
Privacy Preserving OLAP Rakesh Agrawal, IBM Almaden Ramakrishnan Srikant, IBM Almaden Dilys Thomas,...
39
Privacy Preserving OLAP Rakesh Agrawal, IBM Almaden Ramakrishnan Srikant, IBM Almaden Dilys Thomas, Stanford University
-
date post
21-Dec-2015 -
Category
Documents
-
view
224 -
download
1
Transcript of Privacy Preserving OLAP Rakesh Agrawal, IBM Almaden Ramakrishnan Srikant, IBM Almaden Dilys Thomas,...

Privacy Preserving OLAP
Rakesh Agrawal, IBM Almaden
Ramakrishnan Srikant, IBM Almaden
Dilys Thomas, Stanford University
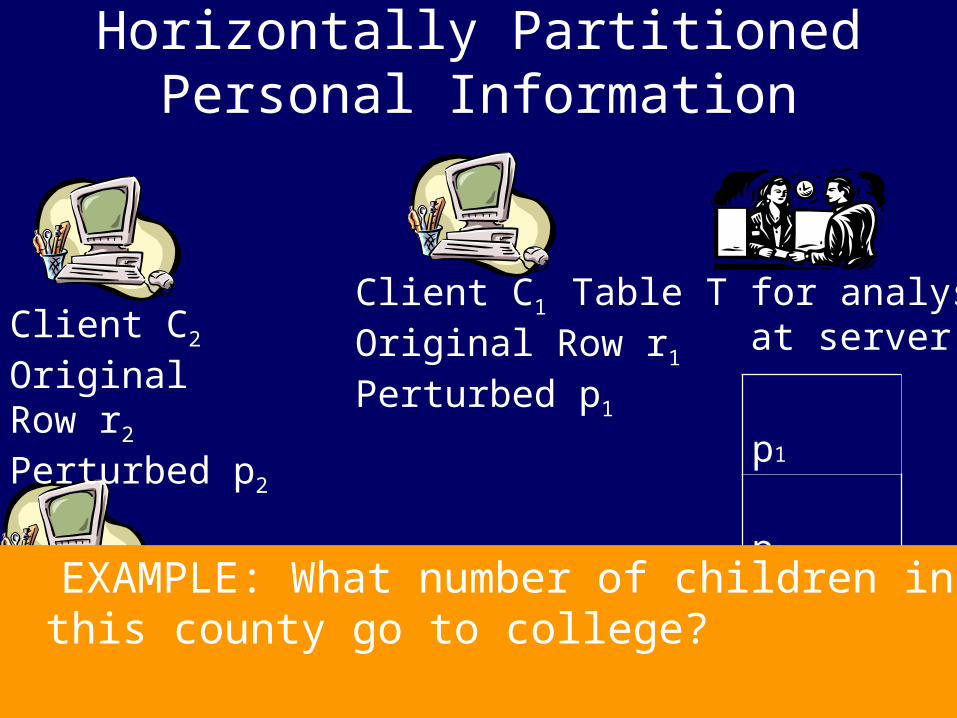
Horizontally Partitioned Personal Information
p1
p2
pn
Table T for analysis at server
Client C1
Original Row r1
Perturbed p1
Client C2
Original Row r2
Perturbed p2
Client Cn
Original Row rn
Perturbed pn
EXAMPLE: What number of children in this county go to college?

Vertically Partitioned Enterprise Information
ID C1
John 1Alice 5Bob 18
ID C1
John 1Alice 7Bob 18
ID C2 C3
John 27 9Alice 53 6
ID C2 C3
John 35 9Alice 53 7
ID C1 C2 C3
John 1 35 9Alice 7 53 7Original Relation D1 Perturbed Relation D’1
Original Relation D2 Perturbed Relation D’2
Perturbed Joined Relation D’
EXAMPLE: What fraction of United customers to New York fly Virgin Atlantic to travel to London?

Talk Outline
• Motivation
• Problem Definition
• Query Reconstruction
• Privacy Guarantees
• Experiments

Privacy Preserving OLAP
Compute
select count(*) from Tselect count(*) from T
where Pwhere P11 and Pand P22 and P and P33 and …. P and …. Pkk
i.e. COUNTT( P1 and P2 and P3 and …. Pk )
We need to
provide error bounds to analyst.
provide privacy guarantees to data sources.
scale to larger # of attributes.

