Project presentation-Xiao Xiao
18
Presented by Xiao Xiao Information Spreading On Social Network
-
Upload
sherry-xiao -
Category
Documents
-
view
89 -
download
1
Transcript of Project presentation-Xiao Xiao

Presented byXiao Xiao
Information Spreading On Social Network

•What kind of information we can get from social media•What do people talk about•Who is influential in a network
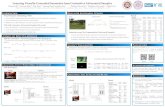
Topics and Words for Female
Source: Schwartz, H. Andrew, et al. "Personality, gender, and age in the language of social media: The open-vocabulary approach." PloS one 8.9 (2013): e73791.
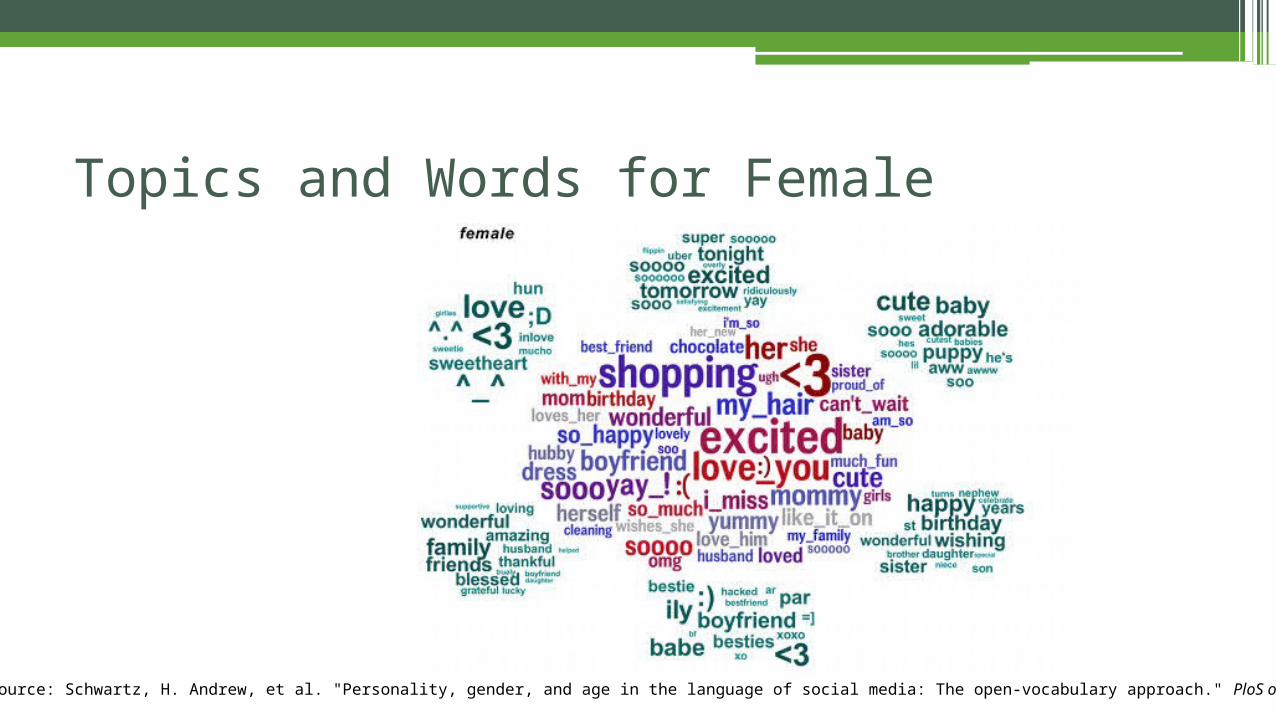
Topics and Words for Male
Source: Schwartz, H. Andrew, et al. "Personality, gender, and age in the language of social media: The open-vocabulary approach." PloS one 8.9 (2013): e73791.

