
Robust data synchronization with ibm tivoli directory integrator sg246164
510
ibm.com/redbooks Robust Data Synchronization with IBM Tivoli Directory Integrator Axel Buecker Franc Cervan Christian Chateauvieux David Druker Eddie Hartman Rana Katikitala Elizabeth Melvin Todd Trimble Johan Varno Complete coverage of architecture and components Helpful solution and operational design guide Extensive hands-on scenarios
-
Upload
banking-at-ho-chi-minh-city -
Category
Technology
-
view
5.423 -
download
4
Transcript of Robust data synchronization with ibm tivoli directory integrator sg246164

ibm.com/redbooks
Robust DataSynchronizationwith IBM Tivoli Directory Integrator
Axel BueckerFranc Cervan
Christian ChateauvieuxDavid Druker
Eddie HartmanRana Katikitala
Elizabeth MelvinTodd TrimbleJohan Varno
Complete coverage of architecture and components
Helpful solution and operational design guide
Extensive hands-on scenarios
Front cover


Robust Data Synchronization with IBM Tivoli Directory Integrator
May 2006
International Technical Support Organization
SG24-6164-00

© Copyright International Business Machines Corporation 2006. All rights reserved.Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADPSchedule Contract with IBM Corp.
First Edition (May 2006)
This edition applies to Version 6.0.0 (with Fixpak 3: TIV-ITDI-FP0003) of IBM Tivoli Directory Integrator.
Note: Before using this information and the product it supports, read the information in “Notices” on page ix.

Contents
Notices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ixTrademarks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . x
Preface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiThe team that wrote this redbook. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiBecome a published author . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xivComments welcome. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiv
Part 1. Architecture and design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
Chapter 1. Business context for evolutionary integration. . . . . . . . . . . . . . 31.1 A close look at the challenge. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.2 Benefits of synchronization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3 Directory Integrator in non-synchronizing scenarios . . . . . . . . . . . . . . . . . . 71.4 Synchronization patterns and approaches . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.4.1 How and when synchronization can be invoked . . . . . . . . . . . . . . . . . 81.4.2 Data flow patterns . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.5 Business and technical scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.5.1 Multiple existing directories and security concern. . . . . . . . . . . . . . . 111.5.2 Existing directory cannot be modified . . . . . . . . . . . . . . . . . . . . . . . . 121.5.3 Single sign-on into multiple directories with Access Manager . . . . . 131.5.4 Data is located in several places. . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.5.5 Use of virtual directory - access data in place. . . . . . . . . . . . . . . . . . 13
1.6 Conclusion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
Chapter 2. Architecting an enterprise data synchronization solution . . . 172.1 Typical business requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2 Detailed data identification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2.1 Data location . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.2.2 Data owner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.2.3 Data access . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.2.4 Initial data format. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.2.5 Unique data. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.3 Plan the data flows . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.3.1 Authoritative attributes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.3.2 Unique link criteria. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.3.3 Special conditions or requirements . . . . . . . . . . . . . . . . . . . . . . . . . . 232.3.4 Final data format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.3.5 Data cleanup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
© Copyright IBM Corp. 2006. All rights reserved. iii

2.3.6 Phased approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.3.7 Frequency . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.4 Review results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.5 Instrument and test a solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.5.1 Create workable units . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.5.2 Naming conventions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.5.3 High availability and failover . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.5.4 System administration. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.5.5 Security . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.5.6 Password synchronization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.6 Who are the players in the solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.6.1 Common roles and responsibilities . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.7 Conclusion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
Chapter 3. Directory Integrator component structure . . . . . . . . . . . . . . . . 413.1 Concept of integration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.1.1 Data sources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.1.2 Data flows . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.1.3 Events . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.2 Base components . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.2.1 AssemblyLines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.2.2 Connectors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503.2.3 Parsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 603.2.4 EventHandlers. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.2.5 Hooks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 623.2.6 Scripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 623.2.7 Function components . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633.2.8 Attribute Map components . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 643.2.9 Branch components . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 643.2.10 Loop components . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 653.2.11 Password synchronization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3.3 Security capability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 673.4 Physical architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
3.4.1 Combination with an enterprise directory . . . . . . . . . . . . . . . . . . . . . 683.4.2 Base topologies. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 703.4.3 Multiple servers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
3.5 Availability and scalability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 753.6 Logging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 803.7 Administration and monitoring. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 843.8 Conclusion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
Part 2. Customer scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
Chapter 4. Penguin Financial Incorporated . . . . . . . . . . . . . . . . . . . . . . . . 91
iv Robust Data Synchronization with IBM Tivoli Directory Integrator

4.1 Business requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 924.1.1 Current architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
4.2 Functional requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 934.3 Solution design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
4.3.1 Architectural decisions for phase 1 . . . . . . . . . . . . . . . . . . . . . . . . . 1004.3.2 Architectural decisions for phase 2 . . . . . . . . . . . . . . . . . . . . . . . . . 101
4.4 Phase 1: User integration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1064.4.1 Detailed data identification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1074.4.2 Data flows . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1114.4.3 Instrument and test a solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
4.5 Phase 2: Password synchronization . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1634.5.1 Components . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1634.5.2 Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1834.5.3 Detailed data identification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1864.5.4 Plan the data flows . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1904.5.5 Review results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1964.5.6 Instrument and test a solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200
Chapter 5. Blue Glue Enterprises . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2675.1 Company profile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2685.2 Blue Glue business requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2685.3 Blue Glue functional requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2695.4 Solution design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2735.5 Phase 1: Human resources data feed. . . . . . . . . . . . . . . . . . . . . . . . . . . 275
5.5.1 Detailed data identification, data flows and review . . . . . . . . . . . . . 2755.5.2 Instrument and test solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 279
5.6 Phase 2: Store management application . . . . . . . . . . . . . . . . . . . . . . . . 3005.6.1 Detailed data identification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3005.6.2 Data flows . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3035.6.3 Review results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3075.6.4 Instrument and test solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313
Part 3. Appendixes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413
Appendix A. Tricky connections . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415Introduction to JDBC drivers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 416Database connectivity to Oracle. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 416
Obtaining the drivers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 418Installing the drivers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 419Driver configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 420
Database connectivity to DB2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 422Obtaining the drivers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 424Installing the drivers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 424Driver configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 424
Contents v

Database connectivity to SQL Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 426Obtaining the drivers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 427Installing the drivers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 427Driver configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 427
Connectivity to Domino Server. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434Identity Manager Notes Agent configuration . . . . . . . . . . . . . . . . . . . . . . . 436
Appendix B. Directory Integrator’s view of JavaScript . . . . . . . . . . . . . . 439The script engine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 440
Scripts and configuration files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 440Scripting tools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 441
Scripts: Where . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442Scripting JavaScript and Java . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443
Core JavaScript. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443Regular expressions (regex) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 444Java through JavaScript . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 446Java to JavaScript and back . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 447
Common tasks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 451Creating arrays and Java utility objects . . . . . . . . . . . . . . . . . . . . . . . . . . 451Managing dates. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 452Working with entries and attributes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453
Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453
Appendix C. Handling exceptions and errors. . . . . . . . . . . . . . . . . . . . . . 455Reading the error dump . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 456Errors = exceptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 459
The error object . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462Exception handling in script . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463
Error Hooks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463Mandatory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 464Connection Failure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 466Mode-specific On Error . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 467Default On Error . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 467
Logging. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 467
Appendix D. Additional material . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 471Locating the Web material . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 471Using the Web material . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 471
How to use the Web material . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 472
Glossary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473
Related publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 477IBM Redbooks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 477
vi Robust Data Synchronization with IBM Tivoli Directory Integrator

Other publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 477Online resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 478How to get IBM Redbooks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 478Help from IBM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 479
Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 481
Contents vii

viii Robust Data Synchronization with IBM Tivoli Directory Integrator

Notices
This information was developed for products and services offered in the U.S.A.
IBM may not offer the products, services, or features discussed in this document in other countries. Consult your local IBM representative for information on the products and services currently available in your area. Any reference to an IBM product, program, or service is not intended to state or imply that only that IBM product, program, or service may be used. Any functionally equivalent product, program, or service that does not infringe any IBM intellectual property right may be used instead. However, it is the user's responsibility to evaluate and verify the operation of any non-IBM product, program, or service.
IBM may have patents or pending patent applications covering subject matter described in this document. The furnishing of this document does not give you any license to these patents. You can send license inquiries, in writing, to: IBM Director of Licensing, IBM Corporation, North Castle Drive Armonk, NY 10504-1785 U.S.A.
The following paragraph does not apply to the United Kingdom or any other country where such provisions are inconsistent with local law: INTERNATIONAL BUSINESS MACHINES CORPORATION PROVIDES THIS PUBLICATION "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do not allow disclaimer of express or implied warranties in certain transactions, therefore, this statement may not apply to you.
This information could include technical inaccuracies or typographical errors. Changes are periodically made to the information herein; these changes will be incorporated in new editions of the publication. IBM may make improvements and/or changes in the product(s) and/or the program(s) described in this publication at any time without notice.
Any references in this information to non-IBM Web sites are provided for convenience only and do not in any manner serve as an endorsement of those Web sites. The materials at those Web sites are not part of the materials for this IBM product and use of those Web sites is at your own risk.
IBM may use or distribute any of the information you supply in any way it believes appropriate without incurring any obligation to you.
Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not tested those products and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products.
This information contains examples of data and reports used in daily business operations. To illustrate them as completely as possible, the examples include the names of individuals, companies, brands, and products. All of these names are fictitious and any similarity to the names and addresses used by an actual business enterprise is entirely coincidental.
COPYRIGHT LICENSE: This information contains sample application programs in source language, which illustrates programming techniques on various operating platforms. You may copy, modify, and distribute these sample programs in any form without payment to IBM, for the purposes of developing, using, marketing or distributing application programs conforming to the application programming interface for the operating platform for which the sample programs are written. These examples have not been thoroughly tested under all conditions. IBM, therefore, cannot guarantee or imply reliability, serviceability, or function of these programs. You may copy, modify, and distribute these sample programs in any form without payment to IBM for the purposes of developing, using, marketing, or distributing application programs conforming to IBM's application programming interfaces.
© Copyright IBM Corp. 2006. All rights reserved. ix

TrademarksThe following terms are trademarks of the International Business Machines Corporation in the United States, other countries, or both:
AIX®Cloudscape™Distributed Relational Database
Architecture™Domino®DB2®DRDA®Everyplace®HACMP™
Informix®IBM®Lotus Notes®Lotus®Metamerge®Netfinity Manager™Netfinity®Notes®iNotes™
OS/2®Redbooks™Redbooks (logo) ™RACF®RDN™Tivoli®Update Connector™WebSphere®
The following terms are trademarks of other companies:
iPlanet, Java, Javadoc, JavaScript, JDBC, JDK, JMX, JVM, J2EE, Solaris, Sun, Sun Java, Sun ONE, and all Java-based trademarks are trademarks of Sun Microsystems, Inc. in the United States, other countries, or both.
Microsoft, Windows NT, Windows, and the Windows logo are trademarks of Microsoft Corporation in the United States, other countries, or both.
Intel, Intel logo, Intel Inside logo, and Intel Centrino logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States, other countries, or both.
UNIX is a registered trademark of The Open Group in the United States and other countries.
Linux is a trademark of Linus Torvalds in the United States, other countries, or both.
Other company, product, or service names may be trademarks or service marks of others.
x Robust Data Synchronization with IBM Tivoli Directory Integrator

Preface
Don’t be fooled by the name; IBM® Tivoli® Directory Integrator integrates anything, and it is not in any way limited to directories. It is a truly generic data integration tool that is suitable for a wide range of problems that usually require custom coding and significantly more resources to address with traditional integration tools.
This IBM Redbook shows you how Directory Integrator can be used for a wide range of applications utilizing its unique architecture and unparalleled flexibility. The following examples may resonate with business needs in your infrastructure, while others can provide insight that can help understand the breadth of Directory Integrator’s capabilities:
� Continuously maintaining records in one or more databases based on information in other data sources such as files, directories and databases.
� Migrating data from one system to another, or synchronizing legacy (or existing) data where systems cannot be replaced or shut down.
� Automatically transforming files from one format to another.
� Adding supplementary identity data to LDAP directories when deploying white pages, provisioning, and access control solutions.
� Reacting to changes to data (such as modification, additions, and deletions) in the infrastructure and driving this information to systems that need to know about it.
� Integrating geographically dispersed systems with multiple choices of protocols and mechanisms; such as MQ, HTTP, secure e-mail and Web Services.
� Extending the capabilities and reach of existing systems and applications, giving them access to the rich communications and transformation capabilities of Directory Integrator.
This book is a valuable resource for security administrators and architects who want to understand and implement a directory synchronization project.
The team that wrote this redbookThis redbook was produced by a team of specialists from around the world working at the International Technical Support Organization, Austin Center.
© Copyright IBM Corp. 2006. All rights reserved. xi

The team that wrote this book is shown in the picture above. They are from top left to right: Rana, Todd and Franc; and bottom left to right: David, Axel, and Beth
Axel Buecker is a Certified Consulting Software IT Specialist at the International Technical Support Organization, Austin Center. He writes extensively and teaches IBM classes worldwide in the areas of software security architecture and network computing technologies. He holds a degree in Computer Science from the University of Bremen, Germany. He has 19 years of experience in a variety of areas related to workstation and systems management, network computing, and e-business solutions. Before joining the ITSO in March 2000, Axel worked for IBM in Germany as a Senior IT Specialist in Software Security Architecture.
Franc Cervan is an IT Specialist working in Technical Presales for the IBM Software Group, Slovenia. He holds a diploma in Industrial Electronics from the University of Ljubljana and has 10 years of experience in security and systems management solutions. After joining IBM in 2003, his area of expertise are Tivoli Security and Automation products.
Christian Chateauvieux is a Consulting IT Specialist helping and mentoring the IBM Tivoli Software Technical Sales Teams across the EMEA geography. He is a
xii Robust Data Synchronization with IBM Tivoli Directory Integrator

technical advocate of Tivoli Security solutions, promoting and supporting the sales and marketing initiatives associated with the Tivoli Directory portfolio and the rest of the IBM Tivoli Security portfolio, including Tivoli Identity Manager and Tivoli Access Manager in EMEA. He is an expert in Tivoli Directory products and joined IBM in 2002. Prior to this he had two years in Metamerge® professional services and support. Christian holds a master’s degree of Computer Sciences from the National Institute of Applied Sciences (INSA) in France and is ITIL certified.
David Druker is a Consulting IT Specialist for Tivoli Security products. He currently works in the IBM Channel Technical Sales organization and is a recognized authority on IBM Tivoli Directory Integrator solutions. David holds a Ph.D. in Speech and Hearing Science from the University of Iowa. He joined IBM in 2002. Prior to that, he wrote code, built scientific apparatus and managed a variety of systems in both business and scientific enterprises.
Eddie Hartman is part of the Tivoli Directory Integrator development team, working with design, documentation and storytelling. Eddie studied Computer Science at SFASU in Nacogdoches, Texas, and at the University of Oslo in Norway.
Rana Katikitala is an Advisory Software Specialist for Tivoli Security in the IBM Software Labs, India. He has eight years of experience in the IT industry in the ares of development, support, and test of operating systems, systems management software, and e-business solutions. He holds a master’s degree in Structural Engineering from Regional Engineering College (REC) Warangal, India. His areas of expertise include IBM OS/2®, Windows® 2000, Netfinity® Manager™, IBM Director, Healthcare domain solutions of HIPAA (Health Insurance Portability and Accountability Act) and HCN (Healthcare Collaborative Network) and Tivoli Security solutions.
Elizabeth Melvin is a Certified Consulting IT Specialist in Austin, Texas, working for the IBM TechWorks Americas Group as a subject matter expert supporting software sales. She has 16 years of experience in a variety of areas including systems security, identity/data management and architecture as well as network computing. She holds a degree in Management of Information Systems from the University of Texas in Austin. Her areas of expertise include security infrastructure and data synchronization software.
Todd Trimble is a Certified IT Product Specialist. He is ITIL certified and has 25 years experience in the security and systems management solutions area. Todd joined IBM in 1998 and has been working with the Tivoli Security products on major customer engagements. He is responsible for providing a validated technical solution that resolves the identified business requirements and eliminates the technical issues and concerns prior to the sale of the IBM Tivoli Security portfolio.
Preface xiii

Johan Varno is the Lead Architect for Tivoli Directory Integrator at the IBM Oslo Development Lab in Norway. He holds a degree in Computer Science from the University in Oslo and an MBA from the Norwegian School of Management. He has 24 years of experience in a variety of areas relating to network technologies, software development, and business development. Prior to working in IBM, Johan was cofounder and CTO of Metamerge.
Thanks to the following people for their contributions to this project:
Keith Sams, Jay Leiserson, Bob Hodges, Ralf Willert, Rudy Sutijiato, Cameron MacLean, Kraicho Kraichev, Lanness Robinson, Jason TodoroffIBM US
Yogendra SoniIBM India
David MooreIBM Australia
Gabrielle VelezInternational Technical Support Organization
Become a published authorJoin us for a two- to six-week residency program! Help write an IBM Redbook dealing with specific products or solutions, while getting hands-on experience with leading-edge technologies. You'll team with IBM technical professionals, Business Partners and/or customers.
Your efforts will help increase product acceptance and customer satisfaction. As a bonus, you'll develop a network of contacts in IBM development labs, and increase your productivity and marketability.
Find out more about the residency program, browse the residency index, and apply online at:
ibm.com/redbooks/residencies.html
Comments welcomeYour comments are important to us!
We want our Redbooks™ to be as helpful as possible. Send us your comments about this or other Redbooks in one of the following ways:
xiv Robust Data Synchronization with IBM Tivoli Directory Integrator

� Use the online Contact us review redbook form found at:
ibm.com/redbooks
� Send your comments in an e-mail to:
� Mail your comments to:
IBM Corporation, International Technical Support OrganizationDept. OSJB Building 90511501 Burnet RoadAustin, Texas 78758-3493
Preface xv

xvi Robust Data Synchronization with IBM Tivoli Directory Integrator

Part 1 Architecture and design
In this part, we introduce the general components of the IBM Tivoli Directory Integrator V6 and what it has to offer in the directory synchronization field of the overall security architecture. After talking about business context, architectures and design, Part 2, “Customer scenarios” on page 89 provides solution oriented scenarios with technical hands-on details.
Part 1
© Copyright IBM Corp. 2006. All rights reserved. 1

2 Robust Data Synchronization with IBM Tivoli Directory Integrator

Chapter 1. Business context for evolutionary integration
The deployment of a new IT system, such as an enterprise portal or a single sign-on service, usually requires integration with existing data in the organization. Sometimes the new system can plug directly into what exists, but very often, and for different reasons that will be described later, this is not the case.
The usual approach to the problem is some combination of copying, merging, modifying, or synchronizing data between two or more systems, such as files, databases, directories, enterprise applications, or other repositories. When choosing an integration approach there are a number of issues to be considered, such as technical consequences and limitations, availability, security, and governance; as well as selecting a solution that balances costs, maintainability, and future flexibility.
As a general purpose integration toolkit, IBM Tivoli Directory Integrator (TDI) represents an easy to use, rapidly installed, incremental, re-usable framework, well suited for maintainability, and offering great flexibility in terms of alternate approaches to solving almost any integration challenge. We will look at some examples and scenarios to illustrate this flexibility in this chapter. The remainder of this book describes the architecture and design of Directory Integrator and looks in depth at how two different business cases can be addressed with Tivoli Directory Integrator.
1
© Copyright IBM Corp. 2006. All rights reserved. 3

1.1 A close look at the challengeNobody wants to shake the infrastructure too hard. It's holding up the house. Furthermore, it has grown to fit, the result of evolution: Natural selection; survival of the highest switching cost.
And yet, businesses still undergo the expense and trauma of infecting their infrastructure with new software. And they usually do it for the same reason: to increase value produced by the organization while decreasing the cost involved in its production. The goal is to improve organizational efficiency, quality, traceability, agility, or all of the above.
But when companies tamper with the underpinnings of the enterprise, they tread softly; sometimes so softly that initial goals evaporate down to just getting new software deployed and running. This task would be less formidable were it not for the riddle of shared data.
Applications need data—annoyingly often the same data. Since most of these products are engineered independently of each other, they probably don't see eye-to-eye on how data is handled. This includes home-grown solutions as well as commercial products, even many built by the same vendor. Some use standards, while others maintain their switching costs with proprietary approaches. And even if two systems agree on a common data store, they probably do not concur on its structure. So you end up with multiple data sources carrying bits and pieces of the same information. Disparate pockets of data, with dependent systems in a tight orbit around them.
Experience shows that this sort of data fragmentation is the rule rather than the exception. It is the result of the evolutionary, periodically explosive growth of a company's machine and software infrastructure, and sustained by the constant fear of breaking something important. Terms like golden directory are born of this inhibiting, but justifiable fear. And when enough data sources are golden the infrastructure becomes very heavy. It solidifies and loses agility, making the ordeal of adding new systems and services even more painful. Nobody plans for this to happen. It is the natural result of unresolved governance. Intrinsically, applications presume ownership of their own data—a presumption likely shared by their principle users in the organization. This works fine for some types of information, but fails dramatically for others; for example (but not limited to) identity data.
Let us rephrase that. Nowhere is this more true than for identity data. Organizations often discover that their identity information data and structure is, more often than not, owned by everybody, and yet by nobody in the organization.
4 Robust Data Synchronization with IBM Tivoli Directory Integrator

This apparently contradictory statement refers to the fact that information about people in the organization is typically managed in multiple places, yet not coordinated in terms of governance or data structure. This is not a big problem when applications and user data live in isolation, for example information about employees residing solely in the HR system and users in the LAN directory1. This indiscretion is often tolerated until the risks involved become too great (or sometimes, until they simply become obvious).
The proliferation of user registries and the ensuing security exposure make the argument for directory integration particularly compelling: An employee may be terminated, but there's no guarantee that there won't be access rights left in some subset of directories, invisibly providing unwarranted access privileges; Sanctioned users are burdened with a multitude of user names and passwords spread all over the place, each of which they must remember and maintain separately, and which they probably write down somewhere. This in itself represents a security risk, in addition to the productivity loss caused by inconsistent provisioning. Not to mention increasingly tougher audit requirements (for example, the Sarbanes-Oxley Act2) forcing people to get serious about traceability and security.
Moreover, identity data fragmentation becomes a serious roadblock as organizations increasingly implement large-scale, cross-organization solutions that require consistent data, managed in a 24x7 environment, scalable for growing usage and demands, and possibly including customers and partners. Deploying enterprise portals and services (like simplified or single sign-on) without an enterprise view of identities is practically impossible. Success, for both tactical deployments and continued strategic growth, hinges on tying the chaos of existing user registries into a holistic model.
Although the utopian proposition is to condense disparate registries down to a single physical directory, the multitude of identity stores won't be going away as long as applications depend on them in their own specific ways. As a result, the common approach to addressing data fragmentation is with integration tools that allow silos to stay in place, but give the appearance of unified access. Ideally, with tools for building integration through careful evolution, rather than revolution. This means that deployment is broken into measured steps, bringing new systems and repositories into the picture over time. If the process is planned correctly, ROI can begin as soon as the first sub-step is complete.
This document is not about implementing a single enterprise-wide directory that becomes the master for all others, although such can certainly be implemented with Tivoli Directory Integrator. However, it is about the options available with
1 Even though integration at this stage also makes sense from a security and data integrity perspective.2 More information about the Sarbanes-Oxley Act can be found at http://www.sarbanes-oxley.com/.
Chapter 1. Business context for evolutionary integration 5

Tivoli Directory Integrator to deal with the wide spectrum of integration challenges encountered when deploying identity based applications in the enterprise.
1.2 Benefits of synchronizationWhen implementing a synchronization solution, the result is an environment where shared data looks the same for all consuming applications. This is because changes are propagated throughout the synchronized network of systems, molded in transit to fit the needs of each consumer. Each data source is kept up-to-date, maintaining the illusion of a single, common repository. Each application accesses its data in an optimal manner, utilizing the repository to its full potential without creating problems for the other applications.
Synchronization strategies are increasingly the choice for deploying new IT systems. For identity management, this is usually a centralized or metadirectory style synchronization, where a high speed store (like a directory) is used to publish the enterprise view of its data. This approach has a number of advantages:
� Security requirements vary from system to system, and they can change over time. A good repository (like a directory) provides fine-grained control over how each piece of data is secured. Some provide group management features as well. These tools enable you to sculpt the enterprise security profile as required.
� Each new IT deployment can be made on an optimal platform instead of shoe-horned between existing systems into an uninviting infrastructure. Applications get to live in individually suited environments bridged by metadirectory synchronization services.
� If the availability and performance requirements are not met by some system (legacy or existing, or new), it can be left in place and simply synchronize its contents to a new repository with the required profile; or multiple repositories to scale.
� A metadirectory uncouples the availability of your data from that of its underlying data sources. It cuts the cord, making it easier to maintain up-time on enterprise data.
� Disruption of IT operations and services must be managed and minimized. Fortunately, the metadirectory's network of synchronized systems evolves over time in managed steps. Branches are added or pruned as required. Tivoli Directory Integrator is designed for infrastructure gardening.
6 Robust Data Synchronization with IBM Tivoli Directory Integrator

� A good metadirectory provides features for on-demand synchronization as well3. Sure, joining data dynamically can be prohibitively expensive in terms of system and network load; but sometimes it's the optimal solution.
1.3 Directory Integrator in non-synchronizing scenariosWhile Tivoli Directory Integrator is a powerful tool to deal with a large number of synchronization scenarios, its core is a general purpose integration engine that can be used by other systems in real-time, providing these systems with very interesting capabilities. Below are some examples of deployed solutions to illustrate such usage:
� A mainframe application sends MQ messages that Tivoli Directory Integrator picks up, then accesses other data systems in the enterprise, performs some operations and transformations on the data set and responds back through MQ to the mainframe.
� The Tivoli Access Manager SSO (single sign-on) service calls Tivoli Directory Integrator during user login in order to authenticate their credentials against one or multiple systems not supported out-of-the-box by Tivoli Access Manager. Automatic provisioning of new users is done as required.
� Tivoli Directory Integrator monitors the operational status of an LDAP directory and sends SNMP traps to enterprise monitoring systems.
� A SOA-based application calls Tivoli Directory Integrator through Web services, and Tivoli Directory Integrator writes data to specially formatted log files and updates databases.
� Tivoli Directory Integrator intercepts LDAP traffic to transparently make multiple directories look like one to an LDAP client application. As in all Tivoli Directory Integrator solutions, any number of Tivoli Directory Integrator connectors, transformation, and scripting can be brought to bear on the data flow.
As seen from the above deployments, Tivoli Directory Integrator isn't limited to synchronizing data. The next sections provide additional scenarios and examples that illustrate how Tivoli Directory Integrator is inserted into a data flow, enabling real-time operations to be executed that otherwise would have required complex and custom code.
3 In addition to change-driven, schedule-driven and event-driven
Chapter 1. Business context for evolutionary integration 7

1.4 Synchronization patterns and approaches This section takes a look at synchronization from a conceptual perspective. First, we look at how and when, meaning how Tivoli Directory Integrator is invoked to perform its work. Then we look at some of the typical data flow patterns that are encountered.
1.4.1 How and when synchronization can be invokedTivoli Directory Integrator-based synchronization solutions are typically deployed in one of the three following manners, although combinations are also frequently used to enable the various data flows that entire solution requires:
� Batch - In this mode Tivoli Directory Integrator is invoked in some manner (through its built-in timer, command line or the Tivoli Directory Integrator API), and expected to perform some small or large job before either terminating or going back to listening for timer events or incoming API calls. This is often used when synchronizing data sources where the latency between change and propagation is not required to be near real-time.
� Event - Tivoli Directory Integrator can accept events and incoming traffic from a number of systems, including directory change notification, JMX™, HTTP, SNMP, and others. This mode is typically used when Tivoli Directory Integrator needs to deal with a single, or a small number of data objects.
� Call-reply - This is a variation of the event mode, but the difference is that the originator of the event expects an answer back. IBM products use the Tivoli Directory Integrator API to call Tivoli Directory Integrator, and solutions in the field often use HTTP, MQ/JMS and Web services to invoke a Tivoli Directory Integrator rule and get a reply back.
There is no single answer to the questions of when to choose between batch or event-driven integration. For example, enterprises have varying requirements regarding the propagation of identity data. Delays can be acceptable in the seconds, minutes, and even in the hours range. It must also be determined whether the data sources can provide a data change history (LDAP directories often have changelogs) or notification mechanisms when data changes. Tivoli Directory Integrator can be utilized both as a batch system, checking for changes every so often, as well as a notified system, reacting only when the source system sends a data change notification.
Also keep in mind that the above modes are not exclusive of each other, all of them can be utilized in the same Tivoli Directory Integrator deployment.
8 Robust Data Synchronization with IBM Tivoli Directory Integrator

1.4.2 Data flow patterns Tivoli Directory Integrator is often used to implement not just one, but a number of data flows. Data can flow from one system to another, but also from many systems to one. As a system becomes the source of data from many systems, it often evolves to the next stage, where it becomes the source for updates into many others.
It is important to understand and then map the intended flow of data. Although the current infrastructure does not yet look like the picture in Figure 1-1, it does illustrate that the enterprise applications are being rolled out with increasing speed in large organizations. These systems often do not share identity repositories (although the same directory may host several instances), simply because the applications have diverging requirements on data format, as well as the system owners have different perspectives on how to manage and access the identity data. A well-crafted integration solution will let each business owner have full control of their data system, while ensuring that common data is kept in harmony across the entire infrastructure.
Figure 1-1 IT infrastructure example
A commonly underestimated part of synchronization projects is the planning of data flows. Successful deployments document the flow of attributes at an early stage and therefore identify the number and type of data flows required. A project might look very complicated at first glance, but once the flows are identified, the project can be approached in incremental steps.
White pages
Provisioning
ContentManagement
Personalprofile
Portal
Personalization
SingleSign-on
Other enterprise applications
LAN
White pages
Provisioning
ContentManagement
Personalprofile
Portal
Personalization
SingleSign-on
Other enterprise applications
LAN
Chapter 1. Business context for evolutionary integration 9

Although the project could at first glance look like a very complex many-to-many data flow scenario, it might after inspection reveal itself to be a number of simple one-to-one, many-to-one or one-to-many data flows. Next, we take a look at these simple data flow patterns that a project typically consists of.
One-to-one data flowThe simplest data flow is the copying or synchronizing of data from a single source to a single target. However, just because the flow is simple, there can be any kind of transformation performed on the data, either in content, syntax, format or protocol. Here are some examples of such data flows:
� Updating a database with data from a file that was made available as a report from another system.
� Generating a file that contains changes made in a database.
� Keeping a directory synchronized with another, transferring only changes as they occur on the source directory.
� Reading an XML file and writing a CSV formatted file with a selected subset of the XML file.
Even though the flows above are conceptually simple, transformation of the data might be required that introduces complexity. For example, when dealing with identity data, there could be a requirement to join a number of groups into a single one in the target directory. This join could have further restrictions based on other data in the source system, such as address, department, or job function.
Many-to-one data flowAs previously discussed, data ends up in multiple repositories for a number of good reasons. As this happens, additional context is built into the systems as well. Both explicit and implicit relationships between the data are established, which are lost when just copying the data to a new system. Furthermore, the existing systems continue to be updated and
managed as before, so copying data quickly looses its relevance. Sometime a federated approach can be used to access this data set in real-time, but often this is not acceptable because of performance or availability requirements. Therefore, a synchronization data flow must involve multiple source systems in the process of maintaining a target system with the re-contextualized data.
A many-to-one data flow uses the source systems for purposes such as verifying information, making decisions in the data flow, and merging (joining) additional attributes to the initial data set that is intended for the target system.
DirectoryTDI
File
Database
emailDirectory
DirectoryTDI
File
Database
emailDirectory
10 Robust Data Synchronization with IBM Tivoli Directory Integrator

One-to-many data flowThe illustration does not fully describe the combinations that are possible in one-to-many scenarios. The main point is that data needs to be updated, maintained or created in several places. For example, as e-mail addresses are added in the e-mail directory, Tivoli Directory Integrator ensures that this is
updated in the single sign-on directory for authentication purposes. However, the ERP system also likes to subscribe to this information as it is used in automated ERP-based messages to employees. So in this example, Tivoli Directory Integrator would update both the SSO directory as well as the ERP system as part of a data flow. Another example is propagating password changes in a directory to a number of other directories.
In one-to-many data flows it is important to consider what could happen if a flow was interrupted and data not updated in all systems as was expected. In transactional systems, roll-back is used to reset the involved systems to the state they had before the data flow started. However, in most identity synchronization projects, this is not much of a problem since the entire data flow can be repeated—it is not like transferring the same amount of money twice to another bank account. However, roll-back or compensating logic can be added to a Tivoli Directory Integrator solution should this be required.
1.5 Business and technical scenariosThe previous section looked at synchronization concepts in general. Also, some of the benefits of synchronization were discussed in another section. Now we investigate some real-life scenarios to illustrate the business context. The examples below are intended to bring them to life so that the reader can more readily recognize and identify synchronization opportunities when faced with a new business or technical deployment challenge. The fictional company PingCo is used to illustrate the scenarios. Let us now look at a few identity use cases to illustrate the issues that throw wrenches into the machinery that organizations have spent years building.
1.5.1 Multiple existing directories and security concernPingCo is building a portal that will be used by both employees and external customers. PingCo has already implemented separate employee and business partner directories, but the employee directory is on the corporate intranet and will not be made accessible to non-VPN external users. The portal will be placed
DirectoryTDI
File
Database
emailDirectory
DirectoryTDI
File
Database
emailDirectory
Chapter 1. Business context for evolutionary integration 11

in the DMZ, with no access into the internal network. One solution is to use Tivoli Directory Integrator to synchronize the employee and the business partner directory into a new directory placed in the DMZ. Only the necessary information about the employees is transferred into the DMZ directory to reduce security exposure. PingCo can choose whether or not to securely synchronize the employee passwords into the external directory, or create new passwords (but the same user name) for employees that access the external portal.
The above scenario could be modified to include organizations with many internal directories, possibly managed by separate business units or other organizational entities that challenges coordination of efforts. Synchronizing the content (with possible filtering of data) from the directories lets them keep ownership of data, yet enables common applications to be deployed on the joint set of identity data on a new directory that reduces the dependence on each sub-directory with minimum performance impact.
1.5.2 Existing directory cannot be modifiedPingCo intends to deploy an enterprise single-sign-on (SSO) service and have a directory with all employees. However, for some reason PingCo cannot let the SSO service use the existing directory directly. Sometimes directories are only accessed in read-only mode, but sometimes applications that use directories also need to store data in them as well. That can become a hurdle for reasons such as:
� Technical. The existing applications that use the directories cannot deal with this change.
� Availability. The business owners of the existing directory are not able to meet the availability requirements of an enterprise (and possible cross-enterprise) SSO service.
� Governance. Existing business owners of the directory don't want others to modify a system that they own and manage.
� Performance. The added performance impact of the SSO service could extend beyond what the directory platform can provide.
� Security. Although the user names are already there, the SSO service adds new data that might be considered even more sensitive.
The solution in this case is a simple synchronization to a new directory. It could even be a separate logical directory tree on the same machine or an entirely different directory implementation on a more scalable and secure physical machine. PingCo would have the choice of where passwords are managed and changed. Any change to one directory would immediately be made on the other as well.
12 Robust Data Synchronization with IBM Tivoli Directory Integrator

With IBM SSO (single sign-on) offerings, Tivoli Access Manager, there is an additional option available as described in the following section. That scenario works with a single directory for Tivoli Access Manager authentication, but keeps all other data in a separate and secure directory.
1.5.3 Single sign-on into multiple directories with Access ManagerPingCo intends to implement a single sign-on service with Tivoli Access Manager, and users are defined in multiple directories. Tivoli Directory Integrator integrates with Tivoli Access Manager Version 5.1 and later through its EAI (External Authentication Interface) so that Tivoli Directory Integrator can authenticate users across any number of back-end sources that Tivoli Directory Integrator supports. For example, when a user provides credentials to Tivoli Access Manager, Tivoli Directory Integrator is invoked and then attempts to authenticate into a number of directories with custom filters and modifications to the base credentials. Tivoli Directory Integrator can also look at the supplied credentials and do direct authentication to a target directory rather than trying all of them if such information is available.
1.5.4 Data is located in several placesPingCo intends to deploy a portal based application that requires information about employees, their work location as well as who their manager is. This information does exist in the infrastructure, but not in a single location. There are directories that contain both unique and overlapping information about employees. The HR system knows about work location and the managers of the employees. To make things even more complicated for the solution architect, the HR group is not willing to provide direct access to their system, but are willing to provide a weekly report with the required information.
This is a classic example of where Tivoli Directory Integrator can bring order to the chaos by connecting to all of the directories, identify the unique set of users, and merge that data with the weekly feed from HR. The end result is a directory where all information is collected and users have work location and manager information added in from the HR system. Once the initial job has been completed, Tivoli Directory Integrator continues to monitor the sources for changes, including the weekly report from HR, and identify the records that have been added, modified, and deleted.
1.5.5 Use of virtual directory - access data in place PingCo needs to authenticate users against one or more directories that cannot be synchronized, possibly because they belong to somebody else who does not allow this to be done. If PingCo uses Tivoli Federated Identity Manager or Tivoli
Chapter 1. Business context for evolutionary integration 13

Access Manager then there are authentication plug-ins available (using the External Authentication Interface) to Tivoli Directory Integrator. However, in other situations, Tivoli Directory Integrator can intercept LDAP messages and forward them to one or more LDAP directories in a round-robin/chaining or other custom logic on behalf of the client. This scenario is often described as a virtual directory approach since the client does not need to know that it's actually communicating with a number of directories in real-time. This approach has some apparent benefits (and sometimes offer the only practical option), such as leaving data in place, removing the requirement for synchronization. However, there are both short-term and long-term issues that should be considered:
� Availability - Some attribute relationships cannot be reliably resolved in real-time due to unstable systems, scheduled maintenance, broken links, latency, firewalls, and so forth; or because some relationships are too complex to resolve quickly. Synchronization can spend the time it takes to map their data.
� Performance - A virtual directory imposes itself into every data access operation. A separate synchronized directory maximizes performance while it maintains the enterprise view via change-based synchronization. Performance requirements are often underestimated as the use of new enterprise applications often grow past what was initially assumed. This is especially true for enterprise portals and single sign-on projects, where a successful deployment creates major benefits, but increases resource consumption.
� Reliability - The virtual directory is dependent on all connected systems being available and online. The owners of those systems might not be willing to provide that level of service to the rest of the enterprise. A synchronized solution will always be available, and there is no impact of an off-line subsystem. Also, if the synchronization engine (not the synchronized directory itself) is offline, data gets out-of-date. This is amended as soon as the synchronization is restarted. If the virtual directory is down, all dependent applications are down as well.
� Agility - New enterprise data means new data relationships, so with both approaches the integration solution must be updated to include these. However, the out-of-band nature of synchronized solutions significantly facilitates maintenance and upgrade since data flows and integration flows can be added without impacting the operational availability of the directories.
� Scalability - Virtual directories can't scale the way real directories can. Even with caching, they will always be limited by the scalability of the systems with the source data. Furthermore, a good enterprise directory can be massively scaled in multi-master-slave configurations for high performance.
14 Robust Data Synchronization with IBM Tivoli Directory Integrator

1.6 ConclusionSynchronization introduces a number of benefits to the architectural design of new enterprise solutions. Rather than trying to craft an optimal situation, synchronization can provide a pragmatic approach that is less costly to build and maintain, while adding operational benefits such as performance, availability and agility. These benefits certainly do not apply to all scenarios, but on the other hand are often not evaluated because the architectural 20-20 vision prevails where the pragmatic mind would have provided quicker time to value as well as a more future-proof solution since changes are often less predictable than we would like.
Chapter 1. Business context for evolutionary integration 15

16 Robust Data Synchronization with IBM Tivoli Directory Integrator

Chapter 2. Architecting an enterprise data synchronization solution
How do you eat an Elephant? The answer is one bite at a time. The Tivoli Directory Integrator getting started guide describes this as the best practice for solving large data synchronization problems as well.
The key to success is to reduce complexity by breaking the problem up into smaller, manageable pieces. This means starting with a portion of the overall solution, preferably one that can be completed in a week or two. Ideally, this is a piece that can be independently put into production. That way, it is already providing return on investment while you tackle the rest of the solution.
This is also the best practice approach for gathering the necessary information to craft a successful enterprise data synchronization solution. This chapter outlines a series of questions that need to be answered prior to the installation of the product, or the creation of a single AssemblyLine. The goal is to collect the necessary information that will allow you to easily build, deploy and manage a successful Tivoli Directory Integrator solution.
Simply consider this a necessary step before you get to enjoy using the product. At a minimum, you must be able to answer the following questions:
2
© Copyright IBM Corp. 2006. All rights reserved. 17

� What typical business requirement is Tivoli Directory Integrator trying to solve?
� What data stores are required to solve the problem?
� How can you instrument and test the solution?
� Who is responsible for what activity?
2.1 Typical business requirementsTivoli Directory Integrator is a truly generic data integration tool that is suitable for a wide range of problems that usually require custom coding and significantly more resources to address with traditional integration tools. It is designed to move, transform, harmonize, propagate, and synchronize data across otherwise incompatible systems.
However, before the tool can be used, it might be necessary to understand what has brought about the data synchronization requirement. For example, is it the result of a company’s acquisition of another firm, in which case the acquired company’s uses need to be integrated and kept in synch with the parent companies data stores, thereby providing a common data source to be used with the development of a new enterprise application? A secondary goal may be the synchronization of user passwords.
Tivoli Directory Integrator can be used in conjunction with the deployment of the IBM Tivoli Identity Manager product to provide a feed from multiple HR systems as well as functioning as a custom Identity Manager adapter.
Both of these scenarios will be further expanded upon later in this book. Regardless of the scenario, it is essential to gain a full understanding of the environment. This allows you to document the solution.
Typically this is accomplished by the development of a series of use cases that are designed to clarify the business needs and refine the solution through an iterative process that ultimately provide you with a complete list of documented and agreed to customer business requirements.
For example, is the data synchronization solution viewed as business critical, and will it need to be instrumented into a high availability solution; or is a guaranteed response time a business requirement that has to be addressed?
It is important to point out, that in most cases you are manipulating user identity data. As such, the appropriate security safeguards for privacy and regulatory compliance requirements need to be addressed during the requirements gathering phase.
18 Robust Data Synchronization with IBM Tivoli Directory Integrator

The ultimate goal is to determine how the information will need to flow through the enterprise to solve the stated business requirements. This is the essential first step in breaking down the complex problem of enterprise data synchronization into manageable pieces.
At a minimum, the solution architect will need to be able to provide:
� An agreed upon definition of the business requirements and the translation of the business objectives into concrete data and directory integration definitions.
� A concise understanding of the various data stores that are part of the solution and under what circumstances the information needs to flow through the organization as well as the authoritative source for each data element that will be managed.
The diagram in Figure 2-1 depicts the various steps required to instrument an enterprise data synchronization solution.
Figure 2-1 Solution architecture process flow
It is important to note that some of the elements in the process flow described in the figure above are outside of the Tivoli Directory Integrator product sphere— indicated by not being placed completely inside the grayed in area. Those found entirely inside of the grayed in area are wholly a part of the solution. Let us take a closer look at each of the different disciplines in order to clarify what we mean.
Data synchronizationsolution
Detailed data identification· Location – data source· Owner· Access· Initial format· Unique data
Review results· Enables initial design documentation
and communication
Plan data flows· Authoritative attributes· Unique link criteria· Special business requirements· Final data format· Data cleanup· Phased approach· Frequency
Business requirements· Business scope· Business benefits
Instrument and test· Workable units· Naming conventions· Availability/failover· System administration· Security· Password synchronization
Tivoli Directory Integrator
Chapter 2. Architecting an enterprise data synchronization solution 19

2.2 Detailed data identificationThis section discusses the best practice for identifying the nature of the data required to solve the defined business problem.
Once the business requirements and corresponding use cases have been clearly stated and agreed upon, the next step in architecting a data synchronization solution is to identify the nature of the data that will be utilized. At a minimum, the solution architect will need to be able to:
� Identify as much as possible about the data.� Provide a document that describes the data flow.� Describe how the results of the first two steps will be reviewed.
By following this best practice technique of identifying, planning, and reviewing the nature of the data, the solution architect will be able to craft the technical solution requirements and design to match the driving business needs.
To continue with the best practice of simplifying a complex problem, the systematic definition of the required data will further simplify the task of creating a successful project. Detailed data identification starts with the understanding that this is the time where the business based use cases are used to add more clarity to what is to be accomplished. At a minimum the solution architect must identify the following:
� Data location� Data owner� Data access� Initial data format� Uniqueness of data
2.2.1 Data locationThe location of the data is typically the primary factor in determining the ultimate solution design and architecture. The solution architect will be required to identify both the physical and logical location of the data to be used to satisfy the use case.
Some examples of physical location are items such as the data exists in a specific regional location, is on a particularly slow or fast hardware platform, or happens to be limited in accessibility due to distance or network speed. These factors are used when planning data flows and designing the physical architecture of the data synchronization solution.
The logical location of the data translates very specifically to IBM Tivoli Directory Integrator components that are mentioned in the following chapter. By
20 Robust Data Synchronization with IBM Tivoli Directory Integrator

determining the data sources in the use case, the solution architect can then determine the type of connection to be used along with the underlying technology to be utilized.
An example of identifying a logical location of data might be that the use case involves synchronizing data located within a directory server. The logical location of the directory server’s data would be described by the server name and/or IP address. The underlying technology to be used to connect to a directory server would typically be the LDAP protocol or possibly via an LDIF file. Similarly, if the use case incorporated the use of a database, the data source would be identified as possibly relational in format and accessibly via a JDBC™ technology connection.
2.2.2 Data ownerDetermining the owner of the data helps the architect identify any possible requirements introduced to the solution due to privacy or compliance concerns. Does the data have a requirement to be handled in a special way or is it even possible to use the data within the desired use case given its current location and form? Regulatory and corporate policies should be reviewed with the data owner at this time as well.
2.2.3 Data accessMany times, the data owner is often the same organization or person who provides the data access. However, this is not always the case. Data access involves the determination of what level of access can be granted to the data store or source to be able to synchronize the required attributes.
An example of this is a business use case that requires the solution to synchronize to an LDAP server. A best practice would be for the owner of the LDAP server to provide an individual login account with special privileges just for Tivoli Directory Integrator to use. The result of this allows the server owner to track the activity generated by the synchronization solution as well as effectively maintain any security policies the organization may have in place for that server. If the solution only requires access to a specific container on that LDAP server, the login account could be limited to read and write privileges within that specified container. This is an example of where the solution architect would specify what access privileges are required to each data source in the use case.
2.2.4 Initial data formatIdentifying the initial data format involves the determination of all the possible values each attribute could have when initially connecting to the data source. The
Chapter 2. Architecting an enterprise data synchronization solution 21

reason for this is that data values tend to show up in one of four states; null, blank, out-of-range and valid. As such, the best practice is to determine when the solution will account for all four possible states, as well as, how to handle any special conditions that could be encountered. For example, how does the solution resolve duplicate or multiple values.
2.2.5 Unique dataThe identification of unique data is typically accomplished at the same time that the initial data format is determined. Often the data values or attributes to be used are in a specific format that needs to be accounted for within the data synchronization solution.
2.3 Plan the data flowsThe second step of designing a solution deals with planning the data flows. Many times this occurs simultaneously with the data identification phase. At a minimum, the solution architect needs to identify the following details:
� Authoritative attributes� Unique link criteria � Special conditions or business requirements� Final data format � Data cleanup � Phased approach� Frequency
Tip: A common pitfall many solutions encounter is the issue of converting integer value data to strings. This happens most often when synchronizing from a database if you are not careful to take note of the format of the field values in a database. For example, many fields within databases designed to handle a numeric entry, such as employee number, use an integer format. Sometimes your data synchronization solution requires you to parse or otherwise process these values as though they were a string within IBM Tivoli Directory Integrator.
Tip: For the advanced user, Tivoli Directory Integrator can be used to help identify some of the specifics of the data by using data and schema discovery functions in Directory Integrator.
22 Robust Data Synchronization with IBM Tivoli Directory Integrator

2.3.1 Authoritative attributesWhen planning the flow of data, identifying which attributes are authoritative in what data source(s) is paramount. For example, an enterprise may determine that the human resources application is authoritative for all attributes describing an employee except for the employee’s e-mail address. The e-mail server is considered the authoritative data source for the e-mail address attribute.
It is ideal that there be only one data store within the enterprise identified as being authoritative per attribute. It is possible to have multiple data stores as authoritative for the same attribute being synchronized. The most common attribute being the user password. It is best not to have any attributes have more than one authoritative data source.
2.3.2 Unique link criteriaWhen synchronizing data within an enterprise, it is a technical requirement to identify some way to link the data sources. Simply put, how do you identify the same user across multiple data stores? A common way to link the multiple data stores is via a user’s unique identification number. For employees, it tends to be their unique employee number. In some cases, it is the e-mail address and in others it is some combination of attribute values.
If there is no pre-existing unique identifier between data sources to be synchronized, one much be generated using some combination of attribute values or by using the best available logic applied to the business case. Fortunately, Tivoli Directory Integrator provides a simple way to link data sources on very simple or detailed linking criteria.
2.3.3 Special conditions or requirementsIn many cases, special conditions or requirements exist within the use cases. This is often more obvious after the solution architect completes the detailed data identification process. A simple example of a special condition would be when the origination data source only contains the values of first name and last name for a user and the requirement is to synchronize their full name into a new attribute in the destination data source. This is where the solution architect would note the condition required to concatenate the user’s first name and last name together to generate the full name.
Tip: This is where the best practice mentioned earlier in the data access section of having separate logins for each connection comes in handy, so you know who is changing what attribute in its authoritative data store.
Chapter 2. Architecting an enterprise data synchronization solution 23

Another example of a special requirement might be that only users in certain departments have their e-mail address synchronized.
2.3.4 Final data formatWhen planning the flow of data for each use case, identifying the expected format of the data in the target system(s) is critical. The solution architect needs to resolve two concerns.
In the first concern we have to perform identification of attributes that might have special or unique formatting of the data values. In some cases, this can create a requirement that might alter the expected flow of data. A common example of this occurs when the use case requires the attribute for a user’s manager to be synchronized into an LDAP data store. Since the solution architect previously identified the nature of the LDAP data store, they can then determine if the LDAP server requires the manager attribute to be the data format of a fully qualified distinguished name.
The second concern regarding the final data format involves what has been mentioned in 2.2.4, “Initial data format” on page 21. The solution must allow for handling any of the four possible data states for the expected output. Once again, those data states are null, blank, out-of-range, and valid. This is less of an issue here. It occurs most often when the destination data store is being altered by many sources.
2.3.5 Data cleanupAt this stage of planning, it has most likely become apparent if a separate or additional data flow might be required to handle data that needs to be either cleaned up or has no matching attribute(s) between the source and destination data stores. These two conditions are the most common and are often referred to as handling dirty data and creating unique link criteria.
If it becomes apparent this task is rather large, it is often a requirement to plan for a complete separate initial phase of the project to clean the data. The on-going data synchronization will continue to focus on accommodating the initial and final data formats mentioned in previous sections and will have solved the unique link criteria requirements.
2.3.6 Phased approachOften times it is necessary to utilize a phased approach when planning your data flows. The need for a phased approach typically occurs when either there is a large amount of data cleanup required or the use case over time plans on
24 Robust Data Synchronization with IBM Tivoli Directory Integrator

changing the data source for specific authoritative attributes. Some common phases in an enterprise data synchronization project are the following:
� Phase 1 - Initial data cleanup and load.
� Phase 2 - Synchronization of data from multiple sources to one data store such as a directory server.
� Phase 3 - The directory server is now the authoritative source for some attributes and the synchronized data flow changes direction.
2.3.7 FrequencyDetermining how often and when the data is to be synchronized for each use case is essential to planning the flow of data as well as an impact upon any sort of guaranteed response times. For example, if the source data is only available or updated once a day, this will determine the configuration of the data flow.
Frequency also ties in closely with the format and technology connection for the data. For example, if the use case requires the source data to come from a message queue, the data flow would be planned to frequently check the queue to process incoming requests. Determining the events that trigger the data flows help to identify frequency.
2.4 Review resultsThe following excerpt shown in Example 2-1 is a sample document that can be used to build the foundation for documenting a solution. Once completed, the documentation becomes a source for reference, approvals, and communication within the project.
Example 2-1 Human Resources to Corporate Directory data flow document sample
This paper contains multiple data sources. Let us take a look at data source one:
Data Flow Human Resources database to Corporate Directory
Data source Human Resources (DB2®)
Note: Be sure to include time in your project for documentation of your solution. At a minimum, plan on writing a functional specification and test plan. With documentation, you will have a smooth transition into production, increased maintainability and can prevent possible project pitfalls should the data not be as expected. You will also find it vital for maintaining and enhancing your work.
Chapter 2. Architecting an enterprise data synchronization solution 25

Connector type JDBC
Parser None
Connector Mode Iterator
Attributes usernamefull nameemployee IDaddress
MultiValued Attributes None
Link Criteria
Special Conditions Make username in UID format using username and employee IDMake cn and sn out of full name
Security Concerns Use SSL
Here is data source two:
Data Flow Human Resources database to Corporate Directory
Data source Corporate Directory (IBM Tivoli Directory Server)
Connector type LDAP
Parser None
Connector Mode Update
Attributes uidcnsngivennameobjectclass
MultiValued Attributes objectclass
Link Criteria uid=username
Special Conditions Create multi-valued objectclass attribute
Security Concerns Use SSL
2.5 Instrument and test a solutionIn this section we discuss some of the areas on which to focus once you have identified the data to be synchronized for your business use case, planned the corresponding data flows, and reviewed the results of your effort. Often times it helps to keep these items in mind throughout the data identification process. You most certainly want to address some or all of these topics as you move into the design of the enterprise data synchronization solution.
26 Robust Data Synchronization with IBM Tivoli Directory Integrator

2.5.1 Create workable unitsAs mentioned at the start of this chapter, the key to success is to reduce complexity by breaking the problem up into smaller, manageable pieces.
Ideally, you identified a portion of the overall solution prior to this point in the process. Creating smaller workable units is an important part of being able to rapidly integrate and enhance your data synchronization solution. So much so, that you will notice that the theme of simplifying and solving is evident even in the architecture and component structure of Tivoli Directory Integrator.
Up to this point, we have walked you through the key integration steps from which to build your data synchronization solution. You have identified the systems involved in the communications, the data flows between these systems and events or frequency of data that trigger the data flows. A common mistake occurs when there is an attempt to integrate too many data stores initially. While you begin to realize the power and flexibility of Tivoli Directory Integrator, keep it in your mind to instrument smaller units of work on which you can build.
2.5.2 Naming conventionsIt is important to establish some naming conventions for your data synchronization solution. Start with creating a consistent way to identify the location of your data. When instrumenting the solution, this can translate into the Tivoli Directory Integrator connector names. For example, if the location of your data is on a directory server, you might place a suffix on your connectors with names such as LdapConn. A connector that updates the directory server might be called UpdateLdapConn. Some choose to identify the data locations based on the name of the software such as Tivoli Directory Server (TDS). Therefore, you might choose UpdateTDSConn.
The point is to begin the process of identifying your naming conventions for identification of the location of the data (the connectors) and also the data flows. It is a good idea to name your data flows to include a verb that can help identify your data flow. This translates into the Tivoli Directory Integrator AssemblyLine component that is covered in the following chapter.
Tip: When implementing your Tivoli Directory Integrator solution, a good practice is to keep the purpose of each AssemblyLine (data flow) as small as feasible while consolidating like functions. This facilitates development and troubleshooting and increases flexibility in implementation.
Chapter 2. Architecting an enterprise data synchronization solution 27

2.5.3 High availability and failoverWhen planning the data flows, it occurs to most solution architects that there will be requirements for their data synchronization solution to include some level of high availability and/or failover capability. While the ensuing chapter and solution scenarios highlight the capabilities and related components of Tivoli Directory Integrator, it is important at this point to identify your solution requirements as they relate to high availability and failover.
High availability typically translates to a data access probability greater than ninety-nine percent of the desired uptime and includes rapid recovery. Uptime, for most enterprises, is represented by a 24x7 around the clock operation. This puts a strong emphasis on the availability of the applications, servers, and interfaces that an enterprise uses to deliver data to their users; applications such as Web servers, directory servers, and databases.
Given this definition, it becomes apparent that in order to determine what the high availability requirements are for your data synchronization solution, you must also get an idea of what the corresponding requirements are for the connected systems involved in your solution. For example, if the connected system is only available to receive updates once a day, your synchronization solution would typically have reduced or low requirements for availability of data.
The availability requirements of the data synchronization solution will help to determine the Tivoli Directory Integrator components and architecture to instrument. Chapter 3, “Directory Integrator component structure” on page 41 provides more detail of the components and architecture with regard to availability by covering such topics as automatic connection reconnect and checkpoint/restart.
When addressing availability, the topic of failover is often raised. The degree for which to plan for failover directly relates the data synchronization solutions’ availability requirements. The goal of failover is to answer the question of what to do if some piece of the solution fails.
The following outline provides questions and categories of things to consider when addressing availability and failover capabilities for your solution.
1. Determine the availability requirements for your solution. Most solutions can be categorized as high, medium, or low availability.
Tip: The use of special characters and spaces in naming AssemblyLines or other Tivoli Directory Integrator components is not a good idea, as it might cause problems later when you want to start Tivoli Directory Integrator from a command prompt to run your solution.
28 Robust Data Synchronization with IBM Tivoli Directory Integrator

This list of questions can help identify availability requirements for your solution:
a. What are the business requirements for the data synchronization solution?
b. How do business requirements translate to availability?
There are some fundamental business/availability rules:
• Desired availability, cost, and complexity are directly related.• Cost and complexity tend to dictate availability choices.• Every enterprise is different based on their business values.
c. What is the availability of the data or connected systems to be synchronized?
d. Are there any special data conditions?
For example, password synchronization requires high availability while many data feeds from human resources applications occur only once daily.
2. Identify which types of failures need to be considered in order to provide adequate failover capability. The availability requirements will determine if your solution needs to address any or all of these types of possible failures.
There are two main categories of failures for which to plan. The first category relates to the overall data synchronization infrastructure. The main aspect to focus on is to answer the question of what happens if any or all of the systems your solution connects to go down.
Identify what the solution must do when the following occurs:
– Connected systems fail.– Power failure.– Network failure.
The second category relates to the perspective of the application environment for your solution; specifically the Tivoli Directory Integrator application. The focus is to answer the question of what happens if any piece or part of the Tivoli Directory Integrator solution fails.
Identify what the solution is to do when the following fails:
– The Tivoli Directory Integrator application goes down.
This includes items like power, hard disk, and/or operating system failures.
– The data flows (Directory Integrator AssemblyLines) fail.
Note: The highest exposure or risk to your solution is if your data synchronization solution requires high availability and fails while the connected systems remain intact.
Chapter 2. Architecting an enterprise data synchronization solution 29

– The Directory Integrator server looses connectivity to one or more systems.
This includes items like loss of network connection, data source, or authorization/access.
2.5.4 System administrationThere are several items to consider when it comes to managing and maintaining your enterprise data synchronization solution. System administration tends to cover a broad range of topics. Some of the topics to be considered when architecting your solution include maintainability, configuration management, archiving and backup, logging and auditing, monitoring, and security of the solution.
Maintainability and configuration managementMaintainability and configuration management has to do with ensuring you account for items such as archiving and backup, version control, and determining if you will be working with multiple configuration environments for your solution.
Archiving and backupWhen addressing archiving and backup needs for your solution, it is important to identify your solution components that contain information important to be maintained.
A Tivoli Directory Integrator solution typically consists of an XML formatted configuration file and a text formatted external properties file. Depending on the nature of the solution, the built in state store is utilized in the solution as well. This occurs more often than not. The state store that is typically used is the built-in Cloudscape™ database that comes with IBM Tivoli Directory Integrator. The state store is most commonly used to hold persistent data such as change numbers used when connecting to directory server changelogs or delta information about a particular connection. The state store could also be configured as an external database you may choose to configure separately.
Note: You can greatly increase the ease of maintainability for your solution by ensuring your solution is properly documented at all stages of its lifecyle.
Note: There is a recommended way to backup your IBM Tivoli Directory Integrator Cloudscape databases that can be found in “Backing up CloudScape databases” on page 42 of the IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1716.
30 Robust Data Synchronization with IBM Tivoli Directory Integrator

One of the simplest ways to administer the archiving and backup of the Tivoli Directory Integrator XML configuration files is to use file naming conventions that increment and determine the status of the configuration based on the file name. It is important to ensure you have at least one backup of the external properties file associated with your solution configuration. Ensuring there is a backup of the external properties file is oftentimes easily overlooked.
As you instrument and test your solution, the list of solution components that you choose to backup and archive may grow. An example of this could be if your solution utilizes any special drivers such as database drivers or possibly any custom application interfaces that are required to connect to specialized data sources. It is ideal to establish an archiving and backup plan that meets your organization’s requirements prior to deploying your solution.
Version controlVersion control can encompass several areas. Most often it involves making considerations for both the software and hardware configurations and versions. In the case of an enterprise data synchronization solution, this can also involve the versions related to the connected system sources and targets as well as the version of the IBM Tivoli Directory Integrator software. It is a good idea to identify things such as which version of some of the software components are being utilized. In the case of IBM Tivoli Directory Integrator, this can include identifying which version of JavaScript™ is utilized with your version of Tivoli Directory Integrator.
Version control of the IBM Tivoli Directory Integrator’s XML configuration files typically occurs in the same manner as mentioned with archiving and backup. Creating incremental filename descriptions is typically the easiest and most effective way to manage version control for this component of your solution.
Multiple configuration environmentsWhen architecting an enterprise data synchronization solution, it is ideal to plan for more than one configuration environment. Typically, you will deploy a minimum of two environments consisting of a test environment and a production environment. Ideally, there is also a staging environment that provides for a transition between the test and production environments.
Having multiple environments raises several items to consider with your solution. A main item is ensuring migration between the environments is easily maintained. Migration of your IBM Tivoli Directory Integrator configurations between environments is relatively simple. There are a few ways to consider maintaining this. A common way is to replicate the configuration files from one environment to another while keeping separate install bases of the server software in each environment. Plan on having a separate external properties file to handle the connection configuration differences between environments.
Chapter 2. Architecting an enterprise data synchronization solution 31

MonitoringSystem administration of your solution involves identifying what parts of your solution you have requirements to monitor and how frequently. Monitoring includes real-time monitoring as well as logging and auditing.
Real-timeMonitoring your solution in real-time is a common requirement. Determining the frequency of the data flows as outlined in previous sections helps to determine your requirements for real-time monitoring. Knowing if the data synchronization solution is up and running is a minimum requirement. If your solution’s requirements are to synchronize data infrequently, then real-time monitoring becomes less critical.
IBM Tivoli Directory Integrator provides an Administration and Monitor Console (AMC) which allows for real-time monitoring of your solutions as well as the ability to check logging results.
Monitoring requirements have a few levels of access control. It is important to identify what organizational role will be performing which types of monitoring. For example, your solution requirements may be that an operator be able to see if the systems are running and restart them but not be able to make configuration changes. The IBM Tivoli Directory Integrator Administration and Monitor Console provides access levels for monitoring your solution.
Logging and auditingLogging and auditing for enterprise solutions can oftentimes involve corporate standards for centralized logging or auditing. An example of this is when there is an enterprise standard for tracking system failures via a common management system that might watch and track Simple Network Management Protocol (SNMP) messages. IBM Tivoli Directory Integrator provides several mechanisms to either utilize a currently installed enterprise standard or provide its own capabilities should there be no corporate direction. Some of the built in logging options include logging to a rolling file, the console, a file, syslog, NT Event Log, or system log.
When an enterprise has a management environment that utilizes technology such as SNMP traps or a database with a reporting application associated to it, IBM Tivoli Directory Integrator can be configured to utilize these options as well.
When architecting your solution, it is important to identify if there are any enterprise standards for logging and auditing and what they may be. This is especially important to identify when considering any auditing requirements. Auditing tends to encompass compliance. Since each enterprise has unique compliance requirements, it is important to identify if there are any auditing rules for your data integration solution as soon as possible. Data auditing requirements
32 Robust Data Synchronization with IBM Tivoli Directory Integrator

can dictate your data flow and can quite easily expand your solution requirements in all areas.
2.5.5 SecurityThe security requirements for you data synchronization solution can be broken down in two main categories. The first involving the security of the data being synchronized and the second covering the security of the server, configurations and system administration interfaces.
Data synchronization security It is important to identify the security requirements of the data you will be synchronizing. Most of the requirements become apparent as you identify the nature of your data and plan your data flows. The following two questions can be asked to further identify these requirements.
1. Does the entire data transmission between sources have to be secure for all data?
Solutions for securing the data transmission involve utilizing technology such as SSL and HTTPS. Both technologies are provided with Directory Integrator.
2. Are there specific data attributes that must be encrypted?
Many times this involves the password attribute. Directory Integrator provides several encryption methods and the ability to encrypt any attribute. It is not limited to just the password attribute.
Server, configuration, and system administration securityThe following questions help to identify the requirements your solution may have relating to the security involved in administering your solution.
1. Does the server and configuration software need to be secure?
The answer to this question is typically yes. Consideration needs to be made for the location and security of where you place the server software and how you maintain access to that environment. Directory Integrator provides password level access control to its configurations and encryption.
2. Do you need to have the access control values used for access to remote systems protected?
Once again, the answer for this question is typically yes. The values used to access the data sources to be synchronized are usually very sensitive and powerful pieces of enterprise information. Directory Integrator provides an encryption for these values by providing a way to encrypt its external properties file.
Chapter 2. Architecting an enterprise data synchronization solution 33

3. Does the remote administration of your solution need to be secure?
Answering yes to this question means you have identified that your solution requires remote administration and secure access control to prevent unauthorized users from access. Directory Integrator provides secure connectivity to its administration and monitor console. Secure remote administration is a typical requirement for data synchronization solutions.
2.5.6 Password synchronizationPassword synchronization is specifically mentioned when architecting a data synchronization solution since it tends to have its own set of data and implementation requirements. High availability, failover, and security are on the top of the list. It is important to incorporate the additional solution requirements that are introduced by password synchronization. The specific components of Tivoli Directory Integrator’s password synchronization capabilities are covered in 3.2.11, “Password synchronization” on page 65.
When implementing password synchronization, it is ideal to have the passwords only flow in one direction. If your business requirements absolutely require bi-directional password synchronization, it is ideal to keep the number of repositories to be synchronized to a minimum. Bi-directional password synchronization introduces architecture issues such as loop and race conditions. This is covered further in our customer scenario one in Chapter 4, “Penguin Financial Incorporated” on page 91.
Below is a list of things to consider when password synchronization is part of your solution:
� Identify the applications that will require passwords to be intercepted.
� Determine the application with the most restrictive default password rules.
For example, RACF® has a requirement the passwords be eight characters in length and alphanumeric.
� Design for additional requirements if the password synchronization is multi-directional.
Note: It is best to place all the values used for accessing the data sources to be synchronized into an external properties file so it can be encrypted. By encrypting all data source information you substantially contribute to the protection of enterprise sensitive data.
34 Robust Data Synchronization with IBM Tivoli Directory Integrator

2.6 Who are the players in the solutionJust as no two organizations are the same, neither are two different synchronization projects. What is common to both though is a subset of responsibilities that historically are found in every Tivoli Directory Integrator production deployment.
This may lead to further training and planning activities, as well as clearing up confusion over who owns what. The assignment of these responsibilities to individuals within an organization is a key part of the success of a production deployment, as is the training of those individuals to a standard where they can comfortably fulfill their duties.
For the purposes of outlining these responsibilities, we consider four standard departments that typically exist in most companies with a significant IT infrastructure. The final identified group for this exercise is the vendor. This is not always the case, however, it is relatively easy to map this model to the operations of the individual environment.
1. IT Infrastructure Group
This group is commonly responsible for:
– Responsible for enterprise directory infrastructure, mapping schemas, and supporting applications.
– Evaluating and introducing new technologies into a company.
– Be the internal advocate for the components in the software infrastructure.
– Providing troubleshooting and internal training services beyond normal operations capabilities.
– Provide the interface to vendors when product faults or advanced questions arise.
2. System Administrators / Operations
This group is commonly responsible for:
– Managing the day-to-day requirements of operating systems and process monitoring.
– Backup, restore, and disaster recovery.
– First line of troubleshooting.
3. Data Management/Security
This group is commonly responsible for:
– Determine and implement identity data management policy for applications.
Chapter 2. Architecting an enterprise data synchronization solution 35

– Determine and implement security policy for applications.
– Develop and implement user and group administration tasks.
– Understand, implement, and execute security audit procedures.
4. Application owners
This group is commonly responsible for:
– Implement and manage business applications that rely on the synchronized data infrastructure.
– Provide application-level troubleshooting.
5. Software Vendors
This group is commonly responsible for:
– Provide software components of the infrastructure.
– Provide planning and (sometimes) implementation services.
– Provide detailed technical support.
– Provide information about lifecycles of the software components for customer planning input (for example, release and end-of-service timeframes).
2.6.1 Common roles and responsibilitiesThe following charts outline the typical IBM Tivoli Directory Integrator administration roles and responsibilities as well as the groups that typically own and participate in those roles.
First let us take a look the systems operations responsibilities.
Table 2-1 Systems operations
Task/Responsibility Owner / Implementer Other Contributors
Define goal of the integration. This usually includes the definition of the business objective and the translation of the business objective into concrete directory integration definitions.
IT Infrastructure Group Each organization should provide a representative to provide input for this task.
Define the data that must flow and the authoritative source for each data element that will be managed.
IT Infrastructure Group Each organization should provide a representative to provide input for this task.
36 Robust Data Synchronization with IBM Tivoli Directory Integrator

Define IBM Tivoli Directory Integrator AssemblyLine to accomplish specified task.
Data Management / Security
IT Infrastructure Group and Software Vendor to specify/provide procedures. Data Management/Security to provide requirements input. Application owners to assist with application integration requirements.
Build prototype IBM Tivoli Directory Integrator AssemblyLine to accomplish specified task.
Data Management / Security
IT Infrastructure Group and Software Vendor to specify/provide procedures. Data Management / Security and Application owners to specify / provide procedures. System administration / operations personnel to over look operation input.
Test prototype IBM Tivoli Directory Integrator AssemblyLine to accomplish specified task.
Data Management / Security
IT Infrastructure Group to specify / provide procedures. System administration / operations to provide test specification input.
Deploy IBM Tivoli Directory Integrator AssemblyLine to accomplish specific task.
System Administration / Operations
IT Infrastructure Group and Software Vendors to specify / provide procedures. Application owners to assist with application integration.
Monitor deployed IBM Tivoli Directory Integrator AssemblyLine to ensure proper operation and to monitor for any error conditions.
System Administration / Operations
IT Infrastructure Group and Data Management / Security to provide information about monitoring and alerts requirements.
Correct any detected IBM Tivoli Directory Integrator AssemblyLine error conditions that occur.
System Administration / Operations
IT Infrastructure Group and Data Management / Security to provide error recovery procedures. Application owners to provide troubleshooting assistance with application integration.
Audit running integrated directory infrastructure to ensure compliance to business rules.
Data Management / Security
System administration / operations to assist with audits and control review.
Monitor and maintain IBM Tivoli Directory Integrator server health.
System Administration / Operations
Software Vendors to provide best practice information.
Task/Responsibility Owner / Implementer Other Contributors
Chapter 2. Architecting an enterprise data synchronization solution 37

Next we take a look at the end to end troubleshooting responsibilities.
Table 2-2 End to end troubleshooting
Next we take a look at support operations responsibilities.
Table 2-3 Support operations
Next we take a look at test and design responsibilities.
Table 2-4 Future testing
Perform software upgrades and software defect resolution.
System Administration / Operations
Software Vendors to provide best practice information.
Perform data backup and restore for disaster recovery.
System Administration / Operations
Software Vendors to provide best practice information.
Task/Responsibility Owner / Implementer Other Contributors
Role / Responsibility Owner / Implementer Other Contributors
Provide initial troubleshooting investigation to determine component error (this is after helpdesk efforts).
System Administration / Operations
IT Infrastructure Group to provide internal training.
Determine if security policy is adversely affecting user experience.
Data Management / Security
IT Infrastructure Group.
Determine if application is faulty. Application Owners IT Infrastructure Group.
Provide detailed troubleshooting when existing procedures fail.
IT Infrastructure Group Software Vendors.
Role / Responsibility Owner / Implementer Other Contributors
Own and maintain one or more test systems for pre-production testing of new applications and regression testing.
All groups are involved It is imperative that all parties are involved in both test and production environments.
Role / Responsibility Owner / Implementer Other Contributors
Maintain currency with IBM Tivoli Directory Integrator versions via aggressive planning and regression strategy.
IT Infrastructure Group Data Management / Security.
38 Robust Data Synchronization with IBM Tivoli Directory Integrator

2.7 ConclusionOnce again it is important to point out that no two organizations are the same. It is probable that the information stated above will not map universally to all organizations. The goal is still the same, to reduce the complexity of the problem by assigning responsibilities. Thereby clearing up confusion over who owns what.
Chapter 2. Architecting an enterprise data synchronization solution 39

