
Salvatore Orlando "Mining query logs to improve web search engines' operations"
51
Beyond Query Suggestions: Recommending Tasks to SE Users Claudio Lucchese * , Gabriele Tolomei *+ , Salvatore Orlando + , Raffaele Perego * , Fabrizio Silvestri * * ISTI - CNR, Pisa, Italy + Università Ca’ Foscari Venezia, Italy C. Lucchese, S. Orlando, R. Perego, F. Silvestri, G. Tolomei. Identifying Task-based Sessions in Search Engine Query Logs. ACM WSDM, Hong Kong, February 9-12, 2011 G. Tolomei, S. Orlando, and F. Silvestri. Towards a task-based search and recommender systems. The 26th IEEE International Conference on Data Engineering, ICDE '10 Workshops, pages 333-336, 2010. C. Lucchese, S. Orlando, R. Perego, F. Silvestri, G. Tolomei. Beyond Query Suggestions: Recommending Tasks to Search Engine Users, submitted to WSDM 2012. TechTalk at Moscow - August 22, 2011 1 mercoledì 24 agosto 2011
-
Upload
yandex -
Category
Technology
-
view
3.296 -
download
3
Transcript of Salvatore Orlando "Mining query logs to improve web search engines' operations"

Beyond Query Suggestions: Recommending Tasks to SE Users
Claudio Lucchese*, Gabriele Tolomei*+, Salvatore Orlando+, Raffaele Perego*, Fabrizio Silvestri**ISTI - CNR, Pisa, Italy
+Università Ca’ Foscari Venezia, Italy
C. Lucchese, S. Orlando, R. Perego, F. Silvestri, G. Tolomei. Identifying Task-based Sessions in Search Engine Query Logs. ACM WSDM, Hong Kong, February 9-12, 2011 G. Tolomei, S. Orlando, and F. Silvestri. Towards a task-based search and recommender systems. The 26th IEEE International Conference on Data Engineering, ICDE '10 Workshops, pages 333-336, 2010.
C. Lucchese, S. Orlando, R. Perego, F. Silvestri, G. Tolomei. Beyond Query Suggestions: Recommending Tasks to Search Engine Users, submitted to WSDM 2012.
TechTalk at Moscow - August 22, 2011
1mercoledì 24 agosto 2011

Contents
• Introduction and Motivations
• Web Task Discovery
• Web Task Recommendation
• Mining Query Logs for Web Task Discovery
• Mining Query Logs for Web Task Recommendation
2mercoledì 24 agosto 2011

Web Task Discovery• What is a Web task?
• Any (atomic) user activity that can be achieved by exploiting the information/services available on the Web, e.g., “find a recipe”, “book a flight”, “read news”, etc.
• Why do we use WSE Query Logs to identify Web tasks?
• “Addiction to Web search” : Users rely on WSEs for satisfying their information needs by issuing possibly interleaved stream of related queries
• How do we discover Web tasks in query logs?
• Task-based Session Discovery
• sessions are sets of possibly non contiguous queries, issued by a user whose aim is to carry out specific “Web tasks”
3mercoledì 24 agosto 2011

Web Task Discovery• What is a Web task?
• Any (atomic) user activity that can be achieved by exploiting the information/services available on the Web, e.g., “find a recipe”, “book a flight”, “read news”, etc.
• Why do we use WSE Query Logs to identify Web tasks?
• “Addiction to Web search” : Users rely on WSEs for satisfying their information needs by issuing possibly interleaved stream of related queries
• How do we discover Web tasks in query logs?
• Task-based Session Discovery
• sessions are sets of possibly non contiguous queries, issued by a user whose aim is to carry out specific “Web tasks”
we argue that there is task interleaving
3mercoledì 24 agosto 2011

The Big Picture of Task Discovery
4mercoledì 24 agosto 2011

The Big Picture of Task Discoveryquery
hong kongflights
...
4mercoledì 24 agosto 2011

The Big Picture of Task Discoveryquery
fly tohong kong
...
4mercoledì 24 agosto 2011

The Big Picture of Task Discoveryquery
nba sportnews
...
4mercoledì 24 agosto 2011

The Big Picture of Task Discoveryquery
pisa tohong kong
...
4mercoledì 24 agosto 2011

The Big Picture of Task Discovery
... ......
long-term session
4mercoledì 24 agosto 2011

The Big Picture of Task Discovery
... ......
1 2 n...
Δt > tφ long-term session
4mercoledì 24 agosto 2011

