
Signalling in the Heterogeneous Architecture Multiprocessor Paradigm
81
SPIE Gran Canaria 2003 A. Nunez 1 Signalling in the Heterogeneous Architecture Multiprocessor Paradigm Antonio Núñez, Victor Reyes, Tomás Bautista Keynote IUMA, Institute for Applied Microelectronics, ULPGC
-
Upload
daria-cardenas -
Category
Documents
-
view
32 -
download
4
description
Signalling in the Heterogeneous Architecture Multiprocessor Paradigm. Antonio Núñez, Victor Reyes, Tomás Bautista Keynote IUMA, Institute for Applied Microelectronics, ULPGC. Index. MPSoC Architectures -> Hetero MPSoC Communication Architectures -> Split Transport and Signalling Networks - PowerPoint PPT Presentation
Transcript of Signalling in the Heterogeneous Architecture Multiprocessor Paradigm

SPIE Gran Canaria 2003 A. Nunez 1
Signalling in the Heterogeneous Architecture Multiprocessor Paradigm
Antonio Núñez, Victor Reyes, Tomás Bautista
Keynote
IUMA, Institute for Applied Microelectronics, ULPGC

SPIE Gran Canaria 2003 A. Nunez 2
Index
MPSoC Architectures -> Hetero MPSoCCommunication Architectures -> Split Transport and Signalling NetworksPrevious and Related workOur SystemC Based Modelling ApproachExperimentsConclusions

SPIE Gran Canaria 2003 A. Nunez 3

SPIE Gran Canaria 2003 A. Nunez 4
Technological ForecastsMoore's Law: number of transistors per chip double every two years
ITRS:Year of 1st shipment 1997 1999 2002 2005 2008 2011 2014Local Clock (GHz) 0,75 1,25 2,1 3,5 6 10 16,9Across Chip (GHz) 0,75 1,2 1,6 2 2,5 3 3,674Chip Size (mm²) 300 340 430 520 620 750 901Dense Lines (nm) 250 180 130 100 70 50 35Number of chip I/O 1515 1867 2553 3492 4776 6532 8935Transistors per chip 11M 21M 76M 200M 520M 1,4B 3,62B
GALSNoC
SoC MPSoC

SPIE Gran Canaria 2003 A. Nunez 5

SPIE Gran Canaria 2003 A. Nunez 6
Processor to DRAM Performance Gap
µProc60%/yr.
DRAM7%/yr.
1
10
100
10001980
1981
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
DRAM
CPU
1982
Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance
Time
“Moore’s Law”

SPIE Gran Canaria 2003 A. Nunez 7
Logic to Memory Area Gap

SPIE Gran Canaria 2003 A. Nunez 8
Logic to Productivity Gap

SPIE Gran Canaria 2003 A. Nunez 9
-> Platform based design-> Communication architectures

SPIE Gran Canaria 2003 A. Nunez 10
Index
MPSoC Architectures -> Hetero MPSoCCommunication Architectures -> Split Transport and Signalling NetworksPrevious and Related workOur SystemC Based Modelling ApproachExperimentsConclusions

SPIE Gran Canaria 2003 A. Nunez 11
Processor Architecture Paradigms Cfr. Ungerer et al, Patterson et al, Tenhunnen et al, Computer special issue
Processor/Memory/Switch Processor- Memory- Communications- dominated systems Communications architecture
Processor-Mono: Speed-up of a single-threaded application Advanced superscalar Trace Cache Superspeculative Multiscalar processors
Processor-Multi: Speed-up of multi-threaded applications Simultaneous multithreading (SMT) Chip multiprocessors (CMPs)
Memory, Processor-in-Memory, IRAM, othersNetwork on Chip Homo
Hetero
Patt, Sohi…
Patterson
Mihal, Tenhunnen, Goosens
Many..

SPIE Gran Canaria 2003 A. Nunez 12
Monoprocessor: Superflow Processor
Fine granularity, data wordThe Superflow processor speculates on instruction flow: two-phase branch predictor combined with
trace cache register data flow: dependence prediction: predict the register
value dependence between instructions source operand value prediction constant value prediction value stride prediction: speculate on constant, incremental
increases in operand values dependence prediction predicts inter-instruction
dependences memory data flow: prediction of load values, of load addresses
and alias prediction

SPIE Gran Canaria 2003 A. Nunez 13
Com-arch in Superflow Processor

SPIE Gran Canaria 2003 A. Nunez 14
Multiscalar ProcessorsA program is represented as a control flow graph (CFG), where basic blocks are nodes, and arcs represent flow of control.
A multiscalar processor walks through the CFG speculatively, taking task-sized steps, without pausing to inspect any of the instructions within a task.
The tasks are distributed to a number of parallel PEs within a processor.
Each PE fetches and executes instructions belonging to its assigned task.
The primary constraint: it must preserve the sequential program semantics.

SPIE Gran Canaria 2003 A. Nunez 15
Multiscalar mode of execution
A
B C
D
E
Task A
PE 0
Task B
PE 1
Task D
PE 2
Task E
PE 3
Dat
a va
lues

SPIE Gran Canaria 2003 A. Nunez 16
Com-arch in Multiscalar processor

SPIE Gran Canaria 2003 A. Nunez 17
Multiscalar, Trace and Speculative Multithreaded Processors
Multiscalar: A program is statically partitioned into tasks which are marked by annotations of the CFG.Trace Processor: Tasks are generated from traces of the trace cache.Speculative multithreading: Tasks are otherwise dynamically constructed.
Common target: Increase of single-thread program performance by dynamically utilizing thread-level speculation additionally to instruction-level parallelism.A „thread“ means a „HW thread“

SPIE Gran Canaria 2003 A. Nunez 18
Multis: Additional utilization of more coarse-grained parallelism
CMPs Chip multiprocessors or multiprocessor chips integrate two or more complete processors on a single chip, every functional unit of a processor is duplicated.
SMPs Simultaneous multithreaded processors store multiple contexts in different register sets on the chip, the functional units are multiplexed between the threads, instructions of different contexts are simultaneously executed.

