
Scaling HDFS to Manage Billions of Files
66
Scaling HDFS to Manage Billions of Files Haohui Mai, Jing Zhao Hortonworks, Inc.
-
Upload
haohui-mai -
Category
Technology
-
view
294 -
download
2
Transcript of Scaling HDFS to Manage Billions of Files

Scaling HDFS to Manage Billions of Files
Haohui Mai, Jing Zhao
Hortonworks, Inc.

About the speakers
• Haohui Mai
• Active committers and PMC in Hadoop
• Ph.D. in Computer Science from UIUC in 2013
• Joined the HDFS team in Hortonworks
• 250+ commits in Hadoop

About the speakers
• Jing Zhao
• Active committers and PMC in Hadoop
• Ph.D. in Computer Science from USC in 2012
• HDFS team member in Hortonworks
• 250+ commits in Hadoop

Past: the scale of data

Past: the scale of data
• In 2007 (PC)
• ~500 GB hard drives
• thousands of files
Past: the scale of data
• In 2007 (PC)
• ~500 GB hard drives
• thousands of files
• In 2007 (Hadoop)
• several hundred nodes
• several hundred TBs
• millions of files

Past: the scale of data
• In 2007 (Hadoop)
• several hundred nodes
• several hundred TBs
• millions of files

Past: the scale of data
• In 2007 (Hadoop)
• several hundred nodes
• several hundred TBs
• millions of files
• In 2015
• 4,000+ nodes (10x)
• 150+ PBs (1000x)
• 400M+ files (100x)

Present: a generic storage system

Present: a generic storage system
• SQL-On-Hadoop
• Machine learning
• Real-time analytics
• Data streaming
• File archives, NFS…
Present: a generic storage system
• SQL-On-Hadoop
• Machine learning
• Real-time analytics
• Data streaming
• File archives, NFS…
• From MR-centric filesystem to a generic distributed storage system

Future: Billions of files in HDFS

Future: Billions of files in HDFS• HDFS clusters continue to grow

Future: Billions of files in HDFS• HDFS clusters continue to grow
• New use cases emerge
• IoT, time series data…

Future: Billions of files in HDFS• HDFS clusters continue to grow
• New use cases emerge
• IoT, time series data…
• Files are natural abstractions of data
• Few big files → many small files in HDFS
• Billions of files in a few years

NameNode limits the scale
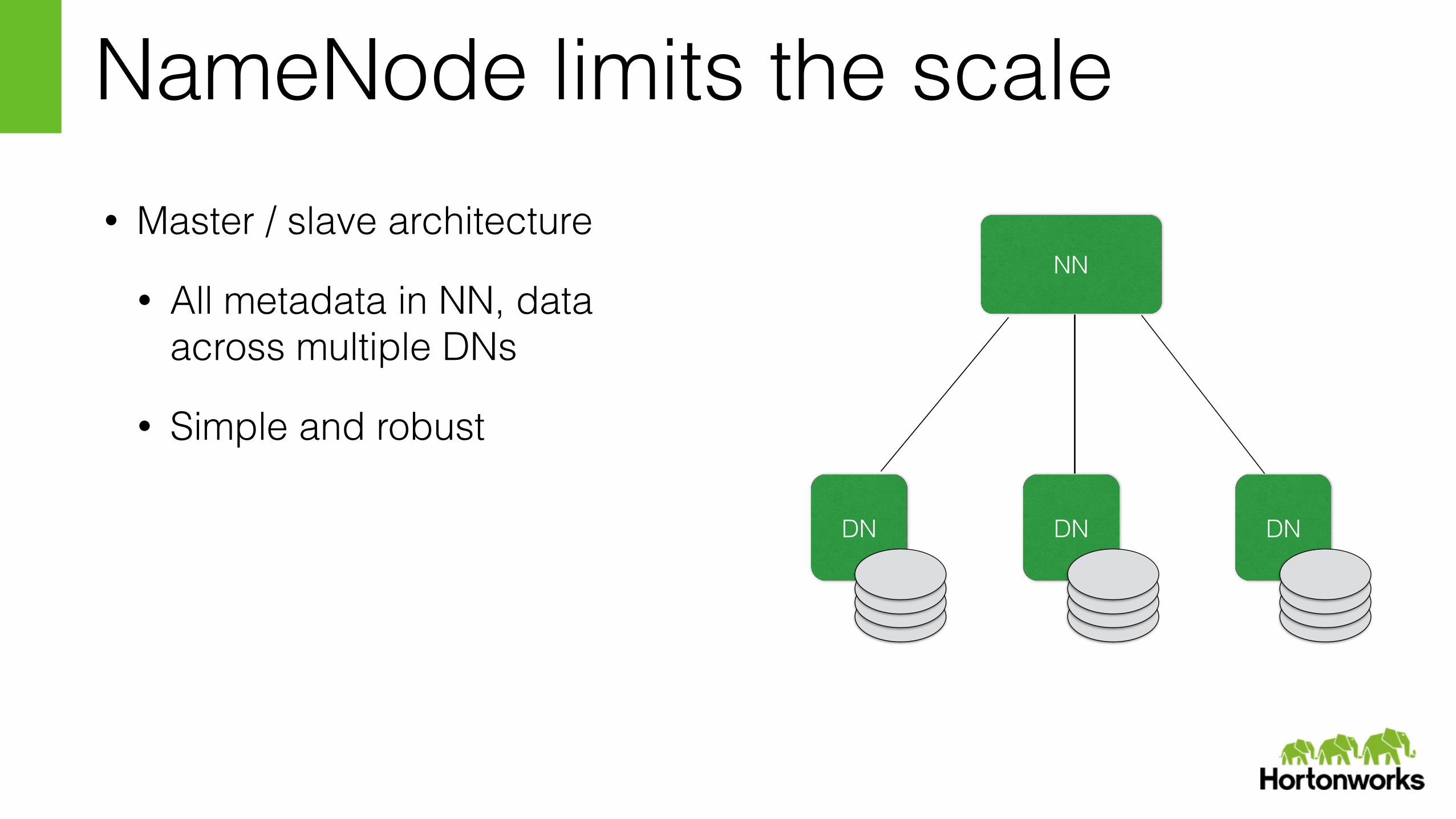
NameNode limits the scale• Master / slave architecture
• All metadata in NN, data across multiple DNs
• Simple and robust
NN
DN DN DN
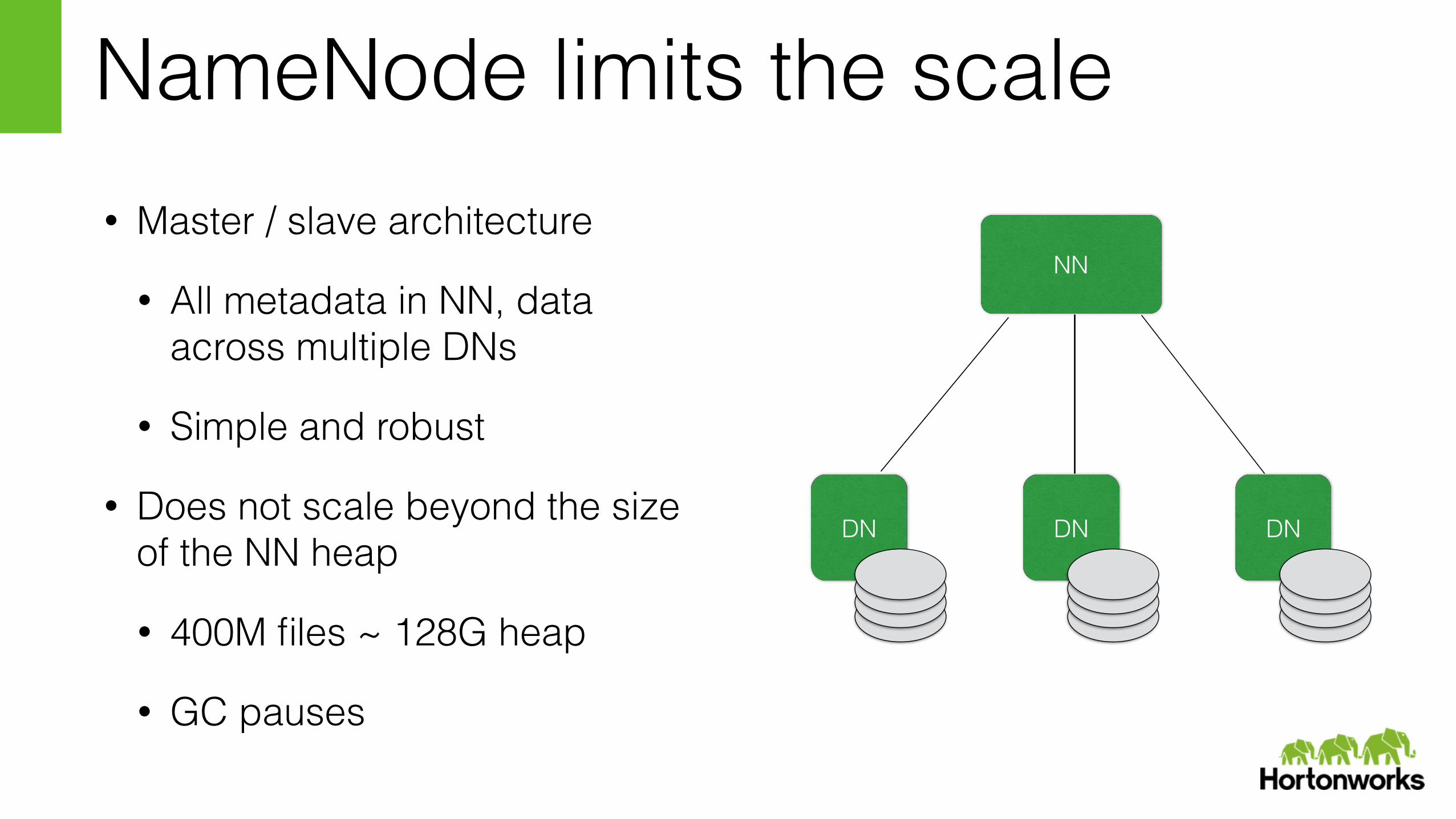
NameNode limits the scale• Master / slave architecture
• All metadata in NN, data across multiple DNs
• Simple and robust
• Does not scale beyond the size of the NN heap
• 400M files ~ 128G heap
• GC pauses
NN
DN DN DN

