyanu Obidele
● Sean Suchter
Questions?
Thank You


















