
Real-Time Graphics Architecture
30
4/18/2007 1 Real-Time Graphics Architecture Lecture 4: Parallelism and Communication Kurt Akeley CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007 Kurt Akeley Pat Hanrahan http://graphics.stanford.edu/cs448-07-spring/ Topics 1. Frame buffers 2. Types of parallelism 3. Communication patterns and requirements 4. Sorting classification for parallel rendering (with examples) CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Transcript of Real-Time Graphics Architecture

4/18/2007
1
Real-Time Graphics Architecture
Lecture 4: Parallelism and Communication
p
Kurt Akeley
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Kurt Akeley
Pat Hanrahanhttp://graphics.stanford.edu/cs448-07-spring/
Topics
1. Frame buffers
2. Types of parallelism
3. Communication patterns and requirements
4. Sorting classification for parallel rendering (with examples)
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007

4/18/2007
2
Frame Buffers
Raster vs. calligraphic
Raster (image order)
dominant choice
Calligraphic (object order)
Earliest choice (Sketchpad)
E&S terminals in the 70s and 80s
Works with light pens
Scene complexity affects frame rate
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Scene complexity affects frame rate
Monitors are expensive
Still required for FAA simulationIncreases absolute brightness of light points

4/18/2007
3
Frame buffer definitions
What is a frame buffer?
What can we learn by considering different definitions?
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Frame buffer definition #1
Storage for commands that are executed to refresh the display
Allows for raster or calligraphic display (e g Megatech)Allows for raster or calligraphic display (e.g. Megatech)
“Frame buffer” for calligraphic display is a “display list”
OpenGL “render list”?
Key point: frame buffer contents are interpreted
Color mapping
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Image scaling, warping
Window system (overlay, separate windows, …)
Address Recalculation Pipeline

4/18/2007
4
Frame buffer definition #2
Image memory used to decouple the render frame rate from the display frame rate
Meets common understanding of frame buffer as imageMeets common understanding of frame buffer as image
Leads naturally to double buffering
One render buffer, one display buffer, swap
n-buffering also possible, can control latency
Key idea: decoupling enables general-purpose GPU
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Visual simulation has high render frame rate
MCAD has low render frame rate
Window manager has no frame rate
Frame buffer definition #3
All pixel-assigned memory used to assemble and display the images being rendered
Key point: frame buffer is active participant in renderingLeads to non-color buffers: depth, stencil, window control
OpenGL treats these buffers as part of frame bufferSome reserve “frame buffer” for color imagesShould be n-buffered in some cases (sort last)RealityEngine frame buffer can be deeper than wide or high
History cycles through this definition
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
2-D manipulation3-D painters algorithm3-D depth, stencil, accumulation, multi-passProgrammable shading

4/18/2007
5
Frame buffer is optional
Calligraphic display
If we don’t define display list as frame buffer
“Follow-the-beam” rendering
Minimizes latency
Saves cost if frames are never “dropped”
Talisman-like image assembly (3-D sprites)
Old idea (visual simulation, window systems)
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Old idea (visual simulation, window systems)
GigaPixel render tile
Frame buffer stores color images only
Depth, stencil, etc. in small tile
Dominant architecture is consistent
SGI architectures look like
ATI architectures, which look like
NVIDIA architectures
Details are evolving, but big picture remains the same
Why is this?
Simplicity of design
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Simplicity of design
Simplicity of algorithms
Simplicity of immediate-mode approach