Uniform Retention ReplacementPerturbation
1
1
3
4
2
5
4
3
1
3
HEADS: RETAINTAILS: REPLACE U.A.R FROM [1-5]
BIAS=0.2
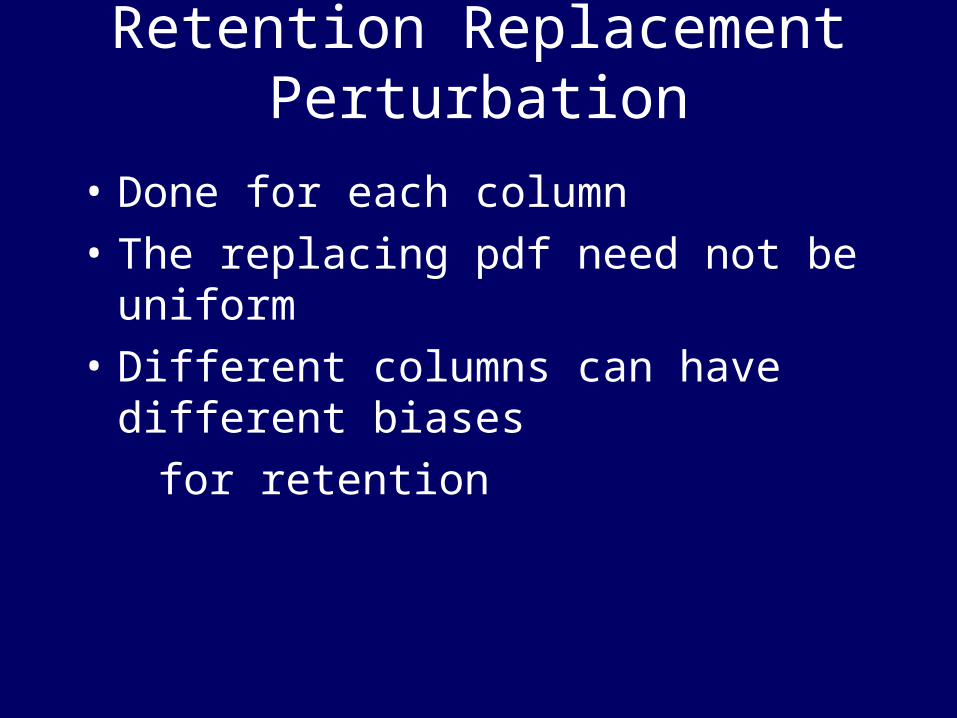
Retention Replacement Perturbation
• Done for each column
• The replacing pdf need not be uniform
• Different columns can have different biases
for retention

