
Serono Science Scientific computing and high performance applications.
15
Serono Science Scientific computing and high performance applications
-
Upload
marilyn-jackson -
Category
Documents
-
view
216 -
download
1
Transcript of Serono Science Scientific computing and high performance applications.

Serono Science
Scientific computingand high performance
applications

Research Computing in Serono
Hardware environment
High performance computing applications

Drug development pipeline
TargetTargetdiscoverydiscovery
TargetTargetvalidationvalidation
ScreeningScreening+ H2L+ H2L PCDPCD Phase I/IIPhase I/II Phase III/IVPhase III/IV
MarketingMarketing
Drug Development pipelineDrug Development pipeline
Proteomics
Genomics Chemistry
Human GeneticsBiostatistics
Transcriptomics
Mouse genetics
Cell biology Pharmacology
SciencesSciences
WGSuArrays
Protein arrays
siRNAcaliper
combichem
MS
Taqman
imaging
cellomics
x-ray RMN
Y2H HTS
TechnologiesTechnologies
genomes
Transcript mapSNPs
Protein structure Patient data
protein map
interactions
screening data
phenotypeimageshaplotype
Data typesData types
pathwaysStructure/activity

Research Computing Vision & Missions
Use in-silico technologies to help identify and progress therapeutic proteins and small molecules that will
successfully feed the development pipelineBy:
Research Knowledge Management Delivering across Research an integrated information environment that puts scientific data, information and knowledge at the scientist’s fingertips
Computational Life Science Developing cutting-edge scientific applications enabling in-silico drug discovery and driving Serono’s competitive advantage
Advanced Data Analysis Providing advanced and pervasive data analysis competencies to make sense of high-throughput and complex data.
Research IT environmentProviding the computing and communication infrastructure to deliver the vision

Research computing activities
1. Data processing Technology driven
2. Predictions and simulation
3. Data analysis Interpretation1
-1
4. Data management

Advanced Data Analysis - Issues
Amount of data
Data complexity
2000 2002 2004
High content cell assays, genomic sequence, QSAR
High density microarrays as a discovery platform
Genome scan data – 100’000 SNP’s, hundreds of patients, several diseases
Biomarkers identification through proteomics and trasncriptomics
Compendium, Virtual Combinatorial Library
Multidimensional decision making
2001-3
2004-7
Analysis cannot be performed in silos – we need information systems able to correlate data available from all sorts of experimental information (Genome scans, DGE, RNAi, Cell assays, proteomics, interactions, phenotypes)
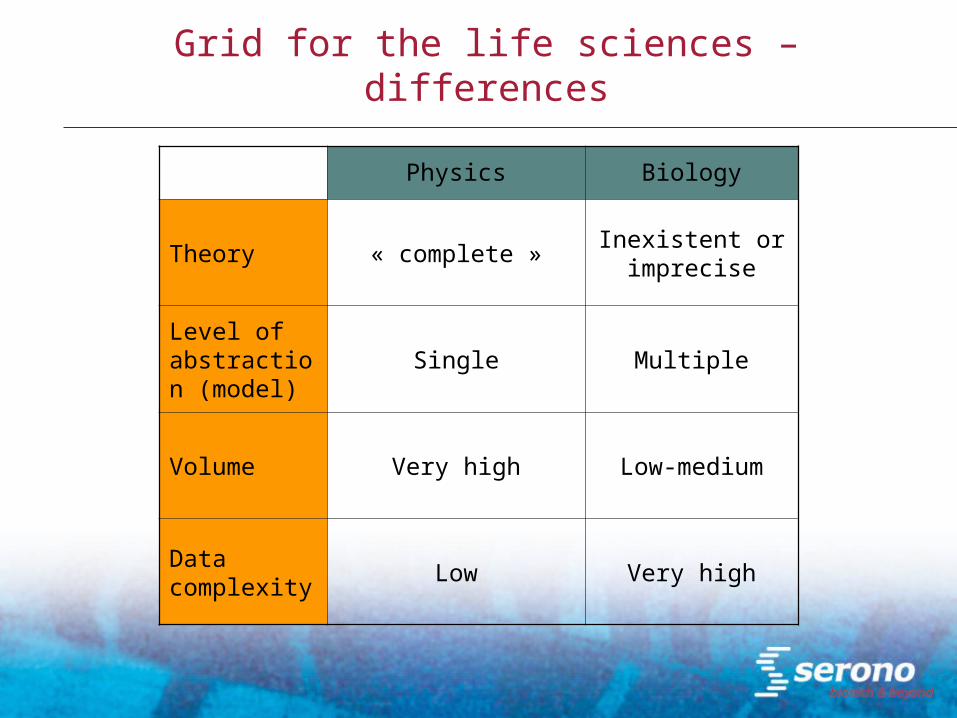
Grid for the life sciences – differences
Physics Biology
Theory « complete »Inexistent or
imprecise
Level of abstraction (model)
Single Multiple
Volume Very high Low-medium
Data complexity
Low Very high