Next-gen arch: HDFS on top of KV stores

Next-gen arch: HDFS on top of KV stores
• Namespace (NS) on top of Key-Value (KV) stores
• Storing the NS into LevelDB
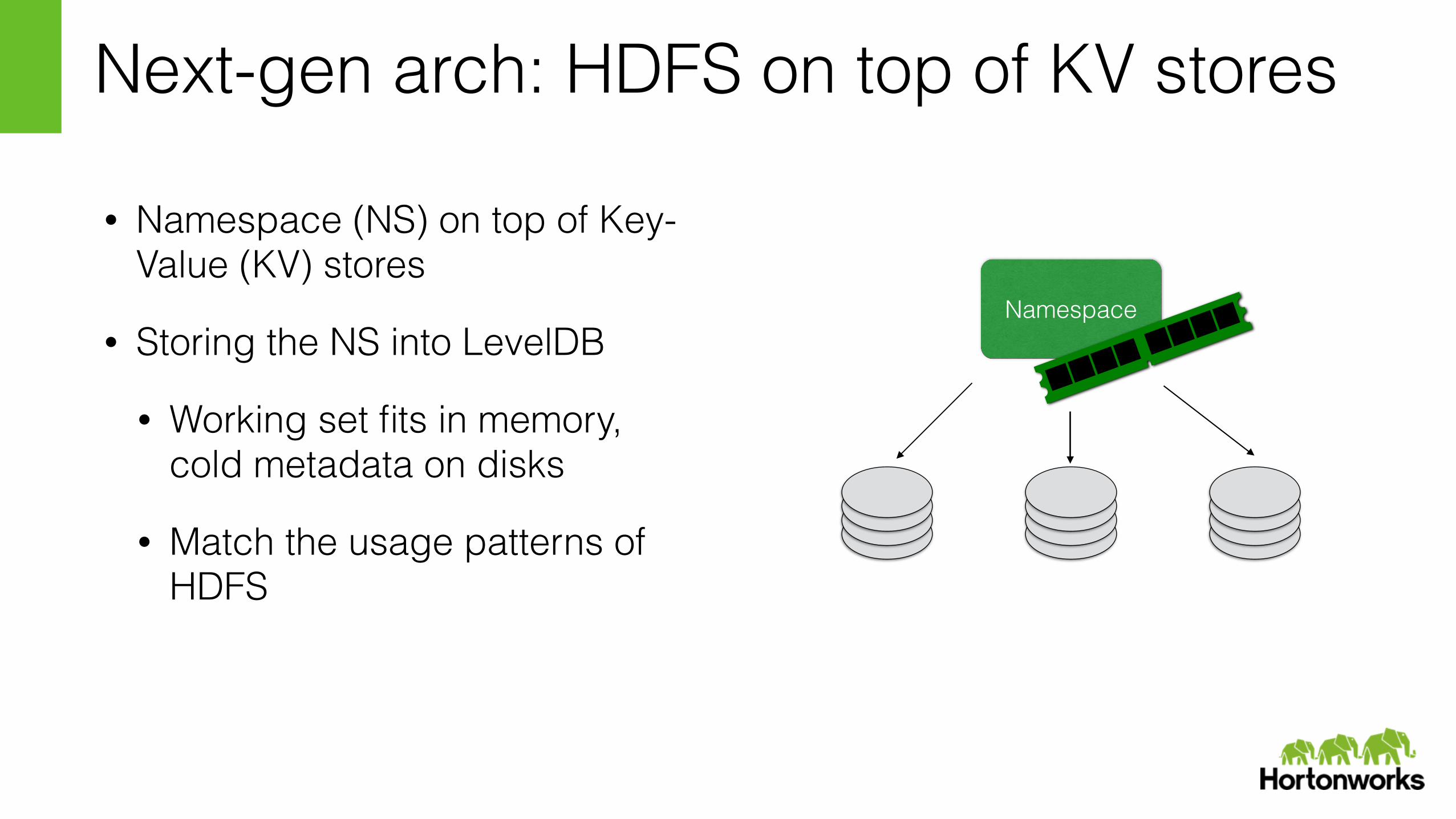
Next-gen arch: HDFS on top of KV stores
• Namespace (NS) on top of Key-Value (KV) stores
• Storing the NS into LevelDB
• Working set fits in memory, cold metadata on disks
• Match the usage patterns of HDFS
Namespace
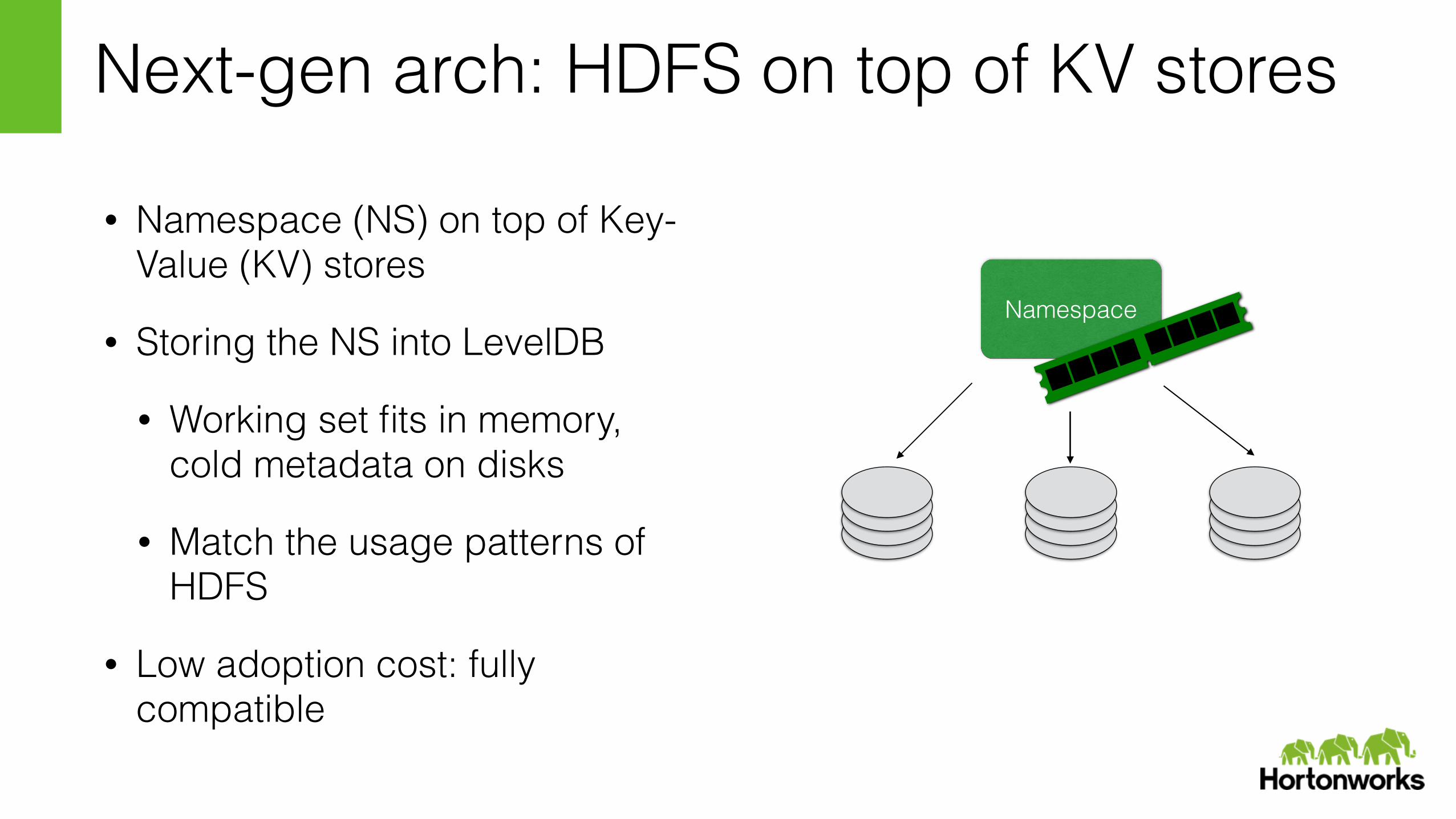
Next-gen arch: HDFS on top of KV stores
• Namespace (NS) on top of Key-Value (KV) stores
• Storing the NS into LevelDB
• Working set fits in memory, cold metadata on disks
• Match the usage patterns of HDFS
• Low adoption cost: fully compatible
Namespace

