
Probability & Statistical Inference Lecture 1
76
Probability & Statistical Inference Lecture 1 MSc in Computing (Data Analytics)
description
Probability & Statistical Inference Lecture 1. MSc in Computing (Data Analytics). Lecture Outline. Introduction General Info Questionnaire Introduction to Statistics Statistics at work The Analytics Process Descriptive Statistics & Distributions Graphs and Visualisation. Introduction. - PowerPoint PPT Presentation
Transcript of Probability & Statistical Inference Lecture 1

Probability & Statistical Inference Lecture 1
MSc in Computing (Data Analytics)

Lecture Outline Introduction
General Info Questionnaire
Introduction to Statistics Statistics at work The Analytics Process Descriptive Statistics & Distributions Graphs and Visualisation

Introduction Name : Aoife D’Arcy Email: [email protected] Bio: Managing Director and Chief Consultant at the
Analytics Store, has degrees in statistics, computer science, and financial & industrial mathematics. With over 10 years of experience in analytics consultancy with major national and international companies in banking, finance, insurance, manufacturing and gaming; Aoife has developed particular expertise in risk analytics, fraud analytics, and customer insight analytics.
Lecture Notes: Will be available online on
www.comp.dit.ie/bmacnamee and later on webcourses

TMP-1Data Mining
TMP-5Research Writing & Scientific Literature
TMP-0Probability & Statistical Inference
TMP-2Data & Database Design for Data
Analytics SPEC9260
Geographic Information Systems
SPEC 9270Machine Learning
TECH9250Complex and Adaptive Agent Based
Computation
INTC 9141 Enterprise Systems Integration
TECH9280Security
TECH9290Ubiquitous Computing
BUS9290Legal Issues for Knowledge
Management
SENG X01Software Project Management
TMP-6Research Methods & Proposal Writing
TMP-4Case Studies in Computing
INTC9221Strategic Issues in IT
INTC9231Internet Systems
SPEC9290Universal Design for Knowledge
Management
TMP-7Research Project & Dissertaion
Core Module
Option Module
Pre-requisite
TMP-3Data Management
SPEC 9160Problem Solving Communication &
Innovation
MATH 4807Financial Mathematics - I
MATH 4810Queuing Theory & Markov Processes
MATH 4814Decision Theory & Games
MATH 4821Industrial & Commercial Statistics
MATH 4809Linear Programming
MATH 4818 Financial Mathematics - II
TMP-9Language Technology
TMP-10Designing and Building Semantic Web
Applications
Programme Overview

Course OutlineWeek Topic
1 Introduction to Statistics2 & 3 Probability Theory4 Introduction to SAS Enterprise Guide5 Probability Distributions6 Confidence Intervals7 & 8 Hypothesis testing9 Assignment10 - 12 Regression Analysis13 Revision

Exam & AssignmentExam The end of term exam accounts for 60% of
the overall mark
Assignment The assignment is worth 40% of the overall
mark. The assignment will be handed out in week 5 Week 9’s class will be dedicated to working
on the assignment.

Software SAS Enterprise Guide will be the software that
will be used during the course.

Applied Statistics and Probability for EngineersJohn Wiley & SonsDouglas C. Montgomery
Probability and Statistics for Engineers and ScientistsPearson EducationR.E. Walpole, R.H. Myers, S.L. Myers, K. Ye
Modelling Binary DataChapman & HallDavid Collett
Probability and Random Processes Oxford University PressG. Grimmett & D. Stirzaker
Statistical InferenceBrooks/ColeGeorge Casella
Recommended Reading

Questionnaire

Section 1: Statistics at work

Statistics in Everyday Life With the increase in the amount of data
available and advancement`s in the power of computers, statistics are being used more and more frequently. We are constantly reading about surveys done where 3 out 5 people prefer brand X or research has shown that having tomatoes in your diet can reduce the risk of dieses Y.
Is it good that statistics are used so much and what happens
when statistics are misused?

Statistics can be misleading An ad claimed:
“9 Out of 10 Dentists prefer Colgate” What is wrong with this statement?
During the Obama presidential election the follow was stated:“According to the Advertising Project, one out of three McCain ads has been negative, criticizing Obama. Nine out of 10 Obama ads have been positive, stressing his own background and ideas.” What is wrong with this statement?

