
Slide 1 Computers for the Post-PC Era Aaron Brown, Jim Beck, Rich Martin, David Oppenheimer, Kathy...
34
Slide 1 Computers for the Post-PC Era Aaron Brown, Jim Beck, Rich Martin, David Oppenheimer, Kathy Yelick, and David Patterson http://iram.cs.berkeley.edu/istore 2000 Grad Visit Day
-
date post
21-Dec-2015 -
Category
Documents
-
view
216 -
download
1
Transcript of Slide 1 Computers for the Post-PC Era Aaron Brown, Jim Beck, Rich Martin, David Oppenheimer, Kathy...

Slide 1
Computers for the Post-PC Era
Aaron Brown, Jim Beck, Rich Martin, David Oppenheimer, Kathy Yelick,
and David Patterson
http://iram.cs.berkeley.edu/istore
2000 Grad Visit Day

Slide 2
Berkeley Approach to Systems
• Find an important problem crossing HW/SW Interface, with HW/SW prototype at end, typically as part of graduate courses
• Assemble a band of 3-6 faculty, 12-20 grad students, 1-3 staff to tackle it over 4 years
• Meet twice a year for 3-day retreats with invited outsiders– Builds team spirit – Get advice on direction, and change course– Offers milestones for project stages– Grad students give 6 to 8 talks Great Speakers
• Write papers, go to conferences, get PhDs, jobs
• End of project party, reshuffle faculty, go to 1

Slide 3
For Example, Projects I Have Worked On
• RISC I,II – Sequin, Ousterhout (CAD)
• SOAR (Smalltalk On A RISC) Ousterhout (CAD)
• SPUR (Symbolic Processing Using RISCs)– Fateman, Hilfinger, Hodges, Katz, Ousterhout
• RAID I,II (Redundant Array of Inexp. Disks)– Katz, Ousterhout, Stonebraker
• NOW I,II (Network of Workstations), (TD)– Culler, Anderson
• IRAM I (Intelligent RAM)– Yelick, Kubiatowicz, Wawrzynek
• ISTORE I,II (Intelligent Storage)– Yelick, Kubiatowicz

Slide 4
Symbolic Processing Using RISCs: ‘85-’89
• Before Commercial RISC chips• Built Workstation Multiprocessor and
Operating System from scratch(!)• Sprite Operating System• 3 chips: Processor, Cache Controller, FPU
– Coined term “snopping cache protocol”– 3C’s cache miss: compulsory, capacity, conflict

Slide 5
Group Photo (in souvenir jackets)
• See www.cs.berkeley.edu/Projects/ARC to learn more about Berkeley Systems
Garth GibsonCMU, Founder ?
Dave Lee Founder Si. Image
MendelRosen-blum,
Stanford,FounderVMware
Ben Zorn Colorado,
M/S
David Wood,Wisconsin
Jim Larus, Wisconsin, M/S
MarkHill
Wisc.
SusanEggersWash-ington
Brent Welch Founder, Scriptics
John Ouster-hout
Founder, Scriptics
George Taylor, Founder, ?
Shing Kong Transmeta

Slide 6
SPUR 10 Year Reunion, January ‘99
• Everyone from North America came!• 19 PhDs: 9 to Academia
– 8/9 got tenure, 2 full professors (already) – 2 Romme fellows (3rd, 4th at Wisconsin)– 3 NSF Presidential Young Investigator
Winners– 2 ACM Dissertation Awards– They in turn produced 30 PhDs (1/99)
• 10 to Industry– Founders of 5 startups, (1 failed)– 2 Department heads (AT&T Bell Labs,
Microsoft)• Very successful group; SPUR Project
“gave them a taste of success, lifelong friends”,

