
Sector CloudSlam 09
33
Sector: An Open Source Cloud for Data Intensive Computing Robert Grossman University of Illinois at Chicago Open Data Group Yunhong Gu University of Illinois at Chicago April 20, 2009
-
Upload
robert-grossman -
Category
Technology
-
view
893 -
download
0
Transcript of Sector CloudSlam 09

Sector: An Open Source Cloud for Data Intensive Computing
Robert GrossmanUniversity of Illinois at Chicago
Open Data Group
Yunhong GuUniversity of Illinois at Chicago
April 20, 2009

Part 1Varieties of Clouds
2

What is a Cloud?
Clouds provide on-demand resources or services over a network with the scale and reliability of a data center.
No standard definition. Cloud architectures are not new. What is new:
– Scale– Ease of use– Pricing model.
3

Categories of Clouds
On-demand resources & services over the Internet at the scale of a data center
On-demand computing instances– IaaS: Amazon EC2, S3, etc.; Eucalyptus– supports many Web 2.0 users
On-demand computing capacity– Data intensive computing– (say 100 TB, 500 TB, 1PB, 5PB)– GFS/MapReduce/Bigtable, Hadoop, Sector, …
4

Requirements for Clouds Designed for Data Intensive Computing
Scale to Data Centers
Scale Across Data Centers
Support Large Data Flows
Security
Business X X
E-science X X X
Health-care
X X
Sector/Sphere is a cloud designed for data intensive computing supporting all four requirements.

Sector Overview
Sector is fast– Over 2x faster than Hadoop using MalStone Benchmark– Sector exploits data locality and network topology to improve
performance Sector is easy to program
– Supports MapReduce style over (key, value) pairs– Supports User-defined Functions over records– Easy to process binary data (images, specialized formats, etc.)
Sector clouds can be wide area
6

Part 2. Sector Design
7

Google’s Layered Cloud Services
Storage Services
Data Services
Compute Services
8
Google’s Stack
Applications
Google File System (GFS)
Google’s MapReduce
Google’s BigTable

Hadoop’s Layered Cloud Services
Storage Services
Compute Services
9
Hadoop’s Stack
Applications
Hadoop Distributed File System (HDFS)
Hadoop’s MapReduce
Data Services

Sector’s Layered Cloud Services
Storage Services
Compute Services
10
Sector’s Stack
Applications
Sector’s Distributed File System (SDFS)
Sphere’s UDFs
Routing & Transport Services
UDP-based Data Transport Protocol (UDT)
Data Services

Computing an Inverted Index Using Hadoop’s MapReduce
1st char
word_x word_y word_y word_z
Page_1word_xBucket-A
Bucket-B
Bucket-Z
Stage 1:Process each HTML file and hash (word, file_id) pair to buckets
Bucket-A
Bucket-B
Bucket-Z
Stage 2:Sort each bucket on local node, merge the same word
HTML page_1
Page_1word_y
Page_1word_z
Page_1word_z
Page_5word_z
Page_10word_z
1, 5, 10word_z
Map
Shuffle
SortReduce

