
Recsys matrix-factorizations
28
Matrix Factorizations for Recommender Systems Dmitriy Selivanov 2017-08-26
-
Upload
dmitriy-selivanov -
Category
Data & Analytics
-
view
194 -
download
0
Transcript of Recsys matrix-factorizations

Matrix Factorizations for Recommender Systems
Dmitriy Selivanov
2017-08-26

Recommender systems are everywhere
Figure 1:

Recommender systems are everywhere
Figure 2:

Recommender systems are everywhere
Figure 3:

Recommender systems are everywhere
Figure 4:

Goals
I Personalized offersI recommended items for a customer given history of activities
(transactions, browsing history, favourites)
I Similar itemsI substitutionsI frequently bought togetherI . . .
I Exploration

Live demo
I http://94.204.253.34/reco-playlist/I http://94.204.253.34/reco-similar-artists/

Main approaches
I Content basedI good for cold startI not personalized
I Collaborative filteringI vanilla collaborative fitleringI matrix factorizationsI . . .
I Hybrid and context aware recommender systemsI best of both worlds

Collaborative filteringTrivial algorithm:
1. take cutomers who also bought item i02. check other items they’ve bought - i1, i2, ...3. calculate similarity with other items sim(i0, i1), sim(i0, i2), . . .
I just frequencyI similarity of the descriptionsI correlationI . . .
4. sort by similarity
Cons:
I recommendations are trivial - usually most popular itemsI not personalizedI cold start - how to recommend new items?I need to keep and work on whole matrix

User-based collaborative filtering1. for a user u0 calculate sim(u0,U) and take top K2. aggregate their opinions about items
I weighted sum of their ratings
Cons:
I cold startI nothing to recommend to new/untypical usersI need to keep and work on whole matrix
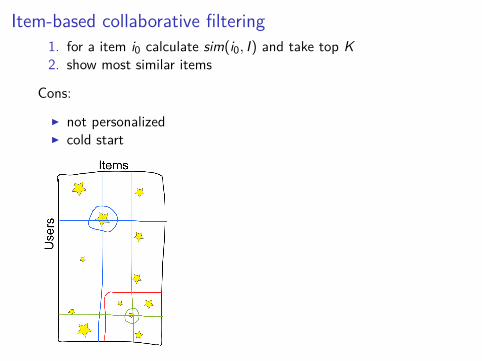
Item-based collaborative filtering1. for a item i0 calculate sim(i0, I) and take top K2. show most similar items
Cons:
I not personalizedI cold start

Latent methodsI Users can be described by small number of latent factors pukI Items can be described by small number of latent factors qki
Figure 5:

Netflix prize
Figure 6:

Explicit feedback - rating predictionI ~ 480k users, 18k movies, 100m ratingsI sparsity ~ 90%I goal is to reduce RMSE by 10% - from 0.9514 to 0.8563
RMSE 2 = 1D
∑u,i∈D
(rui − r̂ui)2

Sparse data
items
user
s

Low rank matrix factorization
R = P ∗ Q
factors
user
s
itemsfact
ors

Reconstruction
items
user
s
items
user
s

SVD
For any matrix X :
X = USV T
I X ∈ Rm∗n
I U,V - columns are orthonormal bases (dot product of any 2columns is zero, unit norm)
I S - matrix with singular values on diagonal

Truncated SVD
Take k largest singular values:
X ≈ UkSkV Tk
Truncated SVD is the best rank k approximation of the matrix X interms of Frobenius norm:
||X − UkSkV Tk ||F
P = Uk√
Sk
Q =√
SkV Tk
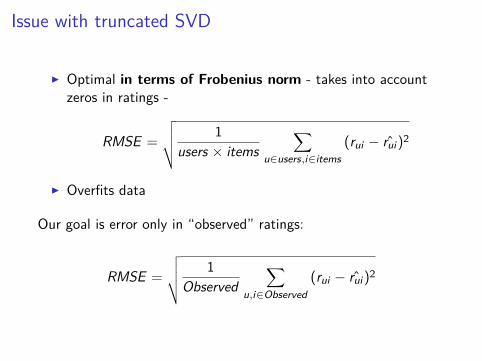
Issue with truncated SVD
I Optimal in terms of Frobenius norm - takes into accountzeros in ratings -
RMSE =√√√√ 1
users × items∑
u∈users,i∈items(rui − r̂ui)2
I Overfits data
Our goal is error only in “observed” ratings:
RMSE =√√√√ 1
Observed∑
u,i∈Observed(rui − r̂ui)2

