
Efficient Nonlinear Finite Element Modeling of Nonrigid Objects via ...

Research ArticleA Parallel Nonrigid Registration Algorithm Based onB-Spline for Medical Images
Xiaogang Du1 Jianwu Dang1 Yangping Wang12 Song Wang1 and Tao Lei3
1School of Electronic amp Information Engineering Lanzhou Jiaotong University Lanzhou 730070 China2Lanzhou Yuxin Information Technology Limited Liability Company Lanzhou 730000 China3College of Electrical amp Information Engineering Shaanxi University of Science amp Technology Xirsquoan 710021 China
Correspondence should be addressed to Jianwu Dang dangjwmaillzjtucn
Received 13 August 2016 Accepted 2 November 2016
Academic Editor Kostas Marias
Copyright copy 2016 Xiaogang Du et al This is an open access article distributed under the Creative Commons Attribution Licensewhich permits unrestricted use distribution and reproduction in any medium provided the original work is properly cited
The nonrigid registration algorithm based on B-spline Free-Form Deformation (FFD) plays a key role and is widely applied inmedical image processing due to the good flexibility and robustness However it requires a tremendous amount of computing timeto obtain more accurate registration results especially for a large amount of medical image data To address the issue a parallelnonrigid registration algorithm based on B-spline is proposed in this paper First the Logarithm Squared Difference (LSD) isconsidered as the similarity metric in the B-spline registration algorithm to improve registration precision After that we create aparallel computing strategy and lookup tables (LUTs) to reduce the complexity of the B-spline registration algorithm As a resultthe computing time of three time-consuming steps including B-splines interpolation LSD computation and the analytic gradientcomputation of LSD is efficiently reduced for the B-spline registration algorithm employs the Nonlinear Conjugate Gradient(NCG) optimization method Experimental results of registration quality and execution efficiency on the large amount of medicalimages show that our algorithm achieves a better registration accuracy in terms of the differences between the best deformationfields and ground truth and a speedup of 17 times over the single-threaded CPU implementation due to the powerful parallelcomputing ability of Graphics Processing Unit (GPU)
1 Introduction
Image registration is a process used inmedical image analysisto determine a spatial transformation that aligns image dataaccording to the spatial coordinate of pixels The processinvolves a reference image and a moving image the movingimage is deformed by a spatial transformation to align withthe reference image [1] With the development of medicalimaging technologies it is easy to obtain many images withdifferent modalities and gain amore complete understandingof anatomy and function by registering and fusing theseimages Generally according to spatial transformation imageregistration is categorized into two types rigid registra-tion and nonrigid registration The rigid registration onlydescribes the motion which is limited to global rotations andtranslations and the nonrigid registration always includesvery complex local and elastic deformations except rigidtransformation
Practically nonrigid registration is always widely appliedin themany clinical procedures to improve the geometric pre-cision such as disease diagnostic [2] neurosurgery [3] andImage-Guided RadiationTherapy (IGRT) [4] Up to presentseveral classical nonrigid registration algorithms have beenproposed and improved in the performance of registrationresults including viscous fluid registration [5] demons reg-istration [6] Finite Element Model (FEM) [7] and B-splineregistration [8] B-spline registration always employs uniformcubic B-spline curves to determine a displacement vectorfield which maps voxels in the moving images to those inthe reference images [8] Each voxelrsquos displacement betweenthe moving image and the reference image is parameterizedin terms of uniformly spaced control points that are alignedwith the voxel mesh and displacement vectors are obtainedvia interpolation of the control-point coefficients using piece-wise continuous B-spline basis functions Recently B-splineregistration became very popular because of their flexibility
Hindawi Publishing CorporationComputational and Mathematical Methods in MedicineVolume 2016 Article ID 7419307 14 pageshttpdxdoiorg10115520167419307
2 Computational and Mathematical Methods in Medicine
and robustness and is therefore able to perform bothmonomodality and multimodality image registration How-ever In the B-spline registration algorithm there are threetime-consuming steps B-spline interpolation similaritymet-ric computation and similaritymetric gradient computationFirst in the process of B-spline interpolation a coarse arrayof B-spline coefficients is considered as the input and afine array of displacement values is computed as the outputdefining the deformation vector field from the moving imageto the reference image Therefore B-spline interpolation isexpensive in terms of executing time for the fine deformationmesh withmany control points In addition similaritymetricis a very crucial step to measure the registration resultsand it has an important influence on the accuracy of theregistration results In addition similaritymetric is calculatedin each iteration of the B-spline registration algorithm andits computational efficiency has a serious impact on theperformance of the whole registration process Finally sim-ilarity metric gradient computation requires evaluating thepartial derivatives of the similaritymetric with respect to eachspline-coefficient value of all control points it is thereforea very time-consuming step to obtain better accuracy ofregistration results in the case of much more control pointsIn summary the B-spline registration algorithm always needsmore execution time for the larger amount of medicalimage data which limits the clinical applications of B-splineregistration [9 10]
Aiming to improve the accuracy and significantly accel-erate B-spline registration algorithm we develop a B-spline-based nonrigid registration algorithm that is suitable forexecuting on GPU by considering the LSD as similaritymetric In our algorithm all of the computation-intensivetasks are designed and implemented on GPU using theparallel computing framework Computing Unified DeviceArchitecture (CUDA) Experiments show that our algorithmimproves the accuracy of registration results and achieves aspeedup ratio of 17 times comparing to the single-threadedserial implementation The main contributions are summa-rized as follows
(1) We introduce the LSD as similarity metric in theB-spline registration algorithm to obtain the higherregistration accuracy for medical images
(2) We design a parallel computing strategy and createLUTs for B-splines registration to improve the execu-tion performance Meanwhile three time-consumingsteps including B-splines interpolation the similar-ity metric LSD and its gradient computation aredesigned in the form of the kernel functions whichare executed in parallel on GPU
The rest of this paper is organized as follows Section 2presents the related works of accelerating B-spline registra-tion using cluster many-core and GPU Section 3 describesour B-spline registration algorithm employed the LSD as thesimilarity metric and NCG optimization Section 4 explainsthe parallel computing details of our proposed algorithmbased on CUDA Section 5 shows experiments results andanalysis Finally Section 6 concludes our work
2 Related Work
The parallel computing technology is an effective way toaccelerate many general purpose applications and has a verycrucial influence on the field of high performance comput-ing Parallel operations can be performed independently ondifferent partition of medical images due to the good dataparallel characteristic of medical images At present parallelcomputing has been widely used in medical image process-ing [11 12] for example image registration [13 14] Thereare three parallel computing technologies for acceleratingmedical image registration cluster many-core and GPUcomputing
Cluster computing is a well-established technology ofaccelerating image processing algorithms and nonrigid reg-istration is also no exception The main strategy of clustercomputing is composed of two stages dividing the medicalimage into many different small partitions and processingthem independently on different computers while minimiz-ing the communication cost Zheng et al [15] used mutualinformation as a similarity metric and developed parallelnonrigid registration algorithms on a computer clusterResults reported in Zheng et al [15] for B-splines show aspeedup of 1198992 for 119899 processors compared to a sequentialimplementation
The recent developments in many-core processor tech-nology offer new opportunities for truly large-scale andcost-effective parallel computing on a single chip Mean-while multiprocessor computing techniques are utilized foraccelerating image registration algorithms Jiang et al [16]used a FPGA-based implementation leading to a speedupof 32 times compared with a 2666GHz CPU executionRohlfing and Maurer Jr [17] reduced computation timemore than 50 times by using 64 CPUs of a shared memorysupercomputer More recently Rohrer et al [18] presented amulticore implementation of the B-spline computation basedon a Cell Broadband Engine platform reporting a speedup of40 times over a sequential CPU implementation Althoughthese techniques provide considerable computation timeimprovements they require either high technical knowledgeor hardware with prices inhibiting wide adoption
Modern GPU is the extension of many-core technologyand has a large number of cores on the chip and this many-core architecture of GPU ismore suitable for parallel comput-ing For algorithms that can be parallelized within the SIMDmodel a single GPU offers the computing power equivalentto a small cluster of desktop computers As noted in theintroduction a bottleneck of the B-spline FFD registrationalgorithm is the cubic B-spline computation Consequentlysomework has been done to speed up this part by using GPUFor example Sigg and Hadwiger [19] developed a cubic B-spline interpolation method utilizing linear interpolation ofthe GPU hardware however such an approach suffers fromthe limitations imposed by the low fixed-point precision ofthe hardware interpolator as reported by Ruijters et al [20]which limits its applicability to robust and precise medicalimage registration
In addition researchers proposed many improvedapproaches to accelerate B-spline registration algorithm
Computational and Mathematical Methods in Medicine 3
with respect to B-spline interpolation and similarity metriccomputation Modat et al [21] presented a parallel-friendlyformulation algorithm that is suitable for GPU it onlytake less than 1min to perform registration of T1-weightedMR images without reducing the registration accuracyShackleford et al [22] employed the SSD as similarity metricand accelerated B-spline registration within the stream-processing model using GPU and this algorithm achieveda good speedup over the single-threaded CPU Ikeda et al[23] proposed an efficient GPU-based acceleration methodfor the nonrigid registration of multimodal images and theirmain contribution is efficient utilization of on-chip memoryfor NormalizedMutual Information (NMI) Ellingwood et al[24] adopted the sum of squared tissue volume difference asa similarity metric and thus developed a multilevel B-splinetransform method to implement nonrigid mass-preservingregistration of two CT lung images on GPU and this methodoutperforms its multithreaded CPU version in terms ofrunning time
3 Our Algorithm
Aiming to significantly improve the accuracy and the per-formance of B-spline registration algorithm we propose aCUDA-based parallel B-spline registration algorithm whichemploys LSD as the similarity metric and used NCG asoptimization strategy In this section we describe the detailsof our B-spline nonrigid image registration algorithm Firstlywe represent the theory of describing nonrigid deforma-tion using the cubic B-spline basis function Secondly weintroduce the LSD as the similarity metric of our algorithmFinally we explain the NCG optimization procedure and thegradient of similarity metric in our algorithm
31 B-Spline Free-FormDeformation B-spline FFD is used asthe nonrigid transformation model and three-dimensional(3D) deformation field is defined by 3D mesh of controlpoints in the Cartesian coordinatesThe deformation field fora voxel located at coordinates (119909 119910 119911) in the reference imagecan be mathematically described as follows [15 21]
(119909 119910 119911) = 3sum119894=0
3sum119895=0
3sum119896=0
119861119894 (119906) 119861119895 (V) 119861119896 (119908) 120601 (119897 119898 119899) (1)
In (1) 119861119894(sdot) is the cubic B-spline basis function in the 119909direction [8] and 120601 represents the deformation mesh In the3Dmedical image data a partition region is composed by theeight adjacent control points and the 3D spacing coordinateof this partition region is shown as follows
Ω119909 = lfloor 119909119873119909 rfloor minus 1Ω119910 = lfloor 119910119873119910rfloor minus 1Ω119911 = lfloor 119911119873119911 rfloor minus 1
(2)
where 119873119909 119873119910 and 119873119911 are the voxel numbers of the 119909 119910and 119911 directions of the control point mesh Displacementof voxels in each region Ω(119909 119910 119911) are affected around 64control points The 64 control points coordinates CP(119897 119898 119899)are calculated in the following scheme [8 25]
CP119897 = lfloor 119909119873119909 minus 1 + 119894rfloor CP119898 = lfloor 119910119873119910 minus 1 + 119895rfloor CP119899 = lfloor 119911119873119911 minus 1 + 119896rfloor
(3)
In the medical image volume data the voxel with thecoordinate (119909 119910 119911) has the local coordinate Local(119906 V 119908) inthe region Ω(119909 119910 119911) and the value is normalized in [0 1] asfollows [8 25]
Local119906 = 119909119873119909 minus lfloor 119909119873119909 rfloor LocalV = 119910119873119910 minus lfloor 119910119873119910rfloor Local119908 = 119911119873119911 minus lfloor 119911119873119911 rfloor
(4)
32 The Similarity Metric LSD A similarity metric quan-tifies the degree of alignment and is used to optimize thetransformationrsquos parameters to achieve maximal alignmentThe similarity metric has a key influence on the accuracyof registration results Sum of Squared Difference (SSD) is avery classical similarity metric based on pixel computationand it is widely used in the monomodality medical imageregistration However when SSD is used as the similaritymetric due to the fact that the SSD values of the differentiterations are very closed in the later stage of optimizationprocess it leads to appear premature convergence rate andalso affects the accuracy of the registration results
Since the function value of the logarithm transformationhas different influence on the different intervals of the defini-tion domain especially when the independent variable valueis more and more small the function value changes morequickly In other words the difference between two values oflogarithmic function is more sensitive to the interval whichhas a small logarithmic values than the interval which has alarge logarithmic values In the latter stage of the registrationprocess the difference between the reference image and themoving image subject to local deformation becomes muchsmaller the logarithmic operation can make the SSD ofsimilarity metric to change more quickly and it is helpfulto find best deformation mesh more effectively Therefore inorder to further improve the accuracy of registration resultswe perform logarithmic operation on SSD and introduce
4 Computational and Mathematical Methods in Medicine
the LSD as the similarity metric of the B-spline registra-tion algorithm LSD can be mathematically described asfollows
LSD = 1119873119909119873119910119873119911sdot 119873119909sum119909=1
119873119910sum119910=1
119873119911sum119911=1
ln ((119865 (119909 + 119879119909 119910 + 119879119910 119911 + 119879119911) minus 119877 (119909 119910 119911))2 + 1) (5)
In (5) 119877(119909 119910 119911) represents the reference image 119865(119909 +119879119909 119910 + 119879119910 119911 + 119879119911) is the moving image with B-splinedeformation and 119873119909 119873119910 and 119873119911 are separately the voxelnumbers in the 119909119910 and 119911 directions of reference andmovingimages In order to promote smooth deformation a penaltyterm119862smooth is added to the LSD valueThefinal cost function119862 to be optimized is a balance between the LSD and thedeformation penalty
119862 = (1 minus 120582) times LSD minus 120582 times 119862smooth (6)
where 0 le 120582 lt 1 The penalty-term 119862smooth was first used forimage registration by Rueckert et al [8]
33 B-Spline Registration Optimization Based on NCG Con-jugate Gradient (CG) is a very effective optimization methodfor optimization problem CG overcomes the shortcoming ofslow convergence of the gradient descent method and alsoavoids the shortage from Newtonrsquos method which needs tostore and compute the Hessian matrix and the inverse matrix[26] The NCG method is an extension of CG and suitablefor minimizing general nonlinear functions Due to the factthat the B-spline registration process is a nonlinear optimiza-tion problem the NCG method is adopted for the entireregistration process optimization in our algorithm So it isimportant to calculate the gradient of the similarity metricfor control points in every iteration and update the controlpoint mesh according to the negative gradient directionfrom the previous search Iteratively the process of updatingparameters of control point mesh can be mathematicallydescribed in
120601119894+1 = 120601119894 minus 120572119894119889119894 119894 = 1 2 3 (7)
where 120601119894 = (120601119909 120601119910 120601119911) denotes the displacement vectorof control points in the iteration process 119894 is the iterationnumber 120572119894 is a scalar which represents the displacementmagnitude of the negative gradient direction and is obtainedusing the inexact linear search method 119889119894 represents thesearch direction which is calculated as
119889119894 =minus120597119862120597120601119894 for 119894 = 1minus 120597119862120597120601119894 + 120573119894119889119894minus1 for 119894 ge 2 (8)
where 120573119894 is a variable which is calculated as
120573119894 = max (0min (120573HS119894 120573DY119894 )) (9)
120573HS119894 = (120597119862120597120601119894)119879 times 120597119862120597120601119894119889119894minus1 (120597119862120597120601119894 minus 120597119862120597120601119894minus1)119879
120573DY119894 = (120597119862120597120601119894)119879 times 120597119862120597120601119894119889119879119894minus1 (120597119862120597120601119894 minus 120597119862120597120601119894minus1)
(10)
As seen in (10) we thus require the derivative 120597119862120597120601 ofthe cost function
120597119862120597120601 = (1 minus 120582) times 120597LSD120597120601 minus 120582 times 120597119862smooth120597120601 (11)
In order to decrease the computational complexity wepropose a voxel-centric approach to evaluate the point-centric gradient using the chain rule We first compute thegradient for every voxel and then gather the information fromall voxels to compute the gradient for control points In (11)120597LSD120597120601 is calculated via the chain rule as
120597LSD120597120601 = 1119873119909119873119910119873119911119873119909sum119909=1
119873119910sum119910=1
119873119911sum119911=1
120597LSD120597 times 120597120597120601 (12)
where 120597LSD120597 denotes the partial derivative of similaritymetric for voxels and it is calculated as follows
120597LSD120597 (119909 119910 119911)= 2 times nabla119865 (119909 119910 119911) times (119865 (119909 + Δ119909 119910 + Δ119910 119911 + Δ119911) minus 119877 (119909 119910 119911))1 + (119865 (119909 + Δ119909 119910 + Δ119910 119911 + Δ119911) minus 119877 (119909 119910 119911))2 (13)
where 119865(119909+Δ119909 119910+Δ119910 119911+Δ119911) is the moving image after thedeformation119877(119909 119910 119911) is the reference image andnabla119865(119909 119910 119911)denotes the initial gradient of the moving image In (12)the second term is the derivative value of deformation fieldwith respect to a control point and the calculation form isdescribed in
120597120597120601 = 3sum119897=0
3sum119898=0
3sum119899=0
119861119897 (119906) 119861119898 (V) 119861119899 (119908) (14)
In (14) 120597120597120601 is the only metric related to the B-splinebasis function and it is also a constant value when the localcoordinates of voxels in the mesh partition are determinedIn order to simplify the parallel computing process of ouralgorithm we set 120582 to 0
4 Parallel Accelerating Procedure forOur Algorithm
To effectively improve the execution efficiency of the B-splineregistration we employ the GPU to accelerate the time-consuming steps of our algorithm In this section we presentthe parallel computing details of our algorithm using the
Computational and Mathematical Methods in Medicine 5
Input Reference and moving images (R F) image resolutions and control points et alOutput Optimized control points meshProcess(1) Read reference images R and moving images F on the CPU(2) Initialize the control points mesh on the CPU(3) Pre-calculate reusable data such as the product of basis function and store it in the LUTs(4) Transfer the above parameters from the CPU to the GPU(5) repeat(6) Update control points mesh and perform B-spline transformation on the GPU(7) Compute the similarity metric LSD on the GPU(8) Compute the gradient vector of LSD and the gradient norm on the GPU(9) Transfer data from the GPU to the CPU for the NCG optimization(10) until abs(119862119894 minus 119862119894minus1) le 119905(11) Transfer the optimized control points mesh from the GPU to the CPU
Algorithm 1 The GPU-accelerated B-spline registration based on LSD and NCG
GPU First we explain the main procedure of our algorithmbased on GPU Secondly we develop the parallel computingstrategy of B-spline registration based on the characteristicof locality of B-spline transformation and design the LUTsfor storing the reusable data for parallel kernel functionsexecuting on the GPU Then we present kernel functionsfor these time-consuming steps Finally we summarize ourproposed parallel algorithm based on GPU
41 The Main Procedure of Our Algorithm In general dataparallelism is the main requirement for an algorithm tobenefit from GPU execution Our nonrigid registration algo-rithm based on B-spline FFD comprises three componentswhich may be considered independently transformation ofthe moving image using the splines interpolation evaluationof a similarity metric and optimization against this similaritymetric In these three components the optimization processalways requires adequate iterations and the current iterationis always dependent to the previous iteration so it is serialprocess and is not implemented in parallel on the GPUIndividually B-splines interpolation and evaluation of asimilaritymetricmay be formulated in a data parallel manneras they mainly consist of voxel-wise computations In ouralgorithmNCG is used for the optimization so the first orderderivative of the similarity metric is computed to determinethe optimal direction of the next iteration Since the LSD isused as the similarity metric for evaluating the registrationquality in our algorithm we also design the parallel kernelfunction of the gradient of similarity metric LSD in terms ofthe highly parallel data features The main framework of ouralgorithm using GPU is shown in Algorithm 1
42 Parallel Computing Strategy for B-Spline Registration Inthe B-spline registration algorithm the elastic deformation ofthe moving image is uniform cubic B-spline transformationwhich is parameterized by control pointmesh Figure 1 showsthat the elastic deformation of the 2D moving image isdescribed using control point mesh In Figure 1(a) since thered control point is the current central control point of 4times 4 regions the displacement vector of the central control
point will be established by the around 4 times 4 regions and isentirely unrelated to the other regions of the moving imagein Figure 1(b) the displacement vector of each pixel locatedin the partition region is determined by its neighboring 4 times4 control points when updating the B-spline transformationon the moving images In other words relative displacementchanges of any control points only affect the pixels in thelocal region and are independent of the other global pixelsof the moving images so B-spline transformation has a goodability to describe the local elastic deformation of movingimages Therefore this locality characteristic of B-splinetransformation is a key foundation for designing the parallelcomputing strategy
To improve effectively the executing speed of our B-spline registration algorithm using GPU we develop a par-allel computing strategy for B-spline registration and createLUTs to store the reusable data in the parallel processingprocedure Our parallel computing strategy is dividing themoving images intomany different small and nonoverlappingpartition regions in terms of the locality characteristic of B-spline transformation and then designing the parallel kernelfunctions to process them independently by many differentthreads on the different cores of GPU while utilizing thedifferent memory of GPU effectively and minimizing thecommunication cost of thread blocks
In order to ensure that the registration process on theGPU can effectively be executed in parallel the followinginitialization needs to be done on the CPU before the entireprocess (1) image volume data is loaded into host memoryand copied from the host memory to the GPU memorythen bounding it to the texture memory of the GPU canimprove the data access efficiency (2) the initial B-splinemesh parameters are loaded from the host memory into theglobalmemory of theGPU (3)we precompute some reusablevalues such as theB-spline basis function products which areconstructed and stored as LUTs in the texture memory of theGPU In terms of the symmetry of volume data we can createthree LUTs for the parallel process as follows
(1) The lookup table LUTbfp of basis function productsFor the same normalized local coordinate (119906 V 119908) we