Source: Schwartz, H. Andrew, et al. "Personality, gender, and age in the language of social media: The open-vocabulary approach." PloS one 8.9 (2013): e73791.
We see clear distinctions, such as use of slang, emoticons, and Internet speak in the youngest group (e.g. ':)’, ‘idk’, and a couple Internet speak topics) or work appearing in the 23 to 29 age group (e.g. ‘at work’, ‘new job’, as a job position topic).
In general, we find a progression of school, college, work, and family when looking at the predominant topics across all age groups.

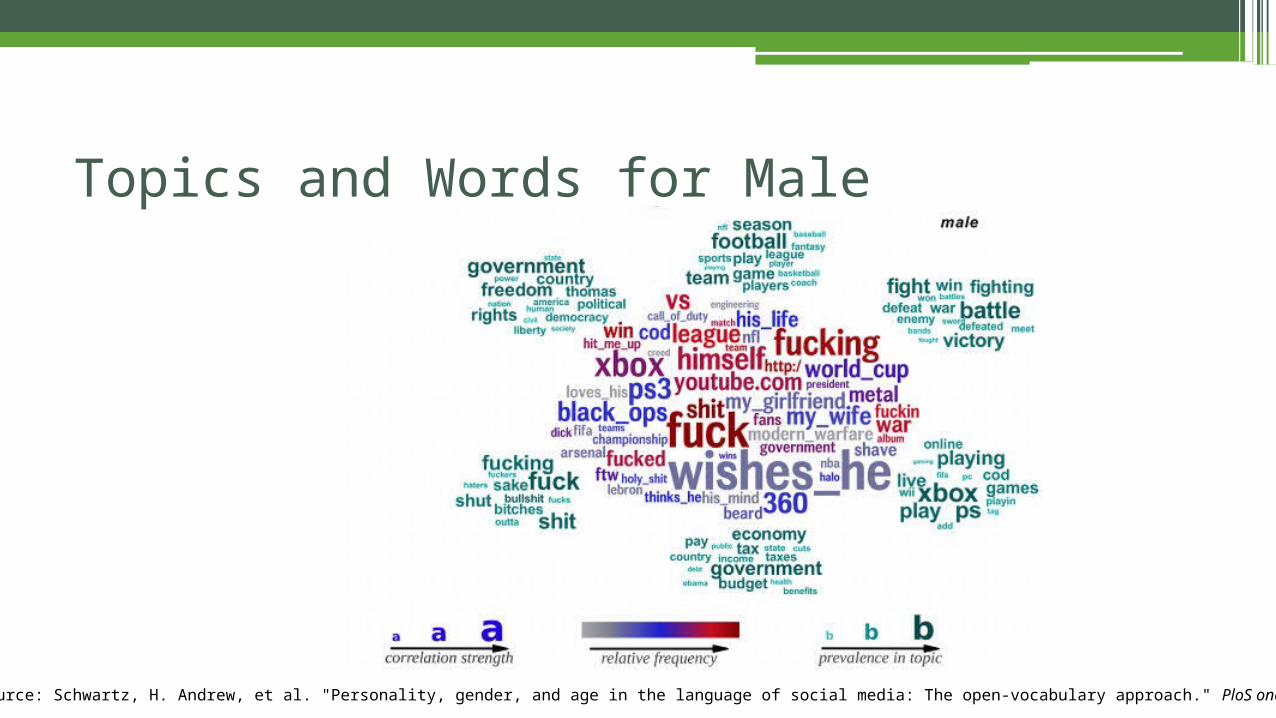
• Latent Dirichlet Allocation (LDA) is a generative model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar.
•To LDA, a document is just a collection of topics where each topic has some particular probability of generating a particular word.
Topic Detection Using LDA

•What's the probability of a sports topic generating that many instances of "average"? We determine this by looking at each training document as a "bag of words" pulled from a distribution selected by a Dirichlet process.
