
Recognition Scene understanding / visual object categorization Pose clustering
40
Kapitel 14 “Recognition” – p. 1 Recognition Scene understanding / visual object categorization Pose clustering Object recognition by local features Image categorization Bag-of-features models Large-scale image search Kapitel 14
-
Upload
davis-deleon -
Category
Documents
-
view
61 -
download
0
description
Kapitel 14. Recognition Scene understanding / visual object categorization Pose clustering Object recognition by local features Image categorization Bag - of -features models Large- scale image search. TexPoint fonts used in EMF. - PowerPoint PPT Presentation
Transcript of Recognition Scene understanding / visual object categorization Pose clustering

Kapitel 14 “Recognition” – p. 1
Recognition Scene understanding / visual object categorization Pose clustering Object recognition by local features Image categorization Bag-of-features models Large-scale image search
Kapitel 14

Kapitel 14 “Recognition” – p. 2
Scene understanding (1)
Scene categorization
•outdoor/indoor
•city/forest/factory/etc.

Kapitel 14 “Recognition” – p. 3
Scene understanding (2)
Object detection
•find pedestrians
Kapitel 14 “Recognition” – p. 4
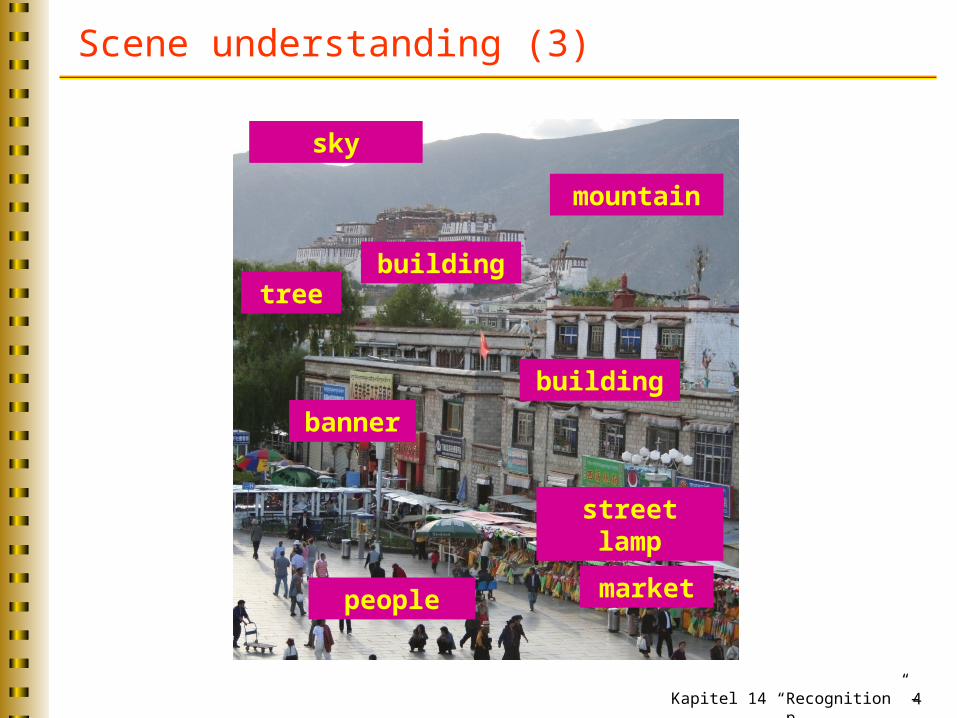
Scene understanding (3)
mountain
building
tree
banner
marketpeople
street lamp
sky
building

Kapitel 14 “Recognition” – p. 5
Visual object categorization (1)

Kapitel 14 “Recognition” – p. 6
Visual object categorization (2)

Kapitel 14 “Recognition” – p. 7
Visual object categorization (3)
Kapitel 14 “Recognition” – p. 8
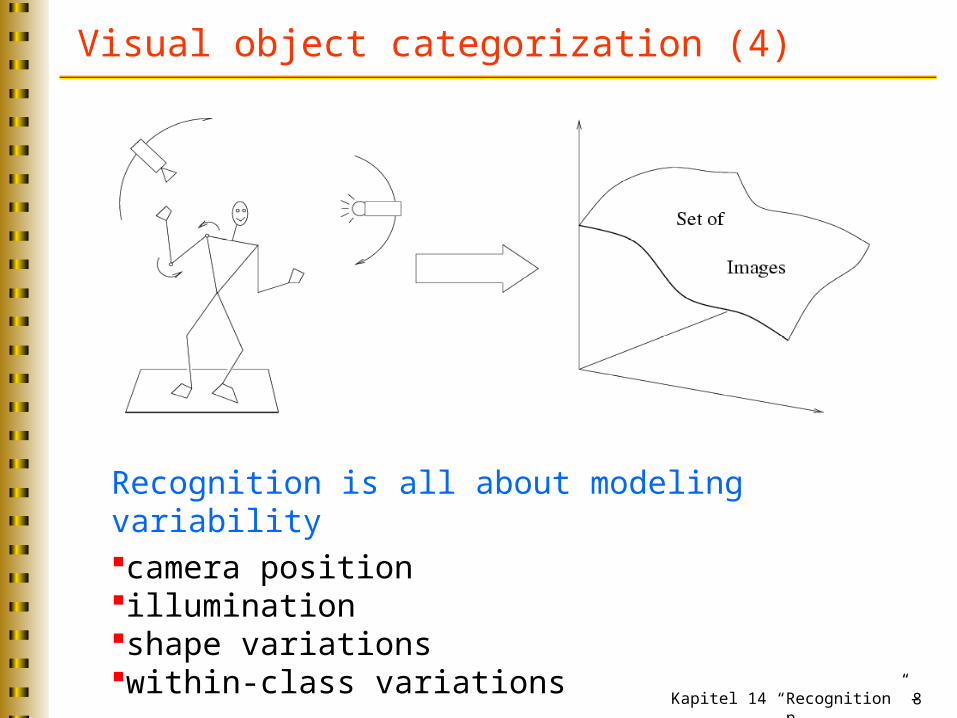
Visual object categorization (4)
Recognition is all about modeling variabilitycamera positionilluminationshape variationswithin-class variations

Kapitel 14 “Recognition” – p. 9
Visual object categorization (5)
Within-class variations (why are they chairs?)

