
Senal de Video
74
Señal de video 1- Estructura de la señal. 2- Fundamentos de colorimetría. 3- Sistema PAL. 4- Video Analógico en componentes. 5- Grabación magnética de video. 6- Video Digital. 7- Grabación de Video Digital. 8- Mezcladores de video. 9- Edición de video. 10-Compresión de video Digital. 11-Grabación de video en DiscoDuro. 12-Equipos de video.
-
Upload
patata1919 -
Category
Documents
-
view
103 -
download
3
Transcript of Senal de Video

Señal de video
1- Estructura de la señal.2- Fundamentos de colorimetría.3- Sistema PAL.4- Video Analógico en componentes.5- Grabación magnética de video.6- Video Digital.7- Grabación de Video Digital.8- Mezcladores de video.9- Edición de video.10-Compresión de video Digital.11-Grabación de video en DiscoDuro.12-Equipos de video.

1. ESTRUCTURA DE LA SEÑAL
Conceptos básicos: Mezcla aditiva espacial : dos puntos separados se ven como uno solo (se mezclan) cuando están
en un ángulo de visión menor de 1 minuto de grado. Integración espacial.
Mezcla aditiva temporal : se aprecia un movimiento continuo (sin saltos de cuadro a cuadro) cuando la frecuencia de cuadro es igual o superior a 1/15 s (como mínimo 15 imágenes / segundo). Integración temporal.
Error de gamma (y): el brillo del tubo de imagen no es proporcional al nivel de señal (varía según la curva de luminancia). Un circuito compensa este efecto en la cámara aplicando a la señal una curva inversa.
Relación de aspecto: relación dimensional entre anchura (W) y altura (H) de la pantalla: A = W/H.El sistema actual de televisión tiene 4/3. Los nuevos sistemas introducen la relación 16/9.
Características del color: Espectro visible: radiación electromagnética cuya longitud de onda va desde 780 nm (límite con
el infrarrojo) a 380 nm (limite con el ultravioleta). 1 nm (nanometro) = 10 exp -9 m = 0,000.000.001 m. Color de un objeto: : radiación del espectro visible reflejada por el objeto. Características de un color:
Matiz o tono: longitud de onda (=lambda) dominante. El tono o matiz se puede definir como la propiedad de la visión que permite decir si un objeto es de color rojo, azul, etc.Saturación: proporción de blanco que tiene el color, permite estimar la proporción de sensación cromática pura.Brillo: intensidad luminosa del color, cantidad de luminancia (Y) = señal de TV en B/N. Cantidad de luz percibida por el ojo, depende del objeto y de su entorno.
Un color correspondiente a una sola longitud de onda es un color monocromático que posee la máxima saturación posible. Cuando se añade luz blanca a una luz monocromática, la pureza decrecerá a medida que la cantidad de blanco aumente. Si la saturación disminuye, el color se vuelve menos vivo y más suave y pasa por un tono pastel y, cuando la cantidad de blanco es mucho mayor que la del color monocromático, se obtiene prácticamente el blanco puro. Si por el contrario el color contiene negro se dice que es un color degradado. Una saturación nula corresponde así a una ausencia de color, a un "color acromático”. El blanco, el gris o el negro tienen una saturación nula.

Como excepción, los colores púrpuras no tienen una sola longitud de onda dominante.En la naturaleza no existen colores espectrales puros (de saturación 100%)
Captación de imagen:
Tubos de Cámara: Este tipo de captación de imagen esta actualmente en desuso, su principio de funcionamiento es básicamente el mismo que el de un tubo de imagen pero captando en lugar de proyectar imágenes.
CCD: Charge Coupled Device.
El CCD se inventó a finales delos 60 por investigadores de Bell Laboratories. Originalmente se concibió como un tipo de memoria de ordenador pero pronto encontró más aplicaciones, sobre todo la captación de imagen, esto último debido a la sensibilidad a la luz que presenta el silicio.
El CCD recoge la luz y la convierte en una señal eléctrica.
Los sensores CCD son de pequeño tamaño y están construidos de semiconductores lo que permite la integración de millones de dispositivos sensibles en un solo chip.
La eficiencia cuántica de los CCD (sensibilidad) es mayor para los rojos.
¿Cómo funciona un CCD?Físicamente, un CCD es una malla muy empaquetada de electrodos de polisilicio colocados sobre la superficie de un chip. Al impactar los fotones sobre el silicio se generan electrones que pueden guardarse temporalmente. Periódicamente se lee el contenido de cada píxel haciendo que los electrones se desplacen físicamente desde la posición donde se originaron (en la superficie del chip), hacia el amplificador de señal con lo que se genera una corriente eléctrica que será proporcional al número de fotones que llegaron al píxel. Para coordinar los periodos de almacenamiento (tiempo de exposición) y vaciado del píxel (lectura del píxel) debe existir una fuente eléctrica externa que marque el ritmo de almacenamiento-lectura: el reloj del sistema.

TIPOS DE CCDExisten varios métodos de captura de imágenes con CCD:ARRAYS LINEALES. Usados en escáneres.
Sensor lineal. Los conjuntos lineales usan una fila única de pixels que escanea linealmente la imagen. Los de un solo CCD hacen tres exposiciones por separado: rojo/verde/azul (RGB) y se empezaron a usar en los primeros escaneres Todavía son usados para capturar imágenes de objetos que no se mueven.
Sensor Trilineal. Se trata de tres CCD lineales unidos que se unan para capturar cada uno de los canales RGB en un solo barrido, son los que dan la resolución más alta y la gama espectral más rica. Se emplean en los escáneres de sobremesa y diapositivas.
ARRAY DE SUPERFICIESon los más empleados actualmente en cámaras digitales, consisten en una superficie donde existen miles de píxeles sensibles a la luz organizados en filas y columnas (una matriz). El CCD es sensible a los fotones de cualquier longitud de onda en mayor o menor grado (en general es más sensible a los rojos e infrarrojos y menos a los azules). Todos los CCD son, por tanto, monocromáticos, y no tendremos ningún problema para capturar imágenes monocromas. Para obtener fotografías en color con dispositivos CCD se han desarrollado distintas tecnologías, las más empleadas son:
MOSAICO DE CCD. El CCD único con máscara de color (CCD en mosaico) es el que se emplea en la mayor parte de las cámaras de video digital o analógico y en las cámaras fotográficas digitales de color.
Antes de llegar al píxel, la luz pasa por un filtro que solo deja pasar los fotones de la longitud de onda deseada. Cada píxel solo es sensible a un color, el CCD se convierte en un mosaico de píxeles sensibles respectivamente al rojo, verde y azul, las imágenes captadas con CCD en mosaico dan un cierto grado de borrosidad lo que las hace ser de baja calidad.

Una solución a éste problema, que se emplea en las cámaras domésticas de video y fotografía digital, es aumentar porcentualmente los píxeles sensibles al verde (el ojo humano es mucho más sensible a éste color).
CCD triple (triCCD). La luz es descompuesta por prismas ópticos y desviada a tres sensores CCD. Los sensores para el verde y rojo suelen ser idénticos pero el sensor azul suele estar optimizado para este color. Las cámaras construidas con esta tecnología son mucho más caras que el resto no solo porque tienen que triplicarse sino porque los CCD deben estar pèrfectamente ajustados para que la luz de un mismo punto del objeto incida exactamente en las mismas coordenadas de pixel de cada uno de los CCD. Las cámaras tri-CCD son la mejor opción. Actualmente existen varios tipos de CCD's. En los catálogos de cámaras siempre se especifica la tecnología de dicho dispositivo. Por ejemplo, existen las cámaras que tienen CCD FIT, CCD IT o las que tienen CCD HAD.
En ocasiones, al captar un objeto luminoso es posible observar una línea luminosa vertical formarse arriba o abajo de dicho objeto. Se conoce como SMEAR. La disminución de este fenómeno depende de la calidad y tecnología del CCD.
Las cámaras CCD IT (Interline Transfer) presentan de manera más importante este fenómeno, mientras que las de CCD FIT (Frame-Interline Transfer) pretenden solucionar este problema. Los CCD's FIT cuentan con una solución de almacenamiento que permite disminuir el fenómeno.
Los CCD's FIT son más caros que los IT pero logran mayor calidad. Hay cámaras que incorporan la tecnología Exwave® HAD (exclusiva de SONY). Tienen excelentes niveles de sensibilidad y cuentan con la capacidad también de disminuir el efecto SMEAR.Hay cámaras SONY que incorporan la tecnología Power HAD CCD, que tiene una calidad equivalente a los CCD's FIT.

CCD rojo CCD azul
CCD verde Los tres combinados
Exploración: cuadro, línea. Electrónicamente es necesario descomponer la imagen de un modo secuencial para ser enviada
de un punto a otro, se optó por leer del mismo modo que leemos un libro de izquierda a derecha y de arriba hacia abajo. La imagen se envía línea a línea hasta completar la altura total y se repite una y otra vez. Para que la sensación visual sea de continuidad al menos tenemos que leer 20 imágenes por segundo. La exploración de Izquierda a derecha es una línea y el conjunto de líneas forma un cuadro. 25 cuadros y 625 líneas para el sistema Europeo.
Exploración entrelazada: campo.
Consiste en duplicar el número de impactos luminosos en la pantalla por segundo para reducir el parpadeo, pero con misma cantidad de información visual.Con 25 imágenes por segundo al aumentar el brillo de la imagen se produce un parpadeo molesto debido a que se esta presentando línea a línea y no como en cine. La solución está en aumentar la frecuencia de cuadro pero la información que hay que transmitir es mas elevada.La solución se encontró observando el comportamiento del ojo humano. La agudeza visual del ojo no es infinita y tiene, muchas limitaciones. Una de estas limitaciones consiste en que el ojo humano no es capaz de distinguir dos puntos luminosos próximos entre sí y alejados del ojo (integración espacial). Otra limitación que tiene el ojo es su memoria visual, si el ojo está recibiendo una señal que lo excita y ésta deja de repente de observarse, el ojo tarda un tiempo en darse cuenta de que la imagen ha desaparecido, a esto se le llama efecto memoria y puede decirse que tarda 50 ms en retener la imagen que ha desaparecido. Por tanto, si la imagen desaparece y vuelve a aparecer en menos de 50 ms, el ojo no se dará cuenta (integración temporal).

Estas limitaciones que tiene el ojo se aprovechan en la exploración entrelazada para poder aumentar el número de imágenes que se transmiten por segundo sin aumentar la frecuencia de cuadro. La solución a este problema consiste en no explorar la imagen de forma continua, una línea a continuación de otra, sino en explorar la imagen dos veces. En una primera exploración se exploran las líneas impares 1, 3, 5, 7... y en la segunda exploración de la misma imagen se exploran las líneas pares 2,4, 6, 8. A cada una de las exploraciones se las denomina campo, y a la imagen completa se la denomina cuadro. El numero de líneas son impares para facilitar el entrelazado.
1 cuadro (frame) se divide en 2 campos (fields) que recorren toda la pantalla de arriba a abajo.
Entrelazado: las líneas de 2 campos consecutivos se intercalan (no se superponen).El entrelazado exige utilizar un número impar de líneas para evitar el solape de las líneas entre campos consecutivos (cada campo tiene x + media línea, en nuestro sistema son 312,5 líneas / campo). Todos los sistemas de TV actuales emplean la técnica del entrelazado.
Exploración progresiva: se recorren todas las líneas de cada cuadro de arriba a abajo y de una sola vez (sin división en campos).
Para que no aumente el parpadeo se hacen varios impactos luminosos consecutivos con el mismo cuadro. Esta técnica se emplea en monitores informáticos y en algunos sistemas de televisión digital
Definición en la señal de vídeo: Concepto de definición: numero de líneas de brillo alternativo (blanco / negro) que pueden
distinguirse en una dirección (vertical u horizontal) en la pantalla.
Definición vertical: coincide con el número de líneas horizontales de imagen en un cuadro (sin considerar el factor de Kell). Definición vertical en sistemas 625/25. 575 líneas horizontales.
Definición horizontal: se toma como valor normalizado el número de líneas verticales de brillo alternativo (blanco / negro) que se pueden distinguir en una sección cuadrada de la pantalla cuya anchura sea igual a la altura total de la pantalla.Sí se habla de "definición" a secas se hace referencia a la definición horizontal. La definición del sistema español de B/N (la luminancia del sistema PA L) es de 400 líneas
Ancho de banda (BW) de la señal de televisión:
El ancho de banda de la señal depende de la resolución horizontal, a mayor resolución mayor frecuencia (>BW), la resolución está definida para una porción cuadrada de la imagen visible (video activo), por tanto, para calcularlo se debe considerar:
- multiplicar por la relación de aspecto (4/3)- compensar la duración de la línea con la duración de video activo (64uS/52 uS)- número de líneas por segundo (625 x 25 = 15. 625). - La mitad de la definición horizontal (400/2), ya que cada pareja de líneas blanco / negro
corresponde a las dos mitades de un ciclo completo de señal. BW=(rel. aspecto)*(dur.linea/dur. periodo activo linea)*(lineas por segundo)*(lineas de
definición/2) Ejemplo para 625/25 y 400 líneas definición BW: (4/3)*(625/52)*(625*25)*(400/2) = 5,1 Mhz.
Es frecuente indicar el numero de líneas de resolución de un sistema de TV por cada MHz:
Ejemplo en sistemas 625/25. 400/5,1 = aprox. 80 lineas/Mhz.
Estructura de una línea de TV (625/25):

Duración de una linea de TV: 64 uS .Frecuencia de línea: 15.625 Hz (15.625 Hz= 1/64 us).
Periodo activo de video en una línea: 52uS.
Periodo no activo de vídeo en una línea (borrado horizontal): 12 microsegundos.
Estructura del borrado horizontal: pórtico anterior (1,5 uS), ISH (4,7 uS) y pórtico posterior (5,8 uS).
Pórtico Anterior: Garantiza el nivel de 0V antes del sincronismo. Pórtico posterior: necesario para la estabilización del haz.
ISH (Impulso de: Sincronismo Horizontal): impulso de 4,7 uS de duración que reinicia la señal de diente
de sierra que dirige la exploración horizontal del tubo de imagen. Esta por debajo del nivel de negro.
Estructura de un campo de TV (625/25):
Duración de un campo de TV: 312,5 líneas o 20 ms.Frecuencia de campo: 50Hz (50 Hz = 1/20 ms).
Periodo activo de video en un campo: 287,5 líneas. 312,5-25
Periodo no activo de video en un campo (periodo de borrado vertical): 25 líneas formadas por el sincronismo vertical (7,5 líneas) y 17,5 líneas sin video activo.
SV (Sincronismo Vertical): el impulso de sincronismo dura 2,5 líneas y reinicia el diente de sierra que dirige la exploración vertical del tubo de imagen.
Estructura del Sincronismo Vertical: 7,5 líneas formadas por 15 impulsos:5 impulsos preigualadores 2,5 líneas, cada impulso dura 1/2 línea (32 us), sirven para que el SV empiece siempre en el mismo instante de tiempo y cada 20 ms.

5 impulsos de sincronismo vertical (ISV): 2,5 líneas, cada impulso dura 1/2 línea (32 us). Se llama ISV tanto a cada uno de los impulsos de 1/2 línea como al conjunto de los 5 impulsos.
5 impulsos postigualadores: 2, 5 líneas, cada impulso dura 1/2 línea (32 us). Evitan que haya que poner un impulso ISH justo después del ISV.Los impulsos pre y post tienen como objetivo que el ISV sea simétrico y al usar un numero de líneas impar y ser ellos 2,5 líneas igualan los tiempos de un campo y otro.
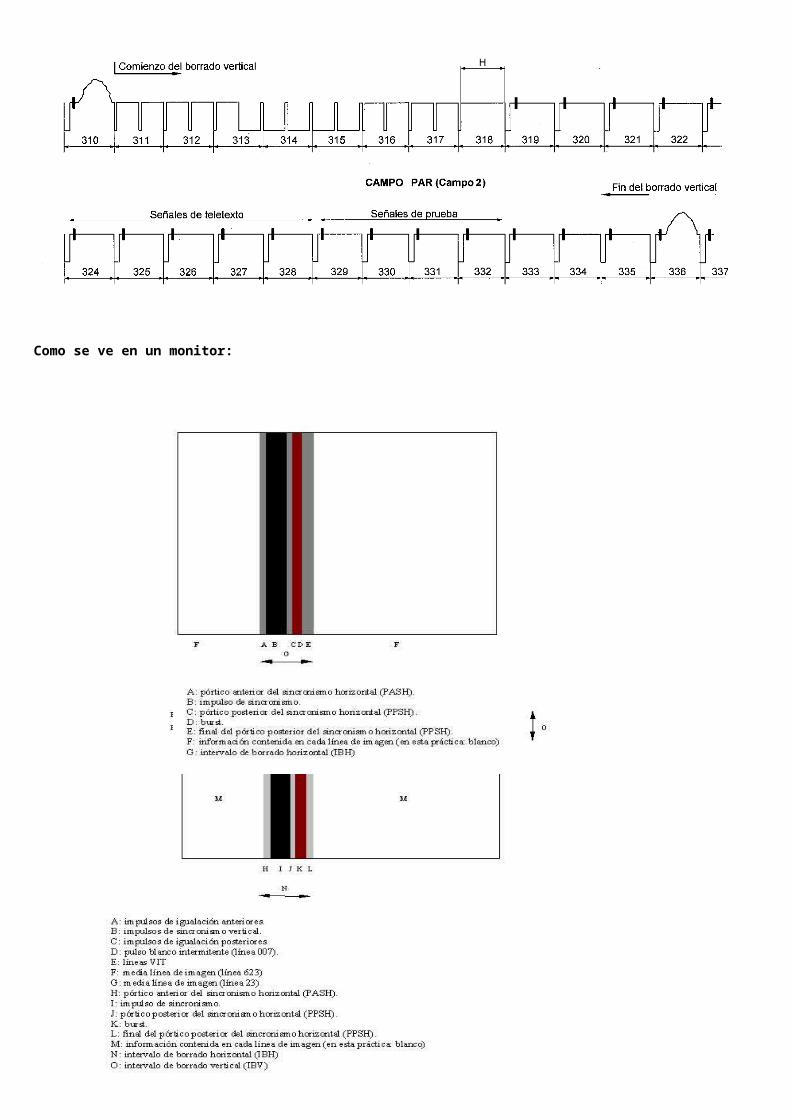
Como se ve en un monitor:
Estructura de la señal de TV (Europa):

625 líneas por cuadro y 25 cuadros por segundo: 625/25.
También se escribe 625/50 para hacer referencia a que la exploración es entrelazada.
312,5 líneas por campo y 50 campos por segundo.
2 campos por cuadro.
Porcentaje de video activo por cuadro: (52-575)/(64-625) = 74,75 %.
Niveles de señal (Europa):
Nivel de borrado y nivel de negro : 0,3 V.
Nivel de fondo de sincronismo (H o V): 0 V.
Nivel de blanco (máximo): 1 V (+0,7 V sobre nivel de negro o borrado).
Margen máximo de niveles (desde el fondo de sincronismo al máximo de blanco): 1
Vpp.
Señal de transmisión:
Señal moduladora: señal en banda base que contiene la información y que va a ser modulada para poder transmitirla (es la señal de televisión descrita en los puntos anteriores).
Señal portadora: señal de frecuencia constante y mucho más alta que la frecuencia máxima que pueda alcanzar la moduladora.
Modulación: proceso electrónico entre las señales moduladora y portadora por el cual se produce la traslación del espectro de la señal moduladora a la zona espectral de la señal portadora.
Señal banda base de vídeo: de 0 a 5 MHz; BW = 5 MHz.
Señal banda base de audio: 1 canal de 20 Hz a 15 kHz; BW = 15 kHz. El audio se modula en FM con portadora de 5,5 MHz y se suma a la señal de vídeo de banda base.
Técnica de modulación para TV: Modulación AM (Modulación de Amplitud) en BLV (Banda Lateral Vestigial). Es una técnica sencilla que ocupa poco espectro. Esta técnica de modulación se emplea en todos los canales de difusión analógica, ya sea terrestre vía satélite o por cable.
Canales de transmisión: norma B (VHF) con canales de 7 MHz y norma G (UHF) con canales de 8 MHz. La norma G (UHF, 8 MHz) es la más utilizada actualmente en difusión terrestre. El mayor ancho de banda de la norma G permite incluir audio digital en sistema NICAM con portadora 5, 85 MHz por encima de la portadora de vídeo.
La técnica de difusión digital (Digital Video Broadcastíng: DVB) utiliza el mismo reparto espectral de canales de 8 MHz, pero multiplexando varios programas por canal y modulando digitalmente

2. FUNDAMENTOS DE TELEVISIóN EN COLOR
Conceptos de colorimetria:
Sólido de colores: representación tridimensional del tono, la saturación y la luminancia de los colores. Los 3 ejes del sólido son los componentes R, G y B.
Diagrama de cromaticidad: intersección del sólido de colores con el plano de Inminencia unidad. Representa bidimensionalmente el tono y la saturación de los colores, sin considerar la luminancia.
Curva "spectrum locus'': borde del diagrama de cromaticidad (saturación 100%).Sobre la curva 'spectrum locus'' se representa la escala de longitudes de onda (es decir la gama
decolores espectrales puros).
Blanco equienergetico (W): centro del diagrama de cromaticidad (saturación 0%).
Cuanto más cerca del blanco W esté un color menor será su saturación 3 componentes definen completamente un color (posición en el sólido de colores).
Suma de componentes = luminancia del color. 3 coeficientes definen tono y saturación de un color (posición en el diagrama de cromaticidad),
perono su luminancia.Suma coeficientes = 1; conociendo dos coeficientes se puede calcular el tercero.
Sólo son reproducibles de forma práctica con 3 componentes determinados aquellos colores que están en el diagrama de cromaticidad dentro del triángulo cuyos vértices son esos 3 componentes.
Mezcla aditiva

La mezcla aditiva consiste en mezclar los colores primarios que son el rojo, verde y azul. Si estos colores se mezclan dos a dos, se obtienen los colores complementarios de estos tres y si se suman los tres colores en una proporción adecuada se obtiene la luz blanca.
SINTESIS ADITIVA DEL COLOR
Se suelen considerar como colores primarios de la síntesis aditiva los colores rojo, verde y azul, puesto que con estos tres colores se pueden conseguir todos los demás colores incluido el blanco. Con la mezcla de dos primarios se obtiene un secundario.
rojo + verde = amarillo verde + azul = cyan azul + rojo = magenta ------------- ------------ Primarios Secundarios
Estos colores son siempre saturados puesto que falta el tercer primario que produciría la desaturación al crear, según su proporción, mayor o menor cantidad de blanco.
azul + rojo + verde = blanco rojo + cyan = blanco verde + magenta = blanco azul + amarillo = blanco amarillo + cyan + magenta = blanco
Solamente se produce el blanco cuando la proporción de los componentes es adecuada, en caso contrario se produce un color terciario más o menos saturado.
Este procedimiento es el que se emplea en los sistemas de televisión. Para poder transmitir la imagen que capta una cámara hay que descomponerla en los tres colores primarios y enviar la porción que tiene la imagen de cada color al receptor para que ésta se pueda reproducir íntegramente.
Leyes de GRASSMANEl físico alemán GRASSMAN descubrió que el ojo humano bajo ciertas circunstancias, se comporta
prácticamente como un receptor lineal.Esta conclusión tan sencilla le llevaron a enumerar una serie de conclusiones que se denominan leyes
de GRASSMAN:
1) Si se mezclan de forma aditiva y en proporciones de intensidad determinada, tres iluminantes elegidos convenientemente es posible imitar todos los colores que se perciben por el ojo humano. Color=xR+yG+zB.
Para conseguir luz blanca con la mezcla de tres colores deben emplearse cantidades iguales de rojo verde y azul, aunque en el experimento de Grassmann no se utilizan iguales cantidades en termino de lúmenes sino en unidades tricromáticas. Las unidades T están relacionadas con los lúmenes de la siguiente forma:
1 unidad T de rojo = 0,30 lúmenes de rojo.
1 unidad T de verde = 0,59 lúmenes de verde. 3 unidades T = 0,30+0,59+0,11 = 1 lúmen de blanco.

