

Reuse of public proteomics data
43
Reuse of public proteomics data Dr. Juan Antonio Vizcaíno EMBL-EBI Hinxton, Cambridge, UK
-
Upload
juan-antonio-vizcaino -
Category
Science
-
view
97 -
download
4
Transcript of Reuse of public proteomics data

Reuse of public proteomics data
Dr. Juan Antonio Vizcaíno
EMBL-EBI
Hinxton, Cambridge, UK

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Countries with at least
100 submitted datasets :
1019 USA
734 Germany
492 United Kingdom
470 China
273 France
209 Netherlands
173 Canada
165 Switzerland
157 Australia
148 Austria
142 Denmark
137 Spain
115 Sweden
109 Japan
100 India
5,198 ProteomeXchange datasets in PRIDE (by March 2017)
Type:
3835 ‘Partial’ submissions (73.8%)
1363 ‘Complete’ submissions (26.2%)
Released: 3462 datasets (66.6%)
Unpublished: 1,736 datasets (33.4%)
Data volume in PRIDE:
Total: ~320 TB
Number of files: ~670,000
PXD000320-324: ~ 4 TB
PXD002319-26 ~2.4 TB
PXD001471 ~1.6 TB
Top Species represented (at least
100 datasets):
2267 Homo sapiens
765 Mus musculus
201 Saccharomyces cerevisiae
169 Arabidopsis thaliana
154 Rattus norvegicus
124Escherichia coli
~ 1000 species in total

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Public proteomics datasets are being increasingly
reused…
Martens & Vizcaíno, Trends Bioch Sci, 2017

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Downloads are increasing
Data download volume for PRIDE Archive in 2016: 243 TB
0
50
100
150
200
250
300
2013 2014 2015 2016
Downloads in TBs

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Data sharing in Proteomics
Vaudel et al., Proteomics, 2016

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
What do researchers think about the main uses
of public proteomics data?
• Verify published results
• Build Spectral libraries
• Find interesting datasets for reanalysis:
• Find new splice isoforms
• Discover new PTMs
Source: MassIVE workshop, ASMS 2017, Nuno Bandeira et al.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Data sharing in Proteomics
Vaudel et al., Proteomics, 2016

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Data sharing in Proteomics

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Data sharing in Proteomics
• Data directly as they are.
• Protein knowledge bases: UniProt, neXtProt.
• Contributing to the Protein Evidence Code.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Protein Evidence codes in UniProt/neXtProt
http://www.uniprot.org/help/protein_existence

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Use of MS data in UniProt

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Data sharing in Proteomics

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Reuse
• Information is not only extracted, but reused in new
experiments with the potential of generating new
knowledge.
• Transitions used in SRM approaches.
• Spectral libraries.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
SRMAtlas
http://www.srmatlas.org/

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
PeptidePicker
http://mrmpeptidepicker.proteincentre.com/

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Spectral searching
• Concept: To compare experimental spectra to other
experimental spectra.
• There are many spectral libraries publicly available (for
instance, from NIST, PeptideAtlas and PRIDE)
• Custom ‘search engines’ have been developed:
• SpectraST (TPP)
• X!Hunter (GPM)
• Bibliospec
• It has been claimed that the searches have more
sensitivity that with sequence database approaches

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Spectral searching (2)
http://peptide.nist.gov/

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
PRIDE Cluster as a Public Data Mining Resource
18
• http://www.ebi.ac.uk/pride/cluster
• Spectral libraries for 16 species.
• All clustering results, as well as specific subsets of interest available.
• Source code (open source) and Java API

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Benchmarking
• Many datasets are reused to benchmark new algorithms
and/or tools. Comparison with previous tools.
• Usually raw data is used as the base (new analysis), but
not always.
• Very common reuse case -> A lot of examples.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Data sharing in Proteomics

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Reprocess
• Data are reprocessed with the intention of obtaining
new knowledge or to provide an updated view on
the results.
• It mainly serves the same purpose of the original
experiment.
• For instance, a shot-gun dataset can be reprocessed
with a different algorithm or an updated sequence
database.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Reprocessing repositories
• These resources collect MS raw data and reprocess it using
one given analysis pipeline, and an up-to date protein
sequence database.
• Main resources: GPMDB and PeptideAtlas (ISB, Seattle).