SPIE Gran Canaria 2003 A. Nunez 19
CMPs-Homo: Com-arch by shared global memory
Pro-cessor
Pro-cessor
Pro-cessor
Pro-cessor
Secndary Cache
Global Memory
Primary Cache
Shared global memory, no caches
Global Memory

SPIE Gran Canaria 2003 A. Nunez 20
CMPs-Homo: Com-arch by shared primary cache
Pro-cessor
Pro-cessor
Pro-cessor
Pro-cessor
Secondary Cache
Global Memory
Primary Cache
Shared primary cache

SPIE Gran Canaria 2003 A. Nunez 21
CMPs-Homo: Com-arch by global memory, caches
Pro-cessor
Pro-cessor
Pro-cessor
Pro-cessor
PrimaryCache
SecondaryCache
SecondaryCache
SecondaryCache
SecondaryCache
Global Memory
PrimaryCache
PrimaryCache
PrimaryCache
Pro-cessor
Pro-cessor
Pro-cessor
Pro-cessor
PrimaryCache
Secondary Cache
Global Memory
PrimaryCache
PrimaryCache
PrimaryCache
Shared caches and memory Shared secondary cache

SPIE Gran Canaria 2003 A. Nunez 22
Com-arch in Hydra: A Single-Chip Multiprocessor
CPU 0
Centralized Bus Arbitration Mechanisms
Cache SRAM Array DRAM Main Memory I/O Device
A S
ingle Chip
PrimaryI-cache
PrimaryD-cache
CPU 0 Memory Controller
Rambus MemoryInterface
Off-chip L3Interface
I/O BusInterface
DMA
CPU 1
PrimaryI-cache
PrimaryD-cache
CPU 1 Memory Controller
CPU 2
PrimaryI-cache
PrimaryD-cache
CPU2 Memory Controller
CPU 3
PrimaryI-cache
PrimaryD-cache
CPU 3 Memory Controller
On-chip Secondary Cache
SPIE Gran Canaria 2003 A. Nunez 23
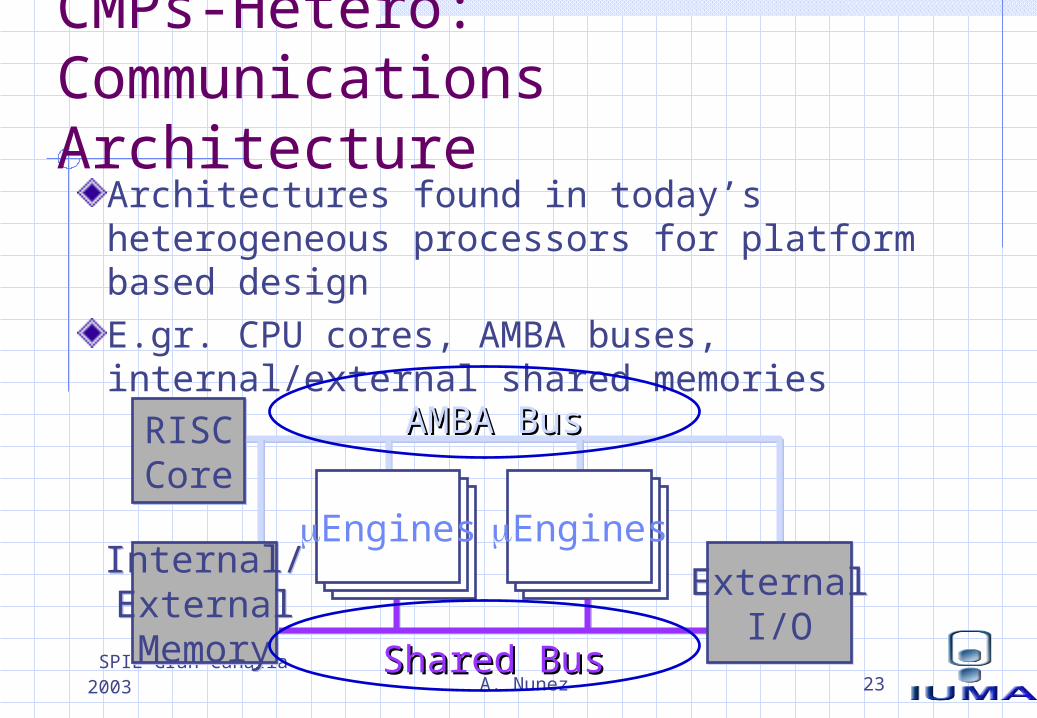
CMPs-Hetero: Communications Architecture
Architectures found in today’s heterogeneous processors for platform based designE.gr. CPU cores, AMBA buses, internal/external shared memories
RISCCoreRISCCore
ExternalI/O
ExternalI/O
AMBA BusAMBA Bus
Shared BusShared Bus
Engines EnginesInternal/ExternalMemory
Internal/ExternalMemory

SPIE Gran Canaria 2003 A. Nunez 24
CMPs-Hetero: Communications Architecture, Arbiters

SPIE Gran Canaria 2003 A. Nunez 25
Multithreaded Processors
Aim: Latency tolerance
What is the problem? Load access latencies measured on an Alpha Server 4100 SMP with four Alpha 21164 processors are: 7 cycles for a primary cache miss which hits in the on-chip L2 cache of the
21164 processor, 21 cycles for a L2 cache miss which hits in the L3 (board-level) cache, 80 cycles for a miss that is served by the memory, and 125 cycles for a dirty miss, i.e., a miss that has to be served from another
processor's cache memory.

SPIE Gran Canaria 2003 A. Nunez 26
MultithreadingMultithreading
The ability to pursue two or more threads of control in parallel within a processor pipeline.
Advantage: The latencies that arise in the computation of a single instruction stream are filled by computations of another thread.
Multithreaded processors are able to bridge latencies by switching to another thread of control - in contrast to chip multiprocessors.

