
Production-Ready High-Speed Data Access for AI & Deep ... · Production-Ready High-Speed Data...
11
MAPR IN PARTNERSHIP WITH NVIDIA EXECUTIVE SUMMARY Artificial Intelligence (AI) is driving the next industrial revolution. AI-driven organizations depend on the ability to get access to as much high-quality data as one can gather. Enterprises are looking for a way to simplify and speed data access for AI workloads. This has quickly become the most pressing challenge standing in the way of infusing the power of AI across the enterprise. Imagine processing millions of financial transactions in real- time in order to show in-app offers instantly for consumers. Or monitoring the health of heavy machinery using sensor data in real time and triggering repair alerts for machinery showing below-par performance, before they break. The MapR ® Data Platform provides industry-leading data access performance with a broad and open approach that enables AI and deep learning (DL) workloads of tomorrow. This software-defined high-performance data platform, when combined with NVIDIA ® ’s leadership in AI and GPU computing offering fast parallelized computation, delivers a versatile, scalable infrastructure required to capitalize on the rapid innovation in the AI world. Presented in this paper are multiple architectural options to address performance, management, security, and resource distribution for running AI/DL workloads. The testing additionally demonstrates industry-leading data access performance metrics. MapR Technologies, Inc. Reference Architecture July 2018 + Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
Transcript of Production-Ready High-Speed Data Access for AI & Deep ... · Production-Ready High-Speed Data...

MAPR IN PARTNERSHIP WITH NVIDIA
EXECUTIVE SUMMARY
Artificial Intelligence (AI) is driving the next industrial revolution. AI-driven organizations depend on the ability to get access to as much high-quality data as one can gather. Enterprises are looking for a way to simplify and speed data access for AI workloads. This has quickly become the most pressing challenge standing in the way of infusing the power of AI across the enterprise. Imagine processing millions of financial transactions in real-time in order to show in-app offers instantly for consumers. Or monitoring the health of heavy machinery using sensor data in real time and triggering repair alerts for machinery showing below-par performance, before they break.
The MapR® Data Platform provides industry-leading data access performance with a broad and open approach that enables AI and deep learning (DL) workloads of tomorrow. This software-defined high-performance data platform, when combined with NVIDIA®’s leadership in AI and GPU computing offering fast parallelized computation, delivers a versatile, scalable infrastructure required to capitalize on the rapid innovation in the AI world.
Presented in this paper are multiple architectural options to address performance, management, security, and resource distribution for running AI/DL workloads. The testing additionally demonstrates industry-leading data access performance metrics.
MapR Technologies, Inc.Reference Architecture July 2018
+
Production-Ready High-Speed Data Access for AI & Deep Learning Workloads

CONTENTS
OVERVIEW 1
MAPR DATA PLATFORM 1
NVIDIA DGX-1 SERVER 1
ARCHITECTURES WITH MAPR AND NVIDIA 2
INDEPENDENT COMPUTE AND STORAGE 2
Direct MapR FUSE-Based POSIX Client 2
Single FUSE Client 2
Multiple FUSE Clients 3
Docker Bind Mounting of MapR FUSE-Based POSIX Client 3
MapR FUSE-Based POSIX Client within Docker Container 4
Kubernetes Management of MapR FUSE-Based POSIX Client (MapR FlexVolume Driver)
4
CONVERGED COMPUTE AND STORAGE 5
GPU Servers Hosting the MapR Data Platform 6
GPU and Non-GPU Systems Hosting the MapR Data Platform 6
IMPLEMENTATION: NVIDIA DGX-1 SERVER WITH MAPR FUSE-BASED POSIX CLIENTS
7
ARCHITECTURE 7
VALIDATION SETUP 7
Validation Results 8
SUMMARY 8
APPENDIX A - MAPR DATA NODE CONFIGURATION 9
APPENDIX B - FIO CONFIGURATION 9
APPENDIX C - TRAINING WITH IMAGENET DATA 9
Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
i

Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
1
OVERVIEW MAPR DATA PLATFORMThe growth in unstructured data is explosive: from medical systems, high-resolution sensors, and smart applications to autonomous vehicle development and industrial IoT devices, there are more data sources emitting more data than at any time in history. The challenge for AI and DL is the inability to easily get access to all the required data. Legacy solutions do not have the scale or cost efficiencies needed. Cloud storage, while being relatively cost-effective in some cases, tends to have high latencies and low throughput that are unacceptable for demanding workloads in addition to surprisingly high costs when data needs to be moved.