6 Computational and Mathematical Methods in Medicine
Pixel (voxel) Control point
Central control point
Point B (u = 26 = 16)
Point D (u = 26
= 46)
Point E (u = 46
= 56)
Point C (u = 16 = 06)
Point A (u = 26
= 16)
(l = 3 m = 2)
(l = 3 m = 1)
(l = 3 m = 0)
(l = 3 m = 3)
(l = 2 m = 2)
(l = 2 m = 1)
(l = 2 m = 0)
(l = 2 m = 3)
(l = 1 m = 2)
(l = 1 m = 1)
(l = 1 m = 0)
(l = 1 m = 3)
(l = 0 m = 2)
(l = 0 m = 1)
(l = 0 m = 0)
(l = 0 m = 3)
Ω1 Ω2 Ω3 Ω4
Ω5Ω6 Ω7 Ω8
Ω9Ω10 Ω11 Ω12
Ω13 Ω14 Ω15 Ω16
(a)
Pixel (voxel) Control point
A (u = 26 = 16)
B (u = 36 = 36)
(b)
Figure 1 The deformation of B-spline mesh deformation in 2D image data (a) shows the displacement vector calculation of central controlpoint (b) illustrates the displacement vector calculation of pixels in a local region The black points are control points and the deformationmesh is constituted by all the black control points the dashed square is a pixel and the image data is constituted by all the dashed squares thedisplacement values in the119883 and 119884 directions can be optimized for each control point The spacing of control point mesh includes six pixelsin the119883 and 119884 directions
precompute basis function products119861(119906)times119861(V)times119861(119908)and store them in the LUTbfp which can be reused inthe kernel functions of computing similarity metricand the gradient of similarity metricTherefore it canavoid repeated calculations and effectively improvethe computational speed For example in Figure 1(a)the two pixels (A and B) are in their respectivelocal partition regions with the same local coordinateso they can reuse the same value of B-spline basisfunction products
(2) The lookup table LUTcpi of control point indexesSince all voxels in the same region compute their dis-placement vectors using the same 64 control pointswe precompute the index set of control points in thesame region and create this LUT for storing them toimprove the executing efficiency
(3) The spatial gradient look-up table LUTgradient ofmoving images Because the gradient of the initialmoving image remains the same value in the entireregistration process we precompute the gradient ofmoving images on the CPU and create a LUT tosave them in the texture memory of GPU which canreduce the complexity of parallel calculation
43 Parallel Kernel Functions of Our Algorithm In everyiteration of our algorithm B-spline transformation sim-ilarity metric and the gradient of similarity metric arethree time-consuming steps In terms of the above parallel
computing strategy we need to design three kernel functionsfor these time-consuming steps and these kernel functionsare executed in parallel on the GPU by multiple threadsto improve the execution efficiency of our B-spline imageregistration algorithm Since B-spline transformation andsimilarity metric computation are calculated for each voxel ofthe moving images we only design a parallel kernel functionwhich sequentially calculates these two steps
431 B-Spline Transformation and Similarity Metric Compu-tation We use the LSD as the similarity metric to evaluatethe quality of deformation field in the proposed algorithmAs described in Section 32 LSD accumulates the square ofthe intensity difference between the reference images and themoving images subject to the deformation field In consider-ation of the computation of LSD with a good parallelizationwe design a kernel function kernelFunctionSimilarity() tocompute LSD and B-spline transformation in parallel onthe GPU in this paper The kernel function is illustrated inAlgorithm 2
432 SimilarityMetric Gradient for Control Points As shownin Figure 1 the displacement of each voxel in the same regionis affected by displacements of 16 control points aroundthe region when the moving image is subject to B-splinedeformation We compute the partial derivatives of all voxelsfor each control point in the same region and all voxelshousing in the same region have the contributions to 16
Computational and Mathematical Methods in Medicine 7
(1) Get the index of the thread and use it to obtain (119909 119910 119911) for the voxel(2) Use Eq (2) to get the coordinates Ω(119909 119910 119911) of the partition which houses the voxel(3) Use Eq (4) to normalized value (119906 V 119908) of voxel (119909 119910 119911) to within the range [0 1](4) V(119909 119910 119911) = 0(5) for (119894 119895 119896) from (0 0 0) to (3 3 3) do(6) 119880 = 120573119894(119906)120573119895(V)120573119896(119908)(7) V = V + 119880 times (Ω)(8) end for(9) Use Eq (6) to compute the similarity metric for the voxel(10) Use Eq (13) to compute 120597LSD120597 for the voxel
Algorithm 2 The pseudocode listing of the kernel function kernelFunctionSimilarity()
(1) Get the block index 119861 and the local thread index 119879(2) for 119875 = 0 to11987311990864 do(3) [119879] = 120597119862120597V[119874 + 119875 + 119879](4) Get the normalized coordinates (119906 V 119908) for the voxel within the region(5) 119894 = 0(6) for (119899119898 119897) from (0 0 0) to (3 3 3) do(7) 119880 = 120573119897(119906)120573119898(V)120573119899(119908)(8) [119879] = [119879] times 119880(9) Reduce [119879] and store in [0](10) syncthreads()(11) if 119879 = 0 then(12) [119894] = [119894] + [0](13) end if(14) syncthreads()(15) 119894 = 119894 + 1(16) end for(17) end for(18) 119878 = LUTcpi[64 times 119861 + 119879](19) [64 times 119878 + 119879] = [119879](20) Use tree-style reduction to reduce the gradient values in the shared memory(21) Store the reduction results in the global memory of GPU
Algorithm 3 The pseudocode listing of the kernel function CalSimilarityGradientKernelFunc()
control points around this partition region so each threadis corresponding to a partition region rather than a controlpoint to improve the executing performance of the kernelfunction on the GPU The kernel function CalSimilarity-GradientKernelFunc() calculating the gradient of similaritymetric for control points is designed as Algorithm 3
44 Summary of the Proposed Algorithm Our algorithm issummarized and illustrated in Figure 2 In the beginningof the registration process the image data precomputingLUTs and the initial B-spline mesh deformation parametersare loaded from the CPU to the GPU More specifically inorder to improve the efficiency of accessing the memory inGPU reference images and precomputing LUTs are boundto the texture memory of the GPU and the initial B-splinemesh data and moving images are loaded into the globalmemory of the GPU secondly two kernel functions areexecuted in parallel by multithreading on the GPU whichare designed to calculate the B-spline transformation for
the moving images according to the deformation meshthe similarity metric and the similarity metric gradient forcontrol points respectively and finally the similarity metricand its gradient values are transferred from the GPU tothe CPU for the NCG optimization the optimal B-splinedeformationmesh is outputtedwhen the optimized conditionwas meted otherwise update B-spline deformation meshparameters and continue to repeat the above registrationprocess until the optimal values are found
5 Experiment Results and Discussion
Weevaluated the performance of the proposed algorithmon amedical imaging dataset that was obtained from the databaseof retrospective image registration evaluation (RIRE) atthe Vanderbilt university [27] This dataset contains a lotof medical image volume data of different patients fromseveral protocols including CT T1-weighted (MR-T1) T2-weighted (MR-T2) and proton density (MR-PD) with a
8 Computational and Mathematical Methods in Medicine
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
GPU video memory
Texture memory
B-spline transformation
Initial deformation mesh Deformation mesh
Calculate the similarity metric
Calculate the similarity metric
derivative
Similarity metric
Similarity metric derivative for control points
Optimization
Nonlinear conjunct gradient
Output the best deformation mesh
The new deformation mesh
CPU GPU
DataOperation
Operation flowData flow
Pre-
com
putin
gda
ta
Image data
Parallel operation
Global memory
Yes
No
Figure 2The parallelization process of the proposed algorithm Light green areas represent the data required in the registration process blueareas describe major steps of our algorithm dashed arrows indicate the directions of data flow and the solid arrows illustrate the directionsof calculation processes
variety of slice thickness All the corresponding slices fromdifferent protocols are originally aligned with each other Weimplemented the proposed algorithm using CUDA C in theMicrosoft Visual Studio NET 2010 and used CUDA60 ofdriver and runtime libraries [28]The experimental hardwareconfiguration is shown in Table 1
51 Accuracy Comparison with Different Similarity MetricsIn the first experiment to validate the registration accuracyof the proposed algorithm we distorted the reference imageMR-T1 with a known nonrigid geometric transformationfield or the so-called ground truth Then we applied the
proposed algorithm and compared the registration results tothe other two B-spline registration algorithms using Sum ofAbsolute Difference (SAD) and SSD as a similarity metricrespectively which are implemented in the Insight Seg-mentation and Registration Toolkit (ITK) [29] And finallywe compared the obtained deformations fields with theground truth Figure 3 shows the registration results of threealgorithms for brain MR-T1 images Note that the registeredmoving images obtained by the proposed algorithm is visu-ally more similar in deformation to the reference image thanthe images produced by the SSD-based algorithm and theSAD-based algorithm respectively Moreover the estimated
Computational and Mathematical Methods in Medicine 9
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 3 Accuracy comparison with different similarity metrics (a) reference image (b) moving image which is distorted reference imagewith geometric distortion (c) ground truth deformation field (d)ndash(f) registered images using SAD-based SSD-based and our algorithmrespectively (g)ndash(i) estimated transformation using SAD-based SSD-based and our algorithm respectively
Table 1 The experimental hardware configuration
No Components Parameters1 CPU Intel(R) Xeon(R) 190GHz times 182 System memory 32GB3 Video card Tesla K20m4 Memory of video card 4GB5 CUDA cores 24966 GPU max clock rate 071 GHz7 Memory clock rate 2600MHz8 Memory bus width 320-bit
Table 2 MSE statistics of the estimated deformation field
Ground truth MSE (average) MSE (standard deviation)SAD SSD Ours SAD SSD Ours
20 0652 0547 0521 0057 0036 003432 0765 0576 0563 0062 0051 004644 0932 0789 0766 0065 0044 002653 1391 0915 0887 0078 0037 0031
transformation field resulting from our algorithm is moresimilar to the ground truth than those obtained using theother two algorithms
To measure the registration accuracy of the proposedalgorithm we computed the mean and standard deviationof the MSE between the ground truth and estimated dis-placement vectors Table 2 displays the MSE statistics of theestimated deformation when compared to the ground truthThe first column shows the mean ground truth deformationwhich represents the magnitude of the displacement vectorthat is used to generate moving images in each experiment
For each mean value of ground truth eight different trans-formation fields with this mean are generated and applied tothe reference image to generate the corresponding movingimage The other columns display the average and standarddeviation of MSE obtained by using three different similaritymetrics for the generated eight pairs of reference-movingimages The results obtained using the proposed algorithmare considerably small compared to those of SAD-based andSSD-based algorithm and our algorithm shows the superioraccuracy in comparison to the other two algorithms
52 AccuracyComparisonwithCPU Implementation For ourB-spline registration algorithm employing LSD as a similaritymetric and NCG as a optimization strategy we respectivelyimplemented it based on CPU and GPU and compared theregistration accuracy impact from the parallel computingframework for the four groups of medical images Since theresolution of these images is 512 times 512 the control pointmesh size the number of control points and the numberof regions are 16 times 16 35 times 35 and 32 times 32 respectivelyIn the GPU-based implementation of our algorithm we setthe grid size to 32 times 32 and the block size to 16 times 16 for thekernel function kernelFunctionSimilarity() and set the gridsize to 4 times 4 and the block size to 8 times 8 for the kernelfunction CalSimilarityGradientKernelFunc() Owing NCG isrespectively adopted in the two implementations we also setthe maximum iteration number to 100 in the optimizationprocess Figure 4 shows the results using two implementa-tions for the first group of chestCT images Figure 5 shows theresults that a reference image andmoving image of the humanhead are matched using two implementations As can beseen from Figures 4 and 5 the CPU-based implementationand the GPU-based implementation of our algorithm canboth work well in describing the elastic deformation between
10 Computational and Mathematical Methods in Medicine
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 4 The registration results for chest images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference result of the two images before registration (d)ndash(f) are respectively the best deformationmesh the moving image subjected to the best deformation and the differential result after registration using CPU-based implementation(g)ndash(i) are the best deformation mesh the moving image subjected to the best deformation and the differential result using our GPU-basedimplementation
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5 The registration results for brain images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference between the reference and moving image before registration (d)ndash(f) are respectively thebest deformation the moving image transformed with best deformation and the difference image after registration using the CPU-basedimplementation (g)ndash(i) are respectively the best deformation the transformedmoving image and the difference after registration using ourGPU-based implementation
reference and moving images and they can both obtainhighly accurate results
In order to evaluate the accuracy of registration resultssome researchers used some mathematical metrics Elling-wood et al [24] used the normalized RootMean Square Error(RMSE) to mathematically evaluate accuracy of the GPU
resultant displacement field against the single-threaded CPUimplementation RMSE is calculated as follows
RMSE = radicsum119909isinΩ 1003817100381710038171003817VCPU (119909) minus VGPU (119909)10038171003817100381710038172sum119909isinΩ 1003817100381710038171003817VCPU (119909)10038171003817100381710038172 (15)
Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

2 Computational and Mathematical Methods in Medicine
and robustness and is therefore able to perform bothmonomodality and multimodality image registration How-ever In the B-spline registration algorithm there are threetime-consuming steps B-spline interpolation similaritymet-ric computation and similaritymetric gradient computationFirst in the process of B-spline interpolation a coarse arrayof B-spline coefficients is considered as the input and afine array of displacement values is computed as the outputdefining the deformation vector field from the moving imageto the reference image Therefore B-spline interpolation isexpensive in terms of executing time for the fine deformationmesh withmany control points In addition similaritymetricis a very crucial step to measure the registration resultsand it has an important influence on the accuracy of theregistration results In addition similaritymetric is calculatedin each iteration of the B-spline registration algorithm andits computational efficiency has a serious impact on theperformance of the whole registration process Finally sim-ilarity metric gradient computation requires evaluating thepartial derivatives of the similaritymetric with respect to eachspline-coefficient value of all control points it is thereforea very time-consuming step to obtain better accuracy ofregistration results in the case of much more control pointsIn summary the B-spline registration algorithm always needsmore execution time for the larger amount of medicalimage data which limits the clinical applications of B-splineregistration [9 10]
Aiming to improve the accuracy and significantly accel-erate B-spline registration algorithm we develop a B-spline-based nonrigid registration algorithm that is suitable forexecuting on GPU by considering the LSD as similaritymetric In our algorithm all of the computation-intensivetasks are designed and implemented on GPU using theparallel computing framework Computing Unified DeviceArchitecture (CUDA) Experiments show that our algorithmimproves the accuracy of registration results and achieves aspeedup ratio of 17 times comparing to the single-threadedserial implementation The main contributions are summa-rized as follows
(1) We introduce the LSD as similarity metric in theB-spline registration algorithm to obtain the higherregistration accuracy for medical images
(2) We design a parallel computing strategy and createLUTs for B-splines registration to improve the execu-tion performance Meanwhile three time-consumingsteps including B-splines interpolation the similar-ity metric LSD and its gradient computation aredesigned in the form of the kernel functions whichare executed in parallel on GPU
The rest of this paper is organized as follows Section 2presents the related works of accelerating B-spline registra-tion using cluster many-core and GPU Section 3 describesour B-spline registration algorithm employed the LSD as thesimilarity metric and NCG optimization Section 4 explainsthe parallel computing details of our proposed algorithmbased on CUDA Section 5 shows experiments results andanalysis Finally Section 6 concludes our work
2 Related Work
The parallel computing technology is an effective way toaccelerate many general purpose applications and has a verycrucial influence on the field of high performance comput-ing Parallel operations can be performed independently ondifferent partition of medical images due to the good dataparallel characteristic of medical images At present parallelcomputing has been widely used in medical image process-ing [11 12] for example image registration [13 14] Thereare three parallel computing technologies for acceleratingmedical image registration cluster many-core and GPUcomputing
Cluster computing is a well-established technology ofaccelerating image processing algorithms and nonrigid reg-istration is also no exception The main strategy of clustercomputing is composed of two stages dividing the medicalimage into many different small partitions and processingthem independently on different computers while minimiz-ing the communication cost Zheng et al [15] used mutualinformation as a similarity metric and developed parallelnonrigid registration algorithms on a computer clusterResults reported in Zheng et al [15] for B-splines show aspeedup of 1198992 for 119899 processors compared to a sequentialimplementation
The recent developments in many-core processor tech-nology offer new opportunities for truly large-scale andcost-effective parallel computing on a single chip Mean-while multiprocessor computing techniques are utilized foraccelerating image registration algorithms Jiang et al [16]used a FPGA-based implementation leading to a speedupof 32 times compared with a 2666GHz CPU executionRohlfing and Maurer Jr [17] reduced computation timemore than 50 times by using 64 CPUs of a shared memorysupercomputer More recently Rohrer et al [18] presented amulticore implementation of the B-spline computation basedon a Cell Broadband Engine platform reporting a speedup of40 times over a sequential CPU implementation Althoughthese techniques provide considerable computation timeimprovements they require either high technical knowledgeor hardware with prices inhibiting wide adoption
Modern GPU is the extension of many-core technologyand has a large number of cores on the chip and this many-core architecture of GPU ismore suitable for parallel comput-ing For algorithms that can be parallelized within the SIMDmodel a single GPU offers the computing power equivalentto a small cluster of desktop computers As noted in theintroduction a bottleneck of the B-spline FFD registrationalgorithm is the cubic B-spline computation Consequentlysomework has been done to speed up this part by using GPUFor example Sigg and Hadwiger [19] developed a cubic B-spline interpolation method utilizing linear interpolation ofthe GPU hardware however such an approach suffers fromthe limitations imposed by the low fixed-point precision ofthe hardware interpolator as reported by Ruijters et al [20]which limits its applicability to robust and precise medicalimage registration
In addition researchers proposed many improvedapproaches to accelerate B-spline registration algorithm
Computational and Mathematical Methods in Medicine 3
with respect to B-spline interpolation and similarity metriccomputation Modat et al [21] presented a parallel-friendlyformulation algorithm that is suitable for GPU it onlytake less than 1min to perform registration of T1-weightedMR images without reducing the registration accuracyShackleford et al [22] employed the SSD as similarity metricand accelerated B-spline registration within the stream-processing model using GPU and this algorithm achieveda good speedup over the single-threaded CPU Ikeda et al[23] proposed an efficient GPU-based acceleration methodfor the nonrigid registration of multimodal images and theirmain contribution is efficient utilization of on-chip memoryfor NormalizedMutual Information (NMI) Ellingwood et al[24] adopted the sum of squared tissue volume difference asa similarity metric and thus developed a multilevel B-splinetransform method to implement nonrigid mass-preservingregistration of two CT lung images on GPU and this methodoutperforms its multithreaded CPU version in terms ofrunning time
3 Our Algorithm
Aiming to significantly improve the accuracy and the per-formance of B-spline registration algorithm we propose aCUDA-based parallel B-spline registration algorithm whichemploys LSD as the similarity metric and used NCG asoptimization strategy In this section we describe the detailsof our B-spline nonrigid image registration algorithm Firstlywe represent the theory of describing nonrigid deforma-tion using the cubic B-spline basis function Secondly weintroduce the LSD as the similarity metric of our algorithmFinally we explain the NCG optimization procedure and thegradient of similarity metric in our algorithm
31 B-Spline Free-FormDeformation B-spline FFD is used asthe nonrigid transformation model and three-dimensional(3D) deformation field is defined by 3D mesh of controlpoints in the Cartesian coordinatesThe deformation field fora voxel located at coordinates (119909 119910 119911) in the reference imagecan be mathematically described as follows [15 21]
(119909 119910 119911) = 3sum119894=0
3sum119895=0
3sum119896=0
119861119894 (119906) 119861119895 (V) 119861119896 (119908) 120601 (119897 119898 119899) (1)
In (1) 119861119894(sdot) is the cubic B-spline basis function in the 119909direction [8] and 120601 represents the deformation mesh In the3Dmedical image data a partition region is composed by theeight adjacent control points and the 3D spacing coordinateof this partition region is shown as follows
Ω119909 = lfloor 119909119873119909 rfloor minus 1Ω119910 = lfloor 119910119873119910rfloor minus 1Ω119911 = lfloor 119911119873119911 rfloor minus 1
(2)
where 119873119909 119873119910 and 119873119911 are the voxel numbers of the 119909 119910and 119911 directions of the control point mesh Displacementof voxels in each region Ω(119909 119910 119911) are affected around 64control points The 64 control points coordinates CP(119897 119898 119899)are calculated in the following scheme [8 25]
CP119897 = lfloor 119909119873119909 minus 1 + 119894rfloor CP119898 = lfloor 119910119873119910 minus 1 + 119895rfloor CP119899 = lfloor 119911119873119911 minus 1 + 119896rfloor
(3)
In the medical image volume data the voxel with thecoordinate (119909 119910 119911) has the local coordinate Local(119906 V 119908) inthe region Ω(119909 119910 119911) and the value is normalized in [0 1] asfollows [8 25]
Local119906 = 119909119873119909 minus lfloor 119909119873119909 rfloor LocalV = 119910119873119910 minus lfloor 119910119873119910rfloor Local119908 = 119911119873119911 minus lfloor 119911119873119911 rfloor
(4)
32 The Similarity Metric LSD A similarity metric quan-tifies the degree of alignment and is used to optimize thetransformationrsquos parameters to achieve maximal alignmentThe similarity metric has a key influence on the accuracyof registration results Sum of Squared Difference (SSD) is avery classical similarity metric based on pixel computationand it is widely used in the monomodality medical imageregistration However when SSD is used as the similaritymetric due to the fact that the SSD values of the differentiterations are very closed in the later stage of optimizationprocess it leads to appear premature convergence rate andalso affects the accuracy of the registration results
Since the function value of the logarithm transformationhas different influence on the different intervals of the defini-tion domain especially when the independent variable valueis more and more small the function value changes morequickly In other words the difference between two values oflogarithmic function is more sensitive to the interval whichhas a small logarithmic values than the interval which has alarge logarithmic values In the latter stage of the registrationprocess the difference between the reference image and themoving image subject to local deformation becomes muchsmaller the logarithmic operation can make the SSD ofsimilarity metric to change more quickly and it is helpfulto find best deformation mesh more effectively Therefore inorder to further improve the accuracy of registration resultswe perform logarithmic operation on SSD and introduce
4 Computational and Mathematical Methods in Medicine
the LSD as the similarity metric of the B-spline registra-tion algorithm LSD can be mathematically described asfollows