SVD-like matrix factorization
J =∑
u,i∈Observed(rui − pu × qi)2 + λ(||Q||+ ||P||)
Non-convex - hard to optimize, but SGD and ALS works good inpractice
Alternating Least Squares
min∑
i∈Observed(ri − qi × P)2 + λ
u∑j=1
p2j
min∑
u∈Observed(ru − pu × Q)2 + λ
i∑j=1
q2j
Ridge regression: P = (QT Q + λI)−1QT y , Q = (PT P + λI)−1PT y

Types of feedback
Explicit
Ratings, likes/dislikes, purchases
I cleaner dataI smallerI hard to collect
Implicit
Browsing, clicks, purchases, . . .
I dirty dataI larger datasetsI generally gives better results

Implicit feedbackI missed entries in matrix are mix of negative preferences and
positive preferencesI consider them as negative with low confidence
I observed entries are positive preferencesI should have high confidence
Model - “Collaborative Filtering for Implicit Feedback Datasets”
I Preferences
Pij ={1 if Rij > 00 otherwise
I Confidence Cui = 1 + f (Rui)I Objective
J∑
u=user
∑i=item
Cui(Pui − XuYi) + λ(||X ||F + ||Y ||F )

Alternating Least Squares for implicit feedback
For fixed Y :
dL/dxu = −2∑
i=itemcui(pui − xT
u yi)yi + 2λxu =
−2∑
i=itemcui(pui − yT
i xu)yi + 2λxu =
−2Y T Cup(u) + 2Y T CuYxu + 2λxu
I Setting dL/dxu = 0 for optimal solution gives us(Y T CuY + λI)xu = Y T Cup(u)
I xu can be obtained by solving system of linear equations:
xu = solve(Y T CuY + λI,Y T Cup(u))

Alternating Least Squares for implicit feedback
Similarly for fixed X :
I dL/dyi = −2XT C ip(i) + 2XT C iYyi + 2λyiI yi = solve(XT C iX + λI,XT C ip(i))
Another optimization:
I XT C iX = XT X + XT (C i − I)XI Y T CuY = Y T Y + Y T (Cu − I)Y
XT X and Y T Y can be precomputed

EvaluationWe only care about how to produce small number of highlyrelevant items
RMSE in not the best measure!
MAP@K - Mean average precision
AveragePrecision =∑n
k=1(P(k)×rel(k))number of relevant documents
## index relevant precision_at_k## 1: 1 0 0.0000000## 2: 2 0 0.0000000## 3: 3 1 0.3333333## 4: 4 0 0.2500000## 5: 5 0 0.2000000
map@5 = 0.1566667

Evaluation
NDCG@K - Normalized Discounted Cumulative GainIntuition is the same as for MAP@K, but also takes into accountvalue of relevance.
DCGp =p∑
i=1
2reli − 1log2(i + 1)
nDCGp = DCGpIDCGp
IDCGp =|REL|∑i=1
2reli − 1log2(i + 1)

Questions?
I http://dsnotes.com/tags/recommender-systems/I http://94.204.253.34/reco-playlist/I http://94.204.253.34/reco-similar-artists/
Contacts:
I [email protected] https://github.com/dselivanov















![Convolutional Matrix Factorization for Document Context-Aware …dm.postech.ac.kr/~pcy1302/data/RecSys16_slide.pdf · 2018-07-23 · [KDD`15, RecSys`14, RecSys`13, KDD`11] a description](https://static.fdocuments.in/doc/165x107/5ede2942ad6a402d666975a9/convolutional-matrix-factorization-for-document-context-aware-dm-pcy1302datarecsys16slidepdf.jpg)


