

Reliability Testing in OPNFV
20
-
Upload
opnfv -
Category
Technology
-
view
362 -
download
0
Transcript of Reliability Testing in OPNFV

2
Agenda
• Overview of reliability
• Reliability research in OPNFV
• Introduction of reliability testing
• Reliability testing framework
• Test case demo
• Work Plan and Related links

3
Overview of Reliability
Reliability is the ability of a system to perform and maintain its functions in routine
circumstances, as well as hostile or unexpected circumstances.
High reliability is often defined as a system availability of 99.999%, which meets
the carrier-level requirement and protects carriers from business and reputation
loss due to system breakdown.
High Reliability
No Single Point of Failure
Overload Control
Automatic Recovery
Fault Isolation
… …

4
Reliability is Critical Important
More and more business
services rely on the Internet
and cloud. A short outage can
cause a huge economic loss.
When the natural disaster
happening, the telecom
reliability supports the nation
security and life emergency.

5
Reliability in NFV and OPNFV
Standard Title
NFV-REL 001 Resiliency Requirements
NFV-REL 002Report on Scalable Architectures
for Reliability Management
NFV-REL 003 E2E reliability models
NFV-REL 004Active monitoring and failure
detection
NFV-REL 005 Quality Accountability Framework
Availability
Multi-Site
Doctor
PinPoint
Escalator
Prediction
OPNFV Platform

6
The Goal of Reliability Testing
Availability Numbers of 9 Downtime In a year(minute) Apply Product
99.9% 3 500 Computer / Server
99.99% 4 50 Enterprise-class Device
99.999% 5 5 Common carrier -class Device
99.9999% 6 0.5 Higher carrier-class Device
Customer Requires
Device had better never have fault
If the fault occur, Do not affect the main services
If the main services affected, locate and recover
the fault as soon as possible
Reliability Testing Goal
Test the product ability of not having fault
Test the product ability of fault recovery
Test the product ability of fault detection, location
and tolerance.

7
Type of Reliability Testing
Known Fault
Known Scenario
Unknown Fault
Unknown ScenarioFault InjectionFault Injection
Reliability Prediction Stability Testing
• Simulate fault directly
• Trigger fault By External trigger
Scenario
• Simulate fault directly
• Trigger it by the Stress
Scenario• Predict it by Modeling

8
Metrics for Service Availability
【General Metrics】
Failure detection time: the time interval between the failure happens and the failure been detected.
Service recovery time: the time interval between the failure happens and the service finish its recovery. the time
interval from the occurrence of an abnormal event (e.g. failure, manual interruption of service, etc.) until recovery
of the service.
Fault repair Time: the time interval between the failure detected and faulty entity is repaired.
Service failover time: the time from the moment of detecting the failure of the instance providing the service until
the service is provided again by a new instance.
【Carrier Metrics】
Network access success rate: the proportion of the end-user can access the network when requested.
Call Drop Rate: the proportion of mobiles which having successfully accessed suffer an abnormal release,
caused by loss of the radio link.

9
Scope of Reliability Testing (1)Item Layer Failure Mode Priority
Hardware
Reliability testing
Controller node
Control node server failure H
Memory failure / Memory condition not ok M
CPU failure / CPU condition not ok M
Management network failure M
Storage network failure M
Compute node
Compute node server failure H
Memory failure / Memory condition not ok M
CPU failure / CPU condition not ok M
Management network failure M
Storage network failure M
Service network failure M
Storage nodeStorage node server failure M
Hard disk failure M
NetworkingHW failure of physical switch/router M
Network Interface failure M