• Introduction
• Namespace on top of KV stores
• Evaluation
• Future work & conclusions
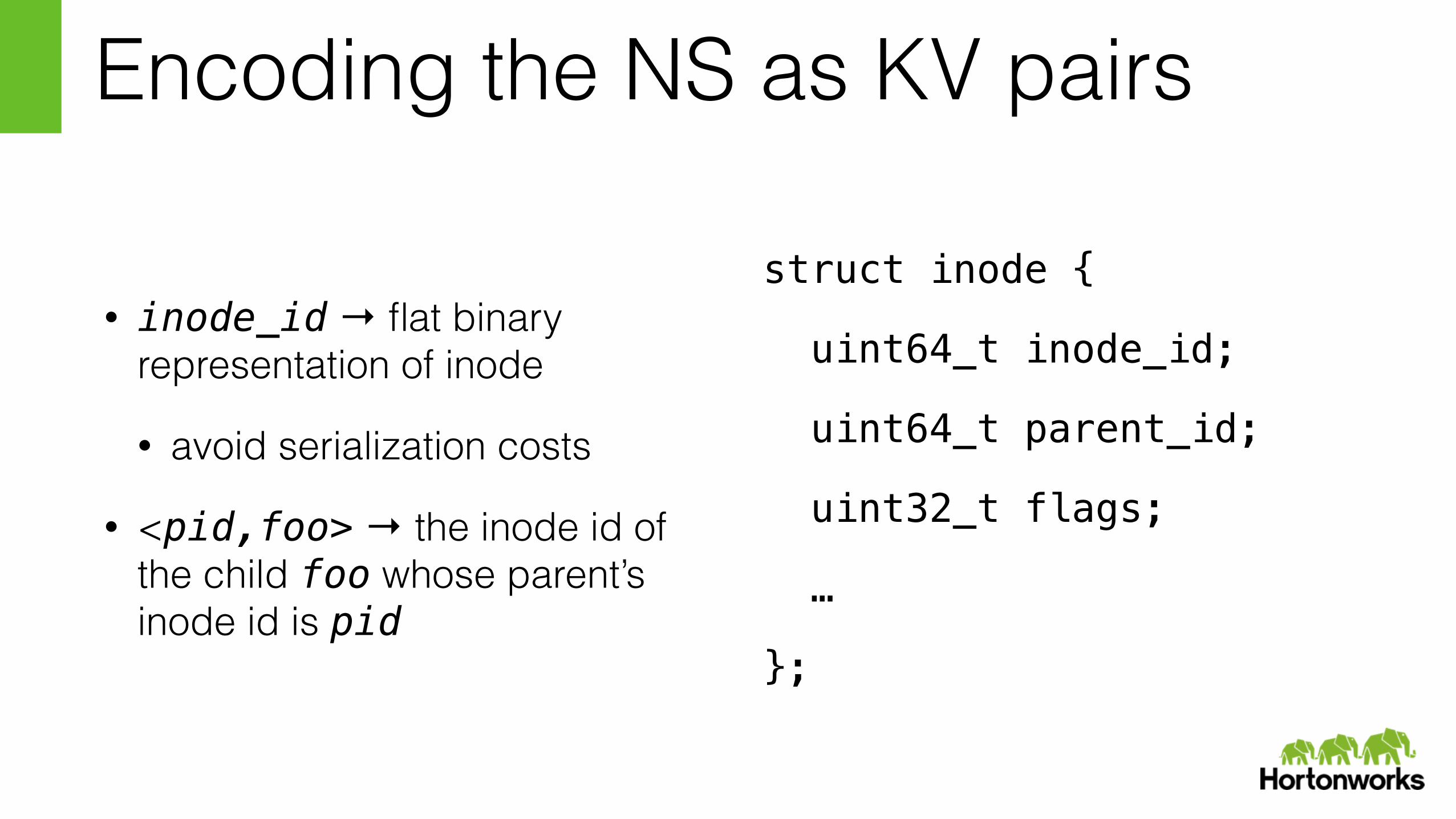
Encoding the NS as KV pairs
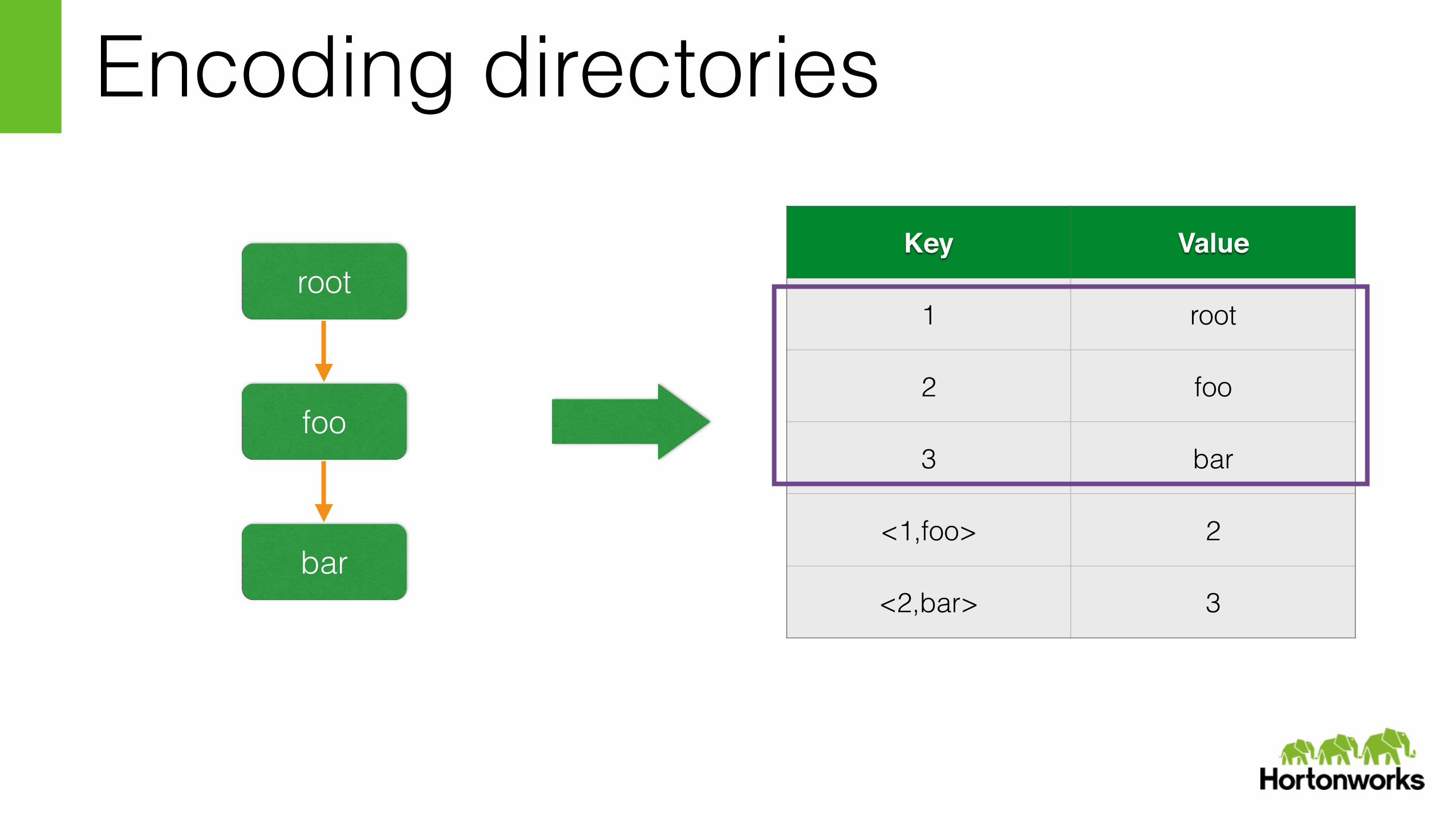
• inode_id → flat binary representation of inode
• avoid serialization costs
• <pid,foo> → the inode id of the child foo whose parent’s inode id is pid
struct inode {
uint64_t inode_id;
uint64_t parent_id;
uint32_t flags;
…
};

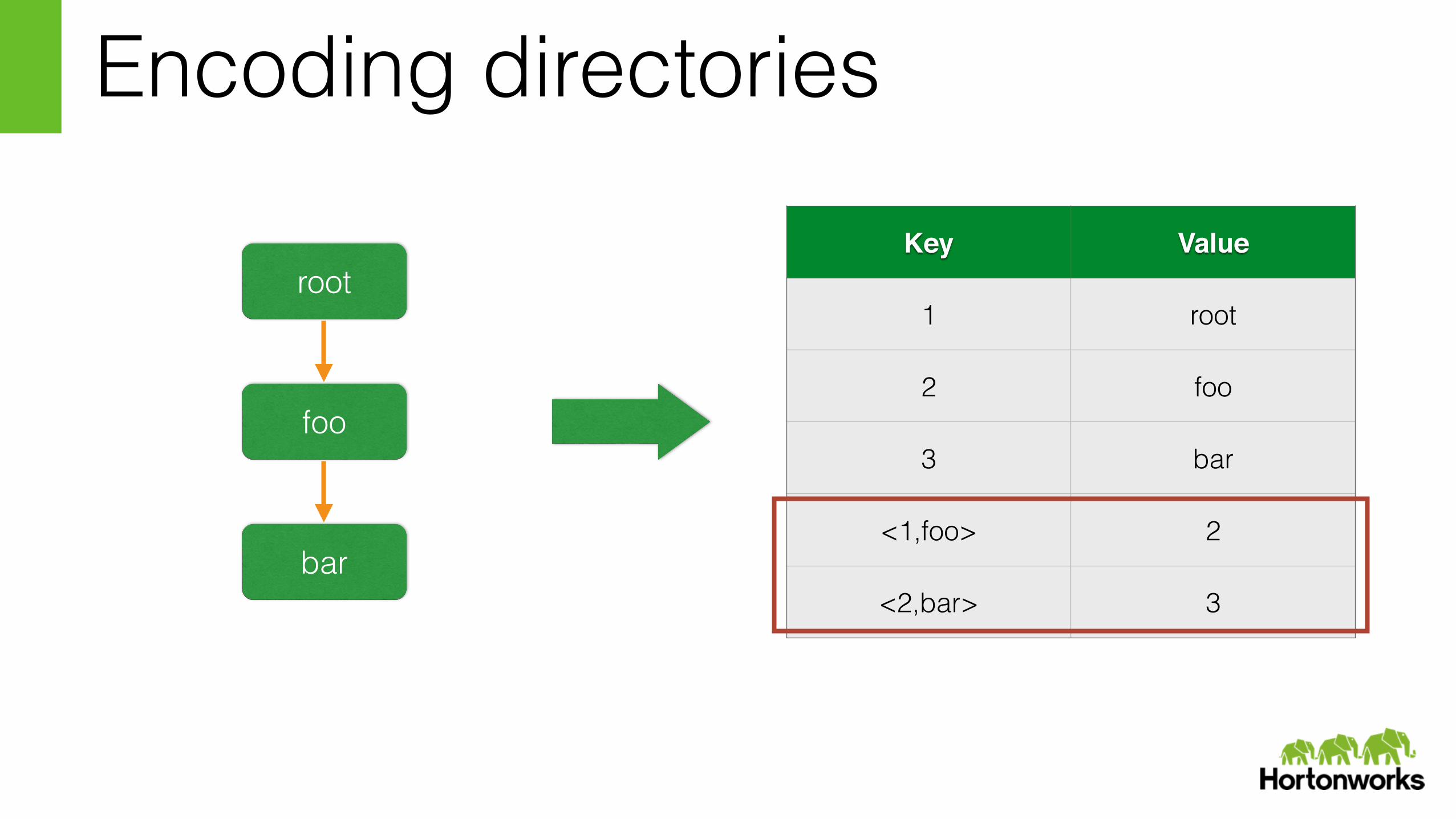
Encoding directories
root
foo
bar
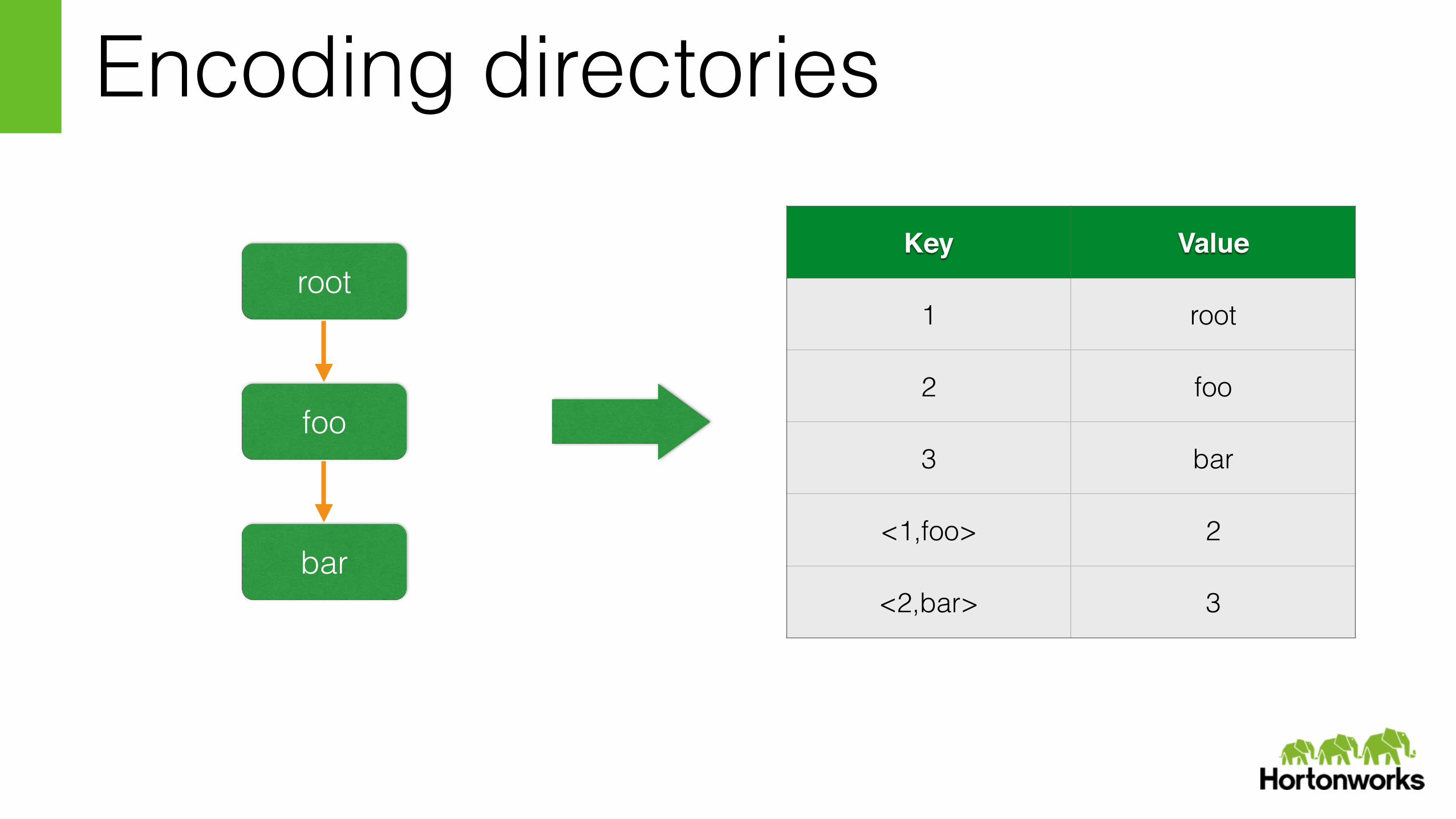
Encoding directories
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
root
foo
bar
Encoding directories
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
root
foo
bar
Encoding directories
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
root
foo
bar