1 unidad T de azul = 0,11 lúmenes de azul.
2) En una mezcla aditiva de dos colores, se produce un tercer color que puede obtenerse mediante la suma de sus componentes primarios.
3 La sensación de igualdad de color persiste si se multiplica o se divide por el mismo valor las cuatro luminancias que afecten a un color (4=color, R, G, B).Estas operaciones de multiplicación o división no producen ningún cambio del espectro luminoso.
4) La luminancia total de un color es igual a la suma de las luminancias de sus componentes primitivosComo cualquier color puede crearse por síntesis aditiva de los colores primarios y al hacer esto sumamos sus respectivas luminancias, podemos deducir que la luminancia de un color cualquiera equivale a la suma de las luminancias de sus componentes primarios.
Ecuación de luminancia: Ecuación de luminancia del sistema NTSC: Y = 0,3*R + 0,59*G +0,11*B.
Con esta ecuación se obtiene la luminancia para que el sistema de color sea compatible con el de B/N. En PAL se utiliza la misma ecuación de luminancia que en NTSC incorrectamente, aunque los
componentes RGB en que se basa cada sistema son diferentes.Esta ecuación se usa al codificar y al decodificar, por lo que no se producen errores en los
receptores de color PAL, pero sí hay leves desviaciones de luminancia en los receptores de B/N.
En la práctica no se respetan las convenciones de representación de los componentes de los diferentes espacios calorimétricos (RGB, R´G´B´ o R"G"B") Se usa siempre la expresión RGB para los primarios del sistema de TV en el que estemos trabajando (aunque no sean los auténticos RGB).
Temperatura de color: La temperatura de color informa de la desviación cromático de la luz que incide sobre la escena hacia el rojo
(temperatura baja) o el azul (temperatura alta). La temperatura de color se mide en grados kelvin: ºK.La luz de una bombilla tiene una temperatura de 3000º Kelvin; esto quiere decir que la luz tiene un tono anaranjado. Nosotros no notamos ese tono naranja a no ser que sea muy fuerte o tengamos otra luz de referencia con mas temperatura; esto es debido a que nuestro cerebro hace una especie de balance de blancos (como las cámaras de vídeo). La película fotográfica no es así y reproduce los tonos anaranjados si no esta equilibrada para esa temperatura de color.
Balance de blancos: ajuste de la ganancia de los componentes R G y B de la cámara a las condiciones de la temperatura de color con la que se esté iluminando la escena.
Blanco equienergético (E) 5500 ºK. Se le considera el blanco puro real, pero a simple vista tiene un aspecto amarillento.
Los estándares de NTSC (blanco C) y PAL (blanco D65) tienen mayor temperatura
de color que el blanco equienergético (son más "azulados") Ejemplos de temperatura de color de algunas fuentes de iluminación:
- luz incandescente: 250OºK- luz halógena para TV: 320OºK- luz solar: 560OºK- luz día nublado: 680OºK
Generalidades de los sistemas de TV en color: Compatibilidad directa: un receptor B/N debe recuperar la señal de luminancia Y en la
transmisión de una señal en TV en color. La información de color debe integrarse de modo que no interfiera con la información de luminancia.
Compatibilidad inversa: un receptor en color debe mostrar imagen en B/N si recibe una transmisión en B/N (evidentemente no podrá representar el color si no se transmite información de color).
Se transmiten 3 señales basadas en R, G y B: Y (luminancia) y las B-Y y R-Y (crominancia). A las señales B-Y y R- Y se les llama "señales diferencia de color', contienen información de crominancia y sólo de crominancia (fueron elegidas precisamente por eso)
Y se transmite como en B/N, para lograr la compatibilidad directa.

B-Y y R-Y se modulan y suman a Y para transmitirlas dentro del mismo canal pero interfiriendo con esta lo mínimo posible.
Saturación maxíma en TV (100%): al menos una de las componentes R G, B vale 0. Saturación nula (0%) gama de grises: los tres componentes R, G, B tienen igual valor. Amplitud o nivel de un color: amplitud o nivel del componente más alto (100% si R, G o B vale l).
La carta de barras estandarizada por la EBU es la de amplitud de color del 75% y saturación 100% (carta del 75%): 100/0/75/0.
Imbricación: El grafico muestra como se introduce la información de croma sobre la de luminancia (NTSC, PAL, etc...)
Sistema NTSC: Se transforman B-Y y R-Y en I y Q, correspondiendo I a los colores de menor agudeza visual. I y Q se modulan en cuadratura (QUAM), con f, (frecuencia subportadora = subcarrier) de 3,58
MHz. BWy = 4,2 MHz; BW I= 0,6 MHz; BW Q = 1,2 MHz (Q es defectuosa por encima de 0,6 MHz). La señal transmitida es la suma de Y + C (C = I + Q moduladas QUAM). Al sumar Y + C, se produce la "imbricación" de los espectros de ambas señales. Esto provoca la
intermodulación de los espectros de Y y C, con "artefactos" (distorsiones, defectos visibles) en la señal Y a partir de 2,4 MHz y en la señal C en todo su ancho de banda. En Y, la C "se cuela" como interferencia de alta frecuencia en forma de franjas diagonales en B/N. En C. las altas frecuencias de Y "se cuelan" en forma de franjas diagonales coloreadas.
En el pórtico posterior de¡ ISH se transmite una salva (burst) de f, para que el receptor sincronice su oscilador de f. y pueda demodular correctamente la información de color.
En la recepción se producen errores de fase diferencia¡ debidos a desviaciones en la relación entre la fase de la salva y la fase de la señal de color. Visualmente, el error de fase diferencial consiste en un viraje en el color de la imagen, proporcional a la magnitud del error.
El error de fase diferencial no se puede corregir técnicamente en la recepción.
Los televisores NTSC tienen un potenciómetro (hue) en el que el usuario hace el ajuste subjetivamente.
Tabla de valores de la señal de barras. NTSC.
color R G B Y (R-Y) (B-Y) r Ψ(grados)
Blanco 1 1 1 1 0 0 0 0
Amarillo 1 1 0 0.89 0.11 -0.89 0.89 173.36
Cian 0 1 1 0.70 -0.70 0.30 0.76 293.21
Verde 0 1 0 0.59 -0.59 -0.59 0.83 225
Magenta 1 0 1 0.41 0.59 0.59 0.83 45
Rojo 1 0 0 0.30 0.70 -0.30 0.76 113.21

Azul 0 0 1 0.11 -0.11 0.89 0.89 353.36
Negro 0 0 0 0 0 0 0 0
Sistema SECAM: BW Y = 5 MHz; BW(B-Y) = 1 MHz; BW(R-Y) = 1 MHz. Se transmiten alternativamente R-Y y B-Y línea a línea: en cada línea se transmite sólo una de
ellas, por lo que la definición vertical del color de la imagen se reduce a la mitad. Al sistema SECAM se le llama 'secuencial" por transmitir las componentes de color de forma alternativa, mientras que el NTSC y el PAL son "simultáneos"
R-Y y B-Y se modulan en FM y se suman a Y. Hay intermodulación del espectro de la señal Y con los espectros de las señales B-Y y R-Y. Esto
produce "artefactos" en la señal Y a partir de 3 MHz y en las señales B-Y y R-Y en todo su BW. El sistema SECAM tiene mayores problemas técnicos en producción y difusión derivados del uso
de la modulación FM para la señal de crominancia.
3. SISTEMA PALFundamentos del sistema PAL:
PAL = Phase Alternation Line (alternacia de fase en cada línea). El sistema PAL está basado en el NTSC, añadiendo una mejora que resuelve los problemas de fase diferencial.
BWy=5Mhz BW b-y=1,3 Mhz BW r-y=1,3 Mhz. Las señales B-Y y R-Y se convierten en las llamadas U y V al multiplicarse por un coeficiente
ponderador: U = 0,493*(B-Y) y V = 0,877*(R-Y). U y V se modulan en cuadratura (QUAM) con U se modula AM con f. sin desfases (0º). V se
modula AM con f. desfasada 90º y 270º (270º = -90º) alternativamente, línea a línea. Las señales U y V ya moduladas se suman entre si, formando la señal C (crominancia).
Se transmite una muestra o salva (burst) de fsc, en el pórtico posterior del ISH, que sirve para que el receptor sincronice su oscilador interno de fsc, con la fsc transmitida. La salva se desfasa 135º y 225º (225º = -135º) alternativamente, línea a línea. Tiene 300 m V de amplitud y dura 10 ciclos de fsc (2,25 us).
El pulso "K"' o "puerta de salva" es la señal que delimita cuando se suma la salva a la señal de video.
El pulso "P" (PAL) invierte en cada línea la fase de f. para el modulador de V y para la salva. A las líneas con V in vertida se les llama líneas PAL" " y las de V no in vertida se les llama "líneas NTSC"
Y+C+salva+sincronismos = CVBS (composite video+ burst+sync) = señal de video compuesto PAL. También se le llama CCVS y FBAS.

Los espectros de Y y C se imbrican como en NTSC, con los mismos problemas de intermodulación. Como f. tiene 4,43 Mhz la banda inferior de C se extenderá 1,3 MHz hacia abajo, hasta 3,13 MHz (4,43-1,3 Mhz). La banda superior de C llegaría, en teoría hasta 5,73 Mhz (4,43+1,3 Mhz), pero esta banda se recorta en 5 Mhz para no interferir con la portadora de audio. Por lo tanto, Y tendrá intermodulación con C a partir de 3,13 MHz, con "artefactos", y C tiene intermodulación con Y en toda la señal, con "artefactos".

Imagen PAL en vectorscopio: En el vectorscopio Se representa U en el eje horizontal y V en el eje vertical. Los colores aparecen como puntos luminosos en la retícula de¡ vectorscopio, su posición
depende de¡ valor de las componentes U y V que definen cada color. La distancia del punto al centro de la retícula indica la saturación del color. La posición angular (fase) del punto indica el tono del color.
El valor de fase debe tomarse respecto a una referencia de fase fija, que es la salva (+- 135º).
Primero se fija la fase de la salva en la retícula para evaluar después la fase de los colores. La información de Y se ve en el vectorscopio como un punto en el centro (saturación nula). La información de alta frecuencia de Y que se cuela como C se ve en el vectorscopio en forma de
círculos que giran alrededor del centro (fase indeterminada).
Debido a la inversión PAL línea a línea, en el vectorscopio cada color aparece con dos vectores opuestos en el eje (simetría vertical).

Cartas de barras de color para PAL: La carta de barras está formada por 8 franjas verticales de los colores blanco, amarillo, cian, verde, magenta,
rojo, azul y negro. Rojo, verde y azul son los primarios y cian, magenta y amarillo sus respectivos complementarios (secundarios en colorimetria). Los colores se ordenan en la carta en escala de luminancía, de mayor a menor.
La carta se define con 4 cifras porcentuales (entre 0% y 100%): o 1 º: nivel máximo de los primarios en las barras sin color (amplitud barra blanca).o 2 º: nivel mínimo de los primarios en las barras sin color (amplitud barra negra). o 3º: nivel máximo de los primarios en las barras con color (nivel del componente más alto).o 4º: nivel minimo de los primarios en las barras con color (nivel del componente más bajo).
La carta de barras estandarizada por la EBU es la de amplitud de color del 75% y saturación 100% (carta del 75%): 100/0/75/0.La carta de barras EBU (75%) se utiliza en intercambios de señal, ajustes y como señal patrón al
inicio de cada grabación.Es frecuente encontrar equipos dónde se utiliza la carta de amplitud de color 100% y saturación 100% (carta del 100%). 100/0/100/0.
La retícula del vectorscopio tiene unas "cajitas" sobre las que deben coincidir los vectores de la carta de barras de color, si es correcta.Cada cajita tiene la letra inicial del colar al que corresponde (Y, Cy, G, Mg, R, B), si es mayúscula corresponde al vector con V no invertida y si es minúscula al vector de V invertida.
La amplitud de la salva en la retícula debe estar en la marca que indica 75%.

Cuando se miden las barras del 100% se descalíbra la representación, se reduce la amplitud de la salva hasta la marca del 100% y se evalúan las barras en las mismas "cajítas".
Demodulador PAL-S : El demodulador PAL-S (simple) se usa en monitores profesionales porque permite apreciar mejor
los defectos de la señal. De la señal de vídeo compuesto se separan los sincronismos, la salva, Y y C. Con C y la
subportadora regenerada a partir de la salva transmitida se recuperan U y V. La señal V se reinvierte en las líneas en que fue invertida al modular.
Si hay errores de fase diferencial (desviación de C respecto a la fase de la salva), el color en pantalla es incorrecto.
Como se ha invertido V alternativamente línea a línea, el error de fase de C afecta de forma opuesta en líneas consecutivas.
En dos líneas consecutivas habrá colores erróneos desviados respecto al color correcto en sentido contrario, por lo que por mezcla aditiva espacial de ambas colores, el ojo vería el color correcto.
El color que se ve siempre es correcto (no como en NTSC), pero pierde saturación si hay mucho error de fase (lo cual se acepta como un "mal menor' frente al error de tono).
Si el error de fase es grande se ve, además, un molesto efecto de "persiana veneciana".
Demodulador PAL-D :
El demodulador PAL- D se usa habitualmente en televisores domésticos: enmascara los defectos de la señal. Respecto al PAL-S, sólo añade un dispositivo de retardo de línea.
En cada línea, se suma la señal C con la señal C de la línea anterior (línea de retardo) y se divide por 2 para mantenerla amplitud correcta.
Si hay un error,de fase diferencial, como la desviación de fase es contraria en cada línea, al sumar dos líneas consectivas se obtienen siempre valores de fase (y por tanto de color) correctos.
En comparación con el PAL-S, no hay mezcla aditiva espacial ni efecto de "persiana veneciana". Como en PAL-S, sigue habiendo desaturación de los colores si existe desfase.

Respecto al PAL-S, la suma de dos líneas consecutivas en PAL-D reduce a la mitad la definición vertical de la imagen de color.
Secuencias de la señal PAL:
Una secuencia es simplemente un patrón repetitivo. La importancia de mantener una secuencia estriba en que si la rompemos por ejemplo al editar, aparecen señales erroneas como resultado de la edición, apareciendo lo que se llama una edición incoherente. En B/N la señal tiene una estructura que se repite cada 2 campos (1 cuadro). En NTSC, la señal tiene una estructura que se repite cada 4 campos (2 cuadros). En PAL la señal tiene una estructura que se repite cada 8 campos (4 cuadros). Secuencia de 2 campos: la estructura del borrado V de dos campos consecutivos es distinta
(campo 1 y campo 2 que forman cada cuadro). Esta secuencia solo es en cuanto a sincronismos. La secuencia de 2 campos también está presente en B/N, NTSC y PAL.
Secuencia de 4 campos en PAL: en 2 cuadros consecutivos (4 campos), las línea 1 del campo 1 y la línea 1 del campo 3 estarán separadas por una cantidad impar de líneas (625), por lo que en una de ellas habrá inversión de la fase de V y en la otra no, porque la inversión se alterna línea a línea.En NTSC existe secuencia de 4 campos, pero debida a otros motivos (la fase de la subportadora respecto al flanco horizontal de la primera línea).
Secuencia de 8 campos en PAL: en cada cuadro se acumulan 90º de desfase en la fsc respecto al cuadro anterior. Si tomamos como referencia la fase de fsc en un punto concreto de cierta línea en cada cuadro, el valor que se mide de la fase de fsc sólo se repetirá cada 4 cuadros u 8 campos (hasta sumar 360º). A la secuencia de 8 campos se le llama "color-framing".
Fase SC-H: relación constante que debe haber entre la fase de fsc, y un punto de referencia constante en cada cuadro de Imagen. Dicha referencia se toma en el flanco inicial de la línea 1 del campo 1 de la secuencia PAL, donde el valor de fase de fsc debe ser 0º. Es de especial importancia en mezclas de señal.
Si se cumple la secuencia más restrictiva (8 campos) se cumplen las inferiores (2 y 4 campos). Si se cumple la secuencia de 4 campos, también se está cumpliendo la de 2 campos
En edición de vídeo, si no se respetan las secuencias de 4 y 8 campos, se producirán colores erróneos durante el primer campo de la edición.Este defecto es poco visible, por lo que en edición al corte sólo es imprescindible respetar la secuencia de 2 campos. Los equipos de montaje (magnetoscopios, editoras) permiten seleccionar si queremos respetar las secuencias de 4 y 8 campos.
Ajustes operativos de la señal PAL: En el monitor de forma de onda (MFO o WFM) se representa el nivel (valor en voltios) de la señal
de video en función del tiempo.Son habituales las representaciones de 1 o 2 líneas y de 1 o 2 campos. En el WFM se ajustan niveles y retardos de las señales.
En el vectorscopio se representan polarmente los valores de los vectores U y V. En el vectorscopio se ajustan valores de fase y niveles de las componentes de crominancia.