The Big Picture of Task Discovery
1 2 ... n
4mercoledì 24 agosto 2011

The Big Picture of Task Discovery
1 2 ... n
fly to Hong Kong
nba news shopping in Hong Kong
4mercoledì 24 agosto 2011

Task/Query RecommendationHow to exploit Task-based Session Knowledge
• We are interested in supplying novel recommendations to WSE users, on the basis of the knowledge of the task-based query sessions
• from intra-task query recommendation
• to task recommendation
• to finally arrive at inter-task query recommendation
5mercoledì 24 agosto 2011

Task/Query RecommendationHow to exploit Task-based Session Knowledge
• We are interested in supplying novel recommendations to WSE users, on the basis of the knowledge of the task-based query sessions
• from intra-task query recommendation
• to task recommendation
• to finally arrive at inter-task query recommendation
We aim to recommend another related task, where the current and the recommended ones are part of a mission
5mercoledì 24 agosto 2011

Task/Query Recommendation From tasks to missions
• From Web task to Web mission
• We argue that single search tasks may be subsumed by composite tasks, namely missions, which user aim to accomplish through a WSE
• Example
• Alice starts interacting with her favorite WSE by submitting queries we recognize as part of the same task, related to “booking of a hotel room in New York”
• The current Alice's task could be included in a mission, composed of more tasks, concerned with “planning a travel to New York”
R. Jones and K.L. Klinkner. 2008. Beyond the session timeout: automatic hierarchical segmentation of search topics in query logs. In CIKM ’08. ACM, 699–708.
6mercoledì 24 agosto 2011

Task/Query Recommendation From intra- to inter-task query suggestions
• Assume we recognize that Alice is performing a query task (several queries) related to “booking of a hotel room in New York”
• query suggestion mechanisms may provide alternative related queries (intra-task query suggestions), such as “cheap new york hotels”, “times square hotel”, “waldorf astoria”, etc. ⇐ this is similar to current query suggestion mechanisms
• Assume we discover that many users performed a task similar to the Alice's one, along with other tasks ➠ they could be part of a composite mission
• e.g., a mission that is concerned with “planning a travel to New York”
• we may also recommend to Alice other tasks, whose underpinning queries look like: “mta subway”, or “broadway shows”, or “JFK airport shuttle” (inter-task query suggestions)
7mercoledì 24 agosto 2011

Task Discovery
8mercoledì 24 agosto 2011

Data Set: AOL Query Log
Original Data Set
Sample Data Set
✓ 1-week collection✓ ~100K queries✓ 1,000 users✓ removed empty queries✓ removed “non-sense” queries✓ removed stop-words✓ applied Porter stemming algorithm
✓ 3-months collection✓ ~20M queries✓ ~657K users
9mercoledì 24 agosto 2011

Data Analysis: query time gap
tφ = 26 min.
84.1% of adjacent query pairs are issued within 26 minutes
10mercoledì 24 agosto 2011

Task-based Session Discoverya combined approach
2) QueryClustering-m
Queries in a time-based sessions are f u r ther g rouped us ing c l u s ter i ng algorithms, which exploit several query features. Two queries (qi, qj) are in the same task-based session iff they belong to the same cluster.
QC-m, where m is one of the clustering method
Methods: QC-MEANS, QC-SCAN, QC-WCC, and QC-HTC
1) TimeSplitting-t
The idea is that if two consecutive queries are far away, they are also likely unrelated
TS-t, where t is the time gap between consecutive queries must be not greater than t
This technique alone produces time-based sessions, but is unable to deal with multi-tasking
Methods: TS-5, TS-15, TS-26, etc.
11mercoledì 24 agosto 2011

QC-m: Query Features and Similarities Semantic-based (µsemantic)
✓ using Wikipedia and Wiktionary for “expanding” a query q
✓ “wikification” of q using vector-space model
✓ relatedness between (qi, qj) computed using cosine-similarity
Content-based (µcontent)✓ two queries (qi, qj) sharing common terms are
likely related✓ µjaccard: Jaccard index on query character 3-
grams
✓ µlevenshtein: normalized Levenshtein (edit) distance
12mercoledì 24 agosto 2011

