
Production and Perception of Vocalic Sequences in Mexican ......iii In support of the first and...
277
Production and Perception of Vocalic Sequences in Mexican Spanish by Anna Limanni A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Department of Spanish and Portuguese University of Toronto © Copyright by Anna Limanni 2014
Transcript of Production and Perception of Vocalic Sequences in Mexican ......iii In support of the first and...

Production and Perception of Vocalic Sequences in Mexican Spanish
by
Anna Limanni
A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy
Department of Spanish and Portuguese University of Toronto
© Copyright by Anna Limanni 2014

ii
Production and Perception of Vocalic Sequences in Mexican
Spanish
Anna Limanni
Doctor of Philosophy
Department of Spanish and Portuguese
University of Toronto
2014
Abstract
This dissertation investigates variation in the production and perception of vocalic sequences in
Mexican Spanish, with an emphasis on the relationship between this variation and the occurrence
of exceptional hiatuses. The dissertation aims to demonstrate that:
(i) The phonetic variation responsible for the occurrence of exceptional hiatuses is present in all
Spanish varieties, including highly diphthongizing varieties (like Mexican Spanish).
(ii) The phonetic variation leading to the production of exceptional hiatuses is rooted in
patterns of articulation.
(iii) Variation in the production of diphthongs, hiatuses and exceptional hiatuses is related to
variation in their perception.
Three studies were conducted to test these goals. The studies used a variety of experimental and
statistical techniques (including duration and formant normalization procedures, electro-
magnetic articulography, discriminant analysis, signal detection measures, and AX perception
tasks) to provide and evaluate acoustic (Chapter 3), articulation (Chapter 4) and perception
(Chapter 5) data.

iii
In support of the first and second goals, the acoustic and articulation results uncover sequence-
specific and speaker-specific variation in the production of diphthongs and hiatuses, as well as
the presence of exceptional hiatuses. The articulation results also offer evidence for the
articulatory stability of diphthongs and tentatively suggest that the actions of the Tongue Tip
(TT) are crucial for achieving the Diphthong-Hiatus contrast and for diphthongization. While the
results of the perception study do not support the third research goal of establishing a production-
perception link for vocalic sequences in Mexican Spanish, they reveal an unexpected, possibly
dialect-specific Vowel effect which merits further investigation.
Overall, the main findings of this dissertation support the idea that the occurrence of exceptional
hiatuses stems from coarticulatory variation found in all Spanish varieties. These findings
challenge the assumption of an underlying syllabicity contrast between diphthongs and
exceptional hiatuses and question the need for a special category of exceptional hiatuses.

iv
Acknowledgments
Completing this dissertation has been the most challenging activity I have ever undertaken.
Thankfully, I was surrounded by many people who helped and guided me along the way. I could
never have finished this dissertation without them and I wish to express my gratitude for their
presence and support.
First of all, I wish to acknowledge the extraordinary group of scholars whose depth of
knowledge, critical sense, attention to detail and great generosity I took advantage of in
completing this dissertation. I begin by thanking my thesis supervisor, Professor Laura Colantoni
who has inspired and guided my research since my Masters year. I am most grateful for her
ability to help me focus on the big picture of my dissertation during those many times when I got
lost in the experimental details. I am also extremely grateful to my thesis co-supervisor,
Professor Pascal van Lieshout for introducing me to articulatory research, for generously
allowing me access to his lab and for patiently training me on the use of the necessary equipment
and software. I also thank my committee members, Professors Alexei Kochetov and María
Cristina Cuervo for carefully reading the numerous (and extremely long) drafts of the chapters of
this dissertation and for offering many detailed comments and suggestions for revisions along the
way.
I thank Professor Ana Teresa Pérez-Leroux for being a member of my oral examination
committee and for her kind words of encouragement over the years. I also thank Professor
Lourdes Aguilar for agreeing to serve as the external appraiser of my dissertation. I have admired
Professor’s Aguilar research for many years and I feel honoured to have received for her insight
and feedback on my work.

v
Next, I wish to acknowledge members of the Oral Dynamics Lab (Department of Speech
Pathology, University of Toronto). I especially thank Dr. Aravind Namasivayam for volunteering
his time and expertise to help me design and run my experiments. His assistance was invaluable
and I cannot thank him enough. I thank Anneke Slis and Heidi Diepstra for giving me the
opportunity to learn from their experiments. In addition, I am grateful to Aravind, Anneke and
Heidi for their continued friendship and support.
I also owe thanks to my many friends and colleagues. Throughout the years they shared my best
and my worst moments and their unfailing encouragement gave me the strength to keep going in
the face of self-doubt. From the Department of Spanish and Portuguese, I wish to acknowledge
Yadira Álvarez, Tanya Battersby, Natalia Mazzaro, Yasaman Rafat and Irina Marinescu. I wish
to give special thanks to my close friend and ally Chiara Frigeni for her unwavering support and
sound advice.
Finally, and most importantly, I would like to thank my family. I thank my husband, Vicente
García, and my son, Jonathan García-Limanni, for their unyielding support, patience and
encouragement and for tolerating my occasional foul moods. I also thank my parents, Giovanni
and Maria Limanni. Although their circumstances did not allow them to continue their studies
beyond elementary school, they always impressed upon me the importance of an education. I
hope that this work makes them proud.

vi
Table of Contents
Table of Contents
Acknowledgments.......................................................................................................................... iv
Table of Contents ........................................................................................................................... vi
List of Tables ................................................................................................................................ xii
List of Figures ............................................................................................................................. xvii
List of Appendices ....................................................................................................................... xxi
Chapter 1 Introduction .....................................................................................................................1
1 Overview .....................................................................................................................................1
2 Sound Variation and Change ......................................................................................................2
2.1 Dialectal Variation and Sound Change ................................................................................4
3 Vocalic Sequences in Spanish .....................................................................................................4
4 Experimental Focus and Design..................................................................................................8
4.1 Dialect and Participant Selection .......................................................................................10
5 Dissertation Outline ..................................................................................................................11
Chapter 2 Literature Review ..........................................................................................................12
1 Introduction ...............................................................................................................................12
2 Theoretical Approaches to Vocalic Sequences .........................................................................13
2.1 Spanish ...............................................................................................................................13
2.1.1 The Phonemic Status of Spanish Glides ................................................................16
2.1.2 Alternating Diphthongs (‘los diptongos alternantes’) in Spanish ..........................22
2.1.3 The Syllabic Representation of Spanish Diphthongs.............................................24
2.2 Other Romance Languages ................................................................................................26
2.2.1 Italian .....................................................................................................................26

vii
2.2.2 Romanian ...............................................................................................................29
2.2.3 French ....................................................................................................................30
2.2.4 Portuguese ..............................................................................................................31
2.3 Non-Romance Languages ..................................................................................................32
2.3.1 English ...................................................................................................................32
2.3.2 Dutch ......................................................................................................................34
2.3.3 German ...................................................................................................................35
2.4 Summary ............................................................................................................................36
3 Experimental Studies ................................................................................................................37
3.1 Acoustic Studies.................................................................................................................37
3.1.1 Frequency Parameters ............................................................................................38
3.1.2 Temporal Parameters .............................................................................................41
3.1.3 Summary ................................................................................................................43
3.2 Articulation Studies ...........................................................................................................44
3.2.1 Summary ................................................................................................................49
3.3 Perception Studies ..............................................................................................................49
3.3.1 Spanish ...................................................................................................................50
3.3.2 Italian .....................................................................................................................55
3.3.3 Romanian ...............................................................................................................57
3.3.4 Non-Romance Languages ......................................................................................59
3.3.5 Summary ................................................................................................................63
4 Conclusions ...............................................................................................................................63
Chapter 3 Acoustic Analysis of Vocalic Sequences in Mexican Spanish .....................................66
1 Introduction ...............................................................................................................................66
2 Experimental Methodology .......................................................................................................68
2.1 Participants .........................................................................................................................68

viii
2.2 Stimuli ................................................................................................................................68
2.3 Tasks and Procedures .........................................................................................................69
2.4 Measurements and Analyses ..............................................................................................71
2.4.1 Temporal Measurements ........................................................................................72
2.4.2 Frequency Measurements ......................................................................................74
2.4.3 Discriminant Analysis ............................................................................................77
3 Results .......................................................................................................................................78
3.1 Sequence Duration .............................................................................................................78
3.1.1 Vowel Effects on Sequence Duration ....................................................................84
3.2 Transition Duration ............................................................................................................88
3.2.1 Vowel Effects on Transition Duration ...................................................................90
3.3 Frequency ...........................................................................................................................94
3.3.1 Diphthong (já, jé, jó) vs. Hiatus (í.a ,í.e, í.o) .........................................................94
3.4 Discriminant Analysis ......................................................................................................102
3.4.1 Data Preparation and Procedures .........................................................................102
3.4.2 Discriminant Analysis Results .............................................................................105
3.4.3 Misclassified Sequences ......................................................................................107
4 Summary and Discussion ........................................................................................................111
4.1 Hypothesis 1: Diphthong vs. Hiatus ................................................................................111
4.2 Hypothesis 2: Vowel Effects ...........................................................................................112
4.3 Hypothesis 3: Exceptional Hiatuses.................................................................................113
4.4 Discussion ........................................................................................................................115
5 Conclusions .............................................................................................................................118
Chapter 4 Articulatory Analysis of Vocalic Sequences in Mexican Spanish ..............................120
1 Introduction .............................................................................................................................120
2 Experimental Methodology .....................................................................................................124

ix
2.1 Participants .......................................................................................................................124
2.2 Stimuli ..............................................................................................................................124
2.3 Instrumentation and Procedure ........................................................................................124
2.4 Data Processing ................................................................................................................127
2.5 Measurement and Analysis ..............................................................................................128
3 Results .....................................................................................................................................130
3.1 Timing (TB-TT Offset) ....................................................................................................130
3.1.1 Vowel Effects on Timing of TB and TT ..............................................................140
3.2 Spatial Displacement (%TT and %TB) ...........................................................................143
3.2.1 Vowel Effects on Spatial Displacement of TB and TT .......................................151
3.3 Discriminant Analysis ......................................................................................................156
3.3.1 Sequences with [a] ...............................................................................................157
3.3.2 Sequences with [e] ...............................................................................................159
3.3.3 Sequences with [o] ...............................................................................................162
4 Summary and Discussion ........................................................................................................163
4.1 Hypothesis 1: Timing of TB and TT................................................................................163
4.2 Hypothesis 2: Magnitude of TT and TB Displacement ...................................................164
4.3 Hypothesis 3: Exceptional Hiatuses.................................................................................165
4.4 Discussion ........................................................................................................................168
5 Conclusions .............................................................................................................................171
Chapter 5 Perception of Vocalic Sequences in Mexican Spanish ...............................................173
1 Introduction .............................................................................................................................173
2 Experimental Methodology .....................................................................................................179
2.1 Participants .......................................................................................................................179
2.1.1 Hearing Screening ................................................................................................179
2.1.2 Handedness Questionnaire ...................................................................................180

x
2.2 Stimuli ..............................................................................................................................181
2.3 Tasks and procedures .......................................................................................................187
2.4 Analysis............................................................................................................................188
2.4.1 Discrimination Measures .....................................................................................189
2.4.2 Statistical Analysis ...............................................................................................195
3 Results .....................................................................................................................................195
3.1 Hypothesis 1: Pair Type Effects ......................................................................................195
3.1.1 Stimulus Type and ISI Effects on Pair Type .......................................................199
3.2 Hypothesis 2: Vowel Effects ...........................................................................................205
3.2.1 ISI and Stimulus Type Effects on V ....................................................................207
3.2.2 Interactions between Pair Type and V .................................................................210
4 Summary and Discussion ........................................................................................................216
4.1 Hypothesis 1: Diphthong vs. Hiatus ................................................................................216
4.2 Hypothesis 2: Vowel Effects ...........................................................................................217
4.3 Hypothesis 3: Production-Perception Link ......................................................................218
4.4 Discussion ........................................................................................................................219
5 Conclusions .............................................................................................................................221
Chapter 6 Conclusions .................................................................................................................222
1 Introduction .............................................................................................................................222
2 Summary of Findings ..............................................................................................................222
2.1 Phonetic Variation and Exceptional Hiatuses ..................................................................222
2.1.1 Sequence-specific Variation ................................................................................223
2.1.2 Speaker-specific Variation ...................................................................................224
2.2 Articulation and Exceptional Hiatuses.............................................................................225
2.3 Production-Perception Link .............................................................................................226
3 Contributions ...........................................................................................................................229

xi
3.1 Empirical Contributions ...................................................................................................229
3.2 Theoretical Contributions ................................................................................................230
3.3 Methodological Contributions .........................................................................................230
4 Future Directions .....................................................................................................................231
References ....................................................................................................................................232
Appendices ...................................................................................................................................246

xii
List of Tables
Table 1. Means and SDs of syllables per second produced by Speakers, by Speech Rate .......... 71
Table 2. Means and SDs of raw and normalized sequence duration for Diphthong and Hiatus, by
Speech Rate ................................................................................................................................... 78
Table 3. ANOVA table for differences between Diphthong and Hiatus in raw sequence duration
(ms), by Speech Rate .................................................................................................................... 79
Table 4. ANOVA table for differences between Diphthong and Hiatus in sequence duration
(normalized), by Speech Rate ....................................................................................................... 82
Table 5. Means and SDs for sequence duration (normalized) of Diphthong and Hiatus, by
Sequence Type, Rate and V .......................................................................................................... 84
Table 6. ANOVA table for differences between Diphthong and Hiatus in sequence duration
(normalized), by Speech Rate and V ............................................................................................ 85
Table 7. Bonferroni post-hoc tests for differences between Diphthong and Hiatus in sequence
duration (normalized), by Speech Rate and V .............................................................................. 86
Table 8. Means and SDs of %Transition for Diphthong and Hiatus, by Speech Rate ................ 88
Table 9. ANOVA table for differences between Diphthong and Hiatus in %Transition, by Speech
Rate ............................................................................................................................................... 89
Table 10. Means and SDs for %Transition of Diphthong and Hiatus, by Sequence Type, Rate
and V ............................................................................................................................................. 91
Table 11. ANOVA table for differences between Diphthong and Hiatus in %Transition, by
Speech Rate and V ........................................................................................................................ 92
Table 12. Bonferroni post-hoc tests for differences between Diphthong and Hiatus in
%Transition, by Speech Rate and V ............................................................................................. 93

xiii
Table 13. ANOVA results for differences between Diphthong and Hiatus in F1 and F2, by
Speech Rate and V ........................................................................................................................ 96
Table 14. Bonferroni post-hoc comparisons of differences in F1 and F2 between Diphthong and
Hiatus, by V .................................................................................................................................. 97
Table 15. Mean values of the polynomial equation constants and coefficients of F1 and F2 for
Diphthong and Hiatus, by V ....................................................................................................... 103
Table 16. ANOVA table for differences between Diphthong and Hiatus in the polynomial
constants and coefficients of F1 and F2 trajectories ................................................................... 104
Table 17. Significant predictors for inclusion in discriminant analysis, by V (acoustics) ......... 105
Table 18. Discriminant analysis summary table for V= [a] (acoustics) ..................................... 105
Table 19. Discriminant analysis summary table for V= [e] (acoustics) ..................................... 106
Table 20. Discriminant analysis summary table for V= [o] (acoustics) .................................... 106
Table 21. Summary of discriminant analysis classification (predicted group membership) of
Diphthong and Hiatus: V= [a] (acoustics) .................................................................................. 108
Table 22. Summary of misclassified sequences with [a], by Speaker (acoustics) ...................... 108
Table 23. Summary of discriminant analysis classification (predicted group membership) of
Diphthong and Hiatus: V= [e] (acoustics) .................................................................................. 109
Table 24. Summary of misclassified sequences with [e], by Speaker (acoustics) ...................... 110
Table 25. Summary of discriminant analysis classification (predicted group membership) of
Diphthong and Hiatus: V= [o] (acoustics) .................................................................................. 110
Table 26. Summary of misclassified sequences with [o], by Speaker (acoustics) ..................... 111
Table 27. EMA static system noise average SDs (in millimeters), by Speaker.......................... 128
Table 28. Means and SDs of TB-TT offset (ms) for Diphthong and Hiatus, by Speech Rate ... 130

xiv
Table 29. ANOVA table for differences between Diphthong and Hiatus in TB-TT offset (ms), by
Speech Rate ................................................................................................................................. 132
Table 30. Means and SDs of TB-TT offset (absolute values) for Diphthong and Hiatus, by
Speech Rate ................................................................................................................................. 138
Table 31. ANOVA table for differences between Diphthong and Hiatus in TB-TT offset
(absolute values), by Speech Rate .............................................................................................. 139
Table 32. Means and SDs of TB-TT Offset (absolute values) for Diphthong and Hiatus, by
Speech Rate and V ...................................................................................................................... 140
Table 33. ANOVA table for differences between Diphthong and Hiatus in TB-TT offset
(absolute values), by Speech Rate and V .................................................................................... 142
Table 34. Means and SDs of maximum TT and TB displacement (%) for Diphthongs and Hiatus,
by Speech Rate ............................................................................................................................ 143
Table 35. ANOVA table for differences between Diphthong and Hiatus in maximum TB and TT
displacement (%), by Speech Rate .............................................................................................. 145
Table 36. Means and SDs of TT displacement at peak TB displacement (%) for Diphthong and
Hiatus, by Sequence Type and Rate ........................................................................................... 149
Table 37. ANOVA table for differences between Diphthong and Hiatus in TT displacement at
peak TB displacement (%), by Speech Rate ............................................................................... 150
Table 38. Means and SDs of TB and TT displacement (%) for Diphthong and Hiatus by Speech
Rate and V................................................................................................................................... 152
Table 39. ANOVA table for differences between Diphthong and Hiatus in TB displacement and
TT displacement at peak TB (%), by Speech Rate and V .......................................................... 154
Table 40. Discriminant analysis summary table for V= [a], using TB-TT offset (absolute) and
%TT at peak TB as predictors (articulation) ............................................................................... 157

xv
Table 41. Summary of discriminant analysis classification (predicted group membership) of
Diphthong and Hiatus for V = [a] (articulation) ......................................................................... 158
Table 42. Summary of misclassified sequences with [a], by Speaker (articulation) .................. 159
Table 43. Discriminant analysis summary table for V= [e], using TB-TT offset (absolute) as
predictor (articulation) ................................................................................................................ 159
Table 44. Summary of discriminant analysis classification (predicted group membership) of
Diphthong and Hiatus for V = [e] (articulation) ......................................................................... 161
Table 45. Summary of misclassified sequences with [e], by Speaker (articulation) .................. 162
Table 46. Discriminant analysis summary table for V= [o], using TB-TT offset (absolute) as
predictor (articulation) ................................................................................................................ 162
Table 47. Summary of discriminant analysis classification (predicted group membership) of
Diphthong and Hiatus for V = [o], (articulation) ........................................................................ 163
Table 48. Summary of misclassified sequences with [o], by Speaker (articulation) .................. 163
Table 49. Temporal characteristics (sequence and transition duration) of nonsense word stimuli
for AX perception task ................................................................................................................ 182
Table 50. Durational differences between categories of Sequence Type (normalized
measurements) for AX perception task ....................................................................................... 182
Table 51. Stimuli list for AX perception task ............................................................................. 185
Table 52. Categorization of correct and incorrect responses for AX perception tasks ............... 189
Table 53. Summary of AX perception task responses, by Response type and Participant across all
conditions .................................................................................................................................... 189
Table 54. Summary of response accuracy (p(c)), sensitivity (A') and bias (β″D) scores by
Participant, across all conditions................................................................................................. 193
Table 55. Summary of p(c), A′ and β″D scores for Pair Type (A = X) ....................................... 196

xvi
Table 56. Summary of p(c), A′ and β″D scores for Pair Type (A≠X) ......................................... 197
Table 57. Summary of p(c), A′ and β″D scores for Stimulus Type (Sequence vs. Word) and ISI
(500 vs. 1000) ............................................................................................................................. 200
Table 58. Summary of p(c), A′ and β″D scores for Pair Type (A≠X), by Stimulus Type (Word vs.
Sequence) and ISI (500 vs. 1000), across Participants ............................................................... 202
Table 59. Summary of p(c), A′ and β″D scores for Pair Type (A≠X), by Stimulus Type (Sequence
vs. Word) and ISI (500 vs. 1000), by Participant ....................................................................... 203
Table 60. Summary of p(c), A′ and β″D scores for V ([a], [e], [o]) ............................................. 206
Table 61. Summary of p(c), A′ and β″D scores for V, by Stimulus Type and ISI, across
participants .................................................................................................................................. 208
Table 62. Wilcoxon Signed Ranks Test results (Bonferroni corrections: α = 0.05/12 = 0.004) for
differences between levels of V by ISI and Stimulus Type ........................................................ 209
Table 63. Results of Wilcoxon Signed Ranks Test results (Bonferroni corrections: α = 0.05/6 =
0.008) for differences within levels of V by ISI and Stimulus Type .......................................... 209
Table 64. Summary of p(c), A′ and β″D scores for V by Stimulus Type and ISI, by Participant 210
Table 65. Summary of p(c), A' and β″D scores for V by Pair Type, across participants............. 211
Table 66. Wilcoxon Signed Ranks Tests results (Bonferroni correction: α = 0.05/18 = 0.003) for
differences between levels of V by Pair Type ............................................................................ 214
Table 67. Summary of p(c), A' and β″D scores for V by Pair Type, by Participant .................... 215

xvii
List of Figures
Figure 1. Spectrogram of a token of [jó] produced by speaker CG, showing the boundaries for
sequence and transition duration measurements ........................................................................... 73
Figure 2. Spectrogram of a token of [jó] produced by speaker CG, showing the 10 intervals
where F1 and F2 frequency measurements were made ................................................................ 75
Figure 3. Bar chart of mean sequence duration (ms) by Sequence Type and Speech Rate .......... 79
Figure 4. Bar chart of mean sequence duration (ms) by Sequence Type, Speech Rate and Speaker
....................................................................................................................................................... 81
Figure 5. Bar chart of mean sequence duration (normalized) by Sequence Type and Rate ......... 82
Figure 6. Bar chart of mean sequence duration (normalized) by Sequence Type, Speech Rate and
Speaker .......................................................................................................................................... 83
Figure 7. Bar chart of mean duration (normalized) by Sequence Type, Speech Rate and V ....... 85
Figure 8. Bar chart of mean duration (normalized) by Sequence Type, V and Speaker: ............. 87
Figure 9. Bar chart of mean %Transition by Sequence Type and Speech Rate ........................... 89
Figure 10. Bar chart of mean % Transition by Sequence Type, Speech Rate and Speaker ......... 90
Figure 11. Bar chart of mean % transition by Sequence Type, Speech Rate and V ..................... 91
Figure 12. Bar chart of mean %Transition for Sequence Type, V and Speaker: .......................... 94
Figure 13. Scatterplot of F1-F2 formant changes from sequence onset to offset, by Sequence
Type and V .................................................................................................................................... 95
Figure 14. Scatterplot of F1-F2 of Sequence Type, for V = [a] ................................................... 98
Figure 15. Scatterplot of F1-F2 of Sequence Type, for V = [a] by Speaker ................................. 99
Figure 16. Scatterplot of F1-F2 of Sequence Type, for V = [e] ................................................. 100

xviii
Figure 17. Scatterplot of F1-F2 of Sequence Type, for V = [e] by Speaker ............................... 100
Figure 18. Scatterplot of F1-F3 of Sequence Type, for V = [o] ................................................. 101
Figure 19. Scatterplot of F1-F2 of Sequence Type, for V = [o] by Speaker .............................. 102
Figure 20. Coil placement for 3D EMA ..................................................................................... 125
Figure 21. Waveform and articulatory movement data from vertical axis of a token of [já] from
the word piano produced by speaker CG, showing the temporal and spatial measurements used to
analyze the data. .......................................................................................................................... 129
Figure 22. Bar chart of mean TB-TT offset (ms) by Sequence Type and Speech Rate ............. 131
Figure 23. Bar chart of mean TB-TT offset (ms) for Sequence Type, by Speech Rate and Speaker
..................................................................................................................................................... 133
Figure 24. Interaction plot of Mean TB-TT offset (ms) for Sequence Type, by Speaker: Rate 1
..................................................................................................................................................... 134
Figure 25. Interaction plot of Mean TB-TT offset (ms) for Sequence Type, by Speaker: Rate 2
..................................................................................................................................................... 134
Figure 26. Waveform and articulatory movement data (vertical dimension) of a token of [jó]
from viola showing anticipatory TT movement, Speaker CG, Rate 2........................................ 136
Figure 27. Waveform and articulatory movement data (vertical dimension) of a token of [jó]
from viola showing TT lead, Speaker AA, Rate 2 ...................................................................... 137
Figure 28. Bar chart of Mean TB-TT offset (absolute values) for Sequence Type, by Speech Rate
..................................................................................................................................................... 138
Figure 29. Bar chart of Mean TB-TT offset (absolute values) for Sequence Type, by Speech Rate
and Speaker ................................................................................................................................. 140
Figure 30. Bar chart of Mean TB-TT offset (absolute values) for Sequence Type, by Speech Rate
and V ........................................................................................................................................... 141

xix
Figure 31. Bar chart of Mean TB-TT offset (absolute values) for Sequence Type, by Speech
Rate, V and Speaker .................................................................................................................... 143
Figure 32. Bar chart of mean magnitude of TT and TB displacement (%) for Sequence Type, by
Speech Rate ................................................................................................................................. 144
Figure 33. Bar chart of mean magnitude of TT and TB displacement (%) for Sequence Type, by
Speaker: Rate 1 and Rate 2 ......................................................................................................... 147
Figure 34. Waveform and articulatory movement data (vertical dimension) of a token of [jó]
from viola with no reduction of %TT, Speaker MM, Rate 1 ...................................................... 148
Figure 35. Waveform and articulatory movement data (vertical dimension) of a token of [jó]
from viola with reduction of %TT, Speaker AN, Rate 1 ............................................................ 148
Figure 36. Bar chart of mean magnitude of TB displacement (%) and TT displacement (%) at
peak TB displacement for Sequence Type, by Speech Rate ....................................................... 150
Figure 37. Bar chart of mean magnitude of TB displacement (%) and TT displacement (%) at
peak TB displacement for Sequence Type, by Speech Rate and Speaker .................................. 151
Figure 38. Bar chart of mean magnitude of TB displacement (%) and TT displacement (%) at
peak TB displacement for Sequence Type, by Speech Rate and V ............................................ 153
Figure 39. Bar chart of mean magnitude of TB displacement and TT displacement at peak TB
displacement for Sequence Type, by Speech Rate and Speaker, V = [a] ................................... 155
Figure 40. Bar chart of mean magnitude of TB displacement and TT displacement at peak TB
displacement for Sequence Type, by Speech Rate and Speaker, V = [e] ................................... 155
Figure 41. Bar chart of mean magnitude of TB displacement and TT displacement at peak TB
displacement for Sequence Type, by Speech Rate and Speaker, V = [o] ................................... 156
Figure 42. Scatterplot of F1-F2 of AX perception task stimuli, by Sequence Type: V = [a] ..... 183
Figure 43. Scatterplot of F1-F2 of AX perception task stimuli, by Sequence Type: V = [e] ..... 184

xx
Figure 44. Scatterplot of F1-F2 of AX perception task stimuli, by Sequence Type: V = [o] ..... 184
Figure 45. Pie chart of AX perception task responses (%) by Response Type, across all
conditions .................................................................................................................................... 190
Figure 46. Bar chart of AX perception task responses (%) by Response Type and Participant,
across all conditions .................................................................................................................... 191
Figure 47. Bar chart of mean p(c), A' and β″D scores, across all conditions ............................... 194
Figure 48. Bar chart of mean p(c), A' and β″D scores for Pair Type (A≠X) ............................... 197
Figure 49. Bar chart of mean p(c), A' and β″D scores for V ........................................................ 205
Figure 50. Bar chart of mean p(c), A' and β″D scores for V by ISI and Stimulus Type .............. 207
Figure 51. Bar chart of mean p(c), A' and β″D scores for V by Pair Type, V = [a] .................... 212
Figure 52. Bar chart of mean p(c), A' and β″D scores for V by Pair Type, V = [e] .................... 212
Figure 53. Bar chart of mean p(c), A' and β″D scores for V by Pair Type, V = [o] .................... 213
Figure 54. Bar chart of mean p(c) scores for V, by Speaker Dialect and Listener Dialect ........ 228

xxi
List of Appendices
Appendix 1: Experiment Stimuli (Chapters 3 and 4).................................................................. 246
Appendix 2: Table of Individual Means and Standard Deviations (Chapter 3) ......................... 247
Appendix 3: Tables of Individual Means and Standard Deviations (Chapter 4) ........................ 250
Appendix 4: Hearing Screening (Chapter 5) .............................................................................. 255
Appendix 5: Handedness Questionnaire (Chapter 5) .................................................................. 256

1
Chapter 1 Introduction
1 Overview
This dissertation is concerned with variation in the production and perception of vocalic
sequences, diphthongs and hiatuses, in Mexican Spanish. Specifically, it investigates the
relationship between this variation and the occurrence of a particular category of vocalic
sequences referred to as exceptional hiatuses.
Vocalic sequences figure prominently in Romance phonology (e.g. Gili Fivela & Bertinetto,
1998 for Italian; Chitoran, 2002 for Romanian; Azevedo, 2005 for Portuguese; Walker, 2001 for
French) in large part because they highlight a complex and often less-than-straightforward
relationship between stress assignment, syllable affiliation and high vocoid sonority in these
languages1. As a result, much has already been written on the topic of vocalic sequences in
Spanish, including exceptional hiatuses (e.g. Aguilar, 1999; Hualde & Prieto, 2002; Cabré &
Prieto, 2006; Chitoran & Hualde, 2007; Garrido, 2007; Colantoni & Limanni, 2010, among
many others).
This dissertation both complements and challenges those previous studies in three interrelated
ways. First, it investigates the production and perception of Spanish vocalic sequences through a
combination of acoustic, articulatory and perception data. As such, the present work adds to
previous studies which have focused mainly on acoustic analysis and syllabification intuitions. It
also highlights the importance of a comprehensive experimental approach which makes use of a
variety of methodological and statistical techniques, including EMA (electro-magnetic
articulography), Discriminant Analysis and Signal Detection Theory measures. Second, this
dissertation analyzes the occurrence of exceptional hiatuses as a phonetically-driven
phenomenon rooted in variation in the production and perception of diphthongs and hiatuses.
Third, it emphasizes how exploring phonetic variation within a specific variety (or dialect, in this
case) of a language contributes to an understanding of how a sound change emerges within and
1 A detailed presentation of the theoretical and experimental literature on vocalic sequences in Spanish and other Romance
languages is provided in Chapter 2.

2
across other varieties or dialects of the same language. In relation to the last two points, this
dissertation proposes that the occurrence of exceptional hiatuses is driven by coarticulatory
variation found in all Spanish varieties, even in those varieties described as highly
diphthongizing and, thus, predicted to produce few of these sequences. This proposal challenges
the view prevalent in Spanish phonology that it is necessary to assume an underlying syllabicity
contrast between diphthongs and exceptional hiatuses (e.g. Harris & Kaisse, 1999; Hualde,
2005). Ultimately, it also calls into question the need for a special category of exceptional
hiatuses.
The dissertation is motivated and informed largely by research which:
1. emphasizes phonetic explanations for the origins of sound variation and change (e.g.
Ohala, 1989; Browman & Goldstein, 1991; Widdison, 1995; Blevins, 2004),
2. examines the link between speech perception and speech production in sound variation
and change (e.g. Beddor et al., 2002; Beddor, 2012),
3. stresses the value of reexamining issues in Spanish phonology through an experimental
lens (e.g. Widdison, 1995, 1997; Eddington, 2004), and
4. studies synchronic dialectal variation and its link to sound change (e.g. Romero, 1995;
Brown & Torres Cacoullos, 2003; Colantoni, 2006).
The present chapter is organized as follows: §2 briefly outlines the research and associated
assumptions which motivated the dissertation; §3 provides an overview of vocalic sequences in
Spanish and explains their suitability as the focus of study; §4 outlines the experimental
methodology, provides a rationale for dialect and participant selection, and presents the main
hypotheses being tested; and, §5 closes the chapter with an outline of the remainder of the
dissertation.
2 Sound Variation and Change
The speech signal is undeniably and inherently variable (Ohala, 1981, 1989, 1993). One source
of this variation is the speaker. Some of this speaker-related variation is apparent. For example,
we recognize speakers of different languages varieties or dialects by the way they pronounce
certain sounds. Even individual speakers of the same variety produce the same sound differently,
such that we might identify one speaker as ‘a clear speaker’ and another as ‘hard to understand’.
Of special interest for developing and testing theories of sound variation and change, however, is

3
the kind of speaker variation that is below the level of awareness, also referred to as “hidden
variation” (Ohala, 1989). This kind of variation is internally motivated and phonetic in nature,
largely rooted in coarticulatory processes (Browman & Goldstein, 1991; Mowrey & Pagliuca,
1995; Beddor, 2012; Ohala, 2012; Recasens, 2012). The speaker, being subject to various
physical constraints related to the vocal tract, produces “an unlimited number of measurably
different phonetic variants of each word in actual speech” (Ohala, 1981, p. 179). These variants
constitute the “pool of synchronic variation” (Ohala, 1989) from which a potential sound change
is drawn.
Another source of variation is the listener. For Ohala (1989), the role of the listener is crucial for
determining whether the phonetic variability present in the speech signal triggers a sound change
or not. In his view, if the listener misinterprets the noise/ambiguity in the speech signal as
intentional, then a sound change is possible. This process is affected by individual differences as
well. For example, different listeners may use different perceptual strategies to deal with the
range of variation in production to the extent that the same phonetic cue may have different
perceptual effects from one listener to another (Beddor et al., 2002; Beddor, 2012). In addition,
some listeners may be more attuned to coarticulatory factors than others. In fact, recent
experimental studies suggest that there is a link between how a contrast is perceived and how it
is produced (Beddor et al., 2002; Beddor, 2012; Newman, 2003; Perkell et al., 2004a, 2004b,
2006).
Regardless of whether we believe that sound change is mainly listener-driven (Ohala, 1989;
Blevins, 2007) or mainly speaker-driven (Lindblom, 1990), non-teleological (Ohala, 1989) or
goal-oriented (Lindblom et al., 1995), the importance of this synchronic variation in production
and perception is its crucial role in the initiation of sound change (Ohala, 1989). This link
between synchronic variation and historical sound change means that the source of a sound
change which has already taken place and is distinguishing feature of the phonology of a
particular language can be investigated experimentally by studying a language where the same
phenomenon appears at the level of phonetic variation. For example, investigations into the
production and perception of nasalization (e.g. Beddor et al., 2002) in languages with synchronic
context-dependent nasalization of vowels can shed light onto the origins of distinctively nasal
vowels in French. Similarly, the phenomenon of syllable-final [s] aspiration and deletion found
in present-day varieties of Spanish can provide insight into a similar process which occurred in

4
Old French (e.g. Romero, 1995). This methodology can also be extended to study varieties or
dialects of the same language to explore a sound change which has occurred or is in progress in
one dialect but not in another.
2.1 Dialectal Variation and Sound Change
An underlying premise of this dissertation is that the phonetic variation that results in exceptional
hiatuses, an observable feature of Peninsular Spanish, is present as “hidden” variation in other
varieties of Spanish (i.e. Mexican Spanish, a diphthongizing variety). The study of synchronic
dialectal variation to understand sound change has numerous experimental precedents for
Spanish. This approach can be found in studies of other phenomena in Spanish, including [s]-
aspiration and deletion (Romero, 1995; Brown & Torres Cacoullos, 2003; Torreira, 2006) and
assibilation of rhotics and palatals (Colantoni, 2006). Importantly, these studies have shown that
the phonetic characteristics associated with [s]-aspiration and assibilation of rhotics and palatals
can be found (to different degrees) in corresponding non-aspirating and non-assibilating varieties
of Spanish. The present dissertation proposes that, just as the pre-conditions for [s] aspiration are
present in non-aspirating varieties of Spanish, so too the pre-conditions for exceptional hiatuses
are found in diphthongizing varieties of Spanish. An examination of these varieties can help
determine why exceptional hiatuses occur and persist in Peninsular Spanish and what their
phonetic origins may be.
3 Vocalic Sequences in Spanish
Sequences of two vowels in Spanish may be syllabified within a single syllable or in two
separate syllables. In the first case, the result is called a diphthong (e.g. Mario, [má.ɾjo]) and in
the second case the result is referred to as a hiatus (e.g. María, [ma.ɾí.a]). Syllabification of these
sequences is said to be largely predictable, as long as stress assignment is known and the
sonority of the vocoids making up the vocalic sequence is also taken into account. This
syllabification generally adheres to the following two prescriptive rules (based on Hualde 2005,
p. 78-80):
(1) a hiatus occurs when
(a) both vowels are [-high] (/a e o/), as in fea [fé.a], ‘ugly-fem.sing.’ or teatro
[te.á.tɾo] ‘theatre’; toalla [to.á.ʝa], ‘towel’

5
(b) a stressed [+high] vowel (/í ú/) is followed or preceded by a [-high] vowel
(/a e o/)2, as in frío [fɾí.o], ‘cold-masc.sing.’, baúl [ba.úl] ‘trunk’, or maíz
[ma.ís] ‘corn’
(2) in all other cases, a [+high] vowel is realized as a glide [j w] and the sequence is a
diphthong, as in diente [djén.te] ‘ tooth’, peine [péj.ne] ‘comb’, duelo [dwé.lo] ‘duel’,
or neutro [néw.tɾo].
Spanish diphthongs are generally described as glide-vowel (GV) sequences while hiatuses in this
language are described as concatenations of two single vowels or vowel-vowel (VV) sequences3
(e.g. Hualde, 2005). Spanish diphthongs may be either: (i) rising diphthongs consisting of a GV
sequence, as in piedra [pjé.ðɾa] ‘stone’ or (ii) falling diphthongs consisting of a VG sequence, as
in peine [péj.ne] ‘comb’4. Similarly, hiatuses can differ according to which vowel is stressed: (i)
the first vowel, as in fea [fé.a], ‘ugly-fem.sing.’; (ii) second vowel, as in teatro [te.á.tɾo]
‘theatre’, or (iii) neither vowel, as in fealdad [fe.al.ðáð], ‘ugliness’.
In terms of phonological status, the diphthong-hiatus contrast represented in 1b and 2 is the most
robust. For example, there are some minimal pairs in the language which contrast GV and VV
sequences:
(3) GV sequence VV sequence
varias [vá.ɾjas] ‘various-fem.’ varías [va.ɾí.as] ‘you vary’
amplio [ámpljo] ‘broad/wide’ amplío [amplí.o] ‘I broaden/widen’
continuo [kon.tí.nwo] ‘continuous’ continúo [kon.ti.nú.o] ‘I continue’
Also, these sequences are distinguished by orthographic convention since stressed high vowels
followed or preceded by a non-high vowel are always marked. Studies on the acoustic properties
of this contrast also suggest that the Diphthong-Hiatus contrast between 1b and 2 above is
relatively predictable at the phonetic level. These studies report that, in general: (i) diphthongs
2 Sequences of two [+high] vowels also occur: cuida [kwí. ða] ‘s/he cares for’; viuda [vjú.ða], ‘widow’ (Hualde, 2005). These
sequences are generally pronounced as rising (Hualde, 2005) but the rising-falling distinction is often blurred (Hualde et al.,
2001) and for this reason they are not included in the present study.
3 The definition of diphthong and hiatus may differ in other languages. Chapter 2 provides a review of how vocalic sequences are
defined in other Romance and non-Romance languages.
4 The terms ‘rising’ and ‘falling’, as they apply to vocalic sequences in Spanish and other Romance languages, are defined
according to sonority (e.g. Hualde, 2005).

6
are shorter than hiatuses (Aguilar, 1999; Hualde & Prieto, 2002); (ii) diphthongs devote a larger
portion of the sequence to the transition between the two vocalic elements than hiatuses (Aguilar,
1999), and (iii) diphthongs have a less steep second formant (F2) slope than hiatuses (Aguilar,
1999).
In reality, however, there is also a great deal of dialectal and individual variation in the
production of these sequences. This variation has been found to occur between speakers of
different dialects (Cabré & Prieto, 2006), between speakers of different varieties of the same
dialect (Garrido, 2007; Colantoni & Limanni, 2010), between speakers of the same variety of a
dialect (Hualde & Prieto, 2002; Macleod, 2007) and within individual speakers of a single dialect
(Hualde, 1999; Macleod, 2007). This variation is found in (i) rates of diphthongization of
hiatuses (Colantoni & Limanni, 2010; Garrido, 2007, 2008) and (ii) the way the diphthong-hiatus
contrast is realized (Colantoni & Limanni, 2010). Interestingly, we observe what appear to be
two competing tendencies in the realization of vocalic sequences both between and within
Spanish varieties, especially as regards the application of the above syllabification rules in 1a
and 2.
On the one hand, there is a diphthongizing tendency in those cases where both vowels in the
sequences are [-high], as in 1a above (Garrido, 2007, 2008; Hualde et al., 2008; García &
Figueroa, 2001; Lope Blanch, 1996). In those cases, the mid vowel in a sequence of [-high]
vowels may become a glide, [e] or [o] (as in teatro [teá.tɾo] and toalla [toá.ʝa], respectively).
Subsequently, the glided mid vowel may raise to [j] and [w], as in teatro [tjá.tɾo] and toalla
[twá.ʝa]5. These changes are subject to individual (Hualde et al., 2008) and dialectal (Garrido,
2007, 2009) variation and are more likely to occur in more casual speech styles and/or faster
speech rates (Aguilar, 1997, 1999). Diphthongization may also occur where a stressed high
vowel follows a non-high vowel, as in maíz [ma.ís] > [májs] ‘corn’ (Garrido, 2007. p. 30). In the
latter case, diphthongization involves a stress shift from the high vowel to the non-high vowel
and gliding of the high vowel ([i] > [j]). This diphthongizing tendency is a synchronic reflection
of the historical preference for diphthongizing hiatuses from all sources. Among these are
5 Other hiatus resolution strategies may also be employed, including elision of one of the vocoids, as in creer > [kɾeɾ] (Garrido,
2008, p.11) and consonant insertion, as in María > [ma.ɾí.ja] (Frago Gracia & Franco Figueroa, 2001, p.87) or canoa > [ka.nó.βa]
(Garrido, 2008, p. 11). However, diphthongization, arguably the most common strategy, is the only one explored here.

7
hiatuses originating from Latin heterosyllabic sequences (ITALIA > [i.tá.li.a] > [i.tá.lja] ‘Italy’)
and those resulting from the deletion of intervocalic consonants (REGINA > [re.í.na] > [réj.na]
‘queen’).
On the other hand, we also find a tendency to produce hiatus where a diphthong is expected.
Specifically, for some speakers there appear to be some lexical exceptions to the rule in 2 above.
These exceptions result in the production of what are generally referred to as exceptional
hiatuses in Spanish phonology (e.g. Hualde, 1999; Hualde & Prieto, 2002; Cabré & Prieto, 2006;
Chitoran & Hualde, 2007)6. Speakers who produce exceptional hiatuses might, for example,
pronounce dueto ‘duet’ as [du.é.to] instead of as [dwé.to] and cliente ‘client’ as [kli.én.te] instead
of as [kljén.te]. Unlike the diphthongization tendency mentioned above which is found (albeit to
varying degrees, e.g. Colantoni & Limanni, 2010) across all Spanish varieties, this hiatization
tendency is a phenomenon generally associated with speakers of Peninsular Spanish. For
example, a Peninsular Spanish speaker may say piano ‘piano’ with a hiatus ([pi.áno]) where an
Argentine speaker would produce the same word with the expected diphthong ([pjá.no]). In the
Spanish phonology literature, these exceptional hiatuses are widely considered to contrast with
diphthongs7 (e.g. Harris & Kaisse, 1999; Hualde & Prieto, 2002; Hualde, 2005; Chitoran &
Hualde, 2007). These authors point to near-minimal pairs (e.g. from Harris & Kaisse, 1999:
vaciaba [ba.θi.á.βa] ‘s/he emptied’ vs. viciaba [bi.θjá.βa] ‘s/he vitiated’) which occur in
Peninsular Spanish as evidence for an underlying syllabicity contrast between diphthongs and
exceptional hiatuses.8
Finally, although the production of hiatuses (at least in the case of exceptional hiatuses) is
predicted to be more variable than the production of diphthongs (Chitoran & Hualde, 2007),
some researchers have found that diphthong production is, in fact, more variable than production
of hiatuses across speakers and dialects (Macleod, 2007).
6 Note, however, that Aguilar (1999, p.64) refers to these ‘exceptional hiatuses’ with stress on the non-high vowel as ‘normal
hiatuses’ and calls hiatuses with stress on the high vowel ‘inverse hiatuses’.
7 In contrast, the similarly exceptional diphthongs which result from the diphthongization of expected hiatuses are not assumed to
contrast with these hiatuses.
8 No minimal pairs occur for this proposed contrast. The suitability of these near-minimal pairs is discussed further in Chapter 2
where the literature concerning these sequences is reviewed in more detail.

8
The apparent complexity and contradictory tendencies observed in the production of these
sequences has resulted in a large body of theoretical and experimental literature dealing with the
characterization of diphthongs, of exceptional hiatuses and of the diphthong/hiatus contrast.
Within this literature (which will be presented and reviewed in more detail in Chapter 2) three
main ideas stood out and shaped the focus of this dissertation. These are discussed below.
4 Experimental Focus and Design
The idea for this dissertation as well as its experimental focus and design were sparked by the
following three proposals arising from the existing literature on Spanish vocalic sequences.
The first proposal is that exceptional hiatuses are triggered by a combination of historic, prosodic
and morphological factors (e.g. Chitoran & Hualde, 2007). The present dissertation argues that
while these factors may contribute to the maintenance of exceptional hiatuses in Peninsular
Spanish, the source of exceptional hiatuses is found in the phonetic variation observed across
Spanish varieties in the production of diphthongs and hiatuses.
The second proposal is that much of the variation observed in diphthong and hiatus production is
rooted in articulation (Colantoni & Limanni, 2010). Inferring from acoustic data, some authors
suggest that both the tendency for hiatuses to diphthongize and the dialectal and individual
variation in the production of hiatuses can be attributed to different gestural coordination patterns
between diphthongs and hiatuses (Chitoran & Hualde, 2007). The present dissertation tests this
proposal with information gathered from articulatory data obtained with EMA (electro-magnetic
articulography: e.g. Van Lieshout, 2006).
Finally, perception studies using syllabification judgments suggest that perception of the
diphthong-hiatus contrast (as well as perception of diphthongs and exceptional hiatuses)
generally matches speakers’ production of the same contrast (Hualde & Prieto, 2002; Face &
Alvord, 2004). The present dissertation tests these observations with perception data obtained
with an AX discrimination task.
Based on the above proposals, the main hypotheses which guide the present dissertation are:

9
(i) The phonetic variation assumed to be responsible for the occurrence of exceptional hiatuses
is present in all Spanish varieties, including those varieties described as having a high
diphthongization tendency.
(ii) The phonetic variation leading to the production of exceptional hiatuses is rooted in
patterns of articulation.
(iii) Variation in the production of diphthongs, hiatuses and exceptional hiatuses is related to
variation in their perception.
These hypotheses are tested in three separate but related experiments. Although each experiment
also tests its own separate set of specific hypotheses, these are all ultimately related to each other
and to the three main hypotheses of the dissertation. Two of the experiments focus on the
production of diphthongs and hiatuses and examine both their acoustic and their articulatory
properties.
The acoustics experiment aims to (i) add to existing acoustic data on vocalic sequences in
Spanish varieties, and (ii) establish that, for the Spanish variety under study, the parameters
which define diphthongs and hiatuses and distinguish them from each other (i.e. sequence
duration, transition duration and F1 and F2 frequency contours) are the same as those found for
other varieties.
The articulation experiment complements the results from the acoustics experiment and serves to
test the second hypothesis. Examining both acoustics and articulation also helps establish
whether there are any non-linearities in the acoustic-articulatory relationship of Spanish vocalic
sequences which could help explain some of the contradictory tendencies of diphthong and
hiatus (and exceptional hiatus) distribution. In addition, the experiment contributes articulatory
data on Spanish vocalic sequences and follows a tradition of experimental articulatory research
in Spanish phonology (e.g. Romero, 1995; Recasens, 2002; Martínez Celdrán & Fernández
Planas, 2007; Colantoni & Kochetov, 2010).
The focus of the final experimental chapter is on the perception of diphthongs, hiatuses and
exceptional hiatuses in Spanish. More specifically, the chapter tests the link between variation in
production and variation in perception of these sequences. The chapter also contributes to
existing perception studies of Spanish vocalic sequences by using a different experimental
methodology than what has been traditionally employed.

10
One final component of the present dissertation motivated by existing literature on Spanish
vocalic sequences was the choice of Spanish variety to study. The next sections will provide
more detail on this aspect of the study.
4.1 Dialect and Participant Selection
Mexican Spanish was selected as the variety for this study for a couple of reasons. First, much of
the existing literature (both theoretical and experimental) on Spanish vocalic sequences is based
on Peninsular, and to a lesser extent, Argentine varieties. A study of Mexican Spanish adds to the
existing literature experimental data and insights from the Spanish variety with the most speakers
(Lope Blanch, 1996). The main reason for selecting Mexican Spanish, however, is that it is
considered a variety with a very advanced tendency towards diphthongization (Lope Blanch,
1996; Garrido, 2008). As such, it is not a variety of Spanish normally associated with the
production of exceptional hiatuses. For example, this variety frequently diphthongizes sequences
of two non-high vowels by gliding and raising the highest member of the pair, as in in teatro
[te.á tɾo] > [tjá.tɾo] and toalla [to.á ʝa] > [twá.ʝa]. In fact, a widespread use of such diphthongized
forms is reported for Mexican Spanish (Lope Blanch, 1996, p. 82; Garrido, 2008, p. 41), even
among “educated” speakers. This diphthongizing characteristic makes Mexican Spanish ideal for
testing the first hypothesis of this dissertation, as stated above.
Participants were ten adult female native speakers of Mexican Spanish, henceforth referred to as
AA, AM, AN, CG, DH, KR, LG, LL, MM, and MV. The rationale for including only female
participants in the study was to control for gender variation in production due to vocal tract size.
To ensure homogeneity (and thus reduce variation due to extra-linguistic factors) in the group,
the participants were all from similar educational backgrounds and ages. In addition, they all
spoke a similar variety of Mexican Spanish, specifically the variety spoken in Mexico City and
surrounding areas, where diphthongization is reportedly widespread across economic and
educational levels (Garrido, 2008, p. 42). None were from southern parts of Mexico where
diphthongization is thought to be somewhat less widespread (Lope Blanch, 1996). They ranged
in age from 23 to 34 years and none reported any history of language, speech or hearing
problems. All were university educated and had spent less than three years in an English-
speaking environment.

11
The participants were recruited through notices posted throughout the University of Toronto
campus and at various private English-language schools surrounding the university campus area.
All the participants but MM were in Canada briefly for periods ranging from 3 to 6 months and
were enrolled in English classes at local private schools. MM had recently completed a MSc. and
would be staying in Canada as a resident. None had any training in phonetics or phonology and
none was aware of the purpose of the study. They were compensated for their participation.
5 Dissertation Outline
The above sections have briefly presented the linguistic variables under study as well as their
associated research questions and theoretical foundations. They have also provided a rationale
for the selection of Mexican Spanish as the Spanish variety at the focus of the study. The
remainder of the dissertation is structured as follows. In Chapter 2, a selection of theoretical and
experimental studies focusing on vocalic sequences for Spanish as well as for other Romance
and non-Romance languages are reviewed.
The experimental portion of the dissertation starts with Chapter 3 (acoustics) followed by
Chapter 4 (articulation) and Chapter 5 (perception). For each of these three experimental
chapters specific research questions and hypotheses are formulated and tested. In each of the
three experimental chapters the methodological and statistical techniques unique to each
experiment are also described and any issues related to these techniques are discussed. Finally, in
each of these three chapters, the experimental results are presented, discussed and evaluated
against the specific hypotheses of the chapter.
In the final chapter, Chapter 6, a general discussion is provided for all three experiments with the
purpose of unifying and evaluating their results against the main objectives and assumptions of
the study. A proposal is made for continued research on the acoustic and articulatory properties
of VV sequences and on the production-perception link in these sequences. The inclusion of
additional varieties of Spanish in future research is also emphasized.

12
Chapter 2 Literature Review
1 Introduction
There is no shortage of literature on vocalic sequences. These sequences, especially diphthongs,
have been examined from a theoretical standpoint, from an experimental perspective and from a
combination of the two. Both the synchronic patterning of these vocalic sequences and their
historical development have been considered. Studies have looked at these sequences in specific
languages (e.g. Salza, 1988; Marotta, 1988 and Van der Beer, 2006 for Italian; Carreira, 1988;
Harris, 1989; Aguilar, 1999 and Garrido, 2007 for Spanish; Lehiste, 1967 for Estonian; Gay,
1968, 1970 and Bond, 1978 for English), within groups of related languages (e.g. Peeters, 1991
for Germanic languages; Sánchez-Miret, 1996 and Recasens, 2004 for Romance languages) and
cross-linguistically (e.g. Lindau et al., 1990; Sánchez-Miret, 1998; Sands, 2004; Nevins &
Chitoran, 2008). Despite this genuine wealth of research, many questions about such sequences
remain unanswered. These questions come up over and over again and concern even the most
basic facts about the production and perception of these sequences, many of which are still not
agreed upon and which, according to some authors, may turn out to be largely language specific
(e.g. Lindau et al., 1990; Peeters, 1991). Ultimately, any answers offered to these questions
probably depend largely upon the particular language or languages being studied, the theoretical
assumptions underlying the study, the experimental methodology employed and possibly even
the choice of sequences included in the investigation.
The present chapter reviews some of the seminal literature on the topic of vocalic sequences and
is organized as follows. In §2, a sampling of important theoretical studies for Spanish and other
languages will be examined. In §3, the experimental literature, both for production and
perception will be reviewed and §4 closes the chapter with some brief concluding remarks.
It quickly becomes obvious in this review that vocalic sequences are difficult to characterize,
both phonetically and phonologically. Part of this difficulty undoubtedly arises from the fact that
any discussion of vocalic sequences invariably involves addressing the difference between
vowels and glides. This task is complicated because glides represent a transitional class of
segment. That is, they straddle the border between vowels and consonants (as evidenced from

13
their being variously described as semiconsonants or semivowels) and can pattern with either
category, depending on the language and/or phonetic context (e.g. Padgett, 2008; Nevins &
Chitoran, 2008). Thus, it comes as no surprise that most of the studies reviewed here are neither
purely theoretical nor purely experimental. Experimental studies look to phonology either for
underlying assumptions (whether these are stated or simply implied) or for explanations of the
experimental results when these results do not reveal what was expected or are not fully
interpretable. In turn, theoretical studies reference experimental results in their phonological
characterization of vocalic sequences (e.g. Marotta, 1988; Nevis & Chitoran, 2008). In addition,
the production of vocalic sequences may be subject to varying degrees of individual and dialectal
variation (e.g. Garrido, 2007; Hualde et al., 2008; Colantoni & Limanni, 2008), adding another
layer of complexity to their characterization.
2 Theoretical Approaches to Vocalic Sequences
Theoretical studies of diphthongs and vocalic sequences in general have been concerned with
different questions depending on the language or language group being studied and the types of
vowels and vocalic sequences these languages have. Because of such differences, this section is
organized according to language and language groups. In §2.1 we begin by looking at studies
pertaining exclusively to Spanish or in which Spanish figures prominently since this is the
language which is the focus of the present investigation. We then turn to other languages in the
Romance family in §2.2 since these often share a similar theoretical focus and are thus directly
relevant to this study. Finally, theoretical studies which focus on non-Romance languages are
reviewed in §2.3. Here we examine the differences and similarities in the types of theoretical
questions being asked and relate the observations and conclusions to the present study.
2.1 Spanish
As described in Chapter 1(§3), sequences of two vowels in Spanish may be syllabified within a
single syllable to form a diphthong (a glide-vowel, GV, sequence) or in two separate syllables to
form a hiatus (a vowel-vowel, VV, sequence). Examples of the types of diphthongs and hiatuses
possible in Spanish are given in Chapter 1 and recapped in (1) and (2) below, with some
additional examples:

14
(1) Hiatuses
a) two [-high] vowels (/a e o/):
fea [fé.a], ‘ugly-fem.sing.’
teatro [te.á.tɾo] ‘theatre’;
toalla [to.á.ʝa], ‘towel’
VV: fealdad [fe.al.ðáð] ‘ugliness’
b) stressed [+high] vowel (/í ú/) and
unstressed [-high] vowel (/a e o/):
í/úV: frío [fɾí.o], ‘cold-masc.sing.’;
púa [pú.a], ‘spine,thorn’
Ví/ú: maíz [ma.ís] ‘corn’;
baúl [ba.úl] ‘trunk’
(2) Diphthongs (Gliding Rule: an unstressed high vocoid next to a different vowel is
realized as a glide: Hualde 2005)
a) Rising (GV)
j/wV: diente [djén.te], ‘ tooth’;
duelo [dwé.lo], ‘duel’
b) Falling (VG)
Vj/w: peine [péj.ne], ‘comb’;
neutro [néw.tɾo], neutral’
On the surface, this syllabification appears fairly straightforward (as long as stress assignment is
known beforehand) and minimal pairs such those in (3) below (repeated from Chapter 1) suggest
that high vowels (in hiatuses) and their corresponding glides (in diphthongs) are in
complementary distribution.
(3) GV sequence VV sequence
varias [vá.ɾjas] ‘various-fem.’ varías [va.ɾí.as] ‘you vary’
amplio [ámpljo] ‘broad/wide’ amplío [amplí.o] ‘I broaden/widen’
continuo [kon.tí.nwo] ‘continuous’ continúo [kon.ti.nú.o] ‘I continue’
Complications arise, however, when speakers diphthongize expected hiatuses (in particular those
consisting of sequences of non-high vowels, as in 1a) or produce the expected diphthongs in (2)
as hiatuses. The former phenomenon results in words such as teatro and toalla (from (1) above)
being pronounced as [teá.tɾo]/[tjá.tɾo] and [toá.ʝa]/[twá.ʝa], respectively, instead of with the
expected hiatus. This diphthongization tendency is observed (to different degrees) across Spanish
varieties and has been described as conditioned by position in the word, proximity to stress,
speech style and/or rate and frequency of usage of lexical items (Alba, 2006; Garrido, 2007,
2008). That is, diphthongization is more likely when the sequences occur in non-initial and/or
stressed syllables (Garrido, 2008), in less formal speech style and/or faster speech rate (Garrido,
2007) and when they involve frequently used words (Alba, 2006). In addition, diphthongization
is conditioned by social factors in that its occurrence may be stigmatized in some dialects

15
varieties (e.g. Peninsular Spanish: Hualde et al., 2008; Andean variety of Colombian Spanish:
Garrido, 2007) but largely accepted in other varieties (e.g. Mexican Spanish: Garrido, 2008;
Caribbean variety of Colombian Spanish: Garrido, 2007). In any case, diphthongization of
expected hiatuses is highly variable inter and intra dialectally as well as at the level of individual
speakers (Alba, 2006; Garrido, 2008; Hualde et al., 2008). Importantly, in the phonological
literature, words which may be produced with these exceptional diphthongs are not considered to
be lexically marked. Rather, they are generally handled through a post-lexical rule, such as the
following Post-Lexical Contraction Rule given in Hualde et al. (2008, p. 1908):
(4) Post-Lexical Contraction Rule: V.V VV
The second phenomenon occurs when speakers produce a word like piano piano ‘piano’ with a
hiatus ([pi.áno]) rather than with the expected diphthong ([pjá.no]). As with the diphthongization
of expected hiatuses, the production of exceptional hiatuses is conditioned by various factors.
These include etymological, prosodic as well as morphological triggers (e.g. Chitoran & Hualde,
2007). For example, exceptional hiatuses tend to occur word-initially and in stressed syllables (as
in the word piano above). They also tend to occur in the presence of morphological boundaries
(as in bienio, ‘2-year period, biennum’ which would be produced as [bi.é.njo] rather than the
expected [bjé.njo]: Hualde, 2005). Finally, they are more likely to occur in words which had
heterosyllabic vocalic sequences in Classical Latin (as in cliente, ‘client’ from Latin CLIENS
produced as [kli.én.te] rather than as [kljén.te]. In contrast to the widespread diphthongization
tendency, however, the production of these exceptional hiatuses is observed mainly in Peninsular
Spanish varieties. In addition, exceptional hiatuses are considered by many authors to contrast
with diphthongs (e.g. Harris & Kaisse, 1999; Hualde & Prieto, 2002; Hualde, 2005; Chitoran &
Hualde, 2007). These authors point to the existence of near-minimal pairs (e.g. from Hualde,
2005: duelo [dwé.lo] ‘duel’ vs. dueto [du.éto] ‘duet’) in Peninsular Spanish as evidence for an
underlying syllabicity contrast between diphthongs and exceptional hiatuses. They maintain that
this contrast requires lexical marking of vocoids [i, u] which are expected to surface as glides [j,
w] but which surface as syllabic nuclei, in violation of (2) above. In relation to this, the
occurrence of exceptional hiatuses has been used as an argument both in favour of (e.g. Harris,
1969) and against (e.g. Harris & Kaisse, 1999) the phonemic status of glides in Spanish.
Theoretical studies on Spanish diphthongs and hiatuses (and exceptional hiatuses) have focused
on three main issues, with discussions of syllable structure and/or stress assignment figuring

16
prominently in all three. The first issue concerns the phonemic status of glides in diphthongs and
deals with the question of whether [j] and [w] are independent phonemes (Harris, 1969) or
simply positional variants of the high vowels /i/ and /u/ (e.g. Colina, 1999; Harris & Kaisse,
1999; Hualde, 1999; Roca, 1997). The arguments used to justify the former are easily refuted by
those who advocate the latter and now form the more accepted position. These arguments and
counterarguments are covered in §2.1.1. A second issue concerns diphthong formation and
focuses on the Spanish alternating diphthongs. The question here is whether surface diphthongs
[je] and [we] arise from underlying vowels /e/ and /o/ or whether the surface vowels arise from
the underlying diphthongs. The arguments in favour of one or the other solution are discussed in
§2.1.2. A final related concern has been the syllabic representation of diphthongs and
monophthongs (and, thus, hiatuses) and whether there are any differences in the representation of
falling vs. rising diphthongs (Carreira, 1988, 1991). This is discussed in §2.1.3.
2.1.1 The Phonemic Status of Spanish Glides
The first issue concerns the status of Spanish glides in the phonology and directly relates to the
difference between a diphthong and a hiatus. In fact, it touches on the three-way distinction of
vowel vs. glide vs. consonant. This is because glides, especially the palatal glide [j], are
associated with both vowels and consonants. The argument for a phonemic distinction (e.g.
Harris, 1969) between /j/ and /i/ and /w/ and /u/ is based largely on evidence from three sources
which capitalize on the above association to different degrees and for different purposes.
First, the existence of near-minimal pairs with [j] (voiced palatal glide) and [ʝ] (voiced palatal
spirant approximant9) on one hand (example (5) below), and with [i] and [j] and [u] and [w] on
the other (example (6) below) would appear to be a strong argument in favour of the contrastive
nature of glides.
(5) deshielo [dez. ʝé.lo]10
‘I defrost’ vs. desierto [de.sjéɾ.to] ‘desert’ (Hualde, 2005)
9 Traditionally this type of segment was called a fricative and often represented by the symbol [y] (e.g Navarro Tomás, 1926).
Some authors continue this tradition (e.g. Borzone de Manrique & Massoni, 1981; Harris & Kaisse, 1999). However, Martinez
Celdrán (2004, 2008) prefers the symbol [ʝ] and uses phonetic data to argue that [ʝ] generally lacks the turbulent noise associated
with true fricatives (although it may be more noisy in emphatic pronunciations) and thus is more properly called a spirant
approximant. Here, we follow Martinez Celdrán in both the use of symbol and in its description.
10 Orthographic <h> is not pronounced in Spanish.

17
(6) vaciaba [baθi.áβa] ‘s/he emptied’ vs. viciaba [bi.θjá.βa] ‘s/he vitiated’
sueco [su.é ko] ‘Swedish’ vs. zueco [θwé. ko]11
‘wooden clog’ (Harris & Kaisse, 1999)
However, closer inspection of both sets of examples casts doubt on their usefulness as evidence
for the phonemic status of glides. First, the difference in syllabification for the two words in (5),
points to a difference in their morphological structure. Specifically, in deshielo, there is a
morpheme boundary (the word is composed of des ‘negative prefix’+ hielo ‘ice’) which places
the more consonantal [ʝ] in onset position where it triggers a process of voicing assimilation of
the preceding coda [s]12
. In desierto, on the other hand, the glide [j] is not preceded by a
morpheme boundary and is thus inside the syllable nucleus. Whitley (1985: 369), for instance,
argues that cases where the supposed contrast occurs in medial position do not provide sufficient
evidence of a phonemic distinction between [j] and [ʝ] since the different realizations are
predictable from syllable structure. In fact, the same examples are used in Harris & Kaisse (1999,
p. 119) to argue that neither the glides nor their more consonantal counterparts are phonemic in
Spanish (i.e. they are merely surface variants of an underlying vowel /i/ or /u/). These authors
argue that a surface contrast such as that observed in (5) appears only as a direct result of the
syllable position of /i/. When /i/ occurs in onset position as in the first word, it is subject to some
degree of consonantalization in the absence of a more appropriate or typical consonantal onset.
Conversely, when /i/ occurs in pre-vocalic nuclear position, as in the second word, it surfaces as
a glide. The examples in (6) seem to suggest, on the other hand, that the glides [j w] contrast with
the vowels [i u]. However, this argument rests on the assumption that these types of near-
minimal pairs are the norm for Spanish speakers. In fact, in these examples, the hiatus
realizations of vaciaba and sueco are ‘exceptional’ and are arguably not the typical realization of
/iV/ and /uV/ for most speakers outside of Peninsular Spanish varieties. Even for those dialects
and speakers where the contrasts in (6) are found, it can be argued that they are not phonemic
(Harris & Kaisse, 1999). We return to the subject of exceptional hiatuses as an argument for the
phonemic status of glides later in this section.
11 Orthographic <z> corresponds to /θ/ in those dialects of Spanish (i.e. Peninsular) where exceptional hiatuses are reported. In all
other Spanish dialects orthographic <z> corresponds to /s/
12 In some dialects, the voicing of /s/ is a clue to its syllabification as a coda consonant since only /s/ in coda position undergoes
voicing. It is also a clue to the consonantal status of [ʝ] since only voiced [+consonantal] segments (i.e. obstruents and sonorants)
trigger this voicing in Spanish, while glides and vowels do not. In dialects which aspirate coda /s/ to [h], aspiration rather that
voicing serves as the diagnostic (Harris & Kaisse, 1999, p. 59).

18
The second argument for a phonemic interpretation of glides comes from a three-syllable stress
assignment window, an often discussed phenomena in Spanish. In short, this window refers to
the observation that in Spanish, primary stress cannot be placed any further than the third (or
antepenultimate) syllable nucleus from the end of a word. The argument involving glides comes
about as a result of rule ordering analyses such as the one presented in Harris (1985) who
assumes that since “only stressed vowels diphthongise, the rule(s) of stress placement must apply
before the rule(s) of diphthongisation” (p. 33). The problem occurs in words such as terapéutiko
/te.ɾa.péu.ti.ko/ ‘therapeutic’ (Colina, 1999 p. 131) which should not be possible since the stress
is on the fourth vowel from the end, thus violating the three-syllable window (which is otherwise
confirmed by the data: for example, a diphthong in the penultimate syllable will block
antepenultimate stress, as in Venez[wé]la ‘Venezuela’ , not *Venéz[we]la, Harris, 1987, p. 32-
33). Such words suggest that it is diphthongization which should precede stress assignment,
leaving a ‘paradox’ situation. Harris suggests that what appears to be the fourth vowel from the
end is in reality the third vowel since the [u] is underlyingly the glide /w/. Therefore, stress is
assigned to the vowel /e/ in the antepenultimate syllable and does not violate the three-syllable
window after all. Carreira (1988) proposes that the paradox can be handled differently, namely
by ordering syllabification before stress assignment and then applying a resyllabification rule to
that output. However, these three-syllable window violations are only problematic in derivational
phonology. In Optimality Theory (OT) accounts which focus on surface forms, there is no
violation at all (Colina, 1999, p. 131) since the three-syllable window applies to surface forms
and it is the glide [w] which appears in the surface form.
A final argument for the phonemic status of glides involves the presence of exceptional hiatuses
in some dialects of Spanish. Harris (1969), for example, claims that the verbs guiar ‘to guide’
and piar ‘to chirp’ form a near-minimal pair in which the former is pronounced consistently as
monosyllabic [gjár] and the latter as disyllabic [pi.ár]. Harris (1969, p. 126-127) attributes the
difference to a difference in the underlying representation of each verb, where guiar has a glide
and piar a vowel (at least in some dialects) but such an explanation is ultimately unsatisfactory.
An OT analysis of these exceptional hiatuses is offered by Colina (1999) who also accounts for
the dialectal and individual variation associated with analogical forms An example of analogical
exceptional hiatus would be the <ia> sequence in diario ‘newspaper, daily’ which may be
realized as [di.á.ɾjo] rather than the expected [djá.ɾjo] through analogy with día [dí.a] ‘day’.