La monitorización de la señal en el WFM y el vectorscopio es necesaria porque es la única forma de evaluación objetiva de la señal. La apreciación de la imagen en el monitor de video es subjetiva.
El ajuste de señales suele hacerse con la carta de barras del 75% y debe repetirse para cada señal que se vaya a utilizar.
El procedimiento a seguir para ajustar una señal es el siguiente: Paso previo. poner el WFM en representación de 1 o 2 líneas ('1H" o '"2H'), señal completa ("flat", sin descalibrar, restauración DC activada "DC RES". Fijar el borrado H en la marca de 300 mV
1º: nivel de negro: en el WFM se ajusta a 300 m V.2º: nivel de video: en el WFM se ajusta el blanco a 1 V.3º: saturación de color: en el vectorscopio se gira el mando de fase ("PHASE") hasta que la salva queda en la marca de +-135º.A continuación se ajusta la saturación hasta que los vectores coinciden en el centro de sus cajitas.4º: fase de color si se observa que hay una desviación en la relación de fase entre la salva y los vectores de las barras, debe ajustarse primero la fase de color, repitiendo después el ajuste de saturación (el ajuste de fase es exclusivamente técnico, no suele realizarlo el operador).
A veces se desajusta deliberadamente la señal para lograr algún efecto estético (ajustes"artísticos").
Sincronización y enfasaje de la señal en PAL:
Sincronización: todas las señales deben tener una estructura temporal idéntica y la misma fase
de fsc.
Enfasaje (fase de H y fase V): una vez sincronizadas las señales, deben retardarse o adelantarse hasta que todas estén en el mismo instante temporal de exploración de la señal (horizontal y vertical).
Enfasaje SC-H (SCH): además de estar en fase H y V, todas las señales deben estar en el mismo campo de la secuencia PAL.Para facilitar el ajuste de fase SC-H se normalizo que en el flanco inicial de la línea 1 del campo 1 de la secuencia de 8 campos la fase de fsc sea de 0º. No es Imprescindible cumplir esta condición con precisión, basta con que todas las señales estén en el mismo campo de la secuencia PAL.
Para poder combinar imágenes en un mezclador (corte, mezcla, etc.), es necesario que todas ellas estén sincronizadas y en fase.
Para sincronizar los equipos de una instalación se les suministra a todos la misma señal de referencia, que se toma como señal patrón para toda la instalación.La referencia puede ser cualquier señal PAL, aunque se ha normalizado el uso de una imagen en negro con salva de color ( Black Burst= BB).
La longitud de los cables y el tiempo de procesado de cada equipo hace que haya desfases entre las señales (aunque estén sincronizadas). Para ajustar estos desfases, se pone en el WFM/Vectorscopio la señal de referencia en externa "EXT" y se procede según la siguiente secuencia:
1º fase H (horizontal).- en el WFM, con la representación de 2 líneas magnificada ("2H" y 'MAG") se iguala el inicio del sincro H de todas las señales que entran al mezclador.2º fase V (vertical).- en el WFM con la representación de 2 campos magnificada (“2FLD" y "MAG') se iguala el inicio del sincro V en todas las señales que entran al mezclador.3º fase SC-H se pone el vectorscopio en la representación "SCH" y se modifica la fáse SC-H de todos los equipos para que la abertura de la circunferencia que aparece quede en todas las señales en la misma dirección (que debe ser la del eje -U, hacia la Izquierda).
4. VíDEO ANALÓGICO EN COMPONENTES

Características de la señal analógica en componentes: La señal normalizada SMPTE/EBU N-10 utiliza las componentes Y, Pb (B-Y) y Pr (R-Y). La componente Y lleva toda la información de luminancia y sólo información de luminancia. Pb y Pr llevan toda la información de crominancia y sólo información de crominancia. La señal Y tiene la misma estructura que la señal B/N (nº líneas, campos, sincronismos, etc.)
excepto: La amplitud de Y va de 0 m V (nivel de borrado y nivel nominal de negro) a 700 m V (pico de blanco). El nivel de fondo de sincronismo es -300 m V.
Pb (B-Y) y Pr (R-Y) son bipolares (pueden tomar igualmente valores negativos y positivos). B-Y y R-Y se convierten en Pb y Pr al aplicarles coeficientes ponderadores que las limitan a ±350 mV. Estos coeficientes se calculan a partir de la amplitud de B-Y y R-Y en las barras del 100%.
La norma define Pb y Pr sin sincronismos, pero pueden llevarlos y algunos equipos los generan. El ancho de banda de Y, Pb y Pr no está limitado en la norma. Los BW de Pb y Pr deben ser siempre iguales entre sí. Es suficiente que el BW de Pb y Pr sea la mitad del de Y (por la peor sensibilidad del ojo a los
cambios de color). El ojo reconoce gran numero de colores (millones) aunque no los discierne cuando están muy juntos.
Señal en componentes RGB: La norma SMPTE/ BU N-20 similar a la N-10, define la señal para los componentes R, G y B. En la norma N-20 los componentes R, G y B tienen amplitud normalizada entre 0 y 700 mV. Los sincros van en la componente G, aunque pueden ir también en R y B, o por separado. El
ancho de banda de R, G y B no está limitado en la norma. Es imprescindible que las 3 componentes tengan el mismo BW.
Es más difícil (y menos habitual) trabajar con los componentes R, G y B porque las 3 componentes deben tener el mismo BW que tendría Y en los componentes Y, Pb y Pr para igualar la calidad.
Medidas en la señal analógica en componentes: Hay problemas por diferencia de ganancia y de retardo entre los 3 canales porque van por
separado. Las diferencias de ganancia y retardo se miden y ajustan con la señal bowtie (pajarita). La señal
bowtie tiene que ser generada por un equipo especial y exige un MFO capaz de analizarla.
Representacion de la señal Bowtie.
El MFO para componentes tiene 4 tipos de representación: parade, overlay, vector y lightning. Parade o secuencial: representa en la pantalla 3 líneas consecutivas, cada una con el nivel de
una de las 3 componentes. En el modo parade se evalúa y ajusta el nivel de negro, de vídeo en Y y croma en Pb y Pr.

Modo Parade. Overlay: presenta en pantalla de forma superpuesta los 3 componentes en el ancho de 1 o 2
líneas. La representación overlay magnificada sirve para ajustar retardos o desfases entre canales.
Vector : presenta en pantalla la componente Pb en el eje horizontal y la Pr en el vertical. Las clásicas cajitas permiten ajustar la ganancia de los canales PB y PR.
Lighning (rayo): en la mitad superior representa la componente Y en el eje vertical (hacia arriba) y Pb en el horizontal; en la mitad inferior representa la componente Y en el eje vertical (hacia abajo) y Pr en el horizontal. Tiene "cajitas" que permiten ajustar la ganancia de Y respecto a Pb y Pr, y marcas para evaluar los retardos.

5. GRABACIÓN MAGNÉTICA DE VÍDEO
La grabación sobre soporte magnético se basa en la propiedad que tienen ciertos materiales (denominados magnéticos) de retener un campo magnético que con anterioridad se les había aplicado.
El fundamento del magnetismo se resume en el denominado ciclo de histéresis. Vamos a explicar este fenómeno.
Si a un material magnético se la aplica un campo magnético creciente H , la magnetización o densidad de flujo magnético B no crece linealmente si no a través de una curva. Esta magnetización solo crece hasta llegar a un punto B(m) en el cual se dice que el material está saturado.
Si ahora se reduce el campo magnético H la magnetización B no sigue la curva de subida sino que desciende de otra manera. Aunque este campo magnético H se anule por completo sigue quedando un campo magnético B(r) , el cual recibe el nombre de remanencia. Si el campo H sigue descendiendo haciéndose negativo llegará un momento en que la magnetización B se hará nula. Este campo magnético recibe el nombre de coercitividad ( H(c) ). Las unidades en que se miden son Oersteds. Este parámetro es el que nos indica la calidad del soporte magnético ya que cuanto mayor es, se podrán grabar señales más fuertes y de mayor ancho de banda.
Vamos a estudiar un poco más detenidamente este fenómeno. En las siguientes figuras vemos como se compartan los materiales magnéticos.

En la primera gráfica vemos que hay un tramo que es reversible ( a-b).,en la segunda vemos la zona lineal ( b-c), en la tercera observamos el proceso de saturación. Estas características nos fijaran la forma de grabar las señales en la cinta magnética.
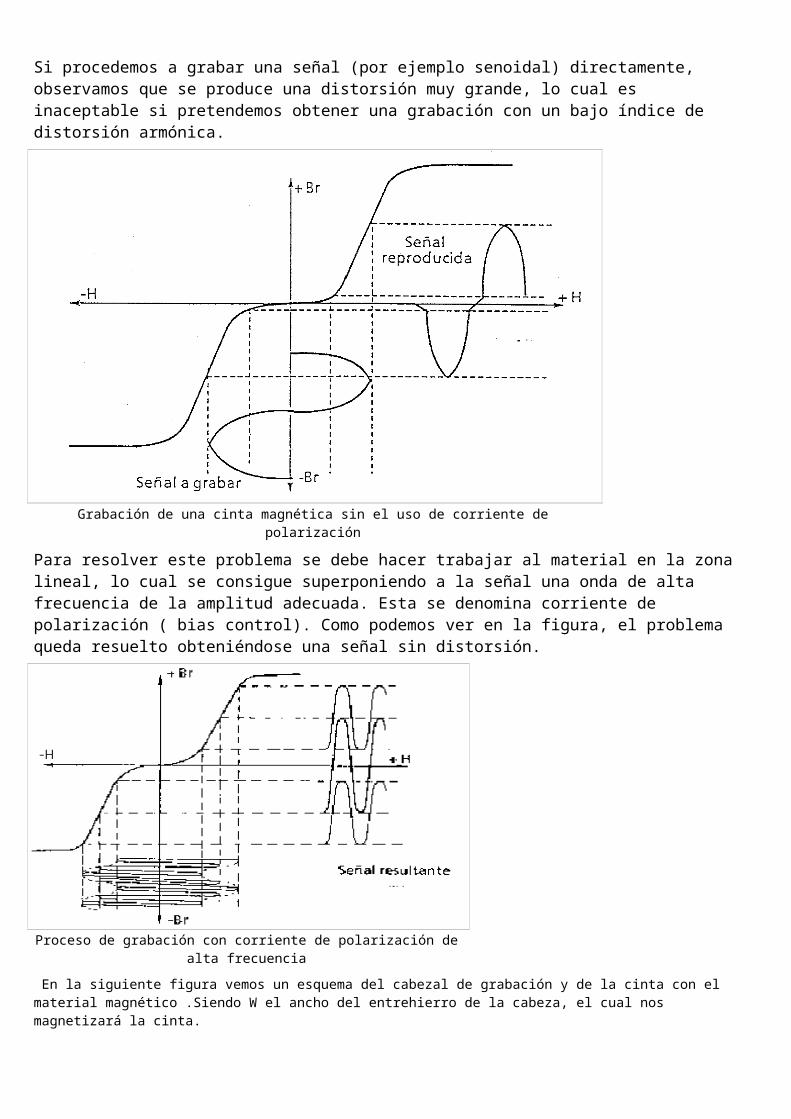
Si procedemos a grabar una señal (por ejemplo senoidal) directamente, observamos que se produce una distorsión muy grande, lo cual es inaceptable si pretendemos obtener una grabación con un bajo índice de distorsión armónica.
Grabación de una cinta magnética sin el uso de corriente de polarización
Para resolver este problema se debe hacer trabajar al material en la zona lineal, lo cual se consigue superponiendo a la señal una onda de alta frecuencia de la amplitud adecuada. Esta se denomina corriente de polarización ( bias control). Como podemos ver en la figura, el problema queda resuelto obteniéndose una señal sin distorsión.

Proceso de grabación con corriente de polarización de alta frecuencia
En la siguiente figura vemos un esquema del cabezal de grabación y de la cinta con el material magnético .Siendo W el ancho del entrehierro de la cabeza, el cual nos magnetizará la cinta.
Una cinta magnética es una cinta de poliéster sobre las que se extiende una emulsión de material magnetizable (sensible a un campo magnético). Dicho material son pequeñas partículas que se comportan como imanes. Están pegadas a la cinta, pero pueden girar y ser orientadas por un campo magnético.
Una cabeza magnética es un anillo de material ferromagnético con un hilo conductor arrollado. El entrehierro es una discontinuidad de material magnéticamente inerte en la cabeza magnética.
La corriente eléctrica que circula por el hilo arrollado a la cabeza crea un campo magnético que circula por el anillo que forma la cabeza.
Magnetización de la cinta: el campo magnético no atraviesa el entrehierro, "lo rodea" por fuera de la cabeza, orientando (polarizando) las partículas magnéticas de la cinta que en ese momento está junto al entrehierro.
Parámetros del ciclo de histéresis:H=Fuerza del campo magnético aplicado.B= Intensidad del flujo magnético.Bm=Densidad del flujo magnético máxima o punto de saturación.Br= Retentividad o magnetismo remanente en la cinta, por ejemplo al anular el campo que provoco la saturación. Br-> (Cinta Metal, etacam SP) > (Cinta 0xido, etacam normal)Hc= Coercitividad o valor que debe tomar H para reducir a cero el magnetismo remanente.
Reproducción de una grabación magnética: Al reproducir, la parte de cinta que coincide con el entrehierro cierra el anillo ferromagnético de
la cabeza, induciendo un débil campo magnético que circula por dicho anillo. El campo generado en la cabeza induce, a su vez, una pequeña corriente eléctrica por el hilo
conductor arrollado a ella: es la señal recuperada. La cabeza de grabación y la de reproducción pueden ser (y suelen ser) la misma. Importante: no se puede grabar señal continua (DC), sólo se puede grabar señal alterna (AC). En audio se suma a la señal una corriente de polarización (Ibias) de muy alta frecuencia,no
audible, para mantener el nivel de señal dentro del margen que hay entre H, y SAT. Con la polarización, cuando la señal es nula la magnetización está en la zona media de H y cuando no sea nula fluctuará alrededor de ese valor central.
En vídeo no hace falta polarización porque la señal se modula en FM para grabarla, La señal FM tiene una frecuencia muy alta de amplitud constante, por lo que por sí sola cumple la
función de polarización.
Grabación: Reproducción:
Frecuencia máxima grabable:
El tamaño de la longitud de onda grabada en la cinta, grabada (1 ciclo señal), para determinadafrecuencia, depende de la velocidad relativa entre la cabeza y la cinta (Vcc).
Cuanto mayor sea Vcc, mayor será la grabada=Vcc/f.

Interesa grabar la frecuencia más alta posible para tener un gran ancho de banda. Para determinada grabada, cuanto mayor sea Vcc más alta podrá ser la frecuencia a grabar. Para determinada Vcc cuanto más pequeña sea grabada, mas alta será la frecuencia grabable.
El límite para grabada lo da el tamaño del entrehierro: dentrehierro=grabada/2Las partículas magnéticas deben ser siempre mucho mas pequeñas que el entrehierro, por esocuando se trabaja con entrehierros muy pequeños debe recurrirse a cintas de metal.
Las cintas de metal son más abrasivas que las de óxido de hierro, por eso en audio analógicoprofesional se prefiere aumentar Vcc, mantener el entrehierro grande y no utilizar cintas de
metal Un límite para determinar fmax grabable nos lo da la Vcc máxima que se puede usar (por
limitaciones mecánicas en la velocidad de arrastre de la cinta). El otro límite para determinar fmax grabable lo determina el dentrehierro mínimo que se puede
usar (por dificultades de fabricación). La relación entre estos valores será: dentrehierro=0,5vcc/fmax Ejemplos con valores habituales
dentrehierro= 2 m; vcc= 10 cm/s; entonces fmax = 25. 000 Hz (valido para audio, no para video).dentrehierro = 1 m; fmax= 10 Mhz; entonces Vcc= 20 m/s (orden de magnitud necesario
en vídeo).
Margen dinámico grabable:Octava: Una octava es un margen entre dos frecuencias en el que la mayor es el doble de la menor: De 1Mhz a 2Mhz hay 1 octava; de 10Hz a 40Hz hay 2 octavas; de 100kHz a 800kHz hay 3 octavas..Al reproducir una grabación, el nivel de la señal sube 6 dB por octava de incremento de la frecuencia. La diferencia entre el nivel menor y el nivel mayor en la reproducción de una grabación no debe superarlos 30 dB, es decir 5 octavas.Una señal de video en banda base tiene, teóricamente, valores de señal entre 0 Hz y 5 MHz. En la práctica, sólo debemos respetar a partir de 50 Hz, que es la frecuencia de campo. De 50 Hz a 5 MHz hay 16,6 octavas, luego hay una diferencia de nivel de 100 dB entre fmin y fmax.Para grabar video se modula la señal banda base con una portadora baja, que permite incrementar lafmin a grabar sin que la fmax crezca demasiado.Ejemplo: modulando AM con 10 MHz de portadora tendremos señal modulada entre 5 y 15 MHz. menosde 2 octavas. La contrapartida es que el incremento de fmax obligará a aumentar vcc.En la práctica se usa modulación FM (no AM) para que el nivel de señal a grabar sea constante y que no dependa de las características de la señal.
Exploración transversal:Sería necesario mover la cinta a decenas de metros por segundo para grabar vídeo en una pista longitudinal (como las de audio), pero esto es mecánicamente inviable. Hubo un sistema experimental a principios de los 50 que grababa de este modo (sistema de Bing Crosby); una bobina de cinta de 1 metro de diametro, apenas duraba 5 minutos.La grabación transversal consiste en grabar en una cinta "ancha" pistas transversales (perpendiculares al movimiento de la cinta). Las pistas transversales se pueden grabar muy deprisa mientras que el arrastre de cinta puede hacerse a una velocidad moderada.La cabeza de vídeo se monta sobre un tambor cilíndrico giratorio perpendicular a la cinta: al girar el tambor se graba una pista perpendicular con vcc elevada, pero con una velocidad de arrastre de la cinta relativamente lenta. Para lograr una vcc alta (velocidad cabeza-cinta) se mueve tanto la cinta como la cabeza (que gira en el tambor), no es posible utilizar cabezas estáticas.La velocidad de arrastre de la cinta es la justa para que cuando se termina de grabar una pista la siguiente se comience a grabar contigua a la anterior. Aunque el tambor es perpendicular a la cinta, como esta se mueve a la vez, las pistas quedan un poco inclinadas.El coste de la cinta es elevado, por lo que habrá de llegarse a soluciones de compromiso en: la anchura de la pista cuanto más ancha sea la pista de vídeo, mas señal se recuperará en la reproducción y más fiable será el sistema, pero se consumirá la cinta mas deprisa. La separación entre pistas (bandas de guarda): cuanto mayor sea, mas difícil será que por un desajuste la cabeza "se cuele" en la pista contigua, pero se consumirá cinta más deprisa.Pista CTL (control track longitudinal): se graba una pista longitudinal en un borde de la cinta con impulsos que marcan el inicio de cada pista de vídeo. Estos impulsos le sirven al magnetoscopio para localizar el inicio de cada pista y controlar las velocidades de arrastre y de giro del tambor.El sonido se graba en otra pista longitudinal de forma convencional con cabezas fijas.
Como ya hemos mencionado en varias ocasiones debido a las restricciones de velocidad que se le imponen a la cinta los cabezales de vídeo deben de ser móviles y no fijos. Todas las máquinas

desarrolladas con posterioridad a las de formato cuádruplex ( 2 pulgadas transversal) adoptaron el sistema de exploración helicoidal.
En primer lugar el cabezal o cabezales se montan sobre un cilindro denominado tambor porta cabezas. Este gira sobre un eje a una velocidad fija que viene dada por el número de campos por segundo que posea la imagen.
Si este tambor estuviese alineado con la cinta no se podría grabar nada ya que unas pistas se grabarían sobre otras. El tambor se le coloca girado con respecto a la cinta. Este ángulo es muy pequeño del orden de 2 a 6 grados, aunque es suficiente para que las distintas pistas no se solapen.
El número de cabezas que se sitúan sobre el tambor suele ser de dos pero en algunos casos es solo una y en sistemas profesionales suelen ser mas.
Ahora ya solo queda situar la cinta sobre el tambor para que podamos hacer la grabación o lectura. Esta operación se conoce como enhebrado de la cinta y en los sistemas de cassette es automática.
En las figuras que siguen vemos algunos tipos de enhebrados o arrollamientos.
Diferentes tipos de arrollamiento de la cinta Tambor con los cabezales y la cinta enhebrada

Número de cabezas de vídeo, arrollamiento y velocidad del tambor:Al estar montada sobre un tambor giratorio, la cabeza de video no está permanentemente en contacto con la cinta, por lo que habrá un tiempo durante el cual no podrá grabar.La señal de vídeo tiene información continua, y sólo se podría dejar de grabar durante el periodo de borrado vertical de cada campo (que se puede regenerar después).Para que la cabeza esté casi constantemente en contacto con la cinta, sería necesario que la cinta se arrollase sobre el tambor casi 360º lo cual no es posible si se graban pistas transversales.La solución aplicada en el formato Cuádruplex fue grabar con 4 cabezas de video equidistantes entre sí 90º en el tambor:
La cinta se arrolla algo más de 90º al tambor. Al girar el tambor en el instante en que una cabeza abandona la cinta otra cabeza entra sobre ella en una pista nueva, contigua a la anterior grabando la señal sin interrupción. Se graban 4 pistas (una con cada cabeza) durante 1 giro de tambor.Al reproducir se procede igual, conmutando de la señal de lectura de una cabeza a la de la siguiente según va pasando cada cabeza sobre la cinta: no importa que la señal quede fragmentada en pistas.La velocidad de giro del tambor y por tanto el número de pistas grabado por segundo, dependerá de cuánta información se graba en cada pista.Se graban 16 líneas de TV: se necesitan 20 pistas para grabar 1 campo completoComo hay 4 cabezas en un giro se graban 4 pistas: en 5 giros se grabarán las 20 pistas de 1 campo. Para grabar 1 segundo (50 campos) se necesitarán 250 giros, luego el tambor girará a 250 rps.El formato de vídeo Cuádruplex, comercializado desde 1956, graba pistas transversales en cintas de 2 pulgadas de ancho (2") del modo descrito.Fue el único sistema profesional de grabación de video hasta finales de los años 70 que podía grabar señal PAL completa (o NTSC) con calidad de difusión o Broadcast.
Calidad Broadcast:Un sistema de video tiene calidad Broadcast cuando la calidad de grabación supera los requisitos del sistema de difusión estandarizado (PAL en España).Para ello se considera el ancho de banda de las componentes Y, B- Y y R- Y que es capaz de respetar el sistema de video.Actualmente hay 2 conceptos de calidad Broadcast: Para difusión analógica (limites PAL): 5 Mhz para Y y 1.3 MHz para B-Y y R-Y. Para difusión digital (DVB): Muestreo 4:2:0, 8 bits/muestra, 5,5 Mhz en Y y 2,75 Mhz en B-Y y R-Y.
Exploración helicoidal:La exploración helicoidal consiste en grabar pistas inclinadas en lugar de transversales. Las principales ventajas de esta técnica son:
-La cinta se arrolla mucho mas a la cabeza, reduciéndose en proporción el número de cabezas.