SPIE Gran Canaria 2003 A. Nunez 27
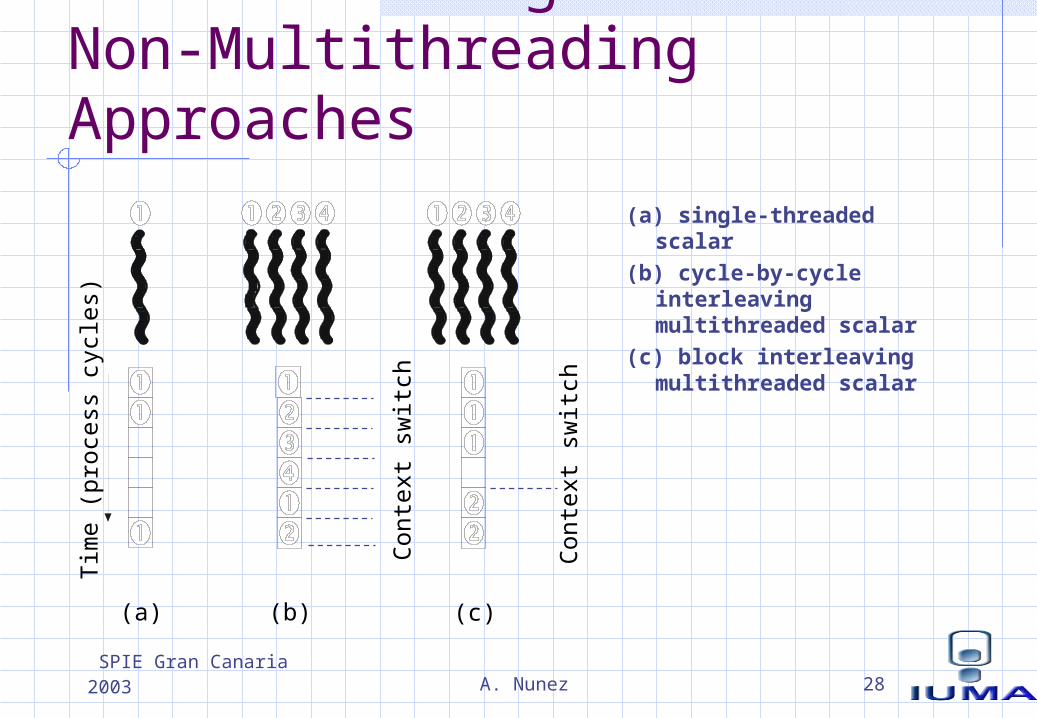
Approaches of Multithreaded Processors
Cycle-by-cycle interleaving An instruction of another thread is fetched and fed into the execution pipeline
at each processor cycle.
Block-interleaving The instructions of a thread are executed successively until an event occurs
that may cause latency. This event induces a context switch.
Simultaneous multithreading SMTs Instructions are simultaneously issued from multiple threads to the FUs of a
superscalar processor. combines a wide issue superscalar instruction issue with multithreading.
SPIE Gran Canaria 2003 A. Nunez 28
Multithreading versus Non-Multithreading Approaches
(a) single-threaded scalar
(b) cycle-by-cycle interleaving multithreaded scalar
(c) block interleaving multithreaded scalar
(a)
Tim
e (p
roce
ss c
ycle
s)
(c)
Con
text
sw
itch
(b)
Con
text
sw
itch

SPIE Gran Canaria 2003 A. Nunez 29
Simultaneous Multithreading (SMT)and Chip Multiprocessors (CMP)
(a) SMT
(b) CMP
(a)
Tim
e (p
roce
ssor
cyc
les)
Issue slots
(b)

SPIE Gran Canaria 2003 A. Nunez 30
Combining SMT and Multimedia
Start with a wide-issue superscalar general-purpose processor
Enhance by simultaneous multithreading
Enhance by multimedia unit(s)
Enhance by on-chip RAM memory for constants and local variables

SPIE Gran Canaria 2003 A. Nunez 31
Branch
ComplInteger
RT WBRI
IDIF
GlobalL/S
LocalL/S
ThreadControl
SimpleInteger
LocalMemory
I/O
Memory-interface DCache
BTAC
ICache
Rename
Register
IDIF
To Memory
The SMT Multimedia Processor

SPIE Gran Canaria 2003 A. Nunez 32
12
4 6 81
4
8
6,32
5,56
3,84
1,98
1
6,33
5,64
3,89
1,99
1
5,67
5,34
3,91
1,99
1
3,533,52
3,27
1,96
1
1,861,86
1,86
1,57
0,960123
4
5
6
7
IPC
Issue
Threads
IPC of Maximum Processor Models

SPIE Gran Canaria 2003 A. Nunez 33
Combining CMP-hetero and Multimedia
Start with a general-purpose processor
Enhance by hierarchical-bus com-arch
Enhance by hardware accelerators and copros including multimedia unit(s)
Enhance by on-chip RAM memories for constants, local variables, frames…

SPIE Gran Canaria 2003 A. Nunez 34
Real implementation example: Philips Eclipse architecture instance for video coding

SPIE Gran Canaria 2003 A. Nunez 35
CMP or SMT?
The performance race between SMT and CMP is not yet decided. CMP is easier to implement, but only SMT has the ability to hide latencies. A functional partitioning is not easily reached within a SMT processor due to the centralized instruction issue.
A separation of the thread queues is a possible solution, although it does not remove the central instruction issue.
A combination of simultaneous multithreading with the CMP may be superior.Research: combine SMT or CMP organization with the ability to create threads with compiler support or fully dynamically out of a single thread
thread-level speculation close to multiscalar

SPIE Gran Canaria 2003 A. Nunez 36
Processor-in-Memory
Technological trends have produced a large and growing gap between processor speed and DRAM access latency. Today, it takes dozens of cycles for data to travel between the CPU and main memory.CPU-centric design philosophy has led to very complex superscalar processors with deep pipelines. Much of this complexity is devoted to hiding memory access latency. Memory wall: the phenomenon that access times are increasingly limiting system performance.Memory-centric design is envisioned for the future