LSD = 1119873119909119873119910119873119911sdot 119873119909sum119909=1
119873119910sum119910=1
119873119911sum119911=1
ln ((119865 (119909 + 119879119909 119910 + 119879119910 119911 + 119879119911) minus 119877 (119909 119910 119911))2 + 1) (5)
In (5) 119877(119909 119910 119911) represents the reference image 119865(119909 +119879119909 119910 + 119879119910 119911 + 119879119911) is the moving image with B-splinedeformation and 119873119909 119873119910 and 119873119911 are separately the voxelnumbers in the 119909119910 and 119911 directions of reference andmovingimages In order to promote smooth deformation a penaltyterm119862smooth is added to the LSD valueThefinal cost function119862 to be optimized is a balance between the LSD and thedeformation penalty
119862 = (1 minus 120582) times LSD minus 120582 times 119862smooth (6)
where 0 le 120582 lt 1 The penalty-term 119862smooth was first used forimage registration by Rueckert et al [8]
33 B-Spline Registration Optimization Based on NCG Con-jugate Gradient (CG) is a very effective optimization methodfor optimization problem CG overcomes the shortcoming ofslow convergence of the gradient descent method and alsoavoids the shortage from Newtonrsquos method which needs tostore and compute the Hessian matrix and the inverse matrix[26] The NCG method is an extension of CG and suitablefor minimizing general nonlinear functions Due to the factthat the B-spline registration process is a nonlinear optimiza-tion problem the NCG method is adopted for the entireregistration process optimization in our algorithm So it isimportant to calculate the gradient of the similarity metricfor control points in every iteration and update the controlpoint mesh according to the negative gradient directionfrom the previous search Iteratively the process of updatingparameters of control point mesh can be mathematicallydescribed in
120601119894+1 = 120601119894 minus 120572119894119889119894 119894 = 1 2 3 (7)
where 120601119894 = (120601119909 120601119910 120601119911) denotes the displacement vectorof control points in the iteration process 119894 is the iterationnumber 120572119894 is a scalar which represents the displacementmagnitude of the negative gradient direction and is obtainedusing the inexact linear search method 119889119894 represents thesearch direction which is calculated as
119889119894 =minus120597119862120597120601119894 for 119894 = 1minus 120597119862120597120601119894 + 120573119894119889119894minus1 for 119894 ge 2 (8)
where 120573119894 is a variable which is calculated as
120573119894 = max (0min (120573HS119894 120573DY119894 )) (9)
120573HS119894 = (120597119862120597120601119894)119879 times 120597119862120597120601119894119889119894minus1 (120597119862120597120601119894 minus 120597119862120597120601119894minus1)119879
120573DY119894 = (120597119862120597120601119894)119879 times 120597119862120597120601119894119889119879119894minus1 (120597119862120597120601119894 minus 120597119862120597120601119894minus1)
(10)
As seen in (10) we thus require the derivative 120597119862120597120601 ofthe cost function
120597119862120597120601 = (1 minus 120582) times 120597LSD120597120601 minus 120582 times 120597119862smooth120597120601 (11)
In order to decrease the computational complexity wepropose a voxel-centric approach to evaluate the point-centric gradient using the chain rule We first compute thegradient for every voxel and then gather the information fromall voxels to compute the gradient for control points In (11)120597LSD120597120601 is calculated via the chain rule as
120597LSD120597120601 = 1119873119909119873119910119873119911119873119909sum119909=1
119873119910sum119910=1
119873119911sum119911=1
120597LSD120597 times 120597120597120601 (12)
where 120597LSD120597 denotes the partial derivative of similaritymetric for voxels and it is calculated as follows
120597LSD120597 (119909 119910 119911)= 2 times nabla119865 (119909 119910 119911) times (119865 (119909 + Δ119909 119910 + Δ119910 119911 + Δ119911) minus 119877 (119909 119910 119911))1 + (119865 (119909 + Δ119909 119910 + Δ119910 119911 + Δ119911) minus 119877 (119909 119910 119911))2 (13)
where 119865(119909+Δ119909 119910+Δ119910 119911+Δ119911) is the moving image after thedeformation119877(119909 119910 119911) is the reference image andnabla119865(119909 119910 119911)denotes the initial gradient of the moving image In (12)the second term is the derivative value of deformation fieldwith respect to a control point and the calculation form isdescribed in
120597120597120601 = 3sum119897=0
3sum119898=0
3sum119899=0
119861119897 (119906) 119861119898 (V) 119861119899 (119908) (14)
In (14) 120597120597120601 is the only metric related to the B-splinebasis function and it is also a constant value when the localcoordinates of voxels in the mesh partition are determinedIn order to simplify the parallel computing process of ouralgorithm we set 120582 to 0
4 Parallel Accelerating Procedure forOur Algorithm
To effectively improve the execution efficiency of the B-splineregistration we employ the GPU to accelerate the time-consuming steps of our algorithm In this section we presentthe parallel computing details of our algorithm using the
Computational and Mathematical Methods in Medicine 5
Input Reference and moving images (R F) image resolutions and control points et alOutput Optimized control points meshProcess(1) Read reference images R and moving images F on the CPU(2) Initialize the control points mesh on the CPU(3) Pre-calculate reusable data such as the product of basis function and store it in the LUTs(4) Transfer the above parameters from the CPU to the GPU(5) repeat(6) Update control points mesh and perform B-spline transformation on the GPU(7) Compute the similarity metric LSD on the GPU(8) Compute the gradient vector of LSD and the gradient norm on the GPU(9) Transfer data from the GPU to the CPU for the NCG optimization(10) until abs(119862119894 minus 119862119894minus1) le 119905(11) Transfer the optimized control points mesh from the GPU to the CPU
Algorithm 1 The GPU-accelerated B-spline registration based on LSD and NCG
GPU First we explain the main procedure of our algorithmbased on GPU Secondly we develop the parallel computingstrategy of B-spline registration based on the characteristicof locality of B-spline transformation and design the LUTsfor storing the reusable data for parallel kernel functionsexecuting on the GPU Then we present kernel functionsfor these time-consuming steps Finally we summarize ourproposed parallel algorithm based on GPU
41 The Main Procedure of Our Algorithm In general dataparallelism is the main requirement for an algorithm tobenefit from GPU execution Our nonrigid registration algo-rithm based on B-spline FFD comprises three componentswhich may be considered independently transformation ofthe moving image using the splines interpolation evaluationof a similarity metric and optimization against this similaritymetric In these three components the optimization processalways requires adequate iterations and the current iterationis always dependent to the previous iteration so it is serialprocess and is not implemented in parallel on the GPUIndividually B-splines interpolation and evaluation of asimilaritymetricmay be formulated in a data parallel manneras they mainly consist of voxel-wise computations In ouralgorithmNCG is used for the optimization so the first orderderivative of the similarity metric is computed to determinethe optimal direction of the next iteration Since the LSD isused as the similarity metric for evaluating the registrationquality in our algorithm we also design the parallel kernelfunction of the gradient of similarity metric LSD in terms ofthe highly parallel data features The main framework of ouralgorithm using GPU is shown in Algorithm 1
42 Parallel Computing Strategy for B-Spline Registration Inthe B-spline registration algorithm the elastic deformation ofthe moving image is uniform cubic B-spline transformationwhich is parameterized by control pointmesh Figure 1 showsthat the elastic deformation of the 2D moving image isdescribed using control point mesh In Figure 1(a) since thered control point is the current central control point of 4times 4 regions the displacement vector of the central control
point will be established by the around 4 times 4 regions and isentirely unrelated to the other regions of the moving imagein Figure 1(b) the displacement vector of each pixel locatedin the partition region is determined by its neighboring 4 times4 control points when updating the B-spline transformationon the moving images In other words relative displacementchanges of any control points only affect the pixels in thelocal region and are independent of the other global pixelsof the moving images so B-spline transformation has a goodability to describe the local elastic deformation of movingimages Therefore this locality characteristic of B-splinetransformation is a key foundation for designing the parallelcomputing strategy
To improve effectively the executing speed of our B-spline registration algorithm using GPU we develop a par-allel computing strategy for B-spline registration and createLUTs to store the reusable data in the parallel processingprocedure Our parallel computing strategy is dividing themoving images intomany different small and nonoverlappingpartition regions in terms of the locality characteristic of B-spline transformation and then designing the parallel kernelfunctions to process them independently by many differentthreads on the different cores of GPU while utilizing thedifferent memory of GPU effectively and minimizing thecommunication cost of thread blocks
In order to ensure that the registration process on theGPU can effectively be executed in parallel the followinginitialization needs to be done on the CPU before the entireprocess (1) image volume data is loaded into host memoryand copied from the host memory to the GPU memorythen bounding it to the texture memory of the GPU canimprove the data access efficiency (2) the initial B-splinemesh parameters are loaded from the host memory into theglobalmemory of theGPU (3)we precompute some reusablevalues such as theB-spline basis function products which areconstructed and stored as LUTs in the texture memory of theGPU In terms of the symmetry of volume data we can createthree LUTs for the parallel process as follows
(1) The lookup table LUTbfp of basis function productsFor the same normalized local coordinate (119906 V 119908) we
6 Computational and Mathematical Methods in Medicine
Pixel (voxel) Control point
Central control point
Point B (u = 26 = 16)
Point D (u = 26
= 46)
Point E (u = 46
= 56)
Point C (u = 16 = 06)
Point A (u = 26
= 16)
(l = 3 m = 2)
(l = 3 m = 1)
(l = 3 m = 0)
(l = 3 m = 3)
(l = 2 m = 2)
(l = 2 m = 1)
(l = 2 m = 0)
(l = 2 m = 3)
(l = 1 m = 2)
(l = 1 m = 1)
(l = 1 m = 0)
(l = 1 m = 3)
(l = 0 m = 2)
(l = 0 m = 1)
(l = 0 m = 0)
(l = 0 m = 3)
Ω1 Ω2 Ω3 Ω4
Ω5Ω6 Ω7 Ω8
Ω9Ω10 Ω11 Ω12
Ω13 Ω14 Ω15 Ω16
(a)
Pixel (voxel) Control point
A (u = 26 = 16)
B (u = 36 = 36)
(b)
Figure 1 The deformation of B-spline mesh deformation in 2D image data (a) shows the displacement vector calculation of central controlpoint (b) illustrates the displacement vector calculation of pixels in a local region The black points are control points and the deformationmesh is constituted by all the black control points the dashed square is a pixel and the image data is constituted by all the dashed squares thedisplacement values in the119883 and 119884 directions can be optimized for each control point The spacing of control point mesh includes six pixelsin the119883 and 119884 directions
precompute basis function products119861(119906)times119861(V)times119861(119908)and store them in the LUTbfp which can be reused inthe kernel functions of computing similarity metricand the gradient of similarity metricTherefore it canavoid repeated calculations and effectively improvethe computational speed For example in Figure 1(a)the two pixels (A and B) are in their respectivelocal partition regions with the same local coordinateso they can reuse the same value of B-spline basisfunction products
(2) The lookup table LUTcpi of control point indexesSince all voxels in the same region compute their dis-placement vectors using the same 64 control pointswe precompute the index set of control points in thesame region and create this LUT for storing them toimprove the executing efficiency
(3) The spatial gradient look-up table LUTgradient ofmoving images Because the gradient of the initialmoving image remains the same value in the entireregistration process we precompute the gradient ofmoving images on the CPU and create a LUT tosave them in the texture memory of GPU which canreduce the complexity of parallel calculation
43 Parallel Kernel Functions of Our Algorithm In everyiteration of our algorithm B-spline transformation sim-ilarity metric and the gradient of similarity metric arethree time-consuming steps In terms of the above parallel
computing strategy we need to design three kernel functionsfor these time-consuming steps and these kernel functionsare executed in parallel on the GPU by multiple threadsto improve the execution efficiency of our B-spline imageregistration algorithm Since B-spline transformation andsimilarity metric computation are calculated for each voxel ofthe moving images we only design a parallel kernel functionwhich sequentially calculates these two steps
431 B-Spline Transformation and Similarity Metric Compu-tation We use the LSD as the similarity metric to evaluatethe quality of deformation field in the proposed algorithmAs described in Section 32 LSD accumulates the square ofthe intensity difference between the reference images and themoving images subject to the deformation field In consider-ation of the computation of LSD with a good parallelizationwe design a kernel function kernelFunctionSimilarity() tocompute LSD and B-spline transformation in parallel onthe GPU in this paper The kernel function is illustrated inAlgorithm 2
432 SimilarityMetric Gradient for Control Points As shownin Figure 1 the displacement of each voxel in the same regionis affected by displacements of 16 control points aroundthe region when the moving image is subject to B-splinedeformation We compute the partial derivatives of all voxelsfor each control point in the same region and all voxelshousing in the same region have the contributions to 16
Computational and Mathematical Methods in Medicine 7
(1) Get the index of the thread and use it to obtain (119909 119910 119911) for the voxel(2) Use Eq (2) to get the coordinates Ω(119909 119910 119911) of the partition which houses the voxel(3) Use Eq (4) to normalized value (119906 V 119908) of voxel (119909 119910 119911) to within the range [0 1](4) V(119909 119910 119911) = 0(5) for (119894 119895 119896) from (0 0 0) to (3 3 3) do(6) 119880 = 120573119894(119906)120573119895(V)120573119896(119908)(7) V = V + 119880 times (Ω)(8) end for(9) Use Eq (6) to compute the similarity metric for the voxel(10) Use Eq (13) to compute 120597LSD120597 for the voxel
Algorithm 2 The pseudocode listing of the kernel function kernelFunctionSimilarity()
(1) Get the block index 119861 and the local thread index 119879(2) for 119875 = 0 to11987311990864 do(3) [119879] = 120597119862120597V[119874 + 119875 + 119879](4) Get the normalized coordinates (119906 V 119908) for the voxel within the region(5) 119894 = 0(6) for (119899119898 119897) from (0 0 0) to (3 3 3) do(7) 119880 = 120573119897(119906)120573119898(V)120573119899(119908)(8) [119879] = [119879] times 119880(9) Reduce [119879] and store in [0](10) syncthreads()(11) if 119879 = 0 then(12) [119894] = [119894] + [0](13) end if(14) syncthreads()(15) 119894 = 119894 + 1(16) end for(17) end for(18) 119878 = LUTcpi[64 times 119861 + 119879](19) [64 times 119878 + 119879] = [119879](20) Use tree-style reduction to reduce the gradient values in the shared memory(21) Store the reduction results in the global memory of GPU
Algorithm 3 The pseudocode listing of the kernel function CalSimilarityGradientKernelFunc()
control points around this partition region so each threadis corresponding to a partition region rather than a controlpoint to improve the executing performance of the kernelfunction on the GPU The kernel function CalSimilarity-GradientKernelFunc() calculating the gradient of similaritymetric for control points is designed as Algorithm 3
44 Summary of the Proposed Algorithm Our algorithm issummarized and illustrated in Figure 2 In the beginningof the registration process the image data precomputingLUTs and the initial B-spline mesh deformation parametersare loaded from the CPU to the GPU More specifically inorder to improve the efficiency of accessing the memory inGPU reference images and precomputing LUTs are boundto the texture memory of the GPU and the initial B-splinemesh data and moving images are loaded into the globalmemory of the GPU secondly two kernel functions areexecuted in parallel by multithreading on the GPU whichare designed to calculate the B-spline transformation for
the moving images according to the deformation meshthe similarity metric and the similarity metric gradient forcontrol points respectively and finally the similarity metricand its gradient values are transferred from the GPU tothe CPU for the NCG optimization the optimal B-splinedeformationmesh is outputtedwhen the optimized conditionwas meted otherwise update B-spline deformation meshparameters and continue to repeat the above registrationprocess until the optimal values are found
5 Experiment Results and Discussion
Weevaluated the performance of the proposed algorithmon amedical imaging dataset that was obtained from the databaseof retrospective image registration evaluation (RIRE) atthe Vanderbilt university [27] This dataset contains a lotof medical image volume data of different patients fromseveral protocols including CT T1-weighted (MR-T1) T2-weighted (MR-T2) and proton density (MR-PD) with a
8 Computational and Mathematical Methods in Medicine
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
GPU video memory
Texture memory
B-spline transformation
Initial deformation mesh Deformation mesh
Calculate the similarity metric
Calculate the similarity metric
derivative
Similarity metric
Similarity metric derivative for control points
Optimization
Nonlinear conjunct gradient
Output the best deformation mesh
The new deformation mesh
CPU GPU
DataOperation
Operation flowData flow
Pre-
com
putin
gda
ta
Image data
Parallel operation
Global memory
Yes
No
Figure 2The parallelization process of the proposed algorithm Light green areas represent the data required in the registration process blueareas describe major steps of our algorithm dashed arrows indicate the directions of data flow and the solid arrows illustrate the directionsof calculation processes
variety of slice thickness All the corresponding slices fromdifferent protocols are originally aligned with each other Weimplemented the proposed algorithm using CUDA C in theMicrosoft Visual Studio NET 2010 and used CUDA60 ofdriver and runtime libraries [28]The experimental hardwareconfiguration is shown in Table 1
51 Accuracy Comparison with Different Similarity MetricsIn the first experiment to validate the registration accuracyof the proposed algorithm we distorted the reference imageMR-T1 with a known nonrigid geometric transformationfield or the so-called ground truth Then we applied the
proposed algorithm and compared the registration results tothe other two B-spline registration algorithms using Sum ofAbsolute Difference (SAD) and SSD as a similarity metricrespectively which are implemented in the Insight Seg-mentation and Registration Toolkit (ITK) [29] And finallywe compared the obtained deformations fields with theground truth Figure 3 shows the registration results of threealgorithms for brain MR-T1 images Note that the registeredmoving images obtained by the proposed algorithm is visu-ally more similar in deformation to the reference image thanthe images produced by the SSD-based algorithm and theSAD-based algorithm respectively Moreover the estimated
Computational and Mathematical Methods in Medicine 9
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 3 Accuracy comparison with different similarity metrics (a) reference image (b) moving image which is distorted reference imagewith geometric distortion (c) ground truth deformation field (d)ndash(f) registered images using SAD-based SSD-based and our algorithmrespectively (g)ndash(i) estimated transformation using SAD-based SSD-based and our algorithm respectively
Table 1 The experimental hardware configuration
No Components Parameters1 CPU Intel(R) Xeon(R) 190GHz times 182 System memory 32GB3 Video card Tesla K20m4 Memory of video card 4GB5 CUDA cores 24966 GPU max clock rate 071 GHz7 Memory clock rate 2600MHz8 Memory bus width 320-bit
Table 2 MSE statistics of the estimated deformation field
Ground truth MSE (average) MSE (standard deviation)SAD SSD Ours SAD SSD Ours
20 0652 0547 0521 0057 0036 003432 0765 0576 0563 0062 0051 004644 0932 0789 0766 0065 0044 002653 1391 0915 0887 0078 0037 0031
transformation field resulting from our algorithm is moresimilar to the ground truth than those obtained using theother two algorithms
To measure the registration accuracy of the proposedalgorithm we computed the mean and standard deviationof the MSE between the ground truth and estimated dis-placement vectors Table 2 displays the MSE statistics of theestimated deformation when compared to the ground truthThe first column shows the mean ground truth deformationwhich represents the magnitude of the displacement vectorthat is used to generate moving images in each experiment
For each mean value of ground truth eight different trans-formation fields with this mean are generated and applied tothe reference image to generate the corresponding movingimage The other columns display the average and standarddeviation of MSE obtained by using three different similaritymetrics for the generated eight pairs of reference-movingimages The results obtained using the proposed algorithmare considerably small compared to those of SAD-based andSSD-based algorithm and our algorithm shows the superioraccuracy in comparison to the other two algorithms
52 AccuracyComparisonwithCPU Implementation For ourB-spline registration algorithm employing LSD as a similaritymetric and NCG as a optimization strategy we respectivelyimplemented it based on CPU and GPU and compared theregistration accuracy impact from the parallel computingframework for the four groups of medical images Since theresolution of these images is 512 times 512 the control pointmesh size the number of control points and the numberof regions are 16 times 16 35 times 35 and 32 times 32 respectivelyIn the GPU-based implementation of our algorithm we setthe grid size to 32 times 32 and the block size to 16 times 16 for thekernel function kernelFunctionSimilarity() and set the gridsize to 4 times 4 and the block size to 8 times 8 for the kernelfunction CalSimilarityGradientKernelFunc() Owing NCG isrespectively adopted in the two implementations we also setthe maximum iteration number to 100 in the optimizationprocess Figure 4 shows the results using two implementa-tions for the first group of chestCT images Figure 5 shows theresults that a reference image andmoving image of the humanhead are matched using two implementations As can beseen from Figures 4 and 5 the CPU-based implementationand the GPU-based implementation of our algorithm canboth work well in describing the elastic deformation between
10 Computational and Mathematical Methods in Medicine
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 4 The registration results for chest images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference result of the two images before registration (d)ndash(f) are respectively the best deformationmesh the moving image subjected to the best deformation and the differential result after registration using CPU-based implementation(g)ndash(i) are the best deformation mesh the moving image subjected to the best deformation and the differential result using our GPU-basedimplementation
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5 The registration results for brain images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference between the reference and moving image before registration (d)ndash(f) are respectively thebest deformation the moving image transformed with best deformation and the difference image after registration using the CPU-basedimplementation (g)ndash(i) are respectively the best deformation the transformedmoving image and the difference after registration using ourGPU-based implementation
reference and moving images and they can both obtainhighly accurate results
In order to evaluate the accuracy of registration resultssome researchers used some mathematical metrics Elling-wood et al [24] used the normalized RootMean Square Error(RMSE) to mathematically evaluate accuracy of the GPU
resultant displacement field against the single-threaded CPUimplementation RMSE is calculated as follows
RMSE = radicsum119909isinΩ 1003817100381710038171003817VCPU (119909) minus VGPU (119909)10038171003817100381710038172sum119909isinΩ 1003817100381710038171003817VCPU (119909)10038171003817100381710038172 (15)
Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

Computational and Mathematical Methods in Medicine 3
with respect to B-spline interpolation and similarity metriccomputation Modat et al [21] presented a parallel-friendlyformulation algorithm that is suitable for GPU it onlytake less than 1min to perform registration of T1-weightedMR images without reducing the registration accuracyShackleford et al [22] employed the SSD as similarity metricand accelerated B-spline registration within the stream-processing model using GPU and this algorithm achieveda good speedup over the single-threaded CPU Ikeda et al[23] proposed an efficient GPU-based acceleration methodfor the nonrigid registration of multimodal images and theirmain contribution is efficient utilization of on-chip memoryfor NormalizedMutual Information (NMI) Ellingwood et al[24] adopted the sum of squared tissue volume difference asa similarity metric and thus developed a multilevel B-splinetransform method to implement nonrigid mass-preservingregistration of two CT lung images on GPU and this methodoutperforms its multithreaded CPU version in terms ofrunning time
