
Some projects in Real-World Sound Analysis
30
Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30 1 1. Real-World Sound 2. Speech Separation 3. Soundtrack Classification 4. Music Audio Analysis Some projects in Real-World Sound Analysis Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA [email protected] http://labrosa.ee.columbia.edu/
Transcript of Some projects in Real-World Sound Analysis

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /301
1. Real-World Sound2. Speech Separation3. Soundtrack Classification4. Music Audio Analysis
Some projects inReal-World Sound Analysis
Dan EllisLaboratory for Recognition and Organization of Speech and Audio
Dept. Electrical Eng., Columbia Univ., NY USA
[email protected] http://labrosa.ee.columbia.edu/

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
LabROSA Overview
2
InformationExtraction
MachineLearning
SignalProcessing
Speech
Music EnvironmentRecognition
Retrieval
Separation

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
1. Real-World Sound
“Imagine two narrow channels dug up from the edge of a lake, with handkerchiefs stretched across each one. Looking only at the motion of the handkerchiefs, you are to answer questions such as: How many boats are there on the lake and where are they?” (after Bregmanʼ90)
• Received waveform is a mixture2 sensors, N sources - underconstrained
• Use prior knowledge (models) to constrain
3
Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
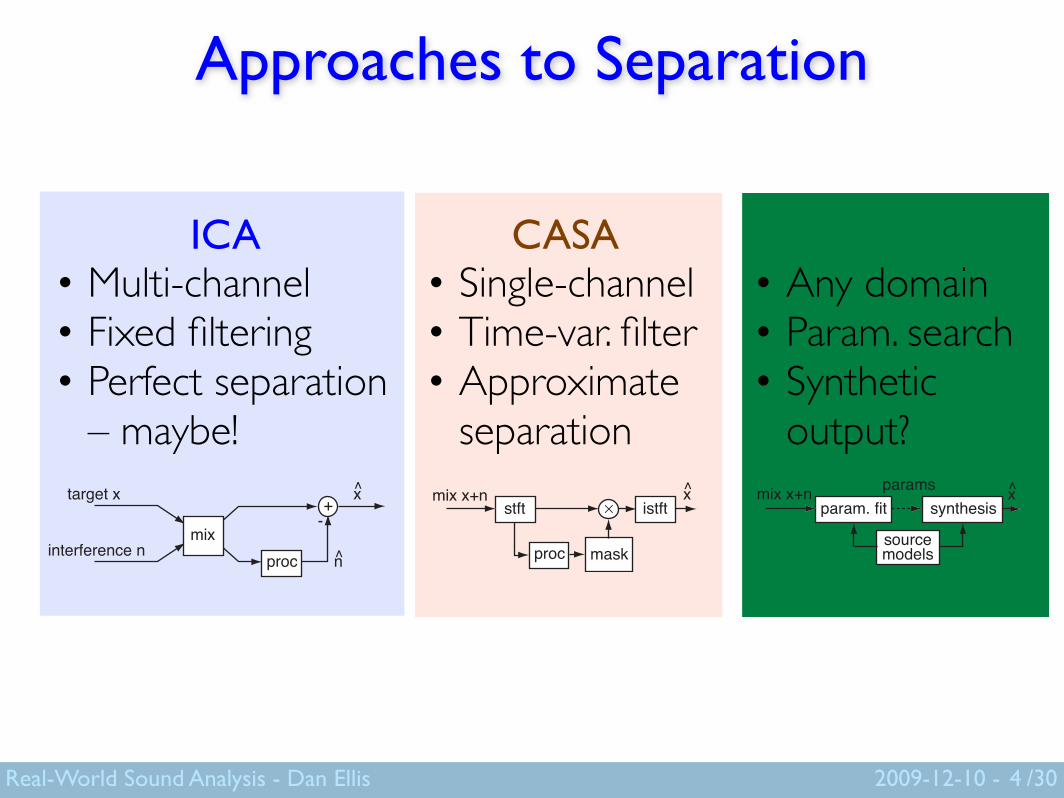
Approaches to Separation
4
ICA• Multi-channel• Fixed filtering• Perfect separation
– maybe!
CASA• Single-channel• Time-var. filter• Approximate
separationtarget x
interference n n̂
x̂-
mix
+
proc
x̂
proc mask
istftmix x+n
stft
Model-based• Any domain• Param. search• Synthetic
output?mix x+n x̂
sourcemodels
param. fitparams
synthesis

