
Replication Database replication is the process of sharing data between databases in different...
34
Replication Database replication is the process of sharing data between databases in different locations. Tables and/or fragments (replicas) copied at different sites. Users at different locations (nodes) can work on their own replica and share, or synchronize, their changes.
-
Upload
cory-cameron -
Category
Documents
-
view
219 -
download
0
Transcript of Replication Database replication is the process of sharing data between databases in different...

Replication
Database replication is the process of sharing data between databases in different locations.
Tables and/or fragments (replicas) copied at different sites.
Users at different locations (nodes) can work on their own replica and share, or synchronize, their changes.

Redundancy
Creates redundancy which leads to a processing overhead to ensure consistency integrity constraints applied.
Node failure may mean an integrity check cannot be carried out so a user may not be able to complete a transaction at their node.

Transparency
Partitioning and Replication should be transparent to users (except perhaps on the failure of a node).
Mechanisms below the logical level should deal with the fragments and replicas.
DBMS should be capable of recombining fragments when the required data comes from more than one fragment.
The DBMS should be able to select a suitable replicate when a query is made on a replicated fragment.

The appropriate mechanism for this is a distribution schema which complements the normal 3-level architecture.
This would include a network directory which holds
•Node locations where each fragment stored.
•Relationships among the distributed fragments and replicates.
•Which fragments are redundant copies of other parts.
•The current status of data in the network.
•Access controls

The Design Master-MS-Access
The database is converted into a Design Master.
e.g. Microsoft Access /Tools/ Replication/ Create Replica.
Microsoft Access then steps through the process of creating a Design Master.

When a database is converted into a Design Master, new tables are added to the database.
Additionally, new fields are added to the tables that exist in the database.

Replica Set
Replicas are created from the Design Master
The Design Master and the replicas make up a replica set.
There is only one Design Master in a replica set.
The Design Master is the only member of the replica set in which you can make changes to the design of the database objects.

Implementation using MS-Access
The simplest way to implement replication is through the Microsoft Access user interface
•Design Masters can be created and members of the replica set•changes synchronized in any two members of the replica set•conflicts resolved in the data after synchronization•the Design Master recovered if it is corrupted
A second way to implement replication is by using the Briefcase that is installed with Windows
The Briefcase component enables you to create a replica and synchronize changes between two replicas in the set.

Replication can implemented through the Microsoft Replication Manager
The Replication Manager uses a component called the Microsoft Jet Synchronizer to create replicas and manage replica sets.
The Replication Manager is required to use some advanced features of replication, such as indirect synchronization, Internet or intranet synchronization, and using synchronization schedules.
see
Microsoft Access 2000 Replication FAQMicrosoft Access 97 Replication FAQ

Replicable vs Local Objects
Each member of the replica set contains a common set of replicable objects, such as tables, queries, forms, reports, macros, or modules.
The Design Master or a replica can contain both replicated and local objects
•objects that are replicated during synchronization•objects that remain on the local computer and are not replicated.
This allows the Design Master or a replica to be customized for a specific group or user while still synchronizing common data with other members in the replica set.

Why Use Replication?-Examples
A contact-management application may monitor sales and orders.
Each sales representative has a laptop computer that can be connected to the company's network.
One approach would be to split the database and have the tables reside in a back-end database on a network server, or on the Internet or an intranet.
The queries, forms, reports, macros, and modules reside in a separate front-end database on the user's computer.
The objects in the front-end database are linked
to the tables in the back-end database.

When sales representatives want to retrieve or update information in the database, they use the front-end database.
This is then used at some later date to update the back-end database on server.
If database replication used, a single database contains both the data and the objects, and replicas made of the database for each sales representative.
Replicas made for each user and ‘synchronized’ with the Design Master on a network server i.e. server and replica database updated so they are consistent.
Sales representatives update the replicas on their computers during the course of a work session, and then synchronize their replicas with the hub replica on the server as needed

Database replication can be used for:
Accessing data
A replica can be maintained of a corporate database on a laptop computer.
Upon connecting to the corporate network, the changes made to the replica on a laptop can be synchronized with the changes in the corporate office replica.
Distributing software
new tables, queries, forms, reports, macros, and modules can be added to the Design Master, or you can modify the existing objects.
The next time the Design Master is synchronized with its replicas, the changes will be dispersed to the replicas.

