
Self Organization of a Massive Document Collection Teuvo Kohonen Samuel Kaski Krista Lagus Jarkko...
31
Self Organization Self Organization of a Massive of a Massive Document Document Collection Collection Teuvo Kohonen Teuvo Kohonen Samuel Kaski Samuel Kaski Krista Lagus Krista Lagus Jarkko Salojarvi Jarkko Salojarvi Jukka Honkela Jukka Honkela Vesa Paatero Vesa Paatero Antti Saarela Antti Saarela
-
Upload
darleen-norman -
Category
Documents
-
view
215 -
download
0
Transcript of Self Organization of a Massive Document Collection Teuvo Kohonen Samuel Kaski Krista Lagus Jarkko...

Self Organization Self Organization of a Massive of a Massive Document Document CollectionCollection
Teuvo KohonenTeuvo KohonenSamuel KaskiSamuel KaskiKrista LagusKrista Lagus
Jarkko SalojarviJarkko SalojarviJukka HonkelaJukka HonkelaVesa PaateroVesa PaateroAntti SaarelaAntti Saarela

Their GoalTheir Goal
Organize large document collections Organize large document collections according to textual similaritiesaccording to textual similarities Search engineSearch engine
Create a useful tool for searching Create a useful tool for searching and exploring large document and exploring large document collectionscollections

Their SolutionTheir Solution
Self-organizing mapsSelf-organizing maps Groups similar documents Groups similar documents
togethertogether Interactive and easily interpretedInteractive and easily interpreted Facilitates data miningFacilitates data mining

Self-organizing mapsSelf-organizing maps
Unsupervised learning neural Unsupervised learning neural networknetwork
Maps multidimensional data onto a 2 Maps multidimensional data onto a 2 dimensional griddimensional grid
Geometric relations of image points Geometric relations of image points indicate similarityindicate similarity

Self-organizing map Self-organizing map algorithmalgorithm
Neurons arranged in a 2 dimensional Neurons arranged in a 2 dimensional gridgrid
Each neuron has a vector of weightsEach neuron has a vector of weights Example: R, G, B valuesExample: R, G, B values

Self-organizing map Self-organizing map algorithm (cont)algorithm (cont)
Initialize the weightsInitialize the weights For each input, a “winner” is chosen For each input, a “winner” is chosen
from the set of neuronsfrom the set of neurons The “winner” is the neuron most The “winner” is the neuron most
similar to the inputsimilar to the input Euclidean distance:Euclidean distance:
sqrt ((rsqrt ((r11 – r – r22))22 + (g + (g11 – g – g22))22 + (b + (b11 – b – b22))22 + + … )… )

Self-organizing map Self-organizing map algorithm (cont)algorithm (cont)
Learning takes place after each inputLearning takes place after each input nnii(t + 1) = n(t + 1) = nii(t) + h(t) + hc(x),ic(x),i(t) * [x(t) – n(t) * [x(t) – nii(t)](t)]
nnii(t)(t) weight vector of neuron i at weight vector of neuron i at regression regression step tstep t
x(t)x(t) input vectorinput vector c(x)c(x) index of “winning” neuronindex of “winning” neuron hhc(x),ic(x),i neighborhood function / smoothing neighborhood function / smoothing
kernelkernel GaussianGaussian Mexican hatMexican hat

Self-organizing map Self-organizing map exampleexample
6 shades of red, green, and blue used as input
500 iterations

The Scope of This WorkThe Scope of This Work
Organizing massive document Organizing massive document collections using a self-organizing collections using a self-organizing mapmap
Researching the up scalability of Researching the up scalability of self-organizing mapsself-organizing maps

Original ImplementationOriginal Implementation
WEBSOM (1996)WEBSOM (1996) Classified ~5000 documentsClassified ~5000 documents Self-organizing map with “histogram Self-organizing map with “histogram
vectors”vectors” Weight vectors based on collection of Weight vectors based on collection of
words whose vocabulary and words whose vocabulary and dimensionality were manually dimensionality were manually controlledcontrolled