3 Our Algorithm
Aiming to significantly improve the accuracy and the per-formance of B-spline registration algorithm we propose aCUDA-based parallel B-spline registration algorithm whichemploys LSD as the similarity metric and used NCG asoptimization strategy In this section we describe the detailsof our B-spline nonrigid image registration algorithm Firstlywe represent the theory of describing nonrigid deforma-tion using the cubic B-spline basis function Secondly weintroduce the LSD as the similarity metric of our algorithmFinally we explain the NCG optimization procedure and thegradient of similarity metric in our algorithm
31 B-Spline Free-FormDeformation B-spline FFD is used asthe nonrigid transformation model and three-dimensional(3D) deformation field is defined by 3D mesh of controlpoints in the Cartesian coordinatesThe deformation field fora voxel located at coordinates (119909 119910 119911) in the reference imagecan be mathematically described as follows [15 21]
(119909 119910 119911) = 3sum119894=0
3sum119895=0
3sum119896=0
119861119894 (119906) 119861119895 (V) 119861119896 (119908) 120601 (119897 119898 119899) (1)
In (1) 119861119894(sdot) is the cubic B-spline basis function in the 119909direction [8] and 120601 represents the deformation mesh In the3Dmedical image data a partition region is composed by theeight adjacent control points and the 3D spacing coordinateof this partition region is shown as follows
Ω119909 = lfloor 119909119873119909 rfloor minus 1Ω119910 = lfloor 119910119873119910rfloor minus 1Ω119911 = lfloor 119911119873119911 rfloor minus 1
(2)
where 119873119909 119873119910 and 119873119911 are the voxel numbers of the 119909 119910and 119911 directions of the control point mesh Displacementof voxels in each region Ω(119909 119910 119911) are affected around 64control points The 64 control points coordinates CP(119897 119898 119899)are calculated in the following scheme [8 25]
CP119897 = lfloor 119909119873119909 minus 1 + 119894rfloor CP119898 = lfloor 119910119873119910 minus 1 + 119895rfloor CP119899 = lfloor 119911119873119911 minus 1 + 119896rfloor
(3)
In the medical image volume data the voxel with thecoordinate (119909 119910 119911) has the local coordinate Local(119906 V 119908) inthe region Ω(119909 119910 119911) and the value is normalized in [0 1] asfollows [8 25]
Local119906 = 119909119873119909 minus lfloor 119909119873119909 rfloor LocalV = 119910119873119910 minus lfloor 119910119873119910rfloor Local119908 = 119911119873119911 minus lfloor 119911119873119911 rfloor
(4)
32 The Similarity Metric LSD A similarity metric quan-tifies the degree of alignment and is used to optimize thetransformationrsquos parameters to achieve maximal alignmentThe similarity metric has a key influence on the accuracyof registration results Sum of Squared Difference (SSD) is avery classical similarity metric based on pixel computationand it is widely used in the monomodality medical imageregistration However when SSD is used as the similaritymetric due to the fact that the SSD values of the differentiterations are very closed in the later stage of optimizationprocess it leads to appear premature convergence rate andalso affects the accuracy of the registration results
Since the function value of the logarithm transformationhas different influence on the different intervals of the defini-tion domain especially when the independent variable valueis more and more small the function value changes morequickly In other words the difference between two values oflogarithmic function is more sensitive to the interval whichhas a small logarithmic values than the interval which has alarge logarithmic values In the latter stage of the registrationprocess the difference between the reference image and themoving image subject to local deformation becomes muchsmaller the logarithmic operation can make the SSD ofsimilarity metric to change more quickly and it is helpfulto find best deformation mesh more effectively Therefore inorder to further improve the accuracy of registration resultswe perform logarithmic operation on SSD and introduce
4 Computational and Mathematical Methods in Medicine
the LSD as the similarity metric of the B-spline registra-tion algorithm LSD can be mathematically described asfollows
LSD = 1119873119909119873119910119873119911sdot 119873119909sum119909=1
119873119910sum119910=1
119873119911sum119911=1
ln ((119865 (119909 + 119879119909 119910 + 119879119910 119911 + 119879119911) minus 119877 (119909 119910 119911))2 + 1) (5)
In (5) 119877(119909 119910 119911) represents the reference image 119865(119909 +119879119909 119910 + 119879119910 119911 + 119879119911) is the moving image with B-splinedeformation and 119873119909 119873119910 and 119873119911 are separately the voxelnumbers in the 119909119910 and 119911 directions of reference andmovingimages In order to promote smooth deformation a penaltyterm119862smooth is added to the LSD valueThefinal cost function119862 to be optimized is a balance between the LSD and thedeformation penalty
119862 = (1 minus 120582) times LSD minus 120582 times 119862smooth (6)
where 0 le 120582 lt 1 The penalty-term 119862smooth was first used forimage registration by Rueckert et al [8]
33 B-Spline Registration Optimization Based on NCG Con-jugate Gradient (CG) is a very effective optimization methodfor optimization problem CG overcomes the shortcoming ofslow convergence of the gradient descent method and alsoavoids the shortage from Newtonrsquos method which needs tostore and compute the Hessian matrix and the inverse matrix[26] The NCG method is an extension of CG and suitablefor minimizing general nonlinear functions Due to the factthat the B-spline registration process is a nonlinear optimiza-tion problem the NCG method is adopted for the entireregistration process optimization in our algorithm So it isimportant to calculate the gradient of the similarity metricfor control points in every iteration and update the controlpoint mesh according to the negative gradient directionfrom the previous search Iteratively the process of updatingparameters of control point mesh can be mathematicallydescribed in
120601119894+1 = 120601119894 minus 120572119894119889119894 119894 = 1 2 3 (7)
where 120601119894 = (120601119909 120601119910 120601119911) denotes the displacement vectorof control points in the iteration process 119894 is the iterationnumber 120572119894 is a scalar which represents the displacementmagnitude of the negative gradient direction and is obtainedusing the inexact linear search method 119889119894 represents thesearch direction which is calculated as
119889119894 =minus120597119862120597120601119894 for 119894 = 1minus 120597119862120597120601119894 + 120573119894119889119894minus1 for 119894 ge 2 (8)
where 120573119894 is a variable which is calculated as
120573119894 = max (0min (120573HS119894 120573DY119894 )) (9)
120573HS119894 = (120597119862120597120601119894)119879 times 120597119862120597120601119894119889119894minus1 (120597119862120597120601119894 minus 120597119862120597120601119894minus1)119879
120573DY119894 = (120597119862120597120601119894)119879 times 120597119862120597120601119894119889119879119894minus1 (120597119862120597120601119894 minus 120597119862120597120601119894minus1)
(10)
As seen in (10) we thus require the derivative 120597119862120597120601 ofthe cost function
120597119862120597120601 = (1 minus 120582) times 120597LSD120597120601 minus 120582 times 120597119862smooth120597120601 (11)
In order to decrease the computational complexity wepropose a voxel-centric approach to evaluate the point-centric gradient using the chain rule We first compute thegradient for every voxel and then gather the information fromall voxels to compute the gradient for control points In (11)120597LSD120597120601 is calculated via the chain rule as
120597LSD120597120601 = 1119873119909119873119910119873119911119873119909sum119909=1
119873119910sum119910=1
119873119911sum119911=1
120597LSD120597 times 120597120597120601 (12)
where 120597LSD120597 denotes the partial derivative of similaritymetric for voxels and it is calculated as follows
120597LSD120597 (119909 119910 119911)= 2 times nabla119865 (119909 119910 119911) times (119865 (119909 + Δ119909 119910 + Δ119910 119911 + Δ119911) minus 119877 (119909 119910 119911))1 + (119865 (119909 + Δ119909 119910 + Δ119910 119911 + Δ119911) minus 119877 (119909 119910 119911))2 (13)
where 119865(119909+Δ119909 119910+Δ119910 119911+Δ119911) is the moving image after thedeformation119877(119909 119910 119911) is the reference image andnabla119865(119909 119910 119911)denotes the initial gradient of the moving image In (12)the second term is the derivative value of deformation fieldwith respect to a control point and the calculation form isdescribed in
120597120597120601 = 3sum119897=0
3sum119898=0
3sum119899=0
119861119897 (119906) 119861119898 (V) 119861119899 (119908) (14)
In (14) 120597120597120601 is the only metric related to the B-splinebasis function and it is also a constant value when the localcoordinates of voxels in the mesh partition are determinedIn order to simplify the parallel computing process of ouralgorithm we set 120582 to 0
4 Parallel Accelerating Procedure forOur Algorithm
To effectively improve the execution efficiency of the B-splineregistration we employ the GPU to accelerate the time-consuming steps of our algorithm In this section we presentthe parallel computing details of our algorithm using the
Computational and Mathematical Methods in Medicine 5
Input Reference and moving images (R F) image resolutions and control points et alOutput Optimized control points meshProcess(1) Read reference images R and moving images F on the CPU(2) Initialize the control points mesh on the CPU(3) Pre-calculate reusable data such as the product of basis function and store it in the LUTs(4) Transfer the above parameters from the CPU to the GPU(5) repeat(6) Update control points mesh and perform B-spline transformation on the GPU(7) Compute the similarity metric LSD on the GPU(8) Compute the gradient vector of LSD and the gradient norm on the GPU(9) Transfer data from the GPU to the CPU for the NCG optimization(10) until abs(119862119894 minus 119862119894minus1) le 119905(11) Transfer the optimized control points mesh from the GPU to the CPU
Algorithm 1 The GPU-accelerated B-spline registration based on LSD and NCG
GPU First we explain the main procedure of our algorithmbased on GPU Secondly we develop the parallel computingstrategy of B-spline registration based on the characteristicof locality of B-spline transformation and design the LUTsfor storing the reusable data for parallel kernel functionsexecuting on the GPU Then we present kernel functionsfor these time-consuming steps Finally we summarize ourproposed parallel algorithm based on GPU
41 The Main Procedure of Our Algorithm In general dataparallelism is the main requirement for an algorithm tobenefit from GPU execution Our nonrigid registration algo-rithm based on B-spline FFD comprises three componentswhich may be considered independently transformation ofthe moving image using the splines interpolation evaluationof a similarity metric and optimization against this similaritymetric In these three components the optimization processalways requires adequate iterations and the current iterationis always dependent to the previous iteration so it is serialprocess and is not implemented in parallel on the GPUIndividually B-splines interpolation and evaluation of asimilaritymetricmay be formulated in a data parallel manneras they mainly consist of voxel-wise computations In ouralgorithmNCG is used for the optimization so the first orderderivative of the similarity metric is computed to determinethe optimal direction of the next iteration Since the LSD isused as the similarity metric for evaluating the registrationquality in our algorithm we also design the parallel kernelfunction of the gradient of similarity metric LSD in terms ofthe highly parallel data features The main framework of ouralgorithm using GPU is shown in Algorithm 1
42 Parallel Computing Strategy for B-Spline Registration Inthe B-spline registration algorithm the elastic deformation ofthe moving image is uniform cubic B-spline transformationwhich is parameterized by control pointmesh Figure 1 showsthat the elastic deformation of the 2D moving image isdescribed using control point mesh In Figure 1(a) since thered control point is the current central control point of 4times 4 regions the displacement vector of the central control
point will be established by the around 4 times 4 regions and isentirely unrelated to the other regions of the moving imagein Figure 1(b) the displacement vector of each pixel locatedin the partition region is determined by its neighboring 4 times4 control points when updating the B-spline transformationon the moving images In other words relative displacementchanges of any control points only affect the pixels in thelocal region and are independent of the other global pixelsof the moving images so B-spline transformation has a goodability to describe the local elastic deformation of movingimages Therefore this locality characteristic of B-splinetransformation is a key foundation for designing the parallelcomputing strategy
To improve effectively the executing speed of our B-spline registration algorithm using GPU we develop a par-allel computing strategy for B-spline registration and createLUTs to store the reusable data in the parallel processingprocedure Our parallel computing strategy is dividing themoving images intomany different small and nonoverlappingpartition regions in terms of the locality characteristic of B-spline transformation and then designing the parallel kernelfunctions to process them independently by many differentthreads on the different cores of GPU while utilizing thedifferent memory of GPU effectively and minimizing thecommunication cost of thread blocks
In order to ensure that the registration process on theGPU can effectively be executed in parallel the followinginitialization needs to be done on the CPU before the entireprocess (1) image volume data is loaded into host memoryand copied from the host memory to the GPU memorythen bounding it to the texture memory of the GPU canimprove the data access efficiency (2) the initial B-splinemesh parameters are loaded from the host memory into theglobalmemory of theGPU (3)we precompute some reusablevalues such as theB-spline basis function products which areconstructed and stored as LUTs in the texture memory of theGPU In terms of the symmetry of volume data we can createthree LUTs for the parallel process as follows
(1) The lookup table LUTbfp of basis function productsFor the same normalized local coordinate (119906 V 119908) we
6 Computational and Mathematical Methods in Medicine
Pixel (voxel) Control point
Central control point
Point B (u = 26 = 16)
Point D (u = 26
= 46)
Point E (u = 46
= 56)
Point C (u = 16 = 06)
Point A (u = 26
= 16)
(l = 3 m = 2)
(l = 3 m = 1)
(l = 3 m = 0)
(l = 3 m = 3)
(l = 2 m = 2)
(l = 2 m = 1)
(l = 2 m = 0)
(l = 2 m = 3)
(l = 1 m = 2)
(l = 1 m = 1)
(l = 1 m = 0)
(l = 1 m = 3)
(l = 0 m = 2)
(l = 0 m = 1)
(l = 0 m = 0)
(l = 0 m = 3)
Ω1 Ω2 Ω3 Ω4
Ω5Ω6 Ω7 Ω8
Ω9Ω10 Ω11 Ω12
Ω13 Ω14 Ω15 Ω16
(a)
Pixel (voxel) Control point
A (u = 26 = 16)
B (u = 36 = 36)
(b)
Figure 1 The deformation of B-spline mesh deformation in 2D image data (a) shows the displacement vector calculation of central controlpoint (b) illustrates the displacement vector calculation of pixels in a local region The black points are control points and the deformationmesh is constituted by all the black control points the dashed square is a pixel and the image data is constituted by all the dashed squares thedisplacement values in the119883 and 119884 directions can be optimized for each control point The spacing of control point mesh includes six pixelsin the119883 and 119884 directions
precompute basis function products119861(119906)times119861(V)times119861(119908)and store them in the LUTbfp which can be reused inthe kernel functions of computing similarity metricand the gradient of similarity metricTherefore it canavoid repeated calculations and effectively improvethe computational speed For example in Figure 1(a)the two pixels (A and B) are in their respectivelocal partition regions with the same local coordinateso they can reuse the same value of B-spline basisfunction products
(2) The lookup table LUTcpi of control point indexesSince all voxels in the same region compute their dis-placement vectors using the same 64 control pointswe precompute the index set of control points in thesame region and create this LUT for storing them toimprove the executing efficiency
(3) The spatial gradient look-up table LUTgradient ofmoving images Because the gradient of the initialmoving image remains the same value in the entireregistration process we precompute the gradient ofmoving images on the CPU and create a LUT tosave them in the texture memory of GPU which canreduce the complexity of parallel calculation
43 Parallel Kernel Functions of Our Algorithm In everyiteration of our algorithm B-spline transformation sim-ilarity metric and the gradient of similarity metric arethree time-consuming steps In terms of the above parallel
computing strategy we need to design three kernel functionsfor these time-consuming steps and these kernel functionsare executed in parallel on the GPU by multiple threadsto improve the execution efficiency of our B-spline imageregistration algorithm Since B-spline transformation andsimilarity metric computation are calculated for each voxel ofthe moving images we only design a parallel kernel functionwhich sequentially calculates these two steps
431 B-Spline Transformation and Similarity Metric Compu-tation We use the LSD as the similarity metric to evaluatethe quality of deformation field in the proposed algorithmAs described in Section 32 LSD accumulates the square ofthe intensity difference between the reference images and themoving images subject to the deformation field In consider-ation of the computation of LSD with a good parallelizationwe design a kernel function kernelFunctionSimilarity() tocompute LSD and B-spline transformation in parallel onthe GPU in this paper The kernel function is illustrated inAlgorithm 2
432 SimilarityMetric Gradient for Control Points As shownin Figure 1 the displacement of each voxel in the same regionis affected by displacements of 16 control points aroundthe region when the moving image is subject to B-splinedeformation We compute the partial derivatives of all voxelsfor each control point in the same region and all voxelshousing in the same region have the contributions to 16
Computational and Mathematical Methods in Medicine 7
(1) Get the index of the thread and use it to obtain (119909 119910 119911) for the voxel(2) Use Eq (2) to get the coordinates Ω(119909 119910 119911) of the partition which houses the voxel(3) Use Eq (4) to normalized value (119906 V 119908) of voxel (119909 119910 119911) to within the range [0 1](4) V(119909 119910 119911) = 0(5) for (119894 119895 119896) from (0 0 0) to (3 3 3) do(6) 119880 = 120573119894(119906)120573119895(V)120573119896(119908)(7) V = V + 119880 times (Ω)(8) end for(9) Use Eq (6) to compute the similarity metric for the voxel(10) Use Eq (13) to compute 120597LSD120597 for the voxel
Algorithm 2 The pseudocode listing of the kernel function kernelFunctionSimilarity()
(1) Get the block index 119861 and the local thread index 119879(2) for 119875 = 0 to11987311990864 do(3) [119879] = 120597119862120597V[119874 + 119875 + 119879](4) Get the normalized coordinates (119906 V 119908) for the voxel within the region(5) 119894 = 0(6) for (119899119898 119897) from (0 0 0) to (3 3 3) do(7) 119880 = 120573119897(119906)120573119898(V)120573119899(119908)(8) [119879] = [119879] times 119880(9) Reduce [119879] and store in [0](10) syncthreads()(11) if 119879 = 0 then(12) [119894] = [119894] + [0](13) end if(14) syncthreads()(15) 119894 = 119894 + 1(16) end for(17) end for(18) 119878 = LUTcpi[64 times 119861 + 119879](19) [64 times 119878 + 119879] = [119879](20) Use tree-style reduction to reduce the gradient values in the shared memory(21) Store the reduction results in the global memory of GPU
Algorithm 3 The pseudocode listing of the kernel function CalSimilarityGradientKernelFunc()
control points around this partition region so each threadis corresponding to a partition region rather than a controlpoint to improve the executing performance of the kernelfunction on the GPU The kernel function CalSimilarity-GradientKernelFunc() calculating the gradient of similaritymetric for control points is designed as Algorithm 3
44 Summary of the Proposed Algorithm Our algorithm issummarized and illustrated in Figure 2 In the beginningof the registration process the image data precomputingLUTs and the initial B-spline mesh deformation parametersare loaded from the CPU to the GPU More specifically inorder to improve the efficiency of accessing the memory inGPU reference images and precomputing LUTs are boundto the texture memory of the GPU and the initial B-splinemesh data and moving images are loaded into the globalmemory of the GPU secondly two kernel functions areexecuted in parallel by multithreading on the GPU whichare designed to calculate the B-spline transformation for
the moving images according to the deformation meshthe similarity metric and the similarity metric gradient forcontrol points respectively and finally the similarity metricand its gradient values are transferred from the GPU tothe CPU for the NCG optimization the optimal B-splinedeformationmesh is outputtedwhen the optimized conditionwas meted otherwise update B-spline deformation meshparameters and continue to repeat the above registrationprocess until the optimal values are found
5 Experiment Results and Discussion
Weevaluated the performance of the proposed algorithmon amedical imaging dataset that was obtained from the databaseof retrospective image registration evaluation (RIRE) atthe Vanderbilt university [27] This dataset contains a lotof medical image volume data of different patients fromseveral protocols including CT T1-weighted (MR-T1) T2-weighted (MR-T2) and proton density (MR-PD) with a
8 Computational and Mathematical Methods in Medicine
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
GPU video memory
Texture memory
B-spline transformation
Initial deformation mesh Deformation mesh
Calculate the similarity metric
Calculate the similarity metric
derivative
Similarity metric
Similarity metric derivative for control points
Optimization
Nonlinear conjunct gradient
Output the best deformation mesh
The new deformation mesh
CPU GPU
DataOperation
Operation flowData flow
Pre-
com
putin
gda
ta
Image data
Parallel operation
Global memory
Yes
No
Figure 2The parallelization process of the proposed algorithm Light green areas represent the data required in the registration process blueareas describe major steps of our algorithm dashed arrows indicate the directions of data flow and the solid arrows illustrate the directionsof calculation processes
variety of slice thickness All the corresponding slices fromdifferent protocols are originally aligned with each other Weimplemented the proposed algorithm using CUDA C in theMicrosoft Visual Studio NET 2010 and used CUDA60 ofdriver and runtime libraries [28]The experimental hardwareconfiguration is shown in Table 1
51 Accuracy Comparison with Different Similarity MetricsIn the first experiment to validate the registration accuracyof the proposed algorithm we distorted the reference imageMR-T1 with a known nonrigid geometric transformationfield or the so-called ground truth Then we applied the
proposed algorithm and compared the registration results tothe other two B-spline registration algorithms using Sum ofAbsolute Difference (SAD) and SSD as a similarity metricrespectively which are implemented in the Insight Seg-mentation and Registration Toolkit (ITK) [29] And finallywe compared the obtained deformations fields with theground truth Figure 3 shows the registration results of threealgorithms for brain MR-T1 images Note that the registeredmoving images obtained by the proposed algorithm is visu-ally more similar in deformation to the reference image thanthe images produced by the SSD-based algorithm and theSAD-based algorithm respectively Moreover the estimated
Computational and Mathematical Methods in Medicine 9
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 3 Accuracy comparison with different similarity metrics (a) reference image (b) moving image which is distorted reference imagewith geometric distortion (c) ground truth deformation field (d)ndash(f) registered images using SAD-based SSD-based and our algorithmrespectively (g)ndash(i) estimated transformation using SAD-based SSD-based and our algorithm respectively
Table 1 The experimental hardware configuration
No Components Parameters1 CPU Intel(R) Xeon(R) 190GHz times 182 System memory 32GB3 Video card Tesla K20m4 Memory of video card 4GB5 CUDA cores 24966 GPU max clock rate 071 GHz7 Memory clock rate 2600MHz8 Memory bus width 320-bit
Table 2 MSE statistics of the estimated deformation field
Ground truth MSE (average) MSE (standard deviation)SAD SSD Ours SAD SSD Ours
20 0652 0547 0521 0057 0036 003432 0765 0576 0563 0062 0051 004644 0932 0789 0766 0065 0044 002653 1391 0915 0887 0078 0037 0031
transformation field resulting from our algorithm is moresimilar to the ground truth than those obtained using theother two algorithms
To measure the registration accuracy of the proposedalgorithm we computed the mean and standard deviationof the MSE between the ground truth and estimated dis-placement vectors Table 2 displays the MSE statistics of theestimated deformation when compared to the ground truthThe first column shows the mean ground truth deformationwhich represents the magnitude of the displacement vectorthat is used to generate moving images in each experiment
For each mean value of ground truth eight different trans-formation fields with this mean are generated and applied tothe reference image to generate the corresponding movingimage The other columns display the average and standarddeviation of MSE obtained by using three different similaritymetrics for the generated eight pairs of reference-movingimages The results obtained using the proposed algorithmare considerably small compared to those of SAD-based andSSD-based algorithm and our algorithm shows the superioraccuracy in comparison to the other two algorithms