•Dirichlet is a distribution specified by a vector parameter α containing some αi corresponding to each topic i, which we write as Dir(α). The formula for computing the probability density function for each topic vector x is proportional to the product over all topics i of . is the probability that the topic is i, so the items in x must sum to 1.
Source: Wikipedia (http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation)
•https://dev.twitter.com/overview/documentation•Rate limits•Cannot collect tweets back to more than one week ago• In my experiment:▫Python▫Tweepy (An easy-to-use Python library for accessing the Twitter API)▫LDA (topic discover)▫D3.js (data virtualization)
Collecting Tweets from Twitter API
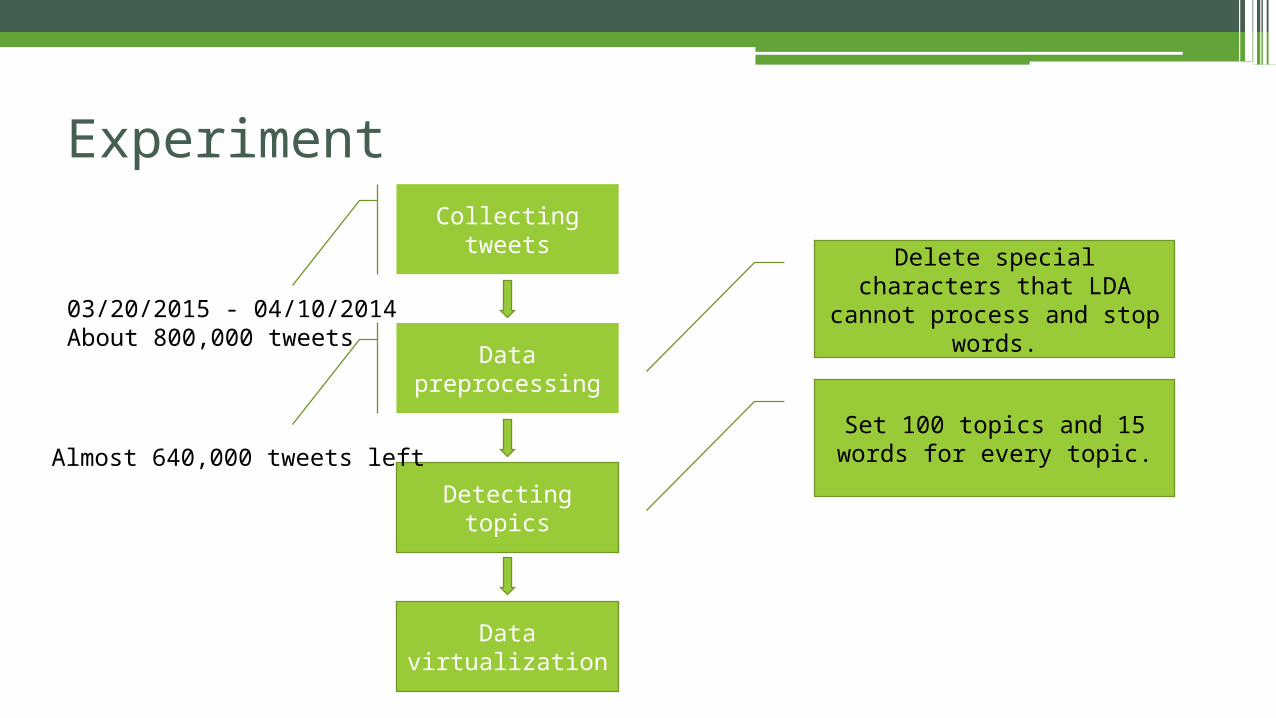
Detecting topics
Data virtualization
Delete special characters that LDA cannot process and stop words.
Set 100 topics and 15 words for every topic.
