
SOME WORKLOAD SCHEDULING ALTERNATIVES IN THE HIGH PERFORMANCE COMPUTING ENVIRONMENT Jim McGalliard,...
46
SOME WORKLOAD SCHEDULING ALTERNATIVES IN THE HIGH PERFORMANCE COMPUTING ENVIRONMENT Jim McGalliard, FEDSIM Tyler Simon, University of Maryland Baltimore County CMG Southern Region Richmond April 25, 2013 1
Transcript of SOME WORKLOAD SCHEDULING ALTERNATIVES IN THE HIGH PERFORMANCE COMPUTING ENVIRONMENT Jim McGalliard,...

1
SOME WORKLOAD SCHEDULING ALTERNATIVES IN THE HIGH PERFORMANCE COMPUTING ENVIRONMENT
Jim McGalliard, FEDSIM Tyler Simon,
University of Maryland Baltimore County
CMG Southern RegionRichmond April 25, 2013

2
TOPICSMAINFRAME VS. HPC WORKLOADSHPC WORKLOAD SCHEDULINGBACKFILLDYNAMIC PRIORITIZATIONMAPREDUCE FRAMEWORK & HADOOPHADOOP WORKLOAD SCHEDULINGDYNAMIC PRIORITIZATION IN HADOOPSOME RESULTS

3
HPC Vs. Mainframe Workload SchedulingCMG’s historical context is MVS on S/360In a traditional mainframe environment, a workload is
runs on a single CPU or perhaps a few CPUsProcessor utilization is optimized on one level by
dispatching a new job on a processor when the current job idles that processor, e.g., by starting an I/O
Possible to achieve very high actual processor utilization (e.g., 103%) due to a variety of optimizations, of which job swapping is one
Not how it’s done on HPC

4
HPC vs. Mainframe Workload SchedulingCurrent generation HPCs have many CPUs – say, tens
of thousands. Due to scale economies, clusters of commodity processors are the most common design. Custom-designed processors (e.g., Cray for many years) are too expensive in terms of price vs. performance.
Many HPC applications map some system – typically, a physical system (e.g., Earth’s atmosphere) – into a matrix or network of many similar nodes.

5
HPC vs. Mainframe Workload Schedulinge.g., the Cubed Sphere…

6
HPC vs. Mainframe Workload SchedulingThe application software simulates the behavior or
dynamics of the system represented by assigning parts of the system to nodes of the cluster. After processing, final results are collected from the nodes.
Often, more nodes can represent the behavior of the system more accurately using more nodes.

7
HPC Workload SchedulingSo, in contrast to a traditional mainframe workload, HPC
jobs may use hundreds or thousands of processor nodes simultaneously.
Halting job execution on 1,000 CPUs so that a single CPU can start an I/O operation is not efficient.
Some HPCs have checkpoint/restart capabilities that could allow job interruption and also easier recovery from a system failure. Most do not.
On an HPC system, typically, once a job is dispatched, it is allowed to run uninterrupted until completion.

8
HPC Workload SchedulingThe use of queues and priority classification is common in
HPC environments, as it is with mainframes.A job class might be categorized by the maximum number
of processors a job might require, the estimated length of processing time, or the need for specialized resources.
Users or user groups may be allocated budgets of CPU time or of other resources.
A consequence of such queue structures is that users must estimated their jobs’ processing times. These may not be accurate.

9
HPC Workload SchedulingCluster HPCs often have very low actual processor
utilization – say, 10 or 20%.High reported utilization may measure CPU allocation
rather than CPU-busy timeWorkload optimization by the sys admin is done at the
job rather than CPU level – deciding which jobs will be dispatched on which processors in what sequence.
The ability of an individual job to use its allocated processors is of interest and subject to Amdahl's Law, among other constraints, but is outside the scope of this presentation.