40 Robust Data Synchronization with IBM Tivoli Directory Integrator

Chapter 3. Directory Integrator component structure
In Chapter 1, we discussed the business drivers for adopting a consistent identity infrastructure across an enterprise. We point out that in many circumstances companies prefer (or are obliged) to maintain more than one user repository. This is because it is hard to consolidate all user accounts into only one directory. In fact, the traditional approaches to directory infrastructures might no longer handle the growing volume of users, organizations, and resources in an enterprise. Companies are deploying department-specific applications, each with its own application-specific user repository, resulting in many individual repositories. These repositories can be LDAP directories, relational database (Oracle, DB2, and so on) tables, flat files in different formats (CSV, XML, and so on), operating systems, and other.
Companies that decide to maintain more than one user repository and to leverage existing data and tools in order to build a consistent identity and data infrastructure have to integrate them by implementing an identity and data management solution. IBM Tivoli Directory Integrator is designed to fit this requirement.
Directory Integrator provides an authoritative, enterprise-spanning identity and data infrastructure critical for security and for provisioning applications, such as portals. It enables integration of a broad set of information into the identity and resource infrastructure. There is virtually no limitation on the type of data or
3
© Copyright IBM Corp. 2006. All rights reserved. 41

system with which Directory Integrator is able to work. It has a number of built-in connectors to directories, databases, formats, and protocols, as well as an open-architecture Java™ development environment to extend existing connectors or create new ones, and tools to configure connectors and apply logic to data as it is processed.
In addition to integrating data between applications or directories, IBM Tivoli Directory Integrator can be helpful for other reasons such as:
� Eliminate the need for an inflexible centralized database.
� Capability for distributed data management.
� Supply of a non-intrusive integration. Business and security rules can be introduced to manage flow, ownership, and structure of information between different systems.
� Supply of a modular, flexible, and scalable solution. This is possible because any integration task is divided into simple pieces, which are then clicked together. This approach enables introduction of Directory Integrator starting with a portion of the overall solution and then expanding to the whole enterprise. Easy and rapid modifications of the designed solution are always possible.
� Capability of both timed and real-time integration. With the event-driven engine, data flow can be triggered by many types of events such as database or directory change, e-mail arrival, file creation or modification, or HTTP calls.
� Capability to intercept password changes and to propagate the new password to multiple accounts.
� Rapid development, testing, deployment, and maintenance with the graphical interface.
� Support of most standard protocols, transports, APIs and formats such as JDBC, LDAP, JMS, JNDI, and XML.
� Support of JavaScript for scripting.
� Easy integration with other IBM products such as the WebSphere® family and other Tivoli security products such as Access Manager and Identity Manager.
� Wide platform support. It can run on UNIX® (AIX®, HP-UX, Solaris™), Windows and Linux® (Red Hat, SuSE and United Linux on Intel®, IBM p-series and s/390 platforms). Refer to the IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1716, and the BM Tivoli Directory Integrator 6.0: Release Notes for more information about the supported platforms, versions, and requirements.
Figure 3-1 shows a general example of an enterprise architecture using IBM Tivoli Directory Integrator. In the following section, we introduce the Directory
42 Robust Data Synchronization with IBM Tivoli Directory Integrator

Integrator concept and show how information is synchronized and exchanged between the various systems.
Figure 3-1 A general data integration environment
3.1 Concept of integrationThe IBM approach is to simplify a large integration project by breaking it into individual small components, then solve it one piece at a time. Integration problems typically can be broken down into three basic parts:
� The systems and devices that have to communicate with each other.� The flows of data among these systems.� The events that trigger when the data flows occur.
These constituent elements of a communications scenario can be described as follows.
3.1.1 Data sourcesThese are the data repositories, systems and devices that talk to each other, such as the Human Resources (HR) database, an enterprise directory, the
WebSphere MQ
AIX
ActiveDirectory
Main-frame
Linux
DirectoryIntegrator
Directory
.net
WebServicesWeb
ServicesDatabase
DirectoryIntegrator
File
LotusDomino
DirectoryIntegrator
Chapter 3. Directory Integrator component structure 43

enterprise resource planning (ERP) system, a customer relationship management (CRM) application, the office phone system, a messaging system with its own address book, or maybe a Microsoft® Access database with a list of company equipment and to whom the equipment has been issued.
Data sources represent a wide variety of systems and repositories, such as databases (for example, IBM DB2, Oracle, Microsoft SQL Server), directories (such as Sun™ Java™ System Directory Server, IBM Tivoli Directory Server, Lotus® Domino®, Novell eDirectory, and Microsoft Active Directory), directory services (Microsoft Exchange), files (for example, Extensible Markup Language (XML), LDAP Data Interchange Format (LDIF), or Simple Object Access Protocol (SOAP) documents), specially formatted e-mail, or any number of interfacing mechanisms that internal systems and external business partners use to communicate with information assets and services.
3.1.2 Data flowsThese are the threads of communications and their content and are usually drawn as arrows that point in the direction of data movement. Each data flow represents a dialogue between two or more systems.
However, for a conversation to be meaningful to all participants, everyone involved must understand what is being communicated. But data sources likely represent their data content in different ways. One system might represent a telephone number as textual information, including the dashes and parentheses used to make the number easier to read. Another system might store it as numerical data.
If these two systems are to communicate about this data, the information must be translated during the conversation. Furthermore, the information in one source might not be complete and might have to be augmented with attributes from other data sources. In addition, only parts of the data in the flow might be relevant to receiving systems.
Therefore, a data flow must also include the mapping, filtering, and transformation of information, shifting its context from input sources to that of the destination systems.
3.1.3 EventsEvents can be described as the circumstances that dictate when one set of data sources communicates with another. One example is whenever an employee is added to, updated within, or deleted from the HR system.
44 Robust Data Synchronization with IBM Tivoli Directory Integrator

An event can also be based on a calendar or a clock-based timer (for example, starting communications every 10 minutes or at 12:00 midnight on Sundays). It can also be a manually initiated one-off event, such as populating a directory or washing the data in a system.
Events are usually tied to a data source and are related to the data flows that are triggered when the specified set of circumstances arises.
In the following section we show how each of these elements is handled by IBM Tivoli Directory Integrator using its base components.
3.2 Base componentsIBM Tivoli Directory Integrator is comprised of two applications:
� Toolkit Integrated Development Environment (IDE)
This program provides a graphical interface to create, test, and debug the integration solutions. The Toolkit IDE is used to create a configuration file (called a config), which is stored as a highly structured XML document and is executed by the run-time engine. The Toolkit IDE executable is called ibmditk. In 3.7, “Administration and monitoring” on page 84 we describe some features of this interface.
� Run-time Server
Using a configuration file you created with the Toolkit IDE, the Run-time Server powers the integration solution. This application is called ibmdisrv, and you can deploy your solution using as many or as few server instances as you want. There are no technical limitations.
From a logical point of view the Directory Integrator architecture is divided into two parts:
� The core system, where most of the system’s functionality is provided. The core handles log files, error detection, dispatching, and data flow execution parameters. This is also where customized configuration and business logic is maintained. The Administration and Monitor Console (AMC) is the interface for working with these core functionalities. Because AMC is a Web console, administration can be done remotely using a Web browser, without the need to physically log on to the Directory Integrator server. AMC is described in more detail in 3.7, “Administration and monitoring” on page 84.
� The components, which serve to provide an abstraction layer for the technical details of the data systems and formats that you want to work with. There are four main types of components: AssemblyLine, Connectors, Parsers, Function Components, and EventHandlers, and because each is wrapped by
Chapter 3. Directory Integrator component structure 45

core functionality that handles things such as integration flow control and customization, the components themselves can remain small and lightweight. For example, if you want to implement your own Parser, you only have to provide two functions: one for interpreting the structure of an incoming bytestream, and one for adding structure to an outgoing one.
This core/component design allows easy extensibility. It also means that you can rapidly build the framework of your solutions by selecting the relevant components and clicking them into place. Components are interchangeable and can be swapped out without affecting the customized logic and configured behavior of your data flows. This means that you can build integration solutions that are quickly augmented and extended while keeping them less vulnerable to changes in the underlying infrastructure.
The key elements of the integration solution are the AssemblyLines. The arrows drawn in Figure 3-1 on page 43 can each represent an AssemblyLine. Each AssemblyLine implements a single uni-directional data flow. A bi-directional synchronization between two or more data sources is implemented by separate AssemblyLines, one for each direction.
3.2.1 AssemblyLinesReal-world industrial AssemblyLines are made up of a number of specialized machines that differ in both function and construction, but have one significant attribute in common: They can be linked to form a continuous path from input sources to output.
An AssemblyLine generally has one or more input units designed to accept whatever raw materials are needed for production (fish fillets, cola syrup, car parts). These ingredients are processed and merged. Sometimes by-products are extracted from the line along the way. At the end of the production line, the finished goods are delivered to waiting output units.
If a production crew gets the order to produce something else, they break the line down, keeping the machines that are still relevant to the new order. New units are connected in the right places, the line is adjusted, and production starts again. IBM Tivoli Directory Integrator AssemblyLines work similar to real-world industrial AssemblyLines.
The general philosophy of an AssemblyLine is that it processes data (for example, entries, records, items, objects) from one data source, transforms and combines it with data from others sources, and finally outputs it to one or more targets.
Figure 3-2 shows an example of a Directory Integrator AssemblyLine.
46 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 3-2 AssemblyLine
Let us take a closer look at what goes on inside an AssemblyLine.
As shown in Figure 3-3 on page 48 an AssemblyLine may consist of many components. The generic part of the component, called the AssemblyLine component, provides kernel functionality like Attribute Maps, Link Criteria, Hooks, and so on. The data-source specific part of the component, called the component interface, is connected to some system or device, and has the intelligence to work with a particular API or protocol. These component interfaces are interchangeable.
This AssemblyLine wrapper makes components work in a similar and predictable fashion. It enables AssemblyLine components to be linked together, as well as providing built-in behaviors and control points for customization.
Chapter 3. Directory Integrator component structure 47

Figure 3-3 AssemblyLine components
How data is organized can differ greatly from system to system. For example, databases typically store information in records with a fixed number of fields. Directories, on the other hand, work with variable objects called entries, and other systems use messages or key-value pairs. As shown in Figure 3-4 on page 49 Directory Integrator simplifies this issue by collecting and storing all types of information in a powerful and flexible Java data container called a work Entry. In turn, the data values themselves are kept in objects called attributes that the entry holds and manages. The work Entry is passed between AssemblyLine components which in turn perform work on the information it contains, for example, joining in additional data, verifying content, computing new attributes and values, as well as changing existing ones, until the data is ready for delivery to one or more target systems. Additional Scripts can also be added to perform these operations.
As a result, attribute mapping, business rules, and transformation logic do not have to deal with type conflicts.
48 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 3-4 Entry objects and Attributes
In addition to the work Entry object used by the AssemblyLine to move data down the flow, Figure 3-4 also shows an additional Java bucket nestled in each of the Connectors. These local storage objects are used to cache data during read and write operations. A Connector’s local Entry object is called its conn object, and exists only within the context of the Connector. When a Connector reads in information, it converts the data to Java objects and stores it in the local conn object. During output, the Connector takes the contents of its conn, converts this data to native types and sends it to the target system.
However, since each conn object is only accessible by its Connector, an additional mechanism is needed to move data from these localized caches to the shared work Entry object after Connector input—and the other direction for output Connectors. Figure 3-4 shows an arcing arrow that illustrates this movement of Attributes between the Connectors’ local conn Entries and the AssemblyLines work Entry object. This process is called Attribute Mapping and is described in more detail in 3.2.8, “Attribute Map components” on page 64. Suffice it to say that Attribute Maps are your instructions to a Connector on which Attributes are brought into the AssemblyLine during input, or included in output operations.
An AssemblyLine is designed and optimized for working with one item at a time, such as one data record, one directory entry or one registry key. However, if you want to do multiple updates or multiple deletes (for example, processing more than a single item at the time) then you must write AssemblyLine scripts to do
Chapter 3. Directory Integrator component structure 49

this. If necessary, this kind of processing can be implemented using JavaScript, Java libraries and standard IBM Tivoli Directory Integrator functionality (such as pooling the data to a sorted datastore, for example with the JDBC Connector, and then reading it back and processing it with a second AssemblyLine).
AssemblyLines should contain as few Connectors as possible (for example, one per data source participating in the flow), while at the same time including enough components and script logic to make them as autonomous as possible. The reasoning behind this is to make the AssemblyLine easy to understand and maintain. It also results in simpler, faster, and more scalable solutions. Another benefit of this can be the reusability of AssemblyLines.
3.2.2 ConnectorsConnectors are like puzzle pieces that click together, while at the same time link to a specific data source.
There are basically two categories of Connectors:
� The first category is where both the transport and the structure of data content is known to the Connector (that is, the schema of the data source can be queried or detected using a well known API such as JDBC or LDAP).
� The second category is where the transport mechanism is known, but not the content structuring. This category requires a Parser (see 3.2.3, “Parsers” on page 60) to interpret or generate the content structure in order for the AssemblyLine to function properly.
Each Connector is characterized by two properties, type and mode. The type is related to the data sources that the Connector links to the AssemblyLine. The mode identifies the role of the Connector in the data flow, and controls how the automated behavior of the AssemblyLine drives the component. Connectors can be in one of the following eight modes.
� Iterator� Lookup� AddOnly� Update� Delete� CallReply� Server� Delta
Each Connector mode determines the behavior of a specific Connector, and not all Connectors support all modes of operation. For example, the File System Connector supports only a single output mode, AddOnly, and not Update, Delete or CallReply. When you use a Connector you must first consult the
50 Robust Data Synchronization with IBM Tivoli Directory Integrator

documentation for this component for a list of supported modes. Connectors in Iterator or Server mode are automatically placed in the Feed section of the AssemblyLine Detail window, Connectors in other modes end up in the Flow section. Each of the connector modes is explained in detail in the next section.
You can change both the type and mode of a Connector whenever you want in order to meet changes in your infrastructure or in the goals of your solution. If you planned for this eventuality, the rest of the AssemblyLine, including data transformations and filtering, will not be affected. That is why it is important to treat each Connector as a black box that either delivers data into the mix or extracts some of it to send to a data source. The more independent each Connector is, the easier your solution will be to augment and maintain.
Whenever you need to include new data to the flow, simply add the relevant Connector to the AssemblyLine. In the example of Figure 3-5 on page 52 we see three Connectors: two input Connectors to an RDBMS and an LDAP Directory, and one output Connector to an XML document.
Let us examine the different Connector modes.
Best practice: By making your Connectors as autonomous as possible, you can readily transfer them to your Connector Library and reuse them to create new solutions faster, even sharing them with others. Using the library feature also makes maintaining and enhancing your Connectors easier, because all you have to do is update the Connector template in your library, and all AssemblyLines derived from this template inherit these enhancements. When you are ready to put your solution to serious work, you can reconfigure your library Connectors to connect to the production data sources instead of those in your test environment, and move your solution from lab to live deployment in minutes.
Chapter 3. Directory Integrator component structure 51

Figure 3-5 AssemblyLine with connectors, parsers, and data sources
Connector modesThis section describes, in detail, each of the Connector modes.
Iterator modeConnectors in Iterator mode are used to scan a data source and extract its data. The Iterator Connector actually iterates through the data source entries, reads their attribute values, and delivers each work Entry to the AssemblyLine and its non-Iterator Connectors. A Connector in Iterator mode is referred to as an Iterator.
AssemblyLines (except the special cases when called with an initial work Entry) typically contain at least one Connector in Iterator mode. Iterators (Connectors in Iterator mode) supply the AssemblyLine with data. If an AssemblyLine has no Iterator, it is often useless unless it gets data from another source (for example, the script or process that started the AssemblyLine, or data created in a Prolog script).
AssemblyLine Connectors that are set to any mode except Iterator are powered in order starting at the top of the Connector list. Iterators on the other hand are
Note: It does not matter exactly what the data source is (database, LDAP directory, XML document, and so forth) and how its data is actually stored. Each Connector presents an abstract layer over the particular data source and you access and process data through instances of the work Entry and Attribute classes.
52 Robust Data Synchronization with IBM Tivoli Directory Integrator

always run first before other non-Iterator Connectors, regardless of their placement in the AssemblyLine. Additionally, if you are using multiple Iterators in a single AssemblyLine, the Iterators are used, one at a time, in their order in the Connectors list.
Multiple Iterators in an AssemblyLine: If you have more than one Connector in Iterator mode, these Connectors are stacked in the order in which they appear in the Config (and the Connector List in the Config Editor, in the Feeds section) and are processed one at a time. So, if you are using two Iterators, the first one reads from its data source, passing the resulting work Entry to the first non-Iterator, until it reaches the end of its data set. When the first Iterator has exhausted its input source, the second Iterator starts reading in data.
An initial work Entry is treated as coming from an invisible Iterator processed before any other Iterators. This means an initial work Entry is passed to the first non-Iterator in the AssemblyLine, skipping all Iterators during the first cycle. This behavior is visible on the AssemblyLine Flow page in Appendix B: AssemblyLine and Connector mode flowcharts of the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720.
Assume you have an AssemblyLine with two Iterators, ItA preceding ItB. The first Iterator, ItA, is used (the AssemblyLine ignoring ItB) until ItA returns no more entries. Then the AssemblyLine switches to ItB (ignoring ItA). If an initial work Entry is passed to this AssemblyLine, then both Iterators are ignored for the first cycle, after which the AssemblyLine starts calling ItA.
Sometimes the initial work Entry is used to pass configuration parameters into an AssemblyLine, but not data. However, the presence of an initial work Entry causes Iterators in the AssemblyLine to be skipped during the first cycle. If you do not want this to happen, you must empty out the work Entry object by calling the task.setWork(null) function in a Prolog script. This causes the first Iterator to operate normally.
Lookup modeLookup mode enables you to join data from different data sources using the relationship between attributes in these systems. A Connector in Lookup mode is often referred to as a Lookup Connector. In order to set up a Lookup Connector you must tell the Connector how you define a match between data already in the AssemblyLine and that found in the connected system. This is called the Connector’s Link Criteria, and each Lookup Connector has an associated Link Criteria tab where you define the rules for finding matching entries.
AddOnly modeConnectors in AddOnly mode (AddOnly Connectors) are used for adding new data entries to a data target. This Connector mode requires almost no
Chapter 3. Directory Integrator component structure 53

configuration. Set the connection parameters and then select the attributes to write from the work Entry.
Update modeConnectors in Update mode (Update Connectors) are used for adding and modifying data in a data target. For each work Entry passed from the AssemblyLine, the Update Connector™ tries to locate a matching entry from the data target to modify with the work Entry’s attributes values received.
As with Lookup Connectors, you must tell the Connector how you define a match between data already in the AssemblyLine and that found in the connected system. This is called the Connector’s Link Criteria, and each Update Connector has an associated Link Criteria tab where you define the rules for finding matching entries. If no such Entry is found, a new Entry is added to the data target. However, if a matching entry is found, it is modified. If more than one entry matches the Link Criteria, the On Multiple Entries Hook is called. Furthermore, the Output Map can be configured to specify which attributes are to be used during an Add or Modify operation.
When doing a Modify operation, only those attributes that are marked as Modify (Mod) in the Output Map are changed in the data target. If the entry passed from the AssemblyLine does not have a value for one attribute, the Null Behavior for that attribute becomes significant. If it is set to Delete, the attribute does not exist in the modifying entry, thus the attribute cannot be changed in the data target. If it is set to NULL, the attribute exists in the modifying entry, but with a null value, which means that the attribute is deleted in the data target.
An important feature that Update Connectors offer is the Compute Changes option. When turned on, the Connector first checks the new values against the old ones and updates only if and where needed. Thus you can skip unnecessary updates that can be really valuable if the update operation is a heavy one for the particular data target you are updating.
Delete modeConnectors in Delete mode (Delete Connectors) are used for deleting data from a data source. For each work Entry passed to the Delete Connector, it tries to locate matching data in the connected system. If a single matching entry is found, it is deleted, otherwise the On No Match Hook is called if none were found, or the On Multiple Entries Hook is more than a single match was found. As with Lookup and Update modes, Delete mode requires you to define rules for finding the matching Entry for deletion. This is configured in the Connector’s Link Criteria tab.
54 Robust Data Synchronization with IBM Tivoli Directory Integrator

CallReply modeCallReply mode is used to make requests to data source services (such as Web services) that require you to send input parameters and receive a reply with return values. Unlike the other modes, CallReply gives access to both Input and Output Attribute Maps.
Server modeThe Server mode, available in a select number of Connectors is meant to provide functionality previously handled by EventHandlers that needed to send back a reply message to the system originating the event. You can find more information about the EventHandler in 3.2.4, “EventHandlers” on page 61.
Server mode is configured using parameters similar to those found in the corresponding EventHandler from previous versions. These components behave in a similar fashion to their EventHandler counterparts, connecting to target systems and either polling or subscribing to event notification services.
On event detection, the Server mode Connector then either proceeds with the Flow section of this AssemblyLine, or if an AssemblyLine Pool has been configured for this AssemblyLine then it contacts the Pool Manager process to request an available AssemblyLine instance to handle this event.
Once the Server mode Connector has been assigned the AssemblyLine instance it needs to continue, it spawns an instance of itself in Iterator mode, tied to the channel/session/connection that will deliver the event data. This Iterator worker object then operates as any normal Iterator does, including following the standard Iterator Hook flow, reading the event entries one at a time and passing them to the other Flow components for processing until there is no more data to read. At this time, the worker Iterator is cleared away, and if necessary, the Pool Manager is informed that this AssemblyLine instance is now available again.
When an AssemblyLine with a Server mode connector uses the AssemblyLine Pool, the AssemblyLine Pool will execute AssemblyLine instances from beginning to end. Before the AssemblyLine instance in the AssemblyLine Pool closes the Flow connectors, the AssemblyLine Pool retrieves those connectors into a pooled connector set that will be reused in the next AssemblyLine instance created by the AssemblyLine Pool (the AssemblyLine Pool uses the tcb.setRuntimeConnector method).
There are two system properties that govern the behavior of connector pooling.
1. com.ibm.di.server.connectorpooltimeoutThis property defines the timeout in seconds before a pooled connector set is released.
Chapter 3. Directory Integrator component structure 55

2. com.ibm.di.server.connectorpoolexcludeThis property defines the connector types that are excluded from pooling. If a connector’s class name appears in this comma separated list it is not included in the connector pool set.
When a new AssemblyLine instance is created by the AssemblyLine Pool, it will look for an available pooled connector set, which, if present, is provided to the new AssemblyLine instance as runtime provided connectors. This ensures proper flow of the AssemblyLine in general in terms of hook execution and so on. Note that connectors are never shared. They are only assigned to a single AssemblyLine instance when used.
Delta modeThe Delta mode is designed to simplify the application of delta information (make the actual changes) in a number of ways. It provides more optimal handling of delta information generated by either the Iterator Delta Store feature (Delta tab for Iterators), or Change Detection Connectors like the IDS/LDAP/AD/Exchange Changelog Connectors, or the ones for RDBMS and Lotus/Domino Changes.
The Delta features in Tivoli Directory Integrator are designed to facilitate synchronization solutions. You can look at the system’s Delta capabilities as divided into two sections: Delta Detection and Delta Application.
Delta Detection: Tivoli Directory Integrator provides a number of change (delta) detection mechanisms and tools:
Delta Store: This is a feature available to Connectors in Iterator mode. If enabled from the Iterator’s Delta tab, the Delta Store feature uses the System Store to take a snapshot of data being iterated. Then on successive runs, each Entry iterated is compared with the snapshot database to see what has changed.
Change Detection: These components leverage information in the connected system to detect changes, and are either used in Iterator or Server mode, depending on the Connector. For example, Iterator mode is used for many of the Change Detection Connectors, like those for LDAP, Exchange, and ActiveDirectory Changelog, as well as the RDBMS and Domino/Notes Change Connectors. We now discuss a few features of Change Detection connectors.
Note: A Connector in Delta mode needs to be paired with another Connector which provides Delta information, otherwise the Delta mode has no delta information to work with.
56 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Iterator State Store featureThis feature uses the System Store to keep track of the starting point for a Change Detection Connector (for example, the changenumber of a directory changelog).
It keeps track of the next change to be processed, even between runs of the AssemblyLine. The value of the Iterator State Store parameter must be globally unique, so that if you have multiple AssemblyLines that use Change Detection Connectors, they will each have their own Iterator state data.
The content of the Iterator State Store works in combination with Connector configuration settings provided for selecting the next change to process—the Start at... parameter(s). For example, in the IBMDirectoryServer Changelog Connector this is the Start at changenumber parameter where you can enter the changelog number where processing is to begin. This parameter can be set to either a specific value (for example, 42), to the first change (for example, 1), or to EOD (End of Data). The EOD setting places the cursor at the end of the change list in order to only process new deltas.
As long as no Iterator State Store is specified, the Change Detection Connector continues to use the Start at... setting each time the Connector performs its selectEntries() operation; for example, when the Iterator is initialized at AssemblyLine startup, or in a Loop. The same happens if there is no value stored for the specified Iterator State Store.
So, the very first time you run the AssemblyLine with the Change Detection Connector there will be no Iterator State Store value yet, so the Start at... parameter(s) will be used. On subsequent executions, the Start at... settings will be ignored and the Iterator State Store value applied instead.
� Change notification featureWhere supported a Change Detection Connector registers with the data source for change notifications, receiving a signal whenever a change is made. If this parameter is set to false the Connector will poll for new changes. If this parameter is set to true then after processing all unprocessed changes the Connector will block through the Server Search Notification Control and get notified by the data source when a change occurs. The Connector will not sleep and timeout when the notification mechanism is used. Other Connectors have to poll the connected system periodically looking for new changes. Those that rely on polling also provide a Sleep interval option to define how often polling occurs.
� Batch retrieval featureWhere supported the batch retrieval feature specifies how searches are performed in the changelog. When set to false the Connector will perform incremental lookup (backward compatible mode). When set to true a query of
Chapter 3. Directory Integrator component structure 57

type changenumber>=some_value will be executed for batch retrieval of all modified entries with optional retrieving on pages.
The System Store based Delta Store feature reports specific changes all the way down to the individual values of attributes. This fine degree of change detection is also available when parsing LDIF files. Other components are limited to simply reporting if an entire Entry has been added, modified or deleted.
This delta information is stored in the work Entry object, and depending on the Change Detection component/feature used may be stored as an Entry-Level operation code, at the Attribute-Level or even at the Attribute Value-Level.
Delta Application (Connector Delta Mode): The Delta mode is designed to simplify the application of delta information in a number of ways.
Firstly, Delta mode handles all types of deltas, adds, modifies and deletes. This reduces most data synch AssemblyLines to two Connectors, one Delta Detection Connector in the Feeds section to pick up the changes, and a second one in Delta mode to apply these changes to a target system.
Furthermore, Delta mode will apply the delta information at the lowest level supported by the target system itself. This is done by first checking the Connector interface to see what level of incremental modification is supported by the data source. If you are working with an LDAP directory, then Delta mode performs Attribute value adds and deletes. In the context of a traditional RDBMS (JDBC), then doing a delete and then an add of a column value does not make sense, so this is handled as a value replacement for that Attribute.
This is dealt with automatically by the Delta mode for those data sources that support this functionality. If the data source offers optimized calls to handle incremental modifications, and these are supported by the Connector Interface, then Delta mode will use these. On the other hand, if the connected system does not offer intelligent delta update mechanisms, Delta mode will simulate these as much as possible, performing pre-update lookups (like Update mode), change computations and subsequent application of the detected changes.
Connector statesThe state of a Connector determines its level of participation in the operation of the AssemblyLine. In general terms, an AssemblyLine performs two levels of Connector operation:
Note: The only Connector that currently supports incremental modification is the LDAP Connector, since LDAP directories provide this functionality.
58 Robust Data Synchronization with IBM Tivoli Directory Integrator

1. Powering up the Connector at the start of AssemblyLine operation and closing its connection when the AssemblyLine completes.
2. Driving the Connector during AssemblyLine operation according to the Connector mode.
Enabled stateEnabled is the normal Connector state. In enabled state, a Connector is powered up and closed, as well as being processed during AssemblyLine operation.
Passive statePassive Connectors (Connectors in passive state) are powered up and closed just like enabled Connectors. However, they are not driven by the AssemblyLine automated behavior. However, Connectors in passive state can be invoked by script code from any of the control points for scripting provided by IBM Tivoli Directory Integrator. For example, if you have a passive Connector in your AssemblyLine called myErrorConnector then you could invoke its add() operation with the following script code:
var err = system.newEntry(); // Create new Entry objecterr.merge(work); // Merge in attributes in the work Entry// This next line sets an attribute called Error err.setAttribute ( "Error", "Operation failed" ); myErrorConnector.add( err ) // Add new err Entry;
Disabled stateIn disabled state, the Connector is neither initialized (and closed) nor operated during normal AssemblyLine activation. If you want to use it in your scripts, then you must initialize it yourself.
The name of a disabled Connector is registered but pointing at null, so you can write conditional code like the following example to handle the situation where you plan on setting myConnector to disabled state.
if (myConnector != null) myConnector.connector.aMethod();
This state is often used during troubleshooting in order to simplify the solution while debugging, helping to localize any problems.
Directory Integrator provides a library of Connectors to choose from, such as Lightweight Directory Access Protocol (LDAP), JDBC, Microsoft Windows NT4 Domain, Lotus Notes®, and POP/IMAP. If you cannot find the one you need, you can extend an existing Connector by overriding any or all of its functions using JavaScript. You can also create your own, either with a scripting language inside the Script Connector wrapper, or develop with Java or C/C++.
Chapter 3. Directory Integrator component structure 59

Furthermore, Directory Integrator supports most transport protocols and mechanisms, such as TCP/IP, FTP, HTTP, and Java Message Service (JMS)/message queuing (MQ). It also supports secure connections and encryption mechanisms as shown in 3.3, “Security capability” on page 67.
Table 3-1 summarizes the more relevant built-in connectors. However, this list can change with the product version. For more information about available connectors, scripting languages, and how to create your own, see the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720.
Table 3-1 Main available connectors
3.2.3 ParsersEven unstructured data, such as text files and bytestreams coming over an IP port, is handled quickly and simply by passing the bytestream through one or more Parsers. The system is shipped with a variety of Parsers, including LDIF, Directory Services Markup Language (DSML), XML, comma-separated values (CSV), SOAP, and fixed-length field. As with Connectors, you can extend and modify these, as well as create your own.
In the example in Figure 3-5 on page 52, a Parser is used to interpret and translate information from an LDIF file. The extracted information is converted to
Applications PeopleSoft, SAP, Siebel ERP, IBM Tivoli Access Manager (through database access, scripting, or API calls)
Databases (using ODBC, JDBC) Oracle, Microsoft Access and SQL Server, IBM DB2 and Informix®
Directories (using LDAP) CA eTrust, Critical Path, IBM Tivoli Directory Server, iPlanet™, Microsoft Active Directory and Exchange, Nexor, Novell, OpenLDAP, Oracle, Siemens
Files, Streams and Internet Protocols CSV, XML, DSML, HTTP, LDIF, SOAP, DNS, POP, IMAP, SMTP, SNMP
Specific Technologies and APIs Microsoft ADSI, CDO, and other COM; Microsoft NT domains; Lotus Domino directory and databases; Java APIs; system commands
Messaging Services IBM MQ
Changes & Deltas LDAP Changelog, Active Directory changes, NT/AD Password sync, TCP connections, HTTP gets and posts
60 Robust Data Synchronization with IBM Tivoli Directory Integrator

a Java object with a canonical data format so that the LDIF Connector can work with this object and dispatch it along the AssemblyLine.
3.2.4 EventHandlersEventHandlers provide functionality for building real-time integration solutions. Figure 3-6 depicts a typical AssemblyLine with an Event handler.
Figure 3-6 AssemblyLine with EventHandler
As with Connectors, EventHandlers can have data source intelligence that enables them to connect to a system or service and wait for an event notification. Examples are the Mailbox EventHandler, which can detect when new messages arrive in a POP3 or IMAP mailbox, and the LDAP EventHandler, which can catch changes made to a directory. When an event occurs, the EventHandler stores the specifics of the event and then performs logic and starts AssemblyLines according to the condition or action rules that you set up.
Sometimes Connectors can also be used to capture events, as is the case with the JMS (MQ) Connector or the LDAP Changelog Connector, both of which can be configured to wait until new data appears and then retrieve it. However, because the EventHandlers operate in their own thread, they can be used to dispatch events to multiple AssemblyLines. This provides a cleaner and more straightforward method of filtering and handling multiple types of events from the same source (such as SOAP or Web services calls). EventHandlers can also be configured for auto start, meaning that if you start up a server, these EventHandlers will be activated immediately.
Chapter 3. Directory Integrator component structure 61

Figure 3-6 on page 61 shows that a system event can trigger the AssemblyLine.
Now that we have introduced the main components of an AssemblyLine, we show how to customize the AssemblyLine in order to add business rules and logic.
3.2.5 HooksHooks enable developers to describe certain actions to be executed under specific circumstances or at any desired points in the execution of an AssemblyLine. For example, hooks can be placed before or after a Connector, or in consequence of a specific event such as an update failure or a read success. IBM Tivoli Directory Integrator automatically calls these user-defined functions as the AssemblyLine runs.
The majority of the scripting in IBM Tivoli Directory Integrator takes place in the Hooks. For example, hooks can be used to build custom logic, to handle Global Variables, and to set specific error processes and logs.in hooks.
A complete list of all hooks can be found in “Chapter 2 IBM Tivoli Directory Integrator concepts, Hooks, List of Hooks” on page 60 of the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718.
3.2.6 ScriptsA key capability of IBM Tivoli Directory Integrator is the ability to extend virtually all of its integration components, functions, and attributes through scripts or Java. Scripting can be anywhere in the system to add or modify the components of an AssemblyLine. Connectors, Parsers, EventHandlers, and Hooks can be customized in order to perform requested tasks. Scripts are commonly used to map attributes, transform data, access libraries (for example, to call Java classes), handle errors, control data flow, and in general to add business logic.
Directory Integrator supports JavaScript plug-in scripting language and extensive script libraries.
Important: With the availability of Directory Integrator 6.0 the functionality of EventHandlers will more and more be fulfilled by using regular Connectors in Server Mode. When developing new AssemblyLines you should utilize Connectors in Server Mode wherever possible. More information can be found in the Connector section in “Server mode” on page 55.
62 Robust Data Synchronization with IBM Tivoli Directory Integrator

3.2.7 Function componentsA Function component is an AssemblyLine wrapper around some function or discreet operation, allowing it to be dropped into an AssemblyLine as well as instantiated/invoked from a script. The idea behind Function components is to allow complex components (for example, the Web Services EventHandler) to be split into smaller logical units and then strung together as needed, as well as to provide more visual helper objects where custom scripting was necessary before. Function components also offer the functionality previously provided by EventHandler Actions (for example, launching AssemblyLines, invoking Parsers, and so on). As with all Tivoli Directory Integrator components, the user can easily create their own scripted Function components, turning custom logic into a library of reusable AssemblyLine components.
Function components are similar to Connectors in CallReply mode in that they have both Input and Output Maps. The Output Map is used to pass parameters to the Function component, while the Input Map lets you retrieve and manipulate return data.
myFunction.callreply( work )
The above example is invoking the AssemblyLine Function called myFunction. Note that calling the AssemblyLine Function method callreply() will cause Attribute Maps and the normal Function component Hook flow to be executed.
Like the other components, Function components have a library folder in the Config Browser where you can configure and manage your Function component library. These can be then dragged into AssemblyLines or chosen from the selection drop-down that appears when you press the Add component button under the AssemblyLine Connector List.
Also like other components, Function components have an interface part (like the Connector interface or Parser interface, in the case of Function components called the Function interface) that implements the function logic. When a Function component is dropped into an AssemblyLine, it is wrapped in an AssemblyLine Function object that provides the generic functionality necessary for the AssemblyLine to manage and execute it.
Also like Connectors, Function components have a State that can be set to active, passive, or disabled. State behavior is identical with that of Connectors. Since Function components are registered as script variables (beans) when the AssemblyLine starts up, you can access them directly from your script using the name given them in the AssemblyLine.
Chapter 3. Directory Integrator component structure 63

3.2.8 Attribute Map componentsThis component lets you define Attribute transformations as freestanding Attribute maps that can be stored in your component Library and dropped into your AssemblyLine.
Adding new Attributes to the work Entry and other data manipulation can be quickly performed using the Attribute Map component, which defines a mapping from the work Entry to itself, allowing you to create new Attributes as well as change existing ones. And all Attributes defined in Attribute Map components are displayed in the work Entry list as well, easing maintenance and support for the Config.
3.2.9 Branch componentsAnalogous to the old EventHandler Conditions, Branches allow the user to define alternate routes in an AssemblyLine. This means that AssemblyLines will no longer necessarily be simple, uni-directional data flows. Branches mean that a single AssemblyLine can handle solutions that previously required a collection of AssemblyLines.
The Branch provides an interface that allows you to define Simple Conditions based on Attributes in the work Entry object. Multiple Conditions are ANDed or ORed, depending on the Match Any checkbox setting.
After Simple Conditions are processed, there is a script editor window at the bottom of the Branch details page where you can create your own Condition in JavaScript. The syntax here is the same as it was for EventHandler Conditions in that you must populate ret.value with either a true or false value in order to control the outcome of Condition evaluation. Scripted Conditions can be combined with Simple ones, or used exclusively.
If a Condition evaluates to true then all components attached to the Branch are executed.
Note: Once Branch component execution is complete, control is passed to the first component appearing in the AssemblyLine Component List after the Branch. Since Branches only implement simple IF logic, should you need an IF-ELSE construct then you must use two Branches: one with your IF test, and the other with a complementary set of Conditions (for example, IF NOT...).
64 Robust Data Synchronization with IBM Tivoli Directory Integrator

3.2.10 Loop componentsThe Loop component provides functionality for adding cyclic logic within an AssemblyLine. Loops can be configured for three modes of operation:
1. ConditionalHere you can define Simple and/or Scripted Conditions that control looping. The details window for this type of Loop construct is the same as for the Branch component described in the previous section.
2. ConnectorThis method lets you set up a Connector for Iterator or Lookup mode, and will cycle through your Loop flow for each Entry returned. This is the preferred way of dealing with Multiple Entries found for a Lookup. The Details pane of this type of Loop will contain the Connector tabs necessary to configure it, connect and discover attributes and set up the Input Map.
Note that you have a parameter called Init Options where you can instruct the AssemblyLine to either
– Do nothing, which means that the Connector will not be prepared in any way between AL cycles.
– Initialize and Select/Lookup causing the Connector to be re-initialized for each AL cycle.
– Select/Lookup only keeping the Connector initialized, but redoes either the Iterator select or the Lookup, depending on the Mode setting.
Note also that there is a Connector Parameters tab that functions similar to an Output Map in that you can select which Connector parameters are to be set from work Attribute values.
3. Attribute ValueBy selecting any Attribute available in the work Entry, the Loop flow will be executed for each of its values. Each value is passed into the Loop in a new work Entry attribute named in the second parameter. This option allows you to easily work with multi-valued attributes, like group membership lists or e-mail.
3.2.11 Password synchronizationThe password synchronization feature, which is more a module than a component, can be very useful when designing an AssemblyLine that has the goal to synchronize passwords.
Password synchronization can be accomplished by treating passwords as any other attributes and using Connectors as shown in the previous sections. However, this module provides enhanced security for this critical data. The
Chapter 3. Directory Integrator component structure 65

password intercept module is available only for certain platforms, such as Microsoft Active Directory, IBM Lotus Domino, and RACF.
When a user attempts to change a password using the traditional tools, this module intercepts password changes before they are completed. While the password change to the target repository is completed with the native methods, the intercepted new password is temporarily stored in a repository such as an LDAP server or an MQ queue. Then Directory Integrator uses an EventHandler to propagate the new password to other repositories that contain user accounts. Because the password is intercepted before it is actually changed, error handling is possible.
Figure 3-7 shows what happens when a user changes the Windows Domain password. The password synchronization module hooks an exit provided by the Windows Operating System to intercept and validate password changes. The module stores the two-way-encrypted new password in the LDAP directory in the ibmDIKey attribute for the user’s entry. If no entry for the user exists in the container, one will be created. The LDAP Changelog Event Handler listens to the Directory Server Changelog and starts an AssemblyLine when a change notification is received.
Figure 3-7 Password interception with Active Directory
Security is a strong point of password synchronization modules: The password interceptor encrypts the new password with a two-way algorithm before sending it to the data store. Furthermore, SSL can be added to this communication. In
passwordcatch
DirectoryIntegrator
LDAP EventHandler
AssemblyLine
Active Directory modifypassword process
ActiveDirectorypassword
store
LDAPpassword
store
TargetDirectory
TargetFile
TargetDatabase
66 Robust Data Synchronization with IBM Tivoli Directory Integrator

general, IBM Tivoli Directory Integrator provides high security in this module and in all of its parts. In IBM Tivoli Directory Integrator multiple password synchronization plug-ins can share the same MQ queues simplifying setup and maintenance of multi-domain password synchronization solutions.
3.3 Security capabilityDirectory Integrator supports distributed environments through a wide range of communication modes, including TCP/IP, HTTP, LDAP, JDBC, and Java Message Service (JMS)/message queuing (MQ). SSL and other encryption mechanisms can be added to any of these methods to secure the information flow. Additionally, the graphical interfaces (IDE and AMC) can be configured to be accessed by SSL. SSLv3 encrypts communications on the wire. The Java Cryptography Extension (JCE) opens a wide range of security capabilities, such as encrypting information in communications and storage, X.509 certificate, and key management to integrate with PKI efforts in the enterprise.
The AMC supports client certificate authentication and access rights to the IBM Tivoli Directory Integrator configuration can be defined per user. The configuration file can optionally be encrypted by IBM Tivoli Directory Integrator server using server certificate. The Configuration Editor accesses such configurations in remote mode.
In the previous sections we introduced the base components and showed that a wide range of data sources are supported. We just saw that communication between different systems can be encrypted. With these elements, hundreds of different solutions can be set up to fit different requirements. In the following section we show some general architectural concepts and some examples.
3.4 Physical architectureIBM Tivoli Directory Integrator can be presented through a number of use cases that can illustrate the technical capabilities and some of the solutions that can be architected, but we cannot show all possible architectures with all of the different data sources and data flows. So we introduce some general considerations about the use of an enterprise directory and some basic structures of data flow, not as a comprehensive list, but as frameworks or some mental structures to the creative mind for further development.
Chapter 3. Directory Integrator component structure 67

3.4.1 Combination with an enterprise directoryThere are two major metadirectory models or approaches to integrating existing enterprise data stores and building an authoritative source for identity information that exist:
� Metaview, which introduces one main central directory store where all data is aggregated and then synchronizes and publishes data from there back to all other authoritative repositories.
� Point-to-Point synchronization, to avoid the central repository and configure event driven automatic data flows and reconciliation between the repositories, based on business rules and technical requirements.
Metadirectories are often used to accomplish the following goals:
� Create a single enterprise view of users from attributes stored in network services.
� Enforce business rules that define the authoritative source for attribute values.
� Handle naming and schema discrepancies.
� Provide data synchronization services between information sources.
� Enable network and security administrators to manage large, complex networks.
� Simplify the management of user access to corporate resources.
As the foundation for a metadirectory solution, IBM Tivoli Directory Integrator supports both solutions and provides a means of managing information that is stored in multiple directories. It provides Connectors for collecting information from many operating system and application specific sources and services, as well as for integrating the data into a unified namespace. It can provide a central enterprise directory, as well as integrate distributed directories directly.
By design IBM Tivoli Directory Integrator seems especially suited for the second approach. As a metadirectory, it extends the directory with services for managing information that is stored in multiple directories. It acts as the hub for making changes between the disparate systems, and it has a number of facilities that enable it to act as the agent for change on these disparate systems. A scenario based on this architecture is shown in Figure 3-1 on page 43. The important design decision is on the authoritative data repository; after that it is a matter of defining the data flows for each AssemblyLine.
There are two possibilities for the implementation of a centralized enterprise directory. The architecture can have one directory with different authoritative data sources for different identity information as shown in Figure 3-8 on page 69, or you can define your central directory as the authoritative data source. In this
68 Robust Data Synchronization with IBM Tivoli Directory Integrator

case, all of the data flows have to be configured in a way such that the central directory server is the prime source for all identity information within the integrated environment. For our scenario depicted in Figure 3-8 we would have to change the arrows to allow data flows only from the enterprise directory to the other repositories. This means that data is essentially managed only on one directory server, and then IBM Tivoli Directory Integrator propagates any changes to the other repositories.
Figure 3-8 Scenario with an enterprise directory
The choice between the solutions depends on the company requirements and structures. There are no technical issues that favor one or the other approach. Mainly it is a matter of choosing the authoritative source for your identity information and considering management, security, privacy, economic, and risk issues.
Regardless of the choice you make, the basic element for identity data integration is data flow. To architect an integrated and reliable identity infrastructure, several data flows must be implemented. Therefore in typical solution design you must determine:
� How does information flow between systems?� When does information flow between systems?� What data and schema transformations are required?
In the next section we discuss different topologies available for data flows.
Appl.SpecificDirectory
NTDomainDirectory
NotesNAB
HRDatabase
Enterprise directory
Bidirectionalentry and attributeflows
Emp No:1234Last Name: KentFirst Name: ClarkTitle: ReporterTel: 555-5555City: Metropolis…..
User Name: Clark Kent/MetropolisDomain: DailyPlanetMailServer: DPXXXXMail:[email protected]……
UserID: clarkkPassword: jf!9serverID: yy01Group: reporter….
ID: ckentPassword: jf!9Role: user
Last Name: KentFirst Name: ClarkTitle: ReporterReports to: Perry WhiteTel: 555-5555City: MetropolisnotesID: Clark Kent/MetropolisMail: [email protected]: jf!9…..
Chapter 3. Directory Integrator component structure 69

3.4.2 Base topologiesIn this section we present some topologies that can be used to architect more complex solutions. For every topology, we identify a data source, a flow, and a destination. In the following examples, each element is drawn in separate boxes. This is just a logical separation. From the physical point of view some of these elements might reside on the same machine. For instance, it is quite common to place a Directory Integrator server on the same machine as its data source. The decision of whether to use different servers depends only on performance and availability.
One-to-oneWe begin with the easiest scenario shown in Figure 3-9. Data exists in a file that must be synchronized, transformed, and maintained in a directory. This file could be updated regularly by an HR application or other enterprise systems.
Figure 3-9 One-to-one integration
A wide range of file formats can be accommodated for the input file. The selection on the file format is defined in the input Connector, mostly configured in Iterator mode. Different ways are available to manipulate and filter the input data stream, such as using the Parser or different scripting methods. A separate output Connector is established to the directory. Directory Integrator discovers the attributes in the file and enables mapping to attributes in the directory as well as applying transformation rules to modify the content of the incoming data.
The file can be read at regular intervals, or read whenever Directory Integrator discovers that it is available. The outside application may also trigger Directory Integrator to read the file at its own leisure.
Many-to-oneThe second scenario is shown in Figure 3-10 on page 71. Data exists in multiple related systems that have to be synchronized, transformed, and maintained in a directory. Different attributes of data must be joined before an update to the directory can take place.
DirectoryDirectoryIntegratorFile
70 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 3-10 Many-to-one integration
Connections are established to each data source using input Connectors. Schemas in databases are automatically detected. Rules may be created that describe how attributes from one source are used with attributes from other systems to create the desired results. Information from the data sources can be combined in any way and mapped to the directory. Administrators can select the authoritative source for each piece of information. Data from one system may be used to look up information in another.
IBM Tivoli Directory Integrator can detect changes in real-time within certain directories, allowing immediate update of other connected systems. Connections may be configured to look up only data that has been modified within a certain time frame, or data sets that conform to a specific search criteria.
One-to-manyA one-to-many scenario is the opposite of that described in the previous example. Information updated in one source is propagated to many destinations. Directory Integrator can perform exactly the same write, update, delete, and create modifications on all connected systems as it does for directories. The rules are simply adapted for the context. Now all systems can share the common authoritative data set.
In this third scenario, presented in Figure 3-11 on page 72, we introduce bidirectional flows. Bidirectional flows can be configured such that there is either only one authoritative data source for each piece of information or concurrent authoritative sources for the same data. In the second case the data in the directory is provisioned from multiple connected systems as well as from possible modifications done by applications connected to the directory. The connected systems could have great interest in this data, especially when Directory Integrator ensures that they always operate on the correct information by updating them whenever the authoritative data changes.
Directory
File
Database
e-mailDirectory
DirectoryIntegrator
Chapter 3. Directory Integrator component structure 71

By configuring the connectors, using Hooks and scripting, administrators can apply rules to define and monitor the flows. However, we recommend being careful with multiple data sources for the same piece of information. A good idea is to have only one point where specific data can be modified. This is not a technical issue, because Directory Integrator easily allows multiple data sources. It is a matter of implementing clear processes and data flows. On the other hand, it is common and often advisable to have sources for specific data on different systems. For example, in Figure 3-11, users could modify their e-mail address or preferences only in the e-mail database, while they could change their password only with an application that directly interacts on the Directory.
Figure 3-11 One-to-many integration
Other data resourcesThere are many reasons why data flows through channels such as message queuing, HTTP, e-mail, FTP, and Web Services. Data might need to pass through firewalls that block protocols like LDAP and database access. Security, high-availability, transactions control, and the desire for asynchronous or synchronous data transfer are other reasons.
It is important to understand that directory Integrator can both send and receive with these mechanisms. This creates a wide scope of solution opportunities, too wide to describe in simple use cases. Some examples are illustrated in Figure 3-12 on page 73.
Directory
File
Database
e-mailDirectory Directory
Integrator
72 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 3-12 Other data sources integration
3.4.3 Multiple serversIn the scenarios shown so far, there is only one IBM Tivoli Directory Integrator server. In this section we present some topologies with multiple server instances.
DistributedIn a distributed architecture, a single point of integration is often undesirable, for reasons such as distance, financial, security, availability or governance.
All of the mechanisms described previously, such as IP, HTTP, Web Services, e-mail, MQ and others can be used to communicate between instances of IBM Tivoli Directory Integrator.
In Figure 3-13 on page 74 the arrows indicate use of such communications mechanisms in two examples. In the first example the input stream is too fast compared to the business rules that IBM Tivoli directory Integrator has to execute and multiple instances can operate on a queue. In the second example a two-way architecture propagates updates in the directory to the rest of the enterprise and consolidates local modifications back to the central directory.
MQ
Main-frame
AIX
DirectoryMain-frame
Linux
Directory
.net
WebServicesWeb
Services
DatabaseDirectoryIntegrator
DirectoryIntegrator
Chapter 3. Directory Integrator component structure 73

Figure 3-13 Distributed integration
FederatedWhile similar to the distributed scenario, federated implies that control and management is not entirely centralized. This could be business units or entities that cooperate, but want to retain local control over how and what information is shared with others.
By sharing certain parts of the Directory Integrator configuration, Directory Integrator servers have access to shared transports, formats, and business rules.
The example scenario shown in Figure 3-14 on page 75 could be that different business units want to retain local control over information shared with others. Local configuration allows administrators to set restrictions on the data sets that are exposed, the attributes that are sent and received, as well as any local transformation rules that need to be applied to the data going to or coming from the other participants.
If a company is spread across multiple sites, it could be beneficial to have an IBM Tivoli Directory Integrator server in each location and then to have data flows only between these servers.
MQ
SourceSource
Source
Source
Directory
Source
DirectoryIntegrator
DirectoryIntegrator
DirectoryIntegrator
DirectoryIntegrator
DirectoryIntegrator
DirectoryIntegrator
74 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 3-14 Federated integration
The main message in this section is that IBM Tivoli Directory Integrator enables you to use any topology and different transport mechanisms to integrate data stored in various formats on multiple disparate systems.
In the following section we introduce another level of complexity by using multiple servers to implement high availability and increase performance.
3.5 Availability and scalabilityHigh availability means that the IT service is continuously available to the customer, as there is little or no downtime and rapid service recovery. The achieved availability can be indicated by metrics. The availability of the service depends on:
� Complexity of the infrastructure architecture� Reliability of the components� Ability to respond quickly and effectively to fault
There are several high availability mechanisms inside IBM Tivoli Directory Integrator on various levels from Connectors and AssemblyLines to the Server itself. Let us take a brief look at some of them.
Source
Source
Directory
SourceIP, HTTP, FTP, e-mail, MQ, Web services
Enterprise single sign-on
Applications Portals
Federated identity solutions
DirectoryIntegrator
DirectoryIntegrator
DirectoryIntegrator
DirectoryIntegrator
Chapter 3. Directory Integrator component structure 75

Automatic connection reconnectAssemblyLines need to access remote servers. Ideally, those remote servers should be online and available for the entire time the AssemblyLine is running. In the real world, however, server and network failures are common.
IBM Tivoli Directory Integrator has an automatic reconnect feature. This is sufficient for short term outages, where the AssemblyLine can just try to reconnect until it succeeds. You can configure this in the Connector’s Reconnect sub-tab as shown in Figure 3-15.
Figure 3-15 Automatic connection reconnect
The parameters you need to provide are:
� Auto reconnect enable - The master switch for the reconnect functionality for this Connector. Check to enable.
� Number of retries - The number of times the Connector will try to re-establish the Connection, once it fails. The default is 1. When the number of retries is exceeded, an exception is thrown.
� Delay between retries - The number of seconds to wait (in seconds) between successive retry attempts. The default is 10 seconds.
This also means that AssemblyLine Connectors have a new reconnect() method that can be called from your script as needed.
If a connection is lost, control passes to the On Connection Failure Hook if enabled. This Hook is available in all Connector modes. Once the Hook completes (or skipped if not enabled) the system then checks if Auto Reconnect has been enabled for this Connector. If it is, then this feature is invoked, otherwise control is passed to the Error Hooks as normal.
76 Robust Data Synchronization with IBM Tivoli Directory Integrator

Typical use of the On Connection Failure Hook is to write some message to the log, or even change Connector parameters, for example, pointing it to some backup data source. However, since reconnect may not be implemented for a Connector you are using, you can simulate reconnect yourself in the On Connection Failure Hook by terminating and then re-initializing the Connector with script code.
Directory Integrator enables the user to checkpoint the operation of AssemblyLines and restart them from the point where they were interrupted by either a controlled or uncontrolled shutdown through the Checkpoint/Restart framework.
Checkpoint/RestartCheckpoint/Restart is not supported in AssemblyLines containing a Connector in Server mode, an Iterator mode Connector with Delta enabled, an AssemblyLine using the Sandbox facility, or a conditional component like a Branch or Loop. The server will abort the AssemblyLine when/if this is discovered.
The Checkpoint/Restart framework stores state information and other parameters at various points during AssemblyLine execution, enabling the server to reinstate the running environment of the AssemblyLine so that it can be restarted in a controlled way. This can be on the original server, but potentially can also be on a different machine. The ability to restart an AssemblyLine is one of the building blocks for failover functionality.
See the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718 for more Checkpoint/Restart details.
Note: If you do not want the Connector to Auto Reconnect after invoking the On Connection Failure Hook, you must either disable Auto Reconnect, or redirect flow by throwing an exception (with calls like system.retryEntry() or system.skipEntry()) or by stopping the AssemblyLine itself with system.abortAssemblyLine( message ).
Note: IBM Tivoli Directory Integrator is not a system that provides general failover functionality straight out-of-the-box. Rather, it has a framework that provides generic building blocks for this kind of functionality, and can in this way reduce the amount of hand-coding that might otherwise be required. Be aware, though, that the framework does not implement full checkpoint and restart functionality at the click of a mouse. Some thought as to how it is applied to the business problem at hand is essential.
Chapter 3. Directory Integrator component structure 77

Failover Services (FoS)Failover Services is an error management mechanism for IBM Tivoli Directory Integrator components. It enables the monitoring of AssemblyLine execution and allows the Administration and Monitor Console (learn more on the AMC in 3.7, “Administration and monitoring” on page 84) administrator to set up alternate actions to be performed on the detection of component failure. You can see an example setup window in Figure 3-16.
Figure 3-16 FoS setup
For more FoS details see the IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1718.
Automatic high availabilityThe basic concept of high availability is to have at least two servers capable of performing the same job and a fail-over mechanism to switch from one server to the other if one of the servers fails.
IBM Tivoli Directory Integrator does not provide such fail-over mechanism out-of-the-box. Therefore, one way to provide automatic high availability is to implement an architecture as shown in Figure 3-17 on page 79, where one IBM Tivoli Directory Integrator Server instance is configured to watch the other just-in-case and can take over if the second one fails to respond.
78 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 3-17 Just-in-case high availability
The other possible way of high available automatic failover mechanism is to install the server in a cluster environment such as HACMP™ for AIX as shown in Figure 3-18.
Figure 3-18 Clustering
However, remember that all AssemblyLine definitions and configurations are stored within one highly structured XML file called Config. Therefore, if one server fails, it is sufficient to start a separate server with the same Config file in order to continue the service. IBM Tivoli Directory Integrator’s main goal is to perform data integration, not real-time services. This means that a short period of unavailability (for example, for maintenance reasons) can be tolerated in most cases.
A fail-over mechanism must be configured between the two servers, depending on functional requirements of the data integration environment.
Scalability is a strong feature of IBM Tivoli Directory Integrator. There is virtually no limit to the number of servers that can be added. As it was already shown on Figure 3-13 on page 74, different servers can work on different data flows or on different data of the same data flow.
TargetSource
DirectoryIntegrator
DirectoryIntegrator
TargetSource
DirectoryIntegrator
DirectoryIntegrator
Chapter 3. Directory Integrator component structure 79

Considering the AssemblyLine mechanisms, no additional effort is required to integrate multiple servers. Each AssemblyLine is designed to work on different data. Different AssemblyLines integrate different data sources regardless of whether these AssemblyLines reside on the same server or on multiple servers.
AssemblyLine PoolWith AssemblyLine Pool you can build high performance solutions that won’t incur connection costs to the target systems for each processed event. Also, the AssemblyLine pool will automatically enable an AssemblyLine to service a number of simultaneous requests, and not execute the requests serially. You can configure Pool options from the Show Dialog button next to the Define ALPool Options on the Config tab of an AssemblyLine as shown in Figure 3-19.
Figure 3-19 AL Pool
The parameters you need to provide are:
� Number of prepared instances - How many instances of the Flow part of this AssemblyLine to instantiate, power up and then keep in the Pool, ready for use.
� Maximum concurrent instances - What is the maximum number of current Flow instances that you want created at any one time.
See the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718 for more ALPool details.
3.6 LoggingIBM Tivoli Directory Integrator enables you to customize and size logs and outputs. It relies on log4j as a logging engine. Log4j is a very flexible framework
Note: pooling is only available if you have a Server mode Connector in the Feeds section of your AssemblyLine.
80 Robust Data Synchronization with IBM Tivoli Directory Integrator

that lets you send your log output to a variety of different destinations, such as files, the Windows EventLog, UNIX Syslog, or a combination of these. It is highly configurable and supports many different types of log appenders and can be tuned so it suits most needs. It can be a great help when you want to troubleshoot or debug your solution. In addition to built-in logging, script code can be added in AssemblyLines to log almost any kind of information. If the logging functionality will not suffice, then there are additional tracing facilities.
The log scheme for the server (ibmdisrv) is described by the file log4j.properties and elements of the Config file, while the console window you get when running from the Config Editor (ibmditk) is governed by the parameters set in executetask.properties. Logging for the Config Editor program itself is configured in the file ce-log4j.properties.
You can create your own appenders to be used by the log4j logging engine by defining them in the log4j.properties file. Additional log4j compliant drivers are available on the Internet, for example, drivers that can log using JMS or JDBC. In order to use those, they need to be installed into the IBM Tivoli Directory Integrator installation jars directory after which appenders can be defined using those additional drivers in log4j.properties.
Configuring the logging of IBM Tivoli Directory Integrator is done globally using the files log4j.properties and/or External Properties or specifically, using the ibmditk tool, for each AssemblyLine, EventHandler, or Config File as a whole. Logging for individual AssemblyLines and EventHandlers is applied in addition to any specification done at the Config level.To provide this level of flexibility and customization, the Java log4j API is used.
All log configuration windows operate in the same way: For each one you can set up one or more log schemes. These are active at the same time, in addition to whatever defaults are set in the log4j.properties and executetask.properties files. In Figure 3-20 on page 82 you can see an example of the Syslog scheme, which enables IBM Tivoli Directory Integrator to log on UNIX Syslog.
Note: Any of the aforementioned properties files can be located in the Solutions Directory, in which case the properties listed in these files override the values in the file in the installation directory.
Chapter 3. Directory Integrator component structure 81

Figure 3-20 Syslog scheme
See the IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1716 for details on schemes configuration.
Key data is logged from the Directory Integrator engine, from its components (Connectors, Parsers, and so on), as well as from user’s scripts. Almost every Connector has a debug parameter called Detailed Log, with which you can turn on and off the Connector’s output to the log file. Seven log levels range from ALL to OFF for sizing the output. ALL logs everything. DEBUG, INFO, WARN, ERROR and FATAL have increasing levels of message filtration. Nothing is logged on OFF.
In order to augment the IBM Tivoli Directory Integrator built-in logging, you can create your own log messages by adding script code in your AssemblyLine. Different information can be dumped, such as the content of an object or attribute, the state of a Connector, or any desired text. This means that you can indicate to the log file or to the console any state of the custom logic of your AssemblyLines. See the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718, for logging details and examples.
Note: IBM Tivoli Directory Integrator logmsg() calls log on INFO level by default. This means that setting loglevel to WARN or lower silences your logmsg as well as all Detailed Log settings. However, the logmsg() call also has a level parameter that can be used to override the log level for individual logmsg() calls.
82 Robust Data Synchronization with IBM Tivoli Directory Integrator

DebuggingIn addition, IBM Tivoli Directory Integrator offers you a Flow Debugger (not to be confused with a script debugger). The Flow Debugger lets you step through your AssemblyLines and examine and change variables and/or run script directly. An example of Flow Debugger usage is shown in Figure 3-21.
Figure 3-21 Flow Debugger
The debugger is started from the Config Editor by clicking the Run Debugger button from the AssemblyLine or EventHandler detail window. Once the selected task is started, the debugger pauses processing at specified breakpoints. Whenever execution is paused, you can use the Evaluate button to display information or run script. There is also an Edit watch list button that offers you the same option, however the resulting watch-list is remembered and evaluated at
Note: Errors from Attribute Map Components do not show the name of the Attribute Map Component, only the name of the AssemblyLine, and often (depending on the error), the name of the attribute being mapped. The message will often contain the name of the attribute that is mapped, which should give you a hint as to which Attribute Map it is that fails.
Chapter 3. Directory Integrator component structure 83

each breakpoint. One example of a variable you might want to watch is work (the work Entry object). By entering work in the Evaluate dialog, or adding it to your watch-list, you can see work serialized to the Output pane of the debugger.
TracingIn addition to the user-configurable logging functionality described in previous section, IBM Tivoli Directory Integrator is instrumented throughout its code with tracing statements, using the JLOG framework, a logging library similar to log4j, but which is used inside Directory Integrator specifically for tracing and First Failure Data Capture (FFDC). To which extent this becomes visible to you, the end user, depends on a number of configuration options in the global configuration file jlog.properties, and the Server command line option -T.
Tracing is done in using JLOG’s PDLogger object. PDLogger or the Problem Determination Logger logs messages in Logxml format (a Tivoli standard), which IBM Support understands and for which they have processing tools.
See the IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1716 for tracing details, configuration and parameters.
3.7 Administration and monitoringConfig Editor is a program that gives you a graphical interface to create, test and debug any AssemblyLines with all the components and the optional scripting. It is an Integrated Development Environment (IDE), introduced in 3.2, “Base components” on page 45, used to create a configuration file that describes your solution, and is powered by the runtime Server. This configuration is called a Config, hence the name Config Editor. The Config Editor is started by initiating the ibmditk batch-file or script, which sets up the Java VM environment parameters and then starts the Config Editor. It enables you to work with multiple Configs at the same time. Configs are stored as highly structured XML documents and can be encrypted. When you start the Config Editor, either from your system’s launch interface or from the command line with the ibmditk
Note: If you evaluate (or watch) the script task.dumpEntry(work), then the work Entry is dumped to the log output pane instead, just as though you had this code in your solution.
Note: Normally, you should be able to troubleshoot, debug and support your solution using the logging options. However, when you contact IBM Support for whatever reason, they may ask you to change some parameters related to the tracing functionality described here to aid the support process.
84 Robust Data Synchronization with IBM Tivoli Directory Integrator

command you will see the Main Panel. In the default layout, using the Cards layout, the left navigation pane provides a tree view of the current configuration, as well as all the current AssemblyLines, EventHandlers, Connectors, and so forth as shown in Figure 3-22. AssemblyLines can be created easily by selecting components. The Attributes definition in the connected elements is automatically discovered and mapping can be done simply by dragging or renaming attributes.
Figure 3-22 Config editor main panel
See the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718, for details on Config Editor.
When the AssemblyLines are ready and the integration solution is deployed, administration and monitoring can be performed.
Once the integration solution is in maintenance mode, operators need to be able to run AssemblyLines manually. One option is to give operators access to the Config Editor. However, since operators should not modify AssemblyLines, this option violates the principle of least privilege. Another possibility is to let
Chapter 3. Directory Integrator component structure 85

operators run AssemblyLines from the command line. However, unless they need shell access for a different reason, this also violates the principle of least privilege. Also, remembering the commands are not user friendly. The Administration and Monitor Console (AMC2) is an application for the remote administration and monitoring of IBM Tivoli Directory Integrator servers, which allows operators to only perform the actions they are allowed to do, and to do so from a user friendly Web browser environment.
AMC2 is using the Remote Server API, Java Server Pages, and Apache Struts. In addition to AssemblyLines monitoring, SSL support, TCB (trusted computing base) awareness, Log files cleanup, Console users management, and configuration changes, you may also set up connections to multiple IBM Tivoli Directory Integrator server instances and configuration files running on them.
AMC2 communicates with IBM Tivoli Directory Integrator servers over SSL using the Java Security Extensions. It is pre-configured to work with the server that it is bundled with. In order to use AMC2 with servers that use other certificates than the one they were shipped with, the server certificates need to be added to the AMC2 truststore, and the AMC2s certificate needs to be added to the server truststores.
AMC2 permissions are assigned per Config. This enables IBM Tivoli Directory Integrator to enforce a separation of roles even when the same server is used for multiple purposes in the organization. For example, a server might be used to synchronize both user accounts and office supply information. If you put all the AssemblyLines related to users in one Config and all the AssemblyLines related to office supplies in another, then operators can have permissions to one but not the other.
There are three permission levels in AMC2:
� Read - This means read\u2013only permission. The user cannot change anything or run anything. This level is useful for auditors and operators in training.
� Execute - This level allows users to execute AssemblyLines and EventHandlers, and view and delete the resulting logs. However, users with execute permissions are not allowed to modify or delete any components or component properties. This permission level is for operators.
Note: The principle of least privilege states that users should only be given those permissions they need to do their jobs. For example, operators who do not need to change IBM Tivoli Directory Integrator AssemblyLines should not be allowed to do it.
86 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Admin - This level allows full control of IBM Tivoli Directory Integrator, similar to the control available through the Config Editor.
A sample of user to Config mapping is shown in Figure 3-23:
Figure 3-23 AMC2 user to Config mapping
See the IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1716 for details about AMC2 files, setup and configuration.
3.8 ConclusionIn this chapter we introduced the architecture and components of Tivoli Directory Integrator that can be used to integrate and reconcile data across multiple repositories on different platforms. Directory Integrator focuses on data rather than users, and it solves the complex integration challenges by breaking them into separate, modular, and scalable pieces.
IBM Tivoli Directory Integrator enables you to create a consistent infrastructure of enterprise identity data, while permitting local administrators to manage users on each platform and environment with their traditional tools.
Note: The Administration and Monitor Console (v.2) has been included in IBM Tivoli Directory Integrator 6.0 and is fully supported but provides only a US English interface.
Chapter 3. Directory Integrator component structure 87

88 Robust Data Synchronization with IBM Tivoli Directory Integrator

Part 2 Customer scenarios
In part 2 we provide two solution oriented scenarios with technical hands-on details.
Part 2
© Copyright IBM Corp. 2006. All rights reserved. 89

90 Robust Data Synchronization with IBM Tivoli Directory Integrator

Chapter 4. Penguin Financial Incorporated
This chapter examines the business requirements, functional requirements, solution design and implementation phases for a typical directory synchronization scenario brought about by the merger of two financial institutions.
4
Note: All names and references for company and other business institutions used in this chapter are fictional. Any match with a real company or institution is coincidental.
© Copyright IBM Corp. 2006. All rights reserved. 91

4.1 Business requirementsMonolithic Financial, a 108 year old full services financial institution located in Bangalore India, has agreed to be acquired by Penguin Services, a 12 year old Tulsa Oklahoma based Internet financial services firm.
The announcement was preceded with a multi- million dollar advertising campaign touting the new organizations name of Penguin Financial with a motto of “We can lend anything to anybody”. The industry analysts while favorable with the merger, questioned how long it would take for the two companies with vastly different backgrounds, infrastructure and philosophy could be merged together to provide a full suite of services to the general public. To silence the critics, Danny Gooch, founder and CEO of the new company publicly touted the deployment of a new full services banking application that would be available for general use within 12 months. This new application would finalize the merger of the two organizations.
At a press conference, Gooch was quoted as saying that the best and the brightest from both organizations have been brought together to successfully integrate the two organizations. When asked by the press how would anybody be able to be founds within the new company, he stated that all individuals within the new company would be able to be reached by a single e-mail address. He also boosted that the new company would actually be able to reduce expenses by allowing end users to use a Web page to manage their own identity information. His final boast before entering his car was that they would even have synchronized passwords across the organization which would further lower user calls to the help desk by the time the merger was complete.
The information technology synchronization team has been tasked with:
1. Developing a synchronized LDAP based directory for use with the new application. The directory must reflect real-time changes from both organizations existing infrastructure.
2. Creating a single e-mail account for all employees.
3. Reducing the expected increase in help desk support costs, by providing for users to update user information via the Web.
4. Providing a corporate security policy that can be applied across a new company.
4.1.1 Current architectureThe current challenges of this business scenario are depicted in Figure 4-1 on page 93.
92 Robust Data Synchronization with IBM Tivoli Directory Integrator

User account information is distributed across two different user repositories. Account information across these systems may not be consistent all the times. Users have to keep track of passwords across multiple systems. New users added to Active Directory will have to be added manually into the Lotus Domino server.
Figure 4-1 Current banking scenario
4.2 Functional requirementsWe extract functional requirements by mapping business requirements to their underlying reasons. We then expand the reasons in increasing detail. Our functional requirements will tie these low level reasons for a business
Domino server
Active Directory
Company A(Penguin Financial)
Company B(Monolithic Financial)
Current situationCompany A has acquired Company BCompany A uses Lotus Domino and Company B uses Active Directory
ProblemsIssues in deploying a new banking application across different systems.Company A and Company B use different e-mail mechanisms.Account information for same user across different systems has to be updated manually.Users have to keep track of passwords in different systems
Chapter 4. Penguin Financial Incorporated 93

requirement to the IBM Tivoli Directory Integrator capability that will fulfill that business requirement.
Let us examine every business requirement, and search for reasons and the functional requirements:
Following are the functional requirements based on the business case.
� Business requirement 1: Enable a synchronized LDAP directory for use with the new application.
After the acquisition there are two user repositories - Active Directory for users acquired from Monolithic Financial and Domino for Penguin Financial users. Development costs for a new full services banking application are expected to be high because access control in the new application needs to be coded for users based on source user repository with no cross-reference information between repositories.
With an enterprise directory in place, users can modify their own account information like password, phone numbers, address, and so on. This enterprise directory will be accessed using a centralized Web portal with a consistent user interface, thereby providing a consistent and simple to use user experience irrespective of where the account is located.
This leads to our first functional requirement shown in Table 4-1.
Table 4-1 Functional requirement for an enterprise directory
The user account information has to be kept in synchronization across all attached systems that store any user related information.
Table 4-2 Functional requirement for synchronization
� Business requirement 2: Provide a single e-mail account for all employees.
After the merger the users cannot be addressed by a single consistent e-mail address. Moreover, these disjunct e-mail accounts split across different mail systems do not relay an impression of a single large company.
All users in Active Directory need to retain their account and will also be given a new Lotus Domino account. The original users in Lotus Domino need not have an Active Directory account.
Requirement Description
A All users are to be integrated into one common user repository - an LDAP based enterprise directory.
Requirement Description
B User information must be in synchronization across all the systems.
94 Robust Data Synchronization with IBM Tivoli Directory Integrator

Table 4-3 Functional requirement for unified mail system
� Business requirement 3: Reduce the expected increase in help desk support costs by providing users with the ability to update user information via the Web.
The challenge for this situation are the new users from the acquired Monolithic Financial environment, because based on functional requirement C they are receiving new accounts for the Lotus Domino mail system and multiple logins inevitably lead to multiple calls for password resets, which are typically the largest percentage of help desk calls, thus help desk support costs will increase. Users are less likely to forget their passwords if they use the same synchronized password for all of their accounts.
The new self-service portlet within the services banking application can reduce the burden on system administrators by delegating the ability to request password resets to the endusers. Regular password change and synchronization can also be achieved via the portlet, which is intercepted by IBM Tivoli Directory Integrator to synchronize the password with both target systems - Microsoft Active Directory and Lotus Domino.
This leads to the next functional requirement shown in Table 4-4.
Table 4-4 Functional requirement for password synchronization
Another expected side effect for Monolithic Financial users is that user productivity and satisfaction is lowered because they have to log into the Domino mail system separately in order to be productive.
Based on functional requirement D, users will only need one password for all involved systems.
We can even go one step further and allow users from Monolithic Financial to keep changing their user password the common and convenient way they used to do it - by using the Windows ctrl+alt+del mechanism.
This leads to the next functional requirement shown in Table 4-5 on page 96.
Requirement Description
C All Active Directory users receive a new Lotus Domino server e-mail account.
Requirement Description
D All users can change and synchronize their passwords via a centralized single self-service portlet.
Chapter 4. Penguin Financial Incorporated 95