Slide 7
Network of Workstations (NOW) ‘94 -’98
Leveraging commodity workstations and OSes to harness the power of clustered machines connected via high-speed switched networks
Construction of HW/SW prototypes: NOW-1 with 32 SuperSPARCs, and NOW-2 with 100 UltraSPARC 1s
NOW-2 cluster held the world record for the fastest Disk-to-Disk Sort for 2 years, 1997-1999
NOW-2 cluster 1st to crack the 40-bit key as part of a key-cracking challenge offered by RSA, 1997
NOW-2 made list of Top 200 supercomputers 1997 NOW a foundation of Virtual Interface (VI)
Architecture, standard allows protected, direct user-level access to network, by Compaq, Intel, & M/S
NOW technology led directly to one Internet startup company (Inktomi), + many other Internet companies use cluster technology

Slide 8
Network of Workstations (NOW) ‘94 -’98
12 PhDs. Note that 3/4 of them went into academia, and that 1/3 are female:
Andrea Arpaci-Desseau, Asst. Professor, Wisconsin, Madison Remzi Arpaci-Desseau, Asst. Professor, Wisconsin, Madison Mike Dahlin, Asst. Professor, University of Texas, Austin Jeanna Neefe Matthews, Asst. Professor, Clarkson Univ. Douglas Ghormley, Researcher, Los Alamos National Labs Kim Keeton, Researcher, Hewlett Packard Labs Steve Lumetta, Assistant Professor, Illinois Alan Mainwaring, Researcher, Sun Microsystems Labs Rich Martin, Assistant Professor, Rutgers University Nisha Talagala, Researcher, Network Storage, Sun Micro. Amin Vahdat, Assistant Professor, Duke University Randy Wang, Assistant Professor, Princeton University

Slide 9
Research in Berkeley Courses• RISC, SPUR, RAID, NOW, IRAM, ISTORE all
started in advanced graduate courses• Make transition from undergraduate student
to researcher in first-year graduate courses– First year architecture, operating systems courses:
select topic, do research, write paper, give talk– Prof meets each team 1-on-1 ~3 times, + TA help – Some papers get submitted and published
• Requires class size < 40 (e.g., Berkeley)– If 1st year course size ~100 students
=> cannot do research in grad courses 1st year or so
– If school offers combined BS/MS (e.g., MIT) or professional MS via TV broadcast (e.g., Stanford), then effective class size ~150-250

Slide 10
Outline
•Background: Berkeley Approach to Systems
•PostPC Motivation•PostPC Microprocessor: IRAM•PostPC Infrastructure Motivation •PostPC Infrastructure: ISTORE•Hardware Architecture•Software Architecture•Conclusions and Feedback

Slide 11
Perspective on Post-PC Era• PostPC Era will be driven by 2 technologies:
1) “Gadgets”:Tiny Embedded or Mobile Devices–ubiquitous: in everything–e.g., successor to PDA, cell phone, wearable computers
2) Infrastructure to Support such Devices–e.g., successor to Big Fat Web Servers, Database Servers

Slide 12
Intelligent RAM: IRAM
Microprocessor & DRAM on a single chip:– 10X capacity vs. SRAM– on-chip memory latency
5-10X, bandwidth 50-100X
– improve energy efficiency 2X-4X (no off-chip bus)
– serial I/O 5-10X v. buses– smaller board area/volume
IRAM advantages extend to:– a single chip system– a building block for larger systems
DRAM
fab
Proc
Bus
D R A M
I/OI/O
$ $Proc
L2$
Logic
fabBus
D R A M
BusI/OI/O

Slide 13
Revive Vector Architecture• Cost: $1M each?• Low latency, high
BW memory system?
• Code density?• Compilers?
• Performance?
• Power/Energy?
• Limited to scientific applications?
• Single-chip CMOS MPU/IRAM• IRAM
• Much smaller than VLIW• For sale, mature (>20 years)
(We retarget Cray compilers)• Easy scale speed with
technology• Parallel to save energy, keep
performance• Multimedia apps vectorizable
too: N*64b, 2N*32b, 4N*16b

