
Shark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott...
22
Shark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Hive on Spark
-
Upload
rosamond-harrell -
Category
Documents
-
view
223 -
download
1
Transcript of Shark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott...

Shark
Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia,
Michael Franklin, Ion Stoica, Scott Shenker
Hive on Spark

Spark Review• Resilient distributed datasets (RDDs):– Immutable, distributed collections of
objects– Can be cached in memory for fast reuse
• Operations on RDDs:– Transformations: define a new RDD
(map, join, …)– Actions: return or output a result (count,
save, …)

Generality of RDDs
• Despite coarse-grained interface, RDDs can express surprisingly many parallel algorithms– These naturally apply the same operation to
many items
• Capture many current programming models– Data flow models: MapReduce, Dryad, SQL, …– Specialized models for iterative apps:
BSP (Pregel), iterative MapReduce, incremental (CBP)
• Support new apps that these models don’t

Spark Review: Fault Tolerance
RDDs maintain lineage information that can be used to reconstruct lost partitions
Ex:messages = textFile(...).filter(_.startsWith(“ERROR”)) .map(_.split(‘\t’)(2))
HDFSFileFilteredRD
DMappedRD
Dfilter(func = _.startsWith(...))
map(func = _.split(...))

Background: Apache Hive
• Data warehouse solution developed at Facebook
• SQL-like language called HiveQL to query structured data stored in HDFS
• Queries compile to Hadoop MapReduce jobs

Hive Architecture

Hive Principles• SQL provides a familiar interface for users• Extensible types, functions, and storage formats• Horizontally scalable with high performance on large datasets

Hive Applications
•Reporting•Ad hoc analysis•ETL for machine learning…

Hive Downsides• Not interactive– Hadoop startup latency is ~20 seconds,
even for small jobs
• No query locality– If queries operate on the same subset of
data, they still run from scratch– Reading data from disk is often
bottleneck
• Requires separate machine learning dataflow

Shark Motivation• Working set of data can often
fit in memory to be reused between queries• Provide low latency on small
queries• Integrate distributed UDF’s
into SQL

Introducing Shark• Shark = Spark +
Hive• Run HiveQL queries through
Spark with Hive UDF, UDAF, SerDe• Utilize Spark’s in-memory RDD
caching and flexible language capabilities

Shark in the AMP Stack
Mesos
Spark
Private Cluster Amazon EC2
…Hadoo
p MPI
Bagel(Pregel on
Spark)
Shark …
Debug Tools
Streaming Spark

Shark• ~2500 lines of Scala/Java code• Implements relational operators
using RDD transformations• Scalable, fault-tolerant, fast• Compatible with Hive– Run HiveQL queries on existing HDFS
data using Hive metadata, without modifications

Example: Log MiningLoad error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(_.startsWith(“ERROR”))
messages = errors.map(_.split(‘\t’)(1))
messages.cache()
messages.filter(_.contains(“foo”)).count
messages.filter(_.contains(“bar”)).count
Spark:
CREATE TABLE log(header string, message string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ LOCATION “hdfs://...”;
CREATE TABLE errors_cached AS SELECT message FROM log WHERE header == “ERROR”;
SELECT count(*) FROM errors_cached WHERE message LIKE “%foo%”;
SELECT count(*) FROM errors_cached WHERE message LIKE “%bar%”;
Shark:

Shark Architecture• Reuse as much Hive code as possible– Convert logical query plan generated
from Hive into Spark execution graph
• Fully support Hive UDFs, UDAFs, storage formats, SerDe’s to ensure compatibility
• Rely on Spark’s fast execution, fault tolerance, and in-memory RDD’s
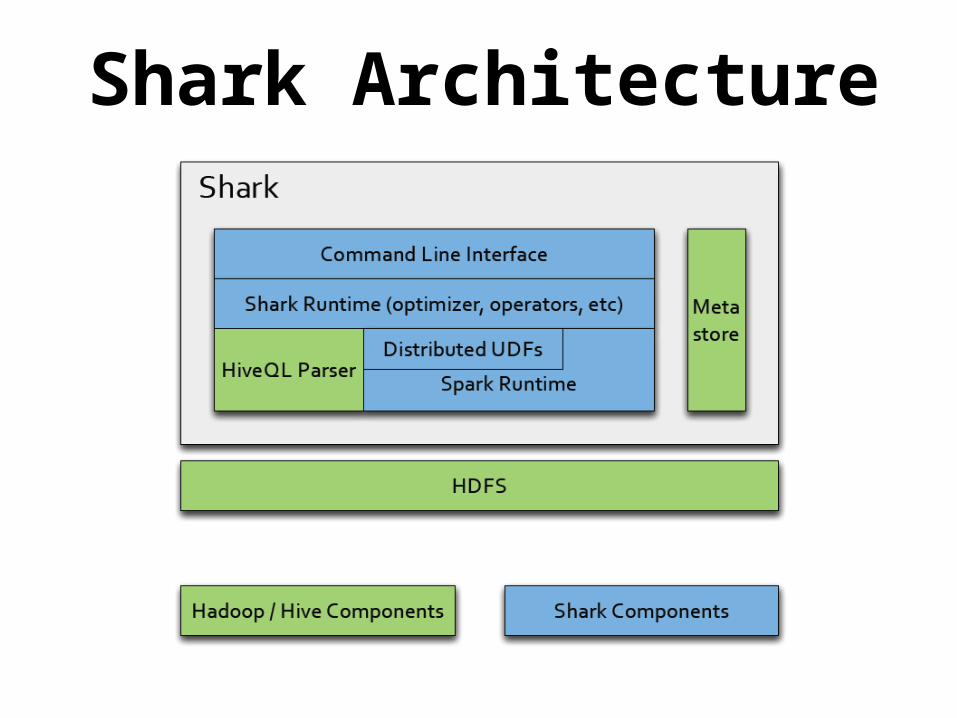
Shark Architecture

Preliminary Benchmarks
• Brown/Stonebraker benchmark 70GB1
– Also used on Hive mailing list2
• 10 Amazon EC2 High Memory Nodes (30GB of RAM/node)
• Naively cache input tables• Compare Shark to Hive 0.7
1 http://database.cs.brown.edu/projects/mapreduce-vs-dbms/2 https://issues.apache.org/jira/browse/HIVE-396 1

Benchmarks: Query 1
SELECT * FROM grep WHERE field LIKE ‘%XYZ%’;
• 30GB input table

Benchmark: Query 2• 5 GB input table
SELECT pagerank, pageURL FROM rankings WHERE pagerank > 10;

Benchmark: Query 3• 30 GB input table
SELECT sourceIP, SUM(adRevenue) FROM uservisits GROUP BY sourceIP;

Current Status• Most of HiveQL fully implemented in
Shark• User selected caching with CTAS• Adding in optimizations such as Map-
Side Join• Performing alpha testing of Shark on
Conviva cluster

Future Work• Automatic caching based on query
analysis–Multi-query optimization
• Distributed UDFs using Shark + Spark– Allow users to implement sophisticated
algorithms as UDFs in Spark– Shark operators and Spark UDFs
take/emit RDDs– Query processing UDFs are streamlined


