Talk Outline
• Motivation• Problem Definition• Query Reconstruction
Inversion method Single attribute Multiple attributesIterative method
• Privacy Guarantees• Experiments
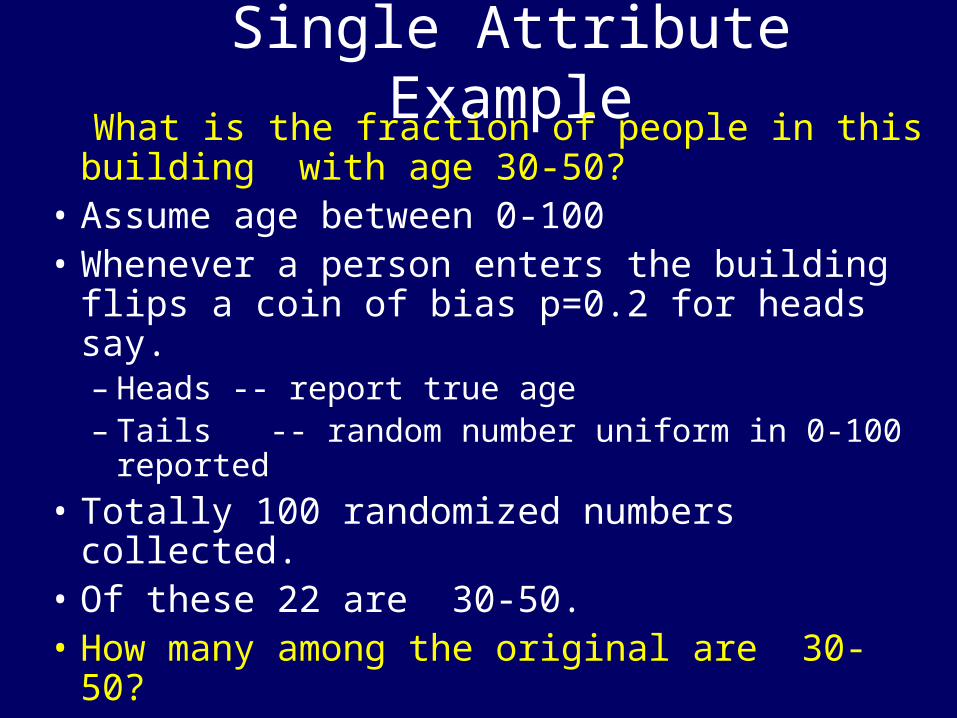
Single Attribute Example What is the fraction of people in this building
with age 30-50?• Assume age between 0-100• Whenever a person enters the building flips
a coin of bias p=0.2 for heads say.– Heads -- report true age– Tails -- random number uniform in 0-100
reported
• Totally 100 randomized numbers collected.• Of these 22 are 30-50.• How many among the original are 30-50?