Slide 14
VIRAM-1: System on a Chip
Prototype scheduled for end of Summer 2000•0.18 um EDL process
•16 MB DRAM, 8 banks
•MIPS Scalar core and caches @ 200 MHz
•4 64-bit vector unit pipelines @ 200 MHz
•4 100 MB parallel I/O lines
•17x17 mm, 2 Watts
•25.6 GB/s memory (6.4 GB/s per direction and per Xbar)
•1.6 Gflops (64-bit), 6.4 GOPs (16-bit)
•140 M transistors (> Intel?)
CPU+$
I/O4 Vector Pipes/Lanes
Memory (64 Mbits / 8 MBytes)
Memory (64 Mbits / 8 MBytes)
Xbar

Slide 15
Outline
•PostPC Infrastructure Motivation and Background: Berkeley’s Past
•PostPC Motivation•PostPC Device Microprocessor:
IRAM•PostPC Infrastructure Motivation• ISTORE Goals •Hardware Architecture•Software Architecture•Conclusions and Feedback

Slide 16
Background: Tertiary Disk (part of NOW)
• Tertiary Disk (1997) – cluster of 20 PCs
hosting 364 3.5” IBM disks (8.4 GB) in 7 19”x 33” x 84” racks, or 3 TB. The 200MHz, 96 MB P6 PCs run FreeBSD and a switched 100Mb/s Ethernet connects the hosts. Also 4 UPS units. – Hosts world’s largest art
database:80,000 images in cooperation with San Francisco Fine Arts Museum:Try www.thinker.org

Slide 17
Tertiary Disk HW Failure Experience
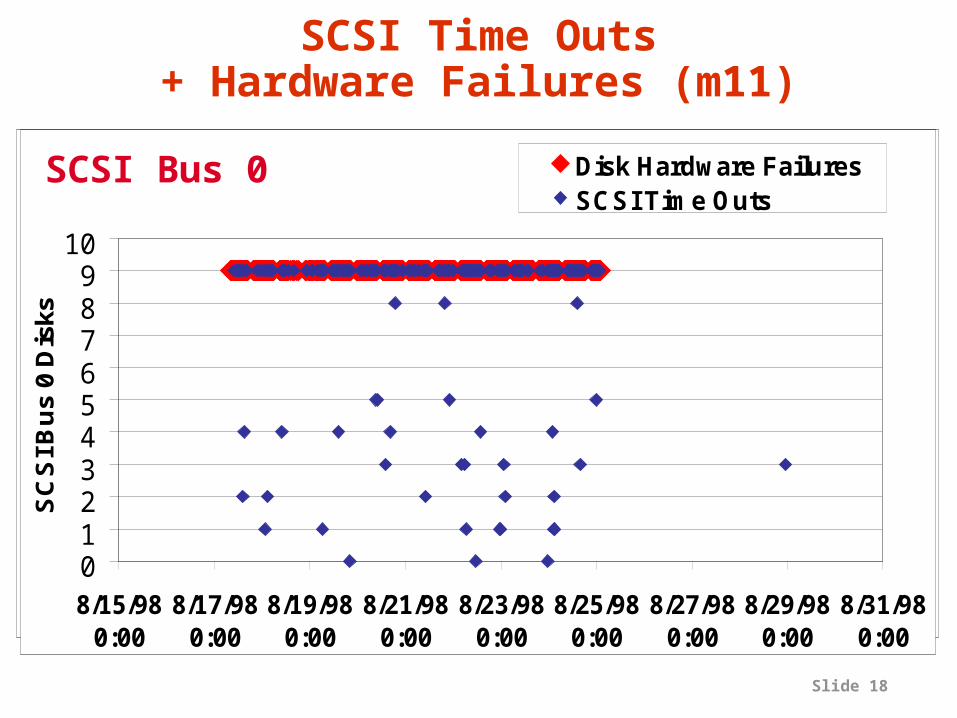
Reliability of hardware components (20 months)7 IBM SCSI disk failures (out of 364, or 2%)6 IDE (internal) disk failures (out of 20, or 30%)1 SCSI controller failure (out of 44, or 2%)1 SCSI Cable (out of 39, or 3%)1 Ethernet card failure (out of 20, or 5%)1 Ethernet switch (out of 2, or 50%)3 enclosure power supplies (out of 92, or 3%)1 short power outage (covered by UPS)
Did not match expectations:SCSI disks more reliable than SCSI cables!
Difference between simulation and prototypes
Slide 18
SCSI Time Outs+ Hardware Failures (m11)
0
2
4
6
8
10
8/17/980:00
8/19/980:00
8/21/980:00
8/23/980:00
8/25/980:00
8/27/980:00
SC
SI
Bu
s 0
Dis
ks
SCSI Time Outs
0123456789
10
8/15/980:00
8/17/980:00
8/19/980:00
8/21/980:00
8/23/980:00
8/25/980:00
8/27/980:00
8/29/980:00
8/31/980:00
SC
SI B
us
0 D
isks
Disk Hardware FailuresSCSI Time Outs
SCSI Bus 0