ProblemProblem
Large vector dimensionality required Large vector dimensionality required to classify massive document to classify massive document collectionscollections Aiming to classify ~7,000,000 patent Aiming to classify ~7,000,000 patent
abstractsabstracts

GoalsGoals
Reduce dimensionality of histogram Reduce dimensionality of histogram vectorsvectors
Research shortcut algorithms to Research shortcut algorithms to improve computation timeimprove computation time
Maintain classification accuracyMaintain classification accuracy

Histogram VectorHistogram Vector
Each component of the vector Each component of the vector corresponds to the frequency of corresponds to the frequency of occurrence of a particular wordoccurrence of a particular word
Words associated with weights that Words associated with weights that reflect their power of discrimination reflect their power of discrimination between topicsbetween topics

Reducing DimensionalityReducing Dimensionality
Find a suitable subset of words that Find a suitable subset of words that accurately classifies the document accurately classifies the document collectioncollection Randomly Projected HistogramsRandomly Projected Histograms

Randomly Projected Randomly Projected HistogramsHistograms
Take original d-dimensional data X Take original d-dimensional data X and project to a k-dimensional ( k and project to a k-dimensional ( k << d ) subspace through the origin<< d ) subspace through the origin
Use a random k x d matrix R, the Use a random k x d matrix R, the elements in each column of which elements in each column of which are normally distributed vectors are normally distributed vectors having unit length:having unit length:
RRk x dk x d X Xd x N d x N => new matrix X=> new matrix Xk x Nk x N
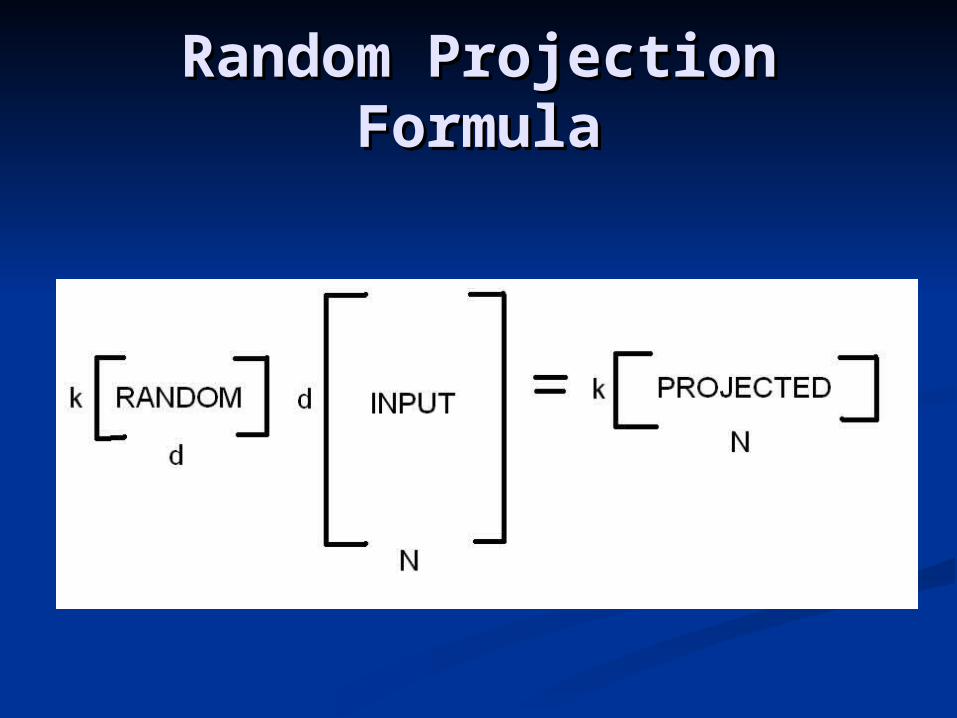
Random Projection Random Projection FormulaFormula