10
The Knapsack Problem
Finding the optimum sequence of jobs, such that, e.g., utilization or throughput is maximized or expansion is minimized, is an example of the Knapsack Problem.
Finding the optimum in a Knapsack Problem is often impossible.
Some variation of the “Greedy algorithm,” in which jobs are sorted on their value, is often implemented.

11
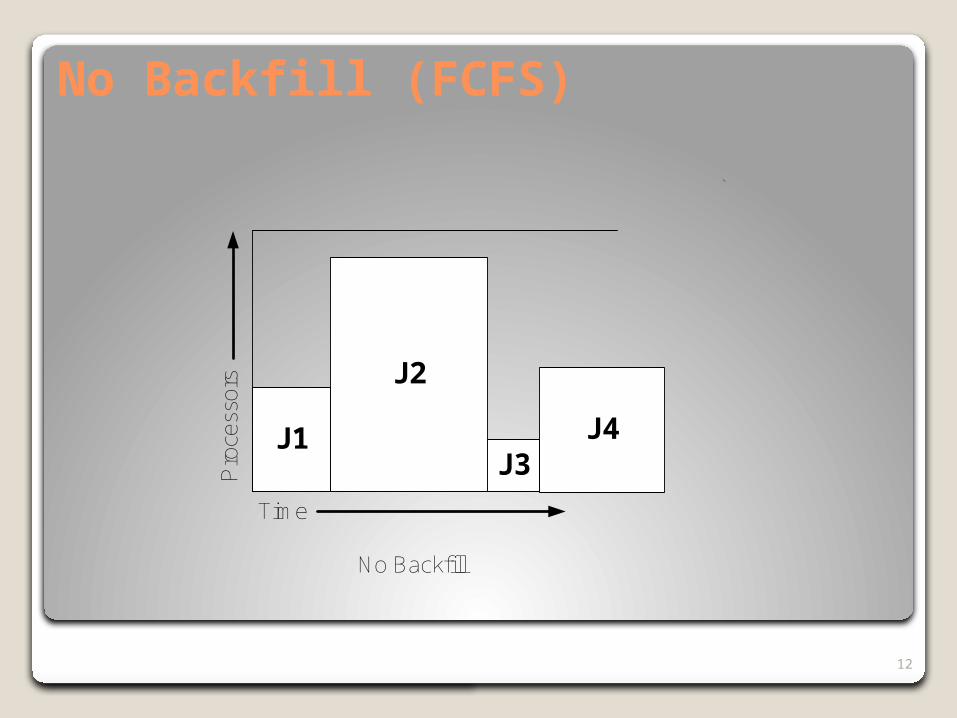
Backfill
HPCs are usually over-subscribed.
Backfill is commonly used to increase processor utilization in an HPC environment.
12
No Backfill (FCFS)
J1
J2
J3
Time
Pro
cess
ors
`
J4
No Backfill
13
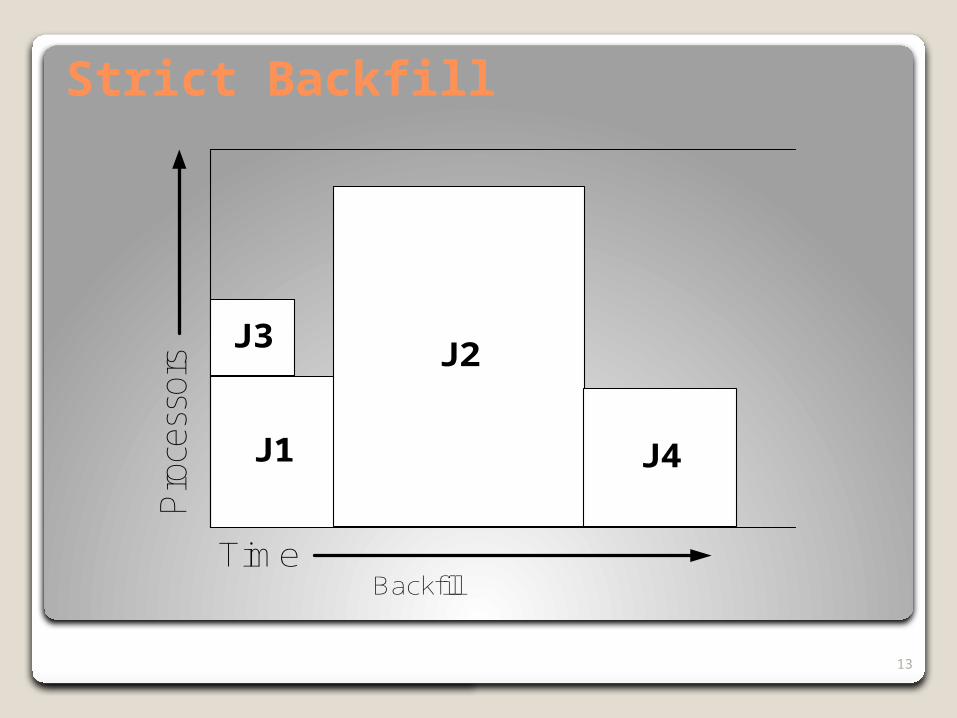
Strict Backfill
J1
J2J3
Time
Pro
cess
ors
J4
Backfill