ExperimentCollecting tweets
03/20/2015 - 04/10/2014About 800,000 tweets
Data preprocessing
Almost 640,000 tweets left
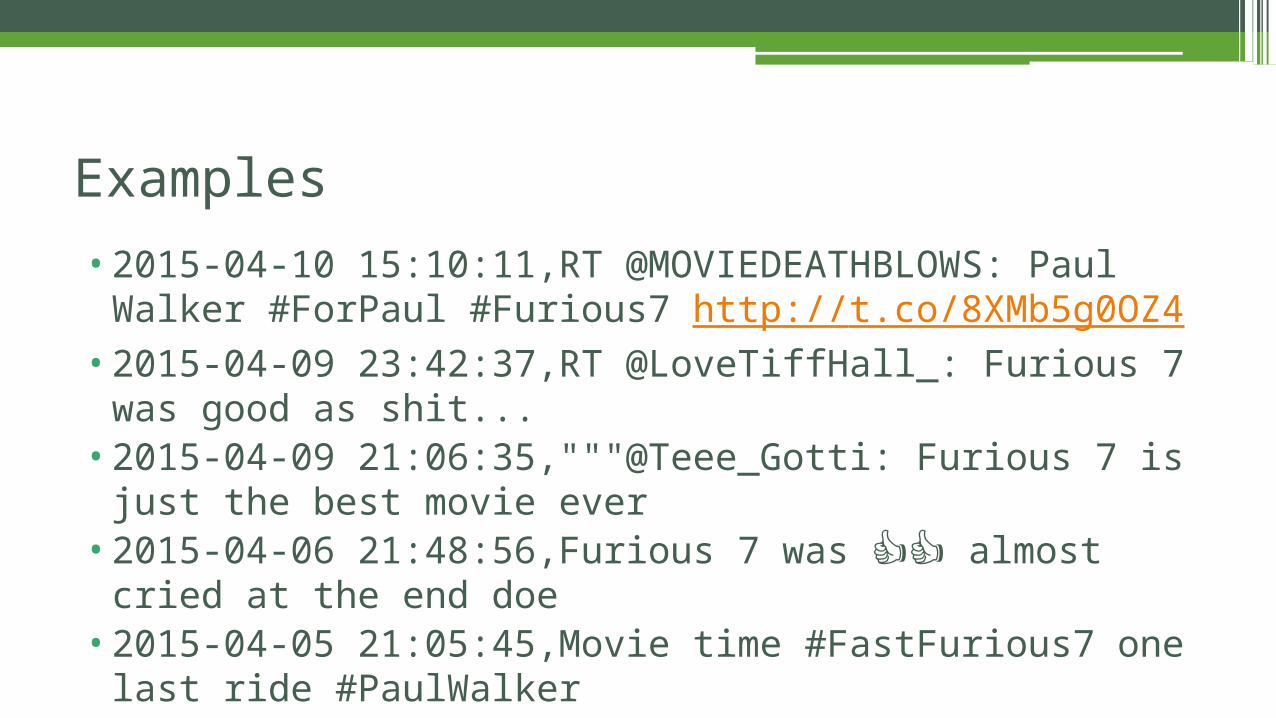
•2015-04-10 15:10:11,RT @MOVIEDEATHBLOWS: Paul Walker #ForPaul #Furious7 http://t.co/8XMb5g0OZ4
•2015-04-09 23:42:37,RT @LoveTiffHall_: Furious 7 was good as shit...