Slide 19
Can we predict a disk failure?•Yes, look for Hardware Error
messages–These messages lasted for 8 days between:
»8-17-98 and 8-25-98
–On disk 9 there were:»1763 Hardware Error Messages, and»297 SCSI Timed Out Messages
•On 8-28-98: Disk 9 on SCSI Bus 0 of m11 was “fired”, i.e. appeared it was about to fail, so it was swapped

Slide 20
Lessons from Tertiary Disk Project
• Maintenance is hard on current systems– Hard to know what is going on, who is to
blame
• Everything can break– Its not what you expect in advance– Follow rule of no single point of failure
• Nothing fails fast– Eventually behaves bad enough that
operator “fires” poor performer, but it doesn’t “quit”
• Most failures may be predicted

Slide 21
Outline
•Background: Berkeley Approach to Systems
•PostPC Motivation•PostPC Microprocessor: IRAM•PostPC Infrastructure Motivation •PostPC Infrastructure: ISTORE•Hardware Architecture•Software Architecture•Conclusions and Feedback

Slide 22
The problem space: big data
• Big demand for enormous amounts of data– today: high-end enterprise and Internet
applications» enterprise decision-support, data mining databases» online applications: e-commerce, mail, web, archives
– future: infrastructure services, richer data» computational & storage back-ends for mobile devices» more multimedia content» more use of historical data to provide better services
• Today’s SMP server designs can’t easily scale• Bigger scaling problems than performance!

Slide 23
The real scalability problems: AME
• Availability– systems should continue to meet quality of
service goals despite hardware and software failures
• Maintainability– systems should require only minimal ongoing
human administration, regardless of scale or complexity
• Evolutionary Growth– systems should evolve gracefully in terms of
performance, maintainability, and availability as they are grown/upgraded/expanded
• These are problems at today’s scales, and will only get worse as systems grow

Slide 24
Principles for achieving AME (1)
• No single points of failure• Redundancy everywhere• Performance robustness is more
important than peak performance– “performance robustness” implies that real-
world performance is comparable to best-case performance
• Performance can be sacrificed for improvements in AME– resources should be dedicated to AME
» compare: biological systems spend > 50% of resources on maintenance
– can make up performance by scaling system

Slide 25
Principles for achieving AME (2)
• Introspection– reactive techniques to detect and adapt to
failures, workload variations, and system evolution
– proactive (preventative) techniques to anticipate and avert problems before they happen

Slide 26
Hardware techniques (2)
• No Central Processor Unit: distribute processing with storage– Serial lines, switches also growing with
Moore’s Law; less need today to centralize vs. bus oriented systems
– Most storage servers limited by speed of CPUs; why does this make sense?
– Why not amortize sheet metal, power, cooling infrastructure for disk to add processor, memory, and network?
– If AME is important, must provide resources to be used to help AME: local processors responsible for health and maintenance of their storage