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
2. Speech Separation
• Given models for sources, find “best” (most likely) states for spectra:
can include sequential constraints...
• E.g. stationary noise:
5
{i1(t), i2(t)} = argmaxi1,i2p(x(t)|i1, i2)p(x|i1, i2) = N (x;ci1+ ci2,Σ) combination
model
inference ofsource state
time / s
freq
/ mel
bin
Original speech
0 1 2
20
40
60
80
In speech-shaped noise (mel magsnr = 2.41 dB)
0 1 2
20
40
60
80
VQ inferred states (mel magsnr = 3.6 dB)
0 1 2
20
40
60
80
Roweis ’01, ’03Kristjannson ’04, ’06

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Speech Mixture Recognition
• Speech recognizers contain speech modelsASR is just argmax P(W | X)
• Recognize mixtures with Factorial HMMi.e. two state sequences, one model for each voiceexploit sequence constraints, speaker differences
• Speaker-specific models...6
Varga & Moore ’90
model 1
model 2
observations / time
Kristjansson, Hershey et al. ’06

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Eigenvoices• Idea: Find
speaker model parameter space
generalize without losing detail?
• Eigenvoice model:
7
Kuhn et al. ’98, ’00Weiss & Ellis ’07, ’08, ’09
Speaker modelsSpeaker subspace bases
µ = µ̄ + U w + B hadapted mean eigenvoice weights channel channelmodel voice bases bases weights
Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
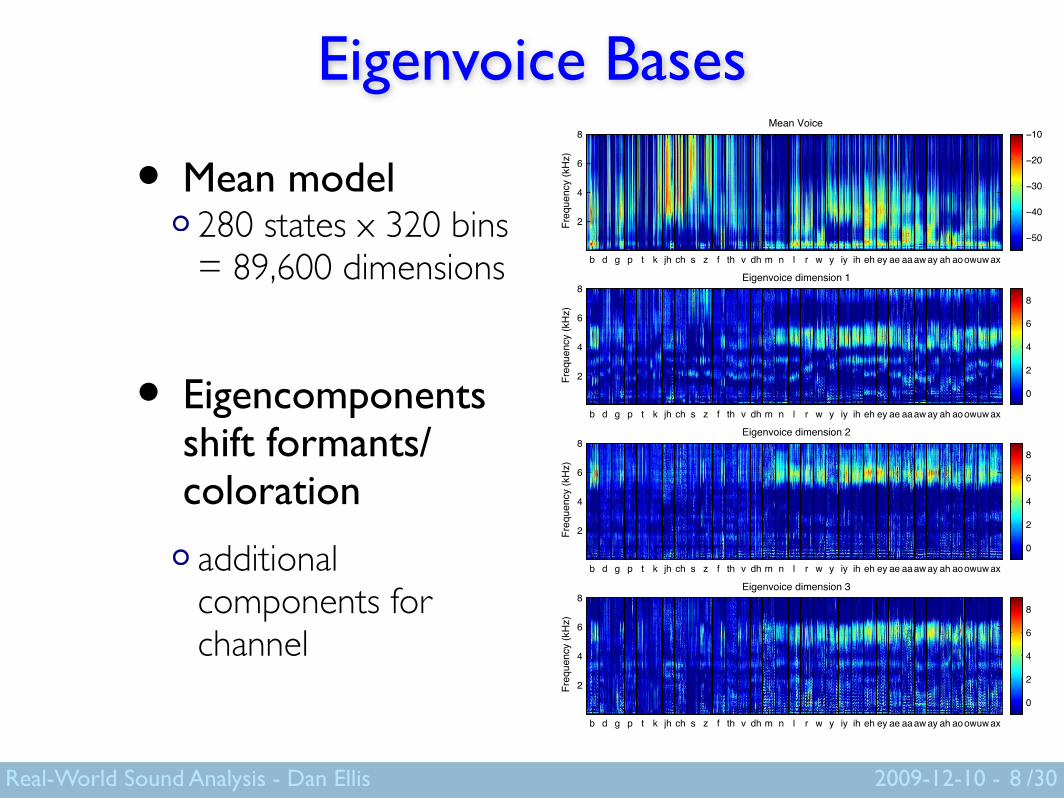
Eigenvoice Bases
• Mean model280 states x 320 bins= 89,600 dimensions
• Eigencomponentsshift formants/coloration
additional components forchannel
8
Freq
uenc
y (kH
z)
Mean Voice
b d g p t k jh ch s z f th v dh m n l r w y iy ih eh ey ae aaaw ay ah aoowuw ax
2
4
6
8
Freq
uenc
y (kH
z)
Eigenvoice dimension 1
b d g p t k jh ch s z f th v dh m n l r w y iy ih eh ey ae aaaw ay ah aoowuw ax
2
4
6
8
Freq
uenc
y (kH
z)
Eigenvoice dimension 2
b d g p t k jh ch s z f th v dh m n l r w y iy ih eh ey ae aaaw ay ah aoowuw ax
2
4
6
8
Freq
uenc
y (kH
z)Eigenvoice dimension 3
b d g p t k jh ch s z f th v dh m n l r w y iy ih eh ey ae aaaw ay ah aoowuw ax
2
4
6
8
50
40
30
20
10
0
2
4
6
8
0
2
4
6
8
0
2
4
6
8

