
Recommending Scientific Papers: Investigating the User Curriculum
17
Recommending Scientific Papers: Investigating the User Curriculum Jonathas Magalhães, Cleyton Souza, Evandro Costa, Joseana Fechine
-
Upload
jonathas-magalhaes -
Category
Technology
-
view
82 -
download
1
Transcript of Recommending Scientific Papers: Investigating the User Curriculum

Recommending Scientific Papers: Investigating the User Curriculum
Jonathas Magalhães, Cleyton Souza, Evandro Costa, Joseana Fechine

Warm up!
• How does research in Brazil work?
• What is Lattes?
• Why is Lattes a big deal in Brazil?

Lattes = Opportunity
• The information available in Lattes creates a great opportunity to recommend science related content to researchers in Brazil…
– Projects
– Contributors
– Call for Papers
– Papers
• … and to test different algorithtms!

Our Work
• In this paper: – (1) We present a Personalized Paper
Recommender System • A user-paper approach that takes into consideration
the Lattes information.
– (2) We test different profiling strategies
– (3) We test how much older information is necessary in order to provide better recommendations.
– (4) We compare our strategy with state of art

Recommendation Algorithm
• 𝑠𝑖𝑚 𝑢𝑠𝑒𝑟 𝑝𝑟𝑜𝑓𝑖𝑙𝑒, 𝑝𝑎𝑝𝑒𝑟
– Cosine similarity
• Age weighting
1 −Δ𝑦
Δ𝑣

Profiling Strategies
• Concepts Profile
–The vector is composed of predefined concepts.
• Terms Profile
–The vector is composed of the set of terms that compose the dictionary.

Research Questions
• 𝑄1: How many years of the user curriculum are necessary to use in order to provide great recommendations?
• 𝑄2: Is there any difference between the concepts profile and terms profile?
• 𝑄3: Is Lopes’s algorithm better than them?
• 𝑄4: Which method should we choose?

Evaluation
• To answer our research questions, we conducted a user study experiment
• We developed a system to collect user’s impression about a set of papers