19
Colina (1999) handles this variation by way of Correspondence Theory and identity constraints.
Specifically, she proposes that speakers who realize such words with hiatus have established a
correspondence relation between certain lexical items (e.g. between diario and día) and are
making use of an IDENTσ constraint which requires that /i/ have the same syllabic role in diario
as in its correspondent día (i.e. it must be in a separate syllable). However, the matter of these
exceptional hiatuses is complicated and appears to be conditioned by other factors, not just
analogy (as discussed above, these include morphological boundaries, position in the word,
proximity to stress, and sequence etymology). For example, there are words which are described
as being consistently produced with an exceptional hiatus but which have no analogical
counterpart with a hiatus. One such word is diablo ‘devil’ (cited in Navarro Tomás, 1926; Harris
& Kaisse, 1999; Hualde, 2005, among others). Similarly, there are also words with clear
analogical relationships but which are cited as occurring as diphthongs. In the data from Harris
(1969) cited above, for example, guiar [gjár] and piar [pi.ár] both have related words with
hiatus: guía [gí.a] ‘guide-N’ and pía [pí.a] ‘chirps’, respectively. Yet only piar is said to have an
exceptional hiatus.
Harris & Kaisse (1999) use distribution data from Argentine (AR) and Castilian Spanish (SC) to
offer a single rule-based analysis to refute the argument of a phonemic status for glides. They
show how underlying /i/ and /u/ surface as either glides in diphthongs or vowels in hiatus. They
propose that “[j] and [w] are derived from /i/ and /u/, respectively, as are peak [i] and [u] in
simple nuclei’ (p. 124). Exceptional hiatus is handled through lexical marking where [i u] are
marked as syllabic [i. u.] to allow them to surface as hiatuses rather than diphthongs. A series of
sequentially-ordered rules then produce the appropriate surface representation. Similarly, they
propose that “all of [i j y ʝ ž ǰ] are realizations of [-consonantal] segments in underlying
representations” (p. 119). In other words, they are all surface variants of /i/. Any derived
consonantal features are supplied by a rule of Consonantalization which applies to onset /i./ and
give rise to [ʝ] and its variants13
. In Harris & Kaisse (1999) dialectal and individual variation in
the production of exceptional hiatuses is handled through differences in the application of a
13 An additional rule of Coronalization is given for AR to produce the coronal fricative [ʒ](symbolized as [ž] by these authors)
which occurs in onset position for this variety (in words with orthographic <y>). This rule applies prior to PreD in AR and
prevents neutralization of syllable–initial [j] with a denuclearized /i./ thus allowing for a surface contrast between yate [ʒá.te]
‘yacht’ and hiato [ʝá.to] ‘hiatus’ (Harris & Kaisse, 1999, p. 139).

20
Prevocalic DeNuclearization (PreD) rule. This rule turns an underlying /i.V/ sequence into [jV].
The authors propose that PreD applies optionally and only postlexically (i.e. at the phrasal level)
in SC but lexically (and presumably not optionally) in AR (Harris & Kaisse, 1999, p. 177-178).
This proposal is illustrated with the following hypothetical derivation for the word vaciaba from
(6) above, for both AR and SC.
(7) Hypothetical derivations based on analysis in Harris & Kaisse (1999, p. 170)
AR SC
Underlying representation /basi.aba/ /baθi.aba/14
Word domain (lexical)
syllabification [ba.si.a.βa] [ba.θi.a.βa]15
stress assignment [ba.si.á.βa] [ba.θi.á.βa]
PreD [ba.sjá.βa] ------------
Output [ba.sjá.βa] [ba.θi.á.βa]
The above derivation shows a dialectal difference in the output: a diphthong realization for AR
and a hiatus realization for SC. However, the application of the optional phrasal level PreD rule
for SC to the above output then gives us the alternate surface form [ba.θjá. βa] for this variety as
well. Thus, SC individuals may choose to apply this rule and optionally realize exceptional
hiatuses as diphthongs. This proposal would seem to explain both dialectal and individual
variation in the production of these hiatuses. Nevertheless, the existence of such variation raises
the question of whether it is necessary to assume an underlying syllabicity contrast at all. First,
Harris & Kaisse (1999) concede that the vaciaba-viciaba or sueco-zueco type of contrasts are
subject to individual variation even in the Peninsular Spanish variety with which they are
associated (as do other authors, e.g. Hualde & Prieto, 2002; Cabré & Prieto, 2006; Chitoran &
Hualde, 2007). Even for those individuals who produce them, these hiatuses are generally limited
to strong positions within the word (Chitoran & Hualde, 2007) and may be affected by speech
style and rate (Aguilar, 1999). Finally, these contrasts are not generally attested outside of the
Peninsular variety. In short, there is little evidence of a strong syllabicity contrast and
diphthongization appears to be the predominant tendency in Spanish. Whitley (1985), for
14 In varieties of Peninsular Spanish orthographic <c> followed by a front vowel corresponds to the phoneme /θ/.
15 Intervocalic /b/ in Spanish is generally realized as an approximant [β].

21
example, likens the hiatus pronunciation of an /iV/ sequence to a kind of ‘recessive’ trait in
Spanish. He maintains that the idiolectal variation, instability and limited distribution associated
with this ‘hiatophilia’ (Whitley, 1985, p. 376) are due to a path of historical erosion of an [iV] ~
[jV] contrast which continues in the present as more and more words join the diphthong
category.
Overall then, the phonemic status of glides in Spanish is not completely clear, at least if we
consider only the above studies. It is not even clear whether this determination is all that crucial
for phonological theory (Padgett, 2008). Perhaps a better approach would be to loosen the
definition of a phonological category so that it is less discrete and fuzzier around the edges. This
proposal is put forth by Hualde (2004) who suggests that glides may be more or less vocalic or
consonantal “depending on the dialect, the style and the speaker” (Hualde, 2004, p. 20) to the
extent that the category boundaries between vowel and glide, in other words between diphthong
and hiatus, will be different for any given speaker. A related approach is taken by Nevins &
Chitoran (2008). These authors attempt to reconcile the cross-linguistic data which shows that
the glides [j w] may pattern either with vowels or consonants. The reason for this, they argue, is
that glides are not represented phonemically as either consonants or vowels. Rather, they differ
featurally from both. Specifically, they possess both consonantal and vocalic features and are
best represented by a combined feature designation of [±vocalic] which gives glides a
constriction degree which is unlike that of vowels or consonants. In addition, these authors cite
articulatory data from Gick (2003-reviewed in §3, this chapter) which suggests that English /j/
consists of both a vocalic gesture (Tongue Dorsum) and a consonantal gesture (Tongue Tip).
They interpret this experimental data as supporting their featural theory and expand on it to
propose that glides are assigned two separate articulators, one vocalic ([Dorsal]) and one
consonantal ([Coronal] for /j/ and [Labial] for /w/. These representations are offered as
explanations as to why /j/ can alternate with a coronal fricative [ʒ] in Argentine Spanish and a
dorsal stop /k/ in Cypriot Greek, for example. Variation in these alternations may arise as a result
of the relative magnitude of each gesture in a particular language (Nevins & Chitoran, 2008, p.
1994). In a similar vein, Padgett (2008) also maintains that glides and vowels (and thus
diphthongs and hiatuses) differ featurally in degree of constriction, with the difference in
syllabicity being a simple consequence of the featural differences (Padgett, 2008, p.1944).

22
2.1.2 Alternating Diphthongs (‘los diptongos alternantes’) in Spanish
As outlined in Chapter 1, diphthongs in Spanish may have resulted from Latin heterosyllabic
sequences (ITALIA > [i.tá.li.a] > [i.tá.lja] ‘Italy’) or from the deletion of intervocalic consonants
(REGINA > [re.í.na] > [réj.na] ‘queen’). Another source is the Latin short mid vowels Ĕ and Ŏ
(/ɛ/ and /ɔ/ in Vulgar Latin). These vowels diphthongized in stressed syllables in some Romance
languages, including Spanish, producing unstressed monophthong~stressed diphthong
alternations such as the following16
:
(8) [e] ~ [jé]: pensar [pen.sár] ‘to think’ ~ pienso [pjén.so] ‘I think’
[o] ~ [wé]17
: contar [kon.tár] ‘to count/tell a story’ ~ cuenta [kwén.ta] ‘he/she
counts/tells a story’
The importance of these sequences to the present dissertation arises from: (i) the fact that this
monophthong~diphthong alternation, like the diphthong-hiatus contrast, is linked to stress
assignment; and, (ii) the prediction that diphthongs historically related to Latin /ɛ/ and /ɔ/ are
without exception produced as diphthongs and may never be produced as exceptional hiatuses
(Hualde, 2005; Chitoran & Hualde, 2007). That is, they never violate the Gliding Rule in (2).
The two competing derivational approaches regarding these alternations involve
monophthongization (Carreira, 1991) and diphthongization (e.g. Harris, 1985; Harris & Kaisse,
1999). The monophthongization approach in Carreira (1991) uses a complicated system of
constraint violations and repair strategies to achieve the correct surface structure. It assumes that
the diphthongs, rather than the simple vowels, are underlying and that the nuclear vowels of the
diphthongs are underspecified. According to Carreira (1991), the Spanish diphthongs [je] and
[we] are derived from underlying sequences consisting of a [+high] vowel and an empty V slot
corresponding to a [-high vowel]: iV (ie) and uV (uo), respectively. These sequences, following
rules of syllabification, default feature assigment and contraction yield the following
intermediate sequences which are associated to a single V slot in the syllable: {je} and {wo}.
However, at this stage in the derivation, {wo} violates a presumed “ban in Spanish on sequences
of tautosyllabic segments that are [+round, +back] (Carreira, 1991, p. 419). According to
16 Modern Spanish does not have /ɛ/ and /ɔ/ in its phonemic inventory.
17 The historical development of this diphthong in Spanish occurred as follows: /wɛ/ > /wo/ > /we/ (Carreira, 1991, p. 438;
Penny, 2002, p.52).

23
Carreira (1991), “this violation is resolved by eliminating the place of articulation features of the
nuclear vowel” (p. 438) and then replacing these features with the Spanish default vowel /e/,
producing the surface form [we]. Because {je} does not violate any constraints, it surfaces as [je]
without undergoing any changes. In the absence of stress, the first element of the diphthong
undergoes deletion and only the mid vowel is left.
Harris (1985), on the other hand, proposes that the underlying mid vowels /e o/ undergo a rule of
diphthongization which applies only in stressed positions (thus reiterating his point of view that
stress assignment precedes diphthongization). The problem of why /o/ [we] instead of [wo]18
is handled through the application of a default rule which follows the diphthongization rule and
assigns a default value of [e] to any prosodic position “that can be occupied by a vowel but in
fact has no vowel feature attached to it” (Harris, 1985, p. 37). Finally, a High-glide rule yields
the necessary glides. Thus, the following steps are assumed in the derivation of the diphthongs:
(9) oV→oe→we; eV→ee→je
Harris and Kaisse (1999) also support the diphthongization hypothesis and suggest that the
underlying mid vowels /e o/ surface as the diphthongs /je/ and /we/ through a diphthongization
rule which follows the application of stress assignment and syllabification rules (Harris &
Kaisse, 1999, p. 138). As with the vowel-glide alternation discussed earlier, these types of
alternations are handled through lexical marking of the relevant underlying vowels (/e! o!/ are
lexically marked to surface as diphthongs whereas /e o/ are not).
Difficulties with these rule-based approaches arise when we observe that the diphthong-
monophthong alternations (like the vowel-glide contrast in diphthongs and hiatuses) are not
entirely predictable (Eddington, 1998, 2004). For example, stressed [e] and [o] in Spanish are not
always realized as diphthongs, as in (10).
(10) [e] ~ [é]: pesar [pe.sár] ‘to weigh’ ~ peso [pé.so] ‘I weigh’
[o] ~ [ó]: coser [ko.sér] ‘to sew’ ~ cose [kó.se] ‘he/she sews’
Similarly, diphthongs may occur in unstressed syllables, as in (11).
18 Limanni (2008) suggests a perceptual explanation based on coarticulation for the [wo] > [we] historical change in Spanish.
Such an explanation would call into question the need for a synchronic rule-based account (Blevins, 2004).

24
(11) [jé] ~ [je]: viejo [bjé.xo] ‘old man’ ~ viejito [bje.xí.to] ‘little old man’
[wé] ~ [we]: cuento [kwén.to] ‘story’ ~ cuentista [kwen.tís.ta] ‘story-teller’
In derivational accounts, an absence of lexical marking on the underlying vowels is assumed to
explain those cases where the mid vowels fail to diphthongize (e.g. Harris & Kaisse, 1999). The
presence of diphthongs in unstressed syllables, on the other hand, has been handled through the
cyclic application of a stress rule which first triggers diphthongization and then moves on to
another syllable (Halle, Harris & Vergnaud, 1991). Eddington (1998, 2004), however, challenges
the rule-based accounts of the diphthong–monophthong alternation in Spanish with experimental
evidence that the alternation is a semi-productive, gradient process influenced by the presence of
certain suffixes and by analogy. Eddington (1998, 2004) further suggests that the alternation is
not triggered by stress since stress, in his view, is not entirely predictable and is stored as an
inherent part of each lexical item.
2.1.3 The Syllabic Representation of Spanish Diphthongs
The issue of how Spanish diphthongs are to be represented in terms of syllable structure also
touches on the difference between diphthongs and monophthongs. However, an additional issue
which turns up is the syllabic difference between rising diphthongs of the form GV and falling
diphthongs of the form VG. The difference has been proposed to be one of syllable weight or
moraic structure. According to moraic theory (Kenstowitz, 1994, p. 428-429; Kager, 1999,
p.147), morae (μ) are the weight-bearing units which make up the syllable (σ). Syllable weight
can be attributed to how many morae are contained within a syllable nucleus. Within this theory,
heavy syllables are bimoraic (μμ) while light syllables are monomoraic (μ). Short vowels differ
from long vowels in that the former are monomoraic and the latter are bimoraic, with two morae
attached to one vocalic position, as represented below (adapted from Kager, 1999, p. 147;
Kikuchi, 1997, p.41):
(12) a. Short Vowels (light syllable) b. Long Vowels (heavy syllable)
[V] [V:]
σ σ V
μ μ μ yt V V

25
While the above structures for simple vowels are generally straightforward (assuming one
accepts syllable and moraic theory), the moraic structure of diphthongs is more complex. The
following two different moraic structures have been proposed for diphthongs (adapted from
Rosenthall, 1994, p. 21):
(13) a. [V1V2] b. [V1V2]
σ σ
V
μ μ μ
V
[V1 V2] [V1 V2]
The first structure (13a) represents diphthongs as monomoraic, where a single mora is linked to
two different vocalic positions. The second structure (13b) represents diphthongs as bimoraic,
where each mora is associated with a different vocalic position. In Spanish, there is phonotactic
evidence of a monomoraic structure, at least for rising diphthongs. First, GV diphthongs can
occur in both open (CV) and closed (CVC) syllables in this language. In addition, Spanish
contains sequences of the type Consonant-Liquid-Glide-Vowel (as in the first syllable of pliegue
[pljé.ge] ‘fold’ and prieto [pɾjé.to] ‘dark’). Syllabifying these glides as part of the onset would go
against the observation that most languages do not allow three consonants in onsets (unless one
of them is /s/). Spanish onsets, in fact, may contain at most two consonants and these are
restricted to combinations of either /f/ + Liquid or Stop + Liquid (Hualde, 2005). This type of
evidence has led to the assumption that in this language rising diphthongs (GV) are best
represented as monomoraic (Carreira, 1991, 1992; Rosenthall, 1994; Holt, 1997). Carreira (1991,
1992) further observes that there are distributional asymmetries between GV and VG
diphthongs. Falling diphthongs, unlike rising diphthongs, for example, may only appear in an
open syllable, as in peine, [péj.ne] ‘comb’. In support of this asymmetry hypothesis, Carreira
(1992) also cites phonetic evidence regarding the duration of rising (GV) vs. falling diphthongs
(VG) which suggests that the latter are longer than the former (which are comparable in duration
to monophthongs). In fact, VG sequences are described as similar in length to VC sequences.
Thus, Carreira (1992, p. 29) proposes that based on distributional and phonetic evidence, VG
diphthongs are bimoraic while GV diphthongs are monomoraic. In fact, the acoustic evidence is
not without controversy. More recent durational data from Aguilar (1997) suggests that the
opposite is true. That is, GV sequences are in fact longer than VG sequences, in support of a

26
more ‘consonantal’ characterization for pre-vocalic glides and a more ‘vocalic’ characterization
for post-vocalic glides. This provides experimental evidence that their long-standing
nomenclature as semiconsonants when prevocalic and semivowels when postvocalic is
warranted.
2.2 Other Romance Languages
As with Spanish vocalic sequences, the notion of syllable affiliation figures prominently in
phonological studies of similar sequences in other Romance languages. Here we look at these
sequences primarily in Italian and Romanian since both these languages can be said to maintain
(albeit to different degrees) a diphthong-hiatus contrast and any analyses pertaining to these two
languages would be directly relevant to Spanish. We also briefly touch on the status of vocalic
sequences in French and Portuguese, two languages which are said to correspond to the two
extremities of the Romance diphthong-hiatus continuum: French is said to have no hiatuses
while Portuguese is characterized as having no diphthongs (e.g. Chitoran & Hualde, 2007).
2.2.1 Italian
Italian, like Spanish, has both falling diphthongs and rising diphthongs. The latter category also
includes the diphthongs inherited from Latin short mid vowels Ĕ and Ŏ. In Italian, as in Spanish,
these appear mainly in stressed syllables, although analogical levelling may place them in
unstressed contexts in some cases (Van der Beer, 2006). They generally alternate with the
corresponding short vowels in unstressed positions and thus are called mobile diphthongs (i
dittonghi mobili) in this language (e.g. Van der Beer, 2006). In Italian, unlike in Spanish,
however, these mobile diphthongs may not appear in closed syllables (examples from Van der
Beer, 2006, p. 53)
(14) [ɛ] ~ [jɛ sederò [se.de.ró] ‘I will sit’ ~ siedo [sjɛ do] ‘I sit’
[ɔ] ~ [wɔ movimento [mɔ.vi.mɛn.to] ‘movement’ ~ muovo [mwɔ vo] ‘I move’
Also like Spanish, Italian has both a palatal glide [j] and a velar glide [w]. However, there have
been arguments put forth that, in reality, only /j/ has autonomous phonological status (Marotta,
1988). According to Marotta (1988), the syllable structure of jV sequences differs from the
structure of wV sequences. Namely, the latter are subject to more stringent distributional
restrictions. For example, in word-initial position [j] may combine with any vowel while [w]

27
may only appear in [wɔ]. Also, in word-internal positions, diphthongs with [j] and any other
vowel may be preceded by almost any class of consonants (except palatal fricatives and
affricates). On the other hand, only [wɔ, wo] may enjoy this combinatorial freedom. Any other
combinations of wV occur only after a velar stop [k g] and thus are more aptly considered a kind
of complex nucleus. Also, mobile diphthongs with [j] participate more readily in analogical
levelling while those with [w] are more resistant to levelling, not appearing in most cases or only
optionally in others. The examples in (14) show this asymmetry in nouns and their diminutives:
(15) Analogical levelling of [jɛ and [wɔ in Standard Italian (Van der Beer, 2006, p.121)
Noun Diminutive
piéde ‘foot’ piedíno
piétra ‘stone’ pietrína
but uómo ‘man’ ométto/omíno
uóvo ‘egg’ ovétto
Therefore, according to Marotta (1988, p. 401), the distribution facts point to the following
analysis for Italian. First, GV sequences are best described as consisting of two elements, the
initial of which belongs to the syllable onset and the second to its nucleus. Thus, if we accept a
strict definition of a diphthong as a combination of two vocalic elements sharing a single
nucleus, jV sequences in Italian are not true diphthongs. Second, only [wo, wɔ] are associated
with a complex nucleus and as such, may be said to be the only true diphthongs in Italian. Finally
combinations of [kw, gw] are syllabified as a complex onset. Van der Beer (2006, p. 92-93), on
the other hand, combines moraic theory and his own experimental durational and perceptual data
(discussed in more detail in §3 below) to propose different options for the structure of rising
diphthongs in Italian, at least the mobile kind. In his analysis, for both jV and wV sequences, the
glides are not part of the onset. He proposes instead that different moraic structures arise in
stressed syllables versus unstressed syllables: in stressed syllables, rising diphthongs (both with
[w] and with [j] are bimoraic while in unstressed syllables they are monomoraic.
Falling diphthongs, on the other hand, are always considered bimoraic (Van der Beer, 2006),
based on distributional evidence that these serve to close the syllable (for example, they may not
appear with geminates). The glide in the VG sequences is thus in coda position, in line with a
proposal by Marotta (1988). Krämer (2009) disagrees with Van der Beer’s analysis of rising

28
diphthongs arguing that Italian syllables are at most bimoraic and coda consonants are assigned a
mora. As a result, “a glide in a stressed closed syllable, as in pianta ['pjanta] ‘plant’, cannot be in
the nucleus” (Krämer, 2009, p. 99) since the presence of a coda consonant would require a
trimoraic structure which does not exist in Italian. In this view, Van der Beer’s analysis works
only for mobile diphthongs and as such loses generality.
Also like Spanish, albeit to a lesser degree (Chitoran & Hualde, 2007), Italian has a diphthong-
hiatus contrast which is maintained through stress assignment and syllabification. That is,
sequences of high vowel and non-high vowel are hiatuses when the high vowel is stressed but
diphthongs when the high vowel is not stressed. Thus, we find the following near-minimal pairs:
Laura [láw.ra] (person’s name) vs. paura [pa.úra] ‘fear’, and faida [fáj.da] ‘feud’ vs. faina
[fa.í.na] ‘stone-marten’ (Bertinetto & Loporcaro 2005: 139). Sequences of two non-high vowels
also form hiatus in Italian, as in coalizione [ko.a.li.t:sjó.ne] ‘coalition’ and stereotipato
[stɛ.re.o.ti.pá.to] ‘stereotyped’ (Bertinetto & Loporcaro, 2005, p. 139). In addition, there are
cases of exceptional hiatus in Italian, as in biennale [bi.e.n:á.le] ‘biennial’. However, the
difference between diphthong and hiatus is said to be difficult to discriminate (Marotta, 1987).
As a consequence, we find the same diphthongizing tendency as in Spanish, both with sequences
of non-high vowels and with exceptional hiatuses, as in coalizione [koa.li.t:sjó.ne] ‘coalition’,
stereotipato [stɛ.reo.ti.pá.to] ‘stereotyped’, and biennale [bje.n:á.le] ‘biennial’. As in Spanish,
the likelihood of diphthongization in these cases rises as proximity to stress decreases and speech
rate increases.
In summary, while much controversy remains as to the syllabic affiliation of diphthongs and the
status of [j] and [w] in Italian, an important observation is made by Marotta (1988) that not all
glides behave equally. Thus, in Italian, [j] may be more consonantal than [w] which has more
vocalic features. This more-or-less approach also figures in Marotta (1987) where the author
suggests that the difference between diphthong and hiatus is best looked at, not as a categorical
opposition, but as a variable continuum which ranges from monophthong on one extreme and
hiatus on the other, with diphthongs falling somewhere in between (Marotta, 1987, p. 882). This
is reminiscent of what was suggested for Spanish in Hualde (2004) and is in line with what is
proposed by Sánchez Miret (1998) in his overview of the literature on diphthongs.

29
2.2.2 Romanian
As in Spanish, Romanian diphthongs may be formed with a high glide (/j w/) or a mid-glide (/e
a/). In Romanian, however, only the latter are classified as phonological diphthongs (Chitoran,
2002; Marin, 2007). The former are regarded as glide-vowel sequences based on their
distributional and orthographic characteristics. For example, the mid vowel diphthongs ([ea] and
[oa]) may follow a complex onset consisting of an obstruent-liquid cluster but sequences of [ja]
or [wa] may not (Chitoran, 2002). In addition, it is argued that since Romanian orthography19
distinguishes between glide-vowel sequences and diphthongs, that these are phonologically
contrastive (Chitoran, 2002). The existence of minimal and near-minimal pairs such as [beá.tǝ]
‘drunk-fem.’and [bjá.tǝ] ‘poor-fem.’ (Chitoran, 2002, p. 211) also suggest that these sequences
be given a different phonological treatment. Thus, the high glides in glide-vowel sequences are
syllabified as part of the onset. In contrast, the mid glides in the diphthongs are syllabified as part
of the nucleus together with their associated vowel (Chitoran, 2002; Marin, 2007). However, the
distributional analysis is complicated by the fact that the glide-vowel sequence [wa] is relatively
infrequent and appears primarily in loan words (Chitoran, 2002, p. 208). In addition, the glide
[w] differs from [j] in that it does not appear in word-initial position and is only followed by [a].
The glide [j], on the other hand, combines freely with all vowels and appears in word-initial
position (Chitoran, 2002, p. 206-207). This points to a different status for these glides,
suggesting that, as in Italian and possibly Spanish, [j] and [w] behave differently. This
observation is supported by experimental data which finds significant acoustic and perceptual
differences between [ea] and [ja] but none between [oa] and [wa] (Chitoran, 2002). An important
observation made here is that what counts as a diphthong phonologically differs from one
language to the next.
A final point must be made about the diphthong-hiatus distinction in Romanian, since this
distinction is said to be robust in this language, even more so than in Spanish (Chitoran &
Hualde, 2007). It is claimed that the difference is predictable etymologically, since the hiatus
sequences derive either from the maintenance of Latin heterosyllabic sequences or from
19 It could be argued, however, that orthography is not the best argument for a synchronic phonological distinction since
orthographic differences may be maintained after a phonological contrast has disappeared. For example, Spanish has both
orthographic <b> and <v>, as shown in the words baca ‘luggage rack’ and vaca ‘cow’. However, both graphemes correspond to
the phoneme /b/. That is, the phonological contrast they once represented disappeared long ago (Hualde, 2005).

30
loanwords from other languages (Chitoran & Hualde, 2007). However, this applies only to the
maintenance of the contrast between [ea] and [ja] and even in these cases, production evidence
from Chitoran (2002, 2003) suggests that some speakers do not produce the prescribed hiatus,
leaning instead towards a diphthong pronunciation. Therefore, even in Romanian, the [iV] ~ [jV]
contrast may not be as robust as claimed.
2.2.3 French
French, unlike Spanish, is said to have no diphthong-hiatus contrast (Chitoran & Hualde, 2007,
p. 44-45). Specifically, in French, sequences of high and non-high vocoids result in gliding of the
first element and are consistently produced as diphthongs. The examples in (16) illustrate how
high vowels alternate with their corresponding glides when they appear next to another vowel:
(16) French high vowel-glide alternations (Tranel, 1987, p. 119)
[i]~[j]: scie [si] ‘saw-N’ ~ scier [sje] ‘to saw’
[y]~[ɥ]: tue [ty] ‘s/he kills’~ tuer [tɥe] ‘to kill’
[u]~[w]: loue [lu] ‘s/he rents’ ~ louer [lwe] ‘to rent’
Some exceptions to gliding exist when the sequences occur in one of two contexts: (i) after a
complex onset, and; (ii) in the presence of a word or morpheme boundary. In the first case,
gliding is blocked after Consonant-Liquid (CL) cluster, as in plier [pli.(j)e]20
‘to fold’, gluant
[gly.ɑ ‘sticky’, and clouer [klu.e] ‘to nail’ (Tranel, 1987, p.120). The second case is illustrated
by examples such as loua [lu.a] ‘s/he praised’ (Walker, 2001, p. 103), semi-aride [sœ.mi.a.rid]
‘semi-arid’, and si adorable [si.a.dɔ.rabl] ‘so cute’ (Tranel, 1987, p. 119). These exceptions are
subject to both dialectal (Durant & Lyche, 1999) and individual variation (Tranel, 1987).
However, the dominant tendency is diphthongization and the alternations in (16) are seen as
evidence that these GV sequences are derived from underlying VV sequences. That is, as in
Spanish, these glides are positional variants of high vowels and their occurrence is predictable.
On the other hand, French is said to differ from Spanish in having a set of phonemic glides in
addition to the derived glides above (Harris & Kaisse, 1999, p.130). This analysis is based on
differences in the phonological behaviour of glide-initial words: phonetically, there is no
20 A transitional glide ([j]) is said to appear in CLi sequences but not generally in Cly or CLu sequences (Durant & Lyche, 1999;
Tranel, 1987; Walker, 2001).

31
difference between them (Harris & Kaisse, 1999, p. 130). Specifically, the glides in some of
these words behave like onset consonants and block the processes of liaison and elision in
preceding definite articles les [le] and le [lœ] while the glides in other words pattern with vowels
and do not block these processes. This difference yields near-minimal pairs such as le whisky
[lœwiski] ‘the whisky’ vs. l’oiseau [lwazo] ‘the bird’ (Tranel, 1987, p. 117) and le yoga [lœjɔga]
‘yoga’ vs. l’iode [ljɔd] ‘iodine (Walker, 2001, p. 105). This contrast is, however, tenuous and
subject to individual variation such that, for some words, both realizations are attested: le
iambe/l’iambe ‘the iamb’ and le hiatus/l’hiatus ‘the hiatus’ (Walker, 2001, p. 106). In fact, the
words which block liaison and elision appear to belong to a class of foreign borrowings while
those with variable realizations seem to be native but arguably uncommon items If this is the
case, the distinction may not really be one of phonemic versus derived glides as much as an
example of lexical diffusion (Wang, 1969; Labov, 1994) where some words are in the process of
being assimilated to the standard patterns of liaison and elision while others lag behind. A similar
analysis is given for word-initial glides in Spanish by Whitley (1985) (see §3.3.1 in this chapter).
2.2.4 Portuguese
Portuguese is also said to not have a diphthong-hiatus contrast (Chitoran & Hualde, 2007, p. 47).
This language has a large inventory of falling diphthongs, as in pai [paj] ‘father’, boi [boj] ‘ox’,
and eu [ew] ‘I’(Azevedo, 2005, p. 29) but a hiatus realization is supposedly preferred for
sequences of high and non-high vocoids (Chitoran & Hualde, 2007). However, diphthongization
is widely attested in such sequences and is said to be subject to individual, dialectal and stylistic
variation (Silva, 1999, p. 96). For example, European Portuguese speakers may diphthongize a
sequence while Brazilian speakers may prefer to maintain hiatus (Silva, 1999, p. 96). In both
cases, an informal speaking style may also produce diphthongs (Mateus & D’Andrade, 200,
p.49; Azevedo, 2005, p. 29-31). Thus, the following words may be realized with either diphthong
or hiatus: pátria [pá.tɾi.ɐ] ~ [pá.tɾjɐ] ‘homeland’ and quieto [ki.ɛ tu] ~ [kjɛ tu] ‘quiet’ (Azevedo,
2005, p. 29). Proximity to word stress may be a conditioning factor such that diphthongization is
more likely to occur in post-tonic syllables (Chitoran & Hualde, 2007, p. 47), although some
counterexamples exist, as in gracioso [gɾa.si.ó.zʊ] ~ [gɾa.sjó.zʊ] ‘graceful, charming’ (Silva,
1999, p. 96). Overall then, even in Portuguese V-V sequences show some instability and
variation and are not immune to the same tendency towards diphthongization exhibited by
Spanish, Italian, French and Romanian.

32
2.3 Non-Romance Languages
This section briefly reviews some of the theoretical questions regarding vocalic sequences in
non-Romance languages. Specifically, we look at three Germanic languages: English, Dutch and
German. Because none of these languages has a strong diphthong-hiatus contrast, some of the
theoretical questions regarding their vocalic sequences differ from those found in the Romance
languages discussed above. For English and German, for example, a major concern has been to
identify the phonological differences between monophthongs and diphthongs. For Dutch, the
focus has been on the differences between ‘genuine’ diphthongs consisting of two vowels and
‘pseudo’ diphthongs consisting of glide-vowel sequences. However, some questions are similar
to those found in the literature on Romance languages. One such question involves the phonemic
status of diphthongs in general and glides more specifically. Related questions include whether
diphthongs are best characterized as single vocalic elements or as sequences of two vocalic
elements.
2.3.1 English
English has three falling diphthongs, /aɪ, ɔɪ, aʊ/21
, as in buy, boy and bough (Kent & Read, 2002,
p. 136). The tense mid vowels of English /e/ and /o/, as in bait and boat, are also produced with a
diphthongal off-glide and may be transcribed phonetically as [eɪ] and [oʊ] (e.g. bait [beɪt] and
boat [boʊt]). Although the latter are generally included in the diphthong category by
experimental researchers (e.g. Gay, 1968; Bond, 1978; Morrison 2009), phonologists have tried
to make a distinction between phonemic and phonetic diphthongs. Pike (1947), for example,
maintains that the two types of diphthongs are structurally different. Specifically, he claims that
phonemic diphthongs are biphonemic (i.e. behave as sequences of two phonemes) while phonetic
diphthongs are monophonemic (i.e. behave as single phonemes), albeit phonetically complex
(Pike, 1947, p. 151). His evidence includes the following: (i) phonetic diphthongs lose part or all
of their diphthongization when they are pronounced rapidly but phonemic diphthongs do not; (ii)
phonetic diphthongs lose most of their diphthongization when they occur in unstressed syllables
while phonemic diphthongs tend to maintain theirs to a greater degree (or lose less of it); and (iii)
American students of phonetics easily perceive the diphthongal nature of /aɪ, ɔɪ, aʊ/ but struggle
21 These diphthongs are variously transcribed as [aɪ, ɔɪ, aʊ], [ai, ɔi, au], and [aj, ɔj, aw].

33
to learn to recognize the glide element in [eɪ] and [oʊ]. Pike’s evidence comes from subjective
observation but there is some experimental evidence to support a different characterization for
these two types of diphthongs. Specifically, according to Lehiste and Peterson (1961) [eɪ, oʏ]
represent ‘single-target’ complex nuclei while [aɪ, ɔɪ, aʊ] are ‘dual-target’ complex nuclei. These
authors suggest that only the latter group are ‘diphthongs’ (Lehiste & Peterson, 1961, p. 276).
Additionally, English has Glide-Vowel sequences involving the palatal glide [j], as in cute [kjut],
and the velar glide [w], as in queen [kwin] (Davis & Hammond, 1995)22
. One issue concerning
these sequences is whether or not they are diphthongs. Some have suggested that only falling
diphthongs could be called ‘true diphthongs’ (e.g. Donegan, 1978) and that GV sequences
behave more like CV sequences. Donegan (1978), for example, argues that GV sequences do not
function as units but VG sequences do. First, she maintains that the glide in GV sequences does
not count in speech timing. That is, the glide forms part of the syllable onset and is not assigned
a mora. Thus, phonologically, GV is equal to V in timing. Secondly, she observes that VG
sequences behave as units in rhyming but GV sequences do not. Thus, paid [pejd] rhymes with
raid [rejd] but not with red [rɛd]. On the other hand, feud [fjud] rhymes with both mood [mud]
and mewed [mjud] (Donegan, 1978, p. 107). Other authors have found a further asymmetry
between jV sequences and wV sequences. Davis & Hammond (1995) argue, on the basis of
phonotactic patterns and evidence from Pig Latin game forms that [j] and [w] in English behave
differently in terms of phonological status. In short, the [w] in CwV sequences in English is said
to pattern like sequences in which the second element is a liquid. For example, like CL
sequences, Cw sequences are not restricted as to the following vowel (e.g. queen, quote, quack).
On the other hand, the C in these sequences must be an obstruent (never a nasal, for example). In
other words, Cw sequences form a complex onset. Therefore, such sequences are not really
rising diphthongs. On the other hand, the authors argue that when [j] occurs in similar sequences
it is part of a complex mono-moraic nucleus with the following V. For example, the only vowel
which may follow [j] is [u] (as in cute). In addition [j] may also be preceded by a nasal (e.g.
music). The situation is complicated by the fact that in some cases [j] may be said to form part of
the onset since it is subject to some of the same restrictions as [w]. For example, neither [w] nor
22 These authors use the symbol [y] to represent the palatal glide in these sequences. In order to avoid confusion with the symbol
for the high front rounded vowel [y], here we use [j].

34
[j] may appear after a consonant + liquid cluster (Davis & Hammond, 1995). However, the
authors turn to an analysis of stress patterns to ultimately conclude that [j] is not part of the onset
since it seems to add no weight to the syllable. That is, most nouns made up of three or more
syllables in which [ju] appears in an open penultimate syllables, do not have stress on this
syllable but rather on the antepenultimate, as in áccuracy (Davis & Hammond, 1995, p. 164-
165). The few exceptions to this rule (e.g. Bermúda) would be lexically marked. This
characterization of [j] as more vocalic and [w] as more consonantal is also proposed by
Buchwald (2006, within an OT framework) who uses similar phonotactic evidence as well as the
behaviour of an aphasic patient to show that [ju] is a diphthong. These analyses are supported by
articulatory data from Gick (2003-discussed in the experimental section below) and echo the
language-specific model for glides proposed by Nevins & Chitoran (2008). Once again then we
are presented with an asymmetry between palatal and velar (dorsal) glides which is apparently
resolved differently in different languages. Recall that for Spanish and Romanian (and Italian, at
least for the mobile diphthongs) it is [j] which appears to be more consonantal while [w] is more
vocalic. For English, phonological patterning would indicate the opposite characterization for
these glides.
2.3.2 Dutch
Dutch phonologists have assumed that two categories of diphthongs exist in this language, a
distinction based on traditional impressionistic transcriptions. The first category is made up of
the genuine diphthongs (/ɛi, ʌy, ɑu/) which traditionally have been given a monophonemic
representation. The second category consists of the pseudo diphthongs (/aj, oj, uj, iw, ew, yw/)
which are given a biphonemic representation (Collier & t’Hart, 1983; Collier et al., 1982). The
presence in the language of long vowels which may be diphthongized creates more confusion
about this distinction. In terms of distribution, genuine diphthongs appear to be more closely
related to long vowels since, like these, they may be followed by a consonant in
monomorphemic words while pseudo diphthongs may not (Collier & t’Hart, 1983, p. 43).
Experimental data abounds for this language and has been focused on whether acoustic,
articulatory and perceptual data support this traditional distinction.
In addition to these two types of falling diphthongs, Dutch also has Glide-Vowel sequences
involving a palatal glide [j] (as in roeien [rú.jə] ‘to row’and fjord [fjórt] ‘fjord’) and a labio-velar

35
glide [ʋ] (as in houweel [hau.ʋíl], ‘pickaxe’ and kwaad [kʋát]), ‘angry’ (Van der Torre, 2003, p.
181-182). The latter is realized as a more vocalic [w] in weak positions (i.e. in unstressed
syllables, in syllable codas, and in word-final position), as in duwen [dý.wə] ‘to push’ (Van der
Torre, 2003, p. 181). These two glides have an asymmetrical distribution as only [ʋ] can appear
as the first element of a complex onset, giving rise to the observation that in this language [ʋ] is
more consonantal and patterns with the liquid class of sonorants while [j] is more vocalic (Van
der Torre, 2003, p. 184). This patterning is similar to that of English [j] and [w] (discussed in the
previous section) and contrasts with the patterning observed for Romance languages.
Finally, Dutch appears to exhibit anti-hiatic tendencies in its treatment of VV sequences.
Specifically, these sequences are broken up through the insertion of a glide which takes on the
characteristics of the preceding vowel, as in diet [dí.jet] ‘diet’, boa [bó.wa], and duo [dý.ɥo]
(Van der Torre, 2003, p. 189-190). This process may be handled through a glide-insertion rule
(Van der Torre, 2003). Two facts, however, call into question the necessity of a phonological
explanation. First of all, the glide [ɥ] does not otherwise occur in Dutch. In addition, no glide
insertion takes place following a low vowel or schwa, as in chaos [xáɔs] ‘chaos’ and Israël
[ɪsraɛl] ‘Israel’ (Van der Torre, 2003, p. 191). Thus, it has been suggested that gliding may
merely reflect a low-level phonetic phenomenon of coarticulation: a consequence of moving
from a high vowel to a non-high vowel in the articulatory space (Van Heuven & Hoos, 1991).
2.3.3 German
German, like English and Dutch, has falling diphthongs: [a ], [a ], and [ ] (Wiese, 1996, p.159).
Glide-vowel sequences of the form of [jV], however, also occur in this language. In these cases,
[j] is thought to represent a variant of unstressed /i/ which appears in prevocalic, non-initial
positions (Wiese, 1996, p. 234). As in Spanish, whether /i/ is realized as /j/ in these contexts is
lexically determined and subject to dialectal and interspeaker variation. Thus, while most
speakers would agree on the pronunciation of the word Union [unjó:n] ‘union’, they might
diverge in their pronunciation of Piano [pjá:no] ~ [piá:no] ‘piano’ and Tiara [tjá:ʀa] ~ [tiá:ʀa]
‘tiara’(Hall, 2008). Proximity to word stress and speech rate/style appear to be conditioning
factors in this variation (Hall, 2008). Thus, [jV] is more likely in a pre-stress position while both
[iV] and [jV] realizations are possible in a post-stress position. Also, [jV] is more common at
faster speech rates. While an overall tendency towards gliding is observed in this language,

36
gliding appears to be blocked in certain cases. First, similar to what we observed for French
above, gliding does not readily occur following complex onsets composed of Obstruent +
Liquid/Nasal (e.g. Bibliothek [bi.bli.o.té:k] ‘library’ or Bosnien [bɔs.ni.ən] ‘Bosnian’). Gliding is
also blocked following two nasals, as in and amniotisch ɪʃ] ‘amniotic’ (Hall, 2007,
p.11-13). Finally, gliding is uncommon in recently coined words with the non-native suffix -esk
‘esque’, as in hippi-esk [hɪpiɛsk] ‘hippiesque’ (Hall, 2008, p. 317). Other non-native suffixes
which appear in more established words, however, allow gliding. These include the suffix –at, as
in Stipendi-at [ʃtipɛn.djá:t] ‘scholarship holder’ and the suffix –ent, as in effizi-ent [ɛfitsjɛnt]
‘efficient’ (Hall, 2008, p. 313). The above suggests a process of lexical diffusion for German
words with non-native suffixes, similar to the patterns for liaison and elision described for
French.
2.4 Summary
The theoretical literature on vocalic sequences, both in Romance and non-Romance languages,
highlights the following issues: (i) palatal glides behave differently from their velar counterparts;
(ii) rising diphthongs may behave differently from falling diphthongs; and, most importantly for
the present dissertation, (iii) where they occur, [iV]~[jV] contrasts are variable and unstable. It
also seems that more recent theoretical articles attempt to use experimental data in formulating
new ways of looking at these sequences and their components. For example, Nevins and
Chitoran (2008) expand on data from Gick (2003) in formulating their theory of glides,
ultimately providing and explanation for the language-specific behaviour of these segments. This
appears to be the direction of recent studies: that the definition and the behaviour of vocalic
sequences vary from language to language and perhaps even from speaker to speaker. While at
first this conclusion may seem the least satisfactory, it may ultimately be the most realistic. Thus,
in the end, the best phonological answer to the question of whether glides are phonemic may be
‘it depends’. A similar answer must be given to the questions of whether diphthongs are best
thought of as monophonemic or biphonemic and whether rising diphthongs are truly diphthongs.
Again, it depends on the language and the definition of diphthong.
The experimental studies concerning vocalic sequences are examined next. However, we should
be cautiously optimistic about finding any definitive answers in experimentation. As pointed out
by Levi (2008) in her examination of phonemic glides (i.e. those which pattern with sonorant

37
consonants) and derived glides (i.e. those which are variants of underlying vowels) in various
languages, the phonological differences apparent in these presumably separate classes of glides
may not count on a matching ‘reliable phonetic difference’ (Levi, 2008, p.1974).
3 Experimental Studies
The tradition of experimental investigation of vocalic sequences is rather long and can be traced
back to the beginning of the 20th
century. An overview of this early history on diphthong and
vowel analysis is provided by Peeters (1991). Depending on the language or group of languages
being investigated, experimental studies on vocalic sequences have sought to: (i) provide an
acoustic and/or articulatory characterization of diphthongs; (ii) examine the acoustic parameters
thought to distinguish diphthongs from hiatuses, diphthongs from monophthongs, and
diphthongs from long monophthongs and/or diphthongized vowels; and, (iii) determine which of
these acoustic or articulatory parameters are crucial for identification of different diphthongs or
for the differentiation between diphthongs and other types of vocalic sequences. This section is
organized according to the primary type of experimental technique employed in the study. It
includes literature on the acoustic and articulatory parameters which have been identified as
important for vocalic sequences. This section also reviews evidence from perceptual studies
which attempt to outline which of these acoustic and articulatory parameters listeners actually
use to identify vocalic sequences and to distinguish among different types of vocalic sequences.
The more abundant acoustic studies are examined first in §3.1 and §3.2 follows with a review of
articulatory studies and their contribution to an understanding of vocalic sequences. Finally, in
§3.3 the relevant perceptual studies are reviewed. A comparison of those studies which focus on
non-Romance languages to those which focus on Romance languages (Spanish in particular)
highlights some important differences in research questions and methodology.
3.1 Acoustic Studies
Acoustic analyses of vocalic sequences have been largely influenced by the work of Lehiste &
Peterson (1961). That study introduced a definition of diphthongs which has become an
established view. In fact, the parameters and vocabulary used to identify or distinguish among
and between these sequences in subsequent studies can be traced to that study. For example, the
study used the following terminology in defining diphthongs: ‘targets’ or steady states, ‘rate of
formant change’ and ‘slope of transition’. At the risk of overgeneralizing, we can think of

38
subsequent studies as testing these various parameters to either confirm or disprove the notion of
a diphthong as consisting of two steady states or ‘target positions’ linked by a glide transition.
The assumption of a tripartite composition of diphthongs (and hiatuses in languages where these
occur) has persisted either tacitly or explicitly in most research. In fact measurements are often
taken assuming this division even when evidence shows that the first and/or second steady state
may not be present, especially at faster speaking rates or more casual speech styles (Holbrook &
Fairbanks, 1962; Gay, 1968; Aguilar, 1999) or that a glide only may be used to successfully
synthesize diphthongs (Gay, 1970). The definition of what constitutes a ‘steady state’ is fairly
straightforward and generally accepted as a period of relative stability where ‘the formants are
parallel to the time axis’ (Lehiste & Peterson, 1961, p. 272). However, there is some debate
about how long this period should be in order to qualify as a steady state. Lehiste & Peterson
(1961), for example, set the minimum at 20 ms, a time interval the authors define as “arbitrarily
chosen” (p. 272). Gay (1968, p. 1571) sets the minimum at 15 m23
.
Overall, studies of Spanish and other languages have shown that diphthongs can be distinguished
from other types of vocalic elements (such as monophthongs and hiatuses) along frequency as
well as temporal parameters, although it is acknowledged that these parameters may not define
all such sequences in all languages or even all speakers all the time. Following Lehiste &
Peterson (1961) a diphthong is generally characterized as consisting of three portions: the first
vowel target (V1), the second vowel target (V2) and the transition (T) between V1 and V2. For
Spanish and other Romance languages (i.e. Italian) research on vocalic sequences almost
invariably includes a reference to syllable structure. Thus, it may not be possible to have a
completely phonetic study in these languages; ultimately phonological concepts are called upon
either to formulate a hypothesis or to explain the results.
3.1.1 Frequency Parameters
Among the parameters identified as relevant in the characterization of diphthongs are the
formant frequencies of the V1 and V2 steady states, with researchers differing on the number of
formants to include: only F1 and F2 (e.g. Borzone de Manrique 1979; Aguilar, 1999, for
23 These times appear to be grounded in human speech perception. That is, they fall within the range of threshold values (10-40
ms) for the perception of just-noticeable differences in duration between two speech sounds (Lehiste, 1976, p. 226).

39
Spanish; Lehiste, 1967, for Estonian) or F1-F3 (Lehiste & Petersen, 1961 and Gottfried et al.,
1993 for English). Some authors (i.e. Gottfried et al., 1993) have also included measures of
fundamental frequency (f0). The general finding in these cases is that the F1 and F2 values of the
steady states of diphthongs differ from the formant values of the corresponding monophthongs.
Thus, these sequences are more than concatenated simple vowels. However, this difference is
largely language-specific. In Spanish, both onset and offset frequencies are affected (e.g.
Borzone de Manrique, 1979). In other languages, on the other hand, it may be only onset or
offset or both that are affected. For example, in Lehiste (1967) frequency measurements included
a comparison of F1 and F2 values of onset and offset components of the Estonian diphthongs
[iu], [ei], [ea], [eu], [ai], [ae], [au] and [eu] to those of their corresponding stressed short vowels.
Here the author finds that the values for the first component (onset) of the long diphthongs in
question closely correspond to those for stressed short vowels. However, the offset component
formants did not closely match the formants of the corresponding short vowels. Thus offset
frequencies but not onset frequencies may distinguish long diphthongs from corresponding V+V
sequences in Estonian. Lehiste (1967) did not look at the transition separately although its
properties are also considered important.
A second important frequency measurement involves changes in F2 from beginning to end of T
(Borzone de Manrique, 1979, for Spanish; Chitoran, 2002, for Romanian). For example,
diphthongs may be distinguished from hiatuses in the following way also: diphthongs have a
more gradual transition from V1 to V2 while hiatuses have a faster transition from V1 to V2,
reflected in a steeper F2 slope (Aguilar, 1999). In addition, in hiatuses we generally find two
clear steady states (corresponding to V1 and V2). In diphthongs, on the other hand, these steady
states may be less evident or not present for either V1 or V2 (Borzone de Manrique, 1979;
Aguilar, 1999). Still, the role of the transition on its own is disputed. For example, Jha (1985)
conducted a spectrographic study of the diphthongs /əi/ and /əu/ in Maithili24
under three
different speech rates. The results suggested that in this language onset F1 and F2 remain
relatively fixed across speech rates and the concomitant changes in duration. On the other hand,
offset targets were only reached at slow rate; at other rates the V2 steady state was rarely reached
and was often not present. Finally, the glide element changed systematically and showed a very
24 Maithili is an Indo-Aryan language spoken in India and Nepal.

40
similar F2 rate of change across the three conditions (in support of Gay, 1968). This stability in
F2 rate of change was achieved through a ‘decrease in F2 transition duration always
accompanied by a decrease in F2 offset frequency for /əi/ and an increase in offset frequency for
/əu/’ (Jha, 1985, p. 113). So, for this language F2 rate of change and onset frequency position are
very important. For English (e.g. Lehiste & Peterson, 1961; Gay, 1968), on the other hand, it is
the onset steady state which may be most important. For Spanish, different authors report
different results. For example, Borzone de Manrique (1979) suggests that, at least for Argentine
Spanish, it may be one or the other steady state depending on where the open vowel occurs on
relation to the glide (i.e. whether it’s a rising or falling diphthong). She also notes that F2 rate of
change in Spanish diphthongs appears to remain invariant across different speaking rates. On the
other hand, Toledo & Antoñanzas-Barroso (1987), also for Argentine Spanish, found significant
differences in F2 rate of change as a result of increased speech rate. Kinoshita & Osanai (2006)
in their study of Australian English /ai/ had also anticipated that the slope of F2 in the transition
would remain fairly constant regardless of speech style and would thus be a better parameter for
speaker identification that the T1 (steady state for V1) and T2 (steady state for V2) second
formant frequencies (especially since they had considerable difficulties identifying these steady
states). However, they found that (i) the angle of the slope was indeed affected by speech style
and thus was not invariant (contra Gay, 1968), and (ii) that analysis of likelihood ratios showed
that this parameter was as good, but not better than the traditional parameters in discriminating
between different speakers (in this case F2 of T1 and T2 of /ai/). However, they did find that T1
and F2 slope of the glide (G) together had better discriminatory power that any other
combination (i.e. G + T2 or T1+T2). According to Kinoshita & Osanai (2006), this ‘suggests the
possibility of the slope of the glide carrying information which complements the information that
the target carries’ (p. 117). Thus for this variety of English, it may be the combination of onset
frequencies + transition which aid in diphthong discrimination.
Spectral characteristics may also be used to distinguish between positional variants of /i u/ in
diphthongs, providing evidence of a glide continuum from more to less consonantal (Hualde,
2004). For example, Borzone de Manrique (1976) finds that in Argentine Spanish, /i u/ appearing
in diphthongs in absolute initial position (e.g. hiena [jé.na] ‘hyena’ and huelo [wé.lo] ‘I smell’)
display different spectral characteristics than those appearing in diphthongs which follow a
consonant (e.g. Viena [bjéna] ‘Vienna’ and duelo [dwé.lo] ‘duel’). Specifically, the former differ

41
from the latter in having a lower F1 and higher F2 and F3 as well as lower intensity in
comparison with the following [e]. These findings point to a greater degree of constriction, and
thus, a more consonantal realization for the variants in absolute initial position.
3.1.2 Temporal Parameters
Among the temporal parameters used to define diphthongs are measures of duration of each
portion of the sequence (Borzone de Manrique, 1979; Lehiste & Peterson, 1961), of the entire
sequence (Aguilar, 1997, 1999; Hualde & Prieto, 2002) or of only a specific portion of the
sequence (e.g. transition only: Borzone de Manrique, 1976; Chitoran, 2002; Lindau et al., 1990).
To allow for comparison of sequence of different durations, temporal measurements are often
normalized either by taking the proportion of the entire sequence taken up by the part of the
sequence measured (e.g. Lehiste & Peterson, 1961) or by manipulation of the waveform by
stretching and compressing to a common length (Aguilar, 1999).
Diphthongs are distinguished temporally from hiatuses in that hiatuses are longer (Aguilar, 1999;
Hualde & Prieto, 2002). Additionally, durational differences may be affected by the vowel
quality. For example, Aguilar (1999, p. 64) found that “hiatuses with [a] are longer than hiatuses
with [e] and [o], whereas for diphthongs, the behaviour is the opposite”. The observation that
durational patterns may be a function of the sequence being studied (as well as the language) is
also found in Lindau et al. (1990) in their cross-linguistic study of /ai/ and /au/ diphthongs in four
non-romance languages (English, Chinese, Hausa, Arabic). Specifically, they find that the
proportion of the diphthong allotted to transition duration appears to be language-specific and
ranges from 16-20% for Arabic and Hausa to 40-50% for Chinese; for English the transition is
the dominant feature and may take up to 73% of the diphthong, in the case of /au/ and up to 60%
of the diphthong for /ai/. Thus, not only is transition duration a language-specific trait, but even
within the same language, these durations may vary according to the diphthong (p. 14). Overall,
they conclude that “the timing of the diphthongal transition is not constant for the 'same'
diphthong in different languages… the transitional range and duration may be language-specific,
and possibly even diphthong-specific as well…diphthongal timing properties must be specified
as part of the phonetic description of diphthongs in different languages” (p. 14). This conclusion
echoes that of Peeters (1991) who argues, based on his perceptual study that what distinguishes
vowels, diphthongs and vowel sequences is not any particular structure or movement pattern

42
since all such sequences might exhibit movement. Where they differ is in the timing of their
movement patterns. Thus, while both a diphthong and a long vowel may exhibit a similar pattern
of movement phonetically, they will differ in terms of timing (e.g. the proportion allotted to
transition, for example may differ from one language to the next). According to Peeters (1991)
these differences are language-specific so that what defines the difference in one language may
not do so in another. Additional studies reported below seem to support this notion of the
importance of timing in different languages.
Van der Beer (2006) measured duration of Italian diphthongs and monophthongs and found the
following: (i) in terms of relative duration, rising diphthongs are comparable to monophthongs;
(ii) both diphthongs and monophthongs are shorter when in an unstressed position; (iii) mobile
diphthongs25
do not differ significantly in duration from other rising diphthongs (thus
phonetically they are not distinct); and, (iv) the asymmetry between diphthongs with [j] and
diphthongs with [w] is shown in terms of the proportion of the ratio of glide transition to vowel
in each type of diphthong (a ratio of 1:3 is found in [jV] diphthongs and a ratio of 1:2 in [wV]
diphthongs). Again, this shows that even within the same language, durational distinctions
depend on the sequence being studied.
Durational measurements are also used to distinguish between onglides and offglides,
traditionally referred to as semiconsonants and semivowels, respectively. Salza (1988) finds
durational differences to support a differentiation between onglides as semiconsonants and
offglides as semivowels in Italian, but only in unstressed syllables. In stressed syllables, their
durations become very similar. Aguilar (1997), on the other hand, also finds that there are
durational differences large enough to maintain the distinction for Spanish. However, these
differences are greater in a reading task than in a more casual speech task (Aguilar, 1997, p.
155).
It is also important to highlight here that the frequency and temporal differences between
diphthongs and hiatuses are not always clear at the acoustic level. For example, the range of
duration values for the two categories may show some overlap (Hualde & Prieto, 2002;
MacLeod, 2007) with additional blurring occurring as a result of faster speech rate or more
25 Refer to §2.2.1 above for a definition of mobile diphthongs.

43
casual speech style (Aguilar, 1997, 1999). In addition, F2 slope and the proportion of the
sequence taken up by the transition may also vary, both by dialect and by individual speaker
(MacLeod, 2007). Overall, it appears that speakers (regardless of dialect) show a higher degree
of variability in the realization of diphthongs compared to the realization of hiatuses (MacLeod,
2007). On the other hand, the diphthong category is identified as more stable than the hiatus
category (Chitoran & Hualde, 2007). The effect of this stability can be seen in the tendency for
hiatuses to diphthongize across Spanish dialects, although this tendency may be blocked under
certain prosodic conditions. For example, exceptional hiatuses are more likely to resist this
tendency in conditions that induce lengthening, as in word-initial position and in stressed
syllables (Chitoran & Hualde, 2007). In addition, the tendency to diphthongize may proceed at
different rates between certain varieties (Garrido, 2007; Colantoni & Limanni, 2010) and for
different speakers (Colantoni & Limanni, 2010). Finally, speakers may select different
coarticulatory strategies to achieve the diphthong-hiatus contrast. For example, Colantoni &
Limanni (2010) present evidence which suggests that speakers of contact and non-contact
varieties of Argentine Spanish use different coarticulatory strategies to achieve diphthongization
in rising sequences. Specifically, the contact variety achieves diphthongization through a shorter
and more coarticulated V1 (the high vocoid). The non-contact variety, on the other hand, does so
through a longer transition (Colantoni & Limanni, 2010, p. 30-31).
3.1.3 Summary
Overall, the acoustic studies reviewed above seem to suggest that the relevant durational and
frequency cues which characterize vocalic sequences may be language-specific and even
sequence-specific. This observation underscores the need to study different languages and
different sequences within those languages, even though many studies tend to focus on the
maximally distinct ones of the type [aj]/[ja]. In addition, individual variation on these two
measures suggests that even speakers of the same variety cannot be treated as a uniform group,
emphasizing the need to consider individual strategies in the use of these acoustic parameters
(and their underlying articulatory correlates). Finally, the acoustic studies also point out that
diphthongs cannot under most circumstances simply be thought of as concatenations of two
vowels. That is, they are different from the sum of their parts. This qualitative difference
between diphthongs and monophthongs is succinctly described in Beberfall (1962, for Spanish)
through an analogy with chemistry: “This characteristic of diphthongs is comparable to what is

44
manifested when two elements combine to form a chemical compound. For example, harmless
sodium chloride can hardly be traced back mechanically to the constituent caustic sodium and
toxic chlorine. Just as sodium chloride is a new product, so is the au diphthong in causa, aula
and in any other word where it is found” (Beberfall, 1962, p. 38).
3.2 Articulation Studies
The studies reviewed above have contributed to the acoustic characterizations of diphthongs,
vowel sequences (i.e. hiatuses or vowel clusters, depending on the language) and vowels in
general. Fewer studies have examined the articulatory properties of these elements. This
experimental gap is understandable given that techniques for acoustic analysis are more readily
available, considerably less expensive to operate, and less invasive than those typically used for
articulatory analysis (see Stone, 1997 for a review of various techniques used in articulatory
research). In addition, data for acoustic analysis may be obtained from a large number of
speakers whereas articulatory studies are often limited to as few as a single speaker (often the
author, depending on the type of instrumentation and degree of invasiveness). Moreover, it is
possible to infer articulatory characteristics from acoustic data. However, it is also acknowledged
that some articulatory-acoustic relations may not be linear (i.e. a set of specific formant values
may not correspond to a single, invariant vocal tract shape) and that using articulatory data to
complement acoustic data increases explanatory power (Recasens, 1999a). The studies reviewed
in this section serve to highlight the value of articulatory data (whether primary or synthesized)
to support or challenge acoustic and theoretical findings.
Kent & Moll (1972) undertake a cinefluorographic (X-ray) analysis to examine the effect of
phonetic context on the articulation of American English vowel + vowel (e.g. /i/ + /o/, as in
Leo’s), diphthong + vowel (e.g. /aɪ/ + /o/, as in viola) and diphthong + diphthong (/aɪ/ + /ɔɪ/, as in
hyoid) sequences. These vocalic sequences were examined in contexts were they were either
adjacent or separated by a non-lingual consonant (p. 280), both within or separated by a word
boundary. The authors looked at two tongue body points and used jaw movements as reference.
Overall, they found little effect of the phonetic context on tongue movement in the sequences
studied. However, they did find an important relationship between the magnitude and rate of
tongue movement for the vowel + vowel sequences. That is, the greater the tongue displacement,
the faster the rate of movement of the tongue. Thus, they find greater mean and peak velocities

45
for /i/ + /ɑ/ than for /i/ + /æ/ since the former requires a greater displacement of the tongue. For
the diphthongs /aɪ/ and /ɔɪ/, they find that “the initial and terminal tongue positions are not
invariant attributes of diphthong production” (Kent & Moll, 1972, p. 292). Hence, the onset and
offset frequency values are not what distinguish one diphthong from another. Rather, they
suggest that “the movement patterns in themselves are sufficient to distinguish /aɪ/ from /ɔɪ/” (p.
292). These patterns of movement for a given diphthong remain similar across different
productions and across differences in tongue displacement. The authors thus conclude that
diphthong production differs from vowel + vowel production in that diphthongs exhibit a relative
independence of magnitude of tongue displacement and tongue movement velocity. They
consider this as “suggestive of a constraint on the velocity of articulatory movement during
diphthong production” (Kent & Moll, 1972 p. 295) and as support for a theory of invariant
formant movement rate in diphthongs (e.g. Gay, 1968). However, their data does show
exceptions to this invariance. In particular, their data for /aɪ/ shows much greater tongue
displacement in the word hyoid than in the phrase I hold (Kent & Moll, 1972, Fig. 11, p. 293),
although the authors dismiss this as an atypical example. In addition, they found a large amount
of individual variation between the two participants. Specifically, these participants displayed
different tongue body-jaw patterns. The male participant tended to use only small jaw
movements while the female speaker used large jaw movements. Thus, while their vocal-tract
configurations were similar for individual segments (e.g. for /i/, p. 282) they each employed
different strategies for achieving the different configurations required for the sequences they
produced in the study. This finding leads the authors to suggest that phoneme targets are best
defined as “spatial attributes of the vocal tract rather than as invariant motor commands to the
component articulators” (Kent & Moll, 1972, p. 296).
Shaiman & Porter (1991) took strain gauge measurements of the upper lip and jaw movements of
six speakers as they produced the vowels /ɑ i/ and the diphthongs /eɪ aɪ / in the fixed segmental
context /pV#pVp/ (#=syllable boundary and V=vowel or diphthong) under two stress conditions
(stressed=stress on first syllable; unstressed=stress on second syllable). Measurements of
articulator displacement and velocity were used to calculate phase angles in order to compare the
timing relationship between the two articulators. These measurements revealed that vowels and
diphthongs differ in the relative timing of upper lip and jaw movements. Specifically, larger
phase angles were found for the diphthongs than for the vowels. That is, the onset of upper lip

46
movement occurred later in the jaw cycle for diphthongs. The authors claim that the difference
occurs as a function of jaw opening duration percentage. Specifically, maximum jaw opening is
reached earlier within the total jaw cycle for diphthongs, perhaps reflecting “the need of the
tongue + jaw synergy to accommodate movement between successive vowel targets” (p. 3006).
Thus, different phase relationships of vowels and diphthongs are achieved by changing the jaw
cycle characteristics rather than the timing of upper lip movements. Phase angle values were
similar for the two vowels and for the two diphthongs. Thus, vowel height (of /ɑ / vs /i/) does not
appear to influence the upper lip-jaw phasing relationship. Similarly, /eɪ/ and /aɪ/ could not be
distinguished by differences in phasing. The unstressed condition (where the first syllable was
unstressed) produced smaller phase angles for both and resulted in smaller differences in the
phase angles for diphthongs and vowels. Thus, while the overall differences between vowels and
diphthongs were maintained in the absence of stress, these differences were reduced so that
diphthongs and vowels “appear more alike” (p. 3006) in this condition. An interesting and
important finding of this study is that two of the participants showed very little difference in
phase angle between vowels and diphthongs. However, they did display the same pattern as all
the other speakers, leading the authors to conclude that “the value of the phase angle itself is not
critical: rather, within a given speaker, the relationship between phase angles for different tasks
is the salient variable” (Shaiman & Porter, 1991, p.3005).
Gick (2003) undertakes an EMA study with three participants to investigate syllable position
effects on phasing relationships in the American English glides /j/ and /w/. His analysis of these
glides in prevocalic and postvocalic positions shows important differences between initial and
final allophones. For both /j/ and /w/, the final allophones (VC, postvocalic position) show a
reduction in gestural magnitude, suggesting they are more vowel-like than the initial allophones
(CV, prevocalic position). Similarly, Kochetov (2006) finds syllable-position effects for Russian
/j/ using EMMA. For example, he reports a consistent reduction in the magnitude of the TB
raising gesture in coda position as compared to onset position (Kochetov, 2006, p. 576). He also
observed a reduction in the magnitude of TB fronting as well as a decreased duration of TB
raising of Russian /j/ in coda position but these effects were more variable.
Gick (2003) also observes a crucial difference between English /w/ and /j/. Namely, he finds
evidence that /w/ consists of two gestures, one vocalic (tongue body/dorsum raising), which he
terms a V-gesture, and one consonantal (lip constriction), which he calls a C-gesture. The

47
relative phasing of these two gestures differs according to syllable position. Thus, in final
position /w/ shows both a reduction in lip constriction as well as a relative lag of this C-gesture
(a lip delay) relative to the V-gesture. In initial position, the opposite effects are seen (i.e. greater
lip constriction; C-gesture occurs prior to V-gesture). This analysis of syllable position effects on
/w/ offers support for the CV vs. VC phasing relations proposed by Browman & Goldstein
(2000). On the other hand, Gick (2003) finds that /j/ appears to be composed of a single V-
gesture (involving tongue body raising and fronting). This gestural distinction between /j/ and
/w/ can account for differences in the phonological behaviour of these two glides in English
(Davis & Hammond, 1995). Gick (2003) also suggests that results for these glides may be
different in other languages. That is, V-gestures and C-gestures are language-specific and
phonologically specified. Thus, for Italian (Marotta, 1987), and possibly Spanish (Nevins &
Chitoran, 2008), [j] may be more consonantal than [w], while for Romanian, both [w] and [j]
may be considered more consonantal than vocalic (Marin, 2007). In addition, a recent EMA
study by Zmarich et al. (2012) suggests that for Italian, prevocalic [w] differs from postvocalic
[w] only in degree of constriction. That is, the onglide shows a greater lip constriction (thus, is
more consonantal) than the offglide. No significant differences in C-gesture (i.e. lip) lag were
found. This result suggests that, at least for this language, onglides and offglides differ featurally
rather than structurally. However, these results are only for [w] and only from a single speaker.
Based on those results, it is not possible to say whether Italian [j] behaves in the same manner.
We also do not know whether all Italian speakers use only degree of constriction to distinguish
between onglides and offglides. It may be that both degree of constriction and phasing are
available as articulatory strategies but individual speakers are able to exploit them to different
degrees.
Collier et al. (1982) collected EMG as well as acoustic data from a single Dutch speaker (the
principal author) during the production of diphthongs and vowels. This data was meant to
complement existing acoustic and perceptual data pointing to two categories of diphthongs in
Dutch: ‘genuine diphthongs’ (traditionally described as having a monophonemic representation)
and ‘pseudo diphthongs’ (described as biphonemic sequences of vowel + glide). The authors
tested the hypothesis that genuine diphthongs could be characterized as comprising a single
gesture while the pseudo diphthongs comprise “two discrete, concatenated gestures” (Collier et
al., 1982, p. 310). To test the hypothesis, the authors collected data on the activity of the