14
Relaxed Backfill

15
Backfill
Backfill is a common HPC workload scheduling optimization at the job-level.
Note, it depends on the programmer’s estimate of the execution time, which is likely to be influenced by the priority queue structure for that data center and machine.

16
Dynamic, Multi-Factor Prioritization
Bill Ward and Tyler Simon, among others, have proposed setting job priorities as the product of several factors:
(Wait Time)Wait Parameter
* (Est’d Proc Time)Proc Parameter
* (CPUs Requested)CPU Parameter
* Queue = Priority

17
Dynamic Priorities with Budgets
Prioritization can also include a user allocation or budget.
Users can increase or decrease the priorities of their jobs by bidding dollars or some measure of their allocation.
Higher bids mean faster results.Lower bids mean more jobs can be run, at a cost of
waiting longer for results.Similar to 1970s time-sharing charge-back systems.

18
MapReduce
As mentioned, Amdahl’s Law explains why it is in an important HPC environment for the application to be coded to exploit parallelism.
Doing so – programming for parallelism - is an historically difficult problem.
MadReduce is a response to this problem.

19
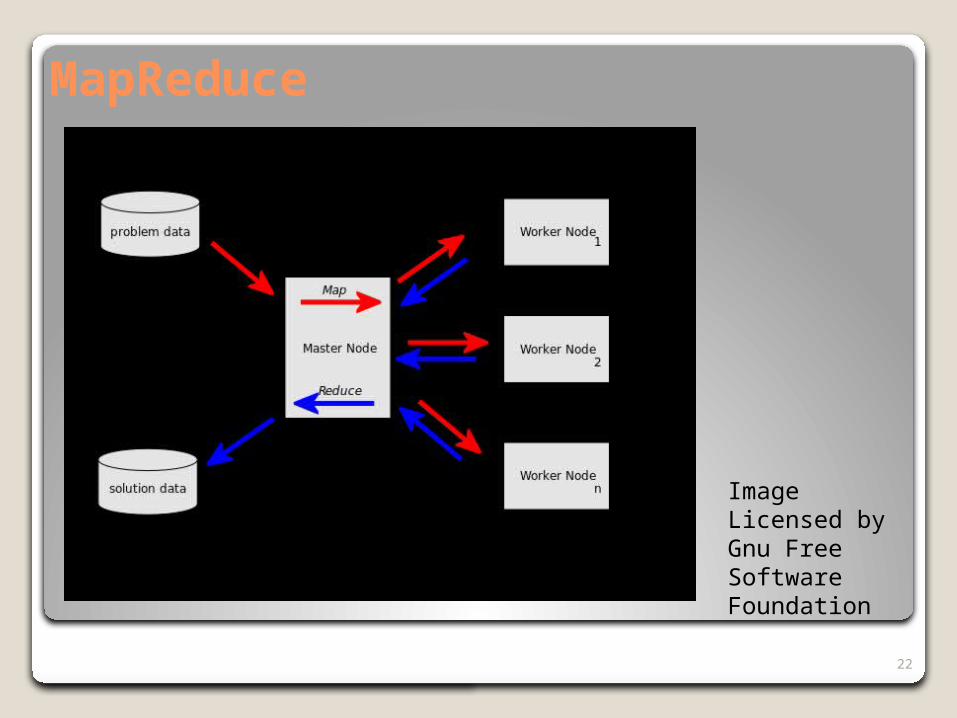
MapReduceMapReduce is a method for simple implementation of
parallelism in a program. The programmer inserts map() and reduce() calls in the code, the compiler, dispatcher, and operating system take care of distributing the code and data onto multiple nodes.
The map() function distributes the input file data onto many disks and the code onto many processors. The code processes this data in parallel. For example, weather parameters in discrete patches of the surface of the globe.