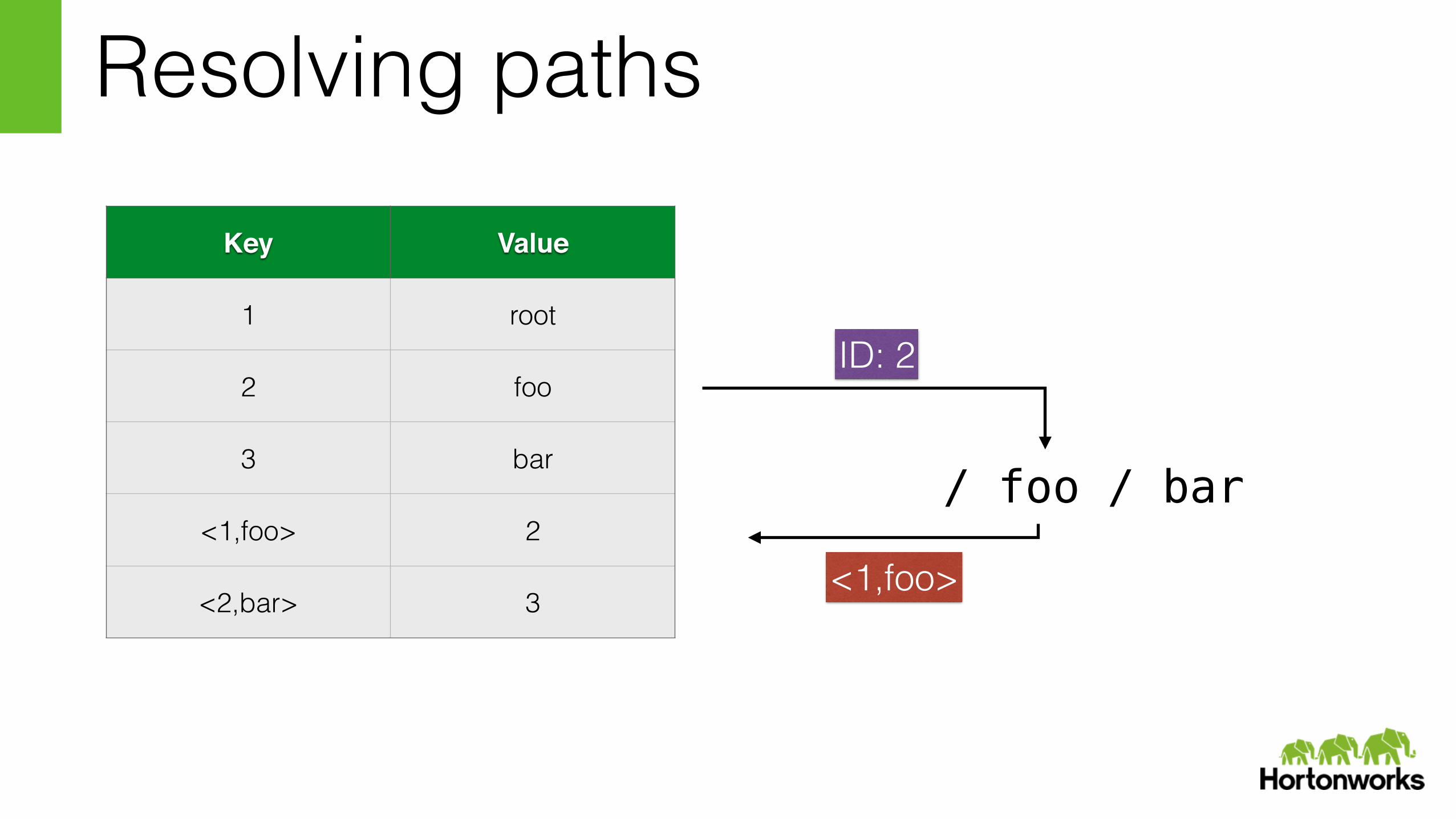
Resolving paths
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3

Resolving paths
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
/ foo / bar

Resolving paths
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
/ foo / barID: 1