Slide 27
ISTORE-1 hardware platform
• 80-node x86-based cluster, 1.4TB storage– cluster nodes are plug-and-play, intelligent, network-
attached storage “bricks”» a single field-replaceable unit to simplify maintenance
– each node is a full x86 PC w/256MB DRAM, 18GB disk– more CPU than NAS; fewer disks/node than cluster
ISTORE Chassis80 nodes, 8 per tray2 levels of switches•20 100 Mbit/s•2 1 Gbit/sEnvironment Monitoring:UPS, redundant PS,fans, heat and vibration sensors...
Intelligent Disk “Brick”Portable PC CPU: Pentium II/266 + DRAM
Redundant NICs (4 100 Mb/s links)Diagnostic Processor
Disk
Half-height canister

Slide 28
A glimpse into the future?
• System-on-a-chip enables computer, memory, redundant network interfaces without significantly increasing size of disk
• ISTORE HW in 5-7 years:– building block: 2006
MicroDrive integrated with IRAM
» 9GB disk, 50 MB/sec from disk» connected via crossbar switch
– 10,000 nodes fit into one rack!
• O(10,000) scale is our ultimate design point

Slide 29
Development techniques• Benchmarking
– One reason for 1000X processor performance was ability to measure (vs. debate) which is better
» e.g., Which most important to improve: clock rate, clocks per instruction, or instructions executed?
– Need AME benchmarks“what gets measured gets done”
“benchmarks shape a field”
“quantification brings rigor”

Slide 30
Time (2-minute intervals)0 10 20 30 40 50 60 70 80 90 100 110
Hit
s p
er s
eco
nd
140
150
160
170
180
190
200
210
data diskfaulted
reconstruction(manual)
sparefaulted
disks replaced
}normal behavior(99% conf)
Time (2-minute intervals)0 10 20 30 40 50 60 70 80 90 100 110
Hit
s p
er s
eco
nd
140
150
160
170
180
190
200
210
220
data diskfaulted
reconstruction(automatic)
sparefaulted
reconstruction(automatic)
}normal behavior(99% conf)
disks replaced
Example results: multiple-faults
• Windows reconstructs ~3x faster than Linux• Windows reconstruction noticeably affects application
performance, while Linux reconstruction does not
Windows2000/IIS
Linux/Apache

Slide 31
Software techniques (1)
• Proactive introspection– Continuous online self-testing of HW and SW
» in deployed systems!» goal is to shake out “Heisenbugs” before they’re
encountered in normal operation» needs data redundancy, node isolation, fault
injection
– Techniques:» fault injection: triggering hardware and software
error handling paths to verify their integrity/existence
» stress testing: push HW/SW to their limits» scrubbing: periodic restoration of potentially
“decaying” hardware or software state•self-scrubbing data structures (like MVS)•ECC scrubbing for disks and memory

Slide 32
Conclusions (1): ISTORE• Availability, Maintainability, and
Evolutionary growth are key challenges for server systems– more important even than performance
• ISTORE is investigating ways to bring AME to large-scale, storage-intensive servers– via clusters of network-attached,
computationally-enhanced storage nodes running distributed code
– via hardware and software introspection– we are currently performing application
studies to investigate and compare techniques• Availability benchmarks a powerful tool?
– revealed undocumented design decisions affecting SW RAID availability on Linux and Windows 2000

Slide 33
Conclusions (2)• IRAM attractive for two Post-PC
applications because of low power, small size, high memory bandwidth– Gadgets: Embedded/Mobile devices– Infrastructure: Intelligent Storage and
Networks
• PostPC infrastructure requires – New Goals: Availability, Maintainability,
Evolution – New Principles: Introspection, Performance
Robustness– New Techniques: Isolation/fault insertion,
Software scrubbing– New Benchmarks: measure, compare AME
metrics

Slide 34
Berkeley Future work
• IRAM: fab and test chip• ISTORE
– implement AME-enhancing techniques in a variety of Internet, enterprise, and info retrieval applications
– select the best techniques and integrate into a generic runtime system with “AME API”
– add maintainability benchmarks» can we quantify administrative work needed to
maintain a certain level of availability?– Perhaps look at data security via
encryption?– Even consider denial of service?


