20
MapReduce
The reduce() function gathers and combines the data from many nodes into generates the output data set.
MapReduce makes it easier for programmers to implement parallel versions of their applications by taking care of the distribution, management, shuffling, and return to and from the many processors and their associated data storage.

21
MapReduce
MapReduce can also take care of reliability by distributing the data redundantly.
Also takes care of load-balancing and performance optimization by distributing the code and data fairly among the many nodes in the cluster.
MapReduce may also be used to implement prioritization by controlling the number of map and reduce slots created and allocated to various users, classes of users, or classes of jobs – the more slots allocated, the faster that user or job will run.
22
MapReduce
Image Licensed by Gnu Free Software Foundation

23
MapReduce
MapReduce was originally developed for use by small teams where FIFO or “social scheduling” was sufficient for workload scheduling.
It has grown to be used for very large problems, such as sorting, searching, and indexing large data sets.
Google uses MapReduce to index the world wide web and holds a patent on the method.
MapReduce is not the only framework for parallel processing and has opponents as well as advocates.

24
HADOOP
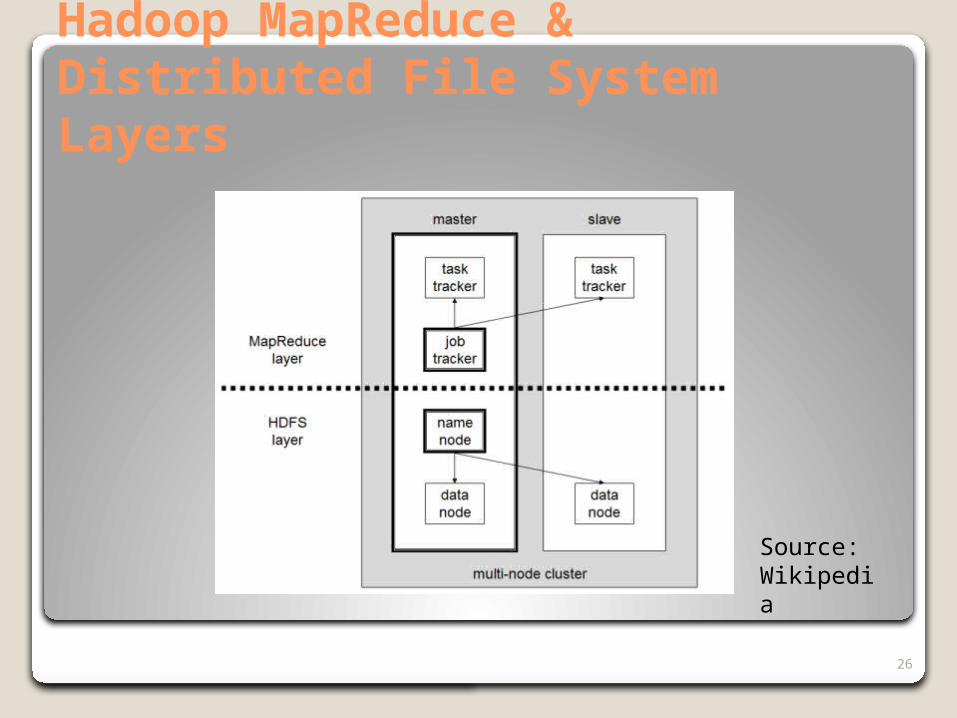
Hadoop is a specific open source implementation of the MapReduce framework written in Java and licensed by Apache
Hadoop also includes a distributed file systemDesigned for very large (thousands of processors) systems
using commodity processors, including grid systemsImplements data replication for checkpoint (failover) and
localityLocality of processors with their data help network
bandwidth