Table 4-5 Functional requirement for Windows password change
� Business requirement 4: We have to provide a password related corporate security policy that can be applied across a new company.
The existing Penguin Financial security policy will be expanded to all new systems including new applications, Enterprise Directory systems, password synchronization solutions, Windows password change mechanism, and so on.
The password synchronization solution based on functional requirements D and E can satisfy all corporate security policy requirements, including the ones listed below, though special attention to password related parts from the existing security policy is required:
– Password policy defining password history, complexity, minimum and maximum password age and minimum password length is enforced.
– Absolutely no passwords are to be stored and maintained outside of their native password stores at any time.
– Passwords are always encrypted when sent over the network and/or public key infrastructure technology is used, preferably both.
This leads to additional functional requirements listed in Table 4-6.
Table 4-6 Functional requirements for corporate security policy
This concludes the functional requirement analysis and allows us to begin designing our technical solution.
4.3 Solution designIn this section we discuss how solution design objectives can be realized using IBM Tivoli Directory Integrator. Our goal is to produce an implementation plan
Requirement Description
E Monolithic Financial users can change and synchronize their password via the common Windows mechanism.
Requirement Description
F Password policy is enforced at all times.
G Passwords are not stored and maintained outside of their native stores.
H PKI and/or encryption technology is used for passwords sent over any network.
96 Robust Data Synchronization with IBM Tivoli Directory Integrator

containing a phased set of implementation steps where the end result satisfies all functional requirements, and therefore also satisfies the original business requirements.
While business and functional requirements are the main parts of the design objectives, we also have to consider other nonfunctional requirements and constraints. These may include objectives that are necessary to meet general business requirements, or practical constraints on constructing sub-systems. IBM Tivoli Directory Integrator implementations often involve nonfunctional requirements relating to:
� High availability and failover
� Maintainability and configuration management
� Logging and auditing
� Archiving and backup
� Security
� Monitoring
Because we focus on the architecture of directory synchronization with IBM Tivoli Directory Integrator software in this book, we do not look in detail at all of these nonfunctional requirements.
The steps involved in producing an implementation plan are:
1. Prioritize the requirements.
2. Map the requirements to IBM Tivoli Directory Integrator features.
3. Define the phases involved in using those features to satisfy the requirements.
Prioritizing the requirements is important because the priorities are one of the primary factors used to define phases of the project. It is rare that a directory synchronization solution can be created as a single deliverable satisfying every requirement. It is far more likely that it will be delivered in phases, and the highest priority requirements should be addressed in the earliest phases.
Assigning priorities to the requirements is often difficult because they are all important. You can more easily compare the priorities of requirements by asking questions that gauge the positive and negative impacts of the requirements:
� How much money can be saved when the requirement is met?
� Are there penalties if the requirement is not met?
� Is there a date by which the requirement must be met?
� Are there other requirements with dependencies on this one?
Chapter 4. Penguin Financial Incorporated 97

After mapping the requirements to IBM Tivoli Directory Integrator features, the requirement priorities and dependencies can be used to decide how to break up the project into phases.
Figure 4-2 on page 99 shows the big picture of the solution design.
IBM Tivoli Directory Server is used as the enterprise directory. IBM Tivoli Directory Integrator takes care of user information provisioning and synchronization across different data sources and targets including password synchronization.
98 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-2 Solution design
Domino server
Active Directory
Lotus Portal Web Application
4. ITDI
IBM Tivoli Directory Server
3. ITDI
2. ITDI
User updates selected attributes and password
Company A(Penguin Financial)
Company B(Monolithic Financial)
ITDI PasswordCatcher
ITDI PasswordCatcher
5. ITDI bi-directional password sync
Scenario description:Company A has acquired Company B1. Company A uses Lotus Notes and Company B uses Active Directory2. Add Company B users to Corporate Directory3. Add Company B users to Domino Server4. Add company A user to Corporate Directory5. Allow for password sync from AD and Portal App which uses ITDS to AD, ITDS and Domino.6. Allow for selected attribute sync from Portal App to Active Directory and Lotus Notes.
Topics covered:· Basic Data Sync (e.g. home phone to/from Corp LDAP to Notes/AD)· Active Directory Changes· Tivoli Directory Server Changes· Domino Changes· Directory Server connector (Tivoli Directory Server to/from AD)· Notes connector· ITIM agent connection (Tivoli Directory Server to Domino Server)· Schema Mapping· Bi-Directional Password Sync· Debugging/Troubleshooting· Unique Names· Connector modes used: Update, Lookup, Iterate
5. ITDIpassword sync
6. ITDI
6. ITDI
ITIM: IBM Tivoli Identity ManagerITDI: IBM Tivoli Directory IntegratorITDI: IBM Tivoli Directory Server
Chapter 4. Penguin Financial Incorporated 99

Project phasesBy analyzing the business requirements again, after the functional requirements have been extracted in 4.2, “Functional requirements” on page 93, it is evident that there is some dependency between individual business requirements. Based on this, and the complexity involved with the use of multiple data sources and synchronization of user passwords across these systems, we have decided for the project to be implemented in two phases:
� Phase 1: User Integration
In the first phase we integrate user account information including user creation and modification.
� Phase 2: Password synchronization
The goal of this phase is to implement password synchronization based on Penguin Financial requirements and policies.
4.3.1 Architectural decisions for phase 1In this section we discuss the architectural decisions made for phase one. In our scenario we have three different data sources as shown in Table 4-11 on page 108. There are multiple ways to establish connections to these data sources.
Change detectionFor detection of changes in Active Directory we use the Active Directory change log Connector. For detection of changes in Tivoli Directory Server we use the IBM Tivoli Directory Server change log Connector. For detection of changes in the Domino server we use the Domino change detection Connector. The Domino change detection Connector must be deployed on a Windows system where a Lotus Notes client is installed. However, the Connector can connect to Domino server on all platforms.
User registrationUser creation in Domino Server consists of two parts: Creation of a user account and registering this user with the Domino Server. Creation of users in Domino Server can be done using the LDAP connector in update mode, but this connector would not be able to register the users with the Domino Server. User registration can be achieved in two ways, by using the Directory Integrator Domino Users Connector or by using the Identity Manager Agent Connector. In order to use the Domino Users Connector requires Tivoli Directory Integrator to be installed on the same system where your Domino Server is running. This involves working directly on systems that are already deployed in production. Many companies, including Penguin Financial, would not prefer this. So we will
100 Robust Data Synchronization with IBM Tivoli Directory Integrator

use the Identity Manager Agent Connector in our solution to create and update users on our Domino Server.
Because of the above mentioned reasons we will develop and deploy phase one of our solution on a separate Windows based system.
4.3.2 Architectural decisions for phase 2This section explains our architectural decisions made for phase two based on the Penguin Financial requirements and Directory Integrator capabilities.
After analyzing the Penguin Financial functional requirements from 4.2, “Functional requirements” on page 93, the following architectural topics related to Directory Integrator capabilities emerged for consideration:
� Password policy� Password store� Loop conditions� Password security
Let us discuss these topics and their related architectural decisions.
Password policyFunctional requirement F is not a real issue. It is related to settings we have to apply outside of IBM Tivoli Directory Integrator, namely in Active Directory to be aligned to the existing password policy in the Penguin Financial environment.
As we intend to implement the Password Synchronizer on Active Directory, we have to implement the password complexity part of our password policy anyway for the Password Synchronizer to work.
We can take advantage of the minimum password age part of the password policy to solve Loop condition issues described later in our timestamp approach part.
Password storeIn “Password Stores” on page 177 we explain the difference between LDAP and MQe password stores in more detail, but related to functional requirement G, it is important to distinguish between a permanent store LDAP is using for passwords and the message queue mechanism MQe is using for temporary password storage.
This leads to our first architectural decision shown in Table 4-7 on page 102, that MQe is used as the password store.
Chapter 4. Penguin Financial Incorporated 101

Table 4-7 Architectural decision for password store
The remaining question to answer is: how many password stores are used? Based on functional requirements D and E, there are two sources of password change, thus there are two password stores. We can use separate password stores for each source or only one password store for both password sources.
Considering the possibility of inconsistency of password changes, if handled separately for reasons such as time synchronization problems, separate AssemblyLines, difficult control and handling, and so on, it is best to use only one common password store and aggregate all password changes at one place.
This leads to our second architectural decision shown in Table 4-8, that a common password store is used for reliability reasons.
Table 4-8 Architectural decision for password store
Loop conditionsA reason for possible loop conditions in our password synchronization scenario are both functional requirements D and E when combined. In that case we have two password change sources and three possible targets; two of them being sources at the same time.
For example, when a user changes a password in Active Directory, password synchronization is triggered and the password is updated in Domino and the enterprise directory. A change in the enterprise directory now triggers a new password synchronization process to update the password in Domino and Active Directory, the initial source, and the loop is closed.
Decision Description
MQe is used as the password store mechanism.
MQe is defined as the password store for security reasons.
Note: From an architectural perspective it is important to keep in mind that the FIFO (first-in-first-out) rule applies for entries when using message queuing.
Decision Description
One Password store exists. A common password store is used for reliability reasons
Note: Active Directory is not a password synchronization target for original Penguin Financial users.
102 Robust Data Synchronization with IBM Tivoli Directory Integrator

There are several approaches to solve this problem:
� External password store
When using LDAP as an external password store, you can build not just very scalable and replicable solutions but also very flexible by storing additional information in it, which you can use to compare sources, targets, passwords, timestamps and so on and thus break the loop.
Based on our password store discussion, this approach is not an option in the situation with Penguin Financial.
� Flags
Flags are common in bidirectional password synchronization using MQ. The theory behind using flags is alternating behavior; in one direction an update is allowed and a flag is set to mark the change, thus the update in the opposite direction is not allowed, but the flag is reset and the flow ends.
The problem with flags can be consistency, because any repeated password change before a flag can be reset is skipped. For example, if a user changes the password twice in a row, the second password change might be skipped if the first one is still in progress and the flag has not been reset yet.
� IBM Tivoli Directory Server internal mechanism
IBM Tivoli Directory Server, used in phase 1, checks internally if a new value for an attribute differs from the old one. This feature can be used for password comparison. In theory, there will be a maximum one and a half loops before the flow will stop. If the source of password change is Active Directory, the first password change is propagated to Directory Server, then back to Active Directory, and once again to Directory Server.
The problem here is similar to the flags if MQ is used. Any new password change during the initial update process is ignored and the final state is inconsistent.
� Timestamps
Timestamps are very useful for time comparison of events. If there is a policy in place such as minimum password age, then based on time difference between two password changes, we can distinguish user based and process based password changes.
The minimum password age setting parameter in Windows is defined in days and the minimum setting is one day. Password processing in IBM Tivoli Directory Integrator occurs in moments, thus any password change for the same user in a time less than the minimum password age can only be process internally.
This leads to our third architectural decision as shown in Table 4-9 on page 104. Timestamp is defined and used for breaking loop conditions.
Chapter 4. Penguin Financial Incorporated 103

Table 4-9 Architectural decision for loop conditions
Password securityFunctional requirement H has many side effects, because of a wide influence from password handling to network architecture and server configuration.
First we have to check what components we need, what are the security capabilities of these components and are there are any special requirements for their usage. Second we have to determine if we can satisfy at least the minimum requirements.
The password synchronization process encompasses two areas, the actual password store and the AssemblyLine that implements the data flow (more details are revealed later in 4.5.4, “Plan the data flows” on page 190):
1. Password store
The functionality of a password store is explained in more detail in “Password Stores” on page 177, but related to our architectural concerns it is important to emphasize that all communication needs to be encrypted.
2. AssemblyLine
The AssemblyLine picks up the password from the password store and sends it to a target for update. We have to investigate three targets for password updates:
– Active Directory
SSL is required to send an updated password to Active Directory. The configuration for our scenario is described in 4.5.6, “Instrument and test a solution” on page 200.
– IBM Tivoli Directory Server
See “Secure Sockets Layer Support” in Chapter 2 of the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718 for details on IBM Tivoli Directory Integrator configuration as an SSL client or server.
– Domino
A Domino HTTP password can be encrypted using Domino’s encryption routines. The configuration for our scenario is described in 4.5.6, “Instrument and test a solution” on page 200.
After a short components analysis, our conclusion is that we can satisfy all minimum security policy requirements for all used components either using SSL or encryption.
Decision Description
Timestamp is defined. Timestamp is used to break loop conditions.
104 Robust Data Synchronization with IBM Tivoli Directory Integrator

To make life easier, we can deploy IBM Tivoli Directory Integrator on our new enterprise directory server. In this particular configuration there is no need to configure an SSL communication link with IBM Tivoli Directory Server running on the same server.
This leads to our final architectural decisions shown in Table 4-10. IBM Tivoli Directory Integrator is located on our enterprise directory server in order to reduce the solution complexity, SSL is used for password updates to Active Directory, and password updates to Domino are encrypted.
Table 4-10 Architectural decision for password security
The final password synchronization architecture at Penguin Financial based on our business and functional requirements as well as our architectural decisions is shown in Figure 4-3 on page 106.
Decision Description
IBM Tivoli Directory Integrator is located on enterprise directory server.
Complexity is reduced as there is no need for SSL encryption when communication is local.
SSL is used for Active Directory updates. SSL is required by Active Directory.
Encryption is used for Domino updates. Using Domino encryption routines there is no need for SSL to satisfy minimum functional requirements.
Chapter 4. Penguin Financial Incorporated 105

Figure 4-3 Final password synchronization architecture
4.4 Phase 1: User integrationThe goal of this phase is to create an enterprise directory, and keep the user account information in synchronization across various data sources.
Portal self-service Application
Domino
CTRL+ALT+DELActive
Directory
IBM Tivoli Directory
Server
IBM Tivoli Directory Integrator
PasswordStorage
PasswordSynchronizer
PasswordStore
PasswordStoreEncryption
PasswordUpdate
(encrypted)
PasswordUpdate(SSL)
PasswordUpdate(local)
Enterprise Directory
Domino Directory
Active Directory
Passwordchange
Passwordchange
PasswordSynchronizer
106 Robust Data Synchronization with IBM Tivoli Directory Integrator

This phase contains the following sections:
� Detailed data identification� Planning the data flows� Instrumenting a solution
4.4.1 Detailed data identificationThe authoritative source for user accounts at Monolithic Financial is the Microsoft Windows 2000 server with Active Directory. User accounts at Penguin Financial are located on a Lotus Domino Server. IBM Tivoli Directory Server will be used to create a centralized enterprise directory and to allow user modification through a self-care Portal application. Table 4-11 on page 108 depicts all data sources involved in this phase. Each server in the figure represents one physical system. The Lotus Domino Server and the Tivoli Directory Server may reside on any hardware/OS platform that these products are supported on, Active Directory has to run on a Microsoft Windows Server platform. In all the three cases the user account information is the data we are interested in.
The access mechanism is the mechanism that will be used by Tivoli Directory Integrator to access the data from our data sources. There are different ways in which you can access data using Tivoli Directory Integrator. For example, to access data from a Domino Server you can use the LDAP protocol (used by the LDAP Connector), HTTP and IIOP (used by Notes Connector), or JNDI with DAML (used by the Identity Manager Notes Agent Connector).
In a Windows domain context, sAMAccountName is an attribute unique to each user. It is used to check the uniqueness of a user account. NotesFullName is an attribute unique to Domino server and it is used to check the uniqueness of a user in Domino Server. We will create a new unique attribute called uid, which will be used to maintain the uniqueness of all user accounts in Tivoli Directory Server. The uid is created whenever a new user is added to our enterprise directory from either Windows Active Directory or Domino Server. Further details on uid are discussed in the next section.
Today there are different system administrators responsible for each of these systems. Privileges for adding or updating user accounts is limited to these administrators. Additionally, individual users can update or modify their personal information. For our solution we create an additional user called IDI Admin. It will be used by Tivoli Directory Integrator and will have the required privileges for adding, deleting, and updating user accounts on all relevant data sources.
Note that the Portal application is not shown in this table. The development and deployment of a Portal application is out of the scope of this book. For the purpose of updating and viewing user information stored in the enterprise
Chapter 4. Penguin Financial Incorporated 107

directory (Tivoli Directory Server) any commonly available LDAP browser may be used.
Table 4-11 Data sources
Domino Server
Description Contains user accounts of Penguin Financial
System pf-usmai01
Domain penguin-fin.com
Data User account information
Unique data “NotesFullName” - this attribute is unique for all the users in the domain
Data storage Domino directory
Access mechanisms LDAP, Identity Manager Agent, Notes client
Windows 2000 Server with Active Directory
Description Contains user accounts of Monolithic Financial
System mf-root1
Domain monolithic-fin.com
Data User account information
Unique data “sAMAccountName” - this attribute is unique for all the users in the domain
Data storage Microsoft Active Directory
Access mechanisms LDAP
Tivoli Directory Server
Description Contains aggregated user information from Active Directory and Domino Server
System pf-used01
Data User account information
Unique data “uid” - this attribute is unique for each user and is created whenever a new user is added to Tivoli Directory Server
Data storage LDAP DB2
Access mechanisms LDAP
108 Robust Data Synchronization with IBM Tivoli Directory Integrator

In the following Table 4-12 we list all the attributes that will be updated and synchronized in our solution. Note that this list is a small subset of available attributes that can be mapped using Tivoli Directory Integrator.
Table 4-12 Attributes used in our solution
Attribute names for some of the attributes are blank. This means these attributes are not used in the respective connectors by our solution.
Attribute Attribute name used with Active Directory Connector
Attribute name used with Tivoli Directory Server Connector
Attribute name used with Identity Manager Notes Agent Connector
Distinguished name
dn $dn $dn
Common name cn cn -
First name givenName givenName erNotesFirstName
Surname or last name
sn sn erNotesLastName
E-mail address mail mail erNotesInternetAddress
Title title title erNotesTitle
Phone number telephoneNumber telephoneNumber erNotesPhoneNumber
Street streetAddress street erNotesStreet
State st st erNotesState
Postcal code postalCode postalCode erNotesZip
Object Class - objectclass -
Unique Tivoli Directory Server attribute
- uid (computed by Directory Integrator)
-
Unique Domino Server attribute
- pfNotesFullName erNotesFullName (generated by Domino)
Unique Active Directory attribute
sAMAccountName pfsAMAccountName -
Chapter 4. Penguin Financial Incorporated 109

At this point you only need to know what attributes you want to synchronize. The attribute names used by various connectors can be updated once you have the connectors up and running.
Table 4-13 lists attributes that are specific to the Identity Manager Notes Agent Connector. These attributes are used when registering a new user with Domino server. Refer to Identity Manager Notes Agent Connector documentation for more information about these and additional attributes.
Table 4-13 Attributes used by the Identity Manager Notes Agent Connector
Now that we have identified the data attributes to be used, we look into what goes inside these attributes. As described in 2.2.4, “Initial data format” on page 21 it is possible that the autoboot value may be null, blank, out-of-range, and valid. It is necessary for us to define what actions need to be taken when an attribute value is one of the above four. For example the value for the telephoneNumber attribute in Tivoli Directory Server is optional and may be null. So if we are adding a user from Active Directory to Tivoli Directory Server, having null or blank for telephoneNumber does not cause any problem. But in the same scenario if the value for the objectclass attribute is null we might get an add error
Attribute Attribute name used with Identity Manager Notes Agent Connector
Domino domain name erNotesMailDomain
Domino server name erNotesMailServer
Domino domain name erNotesMailDomain
Domino server name erNotesMailServer
Domino server certifier ID (including path) erNotesAddCertPath
Certifier password erNotesPasswdAddCert
Domino mail file system erNotesMailSystem
Mail template name (including path) erNotesMailTemplateName
Mail file name (including path() erNotesMailFile
Mail file owner access erNotesMailFileOwnerAccess
Name of ID file (including path) erNotesUserIDfileName
Mail quota size erNotesMailQuotaSize
Initial password for the user erPassword
Notes short name erNotesShortName
110 Robust Data Synchronization with IBM Tivoli Directory Integrator

because of a schema violation exception by Tivoli Directory Server. In this particular example we can handle the situation by logging an error in Tivoli Directory Integrator and skipping the current add operation instead of relying on Tivoli Directory Server to throw a simple error. This creates a more robust solution and makes it easier for the developer to debug the individual modules.
There may be some attributes that are multi-valued like objectclass or NotesFullName. Care should be taken while using these attributes for say uniqueness, or using them to establish a link criteria between different data sources.
4.4.2 Data flowsThe next step in phase 1 is to plan the two data flow scenarios between the involved data sources. Figure 4-4 depicts the data flow between Microsoft Active Directory and Tivoli Directory Server.
Figure 4-4 Data flow between Active Directory and Directory Server
Figure 4-5 on page 112 depicts the data flow between the Domino Server and Tivoli Directory Server.
Windows 2000 Server with Active Directory
Tivoli Directory Server
Initial load of users
Unique attribute: sAMAccountName pfsAMAccountName
Synchronization of user attributes Unique attribute: uid
Link Criteria
Chapter 4. Penguin Financial Incorporated 111

Figure 4-5 Data flow between Domino Server and Directory Server
As a first step we need to identify the authoritative data source for the various data attributes listed in Table 4-12 on page 109.
Authoritative attributesMicrosoft Active Directory is the authoritative data source for FirstName and LastName attributes of users created by Microsoft Active Directory.
Lotus Domino Server is the authoritative data source for FirstName, LastName, and e-mail address attributes for users created by Lotus Domino Server. Lotus Domino Server also is the authoritative data source for the e-mail address attribute for users migrated from Microsoft Active Directory.
Tivoli Directory Server is the authoritative data source for Title, Phone number, Street, State, and Postal code.
Unique link criteriaLet us take a closer look at the link criteria between these data sources.
Between Microsoft Active Directory and Tivoli Directory ServerThe bi-directional arrow with a cross pattern in Figure 4-4 on page 111 shows the unique link criteria between Microsoft Active Directory and Tivoli Directory Server.
The attribute sAMAccountName, which is unique in Microsoft Active Directory, is used for establishing the link criteria. This attribute is mapped to a custom attribute called pfsAMAccountName created in the Tivoli Directory Server.
Domino Server Tivoli Directory Server
Initial load of users
Unique attribute: NotesFullName pfNotesFullName
Synchronization of user attributes
Unique attribute: uid
Link Criteria
Initial load of users
112 Robust Data Synchronization with IBM Tivoli Directory Integrator

Between Lotus Domino Server and Tivoli Directory ServerThe bi-directional arrow with a cross pattern in Figure 4-5 on page 112 shows the unique link criteria between Lotus Domino Server and Tivoli Directory Server.
The attribute FullName, which is unique in Domino server for users, is used for establishing the link criteria. This attribute is mapped to a custom attribute called pfNotesFullName created in the Tivoli Directory Server..
Special conditionsThe attribute uid is a unique attribute in the Tivoli Directory Server. This attribute is computed and created for each user on a successful user add operation to Tivoli Directory Server either from Active Directory or from Domino Server. The value of uid created for users from Domino Server is prefixed with a letter A and the value of uid created for users from Active Directory is prefixed with a letter B. There is no special meaning attached to these prefixes and this approach has been used to keep the implementation simple. You can use any other means of generating a unique ID.
To establish the link between the uid and Notes FullName for users added from Active Directory to Directory Server, we initially populate the pfNotesFullName attribute with the value of uid.
When this user, originally created in Active Directory is added to Domino Server, the Domino Server creates a Notes FullName and this uid is added as another value to the multi valued Notes field FullName in Domino Server.
During the synchronization from Domino Server to Directory Server this uid is replaced by Notes FullName generated by Domino Server during the earlier add operation.
We now describe the various phases for the implementation of these data flows.
Note: The Notes field FullName in Domino Server is a multi valued attribute and we have to ensure that we are taking this into consideration while using this attribute for mapping.
The FullName field value changes if a user is renamed in Domino. If you want to account for this type of changes, then use the Universal ID (Notes field: UnID) of Domino documents. UnID is associated with every object in Domino and does not change even if the object is modified like a user being renamed. UnID is also required if your application wants to keep track of document deletion.
Chapter 4. Penguin Financial Incorporated 113

Initial data cleanup and load phaseData cleanup and initial population of users are one time operations. So these steps need to be executed in sequence and only once during the initial user data migration.
1. As a first step we have to ensure that the user account repository on both the Microsoft Active Directory Server and Notes Domino Server contain the user accounts that we need to provision. For example, accounts in disabled state in Active Directory are not loaded during this operation. Also ensure that the schema in Tivoli Directory Server has been updated as required. For example, we have to create the suffixes for the Penguin Financial domain and the custom attributes like pfsAMAccountname and pfNotesFullName.
2. All the users in Microsoft Active Directory need to be added to Tivoli Directory Server. The right pointed arrow in Figure 4-4 on page 111 shows this step. When a user has to be added, the link criteria checks for the existence of pfsAMAccountName in Tivoli Directory Server with the matching value as specified in sAMAccountName of Microsoft Active Directory. If a matching attribute is found then the add operation fails. If no matching attribute value is found, the add operation succeeds. Additionally the value of uid is copied to the pfNotesFullName attribute.
3. Users who have been added to Directory Server from Active Directory need to be added to Domino Server. The left pointed arrow in Figure 4-5 on page 112 shows this step. To ensure that we are only adding users coming from Microsoft Active Directory, we make sure that each of these users have a pfsAMAccountName attribute set. Before these users are successfully added to Domino their pfNotesFullName attribute contains the value of the uid attribute. Because these users do not exist in Domino Server at this time the Notes FullName field does not yet contain any value. We use this value for uniqueness while adding these users to Domino Server.
4. Users from Domino Server need to be added to Tivoli Directory Server. The right pointed arrow in Figure 4-5 on page 112 shows this step. These users already have a Notes FullName attribute associated with them. When a user is to be added, the link criteria checks for the existence of pfNotesFullName in Tivoli Directory Server with the matching value as specified in NotesFullName of Domino Server. If a matching attribute is found then the add operation fails. If no matching attribute value is found, the add operation succeeds. Additionally the pfNotesFullName attribute for the original Active Directory users who have been added to Domino Server in the previous step are updated.
Synchronization of data phase1. The user account information in Active Directory needs to be kept in
synchronization with Directory Server. This also includes the addition of users
114 Robust Data Synchronization with IBM Tivoli Directory Integrator

to Active Directory in the future. The bi-directional arrow in Figure 4-4 on page 111 shows this step. If the synchronization operation is an update of a particular user, then only the attributes for which Active Directory is the authoritative data source are updated.
2. The user account information in Domino Server needs to be kept in synchronization with Directory Server. This also includes the addition of users to Domino Server in the future. The bi-directional arrow in Figure 4-5 on page 112 shows this step. If the synchronization operation is an update of a particular user, then only the attributes for which Domino Server is the authoritative data source are updated.
3. Any updates to user account information from Directory Server (through an external portal application or by any other means) needs to be synchronized to both Active Directory and Domino Server. The plain bi-directional arrows in Figure 4-4 on page 111 and Figure 4-5 on page 112 show this step. Only those attributes for which Directory Server is an authoritative data source are updated.
FrequencyThe initial data cleanup and load phase requires to be executed only once. Subsequent synchronization of data will be performed by monitoring the data sources continuously for any changes.
4.4.3 Instrument and test a solutionNow that we have completed the detailed data identification and planned the data flows, we look into the more deeper technical aspects of our solution implementation.
Required resources and setupFor the purposes of demonstrating this solution we use the following setup. Please refer to Table 4-11 on page 108 for the data sources involved.
Windows 2000 Server with Active Directory: Microsoft Windows 2000 Server with Service Pack 4 and Active Directory installed and configured.
IBM Tivoli Directory Server: SuSE Linux Enterprise Server 8 with IBM Tivoli Directory Server 5.2 installed and configured.
IBM Lotus Domino Server: Windows 2000 Server with Service Pack4 and Lotus Domino Server 6 installed and configured.
For development and deployment of the solution using Tivoli Directory Integrator we use a system with Windows 2000 Professional with Service Pack4, Tivoli
Chapter 4. Penguin Financial Incorporated 115

Directory Integrator 6, Lotus Notes Client 6, and Tivoli Identity Manager Notes Agent 6 installed and configured.
The data sources may reside on any platform that the product supports. For example, Domino Server can reside on a Windows or Unix platform.
Tivoli Directory Integrator supports various implementations of Unix.
In our scenario we use the Domino change detection connector and Identity Manager Notes Agent for updates to and from Domino server. The Domino change detection connector requires Lotus Notes Client to reside on the same system as the Tivoli Directory Integrator.
Refer to Appendix A, “Tricky connections” on page 415 for more information about available options for connectivity to Domino Server.
Please refer to the individual product documentation if you have questions on installing or configuring these products.
The default schema on Tivoli Directory Integrator has to be modified to add new suffixes and attributes.
� Add the following suffix: dc=penguin-fin,dc=com
� Add the following object class: pfPerson, derived from inetOrgPerson.� Add attributes: pfsAMAccountName and pfNotesFullName of string type
derived from pfPerson.
Edit the configuration and external properties file1. Start IBM Tivoli Directory Integrator by selecting it from the start menu or
executing the ibmditk.bat from the Tivoli Directory Integrator install directory.
2. To create a new configuration file, click File → New... as shown in Figure 4-6 on page 117. Optionally provide a password and click OK.
Note: The IDI Admin user (or any other user used by Tivoli Directory Integrator) should have the required privileges for adding or updating user accounts on Domino Server. This user needs to log on to the Lotus Notes Client using the ID file at least once after the system has been started (or restarted).
Note: Providing a password protects the configuration file and does not allow you to open the configuration file using other XML editors. So it is a good idea to do this once the solution is ready for deployment.
116 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-6 Creating a configuration file
3. In the left pane of the layout window expand ExternalProperties and click Default.
4. In the right pane enter a valid name for an External Properties File as shown in Figure 4-7 on page 118.
Chapter 4. Penguin Financial Incorporated 117

Figure 4-7 External Properties File configuration
Optionally you can encrypt the properties file by checking the Encrypt External Properties and providing a Cipher and Password. Leaving the cipher empty encrypts the file using the default cipher. It is a good idea to encrypt the properties file before or immediately after deploying the solution.
5. Click the Editor tab in the right pane and enter the property variables as shown in Figure 4-8 on page 119.
Note: The actual values you use for the properties depend upon your environment like system name, userid/password, LDAP schema, and so on.
118 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-8 External Properties
A description for each of the values in the external properties is provided in Table 4-14.
Table 4-14 External properties
Property Description
ADLoginName This is the login name Directory Integrator uses to bind to Active Directory. The ID must have sufficient permission to create user accounts in Active Directory.
ADPassword This is the password for the Active Directory login name.
ADSearchBase The subtree in Active Directory from which Directory Integrator is to propagate changes. Only changes to users in this subtree are propagated to Directory Server. Typically, this should be set to the top of the Active Directory tree, so that all users in Active Directory groups are found and copied to Directory Server.
Chapter 4. Penguin Financial Incorporated 119

Establish connectivity to data sourcesNext we establish the connectivity to the various data sources. We need multiple types of Connectors using different Connector modes for each data source. For example, reading entries from Active Directory requires an LDAP Connector in
ADSearchFilter The LDAP search filter that is used to select Active Directory user objects for synchronization with Directory Server. Unless the Active Directory schema has been modified, this typically is the objectClass=user.
ADURL The LDAP URL and port for the Active Directory Domain Controller. The default non-SSL port number for LDAP directories is 389.
ITIMCertificate This is the CA certificate file for access to Identity Manager.
ITIMPassword Identity Manager password.
ITIMUserName Identity Manager userid.
LDAPLoginName The login user ID that Directory Integrator uses to bind to Directory Server. This ID must have been given sufficient access permissions by the Directory Server administrator to create and modify user entries.
LDAPObjectClass The structural LDAP object class used to create new user entries in Directory Server. This may be a custom object class that extends the default schema. It must be a structural object class, not an auxiliary or abstract class. This class must exist in the Directory Server schema or the AssemblyLines in this configuration will not be able to create user entries.
LDAPPassword The password for the Directory Server login ID.
LDAPSearchBase The subtree in Directory Server to search to check if an Active Directory user has an existing entry in Directory Server.
LDAPStoreBase The suffix under which users are added in Directory Server. Used for creating a unique ID when users are added to Directory Server.
LDAPUrl The URL that Directory Integrator uses to connect to Directory Server.
Count A number used for creating unique IDs when users are added to Directory Server.
Property Description
120 Robust Data Synchronization with IBM Tivoli Directory Integrator

Iterator mode, updating entries in Active Directory requires an LDAP Connector in Update mode, and synchronization between Active Directory and Directory Server requires an Active Directory ChangeLog Connector in Iterator mode. Here is an overview of the different data source connections:
� Read Active Directory
� Update Active Directory
� Active Directory Changes
� Read Directory Server
� Lookup Directory Server
� Update Directory Server
� Directory Server Changes
� Read Domino Server
� Update Domino Server
� Domino Server Changes
Read Active DirectoryThis Connector is used for reading user entries from Microsoft Active Directory. This is an LDAP Connector running in Iterator mode.
1. In the left pane of the layout window right-click Connectors and select New Connector...
2. Select the type of Connector you are going to add. In the Select Connector window select the name ibmdi.LDAP. Enter ReadADCon in the name field and select Iterator mode as shown in Figure 4-9 on page 122. Click OK.
Chapter 4. Penguin Financial Incorporated 121

Figure 4-9 Select connector
3. A new Connector is added under Connectors in the left pane. The right pane displays the IBM Tivoli Directory Integrator LDAP Connector in the Connection subtab of the Config... tab as shown in Figure 4-10 on page 123. In the Connector configuration on the right pane there is an Inherit from: button on the top right-hand corner. This button shows the Connector template used for creating this particular Connector.
122 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-10 New connector
4. Let us configure this connector. In the right pane click the LDAP URL label on the left side of the first edit box; some of the labels, displayed in blue, act like a hyperlink and provide another configuration pop-up. The Parameter Information window, as shown in Figure 4-11 on page 124, is displayed. In the External Property drop-down list select ADURL and click OK. The previously defined value specified for the ADURL property in the external properties file, shown in Table 4-14 on page 119, is displayed in the edit box.
Chapter 4. Penguin Financial Incorporated 123

Figure 4-11 Connector parameter information
5. Repeat the above step for the Login username, Login password, Search Base, and Search Filter properties by selecting ADLoginName, ADPassword, ADSearchBase, and ADSearchFilter in the External Property list box respectively. Your connector window will look similar to Figure 4-12 on page 125.
124 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-12 Connector details
6. Next we discover the available attributes in the Active Directory data source. Click the Input Map tab in the right pane. This tab contains a row of iconic buttons we use to test the connection to the data source and discover the Connector schema. If you hover over the buttons using the mouse pointer a brief description of the button is displayed. Click the Plug button to connect to the data source. A Connection established message should be displayed next to the row of buttons. If you are not able to connect please verify the Connector configuration information.
7. Once the connection is established, click the Torch button to discover the schema of the data source. A list of available attributes in the data source is displayed. Scroll through the list to look at what attributes are available in the
Chapter 4. Penguin Financial Incorporated 125

schema. Click the right pointed triangle button to read the next entry. The Connector reads the next entry from the data source as shown in Figure 4-13.
Figure 4-13 Active Directory connector schema
8. At this point we have successfully established a connection to the data source. We have an option to map required attributes from the schema in the Connector itself or map them from within the AssemblyLine later. A good idea is to map those attributes here which you think will be used by all the AssemblyLines that use this Connector. In our case this Connector will be used by only one AssemblyLine. So we go ahead and map the attributes.
126 Robust Data Synchronization with IBM Tivoli Directory Integrator

9. Select the attributes that you want to map and drag them into the Work Attribute window pane. Your window now looks similar to Figure 4-14.
Figure 4-14 Connector schema attribute mapping
We have now completed the Connector configuration, connection to data source, discovery of schema, and mapping of attributes for this Connector. We need to repeat the above steps for the remaining Connectors.
Update Active DirectoryThis Connector is used to update user entries in Microsoft Active Directory. This is an LDAP Connector and it is running in Update mode.
Chapter 4. Penguin Financial Incorporated 127

1. In the left pane of the layout window right-click Connectors and select New Connector...
2. Select the type of Connector you are going to add. In the Select Connector window select the name ibmdi.LDAP. Enter UpdateADCon in the name field and select Update for mode and click OK. A new Connector is added under Connectors in the left pane. The right pane displays the IBM Tivoli Directory Integrator LDAP Connector in the Connection subtab of the Config... tab.
3. Let us configure this connector. In the right pane click the LDAP URL label on the left side of the first edit box. The Parameter Information window is displayed. In the External Property drop-down list select ADURL and click OK. The previously defined value specified for the ADURL property in the external properties file is displayed in the edit box.
4. Repeat the above step for the Login username, Login password, Search Base, and Search Filter properties by selecting ADLoginName, ADPassword, ADSearchBase, and ADSearchFilter in the External Property list box respectively. Your connector window will look similar to Figure 4-15 on page 128.
Figure 4-15 Update Active Directory connector
128 Robust Data Synchronization with IBM Tivoli Directory Integrator

5. Click the Input Map tab in the right pane. Connect to the data source, discover the schema, and read the next entry from the data source. Select the attributes that you want to map and drag them into the Work Attribute window pane. Your window now looks similar to Figure 4-16 on page 129.
Figure 4-16 Update Active Directory connector schema attribute mapping
6. Because this connector operates in Update mode, you have the Link Criteria tab enabled, which needs to be defined. This specifies the condition under which updates to Active Directory are carried out. This tab has another row of iconic buttons. Click the link button with a white star to add new link criteria. A Link Criteria window lets you specify your values. From the Connector Attribute drop-down list select sAMAccountName, select the Operator value as equals, and enter the Value $pfsAMAccountName as shown in Figure 4-17 on page 130. Click OK.
Chapter 4. Penguin Financial Incorporated 129

Figure 4-17 Link Criteria
7. You now have the link criteria defined as shown in Figure 4-18.
Figure 4-18 Link Criteria for the Update Active Directory connector
130 Robust Data Synchronization with IBM Tivoli Directory Integrator

You have now completed the Connector configuration for the Update Active Directory Connector.
Active Directory changesThis Connector monitors the Microsoft Active Directory for any changes. This is an Active Directory Changelog Connector that runs in Iterator mode.
1. In the left pane of the layout window right-click Connectors and select New Connector...
2. Select the type of Connector you are going to add. In the Select Connector window select the name ibmdi.ADChangeLogv2. Enter ADCLogCon in the name field and select Iterate mode (this is the only mode available for this Changelog Connector) and click OK. A new Connector is added under Connectors in the left pane. The right pane displays the Active Directory Changelog Connector v2 in the Connection subtab of the Config... tab.
3. Let us configure this connector. In the right pane click the LDAP URL label on the left of the first edit box. The Parameter Information window is displayed. In the External Property drop-down list select ADURL and click OK. The previously defined value specified for the ADURL property in the external properties file, shown in Table 4-14 on page 119, is displayed in the edit box. Repeat the above step for the Login username, Login password, and LDAP Search Base properties by selecting ADLoginName, ADPassword and ADSearchBase in the External Property list box respectively.
4. Enter ADChanges as the name for the Iterator State Store. This property stores the change number that keeps track of the starting point for the change detection connector. Its value is persistent. So if the AssemblyLine is down for a period of time, and then comes up again, changes from the last stored change number are read and processed. The delete button next to this field deletes the entry stored in the Iterator State Store. This property along with the next Start at property gives you a good control about from what point the changes in Active Directory are to be read. Your Connector window looks similar to Figure 4-19 on page 132.
5. Select the checkbox Use Notifications if you want the connector to be notified as changes happen in the data source. If this check box is selected the Connector will be blocked until a new change has occurred.
Note: You can achieve similar functionality by setting a Timeout value of 0 and specifying a Sleep Interval. This polls the data source at periodic intervals specified by the Sleep Interval value. Polling the data source periodically might not be acceptable in many environments, so utilizing the Use Notifications property should be your preferred method to begin with.
Chapter 4. Penguin Financial Incorporated 131

Figure 4-19 Active Directory Changelog Connector
6. Click the Input Map tab in the right pane. Connect to the data source, discover the schema, and read the next entry from the data source. Select the attributes you want to update in Active Directory and drag them into the Work Attribute window pane. Your window now looks similar to Figure 4-20 on page 133.
132 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-20 Active Directory changelog connector schema attribute mapping
We have now completed the Connector configuration for the Active Directory Changelog Connector.
Note: Sometimes all the attributes you want may not be listed in the schema, because not all entries have all attributes filled. Click the right pointed triangle button (Read the next entry) multiple times to read a few entries until the attributes you want are listed in the schema.
Chapter 4. Penguin Financial Incorporated 133

Read Directory ServerThis Connector reads user information from Tivoli Directory Server. It is an LDAP Connector in Iterator mode.
The configuration of this connector is similar to the Read Active Directory Connector as both are using the LDAP Connector in Iterator mode. The only difference is the values supplied in the Connector configuration window and the attributes to be mapped.
1. Add a new connector using the ibmdi.LDAP Connector template, and name this Connector ReadTDSCon. Select the mode Iterator.
2. In the Connector configuration window fill in the connection information. Fill in the property values for the LDAP URL, Login username, Login password, and LDAP Search Base properties by selecting LDAPUrl, LDAPLoginName, LDAPPassword, and LDAPSearchBase in the External Property list box respectively. Figure 4-21 on page 135 shows the configuration for this Connector.
Note: Sometimes you may get an error while trying to establish a connection to the data source when using the Changelog Connectors. The error maybe something similar to:
com.ibm.db2.jcc.a.SQLException: IO Exception opening socket to server localhost on port 1527. The DB2 Server may be down.
This is likely due to an initialization problem with the Cloudscape database used by Tivoli Directory Integrator. One way this problem can be solved is by running any AssemblyLine; it can be the same AssemblyLine that uses this connector or any other AssemblyLine. Once the AssemblyLine has started go back and try to connect to the Changelog Connector again.
134 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-21 Connector configuration for reading entries from Directory Server
3. In the Input Map window, connect to the data source, discover the schema, and drag the required attributes into the Work Attribute window. Figure 4-22 on page 136 shows the Connector schema attribute mapping.
Chapter 4. Penguin Financial Incorporated 135

.
Figure 4-22 Connector attribute schema mapping for Read Directory Server Connector
Lookup Directory ServerThis Connector does a lookup of entries on Directory Server. It is used in conjunction with the Directory Server Changelog Connector (discussed later) to retrieve information about the changed entry.
1. Add a new connector using the ibmdi.LDAP Connector template, and name this Connector LookupTDSCon. Select the mode Lookup.
2. In the Connector configuration window fill in the connection information. This information is the same as for the Read Directory Server Connector.
3. In the Input Map window, connect to the data source, discover the schema, and drag the required attributes to Work Attribute window. The required attributes are the same as those for the Read Directory Server connector.
136 Robust Data Synchronization with IBM Tivoli Directory Integrator

4. The Link Criteria will be updated when we use this connector in the AssemblyLine.
Update Directory ServerThis Connector updates user information into Tivoli Directory Server. It is an LDAP Connector in Update mode.
1. Add a new connector using the ibmdi.LDAP connector template, and name this Connector UpdateTDSCon. Select the mode Update.
2. In the connector configuration window fill in the connection information. Fill in the property values for the LDAP URL, Login username, Login password, and LDAP Search Base properties by selecting LDAPUrl, LDAPLoginName, LDAPPassword, and LDAPSearchBase in the External Property list box respectively. Figure 4-23 shows the Connector configuration.
Figure 4-23 Update Tivoli Directory Server Connector configuration
3. Click the Output Map tab in the right pane. Connect to the data source, discover the schema, and read the next entry from the data source. Select the attributes you want to map and drag them to the Attribute Map window pane. Figure 4-24 shows the schema and the attributes used.
Chapter 4. Penguin Financial Incorporated 137

Figure 4-24 Update Tivoli Directory Server Connector schema attribute mapping
4. This Connector is used by the AssemblyLines for updates from Domino Server to Directory Server as well as from Active Directory to Directory Server. Hence we will update the Link Criteria in the AssemblyLine configuration and not in the Connector configuration.
5. Click the Hooks tab of the connector, expand On Add, click the hook After Add and add the following script:
count ++;main.getMetamergeConfig().getExternalProperties().setParameter( "count", count );main.getMetamergeConfig().getExternalProperties().saveData();
138 Robust Data Synchronization with IBM Tivoli Directory Integrator

This script increments the count value on a successful add user operation and saves the value to the properties file.
6. Select the hook Default on Error and add the following script:
system.skipEntry();
Directory Server changesThis Connector monitors the Tivoli Directory Server for changes. This is a Tivoli Directory Server Changelog Connector running in Iterator mode.
To add this Connector use the template ibmdi.IBMDirectoryServerChangeLog. Figure 4-25 on page 140 shows the configuration for this Changelog Connector.
Note: An AssemblyLine shuts down when it encounters any errors. Adding this entry will cause the AssemblyLine to continue processing the next entry in case of errors.
Chapter 4. Penguin Financial Incorporated 139

Figure 4-25 Directory Server Changelog Connector configuration
Once the configuration is complete go to the Input Map tab, connect to the data source, discover the schema, and read a few entries.
We only need two attributes from this schema; they are changetype and targetdn. This is because we use the targetdn to do another lookup on the Directory Server to retrieve all the attributes. Drag these two attributes into the Work Attribute window pane.
Read Domino ServerThis connector reads user entries from Domino Server. It is an Identity Manager Agent Connector in Iterator mode.
140 Robust Data Synchronization with IBM Tivoli Directory Integrator

1. While adding this Connector select the ibmdi.ITIMAgentConnector template. In the Connector configuration window accept the default value of https://localhost:45580 for the property Agent URL. For properties UserName, Password, and CA Certificate File use the external properties values of ITIMUserName, ITIMPassword, and ITIMcaCertificate respectively. Your connector should like Figure 4-26.
Figure 4-26 Domino Server Connector configuration
2. Map the attributes you want from the schema by dragging them into the Work Attribute window pane. We map the attributes as shown in Figure 4-27 on page 142.
Note: You need to have the certificate file at hand when configuring this Connector. This can be obtained from a certificate authority like VeriSign or you can create a self-signed certificate using the IBM GSKit.
Chapter 4. Penguin Financial Incorporated 141

Figure 4-27 Domino Server Connector schema attribute mapping
Note: Use of the schema discovery button may fail as this connector does not support the querySchema functionality. You can still use the read the next entry button to get the attributes displayed.
142 Robust Data Synchronization with IBM Tivoli Directory Integrator

This completes our configuration for this Connector.
Update Domino ServerThis Connector is used for updating user entries including user creation in Domino Server. it is an Identity Manager Agent Connector in Update mode.
1. The configuration for this Connector consists of the same steps as for the Read Domino Server Connector except the mode should be selected as Update.
2. Apart from updating the user entries in Domino Server this Connector also creates and registers new users in Domino Server. Properties required for user registration in Domino Server using the Identity Manager Agent Connector are listed in Table 4-13 on page 110. Figure 4-28 on page 144 shows the Connector schema attribute mapping. Some of the attributes may not be discovered when user entries are read from the data source. So we have to add those attributes manually by creating a new attribute in the Connector Attribute window pane. Such attributes are displayed in red color.
Chapter 4. Penguin Financial Incorporated 143

Figure 4-28 Update Domino Server Connector schema mapping
3. In the Hooks section of this Connector add the following script for the Default On Error hook:
system.skipEntry();
This completes our configuration for this Connector.
Domino Server changesThis connector monitors the Lotus Domino Server for any changes. It is a Domino Changelog Connector that runs in Iterator mode.
144 Robust Data Synchronization with IBM Tivoli Directory Integrator

1. To add this Connector select the ibmdi.DominoChangeDetectionConnector template. For the properties Domino Server IP address, UserName, Internet Password, Database, and System Store Key use the external properties values of DomIP, DomUserName, DomPassword, DomDatabase. and DomSystemStoreKey respectively. Your connector should look similar as depicted in Figure 4-29.
Figure 4-29 Domino Server changelog connector configuration
2. Figure 4-30 on page 146 shows the schema attribute mapping for the Domino Changelog Connector.
Chapter 4. Penguin Financial Incorporated 145

Figure 4-30 Domino Changelog Connector schema attribute mapping
We now have completed establishing connections to all data sources using different modes and base templates for creating these Connectors. We discovered the schema for these data sources and selected the attributes for mapping. These Connectors will be used in the following AssemblyLines.
Note that we could have used the base template Connectors in the AssemblyLines directly without the overhead of creating additional Connectors
146 Robust Data Synchronization with IBM Tivoli Directory Integrator

using templates. We have done this to demonstrate a phased approach and to understand the basic concepts of Directory Integrator component reusability.
Using this approach also provides a better understanding of the whole solution.
Creation of AssemblyLinesWe now discuss the different aspects of creating AssemblyLines.
Add users from Active Directory to Directory ServerThis AssemblyLine is used for reading user entries from Microsoft Active Directory and adding them to Tivoli Directory Server. This corresponds to step two of the “Initial data cleanup and load phase” on page 114.
1. In the left pane of the layout window right-click AssemblyLines and select New AssemblyLine..... Give a name for the AssemblyLine, say LoadADtoTDS.
2. Click the Hooks tab of the AssemblyLine. Click Prolog. Add the script as shown in Figure 4-31 in the Prolog - After Init window. This script retrieves the values from external properties file into the variables. These variables are used later in the AssemblyLine.
Figure 4-31 Get external property values into an AssemblyLine
3. In the AssemblyLine component list right-click Feeds and select Add connector component... Select the ReadADCon Connector we created earlier, give it a name, say ReadAD, set the mode to Iterator and click OK.
4. As discussed in “Special conditions” on page 113 we need to create a unique ID for any user added to Directory Server. Add a new variable called uniqueid in the Work Attribute window and add the script as shown inFigure 4-32 on page 148.
Chapter 4. Penguin Financial Incorporated 147

Figure 4-32 Add uniqueid to the ReadAD Connector
5. In the AssemblyLine component list right-click the Flow section and select Add connector component... Select the UpdateTDSCon Connector we created earlier, give it a name, say UpdateTDS, set the mode to Update and click OK.
148 Robust Data Synchronization with IBM Tivoli Directory Integrator

6. Click the Outmap of this Connector. For the $dn attribute click Advanced Mapping and enter the following script:
ret.value = "uid=" + uniqueid + "," + ldapstorebase;
This attribute is used to create a unique distinguished name in Tivoli Directory Server.
7. For the objectclass attribute click Advanced Mapping and enter the following script:
ret.value = ldapobjectclass;
8. Add two new attributes to the attribute map, pfNotesFullName with a value mapped to uniqueid, and pfsAMAccountName with a value mapped to sAMAccountName.
9. Next we establish the link criteria. Open the Link Criteria for the UpdateTDS Connector. Add a new link criteria as follows:
Connector Attribute: pfsAMAccountNameOperator: equalsValue: $sAMAccountName
10.The AssemblyLine is now ready. It should look similar to Figure 4-33 on page 150. Execute the AssemblyLine by clicking the Run button on the top right corner. A new execute window opens that shows the execution details of the AssemblyLine. On successful execution of the AssemblyLine you receive a message like AssemblyLine assemblelinename terminated successfully. If all goes well the users in Microsoft Active Directory are loaded into Tivoli Directory Server.
Chapter 4. Penguin Financial Incorporated 149

Figure 4-33 Load Active Directory to Directory Server AssemblyLine ready to run
In Figure 4-33 you can see that in Attribute Mapping section all attributes are selected in the Add column. Also, the first three attributes, $dn, objectclass, and pfNotesFullName, are not selected for the Mod (modify) operation. This is because the modification of $dn and objectclass to an LDAP entry is a violation of the LDAP schema. And at this point the pfNotesFullName contains the value of uniqueid (uid in the LDAP schema) which is created once for each user and is unique.
Add users from Directory Server to Domino ServerThis AssemblyLine is used to read user entries (added from Active Directory in the previous AssemblyLine) from Directory Server and add them to Domino Server.
150 Robust Data Synchronization with IBM Tivoli Directory Integrator

1. The steps to create this AssemblyLine are similar to the previous one. Create a new AssemblyLine and name it LoadTDStoDom.
2. In the Data Flow tab of the AssemblyLine, add the Connector ReadTDSCon to the Feeds section, set the Mode to Iterator, and name this component ReadTDS.
3. We have to ensure that we are adding only those users that have been added from Active Directory. If the entry has an attribute pfsAMAccountName then we know this user has been added from Active Directory. To perform this check, right-click the Flow section, select Add branch... and name it ADUser. In the window pane on the right add a new condition with the Attribute name pfsAMAccountName and the Operator exists. Uncheck the Case Sensitive check box. Figure 4-34 shows this branch condition.
Figure 4-34 AssemblyLine showing the branch condition
4. Under this branch add a new Connector UpdateDomCon in Update mode. Name this component UpdateDom.
5. In the output map for this Connector the attributes have to be modified as follows:
$dn: ret.value= “eruid=” + work.getString(“uid”);erNotesAddCertPath: ret.value = “C:\\notes\\data\\cert.id”;
erNotesFirstName: givenNameerNotesInternetAddress: mail
Note: erNotesAddCertPath contains the location of the certifier ID file. So this ID may have to be copied from the Domino Server to the Notes client on the Directory Integrator system.
Chapter 4. Penguin Financial Incorporated 151

erNotesLastName: snerNotesMailDomain: “penguin-fin”;erNotesMailFile: ret.value = “mail\\” + work.getString(“uid”) + “.nsf”;erNotesMailFileOwner: ret.value = “6”;erNotesMailQuotaSize: ret.value = “100”;erNotesMailServer: ret.value = CN=pf-usmail01/O=penguin-fin;erNotesMailSystem: ret.value = “1”;erNotesMailTemplateName: ret.value = “mail50.ntf”;
erNotesPasswordAddCert: ret.value = “passw0rd”;erNotesPhoneNumber: telephoneNumbererNotesShortName: var FirstName = work.getString(“givenName”);
var short = FirstName.substring(0,1);ret.value = short + work.getString(“sn”);
erNotesState: sterNotesStreet: streeterNotestitle: titleerNotesUserIDFileName: var idfile = work.getString(“uid”) + “.id”;
ret.value = “C:\\ITDI\\Domino\\IDsCreated\\” + idfile;
erNotesZip: postalCodeerPassword: ret.value = “passw0rd”;
6. Add the following link criteria for this Connector component:
Note: Some attributes like $dn and erNotesAddCertPath are mapped using scripts by selecting Advanced Mapping, other attributes like erNotesFirstName are mapped with attributes from the work Entry. You can tell the difference by looking at the attribute values; Advanced Mapping attributes are associated with a script and a ret.value, and each line of the script terminates with a semi colon. Direct mapping attributes only have an attribute name associated with them.
Note: This Domino template file (mail50.ntf) should exist at the specified location. It is by default installed with the Domino Server.
Note: erNotesShortName has been built using the first letter of first name and last name.
Note: erNotesUserIDFileName specifies the name and location where the Notes ID file is created for newly registered users.
Note: erPassword contains the default password for newly created users.
152 Robust Data Synchronization with IBM Tivoli Directory Integrator

Connector Attribute: erNotesFullNameOperator: equalsValue: $pfNotesFullName
7. Your AssemblyLine is now ready. It should look similar to Figure 4-35. Note the Add/Mod check boxes against the Connector attributes.
Figure 4-35 AssemblyLine for adding users from Directory Server to Domino Server
Add users from Domino Server to Directory ServerThis AssemblyLine is used to read user entries from Domino Server and add them to Directory Server.
1. Create a new AssemblyLine and name it LoadDomtoTDS.
2. In the Hooks tab of the AssemblyLine add the following script under the Prolog hook.
Chapter 4. Penguin Financial Incorporated 153

var ldapobjectclass = main.getMetamergeConfig().getExternalProperties().getParameter("LDAPObjectClass");var ldapstorebase = main.getMetamergeConfig().getExternalProperties().getParameter("LDAPStoreBase");var count = main.getMetamergeConfig().getExternalProperties().getParameter("count");
3. In the Data Flow tab of the AssemblyLine add the Connector ReadDomCon to the Feeds section, set the Mode to Iterator and name it ReadDom.
4. In the Input tab of this Connector add a new work attribute called uniqueid and add the following script for this attribute:
ret.value = “A” + count;
5. In the Flows section add a new Connector UpdateTDSCon in Update mode. Name this component UpdateTDS.
6. In the Output map for this Connector the attribute map has to be modified as follows:
$dn: ret.value= “uid=” + work.getString(“uniqueid”) + “,” + ldapstorebase;cn: ret.value = work.getString(“erNotesFirstName”) + “ “ + work.getString(“erNotesLastName”);givenName: erNotesFirstNamemail: erNotesInternetAddressobjectclass: ret.value = ldapobjectclass;pfNotesFullName: ret.value = work.getString(“erNotesFullName”);postalCode: erNotesZipsn: erNotesLastNamest: erNotesStatestreet: erNotesStreettelephoneNumber: erNotesOfficePhoneNumbertitle: erNotesTitle
7. Add the following link criteria for this Connector.
Connector Attribute: pfNotesFullNameOperator: equalsValue: @erNotesFullName
8. Your AssemblyLine is now ready for execution. It should look similar to Figure 4-36 on page 155.
Note: The @symbol in front of erNotesFullName indicates that all the values of this attribute have to be checked for a match. This is required as erNotesFullName is a multi-valued attribute.
154 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-36 AssemblyLine for loading users from Domino Server to Directory Server
Synchronize users from Active Directory to Directory ServerThis AssemblyLine is used to keep the user information in synchronization between Active Directory and Directory Server. New users added to Active Directory also get added to Directory Server automatically.
1. Create a new AssemblyLine and name it SyncADtoTDS.
2. In the Hooks tab of the AssemblyLine add the following script under the Prolog hook.
var ldapobjectclass = main.getMetamergeConfig().getExternalProperties().getParameter("LDAPObjectClass");var ldapstorebase = main.getMetamergeConfig().getExternalProperties().getParameter("LDAPStoreBase");
Chapter 4. Penguin Financial Incorporated 155

var count = main.getMetamergeConfig().getExternalProperties().getParameter("count");
3. In the Data Flow tab of the AssemblyLine, add a Connector ADCLogCon to the Feeds section, set the Mode to Iterator and name it ADCLog.
4. In the Input tab of this connector add a new work attribute called uniqueid and add the following script for this attribute:
ret.value = “B” + count;
5. In the Flows section add a new Connector UpdateTDSCon in Update mode. Name this component UpdateTDS.
6. In the Output map for this connector the attribute map has to be modified as follows:
$dn: ret.value= “uid=” + work.getString(“uniqueid”) + “,” + ldapstorebase;objectclass: ret.value = ldapobjectclass;pfNotesFullName: uniqueidstreet: StreetAddresspfsAMAccountName: sAMAccountName
7. Add the following link criteria for this connector:
Connector Attribute: pfsAMAccountNameOperator: equalsValue: $sAMAccountName
8. Your AssemblyLine is now ready for execution. It should look similar to Figure 4-37 on page 157.
Note: If some of the attributes are not present, like for example the pfsAMAccountName, add them to the attribute map.
156 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-37 AssemblyLine to synchronize users from Active Directory to Directory Server
Synchronize users from Domino Server to Directory ServerThis AssemblyLine is used to synchronize user information from Domino Server to Directory Server including adding new users.
1. Create a new AssemblyLine and name it SyncDomtoTDS.
2. In the Hooks tab of the AssemblyLine add the following script under Prolog hook:
var ldapobjectclass = main.getMetamergeConfig().getExternalProperties().getParameter("LDAPObjectClass");var ldapstorebase = main.getMetamergeConfig().getExternalProperties().getParameter("LDAPStoreBase");
Chapter 4. Penguin Financial Incorporated 157

var count = main.getMetamergeConfig().getExternalProperties().getParameter("count");
3. In the Data Flow tab of the AssemblyLine, add a Connector DomCLogCon to the Feeds section, set the Mode to Iterator and name it DomCLog.
4. In the Input tab of this connector add a new work attribute called uniqueid and add the following script for this attribute:
ret.value = “A” + count;
5. We need to look at only those changes that were made to our mail domain. In the Flows section add a new branch component and name it penguin-fin. Add the following condition for this branch:
Attribute Name: MailDomainOperator: equalsValue: penguin-fin
Uncheck the Case Sensitive box.
6. Add a new Connector UpdateTDSCon in Update mode under this branch. Name this Connector UpdateTDS.
7. In the Output map for this Connector the attribute map has to be modified as follows:
$dn: ret.value= “uid=” + work.getString(“uniqueid”) + “,” + ldapstorebase;objectclass: ret.value = ldapobjectclass;cn: ret.value = work.getString(“FirstName”) + “ “ + work.getString(“LastName”);givenName: FirstNamemail: InternetAddresspfNotesFullName: ret.value = work.getString(“FullName”);postalCode: zipsn: LastNamest: Statestreet: StreettelephoneNumber: OfficePhoneNumbertitle: JobTitle
8. Add the following link criteria for this connector:
Connector Attribute: pfNotesFullNameOperator: equalsValue: @FullName
9. Your AssemblyLine is now ready for execution. It should look similar to Figure 4-38 on page 159.
158 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-38 AssemblyLine to synchronize users from Domino Server to Directory Server
Synchronize users from all directoriesThis final AssemblyLine synchronizes user information from Directory Server to both Domino Server and Active Directory. Updates to Directory Server are driven from a Web application used by end users updating their individual records.
Note: Sometimes you might experience problems during the initialization of Domino changelog connector. If this problem persists even after trying to start the AssemblyLine or restarting Tivoli Directory Integrator itself, then do the following. Restart the system which has Tivoli Directory Integrator, start Lotus Notes client, login using the same Notes ID that is used by Tivoli Directory Integrator, start the Tivoli Directory Integrator and run the AssemblyLine.
Chapter 4. Penguin Financial Incorporated 159

1. Create a new AssemblyLine and name it SyncTDStoDomAndAD.
2. In the Data Flow tab of the AssemblyLine add a Connector TDSCLogCon to the Feeds section, set the Mode to Iterator and name it TDSCLog.
3. We need to look at only those changes that were made to our domain. In the Flows section add a new branch component and name it penguin-fin. Add the following condition for this branch:
Attribute Name: targetdnOperator: containsValue: penguin-fin
Uncheck the Case Sensitive box.
4. We only handle add or modify changes to Directory Server. Under the penguin-fin branch, add a new branch component called Update. Add the following two conditions to this branch:
Attribute Name: changetypeOperator: equalsValue: add
Attribute Name: changetypeOperator: equalsValue: modify
Uncheck the Case Sensitive box for both the conditions. After adding these conditions, ensure that the Enabled check box is selected at the top and that the Match any radio button is selected.
5. We now need to retrieve all the information about the changed entry. Under the Update branch add a new Connector LookupTDSCon in Lookup mode. Name this connector LookupTDS. This Connector will retrieve information about the changed user.
6. Add the following link criteria for this connector:
Connector Attribute: $dnOperator: equalsValue: $targetdn
7. Under the Update branch add a new Connector UpdateDomCon in Update mode. Name this Connector UpdateDom. This Connector will add new users to Domino Server or update users to Domino Server. Move this Connector below the LookupTDS Connector.
8. From “Add users from Directory Server to Domino Server” on page 150, execute Steps 5 to 6 on this Connector. These steps update the attributes in the output map and establish a link criteria. Your Connector now looks similar to Figure 4-39 on page 161.
160 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-39 Attribute mapping for updates from Directory Server to Domino Server
9. Note the check boxes against the attributes that will be modified.
10.We also need to update the Active Directory users. Under the Update branch add a new branch component called ADUser. Move this branch below the UpdateDom Connector. Add the following condition to this branch:
Attribute Name: pfsAMAccountNameOperator: exists
Uncheck the Case Sensitive box.
11.In the Output Map tab for this Connector map the attributes as shown in Figure 4-40 on page 162.
Chapter 4. Penguin Financial Incorporated 161

Figure 4-40 Attribute mapping for updates from Directory Server to Active Directory
12.Add the following link criteria for this connector:
Connector Attribute: sAMAccountNameOperator: equalsValue: $pfsAMAccountName
13.Your AssemblyLine is now ready for execution.
Problems executing AssemblyLinesIf you have problems executing the AssemblyLine, look at any error messages in the execute window. You can also turn on detailed logging by selecting the Detailed Log checkbox in the Connector configuration for each of the Connectors used in the AssemblyLine.
If you have a fair idea of where the problem lies, additional debug messages can be inserted in the Hooks section of the Connectors.
162 Robust Data Synchronization with IBM Tivoli Directory Integrator

Finally you can try executing the AssemblyLine in debug mode by running the debugger.
4.5 Phase 2: Password synchronizationThis section contains details about the implementation of the password synchronization.
As emphasized in 2.5.6, “Password synchronization” on page 34, “Password synchronization is specifically mentioned when architecting a data synchronization solution since it tends to have its own set of data and implementation requirements”, thus in order to implement a password synchronization solution it is necessary to better understand the password synchronization module in IBM Tivoli Directory Integrator.
Password synchronization was briefly described in 3.2.11, “Password synchronization” on page 65, but let us go into some more details in the following sections 4.5.1, “Components” on page 163 and 4.5.2, “Architecture” on page 183. These two sections are more or less an extract from the Password Synchronization for IBM Tivoli Directory Integrator 6.0 readme file (readme_password_sync_ismp.htm), which you can find in the installation directory after successful installation of the password synchronization module.
After describing these details we implement the solution in the following steps:
1. In 4.5.3, “Detailed data identification” on page 186 we identify the locations, formats, access, and uniqueness of data.
2. In 4.5.4, “Plan the data flows” on page 190 we plan the data flow by analyzing link criterias, special conditions, and final data formats. At the end we provide the document that describes the data flow.
3. In 4.5.5, “Review results” on page 196 we document the results of our effort as a foundation for a successful implementation.
4. In 4.5.6, “Instrument and test a solution” on page 200 we finally put all pieces together into a solution and test it to see if it works or if any modification is needed.
4.5.1 ComponentsThe IBM Tivoli Directory Integrator provides an infrastructure and a number of ready-to-use components for implementing solutions that synchronize user passwords in heterogeneous software environments.
Chapter 4. Penguin Financial Incorporated 163

A password synchronization solution built with the Directory Integrator can intercept password changes on a number of systems. The intercepted changes can be directed back into:
� The same software systems� A different set of software systems
Synchronization is achieved through the Directory Integrator AssemblyLines that can be configured to propagate the intercepted passwords to desired systems.
The components that make up a password synchronization solution are:
� Password Synchronizers - Components that are deployed on the system where password changes occur. They are responsible for intercepting plain (unencrypted) values of the passwords as they are changed.
� Password Stores - Components that receive the intercepted passwords, encrypt and store them in locations that can be accessed by the Directory Integrator.
� Connectors - These are either standard or specialized Directory Integrator Connectors. They connect to locations where the intercepted and encrypted passwords are stored and are able to retrieve and decrypt the passwords.
� AssemblyLines - The AssemblyLines use Connectors to get the intercepted passwords and then build custom logic for sending the passwords to other software systems.
� EventHandlers (optional) - The use of EventHandlers can further automate or schedule the password synchronization process.
The Password Synchronizers, Password Stores, and Connectors are ready-to-use components included in Directory Integrator. As a result, implementing the solution that intercepts the passwords and makes them accessible from Directory Integrator is achieved by deploying and configuring these components.
Password Synchronizer intercepts the password change immediately after the user has submitted it and sends the password as either an LDAP entry, or a WebSphere MQe message. Either way, this change triggers a Directory Integrator AssemblyLine. This AssemblyLine then propagates the change to the target directories.
Note: For the part of the solution that consolidates passwords intercepted from different sources and feeds these passwords into systems that need to be synchronized, a custom AssemblyLine must be implemented. The structure of the AssemblyLine depends mostly on the custom environment and the requirements for the particular solution. Directory Integrator does not include these AssemblyLines; they are implemented by the customer.
164 Robust Data Synchronization with IBM Tivoli Directory Integrator

A password synchronization AssemblyLine usually uses Iterator Connectors to retrieve passwords from the Password Stores. The AssemblyLine then uses other standard Connectors to set these passwords into other systems. If the systems that are synchronized have custom requirements for setting user passwords, these requirements must be addressed in the AssemblyLine and the Connectors that set these passwords. Such customization might consist of setting certain Connector parameters, for example, turning on the Auto Map AD Password option in the LDAP Connector to set user passwords in Active Directory. In more complex cases, scripting might be necessary.
A password synchronization solution might include Directory Integrator Changelog Connectors to automate the process of synchronization. For example, a Changelog Connector might listen for changes in the repository where a Password Store component stores the intercepted passwords and trigger the synchronization AssemblyLine whenever a new password is intercepted. Another example might be using a Timer EventHandler that starts the synchronization AssemblyLine on a schedule.
Each of the components mentioned previously provide interfaces that facilitate the tuning of behavior. Also, the various components can be combined with each other to create custom solutions. These key features provide flexibility for building solutions that meet custom requirements and limitations. The password synchronization suite is mostly comprised of the specialized components that intercept the passwords and make them accessible for Directory Integrator. Once Directory Integrator can access the intercepted passwords through its Connectors, the whole flexibility and openness of the Directory Integrator architecture can be leveraged in organizing the process of password retrieval and propagation to other systems.
Password SynchronizersPassword Synchronizers are components that are deployed on the system where password changes occur. They are responsible for intercepting plain (unencrypted) values of the passwords as they are changed. The following Password Synchronizers are currently available:
� Password Synchronizer for Windows NT/2000/XP
– Intercepts the Windows login password change.
� Password Synchronizer for IBM Tivoli Directory Server
– Intercepts IBM Tivoli Directory Server password changes.
� Password Synchronizer for Domino
– Intercepts changes of the HTTP password for Lotus Notes users.
� Password Synchronizer for Sun ONE™ Directory Server
Chapter 4. Penguin Financial Incorporated 165

– Intercepts Sun ONE Directory Server password changes.
Windows NT/2000/XPThe Password Synchronizer for Windows intercepts password changes of user accounts on Windows NT®, 2000, and XP operating systems.
Password changes are intercepted in all of the following cases:
� When a user changes his own password through the Windows user interface
� When an administrator changes the password of a user through the Windows administrative user interface
� When a password change request to Active Directory is made through LDAP
Windows Password Synchronizer workflowThe Windows Password Synchronizer intercepts a password change before the change is actually committed internally by Windows and Active Directory. The Password Synchronizer passes the new password to the Password Store, where it is available to AssemblyLines for further processing as shown in Figure 4-41.
Figure 4-41 Windows Password Synchronizer
When users try to change their password in Active Directory, Active Directory verifies the local password policy. The password policy can include additional modules. These modules are supposed to ensure that the password is sufficiently complex. The Password Synchronizer’s timpwflt.dll file appears to the operating system as such a module. It takes the password and sends it either as an LDAP entry, which can be written to an LDAP server, or an MQe message, which can be processed by a Changelog Connector or a Connector in Iterator mode.
The Password Synchronizer also accepts the password as sufficiently complex, so it will be changed in Active Directory.
AD ModifyPW Process
ITDIAssemblyLine
ADPW StorePW Catch
LDAP / MQe
166 Robust Data Synchronization with IBM Tivoli Directory Integrator

If the Password Store indicates that the password is stored successfully, the Password Synchronizer enables the password change to be committed in Windows. If the Password Store indicates that the password is not stored, the password change is rejected on the Windows machine. If the password change cannot be performed from the Windows user interface, an error box is displayed with contents similar to one shown in Figure 4-42.
Figure 4-42 Windows password change denied
This is a standard message that is displayed by Windows when the password change is denied. The log files of the Password Synchronizer and the Password Store component indicate the actual reason why the password cannot be stored in the Password Storage.
Changing the Password StoreThe Password Store used by the Windows Password Synchronizer can be changed at any time after the initial deployment of the solution.
To switch the Windows Password Synchronizer to use the LDAP Password Store:
1. Make sure the LDAP Password Store is configured.
2. Double-click the file idiLDAP.reg placed in the installation directory of the Windows Password Synchronizer.
3. Click Yes to change the registry settings.
4. Restart the machine.
To switch the Windows Password Synchronizer to use the MQe Password Store:
1. Make sure the MQe Password Store is configured.
Note: It is possible to send a password change LDAP entry directly to a Directory Integrator AssemblyLine. However, that is a bad idea. If the AssemblyLine is not running for some reason, the password change event would be lost. It is therefore better to either use MQe, which queues messages, or send an LDAP entry to an LDAP server, where the password change can be picked up through change detection.
Chapter 4. Penguin Financial Incorporated 167