Misinterpreted Statistics can be Devastating In 1999 Sally Clarke was wrongly convicted of
the murder of two of her sons. The case was widely criticised because of the way statistical evidence was misrepresented in the original trial, particularly by paediatrician Professor Sir Roy Meadow.
He claimed that, for an affluent non-smoking family like the Clarks, the probability of a single cot death was 1 in 8,543, so the probability of two cot deaths in the same family was around "1 in 73 million" (8543 × 8543).
What is wrong with this assumption?

Video

Challenges As an Analytics practitioner you will face a
number of challenges:
Create insight from data Interpret statistic correctly Communicate statistically driven insight in a way
that is clearly understood

The Analytics Process & Statistics

Section Overview Statistics and Analytics Introduction to CRISP
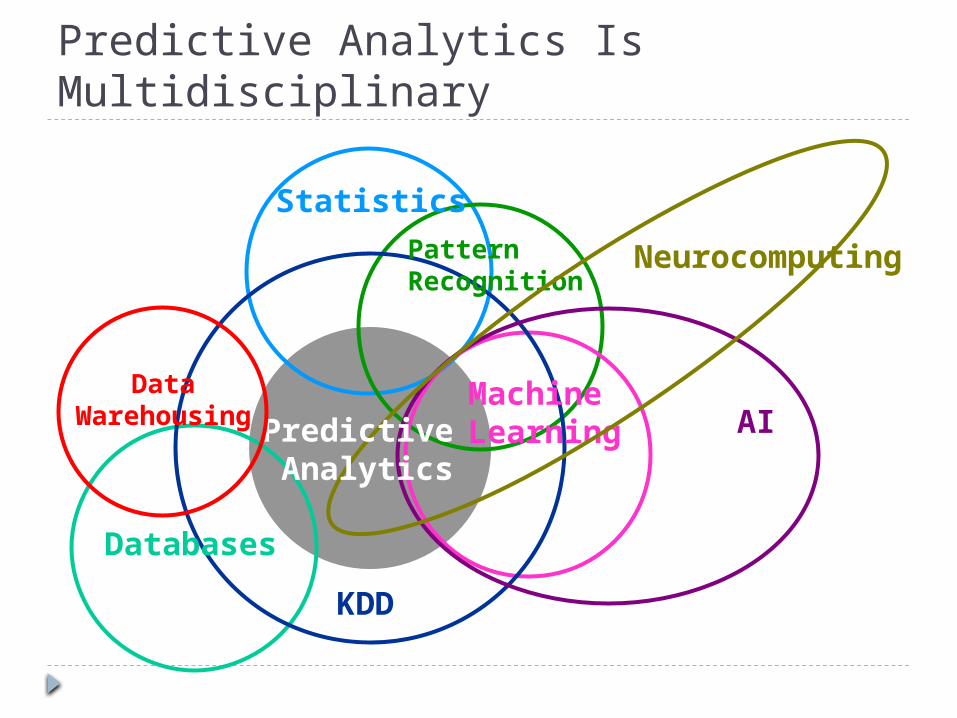
Predictive Analytics Is Multidisciplinary
Databases
StatisticsPatternRecognition
KDD
MachineLearning AI
Neurocomputing
Predictive Analytics
Data Warehousing

CRISP-DM Evolution Over 200 members of the CRISP-DM SIG
worldwide DM Vendors: SPSS, NCR, IBM, SAS, SGI, Data
Distilleries, Syllogic, etc System Suppliers/Consultants: Cap Gemini, ICL
Retail, Deloitte & Touche, etc End Users: BT, ABB, Lloyds Bank, AirTouch,
Experian, etc Crisp-DM 2.0 is due…
Complete information on CRISP-DM is available at: http://www.crisp-dm.org/

CRISP-DM Features of CRISP-DM:
Non-proprietary Application/Industry neutral Tool neutral Focus on business issues
As well as technical analysis Framework for guidance Experience base
Templates for Analysis

Data
Business Understandin
g
Data Understandin
g
Data Preparation
Modelling
Evaluation
Deployment

Phases & Generic TasksBusiness
Understanding Data
Understanding Data
Preparation Modeling Deployment Evaluation
Determine Business Objectives
AssessSituation
DetermineData Mining
Goals
ProduceProject Plan
Business Understanding
This initial phase focuses on understanding the project objectives and requirements from a business perspective, then converting this knowledge into a data mining problem definition and a preliminary plan designed to achieve the objectives

Phases & Generic TasksBusiness
Understanding Data
Understanding Data
Preparation Modeling Deployment Evaluation
CollectInitialData
DescribeData
ExploreData
VerifyData
Quality
Data Understanding
The data understanding phase starts with an initial data collection and proceeds with activities in order to get familiar with the data, to identify data quality problems, to discover first insights into the data or to detect interesting subsets to form hypotheses for hidden information.