Distance Functions: µ1 vs. µ2
✓Convex combination µ1
✓ Conditional formula µ2
Idea: if two queries are close in term of lexical content, the semantic expansion could be unhelpful. Vice-versa, nothing can be said when queries do not share any content feature
✓ Both µ1 and µ2 rely on the estimation of some parameters, i.e., α, t, and b✓ Use the ground-truth for tuning parameters
13mercoledì 24 agosto 2011

• ~500 long-term sessions are first split using the threshold tφ devised before (i.e., 26 minutes), obtaining several time-gap sessions
• Human annotators put together task-related queries that they claim to be part of the same task
• This ground-truth is used for
• to tune some parameter of our method
• more importantly, to evaluate the automatic clustering for task-based session discovery
Ground-truth: construction e use
14mercoledì 24 agosto 2011

Ground-truth: statistics
✓ 4.49 avg. queries per time-gap session
✓ more than 70% time-gap session contains at most 5 queries
✓ 2.57 avg. queries per task-based sessions
✓ ~75% tasks contains at most 3 queries
✓ 1.80 tasks per time-gap session (avg.)✓ ~47% time-gap session contains more
than one task (multi-tasking)✓ 1,046 over 1,424 queries (i.e., ~74%)
included in multi-tasking sessions
15mercoledì 24 agosto 2011

QC-WCC WEIGHTED CONNECTED COMPONENTS
1 8765432time-gap session φ
16mercoledì 24 agosto 2011

QC-WCC WEIGHTED CONNECTED COMPONENTS
1 2
3
4
56
7
8
Build the similarity graph Gφ - O(N2)
1 8765432time-gap session φ
16mercoledì 24 agosto 2011

QC-WCC WEIGHTED CONNECTED COMPONENTS
1 2
3
4
56
7
8
1 8765432time-gap session φ
Drop “weak edges”
16mercoledì 24 agosto 2011

QC-WCC WEIGHTED CONNECTED COMPONENTS
1 2
3
4
56
7
8
1 8765432time-gap session φ
16mercoledì 24 agosto 2011

• Variation of QC-WCC, that does not need to compute the full similarity graph
• Performs into 3 steps:
1. computes the similarities between chronologically consecutive queries in φ and insert the corresponding labeled edge in the graph Gφ - O(N)
2. Drop “weak edges”, thus obtaining clusters corresponding to sub-sequences
• each cluster represented by the chronologically first and last queries: head and tail
3. Pairwise merging of the sub-sequences so obtained,
• by only inserting edges between the heads/tails if the corresponding queries are similar enough
QC-HTCHEAD-TAIL COMPONENTS
17mercoledì 24 agosto 2011

• Run and compare all the proposed approaches with:
• TS-26: time-splitting technique (baseline)
• QFG: session extraction method based on the query-flow graph model (state of the art)
Experiments Setup
P. Boldi, F. Bonchi, C. Castillo, D. Donato, A. Gionis, S. Vigna: The query-flow graph: model and applications. CIKM 2008: 609-618
18mercoledì 24 agosto 2011

• Measure the degree of correspondence between the true tasks (manually-extracted ground-truth), and the predicted tasks (algorithms’ outputs)
• we can use all the external measures commonly used to evaluate a clustering algorithm when used to extract disjoint partitions in a dataset annotated with class labels
Evaluation
a) F-MEASURE✓ evaluates the extent to
which a predicted task contains only and all the queries of a true task
✓ combines p(i, j) and r(i, j) the precision and recall of task i w.r.t. class j
b) RAND✓ pairs of queries instead
of singleton ✓ f00, f01, f10, f11
c) JACCARD✓ pairs of queries instead
of singleton ✓ f01, f10, f11
19mercoledì 24 agosto 2011

• Measure the degree of correspondence between the true tasks (manually-extracted ground-truth), and the predicted tasks (algorithms’ outputs)
• we can use all the external measures commonly used to evaluate a clustering algorithm when used to extract disjoint partitions in a dataset annotated with class labels
Evaluation
a) F-MEASURE✓ evaluates the extent to
which a predicted task contains only and all the queries of a true task
✓ combines p(i, j) and r(i, j) the precision and recall of task i w.r.t. class j
b) RAND✓ pairs of queries instead
of singleton ✓ f00, f01, f10, f11
c) JACCARD✓ pairs of queries instead
of singleton ✓ f01, f10, f11
f00 = #pairs of objʼs w/ different class and taskf01 = #pairs of objʼs w/ different class and same taskf10 = #pairs of objʼs w/ same class and different taskf11 = #pairs of objʼs w/ same class and task
20mercoledì 24 agosto 2011