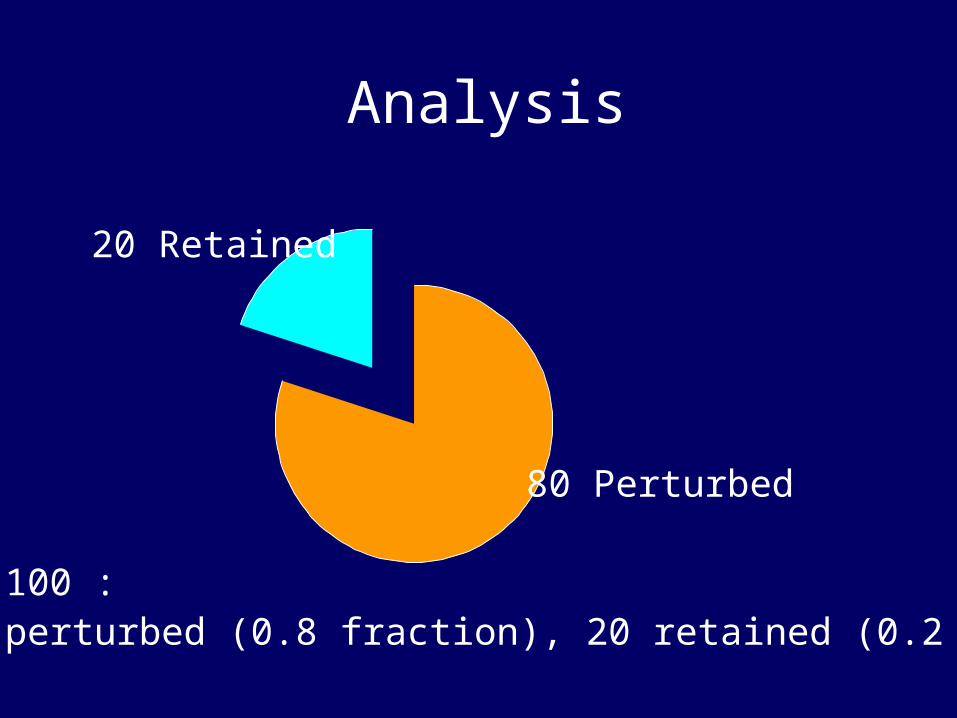
Analysis
80 Perturbed
20 Retained
Out of 100 : 80 perturbed (0.8 fraction), 20 retained (0.2 fraction)
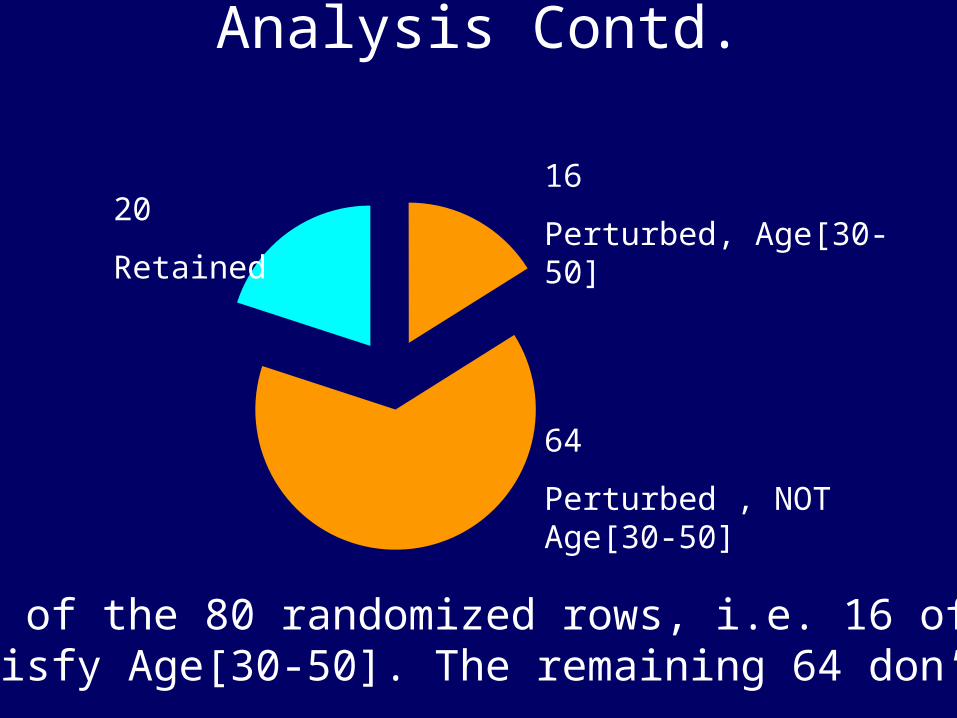
Analysis Contd.
64
Perturbed , NOT Age[30-50]
16
Perturbed, Age[30-50]20
Retained
20% of the 80 randomized rows, i.e. 16 of themsatisfy Age[30-50]. The remaining 64 don’t.
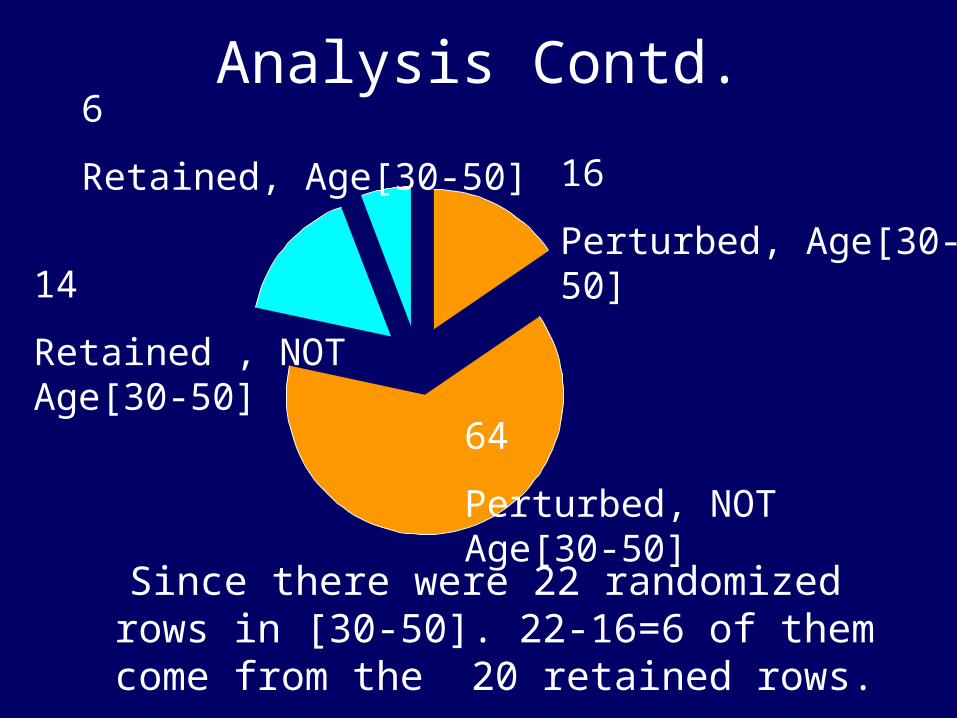
Analysis Contd.
Since there were 22 randomized rows in [30-50]. 22-16=6 of them come from the 20 retained rows.
16
Perturbed, Age[30-50]
64
Perturbed, NOT Age[30-50]
6
Retained, Age[30-50]
14
Retained , NOT Age[30-50]

