
Relax and Adapt: Computing Top -k Matches to XPath Queries
21
Relax and Adapt: Computing Top-k Matches to XPath Queries Amélie Marian (Columbia University) Joint work with: Sihem Amer-Yahia (AT&T Research) Nick Koudas (University of Toronto) Divesh Srivastava (AT&T Research)
-
Upload
dieter-spence -
Category
Documents
-
view
26 -
download
0
description
Relax and Adapt: Computing Top -k Matches to XPath Queries. Amélie Marian (Columbia University) Joint work with: Sihem Amer-Yahia (AT&T Research) Nick Koudas (University of Toronto) Divesh Srivastava (AT&T Research). book. info. edition (paperback). author (Dickens). title - PowerPoint PPT Presentation
Transcript of Relax and Adapt: Computing Top -k Matches to XPath Queries

Relax and Adapt: Computing Top-k Matches to XPath Queries
Amélie Marian (Columbia University)
Joint work with:Sihem Amer-Yahia (AT&T Research)Nick Koudas (University of Toronto)Divesh Srivastava (AT&T Research)

04/19/23 Amélie Marian - Columbia University 2
Example
Heterogeneous XML Data about books Query: book[./info/title=“Great Expectations”] and
[./info/author=“Dickens”] and [./edition=“paperback”]
book
title(Great
Expectations)
edition(paperback)
info
author(Dickens)Query root node:
Distinguished node
title(Great
Expectations)
edition(paperback)
info author(Dickens)
title(Great
Expectations)
info
author(Dickens)
book
title(Great
Expectations)
edition(paperback)
info
author(Dickens)
book book
04/19/23 Amélie Marian - Columbia University 3
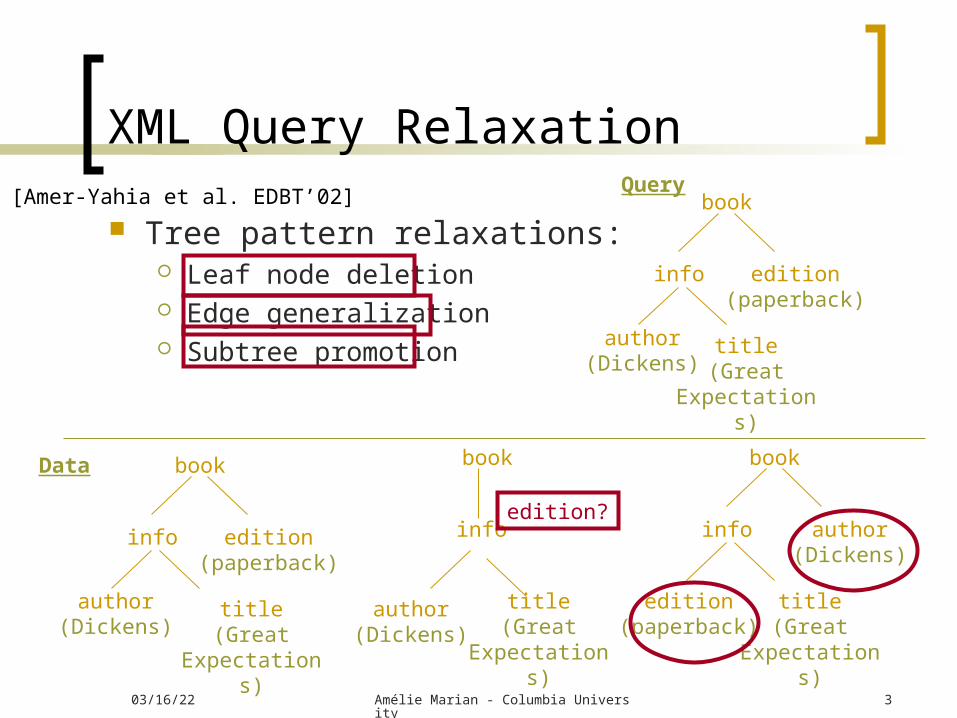
XML Query Relaxation
Tree pattern relaxations: Leaf node deletion Edge generalization Subtree promotion
[Amer-Yahia et al. EDBT’02] book
title(Great
Expectations)
edition(paperback)
info
author(Dickens)
book
title(Great
Expectations)
edition(paperback)
info author(Dickens)
book
title(Great
Expectations)
info
author(Dickens)
book
title(Great
Expectations)
edition(paperback)
info
author(Dickens)
edition?
Query
Data

04/19/23 Amélie Marian - Columbia University 4
Top-k Queries over XML Data:Motivations and Challenges
Structure heterogeneity Efficient identification of approximate matches
Top-k Ranking of approximate matches based on similarity to
query Early pruning
Query processing cost Cost increases with number of matches evaluated
Data explosion Many approximate matches XML path queries akin to joins Prioritization to increase pruning