SPIE Gran Canaria 2003 A. Nunez 37
PIM or Intelligent RAM (IRAM)
PIM (processor-in-memory) or IRAM (intelligent RAM) approaches couple processor execution with large, high-bandwidth, on-chip DRAM banks.PIM or IRAM merge processor and memory into a single chip.Advantages:
The processor-DRAM gap in access speed increases in future. PIM provides higher bandwidth and lower latency for (on-chip-)memory accesses.
DRAM can accommodate 30 to 50 times more data than the same chip area devoted to caches.
On-chip memory may be treated as main memory - in contrast to a cache which is just a redundant memory copy.
PIM decreases energy consumption in the memory system due to the reduction of off-chip accesses.
VIRAM, CODE

SPIE Gran Canaria 2003 A. Nunez 38
V-IRAM-2: 0.13 µm, Fast Logic, 1GHz 16 GFLOPS(64b)/64 GOPS(16b)/128MB
Memory Crossbar Switch
M
M
…
M
M
M
…
M
M
M
…
M
M
M
…
M
M
M
…
M
M
M
…
M
…
M
M
…
M
M
M
…
M
M
M
…
M
M
M
…
M
+
Vector Registers
x
÷
Load/Store
8K I cache 8K D cache
2-way Superscalar VectorProcessor
8 x 64 8 x 64 8 x 64 8 x 64 8 x 64
8 x 64or
16 x 32or
32 x 16
8 x 648 x 64
QueueInstruction
I/OI/O
I/OI/O
SerialI/O

SPIE Gran Canaria 2003 A. Nunez 39
NoC Processor ArchitectureNetwork-on-chip, specialized PEs, advanced interconnect technologiesWill use packet network architectures in 2010
DSPPE Array
ControllerPE
ControllerPE
On-ChipMemoryOn-ChipMemory
SwitchNode
SwitchNode
PEPE PEPE PEPE
ExternalMemoryExternalMemoryPEPE
ExternalI/O
ExternalI/OPacketPacket
NetworkNetworkSwitchNode
SwitchNode

SPIE Gran Canaria 2003 A. Nunez 40
NoC Mescal Communication Architecture General Paradigm
Mescal Communication Architecture is a general, coarse-grained on-chip interconnection scheme for various system components such as Processing Elements, memory and other communicating elements.
PEPEPEPE $$$$ MEMMEMMEMMEM
ProcessingProcessingElementElement
ProcessingProcessingElementElement
ProcessingProcessingElementElement
ProcessingProcessingElementElement
switchswitchswitchswitch
switchswitchswitchswitch
PEPEPEPE PEPEPEPE
$$$$ MEMMEMMEMMEM bridgebridgebridgebridge

SPIE Gran Canaria 2003 A. Nunez 41
NoC Mescal Abstract System Architecture
ProcessingElement
CommunicationInstructions(send/recv)
CommunicationAssist
On-Chip-NetworkOperations
On Chip Network
ProcessingElement
CommunicationAssist
CommunicationInstructions(send/recv)
On-Chip-NetworkOperations
Physical Layer
Data Link Layer
Network Layer
Transport Layer
Session Layer
Presentation Layer
Application Layer

SPIE Gran Canaria 2003 A. Nunez 42
NoC Communication Architecture
Packet Assembler PacketDeassembler
Packet SwitchNetwork Operation
N3
N4
N0
N5N2
N6
N1 N7
Packet Switching Network
Translation of network operations topacket switch operations
On-Chip-NetworkOperations
On-Chip-NetworkOperations
Physical Layer
Network Layer
Data Link Layer
CorrespondingProtocol Stack
SPIE Gran Canaria 2003 A. Nunez 43
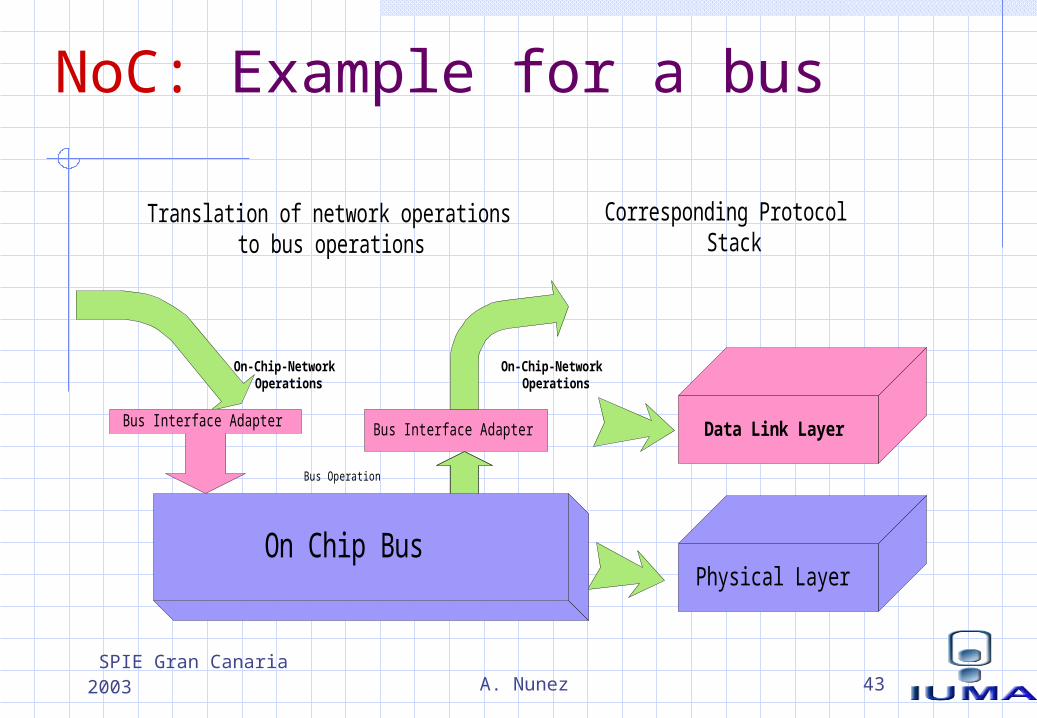
NoC: Example for a bus
Physical Layer
Data Link LayerBus Interface Adapter
On Chip Bus
Bus Interface Adapter
Bus Operation
Translation of network operationsto bus operations
On-Chip-NetworkOperations
On-Chip-NetworkOperations
Corresponding ProtocolStack

SPIE Gran Canaria 2003 A. Nunez 44
Index
MPSoC Architectures -> Hetero MPSoCCommunication Architectures -> Split Transport and Signalling NetworksPrevious and Related workOur SystemC Based Modelling ApproachExperimentsConclusions

SPIE Gran Canaria 2003 A. Nunez 45
Todays Communication Architecture Paradigms: Topology
Single and Shared Transport and Signalling Channel p2p Bus Hierarchical bus Switch
Crossbar Multistage…
Ring Trees Network
Circuit sw Packet sw w/o connection Packet sw w connection..