Kapitel 14 “Recognition” – p. 10
Pose clustering (1)
Working in transformation space - main ideas: Generate many hypotheses of transformation image vs. model,
each built by a tuple of image and model features
Correct transformation hypotheses appear many times
Main steps: Quantize the space of possible transformations
For each tuple of image and model features, solve for the optimal transformation that aligns the matched features
Record a “vote” in the corresponding transformation space bin
Find "peak" in transformation space
Kapitel 14 “Recognition” – p. 11
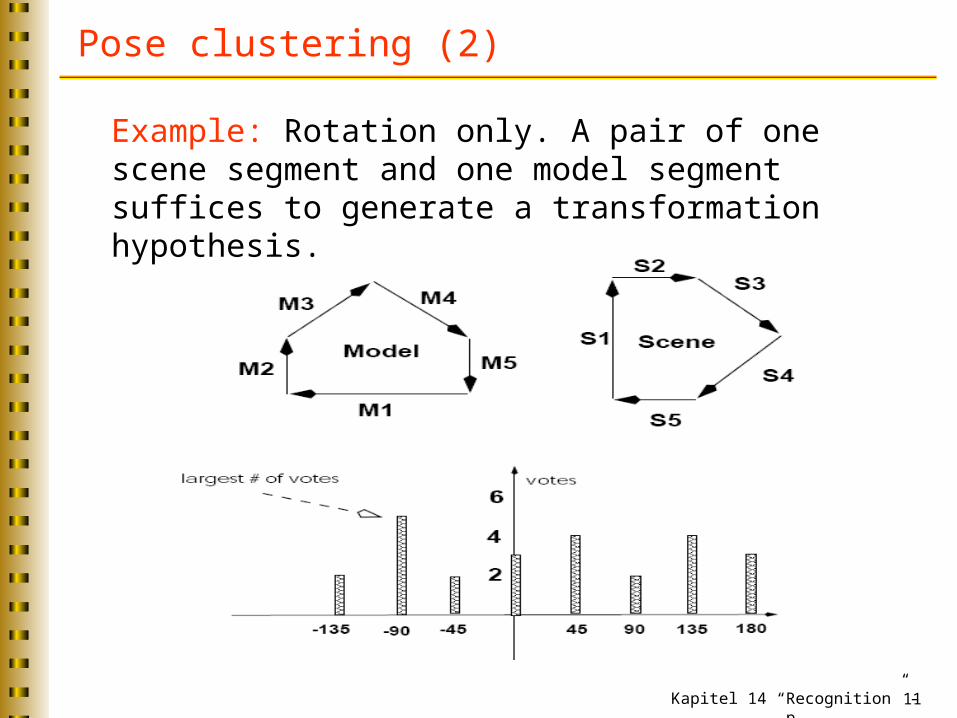
Pose clustering (2)
Example: Rotation only. A pair of one scene segment and one model segment suffices to generate a transformation hypothesis.

Kapitel 14 “Recognition” – p. 12
Pose clustering (3)
2-tuples of image and model corner points are used to generate hypotheses. (a) The corners found in an image. (b) The four best hypotheses found with the edges drawn in. The nose of the plane and the head of the person do not appear because they were not in the models.
C.F. Olson: Efficient pose clustering using a randomized algorithm. IJCV, 23(2): 131-147, 1997.

Kapitel 14 “Recognition” – p. 13
Object recognition by local features (1)
D.G. Lowe: Distinctive image features from scale-invariant keypoints. IJCV, 60(2): 91-110, 2004
The SIFT features of training images are extracted and storedFor a query image
Extract SIFT features Efficient nearest neighbor indexing Pose clustering by Hough transform For clusters with >2 keypoints (object hypotheses): determine
the optimal affine transformation parameters by least squares method; geometry verification
Input Image Stored
Image
Kapitel 14 “Recognition” – p. 14
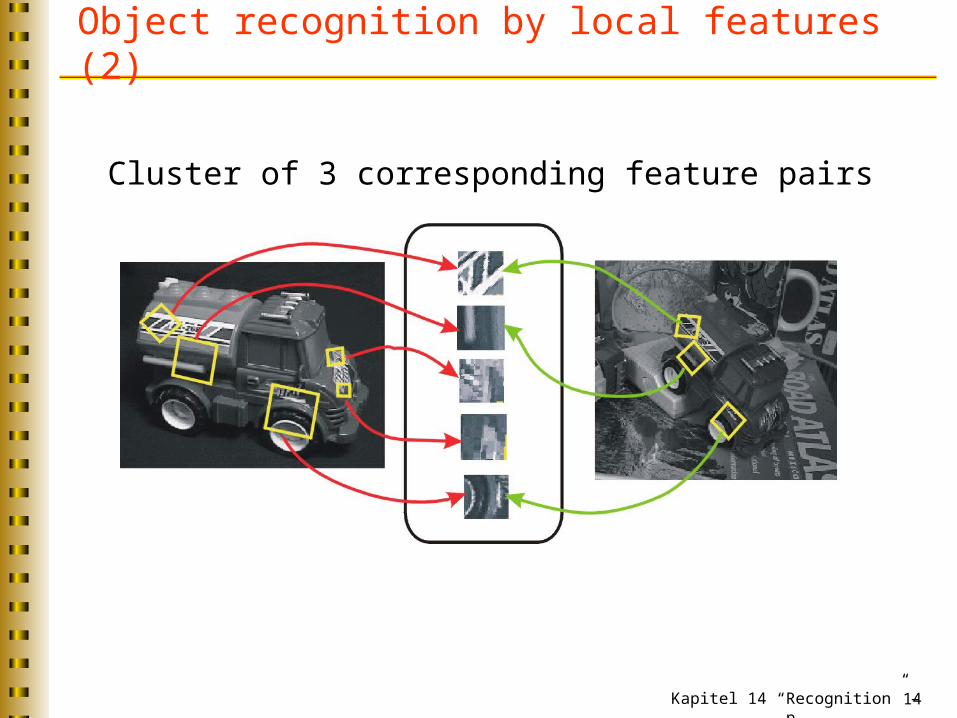
Object recognition by local features (2)
Cluster of 3 corresponding feature pairs