2. Double-click the file idiMQE.reg placed in the installation directory of the Windows Password Synchronizer.
3. Click Yes to change the registry settings.
4. Restart the machine.
For deployment and configuration of the Windows Password Synchronizer, see the Directory Integrator Password Synchronizer Plug-in for Windows documentation (readme_winpwsync_ismp.htm) in the Synchronizer’s installation directory.
IBM Tivoli Directory ServerThe IBM Tivoli Directory Server Password Synchronizer intercepts changes to LDAP passwords in IBM Tivoli Directory Server.
Passwords in Directory Server are stored in the userPassword LDAP attribute. The Directory Server Password Synchronizer intercepts modifications of the userPassword attribute of entries of any object class. Password updates are intercepted for the following types of entry modifications:
� When a new entry is added to the directory and the entry contains the userPassword attribute.
� When an existing entry is modified and one of the modified attributes is the userPassword attribute. This includes the following cases:
– The userPassword attribute is added (for example, the entry did not previously have a userPassword attribute).
– The userPassword attribute is modified (for example, the entry had this attribute and its value is now changed).
– The userPassword attribute is deleted from the entry.
Supported platformsThe IBM Tivoli Directory Server Password Synchronizer is available on the following platforms:
Note: Deletion of entries (users) is not intercepted by the IBM Tivoli Directory Server Password Synchronizer even when the entry contains the userPassword attribute.
Note: The userPassword attribute in Directory Server is multi-valued. Users can have several passwords. The Directory Server Password Synchronizer intercepts and reports a change of any of the password values.
168 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Windows� Linux� Solaris� AIX
Using the Password SynchronizerTwo of the configuration properties of the IBM Tivoli Directory Server Password Synchronizer are of particular interest and directly affect the password synchronization logic:
� syncBase - This property enables restricting the part of the directory tree where passwords are intercepted. The value specified is the LDAP distinguished name (dn) of the root of the tree whose entry passwords you want to intercept. Specifying “o=ibm,c=us”, for example, results in intercepting password update “cn=Kyle Nguyen,ou=Austin,o=IBM,c=US” and skipping the password update for “cn=Henry Nguyen,o=SomeOtherCompany,c=US”. Setting no value to this property results in the interception of password updates in the whole directory tree.
� checkRepository - This property enables turning on or off the functionality that checks for availability of the Password Store. When this property is set to true, the Password Synchronizer first checks whether the Password Store is available. If it is available, the password is changed in the directory, then the password is sent to the Password Store. If the check indicates that the store is not available, the LDAP operation (a part of which is the password update) is rejected on the IBM Tivoli Directory Server. When the checkRepository property is set to false, the Password Synchronizer performs no checks for store availability. The password update is performed in the directory first, then an attempt is made to store it in the Password Store. If the password cannot be stored, a message is logged in the log file (pointed to by the logFile property) to indicate that password synchronization for this user failed.
Stopping the Proxy LayerThe Directory Server Password Synchronizer consists of two layers: a Directory Server plug-in that is hooked into the server, and a Java Proxy Layer. The plug-in intercepts password updates and sends them to the Proxy Layer. The Proxy Layer instantiates the Password Store component on startup and transmits all password updates received by the plug-in to the Password Store. The Proxy Layer is started automatically when Directory Server starts. However, it is not stopped when the Directory Server stops. The Proxy Layer must be stopped explicitly when the Directory Server is shut down. If you do not stop the Java Layer explicitly, the Directory Server Password Synchronizer does not start
Note: The check for availability of the Password Store works with all Password Store components.
Chapter 4. Penguin Financial Incorporated 169

properly the next time the Directory Server is activated. Use the StopProxy utility included in the Directory Server Password Synchronizer to stop the Java Layer.
Changing the Password StoreThe Password Store used by the Directory Server Password Synchronizer can be changed at any time after the initial deployment of the solution.
For deployment and configuration of the IBM Tivoli Directory Server Password Synchronizer as well as for instructions on how to change the Password Store see the Directory Server Password Synchronizer Deployment Instructions (readme_idspwsync_ismp.htm) in the synchronizer’s installation directory.
Lotus DominoThe Domino HTTP Password Synchronizer intercepts changes of the Internet password (also known as the HTTP password) for Notes users.
The following types of password changes are intercepted:
� Administrative password resets
– A user with the necessary rights (usually an administrator) changes his or another user's password without being prompted for the old password:
• The HTTP password is changed by editing the Internet password field of the user's Person document using the Lotus Domino Administrator client.
• The HTTP password is changed by editing the Internet password field of the user's Person document using the Web browser interface.
The Domino HTTP Password Synchronizer is triggered when a user's Person document is edited and saved and the Internet password field of the Person document has been changed.
When synchronizing this type of password change (administrative password reset), the Domino HTTP Password Synchronizer hooks into the internal Domino logic before the password change is committed in Domino. If the Password Synchronizer successfully stores the changed password in the Password Store, the password change is performed in Domino. If the Password Synchronizer cannot store the changed password in the Password Store (for any reason), the password change is not performed in Domino and all other changes to the Person document are also rejected.
170 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Normal user password changes
– A user changes his own password and is prompted for the old password:
• A user changes his password from a Web browser using the Change Password form from the domcfg.nsf (Domino Web server configuration) database.
• A user changes his password from iNotes™.
The Domino HTTP Password Synchronizer is triggered after a user changes his own password through the Password Change Web form or through iNotes. In both cases an administration request document (Change HTTP password in Domino Directory) is posted in the administration requests database. The Password Synchronizer is triggered after a document of this type is successfully processed by the Administration Process in Domino. At this stage the password change is already committed in Domino. If the Password Synchronizer successfully stores the password change in the Password Store, this administration request is marked as processed, so the administration request is not processed again the next time the Password Synchronizer is triggered. If the Password Synchronizer cannot store the password change in the Password Store (for any reason), the administration request is not marked as processed, so the Password Synchronizer attempts to process the administration request again the next time it is triggered.
The Domino HTTP Password Synchronizer can be deployed in the following modes:
� Both administrative password resets and normal user password changes are intercepted.
Important: This only applies for password changes performed by the Lotus Domino Administrator. After entering the new password value in the Internet password field, you must not switch from the Basics page of the opened Person document. If you switch to another page of the Person document before saving the changes, the password is hashed and the Domino HTTP Password Synchronizer is not able to store a version of the password in its own Password Store and no synchronization is triggered in this case.
Note: To enable the Change Password Web form, some setup is necessary in Domino (the Domino Configuration database DOMCFG.NSF must be created and session-based Web authentication must be enabled). For more information see the following articles in the Lotus Domino Administrator help: Creating the Domino Configuration database and Setting up session-based name-and-password authentication.
Chapter 4. Penguin Financial Incorporated 171

� Only normal user password changes are intercepted.
� Only administrative password resets are intercepted.
The component of the Domino HTTP Password Synchronizer that handles password change administration requests is a Domino agent named IDIPWSyncAdminRequestAgent. The IDIPWSyncAdminRequestAgent is a scheduled agent that is automatically (but not immediately) run after documents are created or changed in the administration requests database. It is the Agent Manager process that schedules what time after the actual document change that the agent is run. The Agent Manager checks two Domino Server parameters:
� AMgr_DocUpdateEventDelay - Specifies the delay time, in minutes, that the Agent Manager schedules a document update-triggered agent after a document update event. The default is 5 minutes. The delay time ensures the agent runs no more often than the specified interval, regardless of how frequently document update events occur.
� AMgr_DocUpdateAgentMinInterval - Specifies the minimum elapsed time, in minutes, between executions of the same document update-triggered agent. This lets you control the time interval between executions of a given agent. Default is 30 minutes.
The default values of these parameters mean that the agent is run 5 minutes after an administrative request is created or changed, but no sooner than 30 minutes after a previous run of the same agent.
The AMgr_DocUpdateEventDelay and AMgr_DocUpdateAgentMinInterval parameters can be changed by editing the NOTES.INI file of the Domino Server (if the parameters are not specified there, you can add them, each on a separate line).
Administrative requests stay in the administration requests database for a certain amount of time after they have been posted or last changed. The default value is 7 days (more than any rational values for the AMgr_DocUpdateEventDelay and
Note: Password changes performed through any other interfaces are not intercepted. For example, if passwords are changed through LDAP, or a Notes-Internet password synchronization is enabled, the Domino HTTP Password Synchronizer is not triggered and these password changes are not synchronized.
Note: These parameters affect all document update-triggered agents and setting low values can result in decreased server performance.
172 Robust Data Synchronization with IBM Tivoli Directory Integrator

AMgr_DocUpdateAgentMinInterval parameters). Do the following to check or change the garbage collection interval:
1. In Lotus Domino Administrator, select Files.
2. Right-click the Administration Requests database.
3. Select Properties.
4. Click Replication Settings.
5. Select Space Savers.
The value of interest is Remove documents not modified in the last # days.
When run, the agent processes in a batch all new password changes. It processes 5000 password changes at most. If more than 5000 password changes have been performed since the last run of the agent, it only processes 5000 password changes. The other password changes are processed during subsequent agent runs.
Another important Domino Server parameter that affects the behavior of the IDIPWSyncAdminRequestAgent is the Max LotusScript/Java execution time. This parameter has daytime and nighttime values that specify the maximum time an agent is enabled to run in the corresponding portion of the day. Defaults are 10 minutes for daytime and 15 minutes for nighttime. If the agent exceeds this time frame, it is stopped, and the unprocessed password changes are processed in subsequent runs. Change these values by editing the Max LotusScript/Java execution time fields in the Server Document, section Server Tasks/Agent Manager. Note however that these settings affect all Java and LotusScript agents.
Secure password transferSecure communication is achieved by enabling SSL for the Web-based mechanisms for password change (editing Person documents through the browser, using the Change Password Web form and using iNotes).
When editing Person documents through the Lotus Domino Administrator client, communication is secured by enabling port encryption in Domino.
The Proxy ProcessAfter the password is intercepted (in any of the supported password change mechanisms), it is always passed to the Proxy Process of the Domino HTTP Password Synchronizer. The Proxy Process instantiates a Password Store and uses it to store the password data. The Proxy Process is a Java Domino Server task. It is started by the Domino Server on startup and is stopped when the Domino Server stops. If necessary, the Proxy Process can be stopped and started manually from the Domino Server console.
Chapter 4. Penguin Financial Incorporated 173

To manually stop the Proxy Process, enter the following Domino command:
tell IDIPWSync quit
To manually start the Proxy Process, enter the following Domino command:
load runjava com.ibm.di.plugin.pwsync.domino.DominoProxy
You can check whether the Proxy Process is started by entering the following command on the Domino console:
show tasks
If the Proxy Process is started, a line for the Directory Integrator Password Sync task (which is the Password Synchronizer Proxy Process) appears in the list. For example:
IDI Password Sync Listen for connect requests on TCP Port:19003
Synchronizing the access to the Password StoreSeveral password changes in Domino can be made at the same time from multiple users and from different interfaces. The Domino HTTP Password Synchronizer works with multiple threads of execution and attempts multithread access to the Password Store.
In cases when multithread access to the Password Store might be a problem (such as when the MQe Password Store is used), you can synchronize the access to the Password Store. The configuration file of the Domino HTTP Password Synchronizer ididompwsync.props contains a property named proxy.syncStoreAccess. Set this property to true if you want to synchronize the access to the Password Store. Set this property to false if you want to enable multithread access to the Password Store.
The Domino HTTP Password Synchronizer supports Domino R6 and all platforms supported by Domino R6.
Changing the Password StoreThe Password Store used by the Domino HTTP Password Synchronizer can be changed at any time after the initial deployment of the solution:
Note: It is recommended to set proxy.syncStoreAccess to true when using the MQe Password Store because MQ Everyplace® QueueManagers are not thread-safe. You can safely use multithreaded access when using the LDAP Password Store.
174 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Switching the Domino HTTP Password Synchronizer to use the LDAP Password Store:
a. Make sure the LDAP Password Store is configured. The LDAP Password Store configuration file must be placed in the same folder where the Domino HTTP Password Synchronizer config file (ididompwsync.props) is placed.
b. In the Domino HTTP Password Synchronizer config file (ididompwsync.props), place the following value for the proxy.storeClassName property:
proxy.storeClassName=com.ibm.di.plugin.pwsync.LDAPPasswordSynchronizer
The class com.ibm.di.plugin.pwsync.LDAPPasswordSynchronizer is included in the proxy.jar file shipped with the LDAP Password Store.
c. Restart the Proxy Process of the Domino HTTP Password Synchronizer (see The Proxy Process).
� Switching the Domino HTTP Password Synchronizer to use the MQe Password Store:
a. Make sure the MQe Password Store is configured. The MQe Password Store configuration file must be placed in the same folder where the Domino HTTP Password Synchronizer config file (ididompwsync.props) is placed.
b. In the Domino HTTP Password Synchronizer config file (ididompwsync.props), place the following value for the proxy.storeClassName property:
proxy.storeClassName=com.ibm.di.plugin.mqe.store.MQePasswordStore
The class com.ibm.di.plugin.mqe.store.MQePasswordStore is included in the mqepwstore.jar file shipped with the MQe Password Store.
c. Restart the Proxy Process of the Domino HTTP Password Synchronizer (see The Proxy Process).
For deployment and configuration of the Domino HTTP Password Synchronizer see the Domino HTTP Password Synchronizer Deployment Instructions for Domino R6 (readme_dominopwsync_ismp.htm).
Sun ONE Directory ServerThe Sun ONE Directory Server Password Synchronizer intercepts changes to LDAP passwords in Sun ONE Directory Server.
Passwords in Sun ONE Directory Server are stored in the userPassword LDAP attribute. The Password Synchronizer intercepts updates of the userPassword
Chapter 4. Penguin Financial Incorporated 175

LDAP attribute. The Sun ONE Directory Server Password Synchronizer intercepts modifications of the userPassword attribute of entries of any object class. Password updates are intercepted for the following types of entry modifications:
� When a new entry is added in the directory and the entry contains the userPassword attribute.
� When an existing entry is modified and one of the modified attributes is the userPassword attribute. This includes the following cases:
– The userPassword attribute is added (for example, the entry did not have a userPassword attribute before).
– The userPassword attribute is modified (for example, the entry had this attribute and its value is now changed).
– The userPassword attribute is deleted from the entry.
Supported platformsThe Sun ONE Directory Server Password Synchronizer is available for the Sun ONE Directory Server on the following platforms:
� Windows� Linux� Solaris� AIX
Using the Password SynchronizerTwo of the configuration properties of the Sun ONE Directory Server Password Synchronizer are of particular interest and directly affect the password synchronization logic:
� syncBase - This property enables restricting the part of the directory tree where passwords are intercepted. The value specified is the LDAP distinguished name (dn) of the root of the tree whose entry' passwords you want to intercept. Specifying "o=ibm,c=us", for example, results in intercepting password update "cn=Kyle Nguyen,ou=Austin,o=IBM,c=US" and skipping the
Note: Deletion of complete entries is not intercepted by the Sun ONE Directory Server Password Synchronizer even when the entry contains the userPassword attribute.
Note: The userPassword attribute in Sun ONE Directory Server is multi-valued. Users might have several passwords. The Sun ONE Directory Server Password Synchronizer intercepts and reports any change of any of the password values.
176 Robust Data Synchronization with IBM Tivoli Directory Integrator

password update "cn=Henry Nguyen,o=SomeOtherCompany,c=US". Setting no value to this property results in the interception of password updates in the whole directory tree.
� checkRepository - This property enables turning on or off the functionality that checks for availability of the Password Store. When this property is set to true, the Password Synchronizer first checks whether the Password Store is available. If it is available, the password is changed in the directory, then the password is sent to the Password Store. If the check indicates that the storage is not available, the LDAP operation (a part of which is the password update) is rejected on the Sun ONE Directory Server. When the checkRepository property is set to false, the Password Synchronizer performs no checks for storage availability. The password update is performed in the directory first, then an attempt is made to store it in the Password Store. If the password cannot be stored, a message is logged in the log file (pointed to by the logFile property) to indicate that password synchronization for this user failed.
Changing the Password StoreThe Password Store used by the Sun ONE Directory Server Password Synchronizer can be changed at any time after the initial deployment of the solution.
For deployment and configuration of the Sun ONE Directory Server Password Synchronizer as well as for instructions on how to change the Password Store see Sun ONE Directory Server Password Synchronizer Deployment Instructions (readme_sundspwsync_ismp.htm) in the Synchronizer’s installation directory.
Password StoresPassword Stores are components that receive the intercepted passwords, encrypt and store them in locations that can be accessed by the IBM Tivoli Directory Integrator. The following Password Stores are currently available:
� LDAP Password Store� MQe Password Store
LDAP Password StoreThe LDAP Password Store provides the function necessary to store the intercepted user passwords in an LDAP directory server.
Supported DirectoriesThe LDAP Password Store is available on the following directories:
Note: The check for availability of the Password Store works with all Password Store components.
Chapter 4. Penguin Financial Incorporated 177

� IBM Tivoli Directory Server� Microsoft Active Directory� Sun ONE Directory Server
Using the Password StoreFor each user whose password has been intercepted, the LDAP Password Store maintains an LDAP entry in the storage LDAP directory (the container where the storage entries are added and modified is specified by the suffix property of the LDAP Password Store).
The entry kept in the storage directory always contains the passwords currently used by the original user on the target system. To achieve this, the LDAP Password Store updates the state of the entry in the storage directory whenever the LDAP Password Store receives notification for a password update from the Password Synchronizer.
The LDAP Password Store receives the following data from the Password Synchronizer:
� User identifier (a string)� Type of the password modification� A list of password values
User IdentifierThe user identifier is used for the relative distinguished name of the entry stored in the LDAP directory. For example, if the user identifier is "john" and the suffix property value is "dc=somedc,o=ibm,c=us", then the distinguished name of the entry stored is "ibm-diUserId=john, dc=somedc,o=ibm,c=us".
Special attention is necessary when the LDAP Password Store is used with the IBM Tivoli Directory Server Password Synchronizer or with the Sun ONE Directory Server Password Synchronizer.
The Password Synchronizer reports the LDAP distinguished name of the user for which the password has been changed. For example, "cn=john,o=somecompany,c=us". The LDAP Password Store takes the first element of the distinguished name ("john") to construct the distinguished name of the entry on the storage LDAP directory, for example, "ibm-diUserId=john, dc=somedc,o=ibm,c=us". Therefore the context information (department, company, country, and so forth) is lost. If there are two individuals on the target system with equal names but in different departments, for example, "cn=Kyle Nguyen,ou=dept_1,o=ibm,c=us" and "cn=Kyle Nguyen,ou=dept_2,o=ibm,c=us", they are indistinguishable for the Password Store, and the Password Store acts as though they represent the same person.
178 Robust Data Synchronization with IBM Tivoli Directory Integrator

Type of password modification and List of password valuesThe type of password modification indicates whether the password values have been replaced, new values have been added, or certain values have been deleted. Using this information and the list of passwords representing the change, the Password Store duplicates the change on the entry in the storage directory.
The type of password modification makes sense only when the password can have multiple values (IBM Tivoli Directory Server, Sun ONE Directory Server). When the passwords on the target system are single-valued (Windows), the password modification type is always replace.
When the password (with all its values) is deleted from the target system, the entry in the storage directory is modified so that it does not have value for the LDAP attribute used to store the passwords.
Possible password retrieval from IBM Tivoli Directory IntegratorHere is a possible mechanism for retrieving passwords stored in an LDAP Server by the LDAP Password Store:
An EventHandler is configured to listen for changes in the LDAP Directory used for storage. Whenever the EventHandler detects that an entry has been added or modified in the Password Store container, it starts an AssemblyLine, passing it identification of the modified entry. The AssemblyLine uses an LDAP Connector to read the modified entry, then decrypts the updated password values and propagates the values to systems that must be kept synchronized.
MQ Everyplace Password StoreMQ Everyplace Password Store (MQe Password Store) provides the function necessary to store user passwords into IBM WebSphere MQ Everyplace and transfer user passwords from MQ Everyplace to IBM Tivoli Directory Integrator.
The MQe Password Store package consists of the Storage Component and the MQe Password Store Connector. The Storage Component is actually the Password Store invoked by the Password Synchronizer. The MQe Password Store Connector is a specialized Connector on the IBM Tivoli Directory Integrator side that can retrieve passwords stored into MQ Everyplace.
Solution structure and workflowTwo MQ Everyplace QueueManagers are instantiated and configured: one on the target system, and one on the Directory Integrator machine.
On the QueueManager on the IBM Tivoli Directory Integrator, a local queue is defined. On the QueueManager on the target system, an asynchronous remote queue that references the local queue on the IBM Tivoli Directory Integrator
Chapter 4. Penguin Financial Incorporated 179

QueueManager is defined. A connection and listener object are defined in the QueueManagers to enable network communication.
The following is the workflow for the MQe Password Store:
1. The Password Synchronizer intercepts a password change and sends it to the Storage Component.
2. The Storage Component wraps the password into an MQe message and sends the message to the remote queue on the local QueueManager.
3. The MQe QueueManager on the Storage Component automatically sends the message to the QueueManager on the IBM Tivoli Directory Integrator.
4. The MQe Password Store Connector connects to the local QueueManager and reads the password update messages from the local queue.
Supported WebSphere MQ Everyplace versionThe MQe Password Store contains WebSphere MQ Everyplace v.2.0.0.4 embedded. No separate installation of WebSphere MQ Everyplace is necessary.
Part of the MQe Password Store deployment and configuration is the instantiation and configuration of the MQ Everyplace QueueManagers.
Once the MQe QueueManagers are instantiated and configured it is not recommended to change their configuration. If a change is necessary, the preferred method is to delete the QueueManager and recreate it again following the MQe Password Store deployment instructions. If however, for any reason, you are going to use an MQe administration tool to change QueueManagers settings, make sure this tool is compatible with QueueManagers created with MQ Everyplace v.2.0.0.4.
Using the Password StoreThe LDAP Password Store maintains state of the user's passwords. It keeps the passwords in the LDAP storage entries up to date with the passwords of the corresponding users. In contrast, the MQe Password Store does not maintain state of the user's passwords; it just reports the changes. Each message tells how the passwords of a user have changed, not what the user's password values are.
This difference is important for the design of the AssemblyLine that propagates the password changes to other systems, especially when multi-valued passwords are supported. In the case of the LDAP Password Store, the AssemblyLine must replace the passwords in the systems it keeps synchronized with the passwords read from the LDAP storage. When the MQe Password Store is used, the AssemblyLine must duplicate just the reported password change on the other system.
180 Robust Data Synchronization with IBM Tivoli Directory Integrator

Each MQe message contains the following information:
� User identifier (a string)� Type of the password modification� A list of password values
User IdentifierThe user identifier is the string value that identifies the user in the target system (for LDAP Servers this is the LDAP distinguished name; for Windows this is the user account name). The AssemblyLine must locate the users on the systems that are synchronized based on this user identifier.
Type of password modification and List of password valuesThe type of password modification might be one of replace, add or delete and correspondingly indicates that the password values have been replaced, that new values have been added, or certain values have been deleted.
Add and delete make sense only when multiple password values are supported by the target system. If the target system does not support multiple passwords for a single user, the type is always replace.
Depending on the type of password modification, the list of password values means the following:
replace The passwords for the specified user are replaced with the passwords specified in the list of password values.
add The passwords from the specified list of password values are added to the user's passwords (for example, new passwords are created for this user and the old ones are still in effect).
delete The passwords from the specified list of passwords values are removed from the user's passwords (for example, some of the user's passwords are deleted and the user can no longer use them).
Note: When the target system is an LDAP Server, the MQe Password Store reports the whole LDAP distinguished name as user identifier (for example, "cn=john,o=somecompany,c=us"), in contrast to the LDAP Password Store, where only the value of the first element ("john") is used.
Note: The type of password modification refers to the password attribute, not to the entry or user for which the password is modified. Thus add means that new password values are added to the user's password attribute and not that a new user is added in the system. On the other hand, when a new user is added in the system, it is appropriate to receive modification type replace because of the way the user password is internally set in the target system.
Chapter 4. Penguin Financial Incorporated 181

Availability issuesThe QueueManager on the Storage Component is automatically started and stopped when the Storage Component is started and stopped.
The QueueManager on the Directory Integrator is automatically started and stopped when the MQe Password Store Connector is correspondingly initialized and stopped. This means that the QueueManager on the Storage Component is available only when the Storage Component is available and the QueueManager on the Directory Integrator is available only when the AssemblyLine with the MQe Password Store Connector is running.
There are three interesting cases regarding solution components availability:
� Both QueueManagers are available (the Password Synchronizer is running and the AssemblyLine is running).
Each new intercepted password is immediately transferred between the QueueManagers and retrieved by the MQe Password Store Connector.
� Only the QueueManager on the Storage Component is available (the Password Synchronizer is running and the AssemblyLine is not running).
Each new intercepted message is stored on the local disk by the Storage Component QueueManager. When the AssemblyLine is started, all messages stored offline are automatically transferred to the QueueManager on the Directory Integrator and the MQe Password Store Connector retrieves them from there.
� Only the QueueManager on the Directory Integrator is available (the Password Synchronizer is not running and the AssemblyLine is running).
There are no new messages in this case because the Password Synchronizer is not running. When the Password Synchronizer is started, all messages previously stored on the Storage Component QueueManager are automatically transferred to the QueueManager on the Directory Integrator and the MQe Password Store Connector retrieves them from there.
Specialized ConnectorsThese are either standard or specialized Directory Integrator Connectors. They connect to locations where the intercepted and encrypted passwords are stored and are able to retrieve and decrypt the passwords.
Note: No messages (password updates) are lost regardless of the availability of the Password Synchronizer and the MQe Password Store Connector and when they are started and stopped. However, for message transfer to take place, both QueueManagers must be available at the same time for at least a few minutes.
182 Robust Data Synchronization with IBM Tivoli Directory Integrator

� MQe Password Store Connector
Provides the function necessary to retrieve password update messages from IBM WebSphere MQ Everyplace and send them to Directory Integrator.
Besides the specialized components for password synchronization, there are other standard IBM Tivoli Directory Integrator components that can fit into a password synchronization solution. For example, if the LDAP Password Store is used to store changes into an LDAP server, the LDAP Connector can subsequently retrieve the intercepted passwords.
4.5.2 ArchitectureThere are several layers in the IBM Tivoli Directory Integrator password synchronization architecture.
Figure 4-43 Password store architecture
The target system on the diagram designates the software system where we want to intercept password changes. The Password Synchronizer component hooks into the target system using custom interfaces provided by the target system. The Password Synchronizer component intercepts password changes as they occur in the target system and before the password is hashed irreversibly.
Chapter 4. Penguin Financial Incorporated 183

Also, a Password Store component is deployed on the target system. Once the Password Synchronizer intercepts a password change it immediately sends the password to the Password Store. The Password Store encrypts the password and sends it to a Password Storage.
The password store interfaceA key element of the Directory Integrator password synchronization architecture is the Password Store Interface. The Password Store Interface mediates between the Password Synchronizer and the Password Store components. Password Store components implement this interface and Password Synchronizer components use this interface to interact with the Password Stores. This enables using any Password Synchronizer with any Password Store.
Also, the Password Store used by a Password Synchronizer can be easily changed when necessary. For example, a Password Synchronizer for Directory Server is deployed and configured to use the LDAP Password Store. After time it is decided that you need to use MQe Password Store. Then you need to configure the MQe Password Store, change a single property of the Password Synchronizer, and restart the Directory Server. New password changes are stored in MQ Everyplace. It is not necessary to install the solution again.
The Password Storage is the second layer in the architecture and represents a persistent storage system (for example, an LDAP directory, or WebSphere MQ Everyplace) where the intercepted and already-encrypted passwords are stored in a form and location that are accessible from the IBM Tivoli Directory Integrator. The Password Storage can reside on the target system machine or on another network machine.
The third layer of the architecture is represented by the IBM Tivoli Directory Integrator. Directory Integrator uses a Connector to connect to the Password
Note: Working with passwords requires certain considerations to prevent password compromise. The Password Store provides the capability to encrypt the password before sending it to the LDAP Server or the MQe queue. The Password Store also has the ability to communicate through Secure Socket Layer (SSL). It is recommended that at least one of these measures be used to prevent compromise, or both if feasible.
Additionally, the configuration file of the Password Store must be protected from unauthorized viewing and modification. The configuration file references the security data needed to certify as a legitimate target for the password. The configuration file also references security data for encrypting the password and communicating with the data store. Malevolent modifications of the file could allow for password compromise.
184 Robust Data Synchronization with IBM Tivoli Directory Integrator

Storage and retrieve the passwords stored there. Once in the Directory Integrator, the passwords are decrypted and made available to the AssemblyLine that synchronizes them with other systems. Directory Integrator can be deployed on a machine different than the target system and Password Storage machines.
The next layer in the architecture (in the data flow direction) is represented by the systems whose passwords are synchronized with the target system. The password synchronization AssemblyLine is responsible for connecting to these systems and updating the passwords there.
Architecture optionsFor simplicity, the previous diagram shows password interception on a single target system. Actually, a password synchronization solution might need to intercept password changes on several target systems. This is where the layered password synchronization architecture brings additional value in terms of scalability and customization options:
� The Password Store components of several target systems can be configured to store the intercepted passwords in the same Password Storage. The Directory Integrator AssemblyLine uses a single Connector to connect to the Password Storage and is not affected by the number of target systems whose passwords are intercepted and stored in this Password Storage.
� The AssemblyLine can be configured to connect to several Password Storages (using several Iterator Connectors). This is useful when different Password Storages have to be used, or distinction of the target systems on IBM Tivoli Directory Integrator is necessary.
In either (or both) of these previous approaches, it is possible to add, remove or change target systems in an already existing solution by focusing mainly on the new functionality without affecting the rest of the solution.
On the other end of the data flow, where passwords are updated in systems that you want to keep synchronized, the password synchronization architecture benefits from the inherent scalability of the IBM Tivoli Directory Integrator. Updating passwords on yet another system might be as easy as adding a new Connector in the password synchronization AssemblyLine.
In the case where the target system is also one of the systems updated with the intercepted passwords from other systems, special care must be taken to avoid circular updates. The implementation on the Directory Integrator side must build logic that does not update a system with passwords intercepted on that same system.
Chapter 4. Penguin Financial Incorporated 185

SecurityPublic-private key infrastructure is used to provide secure transport and intermediate storage of password data.
The Password Store components use a public key to encrypt password data before sending it on the wire and storing it in the Password Storage. The Directory Integrator AssemblyLine or specialized Connectors have the corresponding private key and use it to decrypt password data retrieved from the Password Storage.
An additional layer of security is added by Password Store components supporting SSL.
ReliabilityFunctionality for preventing and dealing with possible password desynchronization is built into the password synchronization workflow.
The Password Synchronizer and Password Store components together provide functionality to deal with cases where an external storage system is not available or malfunctions.
The Password Store always reports to the Password Synchronizer whether or not the password was successfully stored into the Password Storage. The Password Synchronizer component can do the following to prevent or handle possible password desynchronizations:
� The Password Synchronizer can cancel the password change in the target system after the Password Store reports that the password is not stored into the Password Storage (due to availability or other reasons), where enabled.
� Where the target system does not enable cancel or rollback on the password change (which you want to do on unsuccessful storage), the failure is logged with information about the user whose password is not stored in the Password Storage. An Administrator can inspect the log and resolve desynchronized passwords.
4.5.3 Detailed data identificationBased on our final customer scenario architecture shown in Figure 4-3 on page 106 and the current IT environment, we will identify the data related to our password synchronization scenario in more detail in this section. We examine the data location, data access, the initial data format and some unique data attributes.
186 Robust Data Synchronization with IBM Tivoli Directory Integrator

Data locationFollowing the password synchronization flow, data can be located either at the password change source, Password Store, Password Storage, or password update target. Details for each location, Active Directory in Table 4-15, Directory Server in Table 4-16, Domino in Table 4-17 on page 187, are provided in the following tables.
Table 4-15 Active Directory parameters
Table 4-16 IBM Tivoli Directory Server parameters
Table 4-17 Domino parameters
Parameter Value
Hostname mf-root1
Domain monolithic-fin.com
IP Address 9.3.5.178
Platform Windows
Repository Active Directory
Search base dc=monolithic-fin,dc=com
Access LDAPS
Unique data sAMAccountName
Parameter Value
Hostname pf-used01
Domain penguin-fin.com
IP Address 9.3.5.177
Platform Linux
Repository IBM Tivoli Directory Server
Search base dc=penguin-fin,dc=com
Access LDAP
Unique data $dn
Parameter Value
Hostname pf-usmail01
Chapter 4. Penguin Financial Incorporated 187

Data accessIn order to retrieve password changes from Active Directory it is necessary to change the security policy and enable password complexity. This is implemented as part of the password policy enforcement based on functional requirement F.
In order to update passwords in Active Directory it is necessary to use certificate services and connect to Active Directory using SSL.
To update passwords in IBM Tivoli Directory Server an administrative account is needed. We will use cn=root from Phase 1 in our scenario.
For the HTTP password update in Domino at least the Editor role for the address book database is required.
The MQe part is internal to the solution so we do not need to consider any data access requirements.
Initial data formatBased on “Password Stores” on page 177, the Password Synchronizer always stores the following attributes in the Password Store:
UserId User identifier (string)
UpdateType Type of the password modification
Passwords A list of password values
As we do not deal with multiple password values in our scenario, the value for the type of the password modification should always be replace. The user identifier and password should be a string.
Domain penguin-fin.com
IP Address 9.3.5.179
Platform Windows
Repository Domino
Database names.nsf
Database View People
Access IIOP
Unique data FullName
Parameter Value
188 Robust Data Synchronization with IBM Tivoli Directory Integrator

Unique dataUsers in our systems are distinguished by these unique identifiers:
� sAMAccountName for Active Directory
� $dn for IBM Tivoli Directory Server
� FullName for Domino
sAMAccountname and FullName attributes are mapped to attributes stored in IBM Tivoli Directory Server as shown in Table 4-18.
Table 4-18 Unique data
Not all attributes exist in all repositories, that is why some fields in the above and following tables are empty.
Updated attributesPassword synchronization is all about passwords. In addition, for every password change a time is recorded in a special attribute pfLastPWChange.
Table 4-19 Updated attributes
The pfLastPWChange value is calculated when a password update is allowed and stored after the password update is executed.
Active Directory Enterprise Directory Domino
$dn
pfNotesFullName FullName
sAMAccountName pfsAMAccountName
Note: The attributes pfNotesFullName and pfsAMAccountName are optional attributes of the pfPerson objectclass introduced in Phase 1 and are used for linking entries from IBM Tivoli Directory Server with Domino and Active Directory.
Work object Active Directory Enterprise Directory
Domino
Passwords userPassword userPassword HTTPPassword
pfLastPWChange pfLastPWChange
Chapter 4. Penguin Financial Incorporated 189

4.5.4 Plan the data flowsThe goal of planning the data flow is to create a flowchart document of the solution. In addition to the previously identified data we need to determine the authoritative attributes, any unique link criteria, special conditions, and a final data format. We also need to understand if a phased approach to password synchronization makes sense.
Authoritative attributesWe have two data sources, Microsoft Active Directory and IBM Tivoli Directory Server, authoritative for passwords at the same time, but the rule is very simple—values are overwritten with every update.
The attribute pfLastPWChange is the single authoritative entry for a timestamp calculation.
The mapping for both authoritative attributes is shown in Table 4-18 on page 189.
Unique link criteriaTo make all the necessary links for updating password changes we use the initial data defined in “Initial data format” on page 188, and the unique data defined in “Unique data” on page 189 according to the mapping defined in Table 4-20.
Table 4-20 Unique link criteria
Note: The attribute pfLastPWChange is an optional attribute of the pfPerson objectclass introduced in Phase 1 and is used to store a timestamp for the last successful password change update.
Action Source Target Link criteria
Get user ITDS $dn=$UserId
Get user AD sAMAccountName=$UserId
Get attributes ITDS ITDS $dn=$UserId
Get attributes AD ITDS pfsAMAccountName=$UserId
Update password Domino FullName=$pfNotesFullName
Update password ITDS AD sAMAccountName=$pfsAMAccountName
Update password AD ITDS pfsAMAccountName=$UserId
Update timestamp ITDS ITDS $dn=$UserId
190 Robust Data Synchronization with IBM Tivoli Directory Integrator

As you may have noticed in the above table, we are not able to update passwords in Domino and/or Active Directory (Target) using UserId for building the link criteria, instead we use the link attributes stored in Directory Server.
A side effect of this is the way our AssemblyLine for password synchronization is built. First we are forced to read the necessary attributes before we can continue with password updates.
Special conditionsOnly users created in Active Directory have an account there. When password changes are updated from Directory Server to Active Directory there is no match in Active Directory for an existing Domino user. This is normal, but in order to maintain complete control over the password synchronization we send a message to the predefined systems (log, file, mail, and so on) for further inspection.
Final data formatFor all attributes identified in “Unique data” on page 189 we define the following data formats as shown in Table 4-21.
Table 4-21 Final data format
Update timestamp AD ITDS pfsAMAccountName=$UserId
Note: For better readability we have used the following abbreviations in the previous table; AD for Active Directory and ITDS for IBM Tivoli Directory Server.
Attribute Data format
sAMAccountName String
$dn String
FullName String
Passwords String
pfLastPWChange String
Action Source Target Link criteria
Chapter 4. Penguin Financial Incorporated 191

The passwords attribute is a string, but what it may contain is defined by the most restrictive default password policy used on the target systems. In our scenario, as described in “Data access” on page 188, password complexity must be enabled for Windows. Password complexity is implemented via Passfilt.dll module with the following hard-coded requirements:
� Passwords must be at least six characters long.
� Passwords may not contain your user name or any part of your full name.
� Passwords must contain characters from at least three of the following four classes:
English upper case letters A, B, C, ... Z
English lower case letters a, b, c, ... z
Westernized Arabic numerals 0, 1, 2, ... 9
Non-alphanumeric characters Punctuation marks and other symbols
Data cleanupAfter a successful password update there is nothing to be cleaned up from the data source, because when the password change is read from the Password Storage it is in fact picked up from it and thus the Password Storage is cleaned up on-the-fly.
Phased approachFrom the architecture point of view it is wise to utilize a phased approach when planning your password synchronization data flow, because the whole process from intercepting a password change all the way to commencing the update on the target system consists of two independent steps:
� Step 1: The changed password is intercepted on the source system and stored into the Password Storage.
� Step 2: The password is picked up from Password Storage and updated on the target system(s).
Note: The attribute pfLastPWChange is a string, but the value inside is in fact the number representing the time in milliseconds from Thursday, Jan 1st 1970 00:00:00 GMT, as defined by ECMAa.
a. ECMA International (http://www.ecma-international.org/) is an industry as-sociation founded in 1961, dedicated to the standardization of information andcommunication systems.
192 Robust Data Synchronization with IBM Tivoli Directory Integrator

We can easily distinguish steps by components involved in each one and use them for the same two steps definition as before:
� Password Store phase� AssemblyLine phase
FrequencyPassword synchronization is a real-time operation. Passwords are to be synchronized on every password change. The source data is provided by the Password Storage which is being checked continuously for any new data to be updated.
Often this process is so fast that it has to be delayed. For example, when a new user (who may have just joined the company) is created in a source repository (Active Directory), the password synchronization process is triggered immediately and the password is processed in order to update a target repository (Domino) even before the new user ID is provisioned on that platform.
FlowchartAfter identifying all the data, flows, and phases, using the architecture defined in 4.3, “Solution design” on page 96 and shown in Figure 4-3 on page 106, we can generate our flowchart shown in Figure 4-44 on page 194 to graphically represent the overall password synchronization solution data flow.
The flowchart is also a very useful tool to verify the solution in theory and review results of data identification and planning.
Chapter 4. Penguin Financial Incorporated 193

Figure 4-44 AssemblyLine flowchart
Get Password
get Attributes$dn=$UserId
set Source=ITDS
TimeStamp OK?
Update Notes PWFullName=$pfNotesFullName
Update AD PWsAMAccountName=$pfsAMAccountName
Update TimeStamp$dn=$UserId
From ITDS?Source=ITDS
ITDS Start AD Start
PW Store
PW Storage
From ITDS?$dn=$UserId
PW Store
From AD?sAMAccountName=$UserId
get AttributespfsAMAccountName=$UserId
set Source=AD
Update ITDS PWpfsAMAccountName=$UserId
From AD?Source=AD
Update Notes PWFullName=$pfNotesFullName
Update TimeStamppfsAMAccountName=$UserId
UserIdPasswordsUpdateType
pfsAMAccountNamepfNotesFullNamepfLastPWChangeSourcemail
HTTPPassword
userPassword
pfLastPWChange
Attributes
194 Robust Data Synchronization with IBM Tivoli Directory Integrator

Let us take a closer look at the flowchart following the phases defined in the “Phased approach” on page 192.
Password Store PhaseA password change is intercepted in two locations. In IBM Tivoli Directory Server as a result of changing a password via the self-service portlet, or in Active Directory if a user used a Windows mechanism to initiate a password change. These are the two starting points for our data flow.
Each Password Synchronizer sends the intercepted data to the Password Store on the local system. This is where the password is encrypted before delivery to the common Password Storage component on the Enterprise Directory. There the encrypted data is available to be picked up by the AssemblyLine for decryption and further processing.
AssemblyLine PhaseThe first Connector in the AssemblyLine runs in Iterator mode to process the entries from the Password Storage one by one. Each picked up entry is first decrypted and then sent as the feed to the rest of the AssemblyLine if the UpdateType is correct. We do not expect multiple values for passwords, so the only valid UpdateType is replace, otherwise the entry is skipped.
Next we need to determine the source of the password change in order to be able to generate the proper link criteria and retrieve additional attributes in the following step. We could perform this part using script components, but then the data flow would not be easy to maintain. The Lookup mode is used for checking on the source in the following order: first we see if the source is IBM Tivoli Directory Server, if it is not we try Active Directory, and if the source is still unknown the entry is skipped.
When we know the source of the password change, we look up IBM Tivoli Directory Server to retrieve the additional attributes needed for further processing. In addition the Source attribute is set for later use.
At this point in time the frequency problem mentioned in “Frequency” on page 193 might occur. A user account created in Active Directory may still not be created in IBM Tivoli Directory Server although the password is already prepared for update. In this kind of situation the update needs to be delayed for a few seconds in order to give the user creation process enough time to finish.
One of the attributes available now is pfLastPWChange used for the timestamp calculation and we use it to check if the user is allowed to change the password. If this is not the case, the mail attribute is used to notify the user about this condition and the entry is skipped; otherwise the flow continues on to the update part.
Chapter 4. Penguin Financial Incorporated 195

Just before we update the target system(s), we once again verify the source; this time using the Source attribute and then continue the flow in the corresponding branch. There are two reasons for separate branches. One is that unique link criteria have to be used for updates as described in “Unique link criteria” on page 190, and the second is to create an AssemblyLine that is easy to understand and maintain.
We update both remaining targets in sequence. If successful, the final step is to update the timestamp.
This is the second point in time to consider the frequency problem mentioned in “Frequency” on page 193. The user created in Active Directory now exists in IBM Tivoli Directory Server, otherwise the flow would not have reached this point, but may not yet exist in Domino. If this is the case the update needs to be delayed for a few seconds in order to allow enough time for the user account creation process to finish. In a worst case scenario there are two delays in a row, defined by delay variables in the External Properties file.
Reaching the end of the AssemblyLine the flow returns to the first Connector to pick up or wait for a new entry.
4.5.5 Review resultsAs a result of our planning effort the following tables provide a document outline that can be used to instrument our solution.
The password synchronization data flow Connectors are shown in tables below:
Table 4-22 getMQ Connector
Parameter Description
Name getMQ
Data source MQe
Connector type MQePasswordStoreConnector
Connector mode Iterator
Parser None
Attributes Passwords
UpdateType
UserId
Attribute Map Input
196 Robust Data Synchronization with IBM Tivoli Directory Integrator

Table 4-23 getITDS Connector
Table 4-24 getAD Connector
Link criteria None
Special conditions Decrypt password
Security concerns None
Parameter Description
Name getITDS
Data source IBM Tivoli Directory Server
Connector type LDAP
Connector mode Lookup
Parser None
Attributes Mail
Source
pfLastPWChange
pfNotesFullName
pfsAMAccountName
Attribute Map Input
Link criteria $dn=UserId
Special conditions None
Security concerns None
Parameter Description
Name getAD
Data source IBM Tivoli Directory Server
Connector type LDAP
Connector mode Lookup
Parser None
Parameter Description
Chapter 4. Penguin Financial Incorporated 197

Table 4-25 updateNotesFrom... Connector
Table 4-26 updateAD Connector
Attributes Mail
Source
pfLastPWChange
pfNotesFullName
pfsAMAccountName
Attribute Map Input
Link criteria pfsAMAccountName=$UserId
Special conditions Delay for users created in AD
Security concerns None
Parameter Description
Name updateNotesFrom...
Data source Domino
Connector type Notes
Connector mode Update
Parser None
Attributes HTTPPassword
Attribute Map Output
Link criteria FullName=$pfNotesFullName
Special conditions Delay for users created in AD
Security concerns Password encryption
Editor role in address book database
Parameter Description
Name updateAD
Data source Active Directory
Connector type LDAP
Parameter Description
198 Robust Data Synchronization with IBM Tivoli Directory Integrator

Table 4-27 updateITDS Connector
Table 4-28 updateTimeStampFromAD Connector
Connector mode Update
Parser None
Attributes userPassword
Attribute Map Output
Link criteria sAMAccountName=$pfsAMAccountName
Special conditions Only originating users have an account
Security concerns Use SSL
Parameter Description
Name updateITDS
Data source IBM Tivoli Directory Server
Connector type LDAP
Connector mode Update
Parser None
Attributes userPassword
Attribute Map Output
Link criteria pfsAMAccountName=$UserId
Special conditions None
Security concerns None
Parameter Description
Name updateTimeStampFromAD
Data source IBM Tivoli Directory Server
Connector type LDAP
Connector mode Update
Parser None
Attributes pfLastPWChange
Parameter Description
Chapter 4. Penguin Financial Incorporated 199

Table 4-29 updateTimeStampFromITDS
4.5.6 Instrument and test a solutionIn this section we create and test our solution based on the phased approach explained in “Phased approach” on page 192.
We begin with the IBM Tivoli Directory Integrator installation on our Enterprise Directory system as decided in 4.3.2, “Architectural decisions for phase 2” on page 101. Our installation directory is /opt/IBM/ITDI/ and we will refer to it as root_dir, the solutions directory is /opt/IBM/Solutions and will be refered to as solution_dir.
Password synchronization phaseInstallation, configuration, and testing in this phase is performed in separate steps for all components that are needed for the password change to be intercepted on each source and transferred to the Password Storage for pick up from an AssemblyLine.
Attribute Map Output
Link criteria pfsAMAccountname=$UserId
Special conditions None
Security concerns None
Parameter Value
Name updateTimeStampFromITDS
Data source IBM Tivoli Directory Server
Connector Type LDAP
Connector mode Update
Parser None
Attributes pfLastPWChange
Attribute map Output
Link criteria $dn=$UserId
Special conditions None
Security concerns None
Parameter Description
200 Robust Data Synchronization with IBM Tivoli Directory Integrator

We follow this installation sequence:
1. Windows Password synchronization module setup
2. IBM Tivoli Directory Server Password synchronization module setup
3. Password Storage setup
4. MQe QueueManagers testing
Windows Password synchronization module setupFollow these steps.
1. Installation
After launching the installer, the IBM Tivoli Directory Integrator Password Synchronization Plugin for Windows NT/2000 is selected for the product and WebSphere MQ Everyplace for the storage method. The module is installed in C:\IBM\DiPlugins\IDI and will be refered to as ad_plugin_dir.
2. Installation verification
If the installation was successful, then you can find the values shown in Table 4-30 in the Windows registry under the directory HKEY_LOCAL_MACHINE\SOFTWARE\IBM\Tivoli Identity Manager\Windows Password Synchronizer.
Table 4-30 Windows Password synchronizer installation verification
3. Enablement setting verification
If enablement is set, then a timpwflt value is added to the existing values in the Notification Packages attribute in directory HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Lsa
4. Module enablement
For the module to be called when a password is changed it is necessary to turn on local password complexity checking as shown in Figure 4-45 on page 202. Global password complexity checking may be enabled or disabled. If it is disabled, the security policy shows that local password complexity checking is enabled, but the functionally is disabled. This is acceptable. In either case, timpwflt.dll will be called.
Name Type Value
Class REG_SZ com.ibm.di.plugin.mqe.store.MQeNTPasswordStore
Classpath REG_SZ “C:\IBM\DiPlugins\IDI”
Java REG_SZ “C:\IBM\DiPlugins\IDI\_jvm\jre\bin\java.exe”
Chapter 4. Penguin Financial Incorporated 201

Figure 4-45 Local password complexity
5. Client MQe QueueManager
This component is used by the Password Store to send messages to the MQe QueueManager Server used by the Password Storage.
Before creating an MQe QueueManager, the properties file mqeconfig.props from the ad_plugin_dir directory needs to be configured as shown in Table 4-31.
Table 4-31 Windows client mqeconfig.props
Attribute Value
clientRootFolder C:\\IBM\\DiPlugins\\IDI\\MQePWStoreRemote
serverIP 9.3.5.177
communicationPort 41001
debug true
202 Robust Data Synchronization with IBM Tivoli Directory Integrator

The MQe QueueManager is created by executing the following command in the ad_plugin_dir directory (on one line):
_jvm\jre\bin\java -cp "./mqeconfig.jar" com.ibm.di.plugin.mqe.config.MQeConfig mqeconfig.props create client
6. Password Store
The keystore penguin.jks containing a key named penguin is first generated using the command line in ad_plugin_dir directory executing the following command (on one line):
.\_jvm\jre\bin\keytool -genkey -alias penguin -keypass passw0rd -storepass passw0rd -keystore penguin.jks -storetype JKS -provider com.ibm.crypto.provider.IBMJCE -keyalg RSA
The key is used for password encryption/decryption. It is verified executing the following command (on one line):
.\_jvm\jre\bin\keytool -list -v -alias penguin -keystore penguin.jks -storepass passw0rd
For use in a properties file the keystore password is encoded executing the following command in the installation directory:
_jvm\jre\bin\java com.ibm.di.plugin.idipwsync.EncodePW passw0rd
Finally the properties for this component are configured in the file mqepwstore.props in the itds_plugin_dir directory as shown in Table 4-32.
Table 4-32 Windows client mqepwstore.props
Tip: If you want to be prompted for a keystore and/or key password instead of typing it into the command line for security reasons, then you can skip the corresponding parameters from the command.
Note: To help create and test a keystore, the idicryptokeys.bat file provided in the ad_plugin_dir directory can be used.
Attribute Value
debug True
logFile C:\\IBM\\DiPlugins\\IDI\\mqestore.log
encryptKeyStoreFilePassword 0f0fe0e2062f0d66
encryptKeyStoreCertificate Penguin
encryptKeyStoreFilePath C:\\IBM\\DiPlugins\\IDI\\penguin.jks
Chapter 4. Penguin Financial Incorporated 203

This finalizes the installation and configuration of the Windows password synchronization module. Testing is done later when the Password Storage is configured as well.
IBM Tivoli Directory Server password synchronization module setupFollow these steps.
1. Installation
After launching the installer, IBM Tivoli Directory Integrator Password Synchronization Plugin for IBM Tivoli Directory Server is selected as the product and WebSphere MQ Everyplace as the storage method. The module is installed in /opt/IBM/DiPlugins/IDS and will be refered to as itds_plugin_dir.
2. Registration with IBM Tivoli Directory Server
The IBM Tivoli Directory Server configuration file ibmslapd.conf needs to be edited by adding (on one line)
ibm-slapdPlugin: preoperation "/opt/IBM/DiPlugins/IDS/pwsync.so" PWSyncInitDebug "/opt/IBM/DiPlugins/IDS/idspwconfig.props"
in section
dn: cn=Directory, cn=RDBM Backends, cn=IBM Directory, cn=Schemas, cn=Configuration
3. Configuration
The properties for this component are set in the idspwconfig.props file in the itds_plugin_dir directory as shown in Table 4-33.
Table 4-33 IBM Tivoli Directory Server idspwconfig.props
notificationPort 41002
qmIniFileName C:\\IBM\\DiPlugins\\IDI\\MQePWStoreRemote\\pwstore_client.ini
encrypt True
Attribute Value
jvmPath /opt/IBM/DiPlugins/IDS/_jvm/jre/bin
jvmClassPath /opt/IBM/DiPlugins/IDS
syncClassName com.ibm.di.plugin.mqe.store.MQePasswordStore
serverPort 18003
logFile /opt/IBM/DiPlugins/IDS/ids_pw_sync.log
Attribute Value
204 Robust Data Synchronization with IBM Tivoli Directory Integrator

4. Java proxy
For terminating the Java Layer the StopProxy utility is used. The following command is included in IBM Tivoli Directory Server shutdown script (on one line):
"/opt/IBM/DiPlugins/IDS/_jvm/jre/bin/java" -jar "/opt/IBM/DiPlugins/IDS/_jvm/jre/lib/ext/stopProxy.jar" 18003
5. Client MQe QueueManager
This component is used by the Password Store to send messages to the MQe QueueManager Server used by the Password Storage.
Before creating an MQe QueueManager, the properties file mqeconfig.props in the itds_plugin_dir directory is configured as shown in Table 4-34.
Table 4-34 IBM Tivoli Directory Server client mqeconfig.props
The MQe QueueManager is created using the console in the itds_plugin_dir directory executing the following command (on one line):
_jvm/jre/bin/java -cp "./mqeconfig.jar" com.ibm.di.plugin.mqe.config.MQeConfig mqeconfig.props create client
syncBase dc=penguin-fin,dc=com
javaLogFile /opt/IBM/DiPlugins/IDS/ids_pws_java.log
checkRepository True
Note: When the Directory Server is shut down, the Java Layer of the Directory Server Password Synchronizer is not automatically terminated. If you do not terminate the Java Layer explicitly, the Directory Server Password Synchronizer does not start properly the next time the Directory Server is started.
Attribute Value
clientRootFolder /opt/IBM/DiPlugins/IDS/MQePWStore
serverIP 127.0.0.1
communicationPort 41001
debug True
Attribute Value
Chapter 4. Penguin Financial Incorporated 205

6. Password Store
The keystore penguin.jks that was generated during the Windows Password Store configuration is copied to the itds_plugin_dir directory and verified executing the following command (on one line):
./_jvm/jre/bin/keytool -list -v -alias penguin -keystore penguin.jks -storepass passw0rd
Finally the properties for this component are configured in the mqepwstore.props file in the itds_plugin_dir directory as shown in Table 4-35.
Table 4-35 IBM Tivoli Directory Server client mqepwstore.props
This finalizes the installation and configuration of the IBM Tivoli Directory Server password synchronization module. Testing is done later when the Password Storage is configured.
Password Storage setupThe Password Storage is automatically installed in the root_dir/jars/plugins directory with the installation of IBM Tivoli Directory Integrator.
1. MQe QueueManager Server
This component is used by the Password Storage to receive messages from Windows and Directory Server Client MQe QueueManagers used by the Password Stores.
Tip: If you want to be prompted for a keystore password instead of typing it into the command line for security reasons, then you can skip the -storepass parameter from the command.
Attribute Value
debug True
logFile opt/IBM/DiPlugins/IDS/mqestore.log
encryptKeyStoreFilePassword 0f0fe0e2062f0d66
encryptKeyStoreCertificate Penguin
encryptKeyStoreFilePath opt/IBM/DiPlugins/IDS/penguin.jks
notificationPort 41002
qmIniFileName opt/IBM/DiPlugins/IDS/MQePWStore/pwstore_client.ini
encrypt True
206 Robust Data Synchronization with IBM Tivoli Directory Integrator

Before creating an MQe QueueManager, the properties file mqeconfig.props in the root_dir/jars/plugins directory needs to be configured as shown in Table 4-36.
Table 4-36 Password Storage server mqeconfig.props
The MQe QueueManager is created using the console in the root_dir/jars/plugins directory executing the following command:
./mqeconfig.sh mqeconfig.props create server
This concludes the Password Storage installation. The configuration is performed using the Config Editor by configuring the specialized MQe Password Store Connector as shown in “Basic Connectors” on page 219.
MQe QueueManagers testingTesting if the MQe QueueManagers are operational is performed in the following sequence.
1. Start the MQe QueueManager Server in test mode executing the following command in the root_dir/jars/plugins directory:
./mqeconfig.sh mqeconfig.props test server
2. Start the IBM Tivoli Directory Server Client MQe QueueManager executing the following command in the ad_plugin_dir or itds_plugin_dir directory (on one line):
_jvm/jre/bin/java -cp "./mqeconfig.jar" com.ibm.di.plugin.mqe.config.MQeConfig mqeconfig.props test client
3. Press Enter to send a test message.
4. Press Enter once again to terminate the Client MQe QueueManager.
5. Press Enter on the MQe QueueManager Server machine again to receive the message.
A message “Success: test MQe message successfully received.” indicates that the two QueueManagers are properly installed and configured to communicate with each other. A message starting with Test failed: indicates that the QueueManagers are not properly installed or configured.
Successful communication between the two MQe QueueManagers on the Enterprise Directory machine is depicted in Figure 4-46.
Attribute Value
serverRootFolder /opt/IBM/ITDI/MQePWStore
communicationPort 41001
debug True
Chapter 4. Penguin Financial Incorporated 207

Figure 4-46 MQe QueueManagers testing
To be sure everything is alright, the same procedure is repeated testing the Windows MQe QueueManager to check that we can receive messages from both queues.
AssemblyLine phaseIn this installation phase the configuration and testing is performed for all components needed for password changes to be picked up from the Password Storage by an AssemblyLine, transferred to all targets, and updated there.
Connectors used in our solution are already documented in 4.5.5, “Review results” on page 196, but as there are special conditions or security concerns for some of them we will finalize our solution in the following sequence of steps:
1. SSL with Active Directory configuration
2. Domino configuration
3. Basic configuration
4. Connectors
5. Scripts
6. AssemblyLine
7. Testing
SSL with Active Directory configurationSee the IBM Tivoli Directory Integrator and Microsoft Active Directory SSL configuration section in IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718 for general instructions.
Note: By testing the MQe QueueManagers only the communication channels are tested and not message encryption/decryption.
208 Robust Data Synchronization with IBM Tivoli Directory Integrator

1. IIS (Internet Information Services) installation
IIS is needed before Certificate Services installation. IIS can be installed from Start → Settings → Control Panel → Add/Remove Programs → Add/Remove Windows Components → Internet Information Services (IIS)
2. Certificate Services installation
Certificates Services can be installed from Start → Settings → Control Panel → Add/Remove Programs → Add/Remove Windows Components → Certificate Services. An Enterprise Certificate Authority (CA) must be installed.
After starting the Certificate Services service a virtual directory is created in IIS that enables the distribution of certificates.
3. Automatic Certificate Request (optional)
If any available CA is set up for Automatic Certificate Request in the Public Key Policies part of the Default Domain Controllers Policy as shown in Figure 4-47 on page 210, then you can choose any Domain Controller when connecting to Active Directory using SSL on port 636, the chosen Domain Controller will automatically request a certificate from the CA.
Restriction: After installing Certificate Services the computer cannot be renamed and cannot join or be removed from a domain.
Chapter 4. Penguin Financial Incorporated 209

Figure 4-47 Automatic certificate request
4. CA Certificate download
Open http://mf-root1/certsrv/certarc.asp in a Web browser on the IBM Tivoli Directory Integrator machine as shown in Figure 4-48 on page 211 and download the certificate to the itds_plugin_dir directory containing the keystore penguin.jks. (see “IBM Tivoli Directory Server password synchronization module setup” on page 204 for details about the keystore).
210 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-48 CA certificate download
Save the CA certificate as MonolithicCA.cer.5. Import and test the CA certificate
We import the CA certificate into the existing keystore penguin.jks executing the following command (on one line):
./_jvm/jre/bin/keytool -import -alias monolithic -keystore penguin.jks -storepass passw0rd -file MonolithicCA.cer
Enter yes when prompted Trust this certificate? [no]
The key is used for SSL with Active Directory. It is verified executing the following command (on one line):
./_jvm/jre/bin/keytool -list -v -alias monolithic -keystore penguin.jks -storepass passw0rd
6. Configure IBM Tivoli Directory Integrator as an SSL client
Edit the #server authentication stanza as shown in Table 4-37 on page 212 and the #client authentication stanza as shown in Table 4-38 on page 212 in the IBM Tivoli Directory Integrator global.properties file.
Tip: If you want to be prompted for the keystore password instead of typing it into the command line for security reasons, then you can skip the -storepass parameter from the command.
Chapter 4. Penguin Financial Incorporated 211

Table 4-37 #server authentication settings
Table 4-38 #client authentication settings
Figure 4-49 IBM Tivoli Directory Integrator SSL settings
Attribute Value
javax.net.ssl.trustStore /opt/IBM/DiPlugins/penguin.jks
javax.net.ssl.trustStorePassword passw0rd
javax.net.ssl.trustStoreType jks
Attribute Value
avax.net.ssl.trustStore /opt/IBM/DiPlugins/penguin.jks
javax.net.ssl.trustStorePassword passw0rd
javax.net.ssl.trustStoreType jks
Note: When you configure SSL, the password is entered in clear text. You can put {protect}- in front of the attribute and the password will be encrypted on the next server run as shown in Figure 4-49. See the “Properties encryption” section in Chapter 5 of the IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1716 for details about properties encryption.
212 Robust Data Synchronization with IBM Tivoli Directory Integrator

7. Cryptography package providers
Edit the java.security file in the root_dir/_jvm/jre/lib/security/ directory as shown in Table 4-39.
Table 4-39 Cryptography package providers
This concludes the configuration of IBM Tivoli Directory Integrator as an SSL client with Active Directory.
Domino configurationFor the configuration of Domino follow these steps.
1. Domino user
Create a dedicated password synchronization user in Domino for connections from IBM Tivoli Directory Integrator and HTTPPassword updates. Then modify the Access Control List in Domino for the names.nsf database and grant Editor privileges to the password synchronization user as shown in Figure 4-50 on page 214.
Attribute Value
security.provider.1 com.ibm.jsse.IBMJSSEProvider
security.provider.2 com.ibm.crypto.provider.IBMJCE
security.provider.3 com.ibm.security.jgss.IBMJGSSProvider
security.provider.4 com.ibm.security.cert.IBMCertPath
Chapter 4. Penguin Financial Incorporated 213
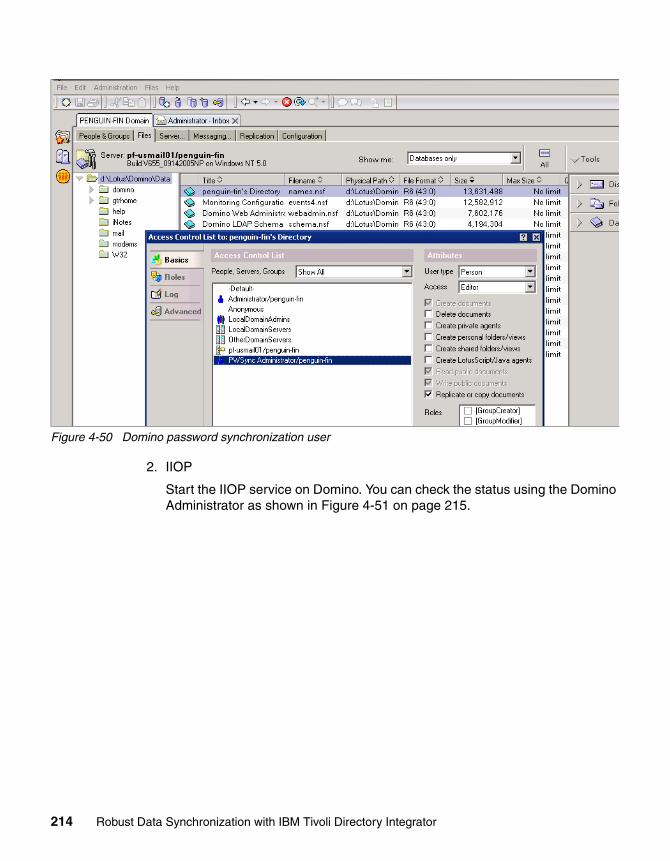
Figure 4-50 Domino password synchronization user
2. IIOP
Start the IIOP service on Domino. You can check the status using the Domino Administrator as shown in Figure 4-51 on page 215.
214 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-51 DIIOP service
The Lotus Notes Connector uses IIOP to communicate with a Domino server. To establish an IIOP session with a Domino server, the Connector needs the IOR string that locates the IIOP process on the server. If you specify a hostname and, optionally, a port number when configuring the Connector. This hostname:port string is in reality the address of the Domino Server’s HTTP service from which the Connector retrieves the IOR string. The Connector requests a document called /diiop_ior.txt from the Domino HTTP server that is expected to contain the IOR string. You can read more about the Lotus Notes Connector in the “Connectors” chapter of the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720.
In order to retrieve the IOR string you can go to URL shown in Figure 4-52 on page 216, or you can get the diiop_ior.txt file directly from the Domino data/domino/html directory in the server installation directory.
Tip: You can replace the hostname:port specification with an IOR string and bypass the first step and also the dependency of the HTTP server.
Chapter 4. Penguin Financial Incorporated 215

Figure 4-52 IOR string
Basic ConfigThis section contains the basic configuration steps for our IBM Tivoli Directory Integrator server instance.
1. Create the basic config file.
A new Config penguin.xml is created in the solution_dir directory, with the default ExternalProperties defined in the external.props file in the same directory. Table 4-40 contains all the values and descriptions for our external properties.
Table 4-40 ExternalProperties file
Note: See IBM Tivoli Directory Integrator 6.0: Getting Started Guide, SC32-1716 for basic Config Editor operations.
Note: You can encrypt and password-protect your Config as well as the ExternalProperties files for security reasons.
Property Value Description
AD.LDAPURL ldap://mf-root1:389 URL to connect to Active Directory on default port
AD.LoginUsername cn=Administrator,cn=users,dc=monolithic-fin,dc=com
Login (full distinguished name) to bind to Active Directory
AD.LoginPassword passw0rd Password associated with Active Directory bind Login
AD.SearchBase dc=monolithic-fin,dc=com Base for search in Active Directory directory information tree
AD_SSL.LDAPURL ldap://mf-root1:636 URL to connect to Active Directory on secure port using SSL
216 Robust Data Synchronization with IBM Tivoli Directory Integrator

AD_SSL.LoginUsername cn=Administrator,cn=users,dc=monolithic-fin,dc=com
Login (full distinguished name) to bind to Active Directory
AD_SSL.LoginPassword passw0rd Password associated with Active Directory bind Login
AD_SSL.SearchBase dc=monolithic-fin,dc=com Base for search in Active Directory directory information tree
AD_SSL.UseSSL true SSL use
AD_SSL.AutoMapADPassword
true Mapping from userPassword format to unicodePwd format
DelayToITDS 5 Time delay in seconds for too slow user creation process in IBM Tivoli Directory Server
DelayToNotes 5 Time delay in seconds for too slow user creation process on Domino
ERROR.Sender ITDI_PWSync_System From field in error mail messages to users
ERROR.Subject ITDI_ERROR Subject field in error mail messages to users
ERROR.File /opt/IBM/ITDI/errHandler.log
A file to append error messages to
ERROR.PollingInterval 60 Interval of Assembyline error status checking
ITDS.LDAPURL ldap://pf-used01:389 URL to connect to IBM Tivoli Directory Server on default port
ITDS.LoginUsername cn=root Login to bind to IBM Tivoli Directory Server
ITDS.LoginPassword passw0rd Password associated with IBM Tivoli Directory Server bind Login
Property Value Description
Chapter 4. Penguin Financial Incorporated 217

ITDS.SearchBase dc=penguin-fin,dc=com Base for search in IBM Tivoli Directory Server directory information tree
MinPasswordAge 15 Minimum time in minutes between two allowed password updates
MQ.QueueManagerIniFile /opt/IBM/ITDI/MQePWStore/pwstore_server.ini
Password Storage ini file
MQ.StorageNotificationServer(s)
localhost:41002,mf-root1:41002
List of Password stores
MQ.KeyStoreFile /opt/IBM/DiPlugins/IDS/penguin.jks
Keystore used for message decryption
MQ.KeyStoreFilePassword
passw0rd Password associated with Keystoe used for message decryption
MQ.KeyStoreCertificateAlias
penguin Alias of key used for message decryption
MQ.KeyStoreCertificatePassword
passw0rd Password associated with key used for message decryption
Notes.Hostname IOR:01055a032900000049444c3a6c6f7475732f646f6d696e6f2f636f7262612f494f626a6563745365727665723a312e300000000001000000000000006c000000010101030a000000392e332e352e31373900acf6310000000438353235363531612d656336382d313036632d656565302d303037653264323233336235004c6f7475734e4f4901000100000001000000010000001400000001015a0301000105000000000001010000000000
IOR string to connect to Domino on default port
Notes.Username PWSync Administrator/penguin-fin
Login (internet username) to bind to Domino
Property Value Description
218 Robust Data Synchronization with IBM Tivoli Directory Integrator

Properties beginning with AD. are used to do lookups only in Active Directory. SSL is not needed for this operation, but the Login value must be a complete distinguished name.
Properties beginning with AD_SSL. are used for password updates in Active Directory, thus SSL is used.
Two Delay. properties (DelayToITDS and DelayToNotes) are used for password update delays.
Properties beginning with ERROR. are used in error handling situations.
Properties beginning with ITDS. are used to do lookups in IBM Tivoli Directory Server. SSL is not needed for this operation and the Login value can be a short name.
The MinPasswordAge property is used in TimeStamp calculation.
Properties beginning with MQ. are used for access to the Password Storage and message decryption.
Properties beginning with Notes. are used for password updates to Domino.
After saving the external.props file, the basic Config is prepared for other components.
Basic ConnectorsThis section contains the basic Connectors for our IBM Tivoli Directory Integrator config.
1. Create basic Connectors
Each basic Connector is created in the Library from a template based on the source type. Then it is configured and tested to successfully connect to the source. Such a Connector is prepared to be a parent for other AssemblyLine Connectors.
We require Connectors to retrieve entries from Password Storage, to determine the source of the password change, and to update passwords. All basic Connectors are listed in Table 4-41 on page 220.
As our first Connector we create getMQ based on the template ibmdi.MQePasswordStoreConnector as shown in Figure 4-53 on page 220.
Notes.Password passw0rd Password associated with Domino bind Login
Notes.Database names.nsf Domino database to open
Notes.DatabaseView People Domino database view
Property Value Description
Chapter 4. Penguin Financial Incorporated 219

Figure 4-53 getMQ Connector
Repeat the procedure using Table 4-41 for all Connectors as follows:
– Type a new Name in the Name field.
– Select a type from the Connectors table list.
– Choose a Mode from the Mode drop-down menu.
Table 4-41 Basic Connectors
When you are done, six basic Connectors are shown in your Config as depicted in Figure 4-54 on page 221.
Name Type Mode
getMQ ibmdi.MQePasswordStoreConnector Iterator
lookupAD ibmdi.LDAP Lookup
lookupITDS ibmdi.LDAP Lookup
updateAD ibmdi.LDAP Update
updateITDS ibmdi.LDAP Update
updateNotes ibmdi.Notes Update
220 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-54 Basic ConnectorsFigure 4-54
2. Configure basic Connectors
Using the information from Table 4-40 on page 216, each Connector is configured and connectivity to the source is tested.
Attention: Parameters not listed in Table 4-40 keep their default values.
Chapter 4. Penguin Financial Incorporated 221

– getMQ Connector
The Config tab for the configured getMQ Connector is shown in Figure 4-55.
Figure 4-55 getMQ Config tab
222 Robust Data Synchronization with IBM Tivoli Directory Integrator

This Connector feeds the AssemblyLine, that is why the Input Map is also configured as shown in Figure 4-56. Use the Input map tab to test connectivity with the data source.
Figure 4-56 getMQ Connector Input Map
Chapter 4. Penguin Financial Incorporated 223

– lookupAD Connector
Figure 4-57 shows the Config tab for the configured lookupAD Connector.
Figure 4-57 lookupAD Config tab
224 Robust Data Synchronization with IBM Tivoli Directory Integrator

– lookupITDS Connector
The Config tab for the configured lookupITDS Connector is shown in Figure 4-58.
Figure 4-58 lookupITDS Config tab
Chapter 4. Penguin Financial Incorporated 225

– updateAD Connector
The Config tab for the configured updateAD Connector is shown in Figure 4-59 without two parameters that did not fit into the figure: Use SSL and Auto Map AD Password, both checked.
Figure 4-59 updateAD Config tab
226 Robust Data Synchronization with IBM Tivoli Directory Integrator

– updateITDS
The updateITDS Update Mode Connector differs from the lookupITDS only in Mode, as can be seen in Table 4-41 on page 220 and in Figure 4-60.
Figure 4-60 updateITDS Config tab
Chapter 4. Penguin Financial Incorporated 227

– updateNotes
The final basic Connector, updateNotes, is configured as shown in Figure 4-61.
Figure 4-61 updateNotes Config tab
Notice the Database setting has been left at its default value. This is fine for our scenario. Also, the IOR string is too long to visually fit into the Hostname field.
This concludes the basic Connector configuration. In the next step some scripts are provided to help with the AssemblyLine setup.
ScriptsWe use scripts for attribute checking and error handling.
� checkTimeStamp
checkTimeStamp is the only attribute checking script. Here is the code:
228 Robust Data Synchronization with IBM Tivoli Directory Integrator

var newDate = new Date();var nowDate = Date.parse(newDate);var nowDateString = String(nowDate);var lastPWChange = work.getString("pfLastPWChange");var diff = (parseInt((nowDate-lastPWChange)/(1000*60)));var min = system.getExternalProperty("MinPasswordAge");
if (diff < min) {var msg = "Minimum password age violation for User: " +
work.getString("UserId") + " @ " + work.getString("Source") +"!\Password age: " + diff + " minutes. Policy requirement: " + min + " minutes! \Please change your password again after the time limit defined by Policy.";
userErrorHandler(msg);system.skipEntry();
}else {
var newAtt = system.newAttribute("pflastpwchange");newAtt.addValue(nowDateString);work.setAttribute(newAtt);
}
This script checks if a user is allowed to update their password. As discussed in “Password policy” on page 101, the minimum password age on Active Directory is one day, thus we have enough time to compare two password change time differences and avoid any loop conditions.
How does the script work? First, the current (machine) time is read into the variable newDate. Then the variable is parsed into the nowDate variable (miliseconds from Jan 1st 1970 0:00:00 GMT) for use in further calculations. It is also prepared for update using a string representation of the number in the variable nowDateString. The last password change executed by a user is read from the pfLastPWChange attribute into the variable lastPWChange. Then Diff is calculated as an integer part of the difference in minutes (thus division by 1000 from miliseconds and by 60 from seconds) from the current time nowDate and the last user password change time lastPWChange. Next diff is compared with min, the minimum password age defined and stored in the external properties.
If the result is less then allowed, then a message is created with information about the user, the source, the time in minutes from the last update and the policy requirement. The message is then sent to the userErrorHandler script (next script explained) and the entry is skipped.
Otherwise, the current time is stored into the pfLastPWChange attribute to be updated after successful password update.
Chapter 4. Penguin Financial Incorporated 229