SPIE Gran Canaria 2003 A. Nunez 46
Todays Communication Architecture Paradigms: Topology
Split Transport and Signalling Transport
Topology (bus, h-bus, switch, ring, network…) Signalling (Addresses and routing, services,
synchronisms) Associated channel
Topology Common channel
Topology… Protocol layer stack: software and process view of
the generation of hardware signalling requires mapping onto actual interfaces

SPIE Gran Canaria 2003 A. Nunez 47
Todays Communications Architecture Paradigms: Bandwidth
Application Granularity
Transport Granularity Fine grain Medium grain Coarse grain Bus sizes, transfer sizes
Traffic Characterization Traffic Characterization E.gr. Streaming, burstiness, interval requests, space-time
distribution

SPIE Gran Canaria 2003 A. Nunez 48
Todays Communications Architecture Paradigms: Protocols
Protocols High level signalling primitives mapping Communications to architecture mapping Access policies mapping, priorities, static, dynamic Traffic and flow control
Burstiness Request Intervals Concurrency

SPIE Gran Canaria 2003 A. Nunez 49
Todays Communications Architecture Paradigms: Signalling
Addressing, routing infoService infoHand-shake and command sync strobes
High level signalling primitives mapping Communications to architecture mapping Access policies mapping, priorities, static, dynamic Traffic and flow control
Burstiness Request Intervals Concurrency Streaming ...

SPIE Gran Canaria 2003 A. Nunez 50
Com-arch Modelling: Ptolemy-MescalUCBerkeley PtolemyI&II, Mescal, UCSD-Dey, PR-Vissers, Goosens, Lippen.., TIMA-Jerraya..Components for channels:
Synchronous digital bus (shared or point-to-point) ARM AMBA bus IBM CoreConnect bus Analog channel
Actors encapsulate the physical layerEach actor has a common interface to make experimentation possiblePtolemy actor interface is a higher level than the channel’s actual electrical interface

SPIE Gran Canaria 2003 A. Nunez 51
Com-arch Modelling: Ptolemy-Mescal
Components for CommAssists Queues Arbitrators PE interfaces Bus interfaces External memory or I/O cycle generators Switches Small memories
Parameterizable components
Programmable components
Designing a CA, very similar to designing a PE

SPIE Gran Canaria 2003 A. Nunez 52
Com-arch Modelling: Ptolemy-Mescal
Encapsulate a PE model as a composite actorCombine with CA components to make a CommunicatorEncapsulate Communicator model as a composite actorCombine multiple Communicators with Channel components to make a complete system

SPIE Gran Canaria 2003 A. Nunez 53
Index
MPSoC Architectures -> Hetero MPSoCCommunication Architectures -> Split Transport and Signalling NetworksPrevious and Related workOur SystemC Based Modelling ApproachExperimentsConclusions

SPIE Gran Canaria 2003 A. Nunez 54
Case study: Communication architecture in HA-MPSoC
Mapping communicating processes and threads on HA-
MPSoC requires efficient ways of implementing the on-
chip communicationPrevious work: comparative performance of different classes of data communication architectures (San Diego)But: The communication architecture can be split in: the data communication architecture, and the signalling and synchronization architectureThe impact of different signalling and synchronization architectural options on the overall performance has not been sufficiently studied

SPIE Gran Canaria 2003 A. Nunez 55
Our focus: Signalling in the HA-MPSoC paradigm, split sync, SystemC modelling
New solutions for signalling and synchronization in the HA-MPSoC paradigmBased in a technique for modelling the communication and synchronization architectures using SystemCHigh abstraction modelling based on the Kahn Process Network Model of ComputationHere: Variations on Dey’s simple communication architecture (bus)

SPIE Gran Canaria 2003 A. Nunez 56
Previous related work: UCSD-Dey
Analysis of the performance of various SoC communication architectures under different classes of on-chip communication trafficIdentifying parts of the application’s “communiation traffic space” for which different communication architectures are well-suited Methodology based on POLIS/PTOLEMY

SPIE Gran Canaria 2003 A. Nunez 57
Previous related work: Dey’s communication architectures
Static Priority Based Shared Bus ArchitectureTwo-level TDMA Based ArchitectureHierarchical Bus ArchitectureRing Based Architecture

SPIE Gran Canaria 2003 A. Nunez 58
Index
MPSoC Architectures -> Hetero MPSoCCommunication Architectures -> Split Transport and Signalling NetworksPrevious and Related workOur SystemC Based Modelling ApproachExperimentsConclusions