48
following muscles (p. 308-309): the genioglossus (responsible for tongue advancement); the
styloglossus (responsible for tongue body retraction); and, the mylohyoid (acts with the other
two muscles to elevate the tongue, providing most of its vertical thrust). The results support the
characterization of genuine diphthongs as single events since gesturally they appear dominated
by the activity of a single muscle. In the case of /ɛi/ the genioglossus is dominant, in the case of
/ɑu/ the styloglossus dominates, and in /ʌy/ it is the mylohyoid muscle. The ‘pseudo diphthongs’,
on the other hand, show two distinct mylohyoid peaks, with the genioglossus and styloglossus
aligned with one or the other peak. The results thus support the phonological characterization of
‘pseudo diphthongs’ as biphonemic. However, because the data came from a single speaker it is
not possible to say whether different speakers would use the same articulatory strategy to
differentiate between these two classes of diphthongs.
The above studies used primary articulatory data. The following study (Marin, 2007) used
synthesized articulatory data to test hypotheses about the differences between Romanian
diphthongs, hiatuses, vowels and glide-vowel sequences. The main proposal put forth by Marin
(2007) is that in Romanian the phonological diphthongs /ea/ and /eo/ represent two vowels which
are synchronously coordinated. When the two gestures have different weight (as when /a/ is
stressed), the percept is of a diphthong. When the two gestures have equal weight (in the absence
of stress), gestural blending occurs and /e/ is perceived. Marin (2007) uses the Task Dynamic
Application (TADA) computational system to model the /e/-/ea/ alternation. This was done by
starting with a base stimulus consisting of /e.a/ in hiatus and manipulating the amount of overlap
between the two. A perceptual study which followed revealed that listeners perceived the
sequences with least overlap (sequential coordination of the vowel gestures) as hiatus, those with
more overlap (synchronous coordination) as diphthongs and those with the most overlap
(blending of two equally weighted gestures) as /e/. The author argues that durational changes
alone could not be responsible for these results since even the shortest stimulus presented to the
listeners fell within the range of natural diphthong durations (as produced in the acoustic study
which preceded the articulatory simulation). The author then proceeded to alter the articulatory
strength of each of the vowels in an effort to simulate stress effects. The results show that when
[a] is weighted more heavily, listeners perceive a diphthong. However, when the two vowels are
weighted equally, the listeners perceive the single vowel [e] (Marin, 2007, p.121). The author

49
interprets these results as favouring her hypothesis. However, she acknowledges that parameters
other than articulatory weight may be needed in order to model the effects of stress.
For Spanish, there are recent attempts, motivated by Browman & Goldstein (2000) as well as by
some of the above studies, to relate articulatory analysis to the differences between diphthongs
and exceptional hiatuses. In particular, it has been suggested that diphthongs and hiatuses display
different gestural coordination patterns (Chitoran & Hualde, 2007). These authors extend an
analysis of syllable position effects on the gestural coordination of CV sequences (Browman &
Goldstein, 2000) to vowel-vowel (VV) sequences. They suggest that diphthongs, like CV
sequences, are characterized by a synchronous coordination mode while hiatuses are
characterized by a sequential coordination mode, as in VC sequences (Chitoran & Hualde, 2007,
p. 61). Since a synchronous relation is considered more stable and a sequential one less stable
(Browman & Goldstein, 2000), this characterization predicts more variation in the production of
hiatuses. However, because these analyses do not come from articulatory data, it remains
uncertain whether Spanish vocalic sequences can be characterized with the same gestural
coordination patterns as sequences of consonants and vowels.
3.2.1 Summary
One of the main points that can be taken away from these studies is that the relevant articulatory
cues which characterize vocalic sequences may (just as we saw for the acoustic cues) differ by
language and even by type of sequence. The studies also suggest that individual speakers may be
able to exploit different articulatory strategies to make the relevant distinction between types of
vocalic sequences. Finally, all these studies serve as an important complement to existing
acoustic and theoretical literature on vocalic sequences. That is, they provide details of the
articulatory parameters underlying the acoustic differences (e.g. Collier et al., 1982). In addition,
they can be used to test featural and syllabic theories of glide production (e.g. Gick, 2003;
Zmarich et al., 2012).
3.3 Perception Studies
Carefully designed perception studies can be important for confirming or challenging hypotheses
based on acoustic and articulatory data and for testing the relationship between production and
perception. In addition, they may play a significant role in testing phonological analyses of glides

50
and vowels. Consequently, perception studies play a crucial role in understanding the differences
between diphthongs and hiatuses. Importantly, they have the potential to help determine the
status of exceptional hiatuses.
While perception studies for vowels, diphthongs and vocalic sequences in English and other
Germanic languages in general are readily available (e.g. Gay, 1970; Bond, 1978; Bladon, 1985;
Peeters & Barry, 1989; Peeters, 1991; Schouten & Peeters, 2000; Morrison & Nearey, 2007),
fewer studies exist for Spanish (or other Romance languages). Perception data for the former set
of languages has generally employed synthesized stimuli and has focused on the following
questions: (i) what parts of a diphthong are necessary for its perception? (ii) how are diphthongs
differentiated from monophthongs and/or vowel sequences? and (iii) how do listeners
differentiate between different diphthongs? Again, Lehiste & Peterson (1961) can be identified
as an overarching influence in these studies. Specifically, it appears that Lehiste & Peterson
(1961) provided the perceptually relevant parameters which this line of research seeks to identify
as most significant in the identification of these sequences.
On the other hand, studies on Spanish and other Romance languages (e.g. Van der Beer, 2006,
Gili Fivela & Bertinetto, 1998, for Italian; Chitoran, 2002; Marin, 2007 for Romanian) have
either used a different methodology and/or have focused on answering the following questions:
(i) can listeners distinguish between diphthongs and hiatuses/bivocalic
sequences/monophthongs?; (ii) do their perception results match their production results?
Frequently, the first question has been approached through syllabification intuition tasks with
these results then being used to answer the second question. Exceptions to the
syllabification/intuition approach include Van der Beer (2006), Chitoran (2002), and Marin
(2007). Because of these differences in questions and methodologies, studies on Spanish and
other Romance languages are reviewed separately from those studies on non-Romance
languages.
3.3.1 Spanish
For Spanish, researchers have relied on the syllabification intuitions of native speakers as a cue
to whether these speakers make the contrast between hiatus and diphthongs. Experiments have
generally focused on the difference between exceptional hiatuses and diphthongs in similar
consonantal environments and have concentrated on sequences of a high front vowel [i] /palatal

51
glide [j] in combination with [a]. For example, Hualde & Prieto (2002) administered such a task
to their participants (6 speakers of the Madrid variety of Peninsular Spanish) following a
production experiment in which they produced the target words, all of which contained
sequences of unstressed [i j] and the stressed vowel [a]. Syllabification categories were decided
by the authors, according to their intuitions as native speakers of this variety of Spanish. Thus,
sequences were classified as either diphthongs or (exceptional) hiatuses, as in the examples
below:
(17) (a) hiatus: el piano [elpi.áno] ‘ the piano’
(b) diphthong: Ulpiano [ulpjáno] ‘Ulpiano’ (a personal name)
For the task, the participants were presented with a written list of the target words and were
asked to decide how many syllables each word contained (by dividing the word into syllables or
tapping or otherwise counting out the syllables) and write down this number beside the word.
They report that only one participant out of six (speaker JT) deviated considerably from his
production performance. JT’s performance was attributed to his lack of awareness of the
‘phonological’ contrast in words which he produced as hiatus but syllabified as diphthong. This
was particularly evident in the word barriada ‘neighbourhood’, a word hypothesized by the
authors to be in the diphthong class. In fact, this particular word created difficulties for other
speakers as well, leading the authors to observe that if this word were excluded from the data, the
participants’ production and syllabification would coincide more closely. The authors conclude
that for JT this particular word belongs to the hiatus category while for some of the other
speakers it “may fluctuate between the two classes” (Hualde & Prieto, 2002, p. 232).
A similar approach is taken by Face & Alvord (2004). Their study was an attempt to replicate the
findings of Hualde & Prieto (2002) for a different variety of Peninsular Spanish (a contact
variety, Spanish-Catalan). In their study, the 5 participants were all speakers of the Barcelona
variety of Peninsular Spanish; bilingual Spanish-Catalan speakers who spoke primarily Spanish.
A production task determined that the speakers indeed produce a diphthong-hiatus contrast in
this variety of Spanish, as shown by durational differences between the two types of sequences:
for each individual speaker, the sequences which were hypothesized to be hiatuses were
significantly longer than those hypothesized to be diphthongs. These results, as well as the
findings of intra and inter-speaker variability in duration, echo those found by Hualde & Prieto
(2002). In other words, there are two kinds of durational overlap: individual speakers may show

52
overlap between diphthongs and hiatuses in terms of duration (when raw numbers rather than
means are compared) and their mean values may differ from those of other speakers. For
example, one speaker’s mean diphthong duration may approach another speaker’s mean hiatus
duration. A different set of participants (10 in total) took part in a second experiment involving
three perception tasks. The goals of these tasks were (i) to replicate the study by Hualde & Prieto
(2002) and (ii) to test perception aurally as well as in terms of syllabification based on written
words. In the first task, listeners heard words from the production experiment presented to them
via headphones. The listeners heard a total of 16 stimuli, 8 of which were altered so that a word
which normally contained a hiatus had that hiatus portion replaced with a diphthong and vice
versa. Listeners heard each word twice, once in its original state and once in its altered state. This
was done to avoid as well as to test for lexical bias, the rationale being that if lexical bias was at
work, then the altered word would be heard in its original form. Participants were asked to report
the number of syllables produced by a speaker for a particular sequence by writing the number
down on a paper. In a second task, participants were asked to syllabify the same sequences as
they themselves would produce it. The purpose of this second task was to compare these results
with those of the production task to see if the results coincide. Finally, in a third task, participants
were asked to identify vowel sequences in isolation as either diphthongs or hiatuses. These
sequences were taken from the words used in the first perceptual task. Therefore, it is possible
some of the formant transitions related to the consonantal context may have been left in, giving
listeners a cue as to the lexical item. In general, however, participants did well in these tasks,
correctly identifying diphthongs and hiatuses, both in isolation and in their natural word
environments (whether modified, switched or not) at well above chance levels. One important
observation was that listeners more often erred on the side of diphthongs, suggesting that when
they are unsure as to one or the other, they will choose a diphthong syllabification over a hiatus
syllabification. The authors attribute this to a frequency effect in the language. That is, in
Spanish most cases of a high vowel-vowel sequence are produced as diphthongs rather than
hiatuses (hence the term exceptional hiatus). An alternative explanation in terms of marked
sequences is also offered. This second explanation assumes that [i.a] is lexically marked while
[ja] is unmarked and thus the second is preferred (if we invoke a theory of markedness where
marked items are dispreferred). This second explanation also requires the assumption that
syllabification is stored in the lexicon and included in underlying representation. Interestingly,
the same word (barriada, ‘neighbourhood’) was a point of disagreement here as well (see

53
Hualde & Prieto, 2002, above). It is the only word where most of the speakers (3 out of 5)
disagreed with the hypothesized syllabification (they syllabified it as hiatus rather than the
hypothesized diphthong), leading the authors to suggest (in a footnote) that a preceding [r] may
promote hiatus.
One possible limitation of the above studies is that they may not reflect perception of the
diphthong-(exceptional) hiatus contrast as much as they reflect how well the person learned to
syllabify certain words in school, in particular where words are presented in their written form.
Another possible limitation is the focus on sequences with the vowel [a] since the articulatory
distance between this vowel and the high vowel/palatal glide may be contributing to the longer
duration and thus to the assumed hiatus percept in these sequences. Thus, the existence of
exceptional hiatuses may be overstated. The hiatus pronunciation of these sequences may simply
reflect articulatory constraints. In fact, it would appear that for many speakers of Peninsular
Spanish, the variety which is said to consistently produce exceptional hiatuses, such sequences
are assigned a diphthong syllabification.
Cabré & Prieto (2006) found this tendency towards a diphthong syllabification of ‘exceptional
hiatuses’ in sequences consisting of high vowel/palatal glide + V. Their study employed a similar
methodology in which a pen-and-paper questionnaire was administered to a total of 15
Peninsular Spanish speakers from different areas of Spain. A corpus of 246 words was included
in the questionnaire. These words were designed to test the effects of various factors on the
participants’ syllabification decisions, which they were to indicate by separating the words into
syllables. These factors included: (1) position in word (initial position thought to favour hiatus);
(2) morphological effects (presence of morphological boundaries thought to favour hiatus); (3)
paradigm effects (a hiatus in a morphologically related word will block diphthongization). The
results show that not all speakers show the initiality effect (1), leading the authors to distinguish
between ‘conservative’ (who tend towards hiatus preservation and judge less that 50% of the
sequences as diphthongs) and ‘innovative’ (who tend to judge the majority of sequences as
diphthongs) speakers, although they comment that ‘there is no clear separation’ between these
two groups, rather, a ‘gradual situation’ (p. 207). In addition, they find that nouns and verbs
behave differently in terms of morphological and paradigm effects. In nouns, for example, uV
sequences (e.g. virt[u.ó]so ‘virtuous’; act[u.á]l ‘present’) are more resistant to diphthongization
than iV sequences (e.g. od[jó]so ‘hateful’; cord[já]l ‘cordial’). In verbs, a form with a stressed

54
high vowel in combination with a morpheme boundary in some form of the paradigm appears to
be required for hiatus preservation (e.g. conf[i.á]r ‘to trust’ with exceptional hiatus, conf[í.o] ‘I
trust’ vs. camb[já]r ‘to change’, with diphthong, cámb[jo] ‘I change’, p. 207). As with effect (1),
many speakers in the sample do not show effects (1) and (2) and have generalized the diphthong
production to these environments. Overall, the study confirms that Spanish in general presents a
tendency to diphthongize. The authors account for this tendency with a correspondence-based
OT analysis. In addition, they propose a universal constraint of PROSODIC PROMINENCE to
account for the tendency for glide formation to be blocked in the phonetically strong initial
position. An important limitation of this study is the fact that the participants gave written rather
than spoken responses. On the other hand, an important contribution of this study is its
recognition of the fact that diphthongs may be more widespread in this variety than previously
recognized and that there are great inter-speaker differences in the distribution of ‘exceptional
hiatuses’. The authors account for this variation “by assuming that each speaker is able to set up
a set of idiosyncratic correspondence relations between different words which are active in the
evaluation process” (p. 233). This statement echoes comments by Docherty (2003) who suggests
in his review of Goldinger & Azuma (2003), Remez (2003) and Local (2003) that an important
implication of assuming a “multiple-trace account of perception and representation whereby
multi-modal experience is encoded in memory, is that, to the extent that speakers of the same
language (even from the same community) have different experiences, they may have built up
slightly different bases on which to interpret the sound patterning to which they are exposed”
(Docherty, 2003, p. 344). He suggests that studies should pay closer attention to individual
differences in production and perception and rethink any assumptions about “linguistic
homogeneity” when selecting participants for such studies.
The results from Whitley (1985) also serve to underscore the importance of controlling for
variation in participants. This author employs a questionnaire methodology in an attempt to
answer the question of whether speakers maintain a phonemic contrast between [i] and [j]. In the
questionnaire, 25 native Spanish speakers from 12 different countries were presented a list of
<yV> or <(h)iV> initial words. The participants’ task was to place the appropriate form of the
coordinating conjunction y [i] ‘and’ before the words. This conjunction undergoes a
morphophonemic change when it occurs before /i/-initial words: it becomes e /e/. Thus, we have
madre y abuela ‘mother and grandmother’ but madre e hija ‘mother and daughter. Whitley

55
(1985) calls this change ‘Conjunction Lowering’ and proposes that participants will apply this
rule before words they perceive as iV-initial (i.e. with initial hiatus) but not before words they
consider to be jV-initial (i.e. with initial diphthong, or non iV-initial). His results show a great
influence of orthography. Speakers consistently (around 75% of the time) applied conjunction
lowering before most i-initial words and failed to apply it 100% of the time in y-initial words. On
the other hand, hi-initial words26
exhibited more variation. On the whole, Conjunction Lowering
was more common with “technical or foreign-looking vocabulary” and less common with
“ordinary words” (Whitley, 1985, p. 373). Thus, frequently used, easily recognized words were
more likely to be given a diphthong interpretation while less frequent ones were more likely to
retain a hiatus interpretation. However, what counted as ‘ordinary’ and ‘frequent’ differed from
speaker to speaker. In this case, the influence of dialect was unclear, with different speakers of
the same dialect showing more or less of a hiatic tendency. What appeared to make a difference
was level of education. That is, speakers with the highest levels of education were more likely to
have assimilated some of the less common words into the diphthong category, presumably
because they were more familiar with them (Whitley, 1985, p. 376). The author concludes that a
hiatus pronunciation of /iV/ sequences is un-Spanish and is limited to a small set of “relatively
unusual” (Whitley, 1985, p. 377) words not yet fully assimilated into the language. This set of
words is smaller for highly educated speakers who may regularly use them (or at least be more
aware of them).
3.3.2 Italian
A syllable-intuition methodology was employed by Gili Favela & Bertinetto (1998) in their
study on a hiatus vs. a diphthong pronunciation of vowels which come into contact between
word prefixes and roots. The study tested possible influences on this judgment, including (i)
prefix length (a longer prefix is predicted to result in a diphthong judgment); (ii) segmental
factors, i.e. the quality of the vowels in contact (high vowels /i u/ more likely to diphthongize
due to inherently shorter duration); (iii) the distance of the prefix-final vowel from the stress in
the root (diphthongization becomes more likely the further away the stressed vowel is from root-
initial position); (iv) word frequency effects (more common words predicted to have a
26 Some i-initial words also fell into this category. however, all these were words with more than two syllables and in all cases
the word stress did not fall on the initial iV sequence (e.g. iatrogénicas ‘iatrogenic-fem. plural’).

56
diphthong); (v) semantic factors whereby a prefix creates a contrastive meaning compared to the
same root without the prefix (this would create a hiatus environment); (vi) regional origin of
participant (assumption is that judgments may vary according to regional preferences). In this
study a corpus of words was presented in written list form to 14 participants from different
regional areas of Italy. The results support most of the expected influences on judgment but had
some surprising revelations. First, the participants were found to be very liberal in assigning
diphthong pronunciations (they did this to around 50% of the stimuli), in line with what was
found for Spanish (Face & Alvord, 2004; Cabré & Prieto, 2006). Second, the regional origin of
the participant did not turn out to be significant, although the authors suspect that people from
different regions may weight the various influencing factors differently. Finally, an important
observation pertains to the auditory classification of these sequences on the part of the authors
(done as participants were asked to read the stimuli aloud as part of their interview process).
They find that with repeated exposure to the same sequences, the authors tend to judge more of
them as diphthongs. This observation is particularly relevant for studies which assign participant
productions of such sequences to one category or another based on the auditory discrimination of
the researchers.
Van der Beer (2006) uses a different methodology to explore the asymmetry in perception
between front and back mobile diphthongs in Italian. To set up his perception study, he uses a
speech shadowing task. In this task, 10 native Italian speakers listened to a series of 16
sentences, as recorded by another native Italian speaker, containing the words in which the target
diphthong (either [jɛ] or [wɔ]) or the corresponding simple vowel ([e] or [o]) was removed and
replaced by noise. Because of lexical conditioning effects, nonsense words were also included in
the sample. The job of the participants here was to repeat each utterance as soon as they heard it,
thus presumably filling in the missing portions with either a diphthong or monophthong. In the
second production task, the same 10 speakers were asked to read a list of target words (including
nonsense words) and apply a specific morphological operation (i.e. diminutivation, inflection, or
derivation) to these. From the above two tasks, the researcher collected a total of 217 stimulus
items which were then used for a third task, the perception task. During this final phase, the
tokens were presented to five listeners who then judged whether the token included a diphthong
or a monophthong. These five judges included two Dutch phoneticians and three native speakers
of Italian with no background in phonetics. The results showed that, while the Italian listeners

57
tended to hear more diphthongs than the Dutch, overall both groups of listeners perceived
diphthongization more often with unstressed front vowels than with unstressed back vowels (at
rates of 85% vs. 64%, respectively), suggesting that back diphthongs are indeed more resistant to
levelling effects. That is, front diphthongs are more likely to spread to unstressed positions than
back diphthongs. Van der Beer proposes a perceptual explanation for this phenomenon,
suggesting that the back diphthongs are more likely to be confused with their corresponding
monophthongs, especially in the absence of stress, because they present a “more parallel and
slightly less extended movement of F1 and F2” (Van der Beer, 2006, p. 65) than the front
diphthongs. The first two formants of these back diphthongs, in fact may be so close together (a
difference of approximately 300 Hz) that they “may combine into a single perceived peak” (Van
der Beer, 2006, p. 66). Besides identifying a perceptual asymmetry between front and back
diphthongs, this study also taps into the cross-linguistic differences in judgment of the
diphthong/monophthong distinction. That is, the fact that Dutch listeners perceived more
monophthongs may reflect findings that Dutch speakers prefer their diphthongs with glide
durations of around 120-140 ms (Peeters & Barry, 1989; Peeters, 1991, p. 304) while the mean
glide duration produced by the Italian speakers here was around 52 ms for [w] and
approximately 35 ms for [j] (Van der Beer, 2006, p. 44). The Dutch speakers may have had
difficulty perceiving these short transitions as glides and thus could not make the same
distinction between diphthongs and monophthongs as the native Italian speakers. On the other
hand, if glide duration alone was the selection criterion, we would predict that the Dutch would
hear more monophthongs with [j] since this glide was shorter than [w].
3.3.3 Romanian
Perception experiments for Romanian employ identification and discrimination tasks rather than
syllabification/intuition tasks. In addition, the stimuli used in these experiments have been
excised from production data, thus controlling for lexical bias.
Chitoran (2002) followed up a production experiment where she identified the acoustic (temporal
and spectral) differences between glide-vowel sequences <ia> [ja] and <ua> [wa] and their
corresponding diphthongs <ea> [ea] and <oa> [oa]. Based on the acoustic results, the author
predicted that listeners would be able to correctly distinguish between [ja] and [ea] since these
differ on the acoustic parameters measured. However, she predicted that the participants would

58
have difficulty distinguishing between [wa] and [oa] since no acoustic differences were found
between them. Fourteen native speakers of Romanian heard the sequences and were asked to
identify them by choosing the orthography that corresponded to what they heard <ia> or <ea>,
and <ua> or <oa>. The results closely matched the predictions. The participants correctly
identified [ja] vs. [ea] at a statistically significant rate. On the other hand, identification of [oa]
vs. [wa] was roughly at chance level. The implications of the study are as follows: (i) the
acoustic differences translate into perceptual differences, and (ii) phonological differences (i.e.
between [oa] and [wa]) are not always manifested phonetically. The author suggests that the
explanation for (ii) requires references to both language-specific and language-universal
properties of such sequences (Chitoran, 2002, p. 220-221). First, the sequence [wa] in Romanian
is relatively infrequent, appearing in a few lexical items which are primarily loanwords. In
addition, there is relatively little acoustic difference between [w] and [o], thus this contrast is
inherently difficult to perceive. This observation is in line with findings reported in Van der Beer
(2006), reviewed above.
Marin (2007) uses both identification and discrimination tasks to test her articulatory hypothesis
regarding Romanian diphthongs as synchronously coordinated. Her perceptual experiments
predict that two vowels ([e#a] and [o#a]) which come together across a word boundary will be
perceived as follows (i) as a diphthong when stress gives one of the vowels more prominence, or
(ii) as a single blended vowel when both vowels have equal prominence in the absence of stress.
Consonantal environment was carefully controlled for and all VV sequences were cropped from
production data in a t_p context. For the identification task, the 10 participants heard the
sequences produced by 5 different speakers at 5 different speech rates (as controlled in the
production task through a visible metronome) and had to decide whether they perceived a
diphthong, a single vowel ([e] or [o]) or something else. The results of this first experiment show
that at the fastest rate (5) more diphthongs were heard in the stressed condition and more single
vowels in the unstressed condition. The author interprets these results as supporting her
hypothesis that increases in speech rate result in a “sporadic shift to synchronous coordination
between two vowels” (Marin, 2007, p. 73). This shift in turn leads to the percept of a single
vowel in the absence of stress and of a diphthong in the presence of stress. However, there are
also some asymmetries evident between [e#á] and [o#á] clusters (Marin, 2007, p. 72). Namely,
even in the presence of stress, 23% of [o#á] clusters are still heard as the single vowel [o],

59
whereas only 1% of [e#á] clusters are heard as [e]. The author does not mention this asymmetry
but suggests that fast speech rate causes a loss of boundary and/or stress information, resulting in
a vowel percept. A discrimination task of the AXB type was subsequently used to test perception
at the two fastest speech rates. In the task, the experimental stimuli (X) were presented together
with a diphthong and a single vowel (A and B). The listeners were asked to decide whether X
sounded more like A or more like B. The results from this task show a similar asymmetry as the
one identified in the previous task. That is, more of the unstressed [o#a] sequences (60%) were
perceived as a single vowel than the unstressed [e#a] sequences (19%). This asymmetry suggests
that the synchronous coordination hypothesis proposed by this author is not a case of all or
nothing (i.e. synchronous vs. asynchronous). Rather, there may be degrees of coordination in
vowel-vowel sequences which are more or less synchronous and which are affected by speech
rate and by vowel quality.
3.3.4 Non-Romance Languages
Most perceptual studies conducted on non-Romance (especially Germanic) vowels and
diphthongs have attempted to provide evidence for the relevant parameters which permit
identification of vowels and diphthongs. These studies can be thought of as testing and
comparing one of three possible hypotheses, summarized as follows in Gottfried et al. (1993):
(18) vowel and diphthong hypotheses
(a) onset + offset hypothesis: the relevant cues are the formant values (i.e. F1 and F2)
at beginning and end of the vowel or diphthong
(b) onset + slope hypothesis: the relevant cues are the onset formant values plus the
rate of F2 change over time.
(c) onset + direction hypothesis: the relevant cues are the onset steady state values plus
direction of formant (F1 and F2) movement.
Evidence from these studies has often been contradictory and suggests that results may reflect
the methodology and types of stimuli employed more than the advantage of any one hypothesis.
Gay (1970) used synthesized speech to provide evidence for the onset + slope hypothesis. He
conducted two experiments to examine the perceptual cues needed to identify the American
English diphthongs /ɔi, ai, au/. The first experiment tested the effects of varying formant
frequency transitions on the listeners’ ability to distinguish /ɔi/ from /ai/ and /au/ from /o/
(representing the phonetically diphthongized vowel, [ou]). The continua created for these two

60
groups included different onset and offset values for F1-F3. Duration for all sequences was kept
constant at 250 ms and no V1 and V2 steady states were included. The author reports that
listeners used “differences in the course and extent of formant frequency transitions” (Gay, 1970,
p. 77) to distinguish /ɔi-ai/ and /au-o/. However, since stimulus duration was fixed, rate of
formant movement was confounded with onset and offset frequency positions. The second
experiment aimed to tease apart the separate effects of these two cues. Here, the stimuli rated by
listeners in the first experiment as the best examples of /ɔi, ai, au/ were reduced in 10 ms steps
from 250 ms to 100 ms, either at onset or offset. This allowed for variation in the rate of change
of the F2 transitions. The author reports that truncating /ai/ at the offset from 250 ms to 180 ms
yields an /a/ percept. Similarly, the /ɔi/-/ai/ distinction is based on duration and slope: an /ai/
percept requires a longer duration (250 ms) and a greater rate of formant frequency change than
/ɔi/ (180 ms). Thus, he concludes that the F2 rate of change is the primary perceptual cue in
distinguishing between diphthong and vowel and between different diphthongs. Overall,
however, the experiment is not completely successful in evaluating the perceptual effects of
slope alone since slope and duration are confounded here. Still, an important contribution of this
study is the proposal that diphthongs are not concatenations of two simple vowels since their
onset and offset target positions neither match their simple vowel counterparts nor do they serve
to identify the diphthongs. Diphthongs are also not vowel + glide combinations since the mere
presence of gliding is not enough for their identification. Rather, Gay (1970) suggests it is the
glides’ movement through time that characterizes diphthongs.
Bond (1978), using the same synthesized American English diphthongs as Gay (1970), provides
evidence for the onset + offset hypothesis. Here, the duration of onset and offset steady state
portions of /ɔi, ai, au/ was kept constant (onsets = 70 ms and offsets = 40 ms). Glide duration, on
the other hand, varied in 10 ms steps from 140 ms to 0 ms, thus also varying total diphthong
duration from 100 ms to 250 ms Three VV sequences were also synthesized which contained
onset and offset values identical (in duration and formant values) to the diphthongs /ɔi, ai, au/ but
which were separated by a 50 ms silent gap. Participants were asked to identify each stimulus as
one of the three diphthongs or VV sequences. The participants easily and accurately identified
sequences as diphthongs even when no glide was present, calling into question the role of the
glide in diphthong perception. On the other hand, a silent gap and a very long glide tended to
produce VV identification. The author suggests that listeners also use speaking rate information

61
in order to identify diphthongs and that these long glide durations and gaps were not deemed
appropriate to a fast speaking rate (which the author believes the participants assumed due to the
short glides presented). However, since the total duration of the diphthongs was not kept
constant, glide duration and total diphthong duration are confounded. Perhaps it is this latter
factor which is causing the VV responses rather than a perceived rate of speech.
Support for the onset + offset hypothesis also comes from Bladon (1985) in a study using natural
speech stimuli. The vowel combinations [ia], [iɛ] and [ie] (i.e. sequences with similar initial
formant values and transition direction but different offsets) and the diphthong [ai] were
recorded by a speaker of British English and subsequently altered to produce stimuli for three
tasks. In the first experiment, the offset portions of [ia], [iɛ] and [ie] were cut at various points,
creating stimuli which ranged in duration from 50 ms to 150 ms in increments of 25 ms Four
phonetically-trained listeners transcribed what they heard. The best responses occurred with
stimuli containing the longest offsets and got progressively worse as offset duration decreased.
This suggests that offsets are crucial for diphthong identification. However, none of the stimuli
used actually exist as diphthongs in English, calling into question the application of these results
to the perception of real diphthongs (Peeters, 1991). In the second experiment, the onset portion
of [ai] was cut. While the actual results for this experiment are not reported, the author
nonetheless concludes that they also support the proposal that transition rate does not determine
diphthong identification. A third experiment compared perception of transitionless diphthongs,
monophthongs and transition-only diphthongs. Here listeners were able to correctly identify the
transitionless diphthongs and the monophthongs 100% of the time based only on V1 and V2
formant values. On the other hand, when identification was based on transition values only, the
same listeners had a 54% error rate. These results point to a reduced role played by the transition
in diphthong identification. However, a careful examination of these last results shows that the
use of mean error rate in identification of transition-only diphthongs may be misleading. In fact,
among these diphthongs, [hɔi] and [hɪə] were correctly identified 70% and 90% of the time,
respectively. Thus, it might be that the perceptual value of the transition differs from diphthong
to diphthong in English.
Gottfried et al. (1993) test the three hypotheses for American English diphthongs in an
experiment which uses natural speech (produced by four untrained speakers of American
English) and statistical pattern recognition to evaluate perception. They created stimuli for /aʊ/,

62
/aɪ/, /oʊ/, /ɔɪ/ and /ju/ and varied the consonantal context ([b_d] vs. [h_d]), the stress condition
(test word stressed or unstressed), and speech rate (slow vs. fast). Their results show that the
onset+ offset hypothesis came out slightly on top of the other two (specifying onset and offset
formant values produced a 96% identification rate compared to 94% for the onset + direction
hypothesis and 93% for the onset + slope hypothesis). Clearly, however, all three hypotheses
produce nearly perfect identification rates.
A different approach is taken by Peeters (1991). He argues that what distinguishes vowels,
diphthongs and vowel sequences is not any particular structure or movement pattern since they
all might exhibit movement. Where they differ is in the timing of their movement patterns. Thus,
while both a diphthong and a long vowel may exhibit a similar pattern of movement in two
languages, they will differ in terms of timing (e.g. the proportion allotted to transition may
differ). According to Peeters (1991), these differences are language-specific and what defines the
difference in one language may not do so in another. He tests this hypothesis in a perception
study carried out on listeners of Dutch, English, and German. The study uses the following
synthesized stimuli: (i) the diphthongs /ai/ and /au/; (ii) the diphthongizing vowels /eɪ/ and /oʊ/;
and, (iii) the bi-vocalic (hiatus) sequences /aʔi/ and /aʔo/. For all stimuli, the total duration was
kept constant at 240 ms while the duration of the onset steady state, the glide portion and the
offset steady state varied from 0 to 240 ms. Listeners heard pairs of stimuli and judged which
member was the better example of a diphthong, a long vowel or a bi-vocalic sequence. The pairs
being compared differed in their component durations in 40 millisecond steps. The results
support the hypothesis that different durational patterns are preferred by listeners of different
languages. Thus, English listeners prefer diphthongs with a longer onset (100-120 ms) than their
Dutch or German counterparts (around 60 ms). English listeners also preferred a short offset or
no offset at all; German listeners preferred offsets equal in duration to onsets; and, Dutch
listeners preferred comparatively short offsets but always longer than 20 ms. The differences in
sensitivity to durational patterns may be a function of the vocalic system of each of these
Germanic languages. That is, the degree to which temporal information is used to identify vowel
contrasts by speakers of each language may have perceptual effects (Miller & Grosjean, 1997).
One limitation of this study is that the spectral values for all the stimuli were kept constant across
all the languages. Therefore, these values may have been a confounding factor in the listeners’
judgments. Still, the focus on internal durational organization as both a cue to the perception of

63
diphthongs and as the factor which distinguishes diphthongs from one language to another is
supported by acoustic evidence for similar diphthongs in other languages (e.g. Lindau et al.,
1990). The importance of timing is also underscored in Collier and t’Hart (1983) who found that
for Dutch listeners the important cue was the timing of the transition onset in both the genuine
diphthong /ɛi/ (with an optimal transition onset time of 120 ms) and the pseudo diphthong /aj/
(180 ms). These authors found that rate of change and the presence of an offset steady portion
were not necessary for diphthong identification.
3.3.5 Summary
The experimental studies reviewed in this section serve to highlight issues already observed in
the acoustic and articulatory studies. Namely, it appears that, as in production, the perceptual
parameters which listeners exploit in order to discriminate between vocalic sequences may vary
by language. In addition, the type of sequence being heard may also affect perception. On the
other hand, individual differences in the perception of vocalic sequences have not figured
prominently in these perceptual studies. Thus, the matter of individual variation in perception
and its possible link to individual variation in production warrants a closer look.
4 Conclusions
This chapter has reviewed several important studies on vocalic sequences, both for Spanish and
other languages. All in all, it would seem that the bulk of theoretical and experimental evidence
reveals few universals about vocalic sequences. Similar sequences in different languages, as well
as different sequences within a single language, may show both phonetic and phonological
variation. This variation may become evident in differences in phonological patterning and may
be interpreted in terms of features or syllabic/moraic structure. In addition, the acoustic and
articulatory parameters which serve to define these sequences may show cross-linguistic
differences. Similarly, these parameters may vary for different sequences occurring within the
same language. Finally, individual speakers may exploit these parameters to different degrees.
Thus, it is important to test a variety of sequences and to both account for and control individual
and dialectal variation.
In addition, those phonetic parameters which may serve to distinguish between different
sequences in a language (e.g. diphthongs and hiatus in Spanish) may overlap suggesting that very

64
finely-grained phonetic detail is required to make the distinction. This fine detail may not be
evident in the acoustics or it may become blurred as speech rate increases or a more casual
speech style is adopted. Moreover, the behaviour of vocalic sequences in different syllable
positions as well as the organization of their component gestures (and perhaps even of individual
muscles) may differ from language to language and sequence to sequence. Still, articulation
studies may be able to provide the fine detail that is not apparent in the acoustics (i.e. articulator
sequencing in different syllable positions; phase relationships between articulators) but which
speakers may exploit in their production and perception. Additionally, individual variation in
articulatory strategy may be missed if the acoustic results do not reflect it. For Spanish, however,
most studies have approached the question of the diphthong-hiatus/exceptional hiatus contrast
from either a theoretical or an acoustic perspective. Some recent studies of Spanish vocalic
sequences propose that the difference between diphthongs and hiatuses as well as the variation
associated with these sequences is rooted in articulatory patterns (Chitoran & Hualde, 2007;
Colantoni & Limanni, 2010). However, these proposals are based on acoustic data as articulatory
data on vocalic sequences in Spanish is lacking.
Finally, the perceptual parameters which identify vocalic sequences and distinguish them from
other sequences appear to vary. However, perception studies provide an important link to
production. For Spanish, this link has largely been established through syllabification and
intuition tasks which have often presented stimuli in written form. A serious limitation of such
studies is that they may reflect schooling (i.e. how well a person learned to syllabify certain
words in school) rather than perception. Thus, testing of the production-perception link for
Spanish vocalic sequences would benefit from a different methodology.
In the next three chapters, the issues of production, perception and variation as they pertain to the
study of Spanish vocalic sequences are examined experimentally. Specifically, three experiments
are carried out to investigate the production and perception of vocalic sequences in Mexican
Spanish through a combination of acoustic, articulation and perception data. In addition to
testing the three hypotheses outlined in Chapter 1 (§4), these three experiments will: (i) add to
existing acoustic data on vocalic sequences in Spanish through the investigation of a variety
other than Argentine or Peninsular Spanish; (ii) complement existing acoustic characterizations
of Spanish diphthongs and hiatuses with articulatory data; (iii) contribute to an understanding of
the link between variation in production and variation in perception of these sequences; (iv)

65
provide insight into the prevalence of exceptional hiatuses in a highly diphthongizing variety of
Spanish, and; (v) contribute to research on vowel-vowel coarticulation within and across
syllables. The focus on a single variety of Spanish also allows for an investigation of individual
variation both in the production and perception of the vocalic sequences under study.

66
Chapter 3 Acoustic Analysis of Vocalic Sequences in Mexican Spanish
1 Introduction
In the previous chapter, we learned that Spanish diphthongs and hiatuses can be distinguished
acoustically along frequential and temporal parameters. For example, hiatuses are longer than
diphthongs (Aguilar, 1999; Hualde & Prieto, 2002; Chitoran & Hualde, 2007). Diphthongs,
while shorter, devote a larger proportion of the sequence to the transition between the V1 and V2
steady states. This longer, more gradual transition gives diphthongs a smoother F2 slope and a
smaller degree of curvature in the F2 trajectory (Aguilar, 1999). The shorter, faster transition
associated with hiatuses, on the other hand, is reflected in a steeper F2 slope and greater degree
of curvature in the F2 trajectory (Aguilar, 1999). These differences between diphthongs and
hiatuses are generally maintained across speech rate and/or speech style changes (Aguilar, 1997,
1999). Thus, on the surface, the acoustic contrast between diphthongs and hiatuses appears fairly
strong in Spanish (Chitoran & Hualde, 2007).
On the other hand, there is considerable evidence of blurring across the two categories. For
example, the range of duration values for the two categories may show some overlap (Hualde &
Prieto, 2002; MacLeod, 2007) both within speakers and across speakers. In addition, F2 slope
and the proportion of the sequence taken up by the transition may also vary across speakers
(MacLeod, 2007). Two important consequences of this categorial blurring are (i) the
diphthongization of hiatic sequences, and (ii) the production of exceptional hiatuses (where an
expected [jV] sequence is realized as [iV]). While diphthongization of hiatic sequences is
uncontroversially the predominant tendency in Spanish (e.g. Colantoni & Limanni, 2010;
Garrido, 2007), the production of exceptional hiatuses has received considerable attention (e.g
Hualde, 1999; Harris & Kaisse, 1999; Hualde & Prieto, 2002; Cabré & Prieto, 2006; Chitoran &
Hualde, 2007). The phenomenon of exceptional hiatuses is said to be triggered by historic,
prosodic and/or morphological triggers (e.g. Cabré & Prieto, 2006; Chitoran & Hualde, 2007-
see Chapter 2 for a more thorough discussion). However, the occurrence of exceptional hiatuses
may be overstated as a result of the Spanish varieties and the types of sequences which are the
focus of many of these studies. Some researchers, for example, have found that both sequence
duration (Aguilar, 1997, 1999) and transition duration (Lindau et al., 1990) may be sequence-

67
specific. They may also be language-specific (Lindau et al., 1990; Peeters, 1991) and speaker-
specific (Cabré & Prieto, 2006; Whitley, 1985). As regards exceptional hiatuses, an emphasis on
Peninsular Spanish speakers (with whom exceptional hiatuses are associated) and on sequences
with the vowel [a] (where the articulatory distance between the non-high vowel and the glide is
maximized and which constitute the bulk of exceptional hiatus cases) may be contributing to an
exaggeration of the ‘hiatus’ characterization of these sequences.
The present chapter aims to address some of these concerns by examining the diphthong-hiatus
contrast in a different variety of Spanish, Mexican Spanish. The study presented here has as its
main objectives (i) to investigate the acoustic properties of diphthongs and hiatuses in Mexican
Spanish, and (ii) to examine the intra- and inter-speaker variation in their production. In relation
to these objectives, the study also examines the effects of speech rate on the categorial and
speaker-specific properties of these sequences and explores whether ‘exceptional hiatuses’ (e.g.
Chitoran & Hualde, 2007) occur in this variety of Spanish. The study tests three hypotheses
linked to these goals. The first hypothesis focuses on the acoustic properties that distinguish
diphthongs from hiatuses in Mexican Spanish.
Hypothesis 1
Diphthongs and hiatuses differ acoustically on temporal and frequential measures.
On the temporal measures, sequence duration is greater for hiatuses than for
diphthongs. Conversely, the proportion of the sequence devoted to the transition
is greater for diphthongs than for hiatuses. On the frequential measures, hiatuses
have more peripheral F1-F2 values than diphthongs. These differences between
hiatuses and diphthongs remain constant under different speech rate conditions.
The second hypothesis looks at the effect of the non-high vowel (V) in the sequence on the
above acoustic properties. This is important because, as mentioned above, most instances of
exceptional hiatuses are found in sequences where [a] is the non-high vowel. An examination of
the phonetic properties of sequences with [a] may explain this occurrence.
Hypothesis 2
The quality of the non-high vowel ([a], [e], or [o]) in the sequence will have
acoustic consequences in both the diphthong and hiatus categories. That is, we
expect to find that diphthongs and hiatuses whose V is [a] to differ significantly
from those with [e] or [o]. For example, we predict that sequences with [a]
(because of the greater tongue/jaw trajectory between [j]/[i] and [a]) will be
longer and/or have shorter transitions than sequences with either [e] or [o].

68
The final hypothesis focuses on individual variation in the production of diphthongs and
hiatuses. Because of their dynamic character, the vocalic sequences under study are ideal
candidates for variability, both within and between speakers. This variability may be evident in
the production of diphthongs (e.g. McDougall 2004, 2006; MacLeod, 2007) as well as in the
realization of the diphthong-hiatus contrast (Colantoni & Limanni,, 2010). The focus on a single
variety of Spanish as well as on speakers who are matched on gender and education level permits
a detailed investigation of individual differences in the production of these sequences.
Hypothesis 3
Individuals may use distinctive patterns of articulation to produce diphthongs and
hiatuses and to achieve the diphthong-hiatus contrast. These distinctive patterns
are reflected acoustically in the temporal and/or the frequential measurements and
may give rise to sequences whose category membership is not clear-cut, as in the
case of exceptional hiatuses.
These hypotheses are tested in an experimental study whose methodology is outlined in §2
below. The results of the acoustic analysis are given in §3 and evaluated and discussed in §4. A
brief conclusion given in §5 ends the chapter and sets the stage for the next two experimental
chapters.
2 Experimental Methodology
2.1 Participants
All ten of the participants described in Chapter 1, §4.1 participated in this experiment. These
participants will be referred to here as AA, AM, AN, CG, DH, KR, LG, LL, MM, and MV.
Participants were compensated for taking part in the experiment.
2.2 Stimuli
The target sequences for this experiment were diphthongs in stressed syllables and hiatuses
where the stressed vowel was the first member of the sequence. The experimental materials were
designed to elicit production of these target sequences at two different speech rates: a
normal/slower rate and a faster but still comfortable (i.e. pronounceable) rate. The stimuli set
consisted of 40 real words (Appendix 1). Of these 40 words, 20 were distractors (of interest for
another experiment), 5 of which were used in the practice sentences for the task and 15 of which
contained simple vowels ([a,e,i,o,u]). The remaining 20 words included the following

69
combinations of the target sequences: (i) hiatus [í.a], [í.e], [í.o] and (ii) diphthong: [já], [jé],
[já]27
. Position in the word and stress were not tested. Therefore, all diphthongs appear in the
first syllable of the target words and this first syllable is always stressed. For hiatuses, the
stressed high vowel itself is in the first syllable.
The number of diphthong tokens is higher than the number of hiatus tokens since the diphthong
category also included tokens which have been identified as possible exceptional hiatuses in
other varieties of Spanish (Hualde, 1999; Hualde, 2005; Chitoran & Hualde, 2007). These were
included in order to test whether this category of sequences is present in Mexican Spanish. If, as
hypothesized, these sequences are indeed produced in this variety, we expect to find instances of
[i.á], [i.é] and [i.ó].
Following Aguilar (1999, p.59), the consonants preceding the target sequences were ‘diffuse’
consonants: labials, dentals or alveolars. Due to lexical gaps, however, it was not always possible
to control for the following consonant. The target words were embedded in the carrier sentence
Digo X para ti “I say X for you” and prepared for presentation to the participants for a reading
task. Because the target words consisted of 2 syllables, the sentences contained 7 syllables.
2.3 Tasks and Procedures
Recordings took place in the Communications Functions Lab, Toronto Rehabilitation Institute
(Department of Speech-Language Pathology, U of T). The participants were seated in a sound-
attenuated booth with an Isomax E6 Omnidirectional flat frequency microphone with the ear set
placed over the participants’ left ear and the boom placed just back from the corner of their
mouth. The recordings were made using a Marantz PMD670 Professional portable solid state
recorder with a sampling rate of 48 kHz.
The participants were recorded as they read words containing the target sequences and
distractors. The list of sentences was randomized and presented to the participants on a computer
monitor using DirectRT presentation software (Empirisoft Corp.). Instructions were provided to
27 Although data was collected for both velar and palatal series of sequences, as well as for both rising and falling sequences only
the rising palatal series is analyzed here since it is the most relevant for the hypotheses being tested. Within this series, data was
also collected for diphthongs in unstressed syllables but this is not included here. Therefore, the number of tokens analyzed
reflects only the rising palatal sequences in stressed syllables. The overall total of tokens recorded (including all types of
sequences as well as distractors and practice words) totaled 3720.

70
the participants both in written form (on the computer monitor) and orally. The experimenter was
always available to provide clarifications whenever necessary. Speech rate was controlled by a
visual metronome which consisted of a flashing green light on the computer monitor above the
location where the sentences appeared. The stimuli were presented to the participants according
to the following procedure. The test sentence appeared first on the computer monitor, and then a
red light flashed above the sentence twice at controlled intervals. The purpose of the red light
was to establish the speech rate that the participant was expected to use for that block of
sentences when the green light flashed. Thus, the red light represented the familiarization mode
and the green light the testing mode. The participant, at this point, simply looked at the sentence
and the flashing light. After the red light had flashed twice, a warning beep (a sine wave, 1000
ms in length) sounded indicating to the participant that the green light was about to appear and
that she was to get ready to read out loud. The participants read the sentences at two rates of
speech. The first reading was at a normal/slow rate, with a 1.5 second interval between flashing
green lights. This converts to a speech rate of approximately 4.7 syllables/second. The second
reading was at a faster but still comfortable rate (with a 1.1 second interval between flashing
green lights). This second speech rate is approximately 6.4 syllables/second. These speech rates
were established through testing of various rates in the course of three pilot studies.
For the reading task, participants were instructed to try to synchronize the first word of the
carrier sentence with the flash of the green light and to finish reading the sentence before the
next flash appeared. Five practice trials for each speech rate were used to familiarize the
participants with the task. The participants repeated each practice and test sentence 3 times
consecutively in each trial. Therefore, each target sentence was produced three times at two
speaking rates, resulting in a total of 40*3*2= 312 utterances per participant. Of these, only the
utterances containing the target vowel sequences were analyzed for the present study: 120 per
participant for a total of 1200. The entire experiment lasted approximately one hour. To avoid
fatigue, the participants were given short breaks after every 12-13 trials. In addition, after
completion of each trial, they were asked whether they were ready to proceed with the next trial
or if they needed a pause.
The syllables/second results obtained for each speaker at each speech rate are given in Table 1.
They show that, overall, the mean number of syllables/second was higher than expected for Rate
1(on average, 1 syllable/second faster). For Rate 2, the number of syllables/second more closely

71
matched the expected rate. The individual numbers also point to a great deal of individual
variation in speech rate.
Table 1. Means and SDs of syllables per second produced by Speakers, by Speech Rate
Rate1 Rate2
%increase Speaker syllable/second SD syllable/second SD
AA 5.2 0.23 5.5 0.26 5.8%
AM 4.9 0.36 5.6 0.32 14.3%
AN 5.7 0.18 5.9 0.35 3.5%
CG 6.5 0.17 6.9 0.19 6.2%
DH 6.6 0.30 7.3 0.27 10.6%
KR 6.0 0.25 6.4 0.27 6.7%
LG 6.4 0.29 6.8 0.25 6.3%
LL 6.3 0.42 7.2 0.36 14.3%
MM 6.4 0.19 6.9 0.27 7.8%
MV 5.0 0.33 5.8 0.21 16.0%
GROUP MEAN 5.9 0.67 6.4 0.71 9.1%
Table 1 highlights that, regardless of whether or not they matched the expected rate, all speakers
increased their speech rate from Rate 1 to Rate 2 and a Repeated-Measures ANOVA confirms a
significant effect of Rate (F(1,9) = 49.81, p=0.000). This can be interpreted as evidence that all the
participants conformed to the task requirements and all can be included in the analyses to follow.
However, it is important to point out that, since all the speakers produced more syllables/second
than predicted for Rate 1, the percentage increase from Rate 1 to Rate 2 was smaller than the
expected 36%. In fact, the increase was less than 20% for all the speakers and for some (e.g. AA
and AN) the increase was negligible.
2.4 Measurements and Analyses
Acoustic studies of diphthongs and hiatuses have generally characterized these sequences as
consisting of three portions: the first vowel target (V1), the second vowel target (V2) and the
transition (T) between V1 and V2. The assumption of this tripartite organization has been useful
in identifying the acoustic properties which distinguish diphthongs from hiatuses. However, this
assumption potentially results in difficulties in measurement, especially since V1 and V2 steady
states may not always be clear for diphthongs (Aguilar, 1999; Kinoshita & Otanai, 2006).
Aguilar (1999) avoids these difficulties by employing a dynamic analysis procedure (a 14-order
LPC analysis performed every 10 ms with a 20 ms window) rather than the traditional
segmentation procedure (V1-T-V2) to model formant trajectories (F1 and F2).

72
The present study follows the tradition of previous acoustic experiments in considering both
frequential and temporal measurements of the target sequences. In terms of how and where to
take these measurements, a middle ground is taken. With frequential measurements, the view
that diphthongs may not always be neatly broken up into readily measurable segments
identifiable as V1-T-V2 is taken. Thus, on these measures, a more dynamical approach is used.
However, for the temporal measurements, both the duration of the entire sequence and the
duration of the transition portion are considered for the following reasons. First, the duration of
the entire sequence allows a comparison between diphthongs and hiatuses. Second, where the
difference in overall duration between diphthongs and hiatuses is not statistically significant (as
may be the case for some speakers, e.g. Colantoni & Limanni, 2010) the transition duration may
still show differences between them. In those cases, the transition portion would still be
measurable even where a V1 and/or a V2 steady state are not present or are difficult to measure.
To prepare the data for measurement and analysis, the carrier sentences were extracted from the
recordings. Then the words containing the target sequences were extracted from these sentences
and saved in separate sound files. Next, word tokens were coded in Excel as Diphthong or Hiatus
as per their expected production (Sequence Type). The independent variables were coded as
follows:
(i) Non-high Vowel (V): [a], [e], [o].
(ii) Speech Rate: Rate 1 and Rate 2.
Subsequent to coding, temporal (§2.4.1) and frequency (§2.4.2) measurements were taken using
Praat (Boersma & Weenink, 2010).
2.4.1 Temporal Measurements
For these measurements, demarcations made on the individual sound files were used to create
annotated Textgrid files in Praat. These files were then used to run scripts which calculated the
durations and wrote the output to an Excel file. The measurements used include:
(i) duration (in ms) of the entire vocalic sequence.
(ii) duration (in ms) of the sequence transition.
For the first measurement, the onset and offset of each sequence were determined using
information from both the waveform and the spectrogram. Specifically, increases in F1 and in

73
intensity were used to determine the sequence onset while a decrease in F1 was used to mark the
sequence offset. The transition duration was measured using criteria outlined in Chitoran (2002)
and Colantoni & Limanni (2010), based on guidelines established in Ren (1986, p. 74). Namely,
the transition onset was determined as the highest F2 before a drop of around 20 Hz. The offset
of the transition was marked as the point where a steady state for V2 began or in cases where no
steady state was detectable, the point where the following consonant began. Figure 1 illustrates
the measurements for sequence and transition duration.
Figure 1. Spectrogram of a token of [jó] produced by speaker CG, showing the boundaries
for sequence and transition duration measurements
These raw duration measurements were then normalized as follows. The sequence duration was
normalized using a z-transformation procedure known as the Lobanov method (cited in Wang,
2007, p. 90) where each participant’s mean sequence duration score ( X calculated across all
tokens for that speaker) was subtracted from her raw score (x, for the individual token) and
divided by her standard deviation (SD, calculated across all tokens for that speaker). The formula
for this procedure is as follows:

74
(19) Lobanov method normalization: z = SD
Xx
For example, Speaker AA had a mean sequence duration score of 187.07 ms (SD=55.52 ms).
Her score for the word bienes (Rate 1, repetition 1) was 161.62 ms Using these numbers in the
above formula, the normalized score (z) for this token of bienes is -0.46, approximately one-half
SD shorter than her mean sequence duration across all tokens (which now represents the zero
point): -0.46 =52.55
07.18762.161.
This normalization allows for the comparison of vocalic sequences across speakers regardless of
individual variation in speech rate. The transition duration, on the other hand, was normalized as
a proportion of the raw duration of the sequence (e.g. Lindau et al., 1990; Aguilar, 1997;
Colantoni & Limanni, 2010). This allows for the comparison of transition durations in sequences
of different durations.
2.4.2 Frequency Measurements
A second script was applied to the sequence duration Textgrid files created in Praat. This script
first divided the total duration of each sequence into 10 equal intervals (McDougall, 2004, 2006;
McDougall & Nolan 2007), as shown in Figure 2. The script then calculated the mean
frequencies of F1 and F2 at the midpoint of each interval and wrote the output to an Excel file
for analysis. This procedure preserves the dynamical aspect of each formant contour while it
time-normalizes each formant contour so that the frequential properties of sequences of different
durations can be easily compared. The frequencies were checked for any clearly odd numbers
and in those cases, frequencies were measured manually.

75
Figure 2. Spectrogram of a token of [jó] produced by speaker CG, showing the 10 intervals
where F1 and F2 frequency measurements were made
Prior to analysis, the Hertz values for all frequencies were transformed to Bark using the
following formula proposed by Traunmüller (1990) (cited in Wang, 2007, p. 88; Hayward, 2000,
p. 142):
(20) Bark = [(26.81 × F) / (1960 + F)] – 0.53, where F = the formant frequency in Hertz
The shape and size of each individual participant’s vocal tract influences these formant values.
Thus, formant values for the same sequence are expected to differ according to participant. The
Bark transformation (a ‘vowel-intrinsic’ technique which uses values from single vowel tokens),
however, may not be the best technique for equalizing the effects of vocal tract variation. In fact,
some authors (e.g. Adank et al., 2004; Flynn, 2011) have found that ‘vowel-extrinsic’ techniques
which use information from multiple vowel tokens (i.e. the Lobanov method cited above)
perform better at minimizing inter-speaker variation.28
Unfortunately, because of the large
number of points measured for each sequence, the z-normalization procedure could not be
carried out. Such a procedure has proved useful for normalizing simple vowel frequencies when
28 All methods tested, however, were found to perform better than raw Hertz values (Adank et al., 2004; Flynn, 2011).

76
measurements are taken either at a single point (i.e. vowel mid-point) or at most at 3 relatively
steady points (Wang, 2007, p. 89). However, when this procedure was applied to the data in the
present study, it distorted the properties of the formant contours of the sequences. This distortion
creates a problem since, for this experiment, we are interested in the relative shape of the formant
contours of these sequences, rather than any absolute formant values. In addition, this type of
frequency normalization is often used to control for gender differences. Thus, because all the
participants were women of similar size and height, variation due to vocal tract size is at least
partially controlled for.
Results for all the above measurements were evaluated statistically29
using Excel and Minitab 14,
with p level set at .05. For these analyses, only the expected realizations (Sequence Type) of the
sequences are used rather than the actual production of the sequences (i.e. those cases where
Diphthong may be realized as Hiatus or cases where Hiatus is realized as Diphthong). The
purpose of this was to avoid using a subjective measure, such as auditory determination by the
author or other listener, to decide if a sequence is realized as a diphthong, hiatus or exceptional
hiatus (e.g. Hualde & Prieto, 2002; Face & Alvord, 2004). Nevertheless, to test Hypothesis 3,
we also needed to determine how well the sequences fit into their expected categories based on
the acoustic parameters (i.e. temporal and frequential) described above and whether ambiguous
sequences exist for this variety of Spanish. Specifically, we were interested in identifying
instances of expected hiatuses produced as diphthongs, and, especially, instances of expected
diphthongs produces as hiatuses (i.e. exceptional hiatuses). Normally, this determination would
be based on auditory discrimination on the part of the researcher or on the syllabification
intuitions of the participants or other native speakers (e.g. Hualde & Prieto, 2002; Face &
Alvord, 2004). However, previous experience, schooling and expectations of how words should
29 Before the data was submitted to statistical analyses, tests for normality of distribution and for equality of variances were
carried out to determine whether the data conformed to the requirements of parametric analyses. Anderson-Darling (AD) tests for
normality of distribution show that both Diphthong and Hiatus categories are normally distributed in terms of normalized
sequence duration and %Transition at both speech rates tested (i.e. p > 0.05 in all cases). The p values obtained are as follows:
(i) normalized duration: Diphthong (Rate 1: p=0.313; Rate 2: p=0.701); Hiatus (Rate 1: p= 0.958; Rate 2: p=0.122), and (ii)
%Transition: Diphthong (Rate 1: p=0.503; Rate 2: p=0.732); Hiatus (Rate 1: p=0.502; Rate 2: p=0.699).
In addition, there were no significant differences between Diphthong and Hiatus at either rate of speech in terms of variance.
Thus, Bartlett’s test values were not significant (i.e. p > 0.05 in all cases, although they approach significance for normalized
duration): for normalized duration, p=0.052; for %Transition, p=0.532.
The frequency measurements, on the other hand, deviated from a normal distribution at several of the time points sampled. Thus,
for those measurements only the equality of variances requirement was met. The results of the Levene’s test (appropriate for any
continuous distribution) show no significant difference in variance between Diphthong and Hiatus in F1 and F2 at either speech
rate: (i) Rate 1 (F1: p=0.151; F2: p= 0.704) and (ii) Rate 2 (F1: p=0.670; F2: p=0.568).

77
be pronounced may affect this judgment (e.g. Docherty, 2003). In addition, repeated exposure to
the same sequences may result in an increased tendency to classify those sequences as
diphthongs (Gili Favela & Bertinetto, 1998). Thus, a more objective way of assigning a surface
category is desirable. The technique used in the present study is described next.
2.4.3 Discriminant Analysis
We use Discriminant Analysis (DA), a multivariate statistical technique used to decide category
membership based on certain measurable predictors (Grimm & Yarnold, 1995). The usefulness
of this technique in phonetics is supported by research which suggests that Discriminant
Analysis is useful in identifying perceptually distinctive contrasts (Port & Crawford, 1989; Faber
& DiPaolo, 1995; Morrison, 2006). An added benefit of DA, especially for the present
experiment, is that the technique works with unequal sample sizes as long the sample size of the
smallest group (in this case, Hiatus) exceeds the number of predictor variables by a factor of 4 or
5 (a condition which this experiment meets). In the present study, category membership is
defined as either Diphthong or Hiatus and the predictors are the durational and frequential
parameters identified in previous sections: normalized sequence duration, proportion of sequence
taken up by the transition, and time-normalized F1-F2 measurements.
The statistical program used to carry out the DA analysis (Minitab 14) uses a measure of squared
distance between groups to classify all observations (i.e. a Mahalanobis distance, D2).
Specifically, a token is classified as Diphthong or Hiatus depending on the degree of difference
of its squared distance to the group mean for the two groups. Any Diphthong tokens
misclassified as Hiatus may be considered cases of exceptional hiatus. Similarly, any Hiatus
tokens misclassified as Diphthong can be considered diphthongized. In all cases, a cross-
validation procedure available in Minitab was also used to assess the classification probabilities
of each token and to correct the error rates.
To test the validity of the Mahalanobis’ distance30
as the criterion for discrimination between the
two categories (Diphthong and Hiatus) an F statistic was calculated and assessed against the
critical F-value associated with the 5% significance level, using the following formula (based on
Gardiner 1997: 316):
30 A test of significance for the discriminant functions is not available in Minitab.

78
(21)
Where: = number of samples for Diphthong
= number of samples for Hiatus
= number of predictors
= the Mahalanobis distance measure
The degrees of freedom for the above equation were calculated as follows: df1=p and df2=
.
The results of all analyses are reported next.
3 Results
3.1 Sequence Duration
In this section we examine the duration of the sequences under study to determine whether there
is a difference on this measure between Diphthong and Hiatus. In interpreting the normalized
duration values, a positive number reflects a duration which is greater than the mean duration for
all sequences (represented by the zero point) while a negative number reflects a duration which
is smaller than the mean duration for all sequences. For both raw and normalized scores, we
predict that the duration values for hiatuses will be greater than the duration values for
diphthongs. A summary of the descriptive statistics for both raw and normalized sequence
durations is provided in Table 2.
Table 2. Means and SDs of raw and normalized sequence duration for Diphthong and
Hiatus, by Speech Rate
Rate 1 Rate 2
Measurement Sequence Type Mean SD Mean SD
raw duration Diphthong 137.86 42.76 121.34 40.32
Hiatus 177.73 36.26 165.74 36.71
normalized
duration
Diphthong 0.34 0.88 -0.16 0.83
Hiatus 1.57 0.72 1.19 0.60
To illustrate the importance of normalizing sequence durations, we examine the raw data first.
The differences between Diphthong and Hiatus for the group are illustrated in Figure 3, where
we observe a clear durational difference between Diphthong and Hiatus at both speech rates.

79
Sequence Type
Du
rati
on
(m
se
c.)
HiatusDiphthong
200
150
100
50
0HiatusDiphthong
Rate = 1 Rate = 2
*Bars are One Standard Error from the Mean
Figure 3. Bar chart of mean sequence duration (ms) by Sequence Type and Speech Rate
A repeated-measures ANOVA (Table 3) with within-subject factors Rate (1 vs. 2) and Sequence
Type (Diphthong vs. Hiatus) confirms our observations31
. First, we find a significant effect of
Sequence Type. Thus, the mean duration of Hiatus is significantly longer than the mean duration
of Diphthong. We also observe a significant Rate effect. However, the Rate*Sequence Type
interaction is not significant. Therefore, although the durations of both Diphthong and Hiatus
decrease as speech rate increases, the category difference remains constant at the two rates of
speech.
Table 3. ANOVA table for differences between Diphthong and Hiatus in raw sequence
duration (ms), by Speech Rate
Source F(df term, df error) p
Main effects Sequence Type F(1,9)=119.80 0.000
Rate F(1,9)=15.14 0.004
Interaction Sequence Type*Rate F(1,9)=0.88 0.372
Other Speaker F(9,27)=16.41 0.000
31 In this and all subsequent ANOVA tables, significant p-values are shaded gray.

80
When we look at the individual data in Figure 4, we see that all the speakers follow the same
pattern32
. That is, for all speakers Hiatus is longer than Diphthong and this difference remains
constant across speech rates. The data also serves to point out that, for most speakers, both
Diphthong and Hiatus are shorter at Rate 2 than they are at Rate 1. However, this durational
difference according to speech rate does not apply to all the speakers, especially for Hiatus
sequences. For example, speakers KR and MM had virtually identical mean durations for
hiatuses at Rate 1 and Rate 2. Speaker AA, on the other hand, produced longer (rather than
shorter) hiatuses at Rate 2. Thus, even though all the participants were found to have increased
their speech rate in terms of overall syllables per second (refer to Table 1, §2.3) some of them
appear to have maintained a constant rate of speech at the sequence level.
The individual data also points to variability in the duration of Diphthong and Hiatus. These
differences are highlighted in Figure 4 and are mirrored in a significant Speaker effect in the
analysis (Table 3). That is, some speakers have mean Hiatus durations which are similar to or
smaller than the mean Diphthong durations of other speakers (in agreement with previous
research, e.g. Hualde & Prieto, 2002). In particular, Speakers AA and AM have mean Diphthong
durations that are approximately equal to or greater than the mean Hiatus durations of almost all
the other speakers. This highlights the necessity to normalize the raw data in order to adequately
compare Diphthong and Hiatus durations across speakers.
32 The individual and group means and standard variations are found Appendix 2 (Table A2.1)

81
Du
rati
on
(m
se
c.)
200
100
0
200
100
0
21 21
Rate 21
200
100
0
21
A A A M A N C G
DH KR LG LL
MM MV
Sequence Type
Diphthong
Hiatus
*Bars are One Standard Error from the Mean
Figure 4. Bar chart of mean sequence duration (ms) by Sequence Type, Speech Rate and
Speaker
The normalized sequence duration data (given in Table 2 and illustrated in Figure 5) suggest that
the Hiatus category is associated with a relatively large positive number at Rate 1 and a smaller
positive number at Rate 2. The Diphthong category, on the other hand, hovers around zero (i.e.
the mean duration of all sequences). These sequences are associated with a small positive
number at Rate 1 and with a small negative number at Rate 2. An increase in speech rate then
results in Hiatus moving closer to zero and Diphthong moving away from zero in a negative
direction. In other words, both the Hiatus and Diphthong categories get shorter as speech rate
increases. This pattern of durational differences is maintained across speech rates and is the same
as what was found with the raw data.

82
Sequence Type
Du
rati
on
(n
orm
aliz
ed
)
HiatusDiphthong
2
1
0
-1
-2HiatusDiphthong
Rate = 1 Rate = 2
*Bars are One Standard Error from the Mean
Figure 5. Bar chart of mean sequence duration (normalized) by Sequence Type and Rate
The results for the repeated-measures ANOVA (Table 4) also mirror the results found in the raw
data. Thus, we find significant main effects of Sequence Type and Rate. The Rate*Sequence
Type interaction, however, is not significant. That is, although both Diphthong and Hiatus are
shorter at Rate 2 than at Rate 1, Diphthong is shorter than Hiatus at both rates of speech. The
overall difference between Diphthong and Hiatus is 1.23 at Rate 1 and 1.34 at Rate 2 (Table
A2.1, Appendix 2).
Table 4. ANOVA table for differences between Diphthong and Hiatus in sequence duration
(normalized), by Speech Rate
Source F(df term, df error) p
Main effects Sequence Type F(1,9)=84.54 0.000
Rate F(1,9)=19.79 0.002
Interaction Sequence Type*Rate F(1,9)=0.72 0.419
Other Speaker F(9,27)=0.27 0.970

83
Figure 6 shows that all speakers behave in this manner, even those who deviated from this
pattern on the raw durations33
. Thus, because normalization eliminates the variance due to
individual speech rate differences, we no longer find any overlap in global Diphthong and Hiatus
duration between speakers and, statistically, there is no significant Speaker effect now (Table 4).
However, individual variation in the realization of Diphthong and Hiatus is preserved. Therefore,
for some speakers the durational difference between Diphthong and Hiatus is larger than for
others. For example, MV appears to have comparatively long diphthongs at Rate 1, resulting in
the smallest durational difference between Diphthong and Hiatus of all the speakers (at 0.26,
Table A2.2, Appendix 2). Speakers CG, DH and KR, on the other hand, produced the largest
durational differences between Diphthong and Hiatus at both speech rates.
Du
rati
on
(n
orm
aliz
ed
)
2
0
-2
2
0
-2
21 21
Rate 21
2
0
-2
21
A A A M A N C G
DH KR LG LL
MM MV
Sequence Type
Diphthong
Hiatus
*Bars are One Standard Error from the Mean
Figure 6. Bar chart of mean sequence duration (normalized) by Sequence Type, Speech
Rate and Speaker
33 The individual and group means and standard variations are found in Appendix 2 (Tables A2.2).