� userErrorHandler
This script is primarily used to notify users about password update violations. Let us first take a look at the code, then the explanation:
function userErrorHandler(errMsg) {
var newDate = new Date();var msg = newDate + " - " + errMsg;
task.logmsg("* EXCEPTION -- " + msg);
system.sendMail(system.getExternalProperty("ERROR.Sender"),work.getString("mail"),system.getExternalProperty("ERROR.Subject"),msg, null);
try {var output =
system.openFileForAppend(system.getExternalProperty("ERROR.File"));} catch(exc) {
task.logmsg("* EXCEPTION -- Error opening file " + exc);}
output.write(msg);output.newLine();output.close();
return true;}
This script takes the error message, for example the one generated by the checkTimeStamp script, adds the current (machine) time and sends it to a user by mail and stores it locally to a file.
Let us take a look at the details. A new message is created using the current time and the original message (errMsg) and logged. Then an e-mail is sent to the user based on the mail attribute from the work Entry. The Mail from: field in the e-mail message shows ERROR.Sender and the Subject: field contains the ERROR.Subject properties from the external properties. The e-mail body contains the error message itself.
Attention: Mail can be sent directly to Domino if the mail host name or address is specified as mail.smtp.host property in the JavaProperties as shown in Figure 4-62. The problem here is the fact, that you cannot use e-mail to notify a user when the e-mail host is not running. That is why we use a local e-mail system on our Linux machine (Postfix), which can queue the message until Domino is available.
230 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-62 Mail smtp host
Finally the error message gets appended to the file specified by the Error.File property in the external properties. If this operation fails, an error is catched and logged.
� adminErrorHandler
Our final script is very similar to the userErrorHandler script we explained before. It is primarily used for notifying administrators about errors like failed updates and non-existing users. Here is the code:
function adminErrorHandler(errMsg) {
var newDate = new Date();var msg = newDate + " - " + errMsg;
task.logmsg("* EXCEPTION -- " + msg);system.sendMail("ITDI","Administrator","ERROR",msg, null);try {
var output = system.openFileForAppend(system.getExternalProperty("ERROR.File"));
} catch(exc) {task.logmsg("* EXCEPTION -- Error opening file " + exc);
}
output.write(msg);output.newLine();output.close();
return true;}
The only difference from the userErrorHandler script is the e-mail part, because we know who the recipients are.
Chapter 4. Penguin Financial Incorporated 231

Now we are ready to assemble the line—the AssemblyLine.
AssemblyLinesEverything, from proper documentation to basic Connectors and Scripts, is prepared for our AssemblyLine; we just have to put all pieces together. We will use the flowchart from 4.5.4, “Plan the data flows” on page 190 to help us with AssemblyLine logic and the Connector tables from 4.5.5, “Review results” on page 196 for Attribute Maps, Link Criteria, and other details.
Let us begin our puzzle and plug the pieces together.
� getMQ
As the first step we need to create a new AssemblyLine; we name it penguinPWSync and drag and drop the getMQ Connector into the AssemblyLine as our first component. This Connector iterates through the Password Storage, picks up entries, and feeds the AssemblyLine, thus it is automatically located in the Feeds section.
The getMQ Connector inherits its complete configuration from the parent Connector in the Library; there is nothing more to configure. After each Entry is successfully read we want to ensure if the UpdateType is correctly defined by specifying a few lines of code on the GetNext Successful Hook, because if the UpdateType is not replace as expected, then the Entry is skipped.
var upType = work.getString("UpdateType");if(!upType.equalsIgnoreCase("replace"))
system.skipEntry();
As you can see in Figure 4-63 on page 233, our AssemblyLine is created. It contains its first configured Connector getMQ with a few entries defined in the work Entry area, and some code on the GetNext Successful Hook.
232 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-63 Start of AssemblyLine building
Next, based on the flowchart, we have to determine the origin of password change and get all attributes needed for further processing.
To determine the source of password change we could use a script to decompose the UserId in the work Entry and determine the source based on the UserId architecture, but we can use a much more simple mechanism in IBM Tivoli Directory Integrator for handling conditions—Loops.
� lookupITDS
The first Loop named lookupITDS builds a link with IBM Tivoli Directory Server using the attribute UserId. If the UserId is not a registered Directory Server user then the building link will fail, and according to the Lookup Mode flowchart, we can catch the flow using the On Error Hook. Enabling the Hook allows the flow to continue to the next component in the AssemblyLine. See “Appendix B” of the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720 for more information about AssemblyLine and Connector Mode flowcharts.
Chapter 4. Penguin Financial Incorporated 233

Here is the script we use for the On Error Hook:
task.logmsg("User: " + work.getString("UserId") + " redirected to the next component");
After the lookupITDS Loop is created, it is configured according to Table 4-42.
Table 4-42 lookupITDS Loop
The fully configured lookupITDS Loop as well as the enabled On Error Hook is shown in Figure 4-64.
Figure 4-64 lookupITDS Loop
� getITDS
Parameter Value
Mode Lookup
Inherit from lookupITDS
Link Criteria $dn=$UserId
234 Robust Data Synchronization with IBM Tivoli Directory Integrator

If the password change in fact comes from IBM Tivoli Directory Server, then we can retrieve the needed attributes by doing another lookup.
This time the getITDS Connector is created inside the lookupITDS Loop and configured in a similar way as the basic Connectors, not using the template but the basic Connector itself as shown in Table 4-43.
Table 4-43 getITDS
Table 4-44 getITDS Link Criteria
Then we configure the Link Criteria as shown in Table 4-44, to be able to retrieve the following attributes:
– mail– pfLastPWChange– pfNotesFullName– pfsAMAccountName
The final input attribute Source is configured by using Advanced mapping:
ret.value = “ITDS”;
The configured getITDS Connector with its work Entry, Work Attributes, and Source attribute Advanced mapping is shown in Figure 4-65 on page 236.
Important: When a Connector is used in a Loop, the Link Criteria is used just as a testing condition. As soon as an Entry is found the condition is true and the flow exits the Loop before any attributes can be mapped.
Name Type Mode
getITDS lookupITDS Lookup
Tip: Instead of doing a classic Connector creation, you can just drag and drop the appropriate Connector from the Connectors Library and rename it. In this case you pick up the lookupITDS Connector and rename it to getITDS.
Attribute Operator Value
$dn equals $UserId
Chapter 4. Penguin Financial Incorporated 235

Figure 4-65 getITDS
Finally we take care of the Lookup Successful Hook. If all attributes have been mapped successfully, then we can exit the Loop (and skip the following Loop too, which checks if the user is an Active Directory user) and proceed to the TimeStamp checking. The following is the script attached to the Lookup Successful Hook:
task.logmsg("User: " + work.getString("UserId") + " redirected to checkTimeStamp");system.skipTo("checkTimeStamp");
Otherwise, if lookupITDS did not get the user, we have to check if the password change originates from Active Directory.
� lookupAD
lookupAD is the next Loop in our AssemblyLine. Similar to the lookupITDS Connector it tries to build a link using the UserId attribute, this time directed at Active Directory. The rules are the same as before, if a link cannot be established then the On Error Hook is activated. Since we have no more
236 Robust Data Synchronization with IBM Tivoli Directory Integrator

potential sources for password change, this time we need to log this event as an Unknown user and skip the Entry altogether:
task.logmsg("Unknown User: " + work.getString("UserId"));system.skipEntry();
The configuration parameters for the lookupAD Loop are shown in Table 4-45.
Table 4-45 lookupAD Loop
The fully configured lookupAD Loop showing the Link Criteria and its position in the AssemblyLine is shown in Figure 4-66.
Figure 4-66 lookupAD Loop
Parameter Value
Mode Lookup
Inherit from lookupAD
Link Criteria sAMAccountName=$UserId
Chapter 4. Penguin Financial Incorporated 237

If the password change in fact comes from Active Directory, then we can retrieve the needed attributes by doing another lookup against IBM Tivoli Directory Server with the known Active Directory user.
� getAD
This time we create the getAD Connector inside the lookupAD Loop and configure it similar to the basic Connectors. We do not use a template but the basic Connector itself as shown in Table 4-43 on page 235.
Table 4-46 getAD
Table 4-47 getAD Link Criteria
Next we configure the Link Criteria as shown in Table 4-47 to be able to retrieve the following attributes:
– mail– pfLastPWChange– pfNotesFullName– pfsAMAccountName
The last input attribute Source is configured by using Advanced mapping:
ret.value = “AD”;
The configured getAD Connector with work Entry, Work Attributes, and Source attribute Advanced mapping is shown in Figure 4-67 on page 239. Notice two possible sources for some attributes in work Entry, either from the getITDS or the getAD Connector.
Name Type Mode
getAD lookupITDS lookup
Tip: To create the Connector, pick up the lookupITDS Connector from Connectors, drag and drop it onto the AssemblyLine and rename it to getAD.
Attribute Operator Value
pfsAMAccountName equals $UserId
238 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-67 getAD
Finally we take care of the Hooks. If all attributes have been mapped successfully, we can skip to the next component in the AssemblyLine; checking TimeStamp. The following script on the Lookup Successful Hook takes care of that:
task.logmsg("User: " + work.getString("UserId") + " redirected to checkTimeStamp");system.skipTo("checkTimeStamp");
Based on concerns in “Frequency” on page 193 and according to our flowchart, this is also the time to implement the delay for a not yet existing IBM Tivoli Directory Server user. Based on the Hook Flow diagram for a Lookup Mode Connector, the On No Match Hook is the right place for the following script:
if(firstUse != null && firstUse != ""){
adminErrorHandler("* No ITDS Account for User: " + work.getString("UserId"));
var firstUse = "";
Chapter 4. Penguin Financial Incorporated 239

system.skipEntry();}else{
task.logmsg("* DelayToITDS");system.sleep(system.getExternalProperty("DelayToITDS"));var firstUse = "firstUse";system.skipTo("getAD");
}
If this is the first time for the flow to call the On No Match Hook, then the else part of the statement is executed; the system waits for the time in seconds defined by the DelayToITDS property from the external properties before it tries to find a match again. If this is the second or subsequent time the flow calls the Hook, the adminErrorHandler function is called. This function is defined in the adminErrorHandler script described in “Scripts” on page 228. To summarize, the error message, containing the UserId, the type and the time of the error, is e-mailed to system administrators and written to an error log file.
See “Appendix B” of the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720 for more information about AssemblyLine and Connector Mode flowcharts.
� checkTimeStamp
Arriving at this point, either from the lookupITDS Loop or the lookupAD Loop, we have collected all necessary attributes to link to the password update targets, send e-mail to users, and check if the password update is allowed. The next action in our flow is performed by the checkTimeStamp script.
The script has already been explained in “Scripts” on page 228, so let us just summarize it again. If a password change is not allowed the Entry is skipped, otherwise the flow continues to the source dependent updates. The script is simply added by dragging and dropping it as the next component in the AssemblyLine as shown in Figure 4-68 on page 241.
240 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-68 checkTimeStamp
Now we are approaching the update part of our flow. As said before updates are source dependent, for example, the password in Active Directory is updated only if it was changed in IBM Tivoli Directory Server and vice versa. To distinguish updates based on the two sources we have, we again use Loops. One Loop is executed if the source of password change is IBM Tivoli Directory Server and the other in case the source was Active Directory.
� fromITDS
First we create the IBM Tivoli Directory Server based Loop called fromITDS. We define a simple Conditional Loop using:
ret.value = (work.getString("Source") == "ITDS");
As the condition if the Source attribute value equals “ITDS”, thus being created by the getITDS Connector inside lookupITDS Loop and identifying IBM Tivoli Directory Server as the source of password change. If this condition is true, then the flow enters the Loop, otherwise the flow continues with the next component in the AssemblyLine.
Chapter 4. Penguin Financial Incorporated 241

The configured fromITDS Loop is shown in Figure 4-69.
Figure 4-69 fromITDS Loop
If the condition fromITDS is true, we follow the flow into the Loop. Knowing the source, we successively update Domino, Active Directory, and TimeStamp at the end.
� updateNotesFromITDS
Inside the fromITDS Loop we create a new Connector by picking up the updateNotes Connector from the Connector pool using the information shown in Table 4-48, dragging and dropping it into the AssemblyLine and renaming it to updateNotesFromITDS.
Table 4-48 updateNotesFromITDS
Name Type Mode
updateNotesFromITDS updateNotes update
242 Robust Data Synchronization with IBM Tivoli Directory Integrator

Then we configure the Link Criteria with the information shown in Table 4-49, in order to be able to update the HTTPPassword.
Table 4-49 updateNotesFromITDS Link Criteria
HTTPPasword is mapped in the Output Map using the Passwords attribute from the work Entry and the Domino encryption mechanism as decided in 4.3.2, “Architectural decisions for phase 2” on page 101. The following script is used for the encryption in the Output Map:
var pwd = work.getString(“Passwords”);var v = updateNotesFromITDS.connector.getDominoSession().evaluate("@Password(\"" + pwd + "\")" ) ;ret.value = v.elementAt(0);
See the “Lotus Notes Connector” section in Chapter 2 of the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720, for more information about security and the Lotus Notes Connector.
Finally we log the successful update with the following script in the Update Successful Hook:
task.logmsg("* Notes HTTP password synchronized for User: " + work.getString("UserId"));
The configured updateNotesFromITDS Connector positioned in the AssemblyLine with a piece of Advanced Mapping script for the HTTPPassword is shown in Figure 4-70 on page 244.
Attribute Operator Value
FullName equals $pfNotesFullName
Chapter 4. Penguin Financial Incorporated 243

Figure 4-70 updateNotesFromITDS
� updateAD
After the Domino password has been updated it is Active Directory’s turn. The next Connector inside the current Loop is the updateAD created in a standard drag and drop and rename approach to have initial properties as shown in Table 4-50.
Table 4-50 updateNotesFromITDS
The Link Criteria as shown in Table 4-51 on page 245 is configured to be able to update the userPassword attribute.
Name Type Mode
updateAD updateAD update
Tip: In our scenario renaming is not necessary for this Connector, because its name will remain unique.
244 Robust Data Synchronization with IBM Tivoli Directory Integrator

Table 4-51 updateAD Link Criteria
Finally we enable two Hooks. Successful updates are logged using the following script on the Update Successful Hook:
task.logmsg("* AD password synchronized for User: " + work.getString("UserId"));
The other Hook is related to a special condition with originating Domino users without an Active Directory account as discussed in “Special conditions” on page 191. In this case we call the adminErrorHandler function:
adminErrorHandler("* No AD Account for User: " + work.getString("UserId"));
This function is defined in the adminErrorHandler script described in “Scripts” on page 228. To summarize, the error message containing UserId, the type and the time of error is e-mailed to system administrators and written to an error log file.
The configured updateAD Connector positioned in the AssemblyLine showing the Passwords to userPassword attribute mapping is shown in Figure 4-71 on page 246.
Attribute Operator Value
sAMAccountName equals $pfsAMAccountName
Important: Although an Active Directory account was not present, the entry cannot be skipped, because the HTTPPassword has already been updated and the TimeStamp still has to be updated.
Chapter 4. Penguin Financial Incorporated 245

Figure 4-71 updateAD
� updateTimeStampFromITDS
The final thing to do inside the current Loop is the TimeStamp update. It updates IBM Tivoli Directory Server, thus drag and drop the updateITDS Connector from the Connector Pool into the AssemblyLine and rename it updateTimeStampFromITDS as detailed in Table 4-52.
Table 4-52 updateTimeStampFromITDS
The Link Criteria as shown in Table 4-53 on page 247 is configured to be able to update the pfLastPWChange attribute.
Name Type Mode
updateTimeStampFromITDS updateITDS Update
246 Robust Data Synchronization with IBM Tivoli Directory Integrator

Table 4-53 updateTimeStampFromITDS Link Criteria
Again, we need to enable two Hooks. If the updates have been successful then the job is done and we can skip the rest of the AssemblyLine and return to the Password storage for new entries. The final logging is done using the following script in the Update Successful Hook:
task.logmsg("* TimeStamp refreshed for User: " + work.getString("UserId"));system.skipEntry();
The On Error Hook needs to be invoked when the update fails. Because we want to know why the adminErrorHandler function is called:
adminErrorHandler("TimeStamp not updated for User: " + work.getString("UserId"));
The function is defined in the adminErrorHandler script described in “Scripts” on page 228. To summarize, the error message containing UserId, the type and the time of error is e-mailed to system administrators and written to an error log file.
The configured updateTimeStampFromITDS Connector positioned in the AssemblyLine showing the pfLastPWChange attribute mapping is depicted in Figure 4-72 on page 248.
Attribute Operator Value
$dn equals $UserId
Chapter 4. Penguin Financial Incorporated 247

Figure 4-72 UpdateTimeStampFromITDS
This concludes our first update Loop for IBM Tivoli Directory Server based changes and there is merely one remaining possibility; Active Directory based changes. Here we use the same principle as with the fromITDS Loop; if the source of password change matches a defined condition then enter the Loop and update targets and TimeStamp.
� fromAD
Note: We use a Loop here only as a visual element in the AssemblyLine in order to emphasize the two-sources-structure. In our particular scenario it is actually not needed because we only have two password change sources. Since we generated two values for the Source attribute, and the flow did not enter the fromITDS Loop, then the password change can only originate fromAD.
248 Robust Data Synchronization with IBM Tivoli Directory Integrator

The Active Directory based Loop called fromAD is created as a simple Conditional Loop using:
ret.value = (work.getString("Source") == "AD");
As the condition to check if the value in the Source attribute equals “AD”, being created by the getAD Connector inside the lookupAD Loop and Active Directory as the source of the password change. If the condition is true, then the flow enters the Loop, otherwise the flow returns to start, because there are no more components in the AssemblyLine.
The configured Loop fromAD is shown in Figure 4-73.
Figure 4-73 fromAD
� updateNotesFromAD
Following the pattern from the fromITDS Loop, the first target to update is Domino. The Connector to be used in the fromAD Loop is almost the same as the updateNotesFromITDS, thus you can use the same parameters to create updateNotesFromAD with the exception of the Output Map, because the
Chapter 4. Penguin Financial Incorporated 249

Connector name is part of the code in the Advanced Mapping. For the updateNotesFromAD Connector the encryption code needs to be as follows:
var pwd = work.getString(“Passwords”);var v = updateNotesFromAD.connector.getDominoSession().evaluate("@Password(\"" + pwd + "\")" ) ;ret.value = v.elementAt(0);
See the “Lotus Notes Connector” section in Chapter 2 of the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720, for more information about security and the Lotus Notes Connector.
Based on concerns in “Frequency” on page 193 and according to our flowchart, this is also the time to implement the delay for not yet existing Domino users. This is another difference between the two Connectors. Based on the Hook Flow diagram for the Update Mode Connector, the Override Add Hook is the right place for the following script:
if(firstUse != null && firstUse != ""){
adminErrorHandler("* No Domino Account for User: " + work.getString("UserId"));
var firstUse = "";system.skipEntry();
}else{
task.logmsg("* DelayToNotes");system.sleep(system.getExternalProperty("DelayToNotes"));var firstUse = "firstUse";system.skipTo("updatesNotesFromAD");
}
If this is the first time for the flow to enter the Override Add Hook, then the else statement is executed, thus the system waits for the time in seconds defined by the DelayToNotes property from the external properties file before it tries to find a match again. The second time the flow runs into the Hook, the adminErrorHandler function is called. The function is defined in the adminErrorHandler script described in “Scripts” on page 228. To summarize, the error message containing UserId, the type and the time of error is e-mailed to system administrators and written to an error log file.
See “Appendix B” of the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720 for more information about AssemblyLine and Connector Mode flowcharts.
The configured updateNotesFromAD Connector positioned in the AssemblyLine showing the Hooks enabled and a piece of code on the Override Add Hook is shown in Figure 4-74 on page 251.
250 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-74 updateNotesFromAD
� updateITDS
After Domino has been updated it is IBM Tivoli Directory Server’s turn, thus the next Connector inside our current Loop is updateITDS created in a standard drag and drop and rename way to have the initial properties as shown in Table 4-54.
Table 4-54 updateITDS
The Link Criteria as shown in Table 4-55 on page 252 is configured in order to be able to update the userPassword attribute.
Name Type Mode
updateITDS updateITDS Update
Tip: In our scenario renaming is not necessary for this Connector because its name will remain unique.
Chapter 4. Penguin Financial Incorporated 251

Table 4-55 updateITDS Link Criteria
Finally we enable a Hook to log successful updates using the following script on the Update Successful Hook:
task.logmsg("* ITDS password synchronized for User: " + work.getString("UserId"));
The configured updateITDS Connector positioned in the AssemblyLine showing the Passwords to userPassword attribute mapping is shown in Figure 4-71 on page 246.
Attribute Operator Value
pfsAMAccountName equals $UserId
Note: There is no need for this Connector to have an On No Match Hook enabled, because to this Connector the flow could have only originated from the getAD Connector, where this condition has already been addressed.
252 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-75 updateITDS
� updateTimeStampFromITDS
Finally, the very last Connector in our AssemblyLine. Again, the last thing to do inside the current Loop is the TimeStamp update. It updates IBM Tivoli Directory Server, thus use the drag and drop and rename operation from the updateITDS Connector in the Connector Library into the AssemblyLine resulting in the properties shown in Table 4-56.
Table 4-56 updateTimeStampFromAD
The Link Criteria as shown in Table 4-57 on page 254 is configured to be able to update the pfLastPWChange attribute.
Name Type Mode
updateTimeStampFromAD updateITDS Update
Chapter 4. Penguin Financial Incorporated 253

Table 4-57 updateTimeStampFromAD Link Criteria
Again we enable two Hooks. If the updates are successful then the job is done and we can return to the Password Storage for new entries. Final logging is performed using the following script on the Update Successful Hook:
task.logmsg("* TimeStamp refreshed for User: " + work.getString("UserId"));system.skipEntry();
The On Error Hook is initiated when the update fails. We want to know why, so the adminErrorHandler function is called:
adminErrorHandler("TimeStamp not updated for User: " + work.getString("UserId"));
The function is defined in the adminErrorHandler script described in “Scripts” on page 228. To summarize, the error message containing UserId, the type and the time of an error is e-mailed to system administrators and written to an error log file.
The configured updateTimeStampFromAD Connector is shown in Figure 4-72 on page 248 as a part of the final configuration with all components expanded.
Attribute Operator Value
pfsAMAccountName equals $UserId
254 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-76 AssemblyLine finished
This concludes our AssemblyLine creation and configuration. The logical next step is testing.
TestingOur testing does not intend to check every possible behavior, but we want to test some most common situations we anticipated in section 4.5.4, “Plan the data flows” on page 190, with Loops and non-existing users. We will check e-mail and log files in addition to screen messages from our Config.
What typical situations are we interested in? Let us look at four distinct situations.
Chapter 4. Penguin Financial Incorporated 255

� Situation 1
Let us run a simple test when an Active Directory user changes the password. Follow the flow and see.
Figure 4-77 Situation 1
In Figure 4-77 you can see an expected flow. For Alan Greene, an Active Directory user with username agreene, the Notes password, IBM Tivoli Directory Server password, and TimeStamp were updated after the first checkTimeStamp call. The password update in IBM Tivoli Directory Server has been intercepted again by the AssemblyLine and in a second round the user is recognized as an IBM Tivoli Directory Server user with the short name uid=B10001; but this time the change is not allowed after the checkTimeStamp call, thus an exception is thrown, the user is notified as shown in Figure 4-78 on page 257 and the loop is prevented.
256 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-78 The agreene mail
Chapter 4. Penguin Financial Incorporated 257

� Situation 2
This time we test loops with an IBM Tivoli Directory Server user and fast password changes triggered from a script.
Figure 4-79 Situation 2
The script sent three password changes in a row for a user with short name uid=B10004, thus there are three passwords in the Password Storage even before the first update can be consummated. As you can see from Figure 4-79, the Notes password, Active Directory password, and the TimeStamp for the IBM Tivoli Directory Server user were successfully updated after the checkTimeStamp call. An Active Directory password change was intercepted and stored in the Password Storage as the last entry, thus the remaining two passwords from our test script had to be handled first, both causing TimeStamp exceptions. Finally, the Active Directory password change caused the user to be recognized as Anna Hill, an Active Directory user with username ahill, but still with no permission to update the password. The final informative e-mail sent to this user is shown in Figure 4-80 on page 259.
258 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-80 The b10004 mail
Chapter 4. Penguin Financial Incorporated 259

� Situation 3
This is a test for an originating Domino user without an Active Directory account.
Figure 4-81 Situation 3
Again, a script has sent three password changes in a row, but this time for an IBM Tivoli Directory Server user Chris Austin with short name uid=a10010, an originating Penguin Financial user with no Active Directory account. As you can see in Figure 4-81, the Notes password was synchronized first, then an exception was thrown for a non-existing Active Directory user. After that the TimeStamp prevented any further changes. This time the problem is not something a user should be aware of, so an e-mail was sent to Administrators only, informing them about the non-existing user as shown in Figure 4-82 on page 261.
260 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-82 Admin no AD user
The TimeStamp exceptions were e-mailed to the user. The last mail is shown in Figure 4-83 on page 262.
Chapter 4. Penguin Financial Incorporated 261

Figure 4-83 The a10010 mail
262 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Situation4
In our last test a user is created in Active Directory, but not synchronized to IBM Tivoli Directory Server, thus the password cannot be updated.
Figure 4-84 Situation 4
Lea Cervan with username lcervan, just created in Active Directory, does not exist in IBM Tivoli Directory Server yet. The DelayToITDS should allow our process enough time for the user synchronization process to finish the user creation task. If the user still does not exist in Directory Server after the DelayToITDS expires, an exception is thrown about a non-existing user in the second AssemblyLine attempt to update the password and the Administrator receives an e-mail as shown in Figure 4-85 on page 264.
Chapter 4. Penguin Financial Incorporated 263

Figure 4-85 The lcervan mail
For the completion of our testing section, as shown in Figure 4-86 on page 265, every event was logged in an error log file as defined in the external properties file.
264 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 4-86 error log
This concludes our testing section and Phase 2 of our scenario.
Chapter 4. Penguin Financial Incorporated 265

266 Robust Data Synchronization with IBM Tivoli Directory Integrator

Chapter 5. Blue Glue Enterprises
This chapter provides an introduction to the overall structure of the Blue Glue Corporation, including its business profile, the business requirements Tivoli Directory Integrator will be used to solve and the development of a use case that will be used to test the resolution of the identified technical issues.
5
Note: All names and references for company and other business institutions used in this chapter are fictional. Any match with a real company or institution is coincidental.
© Copyright IBM Corp. 2006. All rights reserved. 267

5.1 Company profileBlue Glue Enterprises is one of the largest retail operations within the United States. Located in Austin Texas, it has been in business for six years. During that time, the organization has experienced double digit growth and opened up two hundred retail outlets across the United States, Canada, and Mexico. Presently Blue Glue is evaluating the purchase of one of its largest competitors which will immediately provide an additional three hundred locations.
Based upon the unprecedented growth Blue Glue has decided to invest in an Identity Management solution. The purchasing decision was partially based upon a favorable ROI, increased regulatory concerns, and the knowledge that an automated policy based identity management solution would be necessary to manage the increased number of employees. This became a priority when the decision was made to grow the organization through acquisitions.
Identity management as defined by the redbook Identity Management Design Guide with IBM Tivoli Identity Manager, SG24-6996-01, “is the concept of providing a unifying interface to manage all aspects related to individuals and their interactions with the business. It is the process that enables business initiatives by efficiently managing the user lifecycle (including identity/resource provisioning for people (users)), and by integrating it into the required business processes. Identity management encompasses all the data and processes related to the representation of an individual involved in electronic transactions.”
After a thorough evaluation of the market, a decision was made to purchase the IBM Tivoli Identity Manager product. As a component of the Identity Manager product suite, Tivoli Directory Integrator will be used in the deployment to provide a data feed from the corporate human resources system. In addition, it will be used to provision users to an internally developed application.
5.2 Blue Glue business requirementsThe Blue Glue corporate data center is located in Austin Texas. The corporate human resources (HR) system utilizes an Oracle database and has been deemed the authoritative source for all Blue Glue employees. The HR system keeps track of the valid department list, employee by department and, manager designations. Anyone who has an account on a Blue Glue resource is first set up in the HR system. When the individual is added to the HR system, they are assigned a unique employee ID number and then added to a valid department.
It is a business requirement that in order for an employee to be added to the identity management system the department manager’s name must be included
268 Robust Data Synchronization with IBM Tivoli Directory Integrator

in the employees’ record. The following list outlines the business requirements for the HR and provisioning systems.� No software may be installed upon the HR system.
� All additions to the provisioning solution must include the employee’s manager name.
� The addition of new employees within the HR system must be reflected in real-time within the provisioning solution.
� Any change of employee status must be reflected in real-time within the provisioning solution.
� The HR database schema is well known and has been provided to the deployment team. A test environment has been created and the appropriate individuals have been identified and added to the project.
A second set of requirements are based upon provisioning users to a custom store application. Several years ago a decision was made to use Linux and LDAP based solutions where possible. A custom store management application was purchased and then extensively modified. The application utilizes LDAP as its user repository and DB2 as its authorization service. In order to add users, the administrator has to add the user to LDAP as well as to specific table’s within DB2 based upon the individual’s role within the organization. This is a mission critical application and must be one of the first applications to utilize the identity management solution due to the anticipated growth of the business. The following list outlines the business requirements for the store management application system.
� No additional software may be installed on the store management system.
� Automate the synchronization of user information between the store management system’s LDAP server and authorization database.
� Any change of employee status must be reflected in real-time within the store management solution.
� The store management schema is well know and has been provided to the deployment team. A test environment has been created; the appropriate individuals have been identified and added to the project.
5.3 Blue Glue functional requirementsThe Blue Glue functional requirements are determined by examining the details behind the business requirements. By mapping the business requirement details to capabilities of the identity management solution and the Blue Glue software, we are able to determine functional requirements.
Chapter 5. Blue Glue Enterprises 269

� Business requirement 1: A provisioning system will be utilized for management of identities within Blue Glue Enterprises.
It has been determined to implement IBM Tivoli Identity Manager V4.6. for the Blue Glue provisioning system. This is a relatively simple requirement that is described in Table 5-1.
Table 5-1 Functional requirement for provisioning system
� Business requirement 2: Employee information in the human resources database is the source for the user accounts in the new provisioning system. No additional software may be installed on the HR system.
This business requirement means there is a need for the data synchronization connection to the HR database to be capable of being remote or agent-less. IBM Tivoli Directory Integrator is chosen to provide this remote agent-less connection between the HR database and Identity Manager. Functional requirement B in Table 5-2 is the resulting requirement.
� Business requirement 3: All changes to the employee information in the HR database must be reflected in real-time in the provisioning system.These changes include the addition, modification and change in status to an employee within the HR system.
This translates to configuring the database to be able to report on changes made to the employee information as well as being able to detect those changes and act on them. Directory Integrator provides a way to configure and monitor changes on database tables. It also includes mapping the appropriate database field names to proper attributes within the provisioning system. Functional requirements C and D in Table 5-2 are the resulting requirements.
Table 5-2 Functional requirements for HR system
Requirement Description
A Blue Glue provisioning system is IBM Tivoli Identity Manager
Requirement Description
B Directory Integrator is utilized to connect to the HR system remotely.
C Use Directory Integrator RDBMS changelog connection and configura-tion to detect real-time changes in the HR system.
D Map the appropriate employee HR database fields to Identity Manager to be able to synchronize the addition, modification, and change in sta-tus to each employee in the HR system to the provisioning system.
270 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Business requirement 4: When adding employee information from the human resources database to the provisioning system, the department manager’s name must be included in the employee account on the provisioning system.
This means there is a need to ensure the HR database provides a way to match the employee to the correct manager name. In order to maximize the ability of the provisioning system, it is necessary to ensure the manager name for the employee is the manager’s distinguished name as represented in the provisioning system’s directory server. This also means there is a need to load the manager’s accounts into Identity Manager first. There also is a need to accommodate the possibility that there is no distinguished name within Identity Manager for a particular manager listed within the database. Table 5-3 shows the resulting functional requirements.
Table 5-3 Functional requirements for employee manager name
� Business requirement 5: Provide the HR database schema, the Blue Glue store management application schema, a test environment, and proper support to the project.
It is important for Blue Glue to identify the proper staff and resources to support the project. It is also necessary to identify the HR database schema and Blue Glue store management application schema to be able to perform the attribute mappings specified in the other requirements. Table 5-4 shows the resulting requirements.
Table 5-4 Functional requirements for project support
Requirement Description
E Identify the HR database tables that identify the employee’s manager name.
F Synchronize the manager user accounts into Identity Manager first.
G Make the system administrator the default manager for employee accounts in Identity Manager if there is no manager distinguished name.
Requirement Description
H Provide a test environment.
I Provide proper support staff to the project.
J Provide the HR database schema, the Blue Glue application LDAP server schema and the Blue Glue application DB2 database schema.
Chapter 5. Blue Glue Enterprises 271

� Business requirement 6: The Blue Glue store management system is mission critical to the business. No additional software may be installed on the store management system.
The Blue Glue store management application consists of two data sources. An LDAP server that maintains user and group information and a DB2 database used to maintain authorization information for those users.
This business requirements means there is a need for the data synchronization connections to both the LDAP server and the DB2 database to be a remote or agent-less connections. Directory Integrator will provide these connections from a separate server. Functional requirement K in Table 5-5 is the resulting requirement.
� Business requirement 7: Automate the synchronization of user information between the store management system’s LDAP server and authorization database.
IBM Tivoli Directory Integrator provides the automated synchronization between these two data sources and removes the costly manual process currently performed by the administrator of the store management system. Functional requirement L in Table 5-5 shows the resulting requirement.
� Business requirement 8: All changes to the employee status within the provisioning system must be reflected in real-time to the employee’s corresponding information in the store management system.
This means if an employee is added, removed, or information modified in the provisioning system, the changes must be reflected in real-time to both the store management system’s LDAP server and authorization database. It also means there is a need to provide a way to reconcile the user and group information within the LDAP server to the provisioning system.
Functional requirement M in Table 5-5 covers the requirement for real-time synchronization while functional requirements N, O, and P show the requirements addressing the need for specific changes to be synchronized.
Table 5-5 Functional requirements for store management system
Requirement Description
K Directory Integrator is utilized to synchronize the store management application LDAP server and DB2 database remotely.
L Use Directory Integrator to automate the synchronization between the store management system LDAP server and authorization database.
M Use Directory Integrator DSMLv2 Event Handler and LDAP changelog Connector to provide the ability to synchronize real-time changes between Identity Manager and the store management system.
272 Robust Data Synchronization with IBM Tivoli Directory Integrator

5.4 Solution designThe solution design in Chapter 4, “Penguin Financial Incorporated” on page 91 covers many of the solution design concepts that are also considerations for the Blue Glue Enterprise solution. These concepts include the list of non-functional requirements that are typical with IBM Tivoli Directory Integrator implementations. It also covers the topic of prioritizing all the requirements to develop an implementation plan.
By following the solution design principles outlined in 4.3, “Solution design” on page 96 and mapping the requirements to the IBM Tivoli Directory Integrator functionality and features, we are able to generate a solution design. The solution design has two phases that address the two sets of Blue Glue business requirements.
� Phase 1: Human resources data feed
In this first phase, we show how to integrate the human resources information into the Blue Glue provisioning solution.
� Phase 2: Store management application
The goal of this phase is to synchronize the Blue Glue provisioning system with the custom Blue Glue store management application.
The solution uses IBM Tivoli Directory Integrator on its own server to synchronize data between IBM Tivoli Identity Manager, IBM Tivoli Directory Server, and DB2 and Oracle databases. Figure 5-1 on page 274 shows a diagram of the solution design for Blue Glue Enterprises.
N Map the appropriate Identity Manager user and group attributes to the LDAP server to synchronize the addition, deletion or modification of a employee within Identity Manager to the store management system.
O Map the appropriate LDAP server attributes to the provisioning system to allow for reconciliation of user accounts and group information.
P Map the appropriate LDAP server attributes to the authorization database fields and tables.
Requirement Description
Chapter 5. Blue Glue Enterprises 273

Figure 5-1 Blue Glue Enterprises solution design
Let us take a brief look at the solution outline.
� Blue Glue acquires Identity Manager.
Phase 1: Human resources data feed.
� Perform one time data load of known supervisors/managers from the HR database into Identity Manager.
� Directory Integrator performs a lookup into the Identity Manager LDAP for manager’s distinguished name before updating the user account in Identity Manager.
Phase 2: Store management application
� Directory Integrator also functions as an agent-less Identity Manager service to provision users into the Blue Glue store management application which uses an LDAP data store.
CustomLDAP
Application(Directory Server)
Authorization Database
(DB2)
HR Database(Oracle)
1. IBM Tivoli Identity Manager(Linux platform)
Directory Integrator
4 Directory Integrator Search, Add, Update, Delete
users and groups
5. Directory Integrator
3. Directory Integrator Lookup manager
2. Directory Integrator one time Data feed of managers
274 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Directory Integrator updates or deletes user information from the user and access database tables that are needed by the LDAP application for authorization.
5.5 Phase 1: Human resources data feedChapter 2, “Architecting an enterprise data synchronization solution” on page 17 of this redbook describes an approach to architect a data synchronization solution. Let us put that discussion to use while creating the HR data feed. At this point, we have identified the business requirements and will now discuss the detailed data identification, planned data flows for the solution, and result review.
5.5.1 Detailed data identification, data flows and reviewFirst let us look at the scenario that we are trying to resolve. When we do this, each data source that is part of the solution needs to be identified. Specifically we are looking for:
� Data location� Data owner� Data access� Initial data format� Unique data attributes
While we are identifying the various data sources that we have to access, we plan the data flows that we need to solve the stated business problem. Specifically we are looking for:
� Identity authoritative attributes� Determine unique Link Criteria� Note any special business requirements� Finalized data formats� Determine if any data cleanup is required� Assess the frequency under which the data needs to be accessed� Determine how to logically segment the solution into manageable pieces
It is important to point out that many times this is an iterative process during which the required data stores and data flows may in fact change. It is considered a best practice to, at a minimum, draw out the proposed data flows. By doing so, you should be able to gain a concise understanding of the data stores and what is required at a high level to provide a solution.
Figure 5-2 on page 276 is an example of the data flows that are required for our HR data feed.
Chapter 5. Blue Glue Enterprises 275

Figure 5-2 Identity Manager HR data feed
Let us take a closer look at the HR data feed outline.
1. Directory Integrator used to load employees from Oracle database.
2. Perform a lookup in the Identity Manager LDAP to find the manager name prior to provisioning the user.
3. Monitor the change log for employee status changes.
4. Add user to Identity Manager via a DSMLv2 data feed.
Here is the sample review document for the initial HR data load.
HR to Identity Manager – employee data loadData Flow Read from HR database and push to Identity Manager.
Note: It is important to point out that since we are not loading managers separately we need to run this AssemblyLine twice to insure that every user has a manager.
HR Database
IBM Tivoli Identity Manager
IBM Tivoli Directory Integrator
1. Load employeesfrom HR
4. DSMLv2 data feed 2. Lookup manager DN
3. Monitorchange log
276 Robust Data Synchronization with IBM Tivoli Directory Integrator

Data source Human Resources Oracle Database @9.3.5.181:1521:DEMODB
Oracle Schema: HR
Table Names: EMPLOYEES,DEPARTMENTS,LOCATIONS
Connector type JDBC - OracleDriver:oracle.jdbc.driver.OracleDriver
Parser None
Connector mode Iterator
Attributes hr.employees.department_id
hr.employees.email
hr.employees.employee_id
hr.employees.first_name
hr.employees.last_name
hr.departments.department_name
hr.locations.country_id
hr.employees.manager_id
hr.employees.phone_number
cn
uid
MultiValued Attributes None
Link Criteria uid=$manager_id
Special Conditions Create uid from employee_id in string format.
Create cn from first_name + last_name
Security Concerns None for Test
Tip: The SQL command used to join the three Oracle tables is as follows:
SELECT HR.EMPLOYEES.EMPLOYEE_ID, HR.EMPLOYEES.FIRST_NAME, HR.EMPLOYEES.LAST_NAME, HR.EMPLOYEES.PHONE_NUMBER,HR.EMPLOYEES.EMAIL, HR.EMPLOYEES.DEPARTMENT_ID, HR.EMPLOYEES.MANAGER_ID, HR.EMPLOYEES.JOB_ID, HR.DEPARTMENTS.DEPARTMENT_NAME, HR.LOCATIONS.COUNTRY_ID
FROM HR.EMPLOYEES, HR.DEPARTMENTS, HR.LOCATIONS
WHERE HR.EMPLOYEES.DEPARTMENT_ID = HR.DEPARTMENTS.DEPARTMENT_ID AND HR.DEPARTMENTS.LOCATION_ID=HR.LOCATIONS.LOCATION_ID
Chapter 5. Blue Glue Enterprises 277

In addition from actually retrieving data from the Oracle database, we need to perform a lookup into the Identity Manager LDAP to obtain the manager’s DN. This has to occur prior to adding the user to Identity Manager. The following is the review document for accessing the Identity Manager LDAP.
HR Data Feed – Manager LookupData Flow Directory Integrator to Identity Manager
Data source Identity Manager Data store (LDAP)
Connector type LDAP - com.ibm.dsml2.jndi.DSML2InitialContextFactory
Parser None
Connector Mode Lookup (manager lookup) / Update (add employee)
Attributes ersupervisor
erlocal
uid
$dn
cn
erpersonstatus
givenname
objectclass
ou
sn
telephonenumber
title
MultiValued Attributes None
Link Criteria uid=$employee_id (employee add)
Special Conditions Create uid from employee_id in string format
Create $dn from ret.value = "uid=" + work.getString("EMPLOYEE_ID")+ "," + ItimHRFeed.getConnectorParam("jndiSearchBase");
Security Concerns None for Test
278 Robust Data Synchronization with IBM Tivoli Directory Integrator

5.5.2 Instrument and test solutionBased upon our investigations we need to create four Connectors and two AssemblyLines for our solution. It is considered best practices to build the Connectors prior to constructing the AssemblyLines.
It was assumed for this redbook that the Oracle database and Tivoli Identity Manager products were already installed and functioning correctly. We are using Oracle v.9.x and Identity Manager v.4.6. Based upon that assumption, the necessary steps to develop the solution are:
� Install Tivoli Directory Integrator
� Add the Oracle JDBC driver to the Tivoli Directory Integrator class path
� Create a new Tivoli Directory Integrator XML configuration file
� Create an external properties file
� Configure/verify Oracle database change log
� Create the appropriate Connectors
� Test the appropriate Connectors
� Setup an Identity Manager IDI data feed service
� Develop and interactively test the HR AssemblyLines
Install Tivoli Directory IntegratorDirectory Integrator is considered light-footed, rapidly deployed integration middleware. Unlike traditional middleware, Directory Integrator installs in minutes and you can begin building, testing, and deploying solutions immediately.
For more information about installing the IBM Tivoli Directory Integrator, please see "IBM Tivoli Directory Integrator installation instructions" in the IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1716.
In our test environment, we chose to install the product on a Windows platform.
Add the Oracle JDBC driver to the classpathThe JDBC Connector provides access to a variety of systems. To reach a system using JDBC you need a JDBC driver from the system provider. This provider is typically delivered with the product in a jar or zip file. These files must be in your
Important: For the purposes of this redbook it was decided to demonstrate the use of Directory Integrator directly accessing the HR database. This is only one of several approaches that can be taken.
Chapter 5. Blue Glue Enterprises 279

classpath or copied to the extensions directory; otherwise you may get cryptic messages like - Unable to load T2 native library, indicating that the driver was not found on the classpath. You also need to determine which of the classes in this jar or zip file implements the JDBC driver; this information needs to be entered into the JDBC Driver parameter.
For our solution, we are using the Oracle JDBC Type 4 (thin) driver. This driver can be downloaded from the Oracle Web site or simply copied from the system that you want to connect to. By default, the file is located in the /oracle/product/VerXX/db1/jdbc/lib directory and needs to be copied into the /InstallDir/_jvm/jre/lib/ext directory. We chose to copy the classes12.zip file from the database server.
More information about the driver type, class name, and download details can be found in Appendix A, “Tricky connections” on page 415.
Figure 5-3 Oracle JDBC driver - classes12.zip file added to Directory Integrator classpath
Additional information regarding the Oracle JDBC driver can be found in the Oracle JDBC Developer Guide and Reference Release 9.2.
Create a new Directory Integrator XML configuration fileIt is possible to name the configuration file whatever you wish. However, it is best practice to use a naming convention that is based upon what the solution is going to accomplish. As modifications are made to the file it is also important to apply some type of version control to the name. Doing so allows you to more easily locate the correct file as well as the correct version at a later date.
Important: Do not unzip the file.
280 Robust Data Synchronization with IBM Tivoli Directory Integrator

Create an external properties fileThe external properties file can be created using any standard editor and the structure is explained in the IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1716 as a feature that enables you to store sensitive information outside your configuration in a secure format, but still keep it configurable. Think of External Properties as global system variables that can be used throughout your solution. Of course you can access External Properties from your scripts, enabling you to make your code data-driven, changing its functionality based on the value of one or more of these properties. However, the most powerful use of External Properties is as parameter values in the configuration of components, such as Connectors. Figure 5-4 shows the properties file that was used in our HR identity feed solution.
Figure 5-4 HR data feed external properties file
A description of each of the external properties values is given in the following table.
Chapter 5. Blue Glue Enterprises 281

Table 5-6 External properties file
Variable Description
OracleAdmin System account used to access the database.
OracleDriver oracle.jdbc.driver.OracleDriver
OraclePw System account password.
OracleSchema HR - Sample schema provided with the database.
OracleTableName Employees - Stores employee information and is used to build Input Map.
OracleUrl jdbc:oracle:thin:@9.3.5.181:1521:DEMODB - Database location and SID.
ItimAuth Simple authentication to LDAP.
ItimJndiProvider com.ibm.dsml2.jndi.DSML2InitialContextFactory
ItimLdapAccountSearchBase ou=accounts,erglobalid=00000000000000000000,ou=BLUEGLUE,dc=COM - Must contain the erglobalid.
ItimLdapLogin cn=root - The LDAP administrative account.
ItimLdapPw Administrative password.
ItimLdapUrl ItimLdapUrl:ldap://9.3.5.180:389 - LDAP location.
ItimLogin Agent - Identity Manager account.
ItimPwt Agent password.
ItimSearchFilter: (objectclass=inetorgperson)
ItimUrl http://9.3.5.180:9080/enrole/dsml2_event_handler - Identity Manager location/service.
ItimSearchBase dc=peopledata - Must match naming context in Identity Manager service.
personStatus 0 - Account status.
DefaultManager erglobalid=00000000000000000007, ou=0, ou=people, erglobalid=00000000000000000000, ou=BlueGlue, DC=COM - in the event that a user’s manager is not located, he will be assigned the Identity Manager Administrator.
282 Robust Data Synchronization with IBM Tivoli Directory Integrator

Configure/verify Oracle database change logOne of the Blue Glue business requirements is that all changes to the HR systems must be reflected in the identity management solution on a real-time basis. In order to accomplish this, a change log has to be enabled in the Oracle database. When a user is modified or deleted the entry is then stored in the change log. Additional information regarding configuring the Oracle changelog and triggers can be found in the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720. Example 5-1 shows the SQL command that are required to create an Oracle changelog and associated triggers.
Example 5-1 Oracle change log creation
====================Create Change Log=====================
CREATE TABLE "SYSTEM"."CCDCHANGELOG" ( IBMSNAP_COMMITSEQ RAW(10) NOT NULL, IBMSNAP_INTENTSEQ RAW(10) NOT NULL, IBMSNAP_OPERATION CHAR(1) NOT NULL, IBMSNAP_LOGMARKER DATE NOT NULL, EMPLOYEE_ID VARCHAR2 (10), FIRST_NAME VARCHAR2 (20), LAST_NAME VARCHAR2 (20), PHONE_NUMBER VARCHAR2 (12), EMAIL VARCHAR2 (20), DEPARTMENT_ID VARCHAR2 (10) );
=====================================Create Database Trigger for Delete=====================================CREATE TRIGGER "SYSTEM"."DCCDCHANGELOG"AFTER DELETE ON "HR"."EMPLOYEES"FOR EACH ROW BEGIN INSERT INTO "SYSTEM"."CCDCHANGELOG"(EMPLOYEE_ID,MANAGER_ID,JOB_ID,FIRST_NAME,LAST_NAME,PHONE_NUMBER,EMAIL,DEPARTMENT_ID,IBMSNAP_COMMITSEQ,IBMSNAP_INTENTSEQ,IBMSNAP_OPERATION,IBMSNAP_LOGMARKER)VALUES (:OLD.EMPLOYEE_ID,
Chapter 5. Blue Glue Enterprises 283

:OLD.MANAGER_ID,:OLD.JOB_ID,:OLD.FIRST_NAME,:OLD.LAST_NAME,:OLD.PHONE_NUMBER,:OLD.EMAIL,:OLD.DEPARTMENT_ID,LPAD(TO_CHAR("SYSTEM"."SGENERATOR001".NEXTVAL),20,'0'),LPAD(TO_CHAR("SYSTEM"."SGENERATOR001".NEXTVAL),20,'0'),'D',SYSDATE); END;======================================Create Database Trigger for Update=======================================CREATE TRIGGER "SYSTEM"."UCCDCHANGELOG"AFTER UPDATE ON "HR"."TESTEMP"FOR EACH ROW BEGIN INSERT INTO "SYSTEM"."CCDCHANGELOG"(EMPLOYEE_ID,MANAGER_ID,JOB_ID,FIRST_NAME,LAST_NAME,PHONE_NUMBER,EMAIL,DEPARTMENT_ID,IBMSNAP_COMMITSEQ,IBMSNAP_INTENTSEQ,IBMSNAP_OPERATION,IBMSNAP_LOGMARKER)VALUES (:NEW.EMPLOYEE_ID,:NEW.MANAGER_ID,:NEW.JOB_ID,:NEW.FIRST_NAME, :NEW.LAST_NAME,:NEW.PHONE_NUMBER,:NEW.EMAIL,:NEW.DEPARTMENT_ID,LPAD(TO_CHAR("SYSTEM"."SGENERATOR001".NEXTVAL),20,'0'),LPAD(TO_CHAR("SYSTEM"."SGENERATOR001".NEXTVAL),20,'0'),'U',SYSDATE); END;
================================== Create Database Trigger for Add==================================CREATE TRIGGER "SYSTEM"."ICCDCHANGELOG"AFTER INSERT ON "HR"."EMPLOYEES"FOR EACH ROW BEGIN INSERT INTO "SYSTEM"."CCDCHANGELOG"(EMPLOYEE_ID,
284 Robust Data Synchronization with IBM Tivoli Directory Integrator

MANAGER_ID,JOB_ID,FIRST_NAME,LAST_NAME,PHONE_NUMBER,EMAIL,DEPARTMENT_ID,IBMSNAP_COMMITSEQ,IBMSNAP_INTENTSEQ,IBMSNAP_OPERATION,IBMSNAP_LOGMARKER)VALUES (:NEW.EMPLOYEE_ID,:NEW.MANAGER_ID,:NEW.JOB_ID,:NEW.FIRST_NAME, :NEW.LAST_NAME,:NEW.PHONE_NUMBER,:NEW.EMAIL,:NEW.DEPARTMENT_ID,LPAD(TO_CHAR("SYSTEM"."SGENERATOR001".NEXTVAL),20,'0'),LPAD(TO_CHAR("SYSTEM"."SGENERATOR001".NEXTVAL),20,'0'),'I',SYSDATE); END;
Once the change log has been created the following SQL commands can be used to test the correct operation.
Example 5-2 Sample SQL commands for testing the change log
========ADD USER ========INSERT INTO HR.EMPLOYEES VALUES('50', 'ARTHUR','HUNT', 'ahunt', '111-111-1111','16-AUG-94','AD_PRES','','','100','90');==========================MODIFY USER FROM EMPLOYEES==========================UPDATE HR.EMPLOYEESSET PHONE_NUMBER='222-222-2222'WHERE EMPLOYEE_ID='914';==========================DELETE USER FROM EMPLOYEES==========================select * from hr.employeeswhere LAST_NAME = 'HUNT';delete from hr.employeeswhere LAST_NAME = 'HUNT';==========================
Chapter 5. Blue Glue Enterprises 285

DELETE USER FROM CHANGELOG==========================select * from system.ccdchangelog;delete from system.ccdchangelogwhere rownum <=2;
Create the appropriate ConnectorsBased upon our research, we have determined that we need four Connectors. Two are used for access to the Oracle database and two are used in connection with the Identity Manager LDAP access.
The Oracle Connector, depicted in Figure 5-5, is used for the initial employee load and the OracleChanges Connector is used for modifications.
Figure 5-5 Oracle Connector
286 Robust Data Synchronization with IBM Tivoli Directory Integrator

There are two ways to test the Connectors. The first is to press the Select button on the configuration window. The current entry is EMPLOYEES, but the list of table names should be returned if you have a valid connection.
A second way to test the connection is to select the Input Map tab, depicted in Figure 5-6, and then press the connect to data source button , which looks like a power cord connection. If you are able to connect to the database, you see a connection establish message. At that point you can either advance through the entries or discover the schema.
Figure 5-6 Oracle Connector Input Map
The only difference between the Oracle and the OracleChanges Connector is the actual table that we connect to.
The final two Connectors that our solution requires are used to lookup the manager DN prior to provisioning the user, and as the actual Identity Manager HR feed Connector. The ManagerLookup Connector is used to connect to the LDAP server to retrieve the manager DN and the ItimHRFeed Connector is the Identity Manager HR service Connector. First let us look at the ManagerLookup Connector shown in Figure 5-7 on page 288.
Chapter 5. Blue Glue Enterprises 287

Figure 5-7 ManagerLookup Connector
The ManagerLookup Connector is based on a JNDI Connector and is used by both of the AssemblyLines to provide manager information to Identity Manager.
Figure 5-8 on page 289 shows the details for the ItimHRFeed Connector.
288 Robust Data Synchronization with IBM Tivoli Directory Integrator
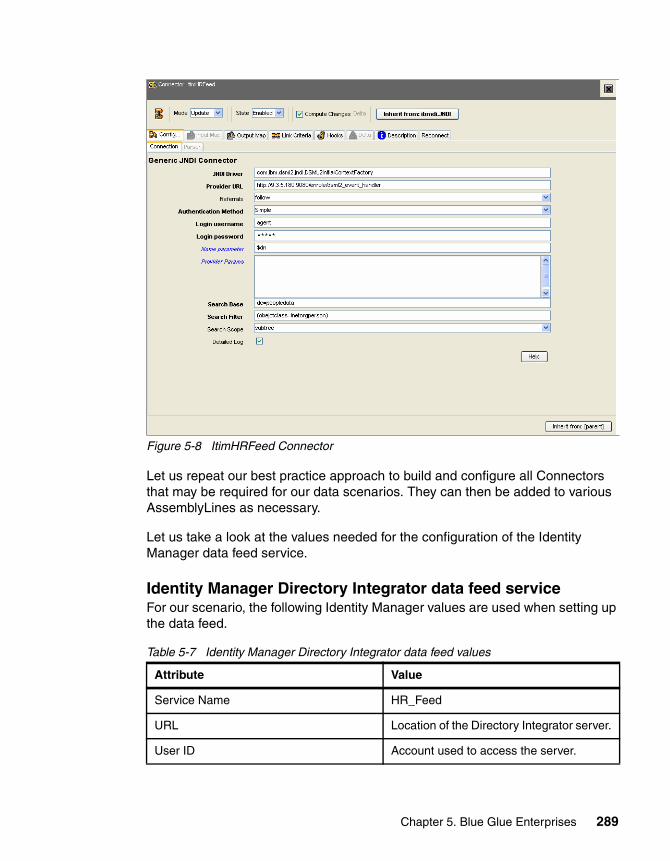
Figure 5-8 ItimHRFeed Connector
Let us repeat our best practice approach to build and configure all Connectors that may be required for our data scenarios. They can then be added to various AssemblyLines as necessary.
Let us take a look at the values needed for the configuration of the Identity Manager data feed service.
Identity Manager Directory Integrator data feed serviceFor our scenario, the following Identity Manager values are used when setting up the data feed.
Table 5-7 Identity Manager Directory Integrator data feed values
Attribute Value
Service Name HR_Feed
URL Location of the Directory Integrator server.
User ID Account used to access the server.
Chapter 5. Blue Glue Enterprises 289

Additional information regarding the Identity Manager data feed can be found in the IBM Tivoli Identity Manager Planning for Deployment Guide, SC32-1708.
Develop and test the HR AssemblyLinesFor experienced users of the product, you may notice a difference in the appearance of the AssemblyLines. The stated direction of the product is to add components or functionality that removes the need for complex scripting within the AssemblyLine. For example, the ability to use loops, branches, and to call AssemblyLines as functions from within other AssemblyLines were added to the product in version 6. As such, these techniques are used in the construction of the following AssemblyLines. They greatly reduce the need for scripting.
The first AssemblyLine that we create is used to perform the initial employee load.
Load Employees from HR Database AssemblyLineIt is important to point out that this AssemblyLine needs to be run twice. The first time it is run, the employee is added to the Identity Manager system. However, we need to make sure that in order to satisfy the business requirement of having the managers DN we have to run the AssemblyLine a second time. The reason for this is that it is possible that the HR system may have an entry that does not include the manager information. By running the AssemblyLine a second time, it performs the manager lookup and ensures the record meets the stated requirement. To Identity Manager, the first pass appears as an add and the second as a modify operation.
Password Account password.
Naming context dc=people - must match Identity ManagerSearchBase value in Connector.
Name Attribute uid
Placement rule var filt = '';var defaults = new Array();var ou = Enrole.getAttributeValues('Person.ou',defaults);if (ou != null && ou.length > 0) { filt = 'ou=' + ou[0]; for (i=1; i<ou.length; ++i) { filt = filt + ',ou=' + ou[i]; } }return filt;
Attribute Value
290 Robust Data Synchronization with IBM Tivoli Directory Integrator

The AssemblyLine, depicted in an overview, uses the previously created Oracle Connector.
Figure 5-9 Load_Employees_from_HR_Database AssemblyLine
Before the AssemblyLine is started, the erSupervisor attribute has been assigned to the default value of ITIM Manager which has been defined in the external properties file. The AssemblyLine Connector is pictured in Figure 5-10 on page 292.
Chapter 5. Blue Glue Enterprises 291

Figure 5-10 Load_Employees AssemblyLine Connector
The Input Map values are listed in the following table.
Table 5-8 Input map values
Attribute Value
COUNTRY_ID country_id
DEPARTMENT_ID department_id
EMAIL e-mail
EMPLOYEE_ID var eid = conn.getObject("EMPLOYEE_ID");var employeeid = eid.toString();ret.value = employeeid;
FIRST_NAME first_name
JOB_ID job_id
LAST_NAME last_name
292 Robust Data Synchronization with IBM Tivoli Directory Integrator

The flow includes an IF_MgrFound loop, depicted in Figure 5-11 on page 294, that has a link attribute of uid=$Manager_ID and performs a manager lookup. If the manager is not found, the On No Match Hook is invoked with a message of “task.logmsg("Manager not found: " + work.getString("Manager_id")); “. If a match is found the attribute map component Set_erSupervisor is invoked and the erSupervisor attribute is mapped to $dn.
MANAGER_ID var managerid = conn.getObject("MANAGER_ID");ret.value = managerid + "";
PHONE_NUMBER phone_number
cn ret.value = conn.getString("FIRST_NAME") + " " + conn.getString("LAST_NAME");
erSupervisor ret.value=system.getExternalProperty("DefaultManager");
uid var uuid = conn.getObject("EMPLOYEE_ID");var uid = uuid.toString();ret.value = uid;
Note: The act of setting the default manager satisfies the business requirement of not adding users to the identity management solution without a valid manager.
Attribute Value
Chapter 5. Blue Glue Enterprises 293

Figure 5-11 IF_MgrFound
The final step in the Loop is to invoke the itimHRFeed which has a Link Criteria of uid=$EMPLOYEE_ID. The Output Map has the following values.
294 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-12 Output Map attributes
The attributes have the following values.
Table 5-9 attribute values
Connector Attribute Mapping
erSupervisor erSupervisor
erlocale COUNTRY_ID
uid uid
$dn ret.value = "uid=" + work.getString("EMPLOYEE_ID")+ "," + ItimHRFeed.getConnectorParam("jndiSearchBase");
cn cn
erpersonstatus ret.value=system.getExternalProperty("personStatus");
givenname FIRST_NAME
mail ret.value = work.getString("EMAIL") + "@BlueGlue.com";
objectclass ret.value = "inetorgperson";
ou DEPARTMENT_NAMEe
SN LAST_NAME
Chapter 5. Blue Glue Enterprises 295

It is important to point out that the only Hooks that are used are informative in nature. For example, the Before Modify Hook contains the following:
task.logmsg ("======== MODIFYING PERSON RECORD FROM HR =================");task.logmsg ("NAME = " + work.getString("cn"));task.logmsg ("UNIQUE ID = " + work.getString("uid"));
The Default On Error Hook contains the following:
task.logmsg ("======== ERROR ENCOUNTERED =================");system.dumpEntry(error);task.dumpEntry(work);
It is considered a best practice to fully document the AssemblyLine and to use the Hooks as a way to present the information.
HR Database Changes AssemblyLineThis AssemblyLine, the overview is shown in Figure 5-13, has been created to satisfy the business requirement that additions and changes to the HR system must be reflected near real-time within the identity management solution.
Figure 5-13 HRDatabaseChanges AssemblyLine
The AssemblyLine uses the previously created OracleChanges Connector, shown in Figure 5-14 on page 297.
telephonenumber PHONE_NUMBER
title JOB_ID
Connector Attribute Mapping
296 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-14 Oracle changelog Connector
What is important to point out with this Connector is that the remove process rows have been selected. The Input Map values are listed in the following table.
Table 5-10 OracleChanges Input Map
Connector Attribute Mapping
DEPARTMENT_ID DEPARTMENT_ID
EMPLOYEE_ID EMPLOYEE_ID
IBMSNAP_OPERATION value=conn.getProperty("IBMSNAP_OPERATION");
cn ret.value = conn.getString("FIRST_NAME") + " " + conn.getString("LAST_NAME");
Chapter 5. Blue Glue Enterprises 297

The flow first looks for the existence of an employee ID which is accomplished by the use of an if statement. In this case, the IF_Record_Not_Null statement, which uses a Link Criteria of EMPLOYEE_ID, equals not null.
If the employee ID is not null the Attribute Map component uid is invoked and the uid attribute is mapped to EMPLOYEE_ID. The following example illustrates the code to accomplish this.
var uuid = work.getObject("EMPLOYEE_ID");var uid = uuid.toString();task.logmsg (uid);ret.value = uid;
At this point a check is made to determine if the change is a delete. This is accomplished by the If_Delete statement. The Link Criteria is in the following example.
// Check the Delta operation code of the work Entryret.value = work.getOperation().equals("delete");
If the change is a delete, the attribute map component set_erpersonstatus is invoked and the attribute erpersonstatus is set to re.value=1, which notifies Identity Manager that the action is a delete.
uid var uuid = conn.getObject("EMPLOYEE_ID");var uid = uuid.toString();task.logmsg (uid);ret.value = uid;
EMAIL EMAIL
EMPLOYEE_ID EMPLOYEE_ID
FIRST_NAME FIRST_NAME
JOB_ID JOB_ID
LAST_NAME LAST_NAME
MANAGER_ID MANAGER_ID
PHONE_NUMBER PHONE_NUMBER
erpersonstatus set_erpersonstatus
DEPARTMENT_NAME EmployeeLookup-Oracle
Connector Attribute Mapping
298 Robust Data Synchronization with IBM Tivoli Directory Integrator

The function component Employee-Lookup-Oracle is then invoked with a Link Criteria of Department_ID = $Department_ID. The Lookup Successful Hook includes the following message:task.logmsg (" === Processing Entry - Department Name = " + work.getString("DEPARTMENT_NAME"));task.logmsg (" === Processing Entry - Employee ID = " + work.getString("EMPLOYEE_ID"));
The final part of the AssemblyLine is to pass the changes to Identity Manager. This is accomplished by the use of a function call and a script component that addresses null entries.
The idea behind function calls allows complex components to be split into smaller logical units and then strung together as needed. In past versions of the product extensive scripting was required to accomplish this task.
In this scenario, the Call_Load_Employees_from_HR_Database function call is invoked. This has the effect of passing the existing Input Map to the load_Employees_from_HR_Database AssemblyLine. The net result is that we are able to take advantage of a previously developed AssemblyLine to load information into Identity Manager.
The use of function calls is explained in greater detail in the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718.
Figure 5-15 Calling another AssemblyLine via a functional component
The script component that addresses null entries contains the following:
task.logmsg("skipping entry");system.skipEntry();
This concludes the HR data feed and maintenance of employees into the identity management solution. Next we take a closer look at the store management application.
Chapter 5. Blue Glue Enterprises 299

5.6 Phase 2: Store management applicationSynchronizing the custom Blue Glue store management application involves two parts. The first part is to be able to create, update, and delete users and group accounts between IBM Tivoli Identity Manager and the custom LDAP server which is part of the Blue Glue store management application. This also includes detection of user accounts and groups within the LDAP server for reconciliation back to the Identity Manager server.
The second part is to synchronize authorization information from the LDAP server to the DB2 authorization database once the user and group membership information is synchronized within the LDAP server. Completing these two synchronization pieces ensures the Blue Glue application is kept synchronized with the company’s identity management solution.
The solution is accomplished using IBM Tivoli Directory Integrator. In the first part, Directory Integrator functions in real-time as an LDAP agent for Identity Manager. Part two involves Directory Integrator performing the data synchronization in real-time between the LDAP server and the DB2 server.
We use the same approach as outlined in Chapter 2, “Architecting an enterprise data synchronization solution” on page 17 and with the HR feed to construct a data synchronization solution for these two pieces. Since the business requirements are already identified, we complete the following steps for our two part synchronization solution:
� Detailed data identification� Plan the data flows� Review the results� Instrument the solution
5.6.1 Detailed data identificationThis is where we identify the data location, owner, access, initial data format and unique data attributes.
The Blue Glue store management application solution involves synchronizing data in three locations, that is, the Identity Manager server, the Blue Glue application LDAP server, and the Blue Glue application DB2 server. Table 5-11 on page 302 gives a detailed description of the data sources involved.
Directory Integrator connects to these data locations using a DMSLv2 Event Handler for the connection to the Identity Manager server, LDAP for the LDAP server connection, and JDBC for the DB2 server connection. All of these connections can be made remotely, which means Directory Integrator can run on its own server or on any of the servers hosting the other data sources. In Blue
300 Robust Data Synchronization with IBM Tivoli Directory Integrator

Glue’s solution, Directory Integrator is running from a Windows platform separate from the other data sources.
Blue Glue chose to use the administrator access accounts to perform this data synchronization. Separate administrator level accounts can be created specifically for the Directory Integrator synchronization process. It is ideal to utilize individual access accounts for Directory Integrator when possible to be able to audit those systems at a more detailed level.
The connection between the Identity Manager server and the Blue Glue application LDAP server allows for multiple values for the group memberships of the users. The connection between LDAP and DB2 does not have any requirement to process multiple valued attributes.
At this time, we are not expecting any other special types of formatted data. As we build our solution, we will add a few options to skip entries if there are unexpected errors and print out any of those errors in case data exists in a format which is unexpected. Since this particular solution involves us defining the input required for the data in Identity Manager before it gets synchronized to LDAP or DB2, we are able to control the initial data format and ensure the required attributes have proper formatting. The data cleanup for this solution happens with the HR feed portion of the Blue Glue scenario.
Chapter 5. Blue Glue Enterprises 301

Table 5-11 Data sources
Identity Manager Server
Description Contains managed user accounts
System Linux – hostname: Augusta (9.3.5.180)
Data User account and group information
Blue Glue application group information via reconciliation
Unique data eruid attribute; user can be a member of multiple groups
Data storage LDAP server
Access mechanisms DSML2 Event Handler via Directory Integrator
Data owner/access itim manager/passw0rd (DSML2 access: agent/agent)
Blue Glue Application LDAP server
Description Contains user and group information for store management application
System Linux – hostname: Pinehurst (9.3.5.182)
Data User account information
Unique data uid attribute; user can be a member of multiple groups
Data storage LDAP server
Access mechanisms LDAP
Data owner/access root/passw0rd
Blue Glue Application DB2 server
Description Contains authorization information for store management application
System Linux – hostname: Dallas (9.3.5.181)
Data User authorization information
Unique data USERNO attribute; no multiple values
Data storage IBM DB2
Access mechanisms JDBC
Data owner/access db2admin/passw0rd
302 Robust Data Synchronization with IBM Tivoli Directory Integrator

5.6.2 Data flowsNext we plan the data flows for the two parts of our solution. Figure 5-16 shows the data flow for the first part of the solution which is between the Identity Manager server and the Blue Glue store application LDAP server.
Figure 5-16 Data flow between Identity Manager and LDAP
Figure 5-17 shows the data flow for the second part of the solution between the Blue Glue store application LDAP server and the DB2 server.
Figure 5-17 Data flow between LDAP and DB2
Identity Manager server
Blue Glue applicationLDAP server
Unique attribute: eruid
Unique attribute:uid
Synchronization of user attributes and group
membership.Directory Integrator Add, Update,
Delete modes
Link Criteria
Reconciliation of users and groups into Identity Manager.
Directory Integrator Iterate mode
Blue Glue applicationDB2 server
Unique attribute: uid Unique attribute:USERNO
Synchronization of authorization information to
access db tableDirectory Integrator Update and
Delete modes
Link Criteria
Blue Glue applicationLDAP server
Synchronization of user attributes to users db tableDirectory Integrator Update
and Delete modes
Chapter 5. Blue Glue Enterprises 303

As we plan the data flows and learn more about our data, we collect information for the following topics:
� Authoritative attributes� Unique Link Criteria� Special conditions or business requirements� Final data format� Data cleanup� Phased approach� Frequency
Authoritative attributes and unique Link CriteriaTable 5-12 lists the attributes expected to be utilized with our solution. The last two attributes listed are listed as being used to perform a similar function. They are both used in our solution to demonstrate two different ways to determine if the function to use is an update or a delete process within Directory Integrator.
For our solution, the authoritative attributes all originate from the Blue Glue identity management solution. This means the attributes originating from our Identity Manager agent Connector are authoritative.
The unique Link Criteria are listed in Figure 5-16 on page 303 and Figure 5-17 on page 303 for each respective piece of our solution. There is no special requirement for calculating the Link Criteria.
Parts of this step of listing the attributes occurs when initially identifying the data format and any unique attributes. Since identifying and planning your data is an iterative process, the results of this step can be listed as part of either identification of the data or planning the data.
Table 5-12 Attributes for Blue Glue application solution
Attribute name used with Identity Manager agent Connector
Attribute name used with LDAP Connector
Attribute name used with DB2 Connector
eruid $dn (calculated value using eruid)
n/a
cn cn USERS.FULLNAME
bgtitle title ACCESS.ACCESSCODE (calculated)
firstname givenname USERS.FIRSTNAME
bghomepostaladdress homepostaladdress ACCESS.LOCALE
mail mail USERS.EMAIL
304 Robust Data Synchronization with IBM Tivoli Directory Integrator

Special conditionsOur solution involves creating a custom Identity Manager agent to manage the Blue Glue store management application. This means we define a data model to create an Identity Manager service and account within Identity Manager. Directory Integrator is then configured to respond to our new Identity Manager service as an LDAP agent connecting to the Blue Glue application LDAP server. We cover the details of defining the Identity Manager agent data model and installing the Identity Manager service and account information when we talk about how to instrument the solution.
n/a objectClass(multi-valued)
n/a
lastname sn USERS.LASTNAME
telephonenumber telephoneNumber n/a
eruid uid USERS.USERNO and ACCESS.USERNO
erpassword userpassword n/a
bgappgroupdn $dn (for group) n/a
bgappgroupname cn (for group) n/a
dn (of user) member n/a
bgappgroupmembership used to map to specific groups(can be multi-valued)
n/a
erAccountStatus employeetype n/a
n/a targetdn USERS.USERDN
n/a n/a ACCESS.DATE (calculated from system date)
n/a changetype used to determine if update or delete
n/a operation used to determine if update or delete
Attribute name used with Identity Manager agent Connector
Attribute name used with LDAP Connector
Attribute name used with DB2 Connector
Chapter 5. Blue Glue Enterprises 305