-Las pistas pueden ser más largas. Hacen falta menos pistas para grabar un campo completo (la velocidad de giro del tambor será más baja).-Se pueden usar cintas más estrechas
El formato B graba en cintas de 1" con 2 cabezas (arrollamiento de 180º), graba 52 líneas por pista, 6 pistas por campo y, como tiene 2 cabezas, graba 1 campo en 3 giros de tambor (150 rps).El sistema B sustituyó al 2 " a finales de los '70 (hasta finales de los '80).
Grabación no segmentada y dynamic tracking (DT): Todo sistema de vídeo sufre irregularidades en la reproducción, y en los formatos Cuádruplex y B
las irregularidades provocan que se vean franjas o cortes horizontales en los cambios de pista. Otro problema de los formatos Cuádruplex y B es que no se puede hacer reproducción en pausa:
cuando la cinta se para, en un giro de tambor no se puede reproducir un cuadro completo. Ambos problemas se solucionan con un sistema que grabe 1 campo en cada pista: grabación no
segmentada. Si inclinamos aún mas las pistas y aumentamos el arrollamiento hasta casi 360º (lo cual es
posible con exploración helicoidal al estar inclinado el tambor), podemos hacer que 1 campo entre completo en una sola pista.
Para reproducir la pista a velocidades distintas de la normal, además de ser no segmentado, el sistema necesita cabezas dinámicas o de "dynamic tracking" (DT).
Las cabezas DT se pueden mover dentro de su alojamiento del tambor mientras exploran la pista, Estas cabezas pueden seguir a la pista aunque el ángulo de esta cambie debido a una variación
en la velocidad de reproducción. Una solución es dotar a los magnetoscopios de cabezales más anchos, así cuando se desvíen un
poco de la pista pueden seguir leyéndola. Esta filosofía es la usada en los magnetoscopios domésticos de 3 o 4 cabezas. Hay que resaltar que estas cabezas supletorias sólo se usan para la lectura a velocidades diferentes a la normal, y no en grabación o reproducción a velocidad estándar; por este motivo el tener 3 o 4 cabezas no mejora la grabación de la señal ni la reproducción a velocidad normal que es la más usada.
Corrector de base de tiempos, TBC (Time Base Corrector): Durante la reproducción de la grabación se producen irregularidades mecánicas (fluctuaciones en la velocidad de lectura) que son mayores en los formatos helicoidales no segmentados.Las imágenes tienen un aspecto tembloroso debido a las fluctuaciones en la duración de las líneas.Para evitar estas irregularidades temporales se usan los TBC.Un TBC Time Base Corrector = Corrector de Base de Tiempos, graba en una memoria digital varias líneas de señal (algunos hasta 1 cuadro), la señal memorizada se lee con un reloj muy preciso, corrigiendo las irregularidades temporales originales.El TBC permite además:
- Ajustar el nivel de negro, el nivel de vídeo, el nivel de croma, la fase de croma y la fase SCH.
- Sincronizar la señal con otra de referencia. - Sustituir líneas perdidas en drop-outs (perdidas de emulsión en la cinta) por la línea
anterior.- Generar imágenes congeladas cuando es capaz de grabar 1 campo o 1 cuadro completo.
El sistema C de 1" graba 1 campo por pista con 1 sola cabeza (arrollamiento en Omega de casi 360º). El tambor gira a 50 rps. Tiene TBC y puede tener DT.Las prestaciones del formato C son superiores a las del formato B, junto al cual sustituyó al cuádruplex hasta la aparición de los formatos analógicos en componentes.
Código de tiempos: El código de tiempos (Time Code: TC) es una señal que identifica cada cuadro: HH:MM:SS:FF. Horas (0-23):minutos (0-59):Segundos (0-59):Frames (0-24). Los impulsos de CTL permiten seguir correctamente las pistas al reproducir, pero al editar es frecuente que "se pierda" o se desvíe, varios cuadros del deseado, debiendo repetir la edición. Por ello surge el TC que asigna un código único a cada cuadro o campo de imagen. Cuando se utilizaba el contador de pulsos CTL como referencia, éste puede resetearse: es decir, el contador no se graba en cinta. El TC sirve para editar con mayor precisión, para identificar univocamente un cuadro de imagen y para facilitar el minutado y archivo de las grabaciones. Por ejemplo, en informativos suele ponerse como TC la hora, lo que se conoce como código horario. LTC: longitudinal Time Code: se graba el TC en una pista longitudinal, como el CTL y el audio (no confundir CTL con LTC). El LTC es difícil de leer a baja velocidad (< de X1) y no identifica el campo, pero sí funciona bien a alta velocidad.

VITC: Vertical Intervale Time Code: se graba el TC en 2 líneas de¡ borrado vertical de cada campo. Identifica los campos, mostrando en el TC un asterisco * en los campos pares. Se lee sin problemas a baja velocidad y en pausa, pero es difícil de leer a alta velocidad (> de X5).Debido a las distintas limitaciones existentes en ambos tipos de TC, en los sistemas de vídeo profesional se combina el uso de LTC y VITC.
Sistemas de bajo coste en cassette: Guardar la cinta en cassette la hace cómoda y manejable y la protege de la suciedad y los
golpes. Los de 1 " no utilizan cassette porque éste sería muy grande. Para hacer un sistema de vídeo en cassettes pequeños, portátil, era necesario reducir la cantidad
de información a grabar: reducción de¡ ancho de banda. Reducir la cantidad de información a grabar simplifica y abarata el equipo: pueden
comercializarse equipos domésticos de bajo precio. Al recortar el BW de la señal PAL a, por ejemplo, 3 MHz.. ¡nos quedaríamos sin crominancia ¡
Subconversión de la crominancia en frecuencia: técnica empleada para evitar la pérdida de la crominancia. Se modula QAM (U y V en cuadratura, como en NTSC y PAL), pero con una frecuencia subportadora muy baja y recortando mucho el BW de la croma.
La señal de Y modulada en FM se suma con la de C modulada en QAM No se intermodulan porque C queda, en frecuencia, por debajo de Y. La luminancia modulada suele estar por encima de 1 MHz. La banda de frecuencias disponible para la crominancia suele quedar entre 300 kHz y 1 MHz
El BW de la croma suele estar en torno a 0,3 MHz (muy bajo), y es imposible mejorarlo porque:-no se puede subir la banda de C más allá de 1 MHz pues ahí comienza la de Y y desplazar Y hacia arriba en el espectro encarecería el sistema.-no se puede bajar la banda de C de los 300 kHz, porque se incrementaría notablemente el número de octavas entre la frecuencia máxima y la mínima a grabar.
El interfaz de conexión entre equipos suele ser PAL, por lo que la intermodulación entre Y y C se producirá al convertir la señal a PAL en la salida del equipo, no en la grabación. Las conexiones tipo "dubbing" y las Y-C (o S-video) evitan la intermodulación entre Y y C pero no las secuencias de hasta 8 campos del PAL.
El sistema U-Matic graba en cintas de 3/4", conservadas en cassettes. Fue presentado a finales de los años 60 y a lo largo del tiempo ha tenido sucesivas mejoras en los BW de Y y C aunque ninguna ha alcanzado la calidad Broadcast.
Grabación acimutal: Al grabar en formatos transversales y helicoidales, se deja un pequeño espacio entre pistas,
llamado bandas de guarda. Estas estrechas franjas permiten que las pequeñas desviaciones mecánicas que producen
durante la lectura no provoquen la reproducción errónea de una pista contigua a la que deseamos reproducir.
Eliminar las bandas de guarda reduciría el gasto de cinta: un cassette duraría más y el tamaño y coste del soporte sería menor. Para poder eliminar las bandas de guarda se recurre a grabar y reproducir las pistas con acimut.
El acimut es una inclinación que se aplica a las cabezas de vídeo, con ángulos opuestos de cabeza a cabeza, de modo que la pista anterior y la posterior a la que estamos grabando o reproduciendo tengan una inclinación opuesta a la de dicha pista.
Al reproducir, la señal que se puede colar de las pistas contiguas es poca: la posición de las partículas magnéticas es casi perpendicular al paso de la cabeza por lo que no se genera campo magnético (para ello deberían estar en posición longitudinal).
La grabación acimutal se introdujo en formatos domésticos: VHS, Betamax, Video 2000, Video 8, etc. Posteriormente se aplicó a formatos profesionales, pero conservando pequeñas bandas de guarda.
En los formatos digitales mas modernos se tiende a eliminar las bandas de guarda, ya que la grabación digital es menos sensible al ruido. Las pistas literalmente se solapan unas sobre otras.
Grabación en componentes: Generaciones: número máximo de copias que se pueden hacer de una señal sin que las pérdidas
de calidad acumuladas en cada copia hagan que la grabación sea inválida para la emisión. El número de generaciones depende estrictamente del formato de vídeo, aunque la mala
conservación o un mantenimiento defectuoso de los equipos pueden influir notablemente. La intermodulación Y-C del PAL, la subconversión en frecuencia y los anchos de banda reducidos
influyen negativamente en el número de generaciones de los formatos de vídeo en compuesto.

En los formatos de 1" el número de generaciones es pequeño, lo cual dificulta los procesos de postproducción.
La grabación en componentes elimina los problemas de las secuencias PAL y la intermodulación Y-C, y permite además aumentar el BW de B-Y y R-Y respecto al que tienen en vídeo compuesto. Grabar en componentes permite incrementar notablemente el número de generaciones de una señal.
En componentes, el BW de B-Y y R-Y no exige ser tan alto como el de Y, con la mitad es suficiente.
Como la cantidad de información de B- Y y R- Y juntas es similar a la de Y se graban 2 pistas paralelas, con 2 cabezas, una para Y y otra para la pareja B- Y y R - Y multiplexadas.
Multiplexación en frecuencia: en el sistema M (o Hawkeye ) de Panasonic y RCA, B-Y y R-Y se modulan cada una en FM con una fp distinta y son grabadas con la misma cabeza.
Multiplexación en tiempo: B-Y y R-Y se graban en una memoria y se leen a doble velocidad una tras otra, realizando este proceso en cada línea.
Durante la grabación de 1 línea de Y se graba 1 línea de C con 1/2 de B-Y y 1/2 de R- Y: cada mitad es 1 línea entera leída a doble velocidad en reproducción se aplica el proceso inverso.
Los sistemas Betacam y Betacam SP de Sony aplican la multiplexación en tiempo, llamando CTDM (Compressed Time Division Multiplex) a la señal de B-Y y R-Y multiplexadas. Panasonic aplicó la multiplexación en tiempo en el formato M-II, sustituto del M, llamándola CTCM.
Los formatos Betacam SP y M-II ofrecen calidad de vídeo Broadcast superior a la de los formatos de 1" Utilizan cintas de metal, con lo que logran aumentar la densidad de grabación para poder utilizar cassettes compactas con cinta de 1/2" y equipos portátiles de formato camascopio o camcorder.
Grabación de audio en pistas de vídeo (audio FM): El sistema Cuádruplex graba 1 canal longitudinal de audio analógico, el sistema B graba 2
canales longitudinales y el sistema C permite grabar hasta 4 canales analógicos. La velocidad de arrastre de la cinta es suficiente para alcanzar un BW en audio de 15 Khz y la
relación S/R es comparable a la de los magnetófonos de bobina abierta profesionales. Los sistemas analógicos modernos (Betacam SP, M-II) tienen 2 canales de audio longitudinales
con peor calidad que los sistemas precedentes (incluso peor que el U-matic), porque la cinta avanza a una velocidad muy baja.
Cuanto menor es la velocidad de arrastre, menor es la frecuencia máxima grabable en pistas longitudinales.
Para mejorar la calidad del sonido, en Betacam SP y M-II se graban otros 2 canales de audio junto al vídeo, modulados en FM, con una portadora distinta cada uno, en la pista de crominancia (CTDM en Betacam SP y CTCM en M-II), en frecuencias inferiores a las ocupadas por la información de vídeo. Estas canales tienen mejor relación señal/ruido, pero no se pueden editar separadamente del video.
6. VÍDEO DIGITAL
Conceptos básicos de digitalización: Distribución serie: por un solo cable coaxial se transmite toda la señal (datos multiplexados). Distribución paralelo: por un conector multipin (un sub-D de 25 pines en video digital) se
transmiten los bits de cada palabra de datos en paralelo, además de una señal de sincronización o reloj.
Regeneración: reconstrucción de una señal débil y distorsionada a partir de los datos digitales originales. La regeneración reduce la acumulación de pérdidas en cada etapa de transmisión.
La mayoría de los equipos de distribución o "de paso" de señal digital regeneran la señal. Técnicas de dispersión de errores: los datos se "barajan" o desordenan, de modo que los errores
"grandes" quedan repartidos en la señal como errores "pequeños" dispersos. Códigos de corrección de errores: datos redundantes añadidos a la señal que permiten corregir
errores "pequeños". Disimulo de errores: cuando las técnicas de dispersión y los códigos de corrección no son
suficientes, mediante interpolación "se inventa" el dato perdido como aproximación entre el anterior y posterior.
Multigeneración: Se pueden hacer infinitas copias de la señal, ya que al regenerarla y protegerla de errores ningún dato cambia en cada nueva generación.
Conversión A/ D: Muestreo: medición o toma del valor de una señal analógica en un instante determinado. Periodo de muestreo (Ts): tiempo transcurrido entre la toma de dos muestras consecutivas.

Frecuencia de muestreo (fs): número de muestras por segundo: fs= 1/Ts.El muestreo genera copias del espectro (réplicas espectrales) de la señal muestreada trasladadas
a+-fs y sus múltiplos.
Aliasing: solape entre réplicas espectrales de una señal al tomar fs, demasiado baja. Teorema de Nyquist: ( fs>=2*BW). La frecuencia de muestreo debe tener al menos, un
valor doble al ancho de banda de la señal en banda base (tambien se puede considerar como f maxima a transmitir) para evitar el aliasing.
El ancho de banda de la señal a muestrear está limitado, por lo que se introduce un filtro paso bajo (llamado "antialiasing") que elimina las frecuencias superiores a la máxima que se puede muestrear.
Sample & Hold (muestreo y retención): un circuito eléctrico mantiene constante ("retiene") el valor de la muestra desde que se toma hasta que llega la siguiente. Mantener el nivel constante durante ese periodo es necesario para darle tiempo al circuito para generar el dato digital.
Cuantificación: asignación de un valor discreto (digital de N bits) a la muestra. Cuantos más bits, con mayor precisión se dará ese valor: nº de niveles de cuantificación= 2
elevado a n. Error o ruido de cuantificación: diferencia entre el nivel real y el nivel de cuantificación asignado.
Las únicas pérdidas de calidad que produce la digitalización es el ruido de cuantificación, por eso siempre se intenta cuantificar con el mayor número de bits posible.
Codificación: asignación de un código digital a cada muestra cuantificada.El código permite adaptar la secuencia binaria generada tras la cuantificación al canal o medio de transmisión o grabación, en función de las peculiaridades técnicas del mismo.
Conversión Digital Analógica (D/A).Conversor D/A : genera un nivel de tensión proporcional al dato codificado y lo mantiene constante hasta que llega el siguiente dato. Su salida es una señal escalonada.Filtro paso bajo recuperador: filtro que elimina las réplicas espectrales que se generaron el muestreo, dejando sólo la banda base. En la práctica, suaviza la forma de la señal escalonada.El filtro recuperador debe tener una frecuencia de corte (frecuencia límite a partir de la cual no pasa señal) igual o inferior a la mitad de la frecuencia de muestreo.
Fundamentos de la norma ITU-R BT-601 (CCIR 601, 4:2:2) para 625/25: Digitaliza Y, Cb (B-Y) y Cr (R-Y).Se mantiene la estructura clásica de 625 líneas repartidas en 2 campos.Cada campo pasa de 287,5 a 288 líneas de vídeo activo (de 575 a 576 líneas / cuadro), al tomar como imagen activa las líneas 23 y 623 enteras (y no la mitad como en analógico).El borrado vertical del campo 1 tiene 24 líneas y el borrado vertical del campo 2 tiene 25 líneas para mantener la estructura de 625 lineas / cuadro.La amplitud de Y se ajusta a un rango que va de 0 a 1.B-Y y R-Y son bipolares, por lo que su amplitud se ajusta entre -0,5 y +0,5, convertidas en Cb y Cr.Los coeficientes ponderadores para pasar de B-Y a Cb y de R- Y a Cr se calculan a partir de los valores máximos que puedan alcanzar con las barras del 100%.
Cuantificación en la norma 601:Norma BT-601-1: cuantifica con 8 bits (1982).8 bits/muestra = 16 millones de colores, calidad excelente. Esta cuantificación puede ser insuficiente para algunas aplicaciones de postproducción y en los keys o chroma-keys.Norma BT-601-3: cuantifica con 10 bits (1992).La norma de 10 bits se utiliza en instalaciones digitales de nueva generación y en el estándar de conexión serie entre equipos (SDI). El uso de sólo 8 bits queda para los formatos de vídeo comprimido y la difusión digital.Cuando la señal de 8 bits se pasa a 10 bits se introducen los datos "00" en los dos bits menos significativos (LSB).Niveles de cuantificación reales de la señal: Son menos de los que permite el número de bits, porque algunos se reservan para palabras de sincronización, sobreniveles y otros usos.En Y se cuantifica con 876 niveles y en Cb y Cr con 896 niveles (de los 1024 posibles).
Frecuencias de muestreo de la norma 601:La frecuencia de muestreo depende, según Nyquist, del ancho de banda que se desee transmitir.Para Y se elige BW=5,5 Mhz y fs=13,5 Mhz (BW teórico de hasta 6,75 MHz).Para Cb y Cr se elige BW= 2,75 Mhz y fs=6,75 Mhz (BW teórico de hasta 3,375 MHz).

El BW puede ser superior para la fs dada, pero como los filtros antialiasing y recuperador serían difíciles de implementar, se establecen los BW indicados como los mínimos que se deben cumplir.Al uso de estas frecuencias de muestreo se le llama "norma 4:2:2".Las frecuencias de muestreo son las mismas para sistemas 625/25 y 525/30.
Familias de muestreo derivadas de la norma 601:4:4:4: muestrea las 3 señales con fs= 13,5 MHz. Habitual en entornas de grafismo e imprescindible si se trabaja con los componentes RGB.4:2:0: muestrea Cb y Cr (las dos) con fs = 6,5 MHz, pero sólo en líneas alternas.Reparte la pérdida de resolución de color por igual en horizontal y en vertical.Este muestreo es el que se utiliza en difusión digital.4:1:1: muestrea Cb y Cr en todas las líneas con fs = 3,375 MHz (BW = 1,375 MHz). Pierde resolución de color sólo en horizontal, por lo que la calidad visual es peor que en 4:2:0. Es más adecuado para una señal que luego tendrá difusión analógica, pues respeta el BW de I y Q en NTSC o de U y V en PAL sin perder resolución vertical.4:1:0:muestrea Cb y Cr con fs = 3,375 MHz (BW= 1,375 MHz) y además sólo en líneas alternas. No se emplea en producción ni difusión, pero es consecuencia de pasar una señal de 4:2:0 a 4:1:1 o viceversa (se acumulan las pérdidas de señal de cada tipo de muestreo).4:2:2:4, 4:4:4:4: muestrean Y, Cb Cr y K, donde K es un canal de key o alpha.El canal de key debe muestearse siempre con la misma calidad que el canal Y.
Estructura de datos de la norma 601:Aplicando el muestreo 4:2:2, se genera una señal que tiene 1728 palabras de datos por línea, de las que 1440 son de vídeo activo. Cada palabra o muestra dura 37 ns y tiene 10 bits.El sistema se gobierna con un reloj de 27 Mhz (27 Mhz = 1/37 ns).La estructura de cada línea es así: 4 palabras EAV+ 280 palabras aux. + 4 palabras SAV + 1440 muestras de vídeo activo.SAV = Start of Active Video, indica el inicio de la parte de señal con vídeo activo.EAV = End of Active Video, indica el fin de la parte de señal con vídeo activo. Además se toma como referencia de inicio de línea digital.Las 1440 muestras de video activo corresponden a: 720 muestras Y + 360 muestras Cb + 360 muestras Cr.Las muestras se toman así: [Cb0 - YO - Cr0] - [Y1] - [Cb2 - Y2 - Cr2] - [Y3]-, etc...Es decir las 3 componentes en las muestras pares y sólo Y en las muestras impares,Hay 1728 palabras/linea = 1.080.000 palabras/cuadro = 27 Megapalabras/segundo = 270 Mbps."Horizontal Ancillary Data" (HANC): son 280 palabras de datos auxiliares por línea que se transmiten durante el periodo de borrado horizontal en todas las líneas. El HANC puede ser ocupado por datos de usuario, permitiendo transmitir hasta 5,4 Mbps."Vertical Ancillary Data" (VANC): son 1440 palabras de datos auxiliares por linda que se transmiten durante el periodo que correspondería al vídeo activo en las 49 líneas de¡ borrado vertical. En el VANC se transmiten datos de código de tiempos, códigos de protección y otra información opcional pudiendo ser ocupado el resto con datos de usuario, hasta 1,7 MBps.En total: HANC + VANC = 7,3 MBps (21% del total de señal).En los HANC + VANC se pueden transmitir hasta 8 canales AES/EBU (interfaz digital de audio: 1 canal AES/EBU = 2 canales audio con fs = 48Khz y hasta 24 bits/muestra).
Señal 601 para 16:9:Se puede conseguir el efecto 16:9 de dos formas:Señal anamórfica sin modificar las frecuencias de muestreo, sólo se expande la señal en horizontalSeñal 16:9 "autentica", se multiplican por 4/3 las frecuencias de muestreo y el número de muestras.En el modo 16:9 "autentico", las frecuencias de muestreo del sistema 4:2:2 son:
fs(Y)=18Mhz;fs(Cb)=9 mhz;fs(Cr)=9 MhzSe genera una señal con 2304 muestras por línea y 360 Mbps.
Interfaz SDI (Serial Digital Interface) ITU-R 656:•Interfaz estandarizado que transmite íntegra la señal de 270 Mbps de la norma 601.Serializa los bits de cada palabra de datos (10 bits/palabra),una tras otra.•La señal recibe un código de aleatorización que la protege de errores y mejora el BW de transmisión. Admite tiradas de más de 200 m de cable (el formato paralelo da problemas a partir de 10 m).Es el estándar de interconexión entre equipos en ámbito profesional.Hay una versión de la norma SDI para la relación de aspecto 16:9, con señal de 360 Mbps.
Señal de vídeo compuesto digital:

La frecuencia de muestreo es fs=4*fsc (4 veces la frecuencia subportadora), por lo que habrámuestreos distintos en PAL y NTSC:fs (PAL) = 4*4,43= 17,73 MHzfs (NTSC) = 4*3,58 = 14,32 MHzEn PAL se toman 1135 muestras de vídeo activo por línea, en NTSC se toman 910 muestras.Es un formato en declive, pues se tiende a utilizar señales en componentes y conexiones SDI.
7. GRABACION MAGNETICA DE VIDEO DIGITALFundamentos de la grabación de señal digital:El BW de la señal digital es muy grande para ser grabado tal cual en una cinta de vídeo. Las soluciones que se aplican para lograrlo, en todos ¡os sistemas, son:1 º: Reducir el tamaño del entrehierro (partículas magnéticas más pequeñas: cintas de metal). 2º: Aumentar la velocidad de arrastre de la cinta.3º: Aumentar el número de cabezas del tambor que graban grabando varias pistas a la vez, de modo que el elevado régimen binario se reparta entre ellas.4º: Aumentar la velocidad de giro del tambor volviendo a un sistema segmentado.5º: Grabar pistas más estrechas, gracias a que la señal digital es menos sensible al ruido.Al régimen binario dé video de entrada se le aplican sistemas de protección de datos: redundancia y aleatorización. Después se reparte entre varios "canales internos", uno para cada cabeza.El DT requiere, como en vídeo analógico, cabezas dinámicas.En algunos sistemas económicos se logra la pausa y la cámara lenta sin introducir DT, sólo con TBCs de memoria de campo o de cuadro.Algunos formatos incluyen la edición con prelectura (preread): las cabezas DT leen antes que las cabezas de grabación y permiten, en la misma pasada, reproducir una pista y grabarla inmediatamente después. Su utilidad es que con un solo VTR podemos insertar rótulos, modificar la imagen, etc.El audio también es digital: las pistas de audio se intercalan con las del vídeo helicoidal, siendo grabadas con las mismas cabezas.Aunque se graban consecutivas, las pistas de audio y video están separadas, por lo tanto pueden ser editadas independientemente (el audio FM analógico de Betacam SP y M-II comparte las pistas con el vídeo mediante multiplexación en frecuencia, por eso no se puede editar por separado)La grabación de audio en pistas helicoidales permite grabar sonido de alta calidad: en la mayoría de los formatos se pueden grabar 4 canales digitales con fs de hasta 48 kHz y al menos 16 bits/muestra. Como los errores en el sonido son mucho mas perceptibles, cada sector de audio se araba 2 en zonas distintas de la cinta.El sonido grabado en pistas helicoidales no puede reproducirse a alta velocidad. Por eso se graba una pista analógica longitudinal de baja calidad (llamada audio CUE) para facilitar la búsqueda en edición.
Formatos de vídeo digital sin compresión:A la grabación digital sin compresión se le llama transparente. Las grabaciones transparentes no tienen límite de generaciones: los datos binarios se respetan al 100% en cada copia.La grabación transparente es muy cara, se usa sólo en instalaciones de postproducción de alto nivel.El formato D-1 graba 600 líneas/cuadro de vídeo digital en componentes 4:2:2 y 8 bits/muestra.Los formatos D-2 y D-3 graban 604 líneas/cuadro de video digital compuesto con muestreo de 4*fsc (17,7 MHz en PAL) y 8 bits/muestra.El uso de señal compuesta reduce aproximadamente a la mitad el régimen binario que se graba, pero incorpora todas las limitaciones y problemas del PA L.El formato D-5 graba 604 líneas/cuadro de señal digital en componentes 4:2:2 con 10 bits/muestra. Puede grabar señal 16:9 muestreando a 18 MHz en Y y a 9 MHz en Cb y Cr, con muestras de 8 bits.El D-5 es el formato de mayor calidad del mercado para imagen de definición estándar.Existe un formato de grabación transparente de video digital en componentes para resoluciones de alta definición. Es el D-6 , y graba más de 1 Gbps.Este formato se utiliza en postproducción de vídeo de alta definición y cine digital.
Formatos con compresión intracuadro “suave”:Se considera compresión suave si el ratio de compresión no es superior a 3:1.Si la compresión es suave, la calidad de la imagen no se resiente, la señal puede acumular muchasetapas de procesado sin pérdidas, aunque no admite un número ilimitado de generaciones como la grabación transparente.El formato Betacam Digital comprirne 604 líneas/cuadro de señal SDI (4:2:2 con 10 bits/muestra) con un ratio 2:1. El flujo binario resultante es de aproximadamente 125 Mbps.

La calidad del Betacam Digital es tal que permite trabajar con 10 bits de precisión pese a la compresión aplicada, dando alta fidelidad de los datos incluso en los LSB.La calidad final de un formato en componentes con compresión suave es superior a la de un formato transparente en vídeo compuesto, siendo este uno de los motivos por los cuales el Betacam Digital ha triunfado comercialmente sobre los D-2 y D-3.El Betacam Digital graba pistas relativamente anchas (26 m) con bandas de guarda entre pistas. Los formatos D-3 y D-5 carecen de bandas de guarda y graban pistas más estrechas (18m) lo que los hace más sensibles a los errores mecánicos.El formato Digital-S o D-9 graba 604 líneas/cuadro de señal 4:2:2 con 8 bits/muestra y ratio de compresión 3,3:1. El flujo binario resultante es de 50 Mbps.La compresión es mayor que en Betacam Digital pero sigue siendo suave. Gracias a ello, la calidad de imagen es tan buena como la de Betacam Digital pero con menos de la mitad de régimen binario.Digital-S sólo utiliza 8 bits/muestra. Si utilizase 9 ó 10 bits/muestra, debido a la limitación a 50 Mbps, la precisión de los LSB; sería muy baja, pues la compresión necesitaría ser mayor y, por tanto, la señal sería menos fiel a la original.Por este motivo el Digital-S no es adecuado para aplicaciones de postproducción que impliquen procesado complejo de la señal.El formato DVCPRO graba una señal similar a la del formato Digital-S, también con 50 Mbps, por lo que los resultados cualitativos de ambos formatos son idénticos.
Formatos con compresión intracuadro “elevada”:Cuando es necesario reducir mucho el régimen binario, se evalúa si es mejor comprimir más, con menos fidelidad, o comprimir menos información, pero con más calidad.La familia de formatos DV reduce un 25% la cantidad de información a comprimir muestreando 4:2:0 o 4:1:1 en lugar del 4:2:2 de la norma 601.El ratio de compresión de los DV es 5.1, obteniendo un régimen binarlo de 25 Mbps.Si comprimieran señal 422, el ratio sería de 6,6:1 y la pérdida de calidad de las muestras sería mayor que la pérdida por la reducción del muestreo.Estos formatos sólo graban 576 líneas/cuadro (sólo digitalizan el vídeo activo). Debido a esto, la información que haya en las líneas del borrado vertical se pierde.El formato DV doméstico graba muestras de 8 bits en modo 4:2:0. Las pistas del DV son muy estrechas (10 m), lo que condiciona la recuperación de datos en condiciones adversas.El formato DVCAM graba muestras de 8 bits en modo 4:2:0. Aumenta el ancho de pista respecto al formato DV (15 m) procesando la señal exactamente igual.El formato DVCPRO graba muestras de 8 bits en modo 4:1:1. Las pistas son más anchas que en DV y DVCAM (18 um) y añade 2 pistas longitudinales CTI y audio CUE.El muestreo 4:1:1 es Broadcast para difusión analógica y el 4:2:0 es Broadcast para difusión digital.Debido a la alta compresión de estos formatos, es posible editar o volcar las grabaciones sin descomprimir la información (interfaz Ilink, Firewire o IEEE 1394), de manera que se acumule e¡ menor número posible de etapas de compresi6n-descompresión.Este interfaz permite transmitir datos a 100 Mbps por lo que, si el magnetoscopio es capaz de ello, se pueden volcar imágenes a 4X la velocidad nominal.
Formatos con compresión intercuadro:Las técnicas de compresión intercuadro, tipo MPEG-2, requieren un sistema de predicción muy complejo pero son más eficaces que ¡as intracuadro.En la compresión intercuadro, la información comprimida de un grupo de cuadros (llamado SOP) está referida a los datos del primero de esos cuadros. Al editar no se pueden romper los GOPS, sino que deben tomarse secuencias GOP completas, Si los GOPs son muy cortos (de 2 cuadros, por ejemplo) se reduce el tamaño de las secuencias de edición pero la compresión es menos eficazPor este motivo la mayoría de los formatos de grabación de video digital comprimido utilizan técnicas de compresión intracuadro.En la actualidad se han desarrollados sistemas de edición muy sofisticados que permiten regenerar los GOPs que se graban en cinta si estos son pequeños, de modo que se pueda editar con precisión de cuadro como en los sistemas de compresión intracuadro.El formato Betacam SX graba 604 líneas/cuadro de seña! 4:2:2 con 8 bits/muestra con compresión intercuadro y ratio 10:1, obteniendo un régimen binario de sólo 18 Mbp . La técnica de compresión es MPEG-2 4:2 P@ML (perfil 4:2:2 y nivel principal) con GOPs IB (IBIBIB...).Pese al elevado régimen de compresión, la calidad de imagen es superior a 1,7 de los formatos de la familia D V y se puede considerar como formato de calidad Broadcast en difusión analógica y digital.Debido a la alta compresión, el Betacam SX es muy sensible a las pérdidas de calidad en etapas de compresión / descompresión, pero en edición convencional al corte (informativos), donde no se descomprime la información, o en emisión resulta excelente.

El formato Betacam SX puede incorporar cabezas extra para reproducir Betacam SP, y hay equipos capaces de volcar información a 4x la velocidad nominal.
8. MEZCLADORES DE VíDEO.
Función de un mezclador de vídeo: Seleccionar una o varias señales de entre varias entradas, realizar combinaciones entre ellas,
aplicarles efectos visuales y dar al final una sola señal "de programa" como salda. Un mezclador no realiza desplazamientos espaciales ni deformaciones geométricas de la imagen, Otras funciones disponibles en algunos mezcladores:
- Dar salidas `auxiliares ` para monitorado, pantallas en plato, dar señal a otros equipos, etc.
- Dar referencia de sincronismos a la sala o estudio (trabajo en modo “genlock”)- Intarcomunicación (del realizador con el plató, control de cámara, etc.)
Elementos fundamentales de un mezclador de vídeo: Matriz de conmutación interna: dispositivo que conmuta entre 'm" señales de entrada hacia "n"
salidas.Cualquiera de las señales de entrada puede ir hacia cualquiera de las salidas .La misma entrada puede ir hacia distintas salidas a la vez. La conmutación se produce durante el periodo de borrado vertical para que no sea visible (para hacerlo bien, todas las señales deben estar sincronizadas).
Bus: fila de botones donde se selecciona, de todas las entradas, la señal de una salida de la matriz.
Módulo Procesador de señales: dispositivo que recibe la salida de al menos dos buses de la matriz, y realiza un procesado entre ellas: mezcla, cortinilla, key, etc., dando lugar a una señal única de salida de dicho módulo.
Banco de mezcla / efectos: conjunto formado por al menos dos buses y un módulo procesador de señal (que recibe las salidas de dichos buses). También puede recibir alguna señal directamente desde el exterior, sin pasar por la matriz.
Mezclador de vídeo básico: Es un banco de mezcla con 2 buses y un módulo procesador de dos señales.
La señal de salida del banco la da el módulo procesador siendo dicha señal siempre la salida de uno de los dos buses o una transición entre ellos.
Transición: paso gradual de la señal de un bus a la del otro, durante el cual las señales de ambos buses están en salida.
Transición por corte: cambio brusco de una señal a otra, como la conmutación de una matriz (por lo que, estrictamente, un corte no es una "transición").La transición por corte puede realizarse en un solo bus, no necesita hacerse en un módulo de
procesado. Mezcla o encadenado: paso gradual y uniforme (en toda la imagen a la vez) de la señal de un bus
a la del otro. Fundido: mezcla donde la señal del segundo bus es un color uniforme generado por el
mezclador.El utilizado mas frecuente es fundido a negro (Fade To Black FTB). Con frecuencia se le llama, incorrectamente, fundido a la mezcla.
Cortinilla: paso gradual de la señal de un bus a la de otro bus según un patrón visual (cortinilla) que genera el mezclador.
Tipos de buses de un mezclador de vídeo: Bus de Programa (program, PGM): su salida es siempre la salida de vídeo del mezclador, excepto
durante una transición, donde también forma parte de la salida la señal del bus de preset. Bus de preselección (preset, PST): su salida es la señal que sustituye a la seleccionada en el bus
de programa al hacer una transición, formando parte de la señal de salida sólo durante dicha transición.
Bus de Previo (preview, PVW): bus que se utiliza exclusivamente para que el operador pueda monitorar cualquier señal que circula por el mezclador o ensayar una transición o efecto. Antiguamente las funciones de PST y PVW se hacían por el mismo bus (y el bus se llamaba indistintamente PST o PVW). Es frecuente que se le llame “previo" al 'preset' aunque no al contrario.
Bus auxiliar (AUX): bus cuya salida va directamente fuera lel mezclador, Por la que se puede enviar cualquier señal que circula por el mezclador. No afecta a la señal de salida de programa.

Módulo procesador de key (keyer): Un módulo procesador de key (keyer) realiza la incrustación de parte de una señal de video sobre
otra, siguiendo el patrón que determine una de ellas o una tercera. En una incrustación intervienen 3 señales:
o Fondo (background, BKG): señal de vídeo sobre la que se hace la incrustación.o Relleno (video FILL o solo FILL) señal de vídeo que se incrusta sobre el fondo (BKG)o Recorte (key source o sólo KEY) señal B/N que determina sobre qué parte de la señal de
fondo (BKG) se incrusta la señal de relleno (FILL). La parte negra de la señal KEY la ocupa la señal BKG y la parte blanca la señal FILL, aunque el efecto puede invertirse o ser gradual (señal KEY con gama de grises).
Formas de obtener la señal de key (recorte):o Key externa (EXT KEY): el equipo que genera la señal FILL (titulador, DVE, paleta grafica,
etc.) tambien genera la señal de KEY y ambas entran por separado. Es la técnica que permite realizar las incrustaciones de mayor calidad.
o Key de luminancia (LUM KEY): si no hay señal de key especifica, se toma como key la lunimancla de la señal FILL.
o Key de crominancia (CROMA KEY): se genera la señal key a partir de un color concreto presenteen la imagen FILL (habitualmente verde o azul), de modo que lo que no sea de ese color
en laimagen FILL se incrustará sobre el BKG.
Bus de key (key bus): bus doble, en el que se seleccionan las señales KEY y FILL que van a un keyer. Ambas se seleccionan con una sola pulsación, ya que en la configuración de¡ mezclador se asocia a cada señal de FILL la señal de key con la que va a trabajar.
Estructura típica de un mezclador de vídeo: Banco de mezcla/efectos (M/E): tiene 2 buses de fondo (A y B) y uno o más buses de key. Todos
ellos van a un módulo procesador, cuya salida vuelve a la matriz para entrar a otros bancos, de modo que se puedan acumular varias capas de efectos.
Banco de preset/program (PST/PGM): tiene 2 buses de fondo (preset y program) y a veces uno o varios buses de key. Todos ellos van a un módulo procesador, cuya salida es la salida final de¡ mezclador (excepto si hay DSK y FTB).
Downstream keyer (DSK): procesador de key situado después del banco PST/PGM, que aplica la última incrustación antes de que la señal salga del mezclador. Puede haber varios "en cascada".Algunos mezcladoras unifican el banco PST con el DSK dándole un formato similar al de un banco M/E más. En estos casos, los procesadores de key que incorpora dicho banco se llaman DSK.
Clean feed: señal de salida del banco PST/PGM, sin aplicación de DSKs, disponible como salida separada e independiente de la salida PGM final.Como la mayoría de las incrustaciones de títulos se hacen en los DSK, es útil disponer de una salida 'limpia " para la distribución o almacenamiento de la señal.
Fade to black (FTB): procesador que lleva a negro la salida de programa del mezclador, incluyendo efectos, keys y DSKs. Es la última etapa de procesado de todo mezclador profesional.
9. EDICIÓN DE VÍDEO
Fundamentos de la edición electrónica:Edición por corte : se sustituye la señal grabada desde el inicio de un campo, es decir, a partir del inicio de una pista en los formatos no segmentados.En los formatos segmentados (como los digitales) se edita desde la primera pista del “grupo de pistas" al que pertenece cada campo (no se puede editar a mitad de campo).Sincronización entre reproductor y grabador: es necesario que ambos VTRs inicien en el mismo instante temporal la exploración de cada pista.Pista CTL : pista longitudinal con impulsos que marcan el inicio de cada campo (sincronizan los VTRs).Punto de entrada: campo en el que el grabador deja de reproducir para comenzar a grabar la señal del reproductor.Si el formato es de vídeo compuesto o si, siendo en componentes la conexión es a través de señal PAL, el punto de entrada elegido se puede desviar varios campos para cumplir la secuencia PAL.Pre-roll: tiempo de reproducción previo al punto de entrada, necesario para estabilizar y sincronizar el funcionamiento mecánico de ambos VTRs (servo lock).La duración del pre-roll depende de la calidad mecánica del equipo, de su mantenimiento y del formato cuanto mejor sea menos tiempo hace falta (en Betacam puede trabajarse con 3 sg).

Modo "electrónico-electrónico" ("e-e" o "e to e"): la salida de vídeo del grabador, cuando no está reproduciendo (es decir, cuando está parado o grabando), es la misma señal que recibe de entrada.Modo "confidente": si el equipo tiene cabezas de dynamic tracking (DT), las utiliza para reproducir la señal grabada inmediatamente después de que pase la cabeza grabadora por la pista.
Edición por corte: Formateo de una cinta: se graba una señal de vídeo (barras o negro) y audio (tonos o silencio) en
toda la cinta, así se le da una estructura de pistas de vídeo y, lo más importante, de pulsos CTL. Ensamble (assemble): se graban todas las pistas a la vez (vídeo, audio, CTL y TC), es decir, según
se graba se formatea la cinta. El corte en el punto de entrada es limpio ("engancha" con los impulsos previamente grabados), pero el corte de salida estropea el formateo de la cinta. No se debe editar por assemble si la cinta esta formateada, pero es necesario hacerlo si no lo está.
Primera edición (first edit ): Primera grabación "a lo bruto" (REC+PLAY) para iniciar el formateo de la cinta virgen. Después se sigue por assemble (la "first edit" es necesaria para poder hacer pre-roll).
Inserto (insert): se borran las pistas que se van a sustituir (de vídeo, canales de audio y/o LTC), pero nunca el CTL, por lo que no se altera el formateo de la cinta. Los cortes de entrada y de salida son limpios. Se pueden editar por separado el vídeo, cada canal de audio y el LTC.Si en un inserto se llega a un punto de la cinta sin formatear o con pulsos CTL defectuosos la edición se parará, por eso es necesario el formateo previo.
Audio split: grabación en la que el punto de entrada (y/o salida) elegido para la grabación de una o varias pistas de audio es distinto del punto elegido para el vídeo.El audio FM grabado en pistas helicoidales de vídeo analógico (canales 3 y 4 en M-II y Betacam SP) no ocupa pistas independientes por lo que no se puede editar separado del vídeo.
Uso de los códigos de tiempos: LTC (TC longitudinal): puede ser leido a velocidades altas, pero da problemas a baja velocidad. VITC (TC en líneas de borrado V): puede leerse a baja velocidad y en pausa, pero no a alta
velocidad. Si hay grabados LTC y VITC iguales, debe elegirse el modo "auto". Si sólo se ha grabado uno de
los dos tipos de TC o si son diferentes, se elige el adecuado.
Interfaces analógicos de señal de vídeo: PAL (CVBS, CCV5, vídeo compuesto): debido al reducido BW en C, la intermodulación Y-C y las
secuencias de 8 campos, no es recomendable si hay conexiones alternativas. Componentes analógicos: el más adecuado en postproducción para formatos en componentes
analógicos (señal posterior al TBC). Dubbing: señal que procede directamente de la demodulación de las cabezas de vídeo, sufriendo
el menor número de alteraciones posible. No pasa por TBC, lleva Y y C separadas (evita la intermodulación), pero no está disponible en todos los formatos. Es adecuado para el montaje por corte, pero no es utilizable en postproducción, ya que no son señales normalizadas.
Y/C o S-video: lleva por separado Y y C según la norma PAL. La única ventaja sobre el PAL es que evita la intermodulacón Y-C. Es adecuado para conectar equipos de formatos diferentes si no es posible conectarlos en componentes.
Interfaces digitales de señal de vídeo:SDI: señal de máxima calidad, la más adecuada para formatos digitales sin compresión o de compresión suave (Betacam Digital), y para postproducción en cualquier formato. Es el estándar actual en instalaciones digitales de alta calidad.Digital paralelo (PDI): cualitativamente es una conexión equivalente al SDI, pero resulta más incómodo: conectores grandes (sub-D de 25 pines), cables de como máximo 10 metros, etc. Presente en pocas instalaciones y tendente a desaparecer.Vídeo digital serie comprimido: Firewire, Ilink, IEEE 1394, QSDI, SDDI, SDTI, etc. Cuando se trabaja con formatos de alta compresión (familia DV, Betacam SX), es conveniente evitar, en la edición o al volcar a servidor, la acumulación de etapas de compresión-descompresión, por lo que siempre que sea posible se debe utilizar un interfaz digital directo. No son válidos para postproducción.
Edición A/B-roll: Elementos mínimos necesarios: 2 VTRs reproductores, 1 VTR grabador, 1 controlador de edición,
1 mezclador de vídeo, 1 mezclador de audio, 1 generador de sincronismos (black-burst) y 1 WFM/vectorscopio.
Modo master-slave : el grabador funciona como "master" y los reproductores son "slaves". La editora recibe impulsos basados en los CTL o TC de¡ grabador "master" y envía los impulsos de