•2015-04-09 21:06:35,"""@Teee_Gotti: Furious 7 is just the best movie
ever•2015-04-06 21:48:56,Furious 7 was almost cried at the end doe👍👍•2015-04-05 21:05:45,Movie time #FastFurious7 one last ride
#PaulWalker
Examples
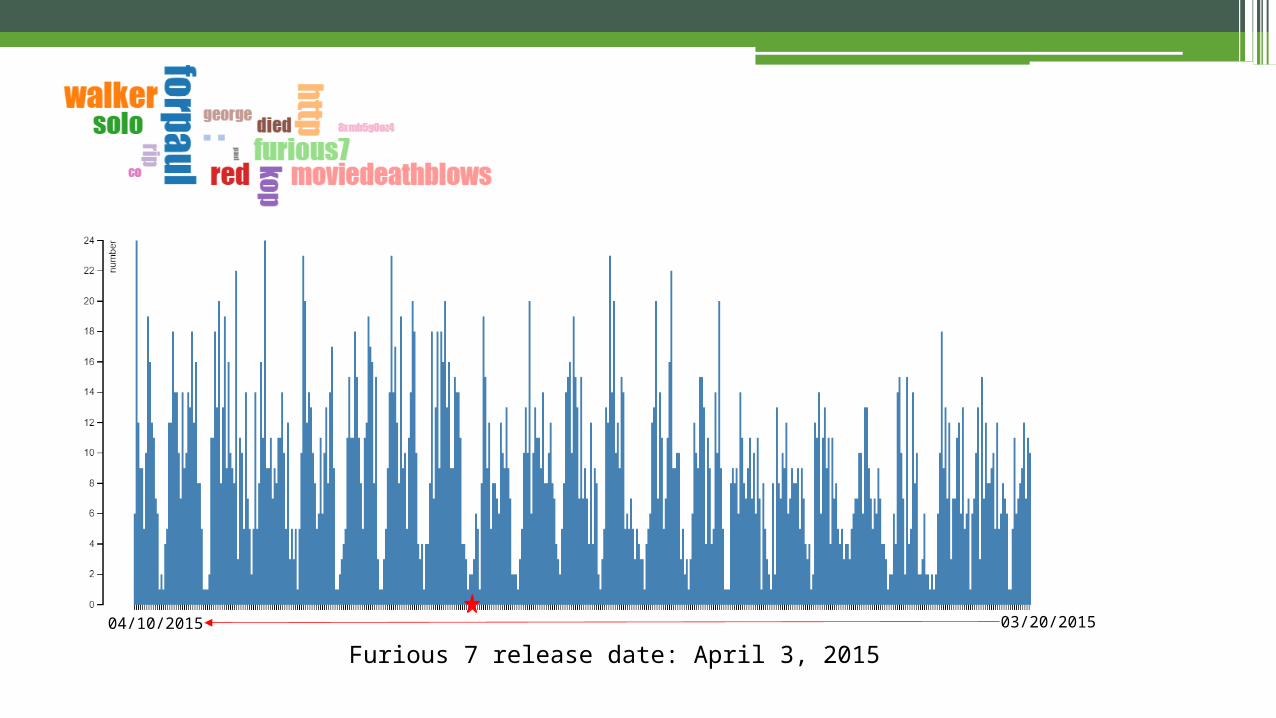
Furious 7 release date: April 3, 2015 03/20/201504/10/2015