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Speaker-Adapted Separation
• Factorial HMM analysiswith tuning of source model parameters = eigenvoice speaker adaptation
9
Weiss & Ellis ’08

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Speaker-Adapted Separation
10

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Speaker-Adapted Separation
• Eigenvoices for Speech Separation taskspeaker adapted (SA) performs midway between speaker-dependent (SD) & speaker-indep (SI)
11
SI
SA
SD

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Spatial Separation
• 2 or 3 sources in reverberation
assume just 2 ‘ears’
• Model interaural spectrum of each sourceas stationary level and time differences:
12
Mandel & Ellis ’07

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
ILD and IPD
• Sources at 0° and 75° in reverb
13
thgiRtfe
Sou
rce
1Sou
rce
2M
ixtu
re
L DLIDPI

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Model-Based EM Source Separation and Localization (MESSL)
can model more sources than sensorsflexible initialization
14
Assign spectrogram pointsto sources
Re-estimatesource parameters
Mandel & Ellis ’09

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
MESSL Results
• Modeling uncertainty improves resultstradeoff between constraints & noisiness
15
2.45 dB2.45 dB
9.12 dB9.12 dB
0.22 dB0.22 dB
-2.72 dB-2.72 dB
12.35 dB12.35 dB8.77 dB8.77 dB

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
MESSL-SP (Source Prior)
16
Outline Introduction Speaker subspace model Monaural speech separation Binaural separation Conclusions
Parameter estimation and source separation
Ron Weiss Underdetermined Source Separation Using Speaker Subspace Models May 4, 2009 27 / 34

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
MESSL-SP Results
• Source models function as priors• Interaural parameter spatial separation
source model prior improves spatial estimate
17
00.20.40.60.81
Ground truth (12.04 dB)
Freq
uenc
y (kH
z)
0 0.5 1 1.50
2
4
6
8DUET (3.84 dB)
0 0.5 1 1.50
2
4
6
82D FD BSS (5.41 dB)
0 0.5 1 1.50
2
4
6
8
MESSL (5.66 dB)
Freq
uenc
y (kH
z)
Time (sec)0 0.5 1 1.5
0
2
4
6
8MESSL SP (10.01 dB)
Time (sec)0 0.5 1 1.5
0
2
4
6
8MESSL EV (10.37 dB)
Time (sec)
0 0.5 1 1.50
2
4
6
8

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
3. Soundtrack Classification
• Short video clips as the evolution of snapshots10-100 sec, one location, no editingbrowsing?
• Need information for indexing...video + audioforeground + background
18

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
MFCC Covariance Representation
• Each clip/segment → fixed-size statisticssimilar to speaker ID and music genre classification
• Full Covariance matrix of MFCCs maps the kinds of spectral shapes present
• Clip-to-clip distances for SVM classifierby KL or 2nd Gaussian model
19
VTS_04_0001 - Spectrogram
freq
/ kH
z
1 2 3 4 5 6 7 8 9012345678
-20
-10
0
10
20
30
time / sec
time / sec
level / dB
value
MFC
C b
in
1 2 3 4 5 6 7 8 92468
101214161820
-20-15-10-505101520
MFCC dimension
MFC
C d
imen
sion
MFCC covariance
5 10 15 20
2
4
6
8
10
12
14
16
18
20
-50
0
50
Video Soundtrack
MFCCfeatures
MFCCCovariance
Matrix