4/18/2007
6
Simplicity of design
Frame buffer operationsBlending: merge fragment and pixel colorDepth Buffering: save nearest fragmentp g gStencil Buffering: simple pixel state machineAccumulation Buffering: high-resolution color arithmeticAntialiasing: (to be covered later)….
All frame buffer operations:Combine fragment and pixel data (not just a replace)
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Combine fragment and pixel data (not just a replace)But replace operation is optimized, e.g., no parity/ECC
Are local (no intra-pixel dependencies)
Why aren’t fragment operations programmable?
Simplicity of algorithms
Frame buffer employs brute-force simplicity
Hidden surface elimination: Depth-buffer vs. sort/painter
Capping: Stencil-based vs object calculationsCapping: Stencil based vs. object calculations
Image-space algorithm is efficientJust samples, never “object” information, locality
Just-in-time calculation, steady cost function
Accumulation Buffer (high-resolution color arithmetic)
The Accumulation Buffer, Haeberli and Akeley, Proceedings of SIGGRAPH ‘90
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Proceedings of SIGGRAPH 90
Volume rendering using 3D textures
Multi-pass rendering
Interactive Multi-pass Programmable Shading, Peercy, Olano, Airey, and Ungar, Proceedings of SIGGRAPH ‘00

4/18/2007
7
Simplicity of immediate-mode
Frame buffer contents are “context”
Matches 2D/window-rendering model
Rendering
System
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Frame buffer: most graphics
state here
Little graphics state here
Decreasing display bandwidth burden
Historically display bandwidth was a limiting factor
Hence “Sproull’s Rule”: fill rate >= display rate
Now display bandwidth is almost inconsequential
Year System FB (GB) Disp (GB) Disp / FB
1984 SGI 2000-series 0.3 0.14 1/21988 SGI GTX 1.8 * 0.29 1/61996 SGI InfiniteReality 12 8 0 60 1/20
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
1996 SGI InfiniteReality 12.8 0.60 1/202006 NVIDIA 7900 GTX 51.2 0.75 1/70
* VRAM provided separate video bandwidth

4/18/2007
8
Parallelism and Communication
Parallelism and communication
Parallelism – using multiple computational units to processes work in parallel
Communication – connecting the computational units to Communication – connecting the computational units to allow work to be distributed and aggregated
Issues
DependenciesOrdering
Sorting
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Sorting
ScalabilityComputation
Bandwidth
Load balancing

4/18/2007
9
Parallelism taxonomy
Hardware parallelism(simultaneous execution on multiple processors)
Virtual parallelism(time sharing a single processor, usually with hardware support)
Data parallelism[aka “parallelism”](same task on similardata sets)
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Task parallelism(different tasks on similar OR differing data sets)
Parallelism taxonomy
Hardware parallelism(simultaneous execution on multiple processors)
Virtual parallelism(time sharing a single processor, usually with hardware support)
Data parallelism[aka “parallelism”](same task on similardata sets)
Frame-parallelism(batch, SGI N-clops)
Object-parallelism(geometry)
Image-parallelism(fragment/pixel)
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Task parallelism(different tasks on similar OR differing data sets)

4/18/2007
10
Parallelism taxonomy
Hardware parallelism(simultaneous execution on multiple processors)
Virtual parallelism(time sharing a single processor, usually with hardware support)
Data parallelism[aka “parallelism”](same task on similardata sets)
Frame-parallelism(batch, SGI N-clops)
Object-parallelism(geometry)
Image-parallelism(fragment/pixel)
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Task parallelism(different tasks on similar OR differing data sets)
Multi-processing(on multiple CPUs)
Pipelining(the graphics pipeline)
Parallelism taxonomy
Hardware parallelism(simultaneous execution on multiple processors)
Virtual parallelism(time sharing a single processor, usually with hardware support)
Data parallelism[aka “parallelism”](same task on similardata sets)
Frame-parallelism(batch, SGI N-clops)
Object-parallelism(geometry)
Image-parallelism(fragment/pixel)
Multi-processing(graphics context switching)
Multi-threading(almost defines a GPU-like processor)
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Task parallelism(different tasks on similar OR differing data sets)
Multi-processing(on multiple CPUs)
Pipelining(the graphics pipeline)