SPIE Gran Canaria 2003 A. Nunez 59
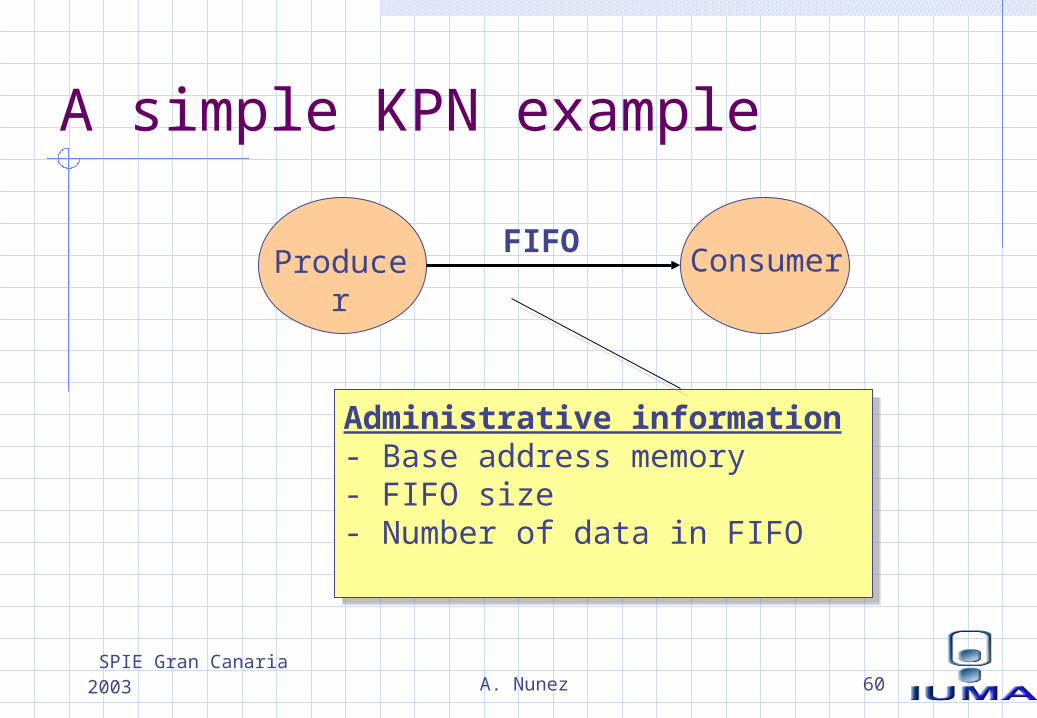
Abstracting high level communication
KPN: concurrent tasks interconnected by channels (FIFOs)Processes have to share service administrative information related to the FIFOsAdministrative information divided in two parts: static and dynamic information The update of the dynamic information of the FIFO is the synchronization aspect of the complete signalling function
SPIE Gran Canaria 2003 A. Nunez 60
Producer
ConsumerFIFO
Administrative information- Base address memory- FIFO size- Number of data in FIFO
Administrative information- Base address memory- FIFO size- Number of data in FIFO
A simple KPN example

SPIE Gran Canaria 2003 A. Nunez 61
Signalling Primitives in MPSoC
Flexiblity and scalability, a protocol for communicating tasks is neededSet of primitives for data communication and synchronization. The Eclipse (Philips Research) example:- Primitives for data communication:
void Read(int port_id, int offset, int n_bytes, Bytes *bytevector)
void Write(int port_id, int offset, int n_bytes, Bytes *bytevector)
- Primitives for data synchronization:
bool GetSpace(int port_id, int n_bytes)
void PutSpace(int port_id, int n_bytes)

SPIE Gran Canaria 2003 A. Nunez 62
Our SystemC-based Modelling
Executable specification of a system described in different abstraction levels (functional untimed, timed, transaction level and cycle-true)TLM is a natural method to perform system level performance simulationSystemC Master/Slave library hides the more complex details of C++ programming and fits well for TLM developmentThe design time of complex MPSoC models can be greatly shortened using the SystemC Master/Slave library

SPIE Gran Canaria 2003 A. Nunez 63
Application modelling
Chain of P processors interconnected
through FIFOsSimulation parameters: number of processes (P), token size (data-granularity), request intervals, waiting cycles, transfer cycles, execution time, total simulation time
Pin P1 PP-2 Pout
FIFO1 FIFOP-1

SPIE Gran Canaria 2003 A. Nunez 64
Index
MPSoC Architectures -> Hetero MPSoCCommunication Architectures -> Split Transport and Signalling NetworksPrevious and Related workOur SystemC Based Modelling ApproachExperimentsConclusions
SPIE Gran Canaria 2003 A. Nunez 65
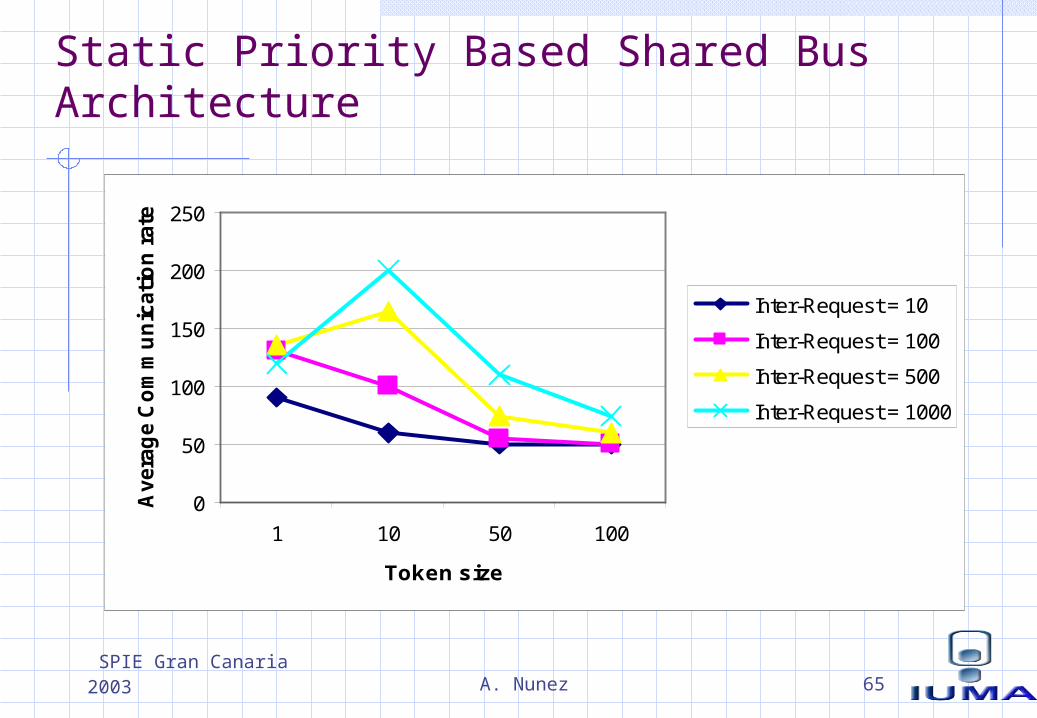
Static Priority Based Shared Bus Architecture
0
50
100
150
200
250
1 10 50 100
Token size
Avera
ge C
om
mu
nic
ati
on
rate
Inter-Request = 10
Inter-Request = 100
Inter-Request = 500
Inter-Request = 1000