52 AccuracyComparisonwithCPU Implementation For ourB-spline registration algorithm employing LSD as a similaritymetric and NCG as a optimization strategy we respectivelyimplemented it based on CPU and GPU and compared theregistration accuracy impact from the parallel computingframework for the four groups of medical images Since theresolution of these images is 512 times 512 the control pointmesh size the number of control points and the numberof regions are 16 times 16 35 times 35 and 32 times 32 respectivelyIn the GPU-based implementation of our algorithm we setthe grid size to 32 times 32 and the block size to 16 times 16 for thekernel function kernelFunctionSimilarity() and set the gridsize to 4 times 4 and the block size to 8 times 8 for the kernelfunction CalSimilarityGradientKernelFunc() Owing NCG isrespectively adopted in the two implementations we also setthe maximum iteration number to 100 in the optimizationprocess Figure 4 shows the results using two implementa-tions for the first group of chestCT images Figure 5 shows theresults that a reference image andmoving image of the humanhead are matched using two implementations As can beseen from Figures 4 and 5 the CPU-based implementationand the GPU-based implementation of our algorithm canboth work well in describing the elastic deformation between
10 Computational and Mathematical Methods in Medicine
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 4 The registration results for chest images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference result of the two images before registration (d)ndash(f) are respectively the best deformationmesh the moving image subjected to the best deformation and the differential result after registration using CPU-based implementation(g)ndash(i) are the best deformation mesh the moving image subjected to the best deformation and the differential result using our GPU-basedimplementation
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5 The registration results for brain images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference between the reference and moving image before registration (d)ndash(f) are respectively thebest deformation the moving image transformed with best deformation and the difference image after registration using the CPU-basedimplementation (g)ndash(i) are respectively the best deformation the transformedmoving image and the difference after registration using ourGPU-based implementation
reference and moving images and they can both obtainhighly accurate results
In order to evaluate the accuracy of registration resultssome researchers used some mathematical metrics Elling-wood et al [24] used the normalized RootMean Square Error(RMSE) to mathematically evaluate accuracy of the GPU
resultant displacement field against the single-threaded CPUimplementation RMSE is calculated as follows
RMSE = radicsum119909isinΩ 1003817100381710038171003817VCPU (119909) minus VGPU (119909)10038171003817100381710038172sum119909isinΩ 1003817100381710038171003817VCPU (119909)10038171003817100381710038172 (15)
Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

4 Computational and Mathematical Methods in Medicine
the LSD as the similarity metric of the B-spline registra-tion algorithm LSD can be mathematically described asfollows
LSD = 1119873119909119873119910119873119911sdot 119873119909sum119909=1
119873119910sum119910=1
119873119911sum119911=1
ln ((119865 (119909 + 119879119909 119910 + 119879119910 119911 + 119879119911) minus 119877 (119909 119910 119911))2 + 1) (5)
In (5) 119877(119909 119910 119911) represents the reference image 119865(119909 +119879119909 119910 + 119879119910 119911 + 119879119911) is the moving image with B-splinedeformation and 119873119909 119873119910 and 119873119911 are separately the voxelnumbers in the 119909119910 and 119911 directions of reference andmovingimages In order to promote smooth deformation a penaltyterm119862smooth is added to the LSD valueThefinal cost function119862 to be optimized is a balance between the LSD and thedeformation penalty
119862 = (1 minus 120582) times LSD minus 120582 times 119862smooth (6)
where 0 le 120582 lt 1 The penalty-term 119862smooth was first used forimage registration by Rueckert et al [8]
33 B-Spline Registration Optimization Based on NCG Con-jugate Gradient (CG) is a very effective optimization methodfor optimization problem CG overcomes the shortcoming ofslow convergence of the gradient descent method and alsoavoids the shortage from Newtonrsquos method which needs tostore and compute the Hessian matrix and the inverse matrix[26] The NCG method is an extension of CG and suitablefor minimizing general nonlinear functions Due to the factthat the B-spline registration process is a nonlinear optimiza-tion problem the NCG method is adopted for the entireregistration process optimization in our algorithm So it isimportant to calculate the gradient of the similarity metricfor control points in every iteration and update the controlpoint mesh according to the negative gradient directionfrom the previous search Iteratively the process of updatingparameters of control point mesh can be mathematicallydescribed in
120601119894+1 = 120601119894 minus 120572119894119889119894 119894 = 1 2 3 (7)
where 120601119894 = (120601119909 120601119910 120601119911) denotes the displacement vectorof control points in the iteration process 119894 is the iterationnumber 120572119894 is a scalar which represents the displacementmagnitude of the negative gradient direction and is obtainedusing the inexact linear search method 119889119894 represents thesearch direction which is calculated as
119889119894 =minus120597119862120597120601119894 for 119894 = 1minus 120597119862120597120601119894 + 120573119894119889119894minus1 for 119894 ge 2 (8)
where 120573119894 is a variable which is calculated as
120573119894 = max (0min (120573HS119894 120573DY119894 )) (9)
120573HS119894 = (120597119862120597120601119894)119879 times 120597119862120597120601119894119889119894minus1 (120597119862120597120601119894 minus 120597119862120597120601119894minus1)119879
120573DY119894 = (120597119862120597120601119894)119879 times 120597119862120597120601119894119889119879119894minus1 (120597119862120597120601119894 minus 120597119862120597120601119894minus1)
(10)
As seen in (10) we thus require the derivative 120597119862120597120601 ofthe cost function
120597119862120597120601 = (1 minus 120582) times 120597LSD120597120601 minus 120582 times 120597119862smooth120597120601 (11)
In order to decrease the computational complexity wepropose a voxel-centric approach to evaluate the point-centric gradient using the chain rule We first compute thegradient for every voxel and then gather the information fromall voxels to compute the gradient for control points In (11)120597LSD120597120601 is calculated via the chain rule as
120597LSD120597120601 = 1119873119909119873119910119873119911119873119909sum119909=1
119873119910sum119910=1
119873119911sum119911=1
120597LSD120597 times 120597120597120601 (12)
where 120597LSD120597 denotes the partial derivative of similaritymetric for voxels and it is calculated as follows
120597LSD120597 (119909 119910 119911)= 2 times nabla119865 (119909 119910 119911) times (119865 (119909 + Δ119909 119910 + Δ119910 119911 + Δ119911) minus 119877 (119909 119910 119911))1 + (119865 (119909 + Δ119909 119910 + Δ119910 119911 + Δ119911) minus 119877 (119909 119910 119911))2 (13)
where 119865(119909+Δ119909 119910+Δ119910 119911+Δ119911) is the moving image after thedeformation119877(119909 119910 119911) is the reference image andnabla119865(119909 119910 119911)denotes the initial gradient of the moving image In (12)the second term is the derivative value of deformation fieldwith respect to a control point and the calculation form isdescribed in
120597120597120601 = 3sum119897=0
3sum119898=0
3sum119899=0
119861119897 (119906) 119861119898 (V) 119861119899 (119908) (14)
In (14) 120597120597120601 is the only metric related to the B-splinebasis function and it is also a constant value when the localcoordinates of voxels in the mesh partition are determinedIn order to simplify the parallel computing process of ouralgorithm we set 120582 to 0
4 Parallel Accelerating Procedure forOur Algorithm
To effectively improve the execution efficiency of the B-splineregistration we employ the GPU to accelerate the time-consuming steps of our algorithm In this section we presentthe parallel computing details of our algorithm using the
Computational and Mathematical Methods in Medicine 5
Input Reference and moving images (R F) image resolutions and control points et alOutput Optimized control points meshProcess(1) Read reference images R and moving images F on the CPU(2) Initialize the control points mesh on the CPU(3) Pre-calculate reusable data such as the product of basis function and store it in the LUTs(4) Transfer the above parameters from the CPU to the GPU(5) repeat(6) Update control points mesh and perform B-spline transformation on the GPU(7) Compute the similarity metric LSD on the GPU(8) Compute the gradient vector of LSD and the gradient norm on the GPU(9) Transfer data from the GPU to the CPU for the NCG optimization(10) until abs(119862119894 minus 119862119894minus1) le 119905(11) Transfer the optimized control points mesh from the GPU to the CPU
Algorithm 1 The GPU-accelerated B-spline registration based on LSD and NCG
GPU First we explain the main procedure of our algorithmbased on GPU Secondly we develop the parallel computingstrategy of B-spline registration based on the characteristicof locality of B-spline transformation and design the LUTsfor storing the reusable data for parallel kernel functionsexecuting on the GPU Then we present kernel functionsfor these time-consuming steps Finally we summarize ourproposed parallel algorithm based on GPU
41 The Main Procedure of Our Algorithm In general dataparallelism is the main requirement for an algorithm tobenefit from GPU execution Our nonrigid registration algo-rithm based on B-spline FFD comprises three componentswhich may be considered independently transformation ofthe moving image using the splines interpolation evaluationof a similarity metric and optimization against this similaritymetric In these three components the optimization processalways requires adequate iterations and the current iterationis always dependent to the previous iteration so it is serialprocess and is not implemented in parallel on the GPUIndividually B-splines interpolation and evaluation of asimilaritymetricmay be formulated in a data parallel manneras they mainly consist of voxel-wise computations In ouralgorithmNCG is used for the optimization so the first orderderivative of the similarity metric is computed to determinethe optimal direction of the next iteration Since the LSD isused as the similarity metric for evaluating the registrationquality in our algorithm we also design the parallel kernelfunction of the gradient of similarity metric LSD in terms ofthe highly parallel data features The main framework of ouralgorithm using GPU is shown in Algorithm 1
42 Parallel Computing Strategy for B-Spline Registration Inthe B-spline registration algorithm the elastic deformation ofthe moving image is uniform cubic B-spline transformationwhich is parameterized by control pointmesh Figure 1 showsthat the elastic deformation of the 2D moving image isdescribed using control point mesh In Figure 1(a) since thered control point is the current central control point of 4times 4 regions the displacement vector of the central control
point will be established by the around 4 times 4 regions and isentirely unrelated to the other regions of the moving imagein Figure 1(b) the displacement vector of each pixel locatedin the partition region is determined by its neighboring 4 times4 control points when updating the B-spline transformationon the moving images In other words relative displacementchanges of any control points only affect the pixels in thelocal region and are independent of the other global pixelsof the moving images so B-spline transformation has a goodability to describe the local elastic deformation of movingimages Therefore this locality characteristic of B-splinetransformation is a key foundation for designing the parallelcomputing strategy
To improve effectively the executing speed of our B-spline registration algorithm using GPU we develop a par-allel computing strategy for B-spline registration and createLUTs to store the reusable data in the parallel processingprocedure Our parallel computing strategy is dividing themoving images intomany different small and nonoverlappingpartition regions in terms of the locality characteristic of B-spline transformation and then designing the parallel kernelfunctions to process them independently by many differentthreads on the different cores of GPU while utilizing thedifferent memory of GPU effectively and minimizing thecommunication cost of thread blocks
In order to ensure that the registration process on theGPU can effectively be executed in parallel the followinginitialization needs to be done on the CPU before the entireprocess (1) image volume data is loaded into host memoryand copied from the host memory to the GPU memorythen bounding it to the texture memory of the GPU canimprove the data access efficiency (2) the initial B-splinemesh parameters are loaded from the host memory into theglobalmemory of theGPU (3)we precompute some reusablevalues such as theB-spline basis function products which areconstructed and stored as LUTs in the texture memory of theGPU In terms of the symmetry of volume data we can createthree LUTs for the parallel process as follows
(1) The lookup table LUTbfp of basis function productsFor the same normalized local coordinate (119906 V 119908) we
6 Computational and Mathematical Methods in Medicine
Pixel (voxel) Control point
Central control point
Point B (u = 26 = 16)
Point D (u = 26
= 46)
Point E (u = 46
= 56)
Point C (u = 16 = 06)
Point A (u = 26
= 16)
(l = 3 m = 2)
(l = 3 m = 1)
(l = 3 m = 0)
(l = 3 m = 3)
(l = 2 m = 2)
(l = 2 m = 1)
(l = 2 m = 0)
(l = 2 m = 3)
(l = 1 m = 2)
(l = 1 m = 1)
(l = 1 m = 0)
(l = 1 m = 3)
(l = 0 m = 2)
(l = 0 m = 1)
(l = 0 m = 0)
(l = 0 m = 3)
Ω1 Ω2 Ω3 Ω4
Ω5Ω6 Ω7 Ω8
Ω9Ω10 Ω11 Ω12
Ω13 Ω14 Ω15 Ω16
(a)
Pixel (voxel) Control point
A (u = 26 = 16)
B (u = 36 = 36)
(b)
Figure 1 The deformation of B-spline mesh deformation in 2D image data (a) shows the displacement vector calculation of central controlpoint (b) illustrates the displacement vector calculation of pixels in a local region The black points are control points and the deformationmesh is constituted by all the black control points the dashed square is a pixel and the image data is constituted by all the dashed squares thedisplacement values in the119883 and 119884 directions can be optimized for each control point The spacing of control point mesh includes six pixelsin the119883 and 119884 directions
precompute basis function products119861(119906)times119861(V)times119861(119908)and store them in the LUTbfp which can be reused inthe kernel functions of computing similarity metricand the gradient of similarity metricTherefore it canavoid repeated calculations and effectively improvethe computational speed For example in Figure 1(a)the two pixels (A and B) are in their respectivelocal partition regions with the same local coordinateso they can reuse the same value of B-spline basisfunction products
(2) The lookup table LUTcpi of control point indexesSince all voxels in the same region compute their dis-placement vectors using the same 64 control pointswe precompute the index set of control points in thesame region and create this LUT for storing them toimprove the executing efficiency
(3) The spatial gradient look-up table LUTgradient ofmoving images Because the gradient of the initialmoving image remains the same value in the entireregistration process we precompute the gradient ofmoving images on the CPU and create a LUT tosave them in the texture memory of GPU which canreduce the complexity of parallel calculation
43 Parallel Kernel Functions of Our Algorithm In everyiteration of our algorithm B-spline transformation sim-ilarity metric and the gradient of similarity metric arethree time-consuming steps In terms of the above parallel
computing strategy we need to design three kernel functionsfor these time-consuming steps and these kernel functionsare executed in parallel on the GPU by multiple threadsto improve the execution efficiency of our B-spline imageregistration algorithm Since B-spline transformation andsimilarity metric computation are calculated for each voxel ofthe moving images we only design a parallel kernel functionwhich sequentially calculates these two steps
431 B-Spline Transformation and Similarity Metric Compu-tation We use the LSD as the similarity metric to evaluatethe quality of deformation field in the proposed algorithmAs described in Section 32 LSD accumulates the square ofthe intensity difference between the reference images and themoving images subject to the deformation field In consider-ation of the computation of LSD with a good parallelizationwe design a kernel function kernelFunctionSimilarity() tocompute LSD and B-spline transformation in parallel onthe GPU in this paper The kernel function is illustrated inAlgorithm 2
432 SimilarityMetric Gradient for Control Points As shownin Figure 1 the displacement of each voxel in the same regionis affected by displacements of 16 control points aroundthe region when the moving image is subject to B-splinedeformation We compute the partial derivatives of all voxelsfor each control point in the same region and all voxelshousing in the same region have the contributions to 16
Computational and Mathematical Methods in Medicine 7
(1) Get the index of the thread and use it to obtain (119909 119910 119911) for the voxel(2) Use Eq (2) to get the coordinates Ω(119909 119910 119911) of the partition which houses the voxel(3) Use Eq (4) to normalized value (119906 V 119908) of voxel (119909 119910 119911) to within the range [0 1](4) V(119909 119910 119911) = 0(5) for (119894 119895 119896) from (0 0 0) to (3 3 3) do(6) 119880 = 120573119894(119906)120573119895(V)120573119896(119908)(7) V = V + 119880 times (Ω)(8) end for(9) Use Eq (6) to compute the similarity metric for the voxel(10) Use Eq (13) to compute 120597LSD120597 for the voxel
Algorithm 2 The pseudocode listing of the kernel function kernelFunctionSimilarity()
(1) Get the block index 119861 and the local thread index 119879(2) for 119875 = 0 to11987311990864 do(3) [119879] = 120597119862120597V[119874 + 119875 + 119879](4) Get the normalized coordinates (119906 V 119908) for the voxel within the region(5) 119894 = 0(6) for (119899119898 119897) from (0 0 0) to (3 3 3) do(7) 119880 = 120573119897(119906)120573119898(V)120573119899(119908)(8) [119879] = [119879] times 119880(9) Reduce [119879] and store in [0](10) syncthreads()(11) if 119879 = 0 then(12) [119894] = [119894] + [0](13) end if(14) syncthreads()(15) 119894 = 119894 + 1(16) end for(17) end for(18) 119878 = LUTcpi[64 times 119861 + 119879](19) [64 times 119878 + 119879] = [119879](20) Use tree-style reduction to reduce the gradient values in the shared memory(21) Store the reduction results in the global memory of GPU
Algorithm 3 The pseudocode listing of the kernel function CalSimilarityGradientKernelFunc()
control points around this partition region so each threadis corresponding to a partition region rather than a controlpoint to improve the executing performance of the kernelfunction on the GPU The kernel function CalSimilarity-GradientKernelFunc() calculating the gradient of similaritymetric for control points is designed as Algorithm 3
44 Summary of the Proposed Algorithm Our algorithm issummarized and illustrated in Figure 2 In the beginningof the registration process the image data precomputingLUTs and the initial B-spline mesh deformation parametersare loaded from the CPU to the GPU More specifically inorder to improve the efficiency of accessing the memory inGPU reference images and precomputing LUTs are boundto the texture memory of the GPU and the initial B-splinemesh data and moving images are loaded into the globalmemory of the GPU secondly two kernel functions areexecuted in parallel by multithreading on the GPU whichare designed to calculate the B-spline transformation for
the moving images according to the deformation meshthe similarity metric and the similarity metric gradient forcontrol points respectively and finally the similarity metricand its gradient values are transferred from the GPU tothe CPU for the NCG optimization the optimal B-splinedeformationmesh is outputtedwhen the optimized conditionwas meted otherwise update B-spline deformation meshparameters and continue to repeat the above registrationprocess until the optimal values are found
5 Experiment Results and Discussion
Weevaluated the performance of the proposed algorithmon amedical imaging dataset that was obtained from the databaseof retrospective image registration evaluation (RIRE) atthe Vanderbilt university [27] This dataset contains a lotof medical image volume data of different patients fromseveral protocols including CT T1-weighted (MR-T1) T2-weighted (MR-T2) and proton density (MR-PD) with a
8 Computational and Mathematical Methods in Medicine
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
GPU video memory
Texture memory
B-spline transformation
Initial deformation mesh Deformation mesh
Calculate the similarity metric
Calculate the similarity metric
derivative
Similarity metric
Similarity metric derivative for control points
Optimization
Nonlinear conjunct gradient
Output the best deformation mesh
The new deformation mesh
CPU GPU
DataOperation
Operation flowData flow
Pre-
com
putin
gda
ta
Image data
Parallel operation
Global memory
Yes
No
Figure 2The parallelization process of the proposed algorithm Light green areas represent the data required in the registration process blueareas describe major steps of our algorithm dashed arrows indicate the directions of data flow and the solid arrows illustrate the directionsof calculation processes
variety of slice thickness All the corresponding slices fromdifferent protocols are originally aligned with each other Weimplemented the proposed algorithm using CUDA C in theMicrosoft Visual Studio NET 2010 and used CUDA60 ofdriver and runtime libraries [28]The experimental hardwareconfiguration is shown in Table 1
51 Accuracy Comparison with Different Similarity MetricsIn the first experiment to validate the registration accuracyof the proposed algorithm we distorted the reference imageMR-T1 with a known nonrigid geometric transformationfield or the so-called ground truth Then we applied the
proposed algorithm and compared the registration results tothe other two B-spline registration algorithms using Sum ofAbsolute Difference (SAD) and SSD as a similarity metricrespectively which are implemented in the Insight Seg-mentation and Registration Toolkit (ITK) [29] And finallywe compared the obtained deformations fields with theground truth Figure 3 shows the registration results of threealgorithms for brain MR-T1 images Note that the registeredmoving images obtained by the proposed algorithm is visu-ally more similar in deformation to the reference image thanthe images produced by the SSD-based algorithm and theSAD-based algorithm respectively Moreover the estimated
Computational and Mathematical Methods in Medicine 9
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 3 Accuracy comparison with different similarity metrics (a) reference image (b) moving image which is distorted reference imagewith geometric distortion (c) ground truth deformation field (d)ndash(f) registered images using SAD-based SSD-based and our algorithmrespectively (g)ndash(i) estimated transformation using SAD-based SSD-based and our algorithm respectively
Table 1 The experimental hardware configuration
No Components Parameters1 CPU Intel(R) Xeon(R) 190GHz times 182 System memory 32GB3 Video card Tesla K20m4 Memory of video card 4GB5 CUDA cores 24966 GPU max clock rate 071 GHz7 Memory clock rate 2600MHz8 Memory bus width 320-bit
Table 2 MSE statistics of the estimated deformation field
Ground truth MSE (average) MSE (standard deviation)SAD SSD Ours SAD SSD Ours
20 0652 0547 0521 0057 0036 003432 0765 0576 0563 0062 0051 004644 0932 0789 0766 0065 0044 002653 1391 0915 0887 0078 0037 0031
transformation field resulting from our algorithm is moresimilar to the ground truth than those obtained using theother two algorithms
To measure the registration accuracy of the proposedalgorithm we computed the mean and standard deviationof the MSE between the ground truth and estimated dis-placement vectors Table 2 displays the MSE statistics of theestimated deformation when compared to the ground truthThe first column shows the mean ground truth deformationwhich represents the magnitude of the displacement vectorthat is used to generate moving images in each experiment
For each mean value of ground truth eight different trans-formation fields with this mean are generated and applied tothe reference image to generate the corresponding movingimage The other columns display the average and standarddeviation of MSE obtained by using three different similaritymetrics for the generated eight pairs of reference-movingimages The results obtained using the proposed algorithmare considerably small compared to those of SAD-based andSSD-based algorithm and our algorithm shows the superioraccuracy in comparison to the other two algorithms
52 AccuracyComparisonwithCPU Implementation For ourB-spline registration algorithm employing LSD as a similaritymetric and NCG as a optimization strategy we respectivelyimplemented it based on CPU and GPU and compared theregistration accuracy impact from the parallel computingframework for the four groups of medical images Since theresolution of these images is 512 times 512 the control pointmesh size the number of control points and the numberof regions are 16 times 16 35 times 35 and 32 times 32 respectivelyIn the GPU-based implementation of our algorithm we setthe grid size to 32 times 32 and the block size to 16 times 16 for thekernel function kernelFunctionSimilarity() and set the gridsize to 4 times 4 and the block size to 8 times 8 for the kernelfunction CalSimilarityGradientKernelFunc() Owing NCG isrespectively adopted in the two implementations we also setthe maximum iteration number to 100 in the optimizationprocess Figure 4 shows the results using two implementa-tions for the first group of chestCT images Figure 5 shows theresults that a reference image andmoving image of the humanhead are matched using two implementations As can beseen from Figures 4 and 5 the CPU-based implementationand the GPU-based implementation of our algorithm canboth work well in describing the elastic deformation between