4/18/2007
11
Parallelism taxonomy
Hardware parallelism(simultaneous execution on multiple processors)
Virtual parallelism(time sharing a single processor, usually with hardware support)
Data parallelism[aka “parallelism”](same task on similardata sets)
Frame-parallelism(batch, SGI N-clops)
Object-parallelism(geometry)
Image-parallelism(fragment/pixel)
Multi-processing(graphics context switching)
Multi-threading(almost defines a GPU-like processor)
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Task parallelism(different tasks on similar OR differing data sets)
Multi-processing(on multiple CPUs)
Pipelining(the graphics pipeline)
Multi-processing(time sharing a single CPU)
Multi-threading (Direct3D-10 “common-core”)
Graphics is embarrassingly parallel
Ample self-similar data sets …
Frames, vertexes, fragments, texels, pixels
With minimal dependenciesWith minimal dependencies
Few intra-set dependenciesPixels (in the frame buffer) are the significant exception
Inter-set dependencies are purely sequential
“Graphics pipeline” is designed to minimize dependencies
Other graphics architectures have more dependencies
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
E.g., for global lighting effects
But graphics pipeline has huge redundanciesHence many opportunities for optimization …
How hard should we work to do things wrong ?

4/18/2007
12
Geometry parallelism trend (SGI)
20
0
5
10
15ModelTransform LengthTransform Width
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
0
1000
2000 G
GTXVGX RE IR
Image parallelism trend (SGI)
Rasterization
100
200
300
400
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
01000 2000 G GTX VGX RE IR

4/18/2007
13
The clear trend
Shorter and wider
Why ?
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Why ?
Communication taxonomy
Sorting
Object ImageDistribution Routing(Introduced by
parallelism)(Introduced by
parallelism)
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Texturing
Fundamental

4/18/2007
14
Sorting is fundamentalSorting
Object ImageDistribution Routing
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
TexturingI. E. Sutherland, R. F. Sproull, and R. A. Schumacher, A characterization of ten hidden surface algorithms
Classified by order of x, y, z radix sorts
Pipelining vs. parallelism
Issue Task Parallelism(pipelining) Data Parallelism
Orderingdependencies Easy Challenging
Sortingdependencies Easy Challenging
Computationscalability
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Bandwidthscalability
Load balancingscalability

4/18/2007
15
Pipelining vs. parallelism
Issue Task Parallelism(pipelining) Data Parallelism
Orderingdependencies Easy Challenging
Sortingdependencies Easy Challenging
Computationscalability Poor Challenging
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Bandwidthscalability Poor Challenging
Load balancingscalability (Nearly) impossible Challenging
Ordering challenges
Fundamental:
Frame buffer operations’ l hPainter’s algorithm
Memory hazards
Texture writesRender Copy to texture Render
Readback
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
From pipelining:
Changes to graphics state

4/18/2007
16
Sorting taxonomy
Application
Command Sort First
Sort-MiddleGeometry
Rasterization
Texture
Command
Sort-Last Fragment
Sort-First
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Sort-Last Image CompositionFragment
Display
Sort-First

4/18/2007
17
Sort-first
Cmd
App
Cmd
App Pre-transformation
Geom
Rast
CmdPoint-to-point communication scales
Coarse tiling incurs load imbalanceTex
Geom
Rast
Cmd
Tex
SORT
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Frag
Disp
Princeton Display Wall, Stanford WireGL
Frag
Disp
Sort-first
Order
Automatic (conceptually)
Sort
Pre-stage (cheat ☺)
Compute scalability
Good
Bandwidth scalability
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Bandwidth scalability
Good
Load balance scalability
Poor

4/18/2007
18
Sort-first
Cmd
App
Cmd
App
Geom
Rast
Cmd
Tex
Geom
Rast
Cmd
Tex
SORT
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
FragFrag
Disp
ROUTE
DIST
Ring parallelism
Cmd
App
Cmd Cmd CmdDIST DIST DIST…Geom
Rast
Cmd
Tex
Geom
Rast
Cmd
Tex
Geom
Rast
Cmd
Tex
Geom
Rast
Cmd
Tex
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Disp
3DLABs
FragROUTE
Frag Frag Frag

4/18/2007
19
Sort-Middle
Image-space work distribution
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Fuchs - InterleavedParke - Tiled