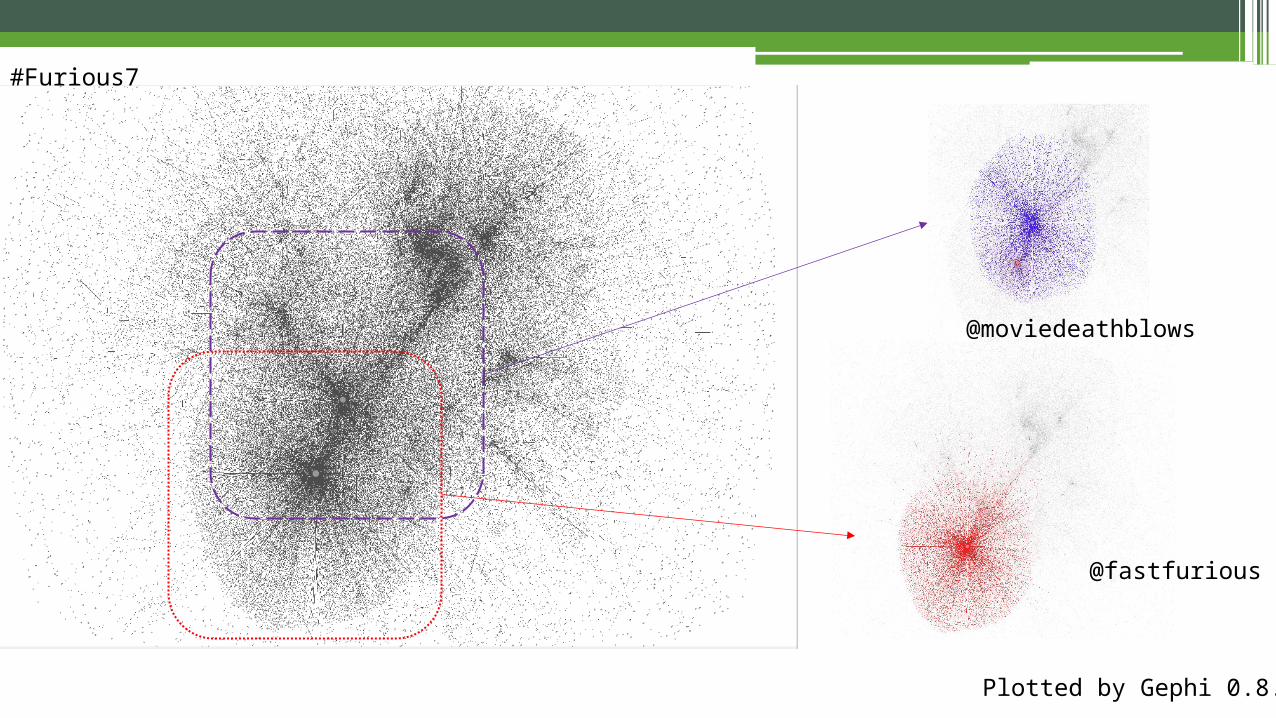
#Furious7
Plotted by Gephi 0.8.2
@fastfurious
@moviedeathblows
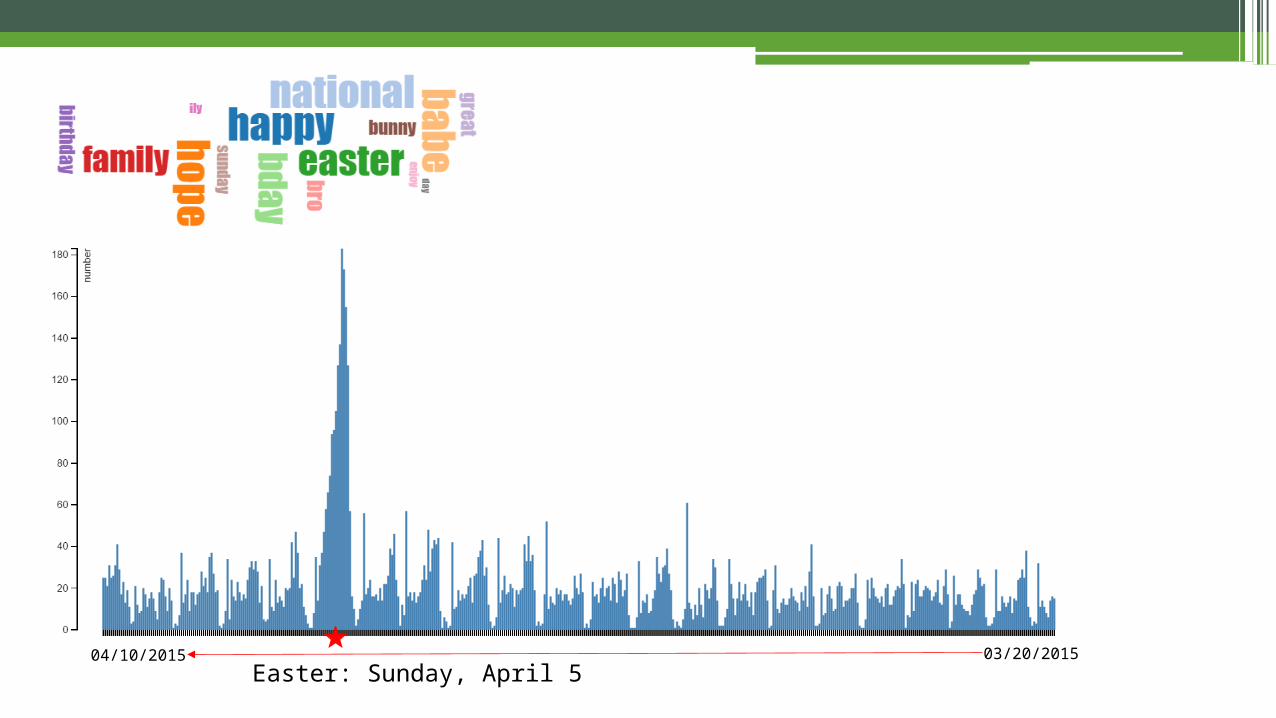
Easter: Sunday, April 503/20/201504/10/2015
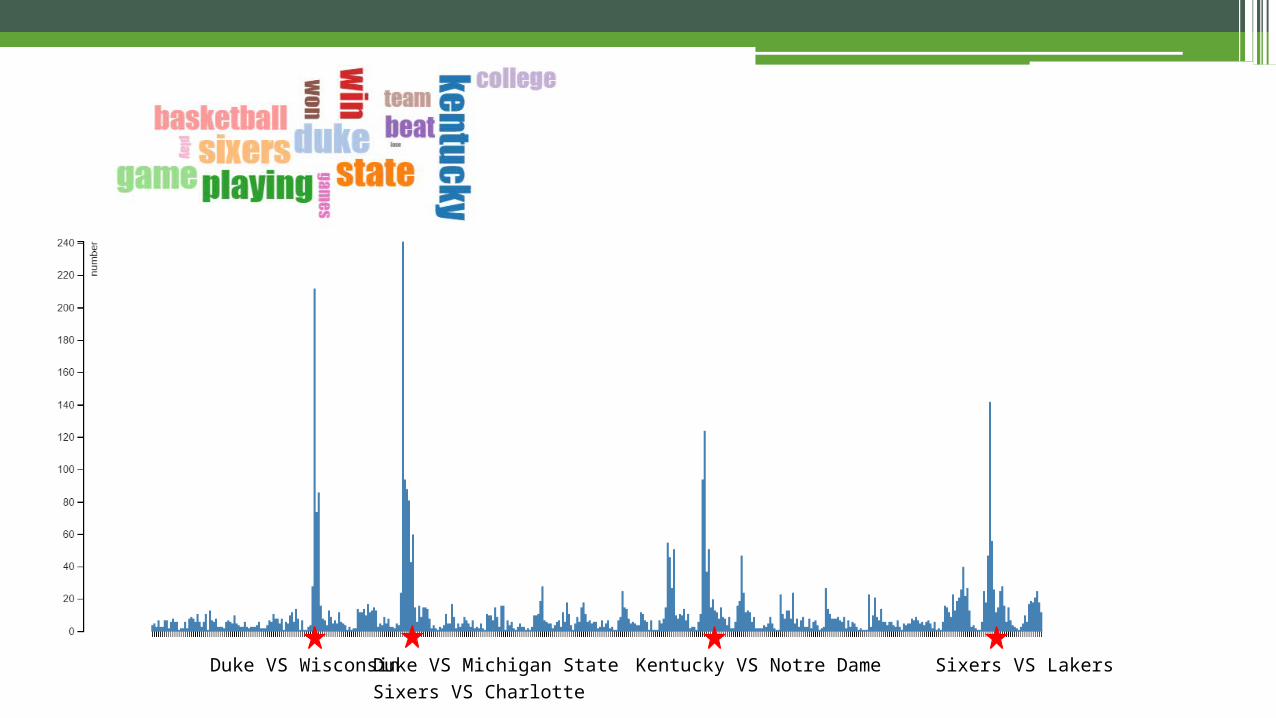
Duke VS Michigan StateDuke VS Wisconsin Kentucky VS Notre Dame Sixers VS Charlotte
Sixers VS Lakers