10 Computational and Mathematical Methods in Medicine
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 4 The registration results for chest images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference result of the two images before registration (d)ndash(f) are respectively the best deformationmesh the moving image subjected to the best deformation and the differential result after registration using CPU-based implementation(g)ndash(i) are the best deformation mesh the moving image subjected to the best deformation and the differential result using our GPU-basedimplementation
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5 The registration results for brain images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference between the reference and moving image before registration (d)ndash(f) are respectively thebest deformation the moving image transformed with best deformation and the difference image after registration using the CPU-basedimplementation (g)ndash(i) are respectively the best deformation the transformedmoving image and the difference after registration using ourGPU-based implementation
reference and moving images and they can both obtainhighly accurate results
In order to evaluate the accuracy of registration resultssome researchers used some mathematical metrics Elling-wood et al [24] used the normalized RootMean Square Error(RMSE) to mathematically evaluate accuracy of the GPU
resultant displacement field against the single-threaded CPUimplementation RMSE is calculated as follows
RMSE = radicsum119909isinΩ 1003817100381710038171003817VCPU (119909) minus VGPU (119909)10038171003817100381710038172sum119909isinΩ 1003817100381710038171003817VCPU (119909)10038171003817100381710038172 (15)
Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

Computational and Mathematical Methods in Medicine 5
Input Reference and moving images (R F) image resolutions and control points et alOutput Optimized control points meshProcess(1) Read reference images R and moving images F on the CPU(2) Initialize the control points mesh on the CPU(3) Pre-calculate reusable data such as the product of basis function and store it in the LUTs(4) Transfer the above parameters from the CPU to the GPU(5) repeat(6) Update control points mesh and perform B-spline transformation on the GPU(7) Compute the similarity metric LSD on the GPU(8) Compute the gradient vector of LSD and the gradient norm on the GPU(9) Transfer data from the GPU to the CPU for the NCG optimization(10) until abs(119862119894 minus 119862119894minus1) le 119905(11) Transfer the optimized control points mesh from the GPU to the CPU
Algorithm 1 The GPU-accelerated B-spline registration based on LSD and NCG
GPU First we explain the main procedure of our algorithmbased on GPU Secondly we develop the parallel computingstrategy of B-spline registration based on the characteristicof locality of B-spline transformation and design the LUTsfor storing the reusable data for parallel kernel functionsexecuting on the GPU Then we present kernel functionsfor these time-consuming steps Finally we summarize ourproposed parallel algorithm based on GPU
41 The Main Procedure of Our Algorithm In general dataparallelism is the main requirement for an algorithm tobenefit from GPU execution Our nonrigid registration algo-rithm based on B-spline FFD comprises three componentswhich may be considered independently transformation ofthe moving image using the splines interpolation evaluationof a similarity metric and optimization against this similaritymetric In these three components the optimization processalways requires adequate iterations and the current iterationis always dependent to the previous iteration so it is serialprocess and is not implemented in parallel on the GPUIndividually B-splines interpolation and evaluation of asimilaritymetricmay be formulated in a data parallel manneras they mainly consist of voxel-wise computations In ouralgorithmNCG is used for the optimization so the first orderderivative of the similarity metric is computed to determinethe optimal direction of the next iteration Since the LSD isused as the similarity metric for evaluating the registrationquality in our algorithm we also design the parallel kernelfunction of the gradient of similarity metric LSD in terms ofthe highly parallel data features The main framework of ouralgorithm using GPU is shown in Algorithm 1
42 Parallel Computing Strategy for B-Spline Registration Inthe B-spline registration algorithm the elastic deformation ofthe moving image is uniform cubic B-spline transformationwhich is parameterized by control pointmesh Figure 1 showsthat the elastic deformation of the 2D moving image isdescribed using control point mesh In Figure 1(a) since thered control point is the current central control point of 4times 4 regions the displacement vector of the central control
point will be established by the around 4 times 4 regions and isentirely unrelated to the other regions of the moving imagein Figure 1(b) the displacement vector of each pixel locatedin the partition region is determined by its neighboring 4 times4 control points when updating the B-spline transformationon the moving images In other words relative displacementchanges of any control points only affect the pixels in thelocal region and are independent of the other global pixelsof the moving images so B-spline transformation has a goodability to describe the local elastic deformation of movingimages Therefore this locality characteristic of B-splinetransformation is a key foundation for designing the parallelcomputing strategy
To improve effectively the executing speed of our B-spline registration algorithm using GPU we develop a par-allel computing strategy for B-spline registration and createLUTs to store the reusable data in the parallel processingprocedure Our parallel computing strategy is dividing themoving images intomany different small and nonoverlappingpartition regions in terms of the locality characteristic of B-spline transformation and then designing the parallel kernelfunctions to process them independently by many differentthreads on the different cores of GPU while utilizing thedifferent memory of GPU effectively and minimizing thecommunication cost of thread blocks
In order to ensure that the registration process on theGPU can effectively be executed in parallel the followinginitialization needs to be done on the CPU before the entireprocess (1) image volume data is loaded into host memoryand copied from the host memory to the GPU memorythen bounding it to the texture memory of the GPU canimprove the data access efficiency (2) the initial B-splinemesh parameters are loaded from the host memory into theglobalmemory of theGPU (3)we precompute some reusablevalues such as theB-spline basis function products which areconstructed and stored as LUTs in the texture memory of theGPU In terms of the symmetry of volume data we can createthree LUTs for the parallel process as follows
(1) The lookup table LUTbfp of basis function productsFor the same normalized local coordinate (119906 V 119908) we
6 Computational and Mathematical Methods in Medicine
Pixel (voxel) Control point
Central control point
Point B (u = 26 = 16)
Point D (u = 26
= 46)
Point E (u = 46
= 56)
Point C (u = 16 = 06)
Point A (u = 26
= 16)
(l = 3 m = 2)
(l = 3 m = 1)
(l = 3 m = 0)
(l = 3 m = 3)
(l = 2 m = 2)
(l = 2 m = 1)
(l = 2 m = 0)
(l = 2 m = 3)
(l = 1 m = 2)
(l = 1 m = 1)
(l = 1 m = 0)
(l = 1 m = 3)
(l = 0 m = 2)
(l = 0 m = 1)
(l = 0 m = 0)
(l = 0 m = 3)
Ω1 Ω2 Ω3 Ω4
Ω5Ω6 Ω7 Ω8
Ω9Ω10 Ω11 Ω12
Ω13 Ω14 Ω15 Ω16
(a)
Pixel (voxel) Control point
A (u = 26 = 16)
B (u = 36 = 36)
(b)
Figure 1 The deformation of B-spline mesh deformation in 2D image data (a) shows the displacement vector calculation of central controlpoint (b) illustrates the displacement vector calculation of pixels in a local region The black points are control points and the deformationmesh is constituted by all the black control points the dashed square is a pixel and the image data is constituted by all the dashed squares thedisplacement values in the119883 and 119884 directions can be optimized for each control point The spacing of control point mesh includes six pixelsin the119883 and 119884 directions
precompute basis function products119861(119906)times119861(V)times119861(119908)and store them in the LUTbfp which can be reused inthe kernel functions of computing similarity metricand the gradient of similarity metricTherefore it canavoid repeated calculations and effectively improvethe computational speed For example in Figure 1(a)the two pixels (A and B) are in their respectivelocal partition regions with the same local coordinateso they can reuse the same value of B-spline basisfunction products
(2) The lookup table LUTcpi of control point indexesSince all voxels in the same region compute their dis-placement vectors using the same 64 control pointswe precompute the index set of control points in thesame region and create this LUT for storing them toimprove the executing efficiency
(3) The spatial gradient look-up table LUTgradient ofmoving images Because the gradient of the initialmoving image remains the same value in the entireregistration process we precompute the gradient ofmoving images on the CPU and create a LUT tosave them in the texture memory of GPU which canreduce the complexity of parallel calculation
43 Parallel Kernel Functions of Our Algorithm In everyiteration of our algorithm B-spline transformation sim-ilarity metric and the gradient of similarity metric arethree time-consuming steps In terms of the above parallel
computing strategy we need to design three kernel functionsfor these time-consuming steps and these kernel functionsare executed in parallel on the GPU by multiple threadsto improve the execution efficiency of our B-spline imageregistration algorithm Since B-spline transformation andsimilarity metric computation are calculated for each voxel ofthe moving images we only design a parallel kernel functionwhich sequentially calculates these two steps
431 B-Spline Transformation and Similarity Metric Compu-tation We use the LSD as the similarity metric to evaluatethe quality of deformation field in the proposed algorithmAs described in Section 32 LSD accumulates the square ofthe intensity difference between the reference images and themoving images subject to the deformation field In consider-ation of the computation of LSD with a good parallelizationwe design a kernel function kernelFunctionSimilarity() tocompute LSD and B-spline transformation in parallel onthe GPU in this paper The kernel function is illustrated inAlgorithm 2
432 SimilarityMetric Gradient for Control Points As shownin Figure 1 the displacement of each voxel in the same regionis affected by displacements of 16 control points aroundthe region when the moving image is subject to B-splinedeformation We compute the partial derivatives of all voxelsfor each control point in the same region and all voxelshousing in the same region have the contributions to 16
Computational and Mathematical Methods in Medicine 7
(1) Get the index of the thread and use it to obtain (119909 119910 119911) for the voxel(2) Use Eq (2) to get the coordinates Ω(119909 119910 119911) of the partition which houses the voxel(3) Use Eq (4) to normalized value (119906 V 119908) of voxel (119909 119910 119911) to within the range [0 1](4) V(119909 119910 119911) = 0(5) for (119894 119895 119896) from (0 0 0) to (3 3 3) do(6) 119880 = 120573119894(119906)120573119895(V)120573119896(119908)(7) V = V + 119880 times (Ω)(8) end for(9) Use Eq (6) to compute the similarity metric for the voxel(10) Use Eq (13) to compute 120597LSD120597 for the voxel
Algorithm 2 The pseudocode listing of the kernel function kernelFunctionSimilarity()
(1) Get the block index 119861 and the local thread index 119879(2) for 119875 = 0 to11987311990864 do(3) [119879] = 120597119862120597V[119874 + 119875 + 119879](4) Get the normalized coordinates (119906 V 119908) for the voxel within the region(5) 119894 = 0(6) for (119899119898 119897) from (0 0 0) to (3 3 3) do(7) 119880 = 120573119897(119906)120573119898(V)120573119899(119908)(8) [119879] = [119879] times 119880(9) Reduce [119879] and store in [0](10) syncthreads()(11) if 119879 = 0 then(12) [119894] = [119894] + [0](13) end if(14) syncthreads()(15) 119894 = 119894 + 1(16) end for(17) end for(18) 119878 = LUTcpi[64 times 119861 + 119879](19) [64 times 119878 + 119879] = [119879](20) Use tree-style reduction to reduce the gradient values in the shared memory(21) Store the reduction results in the global memory of GPU
Algorithm 3 The pseudocode listing of the kernel function CalSimilarityGradientKernelFunc()
control points around this partition region so each threadis corresponding to a partition region rather than a controlpoint to improve the executing performance of the kernelfunction on the GPU The kernel function CalSimilarity-GradientKernelFunc() calculating the gradient of similaritymetric for control points is designed as Algorithm 3
44 Summary of the Proposed Algorithm Our algorithm issummarized and illustrated in Figure 2 In the beginningof the registration process the image data precomputingLUTs and the initial B-spline mesh deformation parametersare loaded from the CPU to the GPU More specifically inorder to improve the efficiency of accessing the memory inGPU reference images and precomputing LUTs are boundto the texture memory of the GPU and the initial B-splinemesh data and moving images are loaded into the globalmemory of the GPU secondly two kernel functions areexecuted in parallel by multithreading on the GPU whichare designed to calculate the B-spline transformation for
the moving images according to the deformation meshthe similarity metric and the similarity metric gradient forcontrol points respectively and finally the similarity metricand its gradient values are transferred from the GPU tothe CPU for the NCG optimization the optimal B-splinedeformationmesh is outputtedwhen the optimized conditionwas meted otherwise update B-spline deformation meshparameters and continue to repeat the above registrationprocess until the optimal values are found
5 Experiment Results and Discussion
Weevaluated the performance of the proposed algorithmon amedical imaging dataset that was obtained from the databaseof retrospective image registration evaluation (RIRE) atthe Vanderbilt university [27] This dataset contains a lotof medical image volume data of different patients fromseveral protocols including CT T1-weighted (MR-T1) T2-weighted (MR-T2) and proton density (MR-PD) with a
8 Computational and Mathematical Methods in Medicine
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
GPU video memory
Texture memory
B-spline transformation
Initial deformation mesh Deformation mesh
Calculate the similarity metric
Calculate the similarity metric
derivative
Similarity metric
Similarity metric derivative for control points
Optimization
Nonlinear conjunct gradient
Output the best deformation mesh
The new deformation mesh
CPU GPU
DataOperation
Operation flowData flow
Pre-
com
putin
gda
ta
Image data
Parallel operation
Global memory
Yes
No
Figure 2The parallelization process of the proposed algorithm Light green areas represent the data required in the registration process blueareas describe major steps of our algorithm dashed arrows indicate the directions of data flow and the solid arrows illustrate the directionsof calculation processes
variety of slice thickness All the corresponding slices fromdifferent protocols are originally aligned with each other Weimplemented the proposed algorithm using CUDA C in theMicrosoft Visual Studio NET 2010 and used CUDA60 ofdriver and runtime libraries [28]The experimental hardwareconfiguration is shown in Table 1
51 Accuracy Comparison with Different Similarity MetricsIn the first experiment to validate the registration accuracyof the proposed algorithm we distorted the reference imageMR-T1 with a known nonrigid geometric transformationfield or the so-called ground truth Then we applied the
proposed algorithm and compared the registration results tothe other two B-spline registration algorithms using Sum ofAbsolute Difference (SAD) and SSD as a similarity metricrespectively which are implemented in the Insight Seg-mentation and Registration Toolkit (ITK) [29] And finallywe compared the obtained deformations fields with theground truth Figure 3 shows the registration results of threealgorithms for brain MR-T1 images Note that the registeredmoving images obtained by the proposed algorithm is visu-ally more similar in deformation to the reference image thanthe images produced by the SSD-based algorithm and theSAD-based algorithm respectively Moreover the estimated
Computational and Mathematical Methods in Medicine 9
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 3 Accuracy comparison with different similarity metrics (a) reference image (b) moving image which is distorted reference imagewith geometric distortion (c) ground truth deformation field (d)ndash(f) registered images using SAD-based SSD-based and our algorithmrespectively (g)ndash(i) estimated transformation using SAD-based SSD-based and our algorithm respectively
Table 1 The experimental hardware configuration
No Components Parameters1 CPU Intel(R) Xeon(R) 190GHz times 182 System memory 32GB3 Video card Tesla K20m4 Memory of video card 4GB5 CUDA cores 24966 GPU max clock rate 071 GHz7 Memory clock rate 2600MHz8 Memory bus width 320-bit
Table 2 MSE statistics of the estimated deformation field
Ground truth MSE (average) MSE (standard deviation)SAD SSD Ours SAD SSD Ours
20 0652 0547 0521 0057 0036 003432 0765 0576 0563 0062 0051 004644 0932 0789 0766 0065 0044 002653 1391 0915 0887 0078 0037 0031
transformation field resulting from our algorithm is moresimilar to the ground truth than those obtained using theother two algorithms
To measure the registration accuracy of the proposedalgorithm we computed the mean and standard deviationof the MSE between the ground truth and estimated dis-placement vectors Table 2 displays the MSE statistics of theestimated deformation when compared to the ground truthThe first column shows the mean ground truth deformationwhich represents the magnitude of the displacement vectorthat is used to generate moving images in each experiment
For each mean value of ground truth eight different trans-formation fields with this mean are generated and applied tothe reference image to generate the corresponding movingimage The other columns display the average and standarddeviation of MSE obtained by using three different similaritymetrics for the generated eight pairs of reference-movingimages The results obtained using the proposed algorithmare considerably small compared to those of SAD-based andSSD-based algorithm and our algorithm shows the superioraccuracy in comparison to the other two algorithms
52 AccuracyComparisonwithCPU Implementation For ourB-spline registration algorithm employing LSD as a similaritymetric and NCG as a optimization strategy we respectivelyimplemented it based on CPU and GPU and compared theregistration accuracy impact from the parallel computingframework for the four groups of medical images Since theresolution of these images is 512 times 512 the control pointmesh size the number of control points and the numberof regions are 16 times 16 35 times 35 and 32 times 32 respectivelyIn the GPU-based implementation of our algorithm we setthe grid size to 32 times 32 and the block size to 16 times 16 for thekernel function kernelFunctionSimilarity() and set the gridsize to 4 times 4 and the block size to 8 times 8 for the kernelfunction CalSimilarityGradientKernelFunc() Owing NCG isrespectively adopted in the two implementations we also setthe maximum iteration number to 100 in the optimizationprocess Figure 4 shows the results using two implementa-tions for the first group of chestCT images Figure 5 shows theresults that a reference image andmoving image of the humanhead are matched using two implementations As can beseen from Figures 4 and 5 the CPU-based implementationand the GPU-based implementation of our algorithm canboth work well in describing the elastic deformation between
10 Computational and Mathematical Methods in Medicine
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 4 The registration results for chest images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference result of the two images before registration (d)ndash(f) are respectively the best deformationmesh the moving image subjected to the best deformation and the differential result after registration using CPU-based implementation(g)ndash(i) are the best deformation mesh the moving image subjected to the best deformation and the differential result using our GPU-basedimplementation
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5 The registration results for brain images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference between the reference and moving image before registration (d)ndash(f) are respectively thebest deformation the moving image transformed with best deformation and the difference image after registration using the CPU-basedimplementation (g)ndash(i) are respectively the best deformation the transformedmoving image and the difference after registration using ourGPU-based implementation
reference and moving images and they can both obtainhighly accurate results
In order to evaluate the accuracy of registration resultssome researchers used some mathematical metrics Elling-wood et al [24] used the normalized RootMean Square Error(RMSE) to mathematically evaluate accuracy of the GPU
resultant displacement field against the single-threaded CPUimplementation RMSE is calculated as follows
RMSE = radicsum119909isinΩ 1003817100381710038171003817VCPU (119909) minus VGPU (119909)10038171003817100381710038172sum119909isinΩ 1003817100381710038171003817VCPU (119909)10038171003817100381710038172 (15)
Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom
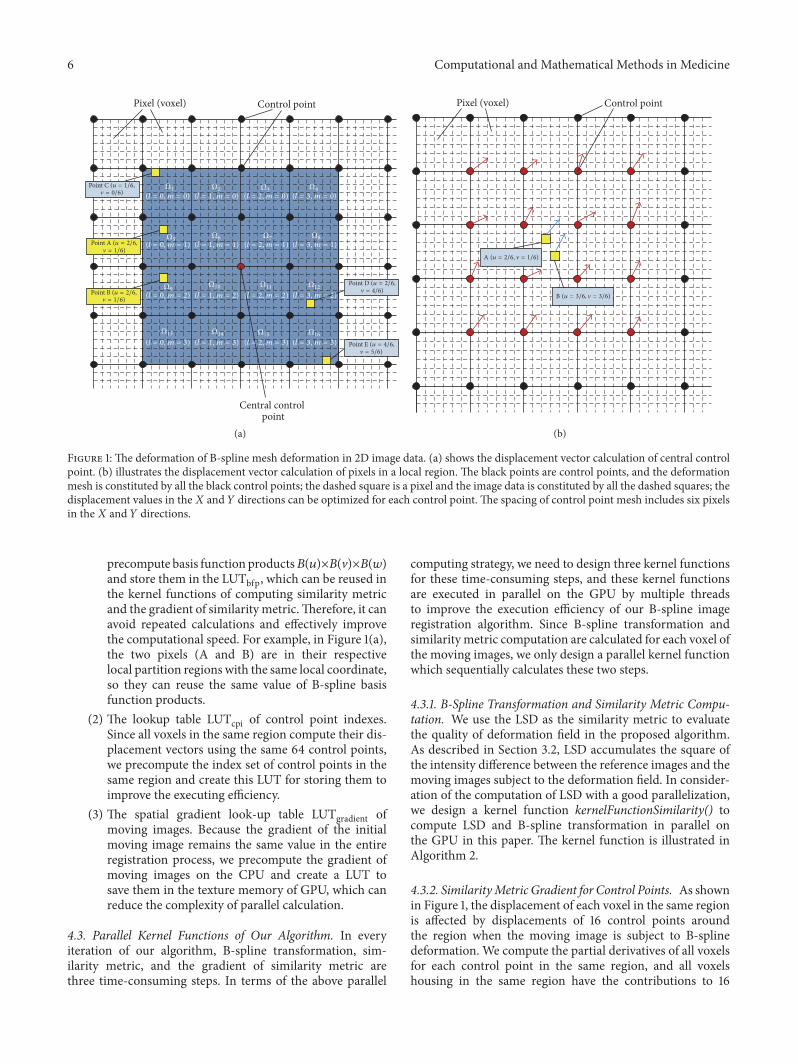
6 Computational and Mathematical Methods in Medicine
Pixel (voxel) Control point
Central control point
Point B (u = 26 = 16)
Point D (u = 26
= 46)
Point E (u = 46
= 56)
Point C (u = 16 = 06)
Point A (u = 26
= 16)
(l = 3 m = 2)
(l = 3 m = 1)
(l = 3 m = 0)
(l = 3 m = 3)
(l = 2 m = 2)
(l = 2 m = 1)
(l = 2 m = 0)
(l = 2 m = 3)
(l = 1 m = 2)
(l = 1 m = 1)
(l = 1 m = 0)
(l = 1 m = 3)
(l = 0 m = 2)
(l = 0 m = 1)
(l = 0 m = 0)
(l = 0 m = 3)
Ω1 Ω2 Ω3 Ω4
Ω5Ω6 Ω7 Ω8
Ω9Ω10 Ω11 Ω12
Ω13 Ω14 Ω15 Ω16
(a)
Pixel (voxel) Control point
A (u = 26 = 16)
B (u = 36 = 36)
(b)
Figure 1 The deformation of B-spline mesh deformation in 2D image data (a) shows the displacement vector calculation of central controlpoint (b) illustrates the displacement vector calculation of pixels in a local region The black points are control points and the deformationmesh is constituted by all the black control points the dashed square is a pixel and the image data is constituted by all the dashed squares thedisplacement values in the119883 and 119884 directions can be optimized for each control point The spacing of control point mesh includes six pixelsin the119883 and 119884 directions
precompute basis function products119861(119906)times119861(V)times119861(119908)and store them in the LUTbfp which can be reused inthe kernel functions of computing similarity metricand the gradient of similarity metricTherefore it canavoid repeated calculations and effectively improvethe computational speed For example in Figure 1(a)the two pixels (A and B) are in their respectivelocal partition regions with the same local coordinateso they can reuse the same value of B-spline basisfunction products
(2) The lookup table LUTcpi of control point indexesSince all voxels in the same region compute their dis-placement vectors using the same 64 control pointswe precompute the index set of control points in thesame region and create this LUT for storing them toimprove the executing efficiency
(3) The spatial gradient look-up table LUTgradient ofmoving images Because the gradient of the initialmoving image remains the same value in the entireregistration process we precompute the gradient ofmoving images on the CPU and create a LUT tosave them in the texture memory of GPU which canreduce the complexity of parallel calculation
43 Parallel Kernel Functions of Our Algorithm In everyiteration of our algorithm B-spline transformation sim-ilarity metric and the gradient of similarity metric arethree time-consuming steps In terms of the above parallel
computing strategy we need to design three kernel functionsfor these time-consuming steps and these kernel functionsare executed in parallel on the GPU by multiple threadsto improve the execution efficiency of our B-spline imageregistration algorithm Since B-spline transformation andsimilarity metric computation are calculated for each voxel ofthe moving images we only design a parallel kernel functionwhich sequentially calculates these two steps
431 B-Spline Transformation and Similarity Metric Compu-tation We use the LSD as the similarity metric to evaluatethe quality of deformation field in the proposed algorithmAs described in Section 32 LSD accumulates the square ofthe intensity difference between the reference images and themoving images subject to the deformation field In consider-ation of the computation of LSD with a good parallelizationwe design a kernel function kernelFunctionSimilarity() tocompute LSD and B-spline transformation in parallel onthe GPU in this paper The kernel function is illustrated inAlgorithm 2
432 SimilarityMetric Gradient for Control Points As shownin Figure 1 the displacement of each voxel in the same regionis affected by displacements of 16 control points aroundthe region when the moving image is subject to B-splinedeformation We compute the partial derivatives of all voxelsfor each control point in the same region and all voxelshousing in the same region have the contributions to 16