Backing up databases
You can automatically back up a database by keeping a replica on a different computer.
Load balancing
A database can be replicated on additional network servers and users reassigned to balance the loads across those servers.
Users who need constant access to a database can be given their own replica, thereby reducing the total network traffic.
Internet or intranet replication
An Internet or intranet server can be configured to be used as a hub for propagating changes to participating replicas.

Why Prevent Replication?
If there are a large number of record updates at multiple replicas
Applications that require frequent updates of existing records in different replicas are likely to have more record conflicts than applications that simply insert new records in a database.
Applications with many record conflicts require more administrative time because the conflicts must be resolved manually.
In this scenario, it would probably not be a good idea to use database replication.

Data consistency is critical at all times
Applications that rely on information being correct at all times, such as funds transfer, airline reservations, and the tracking of package shipments, usually use a transaction method.
While transactions can be processed within a replica, there is no support for processing transactions across replicas.
In this scenario, database replication would not provide the desired results.

There is a need for the immediate dissemination of updates to all users
Applications that are updated frequently are not good candidates for database replication.
Users can't afford the overhead to the database
Some users may have limited space available on their hard disks, and the creation of a replicable database may use all available disk space.

Replication Scenarios
Three different replication scenarios:
1. simple read-only replication (as illustrated in Figure 1),
2. replication to and from a mobile client (as illustrated in Figure 2),
3. and multiple updates.
They may be used in a variety of architectures, for systems that provide:
• data distribution to a network of servers, including those that are mobile or occasionally connected (illustrated in scenarios 1 and 2)
• data consolidation to a central server (scenarios 1 and 2)
• process separation onto more than one server (scenario 1)
• information flow from one server to another (scenario 3)
• data sharing across multiple sites (scenario 3)


Distribution Architecture
These examples use the concept of a three-tier client-server network which includes a central server (first tier), workgroup servers (second tier) , and clients (third tier).
In a real situation, there could be more than one central server (including, for example, a data warehouse server) and many workgroup servers.
A workgroup server might support part of an office (such as a single department) or more than one office.
The network might include local and wide-area connections.

Read-only Replication
With read-only replication, the data is entered and stored on each workgroup server.
Only data relevant to each local workgroup is located here.
The data is also replicated to the central server (consolidated), so the central server will contain a read-only copy of all data from all workgroups.
The data on the central server (logically stored in a single table) has multiple sources (from workgroup servers), but each individual record only has one source.
Alternatives to this scenario, but essentially the same, are:
1) the data is entered on the central server and copied to the workgroup servers, where it is read-only; or
2) the data is entered on one workgroup server and replicated to one or more other servers as read-only copies.

Figure 1.
--An example of simple read-only replication.

Mobile Data
Mobile computing has become much more accessible in recent years, and in most organizations some people work away from the office.
There are now a number of methods for providing data to a mobile workforce, one of which is replication. In this case, the data is downloaded on demand from a local workgroup server.
Updates to the workgroup or central data from the mobile client, such as new customer or order information, are handled in a similar manner.
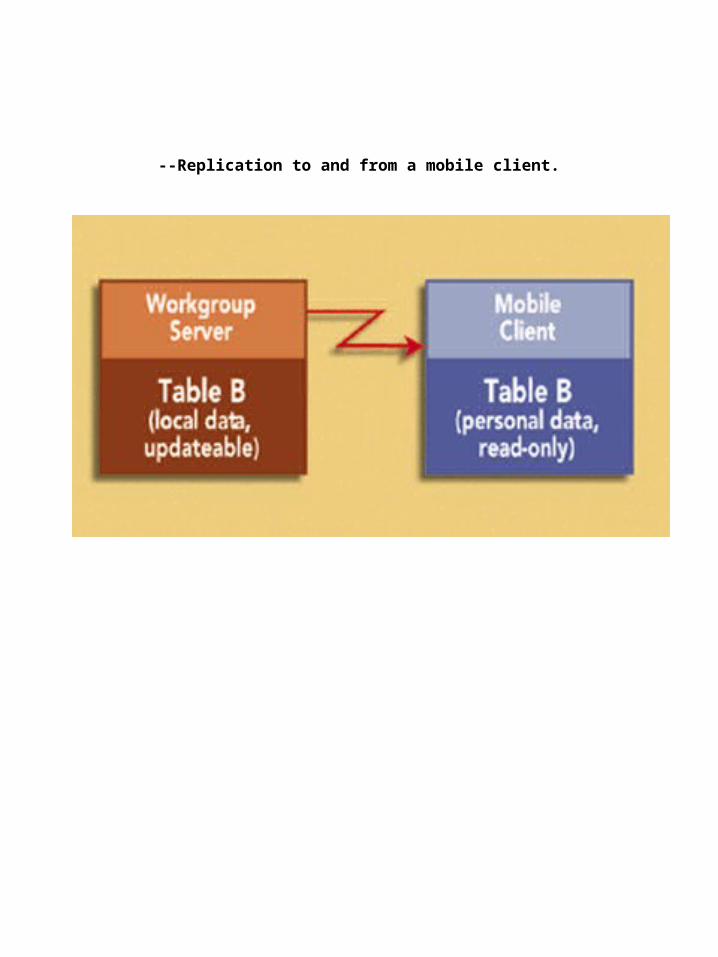
--Replication to and from a mobile client.