Kapitel 14 “Recognition” – p. 15
Object recognition by local features (3)
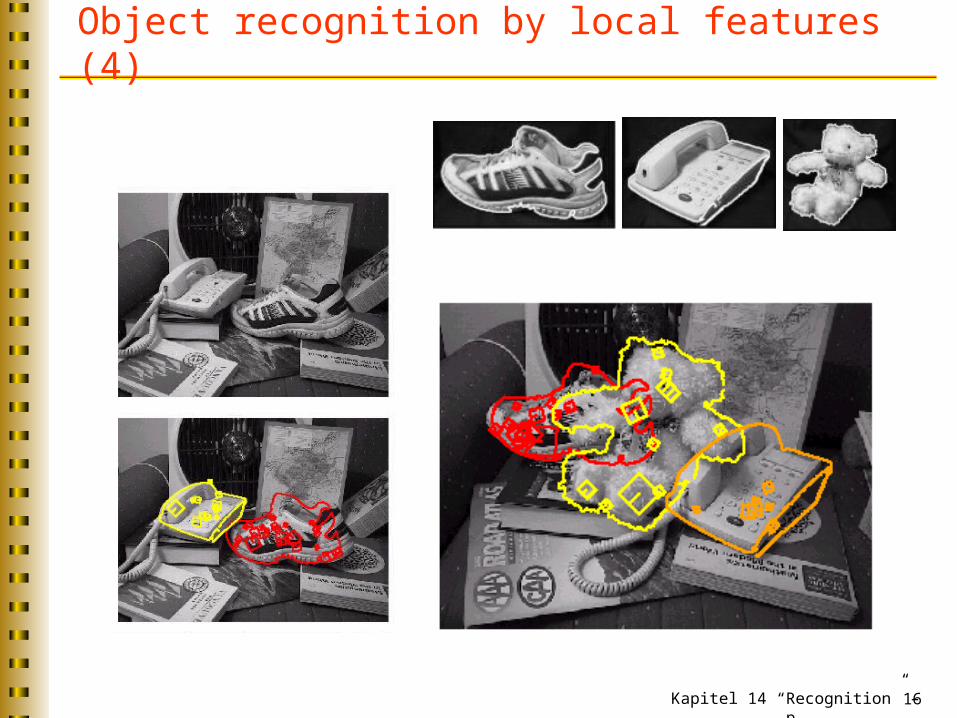
Kapitel 14 “Recognition” – p. 16
Object recognition by local features (4)
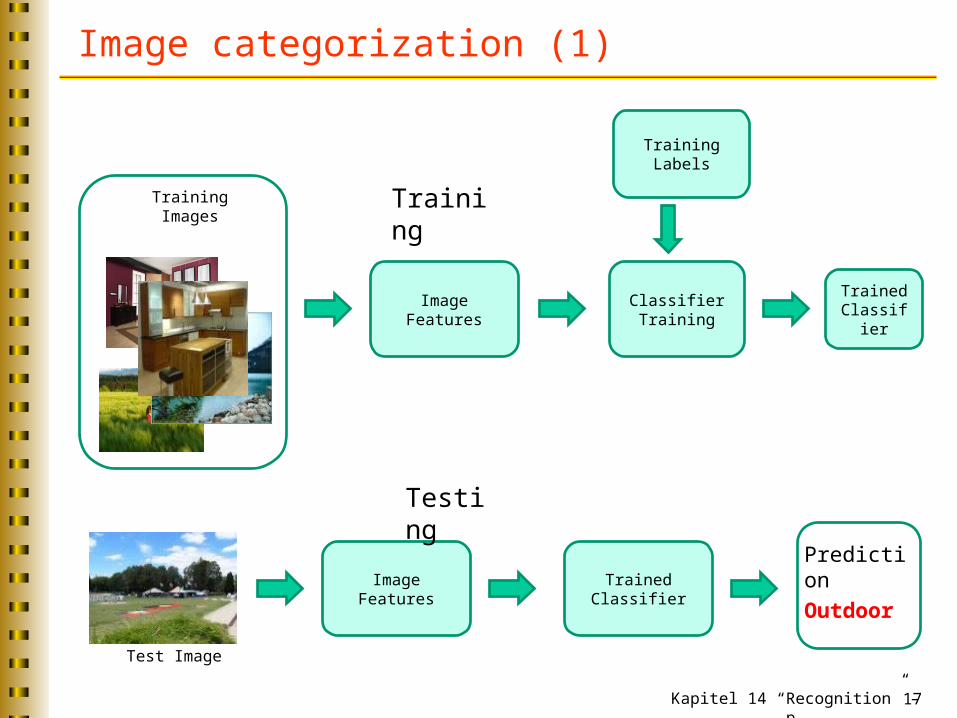
Kapitel 14 “Recognition” – p. 17
Image categorization (1)
Training Labels
Training Images
Classifier Training
Training
Image Features
Image Features
Testing
Test Image
Trained Classifier
Trained Classifier
Outdoor
Prediction