Computational and Mathematical Methods in Medicine 7
(1) Get the index of the thread and use it to obtain (119909 119910 119911) for the voxel(2) Use Eq (2) to get the coordinates Ω(119909 119910 119911) of the partition which houses the voxel(3) Use Eq (4) to normalized value (119906 V 119908) of voxel (119909 119910 119911) to within the range [0 1](4) V(119909 119910 119911) = 0(5) for (119894 119895 119896) from (0 0 0) to (3 3 3) do(6) 119880 = 120573119894(119906)120573119895(V)120573119896(119908)(7) V = V + 119880 times (Ω)(8) end for(9) Use Eq (6) to compute the similarity metric for the voxel(10) Use Eq (13) to compute 120597LSD120597 for the voxel
Algorithm 2 The pseudocode listing of the kernel function kernelFunctionSimilarity()
(1) Get the block index 119861 and the local thread index 119879(2) for 119875 = 0 to11987311990864 do(3) [119879] = 120597119862120597V[119874 + 119875 + 119879](4) Get the normalized coordinates (119906 V 119908) for the voxel within the region(5) 119894 = 0(6) for (119899119898 119897) from (0 0 0) to (3 3 3) do(7) 119880 = 120573119897(119906)120573119898(V)120573119899(119908)(8) [119879] = [119879] times 119880(9) Reduce [119879] and store in [0](10) syncthreads()(11) if 119879 = 0 then(12) [119894] = [119894] + [0](13) end if(14) syncthreads()(15) 119894 = 119894 + 1(16) end for(17) end for(18) 119878 = LUTcpi[64 times 119861 + 119879](19) [64 times 119878 + 119879] = [119879](20) Use tree-style reduction to reduce the gradient values in the shared memory(21) Store the reduction results in the global memory of GPU
Algorithm 3 The pseudocode listing of the kernel function CalSimilarityGradientKernelFunc()
control points around this partition region so each threadis corresponding to a partition region rather than a controlpoint to improve the executing performance of the kernelfunction on the GPU The kernel function CalSimilarity-GradientKernelFunc() calculating the gradient of similaritymetric for control points is designed as Algorithm 3
44 Summary of the Proposed Algorithm Our algorithm issummarized and illustrated in Figure 2 In the beginningof the registration process the image data precomputingLUTs and the initial B-spline mesh deformation parametersare loaded from the CPU to the GPU More specifically inorder to improve the efficiency of accessing the memory inGPU reference images and precomputing LUTs are boundto the texture memory of the GPU and the initial B-splinemesh data and moving images are loaded into the globalmemory of the GPU secondly two kernel functions areexecuted in parallel by multithreading on the GPU whichare designed to calculate the B-spline transformation for
the moving images according to the deformation meshthe similarity metric and the similarity metric gradient forcontrol points respectively and finally the similarity metricand its gradient values are transferred from the GPU tothe CPU for the NCG optimization the optimal B-splinedeformationmesh is outputtedwhen the optimized conditionwas meted otherwise update B-spline deformation meshparameters and continue to repeat the above registrationprocess until the optimal values are found
5 Experiment Results and Discussion
Weevaluated the performance of the proposed algorithmon amedical imaging dataset that was obtained from the databaseof retrospective image registration evaluation (RIRE) atthe Vanderbilt university [27] This dataset contains a lotof medical image volume data of different patients fromseveral protocols including CT T1-weighted (MR-T1) T2-weighted (MR-T2) and proton density (MR-PD) with a
8 Computational and Mathematical Methods in Medicine
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
GPU video memory
Texture memory
B-spline transformation
Initial deformation mesh Deformation mesh
Calculate the similarity metric
Calculate the similarity metric
derivative
Similarity metric
Similarity metric derivative for control points
Optimization
Nonlinear conjunct gradient
Output the best deformation mesh
The new deformation mesh
CPU GPU
DataOperation
Operation flowData flow
Pre-
com
putin
gda
ta
Image data
Parallel operation
Global memory
Yes
No
Figure 2The parallelization process of the proposed algorithm Light green areas represent the data required in the registration process blueareas describe major steps of our algorithm dashed arrows indicate the directions of data flow and the solid arrows illustrate the directionsof calculation processes
variety of slice thickness All the corresponding slices fromdifferent protocols are originally aligned with each other Weimplemented the proposed algorithm using CUDA C in theMicrosoft Visual Studio NET 2010 and used CUDA60 ofdriver and runtime libraries [28]The experimental hardwareconfiguration is shown in Table 1
51 Accuracy Comparison with Different Similarity MetricsIn the first experiment to validate the registration accuracyof the proposed algorithm we distorted the reference imageMR-T1 with a known nonrigid geometric transformationfield or the so-called ground truth Then we applied the
proposed algorithm and compared the registration results tothe other two B-spline registration algorithms using Sum ofAbsolute Difference (SAD) and SSD as a similarity metricrespectively which are implemented in the Insight Seg-mentation and Registration Toolkit (ITK) [29] And finallywe compared the obtained deformations fields with theground truth Figure 3 shows the registration results of threealgorithms for brain MR-T1 images Note that the registeredmoving images obtained by the proposed algorithm is visu-ally more similar in deformation to the reference image thanthe images produced by the SSD-based algorithm and theSAD-based algorithm respectively Moreover the estimated
Computational and Mathematical Methods in Medicine 9
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 3 Accuracy comparison with different similarity metrics (a) reference image (b) moving image which is distorted reference imagewith geometric distortion (c) ground truth deformation field (d)ndash(f) registered images using SAD-based SSD-based and our algorithmrespectively (g)ndash(i) estimated transformation using SAD-based SSD-based and our algorithm respectively
Table 1 The experimental hardware configuration
No Components Parameters1 CPU Intel(R) Xeon(R) 190GHz times 182 System memory 32GB3 Video card Tesla K20m4 Memory of video card 4GB5 CUDA cores 24966 GPU max clock rate 071 GHz7 Memory clock rate 2600MHz8 Memory bus width 320-bit
Table 2 MSE statistics of the estimated deformation field
Ground truth MSE (average) MSE (standard deviation)SAD SSD Ours SAD SSD Ours
20 0652 0547 0521 0057 0036 003432 0765 0576 0563 0062 0051 004644 0932 0789 0766 0065 0044 002653 1391 0915 0887 0078 0037 0031
transformation field resulting from our algorithm is moresimilar to the ground truth than those obtained using theother two algorithms
To measure the registration accuracy of the proposedalgorithm we computed the mean and standard deviationof the MSE between the ground truth and estimated dis-placement vectors Table 2 displays the MSE statistics of theestimated deformation when compared to the ground truthThe first column shows the mean ground truth deformationwhich represents the magnitude of the displacement vectorthat is used to generate moving images in each experiment
For each mean value of ground truth eight different trans-formation fields with this mean are generated and applied tothe reference image to generate the corresponding movingimage The other columns display the average and standarddeviation of MSE obtained by using three different similaritymetrics for the generated eight pairs of reference-movingimages The results obtained using the proposed algorithmare considerably small compared to those of SAD-based andSSD-based algorithm and our algorithm shows the superioraccuracy in comparison to the other two algorithms
52 AccuracyComparisonwithCPU Implementation For ourB-spline registration algorithm employing LSD as a similaritymetric and NCG as a optimization strategy we respectivelyimplemented it based on CPU and GPU and compared theregistration accuracy impact from the parallel computingframework for the four groups of medical images Since theresolution of these images is 512 times 512 the control pointmesh size the number of control points and the numberof regions are 16 times 16 35 times 35 and 32 times 32 respectivelyIn the GPU-based implementation of our algorithm we setthe grid size to 32 times 32 and the block size to 16 times 16 for thekernel function kernelFunctionSimilarity() and set the gridsize to 4 times 4 and the block size to 8 times 8 for the kernelfunction CalSimilarityGradientKernelFunc() Owing NCG isrespectively adopted in the two implementations we also setthe maximum iteration number to 100 in the optimizationprocess Figure 4 shows the results using two implementa-tions for the first group of chestCT images Figure 5 shows theresults that a reference image andmoving image of the humanhead are matched using two implementations As can beseen from Figures 4 and 5 the CPU-based implementationand the GPU-based implementation of our algorithm canboth work well in describing the elastic deformation between
10 Computational and Mathematical Methods in Medicine
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 4 The registration results for chest images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference result of the two images before registration (d)ndash(f) are respectively the best deformationmesh the moving image subjected to the best deformation and the differential result after registration using CPU-based implementation(g)ndash(i) are the best deformation mesh the moving image subjected to the best deformation and the differential result using our GPU-basedimplementation
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5 The registration results for brain images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference between the reference and moving image before registration (d)ndash(f) are respectively thebest deformation the moving image transformed with best deformation and the difference image after registration using the CPU-basedimplementation (g)ndash(i) are respectively the best deformation the transformedmoving image and the difference after registration using ourGPU-based implementation
reference and moving images and they can both obtainhighly accurate results
In order to evaluate the accuracy of registration resultssome researchers used some mathematical metrics Elling-wood et al [24] used the normalized RootMean Square Error(RMSE) to mathematically evaluate accuracy of the GPU
resultant displacement field against the single-threaded CPUimplementation RMSE is calculated as follows
RMSE = radicsum119909isinΩ 1003817100381710038171003817VCPU (119909) minus VGPU (119909)10038171003817100381710038172sum119909isinΩ 1003817100381710038171003817VCPU (119909)10038171003817100381710038172 (15)
Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

Computational and Mathematical Methods in Medicine 7
(1) Get the index of the thread and use it to obtain (119909 119910 119911) for the voxel(2) Use Eq (2) to get the coordinates Ω(119909 119910 119911) of the partition which houses the voxel(3) Use Eq (4) to normalized value (119906 V 119908) of voxel (119909 119910 119911) to within the range [0 1](4) V(119909 119910 119911) = 0(5) for (119894 119895 119896) from (0 0 0) to (3 3 3) do(6) 119880 = 120573119894(119906)120573119895(V)120573119896(119908)(7) V = V + 119880 times (Ω)(8) end for(9) Use Eq (6) to compute the similarity metric for the voxel(10) Use Eq (13) to compute 120597LSD120597 for the voxel
Algorithm 2 The pseudocode listing of the kernel function kernelFunctionSimilarity()
(1) Get the block index 119861 and the local thread index 119879(2) for 119875 = 0 to11987311990864 do(3) [119879] = 120597119862120597V[119874 + 119875 + 119879](4) Get the normalized coordinates (119906 V 119908) for the voxel within the region(5) 119894 = 0(6) for (119899119898 119897) from (0 0 0) to (3 3 3) do(7) 119880 = 120573119897(119906)120573119898(V)120573119899(119908)(8) [119879] = [119879] times 119880(9) Reduce [119879] and store in [0](10) syncthreads()(11) if 119879 = 0 then(12) [119894] = [119894] + [0](13) end if(14) syncthreads()(15) 119894 = 119894 + 1(16) end for(17) end for(18) 119878 = LUTcpi[64 times 119861 + 119879](19) [64 times 119878 + 119879] = [119879](20) Use tree-style reduction to reduce the gradient values in the shared memory(21) Store the reduction results in the global memory of GPU
Algorithm 3 The pseudocode listing of the kernel function CalSimilarityGradientKernelFunc()
control points around this partition region so each threadis corresponding to a partition region rather than a controlpoint to improve the executing performance of the kernelfunction on the GPU The kernel function CalSimilarity-GradientKernelFunc() calculating the gradient of similaritymetric for control points is designed as Algorithm 3
44 Summary of the Proposed Algorithm Our algorithm issummarized and illustrated in Figure 2 In the beginningof the registration process the image data precomputingLUTs and the initial B-spline mesh deformation parametersare loaded from the CPU to the GPU More specifically inorder to improve the efficiency of accessing the memory inGPU reference images and precomputing LUTs are boundto the texture memory of the GPU and the initial B-splinemesh data and moving images are loaded into the globalmemory of the GPU secondly two kernel functions areexecuted in parallel by multithreading on the GPU whichare designed to calculate the B-spline transformation for
the moving images according to the deformation meshthe similarity metric and the similarity metric gradient forcontrol points respectively and finally the similarity metricand its gradient values are transferred from the GPU tothe CPU for the NCG optimization the optimal B-splinedeformationmesh is outputtedwhen the optimized conditionwas meted otherwise update B-spline deformation meshparameters and continue to repeat the above registrationprocess until the optimal values are found
5 Experiment Results and Discussion
Weevaluated the performance of the proposed algorithmon amedical imaging dataset that was obtained from the databaseof retrospective image registration evaluation (RIRE) atthe Vanderbilt university [27] This dataset contains a lotof medical image volume data of different patients fromseveral protocols including CT T1-weighted (MR-T1) T2-weighted (MR-T2) and proton density (MR-PD) with a
8 Computational and Mathematical Methods in Medicine
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
GPU video memory
Texture memory
B-spline transformation
Initial deformation mesh Deformation mesh
Calculate the similarity metric
Calculate the similarity metric
derivative
Similarity metric
Similarity metric derivative for control points
Optimization
Nonlinear conjunct gradient
Output the best deformation mesh
The new deformation mesh
CPU GPU
DataOperation
Operation flowData flow
Pre-
com
putin
gda
ta
Image data
Parallel operation
Global memory
Yes
No
Figure 2The parallelization process of the proposed algorithm Light green areas represent the data required in the registration process blueareas describe major steps of our algorithm dashed arrows indicate the directions of data flow and the solid arrows illustrate the directionsof calculation processes
variety of slice thickness All the corresponding slices fromdifferent protocols are originally aligned with each other Weimplemented the proposed algorithm using CUDA C in theMicrosoft Visual Studio NET 2010 and used CUDA60 ofdriver and runtime libraries [28]The experimental hardwareconfiguration is shown in Table 1
51 Accuracy Comparison with Different Similarity MetricsIn the first experiment to validate the registration accuracyof the proposed algorithm we distorted the reference imageMR-T1 with a known nonrigid geometric transformationfield or the so-called ground truth Then we applied the
proposed algorithm and compared the registration results tothe other two B-spline registration algorithms using Sum ofAbsolute Difference (SAD) and SSD as a similarity metricrespectively which are implemented in the Insight Seg-mentation and Registration Toolkit (ITK) [29] And finallywe compared the obtained deformations fields with theground truth Figure 3 shows the registration results of threealgorithms for brain MR-T1 images Note that the registeredmoving images obtained by the proposed algorithm is visu-ally more similar in deformation to the reference image thanthe images produced by the SSD-based algorithm and theSAD-based algorithm respectively Moreover the estimated
Computational and Mathematical Methods in Medicine 9
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 3 Accuracy comparison with different similarity metrics (a) reference image (b) moving image which is distorted reference imagewith geometric distortion (c) ground truth deformation field (d)ndash(f) registered images using SAD-based SSD-based and our algorithmrespectively (g)ndash(i) estimated transformation using SAD-based SSD-based and our algorithm respectively
Table 1 The experimental hardware configuration
No Components Parameters1 CPU Intel(R) Xeon(R) 190GHz times 182 System memory 32GB3 Video card Tesla K20m4 Memory of video card 4GB5 CUDA cores 24966 GPU max clock rate 071 GHz7 Memory clock rate 2600MHz8 Memory bus width 320-bit
Table 2 MSE statistics of the estimated deformation field
Ground truth MSE (average) MSE (standard deviation)SAD SSD Ours SAD SSD Ours
20 0652 0547 0521 0057 0036 003432 0765 0576 0563 0062 0051 004644 0932 0789 0766 0065 0044 002653 1391 0915 0887 0078 0037 0031
transformation field resulting from our algorithm is moresimilar to the ground truth than those obtained using theother two algorithms
To measure the registration accuracy of the proposedalgorithm we computed the mean and standard deviationof the MSE between the ground truth and estimated dis-placement vectors Table 2 displays the MSE statistics of theestimated deformation when compared to the ground truthThe first column shows the mean ground truth deformationwhich represents the magnitude of the displacement vectorthat is used to generate moving images in each experiment
For each mean value of ground truth eight different trans-formation fields with this mean are generated and applied tothe reference image to generate the corresponding movingimage The other columns display the average and standarddeviation of MSE obtained by using three different similaritymetrics for the generated eight pairs of reference-movingimages The results obtained using the proposed algorithmare considerably small compared to those of SAD-based andSSD-based algorithm and our algorithm shows the superioraccuracy in comparison to the other two algorithms
52 AccuracyComparisonwithCPU Implementation For ourB-spline registration algorithm employing LSD as a similaritymetric and NCG as a optimization strategy we respectivelyimplemented it based on CPU and GPU and compared theregistration accuracy impact from the parallel computingframework for the four groups of medical images Since theresolution of these images is 512 times 512 the control pointmesh size the number of control points and the numberof regions are 16 times 16 35 times 35 and 32 times 32 respectivelyIn the GPU-based implementation of our algorithm we setthe grid size to 32 times 32 and the block size to 16 times 16 for thekernel function kernelFunctionSimilarity() and set the gridsize to 4 times 4 and the block size to 8 times 8 for the kernelfunction CalSimilarityGradientKernelFunc() Owing NCG isrespectively adopted in the two implementations we also setthe maximum iteration number to 100 in the optimizationprocess Figure 4 shows the results using two implementa-tions for the first group of chestCT images Figure 5 shows theresults that a reference image andmoving image of the humanhead are matched using two implementations As can beseen from Figures 4 and 5 the CPU-based implementationand the GPU-based implementation of our algorithm canboth work well in describing the elastic deformation between
10 Computational and Mathematical Methods in Medicine
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 4 The registration results for chest images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference result of the two images before registration (d)ndash(f) are respectively the best deformationmesh the moving image subjected to the best deformation and the differential result after registration using CPU-based implementation(g)ndash(i) are the best deformation mesh the moving image subjected to the best deformation and the differential result using our GPU-basedimplementation
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5 The registration results for brain images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference between the reference and moving image before registration (d)ndash(f) are respectively thebest deformation the moving image transformed with best deformation and the difference image after registration using the CPU-basedimplementation (g)ndash(i) are respectively the best deformation the transformedmoving image and the difference after registration using ourGPU-based implementation
reference and moving images and they can both obtainhighly accurate results
In order to evaluate the accuracy of registration resultssome researchers used some mathematical metrics Elling-wood et al [24] used the normalized RootMean Square Error(RMSE) to mathematically evaluate accuracy of the GPU
resultant displacement field against the single-threaded CPUimplementation RMSE is calculated as follows
RMSE = radicsum119909isinΩ 1003817100381710038171003817VCPU (119909) minus VGPU (119909)10038171003817100381710038172sum119909isinΩ 1003817100381710038171003817VCPU (119909)10038171003817100381710038172 (15)
Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom
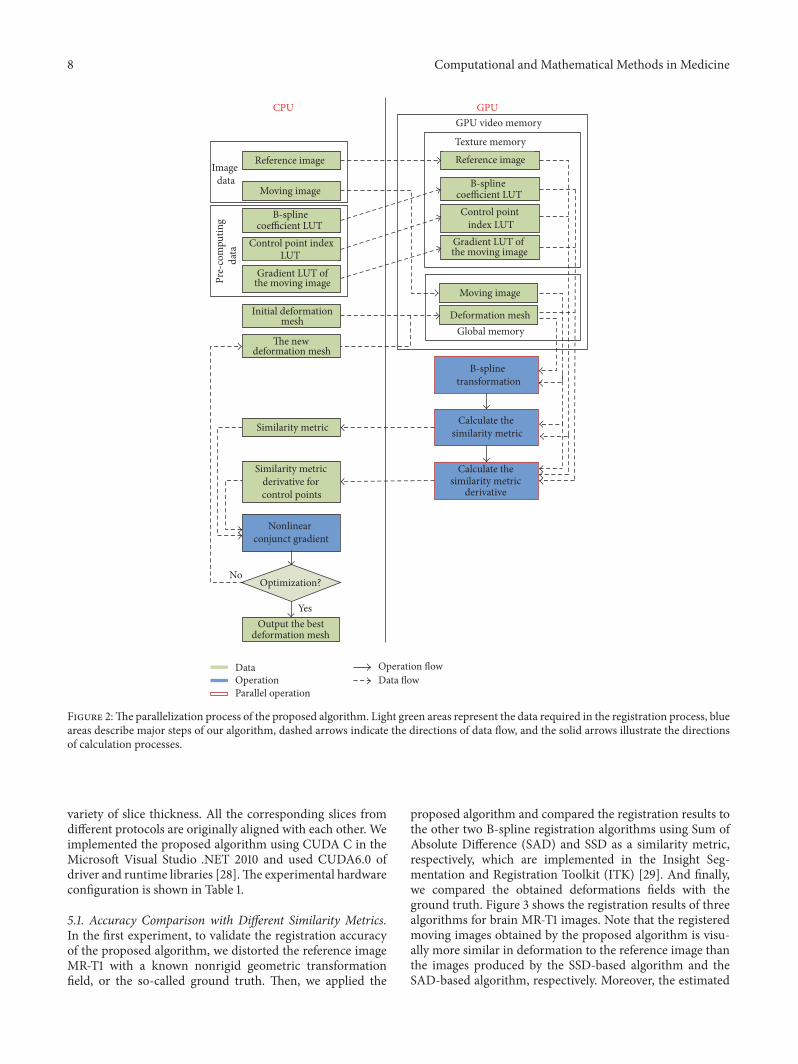
8 Computational and Mathematical Methods in Medicine
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
Reference image
B-spline coefficient LUT
Moving image
Control point index LUT
Gradient LUT of the moving image
GPU video memory
Texture memory
B-spline transformation
Initial deformation mesh Deformation mesh
Calculate the similarity metric
Calculate the similarity metric
derivative
Similarity metric
Similarity metric derivative for control points
Optimization
Nonlinear conjunct gradient
Output the best deformation mesh
The new deformation mesh
CPU GPU
DataOperation
Operation flowData flow
Pre-
com
putin
gda
ta
Image data
Parallel operation
Global memory
Yes
No
Figure 2The parallelization process of the proposed algorithm Light green areas represent the data required in the registration process blueareas describe major steps of our algorithm dashed arrows indicate the directions of data flow and the solid arrows illustrate the directionsof calculation processes
variety of slice thickness All the corresponding slices fromdifferent protocols are originally aligned with each other Weimplemented the proposed algorithm using CUDA C in theMicrosoft Visual Studio NET 2010 and used CUDA60 ofdriver and runtime libraries [28]The experimental hardwareconfiguration is shown in Table 1
51 Accuracy Comparison with Different Similarity MetricsIn the first experiment to validate the registration accuracyof the proposed algorithm we distorted the reference imageMR-T1 with a known nonrigid geometric transformationfield or the so-called ground truth Then we applied the
proposed algorithm and compared the registration results tothe other two B-spline registration algorithms using Sum ofAbsolute Difference (SAD) and SSD as a similarity metricrespectively which are implemented in the Insight Seg-mentation and Registration Toolkit (ITK) [29] And finallywe compared the obtained deformations fields with theground truth Figure 3 shows the registration results of threealgorithms for brain MR-T1 images Note that the registeredmoving images obtained by the proposed algorithm is visu-ally more similar in deformation to the reference image thanthe images produced by the SSD-based algorithm and theSAD-based algorithm respectively Moreover the estimated
Computational and Mathematical Methods in Medicine 9
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 3 Accuracy comparison with different similarity metrics (a) reference image (b) moving image which is distorted reference imagewith geometric distortion (c) ground truth deformation field (d)ndash(f) registered images using SAD-based SSD-based and our algorithmrespectively (g)ndash(i) estimated transformation using SAD-based SSD-based and our algorithm respectively
Table 1 The experimental hardware configuration
No Components Parameters1 CPU Intel(R) Xeon(R) 190GHz times 182 System memory 32GB3 Video card Tesla K20m4 Memory of video card 4GB5 CUDA cores 24966 GPU max clock rate 071 GHz7 Memory clock rate 2600MHz8 Memory bus width 320-bit
Table 2 MSE statistics of the estimated deformation field
Ground truth MSE (average) MSE (standard deviation)SAD SSD Ours SAD SSD Ours
20 0652 0547 0521 0057 0036 003432 0765 0576 0563 0062 0051 004644 0932 0789 0766 0065 0044 002653 1391 0915 0887 0078 0037 0031
transformation field resulting from our algorithm is moresimilar to the ground truth than those obtained using theother two algorithms
To measure the registration accuracy of the proposedalgorithm we computed the mean and standard deviationof the MSE between the ground truth and estimated dis-placement vectors Table 2 displays the MSE statistics of theestimated deformation when compared to the ground truthThe first column shows the mean ground truth deformationwhich represents the magnitude of the displacement vectorthat is used to generate moving images in each experiment
For each mean value of ground truth eight different trans-formation fields with this mean are generated and applied tothe reference image to generate the corresponding movingimage The other columns display the average and standarddeviation of MSE obtained by using three different similaritymetrics for the generated eight pairs of reference-movingimages The results obtained using the proposed algorithmare considerably small compared to those of SAD-based andSSD-based algorithm and our algorithm shows the superioraccuracy in comparison to the other two algorithms