MapR has developed a data platform that is used by customers to support a broad range of demanding AI, DL, and analytic applications. Key aspects of this fabric are the ability to support high-speed data ingestion for a wide variety of data types, extensive data processing to ensure data quality, a robust analytical stack, and the support of multiple training models and versions.
In addition, there are five critical issues that must be addressed to capitalize on the artificial intelligence disruption:
1. Vast Scalability. Supporting virtually unlimited amounts of data
2. Global Namespace. The ability to access all globally distributed data, regardless of where it physically resides
3. Diverse Data. The ability to manage files, objects, containers, tables, and publish/subscribe events with one solution
4. Multi-Tenancy and Security. Built-in security, encryption, and integrated access control to support secure, diverse, distributed access with a platform across locations
5. Seamless AI and Analytics Readiness. The data store must not require data movement to apply the latest AI , DL, and analytical toolkits and manage thousands of training models
Another consideration is how to get data from the source to compute for use-cases that involve Internet of Things (IoT) devices. MapR Edge, also offers the capability to send just the “meaningful” data to the cloud, wisely split portions of machine learning techniques between edge and cloud, and execute the decisions resulting from those techniques.
NVIDIA DGX-1 SERVER NVIDIA DGX™ is an AI supercomputer, purpose-built for the unique demands of deep learning. The DGX-1 server integrates eight NVIDIA Tesla® V100 GPUs configured in a hybrid cube-mesh topology. DGX-1 server uses the NVIDIA GPU Cloud DL Software Stack, and this integrated full stack AI solution enables data scientists and AI researchers.
The NVIDIA GPU Cloud DL Software Stack offers container-based versions of today’s most popular DL frameworks like TensorFlow, PyTorch, Caffe, Caffe2, Microsoft Cognitive Toolkit, MXNet, Torch, and others. The stack includes the necessary libraries, drivers, and communications primitives, all optimized by NVIDIA for maximum GPU-accelerated performance. This fully integrated hardware and software solution enables organizations to rapidly deploy DL workloads, allowing developers and researchers to experiment sooner, iterate faster, and spend less time designing, integrating, and troubleshooting infrastructure.
As with any AI system, the models are only as accurate as the amount and quality of data that they can crunch. Getting large amounts of varied trusted data and ingesting that data to GPU sub-systems as

Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
2
rapidly as the GPU can process is critical to cost-effective production deployment of AI technologies.
ARCHITECTURES WITH MAPR AND NVIDIAMultiple architectures are available using NVIDIA and MapR components. The most efficient architecture depend on which AI and DL applications are run in an enterprise, how data scientists, business analysts, and other users create and consume the applications, and how the enterprise manages IT resources within and between business units. This paper presents an overview of several NVIDIA/MapR architectures.
The MapR distributed file system and object store supports both traditional separation of compute and storage as well as environments where compute and storage are converged.
INDEPENDENT COMPUTE AND STORAGECompute resources are often physically removed from the storage where the computation data resides. This separation allows scaling of either compute or storage infrastructure independently. For many enterprises, this separation is also consistent with IT management of compute and storage infrastructure. MapR and NVIDIA provide both a converged storage/compute solution as well as traditional, independent compute and storage solution for AI and DL.
Performing operations on very large data sets in the non-converged compute/storage environment poses infrastructure challenges. One is the ability to feed GPUs with data as fast as they are able to perform operations on the data. Another challenge that applies to both converged and non-converged compute and storage is sharing resources between users or business units while keeping the data secure and ensuring resources aren’t monopolized by resource-hungry, mundane tasks.
The MapR client architectures in this section support independent compute and storage, while also being applicable to the converged compute and storage architectures described later.
Direct MapR FUSE-Based POSIX Client
For optimal performance, the storage subsystem must be able to provide data as fast as it can be consumed and processed by the GPUs. The MapR FUSE-based POSIX Client can provide parallel access to all servers comprising the MapR Data Platform. This data platform can be comprised of a single or multiple MapR clusters. Any MapR cluster can be made up of thousands of heterogeneous commodity servers with local disk or solid state storage devices for aggregate throughput of terabytes per second to hundreds of DGX-1 servers. A MapR cluster may also be as few as five nodes in a production environment and a single node for a development environment.