Resolving paths
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
/ foo / barID: 1
<1,foo>
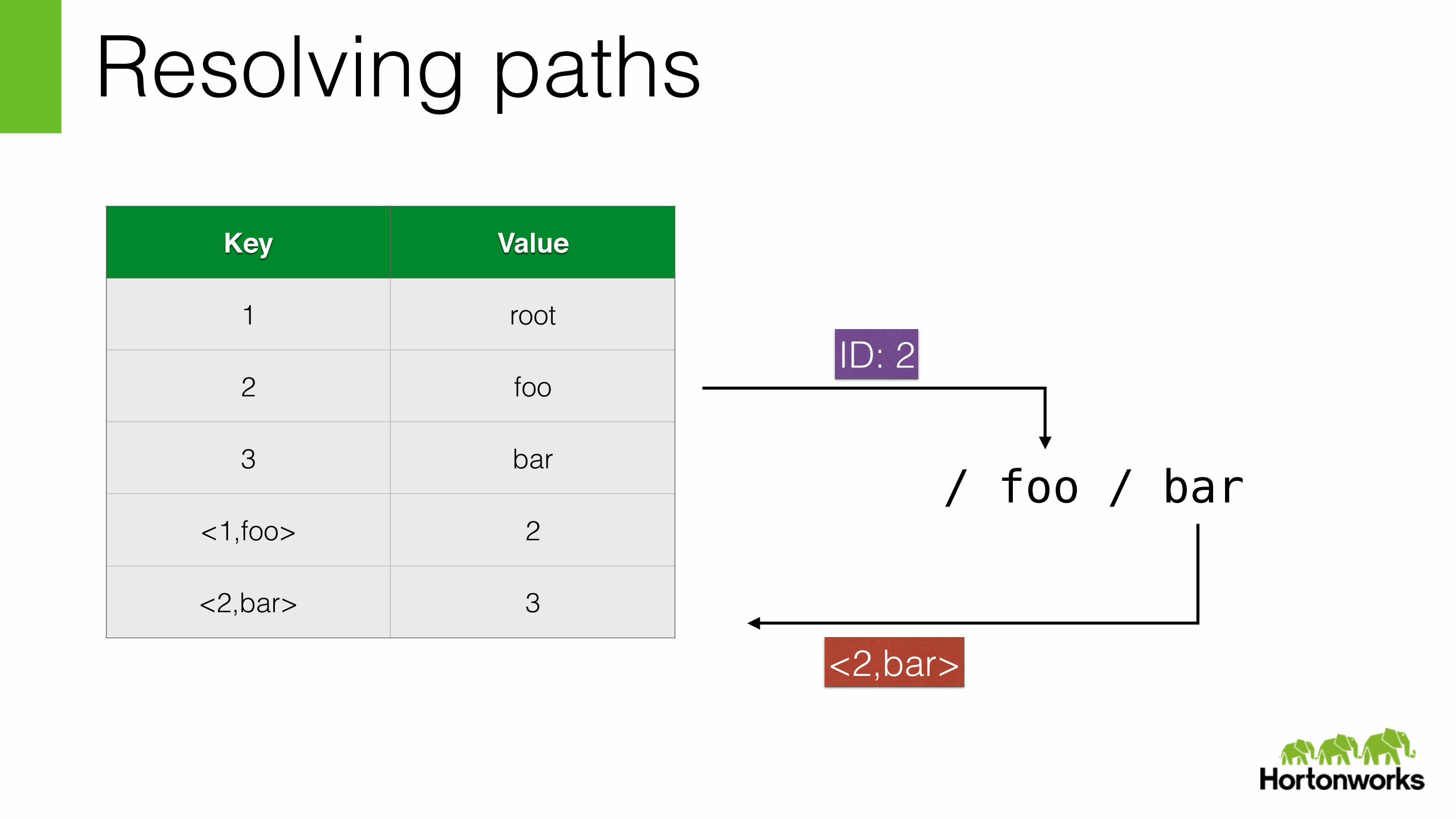
Resolving paths
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
/ foo / bar
<1,foo>
ID: 2
Resolving paths
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
/ foo / bar
ID: 2
<2,bar>
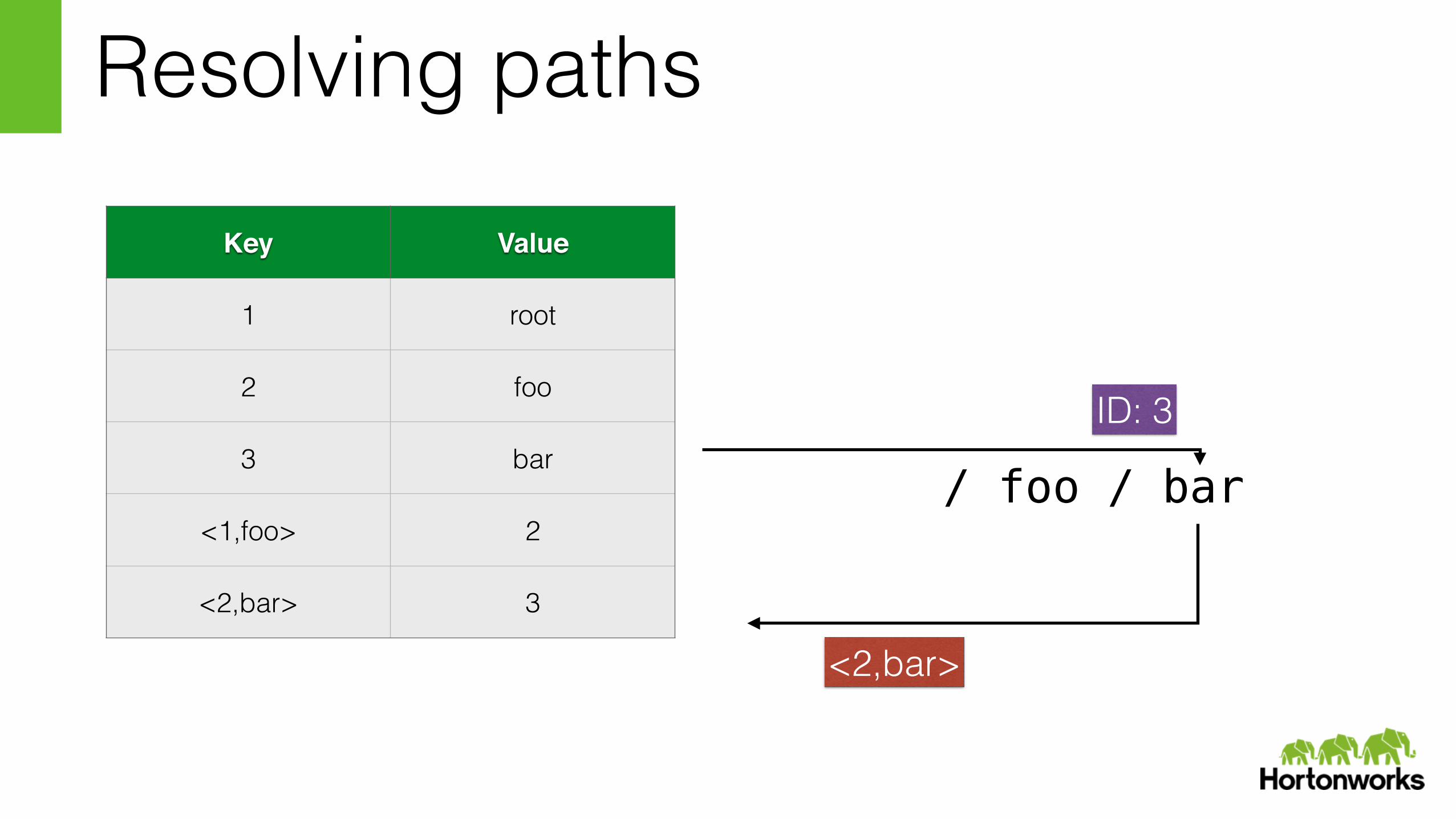
Resolving paths
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
/ foo / bar
<2,bar>
ID: 3
Listing directories
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
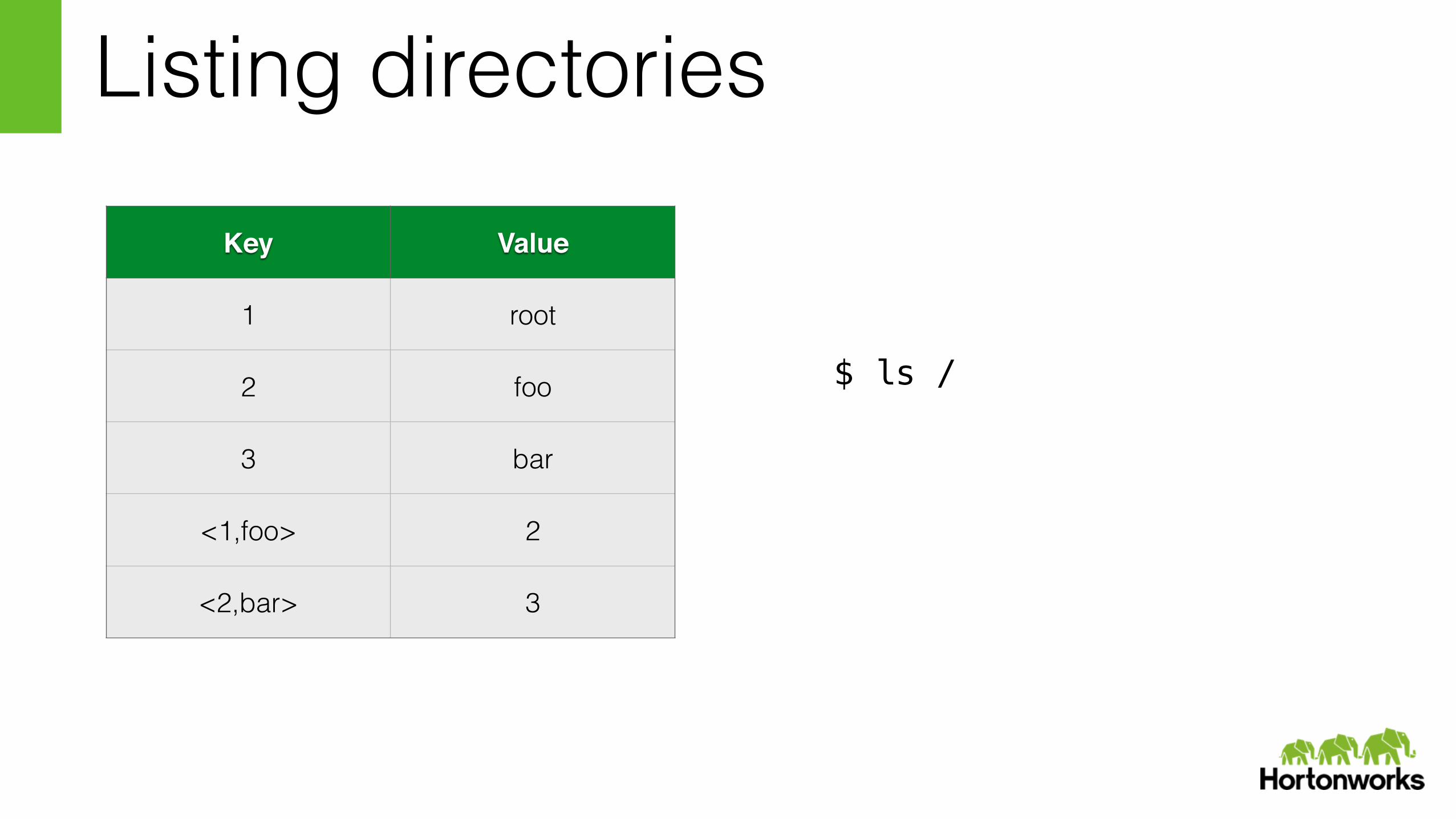
Listing directories
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
$ ls /

Listing directories
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
$ ls /
ID: 1

Listing directories
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
$ ls /
ID: 1
<1,*>

Listing directories
Key Value
1 root
2 foo
3 bar
<1,foo> 2
<2,bar> 3
$ ls /
foo
ID: 1
<1,*>

Integrate with existing HDFS features

Integrate with existing HDFS features• HDFS snapshots
• Metadata only operations
• Append version ids for each key
• Map between snapshot ids and version ids

Integrate with existing HDFS features• HDFS snapshots
• Metadata only operations
• Append version ids for each key
• Map between snapshot ids and version ids
• NameNode High Availability (HA)
• Use edit logs instead of the WAL of the KV stores to persist operations
• Minimal changes in the current HA mechanisms

Current status• Phase I — NS on top of KV interfaces (HDFS-8286)
• NS on top of an in-memory KV store
• Under active development
• Phase II — Partial NS in the memory
• Working set of the NS in the memory, cold metadata on disks
• Scaling the NS beyond the size of heap

• Introduction
• Namespace on top of KV stores
• Evaluation
• Future work & conclusions

Evaluation
• 4 node clusters, connected with 10GbE networks
• 6-core Intel Xeon E5-2630 @ 2.3GHz * 2, 64G DDR3 @ 1333 MHz
• WDC 1TB disks @ 7200 RPM, 64MB cache
• OpenJDK 1.8.0_25