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Latent Semantic Analysis (LSA)
• Probabilistic LSA (pLSA) models each histogram as a mixture of several ‘topics’.. each clip may have several things going on
• Topic sets optimized through EM p(ftr | clip) = ∑topics p(ftr | topic) p(topic | clip)
use p(topic | clip) as per-clip features
20
GMM histogram ftrs GMM histogram ftrs“Topic”
“Top
ic”
AV C
lip
AV C
lipp(ftr | clip)
p(topic
| clip
) p(ftr | topic)
=
*
Hofmann ’99

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Classification Results
• Wide range:
audio (music, ski) vs. non-audio (group, night)large AP uncertainty on infrequent classes
21
Animal
BabyBeach
Birthday
Boat
Crowd
Group of 3
+
Group of 2
Museum
Night
One person
ParkPicn
ic
Playground
ShowSports
Sunset
Wedding
Dancing
Parade
SingingCheer
Music
Concepts
Ski0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
AP
1G + KL1G + MahGMM Hist. + pLSAGuess
Chang, Ellis et al. ’07Lee & Ellis ’10

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Temporal Refinement
• Global vs. local class modelstell-tale acoustics may be ‘washed out’ in statisticstry iterative realignment of HMMs:
“background” (bg) model shared by all clipsMultiple-Instance Learning
22
Old Way:All frames contribute
New Way:Limited temporal extents
time / s
freq
/ kH
z
YT baby 002: voice baby laugh
5 10 150
1
2
3
4
voice babylaugh
time / s
freq
/ kH
z
5 10 150
1
2
3
4
voice laugh
laugh
bg
bg
voice
baby
baby

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Landmark-based Features
neighbor pairs as “features”?
23
• Describe audio with biggest Gabor elementsextract with Matching Pursuit (MP)
Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
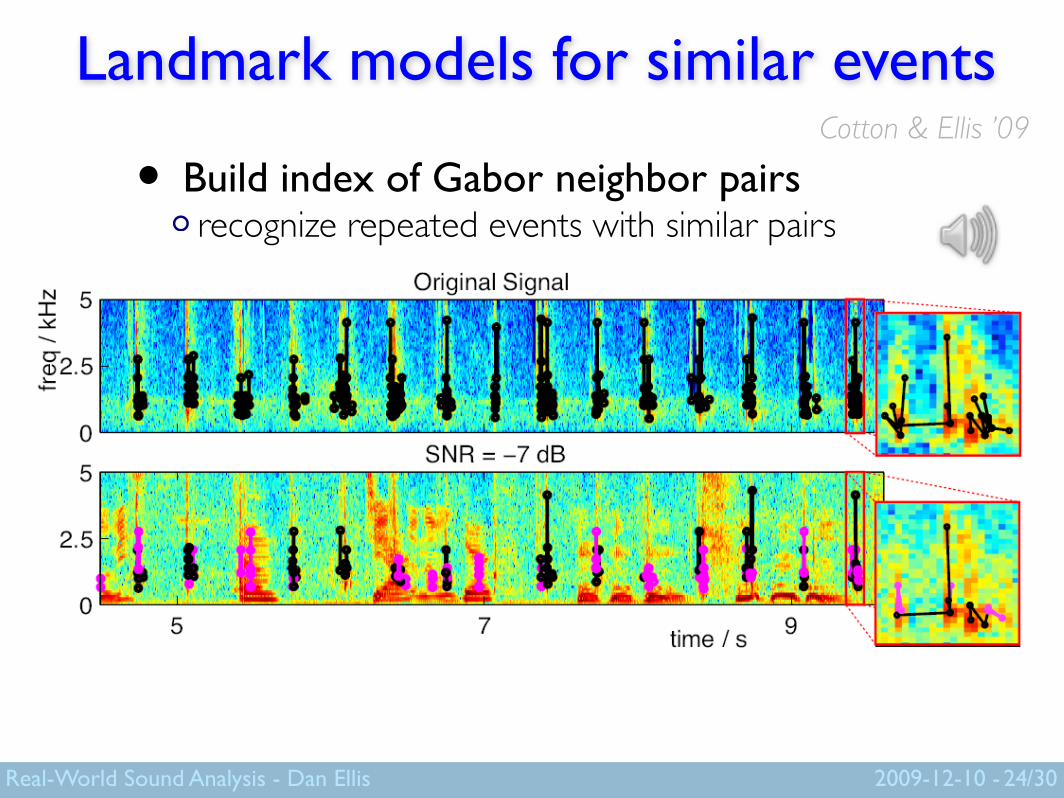
Landmark models for similar events
• Build index of Gabor neighbor pairsrecognize repeated events with similar pairs
24
Cotton & Ellis ’09

