
SOSP 2007 © 2007 Andreas Haeberlen, MPI-SWS 1 Practical accountability for distributed systems...
23
© 2007 Andreas Haeberlen, MPI-SWS 1 SOSP 2007 Practical accountability for distributed systems Andreas Haeberlen MPI-SWS / Rice University Petr Kuznetsov MPI-SWS Peter Druschel MPI-SWS
-
date post
20-Dec-2015 -
Category
Documents
-
view
217 -
download
0
Transcript of SOSP 2007 © 2007 Andreas Haeberlen, MPI-SWS 1 Practical accountability for distributed systems...

© 2007 Andreas Haeberlen, MPI-SWS1
SOSP 2007
Practical accountability for distributed systems
Andreas Haeberlen
MPI-SWS / Rice University
Petr Kuznetsov MPI-SWS
Peter Druschel MPI-SWS

2© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
Motivation
Distributed state, incomplete information General case: Multiple admins with different interests
Admin

3© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
General faults occur in practice
Many faults are not 'fail-stop' Node is still running, but its behavior changes
Examples: Hardware malfunctions Misconfigurations Software modifications by users Hacker attacks ...
4© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
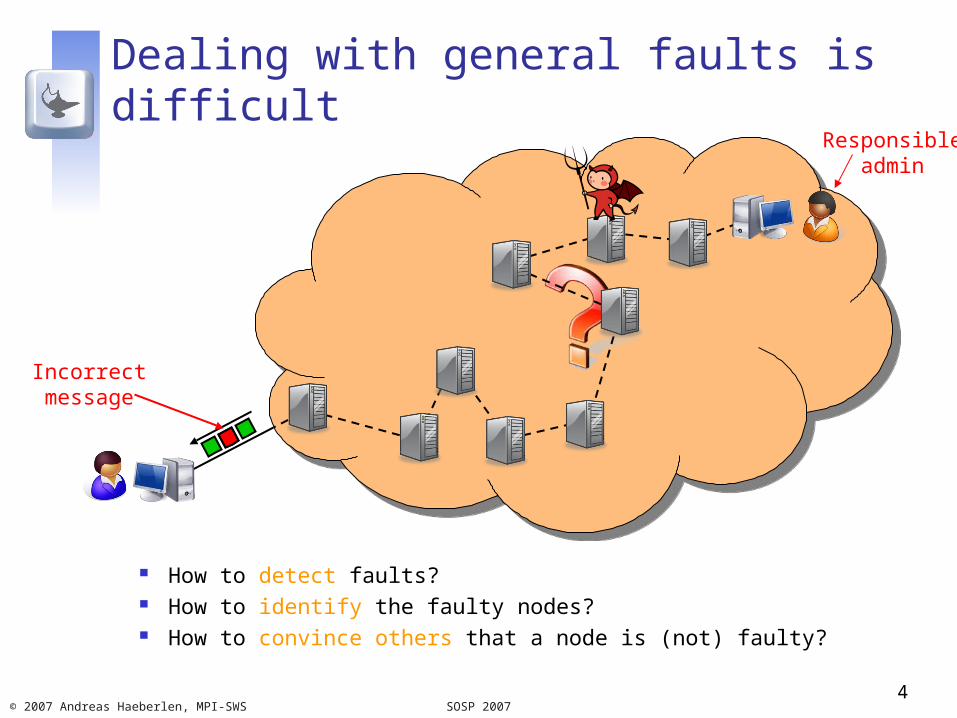
Dealing with general faults is difficult
How to detect faults? How to identify the faulty nodes? How to convince others that a node is (not) faulty?
Incorrectmessage
Responsibleadmin

5© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
Learning from the 'offline' world Relies on accountability Example: Banks
Can be used to detect, identify and convince But: Existing fault-tolerance work mostly focused
on prevention
Goal: A general+practical system for accountability
Requirement Solution
Commitment Signed receipts
Tamper-evident record
Double-entry bookkeeping
Inspections Audits

6© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
Outline
Introduction What is accountability? How can we implement it? How well does it work?

7© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
Ideal accountability
Whenever a node is faulty in any way, the system generates a proof of misbehavior against that node
Fault := Node deviates from expected behavior Recall that our goal is to
detect faults identify the faulty nodes convince others that a node is (or is not) faulty
Can we build a system that provides the following guarantee?
8© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
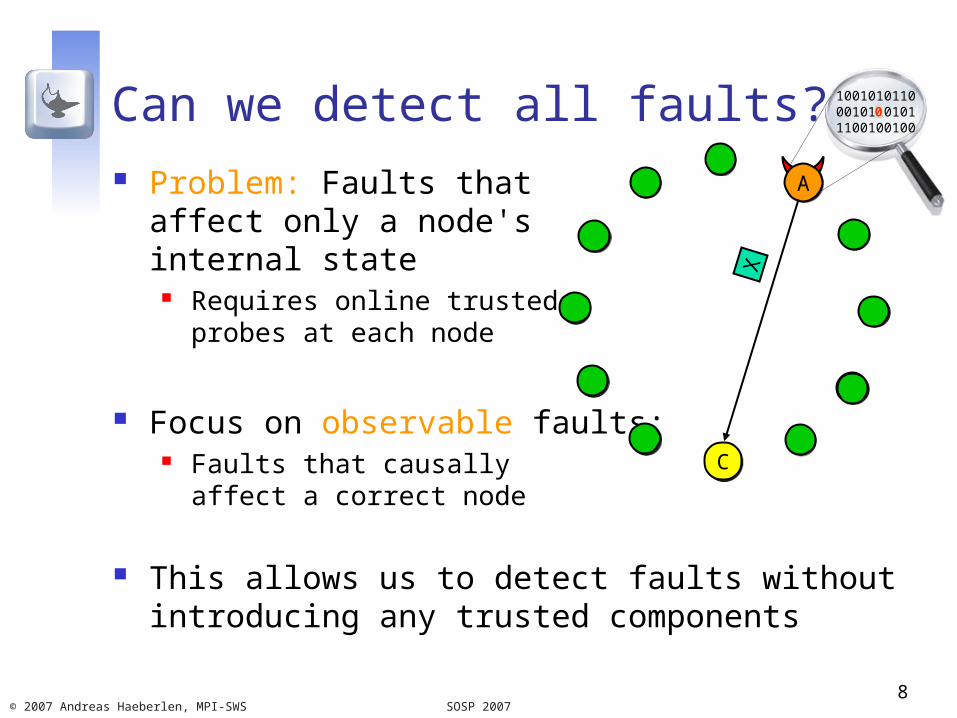
Can we detect all faults? Problem: Faults that
affect only a node's internal state
Requires online trusted probes at each node
Focus on observable faults: Faults that causally
affect a correct node
This allows us to detect faults without introducing any trusted components
AA
X
CC
100101011000101101011100100100
0
9© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
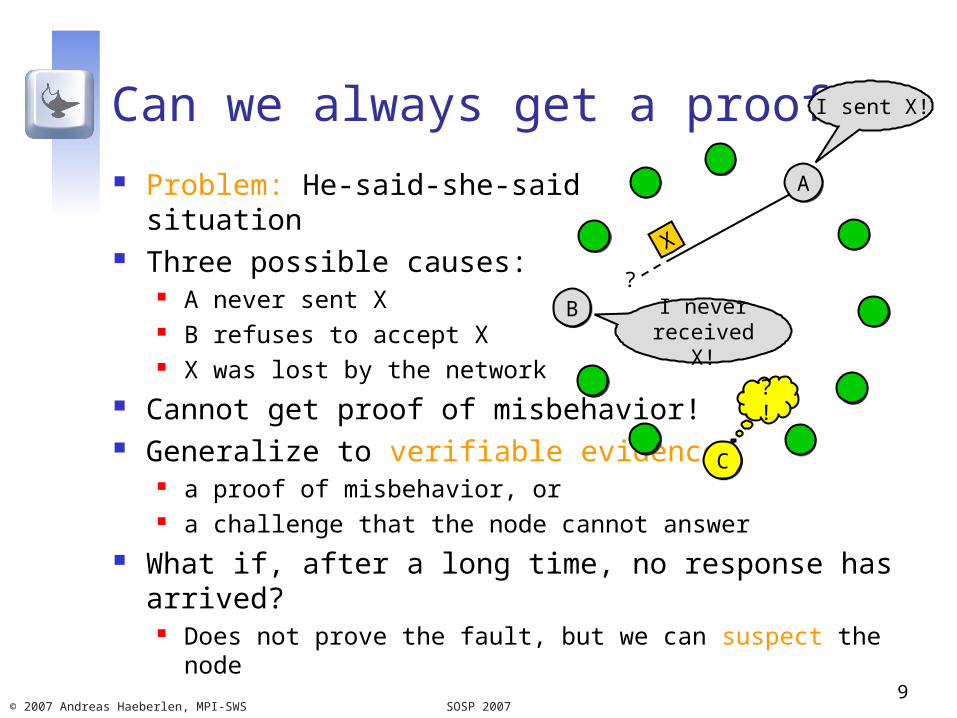
Can we always get a proof? Problem: He-said-she-said
situation Three possible causes:
A never sent X B refuses to accept X X was lost by the network
Cannot get proof of misbehavior! Generalize to verifiable evidence:
a proof of misbehavior, or a challenge that the node cannot answer
What if, after a long time, no response has arrived?
Does not prove the fault, but we can suspect the node
AA
X
BB
CC
?
I sent X!
I neverreceived
X!
?!

10© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
Practical accountability We propose the following definition of a
distributed system with accountability:
This is useful Any (!) fault that affects a correct node is
eventually detected and linked to a faulty node
It can be implemented in practice
Whenever a fault is observed by a correct node, the system eventually generates verifiable evidence against a faulty node

11© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
Outline
Introduction What is accountability? How can we implement it? How well does it work?

12© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
Adds accountability to a given system Implemented as a library Provides secure record, commitment, auditing, etc.
Assumptions:
Implementation: PeerReview
1. System can be modeled as collection of deterministic state machines
2. Nodes have reference implementations of the state machines
3. Correct nodes can eventually communicate4. Nodes can sign messages

13© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
M
PeerReview from 10,000 feet All nodes keep a log of
their inputs & outputs Including all messages
Each node has a set of witnesses, who audit its log periodically
If the witnesses detect misbehavior, they
generate evidence make the evidence
avai-lable to other nodes
Other nodes check evi-dence, report fault
A's log
B's log
AA
BB
M
CCDD
EE
A's witnesses
M

14© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
PeerReview detects tampering
A B
Message Has
h ch
ain
Send(X)
Recv(Y)
Send(Z)
Recv(M)
H0
H1
H2
H3
H4
B's log
ACK
What if a node modifies its log entries?
Log entries form a hash chain
Inspired by secure histories [Maniatis02]
Signed hash is included with every message Node commits to its current state Changes are evident
Hash(log)
Hash(log)
15© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
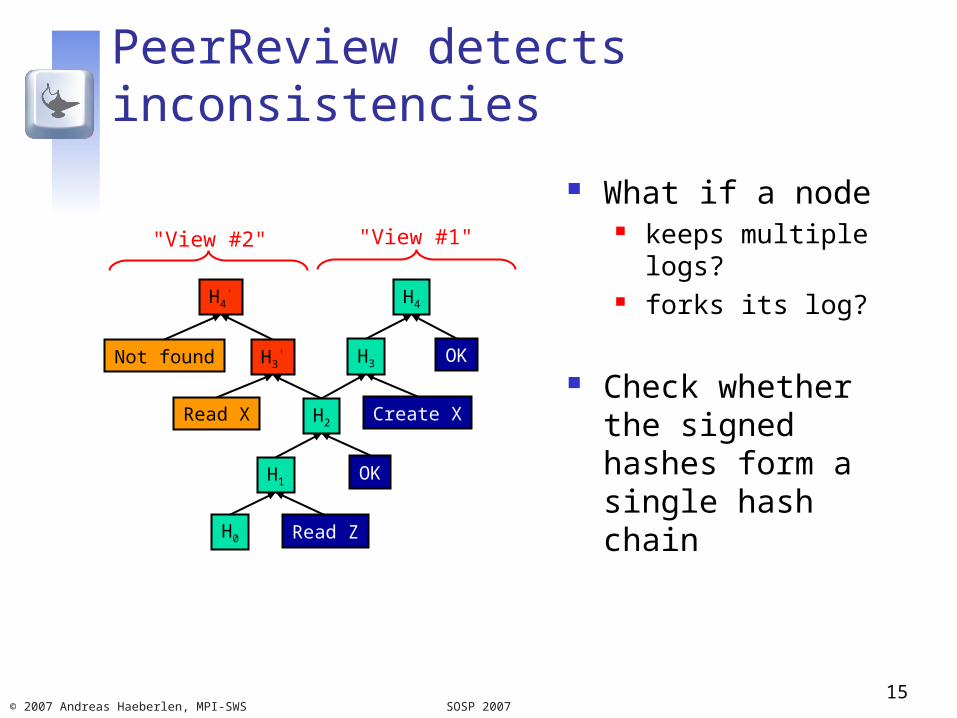
PeerReview detects inconsistencies
What if a node keeps multiple logs? forks its log?
Check whether the signed hashes form a single hash chain
H3'
Read X
H4'
Not found
Read Z
OK
Create X
H0
H1
H2
H3
H4
OK
"View #1""View #2"
16© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
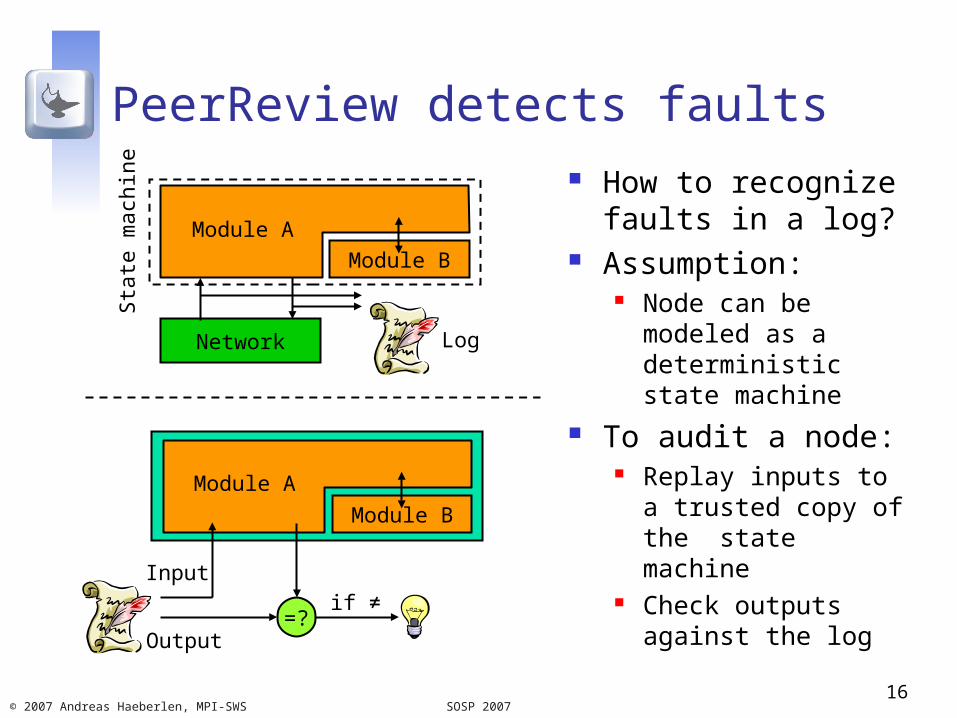
Module B
PeerReview detects faults How to recognize
faults in a log? Assumption:
Node can be modeled as a deterministic state machine
To audit a node: Replay inputs to a
trusted copy of the state machine
Check outputs against the log
Module A
Module B
=?
LogNetwork
Input
Output
Sta
te m
ach
ine
if ≠
Module A

17© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
PeerReview offers provable guarantees
PeerReview guarantees that:
1) Faults will be detected
2) Good nodes cannot be accused
Formal definitions and proof in a TR
If node commits a fault + has a correct witness,
then witness obtains a proof of misbehavior (PoM), or a challenge that the faulty node cannot answer
If node is correct there can never be a PoM, and it can answer any challenge

18© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
Outline
Introduction What is accountability? How can we implement it? How well does it work?
Is it widely applicable? How much does it cost? Does it scale?

19© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
PeerReview is widely applicable App #1: NFS server in the Linux kernel
Many small, latency-sensitive requests Tampering with files Lost updates
App #2: Overlay multicast Transfers large volume of data
Freeloading Tampering with content
App #3: P2P email Complex, large, decentralized
Denial of service Attacks on DHT routing
More information in the paper
Metadata corruption Incorrect access control
Censorship

20© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
How much does PeerReview cost?
Dominant cost depends on number of witnesses W
O(W2) component
Baseline 1 2 3 4 5
100
80
60
40
20
0
Avg t
raffi
c (K
bps/
node)
Number of witnesses
Baseline traffic
Signaturesand ACKs
Checking logs
W dedicatedwitnesses

21© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
Mutual auditing
Small probability of error is inevitable Example: Replication
Can use this to optimize PeerReview Accept that an instance of a fault is found
only with high probability Asymptotic complexity: O(N2) O(log N)
Small randomsample of peers
chosen as witnesses
Node

22© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
PeerReview is scalable
Assumption: Up to 10% of nodes can be faulty Probabilistic guarantees enable scalability
Example: Email system scales to over 10,000 nodeswith P=0.999999
DSL/cableupstream
Email systemw/o accountability
O((log N)2)
O(log N)
Email system+ PeerReview(P=0.999999)
Email system + PeerReview(P=1.0)
System size (nodes)
Avg
traf
fic (
Kbp
s/no
de)

23© 2007 Andreas Haeberlen, MPI-SWS SOSP 2007
Summary Accountability is a new approach to handling
faults in distributed systems detects faults identifies the faulty nodes produces evidence
Our practical definition of accountability:Whenever a fault is observed by a correct node, the system eventually generates verifiable evidenceagainst a faulty node
PeerReview: A system that enforces accountability
Offers provable guarantees and is widely applicable
Thank you!


