Format, frequency, data cleanup and approachThere are a few considerations for the final data format for some attributes. The final data format for the date field to be placed in the DB2 database needs to be in the sql date format. The date is calculated from the system date where Directory Integrator is located. Directory Integrator retrieves the system date in Java format and converts it to the sql date format to be placed into the database properly. All other attributes listed in Table 5-12 on page 304 are represented in string format.
A value for the attributes representing the user ID is required to create users within the Blue Glue application LDAP server and also to synchronize to the corresponding DB2 server. A value for the user ID attribute is required by the Identity Manager server and is delivered to the Directory Integrator solution as part of the request to synchronize users from Identity Manager. This means we do not need to test for null values existing as part of the user ID attributes within our Directory Integrator solution. The Identity Manager server covers this requirement.
Data synchronization to the DB2 database will not be performed unless the title attribute contains a value within the LDAP server. The title attribute determines the access control for the DB2 authorization tables. There is no reason to update anything in DB2 without this information in the title attribute. If the format for this attribute is null, processing to the DB2 database will stop.
The data is synchronized in real-time between the Identity Manager server and the LDAP server and also between the LDAP server and the DB2 server. The data reconciliation process used to reconcile users and groups that are already within the LDAP server into the Identity Manager server is something that is scheduled within the Identity Manager server.
Data cleanup is being performed for the HR feed into the Identity Manager server. All the data synchronization within the part of the solution involves data originating from the Identity Manager server except for the reconciliation process between the Blue Glue application LDAP server and the Identity Manager server. Given that the data to be synchronized to the LDAP server and the DB2 server originates from the Identity Manager server, there is little data cleanup required for this piece of our solution. The reconciliation process within Identity Manager allows for ways to deal with orphaned accounts and data that may have been within the Blue Glue application LDAP server that is not useful to the Blue Glue Identity Management solution.
The approach to our Blue Glue store management application solution is to first integrate the Identity Manager server with the Blue Glue store management application LDAP server. Once that is complete, we then integrate the Blue Glue store management application LDAP server to the store management
306 Robust Data Synchronization with IBM Tivoli Directory Integrator

application’s DB2 server. There is no requirement for pre-loading any special data set prior to implementing the complete solution.
5.6.3 Review resultsBased on our planning, the data flows for the connection from the Identity Manager server to the Blue Glue store management application use the Directory Integrator Event Handler for 2-way data synchronization as an LDAP agent for Identity Manager. Configured as an Identity Manager LDAP agent, the Directory Integrator Event Handler works with four separate AssemblyLines to add, update, delete, or reconcile (iterate) users and groups to and from the Blue Glue LDAP server. An additional data flow synchronizes the LDAP server to the DB2 server.
The following is documentation outlining the results of our planning. There are two sections covering the Identity Manager server to and from the Blue Glue application LDAP server. One of the two sections details the data flow from the Identity Manager server and another details the data flowing to the Identity Manager server. There is another section to cover the Blue Glue LDAP server to the Blue Glue DB2 server.
Identity Manager to Blue Glue store management application LDAPData source: Identity Manager server
Data Flow Identity Manager agent: Identity Manager server to Directory Integrator LDAP agent
Data source Identity Manager server; Identity Manager service calls Directory Integrator Event Handler
Directory Integrator Event Handler @ 9.3.4.207; port 8800
Connector type DMSLv2 Event Handler
Parser None
Connector Mode Configure to call the following AssemblyLines:
Add, update, delete
Binary Attributes erpassword
Attributes eruidcnbgtitlefirstnamebghomepostaladdressmaillastname
Chapter 5. Blue Glue Enterprises 307

telephonenumbererpasswordbgappgroupmembership
MultiValued Attributes bgappgroupmembership
Naming Context dc=ldap
Special Conditions Requires Identity Manager data model for Blue Glue account and service within Identity Manager that is covered when we instrument the solution
Security Concerns None
Data source: LDAP server
Data Flow Identity Manager agent: Identity Manager server via Directory Integrator LDAP agent (Event Handler) to LDAP server to add, update or delete users and groups
Data source Blue Glue store management application LDAP server @ 9.3.5.182; port 389
Connector type LDAP
Parser None
Connector Mode One Connector for user accounts used in add, update, or Delete mode
One Connector for group membership used in update or Lookup mode
Attributes For users Connector:$dncngivennamehomepostaladdressmailobjectclasssntelephonenumbertitleuiduserpassword
For group Connector:$dn (of group)cn (of group)memberobjectclass (of group)
308 Robust Data Synchronization with IBM Tivoli Directory Integrator

MultiValued Attributes objectclass
Link Criteria For users Connector:add: none requireddelete and update: uid = $eruid andobjectclass = inetorperson
For group Connector:add: $dn = $baseDndelete: member = $$dn andobjectclass = groupOfNamesupdate: $dn = $groupDn
Special Conditions Make user $dn from eruid in string formatCreate objectclass values
Process the multi-valued group membership attribute of bgappgroupmembership coming from Identity Manager via the Directory Integrator Event Handler to individually add a user to multiple group memberships within the LDAP server
Security Concerns None
Blue Glue store management application LDAP to Identity ManagerData source: LDAP server
Data Flow Identity Manager agent: LDAP server via Directory Integrator LDAP agent (Event Handler) to Identity Manager server to reconcile of user accounts and group names
Data source Blue Glue store management application LDAP server @ 9.3.5.182; port 389
Connector type LDAP
Parser None
Connector Mode One Connector for user accounts used iterate mode
One Connector for group names used in iterate mode
Attributes For users Connector:cntitlegivennamehomepostaladdressmail
Chapter 5. Blue Glue Enterprises 309

objectclasssntelephonenumberuserpassworduidemployeetype
For group Connector:$dn (of group)cn (of group)objectclass (of group)
MultiValued Attributes grpList This attribute is calculated to contain the group names a user in the LDAP server might be listed as being a member. It will be matched to the bbgappgroupmembership attribute within Identity Manager.
Link Criteria For users Connector: noneFor group Connector:To check membership of a user in a groupmember = $userDN andobjectclass = groupOfNames
Special Conditions Make user $dn from uid in string format with “eruid=” as the prefix
Create objectclass values
Calculate erAccountStatus based on values of either “disabled” or “enabled” in employeetype attribute
User objectclass = erbgappaccount
Process the multi-valued group membership attribute
Group objectclass = erbgappgroup
Group $dn created with cn of group in string format with “bgappgroupname=” as the prefix
Security Concerns None
Data source: Identity Manager server
310 Robust Data Synchronization with IBM Tivoli Directory Integrator

Data Flow Identity Manager agent: From LDAP server reconcile of user and group accounts to Identity Manager server via Directory Integrator LDAP agent (Event Handler).
Data source Identity Manager server; Identity Manager service calls Directory Integrator Event Handler to reconcile LDAP users and groups back into Identity Manager server
Directory Integrator Event Handler @ 9.3.4.207; port 8800
Connector type DMSLv2 Event Handler
Parser None
Connector Mode Configure to call the Search AssemblyLine.
Attributes $dn (of user)cneruidbgtitlefirstnamebghomepostaladdressmaillastnametelephonenumbererAccountStatusbgappgroupdnbgappgroupnameobjectclass (of user)objectclass (of groupbpappgroupmembership$dn (of group)
MultiValued Attributes bgappgroupmembership
Naming Context dc=ldap
Special Conditions Requires Identity Manager data model for Blue Glue account and service within Identity Manager which is covered when we instrument the solution
Security Concerns None
Blue Glue LDAP to Blue Glue DB2Data source: LDAP server
Data Flow LDAP server to two DB2 tables
Data source Blue Glue store management application LDAP server @ 9.3.5.182; port 389
Chapter 5. Blue Glue Enterprises 311

Connector type IBM Tivoli Directory Server LDAP Changelog Connector for change detection and LDAP Connector for retrieving other information from LDAP server
Parser None
Connector Mode LDAP changelog: Iterator mode
LDAP: Lookup mode
Attributes targetdnchangetypeoperation$dncngivennamehomepostaladdressmailsntitleuid
MultiValued Attributes None
Link Criteria LDAP lookup: uid = $uid
Special Conditions Calculate uid from targetdn attributeCalculate operation from changelog Connector operation property
Security Concerns None
Data source: DB2 server
Data Flow LDAP server to two DB2 tables
Data source Blue Glue store management application DB2 server @192.168.10.131:50000/STOREMTables: USERS and ACCESS
Connector type JDBC - com.ibm.db2.jcc.DB2Driver
Parser None
Connector Mode Update and Delete for user and account tables
Attributes USERS.EMAILUSERS.FIRSTNAMEUSERS.FULLNAMEUSERS.LASTNAMEUSERS.USERDNUSERS.USERNO
312 Robust Data Synchronization with IBM Tivoli Directory Integrator

ACCESS.ACCESSCODEACCESS.DATEACCESS.LOCALEACCESS.USERNO
MultiValued Attributes None
Link Criteria USERNO = $uid
Special Conditions Calculate ACCESS.DATE from system date converting Java date to sql date
Security Concerns None
5.6.4 Instrument and test solutionAs determined during the planning stage, the synchronization of the Blue Glue store management application involves two parts.
� The first part is to implement the connection between the Identity Manager server and the Blue Glue store management application LDAP server.
� The second part is to implement the connection between the Blue Glue store management application LDAP server and the Blue Glue store application’s authorization database.
Part one - Identity Manager to store management applicationThe implementation of an Identity Manager agent using Directory Integrator requires the following steps:
� Define an Identity Manager data model and import it into the Identity Manager server.
� Configure the Identity Manager server for management of the new service and account for the Blue Glue application.
� Ensure the proper installation of Directory Integrator on specified platform.
� Create Directory Integrator XML and properties files and base Connectors for connectivity to and from the Identity Manager server and the Blue Glue LDAP server.
� Configure the Directory Integrator Event Handler and AssemblyLines to respond to the Identity Manager server requests to add, modify, delete, and reconcile user and group information between the Identity Manager server and the Blue Glue store management application LDAP server.
� Test the solution.
Chapter 5. Blue Glue Enterprises 313

Define an Identity Manager data modelFive separate files are used to define the Identity Manager server data representation for this configuration.
� schema.dsml
Defines the directory syntax for the account and service classes. This is the place where you define what attributes will be available to you when you go to define the look and feel the Identity Manager form representing the Blue Glue application service and account. If you need to add custom attributes to the Identity Manager server, as we required for our solution, you add those attributes in this file. If the attribute you plan to utilize already exists within the Identity Manager directory server, you do not need to add that attribute to the attribute definitions in this file. The attribute definitions is specifically for attributes that do not currently exist within the Identity Manager directory server.
� resource.def
Contains the resource definition for the creation of an Identity Manager service profile. This file matches the names of your account and service definition XML file names. The service profile name must match the subdirectory name in which these five files are located on your operating system.
� customLabels.properties
Defines labels for the forms displayed in the user interface. It is useful to define these labels in this file, although not required. An alternative is to customize the labels from within the account and service form customization within Identity Manager. Using the customLabels.properties file makes your solution more easily transportable between Identity Manager servers.
� erbgappccount.xml
Defines the account form on the Identity Manager server for the Blue Glue application. For our solution, we chose to customize this form from within Identity Manager so the contents of this file are basic.
� erbgappservice.xml
Defines the services form on the Identity Manager server for the Blue Glue application. We are using a standard service form format for this file. This can also be customized from within Identity Manager.
The schema.dsml file contains the definitions of LDAP attributes and objectclasses for the account, service, and a group object in DSML format. The objectclasses are described in Table 5-13 on page 315.
314 Robust Data Synchronization with IBM Tivoli Directory Integrator

Table 5-13 Entities defined for data model
The attributes associated with the Blue Glue application service objectclass for Identity Manager are described in Table 5-14.
Table 5-14 Definition of service attributes for erbgappservice
The attributes associated with the Blue Glue application account objectclass are described in Table 5-15 on page 316.
Entity Type Objectclass Description
Service erbgappservice This represents a service in Identity Manager to manage remote Blue Glue LDAP accounts.
Account erbgappaccount This represents account entries associated with our new Identity Manager service of type erbgappservice
Supporting Data erbgappgroup This represents the type of a group in which Blue Glue account users may have membership
Attribute Name Label Required Description
erservicename Service name Yes The name of the service to display on the Identity Manager user interface.
erurl URL Yes The URL on which Directory Integrator is listening.
eruid User ID Yes The principal used for authentication to Identity Manager by Directory Integrator.
erpassword Password Yes The password used for authentication to Identity Manager by Directory Integrator.
namingcontexts Naming context
Yes Contextual information that is sent to Directory Integrator, so that Directory Integrator can apply the proper AssemblyLines.
ernamingattribute Name attribute Yes Name identifier of each account.
Chapter 5. Blue Glue Enterprises 315

Table 5-15 Definition of account attributes for erbgappaccount
The attributes associated with the Blue Glue group objectclass are described in Table 5-16. The attribute named, bgappgrouname is used to identify the group name displayed in the Identity Manager user interface when assigning users to group membership for the Blue Glue application.
Table 5-16 Definition of group attributes for erbgappgroupt
Attribute Name Label Required Description
eruid User ID Yes The identifier by which the Identity Manager user account is identified.
erpassword Password No The password by which the Blue Glue LDAP server authenticates the user.
cn Full name Yes The full name of the user.
lastname Last name Yes The last name of the user.
firstname First name No The first name of the user.
telephoneNumber Phone number No User phone number.
mail Mail No User e-mail.
bghomepostaladdress Locale Yes User locale code relative to the Blue Glue application.
bgtitle Title Yes Employee title relative to the Blue Glue application.
bggroupmembership Blue Glue application group membership
No Blue Glue LDAP groups in which the user account may have membership. This can be a multi-valued attribute.
Attribute Name Label Required Description
bgappgroupname Blue Glue application group name
Yes Name of group in Blue Glue application.
bgappgroupdn Blue Glue application group distinguished name
No Distinguished name of the Blue Glue application group.
316 Robust Data Synchronization with IBM Tivoli Directory Integrator

Example 5-3 shows the compilation of our new Blue Glue application related attributes and objectclasses for Identity Manager in the correct format for the required the schema.dsml file.
Example 5-3 Complete Blue Glue application Identity Manager agent schema.dsml file
<?xml version="1.0" encoding="UTF-8"?><!-- ***************************************************************** --><!-- Licensed Materials - Property of IBM --><!-- --><!-- Source File Name = schema.dsml --><!-- --><!-- (C) COPYRIGHT IBM Corp. 1999, 2002 All Rights Reserved --><!-- --><!-- US Government Users Restricted Rights - Use, duplication or --><!-- disclosure restricted by GSA ADP Schedule Contract with IBM Corp. --><!-- ***************************************************************** --><!-- ***************************************************************** --><!-- This document is a Directory Service Markup Language (DSML) --><!-- description of an example service and account data model. --><!-- ***************************************************************** -->
<dsml> <directory-schema> <!-- ******************************************************** --> <!-- attribute definitions --> <!-- ******************************************************** --> <attribute-type single-value = "true" > <name>lastname</name> <description>The last name of a person</description> <object-identifier>lastname-oid</object-identifier> <syntax>1.3.6.1.4.1.1466.115.121.1.15</syntax> </attribute-type>
<attribute-type single-value = "true" > <name>firstname</name> <description>The first name of a person</description> <object-identifier>firstname-oid</object-identifier> <syntax>1.3.6.1.4.1.1466.115.121.1.15</syntax> </attribute-type> <attribute-type single-value = "true" > <name>bghomepostaladdress</name> <description>The locale of a Blue Glue App person</description> <object-identifier>bghomepostaladdress-oid</object-identifier> <syntax>1.3.6.1.4.1.1466.115.121.1.15</syntax> </attribute-type>
<attribute-type single-value = "true" >
Chapter 5. Blue Glue Enterprises 317

<name>bgtitle</name> <description>The employee title of a Blue Glue App person</description> <object-identifier>bgtitle-oid</object-identifier> <syntax>1.3.6.1.4.1.1466.115.121.1.15</syntax> </attribute-type>
<attribute-type single-value = "false" > <name>bgappgroupmembership</name> <description>Membership to the Blue Glue App group</description> <object-identifier>bgappgroupmembership-oid</object-identifier> <syntax>1.3.6.1.4.1.1466.115.121.1.15</syntax> </attribute-type>
<attribute-type single-value = "false" > <name>bgappgroupname</name> <description>Membership to the Blue Glue App group</description> <object-identifier>bgappgroupname-oid</object-identifier> <syntax>1.3.6.1.4.1.1466.115.121.1.15</syntax> </attribute-type> <attribute-type single-value = "false" > <name>bgappgroupdn</name> <description>DN to the Blue Glue App group</description> <object-identifier>bgappgroupdn-oid</object-identifier> <syntax>1.3.6.1.4.1.1466.115.121.1.15</syntax> </attribute-type>
<!-- ******************************************************** --> <!-- class definitions BGAppEntryUUID-oid --> <!-- ******************************************************** --> <class superior="top"> <name>erbgappservice</name> <description>Class representing the Blue Glue App service</description> <object-identifier>erbgappservice-oid</object-identifier> <attribute ref="erservicename" required="true" /> <attribute ref="erurl" required="true" /> <attribute ref="eruid" required="true" /> <attribute ref="erpassword" required="true" /> <attribute ref="ernamingattribute" required="true" /> <attribute ref="namingcontexts" required="true" /> </class>
<class superior="top"> <name>erbgappaccount</name> <description>Class representing the Blue Glue App account</description> <object-identifier>erbgappaccount-oid</object-identifier> <attribute ref="eruid" required="true" /> <attribute ref="erpassword" required="false" /> <attribute ref="cn" required="true" />
318 Robust Data Synchronization with IBM Tivoli Directory Integrator

<attribute ref="lastname" required="true" /> <attribute ref="firstname" required="false" /> <attribute ref="telephoneNumber" required="false" /> <attribute ref="mail" required="false" /> <attribute ref="bghomepostaladdress" required="true" /> <attribute ref="bgtitle" required="true" /> <attribute ref="bgappgroupmembership" required="false" /> </class>
<class superior="top"> <name>erbgappgroup</name> <description>Class representing the Blue Glue App group</description> <object-identifier>erbgappgroup-oid</object-identifier> <attribute ref="bgappgroupname" required="true" /> <attribute ref="bgappgroupdn" required="false" /> </class> </directory-schema></dsml>
The service and account profiles are defined in the resource definition file, resource.def. This file also contains an attribute for the factory for handling the protocol, as well as a list of service properties to send with requests. Example 5-4 represents our completed resource.def file.
Example 5-4 Completed resource.def file
<?xml version="1.0" encoding="UTF-8"?><!-- ***************************************************************** --><!-- Licensed Materials - Property of IBM --><!-- --><!-- Source File Name = resource.def --><!-- --><!-- (C) COPYRIGHT IBM Corp. 2003 All Rights Reserved --><!-- --><!-- US Government Users Restricted Rights - Use, duplication or --><!-- disclosure restricted by GSA ADP Schedule Contract with IBM Corp. --><!-- ***************************************************************** --><!-- This document describes the resource definition for the Blue Glue application service. -->
<Resource> <!-- The system profile contains an overall description and any specific --> <!-- properties to be used for communications. --> <SystemProfile> <Name>Blue Glue App Service</Name> <Description>Blue Glue App Service via Directory Integrator</Description> <BehaviorProperties> <!-- The service provider factory should have the value used to -->
Chapter 5. Blue Glue Enterprises 319

<!-- instantiate the DSMLv2 protocol module.--> <Property Name = "com.ibm.itim.remoteservices.ResourceProperties.SERVICE_PROVIDER_FACTORY" Value = "com.ibm.itim.remoteservices.provider.dsml2.DSML2ServiceProviderFactory"/> </BehaviorProperties> </SystemProfile>
<!-- Protocol properties add values from the service instance to request messages to the --> <!-- end point. --> <ProtocolProperties> <Property Name = "url" LDAPName = "erurl"/> <Property Name = "principal" LDAPName = "erUid" /> <Property Name = "credentials" LDAPName = "erPassword" /> </ProtocolProperties>
<!-- Defines a profile for the custom account type. --> <AccountDefinition ClassName = "erbgappaccount" Description = "Blue Glue App User Account."> </AccountDefinition>
<!-- Defines a profile for the custom service type. --> <ServiceDefinition ServiceProfileName = "BGAppService" ServiceClass = "erbgappservice" AttributeName = "erServiceName" AccountClass = "erbgappaccount" AccountProfileName = "BGAppAccount" Description = "Blue Glue App Service."> </ServiceDefinition></Resource>
There are six attributes that we customized for the Identity Manager user interface display by creating a CustomLabels.properties file. Example 5-5 on page 321 contains the contents of our labels file.
Important: The directory name must match the ServiceProfileName that is defined in the resource.def file. For our solution, we used bgappservice.
The ServiceClass and AccountClass definitions must match the objectclass names defined in the schema.dsml file. Our solution uses erbgappservice and erbgappaccount.
320 Robust Data Synchronization with IBM Tivoli Directory Integrator

Example 5-5 CustomLabels.properties file contents
lastname=Last Namefirstname=First Namebgappgroupmembership=Blue Glue App Groupbgappservice=Blue Glue App Servicebghomepostaladdress = Localebgtitle = Title
The remaining two files we use to define our Identity Manager data model for the Blue Glue application are the two XML files that define the initial form layout for our Blue Glue account and service within Identity Manager. We chose to construct the form layout for our account from within Identity Manager rather than predefine it from within the XML file for the account. This form is represented by the file named erbgappaccount.xml. Example 5-6 shows the minimum file contents for the form descriptor XML files.
Example 5-6 erbgappaccount.xml file contents
<?xml version="1.0" encoding="UTF-8"?><page>
<body><form action="formvalidator0"></form>
</body></page>
We use a relatively typical Identity Manager service form layout for our Blue Glue application service form description. Example 5-7 on page 322 show the default form layout for our Blue Glue application service for Identity Manager.
Note: The name of the file for the account form description matches the account objectclass name in the schema.dsml file and the corresponding AccountClass name in the resource.def file.
Note: The name of the file for the service form description matches the account objectclass name in the schema.dsml file and the corresponding ServivceClass name in the resource.def file.
Chapter 5. Blue Glue Enterprises 321

Example 5-7 erbgappservice.xml file contents
<page><body><form action="formvalidator0"><formElement name="data.erservicename" label="$erservicename" required="true"><input name="data.erservicename" size="50" type="text"/><constraint><type>REQUIRED</type><parameter>true</parameter></constraint></formElement><formElement name="data.description" label="$description" required="true"><input name="data.description" size="50" type="text"/></formElement><formElement name="data.erurl" label="$erurl" required="true"><input name="data.erurl" size="50" type="text"/><constraint><type>REQUIRED</type><parameter>true</parameter></constraint></formElement><formElement name="data.eruid" label="$eruid" required="true"><input name="data.eruid" size="50" type="text"/><constraint><type>REQUIRED</type><parameter>true</parameter></constraint></formElement><formElement name="data.erpassword" label="$erpassword" required="true"><input name="data.erpassword" size="50" type="password"/><constraint><type>REQUIRED</type><parameter>true</parameter></constraint></formElement><formElement name="data.namingcontexts" label="$namingcontexts"><input name="data.namingcontexts" size="50" type="text"/><constraint><type>REQUIRED</type><parameter>true</parameter></constraint></formElement><formElement name="data.ernamingattribute" label="$ernamingattribute"><input name="data.ernamingattribute" size="50" type="text"/></formElement></form></body></page>
IBM Tivoli Identity Manager Version 4.6 provides a way to import our newly defined data model into Identity Manager via a Web browser when logged in with the Identity Manager manager account. The Identity Manager server can import the set of files containing the data model when it is formatted as a jar file. Our five files are located in a subdirectory named bgappservice. A simple way to get our files into the proper format is to zip them into a zip file format being sure to keep the subdirectory name as part of the file contents. Once zipped, the files would be named bgappservice.zip. The next step is to rename the file to bgappservice.jar.
322 Robust Data Synchronization with IBM Tivoli Directory Integrator

Once you have the file files and the subdirectory in a jar format, login to the Identity Manager administration console via a Web browser. Select the Configuration tab on the top navigation bar and the Import/Export option as a configuration option. You can either type in the jar file name bgappservice.jar and be certain to include the full path to the file located on the same system from which you are running your Web browser or use the Browse... button to locate the file. Next, select the option to import the data into Identity Manager as shown in Figure 5-18. A status bar indicates if the upload was successful.
You may verify that the LDAP schema has been imported successfully by using the LDAP directory administration console. Any errors that occur will appear in the Identity Manager log and also the directory log if they are related to schema import problems.
Figure 5-18 Importing the data model into Identity Manager
Configure the Identity Manager serverFollow these four steps in the Identity Manager user interface to configure our Blue Glue application account and service instances:
1. Customize the account form
Within the Configuration tab area we used to import the data model, select the Form Customization option. Without Customization, the account form displayed for our BGAppAccount contains no attributes. This can be modified with the Form Designer. A completed view of the correct attributes and format for the BGAppAccount is shown in Figure 5-19 on page 324.
Important: When using an operating system platform such as Windows XP, do not rely on the built in compression format offered by the operating system. Even though this produces a file in a zip format, it is compressed in a way that does not work well with this process. You will be able to import the file into Identity Manager, but will not be able to see the results. Use a zip file program that is separate from the operating system.
Chapter 5. Blue Glue Enterprises 323

Figure 5-19 Account form design
There are three attributes that are customized from the default textfield format. The first is the bgtitle attribute. This attribute is used by the Blue Glue LDAP server and DB2 authorization database to determine access levels based on the user’s title. For this, we create a drop-down box configured to only allow for values that mean something to the Blue Glue LDAP application. Directory Integrator is then used to synchronize these values required by the LDAP server to the different values required by the DB2 authorization database in part two of our two part solution. Figure 5-20 shows the values configured for the bgtitle drop-down box.
Figure 5-20 Drop-down box configuration for bgtitle attribute
324 Robust Data Synchronization with IBM Tivoli Directory Integrator
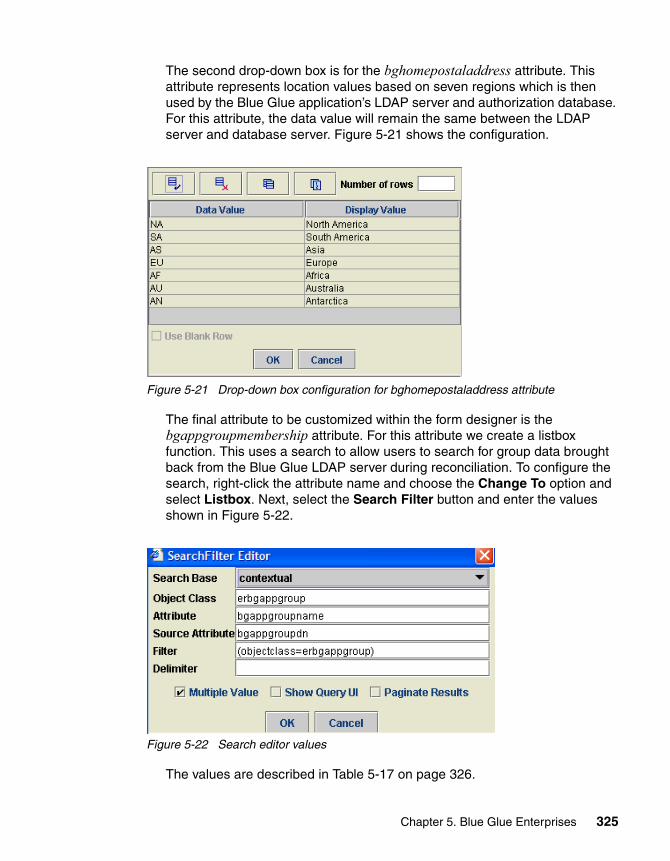
The second drop-down box is for the bghomepostaladdress attribute. This attribute represents location values based on seven regions which is then used by the Blue Glue application’s LDAP server and authorization database. For this attribute, the data value will remain the same between the LDAP server and database server. Figure 5-21 shows the configuration.
Figure 5-21 Drop-down box configuration for bghomepostaladdress attribute
The final attribute to be customized within the form designer is the bgappgroupmembership attribute. For this attribute we create a listbox function. This uses a search to allow users to search for group data brought back from the Blue Glue LDAP server during reconciliation. To configure the search, right-click the attribute name and choose the Change To option and select Listbox. Next, select the Search Filter button and enter the values shown in Figure 5-22.
Figure 5-22 Search editor values
The values are described in Table 5-17 on page 326.
Chapter 5. Blue Glue Enterprises 325

Table 5-17 Search editor values
When you are done customizing the BGAppAccount form, be certain to save your work by pressing the Save Form Template button on the graphical toolbar within the form designer.
2. Customize the service form.
Since we used a default template for the service for when we loaded the data model using the erbgappservice.xml file, there is no customization required for this form. Figure 5-23 shows the resulting pre-configured service form design.
Figure 5-23 Service form design
Parameter Value Explanation
Search Base Contextual Relative to the service.
Object Class bgappgroup Objectclass of the Blue Glue application LDAP group.
Attribute bgappgroupname Name of the attribute to display.
Source Attribute bgappgroupdn Distinguished name of the group in the Blue Glue LDAP server.
Filter (objectclass=erbgappgroup) How to narrow the values from which to select.
Multiple Value checked The user may add more than one value.
326 Robust Data Synchronization with IBM Tivoli Directory Integrator

3. Create a new service using the Blue Glue App Service template.
Within the Identity Manager administration interface, select the Provisioning tab and ensure you have highlighted the Manage Services tab on the left panel and the top of the Blue Glue organization tree. Choose the option to add a new service and select Blue Glue App Service from the drop-down box and press Continue. Figure 5-24 shows the completed service form for the Blue Glue application.
Figure 5-24 Blue Glue App Service definition
Table 5-18 contains descriptions for the attributes used.
Table 5-18 Blue Glue App Service
Parameter Explanation
Service Name A value to display on the user interface.
Description Descriptive Value.
URL The URL of the Directory Integrator server and port number on which the Directory Integrator Event Handler is configured to listen.
User ID The principle used for Identity Manager to authenticate with Directory Integrator.
Password The password used for Identity Manager to authenticate with Directory Integrator.
Naming Context Used to relate requests to the correct context within Directory Integrator.
Chapter 5. Blue Glue Enterprises 327

4. Create a new provisioning policy for the Blue Glue application service.
Within the Identity Manager administration interface, select the Provisioning tab and the Define Provisioning Policies tab on the left-hand panel. Add a new provisioning policy for the Blue Glue Application. Figure 5-25 shows the values to enter for the general description of the provisioning policy.
The provisioning policy that was created for the scenario has a membership of All and an entitlement of the previously configured Blue Glue application service.
Figure 5-25 Blue Glue provisioning policy
Name Attribute The name of the attribute that will be used for searches by the agent when account event notification is used.
Parameter Explanation
328 Robust Data Synchronization with IBM Tivoli Directory Integrator

Note: Identity Manager adapters using the DAML communication provider utilize an xforms.xml file as part of the group of files used to define the Identity Manager data model. This xforms.xml file gives, among other things, configuration options to designate which of two ways the Identity Manager server can be configured to send multi-valued attributes to its adapters.
Identity Manager's DSMLv2 communication interface, however, does not make use of the xforms.xml file, so special care has to be taken when configuring AssemblyLines. Here, the Identity Manager server sends the entire list of attribute values to the Directory Integrator DSMLv2 Event Handler, and does only this when there is a change in one (or more) value of that attribute. The adapter then has to determine how to update the target to overwrite the old multi-value list with the new one.
For example: The current list of groups for an account on a given platform is Group A, B, and C. An administrator changes this on Identity Manager to B, C, and D. Identity Manager sends the new list B, C, and D to the adapter, which has to determine how to overwrite the current list on the target.
The second method has the Identity Manager server only sending the changed items within the list. This method is enabled in DAML adapters when the xforms.xml file uses ConvertReplaceToAddDelete=TRUE. This causes Identity Manager to send each changed item within the multi-value list separately along with its operation. Using the example above, the current list of groups is A, B and C. The user changes it to B, C, and D. Identity Manager will send A - Delete, D -Add.
The following is an example of an attribute with ConvertReplace set in an xforms.xml file:
<EnRoleAttribute Name = "erOracleXRoles" RemoteName = "Role"ConvertReplaceToAddDelete="true" />
This method would provide better networking and computing performance during updates of attributes having a large number (>10k) of values. In addition, it would ease the configuration of the later described Directory Integrator solution that has to maintain group membership information (notably, in the Update AssemblyLine covered later) and perform other reference integrity checks (in the Add and Delete AssemblyLines). As said earlier, however, xforms.xml can only be used with Identity Manager adapters using JNDI with DAML; it therefore does not apply to Directory Integrator based adapters using the DSMLv2 protocol. A different communication provider (for example, RMI over IIOP into Directory Integrator's server API) might help work around this limitation.
Chapter 5. Blue Glue Enterprises 329

Ensure install of Directory IntegratorWe are using the same installation of Directory Integrator we used for our implementation of the HR feed into Identity Manager. During this step, you want to ensure you have the latest software updates to Directory Integrator. The latest news and support information can be obtained from the following Website:
http://www.ibm.com/software/sysmgmt/products/support/IBMDirectoryIntegrator.html
We are using the Directory Integrator configuration editor to build our solution. The executable file for the Directory Integrator configuration editor is ibmditk.
The Identity Manager server and Blue Glue LDAP server are configured for their respective applications.
Create Directory Integrator configuration files and base ConnectorsThis is the time to create a new XML configuration file within Directory Integrator. We also require an external properties file for this configuration. We can either add our attributes to the properties file we created with the HR feed or create a new file. Figure 5-26 on page 331 shows a completed external properties file that covers both parts of our Blue Glue application solution. The first section contains the properties we use for Directory Integrator to connect to the Blue Glue LDAP server as an Identity Manager agent. The second section contains the properties to use for Directory Integrator to connect to the Blue Glue authorization database running DB2. We cover the details on the specifics of the DB2 connection in our implementation description for the second part of our solution.
330 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-26 Directory Integrator Blue Glue application external properties file
Table 5-19 describes how Directory Integrator uses the external property variables when connecting to the Blue Glue LDAP server.
Table 5-19 Blue Glue LDAP Directory Integrator property variable descriptions
Property variable name Description
BlueGlueLdapUrl Host ID and port for LDAP server.
BlueGlueLdapLogin Distinguished name for the LDAP login.
BlueGlueLdapPassword Password for login name used to connect to LDAP server.
BlueGlueSearchFilter Generic search filter to use when connecting.
BlueGlueSearchBase Generic directory search base to use when connecting.
BlueGlueGroupConnector.ldapSearchBase Search base for processing group information in the LDAP server.
Chapter 5. Blue Glue Enterprises 331

Based on the data flow for our solution we identified the need for three types of connections in our solution. The requests to process user and group information originate from the Identity Manager server; they are then processed to and from the LDAP server and results are returned to the Identity Manager server. This translates to the first type of connection being the use of a Directory Integrator DMSLv2 Event Handler to communicate with the Identity Manager server. The next two connections are Directory Integrator Connectors used to connect to the LDAP server to process either user accounts or group information.
In the next sections, we focus on building the reusable base Connectors for our solution. Since one connection requires an Event Handler, we build the remaining two base Connectors that are the LDAP Connectors used to process the user account and group information. We start by building the user account Connector and then the group Connector.
AccountConnectorStart by selecting the Directory Integrator option to add a new Connector to the Connector library. Choose the ibmdi.LDAP Connector from the Connector list. Name the Connector AccountConnector and use the default mode of add only. Open the new Connector in the Connector library and configure the connection information located on the Config tab.
The first five attribute connection values are inherited from the external properties file. Set the inheritance by double clicking on the attribute name and select the appropriate external property name from the provided list. See Figure 5-26 on page 331 and Table 5-19 on page 331 for information about which property values to select.
Figure 5-27 on page 333 shows the connection window and proper selection for configuring the inheritance for the ldapUrl attribute. Keep in mind this is the AccountConnector and to use the property values for the account search base and search filter from the external properties file. Keep the default values for all other attributes.
BlueGlueGroupConnector.ldapSearchFilter Search filter for processing group information in the LDAP server.
BlueGlueAccountConnector.ldapSearchBase Search base for processing user account information in the LDAP server.
BlueGlueAccountConnector.ldapSearchFilter Search filter for processing user account information in the LDAP server.
Property variable name Description
332 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-27 Select external property value
Figure 5-28 on page 334 shows the connection information properly configured for the AccountConnector.
Chapter 5. Blue Glue Enterprises 333

Figure 5-28 LDAP account Connector configuration
GroupConnectorConfiguring the group Connector involves similar steps as the account Connector except we have to use the search base and search filter for the group Connector from the external properties file. Be sure to select the ibmdi.LDAP Connector from the Connector list and name the Connector GroupConnector. Figure 5-29 on page 335 shows the connection information properly configured for the GroupConnector.
334 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-29 LDAP group Connector configuration
The next step is to confirm the connection to the data source for the two Connectors. Do this by choosing the Output Map tab for each Connector and select the button to connect to the data source button , which is identified by the icon that looks like a power plug. Figure 5-30 on page 336 shows the results of successfully testing the connection.
Chapter 5. Blue Glue Enterprises 335

To display any attributes located within the data source, select the arrow shaped icon to the right of the power plug icon . It allows you to step through the data located on that data source provided by the connection information you entered into the configuration of the Connector. Schema discovery is also available for this LDAP connection by selecting the right most icon , which looks like a flashlight.
Figure 5-30 Connected to the data source
After confirming the Connectors connect properly, the next step is to configure the Input and Output Maps and Link Criteria for the account and group Connectors. Based on the information we have documented in the review results section of our solution on page 307, we can fill in the attribute names for the Input and Output Maps for these Connectors. The account Connector Output Map configuration is shown in Figure 5-31.
Figure 5-31 Account Connector Output Map configuration
336 Robust Data Synchronization with IBM Tivoli Directory Integrator

There are two attributes with an advanced mapping script. The first is the value for the $dn attribute, which is the distinguished name for the user to be added into the LDAP server. Here is the complete scripting for $dn.
ret.value = TargetNamingAttribute + "=" + work.getString("eruid") + "," + thisConnector.getConnectorParam("ldapSearchBase");
There are some comments in the example configuration we use, which describes an example of how you might edit this script to account for other unique identifiers within a different LDAP server.
The second attribute with an advanced mapping script is the objectclass attribute. This attribute is a multi-valued attribute and is required when adding users to the LDAP server. The brand of LDAP server you connect to determines if the return value for this attribute mapping can be accomplished with one attribute value or a multi-valued attribute value. For our solution we provide an example of creating this multi-valued attribute. However, by using IBM Tivoli Directory Server, we could have accomplished the same result with one line of script for Blue Glue.
objClass = system.newAttribute("objectClass");objClass.addValue("top");objClass.addValue("person");objClass.addValue("organizationalPerson");objClass.addValue("inetOrgPerson");ret.value = objClass;
To configure the account Connector’s Input Map, change the mode of the Connector to a mode that utilizes the Input Map. Iterator mode is a good choice to use for this purpose. Once the mode is changed, configure the attributes required for the Input Map for the account Connector. The account Connector Input Map configuration is shown in Figure 5-32 on page 338.
The attribute names are also listed in the review results section where we detail the data flow descriptions for the Blue Glue application to the Identity Manager server which starts on page 309. The first part lists the LDAP server attribute names and the second part under the data source title of Identity Manager server lists the attribute names that will be returned to the Identity Manager server via the Input Map. These data flow descriptions also cover the group Connector attributes listed at the end of the attribute lists.
Chapter 5. Blue Glue Enterprises 337

Figure 5-32 Account Connector Input Map configuration
There is one attribute with an advanced mapping script. The attribute named erAccountStatus determines if the Identity Manager user account should be enabled or disabled based on a value in the employeetype attribute in the LDAP server.
if (conn.getString("employeetype") != null){
if (conn.getString("employeetype").equalsIgnoreCase("enabled"))ret.value = "0";
else if (conn.getString("employeetype").equalsIgnoreCase("disabled"))ret.value = "1";
}else ret.value = "0";
We modify some attributes listed in the Input and Output Maps as we implement the AssemblyLines. The attributes configured for these two Connectors in the Connector library represent attributes we plan to use multiple times in several AssemblyLines. By configuring them in the Connector library, we need only change the attribute definition in one place to affect all the places this attribute mapping will be utilized in our solution.
Link Criteria is used in several Connector modes. For our account Connector, we are focused on the update and Delete modes. Both of these modes require Link Criteria and can be set by configuring the Link Criteria for just one of these modes on the account Connector. Place the Connector into Update mode and select the Link Criteria tab and the left most icon choice to add new Link
338 Robust Data Synchronization with IBM Tivoli Directory Integrator

Criteria. Figure 5-33 shows the configuration for the Link Criteria for the account Connector.
Figure 5-33 Account Connector Link Criteria configuration
Next we configure the Output and Input Maps for the group Connector. The group Connector Output Map configuration is shown in Figure 5-34. The lists of attributes we use for the configuration of the group Connector Output and Input Maps is listed in our review results sections just as it was for the account Connector.
Figure 5-34 Group Connector Output Map configuration
There is no advanced mapping for this part of the Output Map configuration.
The group Connector Input Map configuration is shown in Figure 5-35 on page 340.
Chapter 5. Blue Glue Enterprises 339

Figure 5-35 Group Connector Input Map configuration
The Link Criteria configuration for the group Connector is shown in Figure 5-36. We utilize update, delete, and Lookup modes for this Connector.
Figure 5-36 Group Connector Link Criteria configuration
Configure Directory Integrator Event Handler and AssemblyLinesOur solution calls for a way to communicate to and from an Identity Manager server and respond to requests to add, modify, delete, and reconcile user and group information with the Blue Glue store management application LDAP server.
Note: It is a best practice to save your Directory Integrator configuration file frequently. This is a good time to save your work. You can create a separate backup file by selecting the Save as... option and saving the configuration file to designate it is a backup copy. Close the resulting open backup configuration and continue with your original configuration.
340 Robust Data Synchronization with IBM Tivoli Directory Integrator

We have identified three types of connections to data sources. The first two are the already configured account and group Connectors to handle the user account and group information synchronization. The third connection is the DMSLv2 Event Handler which communicates with the Identity Manager server. It receives Identity Manager requests and returns information back to Identity Manager based on the results of those requests.
The type of Identity Manager server requests the Event Handler receives translate to the creation of individual Directory Integrator AssemblyLines for each type of request. The add, modify, and update requests are three separate AssemblyLines named Add, Update, and Delete. The reconciliation process from within the Identity Manager administration console translates to the Identity Manager server issuing a search request and is processed by a Directory Integrator AssemblyLine named Search.
As part of the DMSLv2 Event Handler configuration, we specify the AssemblyLines to run based on these four types of requests. Prior to configuring the DMSLv2 Event Handler, we create base AssemblyLines to use when configuring the Event Handler. Create the new AssemblyLines names Add, Update, Delete, and Search as shown in Figure 5-37. Leave the AssemblyLines empty for now. We will configure each one according to their function.
Figure 5-37 Identity Manager agent AssemblyLines and Connectors
Let us now configure the DMSLv2 Event Handler which processes the Identity Manager server requests. Create a new Event Handler and give it the name of Identity ManagerListener. Chose the ibmdi.DSMLv2EventHandler option from the Event Handler list. Open the new Event Handler and select the Config tab and edit the connection information. Figure 5-38 on page 342 shows the configuration information to use for configuring our Identity ManagerListener Event Handler. Notice the available AssemblyLines are in a pull-down list that is built from the current AssemblyLines in your Directory Integrator configuration file. This explains why we created the base AssemblyLines before configuring this Event Handler.
Chapter 5. Blue Glue Enterprises 341

Figure 5-38 Identity Manager Listener Event Handler configuration
The key settings for the Identity ManagerListener Event Handler are:
� HTTP port
This is the port number on which the Event Handler is listening. This port number must match the port number specified in the URL attribute defined in the Identity Manager service configuration in Figure 5-24 on page 327.
342 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Auth Connector
This is the connection to use if your solution requires authentication. Our solution does not require this so it is set to none.
� Binary attributes
The attribute name we need for our solution is erPassword. You can remove the default list of attributes or leave them just ensure erPassword is part of the list.
� Naming context
The list of naming contexts the Event Handler will serve. Ensure the naming context matches the naming context specified in Figure 5-24 on page 327.
� AssemblyLine for search, add, modify, delete
The names of the AssemblyLines to run for each operation submitted for each defined naming context. In our solution we have one naming context and AssemblyLines named to correspond to the each operation. The modify operation will run the Update AssemblyLine.
Once you have the Identity ManagerListener Event Handler configured, you can test the connection between the Blue Glue application service on the Identity Manager server and the Directory Integrator Event Handler. Press the run button from within the Event Handler configuration. The run button is located in the upper right-hand corner and is a right facing arrow . This starts the Event Handler. Once the Event Handler is started, login to the Identity Manager administration console and navigate to the Provisioning tab for managing services. Select the Blue Glue App Service option and choose to view detailed information. Select the button labeled Test located at the bottom of the detailed information page. A resulting Web page returns a message indicating the test was successful, which means both the Identity Manager server and Directory Integrator Event Handler are configured to communicate together.
Now it is time to configure the four AssemblyLines we created while setting up our Event Handler. The configuration of these AssemblyLines is a slight adaptation to a Directory Integrator configuration that was built using a previous version of Directory Integrator. We chose to keep the configuration similar to its original format to demonstrate how configurations written with a previous version of Directory Integrator can work in the current version. Also, the second part of our solution is built using all the features and capabilities afforded us in the current version of Directory Integrator. After working with AssemblyLines written with both perspectives, it further highlights the advantages with the new components built into the current version of Directory Integrator that are used to simplify the configuration process and reduce scripting. This part of our solution configuration also provides several samples of using JavaScript within Directory Integrator.
Chapter 5. Blue Glue Enterprises 343

The AssemblyLines and their functions are described here:
� Search
Serves reconciliation tasks by performing searches on the LDAP server for existing user accounts and groups.
� Add
Creates user accounts in the LDAP directory server and may set these accounts as members of existing groups if applicable.
� Delete
Deletes user accounts and removes the users from the respective groups for which they are a member.
� Update
Modifies user accounts in the LDAP directory server and can alter group objects depending on the user’s designated group membership information received from the Identity Manager server.
Search AssemblyLineThe Search AssemblyLine is executed when a reconciliation request is issued from the Identity Manager server to retrieve the existing user account and group information from the Blue Glue LDAP server. The search assembly consists of four components.
1. SearchAccounts
This account Connector in Iterator mode searches account entries in the LDAP server and makes attributes available to the rest of the AssemblyLine so that the checkMembership Connector can perform lookups and aggregate the necessary group membership information requested by the Identity Manager server.
2. checkMembership
This group Connector in Lookup mode determines the group membership of each of the accounts fed in by the SearchAccounts Connector. It aggregates a multi-valued attribute into the work Entry. The values of this Connector are the identifiers of the groups for which the accounts are members.
3. filterOutAttributes
This script component ensures that Directory Integrator only returns to Identity Manager the attributes that were requested in the search request.
4. SearchGroups
This second group Connector in Iterator mode is activated only after the SearchAccounts Connector has finished iterating. It permits Directory Integrator to return group entries back to Identity Manager
344 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-39 shows the search AssemblyLine with its four components. Directory Integrator shows all the Connectors in Iterator mode under the Feeds section of the AssemblyLine. When there are two Iterators within an AssemblyLine, the second Iterator is executed after the first Iterator has processed its entries using the components of the AssemblyLine. Even though the SearchGroups Connector is listed second in the display, it is executed after the other components within the AssemblyLine have been executed.
Figure 5-39 Search AssemblyLine
SearchAccounts ConnectorTo create the SearchAccounts Connector in the Search AssemblyLine, open the Search AssemblyLine and expand the Connector library to show account and group Connectors. Drag and drop the account Connector to the white space within the Data Flow tab of the AssemblyLine. Rename the Connector from AccountConnector to SearchAccounts and ensure the Connector is in Iterator mode. You can easily rename the Connector names within the AssemblyLine, depicted in Figure 5-39, by highlighting the Connector you want to rename and pressing the rename icon at the bottom of the data flow box. This icon is third from the left of a set of four icons.
There are two attribute values that need to be modified in this Connector’s Input Map. Those attributes are $dn and objectclass. The advanced mapping script for the $dn attribute is shown below.
ret.value = "eruid=" + conn.getString("uid");
It is important to note that the $dn attribute value does not match the distinguished name of the user account in the LDAP server. Instead, it is mapped to match to the account’s unique identifier within the Identity Manager server.
Chapter 5. Blue Glue Enterprises 345

The advanced mapping script for the objectclass attribute is shown next.
ret.value = "erbgappaccount";
The value for this attribute is set to match the objectClass of the user account entry on the Identity Manager server.
The resulting attribute mapping for the Input Map is shown in Figure 5-40.
Figure 5-40 SearchAccounts Input Map attributes
Figure 5-41 on page 347 shows the Hooks applicable to a Connector in Iterator mode. The Hooks to use in this Connector are shown in bold type and are as follows:
� After GetNext
This Hook is called after the Connector has successfully read the next entry in the search result set.
� End of Data
This Hook is called when the Connector has finished iterating. We use this Hook to be able to disable the checkMemebership Connector on-the-fly.
346 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-41 SearchAccounts Connector Hooks
The custom code for the After GetNext Hook is shown below.
work.setAttribute("userDN", conn.getString("$dn"));
This Hook sets an attribute of the work Entry to the value of the user account LDAP distinguished name. This variable will be used by the CheckMembership Connector as Link Criteria.
The custom code for the End of Data Hook is shown next.
checkMembership.getConfiguration().setEnabled(false);task.getConnector("filterOutAttributes").getConfiguration().setEnabled(false);
The Search AssemblyLine contains multiple Iterators, and because of the way multiple Iterators are sequenced in Directory Integrator AssemblyLines, the execution is the follows:
1. The SearchAccounts, checkMembership Connectors and the filterOutAttributes component are executed until there are no more accounts to process.
2. The SearchGroups Connector in Iterator mode is activated. This Connector, the checkMembership Connector and the filterOutAttributes script component will execute until there are no more groups to process.
Chapter 5. Blue Glue Enterprises 347

The End of Data Hook is to prevent the checkMembership Connector and the filterOutAttributes component from executing after the first Iterator has finished. The Connectors are disabled on-the-fly using our script.
checkMembership ConnectorTo create the checkMemebrship Connector, drag and drop the GroupConnector from the Connector library, ensure the Connector is in Lookup mode and rename it to reflect the name of checkMembership.
There is one attribute to be modified in this Connector’s Input Map. We need to add the attribute named bgappgroupmembership to the Input Map. Here is the script for the attribute mapping.
ret.value = grpList;
This attribute is the only attribute for which the mapping is to be enabled. The modification is to uncheck the box labeled Enabled for all the other attributes listed in the Input Map. All attributes except bgappgroupmembership will be ignored by this Connector.
Figure 5-42 shows the attribute mapping for the entire Input Map of the checkMembership Connector.
Figure 5-42 checkMembership Input Map attributes
One attribute value within the Link Criteria needs to be modified for this Connector. Within the member attribute in the Link Criteria, the inherited value is $$dn. Change the value of the member attribute in the Link Criteria for this Connector to be $userDN.
In this case, we want to find any GroupOfNames records where the LDAP member attribute is equal to the account distinguished name. Translating this into LDAP search filter terms, you get a query like the following:
(&(objectClass=groupOfNames)(member=uid=johnsmith,ou=people,o=blueglue,c=us))
348 Robust Data Synchronization with IBM Tivoli Directory Integrator

The work attribute userDN is created in the After GetNext Hook of the SearchAccounts Connector.
Figure 5-43 shows the resulting Link Criteria configuration.
Figure 5-43 checkMembership Link Criteria
Figure 5-44 on page 350 shows all the Hooks applicable to a Connector in Lookup mode. The Hooks to use in this Connector are shown in bold type and are as follows:
� Before Lookup
This Hook creates a temporary attribute to store all the group distinguished names to which the account belongs. The temporary attribute name is grpList. It is the value we use in the Input Map for the value of the attribute bgappgroupmembership.
� On Multiple Entries
This Hook is called when Connector finds multiple groups that have the user account as a member.
� On No Match
This Hook is called when no groups are found that have the user account.
� After Lookup
This Hook is called when exactly one matching group is retrieved.
Chapter 5. Blue Glue Enterprises 349

Figure 5-44 checkMembership Hooks
The custom code for the Before Lookup Hook is shown next.
var grpList = system.newAttribute("grpList");
The attribute grpList is set in this Hook and is populated in the On Multiple Entries and After Lookup Hooks.
The On Multiple Entries Hook allows you to evaluate the duplicate entries found during a lookup operation. It then allows you to pick the unique entry to be fed into the AssemblyLine work Entry to be processed by the next steps in the data flow. This is achieved by locating the valid entry out of the duplicates by using a setCurrent() method call.
For our solution, we do not need to select one entry out of the duplicates and issue a setCurrent call. Instead, we browse through the returned duplicates and accumulate their identifiers into one attribute. Here is the contents of the script for this Hook.
// get first entry to be handled in Hook 'Lookup successful'var myEntry=thisConnector.getFirstDuplicateEntry();thisConnector.setCurrent(myEntry);
// iterate through rest of duplicate groupstask.logmsg("DEBUG", "+++ User " + work.getString("$dn") + " found in multiple groups ");
350 Robust Data Synchronization with IBM Tivoli Directory Integrator

while ( ( myEntry = thisConnector.getNextDuplicateEntry() ) != null ) {task.logmsg("DEBUG", "+++ => NextGroup " + myEntry.getString("$dn") );grpList.addValue(myEntry.getString("$dn"));
}
The Directory Integrator default is for the AssemblyLines to limit the number of duplicate entries that Lookup Connectors are able to retrieve to ten entries. For our solution it is likely that users can be members of more than ten groups. We have to overwrite the default value and set it to 0 (zero) which allows users to be members of an unlimited number of groups (see the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718). With Directory Integrator 5.x releases, you have to use a large (for example 99999999) number instead. This value is found on the AssemblyLine configuration tab. Figure 5-45 shows this configuration.
Figure 5-45 AssemblyLine settings
If no matching groups are found in the LDAP server, there is not much to return as group membership information to the Identity Manager server. The On No Match Hook is enabled so the AssemblyLine does not stop. The default behavior when no entry matches the Link Criteria is to call the On Error Hook in case the
Chapter 5. Blue Glue Enterprises 351

On No Match Hook is not enabled. The following script shows how to place the logmsg method and some debugging information into this Hook.
task.logmsg("DEBUG", "+++ User " + work.getString("$dn") + " not found in any group");
The After Lookup Hook is called if one matching group is found in the LDAP directory. The value to be returned to Identity Manager is stored in the attribute grpList which is set in the Before Lookup Hook. Here is the script for this Hook.
task.logmsg("DEBUG", "+++ User " + work.getString("$dn") + " found in 1st group " + conn.getString("$dn"));grpList.addValue(conn.getString("$dn"));
filterOutAttributes componentCreate this component by selecting the button to add a new component to the AssemblyLine and click Add script component.... Here is the script to include in this Connector.
work.setAttribute("userDN", null);
if (returnAttributes != null){ if (returnAttributes.size() > 0)
{attrnames = work.getAttributeNames();for (i=0; i < attrnames.length; i++){
if (!attrnames[i].equalsIgnoreCase("$dn") && !returnAttributes.hasValueIC(attrnames[i]))
{work.setAttribute(attrnames[i], null);main.logmsg("clearing" + attrnames[i]);
}else main.logmsg(attrnames[i] + "in ret");
}}
}
task.dumpEntry(work);
The filterOutAttributes script component clears out attributes from the work Entry before the Iterator moves on to the next entry. By doing so, we prevent Directory Integrator from sending back attributes that the Identity Manager server did not request. The AssemblyLine uses an accumulator to pass the entries back to Identity Manager as the flow executes.
By setting an attribute to null in the work Entry we are clearing the attribute and all its values from the entry. We clear the userDN attribute created in the After
352 Robust Data Synchronization with IBM Tivoli Directory Integrator

GetNext Hook of the SearchAccounts Connector. Any additional attributes should also be cleared.
SearchGroups ConnectorFollow the same steps used to create the SearchAccounts Connector within your AssemblyLine to create the SearchGroups Connector with one exception. Use the GroupConnector from the Connector library.
There are two attribute values that need to be modified in this Connector’s Input Map. Those attributes are $dn and objectclass. The advanced mapping script for the $dn attribute is shown here.
ret.value = "bgappgroupname=" + conn.getString("cn");
It is important to note that the $dn attribute value does not match the distinguished name of the group entry in the LDAP server. Instead, it is mapped to match to the group name attribute name within the Identity Manager server, bgappgroupname.
The advanced mapping script for the objectclass attribute is shown next.
ret.value = "erbgappgroup";
The value for this attribute is set to match the objectClass of the group in the Identity Manager server. The value for the attribute bgappgroupdn is also passed to the Identity Manager server so the real distinguished name of the group gets stored in the Identity Manager server.
The resulting attribute mapping for the Input Map is shown in Figure 5-46.
Figure 5-46 SearchGroups Connector Input Map
No Hooks are used in the SearchGroups Connector.
This concludes the configuration of the Search AssemblyLine.
Chapter 5. Blue Glue Enterprises 353

Add AssemblyLineThe Add AssemblyLine creates user accounts in the LDAP directory server and may set these accounts as members of existing groups depending on the information sent by the Identity Manager server. The employees may be members of multiple groups within the LDAP server. This is determined by the Identity Manager server and sent to Directory Integrator via the ITIMListener DSMLv2 Event Handler. The Add AssemblyLine consists of three Connectors.
1. AddAccount
This account Connector in Addonly mode adds the user account in the target system and invokes the resolveMembership Connector to ensure the user account is added to the appropriate set of groups.
2. resolveMembership
This group Connector in Lookup mode reads groups from the LDAP server for which the current user account is a member. If no matching groups are found, this Connector invokes the updateGroup passive Connector to add the user account into groups. If matching groups are found we will perform some logging of such an occurrence.
3. updateGroup
This passive group Connector in Update mode updates the existing groups to add a user account as a member of the group. This Connector is invoked by the resolveMembership Connector.
Figure 5-47 shows the add AssemblyLine with its three Connectors.
Figure 5-47 Add AssemblyLine
For this AssemblyLine, we use an initial work Entry via the Call/Return configuration option at the AssemblyLine configuration tab level. Select the
354 Robust Data Synchronization with IBM Tivoli Directory Integrator

Call/Return tab associated with the Add AssemblyLine. Figure 5-47 on page 354 shows the initial work Entry attribute configuration for this AssemblyLine.
Figure 5-48 Add Call/Return initial work Entry
AddAccount ConnectorTo create the AddAccount Connector in the Add AssemblyLine, open the Add AssemblyLine and expand the Connector library to show the account and group Connectors. Drag and drop the account Connector to the white space within the data flow tab of the AssemblyLine. Rename the Connector from AccountConnector to AddAccount and ensure the Connector is in Addonly mode.
There are no modifications that need to be made to the Output Map inherited from the AccountConnector from the Connector library.
Figure 5-49 on page 356 shows all the Hooks applicable to a Connector in Addonly mode. There is only one Hook to use in this Connector configuration.
� After Add
This Hook is called after the Connector has successfully added the account entry in the target system. It is used to make sure the account is added into any applicable groups.
Chapter 5. Blue Glue Enterprises 355

Figure 5-49 AddAccount Hooks
The custom code for the After Add Hook is shown here.
// Ready to update Groups if requiredif ( work.getString("bgappgroupmembership") != null ){ var usrGroups = work.getAttribute("bgappgroupmembership").getValues() ;
for ( i=0; i<usrGroups.length; i++ ) { try { tmpWorkObj = system.newEntry() ;
tmpWorkObj.setAttribute("baseDN", usrGroups[i]); tmpWorkObj.setAttribute("userDN", conn.getString("$dn")); task.logmsg("INFO", "+++ Checking for Membership in Group: " + tmpWorkObj.getString("baseDN")); resolveMembership.lookup(tmpWorkObj); } catch (e) { task.logmsg("ERROR", "+++ Checking for Group Membership failed"); task.logmsg("ERROR", "+++ Error: " + e.getMessage() ); } }}
The script is used to invoke the resolveMembership Connector after the user account has been successfully added. This script processes however many
356 Robust Data Synchronization with IBM Tivoli Directory Integrator

groups for which the user is a member. It calls the resvoleMembership Connector each time it finds a group name in the multi valued attribute bgappgroupmembership.
resolveMembership ConnectorTo create the resolveMembership Connector, drag and drop the GroupConector from the Connector library and ensure the Connector is in Lookup mode and renamed to reflect the name of resolveMembership. Configure this Connector in Passive state.
There is one modification to be made to the Input Map for the resolveMembership Connector in the Add AssemblyLine. Disable the attribute named objectClass. The modification is to uncheck the box labeled Enabled for this attribute.
One attribute value within the Link Criteria needs to be modified for this Connector. Within the member attribute in the Link Criteria, the inherited value is $$dn. Change the value of the member attribute in the Link Criteria for this Connector to be $userDN.
In this case, we want to find any GroupOfNames records where the LDAP member attribute is equal to the account distinguished name. Translating this into LDAP search filter terms, you get a query like the following:
(&(objectClass=groupOfNames)(member=uid=johnsmith,ou=people,o=blueglue,c=us))
The work attribute userDN is created in the After Add Hook of the AddAccounts Connector. Figure 5-50 shows the resulting Link Criteria configuration.
Figure 5-50 resolveMembership Link Criteria
Figure 5-44 on page 350 shows all the Hooks applicable to the resolveMembership Connector in Lookup mode. The Hooks to use in this Connector are shown in bold type and are as follows:
Chapter 5. Blue Glue Enterprises 357

� Before Lookup
This Hook is scripted to change the Connector configuration dynamically. The search base is set from the group’s DN base. The reason for scripting this Hook is to optimize the search process.
� On Multiple Entries
This Hook is called in case the Connector finds multiple groups with the user account as a member.
� On No Match
This Hook is called if no groups are found to contain the user account as a member.
� After Lookup
This Hook is called if exactly one matching group is retrieved. It is not called if more than one matching group is found.
Figure 5-51 resolveMembership Hooks
The custom code for the Before Lookup Hook is shown here.
thisConnector.connector.setParam("ldapSearchBase", work.getString("baseDN"));thisConnector.connector.setParam("ldapSearchScope", "baselevel" );
At this stage of the AssemblyLine execution, the group DN is known since it has been extracted from Identity Manager’s provided bgappgroupmembership multi
358 Robust Data Synchronization with IBM Tivoli Directory Integrator

valued attribute. However, the Link Criteria is still needed to determine whether the user account is a member of the group within the LDAP server. The script allows reconfiguring the Connector’s search base and search scope parameters dynamically.
The On Multiple Entries Hook allows you to evaluate the duplicate entries found during a lookup operation. It then allows you to pick the unique entry to be fed into the AssemblyLine work Entry to be processed by the next steps in the data flow.
For our solution, we do not need to select one entry out of the duplicates and issue a setCurrent() method call to identify the entry to utilize. The Blue Glue store management application prevents user accounts from being listed multiple times within one group.
The last part of this Hook script is a system.skipEntry() call which is issued to avoid the Error Hook being executed in the scenario. Here is the code for this Hook.
task.logmsg("WARN", "+++ Ambiguous Groups found for: " + work.getString("baseDN"));system.skipEntry();
If no matching groups are found in the LDAP server, we will then add the user account into new groups. The On No Match Hook is used to invoke the updateGroup Connector. This is the code for this Hook.
task.logmsg("INFO", "+++ User " + work.getString("userDN") + " not in Group " + work.getString("baseDN") + " ... now adding");
// Ready to add User to Group
try { newWorkObj = system.newEntry() ; newWorkObj.setAttribute("baseDN", work.getString("baseDN"));
Note: The obejctclass used for the groups has a value of groupOfNames as opposed to GroupOfUniqueNames. The corresponding entry for a user in a group within the Blue Glue store management application is the attribute named member as opposed to uniquemember. Using the groupOfNames objectclass and member attribute for group membership gives some chance a user account can appear more than once as a member of the same group. This is not a concern for our solution given the Blue Glue application prevents this from occurring. Without an application predicating the attribute values for the LDAP server, the choice would be to use the attribute value groupOfUniqueNames for objectclass and the corresponding uniquemember attribute.
Chapter 5. Blue Glue Enterprises 359

newWorkObj.setAttribute("userDN", work.getString("userDN")); updateGroup.update(newWorkObj); } catch (e) { task.logmsg("ERROR", "+++ Adding User to Group failed"); task.logmsg("ERROR", "+++ Error: " + e.getMessage() ); }
The After Lookup Hook is called if exactly one matching group is found in the LDAP server. A log message is output but no other action is performed.
task.logmsg("INFO", "+++ User already in Group");
updateGroup ConnectorTo create the updateGroup Connector, drag and drop the GroupConector from the Connector library and ensure the Connector is in Update mode and renamed to reflect the name of updateGroup. Place this Connector in Passive state.
There are two modifications to be made to the Output Map of this Connector.
1. Uncheck all the boxes that indicate to modify the attributes listed except for the member attribute.
2. Change the mapped value for the member attribute by using advanced mapping and adding the following script:
ret.value = work.getString("userDN");
The userDN attribute is set in the On No Match Hooks of the previous resolveMembership component. This indicates the distinguished name of the user account we will be adding as a member of its respective group.
Figure 5-52 shows the configuration for the Output Map of the updateGroup Connector.
Figure 5-52 updateGroup Connector Output Map
The Link Criteria for the updateGroup Connector is shown in Figure 5-53 on page 361. For this Connector, the Link Criteria expects the distinguished name of
360 Robust Data Synchronization with IBM Tivoli Directory Integrator

the group to the modified. The distinguished name of the group we are looking to match is represented by the $baseDN attribute and is made available by scripting in the resolveMembership Connector in the On No Match Hook.
Figure 5-53 updateGroup Link Criteria
No Hooks are used in the updateGroup Connector.
This concludes the configuration of the Add AssemblyLine.
Delete AssemblyLineThe Delete AssemblyLine deletes user accounts and removes them from any groups in which they are a member. This AssemblyLine gets executed when a delete request is received from the Identity Manager server via the Directory Integrator ITIMListener DSMLv2 Event Handler. It expects the $dn and eruid attributes from the Identity ManagerListener Event Handler. The Delete AssemblyLine consists of two Connectors.
1. DeleteAccount
This account Connector deletes the user account in the LDAP server. It directly processes the initial work Entry attributes coming from the Identity Manager server provided by the ITIMListener DSMLv2 Event Handler.
2. removeMembership
This group Connector in Lookup mode reads groups having the current user account as a member from the LDAP server. This Connector drives updates to remove the user account from groups for which the user does not belong. This is done in case the directory server does not automatically remove the user from groups via referential integrity capabilities.
Figure 5-54 on page 362 shows the Delete AssemblyLine with its two Connectors.
Chapter 5. Blue Glue Enterprises 361

Figure 5-54 Delete AssemblyLine
For this AssemblyLine, we use an initial work Entry via the Call/Return configuration option at the AssemblyLine configuration tab level. The eruid attribute is located here as a placeholder. The value will not be sent by the Identity Manager server. It will send the entry’s distinguished name instead. The eruid attribute is really calculated from the Delete AssemblyLine’s Prolog. Figure 5-55 shows the initial work Entry attribute configuration for this AssemblyLine.
Figure 5-55 Delete Call/Return initial work Entry
Let us take a look at the script in the delete AssemblyLine’s Prolog which is used to generate an attribute to be used later in Link Criteria for a Connector. This script is located in the AssemblyLine Hooks tab.
// // Parse DN to get user erUID // erUserID = getRDNvalue(work.getString("$dn"));
main.logmsg("INFO","+++ erUID: " + erUserID);
362 Robust Data Synchronization with IBM Tivoli Directory Integrator

work.setAttribute("eruid", erUserID);
When driving an account deletion, the Identity Manager server will only send to its agents the distinguished name of the user account that needs to be deleted on the target systems. In order to identify the user account to delete in the LDAP server, we need to match the unique ID from the Identity Manager server to the unique ID in the LDAP server. This matching is done in the Link Criteria for the DeleteAccount Connector and is shown in Figure 5-56 on page 364.
The eruid attribute used in the Link Criteria is not received by Directory Integrator, because the Identity Manager server only sends changed attributes (eruid is not changed in this case) to adapters using JNDI over DSMLv2. What Identity Manager sends to Directory Integrator is the account's distinguished name.
In order for the Link Criteria to work, the eruid attribute is constructed out of the account’s distinguished name. It is important to note that the propagation of delete events can only work if the user account’s identifier value is actually present in the Identity Manager account’s distinguished name.
DeleteAccount ConnectorTo create the DeleteAccount Connector in the Delete AssemblyLine, open the Delete AssemblyLine and expand the Connector library to show the account and group Connectors. Drag and drop the account Connector to the white space within the data flow tab of the AssemblyLine. Rename the Connector from AccountConnector to DeleteAccount and ensure the Connector is in Delete mode.
There are some slight modifications to be made to the Input Map for the DeleteAccount Connector in the Delete AssemblyLine. The only attribute for which the mapping is to be enabled is the $dn attribute. The modification is to uncheck the box labeled Enabled for all the other attributes listed in the Input Map. All attributes except $dn will be ignored by this Connector.
There are no modifications to be made to the Link Criteria inherited from the AccountConnector from the Connector library.
The Link Criteria for the DeleteAccount Connector is shown in Figure 5-56 on page 364. For this Connector, we want to find any user records where the uid attribute equals the eruid attribute. Translating this into LDAP search filter terms, you get a query like the following:
(&(objectClass=inetOrgPerson)(uid=johnsmith))
Chapter 5. Blue Glue Enterprises 363

Figure 5-56 DeleteAccount Link Criteria
No Hooks are used in this Connector configuration.
removeMembership ConnectorTo create the removeMembership Connector, drag and drop the GroupConector from the Connector library and ensure the Connector is in Lookup mode and renamed to reflect the name of removeMembership.
There are two slight modifications to be made to the Input Map for the removeMembership Connector in the Delete AssemblyLine. Only the attributes for which the mapping is enabled are the bgappgroupname and the bgappgroupdn attributes. All other attributes will be ignored by this Connector.
There are no modifications to be made to the Link Criteria inherited from the GroupConnector from the Connector library.
The Link Criteria for the removeMembership Connector is shown in Figure 5-57.
Figure 5-57 removeMembership Link Criteria
Figure 5-58 on page 365 shows all the Hooks applicable to the removeMembership Connector for the Delete AssemblyLine. The Hooks to use in this Connector are shown in bold type and are as follows:
364 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Before Execute
This Hook tells the AssemblyLine to ignore this Connector in case the LDAP server already handles referential integrity.
� On Multiple Entries
This Hook is called in case the Connector finds multiple groups which have the user account as a member.
� On No Match
This Hook is called in case no groups having the user account as a member are found.
� Lookup Successful
This Hook is called if exactly one matching group is found. This Hook can also be called after the On Multiple Entries Hook and On No Match Hook have been called.
Figure 5-58 removeMembership Hooks
The Before Execute Hook is used to tell the AssemblyLine to ignore the Connector if the LDAP server handles referential integrity. If the LDAP server handles referential integrity it will automatically update groups when users are deleted. Her is the script for this Hook.
Chapter 5. Blue Glue Enterprises 365

if (LDAPServerHandlesReferentialIntegrity)system.ignoreEntry();
The On Multiple Entries Hook allows us to examine the duplicate entries found during a lookup operation. We can then pick the unique entry to be fed into the AssemblyLine work Entry for the next steps of the dataflow. This is achieved by picking the valid entry out of the duplicates by using a setCurrent() method call.
For our Connector, we will always choose the first returned duplicate to feed the AssemblyLine. However, we will make sure to process all other duplicates. Here is the script to use for this Hook.
task.logmsg("INFO", "+++ Processing list of Group Membership for User: " + work.getString("$dn") );
// get first entry to be handled in Hook 'Lookup successful'var myEntry=thisConnector.getFirstDuplicateEntry();thisConnector.setCurrent(myEntry);
// iterate through rest of duplicate groupswhile ( (myEntry=thisConnector.getNextDuplicateEntry() ) != null ) {
// trigger raw connector to delete member from existing groupthisConnector.connector.removeAttributeValue(
myEntry.getString("$dn"),"member",work.getString("$dn"));}
Note that the script makes use of a raw Connector method of the LDAP Connector. The removeAttributeValue method allows removing a single attribute value of a multi-valued attribute in a much more effective manner than modifying the entry with all new values for the attribute.
If no matching groups are found in the LDAP directory, there is no need to remove the user account from the existing groups. The script for the On No Match Hook is shown here. If no matching group is found, it ignores the entry.
task.logmsg("DEBUG", "+++ User " + work.getString("$dn") + " not in any Group");system.ignoreEntry();
As seen with the On No Match Hook, an ignoreEntry() call is issued. This means the Lookup Successful Hook is only called if one or more matching groups are found in the LDAP directory. In this Hook, we only deal with the case of one match.
Next we take a look at the script to use in the Lookup Successful Hook. Note that the script makes use of the raw Connector method of the LDAP Connector just as we do in the On Multiple Entries Hook.
366 Robust Data Synchronization with IBM Tivoli Directory Integrator