Why Does This Work?Why Does This Work?
Johnson – Lindenstrauss lemma:Johnson – Lindenstrauss lemma:
““If points in a vector space are If points in a vector space are projected onto a randomly selected projected onto a randomly selected subspace of suitably high dimension, subspace of suitably high dimension, then the distances between the points then the distances between the points are approximately preserved”are approximately preserved”
If the original distances or similarities If the original distances or similarities are themselves suspect, there is little are themselves suspect, there is little reason to preserve them completelyreason to preserve them completely

In Other WordsIn Other Words
The similarity of a pair of projected The similarity of a pair of projected vectors is the same on average as vectors is the same on average as the similarity of the corresponding the similarity of the corresponding pair of original vectorspair of original vectors Similarity is determined by the dot Similarity is determined by the dot
product of the two vectorsproduct of the two vectors
Why Is This Important?Why Is This Important?
We can improve computation time We can improve computation time by reducing the histogram vector’s by reducing the histogram vector’s dimensionalitydimensionality

Loss in AccuracyLoss in Accuracy

Optimizing the Random Optimizing the Random MatrixMatrix
Simplify the projection matrix R in order Simplify the projection matrix R in order to speed up computationsto speed up computations
Store permanent address pointers from all Store permanent address pointers from all the locations of the input vector to all the locations of the input vector to all locations of the projected matrix for which locations of the projected matrix for which the matrix element of R is equal to onethe matrix element of R is equal to one

So…So…
Using randomly projected Using randomly projected histograms, we can reduce the histograms, we can reduce the dimensionality of the histogram dimensionality of the histogram vectorsvectors
Using pointer optimization, we can Using pointer optimization, we can reduce the computing time for the reduce the computing time for the above operationabove operation

Map ConstructionMap Construction
Self-organizing map algorithm is Self-organizing map algorithm is capable of organizing a randomly capable of organizing a randomly initialized mapinitialized map
Convergence of the map can be sped Convergence of the map can be sped up if initialized closer to the final up if initialized closer to the final statestate

Map InitializationMap Initialization
Estimate larger maps based on the Estimate larger maps based on the asymptotic values of a much smaller asymptotic values of a much smaller mapmap Interpolate/extrapolate to determine Interpolate/extrapolate to determine
rough values of larger maprough values of larger map

Optimizing Map Optimizing Map ConvergenceConvergence
Once the self-organized map is smoothly Once the self-organized map is smoothly ordered, though not asymptotically stable, ordered, though not asymptotically stable, we can restrict the search for new winners we can restrict the search for new winners to neurons in the vicinity of the old one.to neurons in the vicinity of the old one.
This is significantly faster than performing This is significantly faster than performing an exhaustive winner search over the an exhaustive winner search over the entire mapentire map
A full search for the winner can be A full search for the winner can be performed intermittently to ensure performed intermittently to ensure matches are global bestsmatches are global bests

Final ProcessFinal Process Preprocess textPreprocess text Construct histogram vector for inputConstruct histogram vector for input Reduce dimensionality by random Reduce dimensionality by random
projectionprojection Initialize small self-organizing mapInitialize small self-organizing map Train the small mapTrain the small map Estimate larger map based on smaller Estimate larger map based on smaller
oneone Repeat last 2 steps until desired map Repeat last 2 steps until desired map
size reachedsize reached

Performance EvaluationPerformance Evaluation
Reduced dimensionalityReduced dimensionality Pointer optimizationPointer optimization Non-random initialization of the mapNon-random initialization of the map Optimized map convergenceOptimized map convergence Multiprocessor parallelismMultiprocessor parallelism

Largest Map So FarLargest Map So Far
6,840,568 patent abstracts written 6,840,568 patent abstracts written in Englishin English
Self-organizing map composed of Self-organizing map composed of 1,002,240 neurons1,002,240 neurons
500-dimension histogram vectors 500-dimension histogram vectors (reduced from 43,222)(reduced from 43,222)
5 ones in each column of the random 5 ones in each column of the random matrixmatrix

What It Looks LikeWhat It Looks Like

ConclusionsConclusions
Self-organizing maps can be Self-organizing maps can be optimized to map massive document optimized to map massive document collections without losing much in collections without losing much in classification accuracyclassification accuracy

Questions?Questions?


