Results: best
Supervised methodQuery Flow Graph (QFG)
K-means (centroid-based) and DB-Scan (density-
based)
P. Boldi, F. Bonchi, C. Castillo, D. Donato, A. Gionis, S. Vigna: The query-flow graph: model and applications. CIKM 2008: 609-618
21mercoledì 24 agosto 2011

Results: best
Supervised methodQuery Flow Graph (QFG)
K-means (centroid-based) and DB-Scan (density-
based)
P. Boldi, F. Bonchi, C. Castillo, D. Donato, A. Gionis, S. Vigna: The query-flow graph: model and applications. CIKM 2008: 609-618
21mercoledì 24 agosto 2011

Task Recommendation
22mercoledì 24 agosto 2011

Crowd-based Task Synthesis
• We need to find recurrent behaviors in the crowd
• We need to identify similar tasks by clustering the associated “virtual documents”
• where each virtual document include the queries performed in the task by a user
User 1
User 2
User 3
....
All the tasks appear different
23mercoledì 24 agosto 2011

Crowd-based Task Synthesis
• We can rewrite each task-oriented session in terms of the new synthesized tasks ids: Th
where Th = {T1 , ... , TK}
• Th can be considered as a representative for an aggregation composed of similar tasks, performed by several distinct users
• The various long term sessions thus become sets/sequences of synthesized tasks in which we can find recurrences
User 1
User 2
User 3
....
same Th
24mercoledì 24 agosto 2011
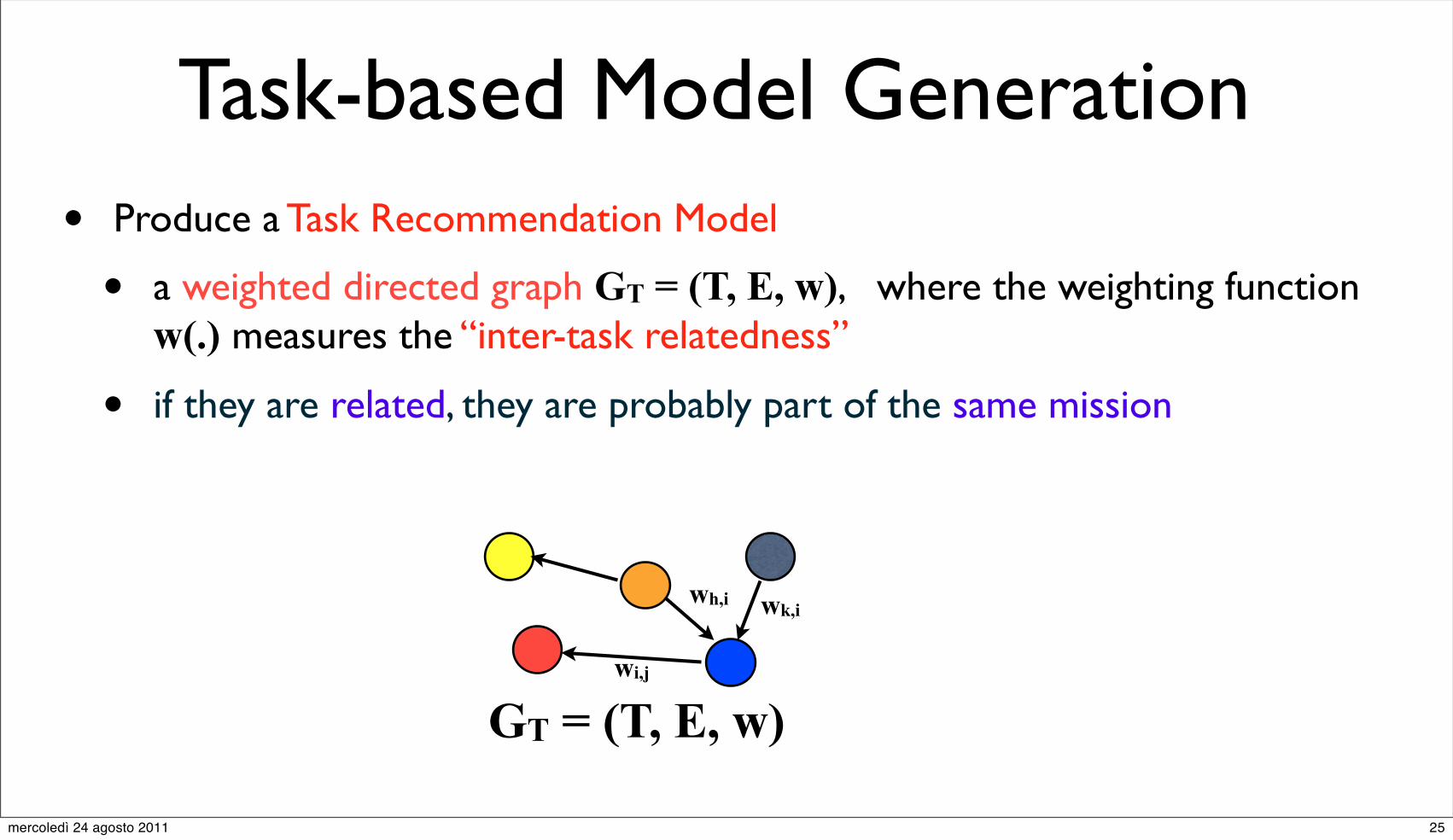
Task-based Model Generation• Produce a Task Recommendation Model
• a weighted directed graph GT = (T, E, w), where the weighting function w(.) measures the “inter-task relatedness”
• if they are related, they are probably part of the same mission
GT = (T, E, w)wi,j
wh,i wk,i
25mercoledì 24 agosto 2011

