
Semiautomatic domain model building from text-data Petr Šaloun Petr Klimánek Zdenek Velart Petr...
17
SMAP 2011, Vigo, Spain, December 1-2, 2011
-
Upload
dominic-jenkins -
Category
Documents
-
view
219 -
download
0
Transcript of Semiautomatic domain model building from text-data Petr Šaloun Petr Klimánek Zdenek Velart Petr...

SMAP 2011, Vigo, Spain, December 1-2, 2011

The basic tasks in creating a domain model: selection of domain and scope consideration of reusability finding a important terms defining classes and class hierarchy defining properties of classes and
constraints creation of instances of classes
Goals designing a method for semiautomatic
domain creation different input documents different languages design and implementation of tool

Algorithm and tasks work with domain model
different document formats different languages domain model
concepts, relations domain model creation = time
consuming‐ manual creation‐ automatic creation‐ semiautomatic creation

natural language processing – NLP Stanford NLP
‐ Stanford Parser‐ Stanford POS tagger‐ Stanford Named Entity Recognizer
multi-language environment – Google Translate
WordNet (synsets)
Tool – Java, SWING, XML, jTidy, JAWS, SNLP, JUNG

An/DT integer/NN character/NN
constant/NN has/VBZ type/NN int/NN ./.
<html><body><p>An integer character
constant has type int.</p></body></html>

input TXT, HTML, PDF removal of occurrences of special
characters using regular expressions numeric designation of chapters and
references removal of single letter prepositions(\\s+[^Aa\\s\\.]{1})+\\s+ parentheses, dashes, and other
translation into English – the tools work only with english text Google Translate

Stanford CoreNLP Stanford Parser, Stanford POS tagger,
Stanford Named Entity Recognizer machine learning over large data,
statistical model of maximum entropy learned models included
Activities tokenization sentence splitting POS tagging - Part-of-speech lemmatization NER - Named Entity Recognition

<html><body><p>An integer character constant has type int.</p></body></html>
An/DT integer/NN character/NN constant/NN has/VBZ type/NN int/NN ./.

tokens marked by POS tagger as nouns are first concept candidates
one word or multi-words nouns identifying token as concept by
disambiguation from WordNet assigning synset – automatic, manual using domain term for searching possible selection of incorrect synset –
with other meaning

unoriented / oriented unnamed / named WordNet – concept must have synset
‐ hyperonyms and hyponyms – IsA relations‐ holonyms and meronyms – partOf relations‐ relation orientation based on concept order
only direct relations from text
lexical-syntactic patterns decomposition of multi-word terms – right part
of term corresponds to existing concept assignment expression
assignment expression IsA expression sentence syntax analysis – amod parser
(adjectival modifier), adjective followed by noun
integral type IsA type


ANSI/ISO C language comparison with existing manually
created ontology 2 experiments
all concept candidates only first 200 candidates 3 variants of experiment
‐ only candidates‐ candidates and IsA proposals‐ candidates and IsA proposals and NER
entities
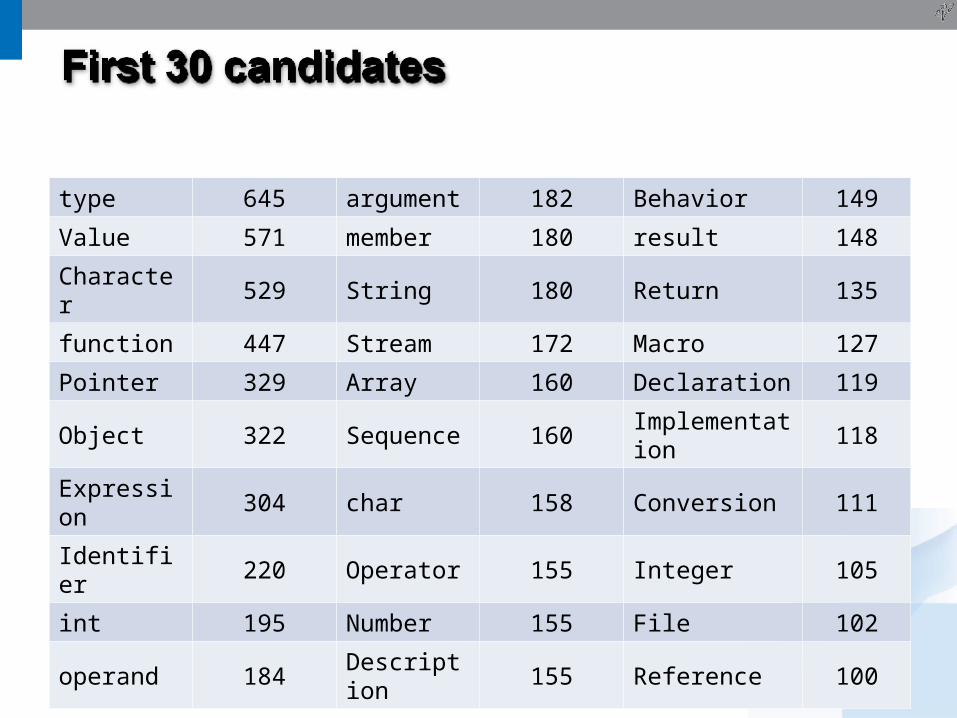
type 645 argument 182 Behavior 149
Value 571 member 180 result 148
Character 529 String 180 Return 135
function 447 Stream 172 Macro 127
Pointer 329 Array 160 Declaration 119
Object 322 Sequence 160 Implementation 118
Expression 304 char 158 Conversion 111
Identifier 220 Operator 155 Integer 105
int 195 Number 155 File 102
operand 184 Description 155 Reference 100

Variant Added Items in model
Found concepts
Found / Items
Found / total in ontology
Found / can be found
All
- 3137 395 13 % 38 % 73 %
IsA 4519 450 10 % 43 % 84 %
IsA + NER 4558 465 10 % 45 % 86 %
200
- 200 98 49 % 9 % 18 %
IsA 1802 152 8 % 15 % 28 %
IsA + NER 1962 318 16 % 31 % 59 %

Variant of experiment without IsA relations only with NER entities
Variant Items Found Concepts / Items
Concepts / total
Concepts / can be found
All + NER 3204 444 13.9 % 42.8 % 82.4 %
200 + NER 360 265 73.6 % 25.5 % 49.2 %

concepts => lightweight ontology enables better automatic relations
mining

Petr ŠalounFEECS, VSB–Technical University of [email protected]
Petr Klimánek(was: Faculty of Science, University of Ostrava)[email protected]
Zdenek VelartFEECS, VSB–Technical University of [email protected]


