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Matching Videos via Fingerprints
• Landmark pairs are a noise-robust fingerprint
• Use to match distinct videos with same sound ambience
25
Cotton & Ellis ’10?
VIdeo IMpLQaiHWbE at 195s
VIdeo Yi1hkNkqHBc at 218 s
195.5 196 196.5 197 197.5 198 198.5 199
218.5 219 219.5 220 220.5 221 221.5 2220
1
2
3
4fre
q / k
Hz
0
1
2
3
4
freq
/ kHz
time / sec
time / sec
Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
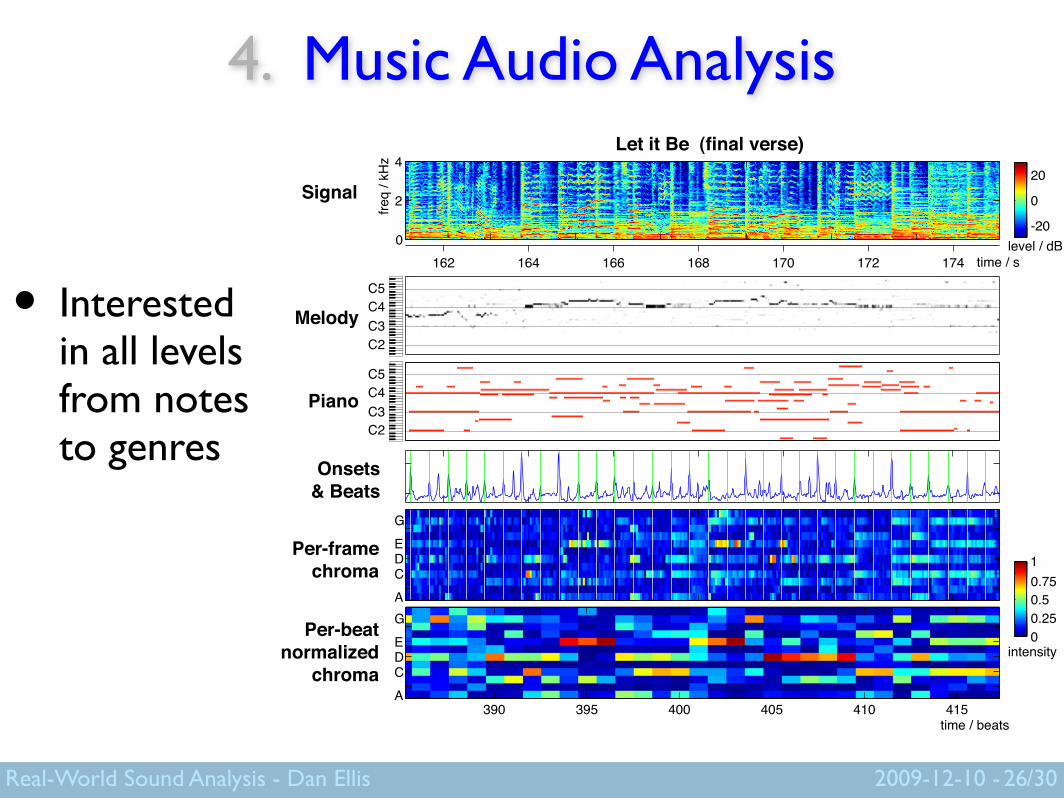
4. Music Audio Analysis
• Interested in all levels from notes to genres
26
freq
/ kH
z
0
2
4
162 164 166 168 170 172 174 time / s
time / beats
level / dB
C4C5
C2
C2
C3
C4C5
Signal
Onsets& Beats
Per-framechroma
Per-beatnormalized
chroma
Melody
Piano
C3
-20
0
20
intensity0
0.50.25
0.751
Let it Be (final verse)
390 395 400 405 410 415
ACDEG
ACDEG