Evaluation (cont.)
Apache Hadoop 2.7.0
2.7.0 InMem LevelDB
NS on top of an in-memory KV map
NS on top of LevelDB
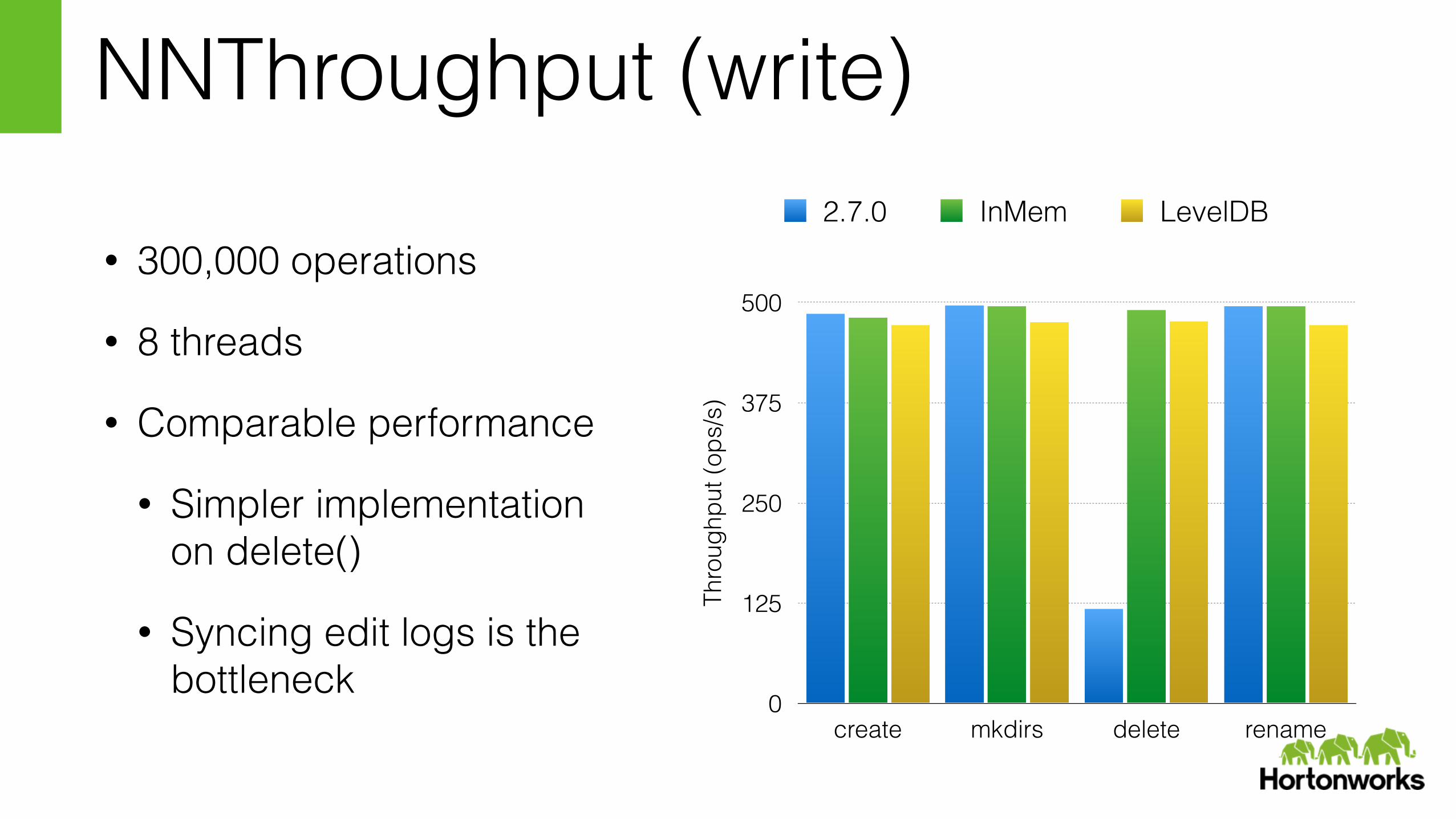
NNThroughput (write)
• 300,000 operations
• 8 threads
• Comparable performance
• Simpler implementation on delete()
• Syncing edit logs is the bottleneck
Thro
ughp
ut (o
ps/s
)0
125
250
375
500
create mkdirs delete rename
2.7.0 InMem LevelDB
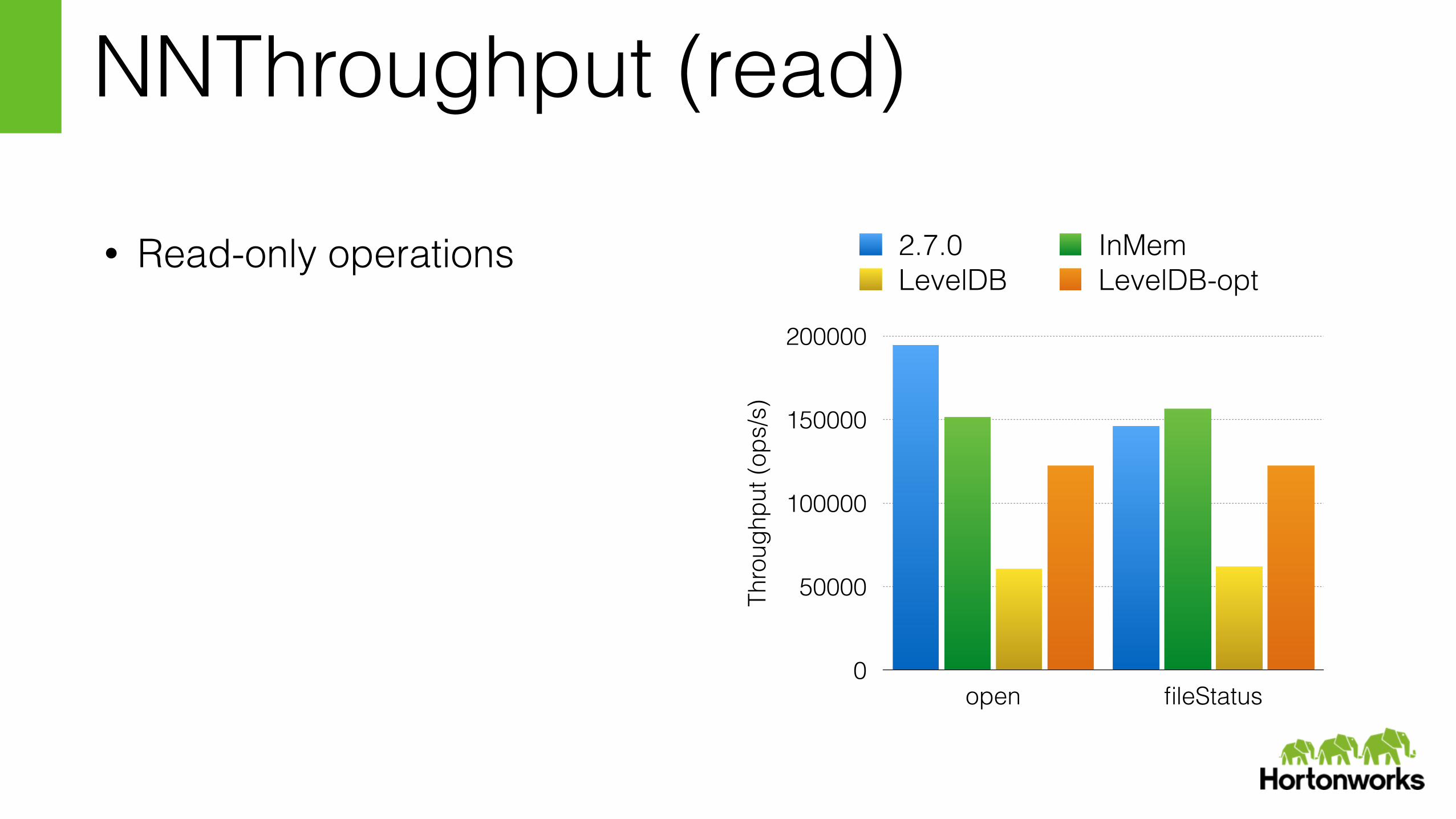
NNThroughput (read)
• Read-only operations
Thro
ughp
ut (o
ps/s
)
0
50000
100000
150000
200000
open fileStatus
2.7.0 InMemLevelDB LevelDB-opt
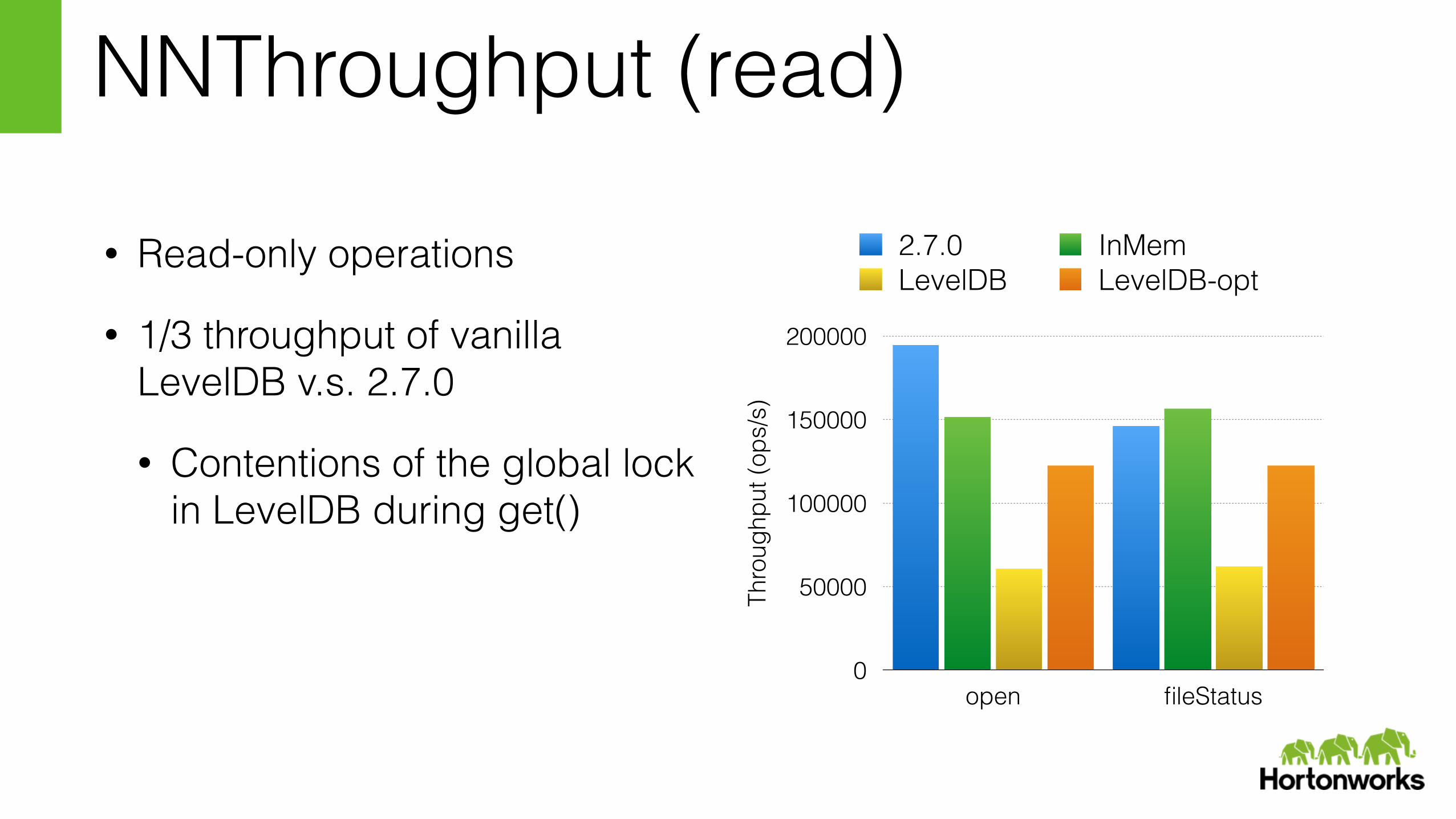
NNThroughput (read)
• Read-only operations
• 1/3 throughput of vanilla LevelDB v.s. 2.7.0
• Contentions of the global lock in LevelDB during get()
Thro
ughp
ut (o
ps/s
)
0
50000
100000
150000
200000
open fileStatus
2.7.0 InMemLevelDB LevelDB-opt
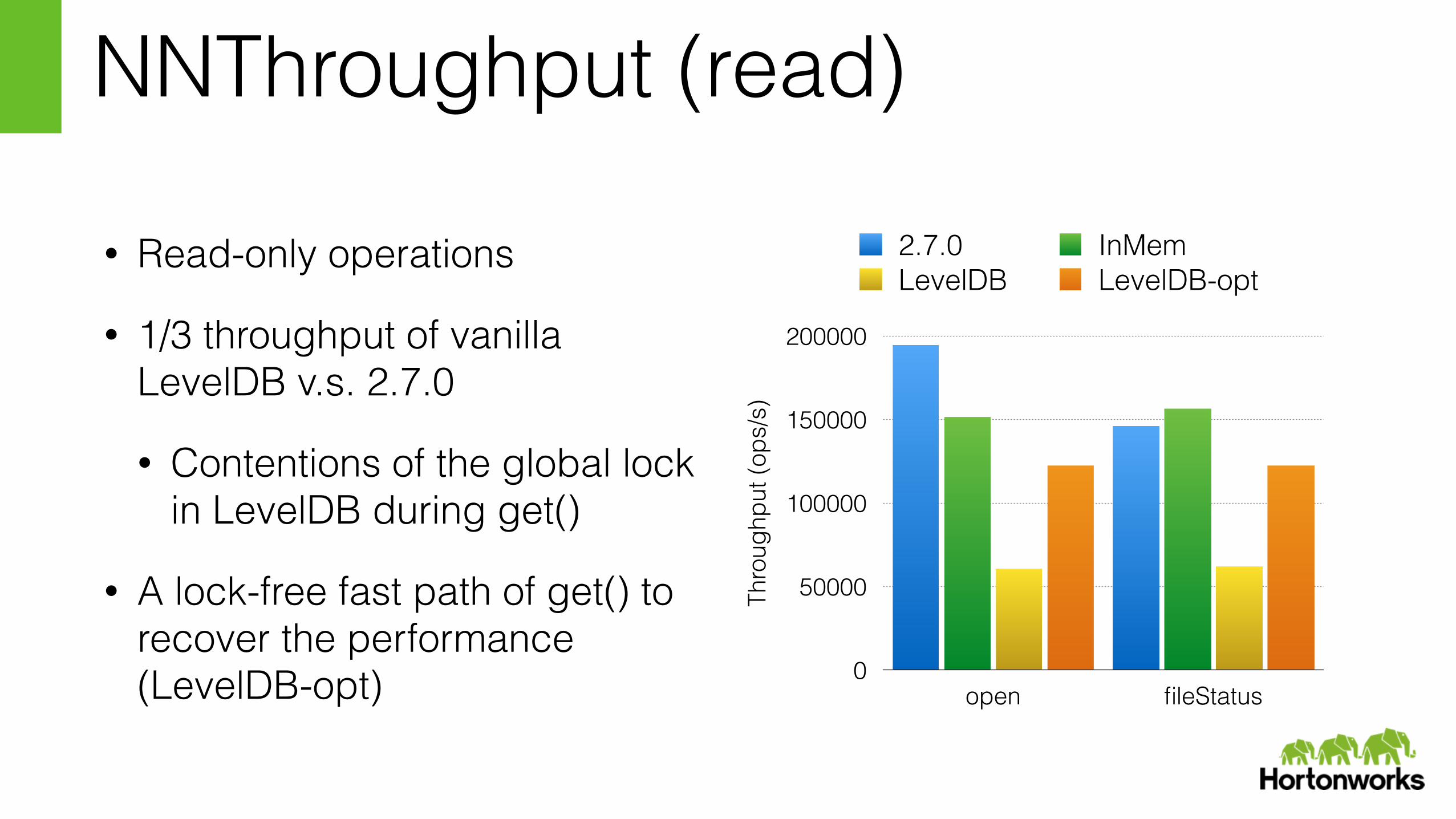
NNThroughput (read)
• Read-only operations
• 1/3 throughput of vanilla LevelDB v.s. 2.7.0