4/18/2007
20
Sort-middle interleaved
App
CmdCmd Geometry work load-balanced,
DISTRIBUTE
Broadcast communication does not scale, but supports ordering
Finely interleaved screen tilingensures excellent load balance
Geom
Rast
SORT
Tex
Cmd
Geom
Rast
Tex
Cmd y ,except clipping and tesselation
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
e su es e celle t load bala ce
SGI Graphics Workstations: RealityEngine, InfiniteReality
Frag
Disp
ROUTE
Frag
Sort-middle interleaved
Order
Force sequence at triangle sort
Sort
Broadcast
Compute scalability
Good
Bandwidth scalability
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Bandwidth scalability
Limited by sort broadcast
Load balance scalability
Good

4/18/2007
21
SGI RealityEngine
240 MB/s
1600 MB/s
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
3200 MB/s
Sort-middle tiled
App
Cmd
App
Cmd
Geom
Rast
SORTPoint-to-point communication scales
Coarse tiling incurs load imbalanceTex
Cmd
Geom
Rast
Tex
Cmd
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Frag
Disp
ROUTE
UNC PixelPlanes, Stanford Argus
Frag
Disp

4/18/2007
22
Sort-middle tiled (immediate mode)
Order
Force sequence at triangle sort
Sort
Can approach point-to-point
Compute scalability
Good
Bandwidth scalability
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Bandwidth scalability
Good
Load balance scalability
Poor for rasterization (due to large triangles)
Sort-middle tiled (chunked)
OrderForce sequence at triangle sortFull frame delay render to texture difficultiesFull-frame delay, render to texture difficulties
SortCan approach point-to-point
Compute scalabilityGood
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Bandwidth scalabilityGood
Load balance scalabilityGood

4/18/2007
23
UNC Pixel-Planes5 (1990)
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Sort-Last

4/18/2007
24
Sort-last fragment
App
Cmd
App
Cmd Improved texture locality
Point-to-point communication scales, but requires more bw
Geom
Rast
Tex
Cmd
Geom
Rast
Tex
Cmd
SORT
Exposes rasterization load imbalance to application
No redundant work in FG
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007Kubota Denali, E&S Freedom 3000
Finely interleaved screen tilinginsures excellent load balance
Frag
Disp
ROUTE
Frag
Disp Possible, but difficult, to maintain ordering
Sort-last fragment
Order
Force sequence at fragment sort
Sort
Point-to-point, high bandwidth
Compute scalability
Good
Bandwidth scalability
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Bandwidth scalability
OK (sorting is the bottleneck)
Load balance scalability
OK (exposed to application)