Idea 1 – Support UDF’s Over Files
Think of MapReduce as– Map acting on (text) records– With fixed Shuffle and Sort– Followed by Reducing acting on (text) records
We generalize this framework as follows:– Support a sequence of User Defined Functions
(UDF) acting on segments (=chunks) of files.– In both cases, framework takes care of assigning
nodes to process data, restarting failed processes, etc.
12
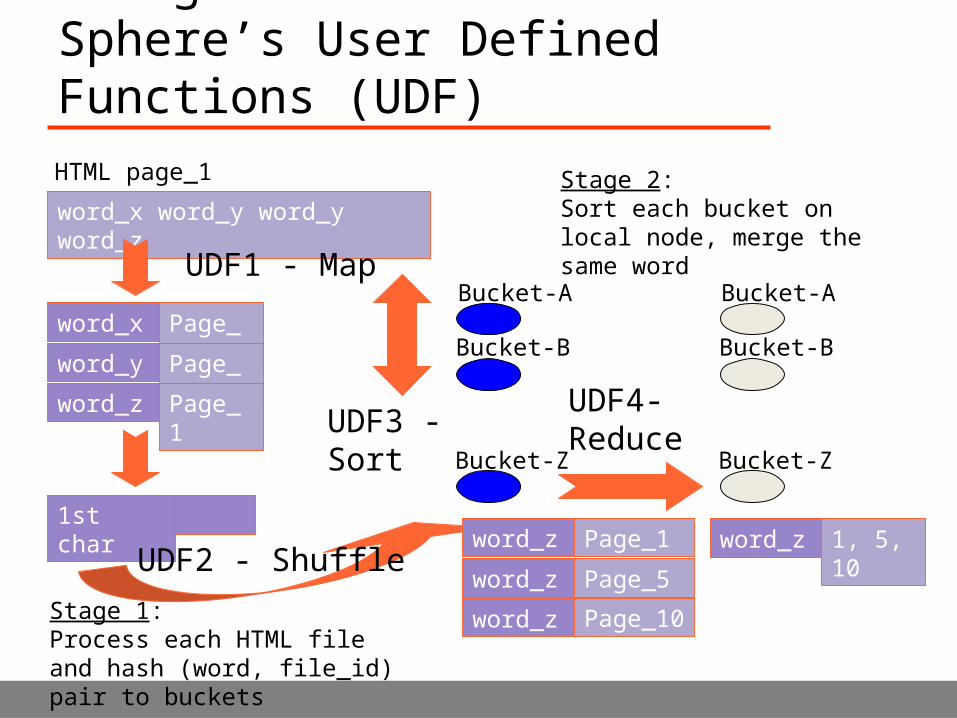
Computing an Inverted Index UsingSphere’s User Defined Functions (UDF)
1st char
word_x word_y word_y word_z
Page_1word_xBucket-A
Bucket-B
Bucket-Z
Stage 1:Process each HTML file and hash (word, file_id) pair to buckets
Bucket-A
Bucket-B
Bucket-Z
Stage 2:Sort each bucket on local node, merge the same word
HTML page_1
Page_1word_y
Page_1word_z
Page_1word_z
Page_5word_z
Page_10word_z
1, 5, 10word_z
UDF1 - Map
UDF2 - Shuffle
UDF3 - SortUDF4-Reduce

Applying UDF using Sector/Sphere
14
Application Sphere Client
SPE SPE SPE
Outputstream
2. Locate & schedule SPE
1. Split data
3. Collect results
Input stream

Sphere’s UDF
Input OutputUDF
Input IntermediateUDF OutputUDF
Input 1OutputUDF
Input 2

Sector Programming Model
Sector dataset consists of one or more physical files Sphere applies User Defined Functions over streams of
data consisting of data segments Data segments can be data records, collections of data
records, or files Example of UDFs: Map function, Reduce function, Split
function for CART, etc. Outputs of UDFs can be returned to originating node,
written to local node, or shuffled to another node.
16

Idea 2: Add Security From the Start
Security server maintains information about users and slaves.
User access control: password and client IP address.
File level access control. Messages are encrypted
over SSL. Certificate is used for authentication.
Sector is HIPAA capable.
Security Server
Master Client
Slaves
dataAAA
SSLSSL

Idea 3: Extend the Stack
Storage Services
18
Storage Services
Routing & Transport ServicesGoogle, Hadoop
Sector
Compute Services
Data Services
Compute Services
Data Services

Sector is Built on Top of UDT
19
• UDT is a specialized network transport protocol.
• UDT can take advantage of wide area high performance 10 Gbps network
• Sector is a wide area distributed file system built over UDT.
• Sector is layered over the native file system (vs being a block-based file system).