• Contentions of the global lock in LevelDB during get()
• A lock-free fast path of get() to recover the performance (LevelDB-opt)
Thro
ughp
ut (o
ps/s
)
0
50000
100000
150000
200000
open fileStatus
2.7.0 InMemLevelDB LevelDB-opt
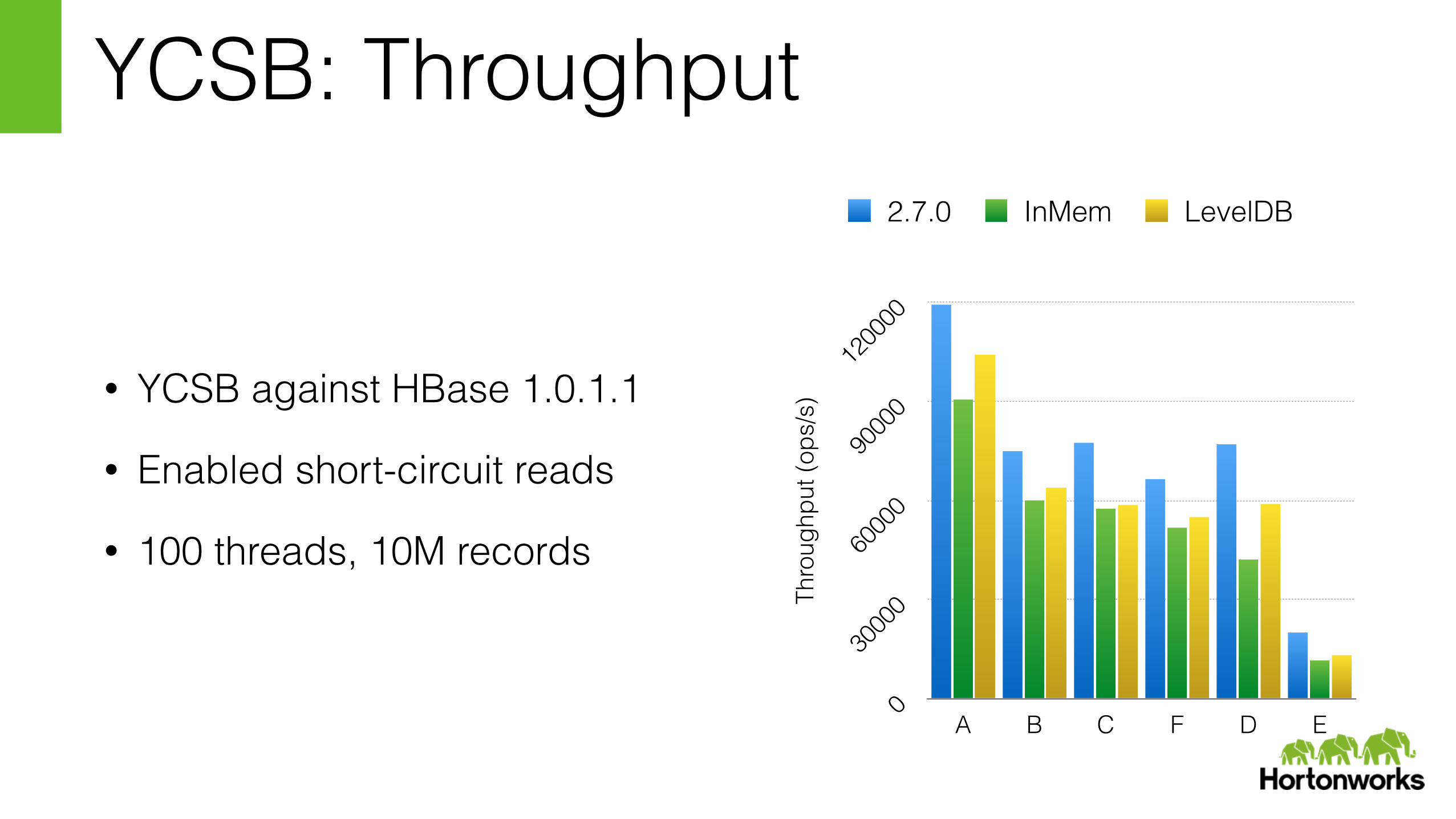
YCSB: Throughput
• YCSB against HBase 1.0.1.1
• Enabled short-circuit reads
• 100 threads, 10M records
Thro
ughp
ut (o
ps/s
)
0
3000
0
6000
0
9000
0
1200
00
A B C F D E
2.7.0 InMem LevelDB
Late
ncy
(us)
0
2500
5000
7500
10000
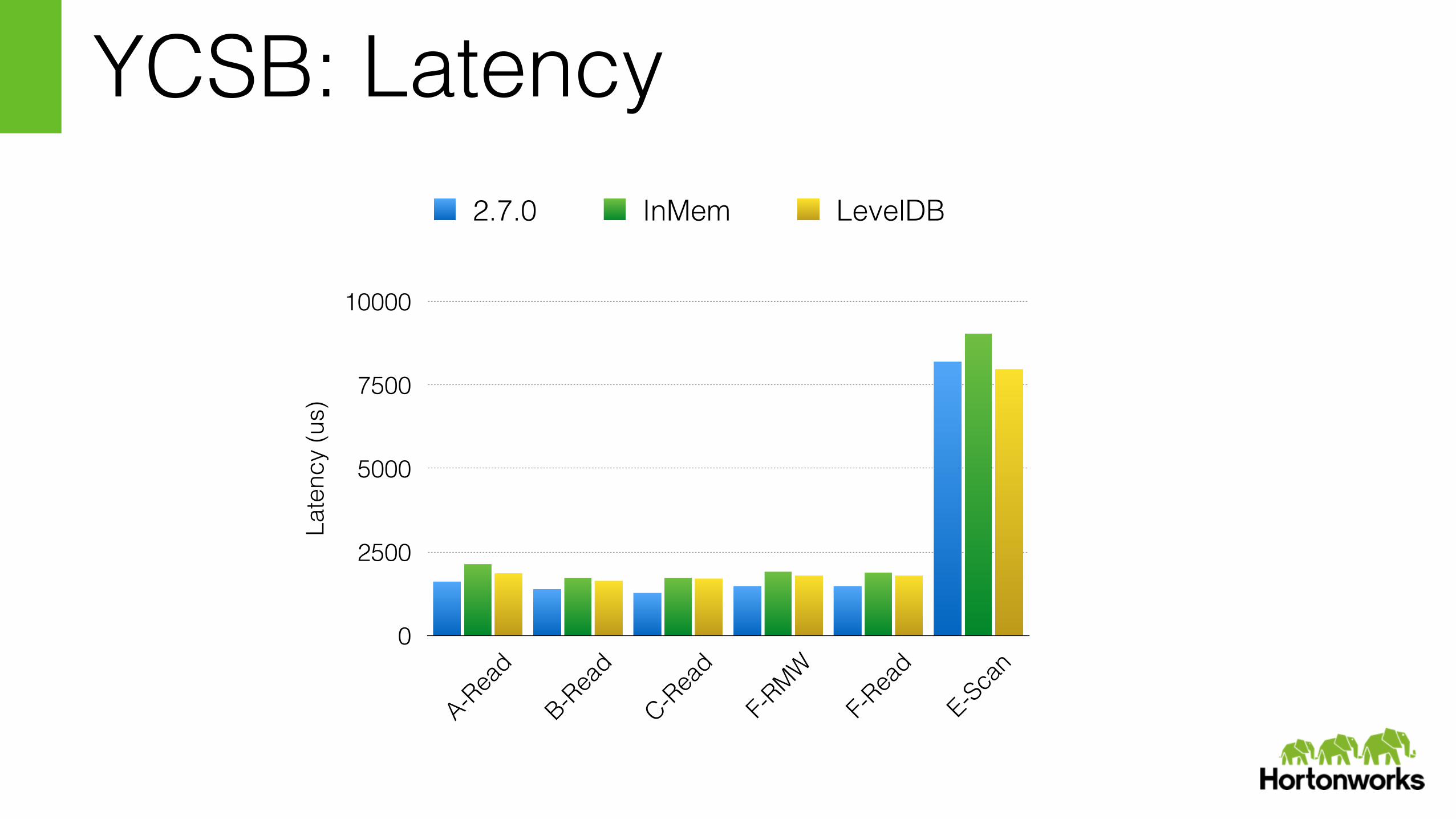
A-Read
B-Read
C-Read
F-RMW
F-Rea
d
E-Scan
2.7.0 InMem LevelDB
YCSB: Latency
Runt
ime
(s)
0
350
700
1050
1400
TeraG
en
TeraS
ort
TeraV
alidate
2.7.0 InMem LevelDB
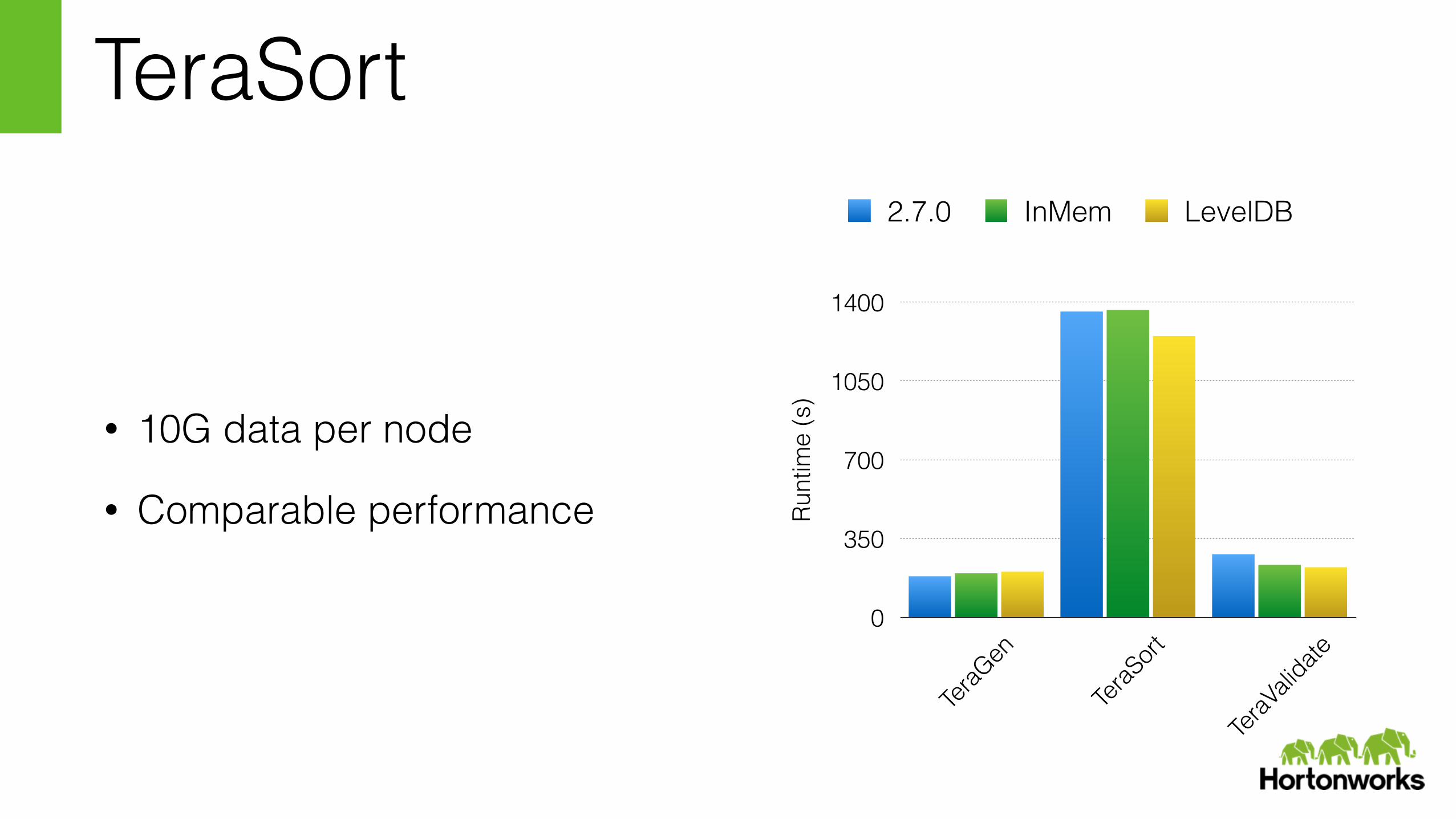
TeraSort
• 10G data per node
• Comparable performance
Thro
ughp
ut (o
p/s)
0
32500
65000
97500
130000
Working set25
6M12
8M 64M
32M
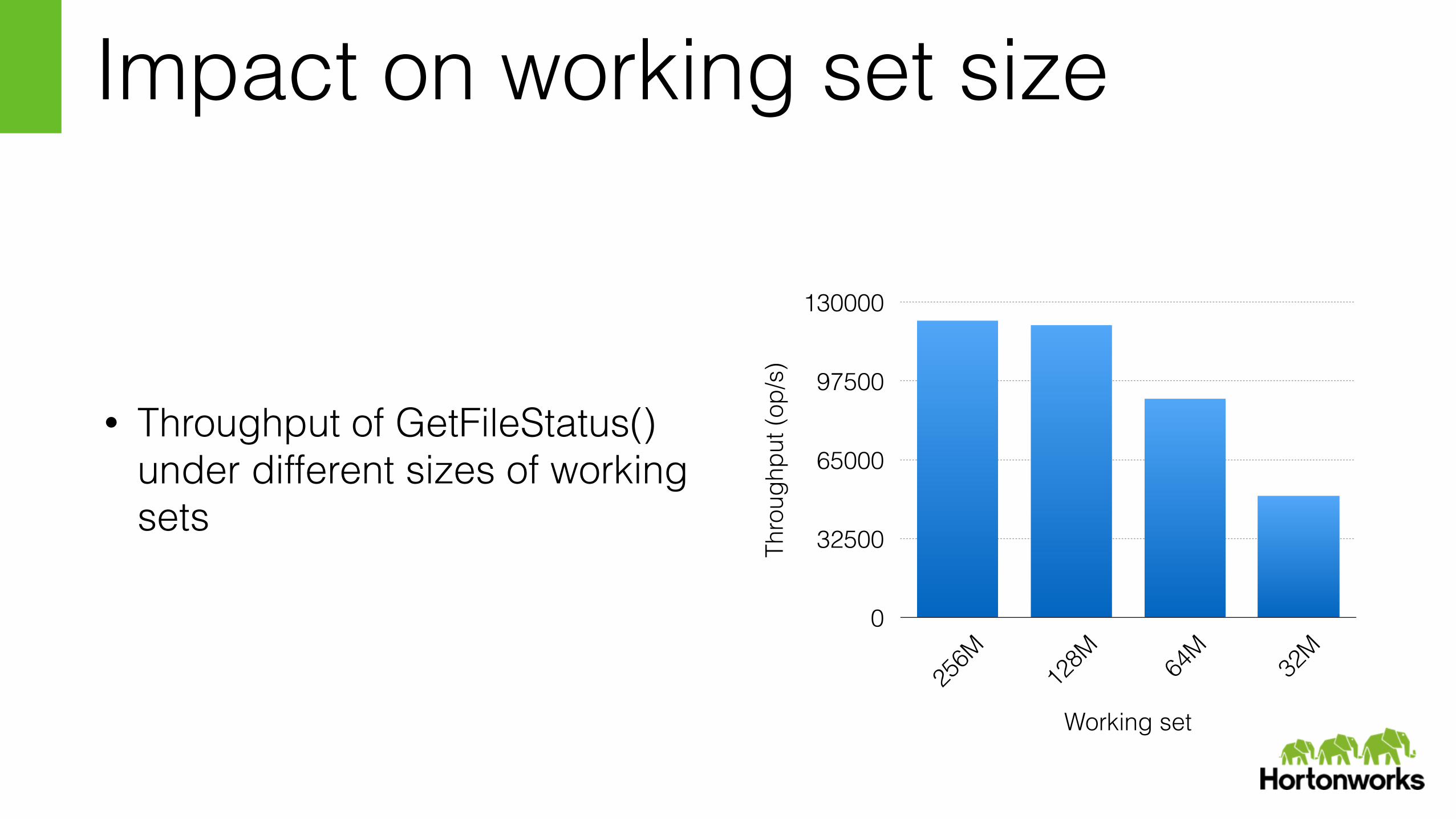
Impact on working set size
• Throughput of GetFileStatus() under different sizes of working sets