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Polyphonic Transcription
• Apply the Eigenvoice idea to musiceigeninstruments? • Subspace NMF
27
Grindlay & Ellis ’09

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Chord Recognition
• Much better results
28
Tsochantaridis et al ’05Weller, Ellis, Jebara ’09Structural Support Vector Machine
Joint features describe match between x and yLearn weights so that is max for correct y
…
Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
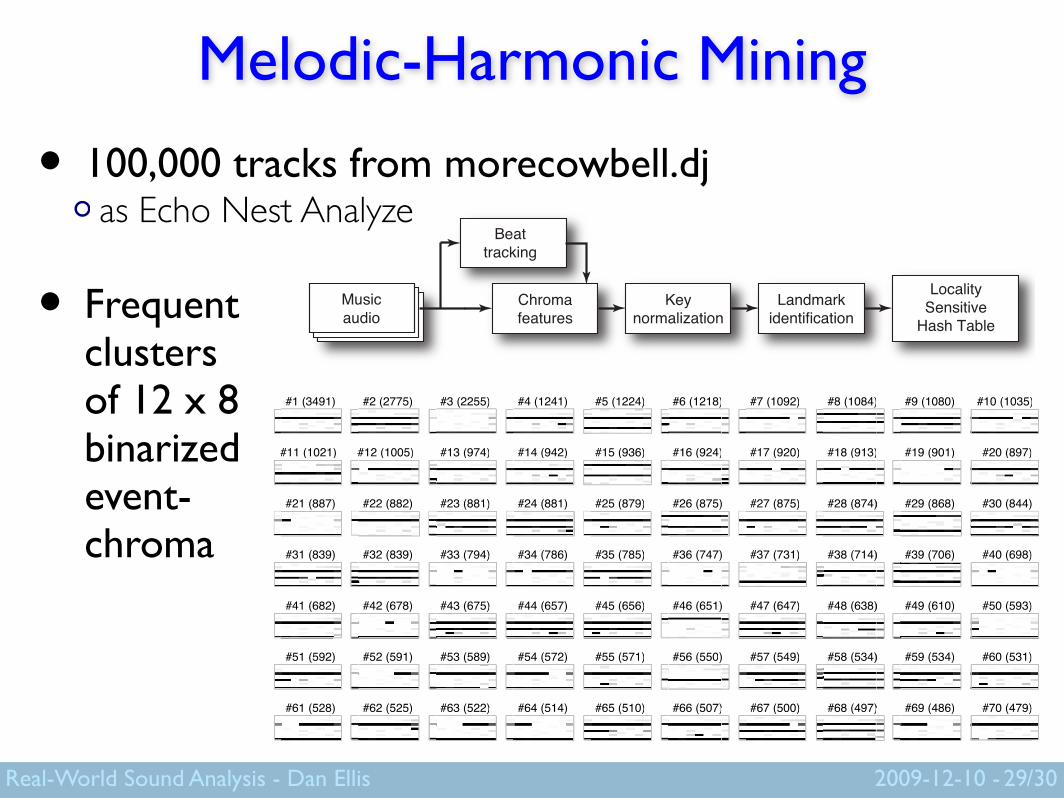
Melodic-Harmonic Mining
• 100,000 tracks from morecowbell.djas Echo Nest Analyze
• Frequent clusters of 12 x 8 binarized event-chroma
29
#1 (3491) #2 (2775) #3 (2255) #4 (1241) #5 (1224) #6 (1218) #7 (1092) #8 (1084) #9 (1080) #10 (1035)
#11 (1021)
#1 (3491)
#12 (1005)
)#2 (2775)
#13 (974)
#3 (2255)
#14 (942)
)#4 (1241)
#15 (936)
)#5 (1224)
#16 (924)
)#6 (1218)
#17 (920)
)#7 (1092)
#18 (913)
)#8 (1084)
#19 (901)
)) #10 (1035)#9 (1080)
#20 (897)#
#21 (887)
#11 (1021) #
#21 (887)#21 (887) #22 (882)
)#12 (1005)
))#22 (882)#22 (882) #23 (881)
#13 (974)
#23 (881)#23 (881) #24 (881)
)#14 (942)
))#24 (881)#24 (881) #25 (879)
)#15 (936)
))#25 (879)#25 (879) #26 (875)
)#16 (924)
))#26 (875)#26 (875) #27 (875)
)#17 (920)
))#27 (875)#27 (875) #28 (874)
)#18 (913)
))#28 (874)#28 (874) #29 (868)
) #20 (897)#19 (901)
))#29 (868)#29 (868) #30 (844)
#31 (839) #32 (839) #33 (794) #34 (786) #35 (785) #36 (747) #37 (731) #38 (714) #39 (706) #40 (698)
#41 (682)
#31 (839)#31 (839)
#42 (678)
))#32 (839)#32 (839)
#43 (675)
#33 (794)#33 (794)
#44 (657)
))#34 (786)#34 (786)
#45 (656)
))#35 (785)#35 (785)
#46 (651)
))#36 (747)#36 (747)
#47 (647)
))#37 (731)#37 (731)
#48 (638)
))#38 (714)#38 (714)
#49 (610)
)) #40 (698)#40 (698)#39 (706)#39 (706)
#50 (593)
#51 (592)
#41 (682)#41 (682)
#52 (591)
))#42 (678)#42 (678)
#53 (589)
#43 (675)#43 (675)
#54 (572)
))#44 (657)#44 (657)
#55 (571)