04/19/23 Amélie Marian - Columbia University 5
Contributions
Whirlpool: adaptive architecture and top-k query processing strategy for XPath queries Goal: early pruning of non-top-k partial matches Approach: partial matches may follow different
plans, and may be at different stages of query execution
Real prototype implementation of Whirlpool Instantiation of Whirlpool for various “routing
strategies” and “prioritization” alternatives

04/19/23 Amélie Marian - Columbia University 6
Closely Related Work
Adaptive query processing Eddies:
Dynamic query join plans to adapt to processing environment
No pruning
Adaptive top-k query processing Upper:
Prioritization of partial matches based on maximum possible scores
Adaptive routing based on scores No joins
[Bruno et al. ICDE’01]
[Avnur and Hellerstein. SIGMOD’00]

04/19/23 Amélie Marian - Columbia University 7
Outline
Whirlpool Architecture Query Processing
Strategy Alternatives
Evaluation Settings Evaluation Results
04/19/23 Amélie Marian - Columbia University 8
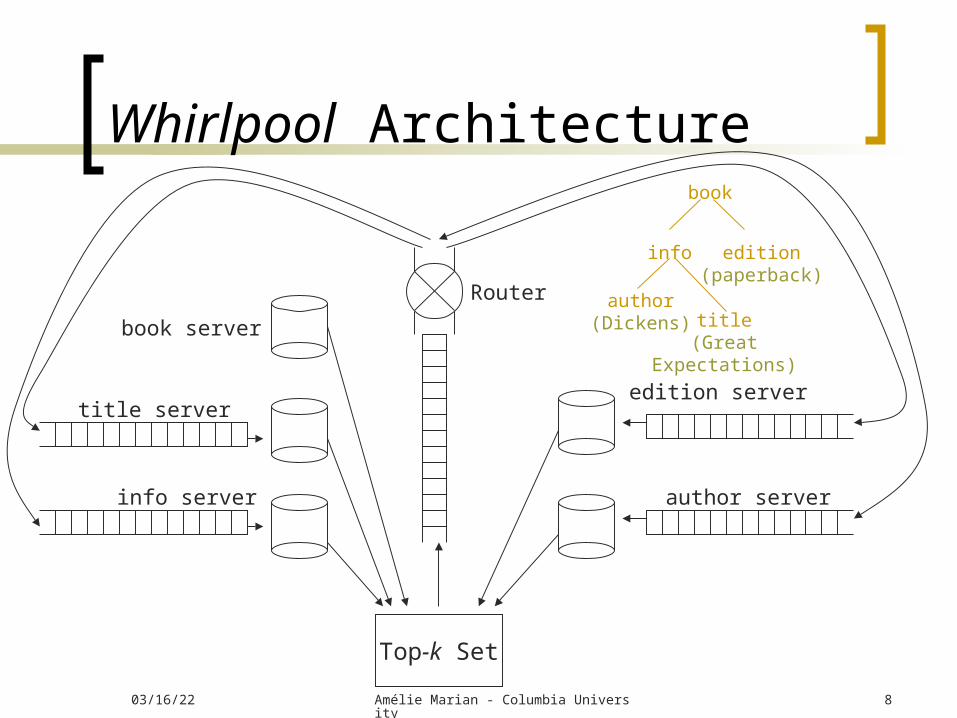
Whirlpool Architecture
Top-k Set
Router
book server
title server
info server
edition server
author server
book
title(Great Expectations)
edition(paperback)
info
author(Dickens)

04/19/23 Amélie Marian - Columbia University 9
Whirlpool Architecture:Components
Top-k Set Only one match with a given root node Used for pruning Complete matches are not processed further,
incomplete matches are sent to the router Router
Router Queue is based on partial matches maximum possible final scores
Dynamically choose which server to send partial match based on routing strategy

04/19/23 Amélie Marian - Columbia University 10
Whirlpool Architecture:Components
Root server: Generates candidate matches
Node servers: Maintain priority queue of partial matches For each partial match that is processed:
1. Compute a set of extended partial (or complete) matches
2. Compute scores of new matches3. Checks partial matches against current top-k set

04/19/23 Amélie Marian - Columbia University 11
Query Processing Alternatives
Prioritization Strategies (at each server) FIFO Current Score Maximum Possible Next Score Maximum Possible Final Score
Routing Decisions (at the router) Static Score-based
Likely to increase score the most Likely to increase score the least
Size-based Likely to produce the fewest matches

04/19/23 Amélie Marian - Columbia University 12
Evaluation Strategies
Lockstep (Static) Partial matches follow same execution plan Partial matches have gone through exactly the same
number of operations Whirlpool Single-threaded (Adaptive)
Partial matches adaptively routed Process the partial match with the highest maximum final
score (Query processing similar to Upper) Only one partial match processed at a time
Whirlpool Multi-threaded (Adaptive) Prioritization strategy at server decides which partial match
to process next at server System determines which server to process next

04/19/23 Amélie Marian - Columbia University 13
Evaluation Metrics
Parameters: Query size Document size k Parallelism Scoring function (tf.idf proposed in paper)
Measures: Query execution time Number of server operations Number of partial matches created