SPIE Gran Canaria 2003 A. Nunez 66
Two-level TDMA Based Architecture
0
50
100
150
200
250
1 10 50 100
Token size
Ave
rag
e C
om
mu
nic
atio
n r
ate
Inter-Request = 10
Inter-Request = 100
Inter-Request = 500
Inter-Request = 1000
SPIE Gran Canaria 2003 A. Nunez 67
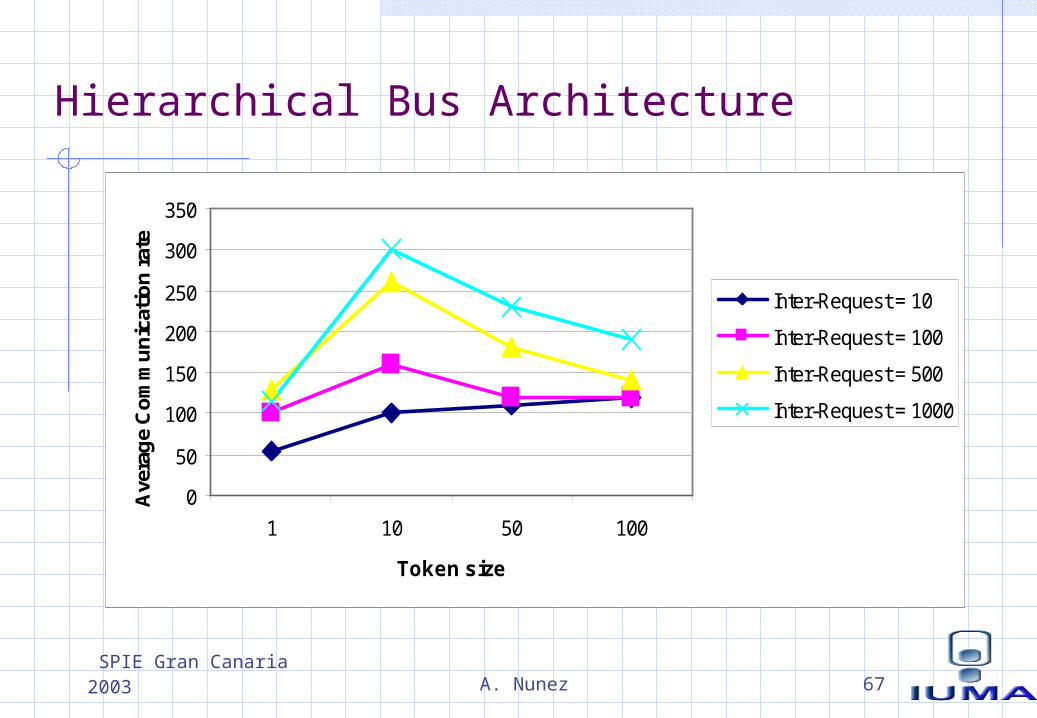
Hierarchical Bus Architecture
0
50
100
150
200
250
300
350
1 10 50 100
Token size
Ave
rag
e C
om
mu
nic
atio
n r
ate
Inter-Request = 10
Inter-Request = 100
Inter-Request = 500
Inter-Request = 1000
SPIE Gran Canaria 2003 A. Nunez 68
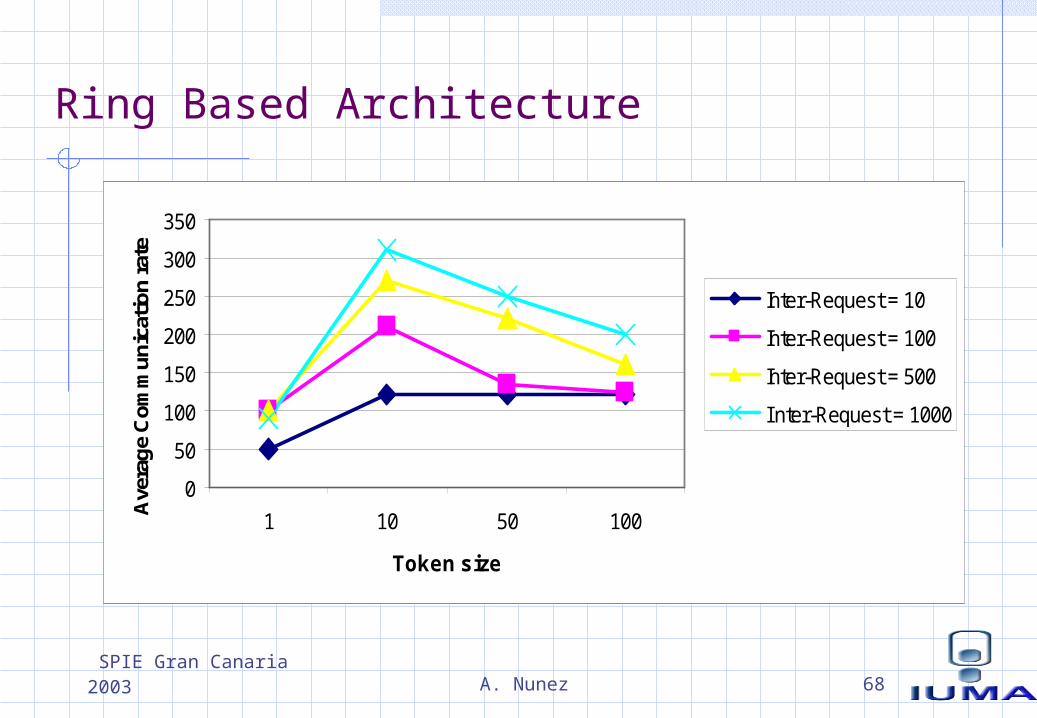
Ring Based Architecture
0
50
100
150
200
250
300
350
1 10 50 100
Token size
Ave
rag
e C
om
mu
nic
atio
n r
ate
Inter-Request = 10
Inter-Request = 100
Inter-Request = 500
I nter-Request = 1000