Task-based Recommendation• Generate a Task-oriented Recommendations
• given a user who is interested in (has just performed) a task Ti
• retrieve from GT the set Rm(Ti), which includes the m-top related nodes/tasks to Ti
• the graph nodes in Rm(Ti) are directly connected to node Ti and are the m ones labeled with the highest weights
Ti
26mercoledì 24 agosto 2011

Task-based Recommendation• Generate a Task-oriented Recommendations
• given a user who is interested in (has just performed) a task Ti
• retrieve from GT the set Rm(Ti), which includes the m-top related nodes/tasks to Ti
• the graph nodes in Rm(Ti) are directly connected to node Ti and are the m ones labeled with the highest weights
Ti
R2(Ti)
26mercoledì 24 agosto 2011

How to Generate the Model• Various methods to generate edges in GT and the
associated weights
• Random-based (baseline): an edge for each pair, whose weights are uniform
• Sequence-based: the frequency of the pairs wrt a given support threshold, by considering the relative order in the original sequences
GT = (T, E, w)wi,j
wh,i wk,i
• Association-Rule based (support): the frequency of the rule wrt a given support threshold. We do not consider the relative order in the original sequences to extract the rules
• Association-Rule based (confidence): the confidence of the rules wrt a given confidence threshold. We do not consider the relative order in the original sequences to extract the rules
27mercoledì 24 agosto 2011

Data Set: AOL 2006 Query Log
Original Data Set
Sample Data Set
✓ Top-600 longest user sessions✓ ~58K queries✓ avg 14 queries per user/day
✓set A : 500 user sessions (training)✓ set B : 100 user sessions (test)
✓ 3-months collection✓ ~20M queries✓ ~657K users
28mercoledì 24 agosto 2011

Data Set: AOL 2006 Query Log
Original Data Set
Sample Data Set
✓ Top-600 longest user sessions✓ ~58K queries✓ avg 14 queries per user/day
✓set A : 500 user sessions (training)✓ set B : 100 user sessions (test)
✓ 3-months collection✓ ~20M queries✓ ~657K users
28mercoledì 24 agosto 2011

Data Set: AOL 2006 Query Log
Original Data Set
Sample Data Set
✓ Top-600 longest user sessions✓ ~58K queries✓ avg 14 queries per user/day
✓set A : 500 user sessions (training)✓ set B : 100 user sessions (test)
✓ 3-months collection✓ ~20M queries✓ ~657K users
From both A and B we extracted the tasks with our QC-HTCSet A was used to generate the graph model using various mining techniques
28mercoledì 24 agosto 2011

Experimental results
• We measured
• precision (proportion of suggestions that actually occur in the 2/3 suffix)
• coverage (proportion of tasks in the 1/3 prefix that are able to provide at least one suggestion)
• changing the weighting in each model, by tuning the corresponding parameters, modifies the coverage ...
• we thus plot precision vs coverage to permit the different models to be fairly compared
GT = (T, E, w)wi,j
wh,i wk,i
• We used the log subset B (test query log) for evaluation
• we divided each long term session in B (with synthesized tasks) into a 1/3 prefix and 2/3 suffix
• the prefix is used to retrieve from GT the tasks: Rm(prefix)
29mercoledì 24 agosto 2011