Phases & Generic TasksBusiness
Understanding Data
Understanding Data
Preparation Modeling Deployment Evaluation
SelectData
CleanData
ConstructData
IntegrateData
FormatData
Data Preparation
The data preparation phase covers all activities to construct the data that will be fed into the modelling tools from the initial raw data. Data preparation tasks are likely to be performed multiple times and not in any prescribed order. Tasks include table, record and attribute selection as well as transformation and cleaning of data for modelling tools.

Phases & Generic TasksBusiness
Understanding Data
Understanding Data
Preparation Modeling Deployment Evaluation
SelectModelingTechnique
GenerateTest Design
BuildModel
AssessModel
Modelling
In this phase, various modelling techniques are selected and applied and their parameters are calibrated to optimal values. Typically, there are several techniques for the same data mining problem type. Some techniques have specific requirements on the form of data. Therefore, stepping back to the data preparation phase is often necessary.

Phases & Generic TasksBusiness
Understanding Data
Understanding Data
Preparation Modeling Deployment Evaluation
EvaluateResults
ReviewProcess
DetermineNext Steps
Evaluation
Before proceeding to final deployment of a model, it is important to thoroughly evaluate it and review the steps executed to construct it to be certain it properly achieves the business objectives. A key objective is to determine if there is some important business issue that has not been sufficiently considered. At the end of this phase, a decision on the use of the data mining results should be reached.

Phases & Generic TasksBusiness
Understanding Data
Understanding Data
Preparation Modeling Deployment Evaluation
Plan Deployment
Plan Monitoring &
Maintenance
ProduceFinal
Report
ReviewProject
Deployment
Creation of a model is generally not the end of the project. Even if the purpose of the model is to increase knowledge of the data, the knowledge gained will need to be organized and presented in a way that the customer can use it. Depending on the requirements, the deployment phase can be as simple as generating a report or as complex as implementing a repeatable data mining process across the enterprise.

Crisp - DM Business Understanding Data Understanding Data Preparation Modelling Evaluation Deployment.

Crisp – DM – Areas covered in this course Business Understanding Data Understanding Data Preparation Modelling Evaluation Deployment

Section 2: Descriptive Statistics & Distributions

Topics1. Introduction to Statistics2. The Basics 3. Measures of location: Mean, Median & Mode.4. Measures of location & Skew.5. Measures of dispersion: range, standard
deviation (variance) & interquartile range.

Introduction to Statistics According to The Random House College
Dictionary, statistics is “the science that deals with the collection, classification, analysis and interpretation of numerical facts or data.” In short, statistics is the science of data.
There are two main branches of Statistics: The branch of statistics devoted to the
organisation, summarization and the description of data sets is called Descriptive Statistics.
The branch of statistics concerned with using sample data to make an inference about a large set of data is called Inferential Statistics.

Process of Data Analysis
Population
Representative Sample
Sample Statistic
A Statistical population is a data set that is our target of interest.
A sample is a subset of data selected from the target population.
If your sample is not representative then it is referred to as being bias
Describe
Make Inferenc
e

Types of Data There are a number of data types that we will
be considering. These can be split into hierarchy of 4 levels of
measurement.1. Categorical
a) Nominalb) Ordinal
2. Intervala) Discreteb) Continuous

Describing Distributions

Describing Distributions

Measures of Location (Central Tendency)
Numbers that attempt to express the location of data on the number line
Variable(s) are said to be distributed over the number line - so we talk of distributions of numbers
•Want a measure of the location of this data on the number line.
•There is 'symmetry' around this point in this particular data – hence the term central tendency

Arithmetic Mean (average) The mean of a data set is one of the most
commonly used statistics. It is a measure of the central tendency of the data set.
The mean of a sample is denoted by (pronounced x bar) and the mean of a population is denoted by µ (pronounced mew).
They are both ( and µ ) computed using the same formula.
X___
X___
n
n
iX 1

Arithmetic Mean - Example Example: Ages of Students in 1st year history of Art
degree course 18, 18, 18, 18, 19, 19, 20, 20, 58
Mean of ages here is 23.11 – but this is not a ‘typical value or a value around which the observed values cluster.
The same thing tends to happen with values that are strictly positive: average salaries, house prices etc.
We say that the mean is sensitive to extreme values