// trigger raw connector to delete member from existing groupthisConnector.connector.removeAttributeValue(
conn.getString("$dn"),"member",work.getString("$dn"));
The Directory Integrator default is for the AssemblyLines to limit the number of duplicate entries that Lookup Connectors are able to retrieve to ten entries. For our solution it is likely that users can be members of more than ten groups. We will overwrite the default value and set it to 0 (zero) which allows users to be member of an unlimited number of groups (see the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718). With Directory Integrator 5.x releases, you have to use a large (for example, 99999999) number instead. This value is found on the AssemblyLine configuration tab. Figure 5-45 on page 351 shows this configuration.
This concludes the configuration of the Delete AssemblyLine.
Update AssemblyLineThe Update AssemblyLine modifies user account and group information in the LDAP directory server. The group information is modified if a user needs to be added or subtracted from a group membership based on the information received from the Identity Manager server via the Directory Integrator ITIMListener Event Handler.
Directory Integrator retrieves the group names the user account should belong to from the Identity Manager server. It is up to Directory Integrator to figure out what groups the user account should be added to or removed from.
Several strategies can be used to determine the changes to be performed. Directory Integrator may maintain cache information for this, or could query the LDAP server to determine which group the account is already a member of and compute the change without a local cache. This is the strategy we chose to use.
The approach to manage existing groups involves the following steps:
1. Remove the user account from the groups for which the user is no longer supposed to be a member. This is achieved by reading the groups information from the LDAP server and comparing the group identifier to the values in the group membership attribute received from Identity Manager.
The following logic is involved in accomplishing this step:
– Read the groups from the target system which have the user account as a member.
– For each group read from the LDAP server, verify that the group identifier is in the list of groups provided by the Identity Manager server.
Chapter 5. Blue Glue Enterprises 367

– If the group from the LDAP server is in the group list provided by the Identity Manager server, remove the group’s identifier from the list of groups from the Identity Manager server.
– If the group from the LDAP server is not in the group list provided by the Identity Manager server, this means the user account is to be removed from this group on the LDAP server. In this case, we will drive execute a passive Connector in Update mode to modify the group on the LDAP server. The modify operation is to remove the identifier for the user account from the multi-valued member attribute in the group object on the LDAP server.
2. Add the user account to the group for which it should be a member.
The following logic is involved in accomplishing this step:
– Iterate through the list of groups provided by the Identity Manager server. At this time this list contains group names to which the user account will be added as a value in the member attribute.
– For each group in the list of groups from the Identity Manager server, execute a passive Connector to add the user account as a member to each group.
The Update AssemblyLine is special since it uses one Connector in Lookup mode to read through the list of groups. This is in place of using a Connector in Iterator mode to perform the read. This AssemblyLine illustrates how to process duplicate entries returned by a Connector in Lookup mode.
The Update AssemblyLine consists of four Connectors
1. updateAccount
This Connector updates the user account object in the LDAP server.
2. removeMembership
This Connector in Lookup mode reads groups from the LDAP server where the current user is a member. This Connector invokes the updateGroup Connector to remove the user account from groups the user no longer belongs to. It also removes unchanged groups from the list of groups provided by the Identity Manager server.
3. addMembership
This script component goes through the list of groups provided by the Identity Manager server. At this stage it contains the groups to which the user should be added as a member. For each group in this list, this Connector executes the updateGroup Connector to update the group by adding the user account as a member to the group.
368 Robust Data Synchronization with IBM Tivoli Directory Integrator

4. updateGroup
This Connector in Update mode and Passive state updates the groups to either add a user account as a member, or remove a user account from the member list. This Connector is either invoked by the removeMembership Connector, or by the addMembership script component.
Figure 5-59 shows the update AssemblyLine with its four Connectors.
Figure 5-59 Update AssemblyLine
For this AssemblyLine, we use an initial work Entry via the Call/Return configuration option at the AssemblyLine configuration tab level. Figure 5-60 shows the configuration.
Chapter 5. Blue Glue Enterprises 369

Figure 5-60 UpdateCall/Return initial work Entry
When performing an account update, the Identity Manager server only sends to its agents the attributes that need to be updated on the target systems. In order to identify the user account to be updated in the LDAP server, we need to match the unique ID from the Identity Manager server to the unique ID in the LDAP server. This matching is done in the Link Criteria for the UpdateAccount Connector and is shown in Figure 5-56 on page 364.
The eruid attribute used in the Link Criteria is not received by Directory Integrator, because the Identity Manager server only sends changed attributes (eruid is not changed in this case) to adapters using JNDI over DSMLv2. What Identity Manager sends to Directory Integrator is the account's distinguished name.
In order for the Link Criteria to work, the eruid attribute is constructed out of the account’s distinguished name. It is important to note that the propagation of deletion events can only work if the user account’s identifier value is actually present in the Identity Manager account’s distinguished name. This script, that is placed in the Prolog section, also makes sure that the eruid attribute is stored in another attribute name called neweruid in case it has been modified.
// Parse DN to get user erUID
erUserID = getRDNvalue(work.getString("$dn"));
main.logmsg("INFO","+++ erUID: " + erUserID);
370 Robust Data Synchronization with IBM Tivoli Directory Integrator

if (work.getString("eruid") != null)work.setAttribute("neweruid", work.getString("eruid"));
work.setAttribute("eruid", erUserID);
handleReferentialIntegrityOnOurOwn = false;
updateAccount ConnectorTo create the updateAccount Connector in the Update AssemblyLine, open the Update AssemblyLine and expand the Connector library to show the account and group Connectors. Drag and drop the account Connector to the white space within the Data Flow tab of the AssemblyLine. Rename the Connector from AccountConnector to updateAccount and ensure the Connector is in Update mode.
There are slight modifications to be made to the Output Map for the updateAccount Connector. There is no need to add or remove attributes. There is, however, a need to ensure the proper attributes are checked or unchecked for their correct modification or add functions. Figure 5-61 on page 371 depicts the correct attribute map settings for the attributes.
It is important to note that the objectclass attribute is not modifiable by the Connector so the modify checkbox is not checked for this attribute. Also, the eruid attribute and $dn attribute are only changed by the Connector in case the eruid attribute value was modified by an Identity Manager administrator. If this is the case, we use the neweruid attribute, created in the AssemblyLine’s Prolog.
Figure 5-61 updateAccount Output Map
There are no modifications to be made to the Link Criteria inherited from the AccountConnector from the Connector library.
Chapter 5. Blue Glue Enterprises 371

The Link Criteria for the updateAccount Connector is shown in Figure 5-62. For this Connector, we want to find any user records where the uid attribute equals the eruid attribute. Translating this into LDAP search filter terms, you get a query like the following:
(&(objectClass=inetOrgPerson)(uid=johnsmith))
Figure 5-62 updateAccount Link Criteria
Figure 5-63 shows all the Hooks applicable to the updateAccount Connector for the Update AssemblyLine. The Hooks to use in this Connector are shown in bold type and are as follows:
� After Lookup
This Hook is scripted to set the userDN attribute needed for the next Connectors. This is set in order to optimize the search process.
� Before Applying Changes
This Hook is scripted to determine whether the Connector is about to perform a modification of the account’s distinguished name. If so, it sets additional attributes needed for the Connectors to ensure group members are kept consistent providing referential integrity.
372 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-63 updateAccount Hooks
The code in the After Lookup Hook sets the userDN attribute allowing for compatibility for older versions of Directory Integrator. Here is the script to use for this Hook.
version = Packages.com.ibm.di.server.Version.version();
if (version.startsWith("Version: "))version = version.substring(9);
if (Packages.com.ibm.di.server.Version.version().compareTo("5.2 -2003-11-04") <= 0)work.setAttribute("userDN", conn.getString("$dn"));elsework.setAttribute("userDN", current.getString("$dn"));
task.logmsg("INFO", "+++ got User DN: " + work.getString("userDN"));
The Before Applying Changes Hook is scripted to determine whether the Connector is about to perform a modification of the account’s distinguished name. Special care is taken when entries have to be moved within the directory branch of the LDAP server. Extra attributes are made available if the directory server is not capable of handling referential integrity. This is the script to use for this Hook.
handleReferentialIntegrityOnOurOwn = false;
Chapter 5. Blue Glue Enterprises 373

// if entry rename/moveif (conn.getAttribute("$dn") != null){
if (LDAPServerHandlesReferentialIntegrity)work.setAttribute("userDN", conn.getString("$dn"));
else // handle ref. integrity on our own{
handleReferentialIntegrityOnOurOwn = true;work.setAttribute("newUserDN", conn.getString("$dn"));
}}task.logmsg("++++++ before applying")system.dumpEntry(conn);
removeMembership ConnectorTo create the removeMembership Connector, drag and drop the GroupConnector from the Connector library and ensure the Connector is in Lookup mode and renamed to reflect the name of removeMembership.
There are two slight modifications to be made to the Input Map for the removeMembership Connector in the Update AssemblyLine. Only the attributes for which the mapping is enabled are the bgappgroupname and the bgappgroupdn attributes. All other attributes will be ignored by this Connector.
One attribute value within the Link Criteria needs to be modified for this Connector. Within the member attribute in the Link Criteria, the inherited value is $$dn. Change the value of the member attribute in the Link Criteria for this Connector to be $userDN.
In this case, we want to find any GroupOfNames records where the LDAP member attribute is equal to the account distinguished name. Translating this into LDAP search filter terms, you get a query like the following:
(&(objectClass=groupOfNames)(member=uid=johnsmith,ou=people,o=blueglue,c=us))
The work attribute userDN is created in the After Lookup Hook of the updateAccount Connector.
The Link Criteria for the removeMembership Connector in the Update AssemblyLine is shown in Figure 5-64.
374 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-64 Update AssemblyLine removeMembership Link Criteria
Figure 5-65 on page 376 shows all the Hooks applicable to the removeMembership Connector for the Update AssemblyLine. The Hooks to use in this Connector are shown in bold type and are as follows:
� Before Execute
This Hook instructs the AssemblyLine to ignore this Connector in case the bgappgroupmembership attribute has not been received from the Identity Manager server.
� On Multiple Entries
This Hook is called in case the Connector finds multiple groups that have the user account as a member.
� On No Match
This Hook is called in case no groups having the user account as a member are found.
� Lookup Successful
This Hook is called if exactly one matching group is found. This Hook can also be called after the On Multiple Entries Hook and On No Match Hook have been called.
Chapter 5. Blue Glue Enterprises 375

Figure 5-65 removeMembership Hooks
If no modifications were made by the Identity Manager administrator to the group membership of the user account then Directory Integrator does not receive the bgappgroupmembership attribute from the Identity Manager server. Also, the LDAP server may handle referential integrity. If both cases occur, there is no need to execute the removeMembership Connector. The Before Execute Hook is used to instruct the AssemblyLine to ignore the Connector and pass the execution to the next component in the AssemblyLine. In this AssemblyLine, that is the addMembership script component. This is the script for this Hook.
if (( work.getAttribute("bgappgroupmembership") == null) && !handleReferentialIntegrityOnOurOwn) system.ignoreEntry();
The On Multiple Entries Hook allows us to examine the duplicate entries found during a lookup operation. We can then pick the unique entry to be fed into the AssemblyLine work Entry for the next steps of the dataflow. This is achieved by picking the valid entry out of the duplicates by using a setCurrent() method call.
For our Connector, we will always choose the first returned duplicate to feed the AssemblyLine. However, we have to make sure to process all other duplicates. Check out the script for this Hook.
// compare list of all found groups where the user is a member// against the list of values within the attribute bgappgroupmembership
376 Robust Data Synchronization with IBM Tivoli Directory Integrator

// then decide which operation is required:// - add to memberlist of group (= hand over to 'addMembership' Connector)// - remove from group memberlist// - do nothing
task.logmsg("INFO", "+++ Processing list of Group Membership for User: " + work.getString("$dn") );
// get first entry to be handled in Hook 'Lookup successful'var myEntry = thisConnector.getFirstDuplicateEntry();thisConnector.setCurrent(myEntry);
// iterate through rest of duplicate groupswhile ( (myEntry = thisConnector.getNextDuplicateEntry() ) != null ) {
// unless we have to handle ref. integrity, no further action required, so drop groupname from bgappgroupmembership
if (handleReferentialIntegrityOnOurOwn){
updateGroup.connector.removeAttributeValue(myEntry.getString("$dn"),"member",work.getString("userDN"));
updateGroup.connector.addAttributeValue(myEntry.getString("$dn"),"member",work.getString("newUserDN"));
}if (work.getAttribute("bpappgroupmembership") != null){
if (work.getAttribute("bgappgroupmembership").contains(myEntry.getString("$dn")))
{
work.getAttribute("bgappgroupmembership").removeValue(myEntry.getString("$dn"));
}else{
// trigger raw connector to delete member from existing groupupdateGroup.connector.removeAttributeValue(
myEntry.getString("$dn"),"member",work.getString("userDN"));}
}}
If no matching groups are found in the LDAP directory, there is no need to remove the user account from the existing groups. However, there is probably the need to insert the user account into new groups. This next Hook is used to tell the AssemblyLine to pass the execution to the next component down the AssemblyLine. In the Update AssemblyLine the next component is the
Chapter 5. Blue Glue Enterprises 377

addMembership script component. The script for the On No Match Hook is shown here.
task.logmsg("DEBUG", "+++ User " + work.getString("$dn") + " not in any Group");system.ignoreEntry();
As seen in the On No Match Hook, an ignoreEntry() call is issued. This means the Lookup Successful Hook is only called if one or more matching groups are found in the LDAP directory. In this Hook, we only deal with the case of one match.
Let us examine the script for the Lookup Successful Hook. If the Identity Manager server provided a bgappgroupmembership attribute that contains the matched group, no update is needed. We remove this value from the list of groups provided by the Identity Manager server.
The last line of the script makes use of a raw Connector method of the LDAP Connector. The removeAttributeValue method allows removing a single attribute value of a multi-valued attribute in a much more effective manner than modifying the entry with all new values for the attribute.
// compare values of bgapppgroupmembership against existing group members:if (handleReferentialIntegrityOnOurOwn){ updateGroup.connector.removeAttributeValue(
conn.getString("$dn"),"member",work.getString("userDN")); updateGroup.connector.addAttributeValue(
conn.getString("$dn"),"member",work.getString("newUserDN"));}
if (work.getAttribute("bgappgroupmembership") != null){
if ( work.getAttribute("bgappgroupmembership").contains(conn.getString("$dn")) )
{// no further action required, so drop groupname from
bgappgroupmembership
work.getAttribute("bgappgroupmembership").removeValue(conn.getString("$dn"));}else{
// trigger raw connector to delete member from existing groupupdateGroup.connector.removeAttributeValue(
conn.getString("$dn"),"member",work.getString("userDN"));}
}
378 Robust Data Synchronization with IBM Tivoli Directory Integrator

The Directory Integrator default is for the Directory Integrator AssemblyLines to limit the number of duplicate entries that Lookup Connectors are able to retrieve to ten entries. For our solution it is likely that users can be members of more than ten groups. We will overwrite the default value and set it to 0 (zero) which allows users to be member of an unlimited number of groups (see the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718). With Directory Integrator 5.x releases, you will need to use a large (for example, 99999999) number instead. This value is found on the AssemblyLine configuration tab. Figure 5-45 on page 351 shows this configuration.
addMembership componentCreate this component by selecting the button to add a new component to the AssemblyLine and choose Add script component...
This script component goes through the list of groups provided by the Identity Manager server. At this stage it contains the groups to which the user account should be added as a member. For each group in this list, this Connector executes the updateGroup Connector to update the group by adding the user account as a member to the group.
// remaining values in bgappgroupmembership are new groups for this account
var newgroups = work.getAttribute("bgappgroupmembership");if (newgroups != null){
if (handleReferentialIntegrityOnOurOwn)member = work.getString("newUserDN");
elsemember = work.getString("userDN");
var group=system.newEntry();group.setAttribute("member",member);for (i = 0; i < newgroups.size(); i++) {
if (newgroups.getValue(i) != "") {
group.setAttribute("groupDn", newgroups.getValue(i));updateGroup.update(group);
}}
}
updateGroup ConnectorTo create the updateGroup Connector, drag and drop the GroupConector from the Connector library and ensure the Connector is in Update mode and renamed to reflect the name of updateGroup. Place this Connector in Passive state.
Chapter 5. Blue Glue Enterprises 379

There is one modification to be made to the Output Map of this Connector. Uncheck all the boxes which indicate to modify the attributes listed except for the member attribute. Figure 5-66 shows the configuration for the Output Map of the updateGroup Connector.
Figure 5-66 Update AssemblyLine updateGroup Connector Output Map
The Link Criteria for the updateGroup Connector is shown in Figure 5-67. For this Connector, we want to find the group record by its distinguished name. The distinguished name is represented by the $groupDN attribute is passed to this Connector by the addMembership script component.
Figure 5-67 Update AssemblyLine updateGroup Link Criteria
No Hooks are used in the updateGroup Connector.
This concludes the configuration of the Update AssemblyLine.
The global scriptThere is a need to create a global script to provide commonly used script functions to two AssemblyLines. Add a new script component to the script library in the left pane of the config window and name it Global. You are presented with a screen in which to add any custom script you may need for the solution.
We have included the Global script used with this solution to make it more simple for you to configure the solution. Copy the contents of the Global script into the script component you just created. Go to the Config tab for the Global script and
380 Robust Data Synchronization with IBM Tivoli Directory Integrator

check the box named Implicitly Included to ensure the functions within the script will be accessible from all the AssemblyLines within the Directory Integrator XML configuration.
For our solution, the Global script defines two variables that are used by the Add and Update AssemblyLines. Those variables are targetNamingAttribute and LDAPServerHandlesReferentialIntegrity.
The following functions can also be found in the Global script in the script library:
� hasSameBase (dn, base)
This function returns true if the distinguished name specified by a string variable dn is a child of the base distinguished name specified by the string variable base. If not, it returns false.
Example:
hasSameBase (“ou=people, o=blueglue, c=us”, “c=us”) returns true;
hasSameBase (“ou=contractors, o=blueglue, c=us”, “o=blueglue”) returns false;
� getRDNAttribute (dn)
This function returns the name of the attribute used as the relative distinguished name (RDN™) of a distinguished name specified as the string variable dn.
Example:
getRDNAttribute (“uid=johnsmith, ou=people, o=blueglue ,c=us”) returns uid;
� getRDNValue(dn)
This function returns the value of the attribute used as the RDN of a distinguished name specified as the string variable dn.
Example:
getRDNValue (“uid=johnsmith, ou=people, o=blueglue, c=us”) returns johnsmith;
� RDNisUid (dn)
This function returns true if the distinguished name specified by a string variable dn uses the uid attribute in its RDN. If not, it returns false.
Example:
RDNisUid (“ou=people, o=blueglue, c=us”) returns false;
RDNisUid (“uid=johnsmith, ou=people, o=blueglue, c=us”) returns true;
Chapter 5. Blue Glue Enterprises 381

� getNonRDNFromDN (dn)
This function returns distinguished name specified as the string variable dn without its RDN.
Example:
getNonRDNFromDN (“ou=people, o=blueglue, c=us”) returns o=blueglue, c=us;
Example 5-8 shows the entire contents of the Global script used for our solution.
Example 5-8 Global script
// Version: 1.4
TargetNamingAttribute = "uid";LDAPServerHandlesReferentialIntegrity = false;
function hasSameBase(dn, base){
// uses ldapjdk.jar// put in lowercase (only necessary with ldapjdk.jar)dn = dn.toLowerCase();base = base.toLowerCase();
arr = Packages.netscape.ldap.LDAPDN.explodeDN(base, false);arr2 = Packages.netscape.ldap.LDAPDN.explodeDN(dn, false);
if (dn.length < base.length)return false;
for (i = 0; i < arr.length; i++)if (!Packages.netscape.ldap.LDAPDN.equals(arr[arr.length -i -1],
arr2[arr2.length -i -1]))return false;
return true;
/*// requires OpenLDAP.jararr = Packages.com.novell.ldap.LDAPDN.explodeDN(base, false);arr2 = Packages.com.novell.ldap.LDAPDN.explodeDN(dn, false);
if (dn.length < base.length)return false;
for (i = 0; i < arr.length; i++)if (!Packages.com.novell.ldap.LDAPDN.equals(arr[arr.length -i -1],
arr2[arr2.length -i -1]))
382 Robust Data Synchronization with IBM Tivoli Directory Integrator

return false;
return true;*/
}
function getRDNvalue (dn){
// compute UID// uses ldapjdk.jararr = Packages.netscape.ldap.LDAPDN.explodeDN(dn, true);
/*// uses ldapjdk.jararr = Packages.com.novell.ldap.LDAPDN.explodeDN(dn, true);*/
return arr[0];}
function getRDNattribute (dn){
// compute UID// uses ldapjdk.jararr = Packages.netscape.ldap.LDAPDN.explodeDN(dn, false);
/*// requires ldapjdk.jararr = Packages.com.novell.ldap.LDAPDN.explodeDN(dn, false);*/
return arr[0].substring(0, arr[0].indexOf("="));}
function RDNisUid (dn){
// uses ldapjdk.jararr = Packages.netscape.ldap.LDAPDN.explodeDN(dn, false);
/*// uses ldapjdk.jararr = Packages.com.novell.ldap.LDAPDN.explodeDN(dn, false);*/if (arr[0].substring(0, arr[0].indexOf("=")).equalsIgnoreCase("uid"))
return true;else return false;
}
function getNonRDNfromDN (dn)
Chapter 5. Blue Glue Enterprises 383

{// uses ldapjdk.jararr = Packages.netscape.ldap.LDAPDN.explodeDN(dn, false);
/*// uses ldapjdk.jararr = Packages.com.novell.ldap.LDAPDN.explodeDN(dn, false);*/
str = "";for (i = 1; i < arr.length; i++){
str += arr[i];if ( i < arr.length -1) str += ",";
}return str;
}
Test the solutionIBM Tivoli Directory Integrator provides the ability to iteratively build and test your solution as you develop your solution. We test the connectivity of the Connectors and Event Handlers along the way. You may also test the functionality of the AssemblyLines as you gradually build them.
Something common to LDAP directory servers plays a role in the characteristics of our solution and how it operates. As defined in the standard LDAP schema, groups of type accessGroup, groupOfNames and groupOfUniqueNames must have a member. The Update and Delete AssemblyLines may consequently fail if the Connectors attempt to remove a member from a group, and this member is the only member in the group. Two work-arounds can be implemented to avoid this situation:
1. A dummy member could be added to all groups. This member would not correspond to any real user in the directory. In the case of the Blue Glue application, it does not allow for groups to exist without having a member so this is not a possibility for our solution.
2. You can modify the standard schema definition on the directory server and change the member attribute of the group objectclass from a required
Tip: Turn on the detailed logging feature for the Connectors used in your AssemblyLines to generate more information for debugging any issues you may have with the configuration of your solution. The detailed logging feature is a checkbox located on the Connection tab under the Config tab for the Connector.
384 Robust Data Synchronization with IBM Tivoli Directory Integrator

attribute to an optional attribute. It is not recommended to modify the standard schema of a directory server.
This is now the time to thoroughly test this part of our solution to make sure it performs and meets the solution requirements.
Part two - LDAP server to authentication databaseImplementing the real-time synchronization from the Blue Glue store management application LDAP server to the authentication database requires the following steps:
� Configure the properties file and base Connectors for connectivity between the LDAP server and the database server.
� Configure the Directory Integrator AssemblyLine.
� Test the solution.
Configure properties and base ConnectorsSince part two involves a connection between an LDAP server and a relational database, we have to make sure we have the configuration information we need to connect to both data sources in our properties file along with Connectors in our Connector library to reuse.
In part one of our solution we defined properties to use to connect to the Blue Glue LDAP server. We now use the properties file to define properties to use to connect to the authorization database. The Blue Glue authorization database is a DB2 database. We identify the property attribute names and values used to connect to a DB2 database and list those in our properties file. The DB2 attribute names and values to use are listed in Figure 5-26 on page 331 in part one of our solution when we describe the initial properties file creation for our entire solution.
Table 5-20 describes how Directory Integrator uses the external property variables when connecting to the Blue Glue authorization server.
Table 5-20 Blue Glue authorization database property variable descriptions
Property variable name Description
Db2Admin Login name for access to DB2 database.
Db2Driver JDBC driver class name.
Db2Pw Password for login name used to connect to DB2 server.
Db2Schema Schema of database to use when connecting.
Db2TableName1 First of two table names within database to use
Chapter 5. Blue Glue Enterprises 385

We need to build three Connectors for our Connector library and combine those into one AssemblyLine to accomplish the synchronization of the Blue Glue LDAP server to the Blue Glue authorization database.
We determined the three reusable base Connectors to build based on our planning stage where we determined the data flows and reviewed the results of our detailed data identification.
Based on our planning, we need a Connector to watch for changes that occur on the Blue Glue LDAP server in real-time. Since the Blue Glue LDAP server is based on the IBM Tivoli Directory Server and we connect to the changelog to watch for changes, our Connector to use is the IBM Tivoli Directory Server Changelog Connector. The Connector we build in our Connector library is called LdapChanges.
To configure the LdapChanges Connector for our Connector library, start by selecting the Directory Integrator option to add a new Connector to the Connector library. Choose the ibmdi.IBMDirectoryServerChangelog Connector from the Connector list. Name the Connector LdapChanges. This Connector only operates in Iterator mode. Open the new Connector in the Connector library and configure the connection information located on the Config tab.
The first three attribute connection values are inherited from the external properties file. Set the inheritance by double-clicking on the attribute name and select the appropriate external property name from the provided list. Since this connection is to connect to the Blue Glue LDAP server, use the same property value names that we used in part one when setting up the account and group Connectors. Table 5-19 on page 331 describes the property variable names for the LDAP server connections within our properties file.
Figure 5-68 on page 388 shows the completed Connector configuration. Some parameters we use in this Connector configuration are described below:
� Changelog base
When connecting to the IBM Tivoli Directory Server, the value for this is cn=changelog. Check to ensure the changelog is enabled on the directory server. If it is not, now is a good time to enable this function.
Db2TableName2 Second of two table names within database to use.
Db2Url JDBC url for host, port and database name to use to connect.
Property variable name Description
386 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Iterator state store
This Connector uses the Directory Integrator Iterator state store to keep track of the last changenumber processed in the directory server. We are using the default configuration for the state store which is the CloudScape database provided with Directory Integrator.
� State key persistence
This is the method to use for saving the changenumber to the system store. The choices are after read, end of cycle, and manual. Our configuration uses the end of cycle option to save the changes after we have successfully processed them through the entire AssemblyLine.
� Timeout
Set this value to 0 to ensure the changelog Connector continuously runs and captures the changes from the Blue Glue LDAP server in real-time.
The next step is to confirm the connection to the data source for the Connector. Do this by choosing the Input Map tab for the Connector and select the button to connect to the data source which is identified by the icon that looks like a power plug . When successful, the Connector lists that a connection has been established.
To display any attributes located within the data source, select the arrow shaped icon to the right of the power plug icon . It allows you to step through the data located on that data source provided by the connection information you entered into the configuration of the Connector.
Note: It is preferable to enable the CloudScape database to operate in networked mode as opposed to the default configuration of embedded mode. This allows for multiple connections to the database.
To configure, make a copy of the global.properties file for backup purposes. Open the original file in a text editor and uncomment the entire paragraph of commands labeled ## Location of the database (networked mode) and similarly comment out the paragraph labeled ## Location of the database (embedded mode). You can choose to edit the solution.properties file instead of or in combination with the global.properties file depending on your desired solution configuration.
Chapter 5. Blue Glue Enterprises 387

Figure 5-68 LdapChanges Connector configuration
Sometimes, we require more information from the directory server than we receive in real-time from the changelog. To ensure we have all the information
Note: You can test the connection from the directory server changelog Connector connection screen by selecting the Query button to the right of the changelog base value box. If successful, it returns a reply window listing the changelog base value from the directory server. The LDAP Connector and JDBC connector also have buttons on their connection pages in the forms of the Context button and the Select table name button.
388 Robust Data Synchronization with IBM Tivoli Directory Integrator

required to perform the updates to the authorization database, we create an LDAP server connection. This means we use an LDAP Connector in Lookup mode to connect to the Blue Glue LDAP server and lookup the information we require. The Connector we create in our Connector library is called LdapLookup.
To configure the LdapLookup Connector for our Connector library, start by selecting the Directory Integrator option to add a new Connector to the Connector library. Choose the ibmdi.LDAP Connector from the Connector list. Name the Connector LdapLookup and select the Lookup mode. Open the new Connector in the Connector library and configure the connection information located on the Config tab.
The first five attribute connection values are inherited from the external properties file. Set the inheritance by double-clicking on the attribute name and select the appropriate external property name from the provided list. Since this connection is to connect to the Blue Glue LDAP server, use the same property value names as we use in part one when setting up the account Connector. Table 5-19 on page 331 describes the property variable names for the LDAP server connections within our properties file.
Figure 5-69 on page 390 shows the completed Connector configuration. Once you have completed the Connector configuration, the next step is to confirm the connection to the data source for the Connector. Do this by choosing the Input Map tab for the Connector and select the button to connect to the data source which is identified by the icon that looks like a power plug . When successful, the Connector lists that a connection has been established.
Chapter 5. Blue Glue Enterprises 389

Figure 5-69 LdapLookup Connector configuration
Once we have detected a change and received all the appropriate information, we then update the authorization database. This requires a Connector to connect to our database using the JDBC Connector. We perform add, modify and delete operations to the database. We change the mode of the Connector as we use it in our AssemblyLine to accomplish the updates and deletes. The Connector in our Connector library is called DbUpdate.
390 Robust Data Synchronization with IBM Tivoli Directory Integrator

To configure the DbUpdate Connector for our Connector library, start by selecting the Directory Integrator option to add a new Connector to the Connector library. Choose the ibmdi.JDBC Connector from the Connector list. Name the Connector DbUpdate and select the Update mode. Open the new Connector in the Connector library and configure the connection information located on the Config tab.
The first five attribute connection values are inherited from the external properties file. Set the inheritance by double-clicking on the attribute name and select the appropriate external property name from the provided list. Table 5-20 on page 385 describes the property variable names for the DB2 server connections within our properties file.
Figure 5-70 on page 392 shows the completed Connector configuration. We did not specify a table name in our Connector in our Connector library because we will be using this Connector to connect to two different tables. The two tables are the USERS and the ACCESS tables. To confirm the connection to the database, choose the Select button to the right of the table name parameter and choose the table name from the displayed list.
Note: When using the JDBC Connector, ensure the proper driver is in the Directory Integrator classpath. Since we are connecting to DB2, the driver is already in the Directory Integrator classpath due to the default system state store being CloudScape which uses the JDBC DB2 driver.
Chapter 5. Blue Glue Enterprises 391

Figure 5-70 DbUpdate Connector configuration
We will configure the Input and Output Maps as well as Link Criteria and Hooks within the AssemblyLine. These Connectors in our Connector library will provide the base connection for which we will expand upon as we build our solution.
Configure AssemblyLineThis part of our solution is accomplished by configuring just one AssemblyLine. Create a new AssemblyLine and name it LdapChngUpdateDb. Figure 5-71 on page 393 shows our configuration with the new Connectors and AssemblyLine added.
392 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-71 Blue Glue solution AssemblyLines and Connectors
The data flow for our LdapChngUpdateDb AssemblyLine is determined by our planning efforts. The logic is listed below along with the names and type of component we use to implement this logic.
1. Watch the Blue Glue LDAP server for changes and capture the type of change and the location of the change; LdapChanges changelog Connector.
2. Check to see if change is something we care about. We care only about changes to user accounts; IF_ChangeToUser branch component.
3. Set an attribute to hold the unique ID value of the user account; GetUid attribute map component.
4. Check to see if the change is an add or modify so we can update the Blue Glue database tables with the proper information; IF_AddModify branch component.
5. If the change is an add or modify, get all the user account information from the Blue Glue LDAP server in the specified location of the directory tree we care about; LdapLookup LDAP Connector in Lookup mode.
6. Check to see if the title attribute has a value. Based on our planning, the authorization database requires a value for the user account’s title. This attribute determines the authorization values; IF_TitleNotNull branch component.
7. If the change to the user account is an add or modify and the title attribute has a value, set the proper value for the accesscode attribute and update the USERS and ACCESS database tables with the proper information and report the tables were updated; SetAccessCode attribute map component, DbUpdateUsers and DbUpdateAccess Connectors in Update mode.
8. If the change is a delete, remove the user and access information from the USER and ACCESS database tables and report the deletion occurred;
Chapter 5. Blue Glue Enterprises 393

DbRemoveUser and DbRemoveAccess Connectors in Delete mode followed by the InfoForDelete script component.
As you noticed in part one of our solution, our configuration was centered on using Connectors and scripts within the AssemblyLines with custom scripts used within the Hooks of the Connectors to determine the flow of the AssemblyLine. Part two of our solution utilizes the Branch and Attribute Map components added with the Connectors and a Script component to customize the flow of the AssemblyLine. Figure 5-72 shows what the LdapChngUpdateDb AssemblyLine looks like with all the components created and configured according to our logical flow of data.
Figure 5-72 LdapChngUpdateDb AssemblyLine data flow
Watch the Blue Glue LDAP server for changesIn order to create our AssemblyLine to synchronize the Blue Glue LDAP server to the Blue Glue authorization database, we start by creating the first component in our data flow. This is the LdapChanges Connector used to watch for changes that occur on the Blue Glue LDAP server in real-time.
Note: You can test the parts of the AssemblyLine as we build by enabling the components in the AssemblyLine you want to test and disabling those which are not required for that part of your testing. You can enable or disable a component by right-clicking on the component and checking or unchecking the Enabled item on the menu.
394 Robust Data Synchronization with IBM Tivoli Directory Integrator

LdapChanges ConnectorTo create the LdapChanges Connector, drag and drop the Connector labeled LdapChanges from the Connector library and ensure it is in Iterator mode.
Figure 5-73 shows the attributes to create for the Input Map. You can either type the attribute names as new attributes or connect to the data source and drag and drop the attribute names from the resulting attribute list. The operation attribute is a new attribute name we create; it cannot be retrieved from the connected source.
Figure 5-73 LdapChanges Input Map
The three attributes allow us to capture the type and location of the change that occurs on the Blue Glue LDAP server. The changetype attribute is the attribute the IBM Tivoli Directory Server uses to record the type of change that it is listing within the changelog. The operation attribute is a feature of the Directory Integrator Connector where it reports the type of change which occurred on the connected directory server. We are using both attributes for our solution to demonstrate two ways to determine changes depending on what is available with the connection and also what type of change for which you are watching. We use the changetype attribute to determine the add and modify type changes to user accounts while we will use the operation attribute to determine deletes. The script to determine the value for our operation attribute is shown is shown here; it gets the value returned by our Connector.
ret.value = conn.getOperation();
Since our Connector works in Iterator mode, there is no Link Criteria to configure. We are not using any Hooks in this Connector.
Check if user information has changedWe only care about synchronizing the information located with the user accounts in the Blue Glue LDAP server. Therefore, we add a branch component named IF_ChangeToUser to check to see if the changes are to the users.
Chapter 5. Blue Glue Enterprises 395

IF_ChangeToUser BranchThe user accounts are located in the part of the directory tree labeled ou=people. Figure 5-74 shows the Branch correctly configured to watch for changes that occur in the ou=people part of the directory tree. All other components are placed under this branch.
Figure 5-74 IF_ChangeToUser branch
Get the user account unique identifierNow that we know we are only dealing with user accounts, we are assured the contents of the targetdn attribute contains a value for the unique identifier of the user whose account was changed. We create an attribute map component named GetUid to map the uid attribute and its value to the work Entry.
GetUid attribute mapWe create the uid attribute by capturing the text within the targetdn attribute between the string value of uid= and the next comma in the string. An example of the string value of the targetdn attribute is the following:
uid=jsmith, ou=people, dc=blueglue,dc=com
We are interested in obtaining the value of jsmith from our example. This is the value which allows us to uniquely identify the user account. Figure 5-75 shows the configuration for the attribute map.
Figure 5-75 GetUid attribute map
The following script shows how we capture the value for the uid attribute.
var nuid = work.getString("targetdn");var uid = nuid.substring(4,nuid.indexOf(","));ret.value = uid;
396 Robust Data Synchronization with IBM Tivoli Directory Integrator

Check if change is add or modifyNow that we have a way to uniquely identify user accounts, we are interested in identifying the type of changes which are either add or modify operations for us to perform an update to the authorization database tables. This means we create a Branch component and name it IF_AddModify to check for these changes.
IF_AddModify branchAfter creating a new Branch and naming it IF_AddModify, define two conditions and be sure to check the Match any option. Be sure to place this Branch underneath the Getuid attribute map component in the data flow. Figure 5-76 shows the configuration of the branch component.
Figure 5-76 IF_AddModify branch
Retrieve detailed user account informationWe now know the user account unique identifier and that we will perform an update to the authorization database. In order to be able to update the database, we have a requirement that we first have a value for the title attribute within the Blue Glue LDAP server. The title attribute determines the values for the authorization database and a user is not valid without a value for this attribute. Since the changelog on the directory server only reports the attributes that changed, we need a Connector to lookup the value for the title attribute located in the Blue Glue LDAP server. Since we require this Connector, we go ahead and retrieve all the user account attributes to be sure to synchronize all the attributes to the most current state. We do this with the LdapLookup Connector.
LdapLookup ConnectorTo create the LdapLookup Connector, drag and drop the Connector labeled LdapLookup from the Connector library and ensure it is in Lookup mode.
Figure 5-77 on page 398 shows the attributes to create for the Input Map. You can either type the attribute names as new attribute or establish a connection to the data source and drag and drop the attribute names from the resulting attribute list. All of the attributes are directly mapped with no need for any advanced mapping to set attribute values.
Chapter 5. Blue Glue Enterprises 397

Figure 5-77 LdapLookup Input Map
Since we created our uid attribute in the attribute map component, the Link Criteria to match the user within the Blue Glue LDAP server is a basic direct mapping. Figure 5-78 shows the configuration of the Link Criteria.
Figure 5-78 LdapLookup Link Criteria
There is the need for a script to be placed in one Hook for this Connector. Figure 5-79 on page 399 shows the Hook used for the LdapLookup Connector. It is highlighted in bold and is the On No Match Hook.
398 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-79 LdapLookup Hooks
The On No Match Hook is used to report if there is no match in the LDAP server for the user account we are processing from the changelog. To ensure we don’t have a user account in the authorization database for a user which does not exist in the LDAP server, we also set the operation attribute to the value of delete to ensure we later process the data to properly remove this user from the authorization database. The condition where our AssemblyLine is processing an add or modify change to a user that does not exist in the directory server happens if you disconnect the synchronization process from the LDAP server and then later restart the synchronization process after some changes may have happened to the LDAP server.
Here is the script for the On No Match Hook.
task.logmsg ("INFO","==== There is no match for uid = " + uid + " in the directory server");// set operation code to delete to synch to database and remove user from databasework.setAttribute("operation", "delete");
Check for value in title attributeNow that we have retrieved the title attribute, we can check to see if there is a value to determine if we can process the updates to the authorization database. We do this with a Branch labeled IF_TitleNotNull.
Chapter 5. Blue Glue Enterprises 399

IF_TitleNotNull BranchAfter creating a new Branch and naming it IF_TitleNotNull, define one condition to check if the title attribute exists. Be sure to place this Branch underneath the LdapLookup Connector component in the data flow. Figure 5-80 shows the configuration of the Branch component.
Figure 5-80 IF_TitleNotNull branch
Configure the proper access codeWe now have the user account information and qualifying data to process an update to the USERS and ACCESS database tables located in our Blue Glue store management application authorization database. The information located in the user account’s title attribute determine the proper access code for our authorization database. We need to script the proper values to set the accesscode attribute. This is done by creating an attribute map component and naming it SetAccessCode.
SetAccessCode attribute mapAfter the attribute map component is created, make sure it is located in the data flow underneath the IF_TititleNotNull branch. We create a new attribute named accesscode. This attribute value is calculated by using a script to match new values for the attribute based on the values returned within the title attribute. Figure 5-81 shows the configuration for the attribute map.
Figure 5-81 SetAccessCode attribute map
400 Robust Data Synchronization with IBM Tivoli Directory Integrator

The following script shows the matching values used to set the accesscode attribute. These values were determined based on the translation between the Blue Glue LDAP server attribute values and the Blue Glue database field values as identified during our planning process.
// Calculate the appropriate access code based on the user's employeetype
var title = work.getString("title").toLowerCase(); title = String(title.trim());
switch(title){case "sysadmin": var accesscode = "A"; break;
case "callcenter": var accesscode = "U"; break;
case "security": var accesscode = "M"; break;
case "employee": var accesscode = "V"; break;
default: var accesscode = ""; break;}
ret.value = accesscode;
Update user account in databaseNow that all the user information has been properly assembled, we update the user information located in the Blue Glue authorization database. This is done with a database Connector named DbUpdateUsers.
DbUpdateUsers ConnectorTo create the DbUpdateUsers Connector, drag and drop the Connector labeled DbUpdate from the Connector library and ensure it is in Update mode. Rename the Connector to reflect the name of DbUpdateUsers and make sure it is located in the data flow just underneath the SetAccessCode attribute map component.
There is one modification that needs to be made on the Connection information tab of this Connector. We want to designate the database table to which we want
Chapter 5. Blue Glue Enterprises 401

to connect. Since we are processing changes to the user information in the authorization database, we select the USERS table location within the database. Figure 5-82 shows the proper connection configuration for this Connector.
Figure 5-82 DbUpdateUsers table name setting
Next we configure the attributes for the Output Map. Figure 5-83 shows the attributes to create and their proper configuration. You can either type the attribute names as new attributes or establish a connection to the data source and drag and drop the attribute names from the resulting attribute list. Once you have created the attribute list for the Output Map, ensure the attributes are properly mapped to the existing work Entry attributes.
Figure 5-83 DbUpdateUsers Output Map
402 Robust Data Synchronization with IBM Tivoli Directory Integrator

To configure the Link Criteria for this Connector, we once again use the uid attribute we created earlier. We match this to the USERNO attribute located within the USERS table of the authorization database. Figure 5-84 shows the configuration of the Link Criteria.
Figure 5-84 DbUpdateUsers Link Criteria
It is necessary for a script to be placed in two Hooks for this Connector. The script is to report on the status of the processing. Figure 5-85 on page 404 shows the Hooks used for the DbUpdateUsers Connector. They are highlighted in bold and are the AfterModify and AfterAdd Hooks.
Chapter 5. Blue Glue Enterprises 403

Figure 5-85 DbUpdateUsers Hooks
The AfterModify and AfterAdd Hooks are used to report on the status of the data flow. Here is the script used in the AfterModify Hook.
task.logmsg ("INFO","==== Modified user with uid = " + uid + " in the user database table");
This is the script used in the AfterAdd Hook.
task.logmsg ("INFO","==== Added user with uid = " + uid + " in the user database table");
Update user access information in databaseNext we need to update the information for the user located within the Blue Glue authorization database ACCESS table. This is done with a database Connector named DbUpdateAccess.
404 Robust Data Synchronization with IBM Tivoli Directory Integrator

DbUpdateAccess ConnectorTo create the DbUpdateAccess Connector, drag and drop the Connector labeled DbUpdate from the Connector library and ensure it is in Update mode. Rename the Connector to reflect the name of DbUpdateAccess and make sure it is located in the data flow just underneath the DbUpdateUsers Connector component.
There is one modification that needs to be made on the Connection information tab for the configuration of this Connector. We want to designate the database table to which we want to connect. Since we are processing changes to the user access information in the authorization database with this Connector, we select the ACCESS table location within the database. Figure 5-86 shows the proper connection configuration for this Connector.
Figure 5-86 DbUpdateAccess table name setting
Next we configure the attributes for the Output Map. Figure 5-87 on page 406 shows the attributes to create and the proper configuration for the Output Map. You can either type the attribute names as new attribute or establish a connection to the data source and drag and drop the attribute names from the resulting attribute list. Once you have created the attribute list for the Output Map, ensure the attributes are properly mapped to the existing work Entry attributes. During our planning process, we identified we would script the system date to be placed into the DATE attribute within the authorization database. Set the DATE attribute to advanced mapping and create the script to return the system date for the database field.
Chapter 5. Blue Glue Enterprises 405

Figure 5-87 DbUpdateAccess Output Map
Here is the script to create the system date in the proper date format required by the database.
var today = new java.util.Date();var now = today.getTime();var currentdate = new java.sql.Date(now);ret.value = currentdate;
To configure the Link Criteria for this Connector, we once again use the uid attribute we created earlier. We match this to the USERNO attribute located within the ACCESS table of the authorization database. Figure 5-88 shows the configuration of the Link Criteria.
Figure 5-88 DbUpdateAccess Link Criteria
We place a script in Hooks in this Connector similar to what was placed within the DbUpdateUsers Connector. This involves two Hooks for this Connector. The script is to report status of the processing. Figure 5-89 on page 407 shows the Hooks used for the DbUpdateAccess Connector. They are highlighted in bold and are the AfterModify and AfterAdd Hooks.
406 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-89 DbUpdateAccess Hooks
The AfterModify and AfterAdd Hooks are used to report on the status of the data flow. Here is the script used in the AfterModify Hook.
task.logmsg ("INFO","==== Modified user with uid = " + uid + " in the access database table");
This is the script used in the AfterAdd Hook.
task.logmsg ("INFO","==== Added user with uid = " + uid + " in the access database table");
Check if change is deleteIf the change to the user account within the Blue Glue LDAP server is not an add or modify, we want to check to see if it is a delete operation. This means we create a Branch component and name it IF_Delete to check for these changes.
Chapter 5. Blue Glue Enterprises 407

IF_Delete BranchAfter creating a new branch and naming it IF_Delete, define one condition to check if the operation attribute has a value equal to delete. Be sure to place this Branch underneath the Getuid attribute map component in the data flow after the IF_AddModify Branch component. We want this Branch component to be on the same level as the IF_AddModify Branch in the dataflow. Both of these Branches are executed after the Getuid attribute map. Consult Figure 5-72 on page 394 for a view of the proper layout of components in our data flow. Figure 5-90 shows the configuration of the branch component.
Figure 5-90 IF_Delete branch
Delete user account in databaseIf the change in the Blue Glue LDAP server is a delete, our data flow will remove the user account from the proper table within the authorization database. This is done with a database Connector named DbRemoveUser.
DbRemoveUser ConnectorTo create the DbRemoveUser Connector, drag and drop the Connector labeled DbUpdate from the Connector library and ensure it is in Delete mode. Rename the Connector to reflect the name of DbRemoveUser and make sure it is located in the data flow just underneath the IF_Delete Branch component.
There is one modification that needs to be made on the Connection information tab for the configuration of this Connector. We want to designate the database table to which we want to connect. Since we are processing changes to the user information in the authorization database with this Connector, we select the USERS table location within the database. Ensure the table name for the connection information is set the USERS as we did for the DbUpdateUsers Connector.
There is no need for an Input Map for this Connector since we are removing the entire record within the USERS database.
To configure the Link Criteria for this Connector, we once again use the uid attribute we created earlier. We match this to the USERNO attribute located within the USERS table of the authorization database. Figure 5-91 on page 409 shows the configuration of the Link Criteria.
408 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure 5-91 DbRemoveUser Link Criteria
We place a script in Hooks in this Connector similar to what was placed within the DbUpdateUsers Connector in order to report on the status of our synchronization process. We also include a Hook to demonstrate a way to use the Error Hooks to skip entries that might represent error conditions for this Connector. In our case, we elect to simply skip the entry which represents the error. In most situations, you want to report more information or possibly just skip the Connector rather than the entire future processing of the entry. In some cases, the error condition is not necessarily an error for your specific Connector in your data flow.
The Hooks we use within the DbRemoveUser Connector are represented in bold type as the On No Match and Delete Error Hooks in Figure 5-92 on page 410.
Chapter 5. Blue Glue Enterprises 409

Figure 5-92 DbRemoveUser Hooks
The On No Match Hook is used to report that we found no match in the database for the user account we plan to delete. If there is no match, we skip processing this entry at this time. Here is the script used in the On No Match Hook.
task.logmsg ("INFO","==== There is no match for uid = " + uid + " in the database");system.skipEntry();
This is the script used in the Delete Error Hook to skip processing the entry if there is an error.
system.skipEntry();
Delete user access information in databaseNext we need to synchronize the information for the user located within the Blue Glue authorization database ACCESS table. This is done with a database Connector named DbRemoveAccess.
DbRemoveAccess ConnectorTo create the DbRemoveAccess Connector, drag and drop the Connector labeled DbUpdate from the Connector library and ensure it is in Delete mode. Rename the Connector to reflect the name of DbRemoveAccess and make sure it is
410 Robust Data Synchronization with IBM Tivoli Directory Integrator

located in the data flow just underneath the DbRemoveUser Connector component.
There is one modification that needs to be made on the Connection information tab for the configuration of this Connector. We want to designate the database table to which we want to connect. Since we are processing changes to the user access information in the authorization database with this Connector, we select the ACCESS table location within the database. Ensure the table name for the connection information is set the ACCESS as we did for the DbUpdateAccess Connector.
There is no need for an Input Map for this Connector since we are removing the entire record within the ACCESS database.
To configure the Link Criteria for this Connector, we once again use the uid attribute we created earlier. We match this to the USERNO attribute located within the ACCESS table of the authorization database. Figure 5-93 shows the configuration of the Link Criteria.
Figure 5-93 DbRemoveAccess Link Criteria
There are no Hooks used for the DbRemoveAccess Connector.
Report successful deletion of user informationFinally we want to report that the deletion of specific user account information was successful. This is done with the InforForDelete script component. This is an example of using the script components within the data flow to perform status reporting for your AssemblyLine.
InfoForDelete scriptA simple script is required for this script component. It is meant to report back the user identification and status of the delete operation for the Blue Glue authorization database. Ensure this script component is located in the data flow just underneath the DbRemoveAccess Connector. Here is the contents of the script.
task.logmsg ("INFO","==== Removed user with uid = " + uid + " from the user and access database tables");
Chapter 5. Blue Glue Enterprises 411

Test the solutionSince this part of the solution consists of only one AssemblyLine, now is the time to test the entire AssemblyLine with all the Connectors and components enabled. If you took advantage of the ability to enable and disable the components along the way to test parts of the solution, this testing phase will be relatively short and simple. This is also where you run through any test use cases and ensure they meet the solution requirements.
This concludes our second customer scenario around the Blue Glue Enterprise environment.
412 Robust Data Synchronization with IBM Tivoli Directory Integrator

Part 3 Appendixes
Part 3
© Copyright IBM Corp. 2006. All rights reserved. 413

414 Robust Data Synchronization with IBM Tivoli Directory Integrator

Appendix A. Tricky connections
You may encounter different issues while establishing connectivity to RDBMS data sources. You need specific information like the type of JDBC driver you want to use, version compatibility, connection parameters, driver class names, and so on.
This appendix discusses these issues within the context of Oracle, IBM DB2, and Microsoft SQL Server 2000 database systems.
In addition we also discuss some of the connectivity details for Lotus Domino Server.
A
© Copyright IBM Corp. 2006. All rights reserved. 415

Introduction to JDBC driversAccording to the JDBC specification, there are four types of JDBC driver architectures:
Type 1 - Drivers that implement the JDBC API as a mapping to another data access API, such as Open Database Connectivity (ODBC). Drivers of this type are generally dependent on a native library, which limits their portability. The JDBC-ODBC Bridge driver is an example of a Type 1 driver.
Type 2 - Drivers that are written partly in the Java programming language and partly in native code. The drivers use a native client library specific to the data source to which they connect. Again, because of the native code, their portability is limited.
Type 3 - Drivers that use a pure Java client and communicate with a middleware server using a database-independent protocol. The middleware server then communicates the client's requests to the data source.
Type 4 - Drivers that are pure Java and implement the network protocol for a specific data source. The client connects directly to the data source.
Database connectivity to OracleBased on the JDBC driver architecture the following types of drivers are available from Oracle.
1. Oracle JDBC Type 1
This is an Oracle ODBC (not JDBC) driver, that you connect to using a JDBC-ODBC bridge driver. Oracle does supply an ODBC driver, but does not supply a bridge driver. Instead, you can get one of these JDBC-ODBC bridge drivers from http://java.sun.com/products/jdbc/drivers.html. This configuration works fine, but a JDBC Type 2 or Type 4 driver will offer more features and will be faster.
2. Oracle JDBC Type 2
There are two flavors of the Type 2 driver.
– JDBC OCI client-side driver
This driver uses Java native methods to call entrypoints in an underlying C library. That C library, called OCI (Oracle Call Interface), interacts with an
Note: We only use Type 4 drivers with Tivoli Directory Integrator, but will discuss other types as well for a better understanding.
416 Robust Data Synchronization with IBM Tivoli Directory Integrator

Oracle database. The JDBC OCI driver requires an Oracle client installation of the same version as the driver. The use of native methods makes the JDBC OCI driver platform specific. Oracle supports Solaris, Windows, and many other platforms. This means that the Oracle JDBC OCI driver is not appropriate for Java applets, because it depends on a C library. Starting from Version 10.1.0, the JDBC OCI driver is available for installation with the OCI Instant Client feature, which does not require a complete Oracle client-installation. Please refer to the Oracle Call Interface for more information.
– JDBC Server-Side Internal driver
This driver uses Java native methods to call entrypoints in an underlying C library. That C library is part of the Oracle server process and communicates directly with the internal SQL engine inside Oracle. The driver accesses the SQL engine by using internal function calls and thus avoiding any network traffic. This allows your Java code to run on the server to access the underlying database in the fastest possible manner. It can only be used to access the same database.
3. Oracle JDBC Type4
Again, there are two flavors of the Type 4 driver.
– JDBC Thin client-side driver
This driver uses Java to connect directly to Oracle. It implements Oracle's SQL*Net Net8 and TTC adapters using its own TCP/IP based Java socket implementation. The JDBC Thin client-side driver does not require Oracle client software to be installed, but does require the server to be configured with a TCP/IP listener. Because it is written entirely in Java, this driver is platform-independent. The JDBC Thin client-side driver can be downloaded into any browser as part of a Java application. (Note that if running in a client browser, that browser must allow the applet to open a Java socket connection back to the server.)
– JDBC Thin server-side driver
This driver uses Java to connect directly to Oracle. This driver is used internally within the Oracle database. This driver offers the same functionality as the JDBC Thin client-side driver, but runs inside an Oracle database and is used to access remote databases. Because it is written entirely in Java, this driver is platform-independent. There is no difference in your code between using the Thin driver from a client application or from inside a server.
Appendix A. Tricky connections 417

Obtaining the driversThe driver files will be available on the datasource you are trying to connect to and where the Oracle server has been installed. Look for the driver files under [ORACLE_HOME]/jdbc/lib directory. The drivers may be in the form of jar or zip file. Both are essentially identical and can be swapped around.
Oracle JDBC Drivers can also be downloaded from the Oracle Web site http://www.oracle.com in the Java Developer Center.
The JDBC Drivers 10.1.0.x, 10.2.0.x and 9.2.0.x are compatible with Oracle database versions 10.1.0.x,10.2.0.x and 9.2.0.x.
It is recommended to use the 10G drivers as they are much faster and have additional support features. For complete details of the features available and the interoperability matrix see the Oracle Web site.
The direct link to driver downloads is: http://www.oracle.com/technology/software/tech/java/sqlj_jdbc/index.html
Download the latest version of JDBC driver that supports your Oracle database.
There will be multiple driver files available. You should select the relevant driver files based on the features required and the Java version on your system.
See the readme file that is available at the download location for specific information about the drivers.
418 Robust Data Synchronization with IBM Tivoli Directory Integrator

Installing the driversThere are two ways in which you can install the drivers on the Tivoli Directory Integrator system.
1. Copy the driver file (either in jar or zip format) to the [TDI_HOME]/_jvm/lib/ext directory.
2. Copy the driver file to any directory of your choice and then add this file including the fully qualified path to the CLASSPATH of your system.
Note: Here is a brief description of some of the files.
classes12.jar: Classes for use with JDK™ 1.2 and JDK 1.3. It contains the JDBC driver classes, except classes for NLS support in Oracle Object and Collection types.
classes12_g.jar: Same as classes12.jar, except that classes were compiled with "javac -g" and contain some tracing information.
classes12dms.jar: Same as classes12.jar, except that it contains additional code to support Oracle Dynamic Monitoring Service. Can only be used when dms.jar is in the classpath. dms.jar is provided as part of recent Oracle Application Server releases.
classes12dms_g.jar: Same as classes12dms.jar except that classes were compiled with "javac -g" and contain some tracing information.
ojdbc14.jar: Classes for use with JDK 1.4 and 5.0. It contains the JDBC driver classes, except classes for NLS support in Oracle Object and Collection types.
ojdbc14_g.jar: Same as ojdbc14.jar, except that classes were compiled with "javac -g" and contain some tracing information.
ojdbc14dms.jar: Same as ojdbc14.jar, except that it contains additional code to support Oracle Dynamic Monitoring Service. Can only be used when dms.jar is in the classpath. dms.jar is provided as part of recent Oracle Application Server releases.
ojdbc14dms_g.jar: Same as ojdbc14dms.jar except that classes were compiled with "javac -g" and contain some tracing information.
There may be additional files for NLS character support.
Appendix A. Tricky connections 419

Driver configurationThis section describes the driver configuration within the context of Tivoli Directory Integrator.
� JDBC URL
The database URL configuration depends on the driver type you want to use. Table A-1 shows the JDBC URL syntax.
Table A-1 Oracle JDBC URL configuration
The selection of OCI or Thin driver depends on the type of application that will use the driver. For example, if you are writing an applet then you must use the thin driver. And if you are using a non-TCP/IP network then you must use the OCI driver.
It is recommended to use thin driver as, among others, it is must faster, runs on any system that has a suitable JVM™ and is easy to administer.
The OCI driver on the other hand requires the OCI C libraries. These are available with an Oracle client installation or with an OCI Instant Client installation.
Note: Do not put multiple versions of the Oracle JDBC drivers in your CLASSPATH.
JDBC URL Description
jdbc:oracle:oci:@ Type 2 Driver. Uses the thick JDBC client and connects to the default local database.
jdbc:oracle:oci:@<tnsname> Type 2 Driver. Uses the thick JDBC client and connects to the specified database.
jdbc:oracle:thin:@ Type 4 Driver. Uses the thin JDBC client and connects to the default local database.
jdbc:oracle:thin:@<host>:port:<sid> Type 4 Driver. Uses the thin JDBC client and connects to a database with the specified sid on the specified host on the specified port.
Note: The driver file in the jar or zip format will contain both the OCI and Thin drivers.
420 Robust Data Synchronization with IBM Tivoli Directory Integrator

The host in Table A-1 is the hostname or IP address of the system you are trying to connect. The port is the port number where the database TCP/IP listener is running and the sid is the database system identifier.
To get the hostname and portnumber, go to the [ORACLE_HOME]/bin directory from a command prompt and execute the following command.
lsnrctl status
You will get a lengthy output and you want to focus your attention to one particular line. This line provides information about the hostname and port number:
...Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(PIPENAME=\\.\pipe\EXTPROC0ipc))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=Dallas)(PORT=1521)))...
To get the sid value execute one of the following SQL commands on the Oracle server.
Show parameter <database name>
Or
select Instance_Name From V$Instance
� Username and password
This is the username and password that you will use to connect to the Oracle server.
� Schema
This represents the schema that you want to use. For example, if you are using the Oracle changelog Connector then you can use the SYSTEM schema. Currently available schemas can be obtained using the Oracle Enterprise Manager console. This field can also be left blank.
� JDBC Driver class
The implementation class name for the JDBC Type 4 driver is oracle.jdbc.driver.DriverOracle.
Figure A-1 on page 422 shows the Directory Integrator connection information for the Oracle database.
Appendix A. Tricky connections 421

Figure A-1 Connection to Oracle database
Database connectivity to DB2Based on the JDBC driver architecture DB2JDBC drivers are divided into four types.
422 Robust Data Synchronization with IBM Tivoli Directory Integrator

1. DB2 JDBC Type 1
A JDBC Type 1 driver is built into Java and basically provides a JDBC-ODBC bridge. It is typically not used any more.
A JDBC Type 1 driver can be used by JDBC 1.2 JDBC 2.0, and JDBC 2.1.
2. DB2 JDBC Type 2
The DB2JDBC Type 2 driver is quite popular and is often referred to as the app driver. The app driver name comes from the notion that this driver will perform a native connect through a local DB2 client to a remote database, and from its package name (COM.ibm.db2.jdbc.app.*).
In other words, you have to have a DB2 client installed on the machine where the application that is making the JDBC calls runs. The JDBC Type 2 driver is a combination of Java and native code, and will therefore always yield better performance than a Java-only Type 3 or Type 4 implementation.
This driver's implementation uses a Java layer that is bound to the native platform C libraries. Programmers using the J2EE™ programming model will gravitate to the Type 2 driver as it provides top performance and complete function. It is also certified for use on J2EE servers.
The implementation class name for this type of driver is com.ibm.db2.jdbc.app.DB2Driver.The JDBC Type 2 drivers can be used to support JDBC 1.2, JDBC 2.0, and JDBC 2.1.
3. DB2 JDBC Type 3
The JDBC Type 3 driver is a pure Java implementation that must talk to middleware that provides a DB2 JDBC Applet Server. This driver was designed to enable Java applets to access DB2 data sources. An application using this driver can talk to another machine where a DB2 client has been installed.
The JDBC Type 3 driver is often referred to as the net driver, appropriately named after its package name (COM.ibm.db2.jdbc.net.*).
The implementation class name for this type of driver is com.ibm.db2.jdbc.net.DB2Driver
The JDBC Type 3 driver can be used with JDBC 1.2, JDBC 2.0, and JDBC 2.1.
4. DB2 JDBC Type 4
The JDBC Type 4 driver is also a pure Java implementation. An application using a JDBC Type 4 driver does not need to interface with a DB2 client for connectivity because this driver comes with Distributed Relational Database
Appendix A. Tricky connections 423

Architecture™ Application Requester (DRDA® AR) functionality built into the driver.
The implementation class name for this type of driver is com.ibm.db2.jcc.DB2Driver.
Obtaining the driversIBM Tivoli Directory Integrator ships with DB2 JDBC drivers.
The driver files are also available on the datasource you are trying to connect to and where DB2 has been installed. Look for the driver files under the [DB2_HOME]/java directory. The drivers may be in the form of jar or zip file.
Legacy CLI-based JDBC drivers are provided in the file db2java.zip. The universal JDBC drivers are provided in the file db2cc.jar.
Installing the driversThere are two ways you can install the drivers on the Tivoli Directory Integrator system.
1. Copy the driver file to the [TDI_HOME]/jars directory.
2. Copy the driver file to any directory of your choice and then add this file including the fully qualified path to the CLASSPATH of your system.
Driver configurationThis section describes the driver configuration within the context of Tivoli Directory Integrator.
� JDBC URL
The JDBC URL configuration depends on the driver type you want to use. Table A-2 on page 425 shows the JDBC URL syntax.
Note: Ensure that multiple versions of the driver are not present in the CLASSPATH.
424 Robust Data Synchronization with IBM Tivoli Directory Integrator

Table A-2 DB2 JDBC URL configuration
In Table A-2 host is the hostname or IP address of the DB2 server and port is the port number where the database TCP/IP listener is running.
In Windows the port number can be obtained from the services file in the /winnt/system32/drivers/etc directory.
� Username and Password
This is the username and password that you will use to connect to the DB2 server.
� Schema
This represents the schema you want to use. Available schemas can be obtained using the DB2 Control Center.
� JDBC Driver class
This is the implementation class name based on the type of driver used. For the Type 4 universal JDBC driver it is com.ibm.db2.jcc.DB2Driver. Class names for other types are specified in the beginning of this section.
Figure A-2 on page 426 shows the connection details for DB2 database.
JDBC URL Description
jdbc:db2:database Type 2 driver. Uses a legacy or existing CLI-based JDBC driver and connects to the specified database. The DB2 server and port information is available from DB2 client catalog directory.
jdbc:db2://<host>:<port>/database Type 4 driver. Uses universal JDBC driver and connects to the specified database on the specified host on the specified port.
Note: Universal DB2 JDBC drivers can also be used in a Type2 configuration, but require a native library.
Appendix A. Tricky connections 425

Figure A-2 Connection to DB2 database
Database connectivity to SQL ServerThe Microsoft SQL Server 2000 driver for JDBC supports the JDBC 1.22 and JDBC 2.0 specification. It is a Type 4 driver.
You can also use other third party drivers for connecting to Microsoft SQL Server.
The jTDS JDBC 3.0 driver distributed under the GNU LGPL is a good choice. This is a Type 4 driver and supports Microsoft SQL Server 6.5, 7, 2000, and 2005. It can be downloaded freely from http://jtds.sourceforge.net. More information about this driver is available from the Web site.
426 Robust Data Synchronization with IBM Tivoli Directory Integrator

Obtaining the driversThe Microsoft SQL Server 2000 driver for JDBC can be downloaded from the Microsoft Web site. The direct link for downloading the SQL server 2000 driver for JDBC is: http://www.microsoft.com/downloads/details.aspx?familyid=86212D54-8488-481D-B46B-AF29BB18E1E5&displaylang=en
The download is an installable program.
Installing the driversInstall the SQL Server 2000 driver for JDBC by running the installation program.
After the installation is complete the driver files are located in the [SQL_DRIVER_INSTALL_DIR]/lib directory. The driver files are msbase.jar, mssqlserver.jar, and msutil.jar. Add all the three jar files to your system CLASSPATH.
Driver configurationThis section describes the driver configuration within the context of Tivoli Directory Integrator.
1. JDBC URL
The complete connection URL format used with the driver manager is
jdbc:microsoft:sqlserver://hostname:port[;property=value...]
where hostname is the TCP/IP address or TCP/IP host name of the server to which you are connecting. port is the number of the TCP/IP port, and property=value specifies the connection properties. See Table A-3 for a list of connection properties and their values.
The following example shows a typical connection URL:
jdbc:microsoft:sqlserver://server1:1433;user=test;password=secret
Table A-3 SQL Server Connection String Properties
Note: We have used this driver successfully to establish connections to Microsoft SQL Server 2000 databases.
Property Description
DatabaseName (OPTIONAL)
The name of the SQL Server database to which you want to connect.
Appendix A. Tricky connections 427

HostProcess (OPTIONAL)
The process ID of the application connecting to SQL Server 2000. The supplied value appears in the “hostprocess” column of the sysprocesses table.
NetAddress (OPTIONAL)
The MAC address of the network interface card of the application connecting to SQL Server 2000. The supplied value appears in the “net_address” column of the sysprocesses table.
Password The case-insensitive password used to connect to your SQL Server database.
PortNumber (OPTIONAL)
The TCP port (use for DataSource connections only). The default is 1433.
ProgramName (OPTIONAL)
The name of the application connecting to SQL Server 2000. The supplied value appears in the “program_name” column of the sysprocesses table.
Property Description
428 Robust Data Synchronization with IBM Tivoli Directory Integrator

HostProcess (OPTIONAL)
The process ID of the application connecting to SQL Server 2000. The supplied value appears in the “hostprocess” column of the sysprocesses table.
NetAddress (OPTIONAL)
The MAC address of the network interface card of the application connecting to SQL Server 2000. The supplied value appears in the “net_address” column of the sysprocesses table.
Password The case-insensitive password used to connect to your SQL Server database.
PortNumber (OPTIONAL)
The TCP port (use for DataSource connections only). The default is 1433.
ProgramName (OPTIONAL)
The name of the application connecting to SQL Server 2000. The supplied value appears in the “program_name” column of the sysprocesses table.
Property Description
Appendix A. Tricky connections 429

SelectMethod SelectMethod={cursor | direct}. Determines whether database cursors are used for Select statements. Performance and behavior of the driver are affected by the SelectMethod setting. The default is direct.
Direct - The direct method sends the complete result set in one request to the driver. It is useful for queries that only produce a small amount of data that you fetch completely. You should avoid using direct when executing queries that produce a large amount of data, as the result set is cached completely on the client and constrains memory. In this mode, each statement requires its own connection to the database. This is accomplished by “cloning” connections. Cloned connections use the same connection properties as the original connection; however, because transactions must occur on a single connection, auto commit mode is required. Due to this, JTA is not supported in direct mode. In addition, some operations, such as updating an insensitive result set, are not supported in direct mode because the driver must create a second statement internally. Exceptions generated due to the creation of cloned statements usually return an error message similar to “Cannot start a cloned connection while in manual transaction mode.”
Cursor - When the SelectMethod is set to cursor, a server-side cursor is generated. The rows are fetched from the server in blocks. The JDBC Statement method setFetchSize can be used to control the number of rows that are fetched per request. The cursor method is useful for queries that produce a large amount of data, data that is too large to cache on the client. Performance tests show that the value of setFetchSize has a serious impact on performance when SelectMethod is set to cursor. There is no simple rule for determining the value that you should use. You should experiment with different setFetchSize values to determine which value gives the best performance for your application.
SendStringParametersAsUnicode
SendStringParametersAsUnicode={true | false}. Determines whether string parameters are sent to the SQL Server database in Unicode or in the default character encoding of the database. True means that string parameters are sent to SQL Server in Unicode. False means that they are sent in the default encoding, which can improve performance because the server does not need to convert Unicode characters to the default encoding. You should, however, use default encoding only if the parameter string data that you specify is consistent with the default encoding of the database.The default is true.
ServerName The IP address (use for DataSource connections only).
Property Description
430 Robust Data Synchronization with IBM Tivoli Directory Integrator

� Username and Password
This is the username and password that you will use to connect to the Microsoft SQL server
� Schema
This represents the schema that you want to use. Schema information is stored in the Master database of your SQL server. If left blank Tivoli Directory Integrator uses the value of JDBC Login.
� JDBC Driver class
This is the implementation class name. The driver class for the SQL server driver is com.microsoft.jdbc.SQLServerDriver.
User The case-insensitive user name used to connect to your SQL Server database.
Note: While trying to connect to Microsoft SQL Server 2000 you might get an error similar to "java.sql.SQLException: [Microsoft][SQLServer 2000 Driver for JDBC][SQLServer]Login failed for user 'user'. Reason: Not associated with a trusted SQL Server connection.
This error message occurs if the SQL Server 2000 authentication mode is set to Windows Authentication mode. The Microsoft SQL Server 2000 driver for JDBC does not support connecting by using Windows NT authentication. You must set the authentication mode of your SQL Server to Mixed mode, which permits both Windows Authentication and SQL Server Authentication.
Because the Microsoft SQL Server 2000 driver for JDBC does not support Windows NT authentication or the Active Directory authentication, you should create a new user from within the SQL Server Enterprise Manager with the required privileges.
There are other third party JDBC drivers available which use Windows Active Directory authentication for connecting to Microsoft SQL 2000 server.
Property Description
Appendix A. Tricky connections 431

Figure A-3 on page 433 shows the connection details for SQL server 2000 database using the Microsoft SQL Server 2000 driver for JDBC.
Note: While using the Microsoft SQL Server 2000 Driver for JDBC, you may experience the following exception:
java.sql.SQLException: [Microsoft][SQLServer 2000 Driver for JDBC]Can't start a cloned connection while in manual transaction mode.
This error occurs when you try to execute multiple statements against an SQL Server database with the JDBC driver while in manual transaction mode (AutoCommit=false) and while using the direct (SelectMethod=direct) mode. Direct mode is the default mode for the driver.
When you use manual transaction mode, you must set the SelectMethod property of the driver to Cursor, or make sure that you use only one active statement on each connection.
432 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure A-3 Connection to SQL server 2000 using Microsoft JDBC driver
Figure A-4 on page 434 shows the connection details for SQL Server 2000 database using the jTDS JDBC driver.
Appendix A. Tricky connections 433

Figure A-4 Connection to SQL server 2000 using jTDS JDBC driver
This concludes the discussion on the JDBC database connectivity.
Connectivity to Domino ServerThere are a variety of ways in which a connection to a Domino datasource can be established. The final selection of what Connector to use and understanding their capabilities and limitations requires careful attention.
434 Robust Data Synchronization with IBM Tivoli Directory Integrator

Following are the Directory Integrator Connectors that you can use for a connection to a Domino Server.
� LDAP Connector� Domino Users Connector� Lotus Notes Connector� Domino Change Detection Connector� Identity Manager Agent Connector
Table A-4 provides some details about the operations possible and specific requirements for each of these Connectors. This table should give you a fair idea on what Connector to use in your environment.
Table A-4 Connectivity options to Domino Server
Here are a few other important considerations.
� If you need to register new users in your environment then you can use either the Domino users Connector or the Identity Manager Agent Connector. If the system on which your Connector is deployed (the system on which Tivoli Directory Integrator is running) is not the same system on which your Domino
Connector Name Operations New User registration
Specific Requirements
LDAP Read No No.
Domino Users Read, Write, Delete
Yes Connector must be deployed on the same system as Domino Server.
Lotus Notes Read Write, Delete
No If using Local Client or Local Server session then Lotus Notes 5.0.8 or higher is required on the same system where the Connector is deployed.An IIOP session does not require a Lotus Notes client.
Domino Changelog
Changes Not Applicable
A Lotus Notes client is required on the same system where the Connector is deployed.
Identity Manager Notes Agent
Read, Write Delete
Yes Identity Manager Notes Agent Connector is a separate program that has to be installed and configured on the same system where a Lotus Notes client is installed.
Appendix A. Tricky connections 435

Server is installed then you can only use the Identity Manager Agent Connector.
� If you just read user information from Domino Server then you can use any of the Connectors except the changelog Connector. The LDAP Connector is the most simple to configure and use.
� There is a difference between creating a user (creating an entry) and registering it. For example, you can use the Lotus Notes Connector in an IIOP session to create a new user on your Domino Server. But this user is not registered. Which means this user can have an Internet e-mail ID, but will not have a Notes ID file, and therefore will not be able to login to the Domino Server from a Notes Client. To be able to do this the user must be registered. This is where the Domino user or Identity Manager Agent Connectors are useful.
� The attribute names used by various Connectors may be different. To determine the attributes you are looking for, connect to the datasource using Tivoli Directory Integrator and read the entries.
After making the decision on the type of Connector to use refer to the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720, for Connector configuration information.
Identity Manager Notes Agent configurationTable A-5 shows the various parameters required for the Identity Manager Notes Agent installation. You can accept default values for most of the properties.
Table A-5 Property values required for Identity Manager Notes Agent installation
Note: It is not necessary to have an Identity Manager server deployed in order to use the Identity Manager Notes Agent with Tivoli Directory Integrator.
Property Description Value
Administration Server Name
The name of the Lotus Domino Server that the Lotus Notes Agent will connect to.
CN=ServerName/O=OrganizationName
Workstation ID file location
The location of the user.id file.
password The password that corresponds to the user ID that the Lotus Notes Agent will use to connect to the Lotus Notes or Lotus Domino Server.
436 Robust Data Synchronization with IBM Tivoli Directory Integrator