Scaling up
Total Rows
Age[30-50]
20 6
100?30
Thus 30 people had age 30-50 in expectation.
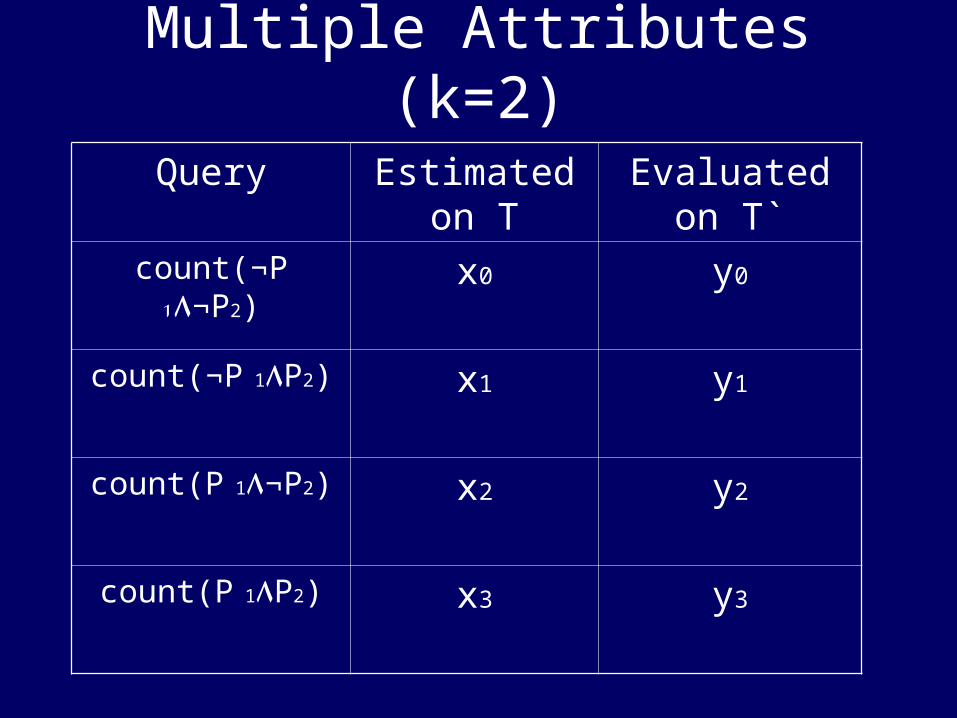
Multiple Attributes (k=2)
Query Estimated on T
Evaluated on T`
count(¬P 1٨¬P2) x0 y0
count(¬P 1٨P2) x1 y1
count(P 1٨¬P2) x2 y2
count(P 1٨P2) x3 y3
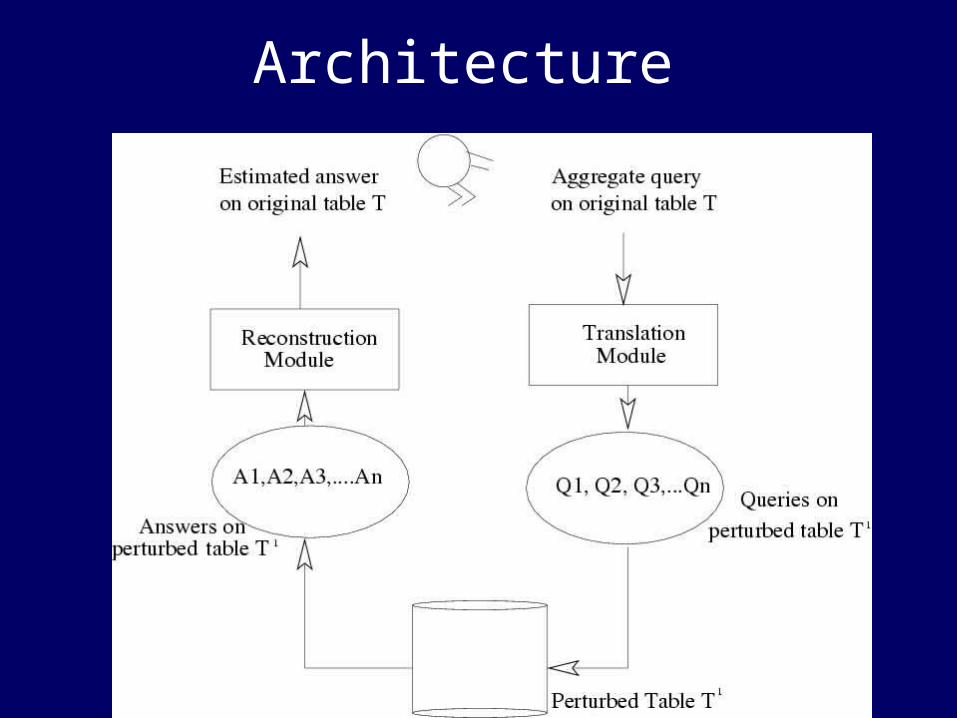
Architecture
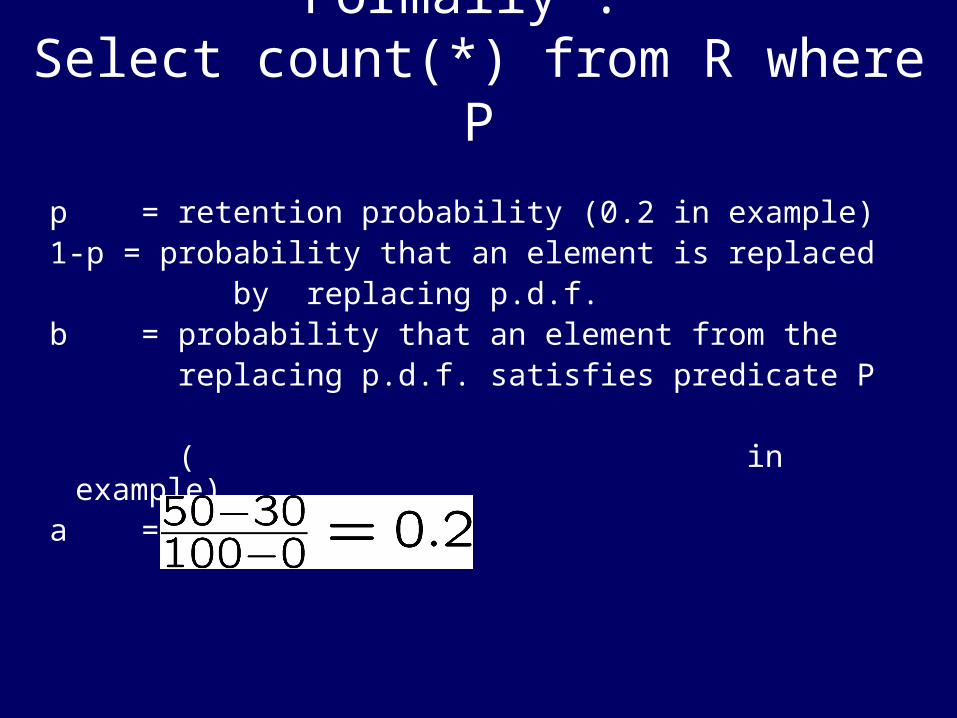
Formally : Select count(*) from R where P
p = retention probability (0.2 in example)1-p = probability that an element is replaced by replacing p.d.f.b = probability that an element from the replacing p.d.f. satisfies predicate P
( in example)a = 1-b