Median The middle value of the ordered set of
values, i.e. 50% higher and 50% lower.
Example: The class age data again 18, 18, 18, 18, 19, 19, 20, 20, 58 The data is ordered, and n = 9, so the
middle number is (n+1)/2 = (9+1)/2 = 5th value = 19
=> median = 19 years

Median• Robust with regard to extreme values
• Often a real value in the distribution or close to 2 real values - in that sense tends to be more typical of actually observed values

Mode The most commonly occurring value in a distribution
Example: The class age data again 18, 18, 18, 18, 19, 19, 20, 20, 58
The mode is 18 years as it occurs more than any other
Tends to show where the data is concentrated
Mode: 18 Mean: 23.11 Median: 19

Skew – The Shape of a DistributionThere are a number of ways of describing the shape of a distribution.
We will consider only one – skew.
Skew is a measure of how asymmetric a distribution is.

Symmetric Distributions = skew is zero

There are few very large data points which create a 'tail' going to the right (i.e. up the number line)
Note: No axis of symmetry here - skew > 0 (i.e. it is positive)
Example: Lifetime of people, house prices
Positive Skew

There are few very small data points which create a 'tail' going to the left (i.e. down the number line)
Note: No axis of symmetry here - skew < 0 (i.e. it is negative)
Examples: Examination Scores, reaction times for drivers
Negative Skew

Mean, Median & Mode are the same and are found in the middle
66
5 6 74 5 6 7 8
3 4 5 6 7 8 9
Mean = 102/17 = 6Median = 6Mode = 6
Skew & Measures of Location - Symmetry

ModeMedianMean
66
5 6 75 6 7 8 95 6 7 8 9 10 11
Mean = 121/17 = 7.12Median = 7Mode = 6
In general: Mode < Median < Mean
Positive Skew

ModeMedianMean
Mean = 83/17 = 4.89Median = 5Mode = 6
In general: Mode > Median > Mean
66
5 6 73 4 5 6 7
1 2 3 4 5 6 7
Negative Skew

• The Mean, Mode and Median all 250 for both companies
• But not the same - look at the difference in ‘spread’ of bills
• Need a measure of spread (dispersion) as well as location to describe a distribution
Measures of Spread (Dispersion)

Location
Spread

Range Simplest measure of spread = largest -
smallest
Example for data in histograms: Esat: Largest = €335 Smallest = €180
Range = €335 - €180 = €155
Meteor: Largest = €295 Smallest = €210Range = €295 - €210 = €85
Very simple to compute
Easy to interpret
Does not use all the data
Subject to effect by extreme values

Range Example: The class age data again
18, 18, 18, 18, 19, 19, 20, 20, 58
Range: 58-18 = 40 years
Is this really indicative of the spread of ages?
=> if the mature student was not there, range would be 2 years - so just 1 extreme value has huge effect on range

Typical Deviation – Average Deviation Consider the following data:
OBS Data Mean Deviation
1 3 5 -22 4 5 -13 8 5 3
Sum 15 15 0Mean 5 5 0

Typical Deviation – Average Squared Deviation (Variance) Consider the following data:
OBS Data Deviation (Deviation)2
1 3 -2 42 4 -1 13 8 3 9
Sum 15 0 14Mean 5 0 14/3

Variance – the formula 1. Square the deviations around the mean before
summing. NB. quantities will be in squared units e.g. cm2 > not original scale:
2. Divide by n-1 (?) to get the average of (deviations )2
2 xx
22
1
nxxs

Standard Deviation
2
1
nxxs
Take the square root of the variance . The value is in the original unit

Quantiles The nth quantile is a value that has a
proportion n of the sample taking values smaller than it and 1-n taking values larger than it.
For Example: if your grade in an industrial engineering class was located at the 84th percentile, then 84% of the grades were lower than your grade and 16% were higher.
The median is the 50th percentile. The 25th percentile and the 75th percentile are called the lower (1st) quartile and upper (3rd) quartile respectively.
The difference between the lower and upper quartile is called the inter-quartile range.