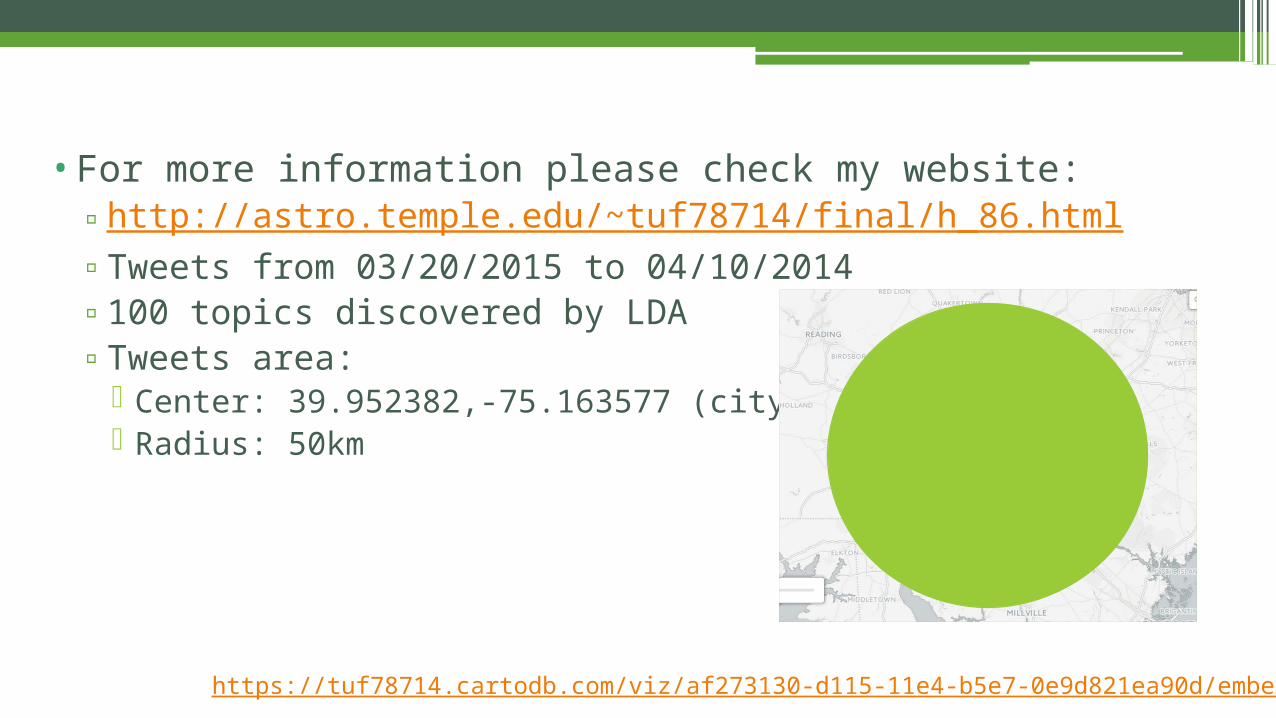
•For more information please check my website:▫http://astro.temple.edu/~tuf78714/final/h_86.html▫Tweets from 03/20/2015 to 04/10/2014▫100 topics discovered by LDA▫Tweets area:
Center: 39.952382,-75.163577 (city hall) Radius: 50km
https://tuf78714.cartodb.com/viz/af273130-d115-11e4-b5e7-0e9d821ea90d/embed_map

Future Work•Collecting the tweets by topic•Collecting the historical tweets of the user who is involved in the
discussion of some specific topic•Calculate the correlation between the user’s historical tweets and the
topic•Find a model to predict the spreading of information

Thanks!