Kapitel 14 “Recognition” – p. 18
Image categorization (2)
Global histogram (distribution):
color, texture, motion, …
histogram matching distance

Kapitel 14 “Recognition” – p. 19
Image categorization (3)
Cars found by color histogram matching
See Chapter “Inhaltsbasierte Suche in Bilddatenbanken
Kapitel 14 “Recognition” – p. 20
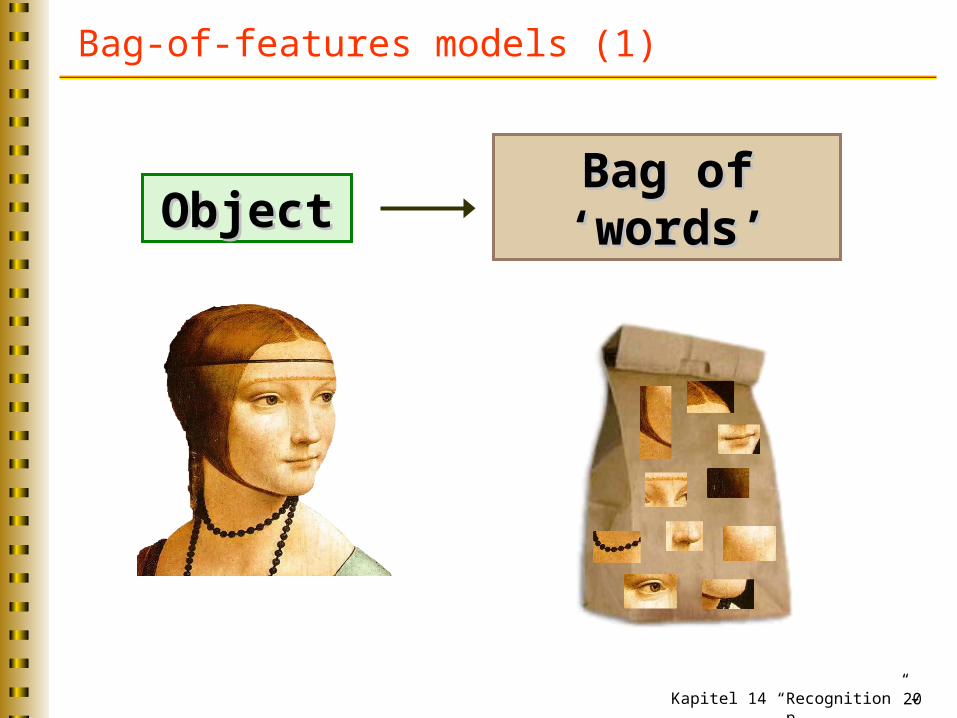
Bag-of-features models (1)
ObjectObjectBag of Bag of ‘words’‘words’

Kapitel 14 “Recognition” – p. 21
Bag-of-features models (2)
Origin 1: Text recognition by orderless document representation (frequencies of words from a dictionary), Salton & McGill (1983)
US Presidential Speeches Tag Cloudhttp://chir.ag/phernalia/preztags/