For direct access to the MapR file system from the DGX OS, the MapR FUSE-based POSIX Client presents a mount of the MapR File System. This file system appears like any other Linux file system mounted on the DGX-1 server. Applications running on the host OS access files in MapR and use the NVIDA CUDA® library to utilize the DGX-1 servers.
Single FUSE Client
When the bandwidth requirement for each DGX-1 server does not exceed five gigabytes per second (for example, when only 10 GbE network interfaces are used for storage), a single MapR FUSE-based POSIX Client on each DGX-1 server is sufficient to accommodate storage bandwidth. Figure 1 shows how all applications on the DGX-1 server access files in the MapR cluster through a single mount point.

Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
3
Figure 1. Single FUSE Client
Multiple FUSE Clients
For highest bandwidth from the MapR cluster to a single DGX-1 server , MapR supports running multiple FUSE-based clients on the server. As shown in Figure 2, each FUSE-based client presents a separate Linux mount point for the MapR cluster, which provides independent security and configuration options to support different users or workloads. For a single workload, each client is configured identically to provide consistent data paths and security to the MapR cluster across all mount points.
MAPR CLUSTERMulti-Cloud, On-Premises, Edge
INTERFACESPOSIXJSONKafka
APPLICATIONS
CUDA DRIVER
MAPR CLIENTS
HOST OS
NVIDIA GPUs
SERVER
Figure 2. Multiple FUSE Clients
Docker Bind Mounting of MapR FUSE-Based POSIX Client
Docker containers provide a mechanism to isolate compute environments of different users on the same server. As Figure 3 shows, MapR FUSE-based POSIX Client access configured on a DGX-1 server, using a single or multiple FUSE clients, can be exposed to any Docker container using the bind mounting specified in the Docker run command. Applications in the Docker container can then access the MapR File System from the bind location within the Docker container. With MapR FUSE-based POSIX Client mounting a MapR cluster in the DGX OS, the storage performance and security advantages of the MapR FUSE-based POSIX Client can be extended to any Docker container when the container is started.
MAPR CLUSTERMulti-Cloud, On-Premises, Edge
INTERFACESPOSIXJSONKafka
APPLICATIONS
CUDA DRIVER
MAPR CLIENT
HOST OS
NVIDIA GPUs
SERVER

Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
4
Figure 3. File-access from DL/AI application using containers (No MapR software needed in containers)
MapR FUSE-Based POSIX Client within Docker Container
Figure 4 shows how containers that need access to MapR-DB (Key/Value and Document Database) and MapR-ES (Global Pub/Sub with Kafka APIs), in addition to the MapR File System, can use MapR containers pre-built with the CUDA Toolkit or NVIDIA containers pre-built with the MapR client. MapR publishes a Persistent Application Client Container with the CUDA Toolkit for this purpose. This includes a JSON NoSQL API for MapR-DB and the Kafka 1.0 API for MapR-ES.
Optionally, the DGX-1 server Docker host can also be configured with the MapR FUSE-based POSIX Client for applications not running within Docker containers, but this is not required when all applications accessing the MapR File System are running within Docker containers.