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
PeptideAtlas and GPMDB

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
proteomicsDB -> Draft Human proteome paper
Wilhelm et al., Nature, 2014
•Around 60% of the data used for the
analysis comes from previous
experiments, most of them stored in
proteomics repositories such as
PRIDE/ProteomeXchange, PASSEL or
MassIVE.
•They complement that data with “exotic”
tissues.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Reprocessing for the validation of controversial data
• Analysis of Tyrannosaurus rex fossils: controversial presence of
collagen (is it a contamination of the sample? Did the sample contain
any T. rex proteins at all?)
Asara et al. (2007) Science 316: 280-5.
Asara et al. (2007) Science 316: 1324-5.
Bern et al. (2009) JPR 9: 4328-32
PRIDE Archive assay accession
8633

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Info from R. Chalkley
Bromenshenk et al. (2011) PLOS One 5: e13181
Reprocessing for the validation of controversial data (2)

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Experimental Protocol
1. Collected samples from healthy, collapsing and collapsed bee colonies.
2. Homogenised bees.
3. Digested with Trypsin
4. Analyzed by LC-MSMS on LTQ
5. Searched using Sequest
6. Filtered Results using Peptide and Protein Prophet
7. Performed further analysis to determine species statistically more
commonly found in collapsing/collapsed colony samplesInfo from R. Chalkley
Bromenshenk et al. (2011) PLOS One 5: e13181
Reprocessing for the validation of controversial data (3)

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
• Big pitfall: Search database was only composed by viral
proteins. Not bee proteins at all!!
• After researching the data, there is no evidence for viral
peptides/proteins in any of their data: honey bee, fruit fly,
wasp, moth, human keratin, bacteria that like sugary
environments, …
• “We believe that there is currently insufficient evidence to
conclude that bees are a natural host for IIV-6, let alone that
the virus is linked to CCD”.Info from R. Chalkley
Knudsen & Chalkley (2011) PLOS One 6:
e20873
Foster (2011), MCP 10: M110.006387
Reprocessing for the validation of controversial data (4)

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Reprocessing for the validation of controversial data
Datasets PXD000561 and PXD000865 in PRIDE Archive

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Various reanalysis of these datasets have been performed…
Reanalysis of Pandey dataset (Nature, 2014) made by J. Choudhary’s group at
Sanger Institute
Wright et al., Nat Commun, 2016Dataset PXD000561
http://www.ebi.ac.uk/gxa

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Meta-analysis approaches
• Putting data coming from a lot of experiments
together, to extract new knowledge. Examples:
• Peptide fragmentation patterns.
• Retention time prediction.
• Data integration of experiments done at different time
points.
• Two different approaches:
• Data as submitted
• Reanalysis all the data together

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Meta-analysis recent examples
Lund-Johanssen et al., Nat Methods, 2016 Drew et al., Mol Systems Biol, 2017
Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Data sharing in Proteomics