84
3.1.1 Vowel Effects on Sequence Duration
Here, we examine whether the non-high vowel (V) in the vocalic sequences under study has any
effect on the duration of the sequence and, if so, whether the effect is different for diphthongs
and hiatuses. Our prediction is that sequences where V= [a] will be longer than those where V=
[e] or [o]. The group descriptive statistics for this section are summarized in Table 5.
Table 5. Means and SDs for sequence duration (normalized) of Diphthong and Hiatus, by
Sequence Type, Rate and V
Sequence Type
Rate 1 Rate 2
Vowel Mean SD Mean SD
Diphthong
[a] 0.77 0.80 0.17 0.69
[e] 0.08 0.89 -0.34 0.93
[o] 0.05 0.67 -0.39 0.66
Hiatus
[a] 1.85 0.74 1.29 0.57
[e] 1.29 0.55 0.93 0.60
[o] 1.27 0.60 1.24 0.59
The overall data (Figure 7 and Table 5)34
suggests a slightly different pattern of V effects for
diphthongs and hiatuses. For diphthongs, we observe that at both speech rates sequences with [a]
are noticeably longer that those with [e] or [o], while the differences between sequences with [e]
and [o] are relatively small. For hiatuses, on the other hand, the above pattern is found only at
Rate 1. At Rate 2, hiatuses with [e] are shortest and little difference is observed between hiatuses
with [a] and those with [o].
34 The individual and group means and standard variations for this section are found in Appendix 2 (Tables A2.3 through A2.5).

85
Du
rati
on
(n
orm
aliz
ed
)
V [o][e][a]
2
1
0
-1
-2[o][e][a]
Rate = 1 Rate = 2
Sequence Type
Diphthong
Hiatus
*Bars are One Standard Error from the Mean
Figure 7. Bar chart of mean duration (normalized) by Sequence Type, Speech Rate and V
A repeated-measures ANOVA with factors Rate (1 vs. 2), Sequence Type (Diphthong vs. Hiatus)
and V ([a] vs. [e] vs. [o]) yielded significant main effects for all the main factors tested. Among
the interactions, only Rate*V was significant.
Table 6. ANOVA table for differences between Diphthong and Hiatus in sequence
duration (normalized), by Speech Rate and V
Source F(df term, df error) p
Main effects
Sequence Type F(1,18)=9.43 0.000
Rate F(1,18)=16.37 0.003
V F(2,18)=23.80 0.000
Interactions
Rate*Sequence Type F(1,18)=1.46 0.258
Rate*V F(2,18)=8.16 0.003
Sequence Type*V F(2,18)=2.30 0.129
Rate*Sequence Type*V F(2,18)=2.67 0.097
Other Speaker F (9,99)= 0.33 0.945
The results for Sequence Type and Rate are as expected: hiatuses are longer than diphthongs and
all sequences are longer at Rate 1 than at Rate 2. The results for the main effect of V confirm that
[a], [e] and [o] have different effects on sequence duration. Post-hoc comparisons (Bonferroni)
between levels of factor V show where these V effects occur.

86
Table 7. Bonferroni post-hoc tests for differences between Diphthong and Hiatus in
sequence duration (normalized), by Speech Rate and V
Vowel vs. t-value p
V
[a] [e] -11.91 0.000
[a] [o] -10.67 0.000
[e] [o] 1.23 0.702
Rate*V
[a] [e] -9.92 0.000
Rate1 [a] [o] -10.22 0.000
[e] [o] -0.30 1.000
[a] [e] -6.92 0.000
Rate2 [a] [o] -4.88 0.002
[e] [o] 2.04 0.835
Rate*Sequence Type*V
Diphthong
Rate1
[a] [e] -9.03 0.000
[a] [o] -7.46 0.000
[e] [o] -0.28 1.000
Rate2
[a] [e] -6.80 0.000
[a] [o] -5.87 0.000
[e] [o] -0.49 1.000
Hiatus
Rate1
[a] [e] -3.41 0.045
[a] [o] -3.47 0.035
[e] [o] -0.06 1.000
Rate2
[a] [e] -2.19 1.000
[a] [o] -0.35 1.000
[e] [o] 1.59 1.000
The above comparisons reveal that sequences with [a] are significantly longer than those with
either [e] or [o]. The difference between [e] and [o], however, is not significant. The Rate*V
interaction found above would seem to suggest that these differences among levels of V should
occur only at one of the speech rates. The post-hoc comparisons for all levels of Rate*V,
however, show that the differences between [a] and [e] and [a] and [o] hold at both speech rates.
These results do not coincide with our observations of what happens to Hiatus at Rate 2. Further
analysis reveals that, in fact, when Diphthong and Hiatus categories are considered separately,
the effects of V on Rate 2 hiatuses are not significant. Thus it appears that differences between
Diphthong and Hiatus may be influencing the Rate*V interaction even though no significant
Rate*Sequence Type*V interaction is found.
To summarize, based on the above results, we can tentatively propose the following hierarchies
of sequence duration according to Sequence Type, Speech Rate and V:

87
(i) Diphthongs (all) and Hiatuses (Rate 1): [a]>[e],[o]
(ii) Hiatuses (Rate 2): [a]=[e]=[o]
Although the group data contains no significant Speaker effect (Table 6), we do see some
individual variation (Figure 8, Tables A2.3-A2.5, Appendix 2), especially with the hiatuses. With
Diphthong, speakers followed the durational differences identified above. In other words, all the
speakers produced longer diphthongs with [a] at both speech rates, with the difference being
greater at Rate 1. In addition, speakers MM and MV produced comparatively long [a] diphthongs
at Rate 1, suggesting a hiatus pronunciation of [já] sequences. In fact, their diphthongs with [a]
(Figure 8) are either comparable to (in the case of MM) or longer than (in the case of MV) their
hiatus counterparts.
Du
rati
on
(n
orm
aliz
ed
)
2
0
-2
2
0
-2[o][e][a] [o][e][a]
V [o][e][a]
2
0
-2[o][e][a]
A A A M A N C G
DH KR LG LL
MM MV
Sequence Ty pe
Diphthong
Hiatus
Rate = 1
Du
rati
on
(n
orm
aliz
ed
)2
0
-2
2
0
-2[o][e][a] [o][e][a]
V [o][e][a]
2
0
-2[o][e][a]
A A A M A N C G
DH KR LG LL
MM MV
Sequence Ty pe
Diphthong
Hiatus
Rate = 2
Figure 8. Bar chart of mean duration (normalized) by Sequence Type, V and Speaker:
Rate 1 and Rate 2
With Hiatus, we find more variability. Although less obvious than with Diphthong, most
speakers (except CG and MV) do adhere to the overall pattern of longer [a] hiatuses at Rate 1. At
Rate 2, differences due to V are less obvious for most speakers, also in line with the overall data.
A couple of speakers show distinct patterns. For example, DH produces short hiatuses with [e] at
both speech rates. This suggests a diphthongized production of the word ríen. MV, on the other

88
hand has comparatively short [o] hiatuses at Rate 1, suggesting a diphthongized production of
ríos.
It’s also important to note that while the differences between Diphthong and Hiatus sequences
were significant for all three non-high vowels, the amount of difference varies according to V
(Tables A2.3-A2.5, Appendix 2). Thus, although sequences with [a] tend to be longest overall,
the difference between [já] and [í.a] is smallest at just over 1 SD (1.08 at Rate 1; 1.12 at Rate 2).
The differences between [jé] and [í.e] (1.21 at Rate 1; 1.28 at Rate 2) and between [jó] and [í.o]
(1.22 at Rate 1; 1.63 at Rate 2) are slightly greater. Thus, diphthong and hiatuses where V= [a]
are closer to each other in duration than their counterparts with [e] or [o].
3.2 Transition Duration
We turn now to our second temporal measurement. Transition duration was measured according
to the criteria outlined in §2.4. As with sequence durations, these raw measurements were
normalized in order to account for sequences and transitions of different durations. In this case,
the sequence transition (T) duration was normalized as a proportion (reported as a percentage,
%Transition) of the raw duration (in ms) of the sequence (e.g. Lindau et al., 1990; Peeters, 1991;
Colantoni & Limanni, 2010) since we are interested only in the relative duration of the transition
rather than its absolute duration. This is because the relative duration of the transition may be
maintained or increased as speech rate changes (i.e. by manipulating the duration of the other
portions of the sequence) while the absolute duration of the sequence is generally expected to
change according to speech rate (as we saw in §3.1). On this measure, we predict that diphthongs
will have a greater %Transition than hiatuses. The descriptive statistics for this measure are
summarized in Table 8.
Table 8. Means and SDs of %Transition for Diphthong and Hiatus, by Speech Rate
Rate 1 Rate 2
Measurement Sequence Type Mean SD Mean SD
%Transition Diphthong 47.34 12.97 47.49 13.73
Hiatus 34.21 8.35 35.71 7.51
As predicted, the transition takes up a larger proportion of the sequence in Diphthong than it
does in Hiatus (Table 8 and Figure 9)35
.
35 The individual and group means and standard variations for this section are found in Appendix 2 (Table A2.6).
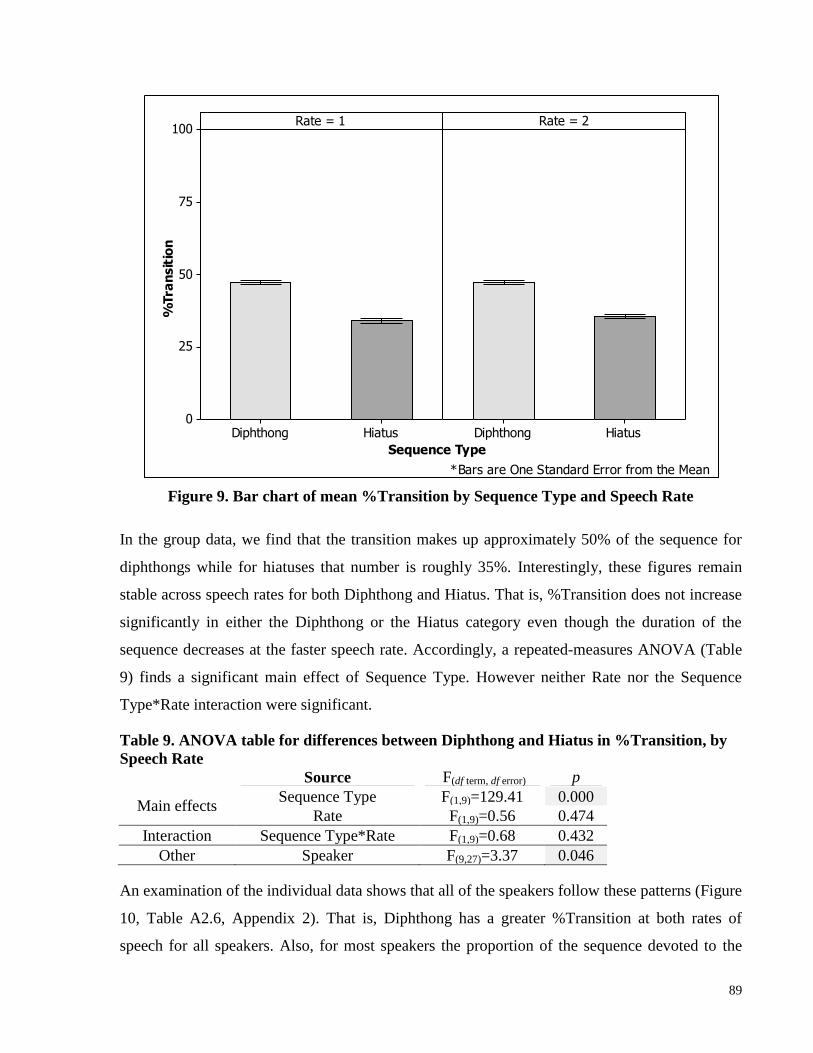
89
Sequence Type
%Tra
nsit
ion
HiatusDiphthong
100
75
50
25
0HiatusDiphthong
Rate = 1 Rate = 2
*Bars are One Standard Error from the Mean
Figure 9. Bar chart of mean %Transition by Sequence Type and Speech Rate
In the group data, we find that the transition makes up approximately 50% of the sequence for
diphthongs while for hiatuses that number is roughly 35%. Interestingly, these figures remain
stable across speech rates for both Diphthong and Hiatus. That is, %Transition does not increase
significantly in either the Diphthong or the Hiatus category even though the duration of the
sequence decreases at the faster speech rate. Accordingly, a repeated-measures ANOVA (Table
9) finds a significant main effect of Sequence Type. However neither Rate nor the Sequence
Type*Rate interaction were significant.
Table 9. ANOVA table for differences between Diphthong and Hiatus in %Transition, by
Speech Rate
Source F(df term, df error) p
Main effects Sequence Type F(1,9)=129.41 0.000
Rate F(1,9)=0.56 0.474
Interaction Sequence Type*Rate F(1,9)=0.68 0.432
Other Speaker F(9,27)=3.37 0.046
An examination of the individual data shows that all of the speakers follow these patterns (Figure
10, Table A2.6, Appendix 2). That is, Diphthong has a greater %Transition at both rates of
speech for all speakers. Also, for most speakers the proportion of the sequence devoted to the

90
transition changes only minimally at the faster rate of speech (Rate 2) for both Diphthong and
Hiatus. On the other hand, there is some variability in the amount of difference between
Diphthong and Hiatus. For example, for Rate 1 this difference ranges from a low of 3.22% (for
CG) to a high of 21.75% (for KR). For Rate 2 the range is from 4.11% (for CG again) to 16.46%
(for LG). This variability is responsible for the significant Speaker effect seen in the data.
%Tra
nsit
ion
100
50
0
100
50
0
21 21
Rate 21
100
50
0
21
A A A M A N C G
DH KR LG LL
MM MV
Sequence Type
Diphthong
Hiatus
*Bars are One Standard Error from the Mean
Figure 10. Bar chart of mean % Transition by Sequence Type, Speech Rate and Speaker
3.2.1 Vowel Effects on Transition Duration
The effects of non-high vowels (V) on %Transition are examined next. On this measure, we
predict that sequences with [a] will have a smaller %Transition than sequences with [e] or [o]. A
summary of the descriptive statistics for the group are given in Table 1036
.
36 The individual means and standard variations for this section are found in Appendix 2 (Tables A2.7 – A2.9).

91
Table 10. Means and SDs for %Transition of Diphthong and Hiatus, by Sequence Type,
Rate and V
Rate 1 Rate 2
Sequence Type Vowel Mean SD Mean SD
Diphthong
[a] 44.24 10.72 49.59 12.18
[e] 48.22 14.37 53.14 18.67
[o] 51.58 12.41 59.83 18.80
Hiatus
[a] 33.95 6.81 36.67 6.81
[e] 32.07 10.08 33.50 8.73
[o] 36.85 8.82 35.98 7.34
Similar to what we observed on the measure of normalized sequence duration, the group results
for %Transition (Figure 11 and Table 10)37
suggest a different pattern of V effects for
diphthongs and hiatuses. For diphthongs, we observe that, as predicted, sequences with [a] have
a shorter %Transition than diphthongs with [e] or [o], especially at Rate 1. At Rate 2, the
difference between [a] and [e] appears smaller while the difference between [a] and [o] remains.
For hiatuses, very little difference is observed in %Transition between sequences with [a] and
those with [o] at either speech rate.
%Tra
nsit
ion
V [o][e][a]
100
75
50
25
0[o][e][a]
Rate = 1 Rate = 2
Sequence Type
Diphthong
Hiatus
*Bars are One Standard Error from the Mean
Figure 11. Bar chart of mean % transition by Sequence Type, Speech Rate and V
37 Refer also to Appendix 2 (Tables A2.7 – A2.9).

92
A repeated-measures ANOVA finds significant main effects of Sequence Type and V as well as
a significant Sequence Type*V interaction. Rate, however, once again is not significant.
Table 11. ANOVA table for differences between Diphthong and Hiatus in %Transition, by
Speech Rate and V
Source F(df term, df error) p
Main effects
Sequence Type F(1,18)=134.08 0.000
Rate F(1,18)=0.38 0.551
V F(2,18)=6.09 0.010
Interactions
Rate*Sequence Type F(1,18)=0.27 0.617
Rate*V F(2,18)=0.56 0.579
Sequence Type*V F(2,18)=5.76 0.012
Rate*Sequence Type*V F(2,18)=0.69 0.515
Other Speaker F(9,99)=2.87 0.062
Post-hoc comparisons (Bonferroni) in Table 12 show that the significant V effect is largely due
to the effect of V on %Transition in diphthongs only. For Hiatus, the quality of V does not have
an effect on %Transition. Therefore, no significant differences exist in the data between hiatuses
with [a] and those with either [e] or [o]. For the Diphthong category, on the other hand,
sequences with [a] have significantly smaller %Transition than those with [o]. However, contrary
to our observations and predictions, diphthongs with [a] do not differ significantly from
diphthongs with [e] while diphthongs with [e] and [o] also differ significantly. Importantly, as
with the normalized duration measurements, we also note that the degree of difference between
Diphthong and Hiatus varies according to V. Here too, the difference between Diphthong and
Hiatus is smallest for sequences with [a], where the mean difference in %Transition is 9.63%
(averaged across both speech rates since no significant rate difference was found). For sequences
with [e], the mean difference in %Transition between Diphthong and Hiatus is 14.88% and for
sequences with [o] it is 15.41%. Thus, diphthongs and hiatuses with [a] are closer in %Transition
than their counterparts with [e] or [o].

93
Table 12. Bonferroni post-hoc tests for differences between Diphthong and Hiatus in
%Transition, by Speech Rate and V
Vowel vs. t-value p
V
[a] [e] 0.04 1.000
[a] [o] 4.64 0.001
[e] [o] 4.60 0.001
Sequence Type*V
[a] [e] 2.12 0.724
Diphthong [a] [o] 5.66 0.000
[e] [o] 3.54 0.035
[a] [e] -2.06 0.806
Hiatus [a] [o] 0.90 1.000
[e] [o] 2.96 0.125
On the basis of the above results, we can propose the following hierarchies of %Transition
according to Sequence Type, Speech Rate and V:
(i) Diphthong (Rate 1 & Rate 2): [a],[e]<[o]
(ii) Hiatus (Rate 1 & Rate 2): [a]=[e]=[o]
Thus, as with sequence duration, diphthongs appear slightly more variable (i.e. more susceptible
to V effects) than hiatuses.
In the individual data (Figure 12; Appendix 2, Tables A2.6-A2.9), most speakers mirror the
global results and we find no significant Speaker effect. That is, the speakers generally have a
larger %Transition for diphthongs with [o] than for those with [a] or [e]. For hiatuses, on the
other hand, most speakers showed the expected consistency across vowels. One exception is
MM, who had a comparatively large %Transition for her [o] hiatuses at Rate 1 (53.46%),
perhaps indicative of a diphthongized pronunciation of ríos. Similarly, at Rate 1, CG has a larger
%Transition for [e] hiatuses (46.44%) than for her [e] diphthongs (41.04%).

94
%Tra
nsit
ion
100
50
0
100
50
0[o][e][a] [o][e][a]
V [o][e][a]
100
50
0[o][e][a]
A A A M A N C G
DH KR LG LL
MM MV
Sequence Ty pe
Diphthong
Hiatus
Rate = 1
%Tra
nsit
ion
100
50
0
100
50
0[o][e][a] [o][e][a]
V [o][e][a]
100
50
0[o][e][a]
A A A M A N C G
DH KR LG LL
MM MV
Sequence Ty pe
Diphthong
Hiatus
Rate = 2
Figure 12. Bar chart of mean %Transition for Sequence Type, V and Speaker:
Rate 1 and Rate 2
3.3 Frequency
Frequency contours for vocalic sequences are expected to differ according to whether the non-
high vowel (V) in the sequence is [a], [e] or [o]. For this reason, it is the within-vowel
comparisons of Sequence Type (Diphthong vs. Hiatus) which are of most interest in this section.
That is, in the analyses that follow, the Sequence Type*V are most important. For all analyses,
repeated-measures ANOVAs were carried out at each time point (1-10), for both F1 and F2 (in
Bark, as specified in §2.4.2).
3.3.1 Diphthong (já, jé, jó) vs. Hiatus (í.a ,í.e, í.o)
At the beginning of the chapter, we predicted that, for all levels of V, hiatuses would have more
peripheral F1-F2 values (lower F1 and higher F2) than diphthongs. Based on the results on the
temporal measurements, we also explore whether the differences in F1 and F2 between
Diphthong and Hiatus will turn out to be less extreme for sequences with [a] than for sequences
with [e] or [o]. As shown in Figure 13, the F1-F2 formant changes from onset to offset of the

95
sequences seem to contradict these predictions (except for the onset frequencies of sequences
with [o]).
F1(Bark)
F2 (
Ba
rk)
16
12
8
48642
8642
16
12
8
4
V = [a] V = [e]
V = [o]
Sequence Type
Diphthong
Hiatus
onset
offset
onset
offset
onset
offset
Figure 13. Scatterplot of F1-F2 formant changes from sequence onset to offset, by Sequence
Type and V
However, the above changes reveal nothing about differences between Diphthong and Hiatus at
other points within the formant contours of the sequences. If any such differences exist they may
be found in the time-normalized F1-F2 contours used in the present dissertation (refer to Figure
2, §2.4.1).
The results of the repeated-measures ANOVAs carried out for factors Sequence Type
(Diphthong vs. Hiatus), Rate (1 vs. 2) and V ([a] vs. [e] vs. [o]) are reported in Table 13, where
all significant p-values are shaded gray. Any interactions between these factors which did not
have consistently significant p-values were left out for the sake of clarity of presentation. This
includes the following interactions: Rate* Sequence Type, Rate*V and Rate*Sequence Type*V.
We immediately notice is that there are no consistent significant Rate effects for either F1 or F2.
On the other hand, there are significant Sequence Type*V interactions for both F1 and F2 at
almost every time point.

96
Table 13. ANOVA results for differences between Diphthong and Hiatus in F1 and F2, by
Speech Rate and V
Rate Sequence Type V Sequence Type*V
Frequency Time F(1,18) p F(1,18) p F(2,18) p F(2,18) p
F1
1 0.71 0.422 10.04 0.011 1.52 0.246 13.61 0.000
2 1.13 0.315 2.08 0.183 0.00 0.996 15.85 0.000
3 1.41 0.266 10.50 0.010 2.41 0.119 33.66 0.000
4 0.15 0.708 21.28 0.001 16.16 0.000 44.23 0.000
5 0.15 0.709 41.67 0.000 59.28 0.000 61.81 0.000
6 1.14 0.314 47.79 0.000 133.39 0.000 47.65 0.000
7 7.76 0.021 23.70 0.001 137.29 0.000 17.40 0.000
8 9.33 0.014 5.06 0.051 127.39 0.000 12.23 0.000
9 5.55 0.043 0.25 0.631 97.14 0.000 12.03 0.000
10 3.83 0.082 0.01 0.927 55.43 0.000 4.34 0.029
F2
1 0.41 0.537 1.73 0.221 41.77 0.000 3.59 0.049
2 1.20 0.302 11.06 0.009 31.07 0.000 7.95 0.003
3 6.29 0.033 44.64 0.000 32.45 0.000 14.91 0.001
4 5.81 0.039 99.59 0.000 55.34 0.000 18.08 0.000
5 1.81 0.211 117.32 0.000 101.68 0.000 19.94 0.000
6 0.34 0.576 75.93 0.000 169.87 0.000 13.55 0.000
7 0.01 0.910 33.62 0.000 193.08 0.000 7.74 0.004
8 0.88 0.372 15.64 0.003 207.54 0.000 2.13 0.148
9 1.41 0.265 0.24 0.633 98.86 0.000 2.45 0.115
10 0.04 0.846 4.69 0.059 13.57 0.000 8.09 0.003
The post-hoc (Bonferroni) comparisons in Table 14 show that, contrary to our predictions, there
are more significant differences between Diphthong and Hiatus in sequences with [a] than in
sequences with either [e] or [o]. In fact, the differences between [já] and [í.a] are found
throughout both F1-F2 contours, except at the very beginning and very end of the sequence.
While significant differences between [jó] and [í.o] occur in the middle of both the F1 and F2
contours, they are most obvious for F2. Fewer significant differences are apparent between [jé]
and [í.e] and these occur mainly in the middle portions (i.e. the transitions) of the F1 and F2
contours.

97
Table 14. Bonferroni post-hoc comparisons of differences in F1 and F2 between Diphthong
and Hiatus, by V
F1 F2
V Time T-Value P-Value T-Value P-Value
[a]
1 -1.13 1.000 2.08 0.607
2 -5.73 0.000 3.58 0.008
3 -8.98 0.000 5.37 0.000
4 -12.35 0.000 7.25 0.000
5 -16.88 0.000 8.47 0.000
6 -16.95 0.000 8.60 0.000
7 -11.27 0.000 6.94 0.000
8 -6.67 0.000 4.65 0.000
9 -3.56 0.009 1.14 1.000
10 -1.14 1.000 1.48 1.000
[e]
1 3.92 0.002 -0.77 1.000
2 0.35 1.000 0.39 1.000
3 -1.93 0.842 2.03 0.677
4 -3.96 0.002 3.13 0.034
5 -4.65 0.000 3.76 0.004
6 -5.15 0.000 4.04 0.002
7 -3.55 0.009 3.05 0.045
8 -0.28 1.000 1.56 1.000
9 2.19 0.459 -0.69 1.000
10 1.82 1.000 -0.98 1.000
[o]
1 5.91 0.000 1.53 1.000
2 0.33 1.000 4.45 0.000
3 -2.63 0.147 8.27 0.000
4 -3.85 0.003 11.39 0.000
5 -3.92 0.003 12.94 0.000
6 -3.55 0.009 11.83 0.000
7 -2.68 0.131 7.27 0.000
8 -1.05 1.000 3.65 0.006
9 -0.39 1.000 0.31 1.000
10 -1.01 1.000 0.32 1.000
In the following sections, we examine in greater detail the differences between Diphthong and
Hiatus that are found with each level of V.
3.3.1.1 Sequences with [a]
In essence, the values (both for F1 and F2) for [í.a] (Hiatus) are more peripheral while those for
[já] (Diphthong) are more centralized (Figure 14). That is, for [í.a] the values for F1 are lower

98
and the values for F2 are higher compared to [já]. Because the onset and offset F1 and F2 values
are similar for [í.a] and [já], the differences in the middle portion of their F1-F2 trajectories result
in a smoother slope for [já] and a steeper slope for [í.a].
Time
Fre
qu
en
cy
(B
ark
)
10987654321
15
10
5
V=[a]
Figure 14. Scatterplot of F1-F2 of Sequence Type, for V = [a]
In the individual data (Figure 15) we find that most of the speakers have a visible difference
between Diphthong and Hiatus in both the F1 and F2 contours. One exception is LG who shows
some overlap in the F2 contours. Speaker AA, on the other hand, stands out as having the most
noticeable difference between Diphthong and Hiatus in both F1 and F2.

99
Time
Fre
qu
en
cy
(B
ark
)15
10
5
15
10
5
10987654321 10987654321
10987654321
15
10
5
10987654321
A A A M A N C G
DH KR LG LL
MM MV
V=[a]
Figure 15. Scatterplot of F1-F2 of Sequence Type, for V = [a] by Speaker
3.3.1.2 Sequences with [e]
Although fewer points of difference were found between [jé] and [í.e], we still observe that,
where these differences occur, values for [í.e] are generally more peripheral than those for [jé],
just as we found for sequences with [a]. This pattern is most obvious in the middle portions of
the F1 and F2 contours, as is evident in the mean frequency values for the group (Figure 16). The
figure also highlights that relatively little movement occurs in the F1-F2 contours, especially for
Diphthong sequences [jé]. These fairly level contours are observed also in the individual data
(Figure 17) where we also note that most speakers have some overlapping values for Diphthong
and Hiatus, especially for F2. For F1, MM maintains the most obvious difference between
Diphthong and Hiatus throughout most of the contour.

100
Time
Fre
qu
en
cy
(B
ark
)
10987654321
15
10
5
V=[e]
Figure 16. Scatterplot of F1-F2 of Sequence Type, for V = [e]
Time
Fre
qu
en
cy
(B
ark
)
15
10
5
15
10
5
10987654321 10987654321
10987654321
15
10
5
10987654321
A A A M A N C G
DH KR LG LL
MM MV
V=[e]
Figure 17. Scatterplot of F1-F2 of Sequence Type, for V = [e] by Speaker

101
3.3.1.3 Sequences with [o]
Again, the values for [í.o] are, for the most part, more peripheral than those for [jó] (Figure 18).
Because the onset and offset F1 and F2 values for [í.o] and [jó] are not significantly different,
this results in a steeper slope for [í.o] (i.e. hiatus). This pattern is most obvious for the F2
contour. It is also evident in the individual data (Figure 19) where some speakers have visible
overlap of Diphthong and Hiatus values for F1. The least overlap is found consistently for F2,
although speakers AN and LG show more overlap than all the others. Speaker AA once again
presents the most noticeable difference between Diphthong and Hiatus in both F1 and F2, just as
she did for [já] and [í.a].
Time
Fre
qu
en
cy
(B
ark
)
10987654321
15
10
5
V=[o]
Figure 18. Scatterplot of F1-F3 of Sequence Type, for V = [o]

102
Time
Fre
qu
en
cy
(B
ark
)15
10
5
15
10
5
10987654321 10987654321
10987654321
15
10
5
10987654321
A A A M A N C G
DH KR LG LL
MM MV
V=[o]
Figure 19. Scatterplot of F1-F2 of Sequence Type, for V = [o] by Speaker
3.4 Discriminant Analysis
We now turn to the question of whether this variety of Spanish has instances of ambiguous
sequences. We are mainly looking for cases of diphthongs produced as hiatuses (i.e. exceptional
hiatuses) but hiatuses produced as diphthongs are also possible. Here, we use Discriminant
Analysis (DA) to decide category membership based on the acoustic predictors tested (refer to
§2.4.3 for an explanation of the technique). To recap, these predictors are: normalized sequence
duration, proportion of sequence taken up by the transition, and time-normalized F1-F2
measurements.
3.4.1 Data Preparation and Procedures
Prior to applying the Discriminant Analysis procedure, however, the total number of predictors
needed to be reduced. Specifically, using all the F1-F2 formant measurements as predictors
created a situation with a very large number of predictors (2 formants X 10 time points = 20
frequency predictors). In addition, many of these measurements are correlated since none of the
10 measurements made along the F1 and F2 contours is entirely independent of the previous or
following measurement (McDougall, 2006). Thus, in an effort to reduce the number of predictors

103
used in DA, regression was used to fit the F1 and F2 contours of the sequences with polynomial
equations. This technique has proved useful in capturing individual differences in diphthong
production (McDougall, 2006, for Australian English). This technique has also been used by
Aguilar (1997, 1999) to capture the differences between the curvatures in the F1–F2 contours of
Peninsular Spanish diphthongs and hiatuses. In Aguilar (1997, 1999) the data for all non-high
vowels was combined to obtain the equation and a quadratic polynomial was found to provide
the best fit. In the present study, because different vowels had different results for frequential
parameters (§3.3) the polynomial equations for each non-high V were obtained separately. For
all three non-high vowels (a, e, and o) the best fit for the F1 contours of both diphthongs and
hiatuses was a cubic polynomial of the form: y= x0+ x1t+ x2t2+ x3t
3. In the equation, t represents
normalized time (i.e. each of the 10 frequency measurement points), the constant term (x0)
represents the value of the y intercept, and the coefficients (x1, x2, x3) represent the slope, shape
and direction of the formant curve. For the F2 contours, the best fit for [a] and [o] sequences
(both Diphthong and Hiatus) and for [e] (Hiatus only) was also a cubic polynomial. For [e]
Diphthong sequences, on the other hand, a quadratic polynomial (y= x0+ x1t+ x2t2) provided the
best fit for the F2 contour. This is in line with the observation made in §3.3.1.2 that the F2
contours of sequences with [e] show relatively little movement. The equations for the diphthong
and hiatus sequences are given in Table 15.
Table 15. Mean values of the polynomial equation constants and coefficients of F1 and F2
for Diphthong and Hiatus, by V
F1 F2
Sequence x0 x1 x2 x3 R-Sq(Adj) x0 x1 x2 x3 R-Sq(Adj)
[í.a] 4.74 -1.00 0.25 -0.01 97.9% 13.46 0.79 -0.16 0.01 98.5%
[já] 4.15 -0.43 0.21 -0.01 99.7% 13.52 0.55 -0.15 0.01 99.9%
[í.e] 4.61 -0.65 0.15 -0.01 92.6% 13.63 0.19 0.02 -0.01 99.1%
[jé] 4.10 -0.33 0.12 -0.01 98.6% 13.71 0.24 -0.03 N/A 99.1%
[í.o] 4.58 -0.66 0.17 -0.01 97.1% 12.28 1.38 -0.30 0.01 98.7%
[jó] 3.85 -0.14 0.08 -0.01 99.3% 12.80 0.73 -0.23 0.01 99.8%
In order to reduce even further the number of predictors used in the Discriminant Analysis,
Repeated Measures ANOVAs (with factor Sequence Type) were carried out on the above
equations. Each non-high V was tested separately and the results of these tests are given in Table
16. They reveal that there are indeed significant differences between Diphthong and Hiatus in the
equation constant term (x0) alone or in combination with one or more of its coefficients (x1, x2,
and x3). These results, on the surface, appear to confirm the findings of the raw frequential data
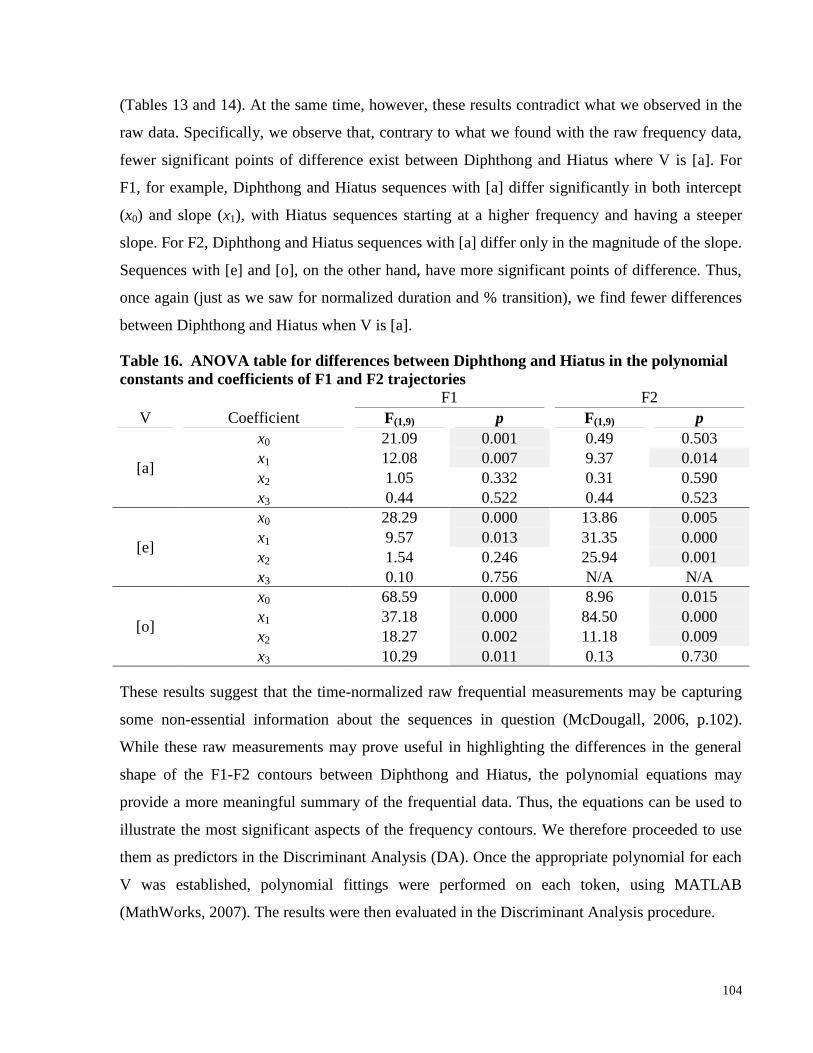
104
(Tables 13 and 14). At the same time, however, these results contradict what we observed in the
raw data. Specifically, we observe that, contrary to what we found with the raw frequency data,
fewer significant points of difference exist between Diphthong and Hiatus where V is [a]. For
F1, for example, Diphthong and Hiatus sequences with [a] differ significantly in both intercept
(x0) and slope (x1), with Hiatus sequences starting at a higher frequency and having a steeper
slope. For F2, Diphthong and Hiatus sequences with [a] differ only in the magnitude of the slope.
Sequences with [e] and [o], on the other hand, have more significant points of difference. Thus,
once again (just as we saw for normalized duration and % transition), we find fewer differences
between Diphthong and Hiatus when V is [a].
Table 16. ANOVA table for differences between Diphthong and Hiatus in the polynomial
constants and coefficients of F1 and F2 trajectories
F1 F2
V Coefficient F(1,9) p F(1,9) p
[a]
x0 21.09 0.001 0.49 0.503
x1 12.08 0.007 9.37 0.014
x2 1.05 0.332 0.31 0.590
x3 0.44 0.522 0.44 0.523
[e]
x0 28.29 0.000 13.86 0.005
x1 9.57 0.013 31.35 0.000
x2 1.54 0.246 25.94 0.001
x3 0.10 0.756 N/A N/A
[o]
x0 68.59 0.000 8.96 0.015
x1 37.18 0.000 84.50 0.000
x2 18.27 0.002 11.18 0.009
x3 10.29 0.011 0.13 0.730
These results suggest that the time-normalized raw frequential measurements may be capturing
some non-essential information about the sequences in question (McDougall, 2006, p.102).
While these raw measurements may prove useful in highlighting the differences in the general
shape of the F1-F2 contours between Diphthong and Hiatus, the polynomial equations may
provide a more meaningful summary of the frequential data. Thus, the equations can be used to
illustrate the most significant aspects of the frequency contours. We therefore proceeded to use
them as predictors in the Discriminant Analysis (DA). Once the appropriate polynomial for each
V was established, polynomial fittings were performed on each token, using MATLAB
(MathWorks, 2007). The results were then evaluated in the Discriminant Analysis procedure.

105
3.4.2 Discriminant Analysis Results
While the temporal measurements (normalized duration and %Transition) were significant for all
non-high vowels, the significant frequency predictors differed for each V (Table 17). For this
reason, we examine the results for each non-high V separately.
Table 17. Significant predictors for inclusion in discriminant analysis, by V (acoustics)
Non-high vowel
Predictors [a] [e] [o]
F1x0
F1x1
F1x2
F1x3
F2x0
F2x1
F2x2
F2 x3 Normalized duration
%Transition
TOTAL 5 7 9
3.4.2.1 Sequences with [a]
Where V= [a], there are five possible predictors: F1x0, F1x1, F2x1, normalized sequence duration,
and %Transition. When all the token files for Diphthong and Hiatus and all five significant
predictors are included in the analysis, we find that approximately 77% of diphthongs and 82%
of hiatuses were classified according to their expected production. Overall, almost 78% of
sequences were correctly classified.
Table 18. Discriminant analysis summary table for V= [a] (acoustics)
TRUE GROUP Squared distance between groups
Put into group Diphthong Hiatus Diphthong Hiatus
Diphthong 276 22 0.000 2.701
Hiatus 84 98 2.701 0.000
Total N 360 120 F (5, 474) = 48.22, p=0.01
N Correct 276 98
Proportion Correct 0.767 0.817
TOTALS N=480(0 missing values) N Correct=374 Proportion Correct= 0.779

106
3.4.2.2 Sequences with [e]
Where V= [e], the total number of possible predictors increases to seven. Including all of them
produces an overall correct classification rate of about 85%. Both Diphthong and Hiatus had
correct classification rates of over 80% with hiatuses having a slight advantage (at 90%) over
diphthongs (at 84%).
Table 19. Discriminant analysis summary table for V= [e] (acoustics)
TRUE GROUP Squared distance between groups
Put into group Diphthong Hiatus Diphthong Hiatus
Diphthong 338 6 0.000 3.984
Hiatus 65 54 3.984 0.000
Total N 403 60 F (5, 457) = 41.52, p=0.01
N Correct 338 54
Proportion Correct 0.839 0.900
TOTALS N= 463(17 missing values) N Correct= 392 Proportion Correct= 0.847
3.4.2.3 Sequences with [o]
The total number of possible predictors is highest when V= [o]. Including all these predictors
gives the best correct classification rate of all the levels of V, at over 95%. In contrast to what we
saw with [a] and [e], however, hiatuses (at 97% correct) did not have an appreciable advantage
over diphthongs (96%).
Table 20. Discriminant analysis summary table for V= [o] (acoustics)
TRUE GROUP Squared distance between groups
Put into group Diphthong Hiatus Diphthong Hiatus
Diphthong 171 2 0.000 14.214
Hiatus 8 58 14.214 0.000
Total N 179 60 F (5, 233) = 68.58, p=0.01
N Correct 171 58
Proportion Correct 0.955 0.967
TOTALS N= (239, 1 missing values) N Correct= 229 Proportion Correct= 0.958
In summary, we note that the squared distances between groups were significant for all three
levels of V. Thus, we can assume that the chosen predictors are successfully discriminating
between Diphthong and Hiatus categories. However, we also find that sequences with [a] have
lower correct classification rates and a smaller squared distance between groups than sequences
with [e] or [o]. Sequences with [o] have the best correct classification rates. Finally, we note that,
while for all three levels of V diphthongs have slightly worse classification rates than hiatuses,

107
the difference in correct classification rate between Diphthong and Hiatus is greatest for
sequences with [a].
We now turn to the question of what words are most likely to be misclassified as well as which
Speakers are most likely to produce misclassified words.
3.4.3 Misclassified Sequences
Because in the Discriminant Analysis some instances of misclassification are due to tokens
whose measurements fall close to the mean for both Diphthong and Hiatus, it’s not enough to
consider the predicted group membership. It is also important to look at the probability of falling
within the predicted group. Arbitrarily, we have divided these probabilities into three groups, the
first of which (50-59%) may be considered to contain marginal cases and the last (70% or
greater) may be considered to contain the most clear-cut cases.
3.4.3.1 Sequences with [a]
The expectation for these sequences was that they would have the highest number of
misclassified cases. In particular, we expected the diphthongs with [a] to be most consistently
classified as hiatuses since they meet the established criteria for words commonly identified as
exceptional hiatuses (e.g. Hualde, 2005). The first criterion is that they all have [a] as the non-
high vowel (Hualde 2005). Second, they appear in stressed syllables (Chitoran & Hualde, 2007).
Also, some of the words have related words with hiatus (Cabré & Prieto, 2006). Finally, they are
derived from Latin heterosyllabic [iV] sequences (Chitoran & Hualde, 2007; Colantoni &
Limanni, 2010). The results in Table 21 illustrate that this expectation was clearly met. In the
Diphthong category, the words with the most misclassifications were, in descending order,
diario, diablo and criada. In the Hiatus category, crías had the highest number of
misclassifications.

108
Table 21. Summary of discriminant analysis classification (predicted group membership)
of Diphthong and Hiatus: V= [a] (acoustics)
Expected group Word
Predicted Group Probability
Diphthong Hiatus 50%-59% 60%-69% 70%+
Diphthong
criada 42 18 5 3 10
diablo 39 21 5 3 13
diario 29 31 5 7 19
piada 51 9 4 2 3
piano 58 2 1 1 0
viaje 57 3 1 2 0
Hiatus crías 15 45 4 5 6
días 7 53 2 0 5
The misclassified cases point to considerable between-speaker variation (Table 22). For
example, AM had the highest number of misclassified Diphthong with [a] (14) followed by MV
(12) and MM (11). These speakers, however, differ on the number of misclassified Hiatus they
contribute. Speakers MV and MM also contribute the highest number of misclassified Hiatus (9
cases and 6 cases, respectively) while AM contributes only 2 cases. At the other end of the
spectrum is KR, with no misclassifications at all, either for Diphthong or Hiatus. The remaining
speakers contribute an intermediate number of misclassified Diphthong cases (between 6 and 10)
and few misclassified Hiatus cases (between 0 and 2).
Table 22. Summary of misclassified sequences with [a], by Speaker (acoustics)
SPEAKER
Expected group Word AA AM AN CG DH KR LG LL MM MV
Diphthong
criada 2 2 4 3 0 0 1 3 1 2
diablo 1 6 1 0 2 0 0 1 6 4
diario 3 3 2 5 5 0 4 3 3 3
piada 1 0 1 0 0 0 0 3 1 3
piano 0 1 0 1 0 0 0 0 0 0
viaje 0 2 0 0 0 0 1 0 0 0
Hiatus crías 2 1 1 1 0 0 0 1 5 4
días 0 1 0 0 0 0 0 0 1 5
TOTAL 9 16 9 10 7 0 6 11 17 21
3.4.3.2 Sequences with [e]
The expectation for diphthongs with [e] was that the word bienio would be most consistently
misclassified as hiatus because of its bimorphemic structure (e.g. Chitoran & Hualde, 2007;
Cabré & Prieto, 2006) and its relative infrequency (e.g. Whitley, 1985). We also expected bienio

109
to contrast with bienes which is a more common word and its diphthong is derived from breaking
of the Latin short mid vowel Ĕ (Chitoran & Hualde, 2007). Thus, bienes should be consistently
identified correctly. The data in Table 23 show that, in fact, bienio is the word with the most
misclassifications: almost 50% of the bienio tokens are misclassified as hiatus (with most of
these at over 70% probability). With bienes, the number is much lower at approximately 15%,
but this number is hardly insignificant. In fact, it is higher than the number for cliente (with
approximately an 8% misclassification rate), a word which is derived from a Latin heterosyllabic
[iV] sequence and should thus have stronger hiatic tendencies. The fewest misclassified cases
occur for pieza (with no misclassifications) and viejo, (with a single misclassification). Finally,
prieto (at 20%) and pliegue (at 17%) had similar misclassification rates as bienes, despite the fact
that they, too, are derived from Latin Ĕ.
Table 23. Summary of discriminant analysis classification (predicted group membership)
of Diphthong and Hiatus: V= [e] (acoustics)
Expected group Word
Predicted Group Probability
Diphthong Hiatus 50%-59% 60%-69% 70%+
Diphthong
bienes 51 9 4 0 5
bienio 29 28 3 3 22
cliente 55 5 3 1 1
pieza 59 0 0 0 0
pliegue 47 12 7 1 4
prieto 50 10 2 6 2
viejo 47 1 0 1 0
Hiatus ríen 6 54 3 2 1
Similar to what we observed for sequences with [a], we find considerable between-speaker
variation for sequences with [e] (Table 24). Speaker AM had the highest number of misclassified
diphthongs with [e] (18) followed by KR (15). These results highlight the degree of within-
speaker variation in response to vowel context for these sequences. For instance, AM also had
the highest number of misclassified Diphthong with [a], thus her behaviour appears consistent
across vowel contexts. Other speakers were equally consistent: speakers AA, AN, LL and LG
had comparable numbers of misclassified diphthongs for [a] and [e]. On the other hand, KR had
no misclassified diphthongs for [a] while for [e] she contributes many more misclassified
sequences. Other speakers also behaved differently according to vowel context. For example,
Speakers MM, MV, DH and CG all had fewer misclassified sequences with [e]. Speakers who
had misclassified Hiatus sequences with [a] generally had fewer misclassified Hiatus sequences

110
with [e]. Surprisingly, Speaker DH had no misclassified cases of ríen, even though she was
previously identified (§3.1.1) as producing very short hiatuses with [e].
Table 24. Summary of misclassified sequences with [e], by Speaker (acoustics)
SPEAKER
Expected group Word AA AM AN CG DH KR LG LL MM MV
Diphthong
bienes 1 6 0 0 0 0 0 2 0 0
bienio 6 6 5 2 0 6 0 1 0 2
cliente 1 2 0 0 0 1 0 1 0 0
pieza 0 0 0 0 0 0 0 0 0 0
pliegue 0 2 3 1 0 3 1 2 0 0
prieto 0 1 0 1 0 5 2 1 0 0
viejo 0 1 0 0 0 0 0 0 0 0
Hiatus ríen 0 0 0 0 0 0 2 0 2 2
TOTAL 8 18 8 4 0 15 5 7 2 4
3.4.3.3 Sequences with [o]
For diphthongs with [o] the words criollo and piojo have been identified as candidates for
exceptional hiatus in Peninsular (Castillian) Spanish (Hualde, 2005, p. 85, Table 5-10) based on
their etymologies. For example, criollo is a loanword from the Portuguese crioulo (with a
heterosyllabic vowel sequence). The diphthong in piojo, on the other hand, originates from a
VCV sequence in the Latin word PEDUCULUS (via deletion of intervocalic C along with other
consonant and vowel change processes). The data in Table 25, however, only partially confirm
these expectations. The word criollo behaves as predicted with approximately 8.5% of cases
misclassified as hiatus, with most of these at over 70% probability. For piojo however, the
expectation was not met. In fact, no cases of piojo were misclassified as hiatus.
Table 25. Summary of discriminant analysis classification (predicted group membership)
of Diphthong and Hiatus: V= [o] (acoustics)
Expected group Word
Predicted Group Probability
Diphthong Hiatus 50%-59% 60%-69% 70%+
Diphthong
criollo 54 5 0 1 4
piojo 60 0 0 0 0
viola 57 3 2 0 1
Hiatus ríos 2 58 0 0 2
Overall, speakers had very few misclassified sequences with [o], regardless of whether they had
few or many misclassified sequences with the other vowels (Table 26). Speaker LG contributed
the highest number of misclassified diphthongs (3). Only 2 cases of misclassified Hiatus were

111
found and both were produced by speaker MV. This result is in line with our observation
(§3.1.1) that her comparatively short [o] hiatuses were indicative of a diphthongized production
of ríos.
Table 26. Summary of misclassified sequences with [o], by Speaker (acoustics)
SPEAKER
Expected group Word AA AM AN CG DH KR LG LL MM MV
Diphthong
criollo 0 1 0 1 0 0 2 0 0 1
piojo 0 0 0 0 0 0 0 0 0 0
viola 0 1 0 0 1 0 1 0 0 0
Hiatus ríos 0 0 0 0 0 0 0 0 0 2
TOTAL 0 2 0 1 1 0 3 0 0 3
4 Summary and Discussion
In this section we summarize the findings of the study, evaluate whether the study hypotheses are
confirmed by the data, and discuss the results in light of previous studies.
4.1 Hypothesis 1: Diphthong vs. Hiatus
Hypothesis 1 stated that diphthongs and hiatuses in Mexican Spanish differ according to certain
acoustic parameters. This hypothesis is confirmed. Thus, we find that category membership of
Diphthong and Hiatus is defined by sequence duration, proportion of sequence dedicated to
transition, and the overall shape of the F1-F2 contours. Furthermore, these category differences
between Diphthong and Hiatus are retained under different speech rate conditions. The last two
measures, in fact, appear immune to speech rate effects. For example, although both Diphthong
and Hiatus experience a decrease in duration as speech rate increases, Diphthong is always
shorter than Hiatus. In terms of %Transition, diphthongs are shorter than hiatuses but have
greater %Transition. Thus, we find a negative relationship between sequence duration and
%Transition. Unlike sequence duration, however, %Transition appears resistant to speech rate
changes in our data sample. That is, even though we found that sequence duration decreases as
speech rate increases, we do not find a corresponding increase in %Transition. With regard to
frequency patterns, the overall pattern is that diphthongs generally have a smoother, more
gradual slope in F1-F2 and more centralized values, while hiatuses have a sharper slope and
more peripheral values. Rate increase once again appears not to have any effect on this last
parameter and F1-F2 contours for both Diphthong and Hiatus remain similar across speech rates.

112
Many of these global differences in duration, %Transition and F1-F2 contours between
Diphthong and Hiatus appear in different degrees according to the identity of the V portion of the
sequence. We discuss these differences among levels of V with more detail below in the
evaluation of Hypothesis 2.
4.2 Hypothesis 2: Vowel Effects
Hypothesis 2 predicted that the quality of the non-high vowel (V) in both Diphthong and Hiatus
sequences would produce acoustic consequences. The specific prediction was that sequences
where V= [a] would have more extreme values on both the temporal and frequential measures.
This hypothesis was also largely confirmed. We find, for example, that at the slower speech rate
(Rate 1) both diphthongs and hiatuses with [a] are longer than those with either [e] or [o].
However, with an increase in speech rate (Rate 2), the pattern was maintained only for
diphthongs. For hiatuses, there were no significant differences in duration attributable to V at
Rate 2. More importantly, however, we find that Diphthong and Hiatus sequences with [a]
(although longer overall) are closer to each other in duration than their counterparts with either
[e] or [o].
As regards %Transition, we find that vowel quality has an effect on diphthongs but not on
hiatuses. Therefore, we find no significant differences between hiatuses with [a] and those with
[e] or [o]. On the other hand, diphthongs with [a] have a significantly smaller %Transition than
those with [o] but do not differ from those with [e]. Most important, however, is the finding that
the degree of differences between Diphthong and Hiatus also varies according to V. Specifically,
the difference between Diphthong and Hiatus in %Transition is smallest for sequences with [a].
Thus, we find that between Diphthong and Hiatus sequences with [a] are closer to each other in
%Transition than their counterparts with either [e] or [o]. This is the same pattern we observed
for sequence duration.
With reference to frequential measurements, the information found in the time-normalized F1-F2
contours suggested that diphthongs and hiatuses with [a] were further apart than those with either
[e] or [o]. That is, there were more significant points of difference between Diphthong and
Hiatus with [a]. However, a different picture emerged when we converted the contours to
polynomial equations and submitted these to statistical analysis. After eliminating some of the

113
redundant information in the time-normalized raw frequential measurements, we found, that
there were, in fact, fewer differences between Diphthong and Hiatus in sequences with [a].
Overall then, on all three measures, we find that Diphthong and Hiatus sequences with [a] are
closer to each other than their counterparts with either [e] or [o]. This outcome may help explain
the observation that most instances of exceptional hiatuses occur with sequences where [a] is the
non-high vowel (e.g. Hualde, 2005). Thus, it is possible that the intrinsic phonetic properties of
sequences with [a] are behind the historic, prosodic and morphological triggers of exceptional
hiatus. In the evaluation of Hypothesis 3, below, we look at how these intrinsic differences
among levels of V combine with individual variation in the production of diphthongs and
hiatuses to produce sequences which do not fall neatly into either the Diphthong or Hiatus
category.
4.3 Hypothesis 3: Exceptional Hiatuses
Hypotheses 3 predicted that individual variation in the production of diphthongs and hiatuses
would (i) be reflected acoustically and (ii) give rise to sequences whose category membership is
ambiguous, as in the case of exceptional hiatuses.
The first part of the hypothesis was confirmed: we indeed found individual variation in the
production of diphthongs and hiatuses, with the variation appearing on one or more of the
parameters considered. On the measure of sequence duration (normalized), some speakers
produce larger differences between Diphthong and Hiatus. For sequences with [a], for example,
we find that Speakers MM and MV had small differences between Diphthong and Hiatus, due to
comparatively long [a] diphthongs, especially at Rate 1. Thus, we might expect them to produce
more exceptional hiatuses with [a] diphthongs than those speakers who had the largest
differences between Diphthong and Hiatus (i.e. AN, CG, DH and KR). As we saw in Table 22
(§3.4.3.1) this is indeed the case for these speakers. Speaker DH, on the other hand, has a small
difference between Diphthong and Hiatus for [e] sequences. In this case, the reason for the small
gap is that she produces relatively short hiatuses with [e] at both speech rates. However, in her
case, we fail to find any cases of diphthongized production of [í.e] sequences (Table 24,
§3.4.3.2). Speaker MV also had a small difference between Diphthong and Hiatus for her [o]
sequences at Rate 1, which results in a diphthongized production of [í.o] sequences (Table 26,
§3.4.3.3). The data for %Transition also points to variability in the amount of difference between

114
Diphthong and Hiatus. On this measure, speakers AA, AM, AN, CG and LG have the smallest
Diphthong-Hiatus differences for sequences with [a] (for Rate 1 and/or Rate 2). For some of
these speakers the difference is due to a small %Transition for diphthongs (Speakers AA, AM
and AN). For others, the small difference between Diphthong and Hiatus is due to a large
%Transition for hiatuses (Speaker LG). For speaker CG, on the other hand, both diphthongs and
hiatuses (at Rate 2) had similar %Transition. CG also had small differences between Diphthong
and Hiatus for her [e] and [o] sequences, in this case due to a relatively large %Transition for
hiatuses. Speaker MM also had a small difference in %Transition between Diphthong and Hiatus
for her [o] sequences at Rate 1 due to a comparatively large %Transition for her [o] hiatuses.
However, this small difference did not result in a diphthongized production of any of her [í.o]
sequences (Table 26, §3.4.3.3). In terms of F1-F2 contours, Speaker AA stands out as having the
most noticeable difference between Diphthong and Hiatus in both F1 and F2 for sequences with
[a] and [o]. On the other hand, MM maintains the most noticeable difference in F1 for sequences
with [e].
The second part of the hypothesis was also confirmed as the speakers produced several
sequences whose category membership was not clear-cut. To test the second part of the
hypothesis, we used Discriminant Analysis to categorize sequences as Diphthong and Hiatus
according to the chosen temporal and frequential parameters. In the analysis, instances of Hiatus
misclassified as Diphthong were considered diphthongized while cases of Diphthong
misclassified as Hiatus were considered exceptional hiatuses. We observed that among the
speakers who contributed the most misclassified Diphthong cases where V= [a] were those who
were identified as having relatively small Diphthong-Hiatus differences on both normalized
duration and %Transition. This list includes MM, MV and AM. Conversely, speaker KR, who
produced larger differences between Diphthong and Hiatus on both measures, had no
misclassified cases of either Diphthong or Hiatus. However, some speakers who also had
relatively large differences between Diphthong and Hiatus on these measures (i.e. DH and LL)
also contributed several cases. Thus, for these speakers the small difference between Diphthong
and Hiatus may lie in the frequency contours. However, in Figure 15 (§3.3.1.1) it is not the case
that these speakers had more overlap in F1-F2 between Diphthong and Hiatus than other
speakers.

115
We also find that while some speakers were consistent across different vowel contexts (i.e.
contributed similar number of misclassified sequences regardless of V), others were less
consistent. For example, Speaker AM contributed the highest number of misclassified
diphthongs for both [a] and [e]. On the other hand, speakers MM and MV, who also contributed
many misclassified sequences with [a], had very few cases with [e].
4.4 Discussion
On many points, the present results for Mexican Spanish vocalic sequences are in agreement
with the results for other dialects of Spanish and other languages. On the other hand, we do find
points of difference which suggest that some features of these sequences are language, dialect
and even sequence-specific. For example, we find that diphthongs are distinguished temporally
from hiatuses in that hiatuses are longer (Aguilar, 1999; Hualde & Prieto, 2002) and devote a
smaller proportion of the sequence to the transition (MacLeod, 2007). An increase in speech rate
tends to decrease the overall duration in all sequences such that the Diphthong- Hiatus contrast is
preserved across changes in speech rate (Aguilar, 1997, 1999). However, in our data an increase
in speech rate did not result in the expected increase in %Transition. Thus, %Transition appears
to be unaffected by speech rate in this variety of Spanish. Our results are in line with Peeters
(1991) who argues that the proportion of the sequence allotted to the transition is language-
specific. Our results also seem to support Ren (1986, p. 85), who suggests the transition from a
high glide ([j] in our case) to a low vowel (in our case a ‘lower’ vowel) is temporally insensitive
(i.e. remains constant across differences in speech rate). Similarly, we establish that durational
differences are affected by the identity of the V in the sequence, as observed by Aguilar (1997,
1999) and Lindau et al. (1990). However, our specific results are not necessarily the same as
those of other authors. For example, Aguilar (1999, p. 64) found that among Rising sequences
such as those used in the present experiment “hiatuses with [a] are longer than hiatuses with [e]
and [o], whereas for diphthongs, the behaviour is the opposite”. In the present study we also
observe a difference in the way the duration of diphthongs and hiatuses is affected by V. Our
results are different from Aguilar (1999) in that we find that diphthongs with [a] are longer than
diphthongs with either [e] or [o], regardless of speech rate. However, for hiatuses, these
durational differences occur only for Rate 1. Rate 2 hiatuses seem unaffected by the identity of
V. Some of these differences may be attributed to the variety of Spanish under study (Mexican

116
Spanish here vs. Peninsular Spanish in Aguilar, 1999). However, the differences may also be the
result of using normalized duration (in the present study) instead of raw duration (Aguilar, 1999).
In terms of frequential differences between diphthongs and hiatuses, the overall pattern we
observe is that diphthongs generally have a smoother, more gradual slope in F1-F2 and more
centralized values, while hiatuses have a sharper slope and more peripheral values. This is in
agreement to the results of Aguilar (1997, 1999). We also found that the F1-F2 contours
remained largely invariant across different speech rates. This result is similar to what was
reported by Borzone de Manrique (1979, p. 202) for diphthongs in Argentine Spanish. She found
that the F2 rate of change for those sequences remained invariant across different speaking rates.
In terms of individual variation, we found that some speakers maintained a more extreme
difference between Diphthong and Hiatus on either the durational or frequential parameters or
both. This result is similar to what has already been observed by other authors (MacLeod, 2007;
Colantoni & Limanni, 2010) and also serves to underscore the view expressed in Docherty
(2003) that even speakers of the same language or variety may not behave in a linguistically
homogeneous manner due to their different experiences with the language. In addition to this
inter-speaker variation in diphthong and hiatus production, we also found considerable intra-
speaker variation related to the identity of the non-high vowel in the sequence. Some speakers,
for example, consistently maintained a similar acoustic distance between Diphthong and Hiatus
across vowel contexts. Others behaved differently according to the identity of the non-high V.
This intra-speaker variation was also reflected in the number of misclassified sequences each
speaker contributed for each V. The misclassified sequences, in particular those cases of
Diphthong classified as Hiatus, also serve to highlight that even those Spanish varieties not
normally associated with the production of exceptional hiatuses can show hiatic tendencies in the
production of some sequences. This finding is in line with Whitley (1985, reviewed in Chapter 2)
who also observed that the influence of dialect on the interpretation of [jV] sequences as [iV]
was unclear. Similar to what we observe in this study, Whitley (1985) found individual variation
was more consistent than dialectal variation with some speakers showing more or less of a hiatic
tendency than other speakers of the same dialect. In addition, Whitley (1985) suggests that the
words that trigger a hiatic pronunciation may differ from variety to variety as well as from
speaker to speaker. In our data, for example, the words prieto and pliegue were the most
consistently misclassified as exceptional hiatus among sequences where V= [e]. In addition, the

117
word bienes also had several misclassified cases. This is unexpected since the diphthongs in all
these words are derived from breaking of the Latin short mid vowel Ĕ and, according to Chitoran
& Hualde (2007, p. 46), all such sequences are obligatorily realized as diphthongs. However,
other factors may be influencing the comparatively high misclassification rates for these words.
For example, the high misclassification rates for prieto may reflect both a language-specific
tendency for a preceding [r] to promote hiatus in Spanish (Hualde & Prieto, 2002) as well as a
more general cross-linguistic pattern of avoiding [j] after rhotics (Van der Beer, 2006; Hall &
Hamann, 2010). The high misclassification rate for pliegue, on the other hand may reflect the
well-documented instability of consonant+lateral clusters in Romance (e.g. Colantoni & Steele,
2005). In addition, in both prieto and pliegue the diphthong [jé] is preceded by a consonant
cluster. Thus, their misclassification rates may also be indicative of a more general tendency to
avoid diphthongs (i.e. a complex nucleus) after a complex onset. This tendency is documented
for other Romance languages including French (e.g. Chitoran & Hualde, 2007), Romanian
(Chitoran, 2002) and Catalán (Cabré & Prieto, 2004) as well as other varieties of Spanish (e.g.
Cabré & Prieto, 2006 for Peninsular Spanish). However, in this case we would also expect
cliente (especially since it is also derived from a Latin heterosyllabic sequence) to have a
comparable number of misclassified cases but it has fewer. Perhaps the explanation for the
unexpected misclassification rates for cliente and bienes is to be found in articulation. We return
to this question in Chapter 4 when we examine the articulatory characteristics of these vocalic
sequences.
Finally, we also find, like other authors (e.g Chitoran & Hualde, 2007; Hualde, 2005) that
diphthongs with [a] have the highest misclassification rate. Our study, however, emphasizes the
phonetic properties of diphthongs with [a] that might explain their hiatic tendency, rather than
their historical source alone. Recall that, on all three measures, we found a smaller degree of
difference between Diphthong and Hiatus in sequences with [a] than in sequences with either [e]
or [o]. This sequence-specific variability in diphthong and hiatus production is likely a reflection
the articulatory properties of the V ([a,e,o]) in the sequences. Specifically, the longer tongue/jaw
trajectories required for sequences with the low vowel [a] are likely responsible for longer
sequences overall as well as a smaller degree of difference between diphthongs and hiatuses with
[a]. This, in turn, results in more sequences with [a] being misclassified. In fact, when we
perform a Discriminant Analysis (using only those predictors identified as statistically

118
significant) on the data for each V separately, we find that the mean squared distance between
groups is smallest for sequences with [a] (2.701), followed by sequences with [e] (3.984).
Sequences with [o] had the largest mean squared distance between Diphthong and Hiatus
(14.214). Consequently, it is not surprising that sequences with [a] had the lowest percentage of
correctly classified sequences (77.9%), followed by sequences with [e] (84.7%). Sequences with
[o] had the greatest percentage of correctly classified sequences (95.8%). With all three levels of
V, hiatuses had a slight advantage over diphthongs in terms of correct classification with the
advantage being greatest for sequences with [a].
5 Conclusions
In this chapter we have shown that Mexican Spanish diphthongs and hiatuses form separate
categories which can be distinguished acoustically along frequential and temporal parameters,
with the distinctions remaining stable across changes in speech rate. We have also shown that
there is evidence of blurring across the two categories such that, in some cases, diphthongs may
be misclassified as hiatus and vice versa. Importantly, this suggests that even Spanish varieties
(like Mexican Spanish) described as highly diphthongizing can produce exceptional hiatuses.
This finding supports the first research goal of this dissertation (as stated Chapter 1).
In addition, we have also identified sequence-specific and speaker-specific tendencies in both
the categorization of diphthongs and hiatuses and in the production of misclassified sequences.
We have attributed the sequence-specific variability to properties of the non-high vowel in the
sequences. We have found that the speaker-specific and sequence-specific tendencies can
intersect. That is, individual speakers may show either a pattern of consistency across vowel
contexts or a different pattern according to vowel context. We suggested at the beginning of the
chapter, in stating Hypothesis 3, that the speaker-specific characteristics of these sequences can
be attributed to distinctive patterns of articulation. In a similar vein, other authors have suggested
that vocalic sequences can be characterized with the same gestural coordination patterns as
sequences of consonants and vowels (Chitoran & Hualde, 2007). However, without data to
provide details of the articulatory parameters underlying these acoustic differences, these
proposals remain untested. Finally, we have not addressed whether a speaker’s production of
misclassified sequences is related to her perception of these sequences. That is, is a speaker who
produces many misclassified Diphthong tokens better able to identify cases of exceptional

119
hiatuses? Related to this is the question of whether a sequence that is consistently misclassified
by a Discriminant Analysis procedure will be similarly subject to misclassification by listeners in
a perception experiment.
The next two chapters describe experiments which attempt to address the articulatory and
perception gaps in the characterization of these vocalic sequences. The relationship between
these sequence-specific and speaker-specific differences to different articulatory patterns and
strategies is examined in Chapter 4. The relationship between the present results and speakers’
perception of unambiguous and ambiguous sequences as either Diphthong or Hiatus is explored
in Chapter 5.