04/19/23 Amélie Marian - Columbia University 14
Evaluation Setting C++ implementation, with POSIX threads Default machine:
Red Hat 7.1 Linux 1.4GHz dual processor 2Gb RAM
XML Documents generated using XMark generating tool
XPath Queries chosen from XMark to illustrate different relaxations
XML nodes stored using Dewey encoding

04/19/23 Amélie Marian - Columbia University 15
Comparison of Adaptive Routing Strategies
Whirlpool-S and Whirlpool-M perform approximately the same number of server operations
0
5
10
15
20
25
30
35
40
Whirlpool-S Whirlpool-M
Qu
ery
Exe
cuti
on
Tim
e
max_score min_score min_alive_partial_matches

04/19/23 Amélie Marian - Columbia University 16
Static Routing Strategies vs. Best Adaptive

04/19/23 Amélie Marian - Columbia University 17
Effect of Parallelism
0
1
2
q1 q2 q3 Rat
io o
f W
hir
lpo
ol-
M q
uer
y ex
ecu
tio
n t
ime
ove
r W
hir
lpo
ol-
S q
uer
y ex
ecu
tio
n t
ime
1 processor 2 processors 4 processors ∞ processors
04/19/23 Amélie Marian - Columbia University 18
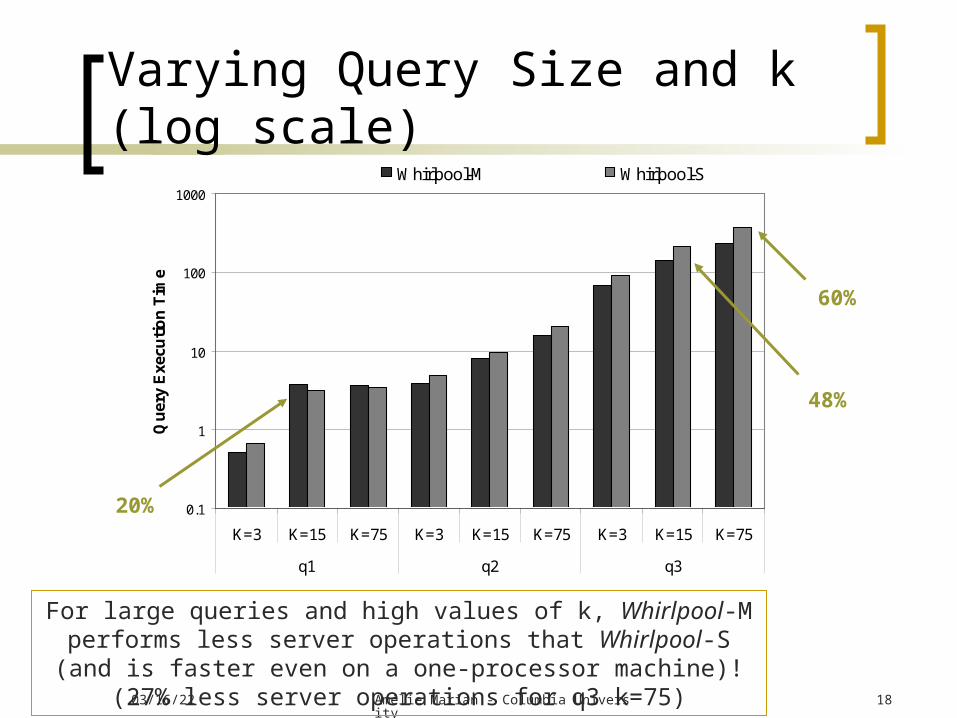
Varying Query Size and k (log scale)
For large queries and high values of k, Whirlpool-M performs less server operations that Whirlpool-S (and is faster even on a one-processor machine)! (27% less server operations for q3 k=75)
0.1
1
10
100
1000
K=3 K=15 K=75 K=3 K=15 K=75 K=3 K=15 K=75
q1 q2 q3
Qu
ery
Exe
cuti
on
Tim
eWhirlpool-M Whirlpool-S
48%
20%
60%

04/19/23 Amélie Marian - Columbia University 19
Varying Query Size and Document Size
0.01
0.1
1
10
100
1000
10000
1M 10M 50M 1M 10M 50M 1M 10M 50M
q1 q2 q3
Qu
ery
Exe
cuti
on
Tim
e
Whirlpool-M Whirlpool-S
Almost twice as fast

04/19/23 Amélie Marian - Columbia University 20
Scalability
Document Size
1M 10M 50M
Q1 100% 93.12% 85.66%
Q2 100% 49.56% 67.66%
Q3 100% 39.59% 31.20%
Percentage of partial matches created by Whirlpool-M as a function of the maximum possible number of partial matches

04/19/23 Amélie Marian - Columbia University 21
Conclusions
Efficient adaptive top-k query processing strategy Minimize number of partial matches evaluated
Benefit from parallelism with little threading overhead
Adapt to different environments Score distribution Selectivity distribution
Extensive experimental evaluation Good scalability


