Transition matrix
(1-p)a + p (1-p)b
(1-p)a (1-p)b+p
CountT(: P) CountT( P) CountT’(: P) CountT’(P)=
i.e. Solve xA=y
A00 = probability that original element satisfies : P and after perturbation satisfies : P
p = probability it was retained
(1-p)a = probability it was perturbed and satisfies : P
A00 = (1-p)a+p

Multiple Attributes
For k attributes,
• x, y are vectors of size 2k
• x=y A-1
Where A=A1 A2 .. Ak [Tensor Product]
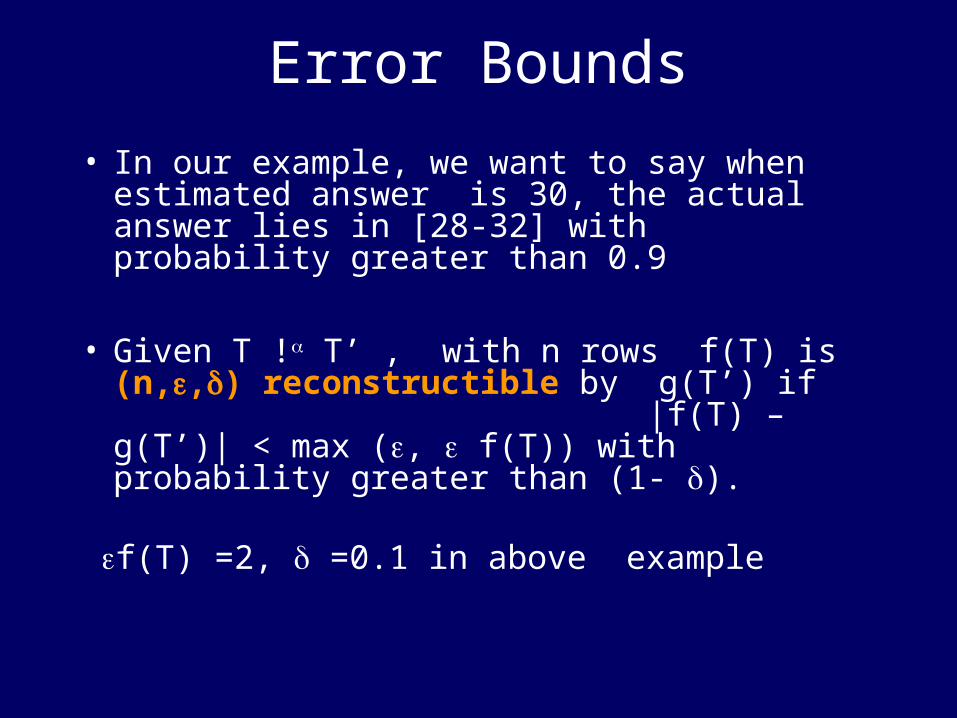
Error Bounds
• In our example, we want to say when estimated answer is 30, the actual answer lies in [28-32] with probability greater than 0.9
• Given T ! T’ , with n rows f(T) is (n,,) reconstructible by g(T’) if |f(T) – g(T’)| < max (, f(T)) with probability greater than (1- ).
f(T) =2, =0.1 in above example
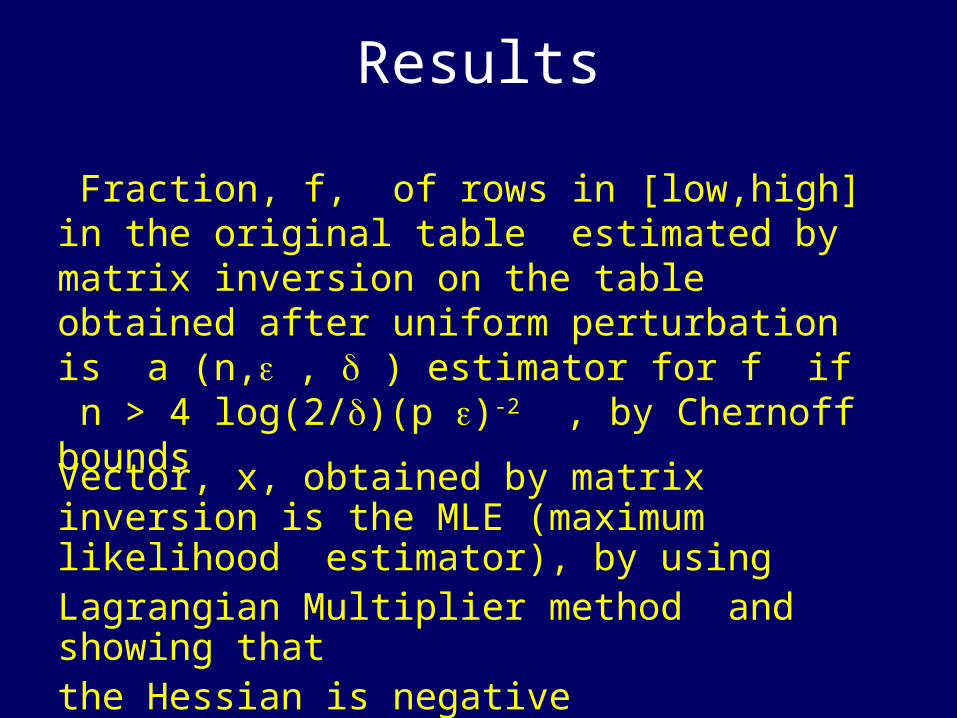
Results
Fraction, f, of rows in [low,high] in the original table estimated by matrix inversion on the table obtained after uniform perturbation is a (n, , ) estimator for f if n > 4 log(2/)(p )-2 , by Chernoff bounds
Vector, x, obtained by matrix inversion is the MLE (maximum likelihood estimator), by usingLagrangian Multiplier method and showing thatthe Hessian is negative

Talk Outline
• Motivation
• Problem Definition
• Query ReconstructionInversion method
Iterative method
• Privacy Guarantees
• Experiments

Iterative Algorithm [AS00]
Iterate:
xpT+1 = q=0
t yq (apqxpT / (r=0
t arq xrT))
[ By Application of Bayes Rule]
Initialize: x0=y
Stop Condition:
Two consecutive x iterates do not differ much