referencia a los "slaves". Si existe una señal de referencia de sincronismos en la instalación, sólo el grabador "master" estará conectado a ella.
Modo sin editor: los reproductores y el grabador se sincronizan siempre con respecto a la señal black-burst de referencia de la instalación, por lo que la editora no controla la sincronización de equipos, solo los puntos de entrada y salida.
GPI: General Purpose Interface. Señal que activa una función programada en el equipo que lo recibe.
Los GPI los genera el controlador de edición para activar una función de un equipo en un instante determinado (cambio de página en un titulador, iniciar la transición de un mezclador etc.). Existen interfaces mas sofisticados que permiten controlar muchas mas funciones a través de una comunicación serie o paralelo, pero con grandes limitaciones de compatibilidad entre fabricantes.
El controlador de edición gobierna los VTRs (sincronizándolos o no) y dispara mediante GPIs (o por un sistema de control más sofisticado) la transición de los mezcladores de vídeo y audio.
Audio en ediciones A/B-roll:Modo AFV (Audio Follow Video): los puntos de entrada, de salida y las transiciones de audio y vídeo son los mismos. Existen mezcladores AFV que manejan a la vez imagen y sonido.Modo audio separate: Se utilizan mezcladores de audio y vídeo separados, que pueden hacer transiciones en momentos distintos. Es la solución más flexible.
Función "preview":El preview consiste en monitorar una simulación de la edición sin grabarla, para evaluar si es válida o debe modificarse.
- Puede verse en el monitor del grabador. la conmutación 'e-e" o el modo 'confi, nos la da automáticamente.
- Puede verse en la salida de programa del mezclador. Para ello la salida del VTR grabador debe entrar al mezclador para que este pueda simular desde la señal ya grabada a la nueva a grabar.- Puede haber un monitor exclusivo para esta función. La señal entra en el desde un selector específico para esta función o desde una salida dedicada de algunos mezcladores. Sólo es razonable en instalaciones muy sofisticadas.
En todos los casos, el equipo que da la imagen "preview" es gobernado por el controlador de edición. Según el modelo de controlador, estará disponible una o varias formas de hacer el "preview".
Conceptos de postproducción: No existe una definición concreta de sala de postproducción. No es más que una sala A/B-roll
"más sofisticada". Elementos típicos de una postproducción lineal clásica: controlador de edición, 2 o más VTR
reprodúctores, 1 VTR grabador, mezclador, de vídeo, mezclador de audio, generador de efectos digitales (DVE), generador de caracteres, fuentes de audio (DAT, CD, magnetofón, MD, etc.), paleta gráfica, biblioteca de imágenes fijas (still-store), etc.
Edición o postproducción lineal: los soportes de reproducción y grabación son VTRs (acceso secuencial).
Edición o postproducción no lineal: el soporte de grabación es un servidor de vídeo con grabación en disco duro (acceso aleatorio).
Volcado a servidor: paso de las grabaciones en cinta de vídeo que se van a utilizar a un servidor de vídeo, en el cual se hará el proceso de edición o postproducción.Alqunos formatos digitales permiten realizar el volcado a velocidades superiores a la de
reproducción. Edición híbrida: se reproduce señal desde un VTR y se graba en un servidor de vídeo, pero sin
hacer un volcado previo. Suele emplearse en trabajos de poca complejidad para ahorrar tiempo (informativos).
EDL (Edit Decision List): listado con los puntos de entrada y salida de todas las señales utilizadas en la postproducción de un programa, así como de los efectos empleados.La mayoría de los controladores de edición generan la EDL electrónicamente y la almacenan en disco. De ese modo puede repetirse automáticamente, haciendo las modificaciones que sean necesarias, e incluso se puede hacer en una sala diferente.
Edición on-line : se llama así a la grabación "master" elaborada si se trata del programa final que va a ser emitido.
Edición off-line: la grabación que se realiza es sólo un "borrador de trabajo. Se emplea un formato de bajo coste y una sala de bajas prestaciones. Se genera una EDL que se empleará para hacer una edición on-line posterior rápidamente (en una sala de alto coste), sin perder tiempo en meditaciones creativas.

Postproducción en PC: el PC es el controlador de edición. En equipos modernos y con formatos comprimidos algunos sistemas permiten realizar algunos procesados de señal (mezclador, DVE, títulos, etc.) desde el PC, aunque con tiempos de renderización elevados (como contrapartida del bajo coste del sistema).
Postproducción en estaciones de trabajo: están orientadas a procesar la señal, por lo que son mucho más rápidas (y caras) que el PC. Frente a una edición clásica con equipos dedicados, es más flexible y económica, pero no se libran de la renderización en los procesos más complejos.
COMPRESIóN DE VÍDEO DIGITAL
Ventajas y limitaciones de la compresión de vídeo digital: La compresión abarata el almacenamiento de la señal en cinta o disco. La compresión facilita la transmisión y difusión: ahorro de BW e incremento del número de
canales. Por las limitaciones técnicas actuales, es imprescindible comprimir la información en algunos
medios: formatos de grabación en cinta de ¼” grabación en disco duro, difusión en canales de 8 MHz, etc.
Se producen pérdidas de calidad que dependen de:La técnica de compresión (las compresiones intercuadro son más eficaces que las intracuadro).El ratio de compresión (cuanto mas se comprima mayores serán las pérdidas visibles)En MPEG-2, del equipo de compresión (según la eficacia en el cálculo de los vectores de
movimiento) Las pérdidas se producen durante la compresión, nunca en la descompresión. Se acumulan las pérdidas en sucesivos procesos de compresión-descompresión. Se produce un retardo en la recuperación o la transmisión de la señal debido al procesado de la
compresión, especialmente grande en compresión intercuadro (MPEG-2).
Categorías de compresión según el nivel de pérdidas: Sin pérdidas reales: técnicas informáticas ("zip", "arj", etc.): ratio de compresión reducido e
irregular. No valida en vídeo por la irregularidad del régimen binario de salida (no se usa). Sin pérdidas subjetivas (compresión suave): máximo 3:1 en compresión intracuadro. Aunque hay
perdidas de datos, no son vísibles, admite muchas generaciones y sólo llega a apreciarse cierta pérdida de calidad acumulando decenas de conversiones
Con pérdidas subjetivas (compresión elevada): a partir de 5:1 en compresión intracuadro. Sólo se ven las pérdidas con patrones de señal específicos e inhabituales. Se producen pérdldas claras con pocas generaciones: es recomendable un interfaz directo (sin descompresión) en edición.
Categorías de compresión según la técnica empleada. Compresión intracuadro : cada cuadro de imagen es comprimido basándose en la redundancia
de la información contenida sólo en dicho cuadro. Compresión intercuadro: cada cuadro de imagen se comprime basándose en la redundancia de
la información existente en diversos cuadros anteriores y/o posteriores.
Técnicas de compresión intracuadro: JPEG, M-JPEG y similares. Redundancia espacial: repetitividad del valor de los pixeles en una imagen, por ejemplo, en
superficies de un mismo color. Si se evita transmitir la información del valor de cada píxel porque son todos iguales o porque siguen un patrón claramente predeterminado, se lograría reducir la cantidad de datos a transmitir.La compresión espacial se basa siempre en la DCT (transformada discreta del coseno).
Cada campo o cuadro de imagen se divide en 3 imágenes monocromas: una imagen con cada una de las tres componentes Y, Cb y Cr (R, G y B en entornos informáticos). Utilizar como imagen básica un campo o un cuadro sólo depende de que se utilice exploración entrelazada o progresiva.
Cada una de las tres imágenes se subdivide en bloques de 8x8 datos: 64 datos por bloque. La DCT transforma los 64 datos iniciales en otros 64 datos distintos. La DCT es bidireccional puede deshacerse al descomprimir con la DCT inversa.
La DCT da muchos valores próximos o iguales a cero: se reduce el régimen binario porque codificar ceros ocupa muy pocos datos.

Los coeficientes se pueden "redondear" para simplificarlos y obtener aún más valores iguales a cero, cuanto más se simplifiquen los coeficientes, mas valores cero saldrán y mayor será la compresión.El grado de compresión se ajusta controlando la precisión con la que se toman los coeficientes.Mayor compresión implica mayores pérdidas y menor fidelidad con la imagen original.
El JPEG es un estándar de compresión basado en la DCT, y uno de los más eficaces. Cuando se aplica cuadro a cuadro para señal de vídeo, se llama M-JPEG (Motion JPEG).
Muchos fabricantes aplican técnicas similares (siempre basadas en la DCT), pero con estructura de datos propietaria, lo que dificulta el intercambio de imágenes sin descomprimir.Técnicas de compresión intercuadro: MPEG-2:
Redundancia temporal: el valor de un píxel se repite a lo largo de varios cuadros. En MPEG-2 se añade compresión temporal a la compresión espacial por DCT: se logra mayor
eficacia (más ratio de compresión para igual calidad o más calidad para igual ratio de compresión).
Se transmiten 3 tipos de cuadros de imagen: I, P y B. Las imágenes I se comprimen exactamente igual que en M-JPEG. Las imágenes P se basan en el cuadro tipo I inmediatamente anterior. El compresor analiza la imagen I y la imagen P (predecida originalmente), detecta el movimiento
que se ha producido entre ambas y establece hacia donde y cuanto se mueve cada bloque de 64 pixeles, reflejándolo en una información llamada vectores de movimiento. Se aplican los vectores de movimiento a la imagen I lo cual da una imagen muy parecida a la imagen P original. El valor de cada píxel de esta imagen regenerada se resta de los de la imagen P original, dando lugar a la imagen diferencia, que tendrá muchos píxeles con valor igual o próximo a cero.
La transmisión de la imagen P la componen los vectores de movimiento y la imagen diferencia comprimida por DCT. El receptor aplicará a la imagen I de referencia (que tiene almacenada en una memoria) los vectores de movimiento y le sumará la imagen diferencia, con lo que recupera la imagen P.
Las imágenes B se codifican de forma similar a las P, pero los vectores de movimiento se obtienen a partir de las imágenes anterior y posterior (I o P), lo que aumenta la eficacia de compresión. Su filosofia se basa en que cuando se realizan panoramicas o desplazamineto de objetos en la escena, que por una parte desvelan partes de la escena y por otra se iran ocultando, según el caso resulta mejor tomar la imagen anterior o la posterior, lo cual complica el algoritmo pero se obtiene un gran nivel de compresión.
La compresión de imágenes P es mas eficaz que la de imágenes I, toman de referencia una imagen I o una imagen P.
La compresión de imágenes B es más eficaz que la de imágenes P, como referencia pueden tomar imágenes I o imágenes P anteriores o posteriores, si se referenciaran sobre imágenes B se acumularían los errores.
Las imágenes forman secuencias que empiezan en cada imagen tipo I. Cada cambio de plano es detectado por el codificador y se codifica como imagen I.
Cada secuencia de imágenes se llama G0P (Group Of Pictures).Si los GOP son muy largos, un fallo en el cuadro I inicial es muy grave porque se extiende a muchos cuadros (todos los del GOP), además habrá un retardo muy elevado para la transmisión.Si los GOP son muy cortos, la compresión será menos eficaz.El tamaño de los GOP es variable y se puede ajustar según convenga (típico 12).
En grabación de vídeo se usan GOP pequeños, típico IB (2 cuadros por GOP) para facilitar la edición. El betacam SX usa GOP BIBIBI, y el betacam IMX solo usa cuadros I. En difusión se puede recurrir a GOP mucho mas largos.
Los cuadros se transmiten desordenados y con un retardo de varios cuadros.

Para la técnica de descompresión, cada fabricante debe arreglárselas para obtener los vectores de movimiento con la mayor eficacia posible, con lo cual cada receptor será mejor o peor según
el fabricante.
Codificación de un macrobloque: El proceso de predicción comienza con la comparación del macrobloque actual con el correlativo
del frame anterior, si no está en esa posición lo busca en la zona de busqueda, si lo encuentra, codifica los vectores de movimiento pero si no lo encuentra codifica la diferencia con el mas parecido.
La busqueda se hace a dos niveles, un primer nivel grueso en una zona amplia y un segundo nivel mas fino en una zona mas reducida.
El codificador compara los resultados y toma las decisiones sobre el bloque identico o el mas aproximado. Pero si la diferencia es mayor que una cifra establecida presume que el bloque no se encuentra en la imagen y codifica dicho macrobloque con codificación espacial (como se hace en un I aunque el sea un P o un B).
Niveles y perfiles en MPEG-2 (Level@Profile):

MPEG-2 es un sistema de descompresión abierto que permite ajustar la calidad y la cantidad de la información al medio de transmisión o almacenamiento.
Las diferentes configuraciones de MPEG-2 se estructuran en niveles y perfiles. El nivel determina la resolución de la imagen. Para entornos 625/25, los niveles definidos son:
Low (bajo): 352*288 pixe1es.Main (principal): 720*576 pixeles (720*608 píxeles en el perfil 4:2:2).High 1440 (alto-1440): 1440*1152píxeles.Hi (alto): 1920*1152 píxeles.
El perfil determina las características de la técnica de compresión. Hasta ahora se han definido:o Simple.o Main (principal).o SNR scalable (escalable en relación señal / ruido)o Spatially scalable (escalable espacialmente).o High (alto).4:2:2.o Cada perfil es más sofisticado que el anterior, excepto el 4:2:2.o Todos los perfiles usan muestreo 4:2:0, el Main puede usar opcionalmente el muestreo
4:2:2.
Las perfiles escalables se transmiten en varias capas de calidad (escalado SNR escalado espacial
o ambos en el perfil High). En la práctica casi no se usan. El perfil 4:2:2 se definió para los ámbitos profesionales de producción, que tienen exigencias
diferentes a la difusión. o No es escalable, usa muestreo 4:22, los GOP son cortos y puede llegar a 50 Mbps.o Muestrea 606 líneas/cuadro para grabar información contenida en las líneas de borrado
vertical analógico. No se utilizan todas las combinaciones posibles entre perfiles y niveles, sólo las que se han
considerado más eficaces. Para cada combinación entre perfil y nivel se define un régimen binarlo máximo por encima del cual se debe usar otra combinación más eficaz.
La combinación entre nivel y perfil utilizados en una grabación o transmisión se expresa como: MPEG-2 *P@ **L (* es el perfil y ** el nivel).
Las dos combinaciones más comunes son:o En difusión MPEG-2 MP@ML. Máximo 15 Mbps (4:2:0).o En producción MPEG-2 4:2:2P@ML, máximo 50 Mbps.
Otras características del formato MPEG-2:o Puede trabajar en modos 4:3 y 16:9.o Puede trabajar con señal entrelazada o progresiva.o Se adapta a todos los sistemas 525/30, 625/25, 1125/25 24 fps, etc,o La norma está abierta a que en el futuro se pueden definir nuevos perfiles y niveles.
El proceso de codificación-decodificación en MPEG no es simetrico. Es mas complicado en la codificación y por tanto mas lento, mientras que el decodificar debe realizar procesos mas sencillos.

Estructura de la señal comprimida MPEG-2:Cada bloque de 8x8 datos codificados más una cabecera forman un paquete de datos.Varios paquetes de datos de bloques más una cabecera forman un paquete llamado "slice".Todos los "slices" de un campo o cuadro más una cabecera forman e¡ paquete de una imagen.Los paquetes de todas las imágenes de un GOP más una cabecera forman un paquete llamado PES(Packetized Elementary Stream).El audio y los datos asociados al canal forman también sus propias secuencias de PES.Los PES de vídeo, de audio y de datos se multiplexan en una trama llamada a (Program Stream). Un PS tiene sólo un canal de vídeo, puede tener ninguno, una o varios canales de audio, y puede llevar (o no) una trama de datos asociados.Los PS de varios canales se agrupan en una sola trama digital para su transmisión por un solo canal"físico". Esta trama, llamada TS (Transport Stream), se forma al fragmentar los PES de cada PS enpaquetes “pequeños” de tamaño fijo (188 bytes), transmitiéndose altemativamente los paquetes de cada uno de los PS contribuyentes.El número de PS que pueden agruparse en un TS sólo lo limita el régimen binario máximo que se pueda utilizar. Por ejemplo, en DVB-T se transmiten alrededor de 4 canales deTV agrupados en un canal de 8 MHz.Aunque se transmitan o almacenen los datos de un solo PS, conviene convertirlo en una trama TS de paquetes "pequeños" para garantizar la fiabilidad, ya que e¡ PS carece de protección frente a errores.Solo se conectan equipos mediante señal PS en el interior de las instalaciones de producción o emisión.En todos los agrupamientos de datos (bloques, slices, PES, etc.), las cabeceras de cada paquete llevan toda la información del origen y tipo de los datos, así como de su posición en la estructura de la señal original.La norma de difusión digital en Europa se llama DVB (Digital Video Broadcasting), basada en MPEG-2.Existen tres versiones de la DVB: DVB-S (satélite), DVB-C (cable), DVB-T (terrestre).Sólo se diferencian en las técnicas de adaptación al canal de transmisión (equivalente al concepto de modulación).
Norma DVB:o Nacio en Europa en 1990, admitida por 170 organismos de 21 paises de todo el mundo.o Permite transmitir por satelite, cable o difusión terrestre, multiprogramas en diferentes calidades
de imagen, junto con sonido digital multicanal, asi como servicios asociados (teletexto, información de programación, etc...)
o La norma DVB-T permite una unica frecuencia en todo el territorio nacional adeams de recepción movil.
o La norma DVB-B se esta utilizando en muchos otrosa paises aparte de europa aprovechando al maximo los transpondedores con soporte de MPEG-2.
o Posibilidades y características del DVB:o Triplica el numero de programas en un canal.o Posibilita Radio junto con Datos.o Permite eleccion flexible de calidad, incluyendo HDTV, sin exceder un canal.o Permite sistemas totalmente seguros de encriptado (nagra, seca, etc...)o Tecnología digital: estabilidad en transmisión, alta calidad de imagen y sonido,
integración en entorno informatico, etc...Soportes de distribución:
DVB-S: Satelite, modulación QPSK (cuatro fases cada uno con dos bit).DVB-C: Cable, modulación 64 QAM (Modulación en cuadratura, 6 bits por simbolo).DVB-T: Terrestre, modulación OFDM (multiportadoras simultaneas, 8K en España 6817
portadoras).DVB-CS (SMATV): Instalaciones colectivas, QAM/QSP.DVB-MS (MMDS): Distribución multipunto con microoondas, QAM.
DVB está construyendo el IRD (integrated receiver decoder) del futuro, se creo la MHP (Multimedia Home Plataform) una plataforma para la convergencia que quiere conseguir un equipo (set top box, TV set, PC, etc...) mediante el cual cualquier operador a traves de cualquier tipo de red pueda ser recibida y comprendida por todos los receptores.
Compresión de audio MPEG:o Se basa principalmente en el enmascaramiento de un sonido débil con uno mas fuerte.o Se divide el espectro en sub-bandas y estas se transmiten o no dependiendo de si estan
enmascaradas o si contienen energía.
Escalabilidad en MPEG-2:

o La información se estructura en capas.o La capa base contiene información principal y puede accederse con todo tipo de decodificadores
(submuestreo).o Las capas de realce se añaden para decodificadores mas complejos (mejora de calidad).o La escalabilidad permite ir mejorando la resolución, la frecuencia de cuadro, alta resolución, etc...o La capa basica se transmite fuertemente protegida, si hay deterioro de señal se pierde por capas.
Aplicaciones MPEG:MPEG-1: Video CD.MPEG-2 MP@ML: DVD, DVB.MPEG-2 4:2:2P@ML: Producción.MPEG-4: Internet.MPEG-7: Metadatos, descripción de contenidos, catalogación automática.
11. GRABACIóN DE VíDEO EN DISCO DURO.
Características básicas de los discos duros: Un disco duro se compone de una serie de discos magnéticos rígidos (entre 12 y 20), coaxiales,
con las dos caras útiles para grabación. Cada superficie se divide en pistas concéntricas (cada pista es un "anillo" de datos). Cada pista se subdivide en sectores, que son la unidad mínima de escritura de datos en un disco duro.
La velocidad de lectura depende de la velocidad de giro de¡ disco y de la densidad de los datos en la superficie del disco.La velocidad de giro es constante, y como en la zona central la cantidad de sectores por pista es menor que en los extremos, la velocidad de lectura es más baja en las pistas más próximas al centro.
El tiempo de acceso a los datos depende del tiempo de búsqueda (tiempo para el desplazamiento de las cabezas hasta la pista correcta) y del tiempo de latencia (tiempo de espera durante el giro hasta que llega hasta la cabeza el inicio del sector que debe leerse).Los tiempos de búsqueda y latencia son aleatorios, por lo que el tiempo de acceso a los datos tendrá un valor mínimo y un valor máximo según se consideren la mejor y la peor situación.
Durante la lectura de una pista, es habitual que la cabeza no lea correctamente todos los sectores, por lo que debe repetirse la pasada, lo cual ralentiza la velocidad de lectura.
Los fabricantes prometen velocidades máximas de lectura muy elevadas, pero poco fiables. En vídeo necesitamos garantizar el régimen binario que deseamos grabar de forma constante, por lo que debemos conocer la velocidad mínima de grabación/lectura del disco para evaluar su validez.
Interfaces de conexión IDE y SCSI: El interfaz IDE es el más común en los PC de sobremesa. La velocidad máxima de transferencia
de datos es de 100 MBps en su última evolución.Aunque esta velocidad parezca elevada, es un bus poco útil porque se satura con facilidad y sólo puede funcionar a la velocidad máxima en situaciones puntuales.
Sólo pueden conectarse 2 unidades de disco en un bus IDE y la velocidad de los datos se reduce notablemente si se desea acudir simultáneamente a los datos de ambos discos.Sólo se utilizan discos IDE en aplicaciones de vídeo para uso doméstico.
El interfaz SCSI es el más común en ordenadores y estaciones de trabajo profesionales. Es más complejo y caro que el IDE, pero garantiza el régimen binario de los datos en cada una de sus versiones, que es lo que interesa en vídeo.El bus SCSI puede trabajar a la velocidad máxima utilizando todos los dispositivos conectados a él simultáneamente, repartiendo entre ellos el régimen binario total.
Generaciones SCSI: se trata de un interfaz creado en los años '80, pero en la actualidad se emplean en todas las aplicaciones evoluciones de mayores prestaciones:
o Año 1995. Fast SCSI: 10 MBps (Mega Bytes por segundo), bus de 8 bits, hasta 7 dispositivos en un bus.
o Año 1996. Ultra SCSI: 20 MBps, bus de 8 bits, hasta 7 dispositivos en un bus.o Año 1997. Ultra Wide SCSI: 40 MBps, bus de 16 bits, hasta 15 dispositivos en un bus.o Ago 1998.- Ultra2 SCSI: 80 MBps, bus de 16 bits, hasta 15 dispositivos en un bus.o Ago 2000.- Ultra160 SCSI: 160 MBps, bus de 16 bits, hasta 15 dispositivos en un bus.
Cada nueva generación SCSI mantiene la compatibilidad con ¡os dispositivos de generaciones anteriores. En un bus SCSI se pueden conectar hasta 7 o 15 dispositivos (según generación).