25
Applications of Hadoop
Data intensive applicationsApplications needing fault
toleranceNot a DBMSYahoo; Facebook; LinkedIn;
AmazonWatson, the IBM system that won
on Jeopardy used Hadoop
26
Hadoop MapReduce & Distributed File System Layers
Source: Wikipedia

27
Hadoop Workload Scheduling
Task Tracker attempts to dispatch processors on nodes near the data (e.g., same rack) the application requires. Hadoop HDFS is “rack aware”
Default Hadoop scheduling is FCFS=FIFOWorkload scheduling to optimize data locality and
also optimize processor utilization are in conflict.There are various alternatives to HDFS and the
default Hadoop scheduler

28
Hadoop Scheduling Alternatives: Fair-Share Scheduler
Fair-Share is a workload scheduler designed to replace FCFS
Organized into pools (a default of one per user)Goal: Ensure Fair Resource UseEach pool entitled to a minimum share of the clusterCan be FIFO or Fair-Share within a poolShares map() and reduce() slots

29
Fair-Share
If excess capacity is available, can be given to a pool that has its minimum
Allows maximum jobs/userAllows maximum jobs/poolAllows pre-emption of jobsCan use size (# of tasks) or priorities

30
Hadoop Scheduling Alternatives: Capacity Scheduler
Organized into queuesQueues share a percent of the clusterGoal: Maximize utilization & throughput, e.g., fast
response time for small jobs and guaranteed response time for production jobs
FIFO within queuesUses pre-emptionQueues can be started and stopped at run timeIf excess capacity is available, can be given to any queue

31
Dynamic Prioritization in Hadoop
Tyler Simon, a collaborator of mine in prior Southern CMG presentations, has studied the application of dynamic prioritization in the Hadoop environment.
An additional consideration in his study: fractional job allocation. Dispatching the job on less than the total number of CPUs requested by the user. Massively parallel jobs can tolerate this.

32
Dynamic Prioritization in Hadoop
Priorities calculated based on same factors as before: actual wait time, estimated processing time, and number of CPUs requested.
Queues are typically structured around those same factors. Using a single queue and reflecting the significance of those factors in the priority calculation is more flexible than fixed queues.
System administrator must still set parameters (relative importance of each factor).

33
Dynamic Prioritization in Hadoop Vs. Fair ShareBackfillNo Pre-emptionFixed shares are optionalImproved Workload Response TimeImproved UtilizationPriorities are dynamic – recalculated at each
scheduling interval

34
Dynamic Prioritization in Hadoop Vs. Ward
Compare to Ward’s proposed dynamic prioritization Use of parameters is the sameSysAdmin implements policy by selecting
parameters the same, but…..Only one queueIncludes fractional Knapsack – fraction of a job may be dispatched to fill the Knapsack

35
Dynamic Prioritization in Hadoop Vs. Ward
Option: System can select its own parameters – self-tuning: run the optimization globally, then calculate priorities when a job completes (or is submitted, or on a schedule)
Or, run the optimization whenever a job completes, selecting the job(s) to run next to yield near-optimum performance for jobs currently in the queue
Can be extended to prioritize on other parameters – e.g., time of day, day of week, reliability, power consumption, etc.