Sample: GP07127N01
Sample Set: PAT
Acquisition_18Project: 20944, 20945 Result Id: Date Acquired: 3/12/03 9:14:21 AM
Acq. Method Set: Med Throughput 8 min TFA
3/12/03 9:24:25 AM, 3/12/03 Date Processed:
processing Processing method:
MED 2 HPLC Sy stem Name:
Run Time: 8.0 MinutesVial: 1
Injection #: 1
Injection Volume: 10.00 ul
Injection Id: 20930
Channel Id 20931 Mobile_Phase H2O TFA 0.1%- ACN TFA 0.05% HPLC_column XTerra MSC8, 4.6x50mm,3.5 uM
Processed Channel Descr. PDA MaxPlot (230.0 nm to 400.0 nm)
AU
0.00
0.10
0.20
0.30
0.40
0.00
20.00
40.00
60.00
80.00
100.00
Minutes
1.00 2.00 3.00 4.00 5.00 6.00 7.00 8.00
3.40
4
3.96
0
5.33
8
1
2
3
RetentionTime (min)
Area % Area
3.40
3.96
5.34
11433
13936
2494928
0.45
0.55
98.99
Processed Channel Descr. PDA 254.0 nm
AU
0.00
0.05
0.10
0.15
0.20
0.00
20.00
40.00
60.00
80.00
100.00
Minutes
1.00 2.00 3.00 4.00 5.00 6.00 7.00 8.00
2.72
7
3.40
4
3.96
0
5.33
8
1
2
3
4
RetentionTime (min)
Area % Area
2.73
3.40
3.96
5.34
8860
7383
7794
1266728
0.69
0.57
0.60
98.14
1
2
SampleName Processed Channel Rt (min) Area %
GP07127N01
GP07127N01
PDA MaxPlot (230.0 nm to 400.0 nm)
PDA 254.0 nm
5.34
5.34
98.99
98.14
SampleName: GP07127N01
CorporateDatabase
Core
Generic End-user Access
LIMSQC
LIMSQC
LIMSQC
PublishDrill-down
IntegratedOracle-Based
Systems
User-friendly interfaces (Web based)
Specialized, complex power-user interfaces
E-notebook
in silico generation tools e.g. Text mining, Data Analysis

HPC Hardware environment
• SGI Origin 3900 64 proc (cc-numa), IRIX, 128 GB
• SGI Altix 3700 BX2 16 proc
• Timelogic Decypher FPGA bioinformatics accelerator x 4
• SGI Origin 3900 32 proc• Linux Xeon cluster, 50 proc
• 10 TB CXFS SAN (Geneva only)
Computational chemistry (docking, combichem, compendium, pharmacophore, structure resolution)
Bioinformatics (public domain tools, sequence databases, peptide identification, in-
silico modeling)
Blast, SW, profiles
Same as above, Boston, Paris
Distributed data storage

High performance computing applicationsin Serono today
• Large scale sequence to sequence comparisons• Genome wide analysis (microRNA, focused gene
prediction, gw profiles, etc.)• Sequence data base monitoring• Gene index and data mapping• Large scale proteomics (peptide identification)• Virtual screening• In-silico biology

Smart is better than More
In combinatorial chemistry design, one scaffold and 4 groups of 800 reagents each generate a library of 320 billions virtual compounds
Enumerated substracture search would take years of CPU time and 1 petabyte of storage
A proprietary non-enumerated search retrieves hits in just a few seconds
VirtualVirtualCombinatorialCombinatorialDatabaseDatabase
VirtualVirtualScreeningScreening
Fast pre-filtering of compounds reduces amount of compounds for time-consuming docking studies
Useful for new compound acquisition, known protein target structure, not for primary screen (replating)
Usual size of virtual screens in Serono: ~1000 compounds

Future grid applications
• Large scale in-silico modeling• Protein-protein interaction• QM-based, dynamic virtual screening • Data grids• Imaging

Past grid evaluations (corporate PC idle cycles)
• High deployment costs – IT resources• Concern about availability of PC resources – habits and
procedures• Foreseen replacement of desktop by even less available
laptops• Modification of software to run effectively on the grid• Previous studies show that a large corporate grid of
1000 desktops is not more efficient than a 64 proc dedicated cluster (Novartis)
The in-house idle-cycle grid model is not efficient

Issues in the pharma industry
• IP considerations• Competitive intelligence• Security policies• Obsession with proprietary data and know-how
Is the current model of « all in-house » sustainable?Distributed (grid-enabled) public domain bioinformatics services will anyway become pervasive and will superceed capabilities available in-house



