La mayoría de los servidores de video utilizan buses Ultra Wide o Ultra2, capaces de transferir señal SDI de forma transparente (a partir de 40 MBps = 320 Mbps).Los buses más antiguos (los de 8 bits) se utilizan en ámbitos de PC o en estaciones de trabajo no orientadas a la manipulación de la señal de vídeo (CD-ROM, unidades de cinta, unidades magnetoópticas, ZIP, JAZZ, DVD), etc.
Grabación de vídeo en disco duro: La tecnología de los discos duros actuales no permite grabar en un solo disco señal SDI (270
Mbps) de forma fiable. Si se comprimen ¡os datos de vídeo, es posible grabar en un solo disco la trama binaria resultante, pero la calidad no será útil en las aplicaciones más exigentes (postproducción),
La capacidad de un disco duro es menor que la de una cinta de vídeo. Debe tenerse en cuenta, además, que el disco es un soporte mucho más caro.Por ejemplo, en un disco duro de 18 Gb podemos almacer 9 minutos de señal SDI.El sistema Betacam SX cuenta con magnetoscopios híbridos que contienen un disco duro de 18 GB que graba hasta 90 minutos de señal de video a 18 Mbps.
Debido a las limitaciones de los discos duros surge la idea de agrupar varios discos para repartir entre todos ellos el régimen binario a grabar y ampliar la capacidad de almacenamiento global del sistema.Por ejemplo, con 8 discos de 18 GB y una modesta velocidad de lectura de 5 Mbps en cada disco, podemos grabar a 9 x 5 = 40 MBps (320 Mbps) mas de 1 hora de señal SDI.
Sistema RAID (Redundant Arrays of Inexpensive Disks) de agrupamiento de discos duros: Para poder repartir los datos de una trama binaria entre varios discos es necesario coordinar el
funcionamiento de los mismos. El sistema RAID estandariza parcialmente el método de agrupamiento de los discos, de manera que de cara al usuario el conjunto de discos se comporte como si se tratara de un solo disco duro, de capacidad y velocidad mucho más elevadas que los convencionales.El sistema RAID agrupa discos duros convencionales (“discos baratos" según las siglas RAID), obteniendo prestaciones muy elevadas con un coste moderado.
Una función añadida de los sistemas RAID es la grabación de los datos con redundancia. Se generan datos redundantes basados en la información a grabar, con el fin de garantizar la lectura del sistema de discos aunque alguno de ellos falle, pues los datos redundantes permiten recuperarlos sin que sea necesario repetir la lectura, lo cual permite elevar la velocidad del conjunto.
Existen hasta ahora 7 configuraciones RAID definidas (denominadas RAID-0, RAID-1, RAID-2...). Cada una de ellas realiza la distribución de los datos entre los discos de una forma diferente, para adaptarse a distintas necesidades de uso (el sistema RAID se ha generalizado en todo tipo de aplicaciones informáticas).
El sistema utilizado para grabar vídeo es el RAID-3. En este sistema se utilizan "n" discos para grabar datos de vídeo y 1 disco extra para grabar datos redundantes. Por lo tanto, se trata de sistemas de "n+1' discos, aunque la capacidad total del sistema es la de los "n" primeros discos.Cuanto mayor sea el número “n”, más baja será la eficacia de la protección por redundancia, pero si 'n" es un número bajo la capacidad de almacenamiento y la velocidad máxima del mismo será menor. En vídeo suelen utilizarse configuraciones de 3+1 a 5+1 discos.
Servidor de vídeo: es un sistema de almacenamiento de imagen y sonido digital en discos duros, normalmente basados en RAID-3, que permite grabar y reproducir con acceso aleatorio e¡ contenido del mismo. Un servidor de vídeo puede proporcionar varios canales simultáneos de grabación/reproducci6n.
Los sistemas RAID-3 para vídeo son SCSI, normalmente de generaciones recientes (UW-SCSI o posteriores) con el fin de manejar el mayor régimen binario posible. No sólo se busca obtener acceso en tiempo real a vídeo con calidad SDI. Es frecuente que el sistema trabaje con vídeo comprimido (son típicas velocidades entre 21 y 50 Mbps) pero que se quiera acceder simultáneamente al contenido del servidor desde diferentes equipos de trabajo, de modo que muchos usuarios puedan disponer a la vez del material almacenado. El régimen binario máximo del sistema SCSI (llamado también ancho de banda) se reparte entre todos los accesos que se puedan hacer.Ejemplos de este modo de funcionamiento son las redacciones digitales de informativos o los sistemas de emisión multicanal, aunque se trabaja con vídeo comprimido, se necesita un servidor potente para proporcionar el mayor número de accesos simultáneos posibles. En otros casos lo que se quiere es acceder a los datos grabados con velocidades superiores a la de reproducción, para realizar un volcado a la máxima velocidad posible.
12. Equipos de vídeo

Dentro de los equipos de vídeo que se utilizan para el tratamiento de la señal de televisión, se puede hacer una distinción entre equipos generadores de señal y equipos de tratamiento de señal. Los equipos que se encargan de generar las señales de vídeo dentro de una instalación de televisión pueden ser cámaras, generadores de caracteres, generadores de efectos digitales y equipos de grafismo electrónico. Todos los demás equipos que se pueden encontrar dentro de un centro de producción de prograrnas de televisión se encargan de modificar o alterar las señales de vídeo que los equipos anteriormente mencionados generan.
Fuentes de señal
Las fuentes de señal que producen señales de vídeo son:- Cámaras.- Generadores de caracteres.- Generadores de efectos digitales.- Equipos de grafismo electrónico.
CámarasSegún la utilización que se le dé a las cámaras de televisión se puede hacer una clasificación en dos grandes grupos: las cámaras de estudio y las cámaras autónomas (ENGs). Las cámaras de estudio disponen normalmente de dos unidades separadas: el cuerpo de cámara y la unidad de control de cámara (CCU). En la cabeza de la cámara se realiza la conversión de imágenes en señales eléctricas y en la CCU se realizan los ajustes necesarios para controlar la calidad de la imagen que recoje la cámara. Las cámaras autónomas combinan en una sola unidad física las dos operaciones de captación de imágenes y el control de calidad de éstas. Las cámaras de televisión disponen de un sistema de filtros para distintas temperaturas de color. Este sistema lo que hace es colocar diferentes filtros entre el sistema de lentes y los espejos dicroicos de la cámara para adaptarla al tipo de iluminación que haya.
Temperatura de color El concepto de temperatura de color tiene que ver con el tipo de iluminación que tiene una imagen. Si se hace una fotografía de una persona que está en plena calle con luz solar y luego se realiza una fotografía de esa misma persona en el interior de una habitación, se puede observar que los colores de sus ropas y de su cara no son iguales. En la fotografía que se ha realizado dentro de una habitación están mas anaranjados. Esta variación de colores está producida por los tipos de iluminación que se han empleado. Cada tipo de iluminación se caracteriza por una temperatura de color distinta. La luz exterior en un día soleado y brillante está sobre los 5.600 'K y la luz interior procedente de bombillas tiene una temperatura de color de unos 2.600 'K. A menor temperatura de color más naranja resulta la imagen. La mayoría de las cámaras están ajustada desde fábrica para que trabajen con la iluminación de un estudio de televisión, aproximadamente 3.200 'K y disponen de filtros para que cuando trabajen en exteriores puedan compensar la diferencia de temperatura de color que hay. En la tabla se muestran algunos valores de temperatura de color según el tipo de luz.
Temperatura de color de ciertos tipos de luz.Balance de blanco. Aunque se cambie de filtro, la mayoría de las veces no se resuelve totalmente el problema, las nubes, sombras, reflexiones y otras condiciones medioambientales influyen en la iluminación existente. Para ajustar la cárnara a la temperatura de color es necesario realizar un balance de blanco cada vez que se emplean nuevas condiciones de iluminación. Este proceso es muy sencillo de realizar, basta con enfocar la cámara en un papel blanco y pulsar un botón que hay en la cámara para que ésta de forma automática ajuste sus amplificadores con ese tipo de iluminación.

Cámaras de estudio.
Este tipo de cámaras son muy robustas y grandes, se utilizan principalmente en estudios de televisión y en retransmisiones en directo de eventos deportivos, por ejemplo. Las cámaras de estudio son muy pesadas ya que llevan acoplado un objetivo zoom de gran tamaño y un amplio visor para que el operador pueda ver comodamente las imágenes. Estas cámaras se conectan mediante un cable triaxial a una unidad de control de cámara (CCU) que se sitúa en el control de imagen.
Cámara de estudio profesional.
Las cámaras de estudio constan de: la cabeza de cámara, el cabezal de cámara y el soporte de cámara. La cabeza de la cámara está formada por el sistema de lentes ópticas, el objetivo, los sensores CCI), el visor de imágenes, cte. En esta parte de la cámara está toda la electrónica que compone una cámara y los controles que sirven para encuadrar la imagen correctamente. El cabezal de la cámara es un sistema mecánico que posibilita que la cámara puede moverse de forma horizontal y vertical de forma suave y sin movimientos bruscos. Este sistema posee también un compensador que permite posicionar la cámara de forma horizontal para impedir que la cámara se desequilibre y se incline hacia adelante o hacia atrás. El soporte de cámara que más se utiliza en las cámaras de estudio es el de tipo pedestal. Consiste, básicamente, en una columna central de altura ajustable, fijada a una base con tres ruedas que se dirijen mediante un volante. Este tipo de soportes está compuesto por una rueda o volante que se emplea para ajustar la altura de la cámara y para girar el pedestal. La altura de la cámara se puede ajustar desde 1 a 2 metros y las ruedas se pueden fijar de distintas formas para que el movimiento de la cámara sea paralelo, por ejemplo.
ENGs Este tipo de cámaras portátiles está compuesto por una cámara y por un grabador de vídeo que almacena las imágenes y el sonido que va captando la cámara. Esta cámara se porta sobre el hombro del operador y su eficacia depende de la resistencia que tiene el operador de cámara. La cámara posee un soporte en su parte inferior con forma de U para adaptarse al

hombro del cámara. La mano derecha del cámara se encaja en un arco de apoyo situado al lado del zoom automático y con los dedos de la mano derecha se puede controlar el avance y el retroceso del zoom y la selección del iris. El conmutador del iris tiene tres posiciones:
- Ajuste manual.- Iris automático.- Control remoto del iris.
Con el dedo pulgar de la mano derecha se controla el mando de pausa del magnetoscopio, quedando libre la mano izquierda para ajustar el aro de enfoque y el aro de apertura del diafragma (f/stop) situado en el objetivo.
Cámara ENG.Partes de una cámara ENG:
1. Visera del objetivo.2. Objetivo.3. Micrófono electret unidireccional.4. Ajuste del foco.5. Controles del visor.6. Visor de imagen.7. Conmutador de avance y retroceso del zoom.8. Conexiones de vídeo.9. Magnetoscopio de grabación de la señal de vídeo.10. Compartimiento para alojar las baterías.
Ajustes de la cámara
A pesar de las diferencias que existen entre los dos tipos de cámaras, el funcionamiento de las cámaras es el mismo y el sistema para captar las imágenes también es similar. Los ajustes más típicos que se realizan en una cámara en el momento de captar las imágenes son: -Ajuste del foco: este tipo de ajuste se encarga de ajustar las lentes que forman la óptica de la cámara para aumentar la definición de la imagen.Al ajustar el foco de una imagen lo que se está haciendo es ajustar la distancia a la cual la imagen tiene la máxima nitidez. Cualquier cosa que esté situada por delante o por detrás de la distancia enfocada aparecerá desenfocada de forma progresiva. A esta distancia de foco se la denomina profundidad de campo.En las cámaras ENG este tipo de ajuste se realiza a través del ajuste del anillo de foco que está situado en la óptica de la cámara y en las cámaras de estudio, este tipo de ajuste se realiza con un control remoto situado en uno de los mandos de la cárnara.-Ajuste del diafragma o iris: cuando se mira de frente un objetivo es posible ver el diafragma o iris de una cámara. Este diafragma está compuesto por una serie de hojas de metal que se solapan unas con otras formando una abertura circular para que pase la luz.Al variar la apertura del diafragma lo que se consigue es variar la cantidad de luz que incide sobre el sensor de imagen (CCD).

Apertura del diafragma o iris.
El tamaño del orificio que forman estas láminas está calibrado en pasos graduados. Estos pasos o números f-stop se encuentran serigrafiados en el anillo de ajuste situado en el objetivo.Un número f pequeño indica una apertura mayor del diafragma y un número f grande indica que la apertura del diafragma va a ser pequeña.Los numeros f estándar son:f/1,4 2 2,8 4 5,6 8 11 16 22 32aunque a veces se utilizan también puntos intermedios.
Números f.
Si se abre el diafragma de f/8 a f/4 la luminosidad de la imagen se cuadruplica y al cerrar la apertura del diafragma de f/4 a f/8 la luminosidad de la imagen se reduce a la cuarta parte.-Zoom: el control del zoom es el ajuste de la distancia local del objetivo.La distancia focal es la distancia que hay desde el centro óptico de la lente hasta el punto donde convergen los rayos de luz en la parte posterior de la lente.Esta distancia se mide en milímetros y el punto donde convergen los rayos de luz es el CCI) o el tubo de imagen.Si la distancia focal aumenta, las imágenes se ven disminuidas y si la distancia focal disminuye la imagen se ve aumentada.
Distancia focal. El ajuste del zoom en una cámara portátil se puede ajustar directamente mediante una rueda situada en la óptica de la cámara o mediante un conmutador eléctrico que actúa sobre un motor que varía la distancia focal desde la posición de máximo alejamiento (W) a la posición de máximo acercamiento (T).
Detalle del mando de control del zoom.

Ópticas de una ENG.
Las ópticas de mayor tamaño que se utilizan en las cámaras de estudio ajustan el zoom mediante un control remoto situado en uno de los mandos que se emplean para manejar la cámara. Generalmente, este control se sitúa en el mando derecho de la cámara; para alejar el zoom hay que girar el mando hacia la izquierda y para acercarlo se ha de girar el mando del control hacia la derecha.
Óptica de una cámara de estudio.
Controles de cámaras.
Todas las cámaras tienen una serie de controles para poder captar de forma correcta las imágenes. Esta serie de controles se pueden dividir en tres grupos:
- Los que se ajustan continuamente para poder captar las diferentes imágenes.- Los que se reajustan de forma ocasional para adaptarse a los cambios que se producen.- Los que no deben tocarse nunca, a menos que se tenga un profundo conocimiento del mantenimiento de la cámara. Esta serie de controles sirven para ajustar la electrónica de la cámara.
En el caso de las cámaras de estudio, la mayoría de los controles que afectan al funcionamiento de la cámara se ajustan a distancia en una CCU (Unidad de Control de Cámara) o RCU (Unidad de Control Remoto). Esta unidad se sitúa en el área técnica junto a los estudios de realización. Desde ese control el operador de imagen puede ajustar, por control remoto, las cámaras durante la realización de un programa en directo. De esta forma, el operador de cámara tiene vía libre para concentrarse en la realización del programa sin preocuparse de ajustar los controles de la cámara. En cada cámara se puede ajustar la ganancia, la temperatura de color, la variación de gamma, la ganancia de cada unos de los colores, etc. mediante los potenciómetros de control. Este tipo de dispositivos dispone de una serie de memorias que pueden guardar los niveles más adecuados dependiendo del programa que se realice sin necesidad de volver a ajustar.
Unidad de control de cámaras (CCU).
El control que más utiliza el operador de imagen es la palanca que hay situada en la parte inferior, con ella se puede variar la apertura del diafragma o iris y el nivel de negro de la señal de vídeo.Funciones del joystick:
- La apertura del diafragma se realiza moviendo la palanca hacia adelante y para cerrarlo sólo hay que tirar de ella.- El nivel de negro se controla girando el cabezal de la palanca sobre su propio eje.

- Al presionar el cabezal se puede monitorar la señal de salida de la cámara para compararla con la señal de prograrna.
En el caso de las cámaras portátiles ENG, los ajustes de los controles los realiza el propio cámara. El número de ajustes que hay que hacer durante la grabación de imágenes es pequeño y las realiza el propio cámara mientras graba las imágenes.
Magnetoscopios.
El primer grabador de vídeo fue desarrollado por la casa AMPEX en 1956 y utilizaba cintas de 2". Grababa las pistas de vídeo de forma transversal sobre una cinta magnética mediante un tambor de varias cabezas que giraban a gran velocidad. En un principio los grabadores de vídeo eran máquinas muy grandes y muy complejas, lo que repercutía en el precio. Sin embargo, la posibilidad de que se pudiese grabar un acontecimiento y emitirlo posteriormente hizo que tuviera una gran acogida en el mundo de la televisión.El tipo de grabación transversal utilizado por Ampex fue sustituido con posterioridad por un sistema de grabación helicoidal que daba la posibilidad de parar la imagen.
Generador de caracteres.
Los generadores de caracteres fueron los primeros equipos gráficos digitales. Un generador de caracteres tiene la apariencia física de un ordenador que trabaja sobre un monitor de televisión. En la figura se puede observar el aspecto físico que tiene un generador de caracteres.
Generador de caracteres.
Los generadores de caracteres, por ejemplo, sirven para insertar los títulos de crédito, operadores, producción, dirección, personal técnico, etc. que intervienen en un programa de televisión.Los primeros generadores de caracteres eran muy básicos, generaban los rótulos en blanco sobre un fondo negro que se utilizaba como señal llave y sólo disponían de uno o dos tipos de letras corno mucho. Actualmente, los generadores de caracteres pueden generar rótulos de cualquier color y con cualquier color de fondo y además es posible generar todo tipo de letras y en cualquier tamaño.Los generadores de caracteres almacenan los rótulos en una memoria que normalmente se direccionan en páginas. Un rotulo que ocupa un cuadro de vídeo se almacenará en una página.Cuando se prepara un programa se almacenan todos los rótulos que se necesiten en el programa en páginas para ir mostrándolos durante la realización del programa con solo ir llamando a las páginas.La presentación de los rótulos se puede hacer página por página, llamando una a una o empleando las funciones de edición: secuencia por corte (CUT), rodillo (ROLL), deslizamiento de línea (CRAWL), efecto máquina de escribir (REVEAL) o subtitulación.
- CUT.Esta función permite la presentación rápida y continua de una serie de páginas determinadas. Se puede hacer de forma manual o automática.Si se hace de forma manual, la página cambiará sólo cuando se pulse una determinada tecla. Mientras que si se opera de forma automática, se puede dar una duración de permanencia para cada página y el equipo se encargará e cambiarlas.- ROLL.Las páginas se van presentando en la pantalla como si se tratase de un rodillo que las desplaza de la parte inferior a la superior.La velocidad de desplazamiento es variable y el rodillo puede terminar en una página en concreto o que sea un rodillo sin fin. Esta es la forma más común de presentar los títulos de crédito al final de los programas de televisión.- CRAWL.Las páginas se visualizan carácter a carácter sobre una línea por la cual se desplazan de derecha a izquierda. Esta línea se puede posicionar en cualquier parte de la panta

lla y la velocidad de desplazamiento de las letras también se puede ajustar.- REVEAL.Este modo de edición también se conoce como stacato y el efecto que produce en la pantalla es como el de la escritura en una máquina de escribir.SUBTITULACIóN.Esta opción se emplea para los doblajes de las películas y tiene la ventaja de que puede programarse para que los títulos cambien simultáneamente con el código de tiempo (LTC) del vídeo reproductor.
Generadores de efectos.
Este tipo de dispositivos, llamados generadores de efectos digitales de vídeo (DVE) se encargan de manipular las imágenes para darles un aspecto totalmente distinto al que tenían en un principio. Para realizar los efectos de imagen lo primero que tienen que realizar es una digitalización de la imagen de vídeo que puede ser almacenada, recuperada y manipulada sin que se degrade lo más mínimo.Estos equipos trabajan en tiempo real, es decir, el efecto se visualiza de forma instantánea y tantas veces como se quiera porque las imágenes se graban en memorias no volátiles.Hoy en día la mayoría de los estudios de televisión disponen de generadores de efectos junto con el mezclador de vídeo. Estos equipos son capaces de realizar efectos en la imagen de vídeo que van mucho más allá de lo que hace un mezclador profesional de vídeo.Normalmente cada generador de efectos dispone de un repertorio propio de efectos digitales, aunque todos normalmente disponen de los siguientes:
- Compresión. Con este tipo de efecto se puede cambiar la relación de aspecto de la imagen. Se puede hacer más ancha o más alta. Es muy típico en los programas de televisión comprimir ciertas imágenes para que éstas aparezcan al lado de los presentadores, por ejemplo, formando una ventana.- Pushes. Un efecto digital muy común es el Push y consiste en que una imagen desplaza a otra hasta sacarla de la pantalla.- Flips. Los Flips son efectos que consisten en girar la imagen tomando como eje el eje central tanto horizontal como vertical del monitor de televisión.- Rotaciones. El concepto de rotación es más amplio y podría englobar el efecto de Flip, también son giros de la imagen pero en este caso se pueden definir los ejes de rotación.
El número de efectos que se pueden hacer con un generador de efectos digitales es limitado. Se puede conseguir que las imágenes se deformen se dividan en fragmentos y que éstos se vuelvan a agrupar. Este tipo de equipos son programables, esto quiere decir que se pueden programar una serie de efectos antes de la realización de un programa y una vez que se está trabajando en directo lanzarlos sin necesidad de ajustar el proceso cada vez que se quiere realizar un efecto.
Generador de efectos digitales.
Los equipos de efectos están formados por dos partes separadas: el procesador de efectos digitales (DVP) y el controlador de efectos digitales (DVC). Equipos de diseño gráfico.
Este tipo de equipos está formado básicamente por un ordenador que tiene en lugar de ratón, una paleta gráfica con la que se puede dibujar y diseñar una gran variedad de imágenes. El programa informático que llevan estos ordenadores hacen que se pueda dibujar cualquier imagen gracias a unos comandos específicos.