))#45 (656)#45 (656)
#56 (550)
))#46 (651)#46 (651)
#57 (549)
))#47 (647)#47 (647)
#58 (534)
))#48 (638)#48 (638)
#59 (534)
)) #50 (593)#50 (593)#49 (610)#49 (610)
#60 (531)
#61 (528)
#51 (592)
#62 (525)
)#52 (591)
#63 (522)
#53 (589)
#64 (514)
)#54 (572)
#65 (510)
)#55 (571)
#66 (507)
)#56 (550)
#67 (500)
)#57 (549)
#68 (497)
)#58 (534)
#69 (486)
) #60 (531)#59 (534)
#70 (479)
#71 (476)
#61 (528)#61 (528)
#72 (468)
))#62 (525)#62 (525)
#73 (468)
#63 (522)#63 (522)
#74 (466)
))#64 (514)#64 (514)
#75 (463)
))#65 (510)#65 (510)
#76 (454)
))#66 (507)#66 (507)
#77 (453)
))#67 (500)#67 (500)
#78 (448)
))#68 (497)#68 (497)
#79 (441)
)) #70 (479)#70 (479)#69 (486)#69 (486)
#80 (440)
#81 (435)
#71 (476)#71 (476)
#82 (430)
))#72 (468)#72 (468)
#83 (430)
#73 (468)#73 (468)
#84 (425)
))#74 (466)#74 (466)
#85 (425)
))#75 (463)#75 (463)
#86 (419)
))#76 (454)#76 (454)
#87 (419)
))#77 (453)#77 (453)
#88 (417)
))#78 (448)#78 (448)
#89 (416)
)) #80 (440)#80 (440)#79 (441)#79 (441)
#90 (414)
#91 (411)
#81 (435)#81 (435)
#91 (411)#91 (411) #92 (410)
))#82 (430)#82 (430)
))#92 (410)#92 (410) #93 (408)
#83 (430)#83 (430)
#93 (408)#93 (408) #94 (406)
))#84 (425)#84 (425)
))#94 (406)#94 (406) #95 (401)
))#85 (425)#85 (425)
))#95 (401)#95 (401) #96 (398)
))#86 (419)#86 (419)
))#96 (398)#96 (398) #97 (397)
))#87 (419)#87 (419)
))#97 (397)#97 (397) #98 (396)
))#88 (417)#88 (417)
))#98 (396)#98 (396) #99 (396)
)) #90 (414)#90 (414)#89 (416)#89 (416)
))#99 (396)#99 (396) #100 (395)
Musicaudio
LocalitySensitive
Hash Table
Beattracking
Chromafeatures
Keynormalization
Landmarkidentification

Real-World Sound Analysis - Dan Ellis 2009-12-10 - /30
Summary
• LabROSA : getting information from sound
• Speechmonaural separation using eigenvoices
binaural + reverb using MESSL
• Environmentalclassification of consumer video
landmark-based events and matching
• Musictranscription of notes, chords, ...
large corpus mining30


