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
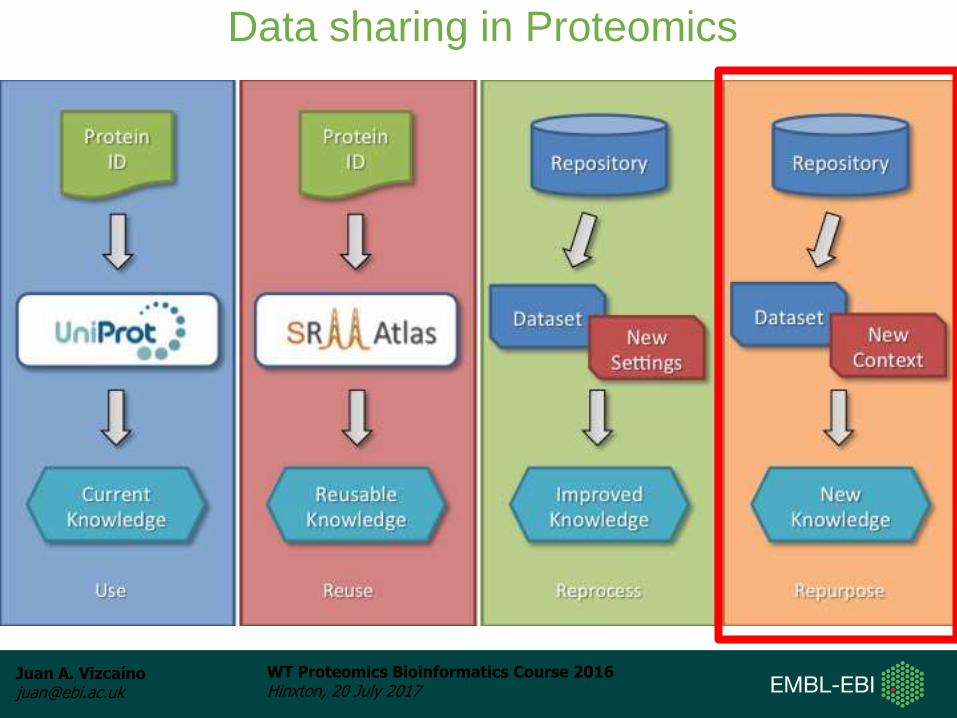
Repurposing
• Data are considered in light of a question or a
context that is different from the original study.
• Proteogenomics studies
• Discovery of novel PTMs.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Examples of repurposing datasets: proteogenomics
Data in public resources can be used for genome annotation purposes

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Public datasets from different omics: OmicsDI
http://www.omicsdi.org/
• Aims to integrate of ‘omics’ datasets (proteomics,
transcriptomics, metabolomics and genomics at present).
PRIDE
MassIVE
jPOST
PASSEL
GPMDB
ArrayExpress
Expression Atlas
MetaboLights
Metabolomics Workbench
GNPS
EGA
Perez-Riverol et al., Nat Biotechnol, 2017

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Repurposing: new PTMs found
• Individual authors can reprocess raw data with new
hypotheses in mind (not taken into account by the original
authors).
• Recent examples (using phosphoproteomics data sets):
• O-GlcNAc-6-phosphate1
• Phosphoglyceryl2
• ADP-ribosylation3
1Hahne & Kuster, Mol Cell Proteomics (2012) 11 10 1063-92Moellering & Cravatt, Science (2013) 341 549-553
3Matic et al., Nat Methods (2012) 9 771-2

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
What do researchers think about the main uses
of public proteomics data?
• Verify published results
• Build Spectral libraries
• Find interesting datasets for reanalysis:
• Find new splice isoforms
• Discover new PTMs
Source: MassIVE workshop, ASMS 2017, Nuno Bandeira et al.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Do you want to know a bit more…?
http://www.slideshare.net/JuanAntonioVizcaino
Martens & Vizcaíno, Trends Bioch Sci, 2017 Vaudel et al., Proteomics, 2016

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
EXERCISE

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Vaudel M, Barsnes H, Berven FS, Sickmann A,
Martens L:
Proteomics 2011;11(5):996-9.
https://github.com/compomics/searchgui https://github.com/compomics/peptide-shaker
Vaudel M, Burkhart J, Zahedi RP, Berven FS, Sickmann A, Martens L,
Barsnes H:
Nature Biotechnology 2015; 33(1):22-4.
CompOmics Open Source Analysis Pipeline

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2016Hinxton, 20 July 2017
Find the desired PRIDE project …
… and start re-analyzing the data!
… inspect the project details ….
Reshake PRIDE data!


