Estos equipos son tan flexibles que las posibilidades que aportan a un estudio de postproducción o de emisión de programas de televisión es increíble.
Aspecto físico de una paleta de diseño gráfico. Las operaciones que se pueden realizar con estos equipos van desde el simple coloreado de una imagen a dibujos que se pueden realizar con técnicas que imitan acuarelas, óleos o aerógrafos.La imagen que se quiere diseñar puede obtenerse o bien digitalizando una imagen real que puede ser una fotografía o una imagen de vídeo o bien diseñando la imagen por completo. Actualmente, con la llegada de procesadores cada vez más rápidos y el diseño de sistemas de almacenamiento de datos con más capacidad y velocidad, existen equipos de diseño gráfico que pueden hacer casi todo el trabajo de postproducción. No sólo pueden diseñar las imágenes, además, son capaces de generar secuencias animadas y diseñar imágenes en 3D capaces de dar una sensación tridimensional a la imagen.
Equipos para el tratamiento de la señal.
Una vez generadas las señales de vídeo, todo lo que se hace a continuación es tratarlas y manejarlas de la forma más adecuada para conseguir unos propósitos determinados, como por ejemplo realizar un programa de televisión.Los principales equipos para el tratamiento de la señal son:
- Mezclador de vídeo.- Editores de vídeo.
Mezcladores de video.
El mezclador de vídeo es la pieza central de un estudio de televisión. Este equipo permite seleccionar una fuente de vídeo de entre todas las que llegan al mezclador y poder realizar transiciones y efectos entre éstas.Dentro de estos equipos existe una gran variedad que van desde los más sencillos y simples hasta los más sofisticados que son capaces de realizar innumerables efectos y transiciones.
Mezclador de vídeo profesional.
El mezclador más básico y barato es un conmutador de vídeo; este dispositivo está formado por conmutadores mecánicos que al pulsarlos direccionan hacia la salida la imagen que se ha seleccionado. La mezcla de imágenes que produce este equipo no es síncrona por lo que resulta inaceptable en un estudio de producción. Este tipo de dispositivos se suele emplear en puestos de monitorado de señales o como selector de entradas en un mezclador más profesional.

Los mezcladores que se utilizan en los estudios de televisión profesional disponen de una circuitería específica que sólo permiten que la transferencia entre señales se realice cuando la señal de vídeo esté en el intervalo de borrado vertical. Para ello es necesario que las dos señales de vídeo que se van a mezclar estén síncronas y ajustadas en fase. Uno de los problemas que pueden tener las señales que entran en un mezclador es que no lleguen al mismo tiempo debido a que la longitud del cable que tienen que recorrer sea distinto. En este caso se dice que las señales están fuera de fase. Si se intentan mezclar dos señales que están fuera de fase aparece un cambio de color en la imagen de salida del mezclador ya que éste presentará los colores con la referencia de una de las cámaras pero a medida que progrese el encadenado los colores de la segunda cámara se verán virados. Cuando el encadenado termine la imagen volverá a tener el color correcto y el problema desaparece. Para solucionar este problema de desfase entre las señales de vídeo normalmente se inserta en la señal una línea de retardo (delay) entre los distribuidores y el mezclador de vídeo para ajustar todas las señales con la que esté más retardada y evitar este problema en el mezclador.
Los efectos más generales son:- Cortes.Son cambios instantáneos de una imagen a otra.- Fundidos.Los fundidos pueden dividirse en dos tipos. Los que parten de la pantalla en negro y la imagen va ganando brillo hasta que su intensidad es la normal y se puede observar dicha imagen (fade-in), y el efecto opuesto (fade-out) en donde la imagen se desvanece hasta que aparece la imagen de negro.- Encadenados.Los encadenados realizan un proceso similar a los fundidos pero mientras una imagen va desapareciendo la otra imagen va ganando en intensidad.
Hoy en día es difícil ver un mezclador que no disponga de la posibilidad de hacer efectos especiales y digitales. Dentro de los efectos, los más comunes son los que se realizan con señales llave. Las señales llave son zonas de la pantalla que se recortan y se rellenan con otra imagen. Existen dos clases de llave según el sistema que se emplee para realizar los recortes en la imagen:
- Llaves de luminancia.Las llaves de lumínancia se producen por una diferencia entre la luminosidad. La zona que hay que recortar en la imagen se selecciona de acuerdo a una señal denominada señal llave (key signal).El mezclador utiliza esta señal llave para recortar la ímagen e insertar en esa zona el contenido de otra imagen.Normalmente la señal llave es una imagen formada por colores blancos y negros, por ser los colores que tienen más diferencia de luminancia.La incrustación por luminancia se emplea para introducir rótulos, crear sombras transparentes, reflejos, etc.- Llave de crominancia.Las llaves de crominancia (chroma-key) es un efecto sirnilar a las llaves de luminancia pero en lugar de trabajar con niveles de luminancia, lo que se hace es trabajar con colores llave.Lo que hace el mezclador es detectar en la imagen el color que se utiliza como imagen llave y sustituir esa parte de la imagen por otra.El chroma key puede realizarse sobre cualquier color, aunque son preferibles los colores primarios (rojo,verde y azul) ya que son señales directas de la cámara. Normalmente el chroma-key se suele utilizar sobre los colores verde y azul, casi nunca sobre el rojo porque es el color que predomina en la piel humana.
Mezcladores digitales.
Con la llegada de la tecnología digital a los estudios de televisión es obligatorio disponer de un mezclador digital que pueda trabajar directamente con este tipo de señales sin necesidad de convertirlas en señales analógicas antes de mezclarlas y después de entrar en el mezclador. Este tipo de mezcladores digitales cumplen la norma. 601 del CCIR y trabajan según el formato de señal digital 4:2:2. Todas las operaciones que se realizan sobre la señal son en formato digital, por lo cual la señal no sufre ningún tipo de degradación al ser manipulada y se pueden realizar muchos más efectos con todas las señales de vídeo que entran al mezclador.
Editores de vídeo.
Al principio cuando no existían los reproductores de vídeo ni las cintas de vídeo tal y como se conocen hoy en día, las noticias y los programas que se emitían por televisión se grababan en formato de cine y se transformaban en señales de televisión mediante unos equipos que se denominaban telecines. Para editar las noticias había que cortar y pegar los trozos de película y formar el contenido de la noticia que se quería emitir.

Con la aparición de las cámaras de televisión y los sistemas de grabación magnética el proceso de montaje de vídeo siguió realizándose mediante cortes mecánicos. Para poder empalmar dos imágenes era necesario recurrir a una técnica muy similar al montaje de cine. Consistía en localizar el impulso de sincronismo vertical entre dos cuadros de imagen mediante un microscopio sobre la propia cinta de vídeo y realizar un corte físico con una cuchilla en ese punto, había que hacer lo mismo con el inicio de la siguiente imagen que se quería montar y realizar una unión física con una cinta adhesiva que unía ambas partes. Durante algunos años, este fue el único procedimiento de montaje. Es evidente que con este sistema no se podían realizar transiciones entre imágenes, como por ejemplo fundidos. Cualquier efecto que se quería hacer, había que realizarlo en directo mediante el mezclador de imagen.Con la aparición de los magnetoscopios de vídeo más modemos se produjo un cambio en la forma de editar los programas de televisión. Ya no había que hacerlo de forma manual, para ello se empleaban dos magnetoscopios de los cuales, uno se encargaba de reproducir y el otro de grabar los cortes que se iban seleccionando por el operador de montaje. El montaje se realizaba de máquina a máquina, uno de los magnetoscopios tenía el módulo de edición y disponía de un circuito electrónico que controlaba tanto al magnetoscopio reproductor como al grabador. Los puntos de edición se marcaban mediante la grabación sobre la pista auxiliar de una señal de control para que el magnetoscopio de edición pudiese controlar la conmutación instantánea de lectura y grabación. Más tarde, en 1967, se desarrolló un método para identificar los cuadros en forma de horas, minutos, segundos y cuadros, mediante una señal que se grababa junto con la información de vídeo en las cintas magnéticas. En 1972 se normalizó este código y desde entonces se conoce como SMPTE timecode. Gracias a este código se hizo posible la realización de ediciones de vídeo precisas porque la búsqueda de determinados cuadros sobre la cinta era una tarea rápida y simple. La edición de vídeo se basa en grabar de forma selectiva material de la cinta de vídeo que reproduce, a la cinta que graba (máster). Este proceso se realiza de forma lineal, esto quiere decir que la secuencia de imágenes que se graban tiene que corresponder con el orden de imágenes que se quiere reproducir. Actualmente, este proceso se realiza empleando una editora de vídeo. Con este equipo electrónico se pueden controlar los dos vídeos al mismo tiempo y programar los puntos de comienzo y final para que el proceso sea más rápido y seguro. La edición de vídeo se puede realizar sobre las pistas de audio y vídeo o sobre alguna de ellas de forma independiente. De esta forma, se puede variar el fondo sonoro de una imagen ya grabada o viceversa. Pasos generales para realizar una edición de vídeo:
- Ajuste de las señales de vídeo fuentes y control de sonido.- Elección del modo de edición.- Elección de los puntos de entrada y/o salida del magnetoscopio reproductor.
- Elección del tipo de transición entre magnetoscopios.- Elección de los puntos de entrada y/o salida en el grabador.- Visionado previo de la edición.- Ejecución de la edición.- Revisión de la edición.
Salas de edición lineal
Según el trabajo que se haga en las salas de edición, éstas se pueden catalogar en varias clases dependiendo del trabajo que se quiera realizar:
- Sala A/B.En estas salas se realiza el montaje máquina a máquina con edición por corte, tienen la posibilidad de incrustar rótulos.Básicamente están compuestas por dos magnetoscopios y una editora de vídeo.- Sala A/B Roll.Esta sala dispone de un vídeo más y un mezclador que le da la posibilidad y la capacidad necesaria para ejecutar encadenados, cortinillas y efectos digitales más complicados.- Sala A/B/C Roll.Estas salas de edición incorporan cuatro vídeos, tres de los cuales pueden reproducir al mismo tiempo. Disponen también de una mesa editora, un mezclador y un generador de efectos digitales.Este tipo de sala es la más completa de todas y casi se puede decir que es como un estudio de realización, ya que algunas disponen de un mezclador de sonido que permite controlar el sonido de la grabación. De lo único de que no disponen es de señales procedentes de las cámaras que hay en un estudio.
Edición no lineal.

Todo este proceso de montaje y edición de las imágenes de vídeo se realiza mediante una manipulación lineal de las cintas de vídeo en donde están grabadas las imágenes. Esto quiere decir que para buscar una imagen que está situada en la mitad de la cinta hay que recorrer la cinta desde el principio hasta encontrar su ubicación exacta.Hoy en día con la llegada de la televisión digital y con la existencia de ordenadores cada vez más potentes y capaces de almacenar una gran cantidad de información han surgido nuevos sistemas para realizar la edición de vídeo.La edición no lineal consiste en el montaje y manipulación de imágenes que se encuentran grabadas en un disco magnético y a las que se accede de forma aleatoria, es decir, se puede acceder de forma inmediata a todas las imágenes que se hayan grabado independientemente de la posición física que ocupen en el disco.El acceso aleatorio ha permitido acelerar los procesos de postproducción y edición y ganar mucho tiempo de trabajo. Al aparecer los primeros editores no lineales, es decir ordenadores que realizaban el montaje, la edición de las imágenes teniendo acceso a discos, se inicia un nuevo proceso hacia la manipulación de imágenes.La edición no lineal se caracteriza sobre todo por que se puede trabajar con las imágenes mediante capas, esto significa que cada efecto o fragmento de la imagen es una capa independiente que se puede poner y quitar según convenga. El resultado final será la suma de todas las capas. Otra ventaja de la edición no lineal es que se pueden modificar las imágenes y correjir el color, su textura, etc.
Matrices de conmutación.
Una matriz de conmutación es un dispositivo que permite interconexionar y gestionar las señales procedentes de la mayoría de los equipos que constituyen una instalación de televisión.Este equipo es el corazón del Control Central Técnico y su principal caracteristica es la capacidad de poder direccionar las señales de manera transparente, es decir sin afectar en las características técnicas de las señales.Una matriz de conmutación es un sistema formado por un conjunto de interruptores que se utiliza en aplicaciones donde se necesita que una entrada determinada sea encaminada hacia una o varias salidas para que la señal sea compartida por varios dispositivos a la vez.Estos equipos están constituidos por conmutadores que pueden ser de dos tipos diferentes:
- Pasivos: son los de peor calidad puesto que son componentes mecánicos que inducen ruidos en la señal eléctrica debido a que la conmutación no es instantánea.
- Activos: están compuestos por componentes eléctricos construidos con semiconductores. Estos conmutadores permiten un cambio instántaneo de la señal de vídeo aprovechando el intervalo de vertical, con lo que se evitan fluctuaciones y oscilaciones.
Esquema de una matriz de conmutación de 4X4.
Una matriz contiene amplificadores, distribuidores y conmutadores que actúan por control remoto desde un panel de control situado en el Control Central Técnico.La matriz tiene una disposición bidimensional, formada por filas y columnas que definen un punto de cruce, tal y como puede verse en la figura Una matriz de conmutación se caracteriza por el número de entradas y salidas que puede manejar y por los diferentes niveles o planos. En cada nivel se maneja sólo una señal de la misma categoría, generalmente una matriz está formada por cuatro niveles que son: dos niveles para el audio (audio 1 y audio 2), un nivel para el vídeo y un nivel para la comunicación.

Panel de conexionado ¨Patch-Panel¨.
Los paneles de conexiones o 'pacth-panels' son partes básicas en una instalación de vídeo porque se utilizan para interconectar los equipos de una instalación de televisión.Un pacth panel está formado por una placa con una serie de conectores etiquetados para poder identificarlos, una serie de puentes en forma de U para realizar las conexiones de carácter fijo y una serie de latiguillos de cable con conectores en los extremos para realizar puentes
Pacth panel de señales de vídeo.
La figura muestra un pequeño ejemplo de conexiona do en un pacth panel con 6 salidas y 6 entradas. La norma general es que en la fila superior se encuentren las salidas de los equipos y la llegada al patch de las señales y en la fila inferior se encuentren las salidas del patch y la entrada a los equipos de las señales de vídeo.En el ejemplo de la figura se muestra cómo se realizan las conexiones partiendo del esquema que hay en la parte superior de la figura.
Ejemplo de conexionado en un patch-panel.
Generadores de sincronismos.
El generador de sincronismo es un sistema electrónico que se encarga de coordinar todas los sistemas que hay en un estudio de televisión. La señal que proporciona un generador de sincronismo se denomina black burst (negro de color) y está compuesta por los impulsos de sincronismo horizontal colocados al final de cada línea para obligar al haz electrónico a realizar un retrazado y comenzar a explorar una nueva línea y los impulsos de sincronismo vertical, colocados al final de cada campo para obligar al haz electrónico a que vuelva a la parte superior de la imagen para comenzar un nuevo campo.

El generador de síncronismos también inserta una señal de burst o salva de color situada en el pórtico posterior de los impulsos de sincronismos horizontal de todas las líneas de vídeo. Esta señal se utiliza en los equipos de televisión como referencia para decodificar y codificar la información de color junto con la señal de luminanciaEl ejemplo más claro que ilustra la necesidad de porqué los equipos electrónicos deben estar sincronizados, se puede ver en un mezclador de vídeo. Si se conectan dos cámaras de vídeo a un mezclador y éstas no están sincronizadas se puede dar el caso de que una cárnara esté barriendo la línea 70 y la otra cámara este barriendo la línea 215. Si se realiza una transición, en el mezclador, de una cámara a otra, en la salida se observará un salto de imagen. Pero si las cámaras están sincronizadas significará que las dos están barriendo la misma línea y no se producirá ningún salto en la imagen cuando se realice el paso de una cámara a otra en el mezclador.
Sincronización de las cámaras de televisión.
Distribuidor de vídeoEn una instalación de vídeo compleja una misma señal puede utilizarse por varios equipos al mismo tiempo. Para ello se utilizan los distribuidores-amplificadores que se encargan de que les llegue la señal en perfecto estado.Estos dispositivos se caracterizan por tener una entrada de vídeo y varias sal¡das que tendrán la misma señal que hay a la entrada respetando a sus características técnicas salvo que la señal se entrada haya sufrido la degradación de amplitud, en este caso el distribuidor es capaz de amplificar la señal para que tenga un buen nivel de tensión.Estos dispositivos tienen una buena respuesta en frecuencia y en fase para evitar el deterioro de los impulsos de sincronismo de la señal de entrada. De este modo, un distribuidor de vídeo es un equipo idóneo para transmitir una única señal de vídeo a diferentes destinos al mismo tiempo.Los distribuidores, por ejemplo, se utilizan para distribuir la señal de sincronismo a todos los equipos que la necesiten.
Esquema eléctrico de un distribuidor. Monitores de vídeo.
Como ya se ha visto en los apartados anteriores, una imagen en color se forma a partir de los tres colores fundamentales: rojo, verde y azul.Los monitores de televisión están formados por tres cañones, uno para cada color, que emiten un haz de electrones capaz de sensibilizar la pantalla para que se ilumine. El ojo humano se encarga de integrar los tres colores en uno sólo cuando el observador se sitúa a una distancia determinada de la pantalla. Los cañones del tubo de imagen, uno para cada color, se encuentran formando un triángulo equilatero imaginario cuyo centro coincide con el eje del tubo y la pantalla de los monitores está formada por una serie de puntos rojos, verdes y azules llamados luminóforos sobre los que inciden los haces de

electrones. Estos luminóforos tienen forma de rectángulo y se encuentran unos junto a otros formando una triada de puntos R, G y B. Entre la pantalla y los cañones de electrones se sitúa una máscara perforada de 0,2 mm de espesor cuyos agujeros se sitúan enfrente del centro de la triada. La misión de esta máscara es la de que los tres haces se crucen justo en el momento de pasar por ella para que incidan en su luminóforo .
Monitor de imagen.
Los monitores de vídeo forman parte de los equipos que se emplean para monitorizar las señales de televisión.Para comprobar que una señal de televisión es correcta lo primero que hay que hacer es verla en un monitor de vídeo. Si en la pantalla del monitor se observa algún tipo de anomalía, lo siguiente que hay que hacer es comprobar esa señal con los equipos de medida para señales de televisión. Debido a esta razón los monitores de imagen hay que ajustarlos de forma periódica para que reproduzcan con fiabilidad las imágenes. La UER (Unión Europea de Radiodifusión) ha recomendado a las organizaciones que la forman un procedimiento para ajustar los monitores de imagen que se utilizan en estudios de televisión, definidos como de calidad 1. Se realiza con la señal PLUGE (Picture Liine-Up Generating Equipment. Generador electrónico de ajuste de imagen)
AUDIO Y MESAS DE AUDIO. ESTUDIOS DE RADIO Y TV.


