52 AccuracyComparisonwithCPU Implementation For ourB-spline registration algorithm employing LSD as a similaritymetric and NCG as a optimization strategy we respectivelyimplemented it based on CPU and GPU and compared theregistration accuracy impact from the parallel computingframework for the four groups of medical images Since theresolution of these images is 512 times 512 the control pointmesh size the number of control points and the numberof regions are 16 times 16 35 times 35 and 32 times 32 respectivelyIn the GPU-based implementation of our algorithm we setthe grid size to 32 times 32 and the block size to 16 times 16 for thekernel function kernelFunctionSimilarity() and set the gridsize to 4 times 4 and the block size to 8 times 8 for the kernelfunction CalSimilarityGradientKernelFunc() Owing NCG isrespectively adopted in the two implementations we also setthe maximum iteration number to 100 in the optimizationprocess Figure 4 shows the results using two implementa-tions for the first group of chestCT images Figure 5 shows theresults that a reference image andmoving image of the humanhead are matched using two implementations As can beseen from Figures 4 and 5 the CPU-based implementationand the GPU-based implementation of our algorithm canboth work well in describing the elastic deformation between
10 Computational and Mathematical Methods in Medicine
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 4 The registration results for chest images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference result of the two images before registration (d)ndash(f) are respectively the best deformationmesh the moving image subjected to the best deformation and the differential result after registration using CPU-based implementation(g)ndash(i) are the best deformation mesh the moving image subjected to the best deformation and the differential result using our GPU-basedimplementation
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5 The registration results for brain images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference between the reference and moving image before registration (d)ndash(f) are respectively thebest deformation the moving image transformed with best deformation and the difference image after registration using the CPU-basedimplementation (g)ndash(i) are respectively the best deformation the transformedmoving image and the difference after registration using ourGPU-based implementation
reference and moving images and they can both obtainhighly accurate results
In order to evaluate the accuracy of registration resultssome researchers used some mathematical metrics Elling-wood et al [24] used the normalized RootMean Square Error(RMSE) to mathematically evaluate accuracy of the GPU
resultant displacement field against the single-threaded CPUimplementation RMSE is calculated as follows
RMSE = radicsum119909isinΩ 1003817100381710038171003817VCPU (119909) minus VGPU (119909)10038171003817100381710038172sum119909isinΩ 1003817100381710038171003817VCPU (119909)10038171003817100381710038172 (15)
Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

Computational and Mathematical Methods in Medicine 9
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 3 Accuracy comparison with different similarity metrics (a) reference image (b) moving image which is distorted reference imagewith geometric distortion (c) ground truth deformation field (d)ndash(f) registered images using SAD-based SSD-based and our algorithmrespectively (g)ndash(i) estimated transformation using SAD-based SSD-based and our algorithm respectively
Table 1 The experimental hardware configuration
No Components Parameters1 CPU Intel(R) Xeon(R) 190GHz times 182 System memory 32GB3 Video card Tesla K20m4 Memory of video card 4GB5 CUDA cores 24966 GPU max clock rate 071 GHz7 Memory clock rate 2600MHz8 Memory bus width 320-bit
Table 2 MSE statistics of the estimated deformation field
Ground truth MSE (average) MSE (standard deviation)SAD SSD Ours SAD SSD Ours
20 0652 0547 0521 0057 0036 003432 0765 0576 0563 0062 0051 004644 0932 0789 0766 0065 0044 002653 1391 0915 0887 0078 0037 0031
transformation field resulting from our algorithm is moresimilar to the ground truth than those obtained using theother two algorithms
To measure the registration accuracy of the proposedalgorithm we computed the mean and standard deviationof the MSE between the ground truth and estimated dis-placement vectors Table 2 displays the MSE statistics of theestimated deformation when compared to the ground truthThe first column shows the mean ground truth deformationwhich represents the magnitude of the displacement vectorthat is used to generate moving images in each experiment
For each mean value of ground truth eight different trans-formation fields with this mean are generated and applied tothe reference image to generate the corresponding movingimage The other columns display the average and standarddeviation of MSE obtained by using three different similaritymetrics for the generated eight pairs of reference-movingimages The results obtained using the proposed algorithmare considerably small compared to those of SAD-based andSSD-based algorithm and our algorithm shows the superioraccuracy in comparison to the other two algorithms
52 AccuracyComparisonwithCPU Implementation For ourB-spline registration algorithm employing LSD as a similaritymetric and NCG as a optimization strategy we respectivelyimplemented it based on CPU and GPU and compared theregistration accuracy impact from the parallel computingframework for the four groups of medical images Since theresolution of these images is 512 times 512 the control pointmesh size the number of control points and the numberof regions are 16 times 16 35 times 35 and 32 times 32 respectivelyIn the GPU-based implementation of our algorithm we setthe grid size to 32 times 32 and the block size to 16 times 16 for thekernel function kernelFunctionSimilarity() and set the gridsize to 4 times 4 and the block size to 8 times 8 for the kernelfunction CalSimilarityGradientKernelFunc() Owing NCG isrespectively adopted in the two implementations we also setthe maximum iteration number to 100 in the optimizationprocess Figure 4 shows the results using two implementa-tions for the first group of chestCT images Figure 5 shows theresults that a reference image andmoving image of the humanhead are matched using two implementations As can beseen from Figures 4 and 5 the CPU-based implementationand the GPU-based implementation of our algorithm canboth work well in describing the elastic deformation between
10 Computational and Mathematical Methods in Medicine
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 4 The registration results for chest images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference result of the two images before registration (d)ndash(f) are respectively the best deformationmesh the moving image subjected to the best deformation and the differential result after registration using CPU-based implementation(g)ndash(i) are the best deformation mesh the moving image subjected to the best deformation and the differential result using our GPU-basedimplementation
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5 The registration results for brain images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference between the reference and moving image before registration (d)ndash(f) are respectively thebest deformation the moving image transformed with best deformation and the difference image after registration using the CPU-basedimplementation (g)ndash(i) are respectively the best deformation the transformedmoving image and the difference after registration using ourGPU-based implementation
reference and moving images and they can both obtainhighly accurate results
In order to evaluate the accuracy of registration resultssome researchers used some mathematical metrics Elling-wood et al [24] used the normalized RootMean Square Error(RMSE) to mathematically evaluate accuracy of the GPU
resultant displacement field against the single-threaded CPUimplementation RMSE is calculated as follows
RMSE = radicsum119909isinΩ 1003817100381710038171003817VCPU (119909) minus VGPU (119909)10038171003817100381710038172sum119909isinΩ 1003817100381710038171003817VCPU (119909)10038171003817100381710038172 (15)
Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom
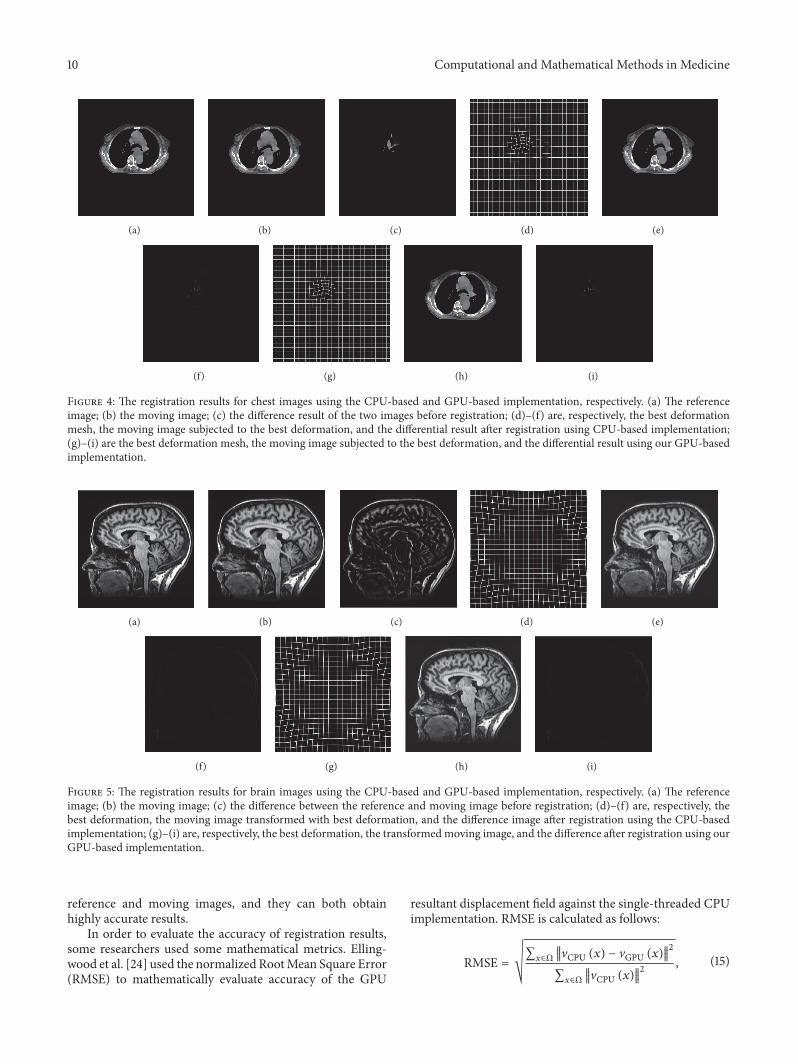
10 Computational and Mathematical Methods in Medicine
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 4 The registration results for chest images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference result of the two images before registration (d)ndash(f) are respectively the best deformationmesh the moving image subjected to the best deformation and the differential result after registration using CPU-based implementation(g)ndash(i) are the best deformation mesh the moving image subjected to the best deformation and the differential result using our GPU-basedimplementation
(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5 The registration results for brain images using the CPU-based and GPU-based implementation respectively (a) The referenceimage (b) the moving image (c) the difference between the reference and moving image before registration (d)ndash(f) are respectively thebest deformation the moving image transformed with best deformation and the difference image after registration using the CPU-basedimplementation (g)ndash(i) are respectively the best deformation the transformedmoving image and the difference after registration using ourGPU-based implementation
reference and moving images and they can both obtainhighly accurate results
In order to evaluate the accuracy of registration resultssome researchers used some mathematical metrics Elling-wood et al [24] used the normalized RootMean Square Error(RMSE) to mathematically evaluate accuracy of the GPU
resultant displacement field against the single-threaded CPUimplementation RMSE is calculated as follows
RMSE = radicsum119909isinΩ 1003817100381710038171003817VCPU (119909) minus VGPU (119909)10038171003817100381710038172sum119909isinΩ 1003817100381710038171003817VCPU (119909)10038171003817100381710038172 (15)
Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

Computational and Mathematical Methods in Medicine 11
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The running times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 6 The performance comparisons of five algorithms for 2D images
where V denotes the resultant displacement field associatedwith a voxel at the coordinate 119909 To measure the registrationquality we generate the deformation field by running theregistration process for 100 iterations and then compare theresults against two CPU-based implementations (single-coreand dual-core) The average RMSE for the four groups ofmedical images is 0027 plusmn 0011 comparing our GPU-basedimplementation against the single-core CPU implementa-tion and the average RMSE value is 0024 plusmn 0008 comparingour GPU-based implementation against the dual-core CPUimplementation so our GPU-based implementation and twoCPU-based implementations can achieve almost the sameaccuracy of image registration To sum up according totwo aspects of the image registration results and the RMSEmetric the experimental results show that both the twoCPU-based implementations and our GPU-based implementationcan generate near-identical vector fields with respect to thereference images and almost achieve good registration resultswith the same precision
53 Execution Speed Evaluation In order to evaluate andcompare the registration performance five different algo-rithm versions are implemented (1) the single-threadedCPU implementation (2) the dual-coreCPU implementationusingOpenMP (3) the basicGPU implementation (this GPUversion has a straightforward and naive kernel function thatcalculates the gradient of similarity metric for each controlpoint) (4) the GPU implementation without LUTs (thisversion designs kernel function that calculates the gradient ofsimilarity metric for each partition rather than each controlpoint to decrease the calculation complexity but it computestemporarily some intermediate values such as basis functionproducts and does not still use LUTs) (5) our algorithm (ouralgorithm computes three time-consuming steps on the GPU
and uses three LUTs and instruction optimization strategy inkernel functions to maximize execution performance)
These versions are performed for four groups of medicalimages In our algorithm we first set the maximum iterationnumber to 100 and define the initial mesh spacing sizeto 10 times 10 Then we set the grid and block size for thetwo kernel functions kernelFunctionSimilarity() (the gridand block size are 32 times 32 and 16 times 16 respectively) andCalSimilarityGradientKernelFunc() (the grid and block sizeare respectively 5 times 5 and 10 times 10) The performance ofour algorithm is compared with the two CPU versions andtwo GPU versions under twomeasures total execution timesand speedup ratio The speedup ratio is a persuasive measureused to compare the performance of GPU to CPU which ismathematically described as speedup = timeCPUtimeGPUwhere time refers to the total execution times The executiontimes and speedup ratio comparisons of five versions for 2Dimages are respectively illustrated in Figure 6
As shown in Figure 6 our algorithm requires approx-imately 25 s to complete the registration process for thereference and moving images with the size of 512 times 512By comparing the execution time of our algorithm with thesingle-core CPU version (the total time is about 220 s) andthe dual-core CPU version (the total time is about 130 s)the running speed of our algorithm is around 9 times fasterthan the single-core CPU version and 5 times faster than thedual-core CPU version In addition our algorithm is about 10seconds less than the basic GPU version in terms of runningtime and our algorithm is about 4 seconds less than the GPUversion without LUTs In Figure 6 the results show that ouralgorithm reduces the calculation complexity and acceleratesthe speed of image registration effectively due to employingthe parallel computing strategy and LUTs
12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

12 Computational and Mathematical Methods in Medicine
Exec
utio
n tim
e (s)
280
260
240
220
200
180
160
140
120
100
80
60
40
20
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versions
Spee
dup
ratio
14
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 7 The performance comparisons of five algorithms for 2D images
Table 3 Four groups of 3D medical images with different sizes
Case 1 Case 2 Case 3 Case 4Reference images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60Moving images 256 times 256 times 30 256 times 256 times 60 512 times 512 times 30 512 times 512 times 60
In the next experiment we evaluate the impact of theinitial B-spline mesh spacing size on the registration effi-ciency For the reference and moving images with the sizeof 512 times 512 we first set the maximum iteration number to100 and respectively set the initial B-spline mesh size to 8 times8 10 times 10 16 times 16 and 32 times 32 for four groups of differentimages Then the grid and block size are respectively 32times 32 and 16 times 16 for the kernel function kernelFunction-Similarity() in our algorithm In addition B-spline spacingsizes in four various datasets require different numbers ofcontrol points and regions so we set reasonable values forthe grid and block sizes to adapt each of datasets for thekernel function CalSimilarityGradientKernelFunc()Figure 7illustrates the execution times and speedup ratio comparisonsof five algorithm versions for different mesh spaces
As shown in Figure 7 the running times of the single-core CPU version decrease about 60 s because control pointmesh spacing size gets larger and the number of controlpoints used to describe deformation field becomes less Theexecution times of three GPU versions decreased less withthe decrease of the amount of control points Especially inour algorithm the mesh spacing size has a less impact on theexecution speed of the entire registration process because themain time-consuming steps are executed by multithreadingin parallel on the GPU
In order to evaluate the calculation efficiency of ouralgorithm for the different amounts of image volume datawe furthermore compare our algorithm with the other four
versions in the elastic registration for four groups of 3Dmedical images with different sizes The sizes of four groupmedical images are shown in Table 3The execution time andspeedup ratio comparison of five versions for 3D images withdifferent resolutions are shown in Figure 8
In Figure 8 experimental results show that the execu-tion time of the single-core CPU version increases moresignificantly with the increasing amount of 3D volume databut the execution time of our algorithm almost has nogrowth because of the powerful parallel computing abilityof GPU Meanwhile our algorithm computes the gradientof the similarity metric for each partition rather than eachcontrol point to reduce the calculation complexity andimprove the efficiency of global memory access and weeffectively create three LUTs and utilize kernel instructionoptimization strategy in the design of kernel functionsTherefore compared with the other two GPU versions ouralgorithm utilizes the GPU parallel computing ability morefully further improves the execution efficiency of B-splineregistration and especially achieves a better speedup ratiowith the increasing amount of image volume data
6 Conclusion
In this paper we have introduced the LSD as similaritymetric and developed a parallel computing strategy andsome effective LUTs that greatly reduce the complexity of B-spline-based registration and then designed highly parallel
Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

Computational and Mathematical Methods in Medicine 13
Exec
utio
n tim
es (s
)2000
1800
1600
1400
1200
1000
800
600
400
200
0
Dataset number1 2 3 4
Single-core CPUDual-core CPUBasic GPU
GPU without LUTOur algorithm
(a) The execution times comparison of five versionsSp
eedu
p ra
tio 14
16
18
20
22
24
12
10
8
6
4
2
0
Dataset number1 2 3 4
Dual-core versus single-coreBasic GPU versus single-coreGPU without LUT versus single-coreOur algorithm versus single-core
(b) The speedup ratio comparison of five versions
Figure 8 The performance comparisons of five algorithms for 3D images with different resolutions
kernel functions for computing the similarity metric and itsgradient on GPU We have demonstrated the accuracy andexecution speed of our algorithm via experiments using thepublicmedical image datasets Experimental results highlightthat our algorithm takes full advantage of the GPU parallelcomputing and the entire B-spline nonrigid registrationprocess achieved the speed ratio of 17 times for the largeamount of volume data compared with the CPU-basedimplementation The future work will focus on the parallelregistration algorithm based on new similarity metrics formultimodality medical images
Competing Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by National Natural Science Foun-dation of China under Grant nos 61562057 and 61461025Lanzhou Science and Technology Innovation and Entrepre-neurship Projects under Grant no 2014-RC-7 the NaturalScience Foundation of Gansu Province in China underGrant no 145RJZA080 and the Youth Science Foundation ofLanzhou Jiaotong University under Grant nos 2013005 and2013009
References
[1] A Sotiras C Davatzikos and N Paragios ldquoDeformable medi-cal image registration a surveyrdquo IEEE Transactions on MedicalImaging vol 32 no 7 pp 1153ndash1190 2013
[2] D P Shamonin E E Bron B P F Lelieveldt M Smits SKlein and M Staring ldquoFast parallel image registration on CPU
and GPU for diagnostic classification of Alzheimerrsquos diseaserdquoFrontiers in Neuroinformatics vol 7 article 50 2014
[3] H Rivaz and D L Collins ldquoNear real-time robust non-rigidregistration of volumetric ultrasound images for neurosurgeryrdquoUltrasound in Medicine and Biology vol 41 no 2 pp 574ndash5872015
[4] C Lu S Chelikani X Papademetris et al ldquoAn integratedapproach to segmentation and nonrigid registration for appli-cation in image-guided pelvic radiotherapyrdquo Medical ImageAnalysis vol 15 no 5 pp 772ndash785 2011
[5] H-H Chang and C-Y Tsai ldquoAdaptive registration of magneticresonance images based on a viscous fluid modelrdquo ComputerMethods and Programs in Biomedicine vol 117 no 2 pp 80ndash912014
[6] J-M PeyratHDelingetteM Sermesant C Xu andNAyacheldquoRegistration of 4D cardiac CT sequences under trajectoryconstraints with multichannel diffeomorphic demonsrdquo IEEETransactions on Medical Imaging vol 29 no 7 pp 1351ndash13682010
[7] J Zhang J Wang X Wang and D Feng ldquoThe adaptiveFEM elastic model for medical image registrationrdquo Physics inMedicine and Biology vol 59 no 1 pp 97ndash118 2014
[8] D Rueckert L I Sonoda C Hayes D L G Hill M OLeach and D J Hawkes ldquoNonrigid registration using free-form deformations application to breast mr imagesrdquo IEEETransactions onMedical Imaging vol 18 no 8 pp 712ndash721 1999
[9] G K Rohde A Aldroubi and B M Dawant ldquoThe adaptivebases algorithm for intensity-based nonrigid image registra-tionrdquo IEEE Transactions on Medical Imaging vol 22 no 11 pp1470ndash1479 2003
[10] S Aylward J Jomier S Barre B Davis and L Ibanez ldquoOpti-mizing ITKrsquos registration methods for multi-processor shared-memory systemsrdquo in Proceedings of the MICCAI Workshop onOpen Source and Open Data Brisbane Australia October 2007
[11] G Pratx and L Xing ldquoGPU computing in medical physics areviewrdquoMedical Physics vol 38 no 5 pp 2685ndash2697 2011
14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

14 Computational and Mathematical Methods in Medicine
[12] A Eklund P Dufort D Forsberg and S M LaConte ldquoMedicalimage processing on theGPU-Past present and futurerdquoMedicalImage Analysis vol 17 no 8 pp 1073ndash1094 2013
[13] R Shams P Sadeghi R Kennedy and R Hartley ldquoA survey ofmedical image registration on multicore and the GPUrdquo IEEESignal Processing Magazine vol 27 no 2 pp 50ndash60 2010
[14] O Fluck C Vetter W Wein A Kamen B Preim and R West-ermann ldquoA survey of medical image registration on graphicshardwarerdquo Computer Methods and Programs in Biomedicinevol 104 no 3 pp e45ndashe57 2011
[15] X Zheng J K Udupa and X Chen ldquoCluster of workstationbased nonrigid image registration using free-form deforma-tionrdquo in Proceedings of the Medical Imaging visualizationImage-Guided Procedures and Modeling Orlando Fla USA2009
[16] J Jiang W Luk and D Rueckert ldquoFPGA-based computationof free-form deformations in medical image registrationrdquo inProceedings of the 2nd International Conference on Field Pro-grammable Technology (FPT rsquo03) pp 234ndash241 December 2003
[17] T Rohlfing andC RMaurer Jr ldquoNonrigid image registration inshared-memory multiprocessor environments with applicationto brains breasts and beesrdquo IEEE Transactions on InformationTechnology in Biomedicine vol 7 no 1 pp 16ndash25 2003
[18] J Rohrer L Gong and G Szekely ldquoParallel mutual informationbased 3D nonrigid registration on a multi-core platformrdquo inProceedings of the MICCAI Workshop in High-PerformanceNew York NY USA September 2008
[19] C Sigg and M Hadwiger ldquoFast third-order texture filteringrdquoGPU Gems vol 2 pp 313ndash329 2005
[20] D Ruijters B M T Haar-Romeny and P Suetens ldquoAccuracyof GPU-based B-spline evaluationrdquo in Proceedings of the 10thIASTED International Conference on Computer Graphics andImaging (CGIM rsquo08) pp 117ndash122 ACTA Press 2008
[21] M Modat G R Ridgway Z A Taylor et al ldquoFast free-form deformation using graphics processing unitsrdquo ComputerMethods and Programs in Biomedicine vol 98 no 3 pp 278ndash284 2010
[22] J A Shackleford N Kandasamy and G C Sharp High-Performance Deformable Image Registration Algorithms forManycore Processors Elsevier New York NY USA 2013
[23] K Ikeda F Ino and K Hagihara ldquoEfficient accelerationof mutual information computation for nonrigid registrationusing CUDArdquo IEEE Journal of Biomedical and Health Informat-ics vol 18 no 3 pp 956ndash968 2014
[24] N D Ellingwood Y Yin M Smith and C-L Lin ldquoEfficientmethods for implementation of multi-level nonrigid mass-preserving image registration on GPUs and multi-threadedCPUsrdquo Computer Methods and Programs in Biomedicine vol127 pp 290ndash300 2016
[25] Z Y Xie and G E Farin ldquoImage registration using hierarchicalB-splinesrdquo IEEE Transactions on Visualization and ComputerGraphics vol 10 no 1 pp 85ndash94 2004
[26] S KleinM Staring and J P Pluim ldquoEvaluation of optimizationmethods for nonrigid medical image registration using mutualinformation and B-splinesrdquo IEEE Transactions on Image Pro-cessing vol 16 no 12 pp 2879ndash2890 2007
[27] httpinsight-journalorgrire[28] NVIDIA CUDA Programming Guide Version 60 2014
httpsdevelopernvidiacomcuda-toolkit[29] H J Johnson M M McCormick and L IbanezThe ITK Soft-
ware Guide Introduction and Development Guidelines KitwareIncorporated Clifton Park NY USA 2015
Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom

Submit your manuscripts athttpwwwhindawicom
Stem CellsInternational
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MEDIATORSINFLAMMATION
of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Behavioural Neurology
EndocrinologyInternational Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Disease Markers
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
BioMed Research International
OncologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Oxidative Medicine and Cellular Longevity
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
PPAR Research
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Immunology ResearchHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
ObesityJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational and Mathematical Methods in Medicine
OphthalmologyJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Diabetes ResearchJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Research and TreatmentAIDS
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Gastroenterology Research and Practice
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Parkinsonrsquos Disease
Evidence-Based Complementary and Alternative Medicine
Volume 2014Hindawi Publishing Corporationhttpwwwhindawicom


