120
Chapter 4 Articulatory Analysis of Vocalic Sequences in Mexican Spanish
1 Introduction
The present chapter reports an experiment which provides articulatory movement data on vocalic
sequences in Mexican Spanish. These sequences include glide-vowel (jV, diphthongs) and high
vowel-vowel (íV, hiatuses) sequences. The experiment was motivated by the desire to test
various claims regarding the articulatory characteristics of these sequences in Spanish. Some of
these claims emerged from the acoustic data analyzed in Chapter 3 of the present thesis; others
have their source in previous studies, both experimental and theoretical.
In the previous chapter, Chapter 3, we found both speaker-specific and sequence-specific
tendencies in the acoustic characterization of diphthongs (Diphthong) and hiatuses (Hiatus) in
Mexican Spanish. We suggested that these tendencies stem in part from speaker-specific and
sequence-specific patterns of articulation. For example, we attributed some of the sequence-
specific variability in diphthong and hiatus production to the articulatory properties of the non-
high vowel ([a,e,o]) in the sequences. We suggested that the longer tongue/jaw trajectories
required for sequences with the low vowel [a], were responsible for the longer duration of these
sequences overall as well as a smaller degree of difference between diphthongs and hiatuses with
[a]. This, we claimed, resulted in more sequences with [a] being misclassified as exceptional
hiatuses (in the case of expected diphthongs) or diphthongized hiatuses (in the case of expected
hiatuses). We also found that some speakers maintained a more extreme acoustic difference
between Diphthong and Hiatus. We suggested that this was a direct result of different speakers
using different articulatory strategies to produce vocalic sequences in general and to achieve the
diphthong-hiatus contrast more specifically (Colantoni & Limanni, 2010; McDougall, 2004,
2006). However, these claims are, so far, untested.
The topic of the articulatory properties of vocalic sequences in Spanish (Chitoran & Hualde,
2007) and other Romance languages (Marin, 2007, for Romanian; Zmarich et al., 2012 for
Italian) has received considerable attention recently. Two main claims regarding these sequences
emerge from the literature. The first claim is that the difference between diphthongs and hiatuses
(or between glides and vowels, by extension) can be found in the timing of these gestures. That

121
is, diphthongs and hiatuses are thought to differ in their gestural coordination patterns (Chitoran
& Hualde, 2007; Marin, 2007). Proponents of this approach expand on work on the gestural
coordination of consonant-vowel (CV) and vowel-consonant (VC) sequences (e.g. Browman &
Goldstein, 2000). They propose that diphthongs, like CV sequences, are characterized by a
synchronous coordination mode while hiatuses are characterized by a sequential coordination
mode as in vowel-consonant (VC) sequences (Chitoran & Hualde, 2007, p. 61). Gick (2003) uses
this characterization to distinguish the velar onglide from the corresponding velar offglide in
English but its application to the differences between diphthongs and hiatuses remains unclear.
The second claim requires the assumption that glides consists of two gestures, a consonantal or
C-gesture and a vocalic gesture or V-gesture (as found for the English velar glide [w], Gick
(2003). Proponents of this approach maintain that the difference between glides and vowels
occurs because glides have greater C-gesture constriction (Nevins & Chitoran, 2008). In support,
they cite phonological evidence, such as for glide-consonant alternations (Nevins & Chitoran,
2008) that these constriction patterns occur for both velar and palatal glides. Experimental
studies (Zmarich et al., 2012 for Italian; Gick, 2003 for English) suggest that this may be the case
for velars (i.e. the [u]-[w] distinction). However, it remains unclear whether this can be applied
to the behaviour of palatals (i.e. the [i]-[j] distinction) since there is no strong phonetic evidence
of the presence of a C-gesture for the palatal glide [j] (Gick, 2003). More importantly for the
present study, these claims are untested for Spanish.
In the present chapter we put these claims to the test via the examination of the nature of the
speaker-specific and sequence-specific articulatory patterns of diphthongs (Diphthong) and
hiatuses (Hiatus) in this variety of Spanish. Specifically, we conduct an experiment which
investigates the nature of the relationship between vocalic gestures (synchronous or sequential)
in diphthongs and hiatuses by providing direct articulatory movement data on glide-vowel (jV,
diphthongs) and high vowel-vowel (íV, hiatuses) sequences. To achieve this objective, the
experiment tests three hypotheses regarding these sequences. The first hypothesis focuses on
timing. That is, we propose that the difference between jV (diphthongs) and íV (hiatuses)
sequences lies in the relative timing of the articulators which constitute glides and vowels. Based
on Nevins & Chitoran (2008) and expanding on Gick (2003) the assumption is made that the
relevant articulators for these sequences are the tongue body (TB), which constitutes a V-gesture,
and the tongue tip (TT) which constitutes a C-gesture. If diphthongs are indeed phased in a

122
synchronous mode and hiatuses in a sequential mode (Chitoran & Hualde, 2007) we should find
a greater temporal offset between the C-gesture and the V-gesture in hiatuses38
. We also expect
speech rate to have some influence on offset values since, as reported in Chapter 3, a faster
speech rate resulted in a decrease in duration for both diphthongs and hiatuses. This duration
reduction can be interpreted as stemming from an increase in the degree of gestural overlap as a
result of the faster speech rate (Browman & Goldstein, 1992). Thus, we expect that this decrease
in duration at the faster speech rate will be reflected in a decrease in offset values. However,
because this phonetic reduction affects all vowel sequences, we expect category distinctions to
be maintained across speech rates (Aguilar, 1999).
Hypothesis 1: Timing hypothesis
Diphthongs and hiatuses differ in the relative timing of TB and TT gestures. The
temporal offset between TB and TT is greater for hiatuses than for diphthongs,
with hiatuses showing a C-gesture (TT) lag. These offset values decrease for all
sequences as speech rate increases but the differences between Diphthong and
Hiatus are maintained.
We might also expect a reduction in the magnitude of the C-gesture for hiatuses relative to
diphthongs if, as put forth by Nevins and Chitoran (2008), glides differ from vowels in having a
greater constriction degree for the C-gesture (see also Padgett 2008, p. 1944). Related to this is
the possibility that the difference between Diphthong and Hiatus is found in the relative
magnitude of either the consonantal (TT) or the vocalic (TB) gestures (Nevins & Chitoran, 2008,
p. 1994) such that for hiatuses the TB dominates while for diphthongs the TT is dominant.
Therefore, the second hypothesis refers to these presumed spatial differences between Diphthong
and Hiatus. To test this hypothesis, we look at the magnitude of both the C-gesture (TT) and the
V-gesture (TB) for diphthongs and hiatuses. Speech rate is also expected to have some influence
on this measure since an increase in speech rate has been shown to produce a reduction in
articulatory displacement for vowels (e.g. Gay, 1974), which may have acoustic consequences
(i.e. be associated with more centralized first and second formant (F1-F2) values). On the other
hand, variations in articulatory patterns do not necessarily produce acoustic consequences (e.g.
Guenther et al., 1999). In the data presented in Chapter 3, for example, we found no consistent
significant differences according to speech rate in F1-F2 values. However, that finding does not
preclude the possibility that the magnitude of articulatory displacement will show a significant
38 This requires the assumption that the initial [i] of a hiatus (like the initial [j] of a diphthong) involves the action of the TT.

123
decrease with an increase in speech rate, since individual speakers may use different strategies to
achieve the required speech rate contrast. That is, to achieve the faster speech rate, they may
decrease movement duration or magnitude, or both (Van Lieshout & Moussa, 2000).
Hypothesis 2: Spatial hypothesis
Diphthongs and hiatuses differ in (i) the magnitude of TT displacement and (ii)
the relative magnitude of TT and/or TB displacement. Diphthongs have greater
TT (C-gesture) displacement than hiatuses while hiatuses have greater TB (V-
gesture) displacement. The magnitude of TT and TB displacement decreases for
all sequences as speech rate increases but the difference between Diphthong and
Hiatus is maintained.
We expect both the gestural timing (Hypothesis 1) and magnitude of TT and TB displacement
(Hypothesis 2) to be affected by the identity of the non-high vowel (V) in the sequence. Based on
the results from the acoustics experiment in Chapter 3, we predict that sequences with [a]
(because of the greater tongue/jaw trajectory between [j]/[i] and [a]) will have more extreme
values than sequences with either [e] or [o] on both the timing and spatial measures. Similarly,
on both relative timing and displacement measures, we predict that the difference between
Diphthong and Hiatus will be smaller for sequences with [a]. For both hypotheses, we also
examine the individual variation in the production of these vowel sequences. This leads us to our
third hypothesis.
Hypothesis 3
Individuals may use distinctive patterns of articulation to produce diphthongs and
hiatuses and to achieve the diphthong-hiatus contrast. For example, individual
participants may differ in their preference for either a timing strategy or a spatial
strategy (or both to some degree). These individual patterns of articulation give
rise to sequences whose category membership is ambiguous (e.g. exceptional
hiatuses).
The chapter is structured as follows. The experiment methodology follows this introduction in
§2. The results are given in §3 and discussed and evaluated against the above hypotheses in §4.
The chapter conclusions are given in §5. The final section also motivates the perception chapter
which follows.

124
2 Experimental Methodology
2.1 Participants
Eight of the ten female native speakers of Mexican Spanish who participated in the acoustic
study took part in the present study. They include AA, AM, AN, CG, DH, KR, LL and MM.
Their participation in both experiments makes it possible to test the proposal that individual
differences in the acoustic production of diphthongs and hiatuses reflect individual differences in
articulatory strategies.
2.2 Stimuli
The materials used for this experiment consisted of the same 40 real words (Appendix 1) used in
the acoustics experiment reported in Chapter 3. As before, 20 words contained the target
sequences: (i) hiatus [í.a], [í.e], [í.o] and (ii) diphthong: [já], [jé],[jó] 39
. The remaining 20 words
consisted of distractors and practice words. As for the acoustic experiment, the words were
embedded in the carrier sentence Digo X para ti “I say X for you” and production was elicited at
two different speech rates. As in the acoustic study, all diphthongs appear in the first syllable of
the target words and this first syllable is always stressed. For hiatuses, the stressed high vowel
itself is in the first syllable.
2.3 Instrumentation and Procedure
Articulatory data were collected with the use of a three-dimensional (3D) AG500 Electro-
Magnetic Articulograph (EMA) system (Carstens Medizinelektronik GmbH, Lenglern,
Germany)40
. Data collection took place in the Oral Dynamics Lab (Department of Speech-
Language Pathology, University of Toronto) under the supervision of the lab’s Research Officer,
Dr. Aravind Namasivayam. For the purpose of this study, twelve small transducer coils were
attached using surgical adhesive (Isodent, Ellman International Mfg) to the following flesh
points on the participants: upper lip (UL), lower lip (LL), tongue tip (TT, 1cm from the tip of the
39 Although data were collected for both rising and falling sequences in this experiment, only the results of the rising palatal
series are reported here. Similarly, data collected for diphthongs in unstressed syllables is not reported. Thus, the number of
tokens analyzed reflects only rising palatal sequences in stressed syllables.
40 For more detailed explanations of the technical aspects (including system accuracy and noise) and experimental principles
underlying the use of 3D-EMA for the study of speech movements, see Hoole, 1996; Van Lieshout ,2006; Yunusova et al., 2008).

125
tongue), tongue body (TB, 3 cm behind the TT coil), tongue dorsum (TD, as far back as the
participant could tolerate), and right and left cheeks. To track jaw movements, a coil was
attached to the mandibular incisors using a custom thermo-plastic impression (Van Lieshout &
Moussa, 2000) to protect the surface of the teeth and ensure a stable location for the jaw coil.
Reference coils on forehead, nosebridge and behind the ears were subsequently used to align all
movement data and correct for head motion (see Data Processing, §2.4 below). Figure 20 shows
the placement of the coils:
Figure 20. Coil placement for 3D EMA
Prior to the start of the experiment, data was collected using a bite plate to which a 3-axis liquid
bubble level was attached at one end. For this trial (bite plate trial), the participant was instructed
to gently bite down and hold this device in her mouth while the experimenter adjusted the
orientation of her head within the EMA cube until the bubble in the spirit level centered between
the two lines on both the longitudinal axis (movement along the coronal plane) and the lateral
axis (movement along the saggital plane). At the same time, the vertical axis (movement along
the transverse plane) was restrained by gaze fixation at the centre of a 19” LCD monitor placed

126
30” in front of the participant’s eyes. The purpose of this bite plate trial was to establish a global
coordinate system by aligning the participant’s head with the cardinal planes of the body. The
data from this trial was subsequently used to normalize head movements.
Participants were recorded as they read words containing target sequences and distractors. The
list of sentences was randomized and presented to the participants on a computer monitor using
DirectRT presentation software (Empirisoft Corp.). Acoustic recordings were collected
simultaneously with the movement data using the same recording equipment and microphone as
for the acoustic experiment reported in Chapter 3, §2.3 but these recordings are not analyzed for
the present experiment. The participants were given written task instructions displayed on the
computer monitor. In addition, the experimenter was available at all times for clarifications. The
stimuli were presented to the participants according to the same procedure used for the acoustic
experiment (Chapter 3, §2.3). As with the acoustics experiment, the participants were given five
practice trials for each speech rate in order to get used to the task. In addition, participants were
engaged in a short conversation with the experimenter prior to the testing phase in order to get
them accustomed to speaking with the coils in their mouth. The participants repeated each
sentence 3 times consecutively in each trial. Thus the target sentences were produced three times
at two speaking rates. Each speaker produced a total of 40 trials*3 utterances*2 speech rates =
240 utterances. Of these, 120 utterances per participant contained the target sequences analyzed
for the present experiment. However, because of a presentation error, Speaker CG recorded 6
additional tokens, bringing the total number of tokens analyzed to 966 instead of the expected
960 (120 utterances*8 participants = 960 possible tokens for analysis). The entire experiment
lasted approximately two hours (1 hour to attach the coils and 1 hour to perform the reading
task). The participants were given frequent short breaks after every few trials. The purpose of
these breaks was two-fold. First, they allowed the participants to rest, thus reducing fatigue.
Second, the breaks were used to monitor the coils and allowed the experimenter to make
corrections where necessary (e.g. re-attach/replace a coil that had become loose). In addition,
participants were given the opportunity to have a brief pause following each trial. All
participants were compensated for taking part in the experiment.

127
2.4 Data Processing
Position calculations and corrections for head movements were carried out using custom-made
software from the Carstens’ company. This software includes a program (CalPos) which
calculates the position and orientation of each sample and a program (NormPos) which conducts
a sample-by-sample head normalization by rotating and shifting the coordinate system such that
all reference sensors remain in the same 3D location across all samples and trials. The NormPos
program uses a normalization pattern file that is based on a single trial. Therefore, the quality of
the head movement correction for the entire experiment depends on the quality of the data from
the reference sensor coils in that trial. Since the quality of data may not be equally good in all
reference coils (i.e. in the case of coil detachment and/or position tracking errors) more than two
reference sensor coils (typically four) are used to allow for redundancy. For the present study,
the nose bridge (coil #5) and the two sensor coils behind the ears (right ear = coil # 12; left ear =
coil #11) usually had the least amount of noise. Noise levels were determined by accuracy
measurements where 3-dimensional (3D) Euclidean distances between pairs of reference sensor
coils (11-12, 5-12, 4-12, 5-11 and 4-11) were calculated. Smaller average standard deviation for
the 3D Euclidean distances between these pairs mean that the distance between the pairs
remained fairly constant throughout all trials for a session (i.e. static system noise was low)
(Hoole and Zierdt, 2010; Yunusova, et al., 2008). Under ideal conditions, the distance between
the pairs of sensors should remain constant throughout all trials for a given session. The average
static system noise for each subject as a function of reference sensor coils pairs can be seen in
Table 27. The mean value for the 8 speakers in the present study was 0.20 mm across all pairs.
This value represents fairly low system noise41
since, overall, the accuracy of the AG500 system
is expected to be approximately 0.50 mm or less in each dimension (X,Y,Z) (Yunusova et al.,
2008).
41 There is, however, the possibility that regions with greater positional errors may not have been captured by the Carstens’
software measurement protocol (Stella et al., 2012; Kroos, 2012).

128
Table 27. EMA static system noise average SDs (in millimeters), by Speaker
Speaker Mean system noise SD (mm)
AA 0.17
AM 0.13
AN 0.24
CG 0.28
DH 0.15
KR 0.31
LL 0.18
MM 0.16
GROUP MEAN 0.20
2.5 Measurement and Analysis
Following processing, the data were measured and analyzed using a custom-made Matlab
application (EGUANA, Ema Gui Analysis, cited in Neto Henriques & Van Lieshout, 2013). The
application allows for the manual selection of the beginning and end points of the segments of
interest as identified from the acoustic signal. In this case, the points of interest for measurement
corresponded to the Glide/High Vowel-V portion of the target words. Once these points are
selected, the application carries out a number of calculations on the articulators selected for
analysis and creates an output file with the resulting measurements. Three articulators must be
selected and in the present case, these include the Tongue Body (TB), the Tongue Tip (TT) and
the Jaw (JAW). For the present study we cite the following temporal and spatial measurements
made on the vertical (up-down) dimension42
:
(i) Temporal measurements
a. offset (measured in milliseconds) between peak amplitudes of TB and TT
gestures
(ii) Spatial measurements
a. peak magnitude (measured in %) of TT and TB displacement
b. magnitude (measured in %) of TT displacement at peak TB displacement
For the spatial measurements, normalized values were used. Normalization was achieved by
setting the maximum amplitude for the constriction for each trial at 100% and the minimum
constriction at 0%. With regards to the spatial measurements, the second measurement (outlined
in (b) above) was used as an additional measure of TT displacement. This was necessary since in
some cases the peak magnitude of TT displacement during the vocalic sequence was difficult to
42 Measurements were also made on the horizontal (front-back) dimension but are not reported here.

129
measure due to blending (partial or complete) with the TT gesture of a following Coronal
consonant (refer to §3.2 for more details).
Temporal measurements reflect the raw offset measurements in milliseconds. For the present
experiment a TB-TT offset value of zero ms means that the peaks for TT and TB coincide, that is
the TT and TB are phased in a synchronous mode. The greater the temporal offset between TB
and TT, the less ‘in-phase’ the two gestures can be assumed to be. Figure 21 illustrates where the
measurements were taken using the sequence [já] from the word piano as produced by speaker
CG43
. Note that while JAW movement also appears, the influence of the JAW on the other
articulators was minimized via a normalization procedure44
. Thus, the TT and TB movements
cited reflect this reduced contribution of the JAW.
Figure 21. Waveform and articulatory movement data from vertical axis of a token of [já]
from the word piano produced by speaker CG, showing the temporal and spatial
measurements used to analyze the data.
43 The JAW signal (JAW minima and maxima) in combination with the acoustic signal were used for segmentation. These data
were manually checked and corrected if no clearly defined maxima or minima were detected.
44 The procedure used is the estimated rotation method (ERM) developed by Westbury et al. (2002) adapted for 3D EMA (as
described in Neto Henriques & Van Lieshout 2013).

130
The output file created by the application was then imported to an EXCEL worksheet for coding.
The tokens were coded as diphthongs (Diphthong) or hiatuses (Hiatus) as per their expected
production (Sequence Type). The independent variables are as follows (these are the same
variables used in the acoustics experiment, as outlined in Chapter 3, §2.4).
(i) Non-high Vowel (V): [a], [e], [o]
(ii) Speech Rate: Rate 1 and Rate 245
Results were evaluated using Repeated-measures ANOVAs on the statistical program MINITAB
14 (Minitab Inc.), with p level set at .0546
. These results are reported next.
3 Results
3.1 Timing (TB-TT Offset)
In this section we examine the temporal offset in milliseconds between peak Tongue Body (TB)
and peak Tongue Tip (TT) to determine whether there is a difference on this measure between
diphthongs (Diphthong) and hiatuses (Hiatus). In interpreting the offset values, a positive
number for the offset reflects a C-gesture (TT) lag (or a V-gesture lead) while a negative number
reflects a C-gesture (TT) lead (or a V-gesture lag). The closer to zero the offset value, the more
‘in-phase’ we can interpret the C-gesture and V-gesture to be. We predict that the offset values
for hiatuses will be greater (due to a TT lag) than the offset values for diphthongs. A summary of
the descriptive statistics for this measure of TB-TT offset is given in Table 28.
Table 28. Means and SDs of TB-TT offset (ms) for Diphthong and Hiatus, by Speech Rate
Rate 1 Rate 2
Sequence Type Mean SD Mean SD
Diphthong 17.85 58.07 12.22 48.75
Hiatus 33.85 76.10 7.00 77.38
45 Measured in syllables/second, these rates are as follows (as outlined in Chapter 3, §2.3): Rate 1 is approximately 4.7
syllables/second; Rate 2 is approximately 6.4 syllables/second.
46 As in Chapter 3, before the data was submitted to statistical analyses, tests for normality of distribution (Anderson-Darling) and
for equality of variances (Bartlett’s or Levene’s) were carried out to determine whether the data conformed to the requirements of
parametric analyses. Most of the measurements met one or both requirements.
Measurement Normality of distribution Equality of variances
TB-TT offset Diphthong: p=0.386; Hiatus: p=0.129 p=0.00 (Bartlett’s)
%TB Diphthong: p<0.05; Hiatus: p<0.05 p=0.236 (Levene’s) %TT Diphthong: p<0.05; Hiatus: p<0.05 p=0.330 (Levene’s) %TT at peak TB Diphthong: p=0.093; Hiatus: p=0.319 p=0.914 (Bartlett’s)

131
Figure 22 shows the mean temporal offset between the peak TB and TT values for diphthongs
and hiatuses at both speech rates. The figure shows positive mean offset values for both
Diphthong and Hiatus at both speech rates, suggesting that, contrary to our prediction, the C-
gesture (TT) lags the V-gesture (TB) in all sequences, not just for Hiatus. This is contrary to our
prediction that only Hiatus should show a TT lag and suggests that the sequence in Figure 21 is
not representative of the average Diphthong. Figure 22 also suggests that there is a significant
difference in TB-TT offset values between Diphthong and Hiatus, at least at the slower speech
rate, Rate 1. At this rate, the difference is in the expected direction, with Diphthong having a
smaller mean offset value than Hiatus. For Rate 2, the mean values for both Diphthong and
Hiatus are smaller, as expected. The difference between Diphthong and Hiatus is also smaller
and this, too is as predicted. That is, the difference becomes smaller since an increase in speech
rate is expected to create more gestural overlap (e.g. Browman & Goldstein, 1992, p. 172) which
in turn would be expected to decrease the offset values. However, the difference between
Diphthong and Hiatus for Rate 2 is in an unexpected direction, with Hiatus having a smaller
mean offset value than Diphthong.
Sequence Type
TB
-TT O
ffse
t in
mse
c.
(ra
w)
HiatusDiphthong
40
30
20
10
0
HiatusDiphthong
Rate = 1 Rate = 2
*Bars are One Standard Error from the Mean
Figure 22. Bar chart of mean TB-TT offset (ms) by Sequence Type and Speech Rate
In any case, a repeated-measures ANOVA with factors Sequence Type and Rate fails to find a
statistical significance for either of the main effects or their interaction (Table 29). Part of the

132
reason for this lack of significance surely lies in the fact that offset values for both Diphthong
and Hiatus had a high degree of variability as evidenced by the large standard deviations (Table
28), especially for hiatuses.
Table 29. ANOVA table for differences between Diphthong and Hiatus in TB-TT offset
(ms), by Speech Rate
Source F(df term, df error) p
Main effects Sequence Type F(1,7) = 0.23 0.648
Rate F(1,7) = 2.08 0.192
Interaction Sequence Type*Rate F(1,7) = 2.48 0.159
Other Speaker F(7,21) = 2.40 0.108
A look at the individual data in Figure 23 highlights what appears to be a lack of consistent
patterning of offset values for Diphthong and Hiatus, despite the fact that there was no
significant Speaker effect47
. Three of the eight speakers (AA, AN and MM) show a stable pattern
of smaller TB-TT offset values for diphthongs and a generally consistent C-gesture (TT) lag for
both Diphthong and Hiatus, for both Rate 1 and Rate 2. Others show this pattern only for Rate 1
(CG) or only for Rate 2 (DH). Of the remaining speakers, some had very small differences
between Diphthong and Hiatus (Rate1: DH, KR and LL; Rate 2: AM and CG). Finally, some
speakers show a C-gesture (TT) lead for some sequences, especially hiatuses (where we would
expect a TT lag). This TT lead is likely causing the lack of significance in the group mean offset
values between Diphthong and Hiatus, especially when the TT lead value is quite large (Rate 1:
AM; Rate 2: KR and LL).
47 Individual means and standard deviations are found in Table A3.1, Appendix 3.

133
TB
-TT O
ffse
t in
mse
c.
(ra
w v
alu
es)
100
0
-100
100
0
-10021
Rate 21
100
0
-10021
AA AM AN
CG DH KR
LL MM
Sequence Type
Diphthong
Hiatus
*Bars are One Standard Error from the Mean
Figure 23. Bar chart of mean TB-TT offset (ms) for Sequence Type, by Speech Rate and
Speaker
Finally, we observe individual differences in the amount of variability in the data with some
speakers producing quite large standard deviations (refer also to Table A3.1, Appendix 3). The
large amount of individual and group variability suggests that this is either not a good measure of
the articulatory differences between diphthongs and hiatuses or that Diphthong and Hiatus (in
this variety of Spanish and for this set of speakers) do not differ consistently on this measure.
On the other hand, a different visual representation of the individual data does reveal a patterned
distribution of offset values. That is, for all speakers, the offset values for diphthongs are
clustering at or near the zero point (Figure 24), with this clustering becoming more pronounced
at Rate 2 (Figure 25). Hiatuses on the other hand, tend to have greater offset values which are
essentially fanning away from the zero point (at both speech rates) in both directions.

134
Sequence TypeSequence Type
TB
-TT O
ffse
t (m
se
c.)
HD
100
50
0
-50
-100
Speaker
AN
CG
DH
KR
LL
MM
AA
AM
Rate 1
Figure 24. Interaction plot of Mean TB-TT offset (ms) for Sequence Type, by Speaker:
Rate 1
Sequence TypeSequence Type
TB
-TT O
ffse
t (m
se
c.)
HD
100
50
0
-50
-100
Speaker
AN
CG
DH
KR
LL
MM
AA
AM
Rate 2
Figure 25. Interaction plot of Mean TB-TT offset (ms) for Sequence Type, by Speaker:
Rate 2
Diphthong
Diphthong
Hiatus
Hiatus

135
Part of the problem identified with the measure of TB-TT offset is the anticipatory movement of
the TT largely due to the presence of consonants in the stimuli words which involve a Tongue
Tip/Tongue Blade articulation. Because coronal consonants in Spanish are the most frequently
occurring consonants by place of articulation (e.g. Guirao & García Jurado, 1990, p. 144) and
since real words were used in the stimuli set, most of the tokens have a coronal consonant either
preceding or following the vocalic sequence in the word. In the data cited here, consonants
which precede the vocalic sequence do not appear to have a great degree of influence on TB-TT
offset. However, the consonants which follow the vocalic sequences may be a cause for concern
(e.g. Recasens, 1999b, p. 81). Some of these consonants require a high degree of TT involvement
and may be the reason for the TT lag in some of the above sequences. In fact, we find that some
of the participants exhibit this anticipatory effect, especially when the consonant following the
vowel sequence is the lateral, [l] (as in the words viola), the rhotic tap [ɾ] (as in the word diario)
or the fricative [s] (as in the word días)48
. Some speakers had this effect with a following [n],
both when this consonant occurred in a syllable coda (as in the word ríen) or a syllable onset (as
in the word bienio and bienes) but these cases with [n] were fewer and most consistently found
with speakers CG and LL and then mainly for Rate 2. A following dental stop (/t/ and /d/, as in
the words prieto and criada) did not appear to produce this effect as often. This can be explained
by the fact that these consonants appeared in intervocalic position, a position where they are
frequently lenited. For example, the voiced dental stop /d/ is almost exclusively produced as an
approximant [ð] in this position (Hualde, 2005; Martínez-Celdrán, 2008). The voiceless dental
stop /t/ may also be voiced and in some cases have an approximant realization in intervocalic
position (Hualde, 2005; Martínez-Celdrán, 2009) 49
. However, lenition may not be the only
explanation for this there is evidence of intervocalic /n/ lenition in Spanish as well, at least for
Peninsular Spanish (Honorof, 2003). Therefore, another possibility is that the anticipatory TT
movement is influenced by the constriction location and the orientation of the tongue tip of a
following alveolar (Kochetov, personal communication, 2013). That is, the anticipatory TT
48 In Mexican Spanish, especially in the variety spoken by the study participants (from Central Mexico), coda [s] (both in word-
final and syllable-final positions) is pronounced fully and is not generally aspirated as in other Spanish varieties (e.g. Hualde
2005).
49 Some varieties of Spanish appear not to participate in the lenition of intervocalic /t/. These varieties include Argentine Spanish
(Colantoni & Marinescu, 2010) and Colombian Spanish (Lewis, 2001). For Mexican Spanish, there are mixed results. For
example, Lavoie (2001) reports that intervocalic /t/ for 4 male speakers from Northern Mexico “is always a robust voiceless stop”
(p. 153). On the other hand, Lope Blanch (1996, Volume 2, Map 16) reports that for intervocalic /t/ tokens collected in Mexico
City (the variety most closely related to the speech of the participants of this study) 10% are voiced and another 2.5% are both
voiced and ‘weakened’.

136
movement is most likely to occur with alveolar consonants ([ɾ], [l], [n] or [s]) than with dental
consonants ([t] and [d]). Although both sets of consonants are generally considered apical (e.g.
Hualde, 2005), the tip-up gesture for the alveolars may start earlier.
With the lateral, in at least one case this anticipatory effect was observed even when [l] occurred
as part of a consonant cluster and did not immediately follow the vocalic sequence (i.e. in diablo,
speaker KR, Rate 2). This is not be surprising given that long-distance coarticulation effects of
liquids are well-documented (e.g. West, 1999, p. 1904). This anticipatory effect was also more
likely to occur at a faster speech rate. Thus, even speakers who did not produce this effect at the
slower speech rate (Rate 1), may have had examples of it at an increased speech rate (Rate 2).
Examples of both the presence (Figure 26) and absence (Figure 27) of this anticipatory effect on
the TT gesture are shown below, using the token viola [bjó.la] at Rate 2 as produced by speakers
CG and AA, respectively.
Figure 26. Waveform and articulatory movement data (vertical dimension) of a token of
[jó] from viola showing anticipatory TT movement, Speaker CG, Rate 2
anticipatory TT movement

137
Figure 27. Waveform and articulatory movement data (vertical dimension) of a token of
[jó] from viola showing TT lead, Speaker AA, Rate 2
In short, the articulatory anticipation of the TT gesture varies from speaker to speaker in terms of
the degree and frequency of the effect as well as in the identity of the following consonants
which appear to trigger the effect. Thus, a measurement which looks at the offset values between
TB and TT without taking into consideration lead or lag may be desirable. Recall that our
primary interest in the present study is in the difference between Diphthong and Hiatus in the
amount of TB-TT offset, regardless of lead or lag. That is, our interest is in the distance from
zero (with zero representing a completely in-phase relationship of TT and TB) rather than the
negative or positive value of the offset when it does not equal zero. Therefore, for the purposes
of this experiment, it might be more appropriate to consider the absolute TB-TT offset values.
Using this transformation, the zero values and positive values in the data are maintained while
the negative values (reflecting a TT lead) are converted to positive values. The descriptive
statistics for this new measure are reported in Table 30.
TT lead

138
Table 30. Means and SDs of TB-TT offset (absolute values) for Diphthong and Hiatus, by
Speech Rate
Rate 1 Rate 2
Sequence Type Mean SD Mean SD
Diphthong 43.30 42.57 36.59 34.41
Hiatus 73.75 38.13 65.63 41.03
On this measure of absolute TB-TT offset (Figure 28), we obtain the predicted results. That is,
the TB-TT offset at both speech rates is greater for hiatuses than it is for diphthongs.
Additionally, the values decrease slightly for both Diphthong and Hiatus at the faster speech rate,
Rate 2. This pattern is similar to what we saw in the previous chapter for sequence duration
(Chapter 3, §3.1). Thus, although the offset duration decreases for both Diphthong and Hiatus as
speech rate increases, the category difference between Diphthong and Hiatus retains its
constancy at both speech rates. The difference in mean offset between Diphthong and Hiatus, in
fact, is essentially the same at Rate 1 (30.45 ms) as it is at Rate 2 (29.04 ms).
Sequence Type
TB
-TT O
ffse
t in
mse
c.
(ab
so
lute
va
lue
s)
HiatusDiphthong
100
75
50
25
0HiatusDiphthong
Rate = 1 Rate = 2
*Bars are One Standard Error from the Mean
Figure 28. Bar chart of Mean TB-TT offset (absolute values) for Sequence Type, by Speech
Rate

139
A repeated-measures ANOVA (Table 31) finds a significant effect of Sequence Type50
. The
decrease in offset at the faster speech rate, however, was not enough for statistical significance.
Thus, no significant effects of Rate or of the Rate*Sequence Type interaction were found.
Table 31. ANOVA table for differences between Diphthong and Hiatus in TB-TT offset
(absolute values), by Speech Rate
Source F(df term, df error) p
Main effects Sequence Type F(1,7) = 26.01 0.001
Rate F(1,7) = 3.07 0.123
Interaction Sequence Type*Rate F(1,7) = 0.02 0.879
Other Speaker F (7,21) = 1.11 0.490
The Speaker effect was also not significant. Furthermore, the individual data (Figure 29) now
clearly shows that most speakers follow this general pattern of a larger TB-TT offset for hiatuses,
although for some speakers the difference between Diphthong and Hiatus is smaller than for
others (similar to what we saw for sequence duration in Chapter 3) 51
. For Rate 1, speakers MM
and AN had the largest differences while speaker CG had almost equal values for Diphthong and
Hiatus (with Hiatus slightly smaller than Diphthong, contrary to the general pattern). For Rate 2,
speakers AM, KR and LL had the largest differences and CG once again had the smallest
difference. In addition, we find that for some speakers a speech rate increase does indeed
produce obvious decreases in offset values, either for diphthongs (AM and KR), hiatuses (AA,
AN and MM) or both (CG).
50 All significant p-values in this and all subsequent tables are shaded gray.
51 The individual Means and SDs are found in Appendix 3 (Tables A3.2).

140
TB
-TT O
ffse
t in
mse
c.
(ab
so
lute
va
lue
s) 100
50
0
100
50
021
Rate 21
100
50
021
AA AM AN
CG DH KR
LL MM
Sequence Type
Diphthong
Hiatus
*Bars are One Standard Error from the Mean
Figure 29. Bar chart of Mean TB-TT offset (absolute values) for Sequence Type, by Speech
Rate and Speaker
3.1.1 Vowel Effects on Timing of TB and TT
Here we consider the effect of the non-high vowel (V) in the sequences on the TB-TT absolute
offset values. The descriptive statistics are given in Table 32.
Table 32. Means and SDs of TB-TT Offset (absolute values) for Diphthong and Hiatus, by
Speech Rate and V
Rate 1 Rate 2
Sequence Type Vowel Mean SD Mean SD
Diphthong
[a] 42.53 39.17 38.85 33.02
[e] 46.08 44.23 35.43 34.12
[o] 38.26 45.34 34.69 37.89
Hiatus
[a] 67.19 32.89 59.69 40.45
[e] 85.00 47.57 88.91 38.43
[o] 75.63 36.13 55.21 37.31
We expected that both Diphthong and Hiatus would have larger offset values when V is [a] than
when V is either [e] or [o]. In addition, we anticipated smaller differences between Diphthong
and Hiatus when V is [a] than when V is either [e] or [o]. A visual inspection of the absolute
offset values (Table 32, Figure 30) suggests some influence of V. However, the effect of V is not

141
always in the predicted direction. For example, we note that sequences with [e] appear to have
longer TB-TT offset values than sequences with [a] or [o], although this difference is found
mainly for hiatuses. For diphthongs, the three levels of V seem to behave similarly at both
speech rates. In addition, we observe relatively small differences between sequences with [a] and
those with [o], for both Diphthong and Hiatus, especially at Rate 2. Overall then, the first
prediction is not met. The difference between Diphthong and Hiatus does, however, appear to be
influenced by the identity of V. Specifically, at Rate 1 the Diphthong-Hiatus difference is
smallest for sequences with [a] (24.66 ms). Sequences with [e] (with a difference of 38.92 ms)
and [o] (with a difference of 37.37 ms), on the other hand, have larger Diphthong-Hiatus
differences than sequences with [a] but do not differ from each other. At Rate 2, the difference
remains largest for sequences with [e] (53.48 ms). In fact, the Diphthong- Hiatus difference for
sequences with [e] increases considerably for Rate 2, due to an increase in offset values for
hiatuses with [e]. Conversely, the Diphthong-Hiatus differences between sequences with [a]
(20.84 ms) and those with [o] (20.52 ms) become similar at Rate 2, largely due to a decrease in
hiatus offset values for [o]. Overall, then, we have more success with our second prediction,
especially for Rate 1.
TB
-TT O
ffse
t in
mse
c.
(ab
so
lute
va
lue
s)
V [o][e][a]
100
80
60
40
20
0[o][e][a]
Rate = 1 Rate = 2
Sequence Type
Diphthong
Hiatus
*Bars are One Standard Error from the Mean
Figure 30. Bar chart of Mean TB-TT offset (absolute values) for Sequence Type, by Speech
Rate and V

142
A repeated-measures ANOVA (Table 33) reveals significant effects of both Sequence Type and
V but no significant effect of Rate. Post-hoc comparisons (Bonferroni) confirm that the main
effect of V is due to a significant difference between sequences with [e] and those with [o] (t = -
2.50, p = 0.043). None of the interactions were significant. In other words, the offset values for
Diphthong were smaller than those for Hiatus across all vowel and speech rate contexts.
Table 33. ANOVA table for differences between Diphthong and Hiatus in TB-TT offset
(absolute values), by Speech Rate and V
Source F(df term, df error) p
Main effects
Sequence Type F(1,14) = 32.90 0.001
Rate F(1,14) = 1.83 0.219
V F(2,14) = 4.08 0.040
Interactions
Rate*Sequence Type F(1,14) = 0.05 0.837
Rate*V F(2,14) = 0.30 0.660
Sequence Type*V F(2,14) = 2.84 0.092
Rate*Sequence Type*V F(2,14) = 1.64 0.229
Other Speaker F (7,77) = 1.49 0.403
Although the Speaker effect was not significant, the individual data (Figure 31) does show some
between-speaker differences in the realization of Diphthong and Hiatus52
. These differences are
influenced by both V and Rate. Specifically, it appears that the differences in Hiatus between
sequences with [e] and those with [a] and [o] can be attributed to the behaviours of Speakers AA,
CG, and MM. These three speakers have greater offset values for hiatuses with [e] than for
hiatuses with [a] or [o] at both speech rates. In addition, Speakers KR and LL exhibited this same
behaviour for [e] sequences but only at Rate 2. Among the remaining speakers we observe
similar offset values for all the V contexts at both speech rates. Some speakers, however, exhibit
more variable production. For example, speaker LL exhibits a high degree of variability in her
Rate 2 production of hiatuses with [e] and [o]. This same speaker also has smaller offset values
for hiatuses than for diphthongs in sequences with [o] at both speech rates, suggesting a
diphthongized production of these sequences.
52 See Tables A3.3-A3.5 in Appendix 3 for individual means and SDs.

143
TB
-TT O
ffse
t in
mse
c.
(ab
so
lute
va
lue
s)
160
80
0
160
80
0[o][e][a]
V [o][e][a]
160
80
0[o][e][a]
AA AM AN
CG DH KR
LL MM
Sequence Ty pe
Diphthong
Hiatus
Rate = 1
TB
-TT O
ffse
t in
mse
c.
(ab
so
lute
va
lue
s)
160
80
0
160
80
0[o][e][a]
V [o][e][a]
160
80
0[o][e][a]
AA AM AN
CG DH KR
LL MM
Sequence Ty pe
Diphthong
Hiatus
Rate = 2
Figure 31. Bar chart of Mean TB-TT offset (absolute values) for Sequence Type, by Speech
Rate, V and Speaker
3.2 Spatial Displacement (%TT and %TB)
Here we look at the maximum displacement (expressed as %) achieved by the TT and the TB
within the segment. Table 34 summarizes the descriptive statistics for this.
Table 34. Means and SDs of maximum TT and TB displacement (%) for Diphthongs and
Hiatus, by Speech Rate
Rate 1 Rate 2
Sequence Type Articulator Mean SD Mean SD
Diphthong ,Tonic (D) TB 95.51 10.00 96.72 10.43
TT 86.75 17.67 90.45 17.99
Hiatus (H) TB 98.01 6.81 94.80 12.73
TT 93.64 11.65 96.46 8.48
If glides (as found in diphthongs) are indeed more consonantal than vowels (as found in hiatuses)
(Nevins & Chitoran, 2008), then we would expect the TT (the C-gesture) to reach a higher
maximum displacement for diphthongs than for hiatuses. We might also expect the TB, or V-
gesture to be dominant in hiatuses. On the other hand, if we adopt the view that diphthongs are
moving targets (i.e. they are characterized by their glide’s movement through time, Gay, 1970),

144
we might expect the opposite to occur. That is, glides in diphthongs may exhibit a smaller TT
and TB displacement than the corresponding high vowels in hiatuses. In fact, in Chapter 3, we
reported that diphthongs in general had higher F1 values and lower F2 values than corresponding
hiatuses, especially in the glide portion (see also Borzone de Manrique, 1979 and Aguilar, 1997
for similar findings for Argentine and Peninsular Spanish, respectively). This suggests that glides
appearing in diphthongs are more, rather than less, sensitive to coarticulation from the non-high
V in the sequence and are produced with a more open articulation than their single-target vowel
counterparts. A first look at the data for these two measures (TB and TT vertical displacement)
in Figure 32 (see also Table 34) suggests that glides do, in fact, have smaller TT displacement
than hiatuses, against our initial hypothesis and in support of the moving-target proposal. On the
other hand, the TB displacement for both Diphthong and Hiatus is virtually identical.
Pe
ak D
isp
lace
me
nt
(%)
TTTBTTTB
100
80
60
40
20
0TTTBTTTB
Rate = 1 Rate = 2Sequence Type
Diphthong
Hiatus
*Bars are One Standard Error from the Mean
Figure 32. Bar chart of mean magnitude of TT and TB displacement (%) for Sequence
Type, by Speech Rate
In fact, we find no significant difference in Sequence Type or Rate between Diphthong and
Hiatus where TB displacement is concerned (Table 35). The Sequence Type*Rate interaction
also failed to reach significance. The interaction, however, did approach significance (p = 0.051)
due to the slightly larger difference between Diphthong and Hiatus for Rate 1. On this measure
of TB displacement we also find a significant Speaker effect.

145
When we look at the magnitude of TT displacement, on the other hand, we find that the
difference between Diphthong and Hiatus is indeed significant. However, it is the hiatuses which
exhibit a higher degree of relative TT displacement, not the diphthongs, as hypothesized. Rate is
also significant since for both Diphthong and Hiatus there is a greater TT displacement at the
faster speech rate (Rate 2). This is also surprising since we might have predicted a reduction, not
an increase, in TT magnitude with an increase in speech rate (e.g. Browman & Goldstein, 1989,
1992). However, a reduction in the magnitude of a gesture need not necessarily accompany an
increase in speech rate. If we consider gestural reduction to be under speaker control (e.g. Jun,
1996; Barry, 1992), it is possible that some speakers may increase TT displacement in order to
counterbalance a large increase in gestural overlap (as measured by a decrease in TB-TT offset
in the present data). We examine this possibility below when we look at the individual results
(Figure 33). The Sequence Type*Rate interaction is not significant. On this measure of
maximum TT displacement we find no significant Speaker effect.
Table 35. ANOVA table for differences between Diphthong and Hiatus in maximum TB
and TT displacement (%), by Speech Rate
%TB %TT
Source F(df term, df error) p F(df term, df error) p
Main effects Sequence Type F(1,7) = 0.13 0.730 F(1,7) = 37.47 0.000
Rate F(1,7) = 0.46 0.519 F(1,7) = 6.93 0.034
Interaction Sequence Type*Rate F(1,7) = 5.54 0.051 F(1,7) = 0.10 0.757
Other Speaker F (7,21) = 5.43 0.046 F (7,21) = 11.90 0.286
When considering the relative magnitude of TT and TB displacement we observe a general
pattern of greater TB displacement relative to TT displacement with the difference between TB
and TT being greater for diphthongs (due to the smaller TT displacement for diphthongs) than
for hiatuses. However, this pattern is reversed for Rate 2 hiatuses. Below we discuss the
individual variation that is likely causing this reverse pattern for Rate 2 hiatuses.
The individual data (Figure 33) generally match the group data53
. That is, we observe very little
difference in TB activity between Diphthong and Hiatus, with the values for both types of
sequences approaching 100% for most speakers. The Speaker effect found on this measure is
53 Individual means and SDs are found in Tables A3.6 and A3.10 in Appendix 3.

146
largely due to speakers KR and LL who have smaller maximum TB displacement for both
Diphthong and Hiatus at both speech rates. This is most obvious for speaker KR with Rate 2
hiatuses. A smaller TB displacement results in KR and LL having a different TB-TT
displacement pattern from the other speakers. That is, where most other speakers have a smaller
TT displacement relative to the TB displacement, speakers KR and LL have the opposite pattern.
In fact, it is probably KR’s behaviour with Rate 2 hiatuses which is responsible for the pattern
observed in Figure 33 (where Rate 2 hiatuses have larger TT displacement relative to TB
displacement). In terms of TT displacement on its own, we find that most of the participants
follow the pattern of slightly greater TT displacement for hiatuses than for diphthongs.
We also find that all the speakers but one (LL) show some degree of increase in TT magnitude at
Rate 2, either for diphthongs only (AN, CG), hiatuses only (DH) or both (AA, AM, MM, KR).
All these speakers had a decrease in TB-TT offset (absolute values, refer to Tables 3 and 4 in
Appendix) either for Diphthong (AM, KR), Hiatus (AA, MM) or both (AN, CG, DH). Speaker
LL, on the other hand had a very small decrease in offset for Diphthong (0.42) at Rate 2 and an
increase in offset for Hiatus at Rate 2. Thus, there may be negative relationship between a
decrease in TB-TT offset and an increase in TT magnitude at the faster Rate. That is, if you have
more of one you may have less of the other. This may be a way of assuring recoverability for the
listener at the faster speech rate (e.g. Flege, 1988). However, the relationship is not completely
clear since the Sequence Type (Diphthong or Hiatus) which undergoes reduction in offset does
not necessarily match the Sequence Type which shows an increase in TT magnitude54
.
54 It is possible that this lack of correspondence between offset reduction and TT magnitude increase may have been influenced
by the use of normalized data for TT magnitude.

147
Pe
ak D
isp
lace
me
nt
(%)
100
50
0
100
50
0TTTBTTTB
TTTBTTTB
100
50
0TTTBTTTB
AA AM AN
CG DH KR
LL MM
Sequence Ty pe
Diphthong
Hiatus
Rate = 1
Pe
ak D
isp
lace
me
nt
(%)
100
50
0
100
50
0TTTBTTTB
TTTBTTTB
100
50
0TTTBTTTB
AA AM AN
CG DH KR
LL MM
Sequence Ty pe
Diphthong
Hiatus
Rate = 2
Figure 33. Bar chart of mean magnitude of TT and TB displacement (%) for Sequence
Type, by Speaker: Rate 1 and Rate 2
Finally, a closer examination of the data reveals a possible reason for the pattern of greater TT
displacement for hiatuses. The explanation can be found in the influence of the following
consonants, just as we saw for the raw values of TT-TB offset (where a following coronal
consonant resulted in an anticipatory TT movement, resulting in a TT lag). That is, another way
in which a following coronal consonant appears to influence a TT gesture associated with a
vocalic sequence is by reducing its magnitude. This effect appears to affect diphthongs more
than hiatuses (whereas the effect on TT lag was reported to affect hiatuses more readily). The
effect is also more obvious as speech rate increases but at both speech rates it is subject to
individual variation. An example of this phenomenon is illustrated below where, by looking at a
larger segment within the word viola [bjóla], produced by Speakers MM and AN, we see the
reduced TT gesture for speaker AN (Figure 34) but not for speaker MM (Figure 35). No similar
effect is observed for TB displacement.

148
Figure 34. Waveform and articulatory movement data (vertical dimension) of a token of
[jó] from viola with no reduction of %TT, Speaker MM, Rate 1
Figure 35. Waveform and articulatory movement data (vertical dimension) of a token of
[jó] from viola with reduction of %TT, Speaker AN, Rate 1

149
In some cases the effect of the following consonant on TT displacement is large enough that it
becomes difficult to measure the TT peak for the vocalic sequence. Thus, it may be best to avoid
this measure of magnitude of TT displacement and use a different measure. Below, we replace
this measure with one which focuses on the magnitude (in %) of TT displacement at peak TB
displacement (written as TT@TB in figures). That is, we look at how much TT involvement
there is in the sequences when the TB is at its maximum vertical displacement (Slis & Van
Lieshout, 2013). This is a more indirect but possibly more reliable way to measure and compare
TT involvement in the production of vocalic sequences. The descriptive statistics for this
measure are given in Table 36.
Table 36. Means and SDs of TT displacement at peak TB displacement (%) for Diphthong
and Hiatus, by Sequence Type and Rate
Rate 1 Rate 2
Sequence Type Mean SD Mean SD
Diphthong 74.58 22.13 78.63 25.24
Hiatus 67.91 20.98 72.32 20.66
A preliminary look at the results in Table 36 and Figure 36 shows that the TT achieves a greater
magnitude at peak TB displacement for diphthongs than it does for hiatuses. This holds for both
speech rates. In addition, we find that while TB displacement does not change significantly as
speech rate increases, TT displacement again appears to increase slightly with an increase in
speech rate, both for diphthongs and hiatuses.

150
Pe
ak D
isp
lace
me
nt
(%)
TT@TBTBTT@TBTB
100
80
60
40
20
0TT@TBTBTT@TBTB
Rate = 1 Rate = 2
Sequence Type
Diphthong
Hiatus
*Bars are One Standard Error from the Mean
Figure 36. Bar chart of mean magnitude of TB displacement (%) and TT displacement (%)
at peak TB displacement for Sequence Type, by Speech Rate
This difference between Diphthong and Hiatus (Sequence Type) on this new measure of TT
displacement at peak TB displacement is statistically significant (Table 37). However, contrary
to our observations, the main effect of Rate was not significant and neither was the Sequence
Type*Rate interaction. Finally, we find a significant Speaker effect.
Table 37. ANOVA table for differences between Diphthong and Hiatus in TT displacement
at peak TB displacement (%), by Speech Rate
%TT at peak TB
Source F(df term, df error) p
Main effects Sequence Type F(1,7) = 22.55 0.002
Rate F(1,7) = 5.30 0.055
Interaction Sequence Type*Rate F(1,7) = 0.02 0.902
Other Speaker F(7,21) = 19.31 0.000
The individual data (Figure 37) shows that while the degree of difference between TB and TT
displacement varies from speaker to speaker, most speakers follow the general pattern of greater
TB displacement55
. Speakers LL and KR, once again are the only exceptions and the Speaker
55 Means and SD values for individual data are found in Table A3.11, Appendix 3.

151
effect in the data is largely due to differences between these two speakers and the remaining
speakers. For example, Speaker LL has the opposite pattern as the other speakers (i.e. slightly
higher TT displacement) at both speech rates while speaker KR has this higher TT displacement
only for Rate 2 hiatuses.
Pe
ak D
isp
lace
me
nt
(%)
100
50
0
100
50
0TT@TBTBTT@TBTB
TT@TBTBTT@TBTB
100
50
0TT@TBTBTT@TBTB
AA AM AN
CG DH KR
LL MM
Sequence Ty pe
Diphthong
Hiatus
Rate = 1
Pe
ak D
isp
lace
me
nt
(%)
100
50
0
100
50
0TT@TBTBTT@TBTB
TT@TBTBTT@TBTB
100
50
0TT@TBTBTT@TBTB
AA AM AN
CG DH KR
LL MM
Sequence Ty pe
Diphthong
Hiatus
Rate = 2
Figure 37. Bar chart of mean magnitude of TB displacement (%) and TT displacement (%)
at peak TB displacement for Sequence Type, by Speech Rate and Speaker
3.2.1 Vowel Effects on Spatial Displacement of TB and TT
In this section we examine the effects of the non-high vowel (V) in the sequences on maximum
TB displacement (TB) and on TT displacement at peak TB displacement (TT@TB). The
descriptive statistics for both measures are given in Table 38.

152
Table 38. Means and SDs of TB and TT displacement (%) for Diphthong and Hiatus by
Speech Rate and V
Rate 1 Rate 2
Sequence Type Articulator Vowel Mean SD Mean SD
Diphthong
TB
[a] 95.12 10.06 97.56 7.71
[e] 97.23 7.34 95.94 12.84
[o] 92.20 13.91 96.83 8.94
TT@TB
[a] 70.45 22.93 75.12 27.71
[e] 77.01 20.09 80.42 23.79
[o] 77.41 24.02 81.59 22.65
Hiatus
TB
[a] 96.96 8.63 94.38 12.29
[e] 99.78 1.02 98.99 2.82
[o] 98.34 5.72 91.61 17.81
TT@TB
[a] 64.52 23.07 72.96 20.57
[e] 69.32 19.29 70.21 22.21
[o] 73.28 17.37 73.07 20.07
In Figure 38, we observe the following differences between Diphthong and Hiatus. First, for all
three levels of V and at both speech rates, the TB displacement is greater than TT displacement
at peak TB. This applies to both Diphthong and Hiatus. Second, we find that for all levels of V,
the TT displacement at peak TB is greater for Diphthong and Hiatus, although this difference is
very small for Rate 2 sequences with [a]. Finally, for all three levels of V and at both speech
rates we observe little difference in TB displacement between Diphthong and Hiatus. Thus, the
observations made in the previous section appear to apply across vowel contexts.

153
Pe
ak D
isp
lace
me
nt
(%)
100
75
50
25
0
21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
Rate 21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
100
75
50
25
0
V = a V = e
V = o
Sequence Type
Diphthong
Hiatus
Rate Sequence Ty
*Bars are One Standard Error from the Mean
Figure 38. Bar chart of mean magnitude of TB displacement (%) and TT displacement (%)
at peak TB displacement for Sequence Type, by Speech Rate and V
The results of repeated-measures ANOVAs are summarized in Table 39. For TB displacement,
we find a significant V effect but no significant Sequence Type or Rate effects. Post-hoc
comparisons (Bonferroni) identify the V difference as occurring between sequences with [e] and
those with [o] (t = -2.710, p = 0.025). Specifically, diphthongs with [e] achieve a slightly greater
TB displacement than diphthongs with [o]. No significant differences exist between sequences
with [a] and those with either [e] or [o]. Among the interactions, only Rate*Sequence Type is
significant, mainly because diphthongs at Rate 1 have slightly smaller TB displacement than
Rate 1 hiatuses. However, a post-hoc comparison fails to reach statistical significance (t = 2.56, p
= 0.075). For TT displacement at peak TB, we find a significant effect of Sequence Type but no
significant effects of Rate or V. Similarly, none of the interactions were significant. The Speaker
effect, however, was significant on both measures.

154
Table 39. ANOVA table for differences between Diphthong and Hiatus in TB displacement
and TT displacement at peak TB (%), by Speech Rate and V
%TB %TT at peak TB
Source F(df term, df error) p F(df term, df error) p
Main effects
Sequence Type F (1,14) = 1.78 0.224 F (1,14) = 30.24 0.001
Rate F (1,14) = 0.27 0.617 F (1,14) = 3.33 0.111
V F (2,14) = 5.53 0.017 F (2,14) = 1.51 0.256
Interactions
Rate* Sequence Type F (1,14) = 6.06 0.048 F (1,14) = 0.05 0.835
Rate*V F (2,14) = 0.11 0.900 F (2,14) = 1.20 0.330
Sequence Type *V F (2,14) = 0.50 0.615 F (2,14) = 0.23 0.798
Rate* Sequence Type *V F (2,14) = 3.16 0.074 F (2,14) = 0.76 0.486
Other Speaker F(7,77) = 9.40 0.000 F(7,14) = 44.67 0.000
The individual data (Figures 39-41) suggests that most speakers have this pattern of similar TB
displacement for diphthongs and hiatuses across V contexts56
. Once again, Speakers KR and LL
may be largely responsible for the significant Speaker effect on this measure since they produce
smaller TB displacement for Rate 2 hiatuses with [o].
For TT displacement at peak TB we observe that while some speakers follow the general of
slightly larger TT displacement for Diphthong than for Hiatus and similar displacement across
vowel contexts, some speakers deviate from this pattern. For example, AA has very little
difference between Diphthong and Hiatus, regardless of V. Others have different behaviours for
different V contexts. For example, AM has lower values for Hiatus when V = [e], similar values
for Diphthong and Hiatus when V = [a] and higher values for Hiatus when V = [o]. Similarly,
CG has smaller values for Hiatus where V = [e] and [o], but larger values for Hiatus where V =
[a].
56 Refer to Tables A3.7-A3.9 (%TB) and A3.12-A3.14 (%TT at peak TB) in Appendix 3 for individual means and SDs.

155
Pe
ak D
isp
lace
me
nt
(%)
100
50
0
100
50
0
21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
Rate 21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
100
50
0
21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
AA AM AN
CG DH KR
LL MM
Sequence Type
Diphthong
Hiatus
Sequence Type Ra
V= [a]
*Bars are One Standard Error from the Mean
Figure 39. Bar chart of mean magnitude of TB displacement and TT displacement at peak
TB displacement for Sequence Type, by Speech Rate and Speaker, V = [a]
Pe
ak D
isp
lace
me
nt
(%)
100
50
0
100
50
0
21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
Rate 21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
100
50
0
21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
AA AM AN
CG DH KR
LL MM
Sequence Type
Diphthong
Hiatus
Sequence Type Ra
V= [e]
*Bars are One Standard Error from the Mean
Figure 40. Bar chart of mean magnitude of TB displacement and TT displacement at peak
TB displacement for Sequence Type, by Speech Rate and Speaker, V = [e]

156
Pe
ak D
isp
lace
me
nt
(%)
100
50
0
100
50
0
21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
Rate 21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
100
50
0
21
TT@TBTBTT@TBTBTT@TBTBTT@TBTB
AA AM AN
CG DH KR
LL MM
Sequence Type
Diphthong
Hiatus
Sequence Type Ra
V= [o]
*Bars are One Standard Error from the Mean
Figure 41. Bar chart of mean magnitude of TB displacement and TT displacement at peak
TB displacement for Sequence Type, by Speech Rate and Speaker, V = [o]
Speakers also differ in the degree of difference between TB and TT displacement. We also note
that while most speakers observe the general pattern of smaller TT displacement and larger TB
displacement, this pattern is reversed in some cases. Speakers KR and LL, in particular, have at
least one example of this reverse pattern for all V contexts. Speaker AM has a single case of this
reverse pattern for Rate 2 hiatuses with [o].
3.3 Discriminant Analysis
We now turn to the question of whether the individual variation found on the timing and spatial
measures results in cases of diphthongs produced as hiatuses (i.e. exceptional hiatuses) and/or
hiatuses produced as diphthongs. As in the acoustics chapter (Chapter 3), we use Discriminant
Analysis (DA) to determine category membership for Diphthong and Hiatus. In this study, the
possible predictors for category membership are: (i) TB-TT offset (absolute values); (ii)
maximum %TB displacement, and; (iii) %TT displacement at peak TB displacement. However,
we can omit the second predictor (maximum TB displacement) since we found no significant
Diphthong-Hiatus difference and no significant V effects with this measure. This mirrors the
decision in Chapter 3 to include only significant predictors in the analysis. In fact, a preliminary

157
analysis which included this predictor produced worse results on the Discriminant Analysis for
all three levels of V than if this predictor was omitted. As in Chapter 3, any Diphthong tokens
misclassified as Hiatus are considered cases of exceptional hiatus. Similarly, any Hiatus tokens
misclassified as Diphthong are considered diphthongized. Although the vowel-related effects
observed in the present chapter were fewer and more subject to individual variation, in order to
maintain consistency with the previous chapter (Chapter 3), we analyze the data for each level of
V separately. This was also done because not all levels of V required the inclusion of both
predictors to obtain the best classification rate. The results of these analyses are given below.
3.3.1 Sequences with [a]
For sequences with this vowel, we obtain the best classification rate when we use both
predictors: TB-TT offset and TT at peak TB. Omitting one or the other predictor (especially TB-
TT offset) lowers the correct classification rates for both diphthongs and hiatuses. Overall,
sequences with [a] had the lowest correct classification rate (just under 70%), similar to what
with found with the acoustic parameters in Chapter 3. This is especially the case for hiatuses. In
fact, the pattern with hiatuses is the opposite of what we observe in the acoustic analysis where
hiatuses were more likely to be correctly identified. Coincidentally, we obtain the same correct
classification rate for diphthongs (71.9%) with the articulatory parameters as we did with the
acoustic parameters in Chapter 3. However, the correct classification rate for hiatuses is much
lower on the articulatory measures (59.4%) than on the acoustic measures (80.8%).
Table 40. Discriminant analysis summary table for V= [a], using TB-TT offset (absolute)
and %TT at peak TB as predictors (articulation)
TRUE GROUP Squared distance between groups
Put into group Diphthong Hiatus Diphthong Hiatus
Diphthong 207 39 0.000 0.401
Hiatus 81 57 0.401 0.000
Total N 288 96 F (2, 378) = 14.40, p = 0.01
N Correct 207 57
Proportion Correct 0.719 0.594
TOTALS N = 384 (0 missing values) N Correct = 264 Proportion Correct = 0.688
The results for misclassified diphthongs and hiatuses with [a] are given in Table 41. Among the
expected diphthongs, the words most likely to be misclassified were diario (about 52% of cases)
and criada (about 44% of cases). Although these two words had similar rates of

158
misclassification, diario had more misclassified cases in the highest probability category.
Coming in third place is diablo with a misclassification rate of about 23%. These three words
were also the top three in terms of misclassification in Chapter 3. The word with the fewest
misclassified cases was viaje (about 10%). With viaje, however, all the misclassified cases were
in the lowest probability category and they were all contributed by the same speaker, DH. The
results for this word also match the results from Chapter 3, where viaje also the fewest
misclassifications (5%). However, in Chapter 3, Speaker DH did not contribute any of the cases.
Finally, in Chapter 3 the words piada and piano also had few misclassifications (with rates of
15% and 3%, respectively) whereas here their misclassification rates are higher, especially for
piano (20% and 19%, respectively). Among the expected hiatuses, días had the most
misclassified cases (23 of 48 cases, about 48%), although crías also had a high rate of
misclassification (16 of 48 cases, about 33%). Few of these cases (especially for días), however,
fall into the highest probability category for misclassification. Still, the misclassification
numbers are higher here than on the acoustic parameters. This is especially the case for días
which had a misclassification rate of only 12% on the acoustic parameters. The word crías had a
misclassification rate of 25% on the acoustic parameters.
Table 41. Summary of discriminant analysis classification (predicted group membership)
of Diphthong and Hiatus for V = [a] (articulation)
Expected group Word
Predicted Group Probability
Diphthong Hiatus 50%-59% 60%-69% 70%+
Diphthong
criada 27 21 8 9 4
diablo 37 11 8 1 2
diario 23 25 8 6 11
piada 38 10 7 1 2
piano 39 9 3 1 5
viaje 43 5 5 0 0
Hiatus crías 16 32 9 3 4
días 23 25 13 9 1
As with the acoustic parameters, there is also a considerable amount of between-speaker
variation with the misclassified cases (Table 42). For example, MM contributed the fewest
misclassified sequences (7 cases: 5 Diphthong and 2 Hiatus) while CG contributed the most
cases (23 cases: 12 Diphthong and 11 Hiatus) with AA coming in at a close second (20 cases: 12
Diphthong and 8 Hiatus).

159
Table 42. Summary of misclassified sequences with [a], by Speaker (articulation)
SPEAKER
Expected group Word AA AM AN CG DH KR LL MM
Diphthong
criada 3 5 3 0 0 3 4 3
diablo 0 4 3 2 2 0 0 0
diario 6 4 6 5 2 1 1 0
piada 0 0 0 1 5 3 1 0
piano 3 0 0 4 0 0 0 2
viaje 0 0 0 0 5 0 0 0
Hiatus crías 2 1 1 5 3 1 3 0
días 6 1 0 6 1 4 3 2
TOTAL 20 15 13 23 18 12 12 7
3.3.2 Sequences with [e]
For sequences with [e], we obtain the best classification rate using only TB-TT offset as a
predictor (Table 43). Including TT at peak TB as a predictor produces slightly worse overall
results (75.5%) mainly due to a drop in correct identification rate for hiatuses (70.2%).
Diphthongs appear to be less affected by the inclusion of this second factor and maintained a
correct classification rate of 76.3%. Overall, sequences with [e] had the highest rate of correctly
classified sequences. Once again, on the articulatory parameters, hiatuses had a worse correct
classification rate than diphthongs.
Table 43. Discriminant analysis summary table for V= [e], using TB-TT offset (absolute) as
predictor (articulation)
TRUE GROUP Squared distance between groups
Put into group Diphthong Hiatus Diphthong Hiatus
Diphthong 252 13 0.000 1.317
Hiatus 77 34 1.317 0.000
Total N 329 47 F (1, 374) = 54.16, p = 0.01
N Correct 252 34
Proportion Correct 0.766 0.723
TOTALS N = 376 (8 missing values) N Correct = 286 Proportion Correct = 0.761
The results for misclassified diphthongs and hiatuses with [e] are summarized in Table 44.
Among the expected diphthongs, the word most likely to be misclassified was pliegue, with over
50% of cases (most of which were in the 70% and higher category) misclassified as Hiatus. This
result is surprising since on the acoustic parameters this word had considerably fewer
misclassified cases (approximately 20% of cases). This inconsistency may reflect errors in the

160
acoustic measurements as some tokens of this word were difficult to segment. The word prieto
here also had a large number of misclassifications (approximately 38%) and this number too is
considerably higher than what we observed for this word on the acoustic parameters (where 17%
of cases were misclassified as hiatus). In Chapter 3, we attributed the misclassification rates for
prieto and pliegue reflected to both language–specific as well as cross-linguistic tendencies. For
example, we suggested that the misclassification rates for prieto reflected a tendency for a
preceding [r] to promote hiatus in Spanish (Hualde & Prieto, 2002) as well as a more general
pattern of cross-linguistic avoidance of [j] after rhotics (Van der Beer, 2006; Hall & Hamann,
2010). Similarly, we suggested that the misclassification rate for pliegue reflected the instability
of consonant + lateral clusters in Romance (e.g. Colantoni & Steele, 2005). Finally, we
suggested that both prieto and pliegue, may simply reflect a more general tendency to avoid
diphthongs (i.e. a complex nucleus) after a complex onset. However, we could not explain why
cliente, a word which also has a complex consonant + lateral onset and which is derived from a
Latin heterosyllabic sequence should have fewer misclassified cases than pliegue. Here, we
suggest that the asymmetry between pliegue and cliente follows from articulatory factors.
Specifically, it is related to the place of articulation of the onset clusters in these words (Chitoran
et al., 2002). In cliente, the cluster follows a back-to-front order of constriction location while in
pliegue the order is front-to-back. In stop-stop clusters (Chitoran et al., 2002), the back-to-front
order has been shown to result in less gestural overlap (i.e. greater temporal lag) between the
stops than the front-to-back order. The greater temporal lag in the [kl] cluster of cliente may be
enough to counteract the decreased lag between the second consonant in the cluster and the
following vowel, an effect which has been shown to occur with consonant clusters (Goldstein et
al., 2007).
Since less gestural overlap results in more recoverability for the first element in the cluster,
cliente can have a diphthong following the cluster. However, if the reduced lag between p+l and
l+j in pliegue is enough to threaten recoverability of [p], then it’s possible that the speakers
repair this situation by increasing the overlap between the lateral and the following glide,
resulting in a hiatic pronunciation. The word viejo here has no misclassified cases. This too is
consistent with the acoustic results, where viejo had the fewest misclassified cases. However, on
the acoustic parameters, viejo tied with pieza for fewest misclassified cases. On the articulatory
parameters, on the other hand, pieza has several misclassified cases (about 29%) with most of

161
these falling in the highest probability category. Interestingly, the word bienio here has fewer
misclassified cases (about 8%) than with the acoustic parameters (almost 50%). Moreover, it has
fewer misclassified cases here than bienes (at about 19%). This last result is the opposite of what
we would expect given the well-documented hiatic tendency for bienio (e.g. Chitoran & Hualde,
2007) and our results for these words in Chapter 3 (where bienes had a misclassification rate of
15% while the misclassification rate for bienio was approximately 50%). The word ríen, an
expected hiatus, here had a misclassification rate of approximately 28%, also higher than what
we observed on the acoustic parameters (where it was 10%).
Table 44. Summary of discriminant analysis classification (predicted group membership)
of Diphthong and Hiatus for V = [e] (articulation)
Expected group Word
Predicted Group Probability
Diphthong Hiatus 50%-59% 60%-69% 70%+
Diphthong
bienes 39 9 2 1 6
bienio 44 4 0 0 4
cliente 41 7 5 2 0
pieza 34 14 2 2 10
pliegue 23 25 3 6 16
prieto 29 18 11 4 3
viejo 42 0 0 0 0
Hiatus ríen 13 34 2 3 8
The between-speaker variation for sequences with [e] is evident in Table 45 with some speakers
clearly contributing more misclassified sequences than others. Here, it is speakers CG, MM and
DH who contribute the most cases (in descending order of number of cases contributed). We also
see patterns of within-speaker variation with some speakers exhibiting results that are consistent
with their results for [a] and other exhibiting less consistent results. For example, among the
three above speakers, MM had the smallest number of misclassified sequences with [a] but the
second highest number with [e]. On the other hand, DH had similar numbers for both vowels
(especially for diphthongs) and CG has the highest number for both vowels.