Kapitel 14 “Recognition” – p. 22
Bag-of-features models (3)
Origin 2: Texture recognition
Texture is characterized by the repetition of basic elements or textons
For stochastic textures, it is the identity of the textons, not their spatial arrangement, that matters
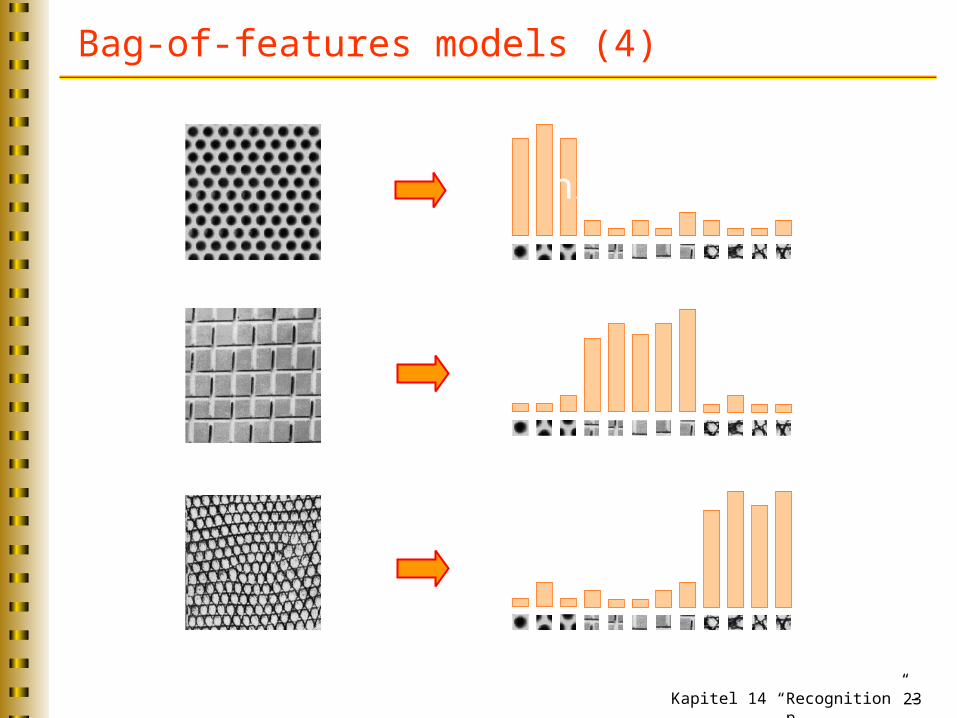
Kapitel 14 “Recognition” – p. 23
Bag-of-features models (4)
Universal texton dictionary
histogram
Kapitel 14 “Recognition” – p. 24
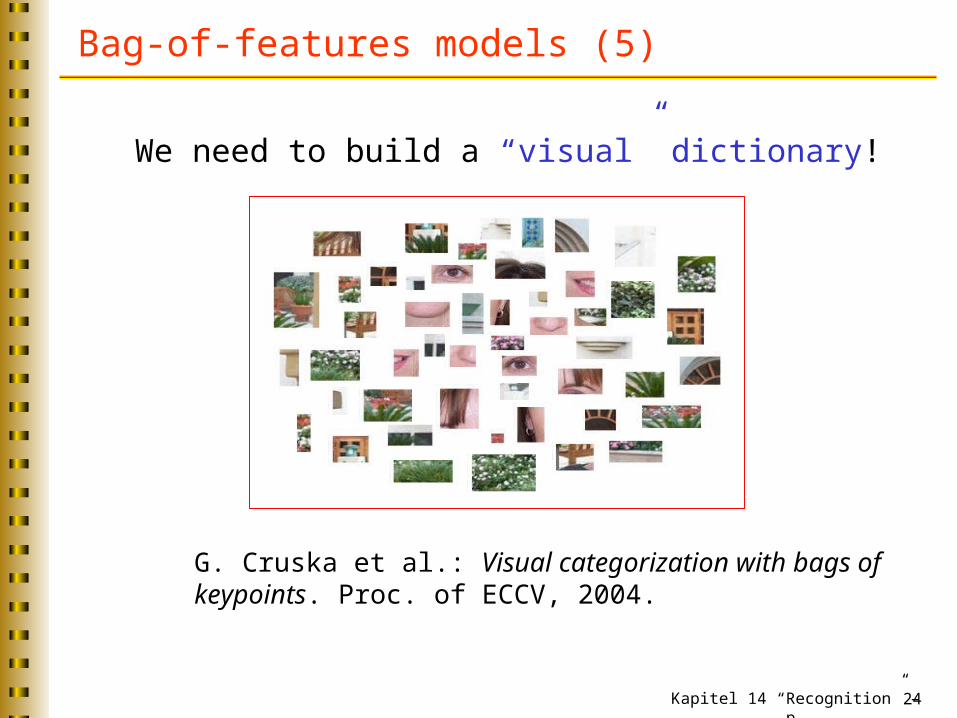
Bag-of-features models (5)
G. Cruska et al.: Visual categorization with bags of keypoints. Proc. of ECCV, 2004.
We need to build a “visual” dictionary!
Kapitel 14 “Recognition” – p. 25
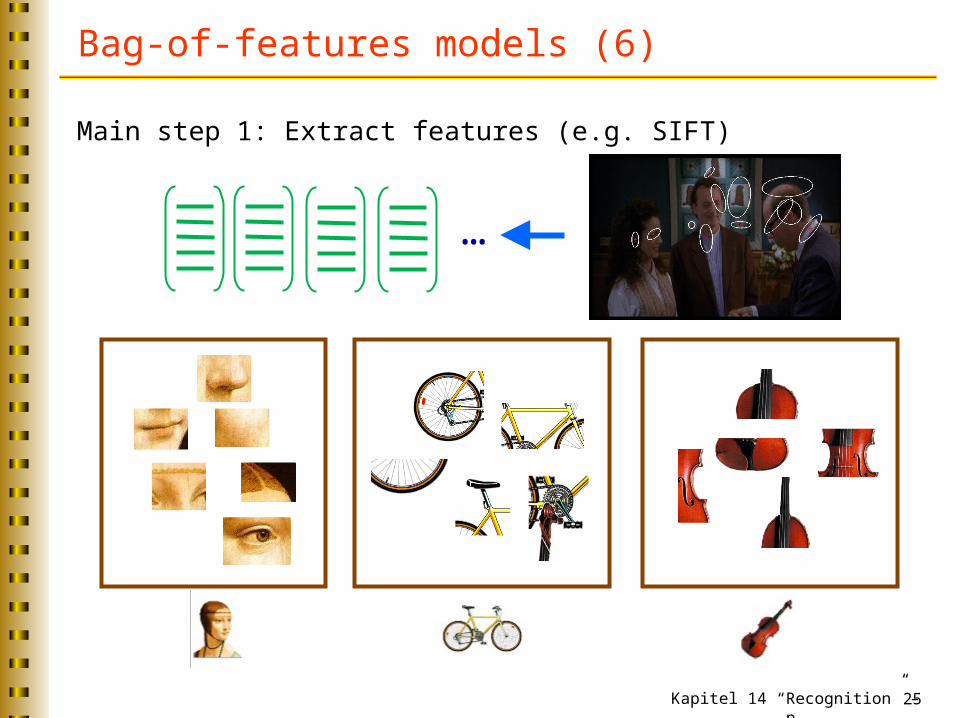
Bag-of-features models (6)
Main step 1: Extract features (e.g. SIFT)
…
Kapitel 14 “Recognition” – p. 26
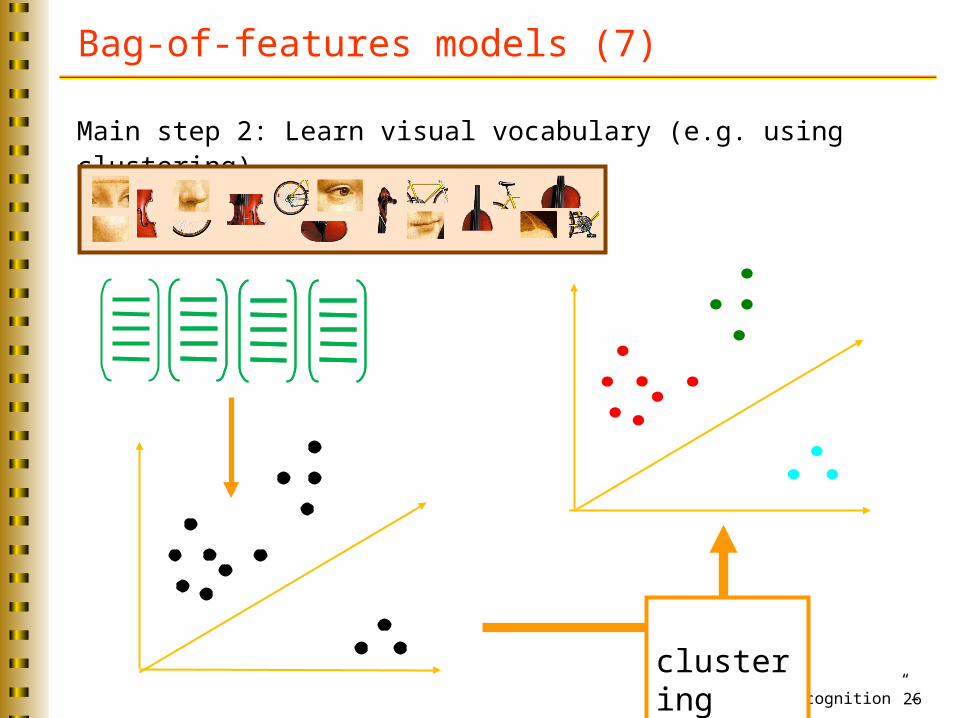
Bag-of-features models (7)
Main step 2: Learn visual vocabulary (e.g. using clustering)
clustering
Kapitel 14 “Recognition” – p. 27
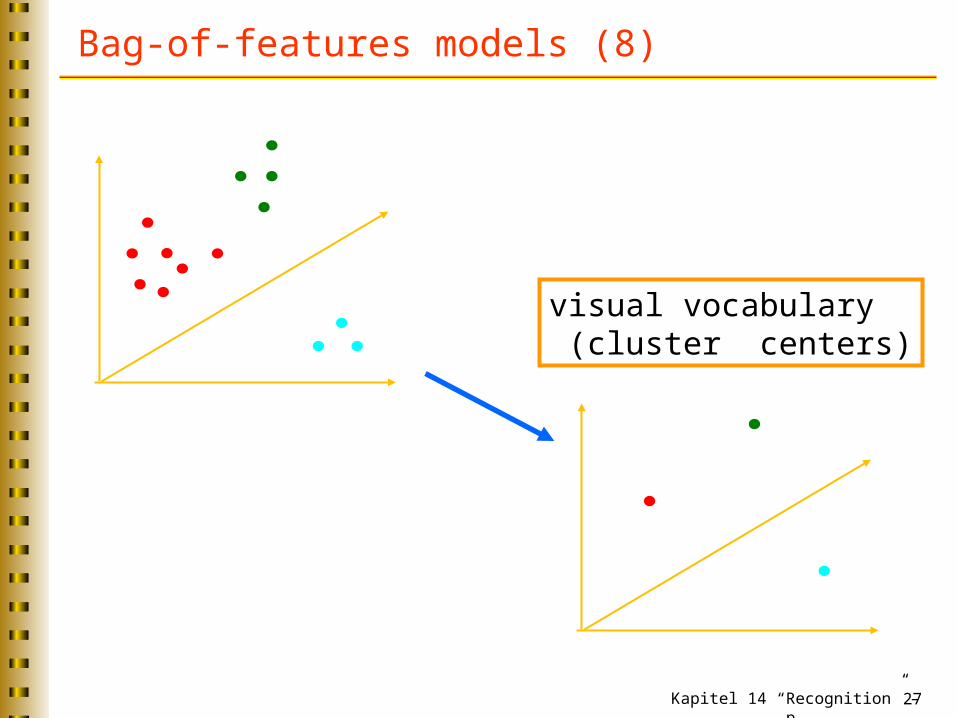
Bag-of-features models (8)
visual vocabulary (cluster centers)