4/18/2007
25
Kubota Denali (1993)
TEM48 5 X6
24 X10
FBM
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
FBM
Denali Technical Overview 1.0
Kubota Pacific Computer, 1993
Image composition
Z comp
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Z comp
Other combiners possible
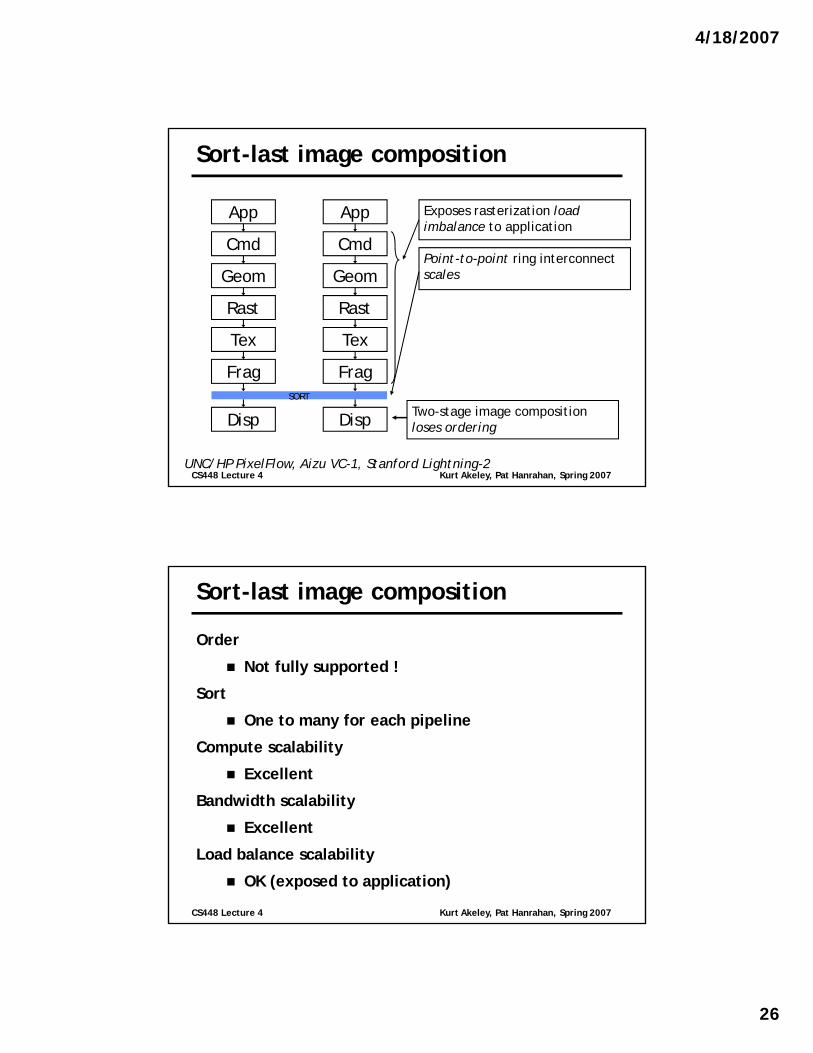
4/18/2007
26
Sort-last image composition
Exposes rasterization load imbalance to application
App
Cmd
App
CmdPoint-to-point ring interconnect scalesGeom
Rast
F
Tex
Cmd
Geom
Rast
F
Tex
Cmd
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007UNC/HP PixelFlow, Aizu VC-1, Stanford Lightning-2
Frag
Disp
Frag
Disp
SORT
Two-stage image compositionloses ordering
Sort-last image composition
Order
Not fully supported !
Sort
One to many for each pipeline
Compute scalability
Excellent
Bandwidth scalability
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Bandwidth scalability
Excellent
Load balance scalability
OK (exposed to application)

4/18/2007
27
UNC Pixel Flow
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
From J. Poulton, J. Eyles, S. Molnar, H. Fuchs,
Pixel Flow: The Realization

4/18/2007
28
Sort-Everywhere
Sort-everywhere: Pomegranate
Cmd
App
Cmd
App
Cmd
Geom
Rast
TexMem
Cmd
Geom
Rast
Tex Mem
DISTRIBUTE
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Frag
Disp
Mem Frag
Disp
Mem
SORT
ROUTE

4/18/2007
29
Architecture comparison
inte
rlea
ved
tile
d (i
mm
d)
tile
d (c
hunk
)
gmen
t
age
com
p.
hereX indicates
an issue
Ordered (X) X
Compute
Sort
-fir
st
Sort
-mid
dle
i
Sort
-mid
dle
t
Sort
-mid
dle
t
Sort
-las
t fr
ag
Sort
-las
t im
a
Sort
-eve
ryw
han issue
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
ComputescalabilityBandwidthscalability X X
Load balancescalability X X X X
Summary
GPU architecture trend
Pipeline hardware-parallel virtual-parallel
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007

4/18/2007
30
Readings
Required
1. S. Molnar, M. Cox, D. Ellsworth, H. Fuchs, A sorting classification of parallel renderingclassification of parallel rendering
2. Fuchs et al., A heterogenous multiprocessor graphics system using processor-enhanced memories (PP5).
3. Eyles et al., PixelFlow: The Realization
Recommended
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
1. F. I. Parke, Simulation and expected performance analysis of multiple processor z-buffer systems
2. H. Fuchs, Distributing a visible surface algorithm over multiple processors
Real-Time Graphics Architecture
Lecture 4: Parallelism and Communication
p
Kurt Akeley
CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007
Kurt Akeley
Pat Hanrahanhttp://graphics.stanford.edu/cs448-07-spring/


