162
Table 45. Summary of misclassified sequences with [e], by Speaker (articulation)
SPEAKER
Expected group Word AA AM AN CG DH KR LL MM
Diphthong
bienes 3 0 1 2 2 0 0 1
bienio 0 0 0 3 1 0 0 0
cliente 3 3 0 0 1 0 0 0
pieza 0 1 0 5 1 3 3 1
pliegue 1 2 4 4 5 3 0 6
prieto 3 2 3 0 3 2 0 5
viejo 0 0 0 0 0 0 0 0
Hiatus ríen 0 1 2 2 0 3 4 1
TOTAL 10 9 10 16 13 11 7 14
3.3.3 Sequences with [o]
The results for this vowel (Table 46) in terms of the articulatory parameters used as predictors
are similar to those obtained with [e]. That is, we obtain slightly better classification results by
omitting TT at peak TB as a predictor than we do by including it. Its inclusion lowers the overall
correct classification rate to 73%. The correct classification rate for diphthong also lowers
(75.2%). Hiatuses, however, are not affected by the inclusion of the second factor and maintain
the same classification rate (66.7%). As with sequences with [a] and [e], diphthongs fared better
than hiatuses on the correct classification rate.
Table 46. Discriminant analysis summary table for V= [o], using TB-TT offset (absolute) as
predictor (articulation)
TRUE GROUP Squared distance between groups
Put into group Diphthong Hiatus Diphthong Hiatus
Diphthong 109 16 0.000 0.508
Hiatus 32 32 0.508 0.000
Total N 141 48 F (1, 374) = 26.71, p = 0.01
N Correct 109 32
Proportion Correct 0.773 0.667
TOTALS N = 189 (3 missing values) N Correct = 141 Proportion Correct = 0.746
Among the expected diphthongs with [o] (Table 47), piojo had the fewest misclassified cases (3
of 48, around 6%). This concurs with the results for this word on the acoustic parameters, where
no instances of piojo were misclassified. For criollo and viola, on the other hand, we get higher
rates of misclassification here than in Chapter 3. Here, about 29% instances of criollo were

163
misclassified while in Chapter 3 we reported a rate of about 8.5%. Similarly, the word viola
which had a misclassification rate of 5% on the acoustic parameters here appears to have a 33%
misclassification rate. The expected hiatus ríos also has a very high misclassification rate here
(33%) compared with the acoustic parameters reported in Chapter 3 (4%).
Table 47. Summary of discriminant analysis classification (predicted group membership)
of Diphthong and Hiatus for V = [o], (articulation)
Expected group Word
Predicted Group Probability
Diphthong Hiatus 50%-59% 60%-69% 70%+
Diphthong
criollo 34 14 3 3 8
piojo 45 3 0 0 3
viola 30 15 2 3 10
Hiatus ríos 16 32 8 4 4
Table 48 shows that Speakers AA, AM and CG contributed the highest numbers of misclassified
diphthongs while Speaker LL contributed the highest number of misclassified hiatuses.
Table 48. Summary of misclassified sequences with [o], by Speaker (articulation)
SPEAKER
Expected group Word AA AM AN CG DH KR LL MM
Diphthong
criollo 4 3 1 1 1 0 2 2
piojo 1 0 0 0 1 1 0 0
viola 0 3 4 5 1 0 0 2
Hiatus ríos 2 3 1 3 0 1 6 0
TOTAL 7 9 6 9 3 2 8 4
4 Summary and Discussion
In this section we provide a summary of the findings of the study and evaluate whether the
results confirm our hypotheses. We also discuss how these results relate to our findings in the
acoustics study reported in Chapter 3 and to previous articulatory studies.
4.1 Hypothesis 1: Timing of TB and TT
Hypothesis 1 stated that diphthongs and hiatuses in Mexican Spanish differ in the relative timing
of TB and TT gestures. We predicted that the temporal offset between TB and TT would be
greater for hiatuses (Hiatus) than for diphthongs (Diphthong). We also predicted that these offset
values would decrease for all sequences as speech rate increases but that the differences between
Diphthong and Hiatus would be maintained. Our predictions were partially confirmed. That is,

164
we found that category membership of Diphthong and Hiatus may indeed be defined by degree
of TB-TT offset, with diphthongs having smaller offset values than hiatuses. However, although
we observed that all sequences experienced a decrease in offset with an increase in speech rate,
the difference was not enough to reach statistical significance. Thus, based on our results, only
the proposed Diphthong-Hiatus difference in TB-TT offset is confirmed; no Rate effects can be
established.
However, in order to achieve the above result for the Diphthong-Hiatus contrast, the original
offset measure had to be modified. We found that the raw TB-TT offset was highly susceptible
to the effects of neighbouring coronal consonants. Thus, in order to capture the expected
differences between Diphthong and Hiatus we used absolute TB-TT offset values instead. We
revisit the benefits and drawbacks of using absolute offset values in the Discussion in §4.4.
These differences in absolute TB-TT offset between Diphthong and Hiatus also appear in
different degrees according to the identity of the non-high vowel (V) in the sequence. We
predicted that sequences with [a] would have larger offset values than sequences with either [e]
or [o]. Similarly, we expected that the difference in offset between Diphthong and Hiatus would
be smallest for sequences with [a]. In fact, only the second prediction was confirmed, mainly due
to the behaviour of hiatuses. Offset values for diphthongs, on the other hand, were similar across
both Vowel and Rate contexts.
Finally, the differences in TB-TT absolute offset between Diphthong and Hiatus are also subject
to individual variation. For example, while most speakers follow the general pattern of a larger
TB-TT offset for hiatuses, some speakers maintain a larger difference between Diphthong and
Hiatus than others, either for Rate 1 or Rate 2. However, most speakers also exhibited variability
in TB-TT offset according to V, especially for hiatuses (§3.1.1).
4.2 Hypothesis 2: Magnitude of TT and TB Displacement
Here we looked at the vertical displacement of the TT and TB for diphthongs and hiatuses. We
predicted that diphthongs would exhibit a greater TT (the C-gesture) displacement while hiatuses
would have a greater TB (the V-gesture) displacement. We also predicted that the magnitude of
TT and TB displacement would decrease for all sequences with an increase in speech rate but
that the differences between Diphthong and Hiatus would be maintained. Our predictions were

165
only partially confirmed. We begin with TB displacement. On this measure, our prediction of a
Diphthong-Hiatus difference in TB displacement was not confirmed. Specifically, it was found
that the TB achieved a similar maximum displacement (close to 100%) for hiatuses and for
diphthongs. Overall, TB displacement also appears to be fairly resistant to Rate effects. In terms
of V effects, we find that sequences with [e] achieve a slightly greater TB displacement than
sequences with [o]. Thus, we fail to find the predicted difference between sequences with [a] and
those with [e] and [o]. Finally, it is on this measure that speakers exhibit the most homogeneous
behaviour. That is, none of the speakers had much difference in TB displacement between
Diphthong and Hiatus. They also generally maintained this pattern across V and Rate contexts.
On the other hand, we found differences between diphthongs and hiatuses in TT displacement.
However, because our original measure (maximum %TT displacement appeared to be affected
by a following coronal consonant, these differences were not in the expected direction for the
Diphthong-Hiatus contrast. That is, we found greater TT displacement for hiatuses than for
diphthongs. Thus, we employed a similar strategy as with TB-TT offset and used an alternate
measure of TT involvement, TT displacement at peak TB displacement (given as TT@TB in
figures). On this new measure, we obtained the predicted results: diphthongs had greater TT
displacement at peak TB displacement than hiatuses, across V contexts. Although not
statistically significant, we also found that TT displacement at peak TB displacement tended to
increase slightly at the faster speech rate (Rate 2) for all levels of V and for both Diphthong and
Hiatus. We also found more between-speaker variability than for TB displacement. For example,
some speakers deviate from the pattern of slightly greater TT displacement for Diphthong than
for Hiatus. That is, they produce a very small difference between Diphthong and Hiatus, either
for some V contexts or across all V contexts. We discuss the significance of these findings as
well as the relationship between individual patterns of increases in TT displacement at the faster
speech rate and their possible relationship to decreases in TB-TT offset in the Discussion in §4.4.
4.3 Hypothesis 3: Exceptional Hiatuses
Hypotheses 3 predicted that individual variation in the production of diphthongs and hiatuses
would be reflected in distinctive patterns of articulation which we defined as a preference for
using either a timing strategy or a spatial strategy (or both) to achieve a contrast between
diphthongs and hiatuses. We also predicted that these individual patterns of articulation would

166
give rise to sequences whose category membership is ambiguous, as in the case of exceptional
hiatuses. To test this second part of the hypothesis, we used Discriminant Analysis to categorize
sequences as Diphthong and Hiatus according to the articulatory parameters identified as
significant (in this case TB-TT offset and TT displacement at peak TB). We further predicted
that the misclassified cases found in the present chapter (defined by articulatory parameters)
would correspond to those found in Chapter 3 (defined by acoustic parameters). Based on the
findings in both chapters, we also expected that: (i) at the group level, sequences with [a] would
have more misclassified cases than sequences with either [e] or [o], and that (ii) at the individual
level, those speakers with the smallest Diphthong-Hiatus differences, either in TB-TT offset or
TT displacement at peak TB displacement (or both) would contribute the most misclassified
cases.
The first part of the hypothesis was confirmed: we indeed found individual variation in the
production of diphthongs and hiatuses, with the variation appearing on one or both of the
parameters considered. As summarized in §4.1, on the timing measure (TB-TT offset, absolute)
some speakers produce larger differences between Diphthong and Hiatus. Similarly, as
summarized in §4.2, some speakers produced smaller differences between Diphthong and Hiatus
on the spatial measure of TT displacement at peak TB displacement, although the values
sometimes differed according to V context.
We also find that sequences with [a] are more likely to be misclassified than sequences with [e]
or [o]. In addition, we observe that among the speakers who contributed the most misclassified
sequences where V = [a] were generally those who were identified as having relatively small
Diphthong-Hiatus differences, either for TB-TT offset (§3.1), TT displacement at peak TB
(§3.2), or both. This includes speakers AA and CG. Similarly, speakers who were identified as
having larger differences between diphthongs and hiatuses on one or both of these measures
contributed fewer misclassified cases. This includes MM, in particular, but also KR and LL to a
lesser extent. However, we also observe that the relationship between a large Diphthong-Hiatus
difference and fewer misclassified sequences does not always hold. For example, we find that
Speaker DH, who had a large Diphthong-Hiatus difference on the measure of TT displacement at
peak TB (§3.2), also contributed several misclassified cases.

167
In summary, the overall results for sequences with [a] are in general in line with what we
observed in Chapter 3. That is, sequences with [a] had a larger number of misclassified cases
than sequences with either [e] or [o]. Secondly, the three words most likely to be misclassified on
the acoustic parameters (diario, diablo and criada) were also the top three misclassified on the
articulatory parameters. Finally, speakers with small Diphthong-Hiatus differences tended to
contribute more misclassified sequences but, as in Chapter 3, this relationship did not always
hold. At the level of individual speakers we also find several matches. For example, Speakers
KR, LL and MM contributed fewer misclassified diphthongs on both the acoustic and
articulatory parameters than other speakers. Similarly, speakers CG, AM and DH contributed
more misclassified sequences with [a] than other speakers on both acoustic and articulatory
measures. However, for some speakers, there was no match. For example, KR had no
misclassified sequences on the acoustic parameters but on the articulatory parameters she had 14
misclassified diphthongs and 4 misclassified hiatuses.
For sequences with [e], we achieved the highest overall correct classification rate and the highest
correct classification rate for hiatuses. Here it is speakers CG, MM and DH who contribute the
highest number of cases. However, these speakers do not necessarily have small Diphthong-
Hiatus differences for sequences with [e]. This list also highlights patterns of within-speaker
variation. For example, some speakers produced results for sequences with [e] that are consistent
with their results for [a] (speakers CG and DH). On the other hand, MM had less consistent
results. Specifically, she had the smallest number of misclassified sequences with [a] but she
contributes the second highest number of cases for [e] sequences. Both the group and individual
results for sequences with [e] differ somewhat from what we observed in Chapter 3. First, on the
acoustic results it was sequences with [o], not [e], which had the smallest number of
misclassified sequences. Secondly, while some of the misclassified words had similar results on
both articulatory and acoustic parameters (i.e. prieto, viejo, bienes), others had much different
results. For example, pieza had several misclassified cases on the articulatory parameters but
only a single case on the acoustic parameters. The word bienio had the opposite behaviour, with
few misclassified cases on the articulatory parameters and several cases on the acoustic
parameters. For the individual results, we also find differences. For example, MM, DH and CG
had very few misclassified sequences with [e] on the acoustic parameters whereas on the

168
articulatory parameters they contribute the highest numbers. Conversely, AM had more
misclassified sequences with [e] on the acoustic parameters than on the articulatory parameters.
For sequences with [o], speakers AA, AM and CG contributed the highest number of
misclassified diphthongs. All these speakers tended to have higher numbers of misclassified
cases across vowel contexts, especially CG. Again, these are not necessarily the speakers with
the smallest Diphthong-Hiatus difference for sequences with [o]. For sequences with [o] we also
find both differences and similarities with our results in Chapter 3. For example, on both acoustic
and articulatory measures, piojo had the fewest misclassified cases and criollo and viola had
similar numbers of misclassified cases. However, the misclassification rates were higher on the
articulatory parameters, most noticeably for criollo and viola.
4.4 Discussion
The results summarized above are generally in agreement with what has been proposed in the
theoretical and experimental literature. They also largely coincide with our findings in the
acoustics experiment presented in Chapter 3. However, there are some crucial points where our
findings appear to be at odds with previous research as well as our results from Chapter 3.
First, we presented evidence of TT involvement (in particular, TT displacement at peak TB
displacement, §3.2.3) in the production of both diphthongs (Diphthong) and hiatuses (Hiatus) in
the Mexican variety of Spanish. This suggests, albeit tentatively, that the initial high vocoids of
these sequences ([j] for Diphthong and [i]for Hiatus) consist of both a C-gesture (Tongue Tip,
TT) and a V-gesture (Tongue Body, TB). This finding is in support of the proposal of Nevins &
Chitoran (2008). At the same time, this evidence suggests that palatal glides (as well as high
front vowels) in Spanish may differ from their English counterparts for which no C-gesture has
been confirmed (Gick, 2003).
Second, we found that diphthongs and hiatuses may be differentiated according to (i) the relative
timing of C-gesture and V-gesture (Chitoran & Hualde, 2007), and (ii) the degree of constriction
of the C-gesture (Nevins & Chitoran, 2008). In terms of timing, we reported that the C-gesture
and the V-gesture are timed or phased more closely together in diphthongs than in hiatuses. This
is as proposed by Chitoran & Hualde (2007). It is also in line with our finding in Chapter 3 that
diphthongs are shorter than hiatuses. In terms of degree of constriction, we found the C-gesture

169
achieved a greater constriction degree for diphthongs than for hiatuses. This is as proposed by
Nevins and Chitoran (2008). Both results are also in agreement with articulatory studies of
Spanish palatal glides (as found in diphthongs) and high front vowels (as found in hiatuses). For
example, Recasens (1985, 2004) and Recasens et al. (1997) report that both the palatal glide [j]
and the high vowel [i] are highly constrained due to the substantial tongue dorsum contact they
require in their articulation (Recasens et al., 1997). However, glides, due to their “narrower
constriction”, are “more constrained and more resistant to coarticulatory effects than their vowel
counterparts” (Recasens, 2004, p. 165). Our results for C-gesture maximum vertical
displacement agree with these findings. In our data, however, it is the action of the TT at peak
TB displacement which constrains the glides, not the tongue dorsum or tongue body, as in
Recasens (2004) and Recasens et al. (1997). In fact, we found no difference between Diphthong
and Hiatus in terms of TB constriction, either at the group level or the individual speaker level.
This dissimilarity may be the result of the technique used to measure lingual activity. Recasens et
al. (1997) use electropalatography (EPG), a technique which captures the degree of contact
between the tongue and the palate. However, this technique may not reflect the full extent of
activity of the TT as separate from TB activity (Fitzpatrick & Ní Chisaide, 2002). In any case,
our results for TB-TT offset also suggest that vowels (in hiatuses) are less constrained and more
subject to coarticulatory effects from a following coronal consonant as well as from the non-high
vowel (V) in the sequence. Our Discriminant Analysis results appear to confirm this since more
hiatuses are misclassified as diphthongs than vice versa. This supports the observation of a
general diphthongization trend across Spanish varieties (e.g. Hualde et al., 2008; Garrido, 2007).
However, it contrasts with our findings in Chapter 3 where we found diphthongs more likely to
be misclassified than hiatuses as well as be more susceptible to the influence of the non-high
vowel in the sequence.
Third, we found instances of both sequence-specific (Aguilar, 1997, 1999; Lindau et al., 1990)
and speaker-specific variability (Colantoni & Limanni, 2010; MacLeod, 2007). As in Chapter 3,
for example, we found that sequences with [a] tended to behave differently from sequences with
[e] or [o]. That is, sequences with [a] had smaller differences between Diphthong and Hiatus and
more misclassified sequences. These results are also consistent with the fact that most cases of
exceptional hiatuses occur when [a] is the non-high vowel in the sequence (e.g. Hualde, 2005;
Chitoran & Hualde, 2007). However, we also observed that the V effects were more pronounced

170
on the acoustic measures than on the articulatory measures. In addition, in Chapter 3, V effects
seemed to target diphthongs while in the present chapter, they are associated with hiatuses. In
terms of inter-speaker variability, we found that some speakers maintained a greater difference
between Diphthong and Hiatus either on the temporal or the spatial measure or both. This result
is similar to what we observed in Chapter 3 and to what has been reported by other authors
(Whitley, 1995; McLeod, 2007; Colantoni & Limanni, 2010). In addition, the speakers identified
as having the smallest Diphthong-Hiatus differences on the articulatory measures were the same
speakers who were identified as having small Diphthong-Hiatus differences on one or more of
the acoustic measures. These speakers include: AA, AM and CG. Similarly, speakers with large
Diphthong-Hiatus differences on the acoustic measures tended to have large differences on the
articulatory measures. These speakers include: DH, KR and LL. However, we did not always
find a match. For example, speakers AN and MM had small Diphthong-Hiatus differences on the
acoustic measures but larger ones on the articulatory measures.
Finally, before leaving this section and this chapter, we need to address the matter of
measurement. Two main issues arise in this respect. First, there is the question of difficulty of
measurement. For example, the contextual effects of the neighboring consonants, in particular
the following consonants, as we found, had a great influence on the variability of our
measurements, especially as speech rate increased. This made it difficult to carry out the
measurement and to determine exactly what we were measuring. This issue was also raised in
Zmarich et al. (2012) in their analysis of the differences in offset (between Tongue Body and Lip
Aperture, in that case) between [au] and [ua] in Italian. Those authors opted to not include the
faster speech rate in their analysis. In the present study, we chose a different option. That is, we
adapted our measurements in order to mitigate the effects of following consonants. This choice,
however, leads us to the question of suitability of the measurements we chose. That is, how well
do these measurements capture the Diphthong-Hiatus contrast? To the extent that they do not
coincide with other research and even our own results from Chapter 3, the answer may be “not
very well”. For example, our findings regarding glides as being more constrained seem to be at
odds with what we saw in Chapter 3 where we found that glides in diphthongs had higher F1
values compared to vowels in hiatuses. This would indicate a more open, less constrained
articulation for glides than for vowels, an effect which has also been reported in other acoustic
studies (e.g. Aguilar, 1999). However, this discrepancy may reflect the fact that in the present

171
chapter we have reduced the influence of the JAW from our measurements whereas the acoustic
measurements include JAW effects. That is, the increase in F1 observed for diphthongs may
reflect a lower JAW position. However, the TT may still achieve a greater constriction for the
palatal glide than for the high front vowel and this is not reflected in the acoustic measurement.
In fact, the actions of the TT appear to be associated with the diphthongization process more
generally. On both our original measures of raw TB-TT offset and peak TT displacement as well
as on our modified measures of absolute TB-TT offset and TT displacement at peak TB
displacement it is the TT which experiences changes while the TB seems to be more stable.
Thus, even if these measures are not the best or most accurate, they do offer some insight into
how diphthongization and the Diphthong-Hiatus contrast are achieved at the articulatory level
through the actions of the TT. They also provide a clue as to why diphthongs are at once more
stable and more variable than hiatuses. Specifically, even though diphthongs seem to exhibit
more variability acoustically (e.g. MacLeod, 2007), they appear to be more stable at the level of
articulation. This stability may explain the tendency for hiatuses to diphthongize across Spanish
varieties (e.g. Colantoni & Limanni, 2010).
5 Conclusions
In this chapter, we examined the articulatory characteristics of vocalic sequences in Mexican
Spanish. We provided evidence, albeit limited and based on variable data, that the Diphthong-
Hiatus contrast in this variety can be achieved through differences in both the temporal
coordination of lingual gestures (TB and TT) and in the magnitude of articulatory gestures (TT).
Our results are also generally consistent with the hypothesis that the palatal glide is more
constrained than the high front vowel (e.g. Recasens et al., 1997). They are also largely
consistent with the results from the acoustics experiment we reported in Chapter 3. An important
difference with our acoustic results, however, is that hiatuses appear to be more variable at the
articulatory level while diphthongs appear more variable at the acoustic level. We suggested that
this inconsistency can be explained by the fact that here we are looking at the actions of specific
articulators (especially the TT) while the acoustic effects reflect the actions of several
articulators acting together (i.e. they include the contribution of the JAW). In fact, we
highlighted the importance of the actions of the TT which we proposed to be largely responsible
for both the Diphthong-Hiatus contrast and the diphthongization process. Having now examined
the acoustic and articulatory distinctions between diphthongs and hiatuses in Mexican Spanish,

172
in the next chapter (Chapter 5) we explore the ways in which these distinctions influence the
perception of these sequences.

173
Chapter 5 Perception of Vocalic Sequences in Mexican Spanish
1 Introduction
In the previous two experimental chapters we found sequence-specific and speaker-specific
variability in the production of diphthongs and hiatuses in Mexican Spanish. We found this
variability both at the acoustic level (Chapter 3) and at the articulatory level (Chapter 4). We
attributed the sequence-specific variability to phonetic properties of the non-high vowel (V) in
the sequences. In both chapters, for example, we found that sequences where V = [a] behaved
differently from sequences where V = [e] or [o]. Specifically, Diphthong and Hiatus sequences
with [a] tended to be closer to each other on all measures than their counterparts with [e] or [o].
Consequently, sequences with [a] were more likely than sequences with [e] or [o] to be
misclassified in a Discriminant Analysis procedure. We pointed out that these results are
consistent with the fact that most cases of exceptional hiatuses occur when V = [a] (e.g. Chitoran
& Hualde, 2007). In terms of speaker-specific variability, we found that some speakers
maintained a greater difference between Diphthong and Hiatus than others and that speakers with
large Diphthong-Hiatus differences on the acoustic measures also tended to have large
differences on the articulatory measures. In relation to this, we also observed that those speakers
who maintained a greater Diphthong-Hiatus difference tended to contribute fewer misclassified
Diphthong sequences. However, we also found that this relationship between a large Diphthong-
Hiatus difference and fewer misclassified sequences did not always hold. We also found
substantial intra-speaker variability related to the identity of V. That is, some speakers
consistently maintained a similar acoustic and articulatory distance between Diphthong and
Hiatus across vowel contexts while others behaved differently according to the identity of V.
This variability also tended to influence the number of misclassified sequences each speaker
contributed for each V.
Still, in spite of the fact that some sequences were identified as ambiguous and misclassified by
the Discriminant Analysis procedure, we have not addressed the question of whether these
statistical misclassifications are perceptually relevant to listeners. That is, will they be similarly
subject to misclassification by listeners in a perception experiment? Faber & DiPaolo (1995)
suggest that Discriminant Analysis may indeed be useful in identifying vowel contrasts that are

174
perceptually distinctive. In fact, an earlier study by Port & Crawford (1989) on the incomplete
neutralization of the German word-final /d/-/t/ contrast reports “a tendency for native speakers
and discriminant analysis to classify the same tokens the same way” (p. 276). More recently,
Morrison (2006) compared the overall correct identification rates of final /d/-/t/ obtained from
Discriminant Analysis and those obtained from a group of Spanish listeners and found that they
were similar. These findings suggest that listeners are using at least some of the cues utilized in
the Discriminant Analysis. Thus, we can expect to find some degree of similarity between the
sequences misclassified by Discriminant Analysis and those that listeners discriminate or fail to
discriminate in a perception task.
We also have yet to address whether a speaker’s production of misclassified sequences is related
to her perception of these sequences. In other words, is a speaker who produces many
misclassified Diphthong tokens better able to discriminate between Diphthong and Exceptional
Hiatus in a perception task? Previous research supports the likelihood of such a link between
distinctness in production and perceptual acuity. For example, Perkell et al. (2004a) tested
participants’ production and perception of two American English vowel contrasts and found that
those participants who were more accurate in perceiving the contrast (as determined through a
discrimination task) produced the same contrast more distinctly. Perkell et al. (2004b, for
American English) report similar findings for the /s/-/ʃ/ contrast. Newman (2003, for American
English) also finds significant, albeit small, correlations between individual differences in the
production of VOT for stop consonants and spectral peaks for voiceless fricatives and individual
differences in their perception.
Other studies on vocalic sequences, both for Spanish and other Romance varieties have
addressed the issue of the production-perception link identified above (refer to Chapter 2 for a
review of the relevant studies). Overall, these studies provide three main insights. First, they
have shown that listeners, when unsure as to what category of vocalic sequence a stimulus
belongs to, will choose a diphthong syllabification over a hiatus syllabification (e.g. Face &
Alvord, 2004; Cabré & Prieto, 2006, both for varieties of Peninsular Spanish; Gili Favela &
Bertinetto, 1998, for different regional varieties of Italian). This is in support of a generalized
diphthongization pattern across Romance varieties (Chitoran & Hualde, 2007). Second, they
have shown that participants’ perception of these sequences is generally consistent with their
production of the same sequences (e.g. Hualde & Prieto, 2002, for Peninsular Spanish), such that

175
speakers who consistently produce certain sequences as hiatuses tend to also identify them as
such in a perception task (either syllabification intuition or labeling). Third, they have suggested
that acoustic differences translate into perceptual differences. For example, Chitoran (2002, for
Romanian) found that the magnitude of acoustic differences found in vocalic sequences can be
used to predict correct identification rates in a perception task. Specifically, her participants
correctly identified sequences at a statistically significant rate when they also differed
statistically on the acoustic parameters measured (i.e. [ja] vs. [ea] sequences in this case). On the
other hand, identification of sequences which did not differ acoustically (i.e. [oa] vs. [wa]) was
roughly at chance level (Chitoran, 2002).
In the present chapter, we combine the insights gained from these previous studies with our own
results from Chapters 3 and 4 to create an experimental perception study which aims to address
the main issues and questions outlined above. We test three hypotheses associated with this
objective. As with the acoustic and articulatory study in the previous two chapters, the present
study focuses on sequences of rising sonority in which the first component is a high front vowel
[i] or a palatal glide [j] and the second component is a non-high vowel (V = [a,e,o]).
The first hypothesis explores possible within-category and between-category variability in the
perception of diphthongs, hiatuses and exceptional hiatuses.
Hypothesis 1
Diphthongs and hiatuses were found to differ systematically and significantly on
both acoustic and articulatory measures. For this reason, we propose that they
belong to different perceptual categories and predict that discrimination between
them will be high. On the other hand, exceptional hiatuses (a subset of the
Diphthong category) pattern with hiatuses on both acoustic and articulatory
measures. For this reason, we propose that exceptional hiatuses are not a separate
perceptual category for this variety of Spanish and predict that discrimination
between Hiatus and Exceptional Hiatus will be low.
The second hypothesis looks at how the quality of the non-high vowel (V) affects the
perceptibility of the sequence.
Hypothesis 2
The quality of V ([a], [e], or [o]) affects the magnitude of acoustic and
articulatory differences found between categories of vocalic sequences, which in
turn affects their perceptibility. Our acoustic and articulatory results suggest that
Diphthong and Hiatus sequences with [a] are perceptually closer to each other
than corresponding sequences with [e] or [o]. Thus, we predict that with

176
sequences where V = [a] participants will exhibit more difficulty (i.e. produce
more incorrect responses) in discriminating between Diphthong, Hiatus and
Exceptional Hiatus than they will with sequences where V is either [e] or [o].
The final hypothesis focuses on the association between individual variation in the production
and perception of the vocalic sequences.
Hypothesis 3
Individuals differ in the degree of acoustic and articulatory difference they
maintain between Diphthong and Hiatus. Overall, the findings in Chapters 3 and 4
showed that a smaller difference tended to result in a greater number of
misclassified sequences, especially misclassified Diphthong sequences. As a
result, we propose that participants who consistently produced misclassified
Diphthong sequences (i.e. produced Exceptional Hiatuses) will be better able to
discriminate between Diphthong and Exceptional Hiatus in a perception task than
those who had fewer misclassified Diphthong sequences.
The experimental strategy adopted in the present study differs in some respects from the one
often employed in perception studies on Spanish vowel sequences (e.g. Hualde & Prieto, 2002;
Face & Alvord, 2004; Cabré & Prieto, 2006). Those studies have tended to rely on native-
speaker syllabification intuitions and/or identification tasks to determine whether participants
perceive the contrast between different categories of sequences. In those tasks which focused on
syllabification intuitions, the words to be discriminated were sometimes presented to the readers
in written form, rather than aurally (e.g. Hualde & Prieto, 2002; Cabré & Prieto, 2006). Thus, in
a strict sense, the participants did not really perceive any stimuli. The main concern with this
methodology, however, is that it may be tapping into learned syllabification and be influenced by
orthography and lexical bias. That is, participants who are highly literate may have learned to
judge these sequences differently and may have learned to perceive a difference in syllabification
which they otherwise would not perceive in a purely aural presentation, with the effects of
lexical bias controlled for. In studies that have presented stimuli aurally (e.g. Face & Alvord,
2004) participants have been asked to identify or classify stimuli according to predetermined
categories (i.e. either diphthong or hiatus) with no option for ambiguous stimuli.
Here, an attempt is made to mitigate some of the concerns with the above methodologies as
follows. First, we use nonsense words (refer to §2.2, this chapter, for details) to control the
possible effects of lexical bias. Second, we use an AX same/different discrimination task (e.g.
Beddor & Gottfried, 1995) to test perception of vocalic sequences in Mexican Spanish. In this
type of task (described in more detail in §2.3, this chapter), participants are asked to decide if

177
two stimuli presented in a single trial are the same or not, without reference to fixed categories.
This task type was selected over other possible discrimination tasks (e.g. ABX or a dual pair
4IAX57
) because of its low cognitive demand (Beddor & Gottfried, 1995; Gerrits & Schouten,
2004) and ease of presentation. However, the AX task has some potential disadvantages which
needed to be addressed. These include: (i) a bias towards Same responses in cases where
discrimination of the two stimuli is difficult, and (ii) response decisions made on the basis of
stimuli characteristics not relevant to the task. Although likely not eliminated, these potential
problems were controlled in the following ways. First, some of the possible distracting
characteristics of the stimuli58
were controlled by (i) ensuring equal loudness across all stimuli;
using stimuli produced by a single speaker to avoid decisions based on speaker differences, and
(iii) using only intra-vowel comparisons in the stimuli pairs (to avoid decisions based on identity
of V). Second, the listeners participated in a practice session (described in §2.3, this chapter) in
which they became familiar with the stimuli and the task requirements. In this practice session,
they also received feedback about correct responses. The purpose of the feedback was to focus
the listeners’ attention on the relevant differences between the pairs (Werker & Tees, 1984, p.
1872-1873). Finally, signal-detection measures (described in §2.4.1, this chapter) were used to
separate response bias from discrimination performance.
We also test the effect of the duration of the inter-stimulus interval (ISI) on the discrimination of
these vocalic sequences. Studies where ISI duration was varied have reported that a longer ISI
encourages better accuracy in between-category discrimination while a shorter ISI encourages
better accuracy in within-category discrimination (Pisoni, 1973; Werker & Tees, 1984; Werker
& Logan, 1985; Cowan & Morse, 1986; Van Hessen & Shouten, 1992; Gerrits, 2001; Gerrits &
Schouten, 2004; Krebs-Lazendic & Best, 2008). These findings reflect a possible “inverse
relationship between the duration of the ISI and discrimination performance” (Werker & Tees,
1984, p.1875), especially when an AX task is used. Specifically, at a shorter ISI (500 ms or
under: Werker, 1994, p. 130), it is believed that the auditory trace of the stimulus is still available
57 In an ABX task participants decide whether X is identical to one of two acoustically different stimuli (A or B). This is
considered more cognitively demanding than an AX task because of the temporal distance between A and X (Beddor &
Gottfried, 1995, p.224). In a dual pair (4IAX) discrimination task (Beddor & Gottfried, 1995; Beddor et al., 2002) two pairs of
stimuli are given at a time, one pair containing two acoustically identical stimuli and the other containing two differing acoustic
stimuli. Pair combinations are: AB–AA, AA–BA, BB-AB and BA–BB (Gerrits & Schouten, 2004). Participants are asked to
identify which pair is different (i.e. which pair contains the differing stimuli).
58 Refer to §2.2 for a more detailed presentation of stimulus preparation procedures.

178
to the listener. Thus, listeners are able to use an auditory mode of perception which makes it
easier for them to perceive contrasts which are not phonemic in nature (i.e. within-category
contrasts, Pisoni 1973). On the other hand, at a longer ISI (over 500 ms: Werker, 1994, p. 130)
the auditory trace of the stimulus is presumably no longer available in the short term memory of
the listeners. In this case, listeners are thought to use a mode of perception in which they recur to
the linguistic representations (or labels) in their long term memory. This is thought to make it
easier for listeners to discriminate contrasts to which they can assign category labels (i.e.
between-category or phonemic contrasts).
Based on our hypothesis that Diphthong and Hiatus form separate perceptual categories, we
predict that discrimination between them will be best at a longer ISI which promotes a linguistic
(Pisoni, 1973; Werker & Tees, 1984; Werker & Logan, 1985) or labeling (Gerrits & Schouten,
2004) mode of perception since this mode of perception presumably results in better between-
category distinctions59
. On the other hand, because exceptional hiatuses pattern with hiatuses on
both acoustic and articulatory measures, we hypothesize that Exceptional Hiatus and Hiatus do
not constitute separate perceptual categories. Therefore, we predict that discrimination between
Exceptional Hiatus and Hiatus will be best at a shorter ISI which promotes an auditory mode of
perception and, presumably, better within-category distinctions (Pisoni, 1973; Werker & Logan,
1985).
Finally, the study examines whether hearing these vocalic sequences within a word or in
isolation affects their perceptibility. Plomp (2002) summarizes research which suggests that
words are better candidates for “the perceptual units of speech” (p. 129) than sounds presented in
isolation. Thus, we might expect participants in the present study to perform better on the
perception task when the sequences are presented in a word vs. when they are presented in
isolation. Studies involving perception of vowels and vowel sequences have had mixed results.
For example, Face & Alvord (2004) found no difference in context (sequence within word vs.
isolated sequence) in an identification task involving Peninsular Spanish diphthongs and
exceptional hiatuses. These results mirror those of Andruski & Nearey (1992) who found that
error rates and confusion matrices were similar for vowels (monophthongs, Western Canadian
59 Refer, however to Chapter 2, §2.1.1, where it is pointed out that there is disagreement concerning the phonological status of
these sequences.

179
English speakers) when presented in isolation or in CVC syllables. Other researchers, however,
have had different results. For example, Strange et al. (1979) achieved better identification rates
for single vowels in CVC syllables than for the same vowels presented to listeners in isolation
while, more recently, Ashby (2007, using simple nonsense words rather than CVC syllables)
found the opposite to be the case (i.e. slightly worse identification rates for vowels in nonsense
words). However, these studies have generally used identification tasks. In those tasks
participants were often asked to select an appropriate label for the stimuli they heard from a fixed
set of alternatives determined a priori by the researcher. The present study aims to verify whether
discrimination of the vocalic sequences under study is affected by presentation context (word vs.
isolated sequence) when an AX discrimination task is used (i.e. with no reference to category
membership).
These hypotheses are tested in an experimental study whose methodology is outlined in §2
below. Results and accompanying statistical analyses are presented in §3 and their relevance to
the above hypotheses and previous studies is discussed in §4. A brief conclusion is given in §5.
2 Experimental Methodology
2.1 Participants
The participants in this experiment were 6 native speakers of Mexican Spanish (AM, AN, DH,
KR, LL, MM) all of whom had already participated in the acoustic and articulatory portion of the
study (reported in Chapters 3 & 4) in previous sessions. All were naïve to the purpose of the
experiment and none had any training in linguistics or phonetics.
2.1.1 Hearing Screening
In order to be eligible for this portion of the study, participants had to have reported no history of
vision, hearing or language problems in their initial contact with the principal investigator. Since
hearing acuity may influence perceptual judgment, all participants were also required to pass a
pure tone audiometry hearing screening of the three frequencies considered to be the major
frequencies for speech: 500, 1000 and 2000 Hz (ASHA; Nittrouer, 2005, 2007). The hearing
screening was carried out at the Communications Functions Lab, Toronto Rehabilitation Centre
(Department of Speech-Language Pathology, U of T) using a GSI 61 Two Channel Clinical
Audiometer. During the procedure, the participants were seated comfortably in a sound-proof

180
room and were presented sounds at the three different frequencies (pitches) and at different
intensity levels (loudness) through headphones specifically designed for the screening procedure.
The participants were instructed to give a response if they heard the sound. Typically, this
response involved raising a finger from the hand corresponding to the ear where the sound was
received. The researcher (under the supervision of Dr. Aravind Namasivayam, an audiologist and
speech-language pathologist and the lab’s Research Manager) sat in a control room adjacent to
the soundproof room and presented the sounds to the listener. A sound of a particular frequency
was presented to one ear for approximately 1 second, and its intensity was raised and lowered
until the person no longer responded consistently. Then, another signal of a different frequency
was presented to the same ear, and its intensity was varied until there was no consistent response.
This procedure was carried out for the three frequencies identified above and the other ear was
then tested in the same way. All of the above participants passed the hearing screening with a
hearing level at or below (i.e. better than) the established threshold60
. The documentation which
accompanied the hearing screening is found in Appendix 4.
2.1.2 Handedness Questionnaire
Although being right or left-handed had no consequences for experiment eligibility, a
handedness questionnaire was administered to all participants since response times on a
perceptual task may also be influenced by the handedness of the participant (Peters & Ivanoff,
1999; Barthélémy, S & Boulinguez, 2001; Dane & Erzurumluoglu, 2003). Specifically, left-
handed people may have a response time advantage since they have been found to be equally fast
in responding with both hands, while right-handed people are faster with their right hand (Peters
& Ivanoff, 1999; Dane & Erzurumluoglu, 2003). Because keyboard responses were required for
this experiment, it was deemed important to ascertain the handedness of the participants through
the use of a questionnaire. The questionnaire used here (Appendix 5) was adapted from the
Edinburgh inventory (Oldfield, 1971) and the Dutch Handedness Questionnaire (Van Strien,
1992). All the participants were right-handed.
60 The threshold level was 25dB HL (Nittrouer , 2005, 2007).

181
2.2 Stimuli
The stimuli used for the perceptual study consisted of nonsense words elicited from speaker MM
following her participation in the acoustic experiment (reported in Chapter 3). As mentioned in
the Introduction, only words containing sequences with a palatal onglide [j] or high front vowel
[i] were used. These words were all of the type [piVpo], where iV represents either a diphthong
(jV), a hiatus (í.V) or follows the same patterns found in exceptional hiatuses ( ), and where V
= [a, e, o]. The use of nonsense words rather than real words in this type of experiment has the
following advantages. First, it allows the testing of the three types of sequences across the three
vowels in the same consonantal environment. This would be impossible to control with real word
tokens since minimal pairs which contrast these types of sequences do not exist in the language
(see Chapter 3, Appendix, Stimuli Table). In addition, this particular dialect of Spanish is
predicted to have few exceptional hiatuses (as discussed in Chapter 1). In fact, as we found in the
acoustic study (Chapter 3) and in the articulation study (Chapter 4) there is considerable
variation in the quantity of potential exceptional hiatuses which individual speakers of this
variety of Spanish may produce. Therefore, this type of sequence may not have surfaced reliably
in real words. Finally, using nonsense words may help avoid responses based on familiarity with
the word (Ganong, 1980; Gow et al., 2008; Clopper et al., 2010).
The audio signals were prepared for presentation in Praat (Boersma & Weenink, 2010) using a
Preprocessing script from GSU Praat Tools 1.9 (Owren, 2009), to ensure equal loudness across
all tokens in the files. One token of each sequence type was then selected for each V, based on
their showing a robust between-category distinction61
. These distinctions were determined first
auditorily by the investigator and confirmed using both temporal and frequency information from
the acoustic signal. In terms of duration, within each V category [a,e,o], the sequence types
(representing diphthongs, hiatuses and exceptional hiatuses) differed in total duration (measured
as per the criteria outlined in §2.4.1, Chapter 3 and normalized as a z-score) as well as in
duration of the Transition portion of the sequence (measured according to the criteria outlined in
§2.4.1, Chapter 3 and normalized as a proportion of the total raw duration of the sequence).
These measures of duration are summarized in Table 49.
61 The speaker who produced these words (MM) was trained by the author to make the sequence types as distinct as possible but
was not aware of the purpose of her recording these additional words.

182
Table 49. Temporal characteristics (sequence and transition duration) of nonsense word
stimuli for AX perception task
Sequence Duration Transition Duration
Type Stimulus
raw
(ms)
normalized
(z-score)
raw
(ms)
normalized
(%Transition)
Diphthong [ja] 82.35 -1.17 68.63 83.33
Hiatus [í.a] 140.51 0.62 62.24 44.30
Exceptional Hiatus [i.á] 150.71 0.93 81.52 54.09
Diphthong [je] 69.83 -1.56 59.24 84.83
Hiatus [í.e] 132.12 0.36 63.47 48.04
Exceptional Hiatus [i.é] 107.09 -0.41 44.84 41.87
Diphthong [jo] 72.88 -1.46 62.70 86.03
Hiatus [í.o] 152.96 1.00 80.40 52.56
Exceptional Hiatus [i.ó] 158.87 1.19 73.71 46.39
For all three levels of V [a,e,o], the shortest sequence was the one corresponding to the
Diphthong category (jV). Sequences corresponding to Hiatus (í.V) and Exceptional Hiatus (i.
were always longer than Diphthong in total sequence duration. Conversely, sequences
corresponding to Diphthong devoted a greater proportion of the sequence to the transition than
Hiatus and Exceptional Hiatus sequences. These patterns reflect our findings from Chapter 362
.
In addition, in most cases, the difference on both durational measures is smaller between Hiatus
and Exceptional Hiatus than between Diphthong and either Hiatus or Exceptional Hiatus (Table
50). The only exception is for the difference in %Transition where V = [e]. In this case the values
for the Diphthong-Exceptional Hiatus (D-E) difference and the Hiatus-Exceptional Hiatus (H-E)
differences are very close, although the Hiatus-Exceptional Hiatus difference is still smaller.
Table 50. Durational differences between categories of Sequence Type (normalized
measurements) for AX perception task
Differences
V Sequence duration (normalized, z-score) Transition duration (normalized, %)
D-H D-E H-E D-H D-E H-E
[a] 1.79 2.10 0.31 39.03 29.24 9.79
[e] 1.92 1.15 0.77 36.79 19.02 17.77
[o] 2.46 2.65 0.19 33.47 39.64 6.17
62 In fact, the differences between Diphthong and Hiatus in the values cited above are exaggerated (especially for transition
duration) when compared to the means of similar sequences taken from stimuli in the acoustic experiment (even those taken from
the speaker who produced the perception stimuli).

183
In terms of frequency, Figures 42-44 represent the time-normalized F1-F2 contours of the stimuli
used for each V63
. These contours suggest that differences exist between Diphthong, Hiatus and
Exceptional Hiatus, at least at some points along the contours. As we saw in Chapter 3 with
similar contours, the differences are greater for sequences where V = [a] and [o] (where both
Hiatus and Exceptional Hiatus sequences have more peripheral formant values and Diphthong
sequence have more centralized values, especially for F2, suggesting a more posterior tongue
position for diphthongs) than for sequences where V = [e] (where all Sequence Types show more
overlap for both F1 and F2).
Figure 42. Scatterplot of F1-F2 of AX perception task stimuli, by Sequence Type: V = [a]
63 Refer to Chapter 3, §2.4.2 for details of how measurements were taken and how these contours were realized.
Time
Fre
qu
en
cy
(B
ark
)
10987654321
16
14
12
10
8
6
4
2
0
V = [a]

184
Figure 43. Scatterplot of F1-F2 of AX perception task stimuli, by Sequence Type: V = [e]
Figure 44. Scatterplot of F1-F2 of AX perception task stimuli, by Sequence Type: V = [o]
Time
Fre
qu
en
cy
(B
ark
)
10987654321
16
14
12
10
8
6
4
2
0
V = [e]
Time
Fre
qu
en
cy
(B
ark
)
10987654321
16
14
12
10
8
6
4
2
0
V = [o]

185
However, when we further summarized the frequency data using polynomial equations and then
used the equations to carry out a Discriminant Analysis64
, we found that for all three levels of V,
Diphthong sequences were consistently correctly classified as Diphthong. On the other hand,
little distinction was made between Hiatus and Exceptional Hiatus sequences (regardless of
which combination of durational and frequency predictors were used) and these two Sequence
Types were consistently misclassified as each other but never as Diphthong. In short, the
acoustic measurements and the Discriminant Analysis of the stimuli chosen for the present
results largely match the results from Chapter 3 as well as the proposal (Hypothesis 1, this
chapter) of little difference between Hiatus and Exceptional Hiatus. Thus, we can assume, with
some degree of confidence, that the stimuli selected for the perception experiment are
representative of the Sequence Type categories under study.
After their suitability was established, the resulting 9 [iV] word tokens were subsequently
extracted from their carrier phrases at onset of initial [p] (taken at stop release) and offset of final
[o] (taken at offset of F2). The iV portions were then excised from each of these 9 word tokens.
The onset of each iV sequence was determined by an increase in F1 on the spectrogram and the
onset of periodicity on the waveform following the initial [p]. The offset of each sequence was
determined as a drop in F2 of V and the last period on the waveform before the following [p]
(Chitoran 2002, refer also to Chapter 3). All cuts were made at zero crossings. Using Adobe
Audition v1.5 software (Adobe Systems Inc., 2004), a 250ms segment of silence was then added
to the beginning and end of each (nonsense) word and sequence file as a way to avoid any
audible transient noise. The stimuli are shown in Table 51 with the sequences of interest given in
bold.
Table 51. Stimuli list for AX perception task
Sequence Type
Diphthong Hiatus Exceptional Hiatus
word sequence word sequence word sequence
[pjá.po] [ja] [pí.apo] [í.a] [pi.ápo] [i.á]
[pjé.po] [je] [pí.epo] [í.e] [pi.épo] [i.é]
[pjó.po] [jo] [pí.opo] [í.o] [pi.ópo] [i.ó]
64 Refer to Chapter 3, §3.4.1 for details on how these procedures were carried out.

186
Stimuli were organized into pairs according to sequence type (jV, í.V, or ) and vowel type [a,
e, o]. That is, each of the tokens for each vowel was paired with each of the three sequence types
for that vowel, for a total of 9 pairings per vowel type. Of the 9 pairings for each vowel type, 3
pairings involved stimuli where both members of the pair were the same (A = X) and 6 pairings
of stimuli the members of the pair were different (A≠X). To illustrate, the 9 possible pairings for
isolated sequences where V = [a] are given in (22) below:
(22) ja-ja: D_D (Diphthong_Diphthong)
ja-í.a: D_H (Diphthong_Hiatus)
ja-i.á: D_E (Diphthong_Exceptional Hiatus)
í.a-í-a: H_H (Hiatus_Hiatus)
í.a-ja: H_D (Hiatus_Diphthong)
í.a-i.á: H_E (Hiatus_Exceptional Hiatus)
i.á-i.á: E_E (Exceptional Hiatus_Exceptional Hiatus)
i.á-ja: E_D (Exceptional Hiatus_Diphthong)
i.á-í.a : E_H (Exceptional Hiatus_Hiatus)
The stimuli were arranged into four blocks separated by Stimulus type (Word vs. Sequence) and
by ISI in ms (500 vs. 1000). These ISIs were selected in order to promote an auditory mode of
discrimination (ISI = 500 ms) and a ‘linguistic’ (Pisoni, 1973; Werker & Tees, 1984; Werker &
Logan, 1985) or ‘labeling’ (Gerrits & Schouten, 2004) mode of discrimination (ISI = 1000 ms).
The durations are based on findings reported in Werker (1994, p. 130) and in Krebs-Lazendic &
Best (2008, p. 291).
Each block consisted of 27 trials corresponding to 3 vowels ([a], [e] and [o]) X 9 pair types (see
above). The order of the blocks was fixed as follows: (i) Word at 500 ISI, (ii) Word at 1000 ISI,
(iii) Sequence at 500 ISI, and (iv) Sequence at 1000 ISI. The order of trials within the blocks,
however, was randomized for each listener. Thus, each listener heard a total of 108 pairs of
perceptual stimuli (27 pairs X 2 stimulus types X 2 ISI)65
. Prior to the test session, each listener
participated in a practice session consisting of 24 trials (6 pairs X 2 stimulus types X 2 ISI)
meant to familiarize them with the stimuli and the task.
65 Participants also heard the same number of stimuli produced by speakers of two other Spanish varieties, Argentine and
Peninsular (presented in separate blocks). Only the results for their performance on the Mexican Spanish (i.e. the native variety)
stimuli are presented here.

187
2.3 Tasks and procedures
Following the administration of the handedness questionnaire and hearing screening, the
participants proceeded to the perceptual testing. As with the previous two experiments, the
participants were tested individually. The perception experiment took place in the same lab
(Communications Functions Lab) where the participants took the handedness questionnaire and
hearing screening, on the same day as these screening procedures.
For the experiment, the listeners were seated in a sound-proof booth in front of a computer
keyboard placed on a flat surface with the left and right Shift keys marked with a green dot
(symbolizing I for Igual = same) and a red dot (symbolizing D for Diferente = different). The
green and red dots also appeared on the computer screen in front of the participants with the
words Igual and Diferente underneath the corresponding dot. In order to account for the
observation that the listener’s preferred hand is generally faster to respond (Peters & Ivanoff
1999; Dane & Erzurumluoglu, 2003), the shift key on which red (different) or green (same)
appeared was counterbalanced across listeners.66
The task employed was an AX discrimination task (e.g. Beddor & Gottfried, 1995) where
listeners hear pairs of stimuli where each stimulus pair consists of a reference stimulus (A) and a
test stimulus (X) and decide if they are the same or different. The AX task in the present
experiment was administered as follows. The listeners first heard the reference stimulus and then
the test stimulus. Following this, the listeners decided whether the two stimuli were the same or
different by pressing on the appropriate key on a computer keyboard. The participants were
instructed to press the green key if they thought the two words or sequences in the pair they
heard were pronounced the same and to press the red key if they thought their pronunciation was
different. They then proceeded to the familiarization (training) trials.
During this training phase, the participants received feedback on their responses. The feedback
consisted of a yellow X which appeared on the computer screen in front of them (between the
green and red dots) if they made an incorrect choice. Whenever the yellow X appeared, the
66 Because listeners from other dialects groups were also tested during the same period (those results are not reported in this
chapter) two of the Mexican participants (AN and DH) had the red (different) key on the left and the green (same) key on the
right. The remaining Mexican listeners received the opposite ordering of the keys (green-same key on left and red-different key
on right).

188
participants then had to press the correct key in order to proceed to the following trial. Following
the familiarization trials, the listeners were given an opportunity to ask questions or review the
task instructions with the investigator. No feedback was given during the experimental phase.
For both training and experimental phases the auditory stimuli were presented at 10dB above HL
(adjusted according to listener, typically 45dB HL to the right ear and 35 dB HL to the left ear)
via free field speakers placed at 45 azimuth to the listener. The speakers were connected to the
GSI 61 audiometer which in turn was connected to a small laptop computer in the control booth.
The computer used DirectRT presentation software (Empirisoft Corp.) to randomize and present
the stimuli. There was a brief break given between each block to avoid fatiguing the listener. The
researcher advanced the next block as soon as the listener indicated she was ready to proceed.
Within each block, participants were not given a time limit within which to make their responses
although they were instructed to respond as quickly as they could. Following each key press
response by the listener, the next trial advanced automatically with a 1000ms interval between
stimuli pair. Discrimination responses as well as response times (RT) were recorded by the
Direct RT software and exported to an EXCEL file for analysis67
. A total of 540 tokens (108 x 5
participants) were collected and are analyzed here68
.
2.4 Analysis
In the present experiment, the number of participants as well as the number of observations
collected from each participant was rather small. In addition, some of the data (in particular for
Pair Type) were not normally distributed. For these reasons, responses were analyzed using
nonparametric discrimination measures. These, in turn were evaluated using nonparametric
statistical tests.
67 Only discrimination responses are reported here.
68 The 108 tokens collected for participant MM (the participant who produced the experiment stimuli) were not included in the
analysis. Although her responses did not differ much from those of the other participants on the accuracy and sensitivity
measures, they differed in regards to response bias. Specifically, she showed a consistently greater liberal bias (i.e. a greater
tendency to respond Different on A≠X pairs) than the others. These differences were enough to affect the results of the statistical
tests with her inclusion. She also exhibited differences with regards to RTs (hers were generally longer than those of the
remaining participants, especially for incorrect responses). However, as pointed out above, the RT data is not analyzed here.

189
2.4.1 Discrimination Measures
Discrimination responses were analyzed in terms of response accuracy, response sensitivity and
response bias. All these measures required that the participant’s correct and incorrect responses
be tabulated and further categorized as illustrated in Table 52 (adapted for AX task from
Macmillan & Creelman, 2005, p.4).
Table 52. Categorization of correct and incorrect responses for AX perception tasks
RESPONSE
DIFFERENT SAME
STIMULUS DIFFERENT HITS (H) MISSES (M)
SAME FALSE ALARMS (F) CORRECT REJECTIONS (CR)
Thus, correct responses are divided into two categories: HITS (H = where A and X are different
and the listener correctly responds Different) and CORRECT REJECTIONS (CR = where A and
X are the same and the listener correctly responds Same, thus rejects that they are different).
Similarly, incorrect responses are divided into two categories: MISSES (M = where A and X are
different but the listener responds Same) and FALSE ALARMS (F = where A and X are the
same but the listener responds Different, thus reporting a difference where there was none).
Table 53 shows the total number of each response type across all participants as well as for each
individual participant across all conditions.
Table 53. Summary of AX perception task responses, by Response type and Participant
across all conditions
Participant
Response type
Total N(trials)
Correct Incorrect
CR H F M
AM 34 30 2 42 108
AN 36 45 0 27 108
DH 32 41 4 31 108
KR 35 54 1 18 108
LL 36 49 0 23 108
OVERALL 173 219 7 141 540
2.4.1.1 Response Accuracy: proportion correct, p(c)
The first discrimination measure reported is the proportion of correct responses or p(c). This
measure reflects listener accuracy at discriminating between pairs of Same and Different stimuli.
It is calculated from the number of correct responses out of the total number (N) of
responses/trials for each condition tested. Recall from above that correct responses fall into two

190
categories: HITS (H) and CORRECT REJECTIONS (CR). The proportion of correct responses
was calculated from the raw count data, according to the following formula:
(23) p(c) = (H + CR)/ N (Macmillan & Creelman, 2005, p. 7)
In Figure 45, the raw data in the above table has been converted to proportions (reported as
percentages) by dividing by the row total N. These figures show that, overall, correct responses
(CR + H) make up the greatest proportion of total responses (N), with a mean of 0.73 (rounded to
two decimal points), representing slightly less than three quarters of the responses.
40.6%Hit
32.0%Correct Rejection
26.1%Miss
1.3%False Alarm
Figure 45. Pie chart of AX perception task responses (%) by Response Type, across all
conditions
The same pattern is seen in individual responses (Figure 46), with all the participants showing a
greater than chance proportion of correct responses. Thus, at first glance it would appear that the
participants are making the appropriate discriminations in the stimuli pairs and are not merely
guessing in their response. On the other hand, individual variation in the responses is also
already apparent. In particular, when we look only at the proportion of correct responses (Hits +
Correct Rejections together), we find that participant AM’s performance is worse than that of the
other four participants, with a proportion of correct responses of only 0.59 (Table 54). Thus, not
all the participants may be discriminating to the same degree.
Correct Responses = 73%

191
Pe
rce
nt
Re
sp
on
se
(%
)
Participant LLKRDHANAM
100
80
60
40
20
0
Response Type
False Alarm
Miss
Correct Rejection
Hit
Figure 46. Bar chart of AX perception task responses (%) by Response Type and
Participant, across all conditions
The measure of proportion correct responses, p(c) is an inherently nonparametric measure
(Macmillan & Creelman 2005: 117), making it suitable for the small amount of data in the
present experiment. However, it does not take response bias into account. In other words, p(c)
may vary according to the listener’s tendency to answer either Different or Same. As such, the
p(c) scores reflect the participants’ response to a combination of the signal + noise. To account
for possible bias, listener responses were also used to calculate response sensitivity (signal only)
and, separately, response bias (noise only).
2.4.1.2 Response Sensitivity: A'
Here we calculated A', a nonparametric measure of perceptual sensitivity (Grier, 1971; Johnson,
1976; Aaronson & Watts, 1987) which is separate from response bias. This measure is used in
lieu of d' in cases where the normal distribution and equal-variances assumptions of d' cannot be
met (Donaldson, 1992; Stanislaw & Todorov, 1999) and/or when only small amounts of data are
available for analysis (Werker & Tees, 1984; Goldinger, 1998). Prior to calculating A′ the HIT
(H) and FALSE ALARM (F) rates were calculated as follows (from Macmillan & Creelman,
2005, p. 19):

192
(24) HIT and FALSE ALARM rate formulas
(a) H (Hit Rate) = Hits/Hits + Misses
(b) F (False Alarm Rate) = False Alarms/False Alarms+ Correct Rejections
As an example, using the data from Table 52 in the above formulas we find that the overall H
and F rates (rounded to two decimals) are as follows:
(i) H = 219/219+141 = 0.61
(ii) F = 7/7+173 = 0.04
Where necessary, H and F proportions were adjusted to avoid values of 1 or 0 with the following
transformations (from Macmillan & Creelman, 2005, p. 19):
(25) H and F transformations
(a) for H = 1: Hits-0.5/Hits + Misses
(b) for F = 0: 0.5/ False Alarms+ Correct Rejections
An example from the data in Table 52 illustrates how these transformations were applied.
Participant AN, for instance, had 36 Correct Rejections and 0 False Alarms; applying the
formula in (25) (ii) above gives her an F rate of 0.5/36 = 0.01.
The H and F rates were then used to calculate A′ according to the following formula (from
Stanislaw & Todorov 1999: 142) which combines the two separate formulas often cited for H≥F
and for H< F (as in Snodgrass & Corwin, 1988).
(26) A′ = , where: sign (H-F) = 1 when H>F,0 when
H = F,and-1 when H<F; max (H, F)
corresponds to the greater of H or F
The full range for A′ is from 0 to 1. However, the practical range for this measure is between 0.5
(indicating chance performance and interpreted as an inability on the part of the listener to detect
differences between A and X, i.e. H = F) and 1 (indicating perfect performance). Values below
0.5 may arise as a result of “sampling error or response confusion” (Stanislaw & Todorov, 1999,
p. 140). Thus, the higher the value of A′ obtained, the greater the degree of sensitivity to a
difference between A and X is assumed to be.
2.4.1.3 Response Bias: β″D
Bias measures are based on the assumption that in this type of discrimination task, the decision-
making process employed by participants depends on two factors. The first is sensitivity to the

193
stimulus characteristics which we measured using A′. The second factor is bias, which reflects
the participants’ response preference rather than any relevant information contained in the
stimulus. That is, each participant makes a personal decision regarding whether it is better to
maximize H and CR or to minimize F and M (Macmillan & Creelman, 2005, p. 37-39). In an AX
discrimination task, for example, each participant may divide the stimulus axis into Same and
Different regions at a different point or criterion (Macmillan & Creelman, 2005). What the bias
measure tells us then is whether the participant is more likely to respond Same or to respond
Different for a particular condition. The measure of response bias used here is β″D. This measure,
rather than the more common β″, was used because of its greater independence from A′
(Donaldson, 1992). It was calculated according to the following formula (adapted from
Donaldson, 1992, p. 276)
(27) β″D = [(1-H) (1-F)-HF]/[(1-H)(1-F)+HF]
In addition to reflecting personal preference for Same or Different responses, the β″D value is of
interest because it can vary from condition to condition. For example, increased familiarity with
a task (a practice effect) may change the value of β″D, independently of sensitivity changes. The
values for β″D range from -1 to 1. A value of 0 is interpreted as having no bias while positive
values are interpreted as a bias toward responding Same (a conservative bias) and negative
values as a bias toward responding Different (a liberal bias).
The results for p(c), A' and β″D scores across all conditions are summarized in Table 54.
Table 54. Summary of response accuracy (p(c)), sensitivity (A') and bias (β″D) scores by
Participant, across all conditions
Participant p(c) A′ β″D
AM 0.59 0.81 0.92
AN 0.75 0.90 0.95
DH 0.68 0.83 0.72
KR 0.82 0.93 0.84
LL 0.79 0.91 0.94
OVERALL
Mean = 0.73 Mean = 0.88 Mean = 0.87
Median = 0.75 Median = 0.90 Median = 0.92
SD = 0.092 SD = 0.053 SD = 0.096
A graphic expression of the mean p(c), A' and β″D scores across all conditions (Figure 47)
illustrates how these measures can give different insights. For example, it is obvious that all the

194
participants had a rather large conservative bias toward Same responses, as reflected in the
positive β″D scores. In addition, we see that removing this bias (i.e. the noise) from the p(c)
scores reduces response variability (as reflected in the smaller standard deviations in the A' score
results).
1.0
0.8
0.6
0.4
0.2
0.0
1.0
0.8
0.6
0.4
0.2
0.0
1.0
0.5
0.0
-0.5
-1.0
p(c) A' ß?D
*Bars are One Standard Error from the Mean
Figure 47. Bar chart of mean p(c), A' and β″D scores, across all conditions
Looking at the results for each participant further illustrates how p(c) and A' measures can differ.
In Table 54, for example, we see that participants AM and DH have very similar scores on A'
(0.81 and 0.83 respectively). Presumably, then, their performance on the discrimination task was
approximately the same. In other words, AM and DH did worse than the other three participants,
all of whom had A' scores of 0.90 or higher. On the other hand, on the measure of p(c), AM and
DH had scores which were further apart (0.59 and 0.68, respectively), giving the impression that
DH did better than AM on the discrimination task. The results for these two participants also
highlight the independence of A' and β″D. For example, AM clearly has a more extreme Same
bias (β″D = 0.92) than DH (β″D = 0.72), even though both scored similarly on sensitivity.
Because there were more Different trials than Same trials in the experiment, DH’s less extreme
Same bias resulted in higher p(c) scores than AM even though their sensitivity (A′) scores were
similar. Thus, eliminating bias from a response can affect its interpretation.
B”D

195
2.4.2 Statistical Analysis
After computing the p(c), A′ and β″D scores, the Friedman Test statistic was used to determine if
any differences between levels of the variables tested were statistically significant (as opposed to
being attributable to chance and/or bias). The Friedman Test Statistic is the nonparametric
equivalent to the repeated-measures ANOVA procedures (Corder & Foreman, 2009, p. 80) used
in Chapters 3 and 4. As in Chapters 3 and 4, these tests were performed on the statistical program
MINITAB 14 (Minitab Inc.), with p level set at .05. In all cases, the test statistic adjusted for ties
is reported. Where appropriate, the Wilcoxon Signed Ranks test was used as a post-hoc test
(Corder & Foreman, 2009, p. 87). When multiple comparisons were conducted, a Bonferroni
procedure was used to correct α for Type I error rate (from Corder & Foreman, 2009, p. 81):
(28) , Where = adjusted α level, α = original α level of 0.05 and k =
number of comparisons
3 Results
For this chapter, the results are organized according to the hypothesis being tested. In §3.1 the
focus is on Hypothesis 1 as we examine the effects of Pair Type (D_D, D_E, D_H, E_D, E_E,
E_H, H_D, H_E, or H_H). In §3.2, we concentrate on Hypothesis 2 and examine the effects of
the non-high vowel (V) in the sequence ([a], [e] or [o]). Within these two sections, we also
examine any differences in discrimination at the level of the individual listeners (Hypothesis 3).
3.1 Hypothesis 1: Pair Type Effects
Here we test the prediction that discrimination is better between pairs with Diphthong and Hiatus
than between pairs consisting of Hiatus and Exceptional Hiatus. The discrimination measures we
are concerned with then are those for pairs where A≠X since we are interested in measuring
sensitivity to differences. Pairs where A = X should (in theory) show no sensitivity and thus have
a p(c) value of 1.00, an A′ value of 0.5 and a β″D value of 1.00. As shown in Table 55, however,
these ideal values for A = X pairs were achieved only for Diphthong-Diphthong (D_D) pairs.
The values for Exceptional Hiatus-Exceptional Hiatus (E_E) and Hiatus-Hiatus (H_H) pairs
deviate from the expected values for some participants (AM and DH for both E_E and H_H
pairs; KR for E_E pairs only), possibly due to “response confusion” (Stanislaw & Todorov,
1999).

196
Table 55. Summary of p(c), A′ and β″D scores for Pair Type (A = X)
Summary of p(c), A′ and β″D scores for Pair Type (A = X)
Pair Type
Participant D_D E_E H_H
p(c)
AM 1.00 0.92 0.92
AN 1.00 1.00 1.00
DH 1.00 0.75 0.92
KR 1.00 0.92 1.00
LL 1.00 1.00 1.00
OVERALL
Mean = 1.00 Mean = 0.92 Mean = 0.97
Median = 1.00 Median = 0.92 Median = 1.00
SD = 0.000 SD = 0.102 SD = 0.044
A′
AM 0.50 0.36 0.36
AN 0.50 0.50 0.50
DH 0.50 0.24 0.36
KR 0.50 0.36 0.50
LL 0.50 0.50 0.50
OVERALL
Mean = 0.50 Mean = 0.39 Mean = 0.44
Median = 0.50 Median = 0.36 Median = 0.50
SD = 0.000 SD = 0.110 SD = 0.077
β″D
AM 1.00 0.99 0.99
AN 1.00 1.00 1.00
DH 1.00 0.97 0.99
KR 1.00 0.99 1.00
LL 1.00 1.00 1.00
OVERALL
Mean = 1.00 Mean = 0.99 Mean = 1.00
Median = 1.00 Median = 0.99 Median = 1.00
SD = 0.000 SD = 0.012 SD = 0.005
Despite these deviations from the expected values, there are no statistically significant
differences between these pairs and Friedman Test results for Pair Type (A = X) are the same for
p(c), A′ and β″D: S69
= 5.00, df = 2, p = 0.082.
The results for the A≠X pairs are illustrated in Figure 48. A first glance suggests that pairs
consisting of Exceptional Hiatus and Hiatus (E_H and H_E) were among those with the lowest
discrimination scores and highest bias scores for all participants. This would seem to support the
prediction that vowel sequences forming a Hiatus are difficult to distinguish from those whose
69 Minitab refers to the Friedman Test statistic (FR, Corder & Foreman, 2009) as S. Because the test uses a chi-square
distribution, it is sometimes also referred to as χ2 in other statistical programs (e.g. SPSS/PAWS).