36
Algorithm – Prioritization
Source:“Multiple Objective Scheduling of HPC Workloads Through Dynamic Prioritization”Tyler Simon,Phoung Nguyen,& Milton Halem

37
Algorithm – Cost Evaluation
38
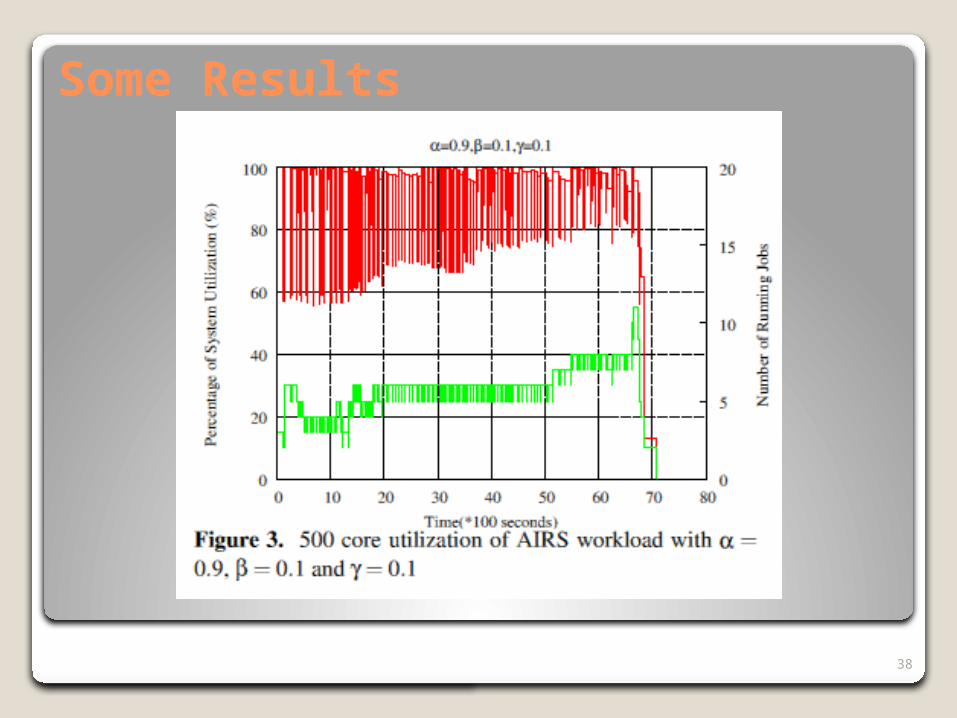
Some Results

39
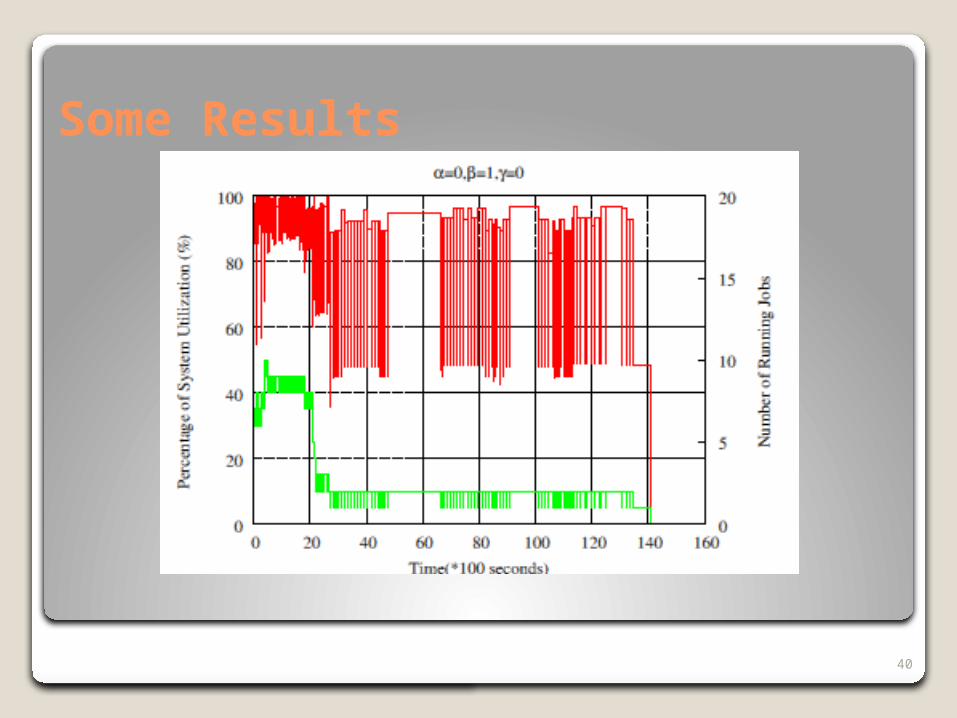
Some Results
40
Some Results

41
Some Results
42
In Conclusion…
Tyler’s results indicate about a 35% reduction in workload response time (batch turnaround time) compared to the default Hadoop scheduler
Many ideas have been published about workload scheduling and optimization in both HPC and Hadoop
Not clear who will come out on topA lot outside the scope of this presentation
43
Bibliography
Glassbrook, Richard, and McGalliard, James. “Performance Management at an Earth Science Supercomputer Center.” CMG 2003.
Heger, Dominique. “Hadoop Performance Tuning – A Pragmatic & Iterative Approach” www.cmg.org/measureit/issues/mit97/m_97_3.pdf
Kumar, Rajeev and Banerjee, Nilanjan. “Analysis of a Multiobjective Evolutionary Algorithm on the 0-1 Knapsack Problem” Theoretical Computer Science 358 (2006).

44
Bibliography• Nguyen, Phoung; Simon, Tyler A.; Halem, Milton;
Chapman, David; and Li, Quang Li. A Hybrid Scheduling Algorithm for Data Intensive Workloads in a Map Reduce Environment, 5th IEEE/ACM International Conference on Utility and Cloud Computing (UCC2012), pp. 161-167, Chicago, Il, (Nov. 5-8, 2012.)