Evaluation
• We used user’s impressions to ranking the papers and compared with the outcome of the recommendation algorithms to answer our research questions
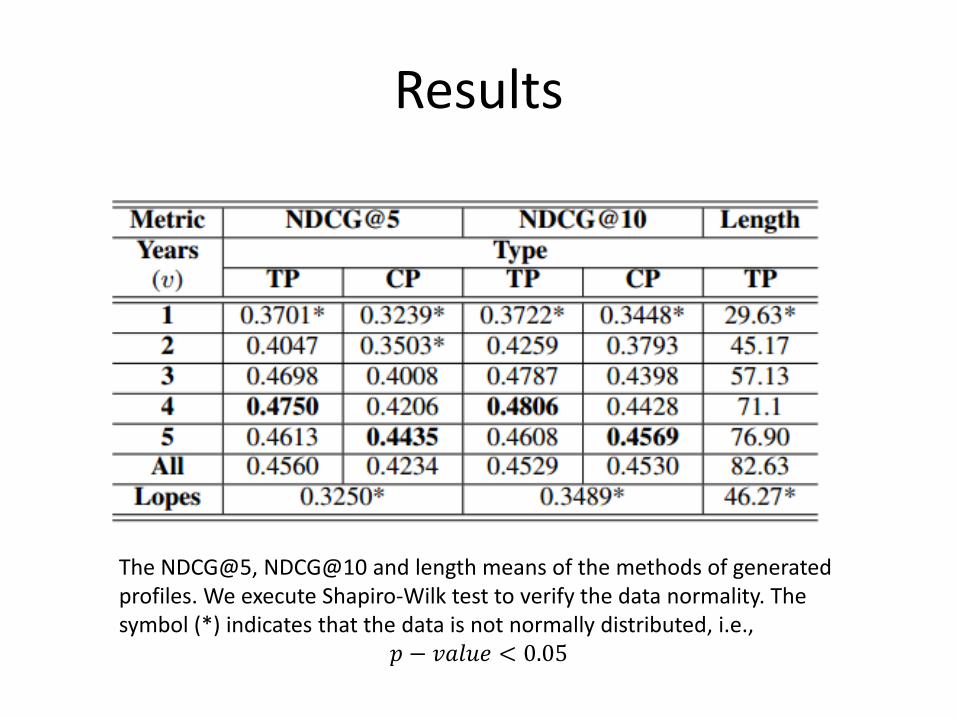
Results
The NDCG@5, NDCG@10 and length means of the methods of generated profiles. We execute Shapiro-Wilk test to verify the data normality. The symbol (*) indicates that the data is not normally distributed, i.e.,
𝑝 − 𝑣𝑎𝑙𝑢𝑒 < 0.05
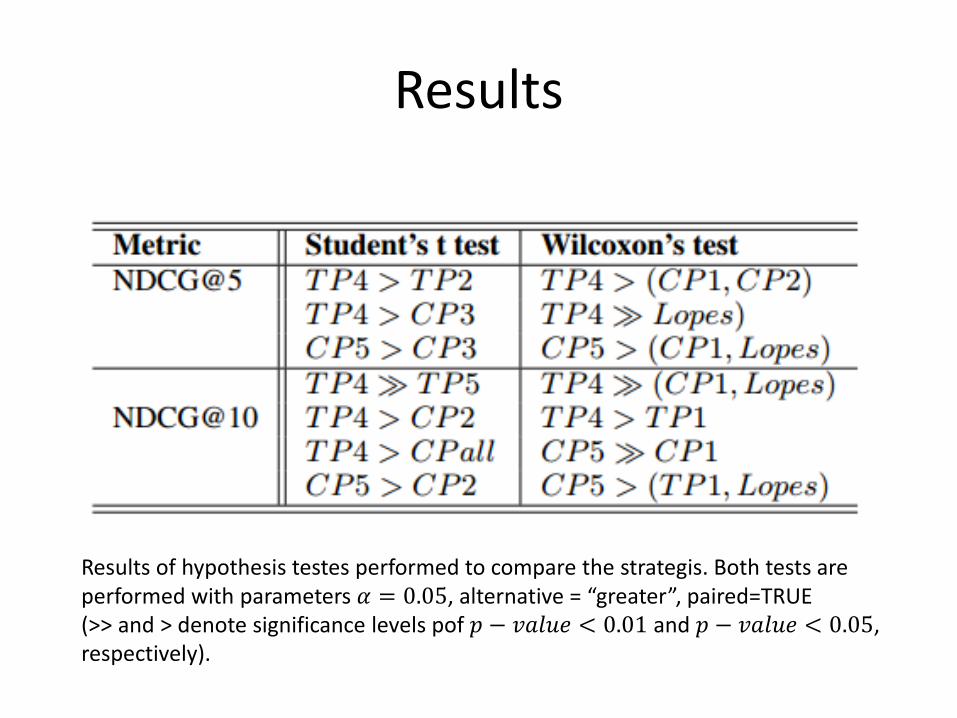
Results
Results of hypothesis testes performed to compare the strategis. Both tests are performed with parameters 𝛼 = 0.05, alternative = “greater”, paired=TRUE (>> and > denote significance levels pof 𝑝 − 𝑣𝑎𝑙𝑢𝑒 < 0.01 and 𝑝 − 𝑣𝑎𝑙𝑢𝑒 < 0.05, respectively).

𝑄1: How many years of the user curriculum are necessary to use in order to provide great recommendations?
Answer: It depends of the profiling strategy: four years for TP and five years for CP, apparently.

𝑄2: Is there any difference between the concepts profile and terms profile?
Answer: Comparing the terms profile TP4 with concepts profile CP5, we verify a not statically proved superiority. Thus, there is no difference.

𝑄3: Is Lopes’s algorithm better than them?
Answer: Yes, both approaches (TP4 and CP5) achieved statiscaly better performance than Lopes.

𝑄4: Which method should we choose?
Answer: It depends on the context, because there is a
trade-off between the techniques. If the system needs an online recommendation with reasonable quality, the CP profiles are the best choice. On the other hand, if the systems can compute the recommendations offline, and the time consuming is not a problem, the T P is better.

Conclusion and Future Work
• We presented and evaluated our approach to a paper Recommender System that considers the user curriculum crawled from the CV-Lattes
• Our main contributions are: – Our algorithms achieved better performance than
state-of-art paper recommendation algorithm dealing with Lattes
– We observed no statistical difference between both profiling strategies.
– We build a dataset that can be used for future research in the are

Conclusion and Future Work
• Our planning:
– To confront our results with data from others CV-oriented networks
– To work in a integration algorithm to combine data from multiple sources
– To improve the recommendation model using paper related information


