SPIE Gran Canaria 2003 A. Nunez 69
Reminder of Dey’s communication architectures
Static Priority Based Shared Bus ArchitectureTwo-level TDMA Based ArchitectureHierarchical Bus ArchitectureRing Based Architecture

SPIE Gran Canaria 2003 A. Nunez 70
Experiments: Additional models of communication architectures
ARB
MEM
P1
Wd
P2
Wd
P3
Wd
P4
Wd
Ws Ws Ws Ws
P1
Wd
P2
Wd
P3
Wd
P4
Wd
ARB
MEM
SYNC
ARB
MEM
P1
Wd
P2
Wd
P3
Wd
P4
Wd
ARB
MEM
P1
Wd
P2 P3 P4
ARB
Wd Wd Wd
Ws Ws Ws Ws
ARB
MEM
P1
Wd - Ws
P2 P3 P4
Wd - Ws Wd - Ws Wd - Ws

SPIE Gran Canaria 2003 A. Nunez 71
ARB
MEM
P1
Wd
P2 P3 P4
Wd Wd Wd
Centralized architecture using shared memory (Mem)
sync

SPIE Gran Canaria 2003 A. Nunez 72
SYNC
ARB
MEM
P1
Wd
P2
Wd
P3
Wd
P4
Wd
Centralized architecture using a central synchronization module (Central)
SPIE Gran Canaria 2003 A. Nunez 73
ARB
MEM
P1
Wd-Ws
P2 P3 P4
Wd-Ws Wd-Ws Wd-Ws
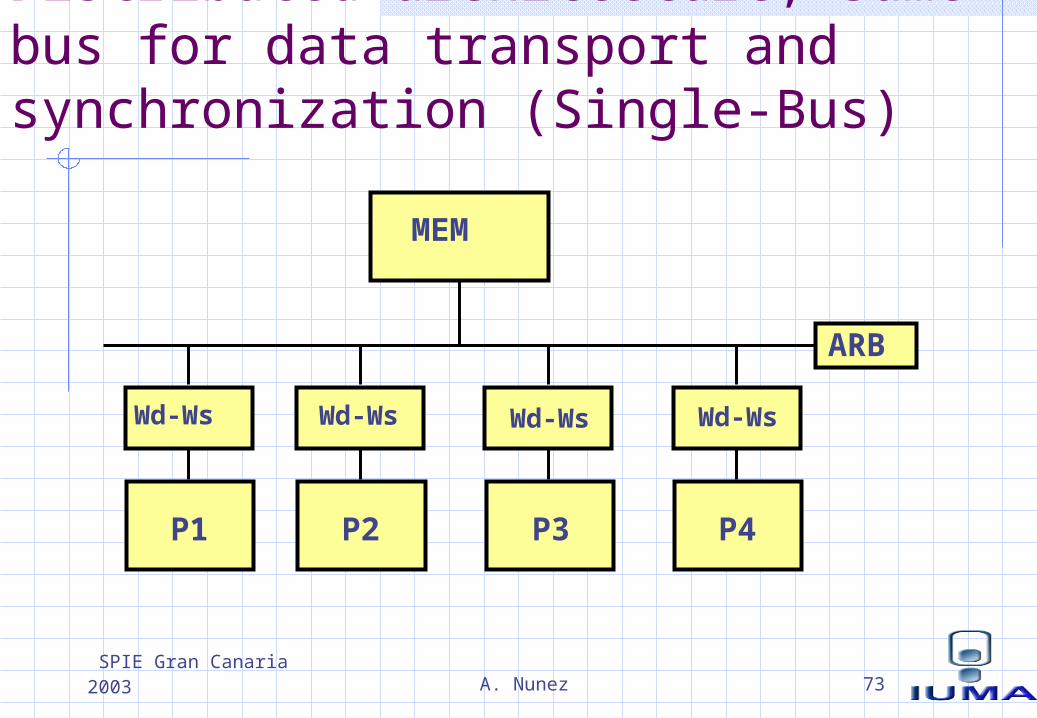
Distributed architecture, same bus for data transport and synchronization (Single-Bus)

SPIE Gran Canaria 2003 A. Nunez 74
ARB
MEM
P1
Wd
P2 P3 P4
ARB
Wd Wd Wd
Ws Ws Ws Ws
Distributed architecture, splitting data transport bus and sync bus (2-Busses)

SPIE Gran Canaria 2003 A. Nunez 75
ARB
MEM
P1
Wd
P2
Wd
P3
Wd
P4
Wd
Ws Ws Ws Ws
Distributed architecture with ring topology for synchronization (Ring)

SPIE Gran Canaria 2003 A. Nunez 76
Implementation example: Philips Eclipse architecture instance for video coding

SPIE Gran Canaria 2003 A. Nunez 77
Additional measurements
Quantify what synchronization topology allows the shortest execution time for an application, i.e. the more efficient from the performance point of viewThe Coprocessor Usage percentage figure (Ucop):
%Ucop = (Texec/Tsim) · 100

SPIE Gran Canaria 2003 A. Nunez 78
.
Coprocessor Usage, P = 4
0123456789
10
1 4 8 16
Token size
%
Ring
Single-bus
Mem
Central
2-busses

SPIE Gran Canaria 2003 A. Nunez 79
Coprocessor Usage, P = 8
00.5
11.5
22.5
33.5
44.5
5
1 4 8 16
Token size
%
Ring
Single-bus
Mem
Central
2-busses

SPIE Gran Canaria 2003 A. Nunez 80
ConclusionsIncreasing importance of communication architecture, MPSoCs <-> NoCsDesign space exploration extended with communication-architecturesSystemC master/slave library powerful modelling toolLarge performance spread found due to communication topologies, signalling protocols, and traffic characteristicsNeed of more qualitative and quantitative modelling, analysis, studies, toolsConsider splitting transport and signallingHierarchical buses, rings, plus splitting ++

SPIE Gran Canaria 2003 A. Nunez 81
Signalling in the Heterogeneous Architecture Multiprocessor Paradigm
Antonio Núñez, Victor Reyes, Tomás Bautista
Keynote
IUMA, Institute for Applied Microelectronics, ULPGC


