Kapitel 14 “Recognition” – p. 28
Bag-of-features models (9)
… Source: B. LeibeAppearance codebook
Example: learned codebook
Kapitel 14 “Recognition” – p. 29
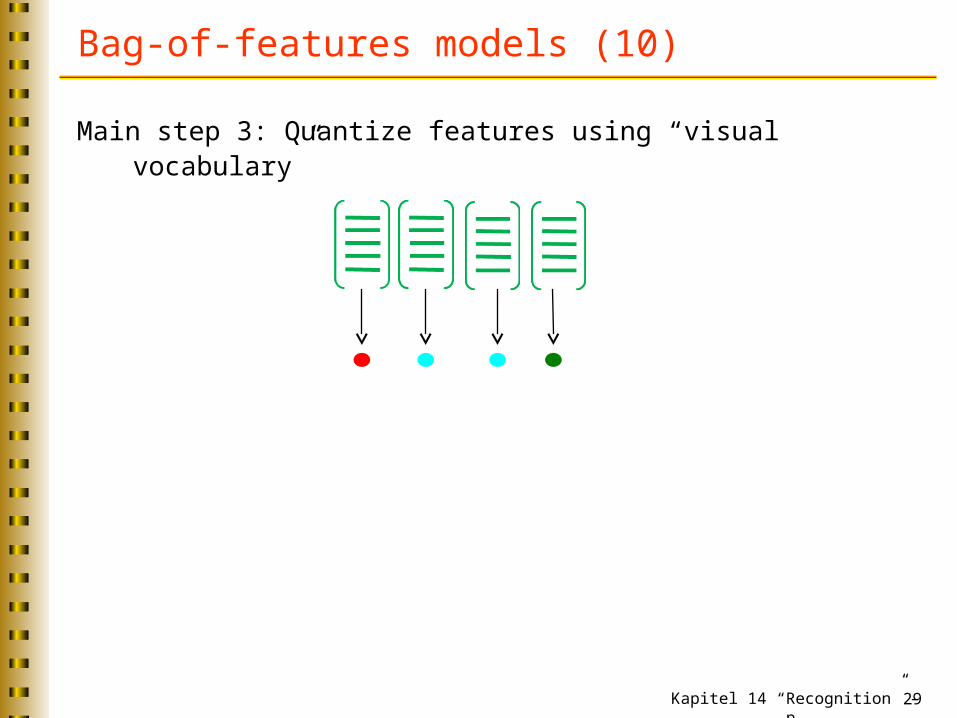
Bag-of-features models (10)
Main step 3: Quantize features using “visual vocabulary”
Kapitel 14 “Recognition” – p. 30
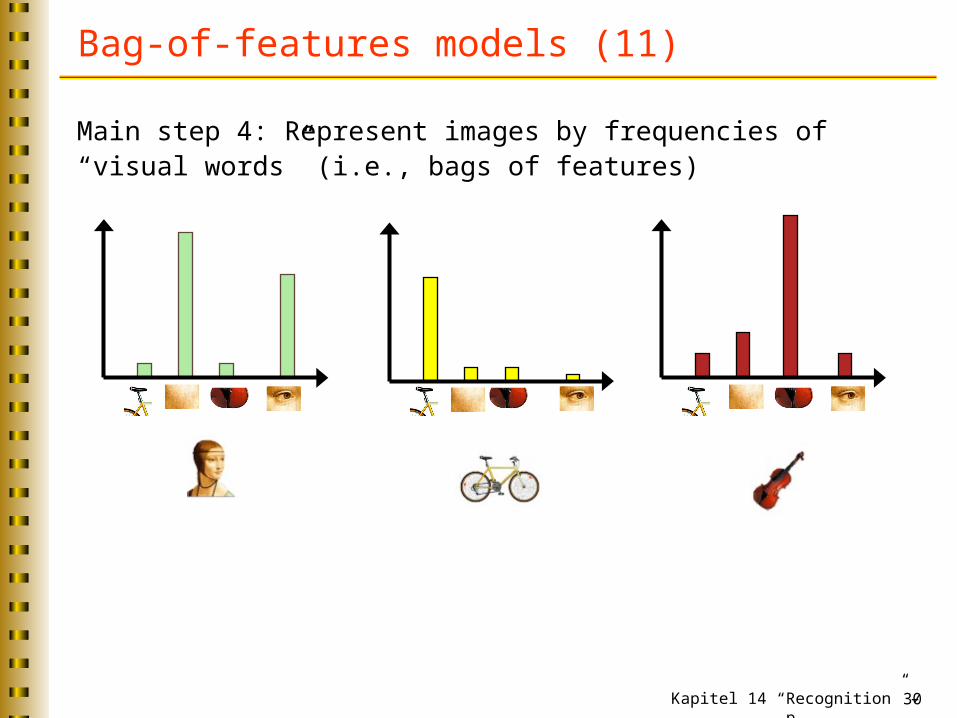
Bag-of-features models (11)
Main step 4: Represent images by frequencies of “visual words” (i.e., bags of features)
Kapitel 14 “Recognition” – p. 31
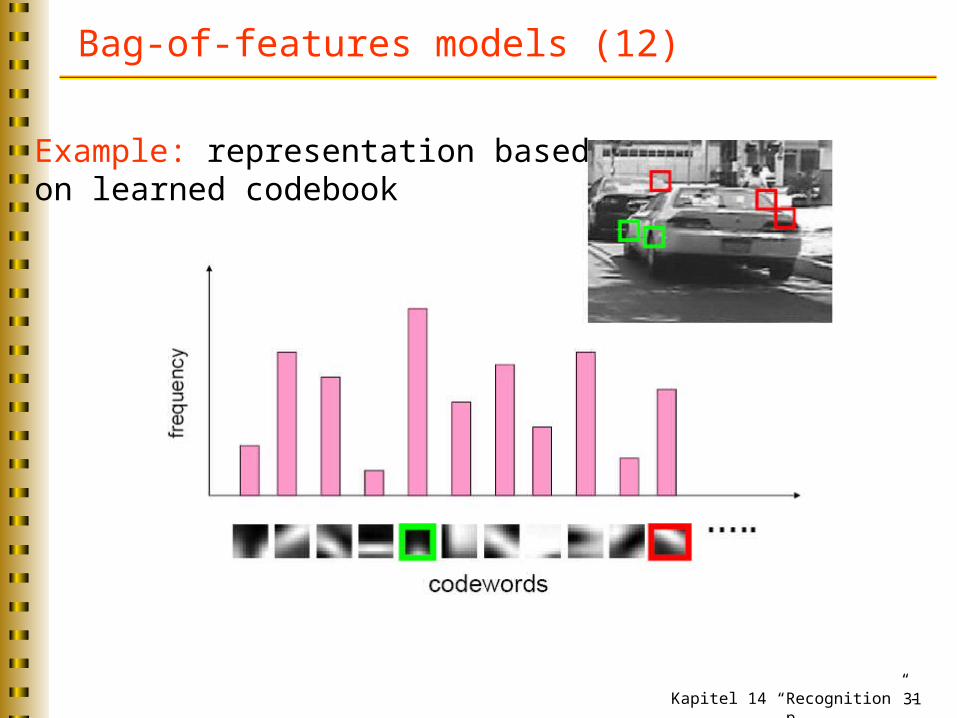
Bag-of-features models (12)
Example: representation basedon learned codebook
Kapitel 14 “Recognition” – p. 32
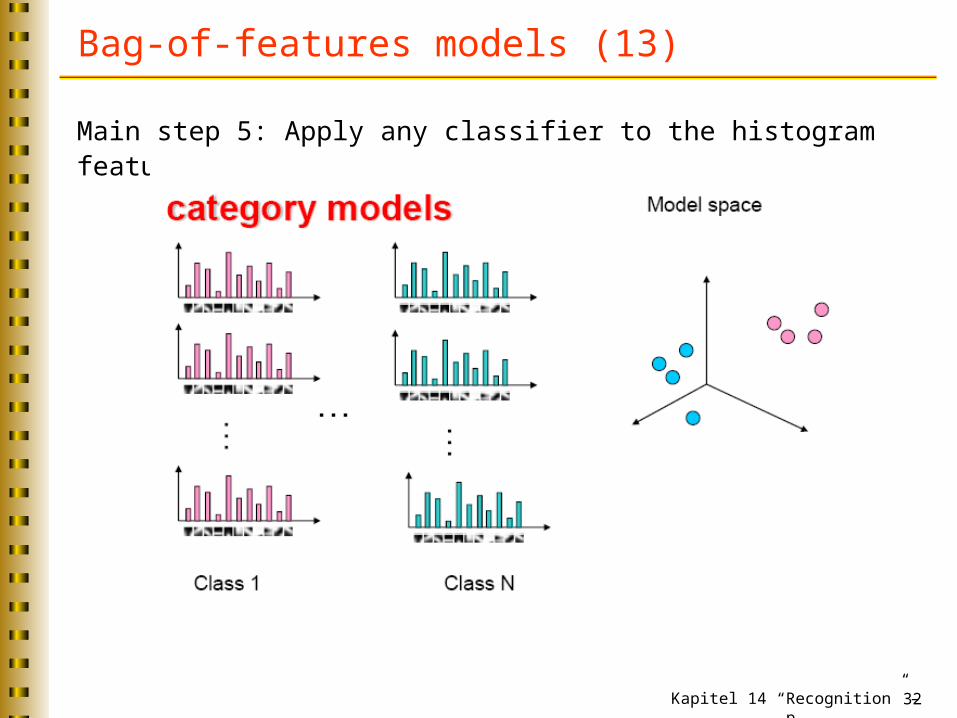
Bag-of-features models (13)
Main step 5: Apply any classifier to the histogram feature vectors