• Rao, B. Thirumala and others. “Performance Issues of Heterogeneous Hadoop Clusters in Cloud Computing.” Global Journal of Computer Science and Technology Volume XI Issue VII May 2011.
• Sandholm, Thomas, and Kai, Kevin. “Dynamic Proportional Share Scheduling in Hadoop,” Proceedings of the 15th International Conference on Job Scheduling Strategies for Parallel Processing, JSSP ‘10. Berlin, Spring-Verlag.

45
Bibliography
Scavlex. http://compprog.wordpress.com/2007/11/20/the-fractional-knapsack-problem.
Simon, Tyler and McGalliard, James. “Multi-Core Processor Memory Contention Benchmark Analysis Case Study,” CMG 2009, Dallas.
Simon, Tyler and others. “Multiple Objective Scheduling of HPC Workoads Through Dynamic Prioritization” HPC 2013, Spring Simulation Conference, The Society for Modeling & Simulation International.

46
BibliographySpear, Carrie and McGalliard, James. “A Queue Simulation
Tool for a High Performance Scientific Computing Center.” CMG 2007, San Diego.
Ward, William A. and others. “Scheduling Jobs on Parallel Systems Using a Relaxed Backfill Strategy.” Revised Papers from the 8th International Workshop on Job Scheduling Strategies for Parallel Processing, JSSP ’02, London, Springer-Verlag.


