10
Scope of Reliability Testing (2)Item Layer Failure Mode Priority
Software Reliability
testing
Controller node
HOST OS failure H
VIM important process failure H
VIM important service failure H
Management network failure—OVS M
Storage network failure—OVS M
Compute node
HOST OS failure H
VIM important service failure M
VIM important process failure M
Management network failure—OVS M
Storage network failure—OVS M
Service network failure-OVS M
Hypervisor(KVM 、libvirt、Qemu)failure H
VM
VM failure H
Gest OS failure M
VM service failure L
VM process failure L
System reliability
testing
Robustness test Various Faults random injection testing M
Stability testing Long time testing with load L
11
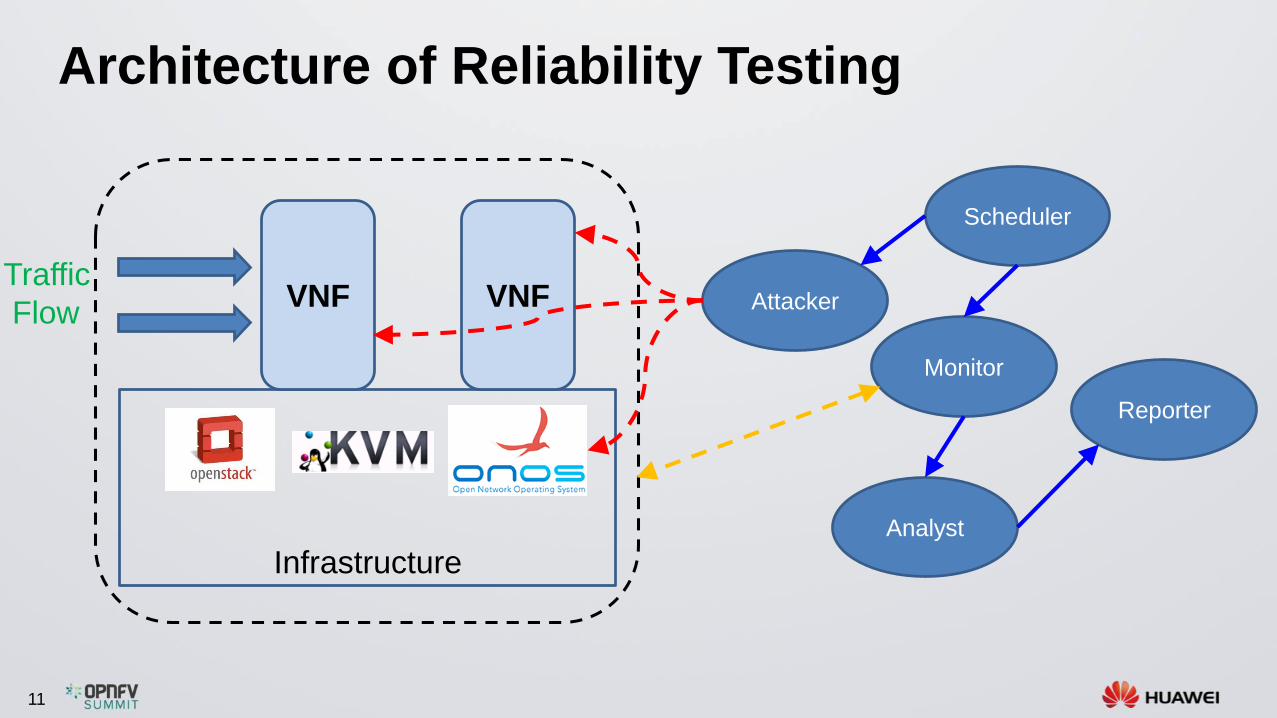
Architecture of Reliability Testing
Infrastructure
VNF VNFTraffic
Flow Attacker
Scheduler
Monitor
Analyst
Reporter

12
Reliability Testing Framework: Yardstick
Goal:
a Test framework for verifying the infrastructure compliance when running VNF applications.
Scope:
Generic test cases to verify the NFVI in perspective of a VNF.
Test stimuli to enable infrastructure testing such as upgrade and recovery.
Covered various aspects: performance, reliability, security and so on.
Design:
Yardstick testing framework is flexible to support various contexts of SUT, and easy to develop additional plugin for fault injection, system monitor, and result evaluation. It is also convenient to integrate other existing test frameworks or test tools.

13
Reliability Testing Workflow
cases.yaml
Yardstick
System under
test(SUT)
TaskCommand
Context
HeatContextBMContext
Heat
Nova Neutron
… …
Runner
Output(Process)
Scenarios
VM VM
Host
Monitor
3.fault Inject
output.json
1.input
2.deploy
5.output
6.undeploy
Note: when some fault injection methods break the SUT(e.g. kill one controller), a option step
recovering the broken SUT might be executed before the scenario is over.
Attacker
4.collect data

14
Case Sample: OpenStack Service HA
Controller
Node #1
Controller
Node #2
Controller
Node #3
Yardstick
Monitor
Controllers HA
nova-api
Attacker
nova-api nova-api
① Check
② setup monitor
③ monitor
service
④ setup attacker
⑤ fault
injection
⑥ get
the SLA⑦ Recover
the broken
⑧ test result

15
Test Case Configure and SLA

16
Test Case Demo Show
1. The nova-api processes
are running on Controller
Node #3.
2. The nova service
is running normally.
Before the Fault Injection

17
Test Case Demo Show
After the Fault Injection
3. The nova-api processes
have been killed.
4. Nova service is still
working normally.
5. ServiceHA test case ran by
using Yardstick and recorded
its test result.

18
Work Plan
TC Name Testing Purpose Priority Status
OpenStack controller
service failure
Verify the services running on the
controller is high available.
H Done
Controller Node
abnormally shutdown
Verify the controllers cluster deployment
is high available.
M Doing
Management network
timeout
Verify the controllers cluster deployment
is high available.
M TODO
VM abnormally
down
Verify the VM running on the compute is
high available.
M TODO

19
Related Links
Wiki of Yardstick project: https://wiki.opnfv.org/yardstick
Requirement of HA project:
https://etherpad.opnfv.org/p/High_Availabiltiy_Requirement_for_OPNFV
HA Test cases in Yardstick: https://etherpad.opnfv.org/p/yardstick_ha

Copyright©2015 Huawei Technologies Co., Ltd. All Rights Reserved.
The information in this document may contain predictive statements including, without limitation,
statements regarding the future financial and operating results, future product portfolio, new technology,
etc. There are a number of factors that could cause actual results and developments to differ materially
from those expressed or implied in the predictive statements. Therefore, such information is provided
for reference purpose only and constitutes neither an offer nor an acceptance. Huawei may change the
information at any time without notice.


