Kapitel 14 “Recognition” – p. 33
Bag-of-features models (14)
Example:
Kapitel 14 “Recognition” – p. 34
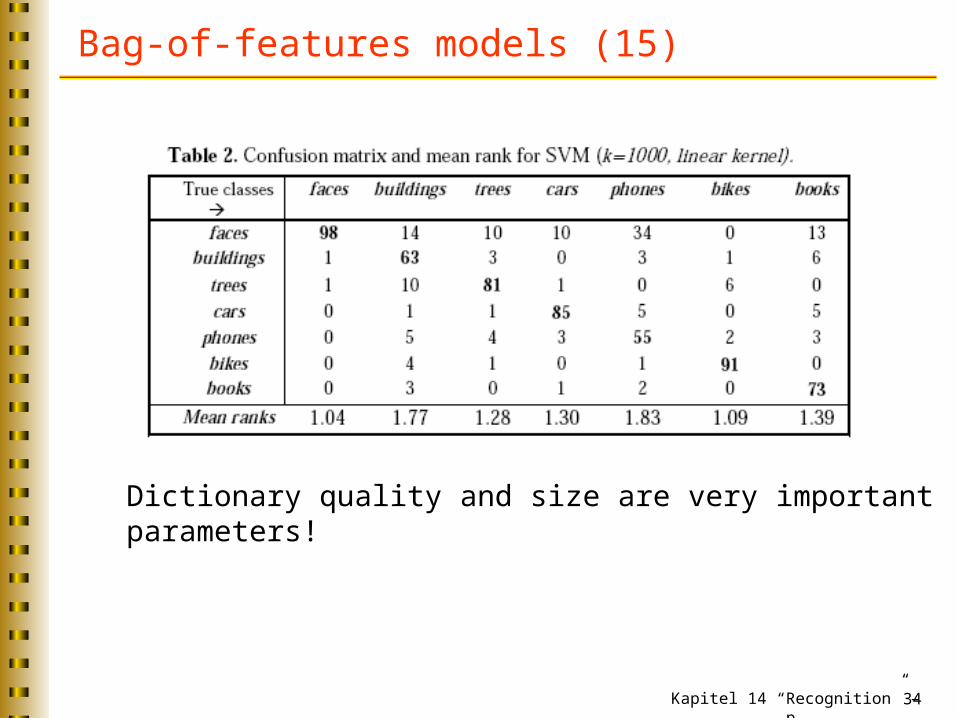
Bag-of-features models (15)
Caltech6 dataset
Dictionary quality and size are very important parameters!