Iterative Algorithm
• RESULT [AA01]: The Iterative Algorithm gives the MLE with the additional constraint that 0 < xi , 8 0 < i < 2k-1

Talk Outline
• Motivation
• Problem Definition
• Query Reconstruction
• Privacy Guarantees
• Experiments

Privacy Guarantees
Say initially know with probability < 0.3 that Alice’s age > 25
After seeing perturbed value can say that with probability > 0.95
Then we say there is a (0.3,0.95) privacy breach

• Let X, Y be random variables where
X = original value, Y= perturbed value.
Let Q, S be subsets of their domains• Apriori Probability
P[ X 2 Q] = Pq · 1
• Posteriori Probability
P[X 2 Q | Y 2 ] ¸ 2
where 0 < 1 < 2 < 1 and P[Y 2 ] > 0
S
Privacy Guarantees
Q
Where pq/mq < s, i.e. Q is a rare set
(mq = probability of Q under replacing pdf)
(1,2) Privacy breach (s,1,2) Privacy breach
S Q

(s, 1, 2) vs (1,2) metric
– Provides more privacy to rare sets
e.g. : in market basket data, medicines are rarer than bread, so we provide more privacy for
medicines than for bread
– For multiple columns, s expresses correlations
– Works for retention replacement perturbation on numeric attributes

(s,1,2) Guarantees
The median value of s is 1
There is no (s,1,2) privacy breach for s < f(1,2,p) for retention replacement perturbation on single as well as multiple columns

Application to Classification[AS00]
• For the first split to compute split criterion/gini index Count(age[0-30] and class-var=‘-’) Count(age[0-30] and class-var=‘+’) Count(: age[0-30] and class-var=‘-’) Count(: age[0-30] and class-var=‘+’)