UDT Has Been Downloaded 25,000+ Times
20
Sterling Commerce
Nifty TVGlobus
Movie2Me
Power Folder
udt.sourceforge.net

Alternatives to TCP – Decreasing Increases AIMD Protocols
increase of packet sending rate x
€
x← x +α (x)
€
x← (1−β ) x
(x)
x
AIMD (TCP NewReno)
UDT
HighSpeed TCP
Scalable TCP
decrease factor

Using UDT Enables Wide Area Clouds
Using UDT, Sector can take advantage of wide area high performance networks (10+ Gbps)
22
10 Gbps per application

Part 3. Experimental Studies
23

Comparing Sector and Hadoop
Hadoop SectorStorage Cloud Block-based file
systemFile-based
Programming Model
MapReduce UDF & MapReduce
Protocol TCP UDP-based protocol (UDT)
Replication At time of writing PeriodicallySecurity Not yet HIPAA capableLanguage Java C++
24

Open Cloud Testbed – Phase 1 (2008)
Phase 1 4 racks 120 Nodes 480 Cores 10+ Gb/s
25
MREN
CENIC Dragon
Hadoop Sector/Sphere Thrift Eucalyptus
C-Wave
Each node in the testbed is a Dell 1435 computer with 12 GB memory, 1TB disk, 2.0GHz dual dual-core AMD Opteron 2212, with 1 Gb/s network interface cards.

MalStone Benchmark
Benchmark developed by Open Cloud Consortium for clouds supporting data intensive computing.
Code to generate synthetic data required is available from code.google.com/p/malgen
Stylized analytic computation that is easy to implement in MapReduce and its generalizations.
26

MalStone B
time27
dk-2 dk-1 dk
sites entities

MalStone B Benchmark
28
MalStone BHadoop v0.18.3 799 minHadoop Streaming v0.18.3 142 minSector v1.19 44 min# Nodes 20 nodes# Records 10 BillionSize of Dataset 1 TB
These are preliminary results and we expect these results to change as we improve the implementations of MalStone B.

Terasort - Sector vs Hadoop Performance
LAN MAN WAN 1 WAN 2Number Cores
58 116 178 236
Hadoop (secs)
2252 2617 3069 3702
Sector (secs)
1265 1301 1430 1526
Locations UIC UIC, SL UIC, SL, Calit2
UIC, SL, Calit2, JHU
All times in seconds.

With Sector, “Wide Area Penalty” < 5%
Used Open Cloud Testbed. And wide area 10 Gb/sec networks. Ran a data intensive computing benchmark on 4
clusters distributed across the U.S. vs one cluster in Chicago.
Difference in performance less than 5% for Terasort.
One expects quite different results, depending upon the particular computation.
30

Penalty for Wide Area Cloud Computing on Uncongested 10 Gb/s
28 Local Nodes
4 x 7 distributed Nodes
Wide Area “Penality”
Hadoop 3 replicas
8650 11600 34%
Hadoop 1 replica
7300 9600 31%
Sector 4200 4400 4.7%
31
All times in seconds using MalStone A benchmark on Open Cloud Testbed.

For More Information & To Obtain Sector
To obtain Sector or learn more about it:sector.sourceforge.net
To learn more about the Open Cloud Consortiumwww.opencloudconsortium.org
For related work by Robert Grossmanblog.rgrossman.com, www.rgrossman.com
For related work by Yunhong Guwww.lac.uic.edu/~yunhong
32

Thank you!
33

















![Sector CSI 04 Spec [260943] 09-09-2009€¦ · Web viewTitle Sector CSI 04 Spec [260943] 09-09-2009 Subject SECTION 260943 NETWORK LIGHTING CONTROLS Leviton LMS Sector Author Christian](https://static.fdocuments.in/doc/165x107/5fa062a55e796a35e842ee05/sector-csi-04-spec-260943-09-09-web-view-title-sector-csi-04-spec-260943-09-09-2009.jpg)