ExampleClass Age data: 18, 18, 18, 18, 19, 19, 20, 20, 58Order No: 1 2 3 4 5 6 7 8 9 1st Quartile = 1+(n-1)/4 =1+ (8)/4 = 3rd score => 18 Median = 1+2×(n-1)/4 = 1+2×(8)/4 = 5th score =>
19 3rd Quartile = 1+3×(n-1)/4 = 1+3×(8)/4 = 7th score =>
20
Interquartile Range : 20 - 18 = 2 years

Coefficient of Variation A problem with s is that it is was scale specific - i.e.
comparison of s calculated on difference scales is hard to do.
Example: Distribution A: 8, 9, 10, 11, 12, 13, 14 Distribution B: 1008, 1009, 1010, 1011, 1012, 1013, 1014
Use two of the measures of spread we have
RangeRange for A: 14 - 8 = 6Range for B: 1014 - 1008 = 6
Standard Deviation (s)
s for A:= 2.16 s for B:= 2.16

Why are the standard deviations the same ?s measures average deviation around the mean.
A A-Mean
B B-Mean
8 -3 1008 -3 9 -2 1009 -2 10 -1 1010 -1 11 0 1011 0 12 1 1012 1 13 2 1013 2 14 3 1014 3
Mean = 11 Mean =1011

Coefficient of variation
%100. XsVC
• C.V. is unit-less (i.e. scale-less) • Can compare difference measurement systems
and standardise for differences in scale E.G. for data above; A: C.V. = ( 2.16 / 11 ) 100% => 19.6 %B: C.V. = ( 2.16 / 1011 ) 100% => 0.2 %

Section 3: Graphs and Visualisation

A way of letting people get a 'picture' of relationships in the data set.
The simpler the better should be a rule in graphical display.
People can remember pictures better.
A good graph should show something that is not easy to ‘see’ using tables.
Graphical Displays

Bar Charts Used to display categorical data or
discrete data with a modest number of values.
A Bar is drawn to represent each category. The Bar height represents the frequency
or % in each category. Allows for visual comparison of relative
frequencies. Need to draw up a frequency distribution
table first.

Table 1.- Counts in each exercise categoryExercise FrequencyV. High 32High 30Medium 52Low 32None 36
Frequency of Exercise Levels from Exercise Data Set
0
10
20
30
40
50
60
V. High High Medium Low None
Freq
uenc
y

So, 5 categories 5 bars heights of bar are the frequencies Clear to see hierarchy in frequency, and can
make a guess at relative percentages between categories
E.G. ‘Low’ looks about 60% of ‘Medium’ Actual = ( 32/52 ) 100% = 61.53 %
Note appropriate title and axis labels

0
10
20
30
40
50
60
V. High HighMedium Low None
Freq
uenc
y
Frequency of Exercise Levels from Exercise Data Set
Do NOT use 3D effects – The angling loses information
Also colouring effects can distract

Can use more than one set of bars to subdivide groups e.g. same data – subdivided by gender
Table 2. Exercise Level By Sex
Gender
Exercise Female
Male
V. High 13 19High 12 18Medium 22 30Low 16 16None 8 28
0
5
10
15
20
25
30
35
Freq
uenc
y
Exercise level by Gender
Female Male

Another way to subdivide groups in the barsDivide segments in each bar to represent the frequency ( or % ) of each group in that category
0
10
20
30
40
50
60
Freq
uenc
y
Exercise level by Gender
MaleFemale
Component bar charts

Histogram Histograms are among the most widely
used method for displaying continuous data
Has similarities with bar chart – but definitely not the same!
A rectangle is drawn to represent the frequency in a grouped frequency distribution table
Components; 2 axes, x and y

Histogram x axis: Grouped intervals are chosen to
appropriately display data.
y axis: Heights are chosen to represent frequency, or some form of relative frequency, % or density.
Example: From the Exercise data set - want to look at height variable for all people.
E.G. Construct grouped frequency distribution table of peoples heights from the Exercise dataset.

Table 3. Heights cm
Frequency
>150 - 155 3>155-160 10>160-165 29>165-170 37>170-175 44>175-180 34>180-185 19>185-190 6Total 182

• Choose intervals to reflect meaningful groupings,
OR
• Choose largest number of intervals that avoids jaggedness.
Be careful with choice of intervals as shape can change.

40455055606570758085
140 150 160 170 180 190 200
Wei
ght
Height
Scatter Plot of Weight by Height
Scatterplots

Used for plotting data over timeX-axis is a time lineY-axis is the value changing over time
Profit - £0,000'sQuarter 1992 1993 1994
1 114 116 1282 142 150 1583 155 153 1694 136 140 159
80
100
120
140
160
180
1 2 3 4 1 2 3 4 1 2 3 4
1992 1993 1994Shows ‘Trend’ & ‘Seasonality’
Time Series Plots


