Talk Outline• Motivation• Problem Definition• Query Reconstruction• Privacy Guarantees• Experiments
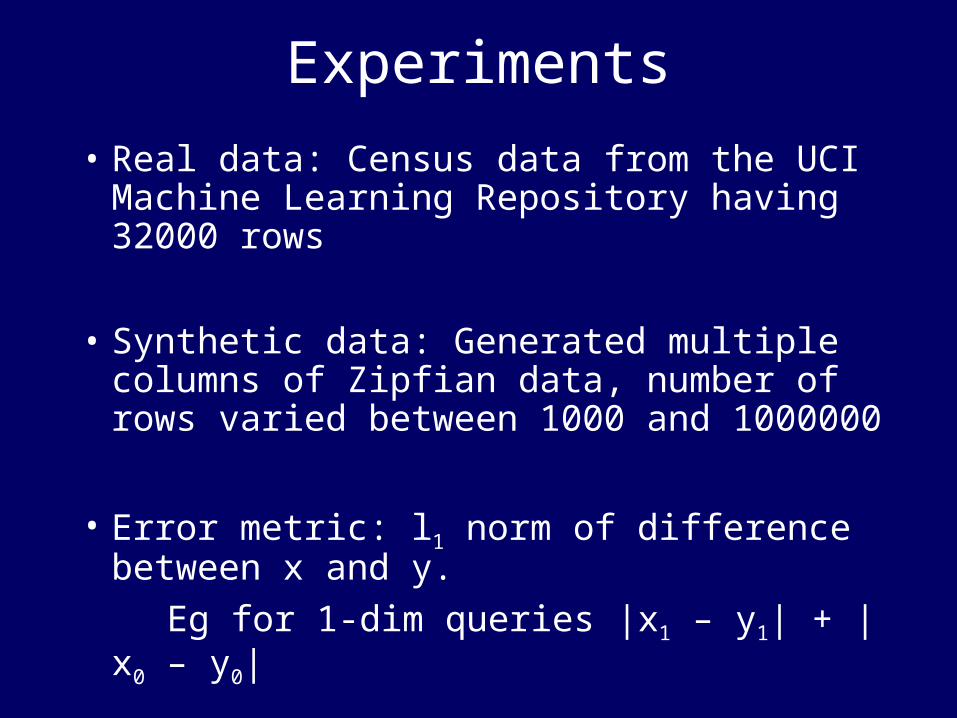
Experiments
• Real data: Census data from the UCI Machine Learning Repository having 32000 rows
• Synthetic data: Generated multiple columns of Zipfian data, number of rows varied between 1000 and 1000000
• Error metric: l1 norm of difference between x and y.
Eg for 1-dim queries |x1 – y1| + | x0 – y0|
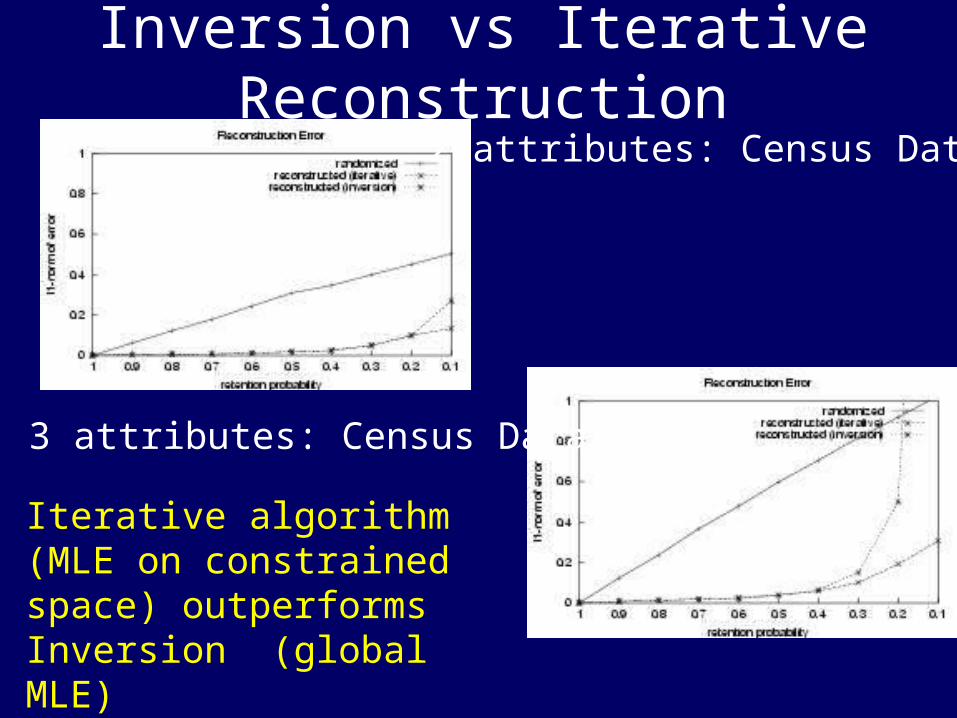
Inversion vs Iterative Reconstruction
2 attributes: Census Data
3 attributes: Census Data
Iterative algorithm (MLE on constrained space) outperforms Inversion (global MLE)
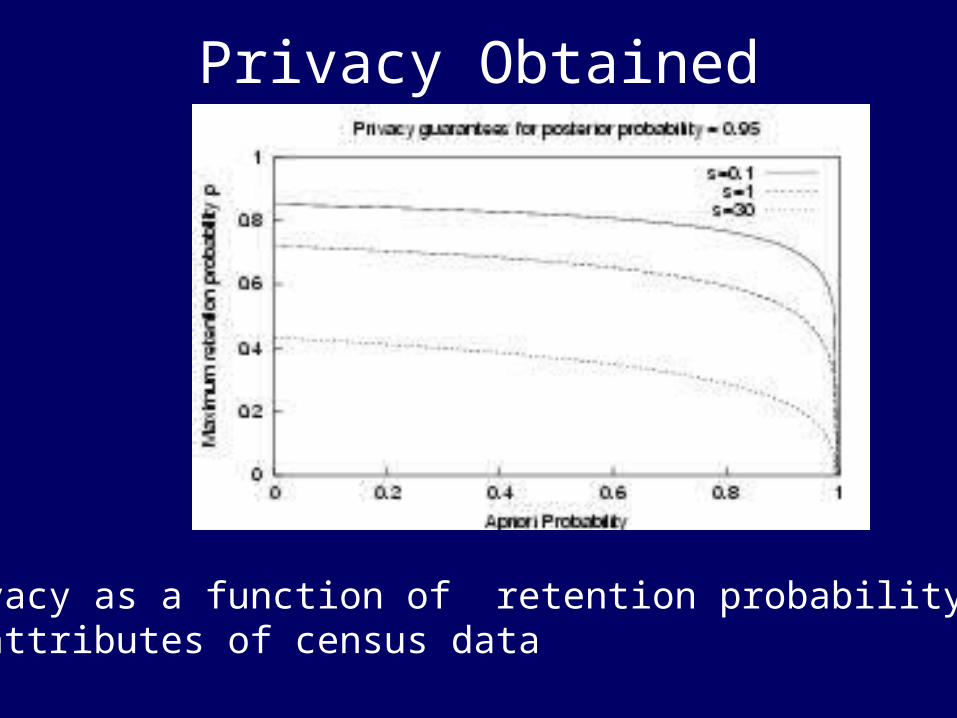
Privacy Obtained
Privacy as a function of retention probability on 3 attributes of census data

Error vs Number of Columns: Census Data
Inversion Algorithm
Iterative Algorithm
Error increases exponentially with increase in number of columns

Error as a function of number of Rows
Error has square root n dependence on number of rows

Conclusion
Possible to run OLAP on data across multiple servers so that probabilistically approximate answers are obtained and data privacy is maintained
The techniques have been tested experimentally on real and synthetic data. More experiments in the paper.
PRIVACY PRESERVING OLAP is PRACTICAL

References
• [AS00] Agrawal, Srikant: Privacy Preserving Data Mining
• [AA01] Agarwal, Aggarwal: On the Quantification of…
• [W65] Randomized Response..• [EGS] Evfimievski, Gehrke, Srikant: Limiting Privacy Breaches..Others in the paper..

The error in the iterative algorithm flattens out as its maximum value is bounded by 2
Error vs Number of Columns:Iterative Algorithm: Zipf Data
• Supported by Privacy Group at Stanford:
Rajeev and Hector


