• Introduction
• Namespace on top of KV stores
• Evaluation
• Future work & conclusions

Future work
• Implementation and stabilization
• Operation concerns
• Compaction and fsck
• Failure recovery
• Cold startup

Conclusions
• HDFS needs to continue to scale

Conclusions
• HDFS needs to continue to scale
• Evolve HDFS towards KV-based architecture

Conclusions
• HDFS needs to continue to scale
• Evolve HDFS towards KV-based architecture
• Scaling beyond the size of the NN heap

Conclusions
• HDFS needs to continue to scale
• Evolve HDFS towards KV-based architecture
• Scaling beyond the size of the NN heap
• Preliminary evaluation looks promising

Acknowledgement
• Xiao Lin, interned with Hortonworks in 2013
• PoC implementation of LevelDB backed namespace
• Zhilei Xu, interned with Hortonworks in 2014
• Integration between various HDFS features and LevelDB
• Performance tuning

Thank you!


Integrating with LevelDBWrite operations in HDFS
• Updating LevelDB inside the global lock
• New LevelDB::Write() w/o blocking calls
• Write edit log
• logSync()

Integrating with LevelDBWrite operations in HDFS
• Updating LevelDB inside the global lock
• New LevelDB::Write() w/o blocking calls
• Write edit log
• logSync()
Pruning edit logs
• Dump memtable into the disks
• Update MANIFEST
• Prune edit logs


