197
pattern resembles an Exceptional Hiatus. However, this support is challenged by the observation
that the lowest discrimination scores were achieved with H_D pairs.
H_EH_DE_HE_DD_HD_E
1.0
0.8
0.6
0.4
0.2
0.0H_EH_DE_HE_DD_HD_E
1.0
0.8
0.6
0.4
0.2
0.0H_EH_DE_HE_DD_HD_E
1.0
0.5
0.0
-0.5
-1.0
p(c) A' ß?D
*Bars are One Standard Error from the Mean
Figure 48. Bar chart of mean p(c), A' and β″D scores for Pair Type (A≠X)
In fact, the Friedman Test results for this data (Table 56) show that, contrary to our predictions,
pairs where A≠X do not differ significantly from each other. Overall then, it does not appear to
be any easier to discriminate between Diphthong and Hiatus than it does between Hiatus and
Exceptional Hiatus. Nor is there any significant difference in response bias between the pairs
either.
Table 56. Summary of p(c), A′ and β″D scores for Pair Type (A≠X)
Pair Type
Participant D_E D_H E_D E_H H_D H_E
p(c)
AM 0.25 0.58 0.50 0.50 0.42 0.25
AN 0.83 0.67 0.75 0.58 0.42 0.50
DH 0.58 0.75 0.50 0.50 0.33 0.75
KR 0.75 0.83 0.92 0.58 0.92 0.50
LL 0.83 0.67 0.92 0.58 0.33 0.75
OVERALL
Mean=0.65 Mean=0.70 Mean=0.72 Mean=0.55 Mean=0.48 Mean=0.55
Med.= 0.75 Med.= 0.67 Med.= 0.75 Med = 0.58 Med=0.42 Med.= 0.50
SD = 0.245 SD= 0.094 SD = 0.211 SD = 0.044 SD=0.248 SD=0.209
Friedman Test: S = 7.38, df = 5, p = 0.194
B”D

198
Table 56 (cont’d)
A′
AM 0.76 0.87 0.85 0.85 0.82 0.76
AN 0.94 0.90 0.92 0.87 0.82 0.85
DH 0.87 0.92 0.85 0.85 0.79 0.92
KR 0.92 0.94 0.97 0.87 0.97 0.85
LL 0.94 0.90 0.97 0.87 0.79 0.92
OVERALL
Mean=0.89 Mean=0.91 Mean=0.91 Mean=0.86 Mean=0.84 Mean=0.86
Med.=0.92 Med.=0.90 Med.=0.92 Med.=0.87 Med.=0.82 Med.=0.85
SD=0.076 SD=0.026 SD=0.060 SD=0.011 SD=0.075 SD=0.066
Friedman Test: S = 7.38, df = 5, p = 0.194
β″D
AM 0.97 0.89 0.92 0.92 0.94 0.97
AN 0.64 0.84 0.77 0.89 0.94 0.92
DH 0.89 0.77 0.92 0.92 0.96 0.77
KR 0.77 0.64 0.35 0.89 0.35 0.92
LL 0.64 0.84 0.35 0.89 0.96 0.77
OVERALL
Mean=0.78 Mean=0.80 Mean=0.66 Mean=0.90 Mean=0.83 Mean=0.87
Med.=0.77 Med.=0.84 Med.=0.77 Med.=0.89 Med.=0.94 Med.=0.92
SD=0.148 SD=0.097 SD=0.291 SD=0.016 SD=0.269 SD=0.094
Friedman Test: S = 7.38, df = 5, p = 0.194
Of note among these different pairs, however, is the amount of individual variation shown in
Table 56. For example, participant AM had lower p(c) values than the other participants on
almost all the A≠X pairs. Since AM’s performance on the A = X pairs was close to or equal to
the group performance, her low p(c) scores on the different pairs might be taken as an indication
that she cannot reliably discriminate differences between Diphthong and Hiatus or between
Hiatus and Exceptional Hiatus. In fact, in the previous two chapters, AM was identified as being
among the participants who had the smallest Diphthong-Hiatus differences and who contributed
the most misclassified sequences (i.e. Exceptional Hiatuses) on both acoustic and articulatory
measures. On the other hand, her A′ and β″D scores suggest that her poor performance is an
indication of a response bias (i.e. she has a strong bias toward responding Same, a strategy which
is successful only with pairs where A = X).
An additional observation regards the possibility of a stimulus ordering effect on response
accuracy (e.g. Cowan & Morse, 1986 for vowel order; Francis & Ciocca, 2003 for tone order) on
these A≠X pairs. Thus, although there are no significant differences found between any of the
pairs, there appears to be a slight ordering effect with pairs of Diphthong (D) and Hiatus (H).
Specifically, it looks as though overall listeners were more likely to respond accurately (i.e. to
notice a difference) when D was presented before H than when H was presented before D. In

199
fact, 4 of the 5 participants had lower p(c) and A′ values and higher β″D values for H_D pairs
than for D_H pairs, with participant KR being the only exception.
Another interesting pattern of note in the above results is that the participants generally have
higher p(c) and A′ scores with E_D (Exceptional Hiatus-Diphthong) pairs than with H_D
(Hiatus-Diphthong) pairs. Once again, KR is the only exception. The difference between E_D
and H_D is especially large for participant LL. These differences are unexpected if we consider
only how Hiatus and Exceptional Hiatus differ from Diphthong in terms of duration and
frequency parameters. That is, given that Hiatus and Exceptional Hiatus are closer to each other
on these parameters than they are to Diphthong, we might expect them to behave similarly in
pairs with Diphthong. These two patterns suggest that there may be other factors influencing the
results for Pair Type. We consider next whether ISI (500 vs. 1000) and/or Stimulus Type (Word
vs. Sequence) can explain these patterns.
3.1.1 Stimulus Type and ISI Effects on Pair Type
On its own, Stimulus Type (Word vs. Sequence) had little effect on discrimination (Table 57).
Participants performed only slightly better (i.e. had higher accuracy and sensitivity scores and
had lower bias scores) when stimuli were presented within a nonsense word (Word condition)
than when they were presented in isolation (Sequence condition). While this slight advantage of
the Word condition is as predicted, the differences are not significant for any of the measures.
However, it is possible that any significant differences between Sequence and Word conditions
may have been attenuated by practice effects. Recall from §2.2 that all the participants heard the
stimuli first in the Word condition and then the Sequence condition. Thus, the experience the
participants acquired with the stimuli characteristics in the Word condition may have resulted in
an improved performance in the Sequence condition which followed. This in turn may have
reduced any advantage of the Word condition. Individual variation is also evident and, again,
AM stands out. For example, she had the lowest values for p(c) and A' for both Word and
Sequence conditions. Although AM’s p(c) score increases in the Sequence condition, this effect
is due to a decrease in bias rather than an increase in sensitivity since she has similar A' values
for both levels of this factor but a smaller β″D score for the Sequence condition. This decrease in
bias likely reflects a practice effect, as pointed out above.

200
In a similar vein, all the participants seemed to perform better when stimuli were presented with
an ISI of 1000 ms than with the shorter ISI of 500 ms (Table 57). This difference, although
small, was found to be statistically significant for p(c) and A′. Response bias, on the other hand,
remained constant (even though AM and KR showed increases in bias at the 1000 ISI condition).
Still, since all the participants received the stimuli at 500 ISI before those at 1000 ISI, the
increases in response accuracy and sensitivity are also likely attributable to a practice effect.
Table 57. Summary of p(c), A′ and β″D scores for Stimulus Type (Sequence vs. Word) and
ISI (500 vs. 1000)
Stimulus Type ISI
Participant Word Sequence 500 1000
p(c)
AM 0.54 0.65 0.57 0.61
AN 0.78 0.72 0.74 0.76
DH 0.74 0.61 0.65 0.70
KR 0.83 0.81 0.78 0.87
LL 0.83 0.74 0.78 0.80
OVERALL
Mean = 0.74 Mean = 0.71 Mean = 0.70 Mean = 0.75
Median = 0.78 Median = 0.72 Median = 0.74 Median = 0.76
SD = 0.120 SD = 0.078 SD = 0.092 SD = 0.099
S = 1.80, df = 1, p = 0.180 S = 5.00, df = 1, p = 0.025
A′
AM 0.80 0.81 0.77 0.83
AN 0.90 0.88 0.89 0.90
DH 0.86 0.79 0.81 0.85
KR 0.92 0.92 0.90 0.94
LL 0.93 0.89 0.90 0.91
OVERALL
Mean = 0.88 Mean = 0.86 Mean = 0.85 Mean = 0.89
Median = 0.90 Median = 0.88 Median = 0.89 Median = 0.90
SD = 0.053 SD = 0.055 SD = 0.060 SD = 0.045
S = 1.00 , df = 1, p = 0.317 S = 5.00, df = 1, p = 0.025
β″D
AM 0.98 0.75 0.84 0.96
AN 0.89 0.92 0.91 0.90
DH 0.60 0.80 0.75 0.67
KR 0.66 0.86 0.76 0.79
LL 0.84 0.91 0.89 0.88
OVERALL
Mean = 0.79 Mean = 0.85 Mean = 0.83 Mean = 0.84
Median = 0.84 Median = 0.86 Median = 0.84 Median = 0.84
SD = 0.159 SD = 0.073 SD = 0.073 SD = 0.113
S = 1.80 , df = 1, p = 0.180 S = 0.20 , df = 1, p = 0.655
When Stimulus Type and ISI are considered in combination with each other, the only statistically
significant result is for A′ (S = 9.73, df = 3, p = 0.021). This occurs because the overall sensitivity
score of the group is worst for the Word condition at 1000 ISI while the other three conditions

201
(Word at 500 ISI, Sequence at 500 ISI and Sequence at 1000 ISI) had comparable values for A′.
However, none of the post-hoc Wilcoxon Signed Rank Tests were significant at the new α of
0.05/3 = 0.02. In fact, in each comparison, the obtained value was p = 0.059.
When we look at the effects of Stimulus Type and ISI in combination with Pair Type (Table 58)
we fail to find any significant effects. Despite this, we do note that some combinations yield
higher accuracy and sensitivity scores and/or lower bias scores than others. For example, the
ordering effect observed earlier between D_H (Diphthong-Hiatus) pairs and H_D (Hiatus-
Diphthong) pairs is now most obvious for Stimulus Type = Word and ISI = 1000. Within this
specific combination of Pair Type, Stimulus Type and ISI we observe that pairs where the
Diphthong is heard first (D_H) have higher discrimination scores (both p(c) and A′) and lower
bias scores (β″D) than pairs where the Hiatus is heard first (H_D). In addition, the H_D pairs
consistently have greater variability, as is evident in larger standard deviations. Similarly, the
difference also observed earlier between E_D (Exceptional Hiatus-Diphthong) pairs and H_D
(Hiatus-Diphthong) pairs is also greatest for Stimulus Type = Word and ISI = 1000. Specifically,
E_D pairs have higher discrimination scores and lower bias scores than D_H pairs. The E_D
pairs also have less variable scores (i.e. smaller standard deviations).

202
Table 58. Summary of p(c), A′ and β″D scores for Pair Type (A≠X), by Stimulus Type
(Word vs. Sequence) and ISI (500 vs. 1000), across Participants
Word Sequence
ISI Pair Type Mean Median SD Mean Median SD
p(c)
500
D_E 0.73 0.67 0.280 0.53 0.67 0.381
D_H 0.67 0.67 0.237 0.60 0.67 0.281
E_D 0.73 0.67 0.280 0.54 0.67 0.300
E_H 0.60 0.67 0.152 0.47 0.33 0.186
H_D 0.60 0.67 0.281 0.40 0.33 0.152
H_E 0.53 0.33 0.300 0.60 0.67 0.152
1000
D_E 0.67 0.67 0.408 0.67 0.67 0.000
D_H 0.74 0.67 0.148 0.80 0.67 0.181
E_D 0.80 1.00 0.299 0.80 0.67 0.181
E_H 0.60 0.67 0.281 0.54 0.67 0.300
H_D 0.40 0.33 0.435 0.53 0.67 0.381
H_E 0.53 0.33 0.448 0.54 0.67 0.300
Friedman Test: S = 24.58 , df = 23 , p = 0.373
A′
500
D_E 0.83 0.84 0.090 0.69 0.84 0.283
D_H 0.82 0.84 0.083 0.79 0.84 0.102
E_D 0.83 0.84 0.090 0.71 0.84 0.282
E_H 0.81 0.84 0.072 0.74 0.68 0.088
H_D 0.79 0.84 0.102 0.71 0.68 0.072
H_E 0.76 0.68 0.106 0.81 0.84 0.072
1000
D_E 0.74 0.84 0.297 0.84 0.84 0.000
D_H 0.85 0.84 0.027 0.86 0.84 0.033
E_D 0.84 0.90 0.095 0.86 0.84 0.033
E_H 0.79 0.84 0.102 0.71 0.84 0.282
H_D 0.57 0.68 0.337 0.69 0.84 0.283
H_E 0.67 0.68 0.282 0.71 0.84 0.282
Friedman Test: S = 24.58 , df = 23 , p = 0.373
β″D
500
D_E 0.34 0.43 0.346 0.54 0.43 0.389
D_H 0.42 0.43 0.290 0.50 0.43 0.341
E_D 0.34 0.43 0.346 0.54 0.43 0.255
E_H 0.51 0.43 0.174 0.66 0.82 0.214
H_D 0.50 0.43 0.341 0.74 0.82 0.174
H_E 0.58 0.82 0.365 0.51 0.43 0.174
1000
D_E 0.37 0.43 0.412 0.43 0.43 0.000
D_H 0.34 0.43 0.192 0.26 0.43 0.236
E_D 0.25 0.00 0.369 0.26 0.43 0.236
E_H 0.50 0.43 0.341 0.54 0.43 0.255
H_D 0.65 0.82 0.432 0.54 0.43 0.389
H_E 0.53 0.82 0.488 0.54 0.43 0.255
Friedman Test: S = 24.58 , df = 23 , p = 0.373

203
When we look at the individual results (Table 59), we see that three of the five participants (AM,
DH and LL) are responsible for the differences between D_H and H_D pairs (for Word at 1000
ISI). Similarly, Participants DH and LL are behind the differences between E_D pairs and H_D
pairs.
Table 59. Summary of p(c), A′ and β″D scores for Pair Type (A≠X), by Stimulus Type
(Sequence vs. Word) and ISI (500 vs. 1000), by Participant
Word
Pair Type
ISI Participant D_E D_H E_D E_H H_D H_E
p(c)
500
AM 0.33 0.33 0.33 0.33 0.33 0.33
AN 1.00 0.67 0.67 0.67 0.67 0.33
DH 0.67 0.67 0.67 0.67 0.33 1.00
KR 0.67 1.00 1.00 0.67 1.00 0.33
LL 1.00 0.67 1.00 0.67 0.67 0.67
1000
AM 0.00 0.67 0.33 0.33 0.33 0.00
AN 0.67 0.67 1.00 0.67 0.67 0.33
DH 0.67 0.67 0.67 1.00 0.00 1.00
KR 1.00 1.00 1.00 0.33 1.00 0.33
LL 1.00 0.67 1.00 0.67 0.00 1.00
A′
500
AM 0.68 0.68 0.68 0.68 0.68 0.68
AN 0.90 0.84 0.84 0.84 0.84 0.68
DH 0.84 0.84 0.84 0.84 0.68 0.90
KR 0.84 0.90 0.90 0.84 0.90 0.68
LL 0.90 0.84 0.90 0.84 0.84 0.84
1000
AM 0.21 0.84 0.68 0.68 0.68 0.21
AN 0.84 0.84 0.90 0.84 0.84 0.68
DH 0.84 0.84 0.84 0.90 0.21 0.90
KR 0.90 0.90 0.90 0.68 0.90 0.68
LL 0.90 0.84 0.90 0.84 0.21 0.90
β″D
500
AM 0.82 0.82 0.82 0.82 0.82 0.82
AN 0.00 0.43 0.43 0.43 0.43 0.82
DH 0.43 0.43 0.43 0.43 0.82 0.00
KR 0.43 0.00 0.00 0.43 0.00 0.82
LL 0.00 0.43 0.00 0.43 0.43 0.43
1000
AM 1.00 0.43 0.82 0.82 0.82 1.00
AN 0.43 0.43 0.00 0.43 0.43 0.82
DH 0.43 0.43 0.43 0.00 1.00 0.00
KR 0.00 0.00 0.00 0.82 0.00 0.82
LL 0.00 0.43 0.00 0.43 1.00 0.00

204
Table 59 (cont’d)
Sequence
Pair Type
ISI Participant D_E D_H E_D E_H H_D H_E
p(c)
500
AM 0.00 0.67 0.67 0.67 0.33 0.67
AN 1.00 0.33 0.67 0.33 0.33 0.67
DH 0.33 1.00 0.00 0.33 0.33 0.33
KR 0.67 0.33 0.67 0.67 0.67 0.67
LL 0.67 0.67 0.67 0.33 0.33 0.67
1000
AM 0.67 0.67 0.67 0.67 0.67 0.00
AN 0.67 1.00 0.67 0.67 0.00 0.67
DH 0.67 0.67 0.67 0.00 0.67 0.67
KR 0.67 1.00 1.00 0.67 1.00 0.67
LL 0.67 0.67 1.00 0.67 0.33 0.67
A′
500
AM 0.67 0.84 0.84 0.84 0.68 0.67
AN 0.90 0.68 0.84 0.68 0.68 0.67
DH 0.68 0.90 0.21 0.68 0.68 0.33
KR 0.84 0.68 0.84 0.84 0.84 0.67
LL 0.84 0.84 0.84 0.68 0.68 0.67
1000
AM 0.84 0.84 0.84 0.84 0.84 0.21
AN 0.84 0.90 0.84 0.84 0.21 0.84
DH 0.84 0.84 0.84 0.21 0.84 0.84
KR 0.84 0.90 0.90 0.84 0.90 0.84
LL 0.84 0.84 0.90 0.84 0.68 0.84
β″D
500
AM 0.84 0.43 0.43 0.43 0.82 0.43
AN 0.00 0.82 0.43 0.82 0.82 0.43
DH 0.82 0.00 1.00 0.82 0.82 0.82
KR 0.43 0.82 0.43 0.43 0.43 0.43
LL 0.43 0.43 0.43 0.82 0.82 0.43
1000
AM 0.43 0.43 0.43 0.43 0.43 1.00
AN 0.43 0.00 0.43 0.43 1.00 0.43
DH 0.43 0.43 0.43 1.00 0.43 0.43
KR 0.43 0.00 0.00 0.43 0.00 0.43
LL 0.43 0.43 0.00 0.43 0.82 0.43
In summary, on all measures we fail to show that discrimination between Diphthong and Hiatus
is better than discrimination between Exceptional Hiatus and Hiatus. We also fail to show that
discrimination between Diphthong and Hiatus is best at the longer ISI while discrimination
between Exceptional Hiatus and Hiatus is best at the shorter ISI. In addition, we find no
statistical difference between Word and Sequence presentations. Despite these statistically nil
results, we do observe some interesting patterns in the data. Specifically, we notice a possible
stimulus ordering effect stimuli pairs consisting of Diphthong (D) and Hiatus (H). A related

205
observation is that participants generally achieved higher discrimination scores with Exceptional
Hiatus-Diphthong (E_D) pairs than with Hiatus-Diphthong (H_D) pairs. A possible explanation
for these patterns is discussed in §4 (Summary and Discussion).
In terms of individual variation, we see that some participants consistently do worse than others.
This is particularly true of AM, who had the most discrimination scores at or below chance level.
Contrary to our predictions, then, contributing many misclassified sequences in Chapters 3 and 4
(thus, supposedly producing Exceptional Hiatus) does not necessarily translate into better
discrimination between Diphthong and Exceptional Hiatus (D_E and E_D pairs).
3.2 Hypothesis 2: Vowel Effects
In this section we examine whether the identity of non-high vowel (V) in the vocalic sequences
under study has any effect on the proportion correct responses of the sequence and, if so, whether
the effect is different for Diphthongs and Hiatuses. Our prediction, based on results from
Chapters 3 and 4, is that sequences where V is [a] will be more difficult to distinguish than those
where V is either [e] or [o]. Figure 49 suggests, however, that the effect of V in the correct
discrimination of AX pairs was not exactly as we predicted.
[o][e][a]
1.0
0.8
0.6
0.4
0.2
0.0[o][e][a]
1.0
0.8
0.6
0.4
0.2
0.0[o][e][a]
1.0
0.5
0.0
-0.5
-1.0
p(c) A' ß?D
*Bars are One Standard Error from the Mean
Figure 49. Bar chart of mean p(c), A' and β″D scores for V
B”D

206
The data in Table 60 confirms that, overall, discrimination scores were highest for sequences
with [o] (both p(c) and A′), followed closely by sequences with [a]. Discrimination scores were
lowest for V = [e]. In terms of bias, while the overall tendency was to respond Same for all level
of V, this bias was lowest for V = [o] and highest for V = [e]. The bias scores for V = [a] were
close to those for [o]. The differences between [e] and the other levels of V results in statistically
significant Friedman Test scores on the discrimination measures (both p(c) and A′). On the bias
measure, however, the differences between [e] and the other levels of V were not statistically
significant, even though β″D scores were higher for stimuli with [e] than for those with [a] or [o].
Table 60. Summary of p(c), A′ and β″D scores for V ([a], [e], [o])
V
Participant [a] [e] [o]
p(c)
AM 0.58 0.42 0.78
AN 0.83 0.56 0.86
DH 0.83 0.47 0.72
KR 0.92 0.61 0.94
LL 0.86 0.58 0.92
OVERALL
Mean = 0.80 Mean = 0.53 Mean = 0.84
Med. = 0.83 Med. = 0.56 Med. = 0.86
SD = 0.131 SD = 0.080 SD = 0.093
Friedman Test: S = 8.40, df = 2, p = 0.015
A′
AM 0.79 0.65 0.90
AN 0.92 0.79 0.93
DH 0.92 0.59 0.86
KR 0.96 0.81 0.97
LL 0.93 0.81 0.96
OVERALL
Mean = 0.90 Mean = 0.73 Mean = 0.92
Med. = 0.92 Med. = 0.79 Med. = 0.93
SD = 0.066 SD = 0.103 SD = 0.045
Friedman Test: S = 8.40, df = 2, p = 0.015
β″D
AM 0.88 0.96 0.84
AN 0.77 0.96 0.72
DH 0.77 0.71 0.74
KR 0.53 0.86 0.35
LL 0.72 0.95 0.53
OVERALL
Mean = 0.73 Mean = 0.89 Mean = 0.64
Med. = 0.77 Med. = 0.95 Med. = 0.72
SD = 0.128 SD = 0.108 SD = 0.195
Friedman Test: S = 5.20, df = 2, p = 0.074

207
Post-hoc comparisons (Wilcoxon Signed Rank Tests) between [a] and [e] (p = 0.059, for both
p(c) and A′) and between [e] and [o] (p = 0.059, for both p(c) and A′), however, fail to be
significant at the Bonferroni corrected α of 0.05/2 = 0.025. Still, these differences suggest a trend
that goes against our predictions for what the effects of the non-high vowel in the sequence (V)
would be. That is, rather than sequences with [a] being the most difficult to discriminate, it is
sequences with [e] which appear to cause more difficulty. In this case, all of the participants
followed the same trend, although AM lower values for p(c) and A′ for sequences with [a] than
the other four participants.
3.2.1 ISI and Stimulus Type Effects on V
When we examine the effects of ISI (500 vs. 1000) and Stimulus Type (Word vs. Sequence) in
combination with V (Figure 50), it appears that the V effect we observed above occurs for both
levels of ISI and both levels of Stimulus Type.
[o][e][a]
1.0
0.8
0.6
0.4
0.2
0.0[o][e][a]
1.0
0.8
0.6
0.4
0.2
0.0[o][e][a]
1.0
0.5
0.0
-0.5
-1.0
p(c) A' ß?D
ISI
500
1000
Word
*Bars are One Standard Error from the Mean
[o][e][a]
1.0
0.8
0.6
0.4
0.2
0.0[o][e][a]
1.0
0.8
0.6
0.4
0.2
0.0[o][e][a]
1.0
0.5
0.0
-0.5
-1.0
p(c) A' ß?D
ISI
500
1000
*Bars are One Standard Error from the Mean
Sequence
Figure 50. Bar chart of mean p(c), A' and β″D scores for V by ISI and Stimulus Type
Specifically, in all conditions stimuli with [e] have lower discrimination scores and higher
positive (Same) bias scores than stimuli with [a] or [o]. Bias scores for [a] and [o] stimuli, on the
other hand, are smaller and even show an overall negative (Different) bias (i.e. [a] Word stimuli
B”D B”D

208
at 500 ISI) or no bias (i.e. [o] Word stimuli at 1000 ISI) in some cases. However, for Stimulus
Type = Sequence, there appears to be an ISI effect where stimuli with [a] and [e] have higher
discriminations scores at 1000 ISI than at 500 ISI. In terms of bias, however, only stimuli with
[a] appear to benefit from the longer ISI in the Sequence condition. Sequences with [o] appear to
change little across conditions.
Accordingly, Friedman Test results (Table 61) show significant effects on all measures when all
the data are considered together.
Table 61. Summary of p(c), A′ and β″D scores for V, by Stimulus Type and ISI, across
participants
Word Sequence
ISI V Mean Median SD Mean Median SD
p(c)
500
[a] 0.87 1.00 0.243 0.69 0.67 0.167
[e] 0.53 0.56 0.097 0.40 0.44 0.098
[o] 0.87 0.89 0.092 0.87 0.89 0.143
1000
[a] 0.80 0.89 0.143 0.87 0.89 0.092
[e] 0.58 0.56 0.148 0.60 0.67 0.171
[o] 0.82 0.89 0.167 0.82 0.89 0.167
Friedman Test: S = 36.16 , df = 11 , p = 0.000
A′
500
[a] 0.84 0.93 0.189 0.76 0.77 0.153
[e] 0.62 0.65 0.118 0.43 0.50 0.152
[o] 0.88 0.90 0.040 0.87 0.90 0.069
1000
[a] 0.84 0.90 0.095 0.88 0.88 0.039
[e] 0.66 0.68 0.155 0.65 0.77 0.255
[o] 0.85 0.90 0.101 0.85 0.90 0.101
Friedman Test: S = 36.01 , df = 11, p = 0.000
β″D
500
[a] -0.04 -0.38 0.563 0.47 0.60 0.283
[e] 0.73 0.82 0.247 0.76 0.92 0.230
[o] 0.10 0.00 0.342 0.07 0.00 0.474
1000
[a] 0.25 0.00 0.369 0.03 0.00 0.393
[e] 0.69 0.67 0.191 0.72 0.67 0.211
[o] 0.00 0.00 0.500 0.17 0.00 0.461
Friedman Test: S = 27.50 , df = 11, p = 0.004
However, post-hoc Wilcoxon Signed Rank Tests (Table 62) fail to show any significant
between-vowel differences at the corrected α level of 0.004.

209
Table 62. Wilcoxon Signed Ranks Test results (Bonferroni corrections: α = 0.05/12 = 0.004)
for differences between levels of V by ISI and Stimulus Type
p-values
Stimulus Type ISI V p(c) A′ β″D
Sequence
500
[a] vs.[e] 0.100 0.100 0.201
[a] vs.[o] 0.201 0.201 0.201
[e] vs.[o] 0.059 0.059 0.106
1000
[a] vs.[e] 0.100 0.100 0.100
[a] vs.[o] 0.593 0.789 0.789
[e] vs.[o] 0.178 0.255 0.178
Word
500
[a] vs.[e] 0.100 0.100 0.100
[a] vs.[o] 0.855 0.855 0.855
[e] vs.[o] 0.059 0.059 0.059
[a] vs.[e] 0.059 0.059 0.059
1000 [a] vs.[o] 1.000 1.000 0.371
[e] vs.[o] 0.059 0.059 0.059
Similarly, there were no significant within-vowel differences, either for ISI or Stimulus Type
(Table 63), despite our earlier observations regarding the effect of ISI within the Sequence
condition when V = [e] or [a].
Table 63. Results of Wilcoxon Signed Ranks Test results (Bonferroni corrections: α =
0.05/6 = 0.008) for differences within levels of V by ISI and Stimulus Type
p-values
V ISI Stimulus Type p(c) A′ β″D
[a] 500 Word vs. Sequence 0.181 0.181 0.201
1000 Word vs. Sequence 0.593 0.855 0.584
[e] 500 Word vs. Sequence 0.100 0.100 1.000
1000 Word vs. Sequence 1.000 1.000 0.789
[o] 500 Word vs. Sequence 1.000 1.000 1.000
1000 Word vs. Sequence 1.000 0.893 0.686
Still, these tests suggest that most differences, although not statistically significant, occur
between levels of V and that at all levels of ISI and Stimulus Type, sequences with [a] and [o] are
discriminated with greater accuracy and sensitivity and with less bias than those with [e]. When
we look at the individual results (Table 64), we see that all of the participants follow this pattern.

210
Table 64. Summary of p(c), A′ and β″D scores for V by Stimulus Type and ISI, by
Participant
V
Word Sequence
ISI Participant [a] [e] [o] [a] [e] [o]
p(c)
500
AM 0.44 0.44 0.78 0.44 0.44 0.89
AN 0.89 0.67 0.78 0.89 0.44 0.78
DH 1.00 0.44 0.89 0.67 0.22 0.67
KR 1.00 0.56 0.89 0.78 0.44 1.00
LL 1.00 0.56 1.00 0.67 0.44 1.00
1000
AM 0.56 0.44 0.56 0.89 0.33 0.89
AN 0.78 0.56 1.00 0.78 0.56 0.89
DH 0.89 0.44 0.78 0.78 0.78 0.56
KR 0.89 0.78 0.89 1.00 0.67 1.00
LL 0.89 0.67 0.89 0.89 0.67 0.78
A′
500
AM 0.50 0.50 0.84 0.50 0.50 0.90
AN 0.90 0.77 0.84 0.90 0.50 0.84
DH 0.93 0.50 0.90 0.77 0.16 0.77
KR 0.93 0.65 0.90 0.84 0.50 0.93
LL 0.93 0.68 0.93 0.77 0.50 0.93
1000
AM 0.68 0.50 0.68 0.90 0.21 0.90
AN 0.84 0.68 0.93 0.84 0.68 0.90
DH 0.90 0.50 0.84 0.84 0.84 0.68
KR 0.90 0.84 0.90 0.93 0.77 0.93
LL 0.90 0.77 0.90 0.88 0.77 0.84
β″D
500
AM 0.92 0.92 0.43 0.60 0.60 0.00
AN 0.00 0.67 0.43 0.00 0.92 0.43
DH -0.38 0.92 0.00 0.67 0.43 0.67
KR -0.38 0.33 0.00 0.43 0.92 -0.38
LL -0.38 0.82 -0.38 0.67 0.92 -0.38
1000
AM 0.82 0.92 0.82 0.00 1.00 0.00
AN 0.43 0.82 -0.38 0.43 0.82 0.00
DH 0.00 0.60 -0.43 0.43 0.43 0.82
KR 0.00 0.43 0.00 -0.38 0.67 -0.38
LL 0.00 0.67 0.00 -0.33 0.67 0.43
3.2.2 Interactions between Pair Type and V
In this section, we test the interaction between Pair Type and V. Of particular interest is
determining whether the differences observed among levels of Pair type are attributable to V
differences. As before, we omit the same (A = X) pairs for all levels of V. When we consider all

211
possible combinations of Pair Type and V together, our results on all measures are statistically
significant (Table 65).
Table 65. Summary of p(c), A' and β″D scores for V by Pair Type, across participants
V
[a] [e] [o]
Pair Type Mean Median SD Mean Median SD Mean Median SD
p(c)
D_E 0.70 0.75 0.326 0.45 0.50 0.371 0.80 1.00 0.274
D_H 0.75 0.75 0.177 0.45 0.50 0.209 0.90 1.00 0.137
E_D 0.85 1.00 0.224 0.55 0.50 0.209 0.75 0.75 0.250
E_H 0.85 0.75 0.137 0.05 0.00 0.112 0.75 0.75 0.177
H_D 0.55 0.50 0.326 0.25 0.25 0.306 0.65 0.75 0.379
H_E 0.60 0.50 0.285 0.25 0.00 0.354 0.80 0.75 0.209
Friedman Test: S = 45.56 , df = 17 , p = 0.000
A′
D_E 0.84 0.89 0.116 0.68 0.79 0.273 0.87 0.93 0.077
D_H 0.88 0.89 0.052 0.76 0.79 0.098 0.91 0.93 0.022
E_D 0.89 0.93 0.061 0.80 0.79 0.095 0.87 0.89 0.071
E_H 0.91 0.89 0.022 0.31 0.22 0.197 0.88 0.89 0.052
H_D 0.79 0.79 0.126 0.53 0.66 0.298 0.81 0.89 0.142
H_E 0.81 0.79 0.105 0.47 0.22 0.341 0.89 0.89 0.057
Friedman Test: S = 45.56 , df = 17 , p = 0.000
β″D
D_E 0.41 0.40 0.419 0.68 0.75 0.396 0.30 0.00 0.411
D_H 0.39 0.40 0.266 0.74 0.75 0.208 0.16 0.00 0.219
E_D 0.23 0.00 0.338 0.64 0.75 0.230 0.38 0.40 0.375
E_H 0.24 0.40 0.219 0.98 1.00 0.040 0.39 0.40 0.266
H_D 0.59 0.75 0.392 0.84 0.91 0.252 0.44 0.40 0.456
H_E 0.56 0.75 0.365 0.83 1.00 0.264 0.31 0.40 0.317
Friedman Test: S = 45.56 , df = 17 , p = 0.000
Figures 51-53 suggests that many of these significant differences occur between levels of V, with
the largest differences between [a] and [e] or between [o] and [e].

212
H_EH_DE_HE_DD_HD_E
1.0
0.8
0.6
0.4
0.2
0.0H_EH_DE_HE_DD_HD_E
1.0
0.8
0.6
0.4
0.2
0.0H_EH_DE_HE_DD_HD_E
1.0
0.5
0.0
-0.5
-1.0
p(c) A' ß?D
V = [a]
*Bars are One Standard Error from the Mean
Figure 51. Bar chart of mean p(c), A' and β″D scores for V by Pair Type, V = [a]
H_EH_DE_HE_DD_HD_E
1.0
0.8
0.6
0.4
0.2
0.0H_EH_DE_HE_DD_HD_E
1.0
0.8
0.6
0.4
0.2
0.0H_EH_DE_HE_DD_HD_E
1.0
0.5
0.0
-0.5
-1.0
p(c) A' ß?D
V = [e]
*Bars are One Standard Error from the Mean
Figure 52. Bar chart of mean p(c), A' and β″D scores for V by Pair Type, V = [e]
B”D
B”D

213
H_EH_DE_HE_DD_HD_E
1.0
0.8
0.6
0.4
0.2
0.0H_EH_DE_HE_DD_HD_E
1.0
0.8
0.6
0.4
0.2
0.0H_EH_DE_HE_DD_HD_E
1.0
0.5
0.0
-0.5
-1.0
p(c) A' ß?D
V = [o]
*Bars are One Standard Error from the Mean
Figure 53. Bar chart of mean p(c), A' and β″D scores for V by Pair Type, V = [o]
More specifically, for all Pair Types where A≠X, stimuli with [a] and [o] appear to be
discriminated more easily and with less bias than those with [e]. The results of the post-hoc
Wilcoxon Signed Ranks Tests of each level of Pair type in combination with each of V (Table
66), however, indicate that none of the differences between levels of V are statistically
significant at the corrected α levels.
B”D

214
Table 66. Wilcoxon Signed Ranks Tests results (Bonferroni correction: α = 0.05/18 = 0.003)
for differences between levels of V by Pair Type
p-values
Pair Type V p(c) A′ β″D
D_E
[a] vs.[e] 0.345 0.225 0.345
[a] vs.[o] 0.715 0.584 0.715
[e] vs.[o] 0.100 0.100 0.100
D_H
[a] vs.[e] 0.181 0.181 0.181
[a] vs.[o] 0.181 0.181 0.181
[e] vs.[o] 0.059 0.059 0.059
E_D
[a] vs.[e] 0.100 0.100 0.100
[a] vs.[o] 0.371 0.371 0.371
[e] vs.[o] 0.100 0.100 0.100
E_H
[a] vs.[e] 0.059 0.059 0.059
[a] vs.[o] 0.465 0.361 0.584
[e] vs.[o] 0.059 0.059 0.059
H_D
[a] vs.[e] 0.059 0.059 0.059
[a] vs.[o] 0.715 0.715 0.715
[e] vs.[o] 0.181 0.181 0.181
H_E
[a] vs.[e] 0.138 0.106 0.281
[a] vs.[o] 0.273 0.201 0.361
[e] vs.[o] 0.059 0.059 0.059
Figures 51-53 also suggest that there are some differences in discrimination and bias according
to Pair Type within each level of V. For example, the ordering effect between Diphthong-Hiatus
(D_H) and Hiatus-Diphthong (H_D) pairs that we observed in §3.1.1 occurs within each level of
V. That is, with all vowels H_D pairs had lower discrimination and higher bias scores than D_H
pairs. On a similar note, the differences between Hiatus-Diphthong (H_D) and Exceptional
Hiatus-Diphthong (E_D) pairs observed in §3.1.1 (i.e. higher discrimination and lower bias
scores with the E_D pairs) also appears with all three levels of V. However, none of the post-hoc
Wilcoxon Signed Ranks Tests for the larger differences within each level of V were statistically
significant at the corrected α levels (Bonferroni corrections: α = 0.05/15 = 0.003) or even at the
original uncorrected α level of 0.05.
In summary, regardless of Pair type, when V is [e] (rather than [a] or [o]), discrimination
between different pairs will be more difficult, and often below chance level. This trend is evident
even when we consider the performance of each participant. As shown in Table 67, the lowest
discrimination and highest bias scores for most participants occur for V = [e]. This is the case not
only for those participants who generally had low discrimination and high bias scores (e.g. AM)

215
but also for those who tended to have higher discrimination scores and lower bias scores (e.g.
KR). It is also only for this vowel that we see p(c) values of 0, A' values of 0.50 or below and
positive β″D values of 1.00.
Table 67. Summary of p(c), A' and β″D scores for V by Pair Type, by Participant
[a]
Participant D_E D_H E_D E_H H_D H_E
p(c)
AM 0.25 0.50 0.50 0.75 0.25 0.25
AN 0.50 0.75 1.00 1.00 0.75 0.50
DH 1.00 1.00 0.75 0.75 0.50 0.50
KR 0.75 0.75 1.00 1.00 1.00 0.75
LL 1.00 0.75 1.00 0.75 0.25 1.00
A′
AM 0.66 0.79 0.79 0.89 0.66 0.66
AN 0.79 0.89 0.93 0.93 0.89 0.79
DH 0.93 0.93 0.89 0.89 0.79 0.79
KR 0.89 0.89 0.93 0.93 0.93 0.89
LL 0.93 0.89 0.93 0.89 0.66 0.93
β″D
AM 0.91 0.75 0.75 0.40 0.91 0.91
AN 0.75 0.40 0.00 0.00 0.40 0.75
DH 0.00 0.00 0.40 0.40 0.75 0.75
KR 0.40 0.40 0.00 0.00 0.00 0.40
LL 0.00 0.40 0.00 0.40 0.91 0.00
[e]
Participant D_E D_H E_D E_H H_D H_E
p(c)
AM 0.00 0.50 0.50 0.00 0.00 0.00
AN 1.00 0.25 0.50 0.00 0.25 0.00
DH 0.25 0.25 0.25 0.25 0.25 0.75
KR 0.50 0.75 0.75 0.00 0.75 0.00
LL 0.50 0.50 0.75 0.00 0.00 0.50
A′
AM 0.22 0.79 0.79 0.22 0.22 0.22
AN 0.93 0.66 0.79 0.22 0.66 0.22
DH 0.66 0.66 0.66 0.66 0.66 0.89
KR 0.79 0.89 0.89 0.22 0.89 0.22
LL 0.79 0.79 0.89 0.22 0.22 0.79
β″D
AM 1.00 0.75 0.75 1.00 1.00 1.00
AN 0.00 0.91 0.75 1.00 0.91 1.00
DH 0.91 0.91 0.91 0.91 0.91 0.40
KR 0.75 0.40 0.40 1.00 0.40 1.00
LL 0.75 0.75 0.40 1.00 1.00 0.75

216
Table 67 (cont’d)
[o]
Participant D_E D_H E_D E_H H_D H_E
p(c)
AM 0.50 0.75 0.50 0.75 1.00 0.50
AN 1.00 1.00 0.75 0.75 0.25 1.00
DH 0.50 1.00 0.50 0.50 0.25 1.00
KR 1.00 1.00 1.00 0.75 1.00 0.75
LL 1.00 0.75 1.00 1.00 0.75 0.75
A′
AM 0.79 0.89 0.79 0.89 0.93 0.79
AN 0.93 0.93 0.89 0.89 0.66 0.93
DH 0.79 0.93 0.79 0.79 0.66 0.93
KR 0.93 0.93 0.93 0.89 0.93 0.89
LL 0.93 0.89 0.93 0.93 0.89 0.89
β″D
AM 0.75 0.40 0.75 0.40 0.00 0.75
AN 0.00 0.00 0.40 0.40 0.91 0.00
DH 0.75 0.00 0.75 0.75 0.91 0.00
KR 0.00 0.00 0.00 0.40 0.00 0.40
LL 0.00 0.40 0.00 0.00 0.40 0.40
4 Summary and Discussion
In this section the findings of the study are summarized and evaluated in terms of whether they
confirm the three hypotheses outlined at the beginning of the chapter.
4.1 Hypothesis 1: Diphthong vs. Hiatus
Hypothesis 1 stated that Diphthong and Hiatus belonged to different perceptual categories and
predicted that discrimination between them would be higher than discrimination between Hiatus
and Exceptional Hiatus which were supposed to not belong to separate perceptual categories. In
relation to the above hypothesis, we also predicted that discrimination between Diphthong and
Hiatus would benefit from a longer ISI, as this is thought to promote better between-category
distinctions (Pisoni, 1973; Werker & Tees, 1984; Werker & Logan, 1985; Gerrits & Schouten,
2004). Correspondingly, we predicted that discrimination between Exceptional Hiatus and Hiatus
would be best at a shorter ISI, which is thought to promote better within-category distinctions
(Pisoni, 1973; Werker & Logan, 1985). Also in relation to the primary hypothesis, we examined
whether presentation context (within a Word or as an isolated Sequence) affected discrimination
with the prediction that the Word context would yield better results.

217
The results on measures of response accuracy, sensitivity and bias fail to confirm Hypothesis 1
and all of its related predictions as we found no statistically significant differences between any
of the A≠X Pair Types. Most importantly, we found no significant differences between
Diphthong and Hiatus pairs and Exceptional Hiatus and Hiatus pairs, despite the expectation that
the latter discrimination should be more difficult. There were also no significant differences
found according to ISI. Thus, the results for ISI could not be used to support the proposal that
diphthongs and hiatuses are separate perceptual categories while hiatuses and exceptional
hiatuses are not. Finally, hearing the stimuli in a Word context or in a Sequence context also had
no apparent effects on their perceptibility (in support of findings by Face & Alvord, 2004 and
Andruski & Nearey, 1992).
These statistically nil results may be to a large extent attributable to experiment design. First of
all, the sample size for the experiment was very small, resulting in decreased power and
contributing to the variability of the results. Second, both ISI and Stimulus Type were presented
in fixed order (i.e. 500 ISI before 1000 ISI; Word before Sequence). The decision to use a fixed
order of presentation makes it impossible to separate practice effects from any real differences
between levels of ISI and/or Stimulus Type from practice effects. Additional concerns about ISI
include: (i) its use as a within-subject factor and (ii) the small difference between the two levels
presented to the participants. With reference to the first concern, a better strategy might have
been to use a between-subjects design where one half the participants received the shorter ISI of
500 ms and the other half the longer ISI of 1000 ms (as suggested in Werker & Logan, 1985:39
for experiments where the effects of ISI on perceptual processing are tested). As regards the
second concern, the difference between 500 ISI and 1000 ISI may not be enough to affect
perception. For example, some authors suggest that the linguistic or labeling mode of perception
can be triggered at ISIs as short as 200 ms (Gerrits, 2001). Thus, the ISI of 500 ms used in the
present experiment may not have been short enough to make a significant difference. A better
choice may have been 250 ms vs. 1000 ms
4.2 Hypothesis 2: Vowel Effects
Hypothesis 2 predicted that the quality of the non-high vowel (V) in the vocalic sequences used
in the stimuli would have perceptual consequences. The specific expectation was that sequences
here V = [a] would be the most difficult to discriminate, based on the behaviour of sequences

218
with [a] in the acoustics and articulatory experiments (Chapter 3 and 4, respectively). On the one
hand, we do find support for this hypothesis. That is, the quality of the non-high V does
influence the responses. On the other hand, the V which was hardest to discriminate was not the
one predicted. That is, on all measures, participants did worse (i.e. they had lower accuracy and
sensitivity scores and higher bias scores) when the non-high vowel (V) in the stimuli was [e]
than when V was either [a] or [o]. This V effect was statistically significant and persisted across
ISI, Stimulus Type and Pair Type conditions. In addition, none of the participants deviated from
this pattern of poorer results for V = [e]. However, these results are tempered by the fact that
(possibly due to the effect of the small sample size) subsequent post-hoc tests for differences
between levels of V were not statistically significant.
4.3 Hypothesis 3: Production-Perception Link
The final hypothesis predicted that, just as we found individual variation in the production of
vocalic sequences in the experiments reported in Chapters 3 and 4, so too we would observe
individual variation in their perception. Specifically, we proposed that those participants who
consistently produced a higher number of misclassified Diphthong sequences (i.e. produced
Exceptional Hiatuses) in Chapters 3 and 4 would be better able to discriminate between
Diphthong and Exceptional Hiatus in an AX perception task than those who had fewer
misclassified Diphthong sequences. The results show that some participants do tend to have
higher accuracy and sensitivity scores and lower bias scores than others. Therefore, the first part
of the hypothesis appears to be accurate. However, contrary to our predictions, these were not the
same participants who produced the most misclassified sequences in the previous two chapters.
For example, AM was identified as being among those who produced the smallest Diphthong-
Hiatus differences and who contributed a large number of misclassified sequences (i.e.
Exceptional Hiatuses) in both Chapters 3 and 4. Thus, according to Hypothesis 3, she should
have been among the best performers on the perception task. In fact, she had the lowest
discrimination scores and highest bias scores across the most conditions with many of her
discrimination scores at chance or below chance level. Similarly, participants who had larger
Diphthong-Hiatus differences on the acoustic and articulatory measures (KR and LL, for
example) had higher discrimination scores and lower bias scores.

219
4.4 Discussion
Overall, problems in the design of the present perception experiment make it difficult to
substantiate any strong claims about the results (regardless of whether they were statistically
significant and statistically nil). To recap, the small number of participants (as well as the small
number of trials per participant) resulted in low power for the experiment. Also, the fixed
ordering of presentation blocks made it difficult to tease apart any effects due to ISI (where
length was also an issue) or Stimulus Style from practice effects. Despite these problems,
however, there are some interesting patterns in the data which warrant some discussion.
First of all, for all levels of V we notice a possible stimulus ordering effect in stimuli pairs
consisting of Diphthong (D) and Hiatus (H). Specifically, participants generally have higher p(c)
and A′ scores with D_H pairs than with H_D pairs. While the difference is not statistically
significant, it raises the question of why it might exist at all. For example, the durational
differences between D_H and H_D are the same. Based on the differences in discrimination
between D_H and H_D we might conclude that hearing the shorter stimulus first exaggerates the
durational difference between D and H. Related to this observation is the possibility is that,
regardless of the durational properties of the stimulus itself, the first stimulus is always
remembered as having a shorter duration than it actually does (Francis & Ciocca, 2003, for
example, suggest that this is what occurs in perception of pitch in pairs of different tones in
Cantonese). Thus, if D is heard as shorter than it actually is, the difference between D and H is
exaggerated when D occurs first. However, if H is heard first and heard as shorter than it actually
is then the difference in duration between H and D is attenuated and participants perceive them
as more similar. Presentation order does not appear to affect H and E pairs which had equally
low mean p(c) values (0.55) regardless of which came first (Figure 48, Table 56). This pattern is
expected if we consider how close E and H are in terms of duration (§2, this chapter). Thus,
regardless of which is presented first, they become even closer in duration. This makes vowel
sequences forming a hiatus difficult to distinguish from those whose pattern resembles
exceptional hiatuses.
However, this explanation regarding the effect of presentation order on durational differences,
does not account for the following pattern also observed in the data. That is, participants
generally had higher p(c) and A′ scores with E_D (Exceptional Hiatus-Diphthong) pairs than

220
with H_D (Hiatus-Diphthong) pairs. These differences are unexpected if we consider only how
Hiatus and Exceptional Hiatus differ from Diphthong in terms of duration and frequency
parameters. That is, given that Hiatus and Exceptional Hiatus are closer to each other on these
parameters than they are to Diphthong, we might expect them to behave similarly in pairs with
Diphthong. The fact that they don’t could be a reflection of the fact that Exceptional Hiatus is
not common in this variety of Spanish (Chapter 1) and its relative ‘strangeness’ may make it
stand out to the listener. This might also explain why there was no obvious ordering effect
observed between E_D and D_E pairs to match the one found between D_H and H_D pairs.
Second, we observed that some of the Pair Type effects we discussed above were influenced by
the identity of V as well since they tended to occur mainly for V = [e]. For example, the worst
results for Hiatus and Exceptional Hiatus pairs (E_H and H_E, especially the former) were found
for V = [e]. Thus, it may be the case that perception of exceptional hiatuses also depends on
vowel context. That is, when V = [e], exceptional hiatuses essentially fall into the category of
hiatuses and cannot be discriminated from them. On the other hand, when V is [a] or [o],
exceptional hiatuses are easier to discriminate, and thus to perceive as different, from hiatuses.
This pattern can be explained if we consider that in those Spanish varieties where exceptional
hiatuses are common, most of them occur with [a] or, less frequently, with [o] as the non-high
vowel (e.g. Hualde, 2005). Exceptional hiatuses with [e], on the other hand, are less likely to
occur (as supported by the Discriminant Analysis results in Chapters 3 and 4). Thus, although
these sequences are present in the stimuli in equal numbers as corresponding sequences with [a]
and [o], they may occur less frequently in natural language situations. The result of this
discrepancy between the experimental situation (in the context of the AX task used here) and a
natural language situation might be that the participants perceive exceptional hiatuses with [e] as
identical to hiatuses with [e].
Finally, we observe an asymmetry between the perception of vocalic sequences in Mexican
Spanish and the production of the same sequences. That is, neither the sequence-specific nor the
participant-specific patterns observed in this experiment seem to match the results from the
production chapters. First, the V effects found here suggest that the small acoustic and
articulatory differences that resulted in Discriminant Analysis misclassification in Chapters 3 and
4 may not be the same differences that are perceptually relevant to the participants as listeners.
Second, the participant-specific patterns of responses we observe here differ from the patterns we

221
observed from the same participants on the production tasks. That is, distinctness in production
(i.e. producing Exceptional Hiatuses) does not match perceptual acuity (i.e. better ability to
discriminate between Diphthong and Exceptional Hiatus) on the AX task. The present results are
in contradiction to studies which report a link between perceptual acuity and contrast in
production (Beddor et al., 2002; Beddor, 2012; Newman, 2003; Perkell et al., 2004a, 2004b,
2006). However, it is important to note that those studies generally focused on strong phonemic
contrasts while the phonemic status of the contrasts examined here is questionable. The results
reported in this chapter are also at odds with previous research on vocalic sequences for
Peninsular Spanish (e.g. Hualde & Prieto, 2002; Face & Alvord, 2004) and other Romance
varieties (Chitoran, 2002). Those studies have found that participants’ perception of these
sequences (tested through syllabification and/or labelling asks) is generally consistent with their
production of the same sequences. One possible source for the discrepancy between this study
and those cited above for Peninsular Spanish is experiment methodology. That is, the difference
in results may reflect the type of perception task used (discrimination used here vs. identification
and/or syllabification in the Peninsular Spanish studies). However, issues in the design of the
perception experiment carried out for the present dissertation make it impossible to substantiate
any strong claims about the results.
5 Conclusions
A principal objective of this dissertation was to investigate the link between variation in the
production of vocalic sequences in Mexican Spanish and variation in the perception of the same
sequences. The present experiment did not produce the expected results with regards to this
objective, in large part due to the experiment design. However, despite the methodological
shortcomings and the highly variable results, the experiment does reveal some interesting
patterns which merit further investigation, especially where V effects are concerned. In the
following chapter, we explore the possibility that the production-perception asymmetry reported
here may in part be a result of the acoustic and articulatory parameters chosen to differentiate
between categories of vocalic sequences in the Discriminant Analysis as well as to dialect-
specific properties of [e].

222
Chapter 6 Conclusions
1 Introduction
This dissertation has investigated the variation present in the production and perception of
vocalic sequences in Mexican Spanish, with an emphasis on the relationship between this
variation and the occurrence of exceptional hiatuses. This chapter revisits the research goals
which motivated the dissertation, reviews and interprets the findings of the three experimental
chapters in light of those goals, discusses the contributions of those experimental findings and
offers suggestions for continued research in the area of Spanish vocalic sequences.
2 Summary of Findings
The central research goals of this dissertation (restated from Chapter 1) were to demonstrate that:
(i) The phonetic variation responsible for the occurrence of exceptional hiatuses is present in
all Spanish varieties, including those varieties described as having a high
diphthongization tendency.
(ii) The phonetic variation leading to the production of exceptional hiatuses is rooted in
patterns of articulation.
(iii) Variation in the production of diphthongs, hiatuses and exceptional hiatuses is related to
variation in their perception.
To achieve the above research goals, three experiments were conducted. The first experiment
(Chapter 3) focused on the acoustic characterization of vocalic sequences in Mexican Spanish,
the second experiment (Chapter 4) examined the articulatory characteristics of these sequences,
and the third experiment (Chapter 5) focused on their perception. The specific hypotheses tested
with each experiment were evaluated at the end of their respective chapters. Here, we offer an
overview of the most important findings from the three experiments and evaluate whether these
findings are in agreement with the three research goals stated above.
2.1 Phonetic Variation and Exceptional Hiatuses
In support of the first research goal, we found sequence-specific and speaker-specific variation in
the production of diphthongs and hiatuses in Mexican Spanish, both at the acoustic level
(Chapter 3) and at the articulatory level (Chapter 4).

223
2.1.1 Sequence-specific Variation
The sequence-specific variation was related to the behaviour of the non-high vowel (V) in the
sequences. That is, sequences with [a] tended to behave differently from sequences with [e] or
[o], both on the acoustic and on the articulatory measures. Specifically, sequences with [a]
showed more extreme values than sequences with [e] or [o]. For example, diphthongs with [a]
were longer and had shorter transitions than their counterparts with [e] and [o]. Similarly,
hiatuses with [a] had larger Tongue Body (TB)-Tongue Tip (TT) offset values than hiatuses with
either [e] or [o]. The degree of differences between Diphthong and Hiatus categories also varied
according to V and tended to be smallest for sequences with [a]. We suggested that this
sequence-specific variability in diphthong and hiatus production likely reflects the articulatory
properties of the non-high V ([a,e,o]) in these sequences. That is, the longer tongue/jaw
trajectories required for sequences with the low vowel [a] result in more extreme values on the
acoustic and articulatory measures as well as smaller Diphthong-Hiatus differences for
sequences with [a].
It is important to point out, however, that the sequence-specific variation related to the behaviour
of the non-high V in the sequences was not completely regular. For example, the Diphthong-
Hiatus differences showed the above V effects on all acoustic measures. In the articulation
results, the difference between Diphthong and Hiatus also appeared to be influenced by the
identity of V, but not as dependably and only on one measure (TB-TT offset). These differences
between the acoustics and articulation results are discussed in more detail in §2.2 below.
Despite these inconsistencies, however, the sequence-specific variation does produce an
important result. That is, as a consequence of their articulatory properties (as described above),
diphthongs with [a] were more likely than diphthongs with [e] or [o] to be misclassified as hiatus
by the Discriminant Analysis procedure. This result was found in both the acoustics and
articulation experiments and is consistent with the observation that most cases of exceptional
hiatuses occur when V = [a] (e.g. Hualde, 2005; Chitoran & Hualde, 2007). Overall, then, the
above results support the hypothesis that phonetic variation is at the root of the occurrence of
exceptional hiatuses (i.e. the misclassified diphthongs in the experiments). The results are also in
accordance with the hypothesis that this variation is also found in diphthongizing varieties of
Spanish, like Mexican Spanish. These varieties, too, produce exceptional hiatuses.

224
Another important observation arising from the Discriminant Analysis is that any diphthong
could be realized as an exceptional hiatus, regardless of historical origin. For example, among
words with diphthongs where V = [e], prieto, pliegue and bienes had several misclassified cases.
This is unexpected since the diphthongs in all these words are derived from breaking of the Latin
short mid vowel Ĕ and the general consensus in Spanish phonology (e.g. Chitoran & Hualde,
2007, p. 46; Cabré & Prieto, 2006, p. 208) is that all such sequences are obligatorily realized as
diphthongs. In fact, in the experiments reported in this dissertation these diphthongs behaved no
differently from the diphthong in the word cliente which is derived from a Latin heterosyllabic
sequence and, thus, expected to be realized with an exceptional hiatus.
2.1.2 Speaker-specific Variation
In terms of speaker-specific variation, we found that those speakers who maintained larger
Diphthong-Hiatus differences tended to contribute fewer misclassified Diphthong sequences. In
other words, they produced fewer sequences that could be considered exceptional hiatuses. In
addition, those who had larger Diphthong-Hiatus differences on the acoustic measures also
tended to have large differences on the articulatory measures. However, the evidence from
individual variation, like that from the sequence-specific variation, was not completely
consistent. For example, the relationship between a larger Diphthong-Hiatus difference and
fewer misclassified sequences did not always hold. To illustrate, Speaker DH, who maintained
relatively large Diphthong-Hiatus differences on the acoustic and articulatory parameters
contributed several misclassified sequences. This suggests that while maintaining a small
Diphthong-Hiatus contrast on these parameters may generally be associated with more
misclassified sequences (and, by extension, more exceptional hiatus production), it is not a
necessary precursor. It may be that a small Diphthong-Hiatus contrast is not necessary at all or
that some participants are making use of phonetic strategies not measured and/or not captured in
the Discriminant Analysis to maintain this contrast. In addition, we also found that while some
speakers consistently maintained a similar acoustic and articulatory distance between Diphthong
and Hiatus across vowel contexts (i.e. contributed similar numbers of misclassified sequences for
the three levels of V), others behaved differently according to the identity of V. As an example,
Speaker AM had many misclassified cases of diphthongs for both V = [a] and V = [e]. On the
other hand, speakers MM and MV, who also contributed many misclassified sequences with

225
V = [a], had very few cases with V = [e]. The perceptual consequences, and/or lack thereof, of
these inconsistencies are examined in §2.3.
2.2 Articulation and Exceptional Hiatuses
Our second research goal too received some support, with the evidence from the articulation
experiment both confirming and contradicting results from the acoustics experiment. For
example, as in the acoustics experiment, we found that sequences with [a] were more likely to be
misclassified than sequences with [e] or [o]. However, the results from the articulation
experiment also differ from the acoustics result in an important way. The Discriminant Analysis
results for the articulation data found that more hiatuses were misclassified as diphthongs than
vice versa. This contrasts with our findings from the acoustics experiment where diphthongs
were more likely to be misclassified than hiatuses as well as be more susceptible to the influence
of the non-high vowel in the sequence. In short, hiatuses appear to be more variable at the
articulatory level while diphthongs appear more variable at the acoustic level (Chapter 4, §4.4).
Since the acoustics are directly based on articulation (e.g. Browman & Goldstein, 1992), the
difference in results may be explained by (i) the different techniques used in the two
experiments, and (ii) the articulatory parameters measured. First, the articulation data looked at
the actions of specific articulators (TB and TT) without the contribution of the JAW while the
acoustic effects reflect the actions of several articulators (including the JAW) acting together
(Chapter 4, §4.4). In addition, the acoustic measurements are a reflection of multiple articulatory
parameters, some of which may fall in regions of acoustic instability, where small articulation
changes cause large acoustic effects (e.g. Stevens, 1989). We did not measure all of these
possible parameters in the articulation experiment, focusing only on TB-TT offset and the
magnitude of TB and TT gestures and these only for the vertical (up-down) dimension.
However, it may also be the case that some of the acoustic effects may not necessarily be
relevant to the Diphthong-Hiatus distinction. In fact, the mismatch between the acoustic and
articulation results may be viewed as reconciling the apparent contradictory propensities of
diphthongs. That is, while diphthongs appear to be more acoustically variable than hiatuses
(MacLeod, 2007), they are, in fact, articulatorily more stable than hiatuses (Chitoran & Hualde,
2007). The articulatory stability is primary and is consistent with the tendency for hiatuses to
diphthongize across Spanish dialects (e.g. Hualde et al., 2008; Garrido, 2007, 2008). However,
since most research on Spanish vocalic sequences looks at acoustic evidence, the acoustic

226
variability is what is most apparent and what is reported. This variability may, in turn, affect the
number of sequences identified in the literature as exceptional hiatuses. That is, it may lead to an
overestimation of the occurrence of exceptional hiatuses, as suggested in Chapter 2 (§2.3).
Additionally, in support of proposals by Chitoran & Hualde (2007) and Nevins & Chitoran
(2008), the results from the articulation experiment provides preliminary evidence that the
Diphthong-Hiatus contrast in Mexican Spanish can be achieved through differences in the
temporal coordination of TB and TT gestures and in the magnitude of the TT gesture. In fact, we
highlighted the importance of the actions of the TT which we suggested was responsible for both
the Diphthong-Hiatus contrast as well as the diphthongization process (Chapter 4, §4.4). This
evidence, of course, is tempered by the observation that the data was highly variable. To reduce
some of this variability, especially the effects of following consonants, measurements were
modified. However, these adjustments raise the question of the appropriateness of the modified
measurements. Thus, more research is warranted to determine how well the chosen
measurements capture the Diphthong-Hiatus contrast.
Overall, however, the findings from the articulation experiment reported in this dissertation
highlight the value of experimental articulatory research to test specific questions related to
Spanish phonology and phonetics. In the present case, we have shown that the behaviour of
vocalic sequences in Spanish can be understood more fully when their articulatory and acoustic
properties are studied together. An investigation of the perception of these sequences completes
the picture and is discussed next.
2.3 Production-Perception Link
The experimental evidence in the present study does not support the third research goal of
establishing a production-perception link for vocalic sequences in Mexican Spanish. This goal
was based on two assumptions. The first assumption was that the participants’ production of
misclassified sequences was related to their perception of these sequences (e.g. Hualde & Prieto,
2002; Face & Alvord, 2004). In other words, the expectation was that a speaker who produced
many misclassified Diphthong tokens (i.e. more exceptional hiatuses) would be better able to
discriminate between Diphthong and Exceptional Hiatus in a perception task. The second
assumption was that perceptually distinctive contrasts could be identified through discriminant
analysis (Port & Crawford, 1989; Faber & DiPaolo, 1995; Morrison, 2006). Thus, the

227
expectation here was that those sequences identified as ambiguous and misclassified by the
discriminant analysis procedure, would be similarly subject to misclassification by listeners in a
perception experiment. In particular, we expected sequences with [a] to have lower
discrimination scores than sequences with [e] or [o] since the former were more likely to be
misclassified in the discriminant analysis.
In fact, with regards to the first assumption, participants performed similarly for all Pair types in
the AX perception task, regardless of whether they produced few or many misclassified
sequences in the production studies. That is, participants who produced many misclassified
diphthongs were not statistically more likely to accurately perceive a difference between
Diphthong and Exceptional Hiatus than participants who produced fewer misclassified
diphthongs. In fact, participant AM (who maintained small Diphthong-Hiatus differences and
contributed a large number of misclassified diphthongs in both production experiments) achieved
lower discrimination scores than participants who had larger Diphthong-Hiatus differences on
the acoustic and articulatory measures (KR and LL). In addition, regarding the second
assumption, the vowel with which participants had the most difficulty was [e], not [a] as
predicted from the acoustic and articulation studies.
These results would appear to be in contradiction to studies which find links between perceptual
acuity and contrast in production (Beddor et al., 2002; Beddor, 2012; Newman, 2003; Perkell et
al., 2004a, 2004b, 2006)70
. They are also in contradiction of previous studies on Spanish vocalic
sequences which have found that participants’ perception of these sequences (tested through
syllabification and/or labelling asks) is generally consistent with their production of the same
sequences (e.g. for Peninsular Spanish: Hualde & Prieto, 2002; Face & Alvord, 2004). However,
issues in the design of the perception experiment carried out for the present dissertation make it
impossible to substantiate any strong claims about the results. First and foremost, the small
number of participants (N = 5) as well as the small number of trials per participant (108) make
the results more susceptible to variation, greatly reducing the statistical power of the experiment.
In addition, both Stimulus Type (Word vs. Sentence) and ISI (500 vs. 1000) were presented as
within-subject factors. More importantly, the blocks in which these factors were combined were
70 Although, as noted in Chapter 5 (§4.4), this discrepancy may simply reflect differences in the type of contrast being examined.

228
presented in fixed order (Chapter 5, §2.2) to all the participants (although the order of trials
within each block was randomized for each participant). In combination, these methodological
limitations make it difficult to confirm any of the observed effects.
As a final observation, it is possible that the production-perception asymmetry found may be a
result of the parameters chosen to differentiate between categories of vocalic sequences in the
Discriminant Analysis. It may be that in order to establish a production-perception link for
Mexican Spanish different acoustic and articulatory parameters need to be included since they
may be more perceptually relevant to Mexican Spanish speakers. Two possible acoustic
parameters are suggested in §4 below.
The production-perception asymmetry observed with V effects points to the importance of such
dialect-specific considerations. Specifically, there are indications that this asymmetry may be
due to dialect-specific phonetic properties of [e]. Data collected from speakers of other varieties
of Spanish during the perception experiment (Chapter 5, footnote 68) suggests that these other
varieties also experience more difficulty with sequences with [e], but only when the Speaker is
Mexican (Figure 54, middle panel).
p(c
)
PENMEXARG
1.0
0.8
0.6
0.4
0.2
0.0PENMEXARG PENMEXARG
Speaker = ARG Speaker = MEX Speaker = PEN
V
a
e
o
Listener
Figure 54. Bar chart of mean p(c) scores for V, by Speaker Dialect and Listener Dialect

229
Although the above data is very preliminary (only proportion correct values were calculated) and
come from a single Peninsular Spanish speaker and only two Argentine Spanish speakers, the
pattern with Mexican Spanish [e] remains the same across Listener dialect. That is, when the
Speaker is Mexican, all listeners (Mexican, Argentine and Peninsular) perform worse with
sequences with [e] than for sequences with [a] and [o]. This suggests that in Mexican Spanish
there is something about vocalic sequences with this vowel that makes them difficult to
distinguish from each other. As we saw in Chapter 3, for example, the absolute formant change
in the F1-F2 contours of sequences with [e] (both diphthongs and hiatuses) is less than for
sequences with [a] and [o]. It may also be the case that Mexican [e] is more [i]-like than in other
varieties, partially explaining why this variety exhibits such advanced diphthongization of mid-
vowel hiatuses (resulting in words like teatro, ‘theatre’ being pronounced as [teá.tɾo] or even
[tjá.tɾo] rather than with the expected hiatus, as in [te.á.tɾo]: see Chapter 1, §4.1; Chapter 2, §2.
1). Some researchers have observed an overlap between [e] and [i] in syllable-initial position in
sequences with a following [a] ([ea] vs. [ia] sequences) in this variety of Spanish, but only in
duration (Garrido, 2008). Still, this similarity in duration may be perceived by listeners as a
similarity in vowel height and/or fronting (Gussenhoven, 2007) and add to the difficulty in
processing and interpreting sequences with [e] in combination with [i] or [j]. Further
investigation of perception (and production) data from different dialects of Spanish would be
needed to test the proposals outlined in this section.
3 Contributions
Despite the methodological concerns and the variability found in the results, this dissertation
contributes to an understanding of vocalic sequences in Spanish in the following ways.
3.1 Empirical Contributions
First, the dissertation adds to existing acoustic data on vocalic sequences in Spanish by
investigating Mexican Spanish, a dialect more often cited in studies of hiatus resolution (e.g.
Alba, 2006) and diphthongization (e.g. Garrido, 2008) than in studies concerning exceptional
hiatuses. More importantly, the dissertation complements existing acoustic characterizations of
these sequences with articulatory data. In combination, the results from the acoustic and
articulation experiments highlight the role of phonetic variation in the production of diphthongs
and hiatuses as the necessary precursor for exceptional hiatuses and provide support for the

230
proposal that this variation is present in all Spanish varieties, including those (like Mexican
Spanish, the variety which was the focus of the dissertation) with an advanced diphthongizing
tendency.
3.2 Theoretical Contributions
The above findings have important theoretical implications. First, the phonetic variation found in
the production of these sequences suggests that exceptional hiatuses can be thought of as
phonetic variants of diphthongs. That is, exceptional hiatuses simply reflect instances of the
low-level phonetic coarticulation that occurs as a consequence of the movement from a glide (a
high vocoid) to a non-high vowel in the articulatory space (Van Heuven & Hoos, 1991). As
such, exceptional hiatuses may occur in any dialect or variety of Spanish, including those with
advanced diphthongization tendencies. In addition, since the movement from glide to vowel is
greatest when the non-high vowel is [a], this would account for the tendency for exceptional
hiatuses to occur more often for words with [ja] sequences. Furthermore, the results suggest that
any diphthong (regardless of etymological origin) can be produced with exceptional hiatus in the
contexts tested here, including diphthongs (i.e. [je]) derived from the breaking of Latin short mid
vowels. This finding is counter to the assertion that these historic diphthongs are realized,
without exception, as diphthongs (Chitoran & Hualde, 2007; Cabré & Prieto, 2006). More
importantly, taken together, the findings described above call into question the need for a special
category of exceptional hiatuses and challenge the long-standing notion in Spanish phonology
that words which may surface with exceptional hiatus need to be lexically marked (e.g. Harris &
Kaisse, 1999; Hualde, 2005). Finally, the observation that diphthongs display more articulatory
stability than hiatuses contributes to an explanation of the change from [iV]> [jV] in the history
of the Spanish language.
3.3 Methodological Contributions
Through the combined use of various experimental techniques (including normalization
procedures, EMA, discriminant analysis, signal detection measures, and AX perception tasks)
the research reported here also make methodological contributions to existing studies of Spanish
vocalic sequences and opens the door to the application of these methodologies to future
examinations of production and perception of vocalic sequences in Spanish.

231
4 Future Directions
Any future experiments would need to correct the methodological shortcomings identified with
the experiments conducted for this dissertation, especially in the articulation and perception
experiments. The possible dialect-specific considerations identified in §2.3 suggest that future
experiments need to also consider testing additional acoustic and articulatory parameters for
inclusion in the Discriminant Analysis. Additional acoustic parameters may include intensity and
pitch. For example, Lehiste (1967), in her study of Estonian, found that intensity peaks reliably
differentiated between V + V sequences (which showed one peak for each V) and diphthongs
(with a single intensity peak) in that language, regardless of vowel quality. Similarly, Mauder &
van Heuven (1996) reported that peak f0 position and f0 movement patterns for a Chilean
Spanish speaker differed for falling diphthongs and hiatuses (e.g. [áj] vs. [a.í]). Finally, the
results from the perception experiment underscore the need to test a larger pool of participants
and to compare the results of participants from different dialects of Spanish. In short, the
findings of this dissertation point to the necessity of continued research on the articulatory
properties of vocalic sequences and on the production-perception link for these sequences for
different varieties of Spanish.