Certification File Location and Password
Typically, the certification file is located in the data directory under the directory where the Lotus Notes or Lotus Domino server is installed. In most cases the file is located in a directory called Notes\Data\cert.id on a shared drive. The Certification Password is created by the Lotus Notes Network Administrator during installation of the Lotus Notes Server. Therefore, you must ask your Lotus Notes Network Administrator for the Certification File Location and Password information.
Lotus Domino Version Number
The version number for your Lotus Domino Server (either Version 5 or Version 6). The default is Version 6.
Lotus Domino Server’s Address Book
The name of the Lotus Domino Server address book that the agent uses, if it is any address book other than the default (NAMES.NSF).
Suspend Group Name
The name of the group to which suspended users will be added.
Optional
Suspend HTTP Group Name
The name of the group to which the suspended users will be added for HTTP access.
Optional
Delete Group Name The name of the group to which the deleted users will be added.
Optional
Deny Access Log Name
The name of the database file that will list the user documents which are deleted or suspended.
Optional
Attributes to be Reconciled
A list of attributes to include in the reconciliation process.
Optional
Not Reconciled Attributes List
A list of attributes to exclude from the reconciliation process.
Optional
Notes IDs Address Book
The name of the database file to use to store ID file and password information for newly created users in Identity Manager. This option is also used by the Shadow utility.
Optional
Property Description Value
Appendix A. Tricky connections 437

Configuration steps1. Ensure that the Notes Admin ID (the same ID that will be used by Tivoli
Directory Integrator) has already logged in using the Notes client, on the same machine where the agent is running. The Identity Manager Notes Agent requires that the last ID logged on the client be the Notes Admin ID.
2. Install the Certificate. Copy the certificate file (self signed certificate created using GSKit or provided by an external CA) to [ITIMAGENT_HOME]/bin directory.
3. Using Windows Services, start the Tivoli Lotus Notes Agent.
4. From a command prompt change the directory to [ITIMAGENT_HOME]/bin and enter the following command:
CertTool –agent NotesAgent
5. Choose the option to Install Certificate and select a key from the PKCS12 file. When asked for a location, enter the full path name of the certificate file. Enter the password when prompted.
6. To verify that the certificate loaded properly, select the option to view the installed certificates, ensure that the certificate you installed is listed.
This concludes our discussion on determining the right choice to connect to a Domino Server in your environment.
Synchronize HTTP Password
Specify whether to synchronize the user password as the Internet/HTTP password for the user.
Short Name Specify whether to use short names as user IDs in Identity Manager.
Audit Short Name Specify whether to use internet addresses as user IDs in Identity Manager. The Internet address is used only when a user’s short name is not present on the resource.
Delete Mail Database File
Specify whether to delete the mail database file of a user when an account is deleted in Identity Manager.
Property Description Value
438 Robust Data Synchronization with IBM Tivoli Directory Integrator

Appendix B. Directory Integrator’s view of JavaScript
Tivoli Directory Integrator reads, writes, searches, and transforms data according to the recipes it finds in its XML configuration file. The XML elements in the file tell Directory Integrator which Connectors, AssemblyLines and other components to construct and execute. Many of these components allow scripted sections in their configurations. A good deal of the power and flexibility of this tool comes from scripting and its skillful use is a key to building successful solutions. This appendix discusses how the scripting mechanism works and shows many useful tips.
Directory Integrator up to Version 6.0 supports JavaScript, as well as three Microsoft scripting languages: VisualBasic, PerlScript and JScript. However, the Microsoft script languages are often deprecated and may be removed from future versions of Directory Integrator. This appendix discusses JavaScript techniques only.
The material in this appendix supplements the scripting section of the IBM Tivoli Directory Integrator concepts chapter in the IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718. Consulting a good JavaScript reference like [Flanagan]1 is essential to mastering Directory Integrator scripting as well.
B
1 David Flanagan. JavaScript: The Definitive Guide, Fourth Edition. (2001) O’Reilly. http://www.oreilly.com/catalog/jscript4/
© Copyright IBM Corp. 2006. All rights reserved. 439

The script engineDirectory Integrator is a Java program and embeds a Java package that implements a JavaScript interpreter and run-time engine. Directory Integrator up through version 6.0 uses the Mozilla Rhino2 JavaScript engine, while version 6.1 and subsequent versions may use the ibmjs (IBM JavaScript) engine. The test cases for this appendix were run with Directory Integrator 6.0, with Fixpack 2 and Interim Fix 8. The JavaScript engine was Rhino 1.5 release 4.13
Rhino and ibmjs are implementations of ECMAScript, 3rd Edition, which is a standard of ECMA International [ECMA262] and of JavaScript 1.5. ECMAScript Version 3 and JavaScript 1.5 are the same language. We will use the term JavaScript in this appendix.
The JavaScript engine in Directory Integrator extends JavaScript in a very important way in that it can script Java. The extension is called LiveConnect. This concept is so important that we will repeat it. JavaScript in Directory Integrator provides a way to script Java. JavaScript itself is a useful and versatile language, but the bridge to the Java classes comprising Directory Integrator makes it extremely powerful as an embedded interpreter. But the ability to script Java has even more value, as the embedded JavaScript engine provides scripting access to the full API of the Java Runtime Environment (JRE or JVM) within which Directory Integrator runs and also to third-party or custom Java classes. Helping you understand how to control both JavaScript and Java functionality from one scripting environment is a principal goal of this appendix.
Scripts and configuration filesWhen an AssemblyLine or other thread begins execution it reads the Directory Integrator configuration file and instantiates all of the Java objects it needs, including Connectors, Function Components, Parsers, and so on. It also reads, parses, and compiles scripted fields in the configuration file.
Directory Integrator stores most scripts in XML CDATA sections—denoted by 
Scripts in ScriptConnectors and in the Script Library, which is the folder labeled Scripts on the left side of the Directory Integrator config editor, can include scripts stored in external files. Using this feature saves space in the configuration file if the scripts are very large; it also allows easy access for reuse. This is useful for utility functions used in a lot of configuration files.
Scripting toolsSuccessful scripting requires a few tools besides Directory Integrator and its documentation. Most important is documentation. Essentials include:
� Directory Integrator API Javadoc™. This is a set of HTML pages packaged with Directory Integrator. The default location is <TDI Install Directory>/docs/api. The drop-down menu Help, Low Level API in the Directory Integrator config editor opens a browser to the index.html at the top of this tree. We find it helpful to also bookmark this file in our browser. All Directory Integrator Java interfaces, objects, fields, and methods are listed. Most, unfortunately not all, methods useful for scripting have some documentation comments. This is where you determine the difference between such constructs as work.getString(), work.getAttribute and work.getObject(). Of course, you need to know that work is an instance of the class com.ibm.di.entry.Entry. We tell you how to find this information out below.
� Java 2 SDK, Standard Edition, Documentation—also in Javadoc format—available at http://java.sun.com/j2se/. It is a good idea to download a local copy.
� JavaScript documentation. See the list of references in “Related publications” on page 477. The Flanagan book is authoritative and the Mozilla reference and guide are handy.
You can test any scripts right in your AssemblyLines and execute arbitrary test code in the Script Component. It is often much quicker, however, to test JavaScript only with the built-in JavaScript shell that is part of Rhino. See the full documentation at http://www.mozilla.org/rhino/shell.html. A simple two-line batch file for Windows that executes the Rhino shell used by Directory Integrator is:
@set CLASSPATH=c:\Program Files\IBM\IBMDirectoryIntegrator\jars\js.jar@"c:\Program Files\IBM\IBMDirectoryIntegrator\_jvm\jre\bin\java" org.mozilla.javascript.tools.shell.Main %*
Running this batch file, or the equivalent Unix/Linux shell script, brings up a js> prompt that accepts JavaScript with LiveConnect support. It does not support Directory Integrator specific classes like Entry or Connector, but you can use it to quickly determine how the JavaScript engine really handles type conversions and
Appendix B. Directory Integrator’s view of JavaScript 441

programming constructs. It is also good for testing regular expressions and separating scripting issues from Directory Integrator behavior.
Scripts: WhereVirtually all Directory Integrator components have scriptable sections. The possibilities for customizing behavior are unlimited, but most scripting goes into Hooks, Attribute Maps, and Script Objects (Script Parser, Script Function Component, Script Components, and so on).
AssemblyLine Connector Hooks are frequently-used locations for scripts. A common technique in a Hook is to get some data and use it to control the execution of the AssemblyLine. Many Hook scripts are as small as one or two statements, but cause a big effect. Here is a simple Hook script:
if (work.getString("emailSystem").equalsIgnoreCase("E2K")) {system.ignoreEntry();
}
The method work.getString() pulls a value out of the work Entry object and puts it into a string. The equalsIgnoreCase() method compares this data to a literal string. If the strings match, system.ignoreEntry() stops processing for this Connector and jumps to the next one.
Advanced Attribute Maps are another important script location. The result of scripts in these maps is to put data either into the work Entry on input or the Conn entry on output. Here is an example that creates a CN (common name) attribute:
ret.value = conn.getString(“givenName”) + “ “ + conn.getString(“sn”);
The ret.value= statement at the end of the Attribute Map script makes the attribute hold the value of the expression on the right side of the equals sign. More precisely, an Attribute Map is an instance of the class com.ibm.di.server.AttributeMapping. The object ret is a script reference to the AttributeMapping4 object and value is a field in that object.
Code in scripts can perform various operations. Scripts can create and modify objects in the Directory Integrator environment, change the flow of control, make network connections, calculate values, and so on. In general, scripts are small computer programs that can do anything the programmer desires. The
4 ret is actually a scripting name defined in the Directory Integrator program to hold this, which is a reference in any Java program to the current object. Therefore ret refers to the AttributeMapping itself. See, for example, http://java.sun.com/docs/books/tutorial/java/javaOO/thiskey.html.
442 Robust Data Synchronization with IBM Tivoli Directory Integrator

environment has some minor constraints, but there is really no limit to what you can do.
Another use of scripts is to change the behavior of something. Merely enabling certain components to accept a script changes the behavior of the component. In the case of error Hooks, enabling them causes the Connector to handle exceptions rather than stopping execution. The script itself is optional, but can modify the action further. This table is a comprehensive list of the places you might enter scripts:
Table 5-21 Scriptable fields
Scripting JavaScript and JavaThis section explains the two sides of the Directory Integrator scripting environment. First we show how to use the most important JavaScript language features. Then we show how to access Java and the combination techniques that provide power and flexibility.
Core JavaScriptCore JavaScript is the base language without the document object model (DOM) extension Web browsers provide to their scripting engines.5 In particular, this means input and output are handled by the Directory Integrator JVM. Nevertheless, core JavaScript is a powerful language on its own. Some of the
Location Comments
Connector Hooks Available Hooks change with Connector mode; some are shared among modes.
Attribute Maps (Advanced Mapping) Found in Connectors and AttributeMap components.
AssemblyLine Hooks Look in tab to the left of Data Flow.
Scripts in Script Library Explicitly include these scripts with Include Additional Prologs dialog in AssemblyLine Config tab.
Scripted Components ScriptConnector; ScriptParser; ScriptedFunctionComponent; Generic Thread; Timer EventHandler;
Scripted conditions in EventHandlers, Loops and Branches
Return ret.value equals true or false.
Function Component Hooks Similar to Connector Hooks.
Appendix B. Directory Integrator’s view of JavaScript 443

more interesting features needed for Directory Integrator work are discussed below.
Regular expressions (regex)JavaScript supports a good subset of Perl regular expressions (Perl is acknowledged to have the best implementation of regular expressions). A typical use is in building unique attribute values. Here is an example.
// duplicate mail address found; generate new trial address
// disassemble addressvar mail = String( work.getString("mail") ); // String() ensures JS stringvar mailArray = mail.split("@"); // JavaScript split functionvar lhs = mailArray[0];var rhs = mailArray[1];
// define regex patterns to process lhsvar reName = /.*[^0-9]/; // everything except number at end of lhsvar reNumb = /\d+$/; // just the number at end of lhs (1 or more digits)
// extract substringsvar name = lhs.match( reName );if (name == null) { name = ""; } // solves the odd case lhs only a numbervar numb = lhs.match(reNumb);
// increment number at end of name part of mail addressvar numb = Number( numb ) + 1; // null string conveniently converted to 0
// if no number at end of original lhs// reassemble and delivervar lhs = name + numb; // numb converted to string in this contextvar mail = lhs + "@" + rhs;work.setAttribute( "mail", mail );
The customer in this example requires unique e-mail addresses in their enterprise directory and e-mail systems. Since many common names are duplicated in a large organization, the above script implements a simple algorithm to ensure uniqueness. This script might be found in the Lookup Successful Hook of an LDAP Connector in Lookup Mode. The Hook is triggered if the Connector finds an e-mail address matching some trial value like <givenName>.<sn>. The regular expression processing finds an already present name, but ignores numbers in the name except at the end. The latter condition is odd, but careful coding ensures even unusual names get handled correctly. Regular expressions are the most concise way to do this type of operation.
5 Directory Integrator can access the Java document object model (DOM) for manipulating XML documents with the XML Parser component. This instance of a Java DOM object is called xmldom in the Directory Integrator scripting environment.
444 Robust Data Synchronization with IBM Tivoli Directory Integrator

In an actual implementation, this routine would be called iteratively in a loop—using an AssemblyLine Loop component, for example. Each time through the Loop, the Connector does a lookup with the new, supposedly unique e-mail address and calls the code above until a unique one is generated. Break the loop with the system.exitBranch() method in the On No Match Hook.
Since unique names are frequently needed, a better idea is to implement the regex processing as a function and call it from the Script Library. The next section discusses such a function.
FunctionsFunctions are a versatile feature of JavaScript that have great utility in Directory Integrator. A good practice is to code frequently used operations as functions and put them in the Script Library. Needing a unique e-mail address is just one of the many times you need a unique identifier of some type. So, you can replace most of the code in the example above with this function and call it from anywhere in your AssemblyLine:
// uniqueID generatorfunction uniqueID( id ) {
var id = String( id );var reName = /.*[^0-9]/;var reNumb = /\d+$/;var name = id.match( reName );if (name == null) { name = ""; }var numb = Number( id.match(reNumb) ) + 1;return ( name + numb );
}
The example Directory Integrator configuration file useFunction AssemblyLine shows how to call this function.
There are several advantages to using functions and storing them in the Script Library:
� Facilitates code reuse. You can call a function from different components within a configuration file and can easily copy the function to other configuration files. If you store frequently used script functions in an external file you can link them to multiple configuration files using the mechanism described in “Scripts and configuration files” on page 440.
� Use local variables. Scripts anywhere in an AssemblyLine execute in one variable scope. This means that a variable defined in a Hook in one Connector is available in other Hooks and Attribute Maps of every other component. This is actually quite helpful, as constants can be defined in an AssemblyLine prolog or Script Library prolog and used elsewhere. However, it means values assigned to variables anywhere in the AssemblyLine keep
Appendix B. Directory Integrator’s view of JavaScript 445

those values, which might lead to unexpected behavior. The values persist across interactions too, until the variable is modified or re-initialized. Variables assigned with the var statement in functions are local only to that function. Taking advantage of this generally leads to tighter, less error-prone code.
� Easy conversion to Java. Coding complex functions that are called often in compiled Java often improves performance. Converting procedures already coded as JavaScript functions makes this relatively simple.
Java through JavaScriptThe Java you get through scripting comes from three different sources. First, Directory Integrator is built with over a thousand Java classes and interfaces that contain thousands of methods. In fact, these classes let you script the same Java methods that the product developers have used to build Directory Integrator itself. Some classes and methods are not amenable for scripting but creative users continue to innovate with even the most obscure parts of the API.
Second, the Java Virtual Machine (JVM) that hosts Directory Integrator includes all the Java classes that are part of the language itself. Some of the most-used classes include6:
java.lang.Stringjava.lang.StringBufferjava.lang.Systemjava.util.Datejava.sql.Timestamp
Finally, Directory Integrator can use other classes found in its class path. These might be classes from third-party applications, for example, JDBC Drivers or the Tivoli Access Manager Java Runtime, or custom classes. The best way to add third-party or custom classes to your classpath is to modify the solution.properties file. Uncomment the line near the top of the file beginning
com.ibm.di.loader.userjars=
And complete it with a path pointing to a directory of third-party jar or zip files. A good place to put this directory is in the solutions directory. The Directory Integrator class loader recurses this local jar file directory and its subdirectories. We suggest putting related files in separate subdirectories. So, given this line in solution.properties:
com.ibm.di.loader.userjars=d:\TDI_solutions\localjars
6 It is typical to denote Java classes with just the class name and leave off the package name. So, most Java programmers refer to java.lang.String as just String. We define all classes with the full package plus class name, but use just the class name subsequently when the usage is unambiguous.
446 Robust Data Synchronization with IBM Tivoli Directory Integrator

Directory Integrator would load all the classes contained in jar files in the following directories (assuming those three subdirectories existed):
D:\TDI_solutions\localjars\mq\D:\TDI_solutions\localjars\msjdbc\D:\TDI_solutions\localjars\Oracle\
Java to JavaScript and backDirectory Integrator creates a number of pre-named Java objects for the JavaScript environment automatically. The IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720, documents most of these objects. Key among them are:
� work, conn, current, error: all instances of com.ibm.di.entry.Entry
� system: an instance of com.ibm.di.function.UserFunctions
� main: an instance of com.ibm.di.server.RS
� task: an instance of com.ibm.di.server.AssemblyLine
Finding methods to operate on these objects is straightforward; just look at the appropriate class documentation in the Directory Integrator API Javadoc.
The AssemblyLine and other threads contain many other objects, whose names vary. Let us list a few of the other important classes:
� com.ibm.di.Connector.
This is the superclass of all Connector classes7. Important subclasses include com.ibm.connector.LDAPConnector, com.ibm.connector.JDBCConnector and com.ibm.connector.FileConnector. You will find these instantiated in AssemblyLineComponents (see below) or as raw Connectors.
� com.ibm.di.server.AssemblyLineComponent.
This is the so-called—and incorrectly so—AssemblyLine Connector. These are the actual objects instantiated by AssemblyLines and house Hooks, Attribute Maps and Link Criteria and Connector objects (Connector subclasses). So, as we have said, Connectors live inside AssemblyLineComponents. The class com.ibm.di.connector.AssemblyLineConnector is not an AssemblyLineComponent.8
7 This is not necessarily true. Connectors have to implement com.ibm.di.connector.ConnectorInterface, but all currently shipping Connectors do subclass Connector since it is the easiest way to build a new Connector.8 It is a Connector to invoke another AssemblyLine.
Appendix B. Directory Integrator’s view of JavaScript 447

� com.ibm.di.entry.Attribute.
This is the principal data carrier in an entry object and a fully functional object in its own right.
Getting references to objects is the first step to using them. The predefined scripting names reference objects that have methods for working with other objects. In particular, the AssemblyLineComponent, Connector and UserFunctions classes have many getter and setter methods for retrieving and manipulating useful objects and properties.
By the way, to call AssemblyLineComponent methods, you can either use the (somewhat confusing) identifier thisConnector or the name of the component. The former only works within the Attribute Maps and Hooks of the component you want to reference. So, for example, suppose you have an AssemblyLine with the following components:
readLDAP (contains LDAP Connector in Iterator mode)writeDB2 (contains JDBC Connector in Update mode)writeFile (contains FileSystem Connector in AddOnly mode)
In a Hook of the readLDAP component, you can call the methods of the writeDB2 component with code like this:
var db2stats = writeDB2.getStats();
Notice that our component names do not contain spaces. In general, because you might be using a component name as a JavaScript identifier, do not put spaces in component names. However, suppose we had labeled the third component write File, which has a space in the name. Script it by calling this method:
var filewriter = task.getConnector(“write File”);
The new identifier filewriter accepts AssemblyLineComponent methods. Directory Integrator—and Java itself—provides numerous methods to reference objects through names that are strings.
Sometimes is it hard to know what sort of object you have or even if you have a Java or JavaScript type. The JavaScript function typeof() distinguishes JavaScript primitives and strings from objects. However, it reports both Java and JavaScript objects as the objects. The function below determines the type of its input and returns the Java class name if it is a Java object.
function whatAmI ( unknown ) {var jstype = typeof( unknown );if ( jstype == "undefined" ) {
return ("undefined"); // not assigned} else if ( unknown == null ) {
return (null); // null
448 Robust Data Synchronization with IBM Tivoli Directory Integrator

} else if ( jstype == "object" ) {if (unknown["getClass"] == null) { // test for Java object
var constructor = unknown.constructor.toString();var type = constructor.match(/ \w+/).toString().substring(1);return ("JavaScript " + type + " object"); // JavaScript object type
} else {return unknown.getClass(); // Java class
}} else {
return(jstype); // JavaScript primitive}
}
Running this in the Rhino shell as a quick test shows:
js> whatAmI( new java.lang.String("I am a java string object"));class java.lang.String
js> whatAmI( "I am a JavaScript string");string
js> whatAmI(new Array(3, 4, 5) )JavaScript Array object
Java to JavaScript conversionsOne of the apparently confusing aspects of scripting Java in Directory Integrator is how the JavaScript LiveConnect engine converts Java types to JavaScript types. It is a bit subtle, but the behavior is completely predictable and manageable. Reading—and re-reading—Chapters 11 and 22 in David Flanagan, JavaScript: The Definitive Guide, Fourth Edition. (2001) O’Reilly will make this all clear, but the following discussion may also help.
First of all, JavaScript performs many automatic conversions of regular JavaScript types. It uses the notion of “context” to make many of these conversions. That is, JavaScript tries to convert types into what it needs. Concatenation with a + operator is a string context. An expression with a - operator is a number context. The == operator is a boolean context. Using the Rhino shell as the ultimate documentation, you can test your code9 10:
js> x = 3; // define a number3
9 In all Rhino shell examples, we declare variables without the keyword var. This makes the shell print the value immediately on the next line and makes our examples shorter and clearer. In coding, we recommend you always use var to make your declarations clear. This is purely a matter of style, however, since all code, except functions, runs in a single AssemblyLine scope.10 We could use the whatAmI() function, but because we know all these expressions are JavaScript primitives, the typeof() operator suffices.
Appendix B. Directory Integrator’s view of JavaScript 449

js> typeof(x);number
js> a = "4"; // define a string4js> typeof(a);string
js> b = a + x; // number automatically converted to a string43js> typeof(b);string
js> y = a - x; // string automatically converted to a number1js> typeof(y);number
js> a==x; // we know this will be falsefalsejs> typeof(a==x); // this is why it worksboolean
In other words, where it makes sense to convert from one type to another, JavaScript does its best. JavaScript is not really an untyped language. It has several primitive types and any number of object types, but it is loosely typed. Types adapt in JavaScript.
Java, on the other hand, is a strongly typed language. You can convert types by casting, but only if the resulting type is a subclass or superclass of the original type. Chapter 6 of Patrick Niemeyer. Learning Java, 2nd Edition. (2002) O’Reilly explains this. All objects have a toString() method that creates a String representation of the object, but conversion to other types depends on whether the class implements appropriate methods.
LiveConnect wraps Java classes so JavaScript can manipulate them. This is great; it means expressions like task.dumpEntry(work) call a Java method for a Java object. JavaScript does not get in the way. However, suppose you need to manipulate Java objects using JavaScript operators, functions and methods? Strings, the most important case, are handled easily by placing the Java String object in the JavaScript string context; JavaScript converts the Java String. Hence:
js> magic = "JavaScript + " + (new java.lang.String("Java")) + " = JavaScript"; // bold claim
JavaScript + Java = JavaScriptjs> typeof(magic); // how about that...string
450 Robust Data Synchronization with IBM Tivoli Directory Integrator

In a very few cases, the name of a Java method collides with a JavaScript method. The most common is String.replace(), which is a regular expression method in JavaScript, but not in Java. This is easily solved with the JavaScript String() function:
js> me = new java.lang.String("david");davidjs> me.replace(/d/,"D");js: "<stdin>", line 54: Cannot convert /d/ to java.lang.Characterjs> String(me).replace(/d/,"D");Davidjs>
The String() function puts the Java String in a JavaScript string context, exactly like concatenating it with an empty string. That technique works too, but we think the String() function makes the code more readable.
Other JavaScript functions, Number() and Boolean() perform analogous conversions if the Java object defines doubleValue() and booleanValue() methods, respectively. All other Java objects stay Java objects.
JavaScript to Java conversionsJavaScript strings automatically become Java String objects when used with Java methods. This is what makes conn.getString(“sn”) work with no special effort. JavaScript numbers automatically convert to appropriate primitive Java types—int, long, double and so on—depending on the form of the number. JavaScript objects do not convert to Java objects, but Directory Integrator scripters never need to send JavaScript objects to Java.
Common tasksThis section contains a few tips and techniques for solving common problems.
Creating arrays and Java utility objectsSome Directory Integrator methods require Java Arrays as arguments. One example is Attribute.setValues(). Contrast creating a JavaScript array (not often needed in Directory Integrator):
js> jsArray = ["a string element", 3.14, true];a string element,3.14,true
with creating a Java Array, which requires Java reflection:
js> javaArray = new java.lang.reflect.Array.newInstance(java.lang.Object,3);[Ljava.lang.Object;@6ec1731f
Appendix B. Directory Integrator’s view of JavaScript 451

js> javaArray[0] = "a string element";a string elementjs> javaArray[1] = 3.14;3.14js> javaArray[2] = true;true
Managing datesJava has several methods for managing and converting dates. Databases and LDAP directories treat dates somewhat differently. Here are some examples of creating and converting dates.
The current time and date followed by a different format:
js> now = java.util.Date();Fri Dec 23 21:15:32 MST 2005js> yearfirst = new java.text.SimpleDateFormat ( "yyyy-MMM-dd HH:mm:ss" );java.text.SimpleDateFormat@f14ae73js> yearfirst.format(now);2005-Dec-23 21:15:32
LDAP directories keep the time of modifications in an operational attribute called modifyTimeStamp in a format called Generalized Time. This function converts such a time to readable format:
// LDAP Generalized Time Converter// returns LDAP time in milliseconds since the epochfunction calcLdapTime ( ldapTime ) { var inputdf = java.text.SimpleDateFormat( "yyyyMMddHHmmss"); var timeX = ldapTime.substring(0,14); // chops off Z for Zulu return inputdf.parse(timeX).getTime(); }
Given this function, and the definition above we can perform this conversion:
js> ldapTime= "20050829043501Z";20050829043501Zjs> epochTime = calcLdapTime( ldapTime );1125311701000js> yearfirst.format( epochTime )2005-Aug-29 04:35:01
The format used by SQL timestamps is similar, but there is a special Java method to handle these times. The code below creates a SQL timestamp with the value of the current time:
js> t = new java.util.Date().getTime();1135400634031js> java.sql.Timestamp(t);
452 Robust Data Synchronization with IBM Tivoli Directory Integrator

2005-12-23 22:03:54.031
Working with entries and attributesEntries are the principal data object in Directory Integrator. Data moves down AssemblyLines in the work Entry, but Directory Integrator automatically creates several other entry objects, including conn, which references data either just read or about to be written by a connector.
Entries act as containers for attributes and can hold any number of attributes. Attributes have a key, called the name and can hold one or more values. The values can be any type of Java object, including strings, numbers or binary entities. An attribute value could hold another attribute or even an entry.
Entries also can hold name/value pairs called properties. Some Connectors use properties for out-of-band information or other operational data. Properties are convenient to hold information used only by scripts, since attribute maps do not map properties. Get entry properties with the entry.getProperty() method.
Both Entry and Attribute also expose methods to get or set an operation property. Directory Integrator uses this property for its own internal purposes, but the scripter can read this value and use it if needed.
ConclusionThis appendix has tried to make use of JavaScript in Directory Integrator less mysterious. There are numerous examples you can cut and paste directly into your code. Other examples only hint at complete solutions and are starting points for your further study. Good scripting!
Appendix B. Directory Integrator’s view of JavaScript 453

454 Robust Data Synchronization with IBM Tivoli Directory Integrator

Appendix C. Handling exceptions and errors
This appendix outlines the features and techniques used to deal with exceptions (and errors) in your TDI solutions. As you will see, although all errors are exceptions, not all exceptions can really be called errors. Confused? Then keep reading.
We begin with a look at how error messages are written and then move to a discussion of the error object itself, along with the mechanisms in TDI that are activated when one occurs. Examples of error logs are provided in order to help you navigate these. There is also a section on how to control logging in your solutions, including tips for preparing your AssemblyLines to deal with problem situations.
Note that the abbreviation "AL" is often used for "AssemblyLine" in the following text. The same applies to "CE", which is short for "Config Editor" - the TDI User Development Environment. This is common practice and will be the case in newsgroup postings, published solutions and other TDI literature.
C
© Copyright IBM Corp. 2006. All rights reserved. 455

Reading the error dumpThe natural place to start this appendix is with a discussion of how to locate where the error is happening. To do this you must be able to interpret the details that TDI writes about the error to the log1. Although not an exhaustive list of possible errors, this section includes examples of some common types, as well as tips on how to deal with them.
When some problem causes your AssemblyLine to fail, TDI writes error information to the log. Here is an example of this:
14:29:36 [DB2e_GroupTable] Lookupjava.lang.Exception: No criteria can be built from input (no link criteria specified)
at com.ibm.di.server.SearchCriteria.buildCriteria(Unknown Source)at com.ibm.di.server.AssemblyLineComponent.lookup(Unknown Source)at com.ibm.di.server.AssemblyLine.msExecuteNextConnector(Unknown Source)at com.ibm.di.server.AssemblyLine.executeMainStep(Unknown Source)at com.ibm.di.server.AssemblyLine.executeMainLoop(Unknown Source)at com.ibm.di.server.AssemblyLine.executeMainLoop(Unknown Source)at com.ibm.di.server.AssemblyLine.executeAL(Unknown Source)at com.ibm.di.server.AssemblyLine.run(Unknown Source)
14:29:36 Error in: NextConnectorOperation: java.lang.Exception: No criteria can be built from input (no link criteria specified)java.lang.Exception: No criteria can be built from input (no link criteria specified)
at com.ibm.di.server.SearchCriteria.buildCriteria(Unknown Source)at com.ibm.di.server.AssemblyLineComponent.lookup(Unknown Source)at com.ibm.di.server.AssemblyLine.msExecuteNextConnector(Unknown Source)at com.ibm.di.server.AssemblyLine.executeMainStep(Unknown Source)at com.ibm.di.server.AssemblyLine.executeMainLoop(Unknown Source)at com.ibm.di.server.AssemblyLine.executeMainLoop(Unknown Source)at com.ibm.di.server.AssemblyLine.executeAL(Unknown Source)at com.ibm.di.server.AssemblyLine.run(Unknown Source)
The trick to reading this message is moving your attention to the top of the error output.
Although the stack trace that makes up most of the dump helps developers locate problems in TDI itself2, details on where the problem originated are written first.
14:29:36 [DB2e_GroupTable] Lookup
1 When you run your AL from the Config Editor, the CE instructs the TDI Server to send log output to the console so that the CE can intercept these messages and display them onscreen for you. See section 5 Logging on page 15 for details on how you can configure logging yourself.2 This is why you should always include the log output when reporting problems to support.
456 Robust Data Synchronization with IBM Tivoli Directory Integrator

java.lang.Exception: No criteria can be built from input (no link criteria specified)
The first item shown is the name of the component where the error originated. This is written inside brackets ([DB2e_GroupTable] in the above example). After the component name comes the operation that failed (Lookup). The next line has both the internal type of the error, also called the exception class (java.lang.Exception), and the error message (No criteria can be built from input (no link criteria specified)).
Putting all this together: TDI is complaining that it cannot build Link Criteria for the Lookup operation in the DB2e_GroupTable Connector. This could be because no Link Criteria was defined, or because you are referencing a work Entry Attribute that was not found in the work Entry when Link Criteria was built. Armed with this information, you can first check that you have set up the Link Criteria correctly. If this is the case then your next step would be to make sure that the work Entry actually holds the Attributes you are referencing in the Value parameter of each Link Criteria. These will be prefixed with the special dollar symbol ($). One way to ensure their presence is to dump out the work Entry to the log:
task.dumpEntry( work );
You should put this code in the Lookup On Error Hook of this Connector so that if the error happens, you will be able to see if the required Attributes are in place or not.
Our example AssemblyLine has more than one problem, and after correcting this first error we can see our next problem:
14:39:25 [DB2e_GroupTable] while mapping attribute "member"undefined: undefined is not a function.
...
This time the error log looks a little different. You still get the component name and operation, which this time is during Advanced Mapping of the mail Attribute. But now the error type is written as "undefined". This is often the case for errors reported by the JavaScript engine itself. The message is clear enough though - undefined is not a function - and tells you that you've misspelled the name of a function call in your script code. After close examination we discover the typo: task.logmgs() instead of task.logmsg().
Appendix C. Handling exceptions and errors 457

Now let us look at a data source error:
14:48:25 [TDS_Update] AddOnlyjavax.naming.directory.SchemaViolationException: [LDAP: error code 65 - Object Class Violation]; remaining name 'uid=ehartman33,o=ibm,c=com'
The first line tells us that the AddOnly operation failed for the TDS_Update Connector. This time the class of the exception is system-specific and is coming from the underlying directory or driver/API class:
javax.naming.directory.SchemaViolationException
The message tells us that the Entry we are trying to write is in violation of schema. You will need to check that your Output Map Attributes are correctly spelled (and are actually defined in the object class of the entry). If all else fails, try disabling Attributes until you determine which one(s) is failing.
Now that we have looked at some example error logs and tips for correcting these, we will turn our attention to the error mechanism itself.
Tip: Bugs in JavaScript code can be among the most difficult to track down. Some script errors cause your AL to crash during initialization (for example, syntax errors), while others remain undetected until a block of code is executed for the first time. The above task.logmgs() example is an example of the latter, since the problem first arises when the JavaScript engine tries to call a method in the task object called "logmgs()".
One approach is to get someone else to look at your code. Unfortunately, this is not always an option. Alternatively, place several (correctly spelled) task.logmsg() calls throughout the problematic script. By seeing which messages get written before the crash, you are able to pinpoint the problem.
If the failing script is long and filled with if-tests, you can also try breaking it down to smaller snippets. This is generally good programming practice anyway, and allows you to perform simpler unit tests on each smaller block of code. Script logic that is frequently reused should be defined as functions in Scripts Components. Placing these in the Script Library will help minimize coding errors and make your solution easier to maintain and enhance.
Another method for isolating script errors is commenting out code until you find the snippet that is causing the problem.
458 Robust Data Synchronization with IBM Tivoli Directory Integrator

Errors = exceptionsAll errors in TDI are represented by Java objects called exceptions. Each type of error - both those internal to TDI itself, as well as errors coming from connected systems - has its own specific exception type.
When an error occurs, the corresponding exception is thrown, disrupting normal program execution3 . The exception is caught by TDI and the Error flow is initiated, as described in Appendix B: TDI AssemblyLine and Connector mode flowcharts of the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720. Although the next chapter covers Error Hooks in more detail, we will need to look at these briefly in order to understand exception handling in TDI.
For example, let us look at part of the Flow Diagram for the AddOnly Connector mode in Figure C-1 on page 460. As you can see, regardless of whether the error originates in a Hook, Attribute Map or internal Connector Interface operation (like Add in the above diagram), the Error Flow is initiated (drawn as a red dotted line in the diagram).
3 Not all exceptions are errors. Some are used to signal changes in standard AssemblyLine processing. For example, methods like system.skipEntry() and system.ignoreEntry() throw special flow-control exceptions that do not initiate the Error Flow. Instead, these are caught by the AssemblyLine and handled as dictated by the exception type. Other exceptions are used to represent special situations like finding no match during a lookup operation, or finding multiple.
Appendix C. Handling exceptions and errors 459

Figure C-1 AddOnly Connector
All Connector modes terminate in the same way, indicated by the orange box at the bottom of above diagram. Details of this behavior are described in the Flow Diagram page called End-Of-Flow in Figure C-2 on page 461.
460 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure C-2 End-Of-Flow for all connector modes
In the case of successful operation, control is first passed to the Mode-specific On Success Hook (for example, AddOnly Success for AddOnly mode) and then to the Default Success Hook. This latter Hook is shared by all modes.
Error flow has similar behavior: control goes first to the Mode-specific Error Hook and then to Default On Error. Just below the Default On Error Hook in the above diagram is a branch with the text: At Least One Error Hook Enabled?
Appendix C. Handling exceptions and errors 461

Notice how if the answer is No (for example, no Error Hooks are enabled) then the AssemblyLine aborts with the error. On the other hand, if at least one of them is enabled then execution continues as though no error had occurred4. This is because TDI assumes that the problem has been dealt with by you.
However, this may not be desired behavior. For instance, if you are creating an Identity Manager Endpoint Adaptor using the DSML v2. EventHandler and have script code in Error Hooks (for example, writing to logs), then your AL will not report back any error to ITIM. This EventHandler expects the AssemblyLine to fail in the case of an error. So when the AL completes normally, the EventHandler reports back to Identity Manager that the operation was successful.
In order to "escalate" the error (instead of "swallowing" it) you have to re-throw the exception. To do this, you must first have access to the exception object itself. TDI provides you with this through the error object.
The error objectThe error object is an Entry, just like work and conn, and is available throughout the life of an AssemblyLine through the pre-registered script variable error. This Java bucket contains a number of Attributes that hold the exception itself, the error message associated with the exception, as well as details on where the error occurred. Here is a description of the various error Attributes.
� status - The error status. The value of this Attribute is initially set to "ok". As soon as an error occurs, it will be set to "fail".
Furthermore, status is the only Attribute in the error object before the first exception is thrown. After an error is encountered, the other Attributes below are added.
� connectorname - Name of the component where the error occurred. This is the name you have given this component in your AssemblyLine.
� operation - The internal name of the operation that failed. For example, "get" for the getNext() operation of an Iterator. Note that this may not be the exact origin of the error, but rather the last operation performed. So, if you get an error in the Input Map of your Iterator, this Attribute will still have the value "get".
� exception - This is the exception object itself.
� message - Clear text message describing the error.
� class - The Java class of the exception. This is typically a good place to start when trying to determine the type of error that has occurred.
4 Note that the error is still counted, and execution will halt if this count exceeds the max. number of errors parameter setting in the Config tab of the AssemblyLine.
462 Robust Data Synchronization with IBM Tivoli Directory Integrator

So to re-throw an exception, you must use the value of the exception Attribute in the error Entry. Retrieving an Attribute value as an object is easily done using the Entry's getObject() method:
throw error.getObject( "exception" );
Exception handling in scriptThere are times when you want to deal with errors in your own script. For example, if you are calling Connector Interface methods manually, or other Java functions that can result in exceptions.
This is done using JavaScript's own exception handling feature: try-catch. The try-catch statement allows you to specify a snippet of code that you want to try. If an exception is thrown during script execution, you have also specified additional code to catch and handle the error. For example:
try {DB2e_Update.connector.putEntry( work );
} catch ( myException ) {task.logmsg( "** Error during DB2e add operation" );task.logmsg( "** " + myException );
}
The try-block in the above snippet is calling the putEntry() method of the DB2e_Update Connector's Interface. If this results in an error then the catch block is executed. The exception object itself is referenced using the variable name in parenthesis after the catch keyword (myException in the above example).
Note that try-catch will effectively "swallow" any exception in the specified try-block, including syntax errors. So you will want to make sure that your code is correct before wrapping it in this statement.
Error HooksThe term Error Hook is used to denote a Hook that is called as the direct result of an exception being thrown. While Function Components offer a single Default
Tip: Note that throwing an exception from your Error Hook script breaks normal Error flow. If you throw an exception from the Mode-specific On Error Hook of a Connector then the flow will escalate to AssemblyLine error handling (for example, the AL On Failure Hook) instead of continuing to the Connector's Default On Error Hook.
Appendix C. Handling exceptions and errors 463

On Error Hook, Connectors actually have four distinct types, including Default On Error.� Mandatory - These are not strictly Error Hooks, but rather the result of
special exceptions thrown during Connector operation. Mandatory Hooks are special in that if the execution flow in the Connector ever reaches one and this Hook is not at least enabled, an error occurs. There are only three mandatory Hooks: On No Match and On Multiple Entries Hooks after lookup operations and No Answer Returned in CallReply mode.
� Connection Failure - Whenever a Connector Interface (CI) operation results in a connection-related error, control is passed to the On Connection Failure Hook. If Auto-Reconnect is enabled, then it is engaged after the Hook completes. If Auto-Reconnect is not enabled, error flow is initiated and the mode-specific Error Hook is called.
� Mode-specific - Each Connector mode has its own mode-specific Error Hook. Regardless of whether this Hook is enabled or not, error flow continues to Default On Error.
� Default On Error - This Hook is shared between Connector modes and is also found in Function Components. Any errors that occur during AL cycling (for example, not during Prolog or Epilog processing) will end up in the Default On Error Hook, unless control is explicitly passed elsewhere.
Each type of Error Hook listed above serves a specific purpose.
MandatoryUsually, if a Hook is not enabled then it is quietly "ignored" during the execution of the Connector. Mandatory Hooks differ in that if the execution flow of the Connector ever reaches one of them, an error occurs if the Hook is not enabled. As noted in the definition list above, Mandatory Hooks are invoked based on the number of results returned by either a lookup (either zero or multiple returned) or callreply operation (only for zero returned).
Several Connector modes perform a lookup: Lookup, Delete, Update and Delta5. Note that for Update mode, whether or not data is found by the lookup is how this mode differentiates between doing an add or modify operation. As a result, there is no On No Match Hook for Update (or Delta) mode.
These Hooks appear in the Flow Diagrams as boxes with solid orange bars on both sides, as shown in this fragment of the Lookup Mode flow:
5 Note that Delta mode is listed here for completeness sake. Delta mode will only perform a lookup if the underlying data source does not offer incremental modify operations. Since Delta mode is only available in the LDAP Connector and LDAP directories support incremental modifies, lookup is never done.
464 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure C-3 Lookup Mode flow diagram
Although all Mandatory Hooks will result in an error if control is passed to them and they are not enabled, On Multiple Entries will also throw an error if no current Entry is set during execution of the Hook.
This behavior is based on the assumption that you are always expecting a single item returned from a lookup or callreply operation. Any other result needs be specifically dealt with by coding the appropriate Hook. In some case, it is impossible to continue with the Connector mode flow - for example, if you are in Delete mode but the initial lookup did not locate the entry to delete, or if multiple entries are found matching your Link Criteria. These situations require conscious intervention, and are sometimes a signal that you should be using a different mechanism to solve the problem.
As an example, let's go back to the situation where our Delete mode Connector found more than a single matching entry. If we allow the Connector flow to continue, the delete operation will be applied using the same Link Criteria that caused the On Multiple Entries exception. Some data sources will allow this (for example, deleting multiple rows in an RDBMS table), while others won't. So we
Appendix C. Handling exceptions and errors 465

can either put script in this Hooks to handle this situation, or we could choose to change the Link Criteria to help ensure a single match6.
Connection FailureThe On Connection Failure Hook is called whenever a Connector Interface operation (like getNext, add or delete) fails with a connection-related error. This could be due to any number of reasons, like a firewall timing out an open connection, or because the data source itself has gone offline.
These types of problems are often referred to as infrastructural errors. They are not specific to data content or the state and behavior of your AssemblyLine. Instead, they occur in the environment where your solution resides. The purpose of the On Connection Failure Hook is to give you the chance to deal with this type of exception differently than you would with standard errors.
Note that if the Auto-Reconnect feature is enabled for the Connector, then it is engaged immediately following this Hook. This means that you have the option of changing Connector parameters in this Hook before (re)connect is attempted, switching to a backup server if desired.
If the (re)connect is successful, then the CI operation that failed is reattempted and flow continues as though no error had occurred. Note that this can have unwanted side-effects in some situations. For example, if the getNext operation fails for an Iterator then performing a re-connect will also reinitialize the result set for iteration. This not only means that processing will resume at the start of the result set again, but that collection of entries returned for iteration may be different than it was initially.
Another potentially dangerous situation is when you are writing to a JDBC data source with the Commit parameter set to On Connector close. Here you run the risk that all writes performed before the Connection Failure are aborted (rollback) by the underlying RDBMS. If re-connect is successful, the AL will continue as though nothing was wrong. However, only updates done after the re-connect will be committed when the Connector is finally closed at AL shutdown. You either need to disable Reconnect, or use a different setting for the JDBC Commit parameter.
If for some reason you do not want to continue to Auto-Reconnect then you must redirect the flow using a command like system.skipEntry() or system.ignoreEntry(). The flowchart detailing this behavior is found in the Flow Diagrams page titled Connector Reconnect, as described in ”Appendix B: TDI AssemblyLine and Connector mode flowcharts” of the IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720.
6 Or we can use a Loop Component to do the On Multiple Found handling for us.
466 Robust Data Synchronization with IBM Tivoli Directory Integrator

Mode-specific On ErrorIf an error occurs during a Connector Interface operation, then the On Error Hook for the Connector mode is invoked7. This Hook is not mandatory, so having it not enabled will not cause additional exceptions to be thrown.
After the mode-specific On Error Hook is executed (or skipped, if not enabled) flow continues to the Default On Error Hook.
Default On ErrorAlthough other error Hooks can precede it - like On Connection Failure or Mode-Specific On Error described in the previous sections - this is the error Hook that is ultimately called for any error-exception thrown during Connector or Function operation.
If this Hook is not enabled then the AssemblyLine aborts with the error and the AL's On Failure Hook is invoked. However, if Default On Error is enabled, the exception is effectively "swallowed" and control is passed to the next AL component.
LoggingAn important part of any error handling scheme is logging. Of course, logging has other uses as well; like passing data to other applications, or writing an AssemblyLine audit trail. As a result, this chapter will deal with logging in more general terms than just error handling.
TDI uses a Java API for logging called Log4j. This flexible framework provides a rich set of features that TDI leverages in such a way as to pass this flexibility on to you. It is not necessary that you know how Log4j works to do logging in TDI. However, any knowledge you do have can be directly applied to your solutions. So without going into the gritty details, logging in log4j can be thought of in three parts: logger, appender, and layout.
The first part (logger) refers to the mechanism that enables logging, and this bit handled for you by TDI.
The second term (appender) is also a job for TDI. This work is carried out a logging component called, not surprisingly, an Appender. TDI provides a range of appenders that each supports a specific log system or mechanism.
7 This is also true of connection failures as well, although the On Connection Failure (and possibly Reconnect feature, if enabled) is executed first.
Appendix C. Handling exceptions and errors 467

Finally, layout defines the format in which your log messages are written. You define the layout for an Appender by setting its parameters.
More information about this topic can be found in the Logging and debugging section of the IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1716.
Figure C-4 The IDI File Roller appender
The window in Figure C-4 is of the IDI File Roller Appender, and the top two parameters are specific to this component. Here you tell the Appender what file to use as well as how many backup copies it should maintain. The next two parameters - Layout and Pattern - are how the log messages are to be written. Finally, the Log Level parameter instructs the logger feature in TDI which message priority levels to enable for this Appender. There are five levels to choose from: DEBUG, INFO, WARN, ERROR, and FATAL; in ascending order of priority. This parameter controls how verbose the Appender will be and setting one level will enable that priority plus all those that are higher. For example, if you set the log level to FATAL, then only this level of messages will be written by the Appender. However, setting it to WARN means that it will handle ERROR and FATAL as well.
Logging can be defined at the Config level, as well as for specific AssemblyLines. Setting up how all AssemblyLines in a Config will do their logging is done under the Config folder of the Config Browser as shown in Figure C-5. Here you will see an Item called Logging.
468 Robust Data Synchronization with IBM Tivoli Directory Integrator

Figure C-5 Setup logging - config level
Selecting this item brings up a Logging Details window where you can add and remove Appenders that will be applied to all ALs.
In addition to Config-level settings, each AssemblyLine offers a Logging tab where you can specify further Appenders for this task. This is shown in our final capture in Figure C-6.
Figure C-6 Setup logging tab
Appendix C. Handling exceptions and errors 469

470 Robust Data Synchronization with IBM Tivoli Directory Integrator

Appendix D. Additional material
This redbook refers to additional material that can be downloaded from the Internet as described below.
Locating the Web materialThe Web material associated with this redbook is available in softcopy on the Internet from the IBM Redbooks Web server. Point your Web browser to:
ftp://www.redbooks.ibm.com/redbooks/SG246164
Alternatively, you can go to the IBM Redbooks Web site at:
ibm.com/redbooks
Select the Additional materials and open the directory that corresponds with the redbook form number, SG24-6164.
Using the Web materialThe additional Web material that accompanies this redbook includes the following files:
File name DescriptionSG246164.zip Zipped Code Samples
D
© Copyright IBM Corp. 2006. All rights reserved. 471

How to use the Web materialCreate a subdirectory (folder) on your workstation, and unzip the contents of the Web material zip file into this folder.
The archive unpacks into two main folders that are organized according to our two customer scenarios.
1. Penguin Financial
a. Password Synchronization
This subfolder contains all files necessary to replay the password synchronization scenario.
2. Blue Glue Enterprise
a. Oracle Database HR to ITIM Data Feed
This subfolder contains all files necessary to replay the HR data feed scenario.
b. ITIM agent and LDAP-to-DB2
This subfolder contains all files necessary to replay the ITIM agent as well as the LDAP-to-DB2 scenario.
472 Robust Data Synchronization with IBM Tivoli Directory Integrator

Glossary
AssemblyLine The basic work object within a Server. It consists of Connectors, Parsers and business logic. Connectors feed data in and out of the AssemblyLine.
AssemblyLine Pool A pool of identical threads that can be used to increase efficiency and where reuse strategy can be configured.
Attribute Contained in Entries and holding Values (single or multiple). See also Task Parameters.
Attribute Mapping Mapping of Attributes from the data source to the AssemblyLine. To be more precise this is mapping from the raw Connector attributes to the work Entry. Attribute mapping is done either in the Input Map tab or the Output Map tab (depends of the mode of the Connector).
CloudScape See System Store.
Components The IBM Tivoli Directory Integrator consists of a kernel being the Server, and the IBM Tivoli Directory Integrator Config Editor. In addition, we talk about components such as Connectors, EventHandlers, Script Components, Function Components, Conditional Components and Parsers. These can, to a certain extent, be distributed and upgraded independent of the kernel.
Computed Changes A special feature of the Update mode of a Connector.
© Copyright IBM Corp. 2006. All rights reserved.
Connector A plug-in into your data source in order to read it. Inside the AssemblyLine we differ between the Raw Connector object and the AssemblyLine Connector object, the latter wrapping the former and having a different set of methods. See "Objects" in IBM Tivoli Directory Integrator 6.0: Reference Guide for more information about objects.
Connectors can work in different modes (for example, Iterate, Delete, Update, AddOnly, Lookup and CallReply).
Delta A special term in Iterator mode, used when synchronizing a master and a slave. See "Deltas and compute changes" in IBM Tivoli Directory Integrator 6.0: Users Guide.
Distinguished Name (DN) In LDAP terms the fully qualified name of an object in the directory. It is usually written in a format known as the User Friendly Name (UFN). The name is a sequence of (RDNs) separated by a single comma ( , ).
Entry A term used for both the Entry object and the top level item used by the AssemblyLine and Connectors (see "Connectors" in IBM Tivoli Directory Integrator 6.0: Reference Guide). An entry typically corresponds to a row in a database table/view, a record from a file or an object in a directory. Entries contain Attributes which contains Values. For example, an Iterator might return the next person (the Entry), having the attributes city, name and phone. The values of the three attributes might be London, Holmes and 5632.
Epilog A piece of code that, if present, is run after the AssemblyLine data flow ends. It typically saves a parameter to be used the next time the AssemblyLine runs. See "AssemblyLine setting tab" in IBM Tivoli Directory Integrator 6.0: Reference Guide. See also Prolog.
473

EventHandler Waits for a specific event, and performs an action. Used to decide when AssemblyLines are started. Usually passes an initial work Entry to the AssemblyLine.
External Properties A way of externalizing certain Component parameters, such as filename, user, password and so forth. If the parameter is not to be used as Component parameter, you probably want to use Task Parameters.
Function Component A unit of logic very similar to a Connector, although without built-in logic to interface with a data source. Also, a Function Component is modeless, i.e. contrary to the Connector's fixed mode in the AssemblyLine (Iterate, AddOnly etc.), a Function Component is not locked into a particular mode of operation.
Iterator A Connector in Iterator mode.
Java VM or JVM Java Virtual Machine. IBM Tivoli Directory Integrator runs inside what is known as a Java Virtual Machine. It has its own memory management and is in most respects a Machine within the Machine.
Javadocs A set of low-level API documentation, embedded in the product's source code and extracted by means of a special process during the product's build. In IBM Tivoli Directory Integrator, the Javadocs can be viewed by selecting Help>Low Level API from the Config Editor.
JMX Java Management Extensions is a set of specifications for application and network management in the J2EE development and application environment. JMX defines a method for Java developers to integrate their applications with existing network management software by dynamically assigning Java objects with management attributes and operations. By encouraging developers to integrate independent Java management modules into existing management systems, the Java Community Process (JCP) and industry leaders hope that developers will consider non-proprietary management as a fundamental issue rather than as an afterthought.
LDIF The Lightweight Directory Interchange Format is an ASCII file format used to exchange data and enable the synchronization of that data between Lightweight Directory Access Protocol (LDAP) servers called Directory System Agents (DSAs). LDAP is a software protocol for enabling anyone to locate organizations, individuals, and other resources such as files and devices in a network. An LDAP directory can be distributed among many servers. LDIF is used to synchronize each LDAP directory.
Link Criteria Used to tell Update, Lookup and Delete-mode Connectors what to access. It links an Attribute from the AssemblyLine to a field (attribute, column) in the datasource.
Message Prefix All error messages and Info messages in IBM Tivoli Directory Integrator are prefixed with a unique Message Prefix. The prefix assigned to TDI is CTGDI.
Mode Connectors have modes: The mode describes what the Connector is used for:
– Iterate– AddOnly– Lookup– Update– Delete– CallReply– Server– Delta
474 Robust Data Synchronization with IBM Tivoli Directory Integrator

Null Value Behavior How Attribute Mapping is to be done when attribute values are missing.
Parser Parsers are used in conjunction with a transport Connector to interpret or generate the content that travels over the Connector's byte stream.
Persistent Object Store See System Store.
Prolog Code that, if present, is run before the AssemblyLine data flow starts. Code can be run both before and after all Connectors are initialized. See also Epilog.
Properties Contained in Entries and holding a single value. Mostly used in Handler Action maps. See also Attribute.
Raw Connector The part of the AssemblyLine that sees the external data source.
Relative Distinguished Name (RDN) In LDAP terms the name of an object that is unique relative to its siblings. RDNs have the form attribute name=attribute value.
RMI Remote Method Invocation; a way of making procedure or method calls on a remote system using a network communication channel. In TDI, used by the Remote API functionality.
Sandbox The feature of the IBM Tivoli Directory Integrator that enables you to record AssemblyLine operations for later playback without any of the data sources being present.
Script Component Something that looks like a Connector in the Config Editor. It can be regarded as Connector without pre-configured input or output capabilities. It is inserted by a separate Script utility in the Config Editor and is not to be confused with an actual Connector or a Script Connector.
Script Connector A Script Connector is a Connector where you write the functionality yourself: It is empty in the sense that, in contrast to an already-existing Connector, the Script Connector does not have the base methods getNextEntry(), findEntry() and so forth implemented. Not to be confused with the Script Component.
SOAP Simple Object Access Protocol is a way for a program running in one kind of operating system to communicate with a program in the same or another kind of an operating system by using the HTTP Protocol and XML as the mechanisms for information exchange.
State Connectors can be in one of these states:– Enabled (the normal state)– Passive (initialized, but not part of the
AssemblyLine flow)– Disabled (not initialized by the
AssemblyLine)
Store Factory The Store Factory provides the bootstrap methods for the various models in the system store. The Store Factory automatically creates the underlying Cloudscape database by using the JDBC URL or file system path designated by the com.ibm.store.database java system property. Through this class, users can obtain instances of Property Store classes and also JDBC Connection objects.
System Store Also known as Persistent Object Store, or POS. The relational database that IBM Tivoli Directory Integrator uses to store Delta Tables (if the CloudScape type is chosen), and the underlying storage method for the objects created and maintained by the Checkpoint/Restart functionality as well as the User Property Store. In the current implementation, the IBM DB2(R) for Java product (also known as CloudScape) is used. See http://www.ibm.com/software/data/cloudscape for more details.
Glossary 475

XML eXtensible Markup Language is a flexible way to create common information formats and share both the format and the data on the World Wide Web, intranets, and elsewhere. For example, computer makers might agree on a standard or common way to describe the information about a computer product (processor speed, memory size, and so forth) and then describe the product information format with XML. Such a standard way of describing data would enable a user to send an intelligent agent (a program) to each computer maker’s Web site, gather data, and then make a valid comparison. XML can be used by any individual or group of individuals or companies that wants to share information in a consistent way.
476 Robust Data Synchronization with IBM Tivoli Directory Integrator

Related publications
The publications listed in this section are considered particularly suitable for a more detailed discussion of the topics covered in this redbook.
IBM RedbooksFor information on ordering these publications, see “How to get IBM Redbooks” on page 478. Note that some of the documents referenced here may be available in softcopy only.
� Identity Management Design Guide with IBM Tivoli Identity Manager, SG24-6996
� Deployment Guide Series: IBM Tivoli Identity Manager, SG24-6477
� Enterprise Security Architecture Using IBM Tivoli Security Solutions, SG24-6014
� Using LDAP for Directory Integration, SG24-6163
� A First Glance at IBM Directory Integrator: Integrating the Enterprise Data Infrastructure, REDP-3729
� A Deeper Look into IBM Directory Integrator, REDP-3728
Other publicationsThese publications are also relevant as further information sources:
� IBM Tivoli Directory Integrator 6.0: Release Notes
� IBM Tivoli Directory Integrator 6.0: Getting Started Guide, SC32-1716
� IBM Tivoli Directory Integrator 6.0: Users Guide, SC32-1718
� IBM Tivoli Directory Integrator 6.0: Administrator Guide, SC32-1716
� IBM Tivoli Directory Integrator 6.0: Reference Guide, SC32-1720
� IBM Tivoli Identity Manager Planning for Deployment Guide, SC32-1708
� JavaScript: The Definitive Guide, Fourth Edition by David Flanagan. O’Reilly, December 2001. ISBN 0596000480
http://www.oreilly.com/catalog/jscript4/
© Copyright IBM Corp. 2006. All rights reserved. 477

� Learning Java, 2nd Edition by Patrick Niemeyer and Jonathan Knudsen. O’Reilly, July 2002. ISBN 0596002858
http://www.oreilly.com/catalog/learnjava2
Online resourcesThese Web sites and URLs are also relevant as further information sources:
� The complete IBM Tivoli Directory Integrator Information Center library, which includes all the product manuals can be found at the following location:
http://publib.boulder.ibm.com/infocenter/tivihelp/v2r1/index.jsp?toc=/com.ibm.IBMDI.doc/toc.xml
� CoreRef. Core JavaScript 1.5 Reference. http://developer.mozilla.org/en/docs/Core_JavaScript_1.5_Reference (online) http://devedge-temp.mozilla.org/library/manuals/2000/javascript/1.5/guide/CoreGuideJS15.zip (download)
� CoreGuide. Core JavaScript 1.5 Guide. http://developer.mozilla.org/en/docs/Core_JavaScript_1.5_Guide (online); http://devedge-temp.mozilla.org/library/manuals/2000/javascript/1.5/reference/CoreReferenceJS15.zip (download)
� FlanaganBlog. David Flanagan’s Weblog. http://www.davidflanagan.com
� JavaScriptMetaFAQ. http://www.jibbering.com/faq/
� JavaScriptFAQ. http://javascript.faqts.com/
� RhinoDocs. Documentation for Rhino JavaScript interpreter. http://www.mozilla.org/rhino/doc.html
How to get IBM RedbooksYou can search for, view, or download Redbooks, Redpapers, Hints and Tips, draft publications and Additional materials, as well as order hardcopy Redbooks or CD-ROMs, at this Web site:
ibm.com/redbooks
478 Robust Data Synchronization with IBM Tivoli Directory Integrator

Help from IBMIBM Support and downloads
ibm.com/support
IBM Global Services
ibm.com/services
Related publications 479

480 Robust Data Synchronization with IBM Tivoli Directory Integrator

Index
Aaccess 21account
orphan 306AccountClass 320Active Directory 44
change log Connector 100Changelog Connector 131changes 131password policy 166password synchronization 165read connectivity 121update connectivity 127
AddOnly mode Connector 53administration 30, 84
security 34Administration and Monitor Console 32, 45
see AMC2After Add Hook 355After GetNext Hook 347After Lookup Hook 349, 358, 372agility 14AMC2 86
permissions 86architectural decision 100archiving 30, 97AssemblyLine 46, 68
Active Directory to Directory Server 147Attribute Map 64Branch 64creation 147, 232debug mode 163Directory Server to Domino Server 150Domino Server to Directory Server 153Feed section 51Flow section 51Function 63Hook 62password synchronization 104, 164Pool 55, 80problem determination 162Script 62synchronize Active Directory to Directory Server
© Copyright IBM Corp. 2006. All rights reserved.
155synchronize Directory Server to both Domino Server and Active Directory 159synchronize Domino Server and Directory Serv-er 157
Attribute Map 49, 64scripting 442
attribute mapping 126attributes 48auditing 32, 97, 301authoritative
attributes 22, 275, 304data repository 68data source 112, 115
Auto Map AD Password 165autoboot value 110Automatic Certificate Request 209availability 14
Bbackup 30, 97base components 45batch retrieval feature 57Before Applying Changes Hook 372Before Execute Hook 365, 375Before Lookup Hook 349, 358bidirectional flow 71Branch 64business
context 3requirements 18, 92, 268rule enforcement 68scenarios 11
CCallReply Connector mode 55, 63CDATA XML section 440certificate 141change
detection 100notification feature 57
Change Detection Connectors 56Changelog
481

base 386timeout 387
Changelog Connector 56, 139Active Directory 131
Checkpoint/Restart 77class loader 446classpath 279CloudScape 387compliance 32
requirements 18, 21Compute Changes option 54conditional Loop 241Config Editor 84configuration
file 30, 116, 280management 30, 97of a Connector 122
connectionautomatic reconnect 76
Connector 50, 68Active Directory change log 100basic configuration 219configuration 122create your own 59debug parameter 82Directory Server change log 100Domino change detection 100external properties 281Identity Manager Agent 101, 140Identity Manager Notes Agent 110JDBC 279library 51, 385list of available ... 60loop 65mode 50, 52
AddOnly 53CallReply 55, 63Changelog 131Delete 54Delta 56Iterator 52, 70, 77, 121, 131, 134, 139, 165Lookup 53, 136Server 55, 77, 80Update 54, 127, 137
Oracle 286password synchronization 164state 58type 50
connectorname 462
corporate security policy 96cost 3CustomLabels.properties 314, 320
Ddata
access 21, 275authoritative source 112, 115cleanup 24, 114container 48encryption 33flow 22, 44, 111, 275
execution 45pattern 9topology 69
format 21fragmentation 4identification 20, 107, 186, 275, 300load 114location 20, 275, 300model
for Identity Manager 314owner 21, 35, 275re-contextualized 10source 43, 70, 190
connectivity 120link criteria 112
synchronization 68, 114security 33two-way 307
database connection 385DB2 44
database connection 385JDBC connectivity 422
debug mode 163debugging 81, 83, 384Delete mode Connector 54delta
application 58detection 56
Delta mode connector 56design
objectives 96responsibilities 38
destination 70Detailed Log 162detection of changes 100Directory Server 44
482 Robust Data Synchronization with IBM Tivoli Directory Integrator

change log Connector 100Changelog Connector 386password synchronization 204password synchronizer 168
directory syntax 314dirty data 24disabled Connector state 59discovery of schema 125dispatching 45distributed architecture 73DMSLv2
EventHandler 300, 332, 341documentation 25Domino
change detection Connector 100garbage collection 173Identity Manager Agent Connector 101password synchronization setup 213password synchronizer 170port encryption 173secure password transfer 173user registration 100
Domino Serverconnection 434
duplicate entry processing 368
Ee-mail account 94embedded mode (CloudScape) 387enabled Connector state 59encryption 33
mechanisms 67of external properties file 34
End of Data Hook 347enterprise directory 94entitlement 328erbgappaccount.xml 321erbgappccount.xml 314erbgappservice.xml 314, 321error
detection 45handling 228, 455hook 463management 78status 462
event 44detection 55
EventHandler 55, 61, 300, 307, 332, 341
exception 459, 462class 457handling 455
Exchange 44extensibility 46external properties file 116, 281, 330
Ffailover 28, 97
requirements 28services 78
federated architecture 74Feed section 51filtering 44First Failure Data Capture 84flag
password synchronization 103flow 70
bidirectional 71Debugger 83section 51
format 21frequency
of synchronization 25function 63, 445
task.setWork(null) 53functional requirements 93, 269
Ggeneral benefits 42GetNext Successful Hook 232global script 380golden directory 4GSKit 141
HHACMP 79help desk call 95high availability 18, 28, 75, 78, 97
requirements 28Hook 62, 72, 138, 144
After Add 355After GetNext 347After Lookup 349, 358, 372Before Applying Changes 372Before Execute 365, 375Before Lookup 349, 358
Index 483

End of Data 347GetNext Successful 232Lookup Successful 236, 365, 375, 444On Connection Failure 76On Error 233On Multiple Entries 54, 349, 358, 365, 375On No Match 54, 239, 293, 349, 358, 365, 375, 398, 445Override Add 250scripting 442Update Successful 243, 252
HR database 43HTTPS 33
IIBM DB2
see DB2IBM GSKit
see GSKitIBM Tivoli Directory Server
see Directory ServerIBM WebSphere
see WebSphereibmdisrv 45ibmditk 45, 84, 330ibmjs 440identity
data fragmentation 5Identity Manager
Agent Connector 101, 140custom agent 305CustomLabels.properties 314, 320data feed service 289data model 314Directory Integrator agent 313directory syntax 314entitlement 328erbgappaccount.xml 321erbgappccount.xml 314erbgappservice.xml 314, 321Notes Agent configuration 436Notes Agent Connector 110provisioning policy 328resource.def 314, 319schema.dsml 317service 327user interface customization 323
influencers 35
iNotespassword change 171
Integrated Development Environment 84intercept
password changes 164Internet Information Services 209Iterator
Delta Store 56mode Connector 52, 70, 77, 134, 139, 165
121State Store 57, 131, 387
JJava
data container 48object 447objects
instantiation 440scripting 440, 446type conversions 449
Java Virtual Machine 446JavaScript 42
error handling 463in Branches 64in Connector states 59in Directory Integrator 439in Scripts 62regular expressions 444type conversions 449
JavaScript-shell 441JDBC
Connector 279, 391driver 416logging 81
JLOG 84JMS
logging 81JScript 439
LLDAP
Connector 134objectclass 314password store 177userPassword attribute 168
link criteria 23, 53–54, 112, 129, 138, 190, 235, 275, 304, 336, 338LiveConnect 440–441
484 Robust Data Synchronization with IBM Tivoli Directory Integrator

location 20log4j 80
API 81logging 32, 45, 80, 97, 384, 456
log4j 80Lookup mode Connector 53, 136Lookup Successful Hook 236, 365, 375, 444Loop 65, 233
condition 102conditional 241link criteria 235
Lotus Dominosee Domino
Mmaintainability 30many-to-one
data flow 10topology 70
mapping 44of attributes 126
message 462metadirectory 6
models 68metaview 68Microsoft Active Directory
see Active DirectoryMicrosoft Exchange
see ExchangeMicrosoft Internet Information Services
see Internet Information ServicesMicrosoft SQL Server
see SQL Serverminimum password age 101mode
Connector 50, 52monitoring 32, 84, 97Mozilla Rhino JavaScript 440multiple server environment 73
Nnaming conventions 27networked mode (CloudScape) 387nonfunctional requirement 97Notes
garbage collection 173password synchronizer 170port encryption 173
secure password transfer 173Novell eDirectory 44Null Behavior 54
Oobjectclass 314On Connection Failure Hook 76On Error Hook 233On Multiple Entries Hook 54, 349, 358, 365, 375On No Match Hook 54, 239, 293, 349, 358, 365, 375, 398, 445one-to-many
data flow 11topology 71
one-to-onedata flow 10topology 70
operation 462Oracle 44
change log configuration 283Connector 286JDBC connectivity 416JDBC driver 279
orphaned account 306Override Add Hook 250owner 21
PParser 60, 70passive Connector state 59password
complexity 192complexity checking 201policy 101, 166protection for configuration file 116reset 95security 104store 101, 104, 164, 177
change 167external 103LDAP 177WebSphere MQe 179
synchronization 34, 42, 65, 95–96, 163architecture 183AssemblyLine 104, 164components 164Connector 164Directory Server setup 204
Index 485

Domino setup 213flags 103flowchart 193loop condition 102phased approach 192Windows setup 201
synchronizer 164–165Directory Server 168Domino 170Notes 170Windows NT/2000/XP 166
performance 14PerlScript 439permissions
for AMC2 86phased approach 24physical architecture 67point-to-point synchronization 68Pool Manager 55port encryption 173principle of least privilege 86privacy 18, 21problem determination 162project
documentation 25phased approach 25
Prolog 362, 370script 52
propertiesfile 30, 34file encryption 34
provisioning policy 328
Rreconciliation 300, 306, 341, 344re-contextualized data 10Redbooks Web site 478
Contact us xvreferential integrity 365, 372, 376regular expressions 444regulatory compliance 18relational database connection 385relative distinguished name 381reliability 14resource.def 314, 319review document 276Run-time Server 45
SSandbox facility 77Sarbanes-Oxley Act 5scalability 14, 75, 79scenarios 11schema
discovery 125discrepancies 68mapping 135violation exception 111
schema.dsml 314, 317Script 48, 62
engine 440Library 445
scriptingJava 440, 446tools 441
scripts 228security 97
capabilities 67policy 96requirements 33
self-service 95server
security 33Server mode Connector 55, 77, 80service 327ServiceClass 320Sleep Interval 131solution
implementation 115test 26testing 255
solution outline 279SQL Server 44
JDBC connectivity 426SSL 33stack trace 456state
Connector 58key persistence 387
Sun ONE Directory Serverpassword synchronizer 175
support operations responsibilities 38synchronization 94
benefits 6frequency 25of data 114of password 95
486 Robust Data Synchronization with IBM Tivoli Directory Integrator

patterns 8security 33
system administration 30systems operations responsibilities 36
Ttask.setWork(null) 53technical scenarios 11test responsibilities 38testing 26, 255timeout
changelog 387Toolkit IDE 45topology
many-to-one 70one-to-many 71one-to-one 70
tracing 81, 84transformation
of information 44transport protocols 60troubleshooting 38, 81try-catch 463two way data synchronization 307type
Connector 50
UUpdate mode Connector 54, 127, 137Update Successful Hook 243, 252Use Notifications 131user
account creation 100userPassword LDAP attribute 168
Vversion control 31virtual directory 14VisualBasic 439
WWebSphere MQe 164, 166–167, 174, 201
availability 182create QueueManager 202password store 179QueueManager Server setup 206
who owns what 35
Windowspassword complexity checking 201password synchronization 201
Windows NT/2000/XPpassword synchronizer 166
work Entry 48initial handling 53
XXML
CDATA 440
Index 487

488 Robust Data Synchronization with IBM Tivoli Directory Integrator

(1.0” spine)0.875”<
->1.498”
460 <->
788 pages
Robust Data Synchronization with
IBM Tivoli Directory Integrator



®
SG24-6164-00 ISBN 0738497479
INTERNATIONAL TECHNICALSUPPORTORGANIZATION
BUILDING TECHNICALINFORMATION BASED ONPRACTICAL EXPERIENCE
IBM Redbooks are developed bythe IBM International Technical Support Organization. Experts from IBM, Customers and Partners from around the world create timely technical information based on realistic scenarios. Specific recommendations are provided to help you implement IT solutions more effectively in your environment.
For more information:ibm.com/redbooks
Robust DataSynchronizationwith IBM Tivoli Directory IntegratorComplete coverage of architecture and components
Helpful solution and operational design guide
Extensive hands-on scenarios
Don’t be fooled by the name; IBM Tivoli Directory Integrator integrates anything, and it is not in any way limited to directories. It is a truly generic data integration tool that is suitable for a wide range of problems that usually require custom coding and significantly more resources to address with traditional integration tools.
This IBM Redbook shows you how Directory Integrator can be used for a wide range of applications utilizing its unique architecture and unparalleled flexibility. We discuss the business context for this evolutionary data integration and tell you how to architect and design an enterprise data synchronization approach. By telling you everything about Directory Integrator’s component structure and then applying all the techniques in two comprehensive business scenarios, we build a formidable base for your own data integration and synchronization projects.
This book is a valuable resource for security administrators and architects who want to understand and implement a directory synchronization project.
Back cover


