INTERFACESPOSIXJSONKafka
APPLICATIONS
CUDA TOOLKIT
MAPR CLIENT
CONTAINER OS USER SPACE
DOCKER ENGINE
CUDA DRIVER
HOST OS
NVIDIA GPUs
SERVER
CONTAINER 1
MAPR CLUSTERMulti-Cloud, On-Premises, Edge
CONTAINER N
Figure 4. Files access from DL/AI application with MapR client software in containers
Kubernetes Management of MapR FUSE-Based POSIX Client (MapR FlexVolume Driver)
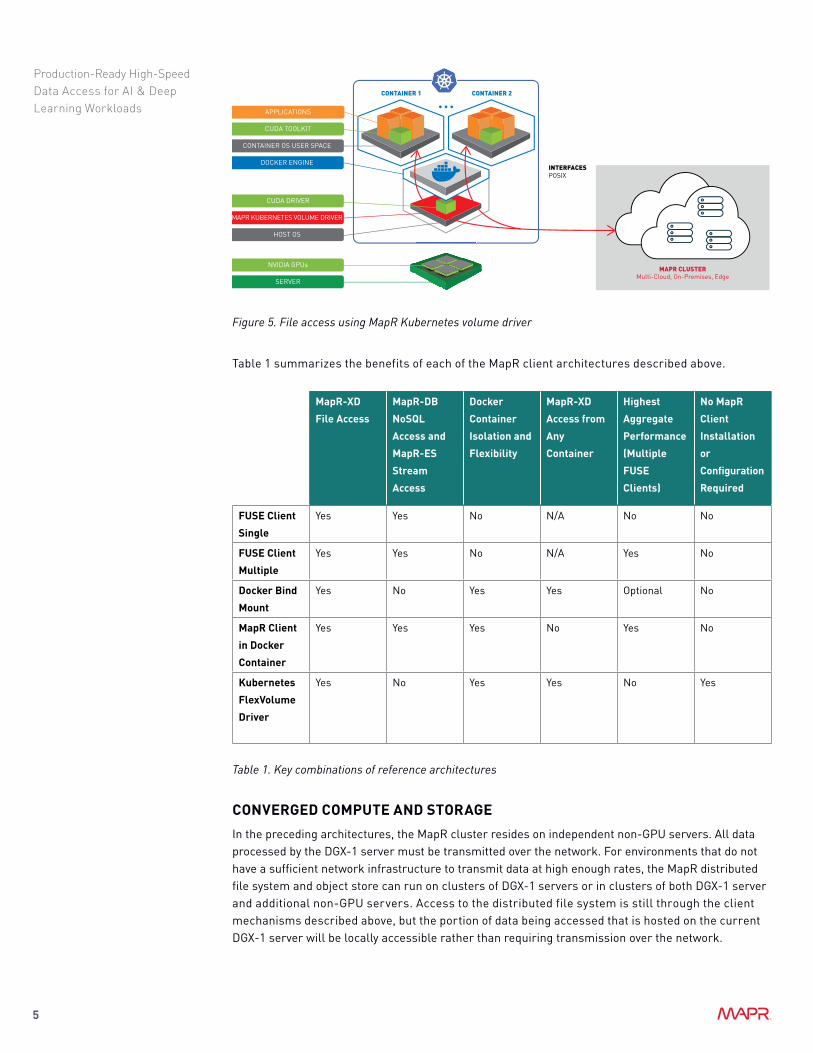
Kubernetes provides management and orchestration of Docker containers across many servers or on just a single server. Figure 5 shows how docker containers under Kubernetes management can access MapR storage through the MapR Kubernetes FlexVolume Driver. No MapR client installation is required for either the host OS on the DGX-1 server or for containers running on the DGX-1 server . Kubernetes manages installation and configuration of the MapR FUSE-based POSIX Client for use by containers under Kubernetes management.
INTERFACESPOSIX
APPLICATIONS
CUDA TOOLKIT
CONTAINER OS USER SPACE
DOCKER ENGINE
CUDA DRIVER
MAPR CLIENT (S)
HOST OS
NVIDIA GPUs
SERVER
CONTAINER 1
MAPR CLUSTERMulti-Cloud, On-Premises, Edge
CONTAINER N
Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
5
INTERFACESPOSIX
APPLICATIONS
CUDA TOOLKIT
CONTAINER OS USER SPACE
DOCKER ENGINE
CUDA DRIVER
MAPR KUBERNETES VOLUME DRIVER
HOST OS
NVIDIA GPUs
SERVER
CONTAINER 1
MAPR CLUSTERMulti-Cloud, On-Premises, Edge
CONTAINER 2
Figure 5. File access using MapR Kubernetes volume driver
Table 1 summarizes the benefits of each of the MapR client architectures described above.
MapR-XD File Access
MapR-DB NoSQL Access and MapR-ES Stream Access
Docker Container Isolation and Flexibility
MapR-XDAccess fromAny Container
Highest Aggregate Performance (Multiple FUSE Clients)
No MapR Client Installation or Configuration Required
FUSE Client Single
Yes Yes No N/A No No
FUSE Client Multiple
Yes Yes No N/A Yes No
Docker Bind Mount
Yes No Yes Yes Optional No
MapR Client in Docker Container
Yes Yes Yes No Yes No
Kubernetes FlexVolume Driver
Yes No Yes Yes No Yes
Table 1. Key combinations of reference architectures
CONVERGED COMPUTE AND STORAGEIn the preceding architectures, the MapR cluster resides on independent non-GPU servers. All data processed by the DGX-1 server must be transmitted over the network. For environments that do not have a sufficient network infrastructure to transmit data at high enough rates, the MapR distributed file system and object store can run on clusters of DGX-1 servers or in clusters of both DGX-1 server and additional non-GPU servers. Access to the distributed file system is still through the client mechanisms described above, but the portion of data being accessed that is hosted on the current DGX-1 server will be locally accessible rather than requiring transmission over the network.

Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
6
GPU Servers Hosting the MapR Data Platform
If aggregate storage on all of the DGX-1 server systems is sufficient, a MapR cluster of only DGX-1 servers can be used. MapR will distribute data throughout the cluster, with replicas of data on multiple nodes, increasing the amount of data that will be accessed locally. MapR topologies and write strategies can be incorporated to ensure data locality for all reads.
MAPR CLUSTER
DGX-1 DGX-1DGX-1DGX-1
MAPR CLUSTER
DGX-1
Figure 6. MapR Cluster of only DGX-1 server systems
GPU and Non-GPU Systems Hosting the MapR Data Platform
If storage capacity needs to grow beyond that available on the DGX-1 servers, additional non-GPU servers can be added to increase the capacity of the MapR cluster. Some data will typically still reside locally on the DGX-1 servers, and using MapR topologies, this data can be kept on the DGX-1 server systems. MapR volumes can also be moved between topologies to bring data local to the DGX-1 server topology for the duration of certain jobs and then moved back out to the non-GPU servers when extremely fast access is not as important. This hot/warm data strategy can be augmented further by the advanced MapR tiering, which would move data to AWS S3-compatible storage per user-specified policy.
MAPR CLUSTER
DGX-1 DGX-1DGX-1DGX-1 DGX-1
Non-GPU Server
Non-GPU Server
Non-GPU Server
Non-GPU Server
Non-GPU Server
Non-GPU Server
Non-GPU Server
Non-GPU Server
Non-GPU Server
DGX-1 Topology
Non-GPU Topology
Figure 7. MapR Cluster of DGX-1 server and non-GPU systems

Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
7
IMPLEMENTATION: NVIDIA DGX-1 SERVER WITH MAPR FUSE-BASED POSIX CLIENTS MapR validated an implementation of the MapR FUSE-based POSIX Client architecture, running eight MapR FUSE-based POSIX platinum clients on a single DGX-1 server. To validate, we trained the ResNet-50 and AlexNet models in TensorFlow with 144 GB ImageNet data in TFRecord format, running directly on Ubuntu 16.04 on the DGX-1 server.
ARCHITECTUREA single DGX-1 server was connected to a MapR cluster with ten data nodes via a Mellanox MSN2700-CS2F 100 GbE switch. The DGX-1 server was connected with four Mellanox MT27700 100 GbE network interfaces and each of the ten MapR data nodes was connected with two Mellanox MT27500 40 GbE network interfaces. For MapR cluster data node configuration, see Appendix A - MapR Data Node Configuration.
The MapR client was configured on the DGX-1 server with eight MapR FUSE-based POSIX platinum clients with numlibs=7 and non-uniform memory access (NUMA) affinity. This presented the MapR cluster on eight different mount points.
MAPR CLUSTER
NVIDIA DGX-1
GPU 3 GPU 0 GPU 4 GPU 7
GPU 2 GPU 1 GPU 5 GPU 6
CPU 0 CPU 1
4x MapR FUSE Platinum Clients 4x MapR FUSE Platinum Clients
/mapr0 /mapr1 /mapr2 /mapr3 /mapr4 /mapr5 /mapr6 /mapr7
NIC 0 NIC 1 NIC 2 NIC 3
Figure 8. Eight FUSE clients running in a high-performance configuration
VALIDATION SETUPFor this high-performance multiple FUSE client setup, Flexible I/O (FIO) Tester was used to demonstrate MapR throughput capacity. FIO exercises the MapR client independently of GPU processing to determine the highest possible rate at which GPUs could be fed with data for AI/DL processing.
For configuration details, see Appendix B - FIO Configuration.
To put the configuration in a DL model training scenario, we utilize the ImageNet data, which consists of 144 GB of JPEG data to train different models with TensorFlow and monitor the disk throughput.
For training details and configuration, see Appendix C - Training with ImageNet Data.
Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
8
Validation Results
FIO performance demonstrates the MapR File System’s capability to utilize the latest 100 gigabit networks for file transfers. 18 GB/s reads and 16 GB/s writes to a single GPU server exceeds the throughput capability of most leading POSIX-based file systems in the market today. And a single MapR cluster can be scaled out with commodity servers to provide the same performance to additional GPU servers.
Block Size (KB)
I/O Type #FIO Procs #MapR Volumes
Read (GB/s) Write (GB/s)
1024 Sequential 160 40 18.1 16.2
128 Sequential 160 40 13.5 14.8
64 Sequential 160 40 12.6 12.6
Table 2. FIO Validation Results (GB/s = gigabyte per second)
NVIDIA GPUs demonstrate industry-leading performance for DL model training. By using data stored in MapR, the GPUs can be fed with data as fast as it can be consumed. It is also evident that MapR maximizes the data transfer speeds of the current generation of NVIDIA GPUs and thereby making these reference architectures future-proof as newer generations are delivered in the market. MapR accommodates very large batch sizes for rapid loading of data for GPU consumption.
Model Training Rate (Image/s)
Read (MB/s) Batch Size
ResNet-50 4146 452 256
AlexNet 11608 1281 4096
Table 3. FIO Validation Results (MB/s = megabyte per second)
This quick experiment validates that a combination of a DGX-1 server and a MapR POSIX Client, alongside a MapR cluster consisting of storage and network speeds corresponding to hot storage, can create a data access system that is future-proof for applications with real-time AI/DL workloads. This shows that model training on GPUs requires at most 1.5 GB/s with FIO showing that this reference architecture offers upto 16 and 18 GB/s.
SUMMARYThis white paper illustrates that MapR provides a flexible data platform for AI and analytics, and with the DGX-1 server, the reference architectures enable high speed data access for DL workloads. MapR provides many file system client and architectural options to address performance, management, security, and resource distribution amongst multiple tenants. For the DGX-1 server, this creates options for running AI/DL workloads natively, in user-managed containers or in Kubernetes-managed containers. Our testing demonstrates that the combination of two technologies – the MapR Data Platform and DGX-1 servers – when put together makes for a unique architecture that is ready to take on real-time applications with AI/DL workloads that require accessing, processing, and analyzing large amounts of data spread across multiple clouds.

MapR and the MapR logo are registered trademarks of MapR and its subsidiaries in the United States and other countries. Other marks and brands may be claimed as the property of others. The product plans, specifications, and descriptions herein are provided for information only and subject to change without notice, and are provided without warranty of any kind, express or implied. Copyright © 2018 MapR Technologies, Inc. For more information visit mapr.com
Production-Ready High-Speed Data Access for AI & Deep Learning Workloads
APPENDIX A - MAPR DATA NODE CONFIGURATIONThe MapR cluster ran on ten data nodes with the configuration in the table.
Component Qty Description
CPU 2 Intel Xeon E5-2660 v3 - 2.3 GHz - 10C
Memory 16 16 GB DDR4 2133 MHz DIMM
Storage 12 Samsung MZ-7KM480 480 GB SSD
Network 2 Mellanox MT27500 40 GbE
MapR 3 storage pools of 4 drives each. One MFS instance per storage pool.
APPENDIX B - FIO CONFIGURATIONWe ran 160 simultaneous, time-based FIO processes on the DGX-1 server with taskset for NUMA affinity, clearing MapR caches before each run to ensure all data is transmitted from storage media on servers in the MapR cluster and using the following FIO parameters:
--direct=1
--thread
--time_based
--refill_buffers
--overwrite=0
--ioengine=libaio
--runtime=60
--numjobs=1
--filesize=8192M
--iodepth=64
The 160 processes were spread across eight MapR clients; 20 processes per client. Runs were repeated with block sizes of 64K, 128K, and 1024K. The sum of data transferred by each of the FIO processes was divided by the time interval between the start of the first FIO process and completion of the last FIO process to determine total throughput.
APPENDIX C - TRAINING WITH IMAGENET DATAFirst, we preprocess the ImageNet data into 1024 TFRecord format files, each 120 MB to 150 MB in size, to ensure TensorFlow can ingest the data with optimal speed. Second, we train the ResNet-50 model, a 50-layer residual network, on eight GPUs with a batch size of 256. And then, to put greater load on the storage subsystem, we train a simpler AlexNet model, which consists of only five convolution layers and three fully connected layers, on eight GPUs with a batch size of 4096.


