Experimental results Recommendation Models
30mercoledì 24 agosto 2011

Experimental results Recommendation Models
31mercoledì 24 agosto 2011

Anecdotal Evidence
actually performed
queries
}
32mercoledì 24 agosto 2011
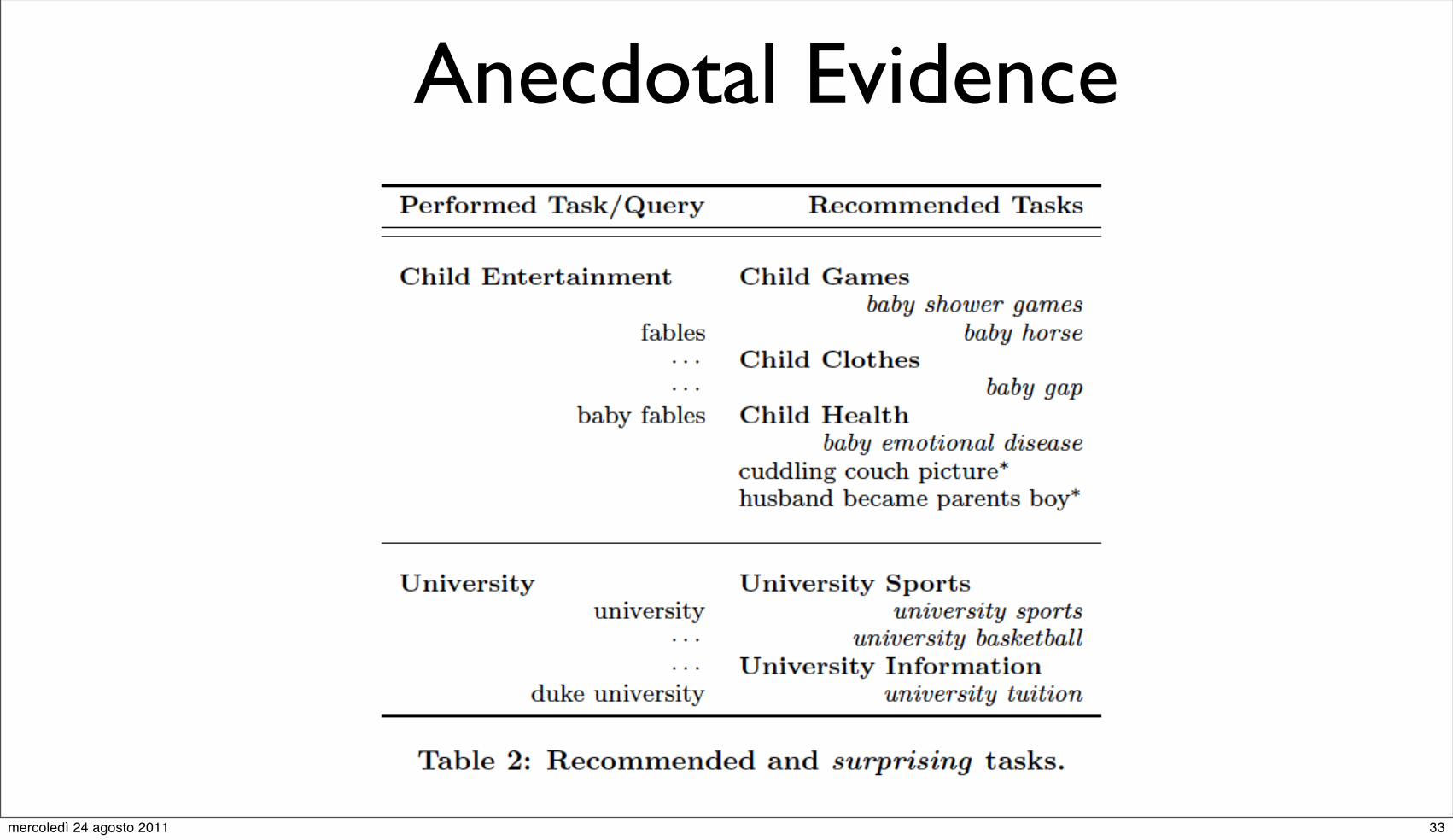
Anecdotal Evidence
33mercoledì 24 agosto 2011

Questions?
34mercoledì 24 agosto 2011


