Multiple Updates
Problems arise with the possibility of two updates being made to the same data on different servers.
The traditional solution is to designate a single source server
Can work by allowing the administrator to make some decisions about which data is "correct."

Any conflicts are processed by a conflict-resolution algorithm that usually chooses one of the following methods:
Priority:
each server is given a unique priority; higher-priority servers "win" over lower-priority servers
Timestamp:
the latest or earliest transaction in the conflict is considered correct; if you choose to do nothing in a conflict situation, the latest transaction wins
Data partitioning:
each row is guaranteed to be manipulated by only one server; this simplifies the architecture to the first scenario
Many other conflict-resolution or avoidance schemes can be implemented by the various products.

Automatically Generated Keys
Another major problem with replication in general has to do with automatically generated keys.
Most systems now use an automatically generated surrogate key to uniquely identify a row of data.
When data for one table is created on a number of servers, you need to ensure that the replicated rows are unique.
There are three accepted ways to do this:
1.set up the key generators to use a predefined number range, different for each server
2.add a server identifier to the primary key
3.replicate into separate tables and read all of the data through a union view; to deal with the potential of duplicate keys in the UNION, a pseudocolumn would be used to represent the source database

Publish and Subscribe
Microsoft uses a "publish-and-subscribe" metaphor:
The DBA makes the data on one database (the publisher) available to the world, and then another database (the subscriber) receives the replicated data.
In keeping with this metaphor, the machine that handles the job of moving the data from publisher to subscriber is called the distributor.
As with all distributed databases, the replication environment must be designed carefully.

With Microsoft, you need to include the following elements in your architecture:
•the data to be replicated (publications),
•the database carrying the source data (publisher)
•the database receiving the replica (subscriber)
•the distribution machine
•how you want the subscriber to use the data (read or update)
•and how often you need the data to be replicated.
The SQL Enterprise Manager is used to designate the publisher database.
The publications are defined and the subscribers selected.

This simple setup can be used to configure complex replication architectures.
It is easy to use the basic tools to build up a structure that can be very difficult to maintain.
Any server can be both publisher and subscriber (and distributor, for that matter), and the same table can contain replicated and source data!

SQL Enterprise Manager has a graphical view of your replication network showing the topology as a network
You can move and place your publishers, subscribers, and distributors on the workspace in any configuration
With this tool, it is relatively easy to set up complex configurations, but the database is not always robust enough to manage them correctly.
The DBA should think through the architecture very carefully, because the system will let you do nearly anything, whether you really want to or not.

Master Mirroring
This is the easiest form of replication to implement.
There is a single master copy, and all changes are made to it.
After changes have been made a backup is made, and copies of the backup are installed on the mirror machines.
This strategy is fairly robust: if the master copy is lost, the mirrors can still operate, and the master can be reconstructed from the mirrors.

this model does not support distributed transactions.
Transaction processing can only be done on the master, and thus the master is a critical component, and is also a bottleneck.
The mirrors can be used only for viewing (reading).
by installing mirrors (which may be geographically separated by thousands of miles) performance for viewing is radically improved, since one machine does not have to handle all the load.
simplicity.

Peer Mirroring
In this scheme, database updates can be performed on multiple "masters".
Synchronization is achieved by having changes propagated from one mirror to another through journal logs.
Consistency should be verified by comparing the contents of each of the peers.
The disadvantage of this system is complexity


















