
More Validity And some reliability. Today’s class Check in Validity In class exercise Reliability.
Upload
alcira-sanabriaCategory
view
215download
2description
Reliability and validity - Page 1/2
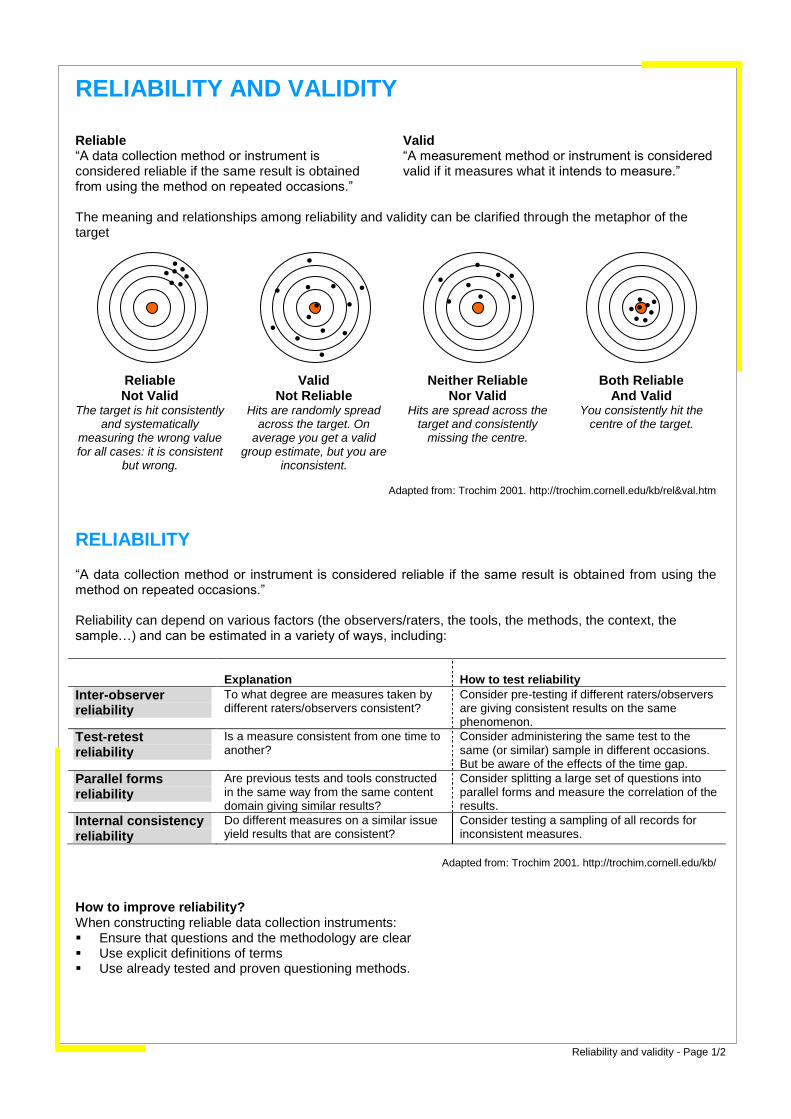
RELIABILITY AND VALIDITY Reliable Valid “A data collection method or instrument is considered reliable if the same result is obtained from using the method on repeated occasions.”
“A measurement method or instrument is considered valid if it measures what it intends to measure.”
The meaning and relationships among reliability and validity can be clarified through the metaphor of the target
Reliable Not Valid
Valid Not Reliable
Neither Reliable Nor Valid
Both Reliable And Valid
The target is hit consistently and systematically
measuring the wrong value for all cases: it is consistent
but wrong.
Hits are randomly spread across the target. On
average you get a valid group estimate, but you are
inconsistent.
Hits are spread across the target and consistently
missing the centre.
You consistently hit the centre of the target.
Adapted from: Trochim 2001. http://trochim.cornell.edu/kb/rel&val.htm
RELIABILITY “A data collection method or instrument is considered reliable if the same result is obtained from using the method on repeated occasions.” Reliability can depend on various factors (the observers/raters, the tools, the methods, the context, the sample…) and can be estimated in a variety of ways, including:
Explanation
How to test reliability
Inter-observer reliability
To what degree are measures taken by different raters/observers consistent?
Consider pre-testing if different raters/observers are giving consistent results on the same phenomenon.
Test-retest reliability
Is a measure consistent from one time to another?
Consider administering the same test to the same (or similar) sample in different occasions. But be aware of the effects of the time gap.
Parallel forms reliability
Are previous tests and tools constructed in the same way from the same content domain giving similar results?
Consider splitting a large set of questions into parallel forms and measure the correlation of the results.
Internal consistency reliability
Do different measures on a similar issue yield results that are consistent?
Consider testing a sampling of all records for inconsistent measures.
Adapted from: Trochim 2001. http://trochim.cornell.edu/kb/
How to improve reliability? When constructing reliable data collection instruments: Ensure that questions and the methodology are clear Use explicit definitions of terms Use already tested and proven questioning methods.
. . . . . . .
. . . . . . . .
.
.
.
. .
. .
. . . . . .
. .
. .
. .
.
.

Reliability and validity - Page 2/2
Examples of reliable measures
A reliable reading comprehension test to measure children's level of competency in English would be
one that has the same results from one week to the next, so long as there has been no instruction in the intervening period.
A ruler is a reliable measure of length.
Examples of measures that may be unreliable
A questionnaire to measure self-esteem may not be reliable if it is administered to people who have just
experienced either success or failure. Asking the question "Have you been tested for HIV?" may not yield reliable data because some people
may answer truthfully on this sensitive topic and some may not. The method of dietary recall to measure food consumption is only as reliable as each respondent’s
memory.
VALIDITY “Validity is the best available approximation to the truth of a given proposition, inference of conclusion. A measurement method or instrument is considered valid if it measures what it intends to measure.” There are different types of validity, and we will focus on internal and external validity.
What is it? Threats
Internal validity
Internal validity is relevant in studies attempting to establish a causal relationship, and it is only relevant for the specific study in question. “Can change be attributed to a program or intervention and not to other possible causes?”
Did the programme really caused the outcome? To base the result on a single group (i.e., not using a control group) means that it is more difficult to assess that the change is due to the programme and not to other factors (e.g., other external influences, changes in the social contexts). Even when you have a control group (that is often not the case in development programmes, also for ethical reasons!), there are challenges in ensuring that the two groups are really comparable and that no social interaction between them leads to muddling results.
External validity
It is related to generalising. It is the degree to which the conclusion of your study will hold for other persons in other places and at other times.
Can you really make a generalisation based on results?
Consider if your study can be biased by your choice of: People: did you focus on “special” people? Places: did you undertake the study in “special” places? Times: did the study happen in a particular time or
following an event that could bias the results?
Adapted from: Trochim 2001. http://trochim.cornell.edu/kb/
Examples of challenges to validity
An evaluation designed to assess the impact of nutrition education on weaning practices is valid if actual
weaning practices are observed. An evaluation that relies only on mothers’ reports may find that it is measuring what mothers know rather than what they do.
An instrument to measure self-esteem in one country may not be valid in another culture. Our understandings of validity change over time. It is still debated whether I.Q. tests are a valid measure
of intelligence. Long ago, measurements of the skull were thought to be a valid measure of intelligence.


