Kapitel 14 “Recognition” – p. 35
Bag-of-features models (16)
Caltech6 dataset
J.C. Niebles, H. Wang, L. Fei-Fei: Unsupervised learning of human action categories using spatial-tempotal words. IJCV, 79(3): 299-318, 2008.
Action recognition

Kapitel 14 “Recognition” – p. 36
Large-scale image search (1)
Query Results from 5k Flickr images
J. Philbin, et al.: Object retrieval with large vocabularies and fast spatial matching. Proc. of CVPR, 2007

Kapitel 14 “Recognition” – p. 37
Large-scale image search (2)
Mobile tourist guide self-localization object/building recognition photo/video augmentation
Aachen Cathedral
[Quack, Leibe, Van Gool, CIVR’08]

Kapitel 14 “Recognition” – p. 38
Large-scale image search (3)

Kapitel 14 “Recognition” – p. 39
Large-scale image search (4)
Application: Image auto-annotationLeft: Wikipedia imageRight: closest match from Flickr
Moulin Rouge
Tour MontparnasseColosseum
ViktualienmarktMaypole
Old Town Square (Prague)

Kapitel 14 “Recognition” – p. 40
Sources
K. Grauman, B. Leibe: Visual Object Recognition. Morgen & Claypool Publishers, 2011
R. Szeliski: Computer Vision: Algorithms and Applications. Springer, 2010. (Chapter 14 “Recognition”)
Course materials from others (G. Bebis, J. Hays, S. Lazebnik, …)


