232
References
Aaronson, D., & Watts, B. (1987). Extensions of Grier's Computational Formulas for A' and B"
to Below-Chance Performance. Psychological Bulletin, 102(3), 439-442.
Adank, P., Smits, R., & Van Hout, R. (2004). A comparison of vowel normalization procedures
for language variation research. Journal of the Acoustical Society of America, 116(30),
99-107.
Aguilar, L. (1997). De la vocal a la consonante. Santiago de Compostela: Universidad de
Santiago de Compostela.
Aguilar, L. (1999). Hiatus and diphthong: Acoustic cues and speech situation differences. Speech
Communication, 28, 57-74.
Alba, M. (2006). Accounting for variability in the production of Spanish vocalic sequences. In
N. Sagarra, & A. Toribio (Eds.), Selected Proceedings of the 9th Hispanic Linguistic
Symposium (p. 273-285). Somerville, MA: Cascadilla Press.
Andruski, J. E., & Nearey, T. M. (1992). On the sufficiency of compund target specification of
isolated vowels and vowels in /bVb/ syllables. Journal of the Acoustical Society of
America, 91(1), 390-410.
Ashby, P. (2007). Phonetic ear-training: Design and duration. In J. Trouvain, & W. Barry (Ed.),
Proceedings of the 16th International Congress of Phonetic Sciences (ICPhS 07) (p.
1657-1660). Saarbrücken: Universität des Saarlandes.
Azevedo, M. M. (2005). Portuguese: A linguistic introduction. Cambridge; New York:
Cambridge University Press.
Barry, M. (1992). Palatalization, assimilation and gestural weakening in connected speech.
Speech Communication, 11, 393-400.
Barthélémy, S., & Boulinguez, P. (2001). Manual reaction time asymmetries in human subjects:
The role of movement planning and attention. Neuroscience Letters, 315(1), 41-44.
Beberfall, L. (1964). The qualitative aspect of the Spanish diphthong. The Modern Language
Journal, 48(3), 136-141.
Beddor, P. S. (2012). Perception grammars and sound change. In M.-J. Solé, & D. Recasens
(Eds.), The initiation of sound change: Production, perception and social factors (p. 37-
55). Amsterdam: John Benjamins.
Beddor, P. S., & Gottfried, T. L. (1995). Methodological issues in cross-language speech
perception research with adults. In W. Strange (Ed.), Speech perception and linguistic
experience: Issues in cross-language research. (p. 207-232). Timonium, MD: York
Press.
Beddor, P. S., Harnsberger, J., & Lindemann, S. (2002). Language-specific patterns of vowel-
vowel coordination: Acoustic structures and their perceptual correlates. Journal of
Phonetics, 30, 591-627.
Bertinetto, P., & Loporcaro, M. (2005). The sound pattern of Standard Italian, as compared with
the varieties spoken in Florence, Milan and Rome. Journal of the International Phonetic
Association, 35, 131-151.

233
Bladon, A. (1985). Diphthongs: a case study of dynamic auditory processing. Speech
Communication, 4, 145-154.
Blevins, J. (2004). Evolutionary phonology: The emergence of sound patterns. Cambridge:
Cambridge University Press.
Boersma, P., & Weenink, D. (2010). Praat: Doing phonetics by computer (Version 5.1.44)
[Computer software]. Retrieved October 12, 2010, from http://www.praat.org
Bond, Z. (1978). The effects of varying glide duration on diphthong identification. Language
and Speech, 21, 253-278.
Borzone de Manrique, A. M. (1976). Acoustic study of /i,u/ in the Spanish diphthong. Language
and Speech, 19, 121-128.
Borzone de Manrique, A. M. (1979). Acoustic analysis of the Spanish diphthongs. Phonetica, 36,
194-206.
Borzone de Manrique, A. M., & Massoni, M. I. (1981). Acoustic analysis and perception of
Spanish fricative consonants. Journal of the Acoustical Spciety of America, 69(4), 1145-
1153.
Browman, C. P., & Goldstein, L. M. (1991). Gestural structures: Distinctiveness, phonological
processes and historical change. In I. Mattingly, & M. Studdert-Kennedy (Eds.),
Modularity and the Motor Theory of speech perception (p. 313-338). Hillsdale, NJ:
Erlbaum.
Browman, C. P., & Goldstein, L. M. (1992). Articulatory Phonology: An overview. Phonetica,
49, 155-180.
Browman, C. P., & Goldstein, L. M. (2000). Competing constraints on intergestural coordination
and self-organization of phonological structures. Bulletin de la Communication Parlée, 5,
25-34.
Brown, E. L., & Torres Cacoullos, R. (2003). Spanish /s/: A different story from beginning
(initial) to end (final). In L. L. Núñez-Cedeño, & R. Cameron (Eds.), A Romance
perspective in language knowledge and use. Selected papers from the 31st Linguistic
Symposium on Romance Languages (LSRL). Current Issues in Linguistic Theory (CILT)
238, p. 22-38. Amsterdam; Philadelphia: John Benjamins.
Buchwald, A. (2006). Representing sound structure: Evidence from aphasia. In J. Alderete, C.-H.
Han, & A. Kochetov (Eds.), Proceedings of the West Coast Conference on Formal
Linguistics (WCCFL). 24, p. 79-87. Somerville, MA: Cascadilla Press.
Cabré, T., & Prieto, P. (2004). Prosodic and analogical effects in lexical glide formation in
Catalan. Probus, 16, 113-150.
Cabré, T., & Prieto, P. (2006). Exceptional hiatuses in Spanish. In F. Mártinez-Gil, & S. Colina
(Eds.), Optimality-theoretic studies in Spanish phonology (p. 205-238). Amsterdam: John
Benjamins.
Carreira, M. (1988). The representation of diphthongs in Spanish. Studies in the Linguistic
Sciences, 18(1), 1-24.

234
Carreira, M. (1991). The alternating diphthongs of Spanish: A paradox revisited. In H. Campos,
& F. Martínez-Gil (Eds.), Current Studies in Spanish Linguistics (p. 407-445).
Washington: Georgetown University Press.
Carreira, M. (1992). The representation of rising diphthongs in Spanish. In C. Laeufer, & T. A.
Morgan (Eds.), Theoretical Analyses in Romance Linguistics (p. 19 -35). Amsterdam:
John Benjamins.
Chitoran, I. (2002). A perception-production study of Romanian diphthongs and glide-vowel
sequences. Journal of the International Phonetic Association, 32, 203-222.
Chitoran, I. (2003). Gestural Timing and the Glide Percept in Romanian. In D. Recasens, M. J.
Solé, & J. Romero (Eds.), Proceedings of the 15th International Congress of Phonetic
Sciences (ICPhS 03), Barcelona, (p. 3013-3016).
Chitoran, I., & Hualde, J. I. (2007). From hiatus to diphthongs. The evolution of vowel
sequences in Romance. Phonology, 24, 37-75.
Chitoran, I., M., G. L., & Byrd, D. (2002). Gestural overlap and recoverability: Articulatory
evidence from Georgian. In C. Gussenhoven, & N. Warner (Eds.), Laboratory Phonology
7 (p. 419–447). Berlin/New York: Mouton de Gruyter.
Clopper , C., Pierrehumbert, J. B., & Tamati, T. (2010). Lexical bias in cross-dialect word
recognition in noise. Laboratory Phonology, 11(1), 65-92.
Colantoni, L. (2006). Macro and micro sound variation and change in Argentine Spanish. In A. J.
Toribio, & N. Sagarra (Eds.), Selected proceedings of the 9th Hispanic Linguistic
Symposium (p. 91-102). Somerville,MA: Cascadilla Press.
Colantoni, L., & Kochetov, A. (2010, March). Palatal nasals or nasal palatalization? Paper
presented at the 40th Linguistic Symposium on Romance Languages (LSRL). Seattle,
WA.
Colantoni, L., & Marinescu, I. (2010). The scope of stop weakening in Argentine Spanish. In M.
Ortega-Llebaria (Ed.), Selected Proceedings of the 4th Conference on Laboratory
Approaches to Spanish Phonology (LASP 4) (p. 100-114). Somerville, MA: Cascadilla
Proceedings Project.
Colantoni, L., & Limanni, A. (2010). Where are hiatuses left? A comparative study of vocalic
sequences in Argentine Spanish. In K. Arregi, Z. Fagyal, S. Montrul, & A. Tremblay
(Eds.), Selected Proceedings of the 38th Linguistic Symposium on Romance Languages
(LSRL) (p. 23-38). Amsterdam: John Benjamins.
Colantoni, L., & Steele, J. (2005). Liquid asymmetries in French and Spanish. Toronto Working
Papers in Linguistics, 24, 1–14.
Colina, S. (1999). Reexamining Spanish glides: analogically conditioned variation in vocoid
sequences in Spanish dialects. In J. Gutiérrez-Rexach, & F. Mártinez-Gil (Eds.),
Advances in Hispanic Linguistics (p. 121-134). Somerville. MA: Cascadilla Press.
Collier, R., & t’Hart, J. (1983). The perceptual relevance of the formant trajectories in Dutch
diphthongs. In M. Van den Broecke, V. Van Heuven, & W. Zonneveld (Eds.), Sound
structures: Studies for Antonie Cohen (p. 31–45). Dordrecht: Foris Publications.
Collier, R., Bell-Berti, F., & Raphael, J. (1982). Some acoustic and physiological observations
on diphthongs. Language and Speech, 25, 305-323.

235
Corder, G. W., & Foreman, D. I. (2009). Nonparametric statistics for non-statisticians. New
Jersey: John Wiley & Sons. Inc.
Cowan, N., & Morse, P. A. (1986). The use of auditory and phonetic memory in vowel
discrimination. Journal of the Acoustical Society of America, 79(2), 500-507.
Dane, S., & Erzurumluoglu, A. (2003). Sex and handedness differences in eye-hand visual
reaction times in handball players. International Journal of Neuroscience, 113(7), 923-
929.
Davis, S., & Hammond, M. (1995). On the status of onglides in American English. Phonology,
12, 159-182.
Docherty, G. (2003). Commentary on papers by Remez, Goldinger/Azuma and Local. Journal of
Phonetics, 31, 305-320.
Donaldson, W. (1992). Measuring recognition memory. Journal of Experimental Psychology:
General, 121(3), 275-277.
Donegan, P. (1985). The natural phonology of vowels. (Outstanding Dissertations in Linguistics:
Series 3). New York: Garland Press.
Durand, J., & Lyche, C. (1999). Regard sur les glissantes en français: français standard. français
du Midi. In N. Serna (Ed.), Cahiers de grammaire 24. Phonologie: théorie et variation.
Toulouse: ERSS-Université deToulouse-Le Mirail.
Eddington, D. (1998). Spanish diphthongization as a non-derivational phenomenon. Rivista di
Linguistica, 10(2), 335-354.
Eddington, D. (2004). Spanish phonology and morphology: Experimental and quantitative
perspectives. Amsterdam: John Benjamins.
Faber, A., & DiPaolo, M. (1995). The discriminability of nearly merged sounds. Language
Variation and Change, 7, 35-78.
Face, T., & Alvord, S. (2004). Lexical and acoustic factors in the perception of the Spanish
diphthong vs. hiatus contrast. Hispania, 87, 553-564.
Fitzpatrick, L., & Ní Chasaide, A. (2002). Estimating lingual constriction location in high
vowels: A comparison of EMA- and EPG-based measures. Journal of Phonetics, 30, 397-
415.
Flege, J. E. (1988). Effect of speaking rate on tongue position and velocity of movement in
vowel production. Journal of the Acoustical Society of America, 84(3), 901-916.
Flynn, N. (2001). Comparing vowel formant normalisation procedures. York Working Papers in
Linguistics, 2(11), 1-28.
Frago Gracia, J. A., & Franco Figueroa, M. (2001). El español de America. Servicio de
Publicaciones: Universidad de Cádiz.
Francis, A., & Ciocca, V. (2003). Stimulus presentation order and the perception of lexical tones
in Cantonese. Journal of the Acoustical Society of America, 114(3), 1611-1621.
Ganong, W. F. (1980). Phonetic categorization in auditory word perception. Journal of
Experimental Psychology: Human Perception and Performance, 6(1), 110-125.

236
Gardiner, W. P. (1997). Statistical analysis methods for chemists: A software-based approach.
Cambridge: The Royal Society of Chemistry.
Garrido, M. (2007). Diphthongization of mid/low vowel sequences in Colombian Spanish. In J.
Holmquist, A. Lorenzino, & L. Sayahi (Eds.), Selected proceedings of the third workshop
on Spanish sociolinguistics (p. 30-37). Somerville, MA: Cascadilla Press.
Garrido, M. (2008). Diphthongization of non-high vowel sequences in Latin American Spanish.
Unpublished doctoral dissertation, University of Illinois at Urbana-Champaign.
Gay, T. (1968). Effects of speaking rate on diphthong formant movements. Journal of the
Acoustical Society of America, 44, 1550-1573.
Gay, T. (1970). A perceptual study of American English diphthongs. Language & Speech, 13,
65–88.
Gay, T. (1974). A cinefluorographic study of vowel production. Journal of Phonetics, 2, 255-
266.
Gerrits, E. (2001). The categorisation of speech sounds by adults and children. Unpublished
doctoral dissertation, Utrecht University.
Gerrits, E., & Schouten, M. E. (2004). Categorical perception depends on the discrimination
task. Perception & Psychophysics, 66(3), 363-376.
Gick, B. (2003). Articulatory correlates of ambisyllabicity in English glides and liquids. In J.
Local, R. Ogden, & R. Temple (Eds.), Phonetic Interpretation: Papers in Laboratory
Phonology VI (p. 222-236). Cambridge: Cambridge University Press.
Gili Fivela, B., & Bertinetto, P. M. (1998). Incontri vocalici tra prefisso e radice (iato o
dittongo?). Quaderni del laboratorio di linguistica, Pisa, (p. 102-122).
Goldinger, S. D. (1998). Signal detection comparisons of phonemic and phonetic priming: The
flexible-bias problem. Perception & Psychophysics, 60(6), 952-965.
Goldinger, S. D., & Azuma, T. (2003). Puzzle-solving science: The quixotic quest for units in
speech perception. Journal of Phonetics, 31, 305-320.
Goldstein, L. M., Chitoran, I., & Selkirk, E. (2007). Syllable structure as coupled oscillator
modes: Evidence from Georgian vs. Tashlhiyt Berber. In J. Trouvain, & W. Barry (Eds.),
Proceedings of the 16th International Congress of Phonetic Sciences (ICPhS 07) (p. 241-
244). Saarbrücken: Universität des Saarlandes.
Gottfried, M., Miller, J., & Meyer, D. (1993). Three approaches to the classification of American
English diphthongs. Journal of Phonetics, 21, 205-229.
Gow, D. W., Segawa, J. A., Ahlfors, S. P., & Lin, F. H. (2008). Lexical influences on speech
perception: A Granger causality analysis of MEG and EEG source estimates.
Neuroimage, 43(3), 614-623.
Grier, J. B. (1971). Nonparametric indexes for sensitivity and bias: Computing formulas.
Psychological Bulletin , 75(6), 424-429.
Grimm, L. G., & Yarnold, P. R. (1995). Reading and understanding multivariate statistics.
Washington, D.C: American Psychological Association.

237
Guirao, M., & García Jurado, M. A. (1990). Frequency of occurence of phonemes in American
Spanish. Revue québécoise de linguistique, 19(2), 135-149.
Guenther, F. H., Espy-Wilson, H. Y., Boyce, S. E., Matthies, M. L., Zandipour, M., & Perkell, J.
S. (1999). Articulatory tradeoffs reduce acoustic variability during American English /r/
production. Journal of the Acoustical Society of America, 15(5), 2854-2865.
Gussenhoven, C. (2007). A vowel height split explained: Compensatory listening and speaker
control. In J. Cole, & J. I. Hualde (Eds.), Laboratory Phonology 9 (p. 145-172).
Berlin/New York: Mouton de Gruyter.
Hall, T. A. (2008). German Glide Formation and the Suffix –esk. Folia Linguistica, 42(2), 307–
329.
Hall, T. A., & Hamann, S. (2010). On the cross-linguistic avoidance of rhotic plus high front
vocoid sequences. Lingua, 120, 1821-1844.
Halle, M., Harris, J. W., & Vergnaud, J.-R. (1991). A re-examination of the stress erasure
convention and Spanish stress. Linguistic Inquiry, 22, 141-159.
Harris, J. (1969). Spanish Phonology. Cambridge: MIT Press.
Harris, J. (1985). Spanish diphthongization and stress: A paradox resolved. Phonology Yearbook,
2, 31-45.
Harris, J., & Kaisse, E. (1999). Palatal vowels, glides and obstruents in Argentinian Spanish.
Phonology, 16, 117-190.
Hayward, K. (2000). Experimental phonetics. New York: Longman, Pearson Education.
Holbrook, A., & Fairbanks, G. (1962). Diphthong formants and their movements. Journal of
Speech and Hearing Research, 5, 38–58.
Holt, D. E. (1997). The Role of the listener in the historical phonology of Spanish and
Portuguese: An Optimality-Theoretic account. Unpublished doctoral dissertation,
Georgetown University, Washington .
Honorof, D. N. (2003). Articulatory evidence for nasal de-occlusivization in Castilian. In D.
Recasens, M. J. Solé, & J. Romero (Eds.), Proceedings of the 15th International
Congress of Phonetic Sciences (ICPhS 03), Barcelona, (p. 1759-1762).
Hoole, P. (1996). Issues in the acquisition, processing, reduction and parameterization of
articulographic data. FIPKM, 34, 158-173.
Hoole, P., & Zierdt, A. (2010). Five-dimensional articulography. In B. Maassen, & P. Van
Lieshout (Ed.), Speech motor control: New developments in basic and applied research
(p. 331-349). New York: Oxford University Press.
Hualde, J. I. (1999). Hiatus with unstressed high vowels in Spanish. In J. Gutiérrez-Rexach, & F.
Martínez-Gil (Eds.), Advances in Hispanic Linguistics (p. 182-197). Somerville, MA:
Cascadilla Press.
Hualde, J. I. (2005). The sounds of Spanish. Cambridge: Cambridge University Press.
Hualde, J. I., & Prieto, M. (2002). On the diphthong/hiatus contrast in Spanish: Some
experimental results. Linguistics, 40, 217-234.

238
Hualde, J. I., Olarrea, A., & Escobar, A. M. (2001). Introducción a la lingüística hispánica.
Cambridge: Cambridge University Press.
Hualde, J., & Chitoran, I. (2003). Explaining the distribution of hiatus in Spanish and Romanian.
In D. Recasens, M. J. Solé, & J. Romero (Eds.), Proceedings of the 15th International
Congress of Phonetic Sciences (ICPhS 03), Barcelona, (p. 1683-1686).
Hualde, J., Simonet, M., & Torreira, F. (2008). Postlexical contraction of nonhigh vowels in
Spanish. Lingua, 118, 1906-1925.
Jha, S. K. (1985). Acoustic analysis of the Maithili diphthongs. Journal of Phonetics, 13, 107-
115.
Johnson, N. S. (1976). A note on the use of A' as a measure of sensitivity. Journal of
Experimental Child Psychology, 22, 530-531.
Jun, J. (1996). Place assimilation is not the result of gestural overlap: Evidence from Korean and
English. Phonology, 13, 377-407.
Kager, R. (1999). Optimality Theory. Cambridge: Cambridge University Press.
Kenstowicz, M. (1994). Phonological theory in generative linguistics. Cambridge: Blackwell.
Kent, R. D., & and Moll, K. L. (1972). Tongue body articulations during vowel and diphthong
gestures. Folia Phoniatrica, 24, 286-300.
Kent, R. D., & Read, C. (2002). The Acoustic Analysis of Speech (2nd ed.). Albany, NY:
Singular/Thompson.
Kikuchi, S. (1997). A correspondence-theoretic approach to alternating diphthongs in Spanish.
Journal of Linguistic Science, 1, 39-50.
Kinoshita, Y., & Osanai, T. (2006). Within Speaker variation in diphthongal dynamics: What can
we compare? In P. Warren, & C. I. Watson (Eds.), Proceedings of the 11th Australian
International Conference on Speech Science & Technology (University of Auckland, New
Zealand), (p. 112-117).
Kochetov, A. (2006). Syllable position effects and gestural organization: Evidence from Russian.
In L. Goldstein, D. Whalen, & C. Best (Eds.), Papers in Laboratory Phonology VIII (p.
565-588). Berlin/New York: Mouton de Gruyter.
Krämer, M. (2009). The phonology of Italian. Oxford: Oxford University Press.
Krebs-Lazendic, L., & and Best, C. T. (2008). Early and late bilinguals’ vowel perception and
production: English vowel contrasts that give Serbian-English bilinguals a H(E)AD-ache.
In A. S. Rauber, M. A. Watkins, & B. O. Baptista (Eds.), New Sounds 2007: Proceedings
of the Fifth International Symposium on the Acquisition of Second Language Speech (p.
282-292). Florianópolis, Brazil: Federal University of Santa Catarina.
Kroos, C. (2012). Evaluation of the measurement precision in three-dimensional Electromagnetic
Articulography(Carstens AG500). Journal of Phonetics, 40, 453-465.
Labov, W. (1994). Principles of Linguistic Change (Vol. I: Internal Factors). Oxford: Blackwell.
Lavoie, L. (2001). Consonant strength: Phonological patterns and phonetic manifestations. New
York: Routledge.

239
Lehiste, I. (1967). Diphthongs versus vowel sequences in Estonian. In B. Hála, & M. Romportl
(Eds.), Proceedings of the 6th International Congress of Phonetic Sciences (ICPhS 67)
(p. 539-544). Prague: Academic Publishing House of the Czechoslovakian Academy of
Sciences.
Lehiste, I. (1976). Suprasegmental features of speech. In N. J. Lass (Ed.), Contemporary issues
in experimental phonetics (p. 225-239). New York: Academic Press.
Lehiste, I., & Peterson, G. (1961). Transitions, glides and diphthongs. Journal of the Acoustical
Society of America, 33(3), 268-277.
Levi, S. V. (2008). Phonemic vs. derived glides. Lingua, 118, 1956-1978.
Lewis, A. (2001). Weakening of intervocalic /p, t, k/ in two Spanish dialects: Toward the
quantification of lenition processes. Unpublished doctoral dissertation. University of
Illinois at Urbana-Champaign.
Limanni, A. (2008). From uo to ue in Spanish and from uo to o in Sicilian: Same problem,
different solutions. In L. Colantoni, & J. Steele (Eds.), Selected Proceedings of the 3rd
Conference on Laboratory Approaches to Spanish Phonology (LASP 3) (p. 125-139).
Somerville, MA: Cascadilla Proceedings Project.
Lindau, M., Kjell, N., & Svantesson, J.-O. (1990). Some cross-linguistic differences in
diphthongs. Journal of the International Phonetic Association, 20, 10-14.
Lindblom, B. (1990). Explaining phonetic variation: A sketch of the H&H theory. In W. J.
Hardcastle, & A. Marchal (Eds.), Speech production and speech modeling (p. 403–439).
Dordrecht: Kluwer Academic Publishing.
Lindblom, B., Guion, S., Hura, S., Moon, S.-J., & Willerman, R. (1995). Is sound change
adaptive? Rivista di Linguistica, 7, 5–37.
Local, J. (2003). Variable domains and variable relevance: Interpreting phonetic exponents.
Journal of Phonetics, 31, 321-339.
Lope Blanch, J. (1996). México. In M. Alvar (Ed.), Manual de dialectología hispánica: El
español de América (p. 81-89). Barcelona: Ariel.
MacLeod, B. (2007). Spanish dialects and variation in vocalic sequences. Master's thesis,
University of Toronto.
Macmillan, N. A., & Creelman, C. D. (2005). Detection Theory: A user's guide. Mahwah, N.J:
Erlbaum.
Marin, S. (2007). Vowel to vowel coordination, diphthongs, and Articulatory Phonology.
Unpublished doctoral dissertation, Yale University.
Marotta, G. (1987). Dittongo e iato in italiano: Una difficile discriminazione. Annali della Scuola
Normale di Pisa, 17, 847-887.
Marotta, G. (1988). The Italian diphthongs and the autosegmental framework. Certamen
Phonologicum, 8, 389-420.
Marotta, G., Rocca, D., & Salza, P. L. (1987). Duration and formant frequencies of Italian
bivocalic sequences. CSELT (Centro Studi e Laboratori Telecomunicazioni) Technical
Reports, 15, 435-439.

240
Martínez Celdrán, E. (2009). Sonorización de las oclusivas sordas en una hablante murciana:
Problemas que plantea. Estudios de Fonética Experimental, XVIII, 253-271.
Martínez Celdrán, E., & Fernández Planas, A. M. (2007). Manual de fonética española:
Articulaciones y sonidos del español. Barcelona: Ariel.
Martínez-Celdrán, E. (2004). Problems in the classification of approximants. Journal of the
International Phonetic Association, 34(2), 201–210.
Martínez-Celdrán, E. (2008). Some chimeras of traditional Spanish phonetics. In L. Laura
Colantoni, & J. Steele (Eds.), Selected Proceedings of the 3rd Conference on Laboratory
Approaches to Spanish Phonology (LASP 3) (p. 32-46). Somerville, MA: Cascadilla
Proceedings Project.
Mateus, M. H., & D’Andrade, E. (2000). The phonology of Portuguese. Oxford: Oxford
University Press.
Mauder, E., & Van Heuven, V. (1996). On the rise and fall of the Spanish diphthongs. In C.
Cremers, & M. Den Dikken (Eds.), Linguistics in the Netherlands 1996 (p. 171-182).
Amsterdam: John Benjamins.
McDougall, K. (2004). Speaker-specific formant dynamics: An experiment on Australian
English /aɪ/. International Journal of Speech, Language and the Law, 11(1), 103-130.
McDougall, K. (2006). Dynamic features of speech and the characterisation of speakers:
Towards a new approach using formant frequencies. International Journal of Speech,
Language and the Law, 13(1), 89-126.
McDougall, K., & Nolan, F. (2007). Discrimination of Speakers Using the Formant Dynamics of
/u:/ in British English. In J. Trouvain, & W. Barry (Eds.), Proceedings of the 16th
International Congress of Phonetic Sciences (ICPhS 07) (p. 1825-1828). Saarbrücken:
Universität des Saarlandes.
Miller, J., & Grosjean, F. (1997). Dialect effects in vowel perception: The role of temporal
information in French. Language and Speech, 40(3), 277-288.
Morrison, G. S. (2009). Likelihood-ratio-based forensic speaker comparison using parametric
representations of vowel formant trajectories. Journal of the Acoustical Society of
America, 125, 2387–2397.
Morrison, S. M. (2006). Methodological issues in L2 perception research and vowel spectral
cues in Spanish listeners’ perception of word-final /t/ and /d/ in Spanish. In M. Díaz-
Campos (Ed.), Selected Proceedings of the 2nd Conference on Laboratory Approaches to
Spanish Phonetics and Phonology (LASP 2) (p. 35-47). Somerville, MA: Cascadilla
Proceedings Project.
Mowrey, R., & Pagliuca, W. (1995). The reductive character of articulatory evolution. Rivista di
Linguistica, 7, 37-124.
Navarro Tomás, T. (1926). Manual de pronunciación española (3ra ed.). Madrid: Imprenta de
los sucesores de Hernando.
Nevins, A., & Chitoran, I. (2008). Phonological representations and the variable patterning of
glides. Lingua, 118, 1979-1997.

241
Newman, R. S. (2003). Using links between speech perception and speech production to evaluate
different acoustic metrics: A preliminary report. Journal of the Acoustical Society of
America, 113(5), 2850-2860.
Nittrouer, S. (2005). Age-related differences in weighting and masking of two cues to word-final
stop voicing in noise. Journal of the Acoustical Society of America, 118, 1072-1088.
Nittrouer, S. (2007). Dynamic spectral structure specifies vowels for children and adults. Journal
of the Acoustical Society of America, 122, 2328-2339.
Ohala, J. J. (1981). The listener as a source of sound change. In C. S. Masek, R. A. Hendrick, &
M. F. Miller (Eds.), Papers from the Parasession on Language and Behavior (p. 178-
203). Chicago: Chicago Linguistic Society.
Ohala, J. J. (1983). The origin of sound patterns in vocal tract constraints. In P. F. MacNeilage
(Ed.), The production of speech (p. 189 - 216). New York: Springer-Verlag.
Ohala, J. J. (1989). Sound change is drawn from a pool of synchronic variation. In L. E. Breivik,
& E. H. Jahr (Eds.), Language Change: Contributions to the study of its causes (Trends
in Linguistics, Studies and Monographs No. 43) (p. 173-198). Berlin: Mouton de Gruyter.
Ohala, J. J. (1993). The phonetics of sound change. In C. Jones (Ed.), Historical Linguistics:
Problems and Perspectives (p. 237-278). London: Longman.
Ohala, J. J. (2012). The listener as a source of sound change: An update. In M.-J. Solé, & D.
Recasens (Eds.), The initiation of sound change: Production, perception, and social
factors (p. 21-35). Amsterdam: John Benjamins.
Oldfield, R. C. (1971). The assessment and analysis of handedness: The Edinburgh Inventory.
Neuropsychologia, 9, 97-113.
Owren, M. (2009). GSU Praat Tools 1.9 [Computer software and manual]. Retrieved September
19, 2009, from http://sites.google.com/site/psyvoso/
Padgett, J. (2008). Glides, vowels, and features. Lingua, 118, 1841–2030.
Peeters, W. J. (1991). Diphthong dynamics: a cross-linguistic perceptual analysis of temporal
patterns in Dutch, English, and German. Unpublished doctoral dissertation, Utrecht
University.
Peeters, W. J., & Barry, W. J. (1989). Diphthong dynamics: production and perception in
Southern British English. First European Conference on Speech Communication and
Technology (EUROSPEECH 1989), Paris, France, (p. 1055-1058). .
Penny, R. (2002). A history of the Spanish language. Cambridge: Cambridge University Press.
Perkell, J. S., Guenther, F. H., Lane, H., Marrone, N., Matthies, M. L., Stockmann, E., . . .
Zandipour, M. (2006). Production and perception of phoneme contrasts covary across
speakers. In J. Harrington, & M. Tabain (Eds.), Speech production: Models, phonetic
processes and techniques (p. 69-84). New York: Psychology Press.
Perkell, J. S., Guenther, F. H., Lane, H., Matthies, M. L., Stockmann, E., Tiede, M., &
Zandipour, M. (2004a). The distinctness of speakers’ productions of vowel contrasts is
related to their discrimination of the contrasts. Journal of the Acoustical Society of
America, 116(4), 2338-2344.

242
Perkell, J. S., Matthies, M. L., Tiede, M., Lane, H., Zandipour, M., Marrone, N., Stockman, E.,
& Guenther, F. H. (2004b). The distinctness of speakers' /s/—/ʃ/ contrast is related to
their auditory discrimination and use of an articulatory saturation effect. Journal of
Speech, Language and Hearing Research, 47, 1259-1269.
Peters, M., & Ivanoff, J. (1999). Performance asymmetries in computer mouse control of right-
handers, and left-handers with left- and right-handed mouse experience. Journal of Motor
Behaviour, 31(1), 86-94.
Pisoni, D. B. (1973). Auditory and phonetic codes in the discrimination of consonants and
vowels. Perception and Psychophysics, 13, 253-260.
Plomp, R. (2002). The intelligent ear: On the nature of sound perception. New Jersey/London:
Lawrence Erlbaum Associates.
Port, R., & Crawford, P. (1989). Incomplete neutralization and pragmatics in German. Journal of
Phonetics, 17, 257-282.
Recasens, D. (1985). Coarticulatory patterns and degrees of coarticulatory resistance in Catalan
CV sequences. Language and Speech, 28, 97-114.
Recasens, D. (1999a). Acoustic analysis. In W. Hardcastle, & N. Hewlett (Eds.), Coarticulation:
Theory, data and techniques (p. 322-336). Cambridge: Cambridge University Press.
Recasens, D. (1999b). Lingual coarticulation. In W. Hardcastle, & N. Hewlett (Eds.),
Coarticulation: Theory, data and techniques (p. 80-104). Cambridge: Cambridge
University Press.
Recasens, D. (2002). An EMA study of VCV coarticulatory direction. Journal of the Acoustical
Society of America, 111, 2828-2841.
Recasens, D. (2004). A production account of sound changes affecting diphthongs and
triphthongs in Romance. Diachronica, 21, 161-197.
Recasens, D. (2012). A phonetic interpretation of sound changes affecting dark /l/ in Romance.
In M. J. Solé, & D. Recasens (Eds.), The Initiation of Sound Change: Production,
perception and social Factors (p. 57-76). Amsterdam: John Benjamins.
Recasens, D., Pallarès, M., & Fontdevila, J. (1997). A model of lingual coarticulation based on
articulatory constraints. Journal of the Acoustical Society of America, 102, 544-561.
Remez, R. E. (2003). Establishing and maintaining perceptual coherence: Unimodal and
multimodal evidence. Journal of Phonetics, 31, 293-304.
Ren, H. (1986). On the acoustic structure of diphthongal syllables. Unpublished doctoral
dissertation, UCLA [Published as UCLA Working Papers in Phonetics 65].
Roca, I. (1997). There are no "glides", at least in Spanish: An Optimality account. Probus, 9,
233-265.
Romero, J. (1995). An articulatory view of historical s-aspiration in Spanish. Haskins
Laboratories Status Report on Speech Research 1994-1995, SR-119/120, 255-266.
Rosenthall, S. (1994). Vowel/glide alternation in a theory of constraint interaction. Unpublished
doctoral dissertation, University of Massachusetts, Amherst.

243
Salza, P. L. (1988). Durations of Italian diphthongs and vowel clusters. Language and Speech,
31, 97-113.
Sánchez-Miret, F. (1998). Some reflections on the notion of diphthong. Papers and Studies in
Contrastive Linguistics, 34, 27-51.
Sands, K. (2004). Patternings of vocalic sequences in the world's languages. Unpublished
doctoral dissertation, University of California, Santa Barbara.
Shaiman, S., & Porter, R. J. (1991). Different phase-stable relationships of the upper lip and jaw
for production of vowels and diphthongs. Journal of the Acoustical Society of America,
90, 3000-3007.
Silva, T. C. (1999). Fonética e fonologia do Português. São Paulo: Editora Contexto.
Slis, A., & Van Lieshout, P. (2013). The effect of phonetic context on speech movements in
repetitive speech. Journal of the Acoustical Society of America, 134(6), 4496-4507.
Snodgrass, J. G., & Corwin, J. (1988). Pragmatics of measuring recognition memory:
Applications to dementia and amnesia. Journal of Experimental Psychology: General,
177(1), 34-50.
Stanislaw, H., & Todorov, N. (1999). Calculation of signal detection theory measures. Behavior
Research Methods, Instruments and Computers, 31(1), 137-149.
Stella, M., Bernardini, P., Sigona, F., Stella, A., Grimaldi, M., & Gili Fivela, B. (2012).
Numerical instabilities and three-dimensional electromagnetic articulography. Journal of
the Acoustical Society of America, 132(6), 3941-3949.
Stevens, K. N. (1989). On the quantal nature of speech. Journal of Phonetics, 132, 3-45.
Stone, M. (1997). Laboratory techniques for investigating speech articulation. In W. J.
Hardcastle, & J. Laver (Eds.), The handbook of phonetic sciences (p. 11-32). Oxford:
Blackwell.
Strange, W., Edman, T. R., & Jenkins, J. L. (1979). Acoustic and phonological factors in vowel
identification. Journal of Experimental Psychology: Human Perception and
Performance, 5(4), 643-656.
Toledo, G. A., & Antoñanzas-Barroso, N. (1987). Influence of speaking rate in Spanish
diphthongs. Proceedings of the 11th International Congress of Phonetic Sciences (ICPhS
87), Tallin, Estonia, (p. 125-138).
Tranel, B. (1987). The sounds of French: An introduction. Cambridge/New York: Cambridge
University Press.
Van der Beer, B. (2006). The Italian ‘mobile diphthongs': A test case for experimental phonetics
and phonological theory. Unpublished doctoral dissertation, Leiden University: LOT,
Utrecht.
Van Hessen, A. J., & Shouten, M. E. (1992). Modeling phoneme perception II: A model of stop
consonant discrimination. Journal of the Acoustical Society of America, 92(4), 1856-
1868.
Van Heuven, V. J., & Hoos, A. (1991). Hiatus deletion: Phonological rule or phonetic
coarticulation? In F. Drijkoningen, & A. Van Kemenade (Eds.), Linguistics in the
Netherlands 1991 (p. 61–70). Amsterdam: John Benjamins.

244
Van Lieshout, P. (2006). La utilización de la articulografia mediosagital electromagnética en la
investigación sobre movilidad oral [The use of Electro-Magnetic Midsagittal
Articulography in oral motor research]. In E. Padrós-Serrat (Ed.), Bases diagnósticas
terapéuticas y posturales del funcionalismo craneofacial. [Diagnostic, therapeutic and
postural basis of craniofacial functionalism] (p. 1140-1156). Madrid: Ripano Editorial
Médica.
Van Lieshout, P., & Moussa, W. (2000). The assessment of speech motor behaviors using
electromagnetic articulography. The Phonetician, 81, 9–22.
Van Strien, J. W. (1992). Classificatie van links- en rechtshandige proefpersonen. [Classification
of left- and right-handed research participants]. Nederlands Tijdschrift voor de
Psychologie, 47, 88-92.
Walker, D. (2001). French sound structure. Calgary: University of Calgary Press.
Wang, H. (2007). English as a lingua franca: Mutual intelligibility of Chinese, Dutch and
American speakers of English. Unpublished doctoral dissertation, Leiden University:
LOT, Utrecht.
Wang, W. S.-Y. (1969). Competing changes as a cause of residue. Language, 45(1), 9-25.
Werker, J. F. (1994). Cross-language speech perception: Developmental change does not involve
loss. In J. Goodman, & H. Nusbaum (Eds.), The development of speech perception: The
transition from speech sounds to spoken words (p. 112-149). Cambridge, MA: MIT
Press.
Werker, J. F., & Logan, J. S. (1985). Cross-language evidence for three factors in speech
perception. Perception and Psychophysics, 37(1), 35-44.
Werker, J. F., & Tees, R. C. (1984). Phonemic and phonetic factors in adult cross-language
speech perception. Journal of the Acoustical Society of America, 75, 1866-1878.
West, P. (1999). The extent of coarticulation of English liquids: An acoustic and articulatory
study. In J. J. Ohala, Y. Hasegawa, M. Ohala, D. Granville, & A. C. Bailey (Eds.),
Proceedings of the 14th International Congress of Phonetic Sciences (ICPhS 99), Volume
3, (p. 2271–2273). San Francisco, USA.
Westbury , J. R., Lindstrom, M. J., & McClean, M. D. (2002). Tongues and lips without jaws: A
comparison of methods for decoupling speech movements. Journal of Speech, Language,
and Hearing Research, 45, 651–662.
Whitley, S. M. (1995). Spanish glides, hiatus, and conjunction lowering. Hispanic Linguistics,
6/7, 355-385.
Widdison, K. A. (1995). On the value of an experimental paradigm in linguistics and its
application to issues in Spanish phonology. Neophilologus, 79, 587-598.
Widdison, K. A. (1997). Phonetic explanations for sibilant patterns in Spanish. Lingua, 102, 253-
264.
Wiese, R. (1996). The Phonology of German. Oxford: Oxford University Press.
Yunusova, Y., Green, J. R., & Mefferd, A. (2008). Accuracy assessment for AG500,
Electromagnetic Articulograph. Journal of Speech, Language, and Hearing Research,
52(2), 1044-1092.

245
Zmarich, C., Van Lieshout, P., Namavisayam, A., Limanni, A., Galatà, V., & Tisato, G. (2012).
Consonantal and vocalic gestures in the articulation of Italian glide /w/ at different
syllable positions. In B. Gili Fivela, A. Stella, L. Garrapa, & M. Grimaldi (Eds.),
Contesto comunicativo e variabilità nella produzione e percezione della lingua, Atti del
7°convegno AISV (Associazione Italiana di Scienze della Voce), Lecce (p. 9-24). Roma:
Bulzoni Editore.

246
Appendices
Appendix 1: Experiment Stimuli (Chapters 3 and 4)
Category Word Gloss V
Diphthong
(N= 7)
viaje trip a
viejo trip a
pieza piece/room e
prieto dark e
pliegue fold e
bienes goods e
viola viola o
Hiatus
(N=4)
días days a
crías baby animals a
ríen they laugh e
ríos rivers o
Possible Exceptional Hiatus
(N=9)
diablo devil a
criada maid a
diario newspaper a
piano piano a
piada chirping a
cliente client e
bienio 2-year period e
piojo louse o
criollo Creole o
Distractor
(N=15)
pesa weight e
presa dam/prey e
plena full e
pisa s/he steps on i
prisa hurry/rush i
plisa s/he pleats i
pasa s/he goes by a
prado field a
plaza main square a
posa s/he poses o
prosa prose o
plomo lead o
puso s/he put u
pruna prune u
pluma feather u
Practice Word
(N=5)
lavo I wash a
fuego fire e
lago lake a
lado side e
juego game a

247
Appendix 2: Table of Individual Means and Standard Deviations (Chapter 3)
Table A2.1. Means and SDs of Raw Sequence Durations, by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 192.23 43.61 231.64 28.43 39.41 184.19 42.13 247.59 20.87 63.40
AM 185.88 41.45 227.59 30.48 41.71 148.44 44.07 194.61 20.16 46.17
AN 139.59 32.42 196.72 19.27 57.13 130.01 35.34 183.85 10.18 53.84
CG 113.06 16.41 162.91 14.54 49.85 100.23 14.09 152.54 11.19 52.31
DH 100.80 18.64 147.92 26.65 47.12 79.52 14.75 128.33 22.50 48.81
KR 114.50 29.99 166.09 11.00 51.59 111.80 25.21 166.16 10.70 54.36
LG 119.03 23.43 158.09 14.28 39.06 110.70 20.66 145.19 12.03 34.49
LL 131.97 30.26 181.01 22.57 49.04 118.94 23.65 141.88 17.14 22.94
MM 123.99 36.26 140.88 18.30 16.89 103.00 31.82 142.88 16.09 39.88
MV 156.80 23.84 164.43 16.72 7.63 126.04 28.65 154.37 10.22 28.33
Total 137.86 42.76 177.73 36.26 39.87 121.34 40.32 165.74 36.71 44.40
Table A2.2. Means and SDs of Normalized Sequence Durations, by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 0.28 0.92 1.11 0.60 0.83 0.11 0.89 1.45 0.44 1.34
AM 0.58 0.89 1.48 0.66 0.90 -0.23 0.95 0.77 0.43 0.99
AN 0.18 0.87 1.72 0.52 1.53 -0.08 0.95 1.37 0.27 1.45
CG 0.21 0.62 2.10 0.55 1.89 -0.27 0.53 1.71 0.42 1.98
DH 0.26 0.71 2.05 1.01 1.78 -0.54 0.56 1.31 0.85 1.85
KR 0.06 0.95 1.69 0.35 1.63 -0.03 0.80 1.69 0.34 1.72
LG 0.22 0.89 1.70 0.54 1.48 -0.10 0.78 1.21 0.46 1.31
LL 0.38 0.91 1.85 0.68 1.47 -0.01 0.71 0.68 0.52 0.69
MM 0.50 1.06 0.99 0.53 0.49 -0.11 0.93 1.05 0.47 1.16
MV 0.70 0.82 0.96 0.57 0.26 -0.35 0.98 0.62 0.35 0.97
Total 0.34 0.88 1.57 0.72 1.23 -0.16 0.83 1.19 0.60 1.34
Table A2.3. Means and SDs of Normalized Sequence Durations for V= [a], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 0.58 0.54 1.38 0.65 0.81 0.34 0.55 1.18 0.31 0.83
AM 0.99 0.58 1.91 0.59 0.93 0.19 0.81 0.97 0.38 0.79
AN 0.55 0.54 2.01 0.58 1.46 0.00 0.42 1.37 0.31 1.37
CG 0.52 0.49 1.98 0.72 1.46 0.05 0.59 1.49 0.46 1.44
DH 0.56 0.78 2.86 0.57 2.30 -0.21 0.59 1.62 0.85 1.83
KR 0.39 0.38 1.84 0.36 1.44 0.25 0.51 1.85 0.31 1.61
LG 0.77 0.89 2.00 0.59 1.23 0.36 0.75 1.51 0.45 1.15
LL 0.94 1.06 2.18 0.82 1.24 0.16 0.76 0.77 0.73 0.61
MM 1.22 1.17 1.34 0.56 0.12 0.45 0.93 1.36 0.41 0.9
MV 1.17 0.86 1.01 0.46 -0.16 0.08 0.70 0.76 0.33 0.68
Total 0.77 0.8 1.85 0.74 1.08 0.17 0.69 1.29 0.57 1.12
248
Table A2.4. Means and SD of normalized sequence durations for V= [e], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 0.03 1.24 0.79 0.40 0.76 -0.11 1.19 1.47 0.32 1.58
AM 0.34 1.11 1.04 0.47 0.71 -0.43 1.11 0.42 0.40 0.85
AN 0.06 1.07 1.43 0.09 1.37 -0.12 1.32 1.36 0.28 1.47
CG -0.12 0.66 2.33 0.44 2.45 -0.58 0.35 1.84 0.01 2.42
DH 0.15 0.45 0.76 0.28 0.61 -0.71 0.30 0.30 0.29 1.00
KR 0.02 1.30 1.68 0.34 1.66 -0.09 1.05 1.52 0.44 1.61
LG -0.17 0.61 1.23 0.33 1.40 -0.43 0.63 0.88 0.29 1.31
LL 0.09 0.47 1.34 0.22 1.25 -0.02 0.65 0.55 0.10 0.57
MM 0.05 0.83 0.70 0.20 0.65 -0.37 0.76 0.59 0.38 0.96
MV 0.33 0.58 1.56 0.06 1.23 -0.66 1.16 0.40 0.22 1.06
Total 0.08 0.89 1.29 0.55 1.21 -0.34 0.93 0.93 0.60 1.28
Table A2.5. Means and SD of normalized sequence durations for V= [o], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 0.26 0.44 0.88 0.58 0.62 0.12 0.54 1.97 0.31 1.84
AM 0.33 0.51 1.04 0.36 0.71 -0.57 0.4 0.7 0.45 1.28
AN -0.26 0.65 1.42 0.35 1.68 -0.12 0.73 1.39 0.32 1.51
CG 0.28 0.47 2.11 0.25 1.83 -0.33 0.32 2.02 0.39 2.35
DH -0.05 0.89 1.71 0.25 1.76 -0.82 0.68 1.68 0.26 2.50
KR -0.52 0.33 1.41 0.23 1.93 -0.41 0.31 1.55 0.21 1.96
LG 0.01 0.94 1.57 0.16 1.56 -0.22 0.8 0.95 0.14 1.17
LL -0.17 0.68 1.71 0.24 1.89 -0.35 0.72 0.62 0.22 0.97
MM 0.13 0.34 0.59 0.06 0.47 -0.69 0.71 0.91 0.15 1.60
MV 0.52 0.74 0.28 0.18 -0.24 -0.59 0.83 0.57 0.47 1.16
Total 0.05 0.67 1.27 0.60 1.22 -0.39 0.66 1.24 0.59 1.63
Table A2.6. Means and SD of %Transition, by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 44.05 11.94 31.76 3.71 12.29 42.33 9.01 29.18 7.24 13.15
AM 40.95 10.96 29.22 6.53 11.73 40.19 9.04 29.80 6.60 10.39
AN 46.44 12.53 27.48 6.19 18.96 44.83 13.85 35.13 5.62 9.70
CG 42.34 10.96 39.12 5.49 3.22 43.37 12.82 39.26 7.49 4.11
DH 52.02 10.08 41.69 8.31 10.33 56.77 16.23 41.56 6.13 15.21
KR 57.50 16.75 35.75 6.32 21.75 47.50 14.55 35.03 4.93 12.47
LG 45.35 13.88 33.84 9.27 11.51 48.38 12.53 31.92 6.00 16.46
LL 50.59 10.90 35.32 6.18 15.27 47.15 11.19 36.96 8.08 10.19
MM 50.00 11.66 37.64 12.94 12.36 52.91 14.71 39.34 7.17 13.57
MV 43.82 9.80 30.25 4.89 13.57 51.34 13.67 38.86 5.74 12.48
Total 47.34 12.97 34.21 8.35 13.13 47.49 13.73 35.71 7.51 11.78

249
Table A2.7. Means and SDs of %Transition for V= [a], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 38.45 9.07 33.03 4.45 5.42 42.83 7.62 32.33 7.05 10.50
AM 36.06 6.22 28.56 4.01 7.50 37.66 6.19 30.58 3.52 7.08
AN 40.18 11.65 26.89 6.36 13.29 39.85 12.59 35.43 7.95 4.42
CG 42.67 7.65 35.88 3.30 6.79 39.70 7.56 39.75 4.85 -0.05
DH 52.59 9.95 39.45 6.98 13.14 53.89 13.63 38.99 5.13 14.90
KR 49.81 9.90 31.29 5.19 18.52 50.26 10.02 33.71 5.82 16.55
LG 42.93 10.93 40.02 9.09 2.91 44.28 8.09 33.33 7.36 10.95
LL 49.05 12.21 33.82 4.67 15.23 47.52 12.02 38.50 8.30 9.02
MM 45.75 8.51 36.46 8.63 9.29 49.68 9.98 41.13 3.81 8.55
MV 44.89 9.78 34.16 3.00 10.73 50.77 9.04 42.98 3.71 7.79
Total 44.24 10.72 33.95 6.81 10.28 45.64 11.04 36.67 6.81 8.97
Table A2.8. Means and SDs of %Transition for V= [e], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 48.77 14.14 30.62 2.67 18.15 38.91 9.66 24.79 9.58 14.12
AM 41.44 12.67 23.02 5.80 18.42 40.48 10.88 21.77 5.68 18.71
AN 48.55 9.63 26.04 6.59 22.51 48.54 13.90 35.45 3.52 13.09
CG 41.04 11.82 46.44 4.67 -5.40 43.65 14.09 34.71 2.02 8.94
DH 50.04 9.83 46.91 8.21 3.13 59.94 18.74 46.04 8.39 13.90
KR 63.63 20.13 41.98 4.18 21.65 41.73 17.82 37.74 4.36 3.99
LG 44.72 16.11 25.55 2.74 19.17 50.67 14.62 27.47 1.23 23.20
LL 50.06 10.03 30.74 2.42 19.32 46.31 10.04 41.05 4.61 5.26
MM 49.39 12.51 24.16 7.71 25.23 52.42 11.41 32.82 9.76 19.60
MV 43.06 10.85 25.18 3.08 17.88 47.42 16.62 33.13 4.98 14.29
Total 48.22 14.37 32.07 10.08 16.15 47.11 15.06 33.50 8.73 13.61
Table A2.9. Means and SDs of %Transition for V= [o], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 44.22 5.82 30.38 3.06 13.84 48.93 6.57 27.29 2.90 21.64
AM 49.62 9.12 36.73 4.15 12.89 44.59 8.14 36.28 3.83 8.31
AN 54.06 15.37 30.11 7.16 23.95 46.12 14.59 34.22 1.22 11.90
CG 44.26 15.21 38.27 2.00 5.99 50.18 16.81 42.83 13.96 7.35
DH 55.47 11.00 40.93 11.56 14.54 55.14 15.06 42.23 4.46 12.91
KR 58.61 13.93 38.44 2.54 20.17 55.43 7.81 34.97 3.66 20.46
LG 51.66 13.04 29.78 4.10 21.88 51.24 13.70 33.57 4.57 17.67
LL 54.71 9.88 42.89 5.05 11.82 48.37 13.15 29.80 7.49 18.57
MM 59.95 10.04 53.46 4.86 6.49 61.46 26.40 42.29 8.06 19.17
MV 43.20 8.36 27.51 1.95 15.69 60.32 11.86 36.36 3.54 23.96
Total 51.58 12.41 36.85 8.82 14.73 52.07 14.54 35.98 7.34 16.09

250
Appendix 3: Tables of Individual Means and Standard Deviations (Chapter 4)
Table A3.1. Means and SDs of TB-TT Offset (raw values, in ms), by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 35.42 39.78 53.80 74.20 18.38 27.29 53.39 36.80 51.00 9.51
AM -16.35 59.07 -58.70 57.30 -42.35 16.00 40.00 -14.60 94.80 -30.60
AN 3.33 60.13 50.00 73.80 46.67 24.90 38.25 44.60 44.70 19.70
CG 43.90 83.20 68.33 32.29 24.43 1.59 52.52 -15.40 47.20 -16.99
DH 46.25 52.56 42.10 61.60 -4.15 24.17 49.11 63.33 14.20 39.16
KR 3.78 51.26 -0.42 87.10 -4.20 -2.08 40.00 -65.40 66.10 -63.32
LL -12.81 34.02 8.75 57.60 21.56 -18.85 37.08 -67.10 79.70 -48.25
MM 40.00 25.66 107.08 28.08 67.08 23.85 57.84 76.25 27.81 52.40
Total 17.85 58.07 33.85 76.10 16.00 12.22 48.75 7.00 77.38 -5.22
Table A3.2. Means and SDs of TB-TT Offset (absolute values, in ms), by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 40.63 34.33 75.40 49.50 34.77 42.50 42.04 55.00 27.57 12.50
AM 43.23 43.05 72.10 37.20 28.87 29.96 30.73 82.90 41.40 52.94
AN 37.29 46.97 84.17 20.98 46.88 34.69 29.45 54.58 30.34 19.89
CG 72.83 58.86 68.33 32.29 -4.50 41.82 31.16 46.25 12.45 4.43
DH 56.88 40.54 71.25 13.84 14.37 50.21 20.83 63.33 14.20 13.12
KR 34.67 37.59 72.90 42.20 38.23 25.00 31.08 76.30 51.90 51.30
LL 22.19 28.67 38.80 42.00 16.61 21.77 35.41 69.60 77.40 47.83
MM 40.00 25.66 107.08 28.08 67.08 47.19 40.65 76.25 27.81 29.06
Total 43.30 42.57 73.75 38.13 30.45 36.59 34.41 65.63 41.03 29.04
Table A3.3. Means and SDs of TB-TT Offset (absolute values, in ms), V= [a], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 45.56 39.77 47.50 50.00 1.94 50.80 50.60 46.70 32.70 -4.10
AM 48.90 50.40 73.33 22.51 24.43 37.50 31.21 70.00 31.80 32.50
AN 34.44 34.34 85.80 26.00 51.36 38.61 32.35 59.20 29.90 20.59
CG 65.80 66.70 40.83 8.01 -24.97 42.22 24.39 40.00 12.65 -2.22
DH 48.06 12.85 61.67 13.29 13.61 53.06 16.64 57.50 12.94 4.44
KR 32.78 23.09 73.30 49.40 40.52 26.39 28.27 60.80 54.60 34.41
LL 25.56 31.90 70.00 38.60 44.44 30.00 43.90 81.70 85.70 51.70
MM 39.17 16.91 85.00 9.49 45.83 32.22 17.68 61.67 19.15 29.45
Total 42.53 39.17 67.19 32.89 24.66 38.85 33.02 59.69 40.45 20.84

251
Table A3.4. Means and SDs of TB-TT Offset (absolute values, in ms), V= [e], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 37.86 23.80 128.30 17.60 90.44 39.76 24.72 85.00 0.00 45.24
AM 40.71 38.45 73.30 72.50 32.59 17.62 16.09 111.70 17.60 94.08
AN 26.90 37.53 91.70 18.90 64.80 34.76 30.35 53.30 40.70 18.54
CG 84.90 54.60 113.33 10.41 28.43 44.12 35.63 60.00 5.00 15.88
DH 74.30 53.60 81.67 5.77 7.37 49.05 19.40 78.33 12.58 29.28
KR 39.52 45.55 38.33 7.64 -1.19 28.81 38.57 118.33 11.55 89.52
LL 20.00 27.20 13.33 2.89 -6.67 16.67 31.68 106.70 79.70 90.03
MM 50.00 30.25 140.00 8.66 90.00 54.30 49.10 96.70 40.40 42.40
Total 46.08 44.23 85.00 47.57 38.92 35.43 34.12 88.91 38.43 53.48
Table A3.5. Means and SDs of TB-TT Offset (absolute values, in ms), V= [o], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 37.20 45.40 78.30 18.90 41.10 32.20 55.80 51.67 2.89 19.47
AM 37.80 40.90 68.30 32.50 30.50 43.70 45.70 80.00 69.50 36.30
AN 67.20 75.00 73.33 10.41 6.13 26.67 21.51 46.70 31.80 20.03
CG 62.80 52.10 78.33 2.89 15.53 36.70 37.10 45.00 5.00 8.30
DH 33.89 23.42 80.00 5.00 46.11 47.20 31.40 60.00 8.66 12.80
KR 23.30 45.40 106.67 12.58 83.37 13.33 7.91 65.00 60.60 51.67
LL 20.56 27.89 1.67 2.89 -18.89 17.22 22.65 8.33 7.64 -8.89
MM 18.33 13.46 118.30 27.50 99.97 60.60 46.60 85.00 18.00 24.40
Total 38.26 45.34 75.63 36.13 37.37 34.69 37.89 55.21 37.31 20.52
Table A3.6. Means and SDs of Maximum TB Displacement (%), by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 99.75 1.73 99.85 0.51 0.10 99.87 0.61 100.00 0.00 0.13
AM 96.24 8.90 99.87 0.47 3.63 97.69 6.93 93.70 10.82 -3.99
AN 95.94 7.77 100.00 0.00 4.06 99.97 0.17 98.96 3.61 -1.01
CG 91.71 9.80 98.66 2.54 6.95 98.79 3.60 100.00 0.00 1.22
DH 98.31 6.94 99.98 0.06 1.67 97.38 8.54 100.00 0.00 2.62
KR 91.89 13.96 94.57 10.42 2.68 90.47 14.93 77.78 22.86 -12.69
LL 90.35 15.46 91.14 14.15 0.79 89.47 19.44 88.40 15.32 -1.07
MM 99.44 1.94 100.00 0.00 0.56 100.33 3.20 100.00 0.00 -0.33
Total 95.51 10.00 98.01 6.81 2.50 96.72 10.43 94.80 12.73 -1.92

252
Table A3.7. Means and SDs of Maximum TB Displacement (%), V= [a], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 99.33 2.83 99.71 0.71 0.38 99.85 0.63 100.00 0.00 0.15
AM 98.03 3.24 99.73 0.66 1.70 94.23 10.54 91.40 13.99 -2.83
AN 91.48 10.43 100.00 0.00 8.52 99.91 0.28 97.92 5.10 -1.99
CG 88.75 11.05 97.88 3.29 9.13 98.24 5.12 100.00 0.00 1.76
DH 99.60 1.70 100.00 0.00 0.40 98.00 5.85 100.00 0.00 2.00
KR 95.68 8.78 90.02 13.61 -5.66 94.81 8.05 69.65 16.10 -25.16
LL 89.17 18.83 88.32 17.41 -0.85 94.22 13.38 96.11 4.88 1.89
MM 98.90 2.84 100.00 0.00 1.10 101.20 5.11 100.00 0.00 -1.20
Total 95.12 10.06 96.96 8.63 1.84 97.56 7.71 94.38 12.29 -3.18
Table A3.8. Means and SDs of Maximum TB Displacement (%), V= [e], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 100.00 0.01 100.00 0.00 0.00 100.00 0.01 100.00 0.00 0.00
AM 98.76 4.09 100.00 0.00 1.24 99.68 1.08 100.00 0.00 0.33
AN 98.94 2.69 100.00 0.00 1.06 100.00 0.00 100.00 0.00 0.00
CG 95.56 6.16 100.00 0.00 4.44 99.57 1.39 100.00 0.00 0.43
DH 99.67 1.51 100.00 0.00 0.33 100.00 0.00 100.00 0.00 0.00
KR 93.35 12.80 98.27 2.83 4.92 85.77 19.21 95.20 5.20 9.43
LL 91.68 11.86 100.00 0.00 8.32 83.49 24.64 97.09 5.00 13.60
MM 99.66 1.24 100.00 0.00 0.34 99.74 0.92 100.00 0.00 0.26
Total 97.21 7.32 99.78 1.02 2.57 95.94 12.84 98.99 2.82 3.05
Table A3.9. Means and SDs of Maximum TB Displacement (%), V= [o], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 100.00 0.00 100.00 0.00 0.00 99.63 1.11 100.00 0.00 0.37
AM 86.74 16.60 100.00 0.00 13.26 99.99 0.04 92.01 8.64 -7.98
AN 97.84 5.72 100.00 0.00 2.16 100.00 0.00 100.00 0.00 0.00
CG 89.94 11.48 98.87 1.96 8.93 98.38 2.78 100.00 0.00 1.62
DH 92.53 15.01 99.93 0.12 7.40 90.01 16.60 100.00 0.00 9.99
KR 75.37 20.26 99.97 0.06 24.60 92.77 11.96 76.60 39.30 -16.17
LL 89.59 17.04 87.93 13.61 -1.66 93.90 12.47 64.29 6.54 -29.61
MM 100.00 0.00 100.00 0.00 0.00 99.98 0.07 100.00 0.00 0.02
Total 92.20 13.91 98.34 5.72 6.14 96.83 8.94 91.61 17.81 -5.22

253
Table A3.10. Means and SDs of Maximum TT Displacement (%), by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 88.87 16.72 95.99 10.21 7.12 Mean SD 98.98 3.40 5.24
AM 74.59 21.56 83.44 13.64 8.85 93.74 10.90 90.62 13.18 9.16
AN 82.62 14.38 96.08 9.20 13.46 81.46 22.72 95.90 11.80 2.93
CG 81.48 21.58 93.46 12.50 11.98 92.97 15.07 93.44 8.44 1.14
DH 85.53 20.32 89.11 18.20 3.58 92.30 16.29 100.00 0.00 16.00
KR 94.55 8.36 98.93 1.95 4.38 84.00 25.05 99.26 2.56 3.43
LL 97.27 6.18 97.74 4.23 0.47 95.83 7.93 93.68 10.76 0.77
MM 89.23 14.89 94.40 9.49 5.17 92.91 15.69 100.00 0.00 9.47
Total 86.75 17.67 93.64 11.65 6.89 90.53 19.69 96.46 8.48 6.01
Table A3.11. Means and SDs of TT Displacement at Peak TB (%), by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 79.82 16.69 78.11 18.99 1.71 85.99 13.04 78.49 14.52 7.50
AM 62.41 24.31 53.27 7.89 9.14 73.68 27.63 64.59 22.81 9.09
AN 72.16 17.30 67.99 12.03 4.17 80.90 24.01 57.97 20.19 22.93
CG 57.95 27.02 55.55 17.74 2.40 68.88 27.19 60.13 23.88 8.75
DH 67.29 19.35 53.88 13.99 13.41 61.72 29.99 62.29 11.64 -0.57
KR 87.39 12.40 74.64 31.18 12.75 91.57 9.41 90.12 13.61 1.45
LL 95.36 7.40 95.28 6.17 0.08 92.19 15.36 91.09 9.87 1.10
MM 74.02 19.98 64.55 10.18 9.47 73.32 29.53 74.40 14.34 -1.08
Total 74.58 22.13 67.91 20.98 6.67 78.63 25.24 72.32 20.66 6.31
Table A3.12. Means and SDs of TT Displacement at Peak TB (%), V= [a], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 77.64 20.15 75.90 26.30 1.74 85.26 14.20 78.65 20.14 6.61
AM 60.38 24.44 55.83 7.23 4.55 63.44 33.49 61.00 7.76 2.44
AN 60.82 12.70 61.08 12.26 -0.26 74.17 30.67 53.10 28.50 21.07
CG 52.67 24.26 66.89 19.08 -14.22 65.79 24.01 80.62 12.23 -14.83
DH 61.96 21.02 43.99 13.01 17.97 52.41 28.94 60.97 14.79 -8.56
KR 85.56 15.39 60.20 40.30 25.36 94.37 5.41 83.23 16.86 11.14
LL 96.02 7.83 92.80 7.82 3.22 96.06 8.11 95.57 4.80 0.49
MM 68.52 17.86 59.51 10.45 9.01 69.44 30.05 70.59 18.66 -1.15
Total 70.45 22.93 64.52 23.07 5.93 75.12 27.71 72.96 20.57 2.16

254
Table A3.13. Means and SDs of TT Displacement at Peak TB (%), V= [e], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 79.74 12.9 74.23 8.81 5.51 85.87 11.96 75.77 2.05 10.10
AM 65.86 24.19 46.68 11.01 19.18 83.24 17.68 39.58 13.12 43.66
AN 80.46 12.51 69.83 3.16 10.63 87.69 15.19 62.36 6.75 25.33
CG 67.98 27.19 42.94 4.05 25.04 75.55 30.10 44.87 12.48 30.68
DH 66.84 18.16 66.12 4.78 0.72 61.29 29.45 66.55 8.92 -5.26
KR 88.47 10.39 91.47 1.54 -3.00 88.85 11.58 98.22 0.62 -9.37
LL 95.67 5.94 99.24 0.42 -3.57 88.55 20.11 96.94 3.61 -8.39
MM 69.76 20.21 64.07 6.68 5.69 71.40 32.64 79.24 8.52 -7.84
Total 77.01 20.09 69.32 19.29 7.69 80.42 23.79 70.21 22.21 10.21
Table A3.14. Means and SDs of TT Displacement at Peak TB (%), V= [o], by Rate
Speaker
Rate 1 Rate 2
Diphthong Hiatus Difference
Diphthong Hiatus Difference
Mean SD Mean SD Mean SD Mean SD
AA 84.38 17.98 86.49 5.95 -2.11 87.75 14.41 79.98 5.19 7.77
AM 58.44 26.09 54.71 1.63 3.73 71.85 28.99 96.78 2.83 -24.93
AN 75.50 23.27 79.99 6.80 -4.49 78.50 24.12 63.39 4.67 15.11
CG 48.46 28.31 45.47 5.31 2.99 62.47 27.84 34.40 2.35 28.07
DH 78.98 14.76 61.40 5.29 17.58 81.37 26.60 60.68 9.06 20.69
KR 89.12 9.73 86.75 4.30 2.37 92.30 9.21 95.82 4.21 -3.52
LL 93.32 9.87 96.29 3.59 -2.97 92.95 12.89 76.30 5.07 16.65
MM 94.95 6.20 75.11 2.79 19.84 85.56 18.10 77.17 9.84 8.39
Total 77.41 24.02 73.28 17.37 4.13 81.59 22.65 73.07 20.07 8.52

255
Appendix 4: Hearing Screening (Chapter 5)
Hearing Screening/Prueba de audición
Date: _______________________________Participant code: _________________________
Por favor conteste las siguientes preguntas indicando con ‘’ la opción que corresponda:
1. ¿Tiene antecedentes de problemas del oído? (por ejemplo, infecciones , exceso de cera,
dolor, mucosidades) Sí / No
2. ¿Tiene un zumbido en los oídos? Sí / No
3. ¿Ha estado expuesta a ruidos fuertes en las últimas 24 horas? (por ejemplo, escuchar música
fuerte en el i-pod) Sí / No
4. ¿Ha estado expuesta a ruidos fuertes por períodos prolongados (meses/años)? Por ejemplo:
trabajar en un club/bar, trabajar en una fábrica ruidosa etc… Sí / No
5. ¿Ha tenido algún trastorno de aprendizaje o de desarrollo del habla, de la lectura o de la
escritura? Sí / No
Right Ear Left Ear
500 1000 2000 500 1000 2000
t
hre
shold
lev
el i
n d
B
-10
t
hre
shold
lev
el i
n d
B
-10
0 0
10 10
20 20
30 30
40 40
50 50
60 60
70 70
80 80
90 90
100 100
110 110
120 120
Pure Tone Average: Pure Tone Average:
_______________ = ______ dB _______________ = ______dB
3 3
256
Appendix 5: Handedness Questionnaire (Chapter 5)
Handedness Questionnaire/Cuestionario de preferencia manual
Date: _______________________________Participant code: _________________________
Indique la mano que utiliza normalmente para las siguientes 10 actividades marcando con ‘’ la
casilla correspondiende a cada columna. Por favor escriba una sola respuesta a cada pregunta.
¿Qué mano utiliza … ? Izquierda Derecha Ninguna preferencia (ambas)
1 para escribir
2 para dibujar
3 para cepillarse los dientes
4 para lanzar una pelota
5 para sujetar una cuchara
6 para peinarse el cabello
7 para afeitarse/maquillarse
8 para usar el mouse de la
computadora
9 para sujetar una raqueta
10 para cortar con tijeras
Totals:
(Scoring : L= -1,R = +1, B = 0)


















